diff --git a/.config/zsh/config/plugins/fzf-tab b/.config/zsh/config/plugins/fzf-tab
deleted file mode 160000
index 7e0eee6..0000000
--- a/.config/zsh/config/plugins/fzf-tab
+++ /dev/null
@@ -1 +0,0 @@
-Subproject commit 7e0eee64df6c7c81a57792674646b5feaf89f263
diff --git a/.config/zsh/config/plugins/zsh-autosuggestions b/.config/zsh/config/plugins/zsh-autosuggestions
deleted file mode 160000
index a411ef3..0000000
--- a/.config/zsh/config/plugins/zsh-autosuggestions
+++ /dev/null
@@ -1 +0,0 @@
-Subproject commit a411ef3e0992d4839f0732ebeb9823024afaaaa8
diff --git a/.config/zsh/config/plugins/zsh-completions b/.config/zsh/config/plugins/zsh-completions
deleted file mode 160000
index 11258bc..0000000
--- a/.config/zsh/config/plugins/zsh-completions
+++ /dev/null
@@ -1 +0,0 @@
-Subproject commit 11258bcd48521b5bc7b683104bb0f5cb9375edee
diff --git a/.config/zsh/config/plugins/zsh-syntax-highlighting b/.config/zsh/config/plugins/zsh-syntax-highlighting
deleted file mode 160000
index caa749d..0000000
--- a/.config/zsh/config/plugins/zsh-syntax-highlighting
+++ /dev/null
@@ -1 +0,0 @@
-Subproject commit caa749d030d22168445c4cb97befd406d2828db0
diff --git a/.config/zsh/config/plugins/zsh-vi-mode b/.config/zsh/config/plugins/zsh-vi-mode
deleted file mode 160000
index debe9c8..0000000
--- a/.config/zsh/config/plugins/zsh-vi-mode
+++ /dev/null
@@ -1 +0,0 @@
-Subproject commit debe9c8ad191b68b143230eb7bee437caba9c74f
diff --git a/.config/zsh/config/completions/completions/_Note b/dots/.config/zsh/config/completions/completions/_Note
similarity index 100%
rename from .config/zsh/config/completions/completions/_Note
rename to dots/.config/zsh/config/completions/completions/_Note
diff --git a/.config/zsh/config/completions/completions/_aws b/dots/.config/zsh/config/completions/completions/_aws
similarity index 100%
rename from .config/zsh/config/completions/completions/_aws
rename to dots/.config/zsh/config/completions/completions/_aws
diff --git a/.config/zsh/config/completions/completions/_bat b/dots/.config/zsh/config/completions/completions/_bat
similarity index 100%
rename from .config/zsh/config/completions/completions/_bat
rename to dots/.config/zsh/config/completions/completions/_bat
diff --git a/.config/zsh/config/completions/completions/_cargo b/dots/.config/zsh/config/completions/completions/_cargo
similarity index 100%
rename from .config/zsh/config/completions/completions/_cargo
rename to dots/.config/zsh/config/completions/completions/_cargo
diff --git a/.config/zsh/config/completions/completions/_cmake b/dots/.config/zsh/config/completions/completions/_cmake
similarity index 100%
rename from .config/zsh/config/completions/completions/_cmake
rename to dots/.config/zsh/config/completions/completions/_cmake
diff --git a/.config/zsh/config/completions/completions/_curl b/dots/.config/zsh/config/completions/completions/_curl
similarity index 100%
rename from .config/zsh/config/completions/completions/_curl
rename to dots/.config/zsh/config/completions/completions/_curl
diff --git a/.config/zsh/config/completions/completions/_delta b/dots/.config/zsh/config/completions/completions/_delta
similarity index 100%
rename from .config/zsh/config/completions/completions/_delta
rename to dots/.config/zsh/config/completions/completions/_delta
diff --git a/.config/zsh/config/completions/completions/_dotnet b/dots/.config/zsh/config/completions/completions/_dotnet
similarity index 100%
rename from .config/zsh/config/completions/completions/_dotnet
rename to dots/.config/zsh/config/completions/completions/_dotnet
diff --git a/.config/zsh/config/completions/completions/_exa b/dots/.config/zsh/config/completions/completions/_exa
similarity index 100%
rename from .config/zsh/config/completions/completions/_exa
rename to dots/.config/zsh/config/completions/completions/_exa
diff --git a/.config/zsh/config/completions/completions/_fail2ban-client b/dots/.config/zsh/config/completions/completions/_fail2ban-client
similarity index 100%
rename from .config/zsh/config/completions/completions/_fail2ban-client
rename to dots/.config/zsh/config/completions/completions/_fail2ban-client
diff --git a/.config/zsh/config/completions/completions/_fd b/dots/.config/zsh/config/completions/completions/_fd
similarity index 100%
rename from .config/zsh/config/completions/completions/_fd
rename to dots/.config/zsh/config/completions/completions/_fd
diff --git a/.config/zsh/config/completions/completions/_firewalld b/dots/.config/zsh/config/completions/completions/_firewalld
similarity index 100%
rename from .config/zsh/config/completions/completions/_firewalld
rename to dots/.config/zsh/config/completions/completions/_firewalld
diff --git a/.config/zsh/config/completions/completions/_golang b/dots/.config/zsh/config/completions/completions/_golang
similarity index 100%
rename from .config/zsh/config/completions/completions/_golang
rename to dots/.config/zsh/config/completions/completions/_golang
diff --git a/.config/zsh/config/completions/completions/_j b/dots/.config/zsh/config/completions/completions/_j
similarity index 100%
rename from .config/zsh/config/completions/completions/_j
rename to dots/.config/zsh/config/completions/completions/_j
diff --git a/.config/zsh/config/completions/completions/_kubectl b/dots/.config/zsh/config/completions/completions/_kubectl
similarity index 100%
rename from .config/zsh/config/completions/completions/_kubectl
rename to dots/.config/zsh/config/completions/completions/_kubectl
diff --git a/.config/zsh/config/completions/completions/_minikube b/dots/.config/zsh/config/completions/completions/_minikube
similarity index 100%
rename from .config/zsh/config/completions/completions/_minikube
rename to dots/.config/zsh/config/completions/completions/_minikube
diff --git a/.config/zsh/config/completions/completions/_mpv b/dots/.config/zsh/config/completions/completions/_mpv
similarity index 100%
rename from .config/zsh/config/completions/completions/_mpv
rename to dots/.config/zsh/config/completions/completions/_mpv
diff --git a/.config/zsh/config/completions/completions/_ninja b/dots/.config/zsh/config/completions/completions/_ninja
similarity index 100%
rename from .config/zsh/config/completions/completions/_ninja
rename to dots/.config/zsh/config/completions/completions/_ninja
diff --git a/.config/zsh/config/completions/completions/_nvim-env b/dots/.config/zsh/config/completions/completions/_nvim-env
similarity index 100%
rename from .config/zsh/config/completions/completions/_nvim-env
rename to dots/.config/zsh/config/completions/completions/_nvim-env
diff --git a/.config/zsh/config/completions/completions/_openssl b/dots/.config/zsh/config/completions/completions/_openssl
similarity index 100%
rename from .config/zsh/config/completions/completions/_openssl
rename to dots/.config/zsh/config/completions/completions/_openssl
diff --git a/.config/zsh/config/completions/completions/_pgsql_utils b/dots/.config/zsh/config/completions/completions/_pgsql_utils
similarity index 100%
rename from .config/zsh/config/completions/completions/_pgsql_utils
rename to dots/.config/zsh/config/completions/completions/_pgsql_utils
diff --git a/.config/zsh/config/completions/completions/_rg b/dots/.config/zsh/config/completions/completions/_rg
similarity index 100%
rename from .config/zsh/config/completions/completions/_rg
rename to dots/.config/zsh/config/completions/completions/_rg
diff --git a/.config/zsh/config/completions/completions/_shellcheck b/dots/.config/zsh/config/completions/completions/_shellcheck
similarity index 100%
rename from .config/zsh/config/completions/completions/_shellcheck
rename to dots/.config/zsh/config/completions/completions/_shellcheck
diff --git a/.config/zsh/config/completions/completions/_vagrant b/dots/.config/zsh/config/completions/completions/_vagrant
similarity index 100%
rename from .config/zsh/config/completions/completions/_vagrant
rename to dots/.config/zsh/config/completions/completions/_vagrant
diff --git a/.config/zsh/config/completions/completions/_wezterm b/dots/.config/zsh/config/completions/completions/_wezterm
similarity index 100%
rename from .config/zsh/config/completions/completions/_wezterm
rename to dots/.config/zsh/config/completions/completions/_wezterm
diff --git a/.config/zsh/config/completions/completions/_yarn b/dots/.config/zsh/config/completions/completions/_yarn
similarity index 100%
rename from .config/zsh/config/completions/completions/_yarn
rename to dots/.config/zsh/config/completions/completions/_yarn
diff --git a/.config/zsh/config/completions/completions/_yt-dlp b/dots/.config/zsh/config/completions/completions/_yt-dlp
similarity index 100%
rename from .config/zsh/config/completions/completions/_yt-dlp
rename to dots/.config/zsh/config/completions/completions/_yt-dlp
diff --git a/.config/zsh/config/completions/completions/aws_zsh_completer.sh b/dots/.config/zsh/config/completions/completions/aws_zsh_completer.sh
similarity index 100%
rename from .config/zsh/config/completions/completions/aws_zsh_completer.sh
rename to dots/.config/zsh/config/completions/completions/aws_zsh_completer.sh
diff --git a/.config/zsh/config/completions/init.zsh b/dots/.config/zsh/config/completions/init.zsh
similarity index 100%
rename from .config/zsh/config/completions/init.zsh
rename to dots/.config/zsh/config/completions/init.zsh
diff --git a/.config/zsh/config/init.zsh b/dots/.config/zsh/config/init.zsh
similarity index 100%
rename from .config/zsh/config/init.zsh
rename to dots/.config/zsh/config/init.zsh
diff --git a/.config/zsh/config/omz/init.zsh b/dots/.config/zsh/config/omz/init.zsh
similarity index 100%
rename from .config/zsh/config/omz/init.zsh
rename to dots/.config/zsh/config/omz/init.zsh
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/.gitattributes b/dots/.config/zsh/config/plugins/fzf-tab/.gitattributes
new file mode 100644
index 0000000..0f95206
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/.gitattributes
@@ -0,0 +1,2 @@
+modules/** linguist-vendored
+modules/Src/aloxaf/*.c -linguist-vendored
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/.github/ISSUE_TEMPLATE/bug_report.md b/dots/.config/zsh/config/plugins/fzf-tab/.github/ISSUE_TEMPLATE/bug_report.md
new file mode 100644
index 0000000..e804a3a
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/.github/ISSUE_TEMPLATE/bug_report.md
@@ -0,0 +1,42 @@
+---
+name: Bug report
+about: Create a report to help us improve
+title: "[BUG]"
+labels: bug
+assignees: ''
+
+---
+
+#### Describe the bug
+A clear and concise description of what the bug is.
+
+I can make sure:
+- [ ] I am using the latest version of fzf-tab
+- [ ] this is the minimal zshrc which can reproduce this bug
+- [ ] fzf-tab is loaded after `compinit`
+- [ ] fzf-tab is loaded after plugins which will wrap Tab, like [junegunn/fzf/completion.zsh](https://github.com/junegunn/fzf/blob/master/shell/completion.zsh)
+- [ ] fzf-tab is loaded before zsh-autosuggestions, zsh-syntax-highlighting and fast-syntax-highlighting.
+
+#### To Reproduce
+Steps to reproduce the behavior:
+1. Type '...'
+2. Press Tab
+4. See error
+
+#### Expected behavior
+A clear and concise description of what you expected to happen.
+
+#### Screenshots
+If applicable, add screenshots to help explain your problem.
+
+#### Environment:
+ - OS: [e.g. Arch Linux]
+ - zsh version: [e.g. 5.8.1]
+
+#### Minimal zshrc
+If applicable, add a minimal zshrc to help us analyze.
+
+#### Log
+If applicable, use `C-x .` to trigger completion and provide the log.
+
+If there are only three lines in your log, please make sure your fzf-tab is loaded with the correct order (see the checklist above).
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/.github/ISSUE_TEMPLATE/feature_request.md b/dots/.config/zsh/config/plugins/fzf-tab/.github/ISSUE_TEMPLATE/feature_request.md
new file mode 100644
index 0000000..524940e
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/.github/ISSUE_TEMPLATE/feature_request.md
@@ -0,0 +1,20 @@
+---
+name: Feature request
+about: Suggest an idea for this project
+title: "[FR]"
+labels: enhancement
+assignees: ''
+
+---
+
+**Is your feature request related to a problem? Please describe.**
+A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
+
+**Describe the solution you'd like**
+A clear and concise description of what you want to happen.
+
+**Describe alternatives you've considered**
+A clear and concise description of any alternative solutions or features you've considered.
+
+**Additional context**
+Add any other context or screenshots about the feature request here.
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/.github/ISSUE_TEMPLATE/question.md b/dots/.config/zsh/config/plugins/fzf-tab/.github/ISSUE_TEMPLATE/question.md
new file mode 100644
index 0000000..9d2f92c
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/.github/ISSUE_TEMPLATE/question.md
@@ -0,0 +1,11 @@
+---
+name: Question
+about: Ask a question about fzf-tab
+title: "[Q]"
+labels: question
+assignees: ''
+
+---
+
+**Describe your question**
+A clear and concise description of your question.
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/.github/workflows/ci.yaml b/dots/.config/zsh/config/plugins/fzf-tab/.github/workflows/ci.yaml
new file mode 100644
index 0000000..893f8a4
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/.github/workflows/ci.yaml
@@ -0,0 +1,36 @@
+name: ci
+
+on:
+ pull_request:
+ push:
+ branches:
+ - master
+
+jobs:
+ test:
+ name: run test
+ runs-on: ${{ matrix.os }}
+ strategy:
+ matrix:
+ os: [ubuntu-latest, macos-latest]
+ steps:
+ - name: checkout
+ uses: actions/checkout@v1
+ with:
+ fetch-depth: 1
+
+ - name: install zsh (ubuntu)
+ if: matrix.os == 'ubuntu-latest'
+ run: sudo apt-get install zsh
+
+ - name: test completion (ubuntu)
+ if: matrix.os == 'ubuntu-latest'
+ run: cd test && zsh -f runtests.zsh fzftab.ztst
+
+ - name: build binary module
+ run: zsh -fc 'source ./fzf-tab.zsh && build-fzf-tab-module'
+
+ - name: test binary module (ubuntu)
+ if: matrix.os == 'ubuntu-latest'
+ run: cd test && zsh -f runtests.zsh fzftab.ztst
+
diff --git a/.config/zsh/config/themes/powerlevel10k/.gitignore b/dots/.config/zsh/config/plugins/fzf-tab/.gitignore
similarity index 100%
rename from .config/zsh/config/themes/powerlevel10k/.gitignore
rename to dots/.config/zsh/config/plugins/fzf-tab/.gitignore
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/LICENSE b/dots/.config/zsh/config/plugins/fzf-tab/LICENSE
new file mode 100644
index 0000000..a3c39eb
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/LICENSE
@@ -0,0 +1,21 @@
+MIT License
+
+Copyright (c) 2019-2021 Aloxaf
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/README.md b/dots/.config/zsh/config/plugins/fzf-tab/README.md
new file mode 100644
index 0000000..6398121
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/README.md
@@ -0,0 +1,138 @@
+# fzf-tab
+
+[](https://github.com/Aloxaf/fzf-tab/actions?query=workflow%3Aci)
+[](https://github.com/Aloxaf/fzf-tab/blob/master/LICENSE)
+
+Replace zsh's default completion selection menu with fzf!
+
+[](https://asciinema.org/a/293849)
+
+
+**Table of Contents**
+
+- [fzf-tab](#fzf-tab)
+- [Install](#install)
+ - [Manual](#manual)
+ - [Antigen](#antigen)
+ - [Zinit](#zinit)
+ - [Oh-My-Zsh](#oh-my-zsh)
+ - [Prezto](#prezto)
+- [Usage](#usage)
+ - [Configure](#configure)
+ - [Binary module](#binary-module)
+- [Difference from other plugins](#difference-from-other-plugins)
+- [Compatibility with other plugins](#compatibility-with-other-plugins)
+- [Related projects](#related-projects)
+
+
+
+# Install
+
+**NOTE: fzf-tab needs to be loaded after `compinit`, but before plugins which will wrap widgets, such as [zsh-autosuggestions](https://github.com/zsh-users/zsh-autosuggestions) or [fast-syntax-highlighting](https://github.com/zdharma-continuum/fast-syntax-highlighting)!!**
+
+### Manual
+
+First, clone this repository.
+
+```zsh
+git clone https://github.com/Aloxaf/fzf-tab ~/somewhere
+```
+
+Then add the following line to your `~/.zshrc`.
+
+```zsh
+source ~/somewhere/fzf-tab.plugin.zsh
+```
+
+### Antigen
+
+```zsh
+antigen bundle Aloxaf/fzf-tab
+```
+
+### Zinit
+
+```zsh
+zinit light Aloxaf/fzf-tab
+```
+
+### Oh-My-Zsh
+
+Clone this repository to your custom directory and then add `fzf-tab` to your plugin list.
+
+```zsh
+git clone https://github.com/Aloxaf/fzf-tab ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/fzf-tab
+```
+
+### Prezto
+
+Clone this repository to your contrib directory and then add `fzf-tab` to your module list in `.zpreztorc`.
+
+```zsh
+git clone https://github.com/Aloxaf/fzf-tab $ZPREZTODIR/contrib/fzf-tab
+```
+
+# Usage
+
+Just press Tab as usual~
+
+Available keybindings:
+
+- Ctrl+Space: select multiple results, can be configured by `fzf-bindings` tag
+
+- F1/F2: switch between groups, can be configured by `switch-group` tag
+
+- /: trigger continuous completion (useful when completing a deep path), can be configured by `continuous-trigger` tag
+
+Available commands:
+
+- `disable-fzf-tab`: disable fzf-tab and fallback to compsys
+
+- `enable-fzf-tab`: enable fzf-tab
+
+- `toggle-fzf-tab`: toggle the state of fzf-tab. This is also a zle widget.
+
+## Configure
+
+A common configuration is:
+
+```zsh
+# disable sort when completing `git checkout`
+zstyle ':completion:*:git-checkout:*' sort false
+# set descriptions format to enable group support
+zstyle ':completion:*:descriptions' format '[%d]'
+# set list-colors to enable filename colorizing
+zstyle ':completion:*' list-colors ${(s.:.)LS_COLORS}
+# preview directory's content with exa when completing cd
+zstyle ':fzf-tab:complete:cd:*' fzf-preview 'exa -1 --color=always $realpath'
+# switch group using `,` and `.`
+zstyle ':fzf-tab:*' switch-group ',' '.'
+```
+
+For more information, please see [Wiki#Configuration](https://github.com/Aloxaf/fzf-tab/wiki/Configuration).
+
+## Binary module
+
+By default, fzf-tab uses [zsh-ls-colors](https://github.com/xPMo/zsh-ls-colors) to parse and apply ZLS_COLORS if you have set the `list-colors` tag.
+
+However, it is a pure zsh script and is slow if you have too many files to colorize.
+fzf-tab is shipped with a binary module to speed up this process. You can build it with `build-fzf-tab-module`, then it will be enabled automatically.
+
+# Difference from other plugins
+
+fzf-tab doesn't do "complete", it just shows you the results of the default completion system.
+
+So it works EVERYWHERE (variables, function names, directory stack, in-word completion, etc.).
+And most of your configuration for default completion system is still valid.
+
+# Compatibility with other plugins
+
+Some plugins may also bind "^I" to their custom widget, like [fzf/shell/completion.zsh](https://github.com/junegunn/fzf/blob/master/shell/completion.zsh) or [ohmyzsh/lib/completion.zsh](https://github.com/ohmyzsh/ohmyzsh/blob/master/lib/completion.zsh#L61-L73).
+
+By default, fzf-tab will call the widget previously bound to "^I" to get the completion list. So there is no problem in most cases, unless fzf-tab is initialized before a plugin which doesn't handle the previous binding properly.
+
+So if you find your fzf-tab doesn't work properly, **please make sure it is the last plugin to bind "^I"** (If you don't know what I mean, just put it to the end of your plugin list).
+
+# Related projects
+
+- https://github.com/lincheney/fzf-tab-completion (fzf tab completion for zsh, bash and GNU readline apps)
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/fzf-tab.plugin.zsh b/dots/.config/zsh/config/plugins/fzf-tab/fzf-tab.plugin.zsh
new file mode 100644
index 0000000..f78964c
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/fzf-tab.plugin.zsh
@@ -0,0 +1,3 @@
+0="${${ZERO:-${0:#$ZSH_ARGZERO}}:-${(%):-%N}}"
+0="${${(M)0:#/*}:-$PWD/$0}"
+source "${0:A:h}/fzf-tab.zsh"
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/fzf-tab.zsh b/dots/.config/zsh/config/plugins/fzf-tab/fzf-tab.zsh
new file mode 100644
index 0000000..24e0455
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/fzf-tab.zsh
@@ -0,0 +1,399 @@
+# temporarily change options
+'builtin' 'local' '-a' '_ftb_opts'
+[[ ! -o 'aliases' ]] || _ftb_opts+=('aliases')
+[[ ! -o 'sh_glob' ]] || _ftb_opts+=('sh_glob')
+[[ ! -o 'no_brace_expand' ]] || _ftb_opts+=('no_brace_expand')
+'builtin' 'setopt' 'no_aliases' 'no_sh_glob' 'brace_expand'
+
+# thanks Valodim/zsh-capture-completion
+-ftb-compadd() {
+ # parse all options
+ local -A apre hpre dscrs _oad
+ local -a isfile _opts __ expl
+ zparseopts -E -a _opts P:=apre p:=hpre d:=dscrs X+:=expl O:=_oad A:=_oad D:=_oad f=isfile \
+ i: S: s: I: x: r: R: W: F: M+: E: q e Q n U C \
+ J:=__ V:=__ a=__ l=__ k=__ o=__ 1=__ 2=__
+
+ # just delegate and leave if any of -O, -A or -D are given or fzf-tab is not enabled
+ if (( $#_oad != 0 || ! IN_FZF_TAB )); then
+ builtin compadd "$@"
+ return
+ fi
+
+ # store matches in $__hits and descriptions in $__dscr
+ local -a __hits __dscr
+ if (( $#dscrs == 1 )); then
+ __dscr=( "${(@P)${(v)dscrs}}" )
+ fi
+ builtin compadd -A __hits -D __dscr "$@"
+ local ret=$?
+ if (( $#__hits == 0 )); then
+ return $ret
+ fi
+
+ # store $curcontext for furthur usage
+ _ftb_curcontext=${curcontext#:}
+
+ # only store the fist `-X`
+ expl=$expl[2]
+
+ # keep order of group description
+ [[ -n $expl ]] && _ftb_groups+=$expl
+
+ # store these values in _ftb_compcap
+ local -a keys=(apre hpre PREFIX SUFFIX IPREFIX ISUFFIX)
+ local key expanded __tmp_value=$'<\0>' # placeholder
+ for key in $keys; do
+ expanded=${(P)key}
+ if [[ -n $expanded ]]; then
+ __tmp_value+=$'\0'$key$'\0'$expanded
+ fi
+ done
+ if [[ -n $expl ]]; then
+ # store group index
+ __tmp_value+=$'\0group\0'$_ftb_groups[(ie)$expl]
+ fi
+ if [[ -n $isfile ]]; then
+ # NOTE: need a extra ${} here or ~ expansion won't work
+ __tmp_value+=$'\0realdir\0'${${(Qe)~${:-$IPREFIX$hpre}}}
+ fi
+ _opts+=("${(@kv)apre}" "${(@kv)hpre}" $isfile)
+ __tmp_value+=$'\0args\0'${(pj:\1:)_opts}
+
+ if (( $+builtins[fzf-tab-compcap-generate] )); then
+ fzf-tab-compcap-generate __hits __dscr __tmp_value
+ else
+ # dscr - the string to show to users
+ # word - the string to be inserted
+ local dscr word i
+ for i in {1..$#__hits}; do
+ word=$__hits[i] dscr=$__dscr[i]
+ if [[ -n $dscr ]]; then
+ dscr=${dscr//$'\n'}
+ elif [[ -n $word ]]; then
+ dscr=$word
+ fi
+ _ftb_compcap+=$dscr$'\2'$__tmp_value$'\0word\0'$word
+ done
+ fi
+
+ # tell zsh that the match is successful
+ builtin compadd -U -qS '' -R -ftb-remove-space ''
+}
+
+# when insert multi results, a whitespace will be added to each result
+# remove left space of our fake result because I can't remove right space
+# FIXME: what if the left char is not whitespace: `echo $widgets[\t`
+-ftb-remove-space() {
+ [[ $LBUFFER[-1] == ' ' ]] && LBUFFER[-1]=''
+}
+
+-ftb-zstyle() {
+ zstyle $1 ":fzf-tab:$_ftb_curcontext" ${@:2}
+}
+
+-ftb-complete() {
+ local -a _ftb_compcap
+ local -Ua _ftb_groups
+ local choice choices _ftb_curcontext continuous_trigger print_query accept_line bs=$'\2' nul=$'\0'
+ local ret=0
+
+ # must run with user options; don't move `emulate -L zsh` above this line
+ (( $+builtins[fzf-tab-compcap-generate] )) && fzf-tab-compcap-generate -i
+ COLUMNS=500 _ftb__main_complete "$@" || ret=$?
+ (( $+builtins[fzf-tab-compcap-generate] )) && fzf-tab-compcap-generate -o
+
+ emulate -L zsh -o extended_glob
+
+ local _ftb_query _ftb_complist=() _ftb_headers=() command opts
+ -ftb-generate-complist # sets `_ftb_complist`
+
+ -ftb-zstyle -s continuous-trigger continuous_trigger || {
+ [[ $OSTYPE == msys ]] && continuous_trigger=// || continuous_trigger=/
+ }
+
+ case $#_ftb_complist in
+ 0) return 1;;
+ 1)
+ choices=("EXPECT_KEY" "${_ftb_compcap[1]%$bs*}")
+ if (( _ftb_continue_last )); then
+ choices[1]=$continuous_trigger
+ fi
+ ;;
+ *)
+ -ftb-generate-query # sets `_ftb_query`
+ -ftb-generate-header # sets `_ftb_headers`
+ -ftb-zstyle -s print-query print_query || print_query=alt-enter
+ -ftb-zstyle -s accept-line accept_line
+
+ choices=("${(@f)"$(builtin print -rl -- $_ftb_headers $_ftb_complist | -ftb-fzf)"}")
+ ret=$?
+ # choices=(query_string expect_key returned_word)
+
+ # insert query string directly
+ if [[ $choices[2] == $print_query ]] || [[ -n $choices[1] && $#choices == 1 ]] ; then
+ local -A v=("${(@0)${_ftb_compcap[1]}}")
+ local -a args=("${(@ps:\1:)v[args]}")
+ [[ -z $args[1] ]] && args=() # don't pass an empty string
+ IPREFIX=$v[IPREFIX] PREFIX=$v[PREFIX] SUFFIX=$v[SUFFIX] ISUFFIX=$v[ISUFFIX]
+ # NOTE: should I use `-U` here?, ../f\tabcd -> ../abcd
+ builtin compadd "${args[@]:--Q}" -Q -- $choices[1]
+
+ compstate[list]=
+ compstate[insert]=
+ if (( $#choices[1] > 0 )); then
+ compstate[insert]='2'
+ [[ $RBUFFER == ' '* ]] || compstate[insert]+=' '
+ fi
+ return $ret
+ fi
+ choices[1]=()
+
+ choices=("${(@)${(@)choices%$nul*}#*$nul}")
+
+ unset CTXT
+ ;;
+ esac
+
+ if [[ -n $choices[1] && $choices[1] == $continuous_trigger ]]; then
+ typeset -gi _ftb_continue=1
+ typeset -gi _ftb_continue_last=1
+ fi
+
+ if [[ -n $choices[1] && $choices[1] == $accept_line ]]; then
+ typeset -gi _ftb_accept=1
+ fi
+ choices[1]=()
+
+ for choice in "$choices[@]"; do
+ local -A v=("${(@0)${_ftb_compcap[(r)${(b)choice}$bs*]#*$bs}}")
+ local -a args=("${(@ps:\1:)v[args]}")
+ [[ -z $args[1] ]] && args=() # don't pass an empty string
+ IPREFIX=$v[IPREFIX] PREFIX=$v[PREFIX] SUFFIX=$v[SUFFIX] ISUFFIX=$v[ISUFFIX]
+ builtin compadd "${args[@]:--Q}" -Q -- "$v[word]"
+ done
+
+ compstate[list]=
+ compstate[insert]=
+ if (( $#choices == 1 )); then
+ compstate[insert]='2'
+ [[ $RBUFFER == ' '* ]] || compstate[insert]+=' '
+ elif (( $#choices > 1 )); then
+ compstate[insert]='all'
+ fi
+ return $ret
+}
+
+fzf-tab-debug() {
+ (( $+_ftb_debug_cnt )) || typeset -gi _ftb_debug_cnt
+ local tmp=${TMPPREFIX:-/tmp/zsh}-$$-fzf-tab-$(( ++_ftb_debug_cnt )).log
+ local -i debug_fd=-1 IN_FZF_TAB=1
+ {
+ exec {debug_fd}>&2 2>| $tmp
+ local -a debug_indent; debug_indent=( '%'{3..20}'(e. .)' )
+ local PROMPT4 PS4="${(j::)debug_indent}+%N:%i> "
+ setopt xtrace
+ : $ZSH_NAME $ZSH_VERSION
+ zle .fzf-tab-orig-$_ftb_orig_widget
+ unsetopt xtrace
+ if (( debug_fd != -1 )); then
+ zle -M "fzf-tab-debug: Trace output left in $tmp"
+ fi
+ } always {
+ (( debug_fd != -1 )) && exec 2>&$debug_fd {debug_fd}>&-
+ }
+}
+
+fzf-tab-complete() {
+ # this name must be ugly to avoid clashes
+ local -i _ftb_continue=1 _ftb_continue_last=0 _ftb_accept=0 ret=0
+ # hide the cursor until finishing completion, so that users won't see cursor up and down
+ # NOTE: MacOS Terminal doesn't support civis & cnorm
+ echoti civis >/dev/tty 2>/dev/null
+ while (( _ftb_continue )); do
+ _ftb_continue=0
+ local IN_FZF_TAB=1
+ {
+ zle .fzf-tab-orig-$_ftb_orig_widget
+ ret=$?
+ } always {
+ IN_FZF_TAB=0
+ }
+ if (( _ftb_continue )); then
+ zle .split-undo
+ zle .reset-prompt
+ zle -R
+ zle fzf-tab-dummy
+ fi
+ done
+ echoti cnorm >/dev/tty 2>/dev/null
+ zle .redisplay
+ (( _ftb_accept )) && zle .accept-line
+ return $ret
+}
+
+# this function does nothing, it is used to be wrapped by other plugins like f-sy-h.
+# this make it possible to call the wrapper function without causing any other side effects.
+fzf-tab-dummy() { }
+
+zle -N fzf-tab-debug
+zle -N fzf-tab-complete
+zle -N fzf-tab-dummy
+
+disable-fzf-tab() {
+ emulate -L zsh -o extended_glob
+ (( $+_ftb_orig_widget )) || return 0
+
+ bindkey '^I' $_ftb_orig_widget
+ case $_ftb_orig_list_grouped in
+ 0) zstyle ':completion:*' list-grouped false ;;
+ 1) zstyle ':completion:*' list-grouped true ;;
+ 2) zstyle -d ':completion:*' list-grouped ;;
+ esac
+ unset _ftb_orig_widget _ftb_orig_list_groupded
+
+ # unhook compadd so that _approximate can work properply
+ unfunction compadd 2>/dev/null
+
+ functions[_main_complete]=$functions[_ftb__main_complete]
+ functions[_approximate]=$functions[_ftb__approximate]
+
+ # Don't remove .fzf-tab-orig-$_ftb_orig_widget as we won't be able to reliably
+ # create it if enable-fzf-tab is called again.
+}
+
+enable-fzf-tab() {
+ emulate -L zsh -o extended_glob
+ (( ! $+_ftb_orig_widget )) || disable-fzf-tab
+
+ typeset -g _ftb_orig_widget="${${$(builtin bindkey '^I')##* }:-expand-or-complete}"
+ if (( ! $+widgets[.fzf-tab-orig-$_ftb_orig_widget] )); then
+ # Widgets that get replaced by compinit.
+ local compinit_widgets=(
+ complete-word
+ delete-char-or-list
+ expand-or-complete
+ expand-or-complete-prefix
+ list-choices
+ menu-complete
+ menu-expand-or-complete
+ reverse-menu-complete
+ )
+ # Note: We prefix the name of the widget with '.' so that it doesn't get wrapped.
+ if [[ $widgets[$_ftb_orig_widget] == builtin &&
+ $compinit_widgets[(Ie)$_ftb_orig_widget] != 0 ]]; then
+ # We are initializing before compinit and being asked to fall back to a completion
+ # widget that isn't defined yet. Create our own copy of the widget ahead of time.
+ zle -C .fzf-tab-orig-$_ftb_orig_widget .$_ftb_orig_widget _main_complete
+ else
+ # Copy the widget before it's wrapped by zsh-autosuggestions and zsh-syntax-highlighting.
+ zle -A $_ftb_orig_widget .fzf-tab-orig-$_ftb_orig_widget
+ fi
+ fi
+
+ zstyle -t ':completion:*' list-grouped false
+ typeset -g _ftb_orig_list_grouped=$?
+
+ zstyle ':completion:*' list-grouped false
+ bindkey -M emacs '^I' fzf-tab-complete
+ bindkey -M viins '^I' fzf-tab-complete
+ bindkey -M emacs '^X.' fzf-tab-debug
+ bindkey -M viins '^X.' fzf-tab-debug
+
+ # make sure we can copy them
+ autoload +X -Uz _main_complete _approximate
+
+ # hook compadd
+ functions[compadd]=$functions[-ftb-compadd]
+
+ # hook _main_complete to trigger fzf-tab
+ functions[_ftb__main_complete]=$functions[_main_complete]
+ function _main_complete() { -ftb-complete "$@" }
+
+ # TODO: This is not a full support, see #47
+ # _approximate will also hook compadd
+ # let it call -ftb-compadd instead of builtin compadd so that fzf-tab can capture result
+ # make sure _approximate has been loaded.
+ functions[_ftb__approximate]=$functions[_approximate]
+ function _approximate() {
+ # if not called by fzf-tab, don't do anything with compadd
+ (( ! IN_FZF_TAB )) || unfunction compadd
+ _ftb__approximate
+ (( ! IN_FZF_TAB )) || functions[compadd]=$functions[-ftb-compadd]
+ }
+}
+
+toggle-fzf-tab() {
+ emulate -L zsh -o extended_glob
+ if (( $+_ftb_orig_widget )); then
+ disable-fzf-tab
+ else
+ enable-fzf-tab
+ fi
+}
+
+build-fzf-tab-module() {
+ local MACOS
+ if [[ ${OSTYPE} == darwin* ]]; then
+ MACOS=true
+ fi
+ pushd $FZF_TAB_HOME/modules
+ CPPFLAGS=-I/usr/local/include CFLAGS="-g -Wall -O2" LDFLAGS=-L/usr/local/lib ./configure --disable-gdbm --without-tcsetpgrp ${MACOS:+DL_EXT=bundle}
+ make -j$(nproc)
+ popd
+}
+
+zmodload zsh/zutil
+zmodload zsh/mapfile
+zmodload -F zsh/stat b:zstat
+
+0="${${ZERO:-${0:#$ZSH_ARGZERO}}:-${(%):-%N}}"
+0="${${(M)0:#/*}:-$PWD/$0}"
+FZF_TAB_HOME="${0:A:h}"
+
+source "$FZF_TAB_HOME"/lib/zsh-ls-colors/ls-colors.zsh fzf-tab-lscolors
+
+typeset -ga _ftb_group_colors=(
+ $'\x1b[94m' $'\x1b[32m' $'\x1b[33m' $'\x1b[35m' $'\x1b[31m' $'\x1b[38;5;27m' $'\x1b[36m'
+ $'\x1b[38;5;100m' $'\x1b[38;5;98m' $'\x1b[91m' $'\x1b[38;5;80m' $'\x1b[92m'
+ $'\x1b[38;5;214m' $'\x1b[38;5;165m' $'\x1b[38;5;124m' $'\x1b[38;5;120m'
+)
+
+# init
+() {
+ emulate -L zsh -o extended_glob
+
+ fpath+=($FZF_TAB_HOME/lib)
+
+ autoload -Uz -- $FZF_TAB_HOME/lib/-#ftb*(:t)
+
+ if (( $+FZF_TAB_COMMAND || $+FZF_TAB_OPTS || $+FZF_TAB_QUERY || $+FZF_TAB_SINGLE_GROUP || $+fzf_tab_preview_init )) \
+ || zstyle -m ":fzf-tab:*" command '*' \
+ || zstyle -m ":fzf-tab:*" extra-opts '*'; then
+ print -P "%F{red}%B[fzf-tab] Sorry, your configuration is not supported anymore\n" \
+ "See https://github.com/Aloxaf/fzf-tab/pull/132 for more information%f%b"
+ fi
+
+ if [[ -n $FZF_TAB_HOME/modules/Src/aloxaf/fzftab.(so|bundle)(#qN) ]]; then
+ module_path+=("$FZF_TAB_HOME/modules/Src")
+ zmodload aloxaf/fzftab
+
+ if [[ $FZF_TAB_MODULE_VERSION != "0.2.2" ]]; then
+ zmodload -u aloxaf/fzftab
+ local rebuild
+ print -Pn "%F{yellow}fzftab module needs to be rebuild, rebuild now?[Y/n]:%f"
+ read -q rebuild
+ if [[ $rebuild == y ]]; then
+ build-fzf-tab-module
+ zmodload aloxaf/fzftab
+ fi
+ fi
+ fi
+}
+
+enable-fzf-tab
+zle -N toggle-fzf-tab
+
+# restore options
+(( ${#_ftb_opts} )) && setopt ${_ftb_opts[@]}
+'builtin' 'unset' '_ftb_opts'
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/lib/-ftb-colorize b/dots/.config/zsh/config/plugins/fzf-tab/lib/-ftb-colorize
new file mode 100644
index 0000000..3b1909b
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/lib/-ftb-colorize
@@ -0,0 +1,34 @@
+#!/hint/zsh
+emulate -L zsh -o cbases -o octalzeroes
+
+local REPLY
+local -a reply stat lstat
+
+# fzf-tab-lscolors::match-by $1 lstat follow
+zstat -A lstat -L -- $1
+# follow symlink
+(( lstat[3] & 0170000 )) && zstat -A stat -- $1 2>/dev/null
+
+fzf-tab-lscolors::from-mode "$1" "$lstat[3]" $stat[3]
+# fall back to name
+[[ -z $REPLY ]] && fzf-tab-lscolors::from-name $1
+
+# If this is a symlink
+if [[ -n $lstat[14] ]]; then
+ local sym_color=$REPLY
+ local rsv_color=$REPLY
+ local rsv=$lstat[14]
+ # If this is not a broken symlink
+ if [[ -e $rsv ]]; then
+ # fzf-tab-lscolors::match-by $rsv stat
+ zstat -A stat -- $rsv
+ fzf-tab-lscolors::from-mode $rsv $stat[3]
+ # fall back to name
+ [[ -z $REPLY ]] && fzf-tab-lscolors::from-name $rsv
+ rsv_color=$REPLY
+ fi
+ dpre=$'\033[0m\033['$sym_color'm'
+ dsuf+=$'\033[0m -> \033['$rsv_color'm'$rsv
+else
+ dpre=$'\033[0m\033['$REPLY'm'
+fi
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/lib/-ftb-fzf b/dots/.config/zsh/config/plugins/fzf-tab/lib/-ftb-fzf
new file mode 100755
index 0000000..19adf04
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/lib/-ftb-fzf
@@ -0,0 +1,102 @@
+#!/hint/zsh
+
+local tmp_dir=${TMPPREFIX:-/tmp/zsh}-fzf-tab-$USER
+[[ -d $tmp_dir ]] || command mkdir $tmp_dir
+
+local ftb_preview_init="
+zmodload zsh/mapfile
+local -a _ftb_compcap=(\"\${(@f)mapfile[$tmp_dir/compcap.$$]}\")
+local -a _ftb_groups=(\"\${(@f)mapfile[$tmp_dir/groups.$$]}\")
+local bs=\$'\2'
+# get descriptoin
+export desc=\${\${\"\$(<{f})\"%\$'\0'*}#*\$'\0'}
+# get ctxt for current completion
+local -A ctxt=(\"\${(@0)\${_ftb_compcap[(r)\${(b)desc}\$bs*]#*\$bs}}\")
+# get group
+if (( \$+ctxt[group] )); then
+ export group=\$_ftb_groups[\$ctxt[group]]
+fi
+# get original word
+export word=\${(Q)ctxt[word]}
+# get real path if it is file
+if (( \$+ctxt[realdir] )); then
+ export realpath=\${ctxt[realdir]}\$word
+fi
+"
+local binds=tab:down,btab:up,change:top,ctrl-space:toggle
+local fzf_command fzf_flags fzf_preview debug_command tmp switch_group fzf_pad
+local ret=0
+
+-ftb-zstyle -s fzf-command fzf_command || fzf_command=fzf
+-ftb-zstyle -a fzf-bindings tmp && binds+=,${(j:,:)tmp}
+-ftb-zstyle -a fzf-flags fzf_flags
+-ftb-zstyle -s fzf-preview fzf_preview
+-ftb-zstyle -a switch-group switch_group || switch_group=(F1 F2)
+-ftb-zstyle -s fzf-pad fzf_pad || fzf_pad=2
+
+-ftb-zstyle -a debug-command debug_command && {
+ ${(eX)debug_command} $fzf_flags
+ return
+}
+
+print -rl -- $_ftb_compcap > $tmp_dir/compcap.$$
+print -rl -- $_ftb_groups > $tmp_dir/groups.$$
+print -r -- ${ftb_preview_init/{f}/\$1} > $tmp_dir/ftb_preview_init.$$
+
+binds=${binds//{_FTB_INIT_}/. $tmp_dir/ftb_preview_init.$$ {f} $'\n'}
+
+local -i header_lines=$#_ftb_headers
+local -i lines=$(( $#_ftb_compcap + fzf_pad + header_lines ))
+local reload_command="$commands[zsh] -f $FZF_TAB_HOME/lib/ftb-switch-group $$ $header_lines $tmp_dir"
+
+# detect if we will use tmux popup
+local use_tmux_popup=0
+if [[ $fzf_command == "ftb-tmux-popup" ]]; then
+ use_tmux_popup=1
+fi
+
+if (( ! use_tmux_popup )); then
+ # fzf will cause the current line to refresh, so move the cursor down.
+ echoti cud1 >/dev/tty
+ # reset cursor before call fzf
+ echoti cnorm >/dev/tty 2>/dev/null
+fi
+
+cat > $tmp_dir/completions.$$
+
+local dd='gdd'
+if (( ${+commands[$dd]} == 0 )) ; then
+ dd='dd'
+fi
+if (( ${+commands[$dd]} == 0 )) ; then
+ dd='true' # nop if dd is not installed
+fi
+
+_ftb_query="${_ftb_query}$(command "$dd" bs=1G count=1 status=none iflag=nonblock < /dev/tty 2>/dev/null)" || true
+
+$fzf_command \
+ --ansi \
+ --bind=$binds \
+ --bind="${switch_group[1]}:reload($reload_command -1),${switch_group[2]}:reload($reload_command 1)" \
+ --color=hl:$(( header_lines == 0 ? 188 : 255 )) \
+ --cycle \
+ --delimiter='\x00' \
+ --expect=$continuous_trigger,$print_query,$accept_line \
+ --header-lines=$header_lines \
+ --height=${FZF_TMUX_HEIGHT:=$(( lines > LINES / 3 * 2 ? LINES / 3 * 2 : lines ))} \
+ --layout=reverse \
+ --multi \
+ --nth=2,3 \
+ --print-query \
+ --query=$_ftb_query \
+ --tiebreak=begin \
+ ${fzf_preview:+--preview=$ftb_preview_init$fzf_preview} \
+ $fzf_flags < $tmp_dir/completions.$$ || ret=$?
+
+if (( ! use_tmux_popup )); then
+ echoti civis >/dev/tty 2>/dev/null
+ echoti cuu1 >/dev/tty
+fi
+
+command rm $tmp_dir/*.$$ 2>/dev/null
+return $ret
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/lib/-ftb-generate-complist b/dots/.config/zsh/config/plugins/fzf-tab/lib/-ftb-generate-complist
new file mode 100644
index 0000000..42dd033
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/lib/-ftb-generate-complist
@@ -0,0 +1,113 @@
+#!/hint/zsh
+
+local dsuf dpre k _v filepath first_word show_group default_color prefix bs=$'\b'
+local -a list_colors group_colors tcandidates reply match mbegin mend
+local -i same_word=1 colorful=0
+local -Ua duplicate_groups=()
+local -A word_map=()
+
+(( $#_ftb_compcap == 0 )) && return
+
+-ftb-zstyle -s show-group show_group || show_group=full
+-ftb-zstyle -s default-color default_color || default_color=$'\x1b[37m'
+-ftb-zstyle -s prefix prefix || {
+ zstyle -m ':completion:*:descriptions' format '*' && prefix='·'
+}
+-ftb-zstyle -a group-colors group_colors || group_colors=($_ftb_group_colors)
+zstyle -a ":completion:$_ftb_curcontext" list-colors list_colors
+
+# init colorize
+if (( $+builtins[fzf-tab-candidates-generate] )); then
+ fzf-tab-candidates-generate -i list_colors
+else
+ local -A namecolors=(${(@s:=:)${(@s.:.)list_colors}:#[[:alpha:]][[:alpha:]]=*})
+ local -A modecolors=(${(@Ms:=:)${(@s.:.)list_colors}:#[[:alpha:]][[:alpha:]]=*})
+ (( $#namecolors == 0 && $#modecolors == 0 )) && list_colors=()
+fi
+
+if (( $#_ftb_groups == 1 )); then
+ -ftb-zstyle -m single-group prefix || prefix=''
+ -ftb-zstyle -m single-group color || group_colors=("$default_color")
+fi
+
+if (( $+builtins[fzf-tab-candidates-generate] )); then
+ fzf-tab-candidates-generate
+else
+ for k _v in "${(@ps:\2:)_ftb_compcap}"; do
+ local -A v=("${(@0)_v}")
+ [[ $v[word] == ${first_word:=$v[word]} ]] || same_word=0
+
+ # add character and color to describe the type of the files
+ dsuf='' dpre=''
+ if (( $+v[realdir] )); then
+ filepath=$v[realdir]${(Q)v[word]}
+ if [[ -d $filepath ]]; then
+ dsuf=/
+ fi
+ # add color and resolve symlink if have list-colors
+ # detail: http://zsh.sourceforge.net/Doc/Release/Zsh-Modules.html#The-zsh_002fcomplist-Module
+ if (( $#list_colors )) && [[ -a $filepath || -L $filepath ]]; then
+ -ftb-colorize $filepath
+ colorful=1
+ elif [[ -L $filepath ]]; then
+ dsuf=@
+ fi
+ if [[ $options[list_types] == off ]]; then
+ dsuf=''
+ fi
+ fi
+
+ # add color to description if they have group index
+ if (( $+v[group] )); then
+ local color=$group_colors[$v[group]]
+ # add a hidden group index at start of string to keep group order when sorting
+ # first group index is for builtin sort, sencond is for GNU sort
+ tcandidates+=$v[group]$'\b'$color$prefix$dpre$'\0'$v[group]$'\b'$k$'\0'$dsuf
+ else
+ tcandidates+=$default_color$dpre$'\0'$k$'\0'$dsuf
+ fi
+
+ # check group with duplicate member
+ if [[ $show_group == brief ]]; then
+ if (( $+word_map[$v[word]] && $+v[group] )); then
+ duplicate_groups+=$v[group] # add this group
+ duplicate_groups+=$word_map[$v[word]] # add previous group
+ fi
+ word_map[$v[word]]=$v[group]
+ fi
+ done
+fi
+
+(( same_word )) && tcandidates[2,-1]=()
+
+# sort and remove sort group or other index
+zstyle -T ":completion:$_ftb_curcontext" sort
+if (( $? != 1 )); then
+ if (( colorful )); then
+ # if enable list_colors, we should skip the first field
+ if [[ ${commands[sort]:A:t} != (|busybox*) ]]; then
+ # this is faster but doesn't work if `find` is from busybox
+ tcandidates=(${(f)"$(command sort -u -t '\0' -k 2 <<< ${(pj:\n:)tcandidates})"})
+ else
+ # slower but portable
+ tcandidates=(${(@o)${(@)tcandidates:/(#b)([^$'\0']#)$'\0'(*)/$match[2]$'\0'$match[1]}})
+ tcandidates=(${(@)tcandidates/(#b)(*)$'\0'([^$'\0']#)/$match[2]$'\0'$match[1]})
+ fi
+ else
+ tcandidates=("${(@o)tcandidates}")
+ fi
+fi
+typeset -gUa _ftb_complist=("${(@)tcandidates//[0-9]#$bs}")
+
+# hide needless group
+if (( $#_ftb_groups )); then
+ local i to_hide indexs=({1..$#_ftb_groups})
+ case $show_group in
+ brief) to_hide=(${indexs:|duplicate_groups}) ;;
+ none) to_hide=($indexs) ;;
+ esac
+ for i in $to_hide; do
+ # NOTE: _ftb_groups is unique array
+ _ftb_groups[i]="__hide__$i"
+ done
+fi
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/lib/-ftb-generate-header b/dots/.config/zsh/config/plugins/fzf-tab/lib/-ftb-generate-header
new file mode 100644
index 0000000..a54fee1
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/lib/-ftb-generate-header
@@ -0,0 +1,35 @@
+#!/hint/zsh
+
+typeset -ga _ftb_headers=()
+local i tmp group_colors
+local -i mlen=0 len=0
+
+if (( $#_ftb_groups == 1 )) && { ! -ftb-zstyle -m single-group "header" }; then
+ return
+fi
+
+# calculate the max column width
+for i in $_ftb_groups; do
+ (( $#i > mlen )) && mlen=$#i
+done
+mlen+=1
+
+-ftb-zstyle -a group-colors group_colors || group_colors=($_ftb_group_colors)
+
+for (( i=1; i<=$#_ftb_groups; i++ )); do
+ [[ $_ftb_groups[i] == "__hide__"* ]] && continue
+
+ if (( len + $#_ftb_groups[i] > COLUMNS - 5 )); then
+ _ftb_headers+=$tmp
+ tmp='' && len=0
+ fi
+ if (( len + mlen > COLUMNS - 5 )); then
+ # the last column doesn't need padding
+ _ftb_headers+=$tmp$group_colors[i]$_ftb_groups[i]$'\033[00m'
+ tmp='' && len=0
+ else
+ tmp+=$group_colors[i]${(r:$mlen:)_ftb_groups[i]}$'\033[00m'
+ len+=$mlen
+ fi
+done
+(( $#tmp )) && _ftb_headers+=$tmp
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/lib/-ftb-generate-query b/dots/.config/zsh/config/plugins/fzf-tab/lib/-ftb-generate-query
new file mode 100644
index 0000000..4f54604
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/lib/-ftb-generate-query
@@ -0,0 +1,40 @@
+#!/hint/zsh
+
+if zmodload -s zsh/pcre; then
+ setopt localoptions rematch_pcre
+fi
+
+local key qtype tmp query_string
+typeset -g _ftb_query=
+-ftb-zstyle -a query-string query_string || query_string=(prefix input first)
+for qtype in $query_string; do
+ if [[ $qtype == prefix ]]; then
+ # find the longest common prefix among descriptions
+ local -a keys=(${_ftb_compcap%$'\2'*})
+ tmp=$keys[1]
+ local MATCH match mbegin mend prefix=(${(s::)tmp})
+ for key in ${keys:1}; do
+ (( $#tmp )) || break
+ [[ $key == $tmp* ]] && continue
+ # interpose characters from the current common prefix and $key and see how
+ # many pairs of equal characters we get at the start of the resulting string
+ [[ ${(j::)${${(s::)key[1,$#tmp]}:^prefix}} =~ '^(((.)\3)*)' ]]
+ # truncate common prefix and maintain loop invariant: ${(s::)tmp} == $prefix
+ tmp[$#MATCH/2+1,-1]=""
+ prefix[$#MATCH/2+1,-1]=()
+ done
+ elif [[ $qtype == input ]]; then
+ local fv=${_ftb_compcap[1]#*$'\2'}
+ local -A v=("${(@0)fv}")
+ tmp=$v[PREFIX]
+ if (( $RBUFFER[(i)$v[SUFFIX]] != 1 )); then
+ tmp=${tmp/%$v[SUFFIX]}
+ fi
+ tmp=${${tmp#$v[hpre]}#$v[apre]}
+ fi
+ if (( $query_string[(I)longest] )); then
+ (( $#tmp > $#_ftb_query )) && _ftb_query=$tmp
+ elif [[ -n $tmp ]]; then
+ _ftb_query=$tmp && break
+ fi
+done
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/lib/ftb-switch-group b/dots/.config/zsh/config/plugins/fzf-tab/lib/ftb-switch-group
new file mode 100644
index 0000000..8d06956
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/lib/ftb-switch-group
@@ -0,0 +1,38 @@
+#!/hint/zsh
+emulate -L zsh -o extended_glob
+
+zmodload zsh/mapfile
+
+# receive arguments
+local pid=$1 header_lines=$2 tmp_dir=$3 offset=$@[-1]
+
+# read completion list
+local -a list=(${(f)mapfile[$tmp_dir/completions.$pid]})
+
+# get total group count
+if (( $#list > 10000 )); then
+ local -Ua total=(${(f)"$(print -l ${list:$header_lines} | grep -a -oP '^\x1b\[[0-9;]*m')"})
+else
+ local -Ua total=(${(M)${list:$header_lines}#$'\x1b['[0-9;]#*m})
+fi
+
+# get current group index, start from 2
+local current=2
+if [[ -f $tmp_dir/current-group.$pid ]]; then
+ current=$(( $(<$tmp_dir/current-group.$pid) + offset ))
+fi
+(( current > $#total )) && current=1
+(( current == 0 )) && current=$#total
+echo $current > $tmp_dir/current-group.$pid
+
+# print headers
+if (( header_lines != 0 )); then
+ print -l ${list[1,header_lines]/${total[current]}/$'\x1b[1m'}
+fi
+
+# print current group
+if (( $#list > 10000 )); then
+ print -l ${list:$header_lines} | grep -a -F "${total[current]}"
+else
+ print -l ${(M)${list:$header_lines}:#${total[current]}*}
+fi
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/lib/ftb-tmux-popup b/dots/.config/zsh/config/plugins/fzf-tab/lib/ftb-tmux-popup
new file mode 100755
index 0000000..68d1e29
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/lib/ftb-tmux-popup
@@ -0,0 +1,88 @@
+#!/hint/zsh
+# Show results with tmux popup
+# Example usage:
+# zstyle ':fzf-tab:*' fzf-command ftb-tmux-popup
+# zstyle ':fzf-tab:*' popup-pad 0 0
+# It can also be used as a standalone tool, like:
+# ls | ftb-tmux-popup
+emulate -L zsh -o extended_glob
+
+# import min
+autoload -Uz zmathfunc
+zmathfunc
+
+: ${tmp_dir:=${TMPPREFIX:-/tmp/zsh}-fzf-tab-$USER}
+
+# fallback to fzf if it is not running in tmux
+if (( ! $+TMUX_PANE )); then
+ fzf $@
+ return
+fi
+
+local ret=0
+
+local -a fzf_opts=($@)
+fzf_opts=(${${fzf_opts/--height*}/--layout*})
+
+# get position of cursor and size of window
+local -a tmp=($(command tmux display-message -p "#{pane_top} #{cursor_y} #{pane_left} #{cursor_x} #{window_height} #{window_width} #{status} #{status-position}"))
+local cursor_y=$((tmp[1] + tmp[2])) cursor_x=$((tmp[3] + tmp[4])) window_height=$tmp[5] window_width=$tmp[6] window_top=0
+
+if [[ $tmp[8] == 'top' ]]; then
+ window_top=$tmp[7]
+ cursor_y=$((cursor_y + window_top))
+fi
+
+# if not called by fzf-tab
+if (( ! $+IN_FZF_TAB )); then
+ [[ -d $tmp_dir ]] || mkdir -p $tmp_dir
+ cat > $tmp_dir/completions.$$
+fi
+
+local text REPLY comp_lines comp_length length popup_pad
+
+zstyle -a ":fzf-tab:$_ftb_curcontext" popup-pad popup_pad || popup_pad=(0 0)
+
+# get the size of content, note we should remove all ANSI color code
+comp_lines=$(( ${#${(f)mapfile[$tmp_dir/completions.$$]}} + $popup_pad[2] ))
+if (( comp_lines <= 500 )); then
+ comp_length=0
+ for line in ${(f)mapfile[$tmp_dir/completions.$$]}; do
+ length=${(m)#${(S)line//$'\x1b['[0-9]#*m}}
+ (( length >= comp_length )) && comp_length=$length
+ done
+else
+ # FIXME: can't get the correct width of CJK characters.
+ comp_length=$( command perl -ne 's/\x1b\[[0-9;]*m//g;s/\x00//g; $m= length() if $m < length(); END { print $m }' < $tmp_dir/completions.$$ )
+fi
+comp_length=$(( comp_length + $popup_pad[1] ))
+
+local popup_height popup_y popup_width popup_x
+
+# calculate the popup height and y position
+if (( cursor_y * 2 > window_height )); then
+ # show above the cursor
+ popup_height=$(( min(comp_lines + 4, cursor_y - window_top) ))
+ popup_y=$cursor_y
+else
+ # show below the cursor
+ popup_height=$(( min(comp_lines + 4, window_height - cursor_y + window_top - 1) ))
+ popup_y=$(( cursor_y + popup_height + 1 ))
+ fzf_opts+=(--layout=reverse)
+fi
+
+# calculate the popup width and x position
+popup_width=$(( min(comp_length + 5, window_width) ))
+popup_x=$(( cursor_x + popup_width > window_width ? window_width - popup_width : cursor_x ))
+
+echo -E "$commands[fzf] ${(qq)fzf_opts[@]} < $tmp_dir/completions.$$ > $tmp_dir/result-$$" > $tmp_dir/fzf-$$
+{
+ tmux popup -x $popup_x -y $popup_y \
+ -w $popup_width -h $popup_height \
+ -d $PWD -E ". $tmp_dir/fzf-$$" || ret=$?
+ echo -E "$(<$tmp_dir/result-$$)"
+} always {
+ command rm $tmp_dir/*-$$
+ (( $+IN_FZF_TAB )) || command rm $tmp_dir/completions.$$
+}
+return $ret
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/lib/zsh-ls-colors/LICENSE b/dots/.config/zsh/config/plugins/fzf-tab/lib/zsh-ls-colors/LICENSE
new file mode 100644
index 0000000..940b4c2
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/lib/zsh-ls-colors/LICENSE
@@ -0,0 +1,21 @@
+MIT License
+
+Copyright (c) 2019 Gamma
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/lib/zsh-ls-colors/README.md b/dots/.config/zsh/config/plugins/fzf-tab/lib/zsh-ls-colors/README.md
new file mode 100644
index 0000000..7736ce6
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/lib/zsh-ls-colors/README.md
@@ -0,0 +1,114 @@
+# zsh-ls-colors
+
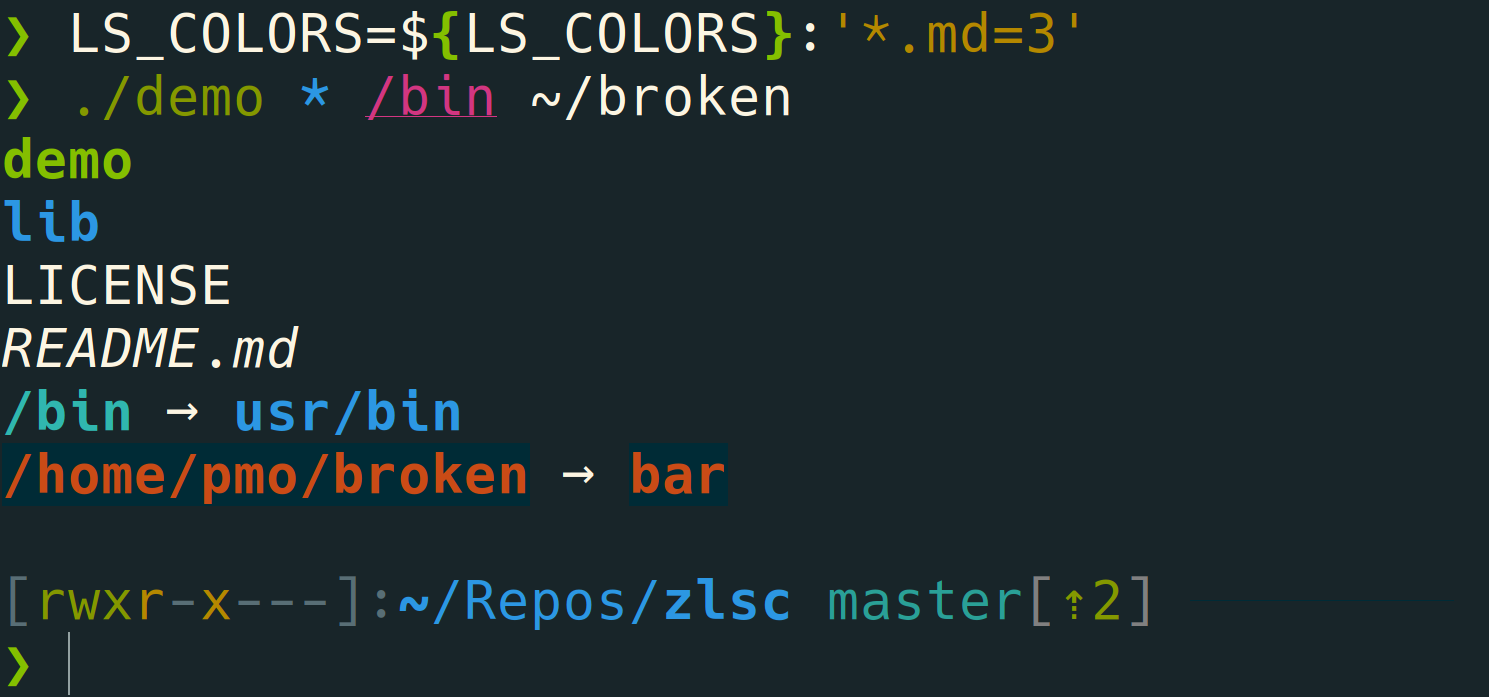
+
+
+A zsh library to use `LS_COLORS` in scripts or other plugins.
+
+For a simple demo, see the `demo` script in this repo.
+
+For more advanced usage,
+instructions are located at top of the source files for `from-mode` and `from-name`.
+If a use case isn't adequately covered,
+please open an issue!
+
+## Using zsh-ls-colors in a plugin
+
+You can use this as a submodule or a subtree.
+
+### submodule:
+
+```sh
+# Add (only once)
+git submodule add git://github.com/xPMo/zsh-ls-colors.git ls-colors
+git commit -m 'Add ls-colors as submodule'
+
+# Update
+cd ls-colors
+git fetch
+git checkout origin/master
+cd ..
+git commit ls-colors -m 'Update ls-colors to latest'
+```
+
+### Subtree:
+
+```sh
+# Initial add
+git subtree add --prefix=ls-colors/ --squash -m 'Add ls-colors as a subtree' \
+ git://github.com/xPMo/zsh-ls-colors.git master
+
+# Update
+git subtree pull --prefix=ls-colors/ --squash -m 'Update ls-colors to latest' \
+ git://github.com/xPMo/zsh-ls-colors.git master
+
+
+# Or, after adding a remote:
+git remote add ls-colors git://github.com/xPMo/zsh-ls-colors.git
+
+# Initial add
+git subtree add --prefix=ls-colors/ --squash -m 'Add ls-colors as a subtree' ls-colors master
+
+# Update
+git subtree pull --prefix=ls-colors/ --squash -m 'Update ls-colors to latest' ls-colors master
+```
+
+### Function namespacing
+
+Since functions are a public namespace,
+this plugin allows you to customize the preifix for your plugin:
+
+```zsh
+# load functions as my-lscolors::{init,match-by,from-name,from-mode}
+source ${0:h}/ls-colors/ls-colors.zsh my-lscolors
+```
+
+### Parameter namespacing
+
+While indirect parameter expansion exists with `${(P)var}`,
+it doesn't play nicely with array parameters.
+
+There are multiple strategies to prevent unnecessary re-parsing:
+
+```zsh
+# Call once when loading.
+# Pollutes global namespace but prevents re-parsing
+ls-color::init
+```
+
+```zsh
+# Don't call init at all and only use ::match-by.
+# Doesn't pollute global namespace but reparses LS_COLORS on every call
+ls-color::match-by $file lstat
+```
+
+```zsh
+# Initialize within a scope with local parameters.
+# Best for not polluting global namespace when multiple filenames need to be parsed.
+(){
+ local -A namecolors modecolors
+ ls-color::init
+
+ for arg; do
+ ...
+ done
+}
+```
+
+```zsh
+# Serialize:
+typeset -g LS_COLORS_CACHE_FILE=$(mktemp)
+(){
+ local -A namecolors modecolors
+ ls-color::init
+ typeset -p modecolors namecolors >| $LS_COLORS_CACHE_FILE
+ zcompile $LS_COLORS_CACHE_FILE
+}
+
+my-function(){
+ local -A namecolors modecolors
+ source $LS_COLORS_CACHE_FILE
+
+ ...
+}
+```
+
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/lib/zsh-ls-colors/demo b/dots/.config/zsh/config/plugins/fzf-tab/lib/zsh-ls-colors/demo
new file mode 100755
index 0000000..a5e468d
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/lib/zsh-ls-colors/demo
@@ -0,0 +1,65 @@
+#!/usr/bin/env zsh
+# set $0 (ref: zdharma.org/Zsh-100-Commits-Club/Zsh-Plugin-Standard.html#zero-handling)
+0="${${ZERO:-${0:#$ZSH_ARGZERO}}:-${(%):-%N}}"
+0="${${(M)0:#/*}:-$PWD/$0}"
+
+# load library functions
+source ls-colors.zsh ''
+
+# to name the functions with a different namespace
+# call source with a different argument
+#source my-plugin::ls
+
+# init (sets modecolors and namecolors)
+# You have options. Either you can pollute global namespace:
+ls-color::init
+# Or you can have ::match-by re-parse colors on every call
+: # (do nothing)
+# Or if you have multiple calls, you can parse colors once for a scope:
+(){
+ local -A modecolors namecolors
+ ls-color::init
+
+ for arg; do
+ ls-color::match-by $arg lstat
+ : do something else
+ done
+}
+
+
+# colors can also be added for other globs after init as well:
+namecolors[*.md]='01' # bold markdown files
+
+# EXTENDED_GLOB is enabled when matching, so things like this are possible:
+namecolors[(#i)(*/|)license(|.*)]='04' # underline LICENSE, or license.txt, or similar
+
+local file reply
+# color each file in the argument list
+for file; do
+ ls-color::match-by $file all
+ # point to symlink resolution if it exists
+ print '\e['$reply[1]'m'$file'\e[0m'${reply[2]:+' → \e['$reply[3]'m'$reply[2]'\e[0m'}
+done
+
+# =======================
+# Alternate manual method:
+for file; do
+ ls-color::match-by $file lstat follow
+ if [[ $reply[2] ]]; then
+ # This is a symlink
+ symlink_color=$reply[1]
+ # If broken, use link color for destination
+ resolved_color=$reply[1]
+ resolved=$reply[2]
+ if [[ -e $file ]]; then
+ # Not broken, update destination color
+ ls-color::match-by $file stat
+ resolved_color=$reply[1]
+ fi
+ print '\e['$symlink_color'm'$file'\e[0m → \e['$resolved_color'm'$resolved'\e[0m'
+ else
+ # This is not a symlink
+ print '\e['$reply[1]'m'$file'\e[0m'
+ fi
+done
+
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/lib/zsh-ls-colors/ls-colors.zsh b/dots/.config/zsh/config/plugins/fzf-tab/lib/zsh-ls-colors/ls-colors.zsh
new file mode 100644
index 0000000..276a7bb
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/lib/zsh-ls-colors/ls-colors.zsh
@@ -0,0 +1,186 @@
+#!/usr/bin/env zsh
+
+# set the prefix for all functions
+local pfx=${1:-'ls-color'}
+
+# {{{ From mode
+# Usage:
+# $1: filename
+# $2: The value of struct stat st_mode
+# If empty, modecolors lookup will be skipped
+# $3: (If symlink) The value of struct stat st_mode
+# for the target of $1's symlink. If unset,
+# interpret as a broken link.
+# Sets REPLY to the console code
+${pfx}::from-mode () {
+
+ emulate -L zsh
+ setopt cbases octalzeroes extendedglob
+
+ [[ -z $2 ]] && return 1
+
+ local -i reg=0
+ local -a codes
+
+ local -i st_mode=$(($2))
+ # See man 7 inode for more info
+ # file type
+ case $(( st_mode & 0170000 )) in
+ $(( 0140000 )) ) codes=( $modecolors[so] ) ;;
+ $(( 0120000 )) ) # symlink, special handling
+ if ! (($+3)); then
+ REPLY=$modecolors[or]
+ elif [[ $modecolors[ln] = target ]]; then
+ "$0" "$1" "${@:3}"
+ else
+ REPLY=$modecolors[ln]
+ fi
+ return
+ ;;
+ $(( 0100000 )) ) codes=( ); reg=1 ;; # regular file
+ $(( 0060000 )) ) codes=( $modecolors[bd] ) ;;
+ $(( 0040000 )) ) codes=( $modecolors[di] ) ;;
+ $(( 0020000 )) ) codes=( $modecolors[cd] ) ;;
+ $(( 0010000 )) ) codes=( $modecolors[pi] ) ;;
+ esac
+
+ # setuid/setgid/sticky/other-writable
+ (( st_mode & 04000 )) && codes+=( $modecolors[su] )
+ (( st_mode & 02000 )) && codes+=( $modecolors[sg] )
+ (( ! reg )) && case $(( st_mode & 01002 )) in
+ # sticky
+ $(( 01000 )) ) codes+=( $modecolors[st] ) ;;
+ # other-writable
+ $(( 00002 )) ) codes+=( $modecolors[ow] ) ;;
+ # other-writable and sticky
+ $(( 01002 )) ) codes+=( $modecolors[tw] ) ;;
+ esac
+
+ # executable
+ if (( ! $#codes )); then
+ (( st_mode & 0111 )) && codes+=( $modecolors[ex] )
+ fi
+
+ # return nonzero if no matching code
+ [[ ${REPLY::=${(j:;:)codes}} ]]
+} # }}}
+# {{{ From name
+# Usage:
+# $1: filename
+#
+# Sets REPLY to the console code
+${pfx}::from-name () {
+
+ emulate -L zsh
+ setopt extendedglob
+
+ # Return non-zero if no keys match
+ [[ ${REPLY::=$namecolors[(k)$1]} ]]
+} # }}}
+# {{{ Init
+# WARNING: initializes namecolors and modecolors in global scope
+${pfx}::init () {
+ emulate -L zsh
+
+ # Use $1 if provided, otherwise use LS_COLORS
+ # Use LSCOLORS on BSD
+ local LS_COLORS=${1:-${LS_COLORS:-$LSCOLORS}}
+
+ # read in LS_COLORS
+ typeset -gA namecolors=(${(@s:=:)${(@s.:.)LS_COLORS}:#[[:alpha:]][[:alpha:]]=*})
+ typeset -gA modecolors=(${(@Ms:=:)${(@s.:.)LS_COLORS}:#[[:alpha:]][[:alpha:]]=*})
+}
+# }}}
+# {{{ Match by
+# Usage:
+# $1: filename
+# Optional (must be $2): g[lobal]: Use existing stat | lstat in parent scope
+# ${@:2}: Append to reply:
+# - l[stat] : Look up using lstat (don't follow symlink), if empty match name
+# - s[tat] : Look up using stat (do follow symlink), if empty match name
+# - n[ame] : Only match name
+# - f[ollow]: Get resolution path of symlink
+# - L[stat] : Same as above but don't match name
+# - S[tat] : Same as above but don't match name
+# - a[ll] : If a broken symlink: lstat follow lstat
+# : If a symlink : lstat follow stat
+# : Otherwise : lstat
+# - A[ll] : If a broken symlink: Lstat follow Lstat
+# : If a symlink : Lstat follow Stat
+# : Otherwise : Lstat
+#
+# or returns non-zero
+${pfx}::match-by () {
+ emulate -L zsh
+ setopt extendedglob cbases octalzeroes
+
+ local arg REPLY name=$1 pfx=${0%::match-by}
+ shift
+
+ # init in local scope if not using global params
+ if ! [[ -v namecolors && -v modecolors ]]; then
+ local -A namecolors modecolors
+ ${pfx}::init
+ fi
+
+ if [[ ${1:l} = (g|global) ]]; then
+ shift
+ else
+ local -a stat lstat
+ declare -ga reply=()
+ fi
+
+ zmodload -F zsh/stat b:zstat
+ for arg; do
+ case ${arg[1]:l} in
+ n|name)
+ ${pfx}::from-name $name
+ reply+=("$REPLY")
+ ;;
+ l|lstat)
+ (($#lstat)) || zstat -A lstat -L $name || return 1
+ if ((lstat[3] & 0170000 )); then
+ # follow symlink
+ (($#stat)) || zstat -A stat $name 2>/dev/null
+ fi
+ ${pfx}::from-mode "$name" "$lstat[3]" $stat[3]
+ if [[ $REPLY || ${2[1]} = L ]]; then
+ reply+=("$REPLY")
+ else # fall back to name
+ "$0" "$name" g n
+ fi
+ ;;
+ s|stat)
+ (($#stat)) || zstat -A stat $name || return 1
+ ${pfx}::from-mode $name $stat[3]
+ reply+=("$REPLY")
+ if [[ $REPLY || ${arg[1]} = S ]]; then
+ reply+=("$REPLY")
+ else # fall back to name
+ "$0" "$name" g n
+ fi
+ ;;
+ f|follow)
+ (($#lstat)) || zstat -A lstat -L $name || return 1
+ reply+=("$lstat[14]")
+ ;;
+ a|all)
+ # Match case
+ "$0" "$name" g ${${${arg[1]%a}:+L}:-l}
+ # won't append if empty
+ reply+=($lstat[14])
+ # $stat[14] will be empty if not a symlink
+ if [[ $lstat[14] ]]; then
+ if [[ -e $name ]]; then
+ "$0" "$name" g ${${${arg[1]%a}:+S}:-s}
+ else
+ reply+=($reply[-2])
+ fi
+ fi
+ ;;
+ *) return 2 ;;
+ esac
+ done
+}
+# }}}
+# vim: set foldmethod=marker:
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/.cvsignore b/dots/.config/zsh/config/plugins/fzf-tab/modules/.cvsignore
new file mode 100644
index 0000000..95cdc58
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/.cvsignore
@@ -0,0 +1,16 @@
+Makefile
+META-FAQ
+config.cache
+config.h
+config.h.in
+config.log
+config.modules
+config.modules.sh
+config.status
+configure
+cscope.out
+stamp-h
+stamp-h.in
+autom4te.cache
+*.swp
+.git
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/.distfiles b/dots/.config/zsh/config/plugins/fzf-tab/modules/.distfiles
new file mode 100644
index 0000000..d618a77
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/.distfiles
@@ -0,0 +1,4 @@
+DISTFILES_SRC='
+ META-FAQ
+ configure config.h.in stamp-h.in
+'
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/.editorconfig b/dots/.config/zsh/config/plugins/fzf-tab/modules/.editorconfig
new file mode 100644
index 0000000..808512e
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/.editorconfig
@@ -0,0 +1,15 @@
+# Top-most editorconfig file
+
+root = true
+
+[*]
+end_of_line = lf
+tab_width = 8
+indent_size = 2
+indent_style = tab
+
+[ChangeLog]
+indent_size = 8
+
+[*.[ch]]
+indent_size = 4
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/.gitignore b/dots/.config/zsh/config/plugins/fzf-tab/modules/.gitignore
new file mode 100644
index 0000000..f420136
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/.gitignore
@@ -0,0 +1,155 @@
+Makefile
+tags
+TAGS
+*.o
+*.o.c
+*.orig
+*.a
+*.so
+*.dll
+*~
+.*.sw?
+\#*
+
+/META-FAQ
+/config.cache
+/config.h
+/config.log
+/config.modules
+/config.modules.sh
+/config.status
+/config.status.lineno
+/cscope.out
+/stamp-h
+/autom4te.cache
+
+Config/defs.mk
+
+CVS
+.#*
+
+Doc/help
+Doc/help.txt
+Doc/help/[_a-zA-Z0-9]*
+
+Doc/intro.pdf
+Doc/intro.ps
+Doc/intro.a4.pdf
+Doc/intro.a4.ps
+Doc/intro.us.pdf
+Doc/intro.us.ps
+Doc/version.yo
+Doc/texi2html.conf
+Doc/zsh*.1
+Doc/zsh.texi
+Doc/zsh.info*
+Doc/*.html
+Doc/zsh.aux
+Doc/zsh.toc
+Doc/zsh.cp
+Doc/zsh.cps
+Doc/zsh.fn
+Doc/zsh.fns
+Doc/zsh.ky
+Doc/zsh.kys
+Doc/zsh.pg
+Doc/zsh.pgs
+Doc/zsh.vr
+Doc/zsh.vrs
+Doc/zsh.log
+Doc/zsh.dvi
+Doc/zsh_a4.dvi
+Doc/zsh_us.dvi
+Doc/zsh.tp
+Doc/zsh.tps
+Doc/zsh.idx
+Doc/zsh_*.ps
+Doc/infodir
+Doc/zsh.pdf
+Doc/zsh_a4.pdf
+Doc/zsh_us.pdf
+
+Doc/Zsh/modlist.yo
+Doc/Zsh/modmenu.yo
+Doc/Zsh/manmodmenu.yo
+
+Etc/FAQ
+Etc/FAQ.html
+
+Src/*.epro
+Src/*.export
+Src/*.mdh
+Src/*.mdh.tmp
+Src/*.mdhi
+Src/*.mdhs
+Src/*.syms
+Src/Makemod.in
+Src/Makemod
+Src/[_a-zA-Z0-9]*.pro
+Src/ansi2knr
+Src/bltinmods.list
+Src/cscope.out
+Src/libzsh.so*
+Src/modules-bltin
+Src/modules.index
+Src/modules.index.tmp
+Src/modules.stamp
+Src/patchlevel.h
+Src/sigcount.h
+Src/signames.c
+Src/signames2.c
+Src/stamp-modobjs
+Src/stamp-modobjs.tmp
+Src/tags
+Src/TAGS
+Src/version.h
+Src/zsh
+Src/zsh.exe
+Src/zshcurses.h
+Src/zshpaths.h
+Src/zshterm.h
+Src/zshxmods.h
+
+Src/Builtins/Makefile.in
+Src/Builtins/*.export
+Src/Builtins/so_locations
+Src/Builtins/*.pro
+Src/Builtins/*.epro
+Src/Builtins/*.syms
+Src/Builtins/*.mdh
+Src/Builtins/*.mdhi
+Src/Builtins/*.mdhs
+Src/Builtins/*.mdh.tmp
+Src/Builtins/rlimits.h
+
+Src/Modules/Makefile.in
+Src/Modules/*.export
+Src/Modules/so_locations
+Src/Modules/*.pro
+Src/Modules/*.epro
+Src/Modules/*.syms
+Src/Modules/*.mdh
+Src/Modules/*.mdhi
+Src/Modules/*.mdhs
+Src/Modules/*.mdh.tmp
+Src/Modules/errnames.c
+Src/Modules/errcount.h
+Src/Modules/curses_keys.h
+
+Src/Zle/Makefile.in
+Src/Zle/*.export
+Src/Zle/so_locations
+Src/Zle/*.pro
+Src/Zle/*.epro
+Src/Zle/*.syms
+Src/Zle/*.mdh
+Src/Zle/*.mdhi
+Src/Zle/*.mdhs
+Src/Zle/*.mdh.tmp
+Src/Zle/thingies.list
+Src/Zle/widgets.list
+Src/Zle/zle_things.h
+Src/Zle/zle_widget.h
+
+Test/*.tmp
+/.project
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/.preconfig b/dots/.config/zsh/config/plugins/fzf-tab/modules/.preconfig
new file mode 100755
index 0000000..f9729bd
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/.preconfig
@@ -0,0 +1,7 @@
+#! /bin/sh
+
+set -e
+
+autoconf
+autoheader
+echo > stamp-h.in
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/.cvsignore b/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/.cvsignore
new file mode 100644
index 0000000..dd265a7
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/.cvsignore
@@ -0,0 +1,2 @@
+defs.mk
+*.swp
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/.distfiles b/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/.distfiles
new file mode 100644
index 0000000..f03668b
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/.distfiles
@@ -0,0 +1,2 @@
+DISTFILES_SRC='
+'
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/aczshoot.m4 b/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/aczshoot.m4
new file mode 100644
index 0000000..3b90c6c
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/aczshoot.m4
@@ -0,0 +1,8 @@
+AC_DEFUN([zsh_OOT],
+[
+AC_CHECK_HEADERS(stdarg.h varargs.h termios.h termio.h)
+
+AC_TYPE_SIGNAL
+
+AC_DEFINE([ZSH_OOT_MODULE], [], [Out-of-tree module])
+])
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/clean.mk b/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/clean.mk
new file mode 100644
index 0000000..918a84f
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/clean.mk
@@ -0,0 +1,43 @@
+#
+# Makefile fragment for cleanup
+#
+# Copyright (c) 1995-1997 Richard Coleman
+# All rights reserved.
+#
+# Permission is hereby granted, without written agreement and without
+# license or royalty fees, to use, copy, modify, and distribute this
+# software and to distribute modified versions of this software for any
+# purpose, provided that the above copyright notice and the following
+# two paragraphs appear in all copies of this software.
+#
+# In no event shall Richard Coleman or the Zsh Development Group be liable
+# to any party for direct, indirect, special, incidental, or consequential
+# damages arising out of the use of this software and its documentation,
+# even if Richard Coleman and the Zsh Development Group have been advised of
+# the possibility of such damage.
+#
+# Richard Coleman and the Zsh Development Group specifically disclaim any
+# warranties, including, but not limited to, the implied warranties of
+# merchantability and fitness for a particular purpose. The software
+# provided hereunder is on an "as is" basis, and Richard Coleman and the
+# Zsh Development Group have no obligation to provide maintenance,
+# support, updates, enhancements, or modifications.
+#
+
+mostlyclean: mostlyclean-recursive mostlyclean-here
+clean: clean-recursive clean-here
+distclean: distclean-recursive distclean-here
+realclean: realclean-recursive realclean-here
+
+mostlyclean-here:
+clean-here: mostlyclean-here
+distclean-here: clean-here
+realclean-here: distclean-here
+
+mostlyclean-recursive clean-recursive distclean-recursive realclean-recursive:
+ @subdirs='$(SUBDIRS)'; if test -n "$$subdirs"; then \
+ target=`echo $@ | sed s/-recursive//`; \
+ for subdir in $$subdirs; do \
+ (cd $$subdir && $(MAKE) $(MAKEDEFS) $$target) || exit 1; \
+ done; \
+ fi
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/config.mk b/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/config.mk
new file mode 100644
index 0000000..fd9abf6
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/config.mk
@@ -0,0 +1,42 @@
+#
+# Makefile fragment for building Makefiles
+#
+# Copyright (c) 1995-1997 Richard Coleman
+# All rights reserved.
+#
+# Permission is hereby granted, without written agreement and without
+# license or royalty fees, to use, copy, modify, and distribute this
+# software and to distribute modified versions of this software for any
+# purpose, provided that the above copyright notice and the following
+# two paragraphs appear in all copies of this software.
+#
+# In no event shall Richard Coleman or the Zsh Development Group be liable
+# to any party for direct, indirect, special, incidental, or consequential
+# damages arising out of the use of this software and its documentation,
+# even if Richard Coleman and the Zsh Development Group have been advised of
+# the possibility of such damage.
+#
+# Richard Coleman and the Zsh Development Group specifically disclaim any
+# warranties, including, but not limited to, the implied warranties of
+# merchantability and fitness for a particular purpose. The software
+# provided hereunder is on an "as is" basis, and Richard Coleman and the
+# Zsh Development Group have no obligation to provide maintenance,
+# support, updates, enhancements, or modifications.
+#
+
+config: Makefile
+ @subdirs='$(SUBDIRS)'; for subdir in $$subdirs; do \
+ (cd $$subdir && $(MAKE) $(MAKEDEFS) $@) || exit 1; \
+ done
+
+CONFIG_INCS = \
+$(dir_top)/Config/clean.mk $(dir_top)/Config/config.mk \
+$(dir_top)/Config/defs.mk $(dir_top)/Config/version.mk
+
+Makefile: Makefile.in $(dir_top)/config.status $(CONFIG_INCS)
+ cd $(dir_top) && \
+ $(SHELL) ./config.status `echo $(subdir)/$@ | sed 's%^./%%'`
+
+$(dir_top)/Config/defs.mk: $(sdir_top)/Config/defs.mk.in $(dir_top)/config.status
+ cd $(dir_top) && \
+ $(SHELL) ./config.status Config/defs.mk
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/defs.mk.in b/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/defs.mk.in
new file mode 100644
index 0000000..2bc1748
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/defs.mk.in
@@ -0,0 +1,114 @@
+#
+# Basic Makefile definitions
+#
+# Copyright (c) 1995-1997 Richard Coleman
+# All rights reserved.
+#
+# Permission is hereby granted, without written agreement and without
+# license or royalty fees, to use, copy, modify, and distribute this
+# software and to distribute modified versions of this software for any
+# purpose, provided that the above copyright notice and the following
+# two paragraphs appear in all copies of this software.
+#
+# In no event shall Richard Coleman or the Zsh Development Group be liable
+# to any party for direct, indirect, special, incidental, or consequential
+# damages arising out of the use of this software and its documentation,
+# even if Richard Coleman and the Zsh Development Group have been advised of
+# the possibility of such damage.
+#
+# Richard Coleman and the Zsh Development Group specifically disclaim any
+# warranties, including, but not limited to, the implied warranties of
+# merchantability and fitness for a particular purpose. The software
+# provided hereunder is on an "as is" basis, and Richard Coleman and the
+# Zsh Development Group have no obligation to provide maintenance,
+# support, updates, enhancements, or modifications.
+#
+
+# fundamentals
+SHELL = /bin/sh
+@SET_MAKE@
+EXEEXT = @EXEEXT@
+
+# headers
+ZSH_CURSES_H = @ZSH_CURSES_H@
+ZSH_TERM_H = @ZSH_TERM_H@
+
+# install basename
+tzsh = @tzsh@
+
+# installation directories
+prefix = @prefix@
+exec_prefix = @exec_prefix@
+bindir = @bindir@
+libdir = @libdir@
+MODDIR = $(libdir)/$(tzsh)/$(VERSION)
+infodir = @infodir@
+mandir = @mandir@
+datarootdir = @datarootdir@
+datadir = @datadir@
+fndir = @fndir@
+fixed_sitefndir = @fixed_sitefndir@
+sitefndir = @sitefndir@
+scriptdir = @scriptdir@
+sitescriptdir = @sitescriptdir@
+htmldir = @htmldir@
+runhelpdir = @runhelpdir@
+runhelp = @runhelp@
+
+# compilation
+CC = @CC@
+CPP = @CPP@
+CPPFLAGS = @CPPFLAGS@
+DEFS = @DEFS@
+CFLAGS = @CFLAGS@
+LDFLAGS = @LDFLAGS@
+EXTRA_LDFLAGS = @EXTRA_LDFLAGS@
+DLCFLAGS = @DLCFLAGS@
+DLLDFLAGS = @DLLDFLAGS@
+LIBLDFLAGS = @LIBLDFLAGS@
+EXELDFLAGS = @EXELDFLAGS@
+LIBS = @LIBS@
+DL_EXT = @DL_EXT@
+DLLD = @DLLD@
+EXPOPT = @EXPOPT@
+IMPOPT = @IMPOPT@
+
+# utilities
+AWK = @AWK@
+ANSI2KNR = @ANSI2KNR@
+YODL = @YODL@ @YODL_OPTIONS@
+YODL2TXT = @YODL@2txt
+YODL2HTML = @YODL@2html
+
+# install utility
+INSTALL_PROGRAM = @INSTALL_PROGRAM@
+INSTALL_DATA = @INSTALL_DATA@
+
+# variables used in determining what to install
+FUNCTIONS_SUBDIRS = @FUNCTIONS_SUBDIRS@
+
+# Additional fpath entries (eg. for vendor specific directories).
+additionalfpath = @additionalfpath@
+
+# flags passed to recursive makes in subdirectories
+MAKEDEFS = \
+prefix='$(prefix)' exec_prefix='$(exec_prefix)' bindir='$(bindir)' \
+libdir='$(libdir)' MODDIR='$(MODDIR)' infodir='$(infodir)' mandir='$(mandir)' \
+datadir='$(datadir)' fndir='$(fndir)' htmldir='$(htmldir)' runhelpdir='$(runhelpdir)' \
+CC='$(CC)' CPPFLAGS='$(CPPFLAGS)' DEFS='$(DEFS)' CFLAGS='$(CFLAGS)' \
+LDFLAGS='$(LDFLAGS)' EXTRA_LDFLAGS='$(EXTRA_LDFLAGS)' \
+DLCFLAGS='$(DLCFLAGS)' DLLDFLAGS='$(DLLDFLAGS)' \
+LIBLDFLAGS='$(LIBLDFLAGS)' EXELDFLAGS='$(EXELDFLAGS)' \
+LIBS='$(LIBS)' DL_EXT='$(DL_EXT)' DLLD='$(DLLD)' \
+AWK='$(AWK)' ANSI2KNR='$(ANSI2KNR)' \
+YODL='$(YODL)' YODL2TXT='$(YODL2TXT)' YODL2HTML='$(YODL2HTML)' \
+FUNCTIONS_INSTALL='$(FUNCTIONS_INSTALL)' tzsh='$(tzsh)'
+
+# override built-in suffix list
+.SUFFIXES:
+
+# parallel build is not supported (pmake, gmake)
+.NOTPARALLEL:
+
+# parallel build is not supported (dmake)
+.NO_PARALLEL:
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/installfns.sh b/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/installfns.sh
new file mode 100755
index 0000000..149f359
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/installfns.sh
@@ -0,0 +1,74 @@
+#!/bin/sh
+
+fndir=$DESTDIR$fndir
+scriptdir=$DESTDIR$scriptdir
+
+/bin/sh $sdir_top/mkinstalldirs $fndir || exit 1;
+
+allfuncs="`grep ' functions=.' ${dir_top}/config.modules |
+ sed -e '/^#/d' -e '/ link=no/d' -e 's/^.* functions=//'`"
+
+allfuncs="`cd $sdir_top; echo ${allfuncs}`"
+
+test -d installfnsdir || mkdir installfnsdir
+
+# We now have a list of files, but we need to use `test -f' to check
+# (1) the glob got expanded (2) we are not looking at directories.
+for file in $allfuncs; do
+ if test -f $sdir_top/$file; then
+ case "$file" in
+ */CVS/*) continue;;
+ esac
+ if test x$FUNCTIONS_SUBDIRS != x && test x$FUNCTIONS_SUBDIRS != xno; then
+ case "$file" in
+ Completion/*/*)
+ subdir="`echo $file | sed -e 's%/[^/]*/[^/]*$%%'`"
+ instdir="$fndir/$subdir"
+ ;;
+ Completion/*)
+ instdir="$fndir/Completion"
+ ;;
+ Scripts/*)
+ instdir="$scriptdir"
+ ;;
+ *)
+ subdir="`echo $file | sed -e 's%/[^/]*$%%' -e 's%^Functions/%%'`"
+ instdir="$fndir/$subdir"
+ ;;
+ esac
+ else
+ case "$file" in
+ Scripts/*)
+ instdir="$scriptdir"
+ ;;
+ *)
+ instdir="$fndir"
+ ;;
+ esac
+ fi
+ basename=`basename $file`
+ ok=0
+ if test -d $instdir || /bin/sh $sdir_top/mkinstalldirs $instdir; then
+ if sed "s|@runhelpdir@|$runhelpdir|" <$sdir_top/$file \
+ >installfnsdir/$basename; then
+ if $INSTALL_DATA installfnsdir/$basename $instdir; then
+ ok=1
+ fi
+ fi
+ fi
+ case $ok in
+ 0)
+ rm -rf installfnsdir
+ exit 1
+ ;;
+ esac
+ read line < $sdir_top/$file
+ case "$line" in
+ '#!'*)
+ chmod +x $instdir/`echo $file | sed -e 's%^.*/%%'`
+ ;;
+ esac
+ fi
+done
+
+rm -rf installfnsdir
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/uninstallfns.sh b/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/uninstallfns.sh
new file mode 100755
index 0000000..7c22388
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/uninstallfns.sh
@@ -0,0 +1,59 @@
+#!/bin/sh
+
+fndir=$DESTDIR$fndir
+scriptdir=$DESTDIR$scriptdir
+
+allfuncs="`grep ' functions=' ${dir_top}/config.modules |
+ sed -e '/^#/d' -e '/ link=no/d' -e 's/^.* functions=//'`"
+
+allfuncs="`cd ${sdir_top}; echo ${allfuncs}`"
+
+case $fndir in
+ *$VERSION*)
+ # Version specific function directory, safe to remove completely.
+ rm -rf $fndir
+ ;;
+ *) # The following will only apply with a custom install directory
+ # with no version information. This is rather undesirable.
+ # But let's try and do the best we can.
+ # We now have a list of files, but we need to use `test -f' to check
+ # (1) the glob got expanded (2) we are not looking at directories.
+ for file in $allfuncs; do
+ case $file in
+ Scripts/*)
+ ;;
+ *)
+ if test -f $sdir_top/$file; then
+ if test x$FUNCTIONS_SUBDIRS != x -a x$FUNCTIONS_SUBDIRS != xno; then
+ file=`echo $file | sed -e 's%%^(Functions|Completion)/%'`
+ rm -f $fndir/$file
+ else
+ bfile="`echo $file | sed -e 's%^.*/%%'`"
+ rm -f "$fndir/$bfile"
+ fi
+ fi
+ ;;
+ esac
+ done
+ ;;
+esac
+
+case $scriptdir in
+ *$VERSION*)
+ # $scriptdir might be the parent of fndir.
+ rm -rf $scriptdir
+ ;;
+ *) for file in $allfuncs; do
+ case $file in
+ Scripts/*)
+ if test -f $sdir_top/$file; then
+ bfile="`echo $file | sed -e 's%^.*/%%'`"
+ rm -f "$scriptdir/$bfile"
+ fi
+ ;;
+ esac
+ done
+ ;;
+esac
+
+exit 0
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/version.mk b/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/version.mk
new file mode 100644
index 0000000..0ebed5e
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Config/version.mk
@@ -0,0 +1,31 @@
+#
+# Makefile fragment for version numbers
+#
+# Copyright (c) 1995-1997 Richard Coleman
+# All rights reserved.
+#
+# Permission is hereby granted, without written agreement and without
+# license or royalty fees, to use, copy, modify, and distribute this
+# software and to distribute modified versions of this software for any
+# purpose, provided that the above copyright notice and the following
+# two paragraphs appear in all copies of this software.
+#
+# In no event shall Richard Coleman or the Zsh Development Group be liable
+# to any party for direct, indirect, special, incidental, or consequential
+# damages arising out of the use of this software and its documentation,
+# even if Richard Coleman and the Zsh Development Group have been advised of
+# the possibility of such damage.
+#
+# Richard Coleman and the Zsh Development Group specifically disclaim any
+# warranties, including, but not limited to, the implied warranties of
+# merchantability and fitness for a particular purpose. The software
+# provided hereunder is on an "as is" basis, and Richard Coleman and the
+# Zsh Development Group have no obligation to provide maintenance,
+# support, updates, enhancements, or modifications.
+#
+
+# This must also serve as a shell script, so do not add spaces around the
+# `=' signs.
+
+VERSION=5.3.1-dev-0
+VERSION_DATE='December 22, 2016'
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/LICENCE b/dots/.config/zsh/config/plugins/fzf-tab/modules/LICENCE
new file mode 100644
index 0000000..08fcf88
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/LICENCE
@@ -0,0 +1,37 @@
+Unless otherwise noted in the header of specific files, files in this
+distribution have the licence shown below.
+
+However, note that certain shell functions are licensed under versions
+of the GNU General Public Licence. Anyone distributing the shell as a
+binary including those files needs to take account of this. Search
+shell functions for "Copyright" for specific copyright information.
+None of the core functions are affected by this, so those files may
+simply be omitted.
+
+--
+
+The Z Shell is copyright (c) 1992-2017 Paul Falstad, Richard Coleman,
+Zoltán Hidvégi, Andrew Main, Peter Stephenson, Sven Wischnowsky, and
+others. All rights reserved. Individual authors, whether or not
+specifically named, retain copyright in all changes; in what follows, they
+are referred to as `the Zsh Development Group'. This is for convenience
+only and this body has no legal status. The Z shell is distributed under
+the following licence; any provisions made in individual files take
+precedence.
+
+Permission is hereby granted, without written agreement and without
+licence or royalty fees, to use, copy, modify, and distribute this
+software and to distribute modified versions of this software for any
+purpose, provided that the above copyright notice and the following
+two paragraphs appear in all copies of this software.
+
+In no event shall the Zsh Development Group be liable to any party for
+direct, indirect, special, incidental, or consequential damages arising out
+of the use of this software and its documentation, even if the Zsh
+Development Group have been advised of the possibility of such damage.
+
+The Zsh Development Group specifically disclaim any warranties, including,
+but not limited to, the implied warranties of merchantability and fitness
+for a particular purpose. The software provided hereunder is on an "as is"
+basis, and the Zsh Development Group have no obligation to provide
+maintenance, support, updates, enhancements, or modifications.
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Makefile.in b/dots/.config/zsh/config/plugins/fzf-tab/modules/Makefile.in
new file mode 100644
index 0000000..4f9aa1a
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Makefile.in
@@ -0,0 +1,87 @@
+#
+# Makefile for top level of zsh distribution
+#
+# Copyright (c) 1995-1997 Richard Coleman
+# All rights reserved.
+#
+# Permission is hereby granted, without written agreement and without
+# license or royalty fees, to use, copy, modify, and distribute this
+# software and to distribute modified versions of this software for any
+# purpose, provided that the above copyright notice and the following
+# two paragraphs appear in all copies of this software.
+#
+# In no event shall Richard Coleman or the Zsh Development Group be liable
+# to any party for direct, indirect, special, incidental, or consequential
+# damages arising out of the use of this software and its documentation,
+# even if Richard Coleman and the Zsh Development Group have been advised of
+# the possibility of such damage.
+#
+# Richard Coleman and the Zsh Development Group specifically disclaim any
+# warranties, including, but not limited to, the implied warranties of
+# merchantability and fitness for a particular purpose. The software
+# provided hereunder is on an "as is" basis, and Richard Coleman and the
+# Zsh Development Group have no obligation to provide maintenance,
+# support, updates, enhancements, or modifications.
+#
+
+subdir = .
+dir_top = .
+SUBDIRS = Src
+
+@VERSION_MK@
+
+# source/build directories
+VPATH = @srcdir@
+sdir = @srcdir@
+sdir_top = @top_srcdir@
+INSTALL = @INSTALL@
+
+@DEFS_MK@
+
+# ========== DEPENDENCIES FOR BUILDING ==========
+
+# default target
+all: config.h config.modules
+ cd Src && $(MAKE) $(MAKEDEFS) $@
+
+# prepare module configuration
+prep:
+ @cd Src && $(MAKE) $(MAKEDEFS) $@
+
+# ========== DEPENDENCIES FOR CLEANUP ==========
+
+@CLEAN_MK@
+
+distclean-here:
+ rm -f Makefile config.h config.status config.log config.cache config.modules config.modules.sh stamp-h Config/defs.mk
+ rm -rf autom4te.cache
+
+realclean-here:
+ cd $(sdir) && rm -f config.h.in stamp-h.in configure
+
+# ========== DEPENDENCIES FOR MAINTENANCE ==========
+
+@CONFIG_MK@
+
+config: config.h
+
+config.status: $(sdir)/configure
+ $(SHELL) ./config.status --recheck
+
+$(sdir)/configure: $(sdir)/aclocal.m4 $(sdir)/aczsh.m4 $(sdir)/configure.ac
+ cd $(sdir) && autoconf
+
+config.h: stamp-h
+stamp-h: $(sdir)/config.h.in config.status
+ cd $(dir_top) && $(SHELL) ./config.status config.h $@
+
+config.modules: $(sdir)/config.h.in config.status config.modules.sh
+ cd $(dir_top) && $(SHELL) ./config.status $@ && \
+ $(SHELL) ./config.modules.sh
+
+$(sdir)/config.h.in: $(sdir)/stamp-h.in
+$(sdir)/stamp-h.in: $(sdir)/configure
+ cd $(sdir) && autoheader
+ echo > $(sdir)/stamp-h.in
+
+FORCE:
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/RECOMPILE_REQUEST b/dots/.config/zsh/config/plugins/fzf-tab/modules/RECOMPILE_REQUEST
new file mode 100644
index 0000000..cbf32b0
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/RECOMPILE_REQUEST
@@ -0,0 +1 @@
+1580588806
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/.cvsignore b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/.cvsignore
new file mode 100644
index 0000000..47b3191
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/.cvsignore
@@ -0,0 +1,35 @@
+*.dll
+*.epro
+*.export
+*.mdh
+*.mdh.tmp
+*.mdhi
+*.mdhs
+*.o
+*.o.c
+*.so
+*.swp
+*.syms
+Makefile
+Makemod.in Makemod
+[_a-zA-Z0-9]*.pro
+ansi2knr
+bltinmods.list
+cscope.out
+libzsh.so*
+modules-bltin
+modules.index
+modules.index.tmp
+modules.stamp
+patchlevel.h
+sigcount.h
+signames.c signames2.c
+stamp-modobjs
+stamp-modobjs.tmp
+tags TAGS
+version.h
+zsh
+zshcurses.h
+zshpaths.h
+zshterm.h
+zshxmods.h
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/.distfiles b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/.distfiles
new file mode 100644
index 0000000..f03668b
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/.distfiles
@@ -0,0 +1,2 @@
+DISTFILES_SRC='
+'
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/.exrc b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/.exrc
new file mode 100644
index 0000000..91d0b39
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/.exrc
@@ -0,0 +1,2 @@
+set ai
+set sw=4
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/.indent.pro b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/.indent.pro
new file mode 100644
index 0000000..1b41514
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/.indent.pro
@@ -0,0 +1,27 @@
+--dont-format-comments
+--procnames-start-lines
+--no-parameter-indentation
+--indent-level4
+--line-comments-indentation4
+--cuddle-else
+--brace-indent0
+--dont-star-comments
+--blank-lines-after-declarations
+--blank-lines-after-procedures
+--no-blank-lines-after-commas
+--comment-indentation33
+--declaration-comment-column33
+--no-comment-delimiters-on-blank-lines
+--continuation-indentation4
+--case-indentation0
+--else-endif-column33
+--no-space-after-casts
+--no-blank-before-sizeof
+--declaration-indentation0
+--continue-at-parentheses
+--no-space-after-function-call-names
+--swallow-optional-blank-lines
+--dont-space-special-semicolon
+--tab-size8
+--line-length132
+--braces-on-if-line
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/Makefile.in b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/Makefile.in
new file mode 100644
index 0000000..2987b64
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/Makefile.in
@@ -0,0 +1,164 @@
+#
+# Makefile for Src subdirectory
+#
+# Copyright (c) 1995-1997 Richard Coleman
+# All rights reserved.
+#
+# Permission is hereby granted, without written agreement and without
+# license or royalty fees, to use, copy, modify, and distribute this
+# software and to distribute modified versions of this software for any
+# purpose, provided that the above copyright notice and the following
+# two paragraphs appear in all copies of this software.
+#
+# In no event shall Richard Coleman or the Zsh Development Group be liable
+# to any party for direct, indirect, special, incidental, or consequential
+# damages arising out of the use of this software and its documentation,
+# even if Richard Coleman and the Zsh Development Group have been advised of
+# the possibility of such damage.
+#
+# Richard Coleman and the Zsh Development Group specifically disclaim any
+# warranties, including, but not limited to, the implied warranties of
+# merchantability and fitness for a particular purpose. The software
+# provided hereunder is on an "as is" basis, and Richard Coleman and the
+# Zsh Development Group have no obligation to provide maintenance,
+# support, updates, enhancements, or modifications.
+#
+
+subdir = Src
+dir_top = ..
+SUBDIRS =
+
+@VERSION_MK@
+
+# source/build directories
+VPATH = @srcdir@
+sdir = @srcdir@
+sdir_top = @top_srcdir@
+INSTALL = @INSTALL@
+LN = @LN@
+
+@DEFS_MK@
+
+sdir_src = $(sdir)
+dir_src = .
+
+# ========= DEPENDENCIES FOR BUILDING ==========
+
+LINK = $(CC) $(LDFLAGS) $(EXELDFLAGS) $(EXTRA_LDFLAGS) -o $@
+DLLINK = $(DLLD) $(LDFLAGS) $(LIBLDFLAGS) $(DLLDFLAGS) -o $@
+
+all: zsh.export modules
+.PHONY: all
+
+modules: headers
+.PHONY: modules
+
+L = @L@
+
+LSTMP =
+LLIST =
+NSTMP = stamp-modobjs
+NLIST = `cat stamp-modobjs`
+
+LIBZSH = libzsh-$(VERSION).$(DL_EXT)
+NIBZSH =
+INSTLIB = @INSTLIB@
+UNINSTLIB = @UNINSTLIB@
+
+ZSH_EXPORT = $(EXPOPT)zsh.export
+ZSH_NXPORT =
+ENTRYOBJ = modentry..o
+NNTRYOBJ =
+
+LDRUNPATH = LD_RUN_PATH=$(libdir)/$(tzsh)
+NDRUNPATH =
+
+EXTRAZSHOBJS = @EXTRAZSHOBJS@
+
+stamp-modobjs: modobjs
+ @if cmp -s stamp-modobjs.tmp stamp-modobjs; then \
+ rm -f stamp-modobjs.tmp; \
+ echo "\`stamp-modobjs' is up to date."; \
+ else \
+ mv -f stamp-modobjs.tmp stamp-modobjs; \
+ echo "Updated \`stamp-modobjs'."; \
+ fi
+
+modobjs: headers rm-modobjs-tmp
+.PHONY: modobjs
+
+rm-modobjs-tmp:
+ rm -f stamp-modobjs.tmp
+.PHONY: rm-modobjs-tmp
+
+@CONFIG_MK@
+
+Makemod: $(CONFIG_INCS) $(dir_top)/config.modules
+ @case $(sdir_top) in \
+ /*) top_srcdir=$(sdir_top) ;; \
+ *) top_srcdir=$(subdir)/$(sdir_top) ;; \
+ esac; \
+ export top_srcdir; \
+ echo 'cd $(dir_top) && $(SHELL)' \
+ '$$top_srcdir/$(subdir)/mkmakemod.sh $(subdir) Makemod'; \
+ cd $(dir_top) && \
+ $(SHELL) $$top_srcdir/$(subdir)/mkmakemod.sh $(subdir) Makemod
+prep: Makemod
+ @$(MAKE) -f Makemod $(MAKEDEFS) prep || rm -f Makemod
+.PHONY: prep
+
+FORCE:
+.PHONY: FORCE
+
+# ========== LINKING IN MODULES ==========
+
+mymods.conf:
+ @echo Linking with the standard modules.
+
+modules: $(@E@NTRYOBJ)
+
+$(ENTRYOBJ): FORCE
+ @$(MAKE) -f Makemod $(MAKEDEFS) $@
+
+# ========== DEPENDENCIES FOR CLEANUP ==========
+
+# Since module cleanup rules depend on Makemod, they come first. This
+# forces module stuff to get cleaned before Makemod itself gets
+# deleted.
+
+mostlyclean-here:
+ rm -f stamp-modobjs stamp-modobjs.tmp
+.PHONY: mostlyclean-here
+
+clean-here:
+ rm -f modules.stamp zsh$(EXEEXT)
+ rm -f libzsh-*.$(DL_EXT)
+.PHONY: clean-here
+
+distclean-here:
+ rm -f TAGS tags
+ rm -f Makefile
+.PHONY: distclean-here
+
+mostlyclean: mostlyclean-modules
+clean: clean-modules
+distclean: distclean-modules
+realclean: realclean-modules
+.PHONY: mostlyclean clean distclean realclean
+
+# Don't remake Makemod just to delete things, even if it doesn't exist.
+mostlyclean-modules clean-modules distclean-modules realclean-modules:
+ if test -f Makemod; then \
+ $(MAKE) -f Makemod $(MAKEDEFS) `echo $@ | sed 's/-modules//'`; \
+ fi; \
+ exit 0
+.PHONY: mostlyclean-modules clean-modules distclean-modules \
+ realclean-modules
+
+@CLEAN_MK@
+
+# ========== RECURSIVE MAKES ==========
+
+modobjs modules headers proto zsh.export: Makemod
+ @$(MAKE) -f Makemod $(MAKEDEFS) $@
+.PHONY: headers proto
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/Makemod.in.in b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/Makemod.in.in
new file mode 100644
index 0000000..ea0cdc3
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/Makemod.in.in
@@ -0,0 +1,192 @@
+#
+# Makemod.in.in
+#
+# Copyright (c) 1995-1997 Richard Coleman
+# All rights reserved.
+#
+# Permission is hereby granted, without written agreement and without
+# license or royalty fees, to use, copy, modify, and distribute this
+# software and to distribute modified versions of this software for any
+# purpose, provided that the above copyright notice and the following
+# two paragraphs appear in all copies of this software.
+#
+# In no event shall Richard Coleman or the Zsh Development Group be liable
+# to any party for direct, indirect, special, incidental, or consequential
+# damages arising out of the use of this software and its documentation,
+# even if Richard Coleman and the Zsh Development Group have been advised of
+# the possibility of such damage.
+#
+# Richard Coleman and the Zsh Development Group specifically disclaim any
+# warranties, including, but not limited to, the implied warranties of
+# merchantability and fitness for a particular purpose. The software
+# provided hereunder is on an "as is" basis, and Richard Coleman and the
+# Zsh Development Group have no obligation to provide maintenance,
+# support, updates, enhancements, or modifications.
+#
+
+# ========== OVERRIDABLE VARIABLES ==========
+
+# subdir is done by mkmakemod.sh
+# dir_top is done by mkmakemod.sh
+# SUBDIRS is done by mkmakemod.sh
+
+@VERSION_MK@
+
+# source/build directories
+VPATH = @srcdir@
+sdir = @srcdir@
+sdir_top = @top_srcdir@
+INSTALL = @INSTALL@
+
+@DEFS_MK@
+
+sdir_src = $(sdir_top)/Src
+dir_src = $(dir_top)/Src
+
+# ========== COMPILATION RULES ==========
+
+DNCFLAGS =
+
+COMPILE = $(CC) -c -I. -I$(dir_top)/Src -I$(sdir_top)/Src -I$(sdir_top)/Src/Zle -I$(sdir) $(CPPFLAGS) $(DEFS) $(CFLAGS) $(D@L@CFLAGS)
+DLCOMPILE = $(CC) -c -I. -I$(dir_top)/Src -I$(sdir_top)/Src -I$(sdir_top)/Src/Zle -I$(sdir) $(CPPFLAGS) $(DEFS) -DMODULE $(CFLAGS) $(DLCFLAGS)
+LINK = $(CC) $(LDFLAGS) $(EXELDFLAGS) $(EXTRA_LDFLAGS) -o $@
+DLLINK = $(DLLD) $(LDFLAGS) $(LIBLDFLAGS) $(DLLDFLAGS) -o $@
+
+KNR_OBJ=.o
+KNROBJ=._foo_
+
+ANSIOBJ=.o
+ANSI_OBJ=._foo_
+
+.SUFFIXES: .c .$(DL_EXT) ..o .._foo_ .o ._foo_ .syms .pro .epro
+
+.c$(ANSI@U@OBJ):
+ $(COMPILE) -o $@ $<
+ @rm -f $(dir_src)/stamp-modobjs
+
+.c$(KNR@U@OBJ):
+ @ANSI2KNR@ $< > $@.c
+ $(COMPILE) -o $@ $@.c
+ rm -f $@.c
+ @rm -f $(dir_src)/stamp-modobjs
+
+.c.$(ANSI@U@OBJ):
+ $(DLCOMPILE) -o $@ $<
+
+.c.$(KNR@U@OBJ):
+ @ANSI2KNR@ $< > $@.c
+ $(DLCOMPILE) -o $@ $@.c
+ rm -f $@.c
+
+.c.syms:
+ $(AWK) -f $(sdir_src)/makepro.awk $< $(subdir) > $@
+
+.syms.epro:
+ (echo '/* Generated automatically */'; sed -n '/^E/{s/^E//;p;}' < $<) \
+ > $@
+ (echo '/* Generated automatically */'; sed -n '/^L/{s/^L//;p;}' < $<) \
+ > `echo $@ | sed 's/\.epro$$/.pro/'`
+
+PROTODEPS = $(sdir_src)/makepro.awk
+
+# ========== DEPENDENCIES FOR BUILDING ==========
+
+all: modobjs modules
+.PHONY: all
+
+modobjs: $(MODOBJS)
+modules: $(MODULES)
+headers: $(MDHS)
+proto: $(PROTOS)
+.PHONY: modobjs modules headers proto
+
+prep:
+ @case $(sdir_top) in \
+ /*) top_srcdir=$(sdir_top) ;; \
+ *) top_srcdir=$(subdir)/$(sdir_top) ;; \
+ esac; \
+ export top_srcdir; \
+ cd $(dir_top) || exit 1; \
+ subdirs='$(SUBDIRS)'; \
+ for subdir in $$subdirs; do \
+ dir=$(subdir)/$$subdir; \
+ test -d $$dir || mkdir $$dir; \
+ $(SHELL) $$top_srcdir/Src/mkmakemod.sh $$dir Makefile || exit 1; \
+ ( cd $$dir && $(MAKE) $(MAKEDEFS) $@ ) || exit 1; \
+ done
+.PHONY: prep
+
+headers: $(dir_src)/modules.stamp
+$(dir_src)/modules.stamp: $(MDDS)
+ $(MAKE) -f $(makefile) $(MAKEDEFS) prep
+ echo 'timestamp for *.mdd files' > $@
+.PHONY: headers
+
+FORCE:
+.PHONY: FORCE
+
+# ========== DEPENDENCIES FOR INSTALLING ==========
+
+install: install.bin install.modules
+uninstall: uninstall.bin uninstall.modules
+.PHONY: install uninstall
+
+install.bin: install.bin-here
+uninstall.bin: uninstall.bin-here
+install.modules: install.modules-here
+uninstall.modules: uninstall.modules-here
+.PHONY: install.bin uninstall.bin install.modules uninstall.modules
+
+install.bin-here uninstall.bin-here:
+install.modules-here uninstall.modules-here:
+.PHONY: install.bin-here install.modules-here
+
+# ========== DEPENDENCIES FOR CLEANUP ==========
+
+@CLEAN_MK@
+
+mostlyclean-here:
+ rm -f *.o *.export *.$(DL_EXT)
+.PHONY: mostlyclean-here
+
+clean-here:
+ rm -f *.o.c *.syms *.pro *.epro *.mdh *.mdhi *.mdhs *.mdh.tmp
+.PHONY: clean-here
+
+distclean-here:
+ rm -f $(makefile) $(makefile).in
+.PHONY: distclean-here
+
+# ========== RECURSIVE MAKES ==========
+
+install.bin uninstall.bin install.modules uninstall.modules \
+modobjs modules headers proto:
+ @subdirs='$(SUBDIRS)'; for subdir in $$subdirs; do \
+ ( cd $$subdir && $(MAKE) $(MAKEDEFS) $@ ) || exit 1; \
+ done
+
+# ========== DEPENDENCIES FOR MAINTENANCE ==========
+
+$(makefile): $(makefile).in $(dir_top)/config.status
+ @case $(sdir_top) in \
+ /*) top_srcdir=$(sdir_top) ;; \
+ *) top_srcdir=$(subdir)/$(sdir_top) ;; \
+ esac; \
+ export top_srcdir; \
+ echo 'cd $(dir_top) && $(SHELL)' \
+ '$$top_srcdir/Src/mkmakemod.sh -m $(subdir) $(makefile)'; \
+ cd $(dir_top) && \
+ $(SHELL) $$top_srcdir/Src/mkmakemod.sh -m $(subdir) $(makefile)
+
+$(makefile).in: $(sdir_src)/mkmakemod.sh $(sdir_src)/Makemod.in.in $(MDDS) \
+ $(dir_top)/config.modules
+ @case $(sdir_top) in \
+ /*) top_srcdir=$(sdir_top) ;; \
+ *) top_srcdir=$(subdir)/$(sdir_top) ;; \
+ esac; \
+ export top_srcdir; \
+ echo 'cd $(dir_top) && $(SHELL)' \
+ '$$top_srcdir/Src/mkmakemod.sh -i $(subdir) $(makefile)'; \
+ cd $(dir_top) && \
+ $(SHELL) $$top_srcdir/Src/mkmakemod.sh -i $(subdir) $(makefile)
+
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/aloxaf/.cvsignore b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/aloxaf/.cvsignore
new file mode 100644
index 0000000..f72db84
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/aloxaf/.cvsignore
@@ -0,0 +1,18 @@
+Makefile
+Makefile.in
+*.export
+so_locations
+*.pro
+*.epro
+*.syms
+*.o
+*.o.c
+*.so
+*.mdh
+*.mdhi
+*.mdhs
+*.mdh.tmp
+*.swp
+errnames.c errcount.h
+*.dll
+curses_keys.h
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/aloxaf/.distfiles b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/aloxaf/.distfiles
new file mode 100644
index 0000000..f03668b
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/aloxaf/.distfiles
@@ -0,0 +1,2 @@
+DISTFILES_SRC='
+'
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/aloxaf/.exrc b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/aloxaf/.exrc
new file mode 100644
index 0000000..91d0b39
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/aloxaf/.exrc
@@ -0,0 +1,2 @@
+set ai
+set sw=4
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/aloxaf/.gitignore b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/aloxaf/.gitignore
new file mode 100644
index 0000000..92f708e
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/aloxaf/.gitignore
@@ -0,0 +1,8 @@
+Makefile.in
+*.epro
+*.export
+*.mdh
+*.mdhi
+*.mdhs
+*.pro
+*.syms
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/aloxaf/fzftab.c b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/aloxaf/fzftab.c
new file mode 100644
index 0000000..d945f86
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/aloxaf/fzftab.c
@@ -0,0 +1,543 @@
+#include "fzftab.mdh"
+#include "fzftab.pro"
+#include
+#include
+#include
+#include
+
+const char* get_color(char* file, const struct stat* sb);
+const char* get_suffix(char* file, const struct stat* sb);
+const char* colorize_from_mode(char* file, const struct stat* sb);
+const char* colorize_from_name(char* file);
+char** fzf_tab_colorize(char* file);
+int compile_patterns(char* nam, char** list_colors);
+char* ftb_strcat(char* dst, int n, ...);
+
+/* Indixes into the terminal string arrays. */
+#define COL_NO 0
+#define COL_FI 1
+#define COL_DI 2
+#define COL_LN 3
+#define COL_PI 4
+#define COL_SO 5
+#define COL_BD 6
+#define COL_CD 7
+#define COL_OR 8
+#define COL_MI 9
+#define COL_SU 10
+#define COL_SG 11
+#define COL_TW 12
+#define COL_OW 13
+#define COL_ST 14
+#define COL_EX 15
+#define COL_LC 16
+#define COL_RC 17
+#define COL_EC 18
+#define COL_TC 19
+#define COL_SP 20
+#define COL_MA 21
+#define COL_HI 22
+#define COL_DU 23
+#define COL_SA 24
+
+#define NUM_COLS 25
+
+/* Names of the terminal strings. */
+static char* colnames[] = { "no", "fi", "di", "ln", "pi", "so", "bd", "cd", "or", "mi", "su", "sg",
+ "tw", "ow", "st", "ex", "lc", "rc", "ec", "tc", "sp", "ma", "hi", "du", "sa", NULL };
+
+/* Default values. */
+static char* defcols[]
+ = { "0", "0", "1;31", "1;36", "33", "1;35", "1;33", "1;33", NULL, NULL, "37;41", "30;43",
+ "30;42", "34;42", "37;44", "1;32", "\033[", "m", NULL, "0", "0", "7", NULL, NULL, "0" };
+
+static char* fzf_tab_module_version;
+
+struct pattern {
+ Patprog pat;
+ char color[50];
+};
+
+static int opt_list_type = OPT_INVALID;
+static int pat_cnt = 0;
+static struct pattern* name_color = NULL;
+static char mode_color[NUM_COLS][20];
+
+// TODO: use ZLS_COLORS ?
+int compile_patterns(char* nam, char** list_colors)
+{
+ // clean old name_color and set pat_cnt = 0
+ if (pat_cnt != 0) {
+ while (--pat_cnt) {
+ freepatprog(name_color[pat_cnt].pat);
+ }
+ free(name_color);
+ }
+ // initialize mode_color with default value
+ for (int i = 0; i < NUM_COLS; i++) {
+ if (defcols[i]) {
+ strcpy(mode_color[i], defcols[i]);
+ }
+ }
+ // empty array, just return
+ if (list_colors == NULL) {
+ return 0;
+ }
+
+ // how many pattens?
+ while (list_colors[pat_cnt] != NULL) {
+ pat_cnt++;
+ }
+ name_color = zshcalloc(pat_cnt * sizeof(struct pattern));
+
+ for (int i = 0; i < pat_cnt; i++) {
+ char* pat = ztrdup(list_colors[i]);
+ char* color = strrchr(pat, '=');
+ if (color == NULL)
+ continue;
+ *color = '\0';
+ tokenize(pat);
+ remnulargs(pat);
+
+ // mode=color
+ bool skip = false;
+ for (int j = 0; j < NUM_COLS; j++) {
+ if (strpfx(colnames[j], list_colors[i])) {
+ strcpy(mode_color[j], color + 1);
+ name_color[i].pat = NULL;
+ skip = true;
+ }
+ }
+ if (skip) {
+ continue;
+ }
+
+ // name=color
+ if (!(name_color[i].pat = patcompile(pat, PAT_ZDUP, NULL))) {
+ zwarnnam(nam, "bad pattern: %s", list_colors[i]);
+ return 1;
+ }
+
+ strcpy(name_color[i].color, color + 1);
+ free(pat);
+ }
+ return 0;
+}
+
+// TODO: use zsh mod_export function `file_type` ?
+const char* get_suffix(char* file, const struct stat* sb)
+{
+ struct stat sb2;
+ mode_t filemode = sb->st_mode;
+
+ if (S_ISBLK(filemode))
+ return "#";
+ else if (S_ISCHR(filemode))
+ return "%";
+ else if (S_ISDIR(filemode))
+ return "/";
+ else if (S_ISFIFO(filemode))
+ return "|";
+ else if (S_ISLNK(filemode))
+ if (strpfx(mode_color[COL_LN], "target")) {
+ if (stat(file, &sb2) == -1) {
+ return "@";
+ }
+ return get_suffix(file, &sb2);
+ } else {
+ return "@";
+ }
+ else if (S_ISREG(filemode))
+ return (filemode & S_IXUGO) ? "*" : "";
+ else if (S_ISSOCK(filemode))
+ return "=";
+ else
+ return "?";
+}
+
+const char* get_color(char* file, const struct stat* sb)
+{
+ // no list-colors, return empty color
+ if (pat_cnt == 0) {
+ return "";
+ }
+ const char* ret;
+ if ((ret = colorize_from_mode(file, sb)) || (ret = colorize_from_name(file))) {
+ return ret;
+ }
+ return mode_color[COL_FI];
+}
+
+const char* colorize_from_name(char* file)
+{
+ for (int i = 0; i < pat_cnt; i++) {
+ if (name_color && name_color[i].pat && pattry(name_color[i].pat, file)) {
+ return name_color[i].color;
+ }
+ }
+ return NULL;
+}
+
+const char* colorize_from_mode(char* file, const struct stat* sb)
+{
+ struct stat sb2;
+
+ switch (sb->st_mode & S_IFMT) {
+ case S_IFDIR:
+ return mode_color[COL_DI];
+ case S_IFLNK: {
+ if (strpfx(mode_color[COL_LN], "target")) {
+ if (stat(file, &sb2) == -1) {
+ return mode_color[COL_OR];
+ }
+ return get_color(file, &sb2);
+ }
+ }
+ case S_IFIFO:
+ return mode_color[COL_PI];
+ case S_IFSOCK:
+ return mode_color[COL_SO];
+ case S_IFBLK:
+ return mode_color[COL_BD];
+ case S_IFCHR:
+ return mode_color[COL_CD];
+ default:
+ break;
+ }
+
+ if (sb->st_mode & S_ISUID) {
+ return mode_color[COL_SU];
+ } else if (sb->st_mode & S_ISGID) {
+ return mode_color[COL_SG];
+ // tw ow st ??
+ } else if (sb->st_mode & S_IXUSR) {
+ return mode_color[COL_EX];
+ }
+
+ /* Check for suffix alias */
+ size_t len = strlen(file);
+ /* shortest valid suffix format is a.b */
+ if (len > 2) {
+ const char* suf = file + len - 1;
+ while (suf > file + 1) {
+ if (suf[-1] == '.') {
+ if (sufaliastab->getnode(sufaliastab, suf)) {
+ return mode_color[COL_SA];
+ }
+ break;
+ }
+ suf--;
+ }
+ }
+
+ return NULL;
+}
+
+struct {
+ char** array;
+ size_t len;
+ size_t size;
+} ftb_compcap;
+
+// Usage:
+// initialize fzf-tab-generate-compcap -i
+// output to _ftb_compcap fzf-tab-generate-compcap -o
+// add a entry fzf-tab-generate-compcap word desc opts
+static int bin_fzf_tab_compcap_generate(char* nam, char** args, Options ops, UNUSED(int func))
+{
+ if (OPT_ISSET(ops, 'o')) {
+ // write final result to _ftb_compcap
+ setaparam("_ftb_compcap", ftb_compcap.array);
+ ftb_compcap.array = NULL;
+ return 0;
+ } else if (OPT_ISSET(ops, 'i')) {
+ // init
+ if (ftb_compcap.array)
+ freearray(ftb_compcap.array);
+ ftb_compcap.array = zshcalloc(1024 * sizeof(char*));
+ ftb_compcap.len = 0, ftb_compcap.size = 1024;
+ return 0;
+ }
+ if (ftb_compcap.array == NULL) {
+ zwarnnam(nam, "please initialize it first");
+ return 1;
+ }
+
+ // get paramaters
+ char **words = getaparam(args[0]), **dscrs = getaparam(args[1]), *opts = getsparam(args[2]);
+ if (!words || !dscrs || !opts) {
+ zwarnnam(nam, "wrong argument");
+ return 1;
+ }
+
+ char *bs = metafy("\2", 1, META_DUP), *nul = metafy("\0word\0", 6, META_DUP);
+ size_t dscrs_cnt = arrlen(dscrs);
+
+ for (int i = 0; words[i]; i++) {
+ // TODO: replace '\n'
+ char* buffer = zshcalloc(256 * sizeof(char));
+ char* dscr = i < dscrs_cnt ? dscrs[i] : words[i];
+
+ buffer = ftb_strcat(buffer, 5, dscr, bs, opts, nul, words[i]);
+ ftb_compcap.array[ftb_compcap.len++] = buffer;
+
+ if (ftb_compcap.len == ftb_compcap.size) {
+ ftb_compcap.array
+ = zrealloc(ftb_compcap.array, (1024 + ftb_compcap.size) * sizeof(char*));
+ ftb_compcap.size += 1024;
+ memset(ftb_compcap.array + ftb_compcap.size - 1024, 0, 1024 * sizeof(char*));
+ }
+ }
+
+ zsfree(bs);
+ zsfree(nul);
+
+ return 0;
+}
+
+// cat n string, return the pointer to the new string
+// `size` is the size of dst
+// dst will be reallocated if is not big enough
+char* ftb_strcat(char* dst, int n, ...)
+{
+ va_list valist;
+ va_start(valist, n);
+
+ char* final = zrealloc(dst, 128);
+ size_t size = 128, max_len = 128 - 1;
+ dst = final;
+
+ for (int i = 0, idx = 0; i < n; i++) {
+ char* src = va_arg(valist, char*);
+ for (; *src != '\0'; dst++, src++, idx++) {
+ if (idx == max_len) {
+ size += size / 2;
+ final = zrealloc(final, size);
+ max_len = size - 1;
+ dst = &final[idx];
+ }
+ *dst = *src;
+ }
+ }
+ *dst = '\0';
+ va_end(valist);
+
+ return final;
+}
+
+// accept an
+char** fzf_tab_colorize(char* file)
+{
+ // TODO: can avoid so many zalloc here?
+ file = unmeta(file);
+
+ struct stat sb;
+ if (lstat(file, &sb) == -1) {
+ return NULL;
+ }
+
+ const char* suffix = "";
+ if (isset(opt_list_type)) {
+ suffix = get_suffix(file, &sb);
+ }
+ const char* color = get_color(file, &sb);
+
+ char* symlink = "";
+ const char* symcolor = "";
+ if ((sb.st_mode & S_IFMT) == S_IFLNK) {
+ symlink = zalloc(PATH_MAX);
+ int end = readlink(file, symlink, PATH_MAX);
+ symlink[end] = '\0';
+ if (stat(file, &sb) == -1) {
+ symcolor = mode_color[COL_OR];
+ } else {
+ char tmp[PATH_MAX];
+ realpath(file, tmp);
+ symcolor = get_color(file, &sb);
+ }
+ }
+
+ char** reply = zshcalloc((4 + 1) * sizeof(char*));
+
+ if (strlen(color) != 0) {
+ reply[0] = zalloc(128);
+ reply[1] = zalloc(128);
+ sprintf(reply[0], "%s%s%s", mode_color[COL_LC], color, mode_color[COL_RC]);
+ sprintf(reply[1], "%s%s%s", mode_color[COL_LC], "0", mode_color[COL_RC]);
+ } else {
+ reply[0] = ztrdup("");
+ reply[1] = ztrdup("");
+ }
+
+ reply[2] = ztrdup(suffix);
+
+ if (symlink[0] != '\0') {
+ reply[3] = zalloc(PATH_MAX);
+ sprintf(reply[3], "%s%s%s%s%s%s%s", mode_color[COL_LC], symcolor, mode_color[COL_RC],
+ symlink, mode_color[COL_LC], "0", mode_color[COL_RC]);
+ free(symlink);
+ } else {
+ reply[3] = ztrdup("");
+ }
+ for (int i = 0; i < 4; i++) {
+ reply[i] = metafy(reply[i], -1, META_REALLOC);
+ }
+
+ return reply;
+}
+
+static int bin_fzf_tab_candidates_generate(char* nam, char** args, Options ops, UNUSED(int func))
+{
+ if (OPT_ISSET(ops, 'i')) {
+ // compile list_colors pattern
+ if (*args == NULL) {
+ zwarnnam(nam, "please specify an array");
+ return 1;
+ } else {
+ char** array = getaparam(*args);
+ return compile_patterns(nam, array);
+ }
+ }
+
+ char **ftb_compcap = getaparam("_ftb_compcap"), **group_colors = getaparam("group_colors"),
+ *default_color = getsparam("default_color"), *prefix = getsparam("prefix");
+
+ size_t group_colors_len = arrlen(group_colors);
+ size_t ftb_compcap_len = arrlen(ftb_compcap);
+
+ char *bs = metafy("\b", 1, META_DUP), *nul = metafy("\0", 1, META_DUP),
+ *soh = metafy("\2", 1, META_DUP);
+
+ char **candidates = zshcalloc(sizeof(char*) * (ftb_compcap_len + 1)),
+ *filepath = zshcalloc(PATH_MAX * sizeof(char)), *dpre = zshcalloc(128),
+ *dsuf = zshcalloc(128);
+
+ char* first_word = zshcalloc(512 * sizeof(char));
+ int same_word = 1;
+
+ for (int i = 0; i < ftb_compcap_len; i++) {
+ char *word = "", *group = NULL, *realdir = NULL;
+ strcpy(dpre, "");
+ strcpy(dsuf, "");
+
+ // extract all the variables what we need
+ char** compcap = sepsplit(ftb_compcap[i], soh, 1, 0);
+ char* desc = compcap[0];
+ char** info = sepsplit(compcap[1], nul, 1, 0);
+
+ for (int j = 0; info[j]; j += 2) {
+ if (!strcmp(info[j], "word")) {
+ word = info[j + 1];
+ // unquote word
+ parse_subst_string(word);
+ remnulargs(word);
+ untokenize(word);
+ } else if (!strcmp(info[j], "group")) {
+ group = info[j + 1];
+ } else if (!strcmp(info[j], "realdir")) {
+ realdir = info[j + 1];
+ }
+ }
+
+ // check if all the words are the same
+ if (i == 0) {
+ first_word = ftb_strcat(first_word, 1, word);
+ } else if (same_word && strcmp(word, first_word) != 0) {
+ same_word = 0;
+ }
+
+ // add character and color to describe the type of the files
+ if (realdir) {
+ filepath = ftb_strcat(filepath, 2, realdir, word);
+ char** reply = fzf_tab_colorize(filepath);
+ if (reply != NULL) {
+ dpre = ftb_strcat(dpre, 2, reply[1], reply[0]);
+ if (reply[3][0] != '\0') {
+ dsuf = ftb_strcat(dsuf, 4, reply[1], reply[2], " -> ", reply[3]);
+ } else {
+ dsuf = ftb_strcat(dsuf, 2, reply[1], reply[2]);
+ }
+ if (dpre[0] != '\0') {
+ setiparam("colorful", 1);
+ }
+ freearray(reply);
+ }
+ }
+
+ char* result = zshcalloc(256 * sizeof(char));
+
+ // add color to description if they have group index
+ if (group) {
+ // use strtol ?
+ int group_index = atoi(group);
+ char* color = group_index >= group_colors_len ? "" : group_colors[group_index - 1];
+ // add prefix
+ result = ftb_strcat(
+ result, 11, group, bs, color, prefix, dpre, nul, group, bs, desc, nul, dsuf);
+ } else {
+ result = ftb_strcat(result, 6, default_color, dpre, nul, desc, nul, dsuf);
+ }
+ // quotedzputs(result, stdout);
+ // putchar('\n');
+ candidates[i] = result;
+
+ freearray(info);
+ freearray(compcap);
+ }
+
+ setaparam("tcandidates", candidates);
+ setiparam("same_word", same_word);
+ zsfree(dpre);
+ zsfree(dsuf);
+ zsfree(filepath);
+ zsfree(first_word);
+
+ return 0;
+}
+
+static struct builtin bintab[] = {
+ BUILTIN("fzf-tab-compcap-generate", 0, bin_fzf_tab_compcap_generate, 0, -1, 0, "io", NULL),
+ BUILTIN("fzf-tab-candidates-generate", 0, bin_fzf_tab_candidates_generate, 0, -1, 0, "i", NULL),
+};
+
+static struct paramdef patab[] = {
+ STRPARAMDEF("FZF_TAB_MODULE_VERSION", &fzf_tab_module_version),
+};
+
+// clang-format off
+static struct features module_features = {
+ bintab, sizeof(bintab) / sizeof(*bintab),
+ NULL, 0,
+ NULL, 0,
+ patab, sizeof(patab) / sizeof(*patab),
+ 0,
+};
+// clang-format on
+
+int setup_(UNUSED(Module m)) { return 0; }
+
+int features_(Module m, char*** features)
+{
+ *features = featuresarray(m, &module_features);
+ return 0;
+}
+
+int enables_(Module m, int** enables) { return handlefeatures(m, &module_features, enables); }
+
+int boot_(UNUSED(Module m))
+{
+ fzf_tab_module_version = ztrdup("0.2.2");
+ // different zsh version may have different value of list_type's index
+ // so query it dynamically
+ opt_list_type = optlookup("list_types");
+ return 0;
+}
+
+int cleanup_(UNUSED(Module m)) { return setfeatureenables(m, &module_features, NULL); }
+
+int finish_(UNUSED(Module m))
+{
+ printf("fzf-tab module unloaded.\n");
+ fflush(stdout);
+ return 0;
+}
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/aloxaf/fzftab.mdd b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/aloxaf/fzftab.mdd
new file mode 100644
index 0000000..371bb95
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/aloxaf/fzftab.mdd
@@ -0,0 +1,7 @@
+name=aloxaf/fzftab
+link=dynamic
+load=no
+
+autofeatures="b:fzf-tab-colorize p:FZF_TAB_MODULE_VERSION"
+
+objects="fzftab.o"
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/builtin.c b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/builtin.c
new file mode 100644
index 0000000..93fa911
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/builtin.c
@@ -0,0 +1,7236 @@
+/*
+ * builtin.c - builtin commands
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+/* this is defined so we get the prototype for open_memstream */
+#define _GNU_SOURCE 1
+
+#include "zsh.mdh"
+#include "builtin.pro"
+
+/* Builtins in the main executable */
+
+static struct builtin builtins[] =
+{
+ BIN_PREFIX("-", BINF_DASH),
+ BIN_PREFIX("builtin", BINF_BUILTIN),
+ BIN_PREFIX("command", BINF_COMMAND),
+ BIN_PREFIX("exec", BINF_EXEC),
+ BIN_PREFIX("noglob", BINF_NOGLOB),
+ BUILTIN("[", BINF_HANDLES_OPTS, bin_test, 0, -1, BIN_BRACKET, NULL, NULL),
+ BUILTIN(".", BINF_PSPECIAL, bin_dot, 1, -1, 0, NULL, NULL),
+ BUILTIN(":", BINF_PSPECIAL, bin_true, 0, -1, 0, NULL, NULL),
+ BUILTIN("alias", BINF_MAGICEQUALS | BINF_PLUSOPTS, bin_alias, 0, -1, 0, "Lgmrs", NULL),
+ BUILTIN("autoload", BINF_PLUSOPTS, bin_functions, 0, -1, 0, "dmktrRTUwWXz", "u"),
+ BUILTIN("bg", 0, bin_fg, 0, -1, BIN_BG, NULL, NULL),
+ BUILTIN("break", BINF_PSPECIAL, bin_break, 0, 1, BIN_BREAK, NULL, NULL),
+ BUILTIN("bye", 0, bin_break, 0, 1, BIN_EXIT, NULL, NULL),
+ BUILTIN("cd", BINF_SKIPINVALID | BINF_SKIPDASH | BINF_DASHDASHVALID, bin_cd, 0, 2, BIN_CD, "qsPL", NULL),
+ BUILTIN("chdir", BINF_SKIPINVALID | BINF_SKIPDASH | BINF_DASHDASHVALID, bin_cd, 0, 2, BIN_CD, "qsPL", NULL),
+ BUILTIN("continue", BINF_PSPECIAL, bin_break, 0, 1, BIN_CONTINUE, NULL, NULL),
+ BUILTIN("declare", BINF_PLUSOPTS | BINF_MAGICEQUALS | BINF_PSPECIAL | BINF_ASSIGN, (HandlerFunc)bin_typeset, 0, -1, 0, "AE:%F:%HL:%R:%TUZ:%afghi:%klmp:%rtuxz", NULL),
+ BUILTIN("dirs", 0, bin_dirs, 0, -1, 0, "clpv", NULL),
+ BUILTIN("disable", 0, bin_enable, 0, -1, BIN_DISABLE, "afmprs", NULL),
+ BUILTIN("disown", 0, bin_fg, 0, -1, BIN_DISOWN, NULL, NULL),
+ BUILTIN("echo", BINF_SKIPINVALID, bin_print, 0, -1, BIN_ECHO, "neE", "-"),
+ BUILTIN("emulate", 0, bin_emulate, 0, -1, 0, "lLR", NULL),
+ BUILTIN("enable", 0, bin_enable, 0, -1, BIN_ENABLE, "afmprs", NULL),
+ BUILTIN("eval", BINF_PSPECIAL, bin_eval, 0, -1, BIN_EVAL, NULL, NULL),
+ BUILTIN("exit", BINF_PSPECIAL, bin_break, 0, 1, BIN_EXIT, NULL, NULL),
+ BUILTIN("export", BINF_PLUSOPTS | BINF_MAGICEQUALS | BINF_PSPECIAL | BINF_ASSIGN, (HandlerFunc)bin_typeset, 0, -1, 0, "E:%F:%HL:%R:%TUZ:%afhi:%lp:%rtu", "xg"),
+ BUILTIN("false", 0, bin_false, 0, -1, 0, NULL, NULL),
+ /*
+ * We used to behave as if the argument to -e was optional.
+ * But that's actually not useful, so it's more consistent to
+ * cause an error.
+ */
+ BUILTIN("fc", 0, bin_fc, 0, -1, BIN_FC, "aAdDe:EfiIlLmnpPrRt:W", NULL),
+ BUILTIN("fg", 0, bin_fg, 0, -1, BIN_FG, NULL, NULL),
+ BUILTIN("float", BINF_PLUSOPTS | BINF_MAGICEQUALS | BINF_PSPECIAL | BINF_ASSIGN, (HandlerFunc)bin_typeset, 0, -1, 0, "E:%F:%HL:%R:%Z:%ghlp:%rtux", "E"),
+ BUILTIN("functions", BINF_PLUSOPTS, bin_functions, 0, -1, 0, "kmMstTuUWx:z", NULL),
+ BUILTIN("getln", 0, bin_read, 0, -1, 0, "ecnAlE", "zr"),
+ BUILTIN("getopts", 0, bin_getopts, 2, -1, 0, NULL, NULL),
+ BUILTIN("hash", BINF_MAGICEQUALS, bin_hash, 0, -1, 0, "Ldfmrv", NULL),
+
+#ifdef ZSH_HASH_DEBUG
+ BUILTIN("hashinfo", 0, bin_hashinfo, 0, 0, 0, NULL, NULL),
+#endif
+
+ BUILTIN("history", 0, bin_fc, 0, -1, BIN_FC, "adDEfiLmnpPrt:", "l"),
+ BUILTIN("integer", BINF_PLUSOPTS | BINF_MAGICEQUALS | BINF_PSPECIAL | BINF_ASSIGN, (HandlerFunc)bin_typeset, 0, -1, 0, "HL:%R:%Z:%ghi:%lp:%rtux", "i"),
+ BUILTIN("jobs", 0, bin_fg, 0, -1, BIN_JOBS, "dlpZrs", NULL),
+ BUILTIN("kill", BINF_HANDLES_OPTS, bin_kill, 0, -1, 0, NULL, NULL),
+ BUILTIN("let", 0, bin_let, 1, -1, 0, NULL, NULL),
+ BUILTIN("local", BINF_PLUSOPTS | BINF_MAGICEQUALS | BINF_PSPECIAL | BINF_ASSIGN, (HandlerFunc)bin_typeset, 0, -1, 0, "AE:%F:%HL:%R:%TUZ:%ahi:%lp:%rtux", NULL),
+ BUILTIN("log", 0, bin_log, 0, 0, 0, NULL, NULL),
+ BUILTIN("logout", 0, bin_break, 0, 1, BIN_LOGOUT, NULL, NULL),
+
+#if defined(ZSH_MEM) & defined(ZSH_MEM_DEBUG)
+ BUILTIN("mem", 0, bin_mem, 0, 0, 0, "v", NULL),
+#endif
+
+#if defined(ZSH_PAT_DEBUG)
+ BUILTIN("patdebug", 0, bin_patdebug, 1, -1, 0, "p", NULL),
+#endif
+
+ BUILTIN("popd", BINF_SKIPINVALID | BINF_SKIPDASH | BINF_DASHDASHVALID, bin_cd, 0, 1, BIN_POPD, "q", NULL),
+ BUILTIN("print", BINF_PRINTOPTS, bin_print, 0, -1, BIN_PRINT, "abcC:Df:ilmnNoOpPrRsSu:v:x:X:z-", NULL),
+ BUILTIN("printf", BINF_SKIPINVALID | BINF_SKIPDASH, bin_print, 1, -1, BIN_PRINTF, "v:", NULL),
+ BUILTIN("pushd", BINF_SKIPINVALID | BINF_SKIPDASH | BINF_DASHDASHVALID, bin_cd, 0, 2, BIN_PUSHD, "qsPL", NULL),
+ BUILTIN("pushln", 0, bin_print, 0, -1, BIN_PRINT, NULL, "-nz"),
+ BUILTIN("pwd", 0, bin_pwd, 0, 0, 0, "rLP", NULL),
+ BUILTIN("r", 0, bin_fc, 0, -1, BIN_R, "IlLnr", NULL),
+ BUILTIN("read", 0, bin_read, 0, -1, 0, "cd:ek:%lnpqrst:%zu:AE", NULL),
+ BUILTIN("readonly", BINF_PLUSOPTS | BINF_MAGICEQUALS | BINF_PSPECIAL | BINF_ASSIGN, (HandlerFunc)bin_typeset, 0, -1, BIN_READONLY, "AE:%F:%HL:%R:%TUZ:%afghi:%lptux", "r"),
+ BUILTIN("rehash", 0, bin_hash, 0, 0, 0, "df", "r"),
+ BUILTIN("return", BINF_PSPECIAL, bin_break, 0, 1, BIN_RETURN, NULL, NULL),
+ BUILTIN("set", BINF_PSPECIAL | BINF_HANDLES_OPTS, bin_set, 0, -1, 0, NULL, NULL),
+ BUILTIN("setopt", 0, bin_setopt, 0, -1, BIN_SETOPT, NULL, NULL),
+ BUILTIN("shift", BINF_PSPECIAL, bin_shift, 0, -1, 0, "p", NULL),
+ BUILTIN("source", BINF_PSPECIAL, bin_dot, 1, -1, 0, NULL, NULL),
+ BUILTIN("suspend", 0, bin_suspend, 0, 0, 0, "f", NULL),
+ BUILTIN("test", BINF_HANDLES_OPTS, bin_test, 0, -1, BIN_TEST, NULL, NULL),
+ BUILTIN("ttyctl", 0, bin_ttyctl, 0, 0, 0, "fu", NULL),
+ BUILTIN("times", BINF_PSPECIAL, bin_times, 0, 0, 0, NULL, NULL),
+ BUILTIN("trap", BINF_PSPECIAL | BINF_HANDLES_OPTS, bin_trap, 0, -1, 0, NULL, NULL),
+ BUILTIN("true", 0, bin_true, 0, -1, 0, NULL, NULL),
+ BUILTIN("type", 0, bin_whence, 0, -1, 0, "ampfsSw", "v"),
+ BUILTIN("typeset", BINF_PLUSOPTS | BINF_MAGICEQUALS | BINF_PSPECIAL | BINF_ASSIGN, (HandlerFunc)bin_typeset, 0, -1, 0, "AE:%F:%HL:%R:%TUZ:%afghi:%klp:%rtuxmz", NULL),
+ BUILTIN("umask", 0, bin_umask, 0, 1, 0, "S", NULL),
+ BUILTIN("unalias", 0, bin_unhash, 0, -1, BIN_UNALIAS, "ams", NULL),
+ BUILTIN("unfunction", 0, bin_unhash, 1, -1, BIN_UNFUNCTION, "m", "f"),
+ BUILTIN("unhash", 0, bin_unhash, 1, -1, BIN_UNHASH, "adfms", NULL),
+ BUILTIN("unset", BINF_PSPECIAL, bin_unset, 1, -1, BIN_UNSET, "fmv", NULL),
+ BUILTIN("unsetopt", 0, bin_setopt, 0, -1, BIN_UNSETOPT, NULL, NULL),
+ BUILTIN("wait", 0, bin_fg, 0, -1, BIN_WAIT, NULL, NULL),
+ BUILTIN("whence", 0, bin_whence, 0, -1, 0, "acmpvfsSwx:", NULL),
+ BUILTIN("where", 0, bin_whence, 0, -1, 0, "pmsSwx:", "ca"),
+ BUILTIN("which", 0, bin_whence, 0, -1, 0, "ampsSwx:", "c"),
+ BUILTIN("zmodload", 0, bin_zmodload, 0, -1, 0, "AFRILP:abcfdilmpsue", NULL),
+ BUILTIN("zcompile", 0, bin_zcompile, 0, -1, 0, "tUMRcmzka", NULL),
+};
+
+/****************************************/
+/* Builtin Command Hash Table Functions */
+/****************************************/
+
+/* hash table containing builtin commands */
+
+/**/
+mod_export HashTable builtintab;
+
+/**/
+void
+createbuiltintable(void)
+{
+ builtintab = newhashtable(85, "builtintab", NULL);
+
+ builtintab->hash = hasher;
+ builtintab->emptytable = NULL;
+ builtintab->filltable = NULL;
+ builtintab->cmpnodes = strcmp;
+ builtintab->addnode = addhashnode;
+ builtintab->getnode = gethashnode;
+ builtintab->getnode2 = gethashnode2;
+ builtintab->removenode = removehashnode;
+ builtintab->disablenode = disablehashnode;
+ builtintab->enablenode = enablehashnode;
+ builtintab->freenode = freebuiltinnode;
+ builtintab->printnode = printbuiltinnode;
+
+ (void)addbuiltins("zsh", builtins, sizeof(builtins)/sizeof(*builtins));
+}
+
+/* Print a builtin */
+
+/**/
+static void
+printbuiltinnode(HashNode hn, int printflags)
+{
+ Builtin bn = (Builtin) hn;
+
+ if (printflags & PRINT_WHENCE_WORD) {
+ printf("%s: builtin\n", bn->node.nam);
+ return;
+ }
+
+ if (printflags & PRINT_WHENCE_CSH) {
+ printf("%s: shell built-in command\n", bn->node.nam);
+ return;
+ }
+
+ if (printflags & PRINT_WHENCE_VERBOSE) {
+ printf("%s is a shell builtin\n", bn->node.nam);
+ return;
+ }
+
+ /* default is name only */
+ printf("%s\n", bn->node.nam);
+}
+
+/**/
+static void
+freebuiltinnode(HashNode hn)
+{
+ Builtin bn = (Builtin) hn;
+
+ if(!(bn->node.flags & BINF_ADDED)) {
+ zsfree(bn->node.nam);
+ zsfree(bn->optstr);
+ zfree(bn, sizeof(struct builtin));
+ }
+}
+
+/**/
+void
+init_builtins(void)
+{
+ if (!EMULATION(EMULATE_ZSH)) {
+ HashNode hn = reswdtab->getnode2(reswdtab, "repeat");
+ if (hn)
+ reswdtab->disablenode(hn, 0);
+ }
+}
+
+/* Make sure we have space for a new option and increment. */
+
+#define OPT_ALLOC_CHUNK 16
+
+/**/
+static int
+new_optarg(Options ops)
+{
+ /* Argument index must be a non-zero 6-bit number. */
+ if (ops->argscount == 63)
+ return 1;
+ if (ops->argsalloc == ops->argscount) {
+ char **newptr =
+ (char **)zhalloc((ops->argsalloc + OPT_ALLOC_CHUNK) *
+ sizeof(char *));
+ if (ops->argsalloc)
+ memcpy(newptr, ops->args, ops->argsalloc * sizeof(char *));
+ ops->args = newptr;
+ ops->argsalloc += OPT_ALLOC_CHUNK;
+ }
+ ops->argscount++;
+ return 0;
+}
+
+
+/* execute a builtin handler function after parsing the arguments */
+
+/**/
+int
+execbuiltin(LinkList args, LinkList assigns, Builtin bn)
+{
+ char *pp, *name, *optstr;
+ int flags, argc, execop, xtr = isset(XTRACE);
+ struct options ops;
+
+ /* initialise options structure */
+ memset(ops.ind, 0, MAX_OPS*sizeof(unsigned char));
+ ops.args = NULL;
+ ops.argscount = ops.argsalloc = 0;
+
+ /* initialize some local variables */
+ name = (char *) ugetnode(args);
+
+ if (!bn->handlerfunc) {
+ DPUTS(1, "Missing builtin detected too late");
+ deletebuiltin(bn->node.nam);
+ return 1;
+ }
+ /* get some information about the command */
+ flags = bn->node.flags;
+ optstr = bn->optstr;
+
+ /* Set up the argument list. */
+ /* count the arguments */
+ argc = countlinknodes(args);
+
+ {
+ /*
+ * Keep all arguments, including options, in an array.
+ * We don't actually need the option part of the argument
+ * after option processing, but it makes XTRACE output
+ * much simpler.
+ */
+ VARARR(char *, argarr, argc + 1);
+ char **argv;
+
+ /*
+ * Get the actual arguments, into argv. Remember argarr
+ * may be an array declaration, depending on the compiler.
+ */
+ argv = argarr;
+ while ((*argv++ = (char *)ugetnode(args)));
+ argv = argarr;
+
+ /* Sort out the options. */
+ if (optstr) {
+ char *arg = *argv;
+ int sense; /* 1 for -x, 0 for +x */
+ /* while arguments look like options ... */
+ while (arg &&
+ /* Must begin with - or maybe + */
+ ((sense = (*arg == '-')) ||
+ ((flags & BINF_PLUSOPTS) && *arg == '+'))) {
+ /* Digits aren't arguments unless the command says they are. */
+ if (!(flags & BINF_KEEPNUM) && idigit(arg[1]))
+ break;
+ /* For cd and friends, a single dash is not an option. */
+ if ((flags & BINF_SKIPDASH) && !arg[1])
+ break;
+ if ((flags & BINF_DASHDASHVALID) && !strcmp(arg, "--")) {
+ /*
+ * Need to skip this before checking whether this is
+ * really an option.
+ */
+ argv++;
+ break;
+ }
+ /*
+ * Unrecognised options to echo etc. are not really
+ * options.
+ *
+ * Note this flag is not smart enough to handle option
+ * arguments. In fact, ideally it shouldn't be added
+ * to any new builtins, to preserve standard option
+ * handling as much as possible.
+ */
+ if (flags & BINF_SKIPINVALID) {
+ char *p = arg;
+ while (*++p && strchr(optstr, (int) *p));
+ if (*p)
+ break;
+ }
+ /* handle -- or - (ops.ind['-']), and +
+ * (ops.ind['-'] and ops.ind['+']) */
+ if (arg[1] == '-')
+ arg++;
+ if (!arg[1]) {
+ ops.ind['-'] = 1;
+ if (!sense)
+ ops.ind['+'] = 1;
+ }
+ /* save options in ops, as long as they are in bn->optstr */
+ while (*++arg) {
+ char *optptr;
+ if ((optptr = strchr(optstr, execop = (int)*arg))) {
+ ops.ind[(int)*arg] = (sense) ? 1 : 2;
+ if (optptr[1] == ':') {
+ char *argptr = NULL;
+ if (optptr[2] == ':') {
+ if (arg[1])
+ argptr = arg+1;
+ /* Optional argument in same word*/
+ } else if (optptr[2] == '%') {
+ /* Optional numeric argument in same
+ * or next word. */
+ if (arg[1] && idigit(arg[1]))
+ argptr = arg+1;
+ else if (argv[1] && idigit(*argv[1]))
+ argptr = arg = *++argv;
+ } else {
+ /* Mandatory argument */
+ if (arg[1])
+ argptr = arg+1;
+ else if ((arg = *++argv))
+ argptr = arg;
+ else {
+ zwarnnam(name, "argument expected: -%c",
+ execop);
+ return 1;
+ }
+ }
+ if (argptr) {
+ if (new_optarg(&ops)) {
+ zwarnnam(name,
+ "too many option arguments");
+ return 1;
+ }
+ ops.ind[execop] |= ops.argscount << 2;
+ ops.args[ops.argscount-1] = argptr;
+ while (arg[1])
+ arg++;
+ }
+ }
+ } else
+ break;
+ }
+ /* The above loop may have exited on an invalid option. (We *
+ * assume that any option requiring metafication is invalid.) */
+ if (*arg) {
+ if(*arg == Meta)
+ *++arg ^= 32;
+ zwarnnam(name, "bad option: %c%c", "+-"[sense], *arg);
+ return 1;
+ }
+ arg = *++argv;
+ /* for the "print" builtin, the options after -R are treated as
+ options to "echo" */
+ if ((flags & BINF_PRINTOPTS) && ops.ind['R'] &&
+ !ops.ind['f']) {
+ optstr = "ne";
+ flags |= BINF_SKIPINVALID;
+ }
+ /* the option -- indicates the end of the options */
+ if (ops.ind['-'])
+ break;
+ }
+ } else if (!(flags & BINF_HANDLES_OPTS) && *argv &&
+ !strcmp(*argv, "--")) {
+ ops.ind['-'] = 1;
+ argv++;
+ }
+
+ /* handle built-in options, for overloaded handler functions */
+ if ((pp = bn->defopts)) {
+ while (*pp) {
+ /* only if not already set */
+ if (!ops.ind[(int)*pp])
+ ops.ind[(int)*pp] = 1;
+ pp++;
+ }
+ }
+
+ /* Fix the argument count by subtracting option arguments */
+ argc -= argv - argarr;
+
+ if (errflag) {
+ errflag &= ~ERRFLAG_ERROR;
+ return 1;
+ }
+
+ /* check that the argument count lies within the specified bounds */
+ if (argc < bn->minargs || (argc > bn->maxargs && bn->maxargs != -1)) {
+ zwarnnam(name, (argc < bn->minargs)
+ ? "not enough arguments" : "too many arguments");
+ return 1;
+ }
+
+ /* display execution trace information, if required */
+ if (xtr) {
+ /* Use full argument list including options for trace output */
+ char **fullargv = argarr;
+ printprompt4();
+ fprintf(xtrerr, "%s", name);
+ while (*fullargv) {
+ fputc(' ', xtrerr);
+ quotedzputs(*fullargv++, xtrerr);
+ }
+ if (assigns) {
+ LinkNode node;
+ for (node = firstnode(assigns); node; incnode(node)) {
+ Asgment asg = (Asgment)node;
+ fputc(' ', xtrerr);
+ quotedzputs(asg->name, xtrerr);
+ if (asg->flags & ASG_ARRAY) {
+ fprintf(xtrerr, "=(");
+ if (asg->value.array) {
+ if (asg->flags & ASG_KEY_VALUE) {
+ LinkNode keynode, valnode;
+ keynode = firstnode(asg->value.array);
+ for (;;) {
+ if (!keynode)
+ break;
+ valnode = nextnode(keynode);
+ if (!valnode)
+ break;
+ fputc('[', xtrerr);
+ quotedzputs((char *)getdata(keynode),
+ xtrerr);
+ fprintf(stderr, "]=");
+ quotedzputs((char *)getdata(valnode),
+ xtrerr);
+ keynode = nextnode(valnode);
+ }
+ } else {
+ LinkNode arrnode;
+ for (arrnode = firstnode(asg->value.array);
+ arrnode;
+ incnode(arrnode)) {
+ fputc(' ', xtrerr);
+ quotedzputs((char *)getdata(arrnode),
+ xtrerr);
+ }
+ }
+ }
+ fprintf(xtrerr, " )");
+ } else if (asg->value.scalar) {
+ fputc('=', xtrerr);
+ quotedzputs(asg->value.scalar, xtrerr);
+ }
+ }
+ }
+ fputc('\n', xtrerr);
+ fflush(xtrerr);
+ }
+ /* call the handler function, and return its return value */
+ if (flags & BINF_ASSIGN)
+ {
+ /*
+ * Takes two sets of arguments.
+ */
+ HandlerFuncAssign assignfunc = (HandlerFuncAssign)bn->handlerfunc;
+ return (*(assignfunc)) (name, argv, assigns, &ops, bn->funcid);
+ }
+ else
+ {
+ return (*(bn->handlerfunc)) (name, argv, &ops, bn->funcid);
+ }
+ }
+}
+
+/* Enable/disable an element in one of the internal hash tables. *
+ * With no arguments, it lists all the currently enabled/disabled *
+ * elements in that particular hash table. */
+
+/**/
+int
+bin_enable(char *name, char **argv, Options ops, int func)
+{
+ HashTable ht;
+ HashNode hn;
+ ScanFunc scanfunc;
+ Patprog pprog;
+ int flags1 = 0, flags2 = 0;
+ int match = 0, returnval = 0;
+
+ /* Find out which hash table we are working with. */
+ if (OPT_ISSET(ops,'p')) {
+ return pat_enables(name, argv, func == BIN_ENABLE);
+ } else if (OPT_ISSET(ops,'f'))
+ ht = shfunctab;
+ else if (OPT_ISSET(ops,'r'))
+ ht = reswdtab;
+ else if (OPT_ISSET(ops,'s'))
+ ht = sufaliastab;
+ else if (OPT_ISSET(ops,'a'))
+ ht = aliastab;
+ else
+ ht = builtintab;
+
+ /* Do we want to enable or disable? */
+ if (func == BIN_ENABLE) {
+ flags2 = DISABLED;
+ scanfunc = ht->enablenode;
+ } else {
+ flags1 = DISABLED;
+ scanfunc = ht->disablenode;
+ }
+
+ /* Given no arguments, print the names of the enabled/disabled elements *
+ * in this hash table. If func == BIN_ENABLE, then scanhashtable will *
+ * print nodes NOT containing the DISABLED flag, else scanhashtable will *
+ * print nodes containing the DISABLED flag. */
+ if (!*argv) {
+ queue_signals();
+ scanhashtable(ht, 1, flags1, flags2, ht->printnode, 0);
+ unqueue_signals();
+ return 0;
+ }
+
+ /* With -m option, treat arguments as glob patterns. */
+ if (OPT_ISSET(ops,'m')) {
+ for (; *argv; argv++) {
+ queue_signals();
+
+ /* parse pattern */
+ tokenize(*argv);
+ if ((pprog = patcompile(*argv, PAT_STATIC, 0)))
+ match += scanmatchtable(ht, pprog, 0, 0, 0, scanfunc, 0);
+ else {
+ untokenize(*argv);
+ zwarnnam(name, "bad pattern : %s", *argv);
+ returnval = 1;
+ }
+ unqueue_signals();
+ }
+ /* If we didn't match anything, we return 1. */
+ if (!match)
+ returnval = 1;
+ return returnval;
+ }
+
+ /* Take arguments literally -- do not glob */
+ queue_signals();
+ for (; *argv; argv++) {
+ if ((hn = ht->getnode2(ht, *argv))) {
+ scanfunc(hn, 0);
+ } else {
+ zwarnnam(name, "no such hash table element: %s", *argv);
+ returnval = 1;
+ }
+ }
+ unqueue_signals();
+ return returnval;
+}
+
+/* set: either set the shell options, or set the shell arguments, *
+ * or declare an array, or show various things */
+
+/**/
+int
+bin_set(char *nam, char **args, UNUSED(Options ops), UNUSED(int func))
+{
+ int action, optno, array = 0, hadopt = 0,
+ hadplus = 0, hadend = 0, sort = 0;
+ char **x, *arrayname = NULL;
+
+ /* Obsolescent sh compatibility: set - is the same as set +xv *
+ * and set - args is the same as set +xv -- args */
+ if (!EMULATION(EMULATE_ZSH) && *args && **args == '-' && !args[0][1]) {
+ dosetopt(VERBOSE, 0, 0, opts);
+ dosetopt(XTRACE, 0, 0, opts);
+ if (!args[1])
+ return 0;
+ }
+
+ /* loop through command line options (begins with "-" or "+") */
+ while (*args && (**args == '-' || **args == '+')) {
+ action = (**args == '-');
+ hadplus |= !action;
+ if(!args[0][1])
+ *args = "--";
+ while (*++*args) {
+ if(**args == Meta)
+ *++*args ^= 32;
+ if(**args != '-' || action)
+ hadopt = 1;
+ /* The pseudo-option `--' signifies the end of options. */
+ if (**args == '-') {
+ hadend = 1;
+ args++;
+ goto doneoptions;
+ } else if (**args == 'o') {
+ if (!*++*args)
+ args++;
+ if (!*args) {
+ printoptionstates(hadplus);
+ inittyptab();
+ return 0;
+ }
+ if(!(optno = optlookup(*args)))
+ zerrnam(nam, "no such option: %s", *args);
+ else if(dosetopt(optno, action, 0, opts))
+ zerrnam(nam, "can't change option: %s", *args);
+ break;
+ } else if(**args == 'A') {
+ if(!*++*args)
+ args++;
+ array = action ? 1 : -1;
+ arrayname = *args;
+ if (!arrayname)
+ goto doneoptions;
+ else if (!isset(KSHARRAYS))
+ {
+ args++;
+ goto doneoptions;
+ }
+ break;
+ } else if (**args == 's')
+ sort = action ? 1 : -1;
+ else {
+ if (!(optno = optlookupc(**args)))
+ zerrnam(nam, "bad option: -%c", **args);
+ else if(dosetopt(optno, action, 0, opts))
+ zerrnam(nam, "can't change option: -%c", **args);
+ }
+ }
+ args++;
+ }
+ if (errflag)
+ return 1;
+ doneoptions:
+ inittyptab();
+
+ /* Show the parameters, possibly with values */
+ queue_signals();
+ if (!arrayname)
+ {
+ if (!hadopt && !*args)
+ scanhashtable(paramtab, 1, 0, 0, paramtab->printnode,
+ hadplus ? PRINT_NAMEONLY : 0);
+
+ if (array) {
+ /* display arrays */
+ scanhashtable(paramtab, 1, PM_ARRAY, 0, paramtab->printnode,
+ hadplus ? PRINT_NAMEONLY : 0);
+ }
+ if (!*args && !hadend) {
+ unqueue_signals();
+ return 0;
+ }
+ }
+ if (sort)
+ strmetasort(args, sort < 0 ? SORTIT_BACKWARDS : 0, NULL);
+ if (array) {
+ /* create an array with the specified elements */
+ char **a = NULL, **y;
+ int len = arrlen(args);
+
+ if (array < 0 && (a = getaparam(arrayname)) && arrlen_gt(a, len)) {
+ a += len;
+ len += arrlen(a);
+ }
+ for (x = y = zalloc((len + 1) * sizeof(char *)); len--;) {
+ if (!*args)
+ args = a;
+ *y++ = ztrdup(*args++);
+ }
+ *y++ = NULL;
+ setaparam(arrayname, x);
+ } else {
+ /* set shell arguments */
+ freearray(pparams);
+ pparams = zarrdup(args);
+ }
+ unqueue_signals();
+ return 0;
+}
+
+/**** directory-handling builtins ****/
+
+/**/
+int doprintdir = 0; /* set in exec.c (for autocd) */
+
+/* pwd: display the name of the current directory */
+
+/**/
+int
+bin_pwd(UNUSED(char *name), UNUSED(char **argv), Options ops, UNUSED(int func))
+{
+ if (OPT_ISSET(ops,'r') || OPT_ISSET(ops,'P') ||
+ (isset(CHASELINKS) && !OPT_ISSET(ops,'L')))
+ printf("%s\n", zgetcwd());
+ else {
+ zputs(pwd, stdout);
+ putchar('\n');
+ }
+ return 0;
+}
+
+/* the directory stack */
+
+/**/
+mod_export LinkList dirstack;
+
+/* dirs: list the directory stack, or replace it with a provided list */
+
+/**/
+int
+bin_dirs(UNUSED(char *name), char **argv, Options ops, UNUSED(int func))
+{
+ LinkList l;
+
+ queue_signals();
+ /* with -v, -p or no arguments display the directory stack */
+ if (!(*argv || OPT_ISSET(ops,'c')) || OPT_ISSET(ops,'v') ||
+ OPT_ISSET(ops,'p')) {
+ LinkNode node;
+ char *fmt;
+ int pos = 1;
+
+ /* with the -v option, display a numbered list, starting at zero */
+ if (OPT_ISSET(ops,'v')) {
+ printf("0\t");
+ fmt = "\n%d\t";
+ /* with the -p option, display entries one per line */
+ } else if (OPT_ISSET(ops,'p'))
+ fmt = "\n";
+ else
+ fmt = " ";
+ if (OPT_ISSET(ops,'l'))
+ zputs(pwd, stdout);
+ else
+ fprintdir(pwd, stdout);
+ for (node = firstnode(dirstack); node; incnode(node)) {
+ printf(fmt, pos++);
+ if (OPT_ISSET(ops,'l'))
+ zputs(getdata(node), stdout);
+ else
+ fprintdir(getdata(node), stdout);
+
+ }
+ unqueue_signals();
+ putchar('\n');
+ return 0;
+ }
+ /* replace the stack with the specified directories */
+ l = znewlinklist();
+ while (*argv)
+ zaddlinknode(l, ztrdup(*argv++));
+ freelinklist(dirstack, freestr);
+ dirstack = l;
+ unqueue_signals();
+ return 0;
+}
+
+/* cd, chdir, pushd, popd */
+
+/**/
+void
+set_pwd_env(void)
+{
+ Param pm;
+
+ /* update the PWD and OLDPWD shell parameters */
+
+ pm = (Param) paramtab->getnode(paramtab, "PWD");
+ if (pm && PM_TYPE(pm->node.flags) != PM_SCALAR) {
+ pm->node.flags &= ~PM_READONLY;
+ unsetparam_pm(pm, 0, 1);
+ }
+
+ pm = (Param) paramtab->getnode(paramtab, "OLDPWD");
+ if (pm && PM_TYPE(pm->node.flags) != PM_SCALAR) {
+ pm->node.flags &= ~PM_READONLY;
+ unsetparam_pm(pm, 0, 1);
+ }
+
+ assignsparam("PWD", ztrdup(pwd), 0);
+ assignsparam("OLDPWD", ztrdup(oldpwd), 0);
+
+ pm = (Param) paramtab->getnode(paramtab, "PWD");
+ if (!(pm->node.flags & PM_EXPORTED))
+ addenv(pm, pwd);
+ pm = (Param) paramtab->getnode(paramtab, "OLDPWD");
+ if (!(pm->node.flags & PM_EXPORTED))
+ addenv(pm, oldpwd);
+}
+
+/* set if we are resolving links to their true paths */
+static int chasinglinks;
+
+/* The main pwd changing function. The real work is done by other *
+ * functions. cd_get_dest() does the initial argument processing; *
+ * cd_do_chdir() actually changes directory, if possible; cd_new_pwd() *
+ * does the ancillary processing associated with actually changing *
+ * directory. */
+
+/**/
+int
+bin_cd(char *nam, char **argv, Options ops, int func)
+{
+ LinkNode dir;
+ struct stat st1, st2;
+
+ if (isset(RESTRICTED)) {
+ zwarnnam(nam, "restricted");
+ return 1;
+ }
+ doprintdir = (doprintdir == -1);
+
+ chasinglinks = OPT_ISSET(ops,'P') ||
+ (isset(CHASELINKS) && !OPT_ISSET(ops,'L'));
+ queue_signals();
+ zpushnode(dirstack, ztrdup(pwd));
+ if (!(dir = cd_get_dest(nam, argv, OPT_ISSET(ops,'s'), func))) {
+ zsfree(getlinknode(dirstack));
+ unqueue_signals();
+ return 1;
+ }
+ cd_new_pwd(func, dir, OPT_ISSET(ops, 'q'));
+
+ if (stat(unmeta(pwd), &st1) < 0) {
+ setjobpwd();
+ zsfree(pwd);
+ pwd = NULL;
+ pwd = metafy(zgetcwd(), -1, META_DUP);
+ } else if (stat(".", &st2) < 0) {
+ if (chdir(unmeta(pwd)) < 0)
+ zwarn("unable to chdir(%s): %e", pwd, errno);
+ } else if (st1.st_ino != st2.st_ino || st1.st_dev != st2.st_dev) {
+ if (chasinglinks) {
+ setjobpwd();
+ zsfree(pwd);
+ pwd = NULL;
+ pwd = metafy(zgetcwd(), -1, META_DUP);
+ } else if (chdir(unmeta(pwd)) < 0)
+ zwarn("unable to chdir(%s): %e", pwd, errno);
+ }
+ unqueue_signals();
+ return 0;
+}
+
+/* Get directory to chdir to */
+
+/**/
+static LinkNode
+cd_get_dest(char *nam, char **argv, int hard, int func)
+{
+ LinkNode dir = NULL;
+ LinkNode target;
+ char *dest;
+
+ if (!argv[0]) {
+ if (func == BIN_POPD && !nextnode(firstnode(dirstack))) {
+ zwarnnam(nam, "directory stack empty");
+ return NULL;
+ }
+ if (func == BIN_PUSHD && unset(PUSHDTOHOME))
+ dir = nextnode(firstnode(dirstack));
+ if (dir)
+ zinsertlinknode(dirstack, dir, getlinknode(dirstack));
+ else if (func != BIN_POPD) {
+ if (!home) {
+ zwarnnam(nam, "HOME not set");
+ return NULL;
+ }
+ zpushnode(dirstack, ztrdup(home));
+ }
+ } else if (!argv[1]) {
+ int dd;
+ char *end;
+
+ doprintdir++;
+ if (argv[0][1] && (argv[0][0] == '+' || argv[0][0] == '-')
+ && strspn(argv[0]+1, "0123456789") == strlen(argv[0]+1)) {
+ dd = zstrtol(argv[0] + 1, &end, 10);
+ if (*end == '\0') {
+ if ((argv[0][0] == '+') ^ isset(PUSHDMINUS))
+ for (dir = firstnode(dirstack); dir && dd; dd--, incnode(dir));
+ else
+ for (dir = lastnode(dirstack); dir != (LinkNode) dirstack && dd;
+ dd--, dir = prevnode(dir));
+ if (!dir || dir == (LinkNode) dirstack) {
+ zwarnnam(nam, "no such entry in dir stack");
+ return NULL;
+ }
+ }
+ }
+ if (!dir)
+ zpushnode(dirstack, ztrdup(strcmp(argv[0], "-")
+ ? (doprintdir--, argv[0]) : oldpwd));
+ } else {
+ char *u, *d;
+ int len1, len2, len3;
+
+ if (!(u = strstr(pwd, argv[0]))) {
+ zwarnnam(nam, "string not in pwd: %s", argv[0]);
+ return NULL;
+ }
+ len1 = strlen(argv[0]);
+ len2 = strlen(argv[1]);
+ len3 = u - pwd;
+ d = (char *)zalloc(len3 + len2 + strlen(u + len1) + 1);
+ strncpy(d, pwd, len3);
+ strcpy(d + len3, argv[1]);
+ strcat(d, u + len1);
+ zpushnode(dirstack, d);
+ doprintdir++;
+ }
+
+ target = dir;
+ if (func == BIN_POPD) {
+ if (!dir) {
+ target = dir = firstnode(dirstack);
+ } else if (dir != firstnode(dirstack)) {
+ return dir;
+ }
+ dir = nextnode(dir);
+ }
+ if (!dir) {
+ dir = firstnode(dirstack);
+ }
+ if (!dir || !getdata(dir)) {
+ DPUTS(1, "Directory not set, not detected early enough");
+ return NULL;
+ }
+ if (!(dest = cd_do_chdir(nam, getdata(dir), hard))) {
+ if (!target)
+ zsfree(getlinknode(dirstack));
+ if (func == BIN_POPD)
+ zsfree(remnode(dirstack, dir));
+ return NULL;
+ }
+ if (dest != (char *)getdata(dir)) {
+ zsfree(getdata(dir));
+ setdata(dir, dest);
+ }
+ return target ? target : dir;
+}
+
+/* Change to given directory, if possible. This function works out *
+ * exactly how the directory should be interpreted, including cdpath *
+ * and CDABLEVARS. For each possible interpretation of the given *
+ * path, this calls cd_try_chdir(), which attempts to chdir to that *
+ * particular path. */
+
+/**/
+static char *
+cd_do_chdir(char *cnam, char *dest, int hard)
+{
+ char **pp, *ret;
+ int hasdot = 0, eno = ENOENT;
+ /*
+ * nocdpath indicates that cdpath should not be used.
+ * This is the case iff dest is a relative path
+ * whose first segment is . or .., but if the path is
+ * absolute then cdpath won't be used anyway.
+ */
+ int nocdpath;
+#ifdef __CYGWIN__
+ /*
+ * Normalize path under Cygwin to avoid messing with
+ * DOS style names with drives in them
+ */
+ static char buf[PATH_MAX+1];
+#ifdef HAVE_CYGWIN_CONV_PATH
+ cygwin_conv_path(CCP_WIN_A_TO_POSIX | CCP_RELATIVE, dest, buf,
+ PATH_MAX);
+#else
+#ifndef _SYS_CYGWIN_H
+ void cygwin_conv_to_posix_path(const char *, char *);
+#endif
+
+ cygwin_conv_to_posix_path(dest, buf);
+#endif
+ dest = buf;
+#endif
+ nocdpath = dest[0] == '.' &&
+ (dest[1] == '/' || !dest[1] || (dest[1] == '.' &&
+ (dest[2] == '/' || !dest[2])));
+
+ /*
+ * If we have an absolute path, use it as-is only
+ */
+ if (*dest == '/') {
+ if ((ret = cd_try_chdir(NULL, dest, hard)))
+ return ret;
+ zwarnnam(cnam, "%e: %s", errno, dest);
+ return NULL;
+ }
+
+ /*
+ * If cdpath is being used, check it for ".".
+ * Don't bother doing this if POSIXCD is set, we don't
+ * need to know (though it doesn't actually matter).
+ */
+ if (!nocdpath && !isset(POSIXCD))
+ for (pp = cdpath; *pp; pp++)
+ if (!(*pp)[0] || ((*pp)[0] == '.' && (*pp)[1] == '\0'))
+ hasdot = 1;
+ /*
+ * If
+ * (- there is no . in cdpath
+ * - or cdpath is not being used)
+ * - and the POSIXCD option is not set
+ * try the directory as-is (i.e. from .)
+ */
+ if (!hasdot && !isset(POSIXCD)) {
+ if ((ret = cd_try_chdir(NULL, dest, hard)))
+ return ret;
+ if (errno != ENOENT)
+ eno = errno;
+ }
+ /* if cdpath is being used, try given directory relative to each element in
+ cdpath in turn */
+ if (!nocdpath)
+ for (pp = cdpath; *pp; pp++) {
+ if ((ret = cd_try_chdir(*pp, dest, hard))) {
+ if (isset(POSIXCD)) {
+ /*
+ * For POSIX we need to print the directory
+ * any time CDPATH was used, except in the
+ * special case of an empty segment being
+ * treated as a ".".
+ */
+ if (**pp)
+ doprintdir++;
+ } else {
+ if (strcmp(*pp, ".")) {
+ doprintdir++;
+ }
+ }
+ return ret;
+ }
+ if (errno != ENOENT)
+ eno = errno;
+ }
+ /*
+ * POSIX requires us to check "." after CDPATH rather than before.
+ */
+ if (isset(POSIXCD)) {
+ if ((ret = cd_try_chdir(NULL, dest, hard)))
+ return ret;
+ if (errno != ENOENT)
+ eno = errno;
+ }
+
+ /* handle the CDABLEVARS option */
+ if ((ret = cd_able_vars(dest))) {
+ if ((ret = cd_try_chdir(NULL, ret,hard))) {
+ doprintdir++;
+ return ret;
+ }
+ if (errno != ENOENT)
+ eno = errno;
+ }
+
+ /* If we got here, it means that we couldn't chdir to any of the
+ multitudinous possible paths allowed by zsh. We've run out of options!
+ Add more here! */
+ zwarnnam(cnam, "%e: %s", eno, dest);
+ return NULL;
+}
+
+/* If the CDABLEVARS option is set, return the new *
+ * interpretation of the given path. */
+
+/**/
+char *
+cd_able_vars(char *s)
+{
+ char *rest, save;
+
+ if (isset(CDABLEVARS)) {
+ for (rest = s; *rest && *rest != '/'; rest++);
+ save = *rest;
+ *rest = 0;
+ s = getnameddir(s);
+ *rest = save;
+
+ if (s && *rest)
+ s = dyncat(s, rest);
+
+ return s;
+ }
+ return NULL;
+}
+
+/* Attempt to change to a single given directory. The directory, *
+ * for the convenience of the calling function, may be provided in *
+ * two parts, which must be concatenated before attempting to chdir. *
+ * Returns NULL if the chdir fails. If the directory change is *
+ * possible, it is performed, and a pointer to the new full pathname *
+ * is returned. */
+
+/**/
+static char *
+cd_try_chdir(char *pfix, char *dest, int hard)
+{
+ char *buf;
+ int dlen, dochaselinks = 0;
+
+ /* handle directory prefix */
+ if (pfix && *pfix) {
+ if (*pfix == '/') {
+#ifdef __CYGWIN__
+/* NB: Don't turn "/"+"bin" into "//"+"bin" by mistake! "//bin" may *
+ * not be what user really wants (probably wants "/bin"), but *
+ * "//bin" could be valid too (see fixdir())! This is primarily for *
+ * handling CDPATH correctly. Likewise for "//"+"bin" not becoming *
+ * "///bin" (aka "/bin"). */
+ int root = pfix[1] == '\0' || (pfix[1] == '/' && pfix[2] == '\0');
+ buf = tricat(pfix, ( root ? "" : "/" ), dest);
+#else
+ buf = tricat(pfix, "/", dest);
+#endif
+ } else {
+ int pfl = strlen(pfix);
+ dlen = strlen(pwd);
+ if (dlen == 1 && *pwd == '/')
+ dlen = 0;
+ buf = zalloc(dlen + pfl + strlen(dest) + 3);
+ if (dlen)
+ strcpy(buf, pwd);
+ buf[dlen] = '/';
+ strcpy(buf + dlen + 1, pfix);
+ buf[dlen + 1 + pfl] = '/';
+ strcpy(buf + dlen + pfl + 2, dest);
+ }
+ } else if (*dest == '/')
+ buf = ztrdup(dest);
+ else {
+ dlen = strlen(pwd);
+ if (pwd[dlen-1] == '/')
+ --dlen;
+ buf = zalloc(dlen + strlen(dest) + 2);
+ strcpy(buf, pwd);
+ buf[dlen] = '/';
+ strcpy(buf + dlen + 1, dest);
+ }
+
+ /* Normalise path. See the definition of fixdir() for what this means.
+ * We do not do this if we are chasing links.
+ */
+ if (!chasinglinks)
+ dochaselinks = fixdir(buf);
+ else
+ unmetafy(buf, &dlen);
+
+ /* We try the full path first. If that fails, try the
+ * argument to cd relatively. This is useful if the cwd
+ * or a parent directory is renamed in the interim.
+ */
+ if (lchdir(buf, NULL, hard) &&
+ (pfix || *dest == '/' || lchdir(unmeta(dest), NULL, hard))) {
+ free(buf);
+ return NULL;
+ }
+ /* the chdir succeeded, so decide if we should force links to be chased */
+ if (dochaselinks)
+ chasinglinks = 1;
+ return metafy(buf, -1, META_NOALLOC);
+}
+
+/* do the extra processing associated with changing directory */
+
+/**/
+static void
+cd_new_pwd(int func, LinkNode dir, int quiet)
+{
+ char *new_pwd, *s;
+ int dirstacksize;
+
+ if (func == BIN_PUSHD)
+ rolllist(dirstack, dir);
+ new_pwd = remnode(dirstack, dir);
+
+ if (func == BIN_POPD && firstnode(dirstack)) {
+ zsfree(new_pwd);
+ new_pwd = getlinknode(dirstack);
+ } else if (func == BIN_CD && unset(AUTOPUSHD))
+ zsfree(getlinknode(dirstack));
+
+ if (chasinglinks) {
+ s = findpwd(new_pwd);
+ if (s) {
+ zsfree(new_pwd);
+ new_pwd = s;
+ }
+ }
+ if (isset(PUSHDIGNOREDUPS)) {
+ LinkNode n;
+ for (n = firstnode(dirstack); n; incnode(n)) {
+ if (!strcmp(new_pwd, getdata(n))) {
+ zsfree(remnode(dirstack, n));
+ break;
+ }
+ }
+ }
+
+ /* shift around the pwd variables, to make oldpwd and pwd relate to the
+ current (i.e. new) pwd */
+ zsfree(oldpwd);
+ oldpwd = pwd;
+ setjobpwd();
+ pwd = new_pwd;
+ set_pwd_env();
+
+ if (isset(INTERACTIVE) || isset(POSIXCD)) {
+ if (func != BIN_CD && isset(INTERACTIVE)) {
+ if (unset(PUSHDSILENT) && !quiet)
+ printdirstack();
+ } else if (doprintdir) {
+ fprintdir(pwd, stdout);
+ putchar('\n');
+ }
+ }
+
+ /* execute the chpwd function */
+ fflush(stdout);
+ fflush(stderr);
+ if (!quiet)
+ callhookfunc("chpwd", NULL, 1, NULL);
+
+ dirstacksize = getiparam("DIRSTACKSIZE");
+ /* handle directory stack sizes out of range */
+ if (dirstacksize > 0) {
+ int remove = countlinknodes(dirstack) -
+ (dirstacksize < 2 ? 2 : dirstacksize);
+ while (remove-- >= 0)
+ zsfree(remnode(dirstack, lastnode(dirstack)));
+ }
+}
+
+/* Print the directory stack */
+
+/**/
+static void
+printdirstack(void)
+{
+ LinkNode node;
+
+ fprintdir(pwd, stdout);
+ for (node = firstnode(dirstack); node; incnode(node)) {
+ putchar(' ');
+ fprintdir(getdata(node), stdout);
+ }
+ putchar('\n');
+}
+
+/* Normalise a path. Segments consisting of ., and foo/.. *
+ * combinations, are removed and the path is unmetafied.
+ * Returns 1 if we found a ../ path which should force links to
+ * be chased, 0 otherwise.
+ */
+
+/**/
+int
+fixdir(char *src)
+{
+ char *dest = src, *d0 = dest;
+#ifdef __CYGWIN__
+ char *s0 = src;
+#endif
+ /* This function is always called with n path containing at
+ * least one slash, either because one was input by the user or
+ * because the caller has prepended either pwd or a cdpath dir.
+ * If asked to make a relative change and pwd is set to ".",
+ * the current directory has been removed out from under us,
+ * so force links to be chased.
+ *
+ * Ordinarily we can't get here with "../" as the first component
+ * but handle the silly special case of ".." in cdpath.
+ *
+ * Order of comparisons here looks funny, but it short-circuits
+ * most rapidly in the event of a false condition. Set to 2
+ * here so we still obey the (lack of) CHASEDOTS option after
+ * the first "../" is preserved (test chasedots > 1 below).
+ */
+ int chasedots = (src[0] == '.' && pwd[0] == '.' && pwd[1] == '\0' &&
+ (src[1] == '/' || (src[1] == '.' && src[2] == '/'))) * 2;
+
+/*** if have RFS superroot directory ***/
+#ifdef HAVE_SUPERROOT
+ /* allow /.. segments to remain */
+ while (*src == '/' && src[1] == '.' && src[2] == '.' &&
+ (!src[3] || src[3] == '/')) {
+ *dest++ = '/';
+ *dest++ = '.';
+ *dest++ = '.';
+ src += 3;
+ }
+#endif
+
+ for (;;) {
+ /* compress multiple /es into single */
+ if (*src == '/') {
+#ifdef __CYGWIN__
+ /* allow leading // under cygwin, but /// still becomes / */
+ if (src == s0 && src[1] == '/' && src[2] != '/')
+ *dest++ = *src++;
+#endif
+ *dest++ = *src++;
+ while (*src == '/')
+ src++;
+ }
+ /* if we are at the end of the input path, remove a trailing / (if it
+ exists), and return ct */
+ if (!*src) {
+ while (dest > d0 + 1 && dest[-1] == '/')
+ dest--;
+ *dest = '\0';
+ return chasedots;
+ }
+ if (src[0] == '.' && src[1] == '.' &&
+ (src[2] == '\0' || src[2] == '/')) {
+ if (isset(CHASEDOTS) || chasedots > 1) {
+ chasedots = 1;
+ /* and treat as normal path segment */
+ } else {
+ if (dest > d0 + 1) {
+ /*
+ * remove a foo/.. combination:
+ * first check foo exists, else return.
+ */
+ struct stat st;
+ *dest = '\0';
+ if (stat(d0, &st) < 0 || !S_ISDIR(st.st_mode)) {
+ char *ptrd, *ptrs;
+ if (dest == src)
+ *dest = '.';
+ for (ptrs = src, ptrd = dest; *ptrs; ptrs++, ptrd++)
+ *ptrd = (*ptrs == Meta) ? (*++ptrs ^ 32) : *ptrs;
+ *ptrd = '\0';
+ return 1;
+ }
+ for (dest--; dest > d0 + 1 && dest[-1] != '/'; dest--);
+ if (dest[-1] != '/')
+ dest--;
+ }
+ src++;
+ while (*++src == '/');
+ continue;
+ }
+ }
+ if (src[0] == '.' && (src[1] == '/' || src[1] == '\0')) {
+ /* skip a . section */
+ while (*++src == '/');
+ } else {
+ /* copy a normal segment into the output */
+ while (*src != '/' && *src != '\0')
+ if ((*dest++ = *src++) == Meta)
+ dest[-1] = *src++ ^ 32;
+ }
+ }
+ /* unreached */
+}
+
+/**/
+mod_export void
+printqt(char *str)
+{
+ /* Print str, but turn any single quote into '\'' or ''. */
+ for (; *str; str++)
+ if (*str == '\'')
+ printf(isset(RCQUOTES) ? "''" : "'\\''");
+ else
+ putchar(*str);
+}
+
+/**/
+mod_export void
+printif(char *str, int c)
+{
+ /* If flag c has an argument, print that */
+ if (str) {
+ printf(" -%c ", c);
+ quotedzputs(str, stdout);
+ }
+}
+
+/**** history list functions ****/
+
+/* fc, history, r */
+
+/**/
+int
+bin_fc(char *nam, char **argv, Options ops, int func)
+{
+ zlong first = -1, last = -1;
+ int retval;
+ char *s;
+ struct asgment *asgf = NULL, *asgl = NULL;
+ Patprog pprog = NULL;
+
+ /* fc is only permitted in interactive shells */
+#ifdef FACIST_INTERACTIVE
+ if (!interact) {
+ zwarnnam(nam, "not interactive shell");
+ return 1;
+ }
+#endif
+ if (OPT_ISSET(ops,'p')) {
+ char *hf = "";
+ zlong hs = DEFAULT_HISTSIZE;
+ zlong shs = 0;
+ int level = OPT_ISSET(ops,'a') ? locallevel : -1;
+ if (*argv) {
+ hf = *argv++;
+ if (*argv) {
+ char *check;
+ hs = zstrtol(*argv++, &check, 10);
+ if (*check) {
+ zwarnnam("fc", "HISTSIZE must be an integer");
+ return 1;
+ }
+ if (*argv) {
+ shs = zstrtol(*argv++, &check, 10);
+ if (*check) {
+ zwarnnam("fc", "SAVEHIST must be an integer");
+ return 1;
+ }
+ } else
+ shs = hs;
+ if (*argv) {
+ zwarnnam("fc", "too many arguments");
+ return 1;
+ }
+ } else {
+ hs = histsiz;
+ shs = savehistsiz;
+ }
+ }
+ if (!pushhiststack(hf, hs, shs, level))
+ return 1;
+ if (*hf) {
+ struct stat st;
+ if (stat(hf, &st) >= 0 || errno != ENOENT)
+ readhistfile(hf, 1, HFILE_USE_OPTIONS);
+ }
+ return 0;
+ }
+ if (OPT_ISSET(ops,'P')) {
+ if (*argv) {
+ zwarnnam("fc", "too many arguments");
+ return 1;
+ }
+ return !saveandpophiststack(-1, HFILE_USE_OPTIONS);
+ }
+ /* with the -m option, the first argument is taken *
+ * as a pattern that history lines have to match */
+ if (*argv && OPT_ISSET(ops,'m')) {
+ tokenize(*argv);
+ if (!(pprog = patcompile(*argv++, 0, NULL))) {
+ zwarnnam(nam, "invalid match pattern");
+ return 1;
+ }
+ }
+ queue_signals();
+ if (OPT_ISSET(ops,'R')) {
+ /* read history from a file */
+ readhistfile(*argv, 1, OPT_ISSET(ops,'I') ? HFILE_SKIPOLD : 0);
+ unqueue_signals();
+ return 0;
+ }
+ if (OPT_ISSET(ops,'W')) {
+ /* write history to a file */
+ savehistfile(*argv, 1, OPT_ISSET(ops,'I') ? HFILE_SKIPOLD : 0);
+ unqueue_signals();
+ return 0;
+ }
+ if (OPT_ISSET(ops,'A')) {
+ /* append history to a file */
+ savehistfile(*argv, 1, HFILE_APPEND |
+ (OPT_ISSET(ops,'I') ? HFILE_SKIPOLD : 0));
+ unqueue_signals();
+ return 0;
+ }
+
+ if (zleactive) {
+ unqueue_signals();
+ zwarnnam(nam, "no interactive history within ZLE");
+ return 1;
+ }
+
+ /* put foo=bar type arguments into the substitution list */
+ while (*argv && equalsplit(*argv, &s)) {
+ Asgment a = (Asgment) zhalloc(sizeof *a);
+
+ if (!**argv) {
+ zwarnnam(nam, "invalid replacement pattern: =%s", s);
+ return 1;
+ }
+ if (!asgf)
+ asgf = asgl = a;
+ else {
+ asgl->node.next = &a->node;
+ asgl = a;
+ }
+ a->name = *argv;
+ a->flags = 0;
+ a->value.scalar = s;
+ a->node.next = a->node.prev = NULL;
+ argv++;
+ }
+ /* interpret and check first history line specifier */
+ if (*argv) {
+ first = fcgetcomm(*argv);
+ if (first == -1) {
+ unqueue_signals();
+ return 1;
+ }
+ argv++;
+ }
+ /* interpret and check second history line specifier */
+ if (*argv) {
+ last = fcgetcomm(*argv);
+ if (last == -1) {
+ unqueue_signals();
+ return 1;
+ }
+ argv++;
+ }
+ /* There is a maximum of two history specifiers. At least, there *
+ * will be as long as the history list is one-dimensional. */
+ if (*argv) {
+ unqueue_signals();
+ zwarnnam("fc", "too many arguments");
+ return 1;
+ }
+ /* default values of first and last, and range checking */
+ if (last == -1) {
+ if (OPT_ISSET(ops,'l') && first < curhist) {
+ /*
+ * When listing base our calculations on curhist,
+ * to show anything added since the edited history line.
+ * Also, in that case curhist will have been modified
+ * past the current history line; then we want to
+ * show everything, because the user expects to
+ * see the result of "print -s". Otherwise, we subtract
+ * -1 from the line, because the user doesn't usually expect
+ * to see the command line that caused history to be
+ * listed.
+ */
+ last = (curline.histnum == curhist) ? addhistnum(curhist,-1,0)
+ : curhist;
+ if (last < firsthist())
+ last = firsthist();
+ }
+ else
+ last = first;
+ }
+ if (first == -1) {
+ /*
+ * When listing, we want to see everything that's been
+ * added to the history, including by print -s, so use
+ * curhist.
+ * When reexecuting, we want to restrict to the last edited
+ * command line to avoid giving the user a nasty turn
+ * if some helpful soul ran "print -s 'rm -rf /'".
+ */
+ first = OPT_ISSET(ops,'l')? addhistnum(curhist,-16,0)
+ : addhistnum(curline.histnum,-1,0);
+ if (first < 1)
+ first = 1;
+ if (last < first)
+ last = first;
+ }
+ if (OPT_ISSET(ops,'l')) {
+ /* list the required part of the history */
+ retval = fclist(stdout, ops, first, last, asgf, pprog, 0);
+ unqueue_signals();
+ }
+ else {
+ /* edit history file, and (if successful) use the result as a new command */
+ int tempfd;
+ FILE *out;
+ char *fil;
+
+ retval = 1;
+ if ((tempfd = gettempfile(NULL, 1, &fil)) < 0
+ || ((out = fdopen(tempfd, "w")) == NULL)) {
+ unqueue_signals();
+ zwarnnam("fc", "can't open temp file: %e", errno);
+ } else {
+ /*
+ * Nasty behaviour results if we use the current history
+ * line here. Treat it as if it doesn't exist, unless
+ * that gives us an empty range.
+ */
+ if (last >= curhist) {
+ last = curhist - 1;
+ if (first > last) {
+ unqueue_signals();
+ zwarnnam("fc",
+ "current history line would recurse endlessly, aborted");
+ fclose(out);
+ unlink(fil);
+ return 1;
+ }
+ }
+ ops->ind['n'] = 1; /* No line numbers here. */
+ if (!fclist(out, ops, first, last, asgf, pprog, 1)) {
+ char *editor;
+
+ if (func == BIN_R)
+ editor = "-";
+ else if (OPT_HASARG(ops, 'e'))
+ editor = OPT_ARG(ops, 'e');
+ else
+ editor = getsparam("FCEDIT");
+ if (!editor)
+ editor = getsparam("EDITOR");
+ if (!editor)
+ editor = DEFAULT_FCEDIT;
+
+ unqueue_signals();
+ if (fcedit(editor, fil)) {
+ if (stuff(fil))
+ zwarnnam("fc", "%e: %s", errno, fil);
+ else {
+ loop(0,1);
+ retval = lastval;
+ }
+ }
+ } else
+ unqueue_signals();
+ }
+ unlink(fil);
+ }
+ return retval;
+}
+
+/* History handling functions: these are called by ZLE, as well as *
+ * the actual builtins. fcgetcomm() gets a history line, specified *
+ * either by number or leading string. fcsubs() performs a given *
+ * set of simple old=new substitutions on a given command line. *
+ * fclist() outputs a given range of history lines to a text file. */
+
+/* get the history event associated with s */
+
+/**/
+static zlong
+fcgetcomm(char *s)
+{
+ zlong cmd;
+
+ /* First try to match a history number. Negative *
+ * numbers indicate reversed numbering. */
+ if ((cmd = atoi(s)) != 0 || *s == '0') {
+ if (cmd < 0)
+ cmd = addhistnum(curline.histnum,cmd,HIST_FOREIGN);
+ if (cmd < 0)
+ cmd = 0;
+ return cmd;
+ }
+ /* not a number, so search by string */
+ cmd = hcomsearch(s);
+ if (cmd == -1)
+ zwarnnam("fc", "event not found: %s", s);
+ return cmd;
+}
+
+/* Perform old=new substitutions. Uses the asgment structure from zsh.h, *
+ * which is essentially a linked list of string,replacement pairs. */
+
+/**/
+static int
+fcsubs(char **sp, struct asgment *sub)
+{
+ char *oldstr, *newstr, *oldpos, *newpos, *newmem, *s = *sp;
+ int subbed = 0;
+
+ /* loop through the linked list */
+ while (sub) {
+ oldstr = sub->name;
+ newstr = sub->value.scalar;
+ sub = (Asgment)sub->node.next;
+ oldpos = s;
+ /* loop over occurences of oldstr in s, replacing them with newstr */
+ while ((newpos = (char *)strstr(oldpos, oldstr))) {
+ newmem = (char *) zhalloc(1 + (newpos - s)
+ + strlen(newstr) + strlen(newpos + strlen(oldstr)));
+ ztrncpy(newmem, s, newpos - s);
+ strcat(newmem, newstr);
+ oldpos = newmem + strlen(newmem);
+ strcat(newmem, newpos + strlen(oldstr));
+ s = newmem;
+ subbed = 1;
+ }
+ }
+ *sp = s;
+ return subbed;
+}
+
+/* Print a series of history events to a file. The file pointer is *
+ * given by f, and the required range of events by first and last. *
+ * subs is an optional list of foo=bar substitutions to perform on the *
+ * history lines before output. com is an optional comp structure *
+ * that the history lines are required to match. n, r, D and d are *
+ * options: n indicates that each line should be numbered. r indicates *
+ * that the lines should be output in reverse order (newest first). *
+ * D indicates that the real time taken by each command should be *
+ * output. d indicates that the time of execution of each command *
+ * should be output; d>1 means that the date should be output too; d>3 *
+ * means that mm/dd/yyyy form should be used for the dates, as opposed *
+ * to dd.mm.yyyy form; d>7 means that yyyy-mm-dd form should be used. */
+
+/**/
+static int
+fclist(FILE *f, Options ops, zlong first, zlong last,
+ struct asgment *subs, Patprog pprog, int is_command)
+{
+ int fclistdone = 0, xflags = 0;
+ zlong tmp;
+ char *s, *tdfmt, *timebuf;
+ Histent ent;
+
+ /* reverse range if required */
+ if (OPT_ISSET(ops,'r')) {
+ tmp = last;
+ last = first;
+ first = tmp;
+ }
+ if (is_command && first > last) {
+ zwarnnam("fc", "history events can't be executed backwards, aborted");
+ if (f != stdout)
+ fclose(f);
+ return 1;
+ }
+
+ ent = gethistent(first, first < last? GETHIST_DOWNWARD : GETHIST_UPWARD);
+ if (!ent || (first < last? ent->histnum > last : ent->histnum < last)) {
+ if (first == last) {
+ char buf[DIGBUFSIZE];
+ convbase(buf, first, 10);
+ zwarnnam("fc", "no such event: %s", buf);
+ } else
+ zwarnnam("fc", "no events in that range");
+ if (f != stdout)
+ fclose(f);
+ return 1;
+ }
+
+ if (OPT_ISSET(ops,'d') || OPT_ISSET(ops,'f') ||
+ OPT_ISSET(ops,'E') || OPT_ISSET(ops,'i') ||
+ OPT_ISSET(ops,'t')) {
+ if (OPT_ISSET(ops,'t')) {
+ tdfmt = OPT_ARG(ops,'t');
+ } else if (OPT_ISSET(ops,'i')) {
+ tdfmt = "%Y-%m-%d %H:%M";
+ } else if (OPT_ISSET(ops,'E')) {
+ tdfmt = "%f.%-m.%Y %H:%M";
+ } else if (OPT_ISSET(ops,'f')) {
+ tdfmt = "%-m/%f/%Y %H:%M";
+ } else {
+ tdfmt = "%H:%M";
+ }
+ timebuf = zhalloc(256);
+ } else {
+ tdfmt = timebuf = NULL;
+ }
+
+ /* xflags exclude events */
+ if (OPT_ISSET(ops,'L')) {
+ xflags |= HIST_FOREIGN;
+ }
+ if (OPT_ISSET(ops,'I')) {
+ xflags |= HIST_READ;
+ }
+
+ for (;;) {
+ if (ent->node.flags & xflags)
+ s = NULL;
+ else
+ s = dupstring(ent->node.nam);
+ /* this if does the pattern matching, if required */
+ if (s && (!pprog || pattry(pprog, s))) {
+ /* perform substitution */
+ fclistdone |= (subs ? fcsubs(&s, subs) : 1);
+
+ /* do numbering */
+ if (!OPT_ISSET(ops,'n')) {
+ char buf[DIGBUFSIZE];
+ convbase(buf, ent->histnum, 10);
+ fprintf(f, "%5s%c ", buf,
+ ent->node.flags & HIST_FOREIGN ? '*' : ' ');
+ }
+ /* output actual time (and possibly date) of execution of the
+ command, if required */
+ if (tdfmt != NULL) {
+ struct tm *ltm;
+ int len;
+ ltm = localtime(&ent->stim);
+ if ((len = ztrftime(timebuf, 256, tdfmt, ltm, 0L)) >= 0) {
+ fwrite(timebuf, 1, len, f);
+ fprintf(f, " ");
+ }
+ }
+ /* display the time taken by the command, if required */
+ if (OPT_ISSET(ops,'D')) {
+ long diff;
+ diff = (ent->ftim) ? ent->ftim - ent->stim : 0;
+ fprintf(f, "%ld:%02ld ", diff / 60, diff % 60);
+ }
+
+ /* output the command */
+ if (f == stdout) {
+ nicezputs(s, f);
+ putc('\n', f);
+ } else {
+ int len;
+ unmetafy(s, &len);
+ fwrite(s, 1, len, f);
+ putc('\n', f);
+ }
+ }
+ /* move on to the next history line, or quit the loop */
+ if (first < last) {
+ if (!(ent = down_histent(ent)) || ent->histnum > last)
+ break;
+ }
+ else {
+ if (!(ent = up_histent(ent)) || ent->histnum < last)
+ break;
+ }
+ }
+
+ /* final processing */
+ if (f != stdout)
+ fclose(f);
+ if (!fclistdone) {
+ if (subs)
+ zwarnnam("fc", "no substitutions performed");
+ else if (xflags || pprog)
+ zwarnnam("fc", "no matching events found");
+ return 1;
+ }
+ return 0;
+}
+
+/* edit a history file */
+
+/**/
+static int
+fcedit(char *ename, char *fn)
+{
+ char *s;
+
+ if (!strcmp(ename, "-"))
+ return 1;
+
+ s = tricat(ename, " ", fn);
+ execstring(s, 1, 0, "fc");
+ zsfree(s);
+
+ return !lastval;
+}
+
+/**** parameter builtins ****/
+
+/* Separate an argument into name=value parts, returning them in an *
+ * asgment structure. Because the asgment structure used is global, *
+ * only one of these can be active at a time. The string s gets placed *
+ * in this global structure, so it needs to be in permanent memory. */
+
+/**/
+static Asgment
+getasg(char ***argvp, LinkList assigns)
+{
+ char *s = **argvp;
+ static struct asgment asg;
+
+ /* sanity check for valid argument */
+ if (!s) {
+ if (assigns) {
+ Asgment asgp = (Asgment)firstnode(assigns);
+ if (!asgp)
+ return NULL;
+ (void)uremnode(assigns, &asgp->node);
+ return asgp;
+ }
+ return NULL;
+ }
+
+ /* check if name is empty */
+ if (*s == '=') {
+ zerr("bad assignment");
+ return NULL;
+ }
+ asg.name = s;
+ asg.flags = 0;
+
+ /* search for `=' */
+ for (; *s && *s != '='; s++);
+
+ /* found `=', so return with a value */
+ if (*s) {
+ *s = '\0';
+ asg.value.scalar = s + 1;
+ } else {
+ /* didn't find `=', so we only have a name */
+ asg.value.scalar = NULL;
+ }
+ (*argvp)++;
+ return &asg;
+}
+
+/* for new special parameters */
+enum {
+ NS_NONE,
+ NS_NORMAL,
+ NS_SECONDS
+};
+
+static const struct gsu_scalar tiedarr_gsu =
+{ tiedarrgetfn, tiedarrsetfn, tiedarrunsetfn };
+
+/* Install a base if we are turning on a numeric option with an argument */
+
+static int
+typeset_setbase(const char *name, Param pm, Options ops, int on, int always)
+{
+ char *arg = NULL;
+
+ if ((on & PM_INTEGER) && OPT_HASARG(ops,'i'))
+ arg = OPT_ARG(ops,'i');
+ else if ((on & PM_EFLOAT) && OPT_HASARG(ops,'E'))
+ arg = OPT_ARG(ops,'E');
+ else if ((on & PM_FFLOAT) && OPT_HASARG(ops,'F'))
+ arg = OPT_ARG(ops,'F');
+
+ if (arg) {
+ char *eptr;
+ int base = (int)zstrtol(arg, &eptr, 10);
+ if (*eptr) {
+ if (on & PM_INTEGER)
+ zwarnnam(name, "bad base value: %s", arg);
+ else
+ zwarnnam(name, "bad precision value: %s", arg);
+ return 1;
+ }
+ if ((on & PM_INTEGER) && (base < 2 || base > 36)) {
+ zwarnnam(name, "invalid base (must be 2 to 36 inclusive): %d",
+ base);
+ return 1;
+ }
+ pm->base = base;
+ } else if (always)
+ pm->base = 0;
+
+ return 0;
+}
+
+/* Install a width if we are turning on a padding option with an argument */
+
+static int
+typeset_setwidth(const char * name, Param pm, Options ops, int on, int always)
+{
+ char *arg = NULL;
+
+ if ((on & PM_LEFT) && OPT_HASARG(ops,'L'))
+ arg = OPT_ARG(ops,'L');
+ else if ((on & PM_RIGHT_B) && OPT_HASARG(ops,'R'))
+ arg = OPT_ARG(ops,'R');
+ else if ((on & PM_RIGHT_Z) && OPT_HASARG(ops,'Z'))
+ arg = OPT_ARG(ops,'Z');
+
+ if (arg) {
+ char *eptr;
+ pm->width = (int)zstrtol(arg, &eptr, 10);
+ if (*eptr) {
+ zwarnnam(name, "bad width value: %s", arg);
+ return 1;
+ }
+ } else if (always)
+ pm->width = 0;
+
+ return 0;
+}
+
+/* function to set a single parameter */
+
+/**/
+static Param
+typeset_single(char *cname, char *pname, Param pm, UNUSED(int func),
+ int on, int off, int roff, Asgment asg, Param altpm,
+ Options ops, int joinchar)
+{
+ int usepm, tc, keeplocal = 0, newspecial = NS_NONE, readonly, dont_set = 0;
+ char *subscript;
+
+ /*
+ * Do we use the existing pm? Note that this isn't the end of the
+ * story, because if we try and create a new pm at the same
+ * locallevel as an unset one we use the pm struct anyway: that's
+ * handled in createparam(). Here we just avoid using it for the
+ * present tests if it's unset.
+ *
+ * POSIXBUILTINS horror: we need to retain the 'readonly' or 'export'
+ * flags of an unset parameter.
+ */
+ usepm = pm && (!(pm->node.flags & PM_UNSET) ||
+ (isset(POSIXBUILTINS) &&
+ (pm->node.flags & (PM_READONLY|PM_EXPORTED))));
+
+ /*
+ * We need to compare types with an existing pm if special,
+ * even if that's unset
+ */
+ if (!usepm && pm && (pm->node.flags & PM_SPECIAL))
+ usepm = 2; /* indicate that we preserve the PM_UNSET flag */
+
+ /*
+ * Don't use an existing param if
+ * - the local level has changed, and
+ * - we are really locallizing the parameter
+ */
+ if (usepm && locallevel != pm->level && (on & PM_LOCAL)) {
+ /*
+ * If the original parameter was special and we're creating
+ * a new one, we need to keep it special.
+ *
+ * The -h (hide) flag prevents an existing special being made
+ * local. It can be applied either to the special or in the
+ * typeset/local statement for the local variable.
+ */
+ if ((pm->node.flags & PM_SPECIAL)
+ && !(on & PM_HIDE) && !(pm->node.flags & PM_HIDE & ~off))
+ newspecial = NS_NORMAL;
+ usepm = 0;
+ }
+
+ /* attempting a type conversion, or making a tied colonarray? */
+ tc = 0;
+ if (ASG_ARRAYP(asg) && PM_TYPE(on) == PM_SCALAR &&
+ !(usepm && (PM_TYPE(pm->node.flags) & (PM_ARRAY|PM_HASHED))))
+ on |= PM_ARRAY;
+ if (usepm && ASG_ARRAYP(asg) && newspecial == NS_NONE &&
+ PM_TYPE(pm->node.flags) != PM_ARRAY &&
+ PM_TYPE(pm->node.flags) != PM_HASHED) {
+ if (on & (PM_EFLOAT|PM_FFLOAT|PM_INTEGER)) {
+ zerrnam(cname, "%s: can't assign array value to non-array", pname);
+ return NULL;
+ }
+ if (pm->node.flags & PM_SPECIAL) {
+ zerrnam(cname, "%s: can't assign array value to non-array special", pname);
+ return NULL;
+ }
+ tc = 1;
+ usepm = 0;
+ }
+ else if (usepm || newspecial != NS_NONE) {
+ int chflags = ((off & pm->node.flags) | (on & ~pm->node.flags)) &
+ (PM_INTEGER|PM_EFLOAT|PM_FFLOAT|PM_HASHED|
+ PM_ARRAY|PM_TIED|PM_AUTOLOAD);
+ /* keep the parameter if just switching between floating types */
+ if ((tc = chflags && chflags != (PM_EFLOAT|PM_FFLOAT)))
+ usepm = 0;
+ }
+
+ /*
+ * Extra checks if converting the type of a parameter, or if
+ * trying to remove readonlyness. It's dangerous doing either
+ * with a special or a parameter which isn't loaded yet (which
+ * may be special when it is loaded; we can't tell yet).
+ */
+ if ((readonly =
+ ((usepm || newspecial != NS_NONE) &&
+ (off & pm->node.flags & PM_READONLY))) ||
+ tc) {
+ if (pm->node.flags & PM_SPECIAL) {
+ int err = 1;
+ if (!readonly && !strcmp(pname, "SECONDS"))
+ {
+ /*
+ * We allow SECONDS to change type between integer
+ * and floating point. If we are creating a new
+ * local copy we check the type here and allow
+ * a new special to be created with that type.
+ * We then need to make sure the correct type
+ * for the special is restored at the end of the scope.
+ * If we are changing the type of an existing
+ * parameter, we do the whole thing here.
+ */
+ if (newspecial != NS_NONE)
+ {
+ /*
+ * The first test allows `typeset' to copy the
+ * existing type. This is the usual behaviour
+ * for making special parameters local.
+ */
+ if (PM_TYPE(on) == 0 || PM_TYPE(on) == PM_INTEGER ||
+ PM_TYPE(on) == PM_FFLOAT || PM_TYPE(on) == PM_EFLOAT)
+ {
+ newspecial = NS_SECONDS;
+ err = 0; /* and continue */
+ tc = 0; /* but don't do a normal conversion */
+ }
+ } else if (!setsecondstype(pm, on, off)) {
+ if (asg->value.scalar &&
+ !(pm = assignsparam(
+ pname, ztrdup(asg->value.scalar), 0)))
+ return NULL;
+ usepm = 1;
+ err = 0;
+ }
+ }
+ if (err)
+ {
+ zerrnam(cname, "%s: can't change type of a special parameter",
+ pname);
+ return NULL;
+ }
+ } else if (pm->node.flags & PM_AUTOLOAD) {
+ zerrnam(cname, "%s: can't change type of autoloaded parameter",
+ pname);
+ return NULL;
+ }
+ }
+ else if (newspecial != NS_NONE && strcmp(pname, "SECONDS") == 0)
+ newspecial = NS_SECONDS;
+
+ if (isset(POSIXBUILTINS)) {
+ /*
+ * Stricter rules about retaining readonly attribute in this case.
+ */
+ if ((on & (PM_READONLY|PM_EXPORTED)) &&
+ (!usepm || (pm->node.flags & PM_UNSET)) &&
+ !ASG_VALUEP(asg))
+ on |= PM_UNSET;
+ else if (usepm && (pm->node.flags & PM_READONLY) &&
+ !(on & PM_READONLY)) {
+ zerr("read-only variable: %s", pm->node.nam);
+ return NULL;
+ }
+ /* This is handled by createparam():
+ if (usepm && (pm->node.flags & PM_EXPORTED) && !(off & PM_EXPORTED))
+ on |= PM_EXPORTED;
+ */
+ }
+
+ /*
+ * A parameter will be local if
+ * 1. we are re-using an existing local parameter
+ * or
+ * 2. we are not using an existing parameter, but
+ * i. there is already a parameter, which will be hidden
+ * or
+ * ii. we are creating a new local parameter
+ */
+ if (usepm) {
+ if ((asg->flags & ASG_ARRAY) ?
+ !(PM_TYPE(pm->node.flags) & (PM_ARRAY|PM_HASHED)) :
+ (asg->value.scalar && (PM_TYPE(pm->node.flags &
+ (PM_ARRAY|PM_HASHED))))) {
+ zerrnam(cname, "%s: inconsistent type for assignment", pname);
+ return NULL;
+ }
+ on &= ~PM_LOCAL;
+ if (!on && !roff && !ASG_VALUEP(asg)) {
+ if (OPT_ISSET(ops,'p'))
+ paramtab->printnode(&pm->node, PRINT_TYPESET);
+ else if (!OPT_ISSET(ops,'g') &&
+ (unset(TYPESETSILENT) || OPT_ISSET(ops,'m')))
+ paramtab->printnode(&pm->node, PRINT_INCLUDEVALUE);
+ return pm;
+ }
+ if ((pm->node.flags & PM_RESTRICTED) && isset(RESTRICTED)) {
+ zerrnam(cname, "%s: restricted", pname);
+ return pm;
+ }
+ if ((on & PM_UNIQUE) && !(pm->node.flags & PM_READONLY & ~off)) {
+ Param apm;
+ char **x;
+ if (PM_TYPE(pm->node.flags) == PM_ARRAY) {
+ x = (*pm->gsu.a->getfn)(pm);
+ uniqarray(x);
+ if (pm->node.flags & PM_SPECIAL) {
+ if (zheapptr(x))
+ x = zarrdup(x);
+ (*pm->gsu.a->setfn)(pm, x);
+ } else if (pm->ename && x)
+ arrfixenv(pm->ename, x);
+ } else if (PM_TYPE(pm->node.flags) == PM_SCALAR && pm->ename &&
+ (apm =
+ (Param) paramtab->getnode(paramtab, pm->ename))) {
+ x = (*apm->gsu.a->getfn)(apm);
+ uniqarray(x);
+ if (x)
+ arrfixenv(pm->node.nam, x);
+ }
+ }
+ if (usepm == 2) /* do not change the PM_UNSET flag */
+ pm->node.flags = (pm->node.flags | (on & ~PM_READONLY)) & ~off;
+ else {
+ /*
+ * Keep unset if using readonly in POSIX mode.
+ */
+ if (!(on & PM_READONLY) || !isset(POSIXBUILTINS))
+ off |= PM_UNSET;
+ pm->node.flags = (pm->node.flags |
+ (on & ~PM_READONLY)) & ~off;
+ }
+ if (on & (PM_LEFT | PM_RIGHT_B | PM_RIGHT_Z)) {
+ if (typeset_setwidth(cname, pm, ops, on, 0))
+ return NULL;
+ }
+ if (on & (PM_INTEGER | PM_EFLOAT | PM_FFLOAT)) {
+ if (typeset_setbase(cname, pm, ops, on, 0))
+ return NULL;
+ }
+ if (!(pm->node.flags & (PM_ARRAY|PM_HASHED))) {
+ if (pm->node.flags & PM_EXPORTED) {
+ if (!(pm->node.flags & PM_UNSET) && !pm->env && !ASG_VALUEP(asg))
+ addenv(pm, getsparam(pname));
+ } else if (pm->env && !(pm->node.flags & PM_HASHELEM))
+ delenv(pm);
+ DPUTS(ASG_ARRAYP(asg), "BUG: typeset got array value where scalar expected");
+ if (asg->value.scalar &&
+ !(pm = assignsparam(pname, ztrdup(asg->value.scalar), 0)))
+ return NULL;
+ } else if (asg->flags & ASG_ARRAY) {
+ int flags = (asg->flags & ASG_KEY_VALUE) ? ASSPM_KEY_VALUE : 0;
+ if (!(pm = assignaparam(pname, asg->value.array ?
+ zlinklist2array(asg->value.array) :
+ mkarray(NULL), flags)))
+ return NULL;
+ }
+ if (errflag)
+ return NULL;
+ pm->node.flags |= (on & PM_READONLY);
+ if (OPT_ISSET(ops,'p'))
+ paramtab->printnode(&pm->node, PRINT_TYPESET);
+ return pm;
+ }
+
+ if ((asg->flags & ASG_ARRAY) ?
+ !(on & (PM_ARRAY|PM_HASHED)) :
+ (asg->value.scalar && (on & (PM_ARRAY|PM_HASHED)))) {
+ zerrnam(cname, "%s: inconsistent type for assignment", pname);
+ return NULL;
+ }
+
+ /*
+ * We're here either because we're creating a new parameter,
+ * or we're adding a parameter at a different local level,
+ * or we're converting the type of a parameter. In the
+ * last case only, we need to delete the old parameter.
+ */
+ if (tc) {
+ /* Maintain existing readonly/exported status... */
+ on |= ~off & (PM_READONLY|PM_EXPORTED) & pm->node.flags;
+ /* ...but turn off existing readonly so we can delete it */
+ pm->node.flags &= ~PM_READONLY;
+ /*
+ * If we're just changing the type, we should keep the
+ * variable at the current level of localness.
+ */
+ keeplocal = pm->level;
+ /*
+ * Try to carry over a value, but not when changing from,
+ * to, or between non-scalar types.
+ *
+ * (We can do better now, but it does have user-visible
+ * implications.)
+ */
+ if (!ASG_VALUEP(asg) && !((pm->node.flags|on) & (PM_ARRAY|PM_HASHED))) {
+ asg->value.scalar = dupstring(getsparam(pname));
+ asg->flags = 0;
+ }
+ /* pname may point to pm->nam which is about to disappear */
+ pname = dupstring(pname);
+ unsetparam_pm(pm, 0, 1);
+ }
+
+ if (newspecial != NS_NONE) {
+ Param tpm, pm2;
+ if ((pm->node.flags & PM_RESTRICTED) && isset(RESTRICTED)) {
+ zerrnam(cname, "%s: restricted", pname);
+ return pm;
+ }
+ if (pm->node.flags & PM_SINGLE) {
+ zerrnam(cname, "%s: can only have a single instance", pname);
+ return pm;
+ }
+ /*
+ * For specials, we keep the same struct but zero everything.
+ * Maybe it would be easier to create a new struct but copy
+ * the get/set methods.
+ */
+ tpm = (Param) zshcalloc(sizeof *tpm);
+
+ tpm->node.nam = pm->node.nam;
+ if (pm->ename &&
+ (pm2 = (Param) paramtab->getnode(paramtab, pm->ename)) &&
+ pm2->level == locallevel) {
+ /* This is getting silly, but anyway: if one of a path/PATH
+ * pair has already been made local at the current level, we
+ * have to make sure that the other one does not have its value
+ * saved: since that comes from an internal variable it will
+ * already reflect the local value, so restoring it on exit
+ * would be wrong.
+ *
+ * This problem is also why we make sure we have a copy
+ * of the environment entry in tpm->env, rather than relying
+ * on the restored value to provide it.
+ */
+ tpm->node.flags = pm->node.flags | PM_NORESTORE;
+ } else {
+ copyparam(tpm, pm, 1);
+ }
+ tpm->old = pm->old;
+ tpm->level = pm->level;
+ tpm->base = pm->base;
+ tpm->width = pm->width;
+ if (pm->env)
+ delenv(pm);
+ tpm->env = NULL;
+
+ pm->old = tpm;
+ /*
+ * The remaining on/off flags should be harmless to use,
+ * because we've checked for unpleasant surprises above.
+ */
+ pm->node.flags = (PM_TYPE(pm->node.flags) | on | PM_SPECIAL) & ~off;
+ /*
+ * Readonlyness of special parameters must be preserved.
+ */
+ pm->node.flags |= tpm->node.flags & PM_READONLY;
+ if (newspecial == NS_SECONDS) {
+ /* We save off the raw internal value of the SECONDS var */
+ tpm->u.dval = getrawseconds();
+ setsecondstype(pm, on, off);
+ }
+
+ /*
+ * Final tweak: if we've turned on one of the flags with
+ * numbers, we should use the appropriate integer.
+ */
+ if (on & (PM_LEFT|PM_RIGHT_B|PM_RIGHT_Z)) {
+ if (typeset_setwidth(cname, pm, ops, on, 1))
+ return NULL;
+ }
+ if (on & (PM_INTEGER|PM_EFLOAT|PM_FFLOAT)) {
+ if (typeset_setbase(cname, pm, ops, on, 1))
+ return NULL;
+ }
+ } else if ((subscript = strchr(pname, '['))) {
+ if (on & PM_READONLY) {
+ zerrnam(cname,
+ "%s: can't create readonly array elements", pname);
+ return NULL;
+ } else if ((on & PM_LOCAL) && locallevel) {
+ *subscript = 0;
+ pm = (Param) (paramtab == realparamtab ?
+ /* getnode2() to avoid autoloading */
+ paramtab->getnode2(paramtab, pname) :
+ paramtab->getnode(paramtab, pname));
+ *subscript = '[';
+ if (!pm || pm->level != locallevel) {
+ zerrnam(cname,
+ "%s: can't create local array elements", pname);
+ return NULL;
+ }
+ }
+ if (PM_TYPE(on) == PM_SCALAR && !ASG_ARRAYP(asg)) {
+ /*
+ * This will either complain about bad identifiers, or will set
+ * a hash element or array slice. This once worked by accident,
+ * creating a stray parameter along the way via createparam(),
+ * now called below in the isident() branch.
+ */
+ if (!(pm = assignsparam(
+ pname,
+ ztrdup(asg->value.scalar ? asg->value.scalar : ""), 0)))
+ return NULL;
+ dont_set = 1;
+ asg->flags = 0;
+ keeplocal = 0;
+ on = pm->node.flags;
+ } else if (PM_TYPE(on) == PM_ARRAY && ASG_ARRAYP(asg)) {
+ int flags = (asg->flags & ASG_KEY_VALUE) ? ASSPM_KEY_VALUE : 0;
+ if (!(pm = assignaparam(pname, asg->value.array ?
+ zlinklist2array(asg->value.array) :
+ mkarray(NULL), flags)))
+ return NULL;
+ dont_set = 1;
+ keeplocal = 0;
+ on = pm->node.flags;
+ } else {
+ zerrnam(cname,
+ "%s: inconsistent array element or slice assignment", pname);
+ return NULL;
+ }
+ }
+ /*
+ * As we can hide existing parameters, we allow a name if
+ * it's not a normal identifier but is one of the special
+ * set found in the parameter table. The second test is
+ * because we can set individual positional parameters;
+ * however "0" is not a positional parameter and is OK.
+ *
+ * It would be neater to extend isident() and be clearer
+ * about where we allow various parameter types. It's
+ * not entirely clear to me isident() should reject
+ * specially named parameters given that it accepts digits.
+ */
+ else if ((isident(pname) || paramtab->getnode(paramtab, pname))
+ && (!idigit(*pname) || !strcmp(pname, "0"))) {
+ /*
+ * Create a new node for a parameter with the flags in `on' minus the
+ * readonly flag
+ */
+ pm = createparam(pname, on & ~PM_READONLY);
+ if (!pm) {
+ if (on & (PM_LEFT | PM_RIGHT_B | PM_RIGHT_Z |
+ PM_INTEGER | PM_EFLOAT | PM_FFLOAT))
+ zerrnam(cname, "can't change variable attribute: %s", pname);
+ return NULL;
+ }
+ if (on & (PM_LEFT | PM_RIGHT_B | PM_RIGHT_Z)) {
+ if (typeset_setwidth(cname, pm, ops, on, 0))
+ return NULL;
+ }
+ if (on & (PM_INTEGER | PM_EFLOAT | PM_FFLOAT)) {
+ if (typeset_setbase(cname, pm, ops, on, 0))
+ return NULL;
+ }
+ } else {
+ if (idigit(*pname))
+ zerrnam(cname, "not an identifier: %s", pname);
+ else
+ zerrnam(cname, "not valid in this context: %s", pname);
+ return NULL;
+ }
+
+ if (altpm && PM_TYPE(pm->node.flags) == PM_SCALAR) {
+ /*
+ * It seems safer to set this here than in createparam(),
+ * to make sure we only ever use the colonarr functions
+ * when u.data is correctly set.
+ */
+ struct tieddata *tdp = (struct tieddata *)
+ zalloc(sizeof(struct tieddata));
+ if (!tdp)
+ return NULL;
+ tdp->joinchar = joinchar;
+ tdp->arrptr = &altpm->u.arr;
+
+ pm->gsu.s = &tiedarr_gsu;
+ pm->u.data = tdp;
+ }
+
+ if (keeplocal)
+ pm->level = keeplocal;
+ else if (on & PM_LOCAL)
+ pm->level = locallevel;
+ if (ASG_VALUEP(asg) && !dont_set) {
+ Param ipm = pm;
+ if (pm->node.flags & (PM_ARRAY|PM_HASHED)) {
+ char **arrayval;
+ int flags = (asg->flags & ASG_KEY_VALUE) ? ASSPM_KEY_VALUE : 0;
+ if (!ASG_ARRAYP(asg)) {
+ /*
+ * Attempt to assign a scalar value to an array.
+ * This can happen if the array is special.
+ * We'll be lenient and guess what the user meant.
+ * This is how normal assigment works.
+ */
+ if (*asg->value.scalar) {
+ /* Array with one value */
+ arrayval = mkarray(ztrdup(asg->value.scalar));
+ } else {
+ /* Empty array */
+ arrayval = mkarray(NULL);
+ }
+ } else if (asg->value.array)
+ arrayval = zlinklist2array(asg->value.array);
+ else
+ arrayval = mkarray(NULL);
+ if (!(pm=assignaparam(pname, arrayval, flags)))
+ return NULL;
+ } else {
+ DPUTS(ASG_ARRAYP(asg), "BUG: inconsistent array value for scalar");
+ if (!(pm = assignsparam(pname, ztrdup(asg->value.scalar), 0)))
+ return NULL;
+ }
+ if (pm != ipm) {
+ DPUTS(ipm->node.flags != pm->node.flags,
+ "BUG: parameter recreated with wrong flags");
+ unsetparam_pm(ipm, 0, 1);
+ }
+ } else if (newspecial != NS_NONE &&
+ !(pm->old->node.flags & (PM_NORESTORE|PM_READONLY))) {
+ /*
+ * We need to use the special setting function to re-initialise
+ * the special parameter to empty.
+ */
+ switch (PM_TYPE(pm->node.flags)) {
+ case PM_SCALAR:
+ pm->gsu.s->setfn(pm, ztrdup(""));
+ break;
+ case PM_INTEGER:
+ /*
+ * Restricted integers are dangerous to initialize to 0,
+ * so don't do that.
+ */
+ if (!(pm->old->node.flags & PM_RESTRICTED))
+ pm->gsu.i->setfn(pm, 0);
+ break;
+ case PM_EFLOAT:
+ case PM_FFLOAT:
+ pm->gsu.f->setfn(pm, 0.0);
+ break;
+ case PM_ARRAY:
+ pm->gsu.a->setfn(pm, mkarray(NULL));
+ break;
+ case PM_HASHED:
+ pm->gsu.h->setfn(pm, newparamtable(17, pm->node.nam));
+ break;
+ }
+ }
+ pm->node.flags |= (on & PM_READONLY);
+
+ if (OPT_ISSET(ops,'p'))
+ paramtab->printnode(&pm->node, PRINT_TYPESET);
+
+ return pm;
+}
+
+/*
+ * declare, export, float, integer, local, readonly, typeset
+ *
+ * Note the difference in interface from most builtins, covered by the
+ * BINF_ASSIGN builtin flag. This is only made use of by builtins
+ * called by reserved word, which only covers declare, local, readonly
+ * and typeset. Otherwise assigns is NULL.
+ */
+
+/**/
+int
+bin_typeset(char *name, char **argv, LinkList assigns, Options ops, int func)
+{
+ Param pm;
+ Asgment asg;
+ Patprog pprog;
+ char *optstr = TYPESET_OPTSTR;
+ int on = 0, off = 0, roff, bit = PM_ARRAY;
+ int i;
+ int returnval = 0, printflags = 0;
+ int hasargs;
+
+ /* hash -f is really the builtin `functions' */
+ if (OPT_ISSET(ops,'f'))
+ return bin_functions(name, argv, ops, func);
+
+ /* POSIX handles "readonly" specially */
+ if (func == BIN_READONLY && isset(POSIXBUILTINS) && !OPT_PLUS(ops, 'g'))
+ ops->ind['g'] = 1;
+
+ /* Translate the options into PM_* flags. *
+ * Unfortunately, this depends on the order *
+ * these flags are defined in zsh.h */
+ for (; *optstr; optstr++, bit <<= 1)
+ {
+ int optval = STOUC(*optstr);
+ if (OPT_MINUS(ops,optval))
+ on |= bit;
+ else if (OPT_PLUS(ops,optval))
+ off |= bit;
+ }
+ roff = off;
+
+ /* Sanity checks on the options. Remove conflicting options. */
+ if (on & PM_FFLOAT) {
+ off |= PM_UPPER | PM_ARRAY | PM_HASHED | PM_INTEGER | PM_EFLOAT;
+ /* Allow `float -F' to work even though float sets -E by default */
+ on &= ~PM_EFLOAT;
+ }
+ if (on & PM_EFLOAT)
+ off |= PM_UPPER | PM_ARRAY | PM_HASHED | PM_INTEGER | PM_FFLOAT;
+ if (on & PM_INTEGER)
+ off |= PM_UPPER | PM_ARRAY | PM_HASHED | PM_EFLOAT | PM_FFLOAT;
+ /*
+ * Allowing -Z with -L is a feature: left justify, suppressing
+ * leading zeroes.
+ */
+ if (on & (PM_LEFT|PM_RIGHT_Z))
+ off |= PM_RIGHT_B;
+ if (on & PM_RIGHT_B)
+ off |= PM_LEFT | PM_RIGHT_Z;
+ if (on & PM_UPPER)
+ off |= PM_LOWER;
+ if (on & PM_LOWER)
+ off |= PM_UPPER;
+ if (on & PM_HASHED)
+ off |= PM_ARRAY;
+ if (on & PM_TIED)
+ off |= PM_INTEGER | PM_EFLOAT | PM_FFLOAT | PM_ARRAY | PM_HASHED;
+
+ on &= ~off;
+
+ queue_signals();
+
+ /* Given no arguments, list whatever the options specify. */
+ if (OPT_ISSET(ops,'p')) {
+ printflags |= PRINT_TYPESET;
+ if (OPT_HASARG(ops,'p')) {
+ char *eptr;
+ int pflag = (int)zstrtol(OPT_ARG(ops,'p'), &eptr, 10);
+ if (pflag == 1 && !*eptr)
+ printflags |= PRINT_LINE;
+ else if (pflag || *eptr) {
+ zwarnnam(name, "bad argument to -p: %s", OPT_ARG(ops,'p'));
+ unqueue_signals();
+ return 1;
+ }
+ /* -p0 treated as -p for consistency */
+ }
+ }
+ hasargs = *argv != NULL || (assigns && firstnode(assigns));
+ if (!hasargs) {
+ if (!OPT_ISSET(ops,'p')) {
+ if (!(on|roff))
+ printflags |= PRINT_TYPE;
+ if (roff || OPT_ISSET(ops,'+'))
+ printflags |= PRINT_NAMEONLY;
+ }
+ scanhashtable(paramtab, 1, on|roff, 0, paramtab->printnode, printflags);
+ unqueue_signals();
+ return 0;
+ }
+
+ if (!(OPT_ISSET(ops,'g') || OPT_ISSET(ops,'x') || OPT_ISSET(ops,'m')) ||
+ OPT_PLUS(ops,'g') || *name == 'l' ||
+ (!isset(GLOBALEXPORT) && !OPT_ISSET(ops,'g')))
+ on |= PM_LOCAL;
+
+ if (on & PM_TIED) {
+ Param apm;
+ struct asgment asg0, asg2;
+ char *oldval = NULL, *joinstr;
+ int joinchar, nargs;
+
+ if (OPT_ISSET(ops,'m')) {
+ zwarnnam(name, "incompatible options for -T");
+ unqueue_signals();
+ return 1;
+ }
+ on &= ~off;
+ nargs = arrlen(argv) + (assigns ? countlinknodes(assigns) : 0);
+ if (nargs < 2) {
+ zwarnnam(name, "-T requires names of scalar and array");
+ unqueue_signals();
+ return 1;
+ }
+ if (nargs > 3) {
+ zwarnnam(name, "too many arguments for -T");
+ unqueue_signals();
+ return 1;
+ }
+
+ if (!(asg = getasg(&argv, assigns))) {
+ unqueue_signals();
+ return 1;
+ }
+ asg0 = *asg;
+ if (ASG_ARRAYP(&asg0)) {
+ unqueue_signals();
+ zwarnnam(name, "first argument of tie must be scalar: %s",
+ asg0.name);
+ return 1;
+ }
+
+ if (!(asg = getasg(&argv, assigns))) {
+ unqueue_signals();
+ return 1;
+ }
+ if (!ASG_ARRAYP(asg) && asg->value.scalar) {
+ unqueue_signals();
+ zwarnnam(name, "second argument of tie must be array: %s",
+ asg->name);
+ return 1;
+ }
+
+ if (!strcmp(asg0.name, asg->name)) {
+ unqueue_signals();
+ zerrnam(name, "can't tie a variable to itself: %s", asg0.name);
+ return 1;
+ }
+ if (strchr(asg0.name, '[') || strchr(asg->name, '[')) {
+ unqueue_signals();
+ zerrnam(name, "can't tie array elements: %s", asg0.name);
+ return 1;
+ }
+ if (ASG_VALUEP(asg) && ASG_VALUEP(&asg0)) {
+ unqueue_signals();
+ zerrnam(name, "only one tied parameter can have value: %s", asg0.name);
+ return 1;
+ }
+
+ /*
+ * Third argument, if given, is character used to join
+ * the elements of the array in the scalar.
+ */
+ if (*argv)
+ joinstr = *argv;
+ else if (assigns && firstnode(assigns)) {
+ Asgment nextasg = (Asgment)firstnode(assigns);
+ if (ASG_ARRAYP(nextasg) || ASG_VALUEP(nextasg)) {
+ zwarnnam(name, "third argument of tie must be join character");
+ unqueue_signals();
+ return 1;
+ }
+ joinstr = nextasg->name;
+ } else
+ joinstr = NULL;
+ if (!joinstr)
+ joinchar = ':';
+ else if (!*joinstr)
+ joinchar = 0;
+ else if (*joinstr == Meta)
+ joinchar = joinstr[1] ^ 32;
+ else
+ joinchar = *joinstr;
+ /*
+ * Keep the old value of the scalar. We need to do this
+ * here as if it is already tied to the same array it
+ * will be unset when we retie the array. This is all
+ * so that typeset -T is idempotent.
+ *
+ * We also need to remember here whether the damn thing is
+ * exported and pass that along. Isn't the world complicated?
+ */
+ if ((pm = (Param) paramtab->getnode(paramtab, asg0.name))
+ && !(pm->node.flags & PM_UNSET)
+ && (locallevel == pm->level || !(on & PM_LOCAL))) {
+ if (pm->node.flags & PM_TIED) {
+ unqueue_signals();
+ if (PM_TYPE(pm->node.flags) != PM_SCALAR) {
+ zwarnnam(name, "already tied as non-scalar: %s", asg0.name);
+ } else if (!strcmp(asg->name, pm->ename)) {
+ /*
+ * Already tied in the fashion requested.
+ */
+ struct tieddata *tdp = (struct tieddata*)pm->u.data;
+ int flags = (asg->flags & ASG_KEY_VALUE) ?
+ ASSPM_KEY_VALUE : 0;
+ /* Update join character */
+ tdp->joinchar = joinchar;
+ if (asg0.value.scalar)
+ assignsparam(asg0.name, ztrdup(asg0.value.scalar), 0);
+ else if (asg->value.array)
+ assignaparam(
+ asg->name, zlinklist2array(asg->value.array),flags);
+ return 0;
+ } else {
+ zwarnnam(name, "can't tie already tied scalar: %s",
+ asg0.name);
+ }
+ return 1;
+ }
+ if (!asg0.value.scalar && !asg->value.array &&
+ !(PM_TYPE(pm->node.flags) & (PM_ARRAY|PM_HASHED)))
+ oldval = ztrdup(getsparam(asg0.name));
+ on |= (pm->node.flags & PM_EXPORTED);
+ }
+ /*
+ * Create the tied array; this is normal except that
+ * it has the PM_TIED flag set. Do it first because
+ * we need the address.
+ *
+ * Don't attempt to set it yet, it's too early
+ * to be exported properly.
+ */
+ asg2.name = asg->name;
+ asg2.flags = 0;
+ asg2.value.array = (LinkList)0;
+ if (!(apm=typeset_single(name, asg->name,
+ (Param)paramtab->getnode(paramtab,
+ asg->name),
+ func, (on | PM_ARRAY) & ~PM_EXPORTED,
+ off, roff, &asg2, NULL, ops, 0))) {
+ if (oldval)
+ zsfree(oldval);
+ unqueue_signals();
+ return 1;
+ }
+ /*
+ * Create the tied colonarray. We make it as a normal scalar
+ * and fix up the oddities later.
+ */
+ if (!(pm=typeset_single(name, asg0.name,
+ (Param)paramtab->getnode(paramtab,
+ asg0.name),
+ func, on, off, roff, &asg0, apm,
+ ops, joinchar))) {
+ if (oldval)
+ zsfree(oldval);
+ unsetparam_pm(apm, 1, 1);
+ unqueue_signals();
+ return 1;
+ }
+
+ /*
+ * pm->ename is only deleted when the struct is, so
+ * we need to free it here if it already exists.
+ */
+ if (pm->ename)
+ zsfree(pm->ename);
+ pm->ename = ztrdup(asg->name);
+ if (apm->ename)
+ zsfree(apm->ename);
+ apm->ename = ztrdup(asg0.name);
+ if (asg->value.array) {
+ int flags = (asg->flags & ASG_KEY_VALUE) ? ASSPM_KEY_VALUE : 0;
+ assignaparam(asg->name, zlinklist2array(asg->value.array), flags);
+ } else if (oldval)
+ assignsparam(asg0.name, oldval, 0);
+ unqueue_signals();
+
+ return 0;
+ }
+ if (off & PM_TIED) {
+ unqueue_signals();
+ zerrnam(name, "use unset to remove tied variables");
+ return 1;
+ }
+
+ /* With the -m option, treat arguments as glob patterns */
+ if (OPT_ISSET(ops,'m')) {
+ if (!OPT_ISSET(ops,'p')) {
+ if (!(on|roff))
+ printflags |= PRINT_TYPE;
+ if (!on)
+ printflags |= PRINT_NAMEONLY;
+ }
+
+ while ((asg = getasg(&argv, assigns))) {
+ LinkList pmlist = newlinklist();
+ LinkNode pmnode;
+
+ tokenize(asg->name); /* expand argument */
+ if (!(pprog = patcompile(asg->name, 0, NULL))) {
+ untokenize(asg->name);
+ zwarnnam(name, "bad pattern : %s", asg->name);
+ returnval = 1;
+ continue;
+ }
+ if (OPT_PLUS(ops,'m') && !ASG_VALUEP(asg)) {
+ scanmatchtable(paramtab, pprog, 1, on|roff, 0,
+ paramtab->printnode, printflags);
+ continue;
+ }
+ /*
+ * Search through the parameter table and change all parameters
+ * matching the glob pattern to have these flags and/or value.
+ * Bad news: if the parameter gets altered, e.g. by
+ * a type conversion, then paramtab can be shifted around,
+ * so we need to store the parameters to alter on a separate
+ * list for later use.
+ */
+ for (i = 0; i < paramtab->hsize; i++) {
+ for (pm = (Param) paramtab->nodes[i]; pm;
+ pm = (Param) pm->node.next) {
+ if (((pm->node.flags & PM_RESTRICTED) && isset(RESTRICTED)) ||
+ (pm->node.flags & PM_UNSET))
+ continue;
+ if (pattry(pprog, pm->node.nam))
+ addlinknode(pmlist, pm);
+ }
+ }
+ for (pmnode = firstnode(pmlist); pmnode; incnode(pmnode)) {
+ pm = (Param) getdata(pmnode);
+ if (!typeset_single(name, pm->node.nam, pm, func, on, off, roff,
+ asg, NULL, ops, 0))
+ returnval = 1;
+ }
+ }
+ unqueue_signals();
+ return returnval;
+ }
+
+ /* Take arguments literally. Don't glob */
+ while ((asg = getasg(&argv, assigns))) {
+ HashNode hn = (paramtab == realparamtab ?
+ /* getnode2() to avoid autoloading */
+ paramtab->getnode2(paramtab, asg->name) :
+ paramtab->getnode(paramtab, asg->name));
+ if (OPT_ISSET(ops,'p')) {
+ if (hn)
+ paramtab->printnode(hn, printflags);
+ else {
+ zwarnnam(name, "no such variable: %s", asg->name);
+ returnval = 1;
+ }
+ continue;
+ }
+ if (!typeset_single(name, asg->name, (Param)hn,
+ func, on, off, roff, asg, NULL,
+ ops, 0))
+ returnval = 1;
+ }
+ unqueue_signals();
+ return returnval;
+}
+
+/* Helper for bin_functions() when run as "autoload -X" */
+
+/**/
+int
+eval_autoload(Shfunc shf, char *name, Options ops, int func)
+{
+ if (!(shf->node.flags & PM_UNDEFINED))
+ return 1;
+
+ if (shf->funcdef) {
+ freeeprog(shf->funcdef);
+ shf->funcdef = &dummy_eprog;
+ }
+ if (OPT_MINUS(ops,'X')) {
+ char *fargv[3];
+ fargv[0] = name;
+ fargv[1] = "\"$@\"";
+ fargv[2] = 0;
+ shf->funcdef = mkautofn(shf);
+ return bin_eval(name, fargv, ops, func);
+ }
+
+ return !loadautofn(shf, (OPT_ISSET(ops,'k') ? 2 :
+ (OPT_ISSET(ops,'z') ? 0 : 1)), 1,
+ OPT_ISSET(ops,'d'));
+}
+
+/* Helper for bin_functions() for -X and -r options */
+
+/**/
+static int
+check_autoload(Shfunc shf, char *name, Options ops, int func)
+{
+ if (OPT_ISSET(ops,'X'))
+ {
+ return eval_autoload(shf, name, ops, func);
+ }
+ if ((OPT_ISSET(ops,'r') || OPT_ISSET(ops,'R')) &&
+ (shf->node.flags & PM_UNDEFINED))
+ {
+ char *dir_path;
+ if (shf->filename && (shf->node.flags & PM_LOADDIR)) {
+ char *spec_path[2];
+ spec_path[0] = shf->filename;
+ spec_path[1] = NULL;
+ if (getfpfunc(shf->node.nam, NULL, &dir_path, spec_path, 1)) {
+ /* shf->filename is already correct. */
+ return 0;
+ }
+ if (!OPT_ISSET(ops,'d')) {
+ if (OPT_ISSET(ops,'R')) {
+ zerr("%s: function definition file not found",
+ shf->node.nam);
+ return 1;
+ }
+ return 0;
+ }
+ }
+ if (getfpfunc(shf->node.nam, NULL, &dir_path, NULL, 1)) {
+ dircache_set(&shf->filename, NULL);
+ if (*dir_path != '/') {
+ dir_path = zhtricat(metafy(zgetcwd(), -1, META_HEAPDUP),
+ "/", dir_path);
+ dir_path = xsymlink(dir_path, 1);
+ }
+ dircache_set(&shf->filename, dir_path);
+ shf->node.flags |= PM_LOADDIR;
+ return 0;
+ }
+ if (OPT_ISSET(ops,'R')) {
+ zerr("%s: function definition file not found",
+ shf->node.nam);
+ return 1;
+ }
+ /* with -r, we don't flag an error, just let it be found later. */
+ }
+ return 0;
+}
+
+/* List a user-defined math function. */
+static void
+listusermathfunc(MathFunc p)
+{
+ int showargs;
+
+ if (p->module)
+ showargs = 3;
+ else if (p->maxargs != (p->minargs ? p->minargs : -1))
+ showargs = 2;
+ else if (p->minargs)
+ showargs = 1;
+ else
+ showargs = 0;
+
+ printf("functions -M%s %s", (p->flags & MFF_STR) ? "s" : "", p->name);
+ if (showargs) {
+ printf(" %d", p->minargs);
+ showargs--;
+ }
+ if (showargs) {
+ printf(" %d", p->maxargs);
+ showargs--;
+ }
+ if (showargs) {
+ /*
+ * function names are not required to consist of ident characters
+ */
+ putchar(' ');
+ quotedzputs(p->module, stdout);
+ showargs--;
+ }
+ putchar('\n');
+}
+
+
+static void
+add_autoload_function(Shfunc shf, char *funcname)
+{
+ char *nam;
+ if (*funcname == '/' && funcname[1] &&
+ (nam = strrchr(funcname, '/')) && nam[1] &&
+ (shf->node.flags & PM_UNDEFINED)) {
+ char *dir;
+ nam = strrchr(funcname, '/');
+ if (nam == funcname) {
+ dir = "/";
+ } else {
+ *nam++ = '\0';
+ dir = funcname;
+ }
+ dircache_set(&shf->filename, NULL);
+ dircache_set(&shf->filename, dir);
+ shf->node.flags |= PM_LOADDIR;
+ shf->node.flags |= PM_ABSPATH_USED;
+ shfunctab->addnode(shfunctab, ztrdup(nam), shf);
+ } else {
+ Shfunc shf2;
+ Funcstack fs;
+ const char *calling_f = NULL;
+ char buf[PATH_MAX+1];
+
+ /* Find calling function */
+ for (fs = funcstack; fs; fs = fs->prev) {
+ if (fs->tp == FS_FUNC && fs->name && (!shf->node.nam || 0 != strcmp(fs->name,shf->node.nam))) {
+ calling_f = fs->name;
+ break;
+ }
+ }
+
+ /* Get its directory */
+ if (calling_f) {
+ /* Should contain load directory, and be loaded via absolute path */
+ if ((shf2 = (Shfunc) shfunctab->getnode2(shfunctab, calling_f))
+ && (shf2->node.flags & PM_LOADDIR) && (shf2->node.flags & PM_ABSPATH_USED)
+ && shf2->filename)
+ {
+ if (strlen(shf2->filename) + strlen(funcname) + 1 < PATH_MAX)
+ {
+ sprintf(buf, "%s/%s", shf2->filename, funcname);
+ /* Set containing directory if the function file
+ * exists (do normal FPATH processing otherwise) */
+ if (!access(buf, R_OK)) {
+ dircache_set(&shf->filename, NULL);
+ dircache_set(&shf->filename, shf2->filename);
+ shf->node.flags |= PM_LOADDIR;
+ shf->node.flags |= PM_ABSPATH_USED;
+ }
+ }
+ }
+ }
+
+ shfunctab->addnode(shfunctab, ztrdup(funcname), shf);
+ }
+}
+
+/* Display or change the attributes of shell functions. *
+ * If called as autoload, it will define a new autoloaded *
+ * (undefined) shell function. */
+
+/**/
+int
+bin_functions(char *name, char **argv, Options ops, int func)
+{
+ Patprog pprog;
+ Shfunc shf;
+ int i, returnval = 0;
+ int on = 0, off = 0, pflags = 0, roff, expand = 0;
+
+ /* Do we have any flags defined? */
+ if (OPT_PLUS(ops,'u'))
+ off |= PM_UNDEFINED;
+ else if (OPT_MINUS(ops,'u') || OPT_ISSET(ops,'X'))
+ on |= PM_UNDEFINED;
+ if (OPT_MINUS(ops,'U'))
+ on |= PM_UNALIASED|PM_UNDEFINED;
+ else if (OPT_PLUS(ops,'U'))
+ off |= PM_UNALIASED;
+ if (OPT_MINUS(ops,'t'))
+ on |= PM_TAGGED;
+ else if (OPT_PLUS(ops,'t'))
+ off |= PM_TAGGED;
+ if (OPT_MINUS(ops,'T'))
+ on |= PM_TAGGED_LOCAL;
+ else if (OPT_PLUS(ops,'T'))
+ off |= PM_TAGGED_LOCAL;
+ if (OPT_MINUS(ops,'W'))
+ on |= PM_WARNNESTED;
+ else if (OPT_PLUS(ops,'W'))
+ off |= PM_WARNNESTED;
+ roff = off;
+ if (OPT_MINUS(ops,'z')) {
+ on |= PM_ZSHSTORED;
+ off |= PM_KSHSTORED;
+ } else if (OPT_PLUS(ops,'z')) {
+ off |= PM_ZSHSTORED;
+ roff |= PM_ZSHSTORED;
+ }
+ if (OPT_MINUS(ops,'k')) {
+ on |= PM_KSHSTORED;
+ off |= PM_ZSHSTORED;
+ } else if (OPT_PLUS(ops,'k')) {
+ off |= PM_KSHSTORED;
+ roff |= PM_KSHSTORED;
+ }
+ if (OPT_MINUS(ops,'d')) {
+ on |= PM_CUR_FPATH;
+ off |= PM_CUR_FPATH;
+ } else if (OPT_PLUS(ops,'d')) {
+ off |= PM_CUR_FPATH;
+ roff |= PM_CUR_FPATH;
+ }
+
+ if ((off & PM_UNDEFINED) || (OPT_ISSET(ops,'k') && OPT_ISSET(ops,'z')) ||
+ (OPT_ISSET(ops,'x') && !OPT_HASARG(ops,'x')) ||
+ (OPT_MINUS(ops,'X') && (OPT_ISSET(ops,'m') || !scriptname))) {
+ zwarnnam(name, "invalid option(s)");
+ return 1;
+ }
+
+ if (OPT_ISSET(ops,'x')) {
+ char *eptr;
+ expand = (int)zstrtol(OPT_ARG(ops,'x'), &eptr, 10);
+ if (*eptr) {
+ zwarnnam(name, "number expected after -x");
+ return 1;
+ }
+ if (expand == 0) /* no indentation at all */
+ expand = -1;
+ }
+
+ if (OPT_PLUS(ops,'f') || roff || OPT_ISSET(ops,'+'))
+ pflags |= PRINT_NAMEONLY;
+
+ if (OPT_MINUS(ops,'M') || OPT_PLUS(ops,'M')) {
+ MathFunc p, q, prev;
+ /*
+ * Add/remove/list function as mathematical.
+ */
+ if (on || off || pflags || OPT_ISSET(ops,'X') || OPT_ISSET(ops,'u')
+ || OPT_ISSET(ops,'U') || OPT_ISSET(ops,'w')) {
+ zwarnnam(name, "invalid option(s)");
+ return 1;
+ }
+ if (!*argv) {
+ /* List functions. */
+ queue_signals();
+ for (p = mathfuncs; p; p = p->next)
+ if (p->flags & MFF_USERFUNC)
+ listusermathfunc(p);
+ unqueue_signals();
+ } else if (OPT_ISSET(ops,'m')) {
+ /* List matching functions. */
+ for (; *argv; argv++) {
+ queue_signals();
+ tokenize(*argv);
+ if ((pprog = patcompile(*argv, PAT_STATIC, 0))) {
+ for (p = mathfuncs, q = NULL; p; q = p) {
+ MathFunc next;
+ do {
+ next = NULL;
+ if ((p->flags & MFF_USERFUNC) &&
+ pattry(pprog, p->name)) {
+ if (OPT_PLUS(ops,'M')) {
+ next = p->next;
+ removemathfunc(q, p);
+ p = next;
+ } else
+ listusermathfunc(p);
+ }
+ /* if we deleted one, retry with the new p */
+ } while (next);
+ if (p)
+ p = p->next;
+ }
+ } else {
+ untokenize(*argv);
+ zwarnnam(name, "bad pattern : %s", *argv);
+ returnval = 1;
+ }
+ unqueue_signals();
+ }
+ } else if (OPT_PLUS(ops,'M')) {
+ /* Delete functions. -m is allowed but is handled above. */
+ for (; *argv; argv++) {
+ queue_signals();
+ for (p = mathfuncs, q = NULL; p; q = p, p = p->next) {
+ if (!strcmp(p->name, *argv)) {
+ if (!(p->flags & MFF_USERFUNC)) {
+ zwarnnam(name, "+M %s: is a library function",
+ *argv);
+ returnval = 1;
+ break;
+ }
+ removemathfunc(q, p);
+ break;
+ }
+ }
+ unqueue_signals();
+ }
+ } else {
+ /* Add a function */
+ int minargs, maxargs;
+ char *funcname = *argv++;
+ char *modname = NULL;
+ char *ptr;
+
+ if (OPT_ISSET(ops,'s')) {
+ minargs = maxargs = 1;
+ } else {
+ minargs = 0;
+ maxargs = -1;
+ }
+
+ ptr = itype_end(funcname, IIDENT, 0);
+ if (idigit(*funcname) || funcname == ptr || *ptr) {
+ zwarnnam(name, "-M %s: bad math function name", funcname);
+ return 1;
+ }
+
+ if (*argv) {
+ minargs = (int)zstrtol(*argv, &ptr, 0);
+ if (minargs < 0 || *ptr) {
+ zwarnnam(name, "-M: invalid min number of arguments: %s",
+ *argv);
+ return 1;
+ }
+ if (OPT_ISSET(ops,'s') && minargs != 1) {
+ zwarnnam(name, "-Ms: must take a single string argument");
+ return 1;
+ }
+ maxargs = minargs;
+ argv++;
+ }
+ if (*argv) {
+ maxargs = (int)zstrtol(*argv, &ptr, 0);
+ if (maxargs < -1 ||
+ (maxargs != -1 && maxargs < minargs) ||
+ *ptr) {
+ zwarnnam(name,
+ "-M: invalid max number of arguments: %s",
+ *argv);
+ return 1;
+ }
+ if (OPT_ISSET(ops,'s') && maxargs != 1) {
+ zwarnnam(name, "-Ms: must take a single string argument");
+ return 1;
+ }
+ argv++;
+ }
+ if (*argv)
+ modname = *argv++;
+ if (*argv) {
+ zwarnnam(name, "-M: too many arguments");
+ return 1;
+ }
+
+ p = (MathFunc)zshcalloc(sizeof(struct mathfunc));
+ p->name = ztrdup(funcname);
+ p->flags = MFF_USERFUNC;
+ if (OPT_ISSET(ops,'s'))
+ p->flags |= MFF_STR;
+ p->module = modname ? ztrdup(modname) : NULL;
+ p->minargs = minargs;
+ p->maxargs = maxargs;
+
+ queue_signals();
+ for (q = mathfuncs, prev = NULL; q; prev = q, q = q->next) {
+ if (!strcmp(q->name, funcname)) {
+ removemathfunc(prev, q);
+ break;
+ }
+ }
+
+ p->next = mathfuncs;
+ mathfuncs = p;
+ unqueue_signals();
+ }
+
+ return returnval;
+ }
+
+ if (OPT_MINUS(ops,'X')) {
+ Funcstack fs;
+ char *funcname = NULL;
+ int ret;
+ if (*argv && argv[1]) {
+ zwarnnam(name, "-X: too many arguments");
+ return 1;
+ }
+ queue_signals();
+ for (fs = funcstack; fs; fs = fs->prev) {
+ if (fs->tp == FS_FUNC) {
+ /*
+ * dupstring here is paranoia but unlikely to be
+ * problematic
+ */
+ funcname = dupstring(fs->name);
+ break;
+ }
+ }
+ if (!funcname)
+ {
+ zerrnam(name, "bad autoload");
+ ret = 1;
+ } else {
+ if ((shf = (Shfunc) shfunctab->getnode(shfunctab, funcname))) {
+ DPUTS(!shf->funcdef,
+ "BUG: Calling autoload from empty function");
+ } else {
+ shf = (Shfunc) zshcalloc(sizeof *shf);
+ shfunctab->addnode(shfunctab, ztrdup(funcname), shf);
+ }
+ if (*argv) {
+ dircache_set(&shf->filename, NULL);
+ dircache_set(&shf->filename, *argv);
+ on |= PM_LOADDIR;
+ }
+ shf->node.flags = on;
+ ret = eval_autoload(shf, funcname, ops, func);
+ }
+ unqueue_signals();
+ return ret;
+ } else if (!*argv) {
+ /* If no arguments given, we will print functions. If flags *
+ * are given, we will print only functions containing these *
+ * flags, else we'll print them all. */
+ int ret = 0;
+
+ queue_signals();
+ if (OPT_ISSET(ops,'U') && !OPT_ISSET(ops,'u'))
+ on &= ~PM_UNDEFINED;
+ scanshfunc(1, on|off, DISABLED, shfunctab->printnode,
+ pflags, expand);
+ unqueue_signals();
+ return ret;
+ }
+
+ /* With the -m option, treat arguments as glob patterns */
+ if (OPT_ISSET(ops,'m')) {
+ on &= ~PM_UNDEFINED;
+ for (; *argv; argv++) {
+ queue_signals();
+ /* expand argument */
+ tokenize(*argv);
+ if ((pprog = patcompile(*argv, PAT_STATIC, 0))) {
+ /* with no options, just print all functions matching the glob pattern */
+ if (!(on|off) && !OPT_ISSET(ops,'X')) {
+ scanmatchshfunc(pprog, 1, 0, DISABLED,
+ shfunctab->printnode, pflags, expand);
+ } else {
+ /* apply the options to all functions matching the glob pattern */
+ for (i = 0; i < shfunctab->hsize; i++) {
+ for (shf = (Shfunc) shfunctab->nodes[i]; shf;
+ shf = (Shfunc) shf->node.next)
+ if (pattry(pprog, shf->node.nam) &&
+ !(shf->node.flags & DISABLED)) {
+ shf->node.flags = (shf->node.flags |
+ (on & ~PM_UNDEFINED)) & ~off;
+ if (check_autoload(shf, shf->node.nam,
+ ops, func)) {
+ returnval = 1;
+ }
+ }
+ }
+ }
+ } else {
+ untokenize(*argv);
+ zwarnnam(name, "bad pattern : %s", *argv);
+ returnval = 1;
+ }
+ unqueue_signals();
+ }
+ return returnval;
+ }
+
+ /* Take the arguments literally -- do not glob */
+ queue_signals();
+ for (; *argv; argv++) {
+ if (OPT_ISSET(ops,'w'))
+ returnval = dump_autoload(name, *argv, on, ops, func);
+ else if ((shf = (Shfunc) shfunctab->getnode(shfunctab, *argv))) {
+ /* if any flag was given */
+ if (on|off) {
+ /* turn on/off the given flags */
+ shf->node.flags = (shf->node.flags | (on & ~PM_UNDEFINED)) & ~off;
+ if (check_autoload(shf, shf->node.nam, ops, func))
+ returnval = 1;
+ } else
+ /* no flags, so just print */
+ printshfuncexpand(&shf->node, pflags, expand);
+ } else if (on & PM_UNDEFINED) {
+ int signum = -1, ok = 1;
+
+ if (!strncmp(*argv, "TRAP", 4) &&
+ (signum = getsignum(*argv + 4)) != -1) {
+ /*
+ * Because of the possibility of alternative names,
+ * we must remove the trap explicitly.
+ */
+ removetrapnode(signum);
+ }
+
+ if (**argv == '/') {
+ char *base = strrchr(*argv, '/') + 1;
+ if (*base &&
+ (shf = (Shfunc) shfunctab->getnode(shfunctab, base))) {
+ char *dir;
+ /* turn on/off the given flags */
+ shf->node.flags =
+ (shf->node.flags | (on & ~PM_UNDEFINED)) & ~off;
+ if (shf->node.flags & PM_UNDEFINED) {
+ /* update path if not yet loaded */
+ if (base == *argv + 1)
+ dir = "/";
+ else {
+ dir = *argv;
+ base[-1] = '\0';
+ }
+ dircache_set(&shf->filename, NULL);
+ dircache_set(&shf->filename, dir);
+ }
+ if (check_autoload(shf, shf->node.nam, ops, func))
+ returnval = 1;
+ continue;
+ }
+ }
+
+ /* Add a new undefined (autoloaded) function to the *
+ * hash table with the corresponding flags set. */
+ shf = (Shfunc) zshcalloc(sizeof *shf);
+ shf->node.flags = on;
+ shf->funcdef = mkautofn(shf);
+ shfunc_set_sticky(shf);
+ add_autoload_function(shf, *argv);
+
+ if (signum != -1) {
+ if (settrap(signum, NULL, ZSIG_FUNC)) {
+ shfunctab->removenode(shfunctab, *argv);
+ shfunctab->freenode(&shf->node);
+ returnval = 1;
+ ok = 0;
+ }
+ }
+
+ if (ok && check_autoload(shf, shf->node.nam, ops, func))
+ returnval = 1;
+ } else
+ returnval = 1;
+ }
+ unqueue_signals();
+ return returnval;
+}
+
+/**/
+Eprog
+mkautofn(Shfunc shf)
+{
+ Eprog p;
+
+ p = (Eprog) zalloc(sizeof(*p));
+ p->len = 5 * sizeof(wordcode);
+ p->prog = (Wordcode) zalloc(p->len);
+ p->strs = NULL;
+ p->shf = shf;
+ p->npats = 0;
+ p->nref = 1; /* allocated from permanent storage */
+ p->pats = (Patprog *) p->prog;
+ p->flags = EF_REAL;
+ p->dump = NULL;
+
+ p->prog[0] = WCB_LIST((Z_SYNC | Z_END), 0);
+ p->prog[1] = WCB_SUBLIST(WC_SUBLIST_END, 0, 3);
+ p->prog[2] = WCB_PIPE(WC_PIPE_END, 0);
+ p->prog[3] = WCB_AUTOFN();
+ p->prog[4] = WCB_END();
+
+ return p;
+}
+
+/* unset: unset parameters */
+
+/**/
+int
+bin_unset(char *name, char **argv, Options ops, int func)
+{
+ Param pm, next;
+ Patprog pprog;
+ char *s;
+ int match = 0, returnval = 0;
+ int i;
+
+ /* unset -f is the same as unfunction */
+ if (OPT_ISSET(ops,'f'))
+ return bin_unhash(name, argv, ops, func);
+
+ /* with -m option, treat arguments as glob patterns */
+ if (OPT_ISSET(ops,'m')) {
+ while ((s = *argv++)) {
+ queue_signals();
+ /* expand */
+ tokenize(s);
+ if ((pprog = patcompile(s, PAT_STATIC, NULL))) {
+ /* Go through the parameter table, and unset any matches */
+ for (i = 0; i < paramtab->hsize; i++) {
+ for (pm = (Param) paramtab->nodes[i]; pm; pm = next) {
+ /* record pointer to next, since we may free this one */
+ next = (Param) pm->node.next;
+ if ((!(pm->node.flags & PM_RESTRICTED) ||
+ unset(RESTRICTED)) &&
+ pattry(pprog, pm->node.nam)) {
+ unsetparam_pm(pm, 0, 1);
+ match++;
+ }
+ }
+ }
+ } else {
+ untokenize(s);
+ zwarnnam(name, "bad pattern : %s", s);
+ returnval = 1;
+ }
+ unqueue_signals();
+ }
+ /* If we didn't match anything, we return 1. */
+ if (!match)
+ returnval = 1;
+ return returnval;
+ }
+
+ /* do not glob -- unset the given parameter */
+ queue_signals();
+ while ((s = *argv++)) {
+ char *ss = strchr(s, '['), *subscript = 0;
+ if (ss) {
+ char *sse;
+ *ss = 0;
+ if ((sse = parse_subscript(ss+1, 1, ']'))) {
+ *sse = 0;
+ subscript = dupstring(ss+1);
+ *sse = ']';
+ remnulargs(subscript);
+ untokenize(subscript);
+ }
+ }
+ if ((ss && !subscript) || !isident(s)) {
+ if (ss)
+ *ss = '[';
+ zerrnam(name, "%s: invalid parameter name", s);
+ returnval = 1;
+ continue;
+ }
+ pm = (Param) (paramtab == realparamtab ?
+ /* getnode2() to avoid autoloading */
+ paramtab->getnode2(paramtab, s) :
+ paramtab->getnode(paramtab, s));
+ /*
+ * Unsetting an unset variable is not an error.
+ * This appears to be reasonably standard behaviour.
+ */
+ if (!pm)
+ continue;
+ else if ((pm->node.flags & PM_RESTRICTED) && isset(RESTRICTED)) {
+ zerrnam(name, "%s: restricted", pm->node.nam);
+ returnval = 1;
+ } else if (ss) {
+ if (PM_TYPE(pm->node.flags) == PM_HASHED) {
+ HashTable tht = paramtab;
+ if ((paramtab = pm->gsu.h->getfn(pm)))
+ unsetparam(subscript);
+ paramtab = tht;
+ } else if (PM_TYPE(pm->node.flags) == PM_SCALAR ||
+ PM_TYPE(pm->node.flags) == PM_ARRAY) {
+ struct value vbuf;
+ vbuf.isarr = (PM_TYPE(pm->node.flags) == PM_ARRAY ?
+ SCANPM_ARRONLY : 0);
+ vbuf.pm = pm;
+ vbuf.flags = 0;
+ vbuf.start = 0;
+ vbuf.end = -1;
+ vbuf.arr = 0;
+ *ss = '[';
+ if (getindex(&ss, &vbuf, SCANPM_ASSIGNING) == 0 &&
+ vbuf.pm && !(vbuf.pm->node.flags & PM_UNSET)) {
+ if (PM_TYPE(pm->node.flags) == PM_SCALAR) {
+ setstrvalue(&vbuf, ztrdup(""));
+ } else {
+ /* start is after the element for reverse index */
+ int start = vbuf.start - !!(vbuf.flags & VALFLAG_INV);
+ if (arrlen_gt(vbuf.pm->u.arr, start)) {
+ char *arr[2];
+ arr[0] = "";
+ arr[1] = 0;
+ setarrvalue(&vbuf, zarrdup(arr));
+ }
+ }
+ }
+ returnval = errflag;
+ errflag &= ~ERRFLAG_ERROR;
+ } else {
+ zerrnam(name, "%s: invalid element for unset", s);
+ returnval = 1;
+ }
+ } else {
+ if (unsetparam_pm(pm, 0, 1))
+ returnval = 1;
+ }
+ if (ss)
+ *ss = '[';
+ }
+ unqueue_signals();
+ return returnval;
+}
+
+/* type, whence, which, command */
+
+static LinkList matchednodes;
+
+static void
+fetchcmdnamnode(HashNode hn, UNUSED(int printflags))
+{
+ Cmdnam cn = (Cmdnam) hn;
+ addlinknode(matchednodes, cn->node.nam);
+}
+
+/**/
+int
+bin_whence(char *nam, char **argv, Options ops, int func)
+{
+ HashNode hn;
+ Patprog pprog;
+ int returnval = 0;
+ int printflags = 0;
+ int aliasflags;
+ int csh, all, v, wd;
+ int informed = 0;
+ int expand = 0;
+ char *cnam, **allmatched = 0;
+
+ /* Check some option information */
+ csh = OPT_ISSET(ops,'c');
+ v = OPT_ISSET(ops,'v');
+ all = OPT_ISSET(ops,'a');
+ wd = OPT_ISSET(ops,'w');
+
+ if (OPT_ISSET(ops,'x')) {
+ char *eptr;
+ expand = (int)zstrtol(OPT_ARG(ops,'x'), &eptr, 10);
+ if (*eptr) {
+ zwarnnam(nam, "number expected after -x");
+ return 1;
+ }
+ if (expand == 0) /* no indentation at all */
+ expand = -1;
+ }
+
+ if (OPT_ISSET(ops,'w'))
+ printflags |= PRINT_WHENCE_WORD;
+ else if (OPT_ISSET(ops,'c'))
+ printflags |= PRINT_WHENCE_CSH;
+ else if (OPT_ISSET(ops,'v'))
+ printflags |= PRINT_WHENCE_VERBOSE;
+ else
+ printflags |= PRINT_WHENCE_SIMPLE;
+ if (OPT_ISSET(ops,'f'))
+ printflags |= PRINT_WHENCE_FUNCDEF;
+
+ if (func == BIN_COMMAND)
+ if (OPT_ISSET(ops,'V')) {
+ printflags = aliasflags = PRINT_WHENCE_VERBOSE;
+ v = 1;
+ } else {
+ aliasflags = PRINT_LIST;
+ printflags = PRINT_WHENCE_SIMPLE;
+ v = 0;
+ }
+ else
+ aliasflags = printflags;
+
+ /* With -m option -- treat arguments as a glob patterns */
+ if (OPT_ISSET(ops,'m')) {
+ cmdnamtab->filltable(cmdnamtab);
+ if (all) {
+ pushheap();
+ matchednodes = newlinklist();
+ }
+ queue_signals();
+ for (; *argv; argv++) {
+ /* parse the pattern */
+ tokenize(*argv);
+ if (!(pprog = patcompile(*argv, PAT_STATIC, NULL))) {
+ untokenize(*argv);
+ zwarnnam(nam, "bad pattern : %s", *argv);
+ returnval = 1;
+ continue;
+ }
+ if (!OPT_ISSET(ops,'p')) {
+ /* -p option is for path search only. *
+ * We're not using it, so search for ... */
+
+ /* aliases ... */
+ informed +=
+ scanmatchtable(aliastab, pprog, 1, 0, DISABLED,
+ aliastab->printnode, printflags);
+
+ /* and reserved words ... */
+ informed +=
+ scanmatchtable(reswdtab, pprog, 1, 0, DISABLED,
+ reswdtab->printnode, printflags);
+
+ /* and shell functions... */
+ informed +=
+ scanmatchshfunc(pprog, 1, 0, DISABLED,
+ shfunctab->printnode, printflags, expand);
+
+ /* and builtins. */
+ informed +=
+ scanmatchtable(builtintab, pprog, 1, 0, DISABLED,
+ builtintab->printnode, printflags);
+ }
+ /* Done search for `internal' commands, if the -p option *
+ * was not used. Now search the path. */
+ informed +=
+ scanmatchtable(cmdnamtab, pprog, 1, 0, 0,
+ (all ? fetchcmdnamnode : cmdnamtab->printnode),
+ printflags);
+ run_queued_signals();
+ }
+ unqueue_signals();
+ if (all) {
+ allmatched = argv = zlinklist2array(matchednodes);
+ matchednodes = NULL;
+ popheap();
+ } else
+ return returnval || !informed;
+ }
+
+ /* Take arguments literally -- do not glob */
+ queue_signals();
+ for (; *argv; argv++) {
+ if (!OPT_ISSET(ops,'p') && !allmatched) {
+ char *suf;
+
+ /* Look for alias */
+ if ((hn = aliastab->getnode(aliastab, *argv))) {
+ aliastab->printnode(hn, aliasflags);
+ informed = 1;
+ if (!all)
+ continue;
+ }
+ /* Look for suffix alias */
+ if ((suf = strrchr(*argv, '.')) && suf[1] &&
+ suf > *argv && suf[-1] != Meta &&
+ (hn = sufaliastab->getnode(sufaliastab, suf+1))) {
+ sufaliastab->printnode(hn, printflags);
+ informed = 1;
+ if (!all)
+ continue;
+ }
+ /* Look for reserved word */
+ if ((hn = reswdtab->getnode(reswdtab, *argv))) {
+ reswdtab->printnode(hn, printflags);
+ informed = 1;
+ if (!all)
+ continue;
+ }
+ /* Look for shell function */
+ if ((hn = shfunctab->getnode(shfunctab, *argv))) {
+ printshfuncexpand(hn, printflags, expand);
+ informed = 1;
+ if (!all)
+ continue;
+ }
+ /* Look for builtin command */
+ if ((hn = builtintab->getnode(builtintab, *argv))) {
+ builtintab->printnode(hn, printflags);
+ informed = 1;
+ if (!all)
+ continue;
+ }
+ /* Look for commands that have been added to the *
+ * cmdnamtab with the builtin `hash foo=bar'. */
+ if ((hn = cmdnamtab->getnode(cmdnamtab, *argv)) && (hn->flags & HASHED)) {
+ cmdnamtab->printnode(hn, printflags);
+ informed = 1;
+ if (!all)
+ continue;
+ }
+ }
+
+ /* Option -a is to search the entire path, *
+ * rather than just looking for one match. */
+ if (all && **argv != '/') {
+ char **pp, *buf;
+
+ pushheap();
+ for (pp = path; *pp; pp++) {
+ if (**pp) {
+ buf = zhtricat(*pp, "/", *argv);
+ } else buf = dupstring(*argv);
+
+ if (iscom(buf)) {
+ if (wd) {
+ printf("%s: command\n", *argv);
+ } else {
+ if (v && !csh) {
+ zputs(*argv, stdout), fputs(" is ", stdout);
+ quotedzputs(buf, stdout);
+ } else
+ zputs(buf, stdout);
+ if (OPT_ISSET(ops,'s') || OPT_ISSET(ops, 'S'))
+ print_if_link(buf, OPT_ISSET(ops, 'S'));
+ fputc('\n', stdout);
+ }
+ informed = 1;
+ }
+ }
+ if (!informed && (wd || v || csh)) {
+ /* this is information and not an error so, as in csh, use stdout */
+ zputs(*argv, stdout);
+ puts(wd ? ": none" : " not found");
+ returnval = 1;
+ }
+ popheap();
+ } else if (func == BIN_COMMAND && OPT_ISSET(ops,'p') &&
+ (hn = builtintab->getnode(builtintab, *argv))) {
+ /*
+ * Special case for "command -p[vV]" which needs to
+ * show a builtin in preference to an external command.
+ */
+ builtintab->printnode(hn, printflags);
+ informed = 1;
+ } else if ((cnam = findcmd(*argv, 1,
+ func == BIN_COMMAND &&
+ OPT_ISSET(ops,'p')))) {
+ /* Found external command. */
+ if (wd) {
+ printf("%s: command\n", *argv);
+ } else {
+ if (v && !csh) {
+ zputs(*argv, stdout), fputs(" is ", stdout);
+ quotedzputs(cnam, stdout);
+ } else
+ zputs(cnam, stdout);
+ if (OPT_ISSET(ops,'s') || OPT_ISSET(ops,'S'))
+ print_if_link(cnam, OPT_ISSET(ops,'S'));
+ fputc('\n', stdout);
+ }
+ informed = 1;
+ } else {
+ /* Not found at all. That's not an error as such so this goes to stdout */
+ if (v || csh || wd)
+ zputs(*argv, stdout), puts(wd ? ": none" : " not found");
+ returnval = 1;
+ }
+ }
+ if (allmatched)
+ freearray(allmatched);
+
+ unqueue_signals();
+ return returnval || !informed;
+}
+
+/**** command & named directory hash table builtins ****/
+
+/*****************************************************************
+ * hash -- explicitly hash a command. *
+ * 1) Given no arguments, list the hash table. *
+ * 2) The -m option prints out commands in the hash table that *
+ * match a given glob pattern. *
+ * 3) The -f option causes the entire path to be added to the *
+ * hash table (cannot be combined with any arguments). *
+ * 4) The -r option causes the entire hash table to be discarded *
+ * (cannot be combined with any arguments). *
+ * 5) Given argument of the form foo=bar, add element to command *
+ * hash table, so that when `foo' is entered, then `bar' is *
+ * executed. *
+ * 6) Given arguments not of the previous form, add it to the *
+ * command hash table as if it were being executed. *
+ * 7) The -d option causes analogous things to be done using *
+ * the named directory hash table. *
+ *****************************************************************/
+
+/**/
+int
+bin_hash(char *name, char **argv, Options ops, UNUSED(int func))
+{
+ HashTable ht;
+ Patprog pprog;
+ Asgment asg;
+ int returnval = 0;
+ int printflags = 0;
+
+ if (OPT_ISSET(ops,'d'))
+ ht = nameddirtab;
+ else
+ ht = cmdnamtab;
+
+ if (OPT_ISSET(ops,'r') || OPT_ISSET(ops,'f')) {
+ /* -f and -r can't be used with any arguments */
+ if (*argv) {
+ zwarnnam("hash", "too many arguments");
+ return 1;
+ }
+
+ /* empty the hash table */
+ if (OPT_ISSET(ops,'r'))
+ ht->emptytable(ht);
+
+ /* fill the hash table in a standard way */
+ if (OPT_ISSET(ops,'f'))
+ ht->filltable(ht);
+
+ return 0;
+ }
+
+ if (OPT_ISSET(ops,'L')) printflags |= PRINT_LIST;
+
+ /* Given no arguments, display current hash table. */
+ if (!*argv) {
+ queue_signals();
+ scanhashtable(ht, 1, 0, 0, ht->printnode, printflags);
+ unqueue_signals();
+ return 0;
+ }
+
+ queue_signals();
+ while (*argv) {
+ void *hn;
+ if (OPT_ISSET(ops,'m')) {
+ /* with the -m option, treat the argument as a glob pattern */
+ tokenize(*argv); /* expand */
+ if ((pprog = patcompile(*argv, PAT_STATIC, NULL))) {
+ /* display matching hash table elements */
+ scanmatchtable(ht, pprog, 1, 0, 0, ht->printnode, printflags);
+ } else {
+ untokenize(*argv);
+ zwarnnam(name, "bad pattern : %s", *argv);
+ returnval = 1;
+ }
+ argv++;
+ continue;
+ }
+ if (!(asg = getasg(&argv, NULL))) {
+ zwarnnam(name, "bad assignment");
+ returnval = 1;
+ break;
+ } else if (ASG_VALUEP(asg)) {
+ if(isset(RESTRICTED)) {
+ zwarnnam(name, "restricted: %s", asg->value.scalar);
+ returnval = 1;
+ } else {
+ /* The argument is of the form foo=bar, *
+ * so define an entry for the table. */
+ if(OPT_ISSET(ops,'d')) {
+ /* shouldn't return NULL if asg->name is not NULL */
+ if (*itype_end(asg->name, IUSER, 0)) {
+ zwarnnam(name,
+ "invalid character in directory name: %s",
+ asg->name);
+ returnval = 1;
+ continue;
+ } else {
+ Nameddir nd = hn = zshcalloc(sizeof *nd);
+ nd->node.flags = 0;
+ nd->dir = ztrdup(asg->value.scalar);
+ }
+ } else {
+ Cmdnam cn = hn = zshcalloc(sizeof *cn);
+ cn->node.flags = HASHED;
+ cn->u.cmd = ztrdup(asg->value.scalar);
+ }
+ ht->addnode(ht, ztrdup(asg->name), hn);
+ if(OPT_ISSET(ops,'v'))
+ ht->printnode(hn, 0);
+ }
+ } else if (!(hn = ht->getnode2(ht, asg->name))) {
+ /* With no `=value' part to the argument, *
+ * work out what it ought to be. */
+ if(OPT_ISSET(ops,'d')) {
+ if(!getnameddir(asg->name)) {
+ zwarnnam(name, "no such directory name: %s", asg->name);
+ returnval = 1;
+ }
+ } else {
+ if (!hashcmd(asg->name, path)) {
+ zwarnnam(name, "no such command: %s", asg->name);
+ returnval = 1;
+ }
+ }
+ if(OPT_ISSET(ops,'v') && (hn = ht->getnode2(ht, asg->name)))
+ ht->printnode(hn, 0);
+ } else if(OPT_ISSET(ops,'v'))
+ ht->printnode(hn, 0);
+ }
+ unqueue_signals();
+ return returnval;
+}
+
+/* unhash: remove specified elements from a hash table */
+
+/**/
+int
+bin_unhash(char *name, char **argv, Options ops, int func)
+{
+ HashTable ht;
+ HashNode hn, nhn;
+ Patprog pprog;
+ int match = 0, returnval = 0, all = 0;
+ int i;
+
+ /* Check which hash table we are working with. */
+ if (func == BIN_UNALIAS) {
+ if (OPT_ISSET(ops,'s'))
+ ht = sufaliastab; /* suffix aliases */
+ else
+ ht = aliastab; /* aliases */
+ if (OPT_ISSET(ops, 'a')) {
+ if (*argv) {
+ zwarnnam(name, "-a: too many arguments");
+ return 1;
+ }
+ all = 1;
+ } else if (!*argv) {
+ zwarnnam(name, "not enough arguments");
+ return 1;
+ }
+ } else if (OPT_ISSET(ops,'d'))
+ ht = nameddirtab; /* named directories */
+ else if (OPT_ISSET(ops,'f'))
+ ht = shfunctab; /* shell functions */
+ else if (OPT_ISSET(ops,'s'))
+ ht = sufaliastab; /* suffix aliases, must precede aliases */
+ else if (func == BIN_UNHASH && (OPT_ISSET(ops,'a')))
+ ht = aliastab; /* aliases */
+ else
+ ht = cmdnamtab; /* external commands */
+
+ if (all) {
+ queue_signals();
+ for (i = 0; i < ht->hsize; i++) {
+ for (hn = ht->nodes[i]; hn; hn = nhn) {
+ /* record pointer to next, since we may free this one */
+ nhn = hn->next;
+ ht->freenode(ht->removenode(ht, hn->nam));
+ }
+ }
+ unqueue_signals();
+ return 0;
+ }
+
+ /* With -m option, treat arguments as glob patterns. *
+ * "unhash -m '*'" is legal, but not recommended. */
+ if (OPT_ISSET(ops,'m')) {
+ for (; *argv; argv++) {
+ queue_signals();
+ /* expand argument */
+ tokenize(*argv);
+ if ((pprog = patcompile(*argv, PAT_STATIC, NULL))) {
+ /* remove all nodes matching glob pattern */
+ for (i = 0; i < ht->hsize; i++) {
+ for (hn = ht->nodes[i]; hn; hn = nhn) {
+ /* record pointer to next, since we may free this one */
+ nhn = hn->next;
+ if (pattry(pprog, hn->nam)) {
+ ht->freenode(ht->removenode(ht, hn->nam));
+ match++;
+ }
+ }
+ }
+ } else {
+ untokenize(*argv);
+ zwarnnam(name, "bad pattern : %s", *argv);
+ returnval = 1;
+ }
+ unqueue_signals();
+ }
+ /* If we didn't match anything, we return 1. */
+ if (!match)
+ returnval = 1;
+ return returnval;
+ }
+
+ /* Take arguments literally -- do not glob */
+ queue_signals();
+ for (; *argv; argv++) {
+ if ((hn = ht->removenode(ht, *argv))) {
+ ht->freenode(hn);
+ } else if (func == BIN_UNSET && isset(POSIXBUILTINS)) {
+ /* POSIX: unset: "Unsetting a variable or function that was *
+ * not previously set shall not be considered an error." */
+ returnval = 0;
+ } else {
+ zwarnnam(name, "no such hash table element: %s", *argv);
+ returnval = 1;
+ }
+ }
+ unqueue_signals();
+ return returnval;
+}
+
+/**** alias builtins ****/
+
+/* alias: display or create aliases. */
+
+/**/
+int
+bin_alias(char *name, char **argv, Options ops, UNUSED(int func))
+{
+ Alias a;
+ Patprog pprog;
+ Asgment asg;
+ int returnval = 0;
+ int flags1 = 0, flags2 = DISABLED;
+ int printflags = 0;
+ int type_opts;
+ HashTable ht = aliastab;
+
+ /* Did we specify the type of alias? */
+ type_opts = OPT_ISSET(ops, 'r') + OPT_ISSET(ops, 'g') +
+ OPT_ISSET(ops, 's');
+ if (type_opts) {
+ if (type_opts > 1) {
+ zwarnnam(name, "illegal combination of options");
+ return 1;
+ }
+ if (OPT_ISSET(ops,'g'))
+ flags1 |= ALIAS_GLOBAL;
+ else
+ flags2 |= ALIAS_GLOBAL;
+ if (OPT_ISSET(ops, 's')) {
+ /*
+ * Although we keep suffix aliases in a different table,
+ * it is useful to be able to distinguish Alias structures
+ * without reference to the table, so we have a separate
+ * flag, too.
+ */
+ flags1 |= ALIAS_SUFFIX;
+ ht = sufaliastab;
+ } else
+ flags2 |= ALIAS_SUFFIX;
+ }
+
+ if (OPT_ISSET(ops,'L'))
+ printflags |= PRINT_LIST;
+ else if (OPT_PLUS(ops,'g') || OPT_PLUS(ops,'r') || OPT_PLUS(ops,'s') ||
+ OPT_PLUS(ops,'m') || OPT_ISSET(ops,'+'))
+ printflags |= PRINT_NAMEONLY;
+
+ /* In the absence of arguments, list all aliases. If a command *
+ * line flag is specified, list only those of that type. */
+ if (!*argv) {
+ queue_signals();
+ scanhashtable(ht, 1, flags1, flags2, ht->printnode, printflags);
+ unqueue_signals();
+ return 0;
+ }
+
+ /* With the -m option, treat the arguments as *
+ * glob patterns of aliases to display. */
+ if (OPT_ISSET(ops,'m')) {
+ for (; *argv; argv++) {
+ queue_signals();
+ tokenize(*argv); /* expand argument */
+ if ((pprog = patcompile(*argv, PAT_STATIC, NULL))) {
+ /* display the matching aliases */
+ scanmatchtable(ht, pprog, 1, flags1, flags2,
+ ht->printnode, printflags);
+ } else {
+ untokenize(*argv);
+ zwarnnam(name, "bad pattern : %s", *argv);
+ returnval = 1;
+ }
+ unqueue_signals();
+ }
+ return returnval;
+ }
+
+ /* Take arguments literally. Don't glob */
+ queue_signals();
+ while ((asg = getasg(&argv, NULL))) {
+ if (asg->value.scalar && !OPT_ISSET(ops,'L')) {
+ /* The argument is of the form foo=bar and we are not *
+ * forcing a listing with -L, so define an alias */
+ ht->addnode(ht, ztrdup(asg->name),
+ createaliasnode(ztrdup(asg->value.scalar), flags1));
+ } else if ((a = (Alias) ht->getnode(ht, asg->name))) {
+ /* display alias if appropriate */
+ if (!type_opts || ht == sufaliastab ||
+ (OPT_ISSET(ops,'r') &&
+ !(a->node.flags & (ALIAS_GLOBAL|ALIAS_SUFFIX))) ||
+ (OPT_ISSET(ops,'g') && (a->node.flags & ALIAS_GLOBAL)))
+ ht->printnode(&a->node, printflags);
+ } else
+ returnval = 1;
+ }
+ unqueue_signals();
+ return returnval;
+}
+
+
+/**** miscellaneous builtins ****/
+
+/* true, : (colon) */
+
+/**/
+int
+bin_true(UNUSED(char *name), UNUSED(char **argv), UNUSED(Options ops), UNUSED(int func))
+{
+ return 0;
+}
+
+/* false builtin */
+
+/**/
+int
+bin_false(UNUSED(char *name), UNUSED(char **argv), UNUSED(Options ops), UNUSED(int func))
+{
+ return 1;
+}
+
+/* the zle buffer stack */
+
+/**/
+mod_export LinkList bufstack;
+
+/* echo, print, printf, pushln */
+
+#define print_val(VAL) \
+ if (prec >= 0) \
+ count += fprintf(fout, spec, width, prec, VAL); \
+ else \
+ count += fprintf(fout, spec, width, VAL);
+
+/*
+ * Because of the use of getkeystring() to interpret the arguments,
+ * the elements of args spend a large part of the function unmetafied
+ * with the lengths in len. This may have seemed a good idea once.
+ * As we are stuck with this for now, we need to be very careful
+ * deciding what state args is in.
+ */
+
+/**/
+int
+bin_print(char *name, char **args, Options ops, int func)
+{
+ int flen, width, prec, type, argc, n, narg, curlen = 0;
+ int nnl = 0, fmttrunc = 0, ret = 0, maxarg = 0, nc = 0;
+ int flags[6], *len, visarr = 0;
+ char *start, *endptr, *c, *d, *flag, *buf = NULL, spec[14], *fmt = NULL;
+ char **first, **argp, *curarg, *flagch = "'0+- #", save = '\0', nullstr = '\0';
+ size_t rcount = 0, count = 0;
+ size_t *cursplit = 0, *splits = 0;
+ FILE *fout = stdout;
+#ifdef HAVE_OPEN_MEMSTREAM
+ size_t mcount;
+#define ASSIGN_MSTREAM(BUF,FOUT) \
+ do { \
+ if ((FOUT = open_memstream(&BUF, &mcount)) == NULL) { \
+ zwarnnam(name, "open_memstream failed"); \
+ return 1; \
+ } \
+ } while (0)
+ /*
+ * Some implementations of open_memstream() have a bug such that,
+ * if fflush() is followed by fclose(), another NUL byte is written
+ * to the buffer at the wrong position. Therefore we must fclose()
+ * before reading.
+ */
+#define READ_MSTREAM(BUF,FOUT) \
+ ((fclose(FOUT) == 0) ? mcount : (size_t)-1)
+#define CLOSE_MSTREAM(FOUT) 0
+
+#else /* simulate HAVE_OPEN_MEMSTREAM */
+
+#define ASSIGN_MSTREAM(BUF,FOUT) \
+ do { \
+ int tempfd; \
+ char *tmpf; \
+ if ((tempfd = gettempfile(NULL, 1, &tmpf)) < 0) { \
+ zwarnnam(name, "can't open temp file: %e", errno); \
+ return 1; \
+ } \
+ unlink(tmpf); \
+ if ((FOUT = fdopen(tempfd, "w+")) == NULL) { \
+ close(tempfd); \
+ zwarnnam(name, "can't open temp file: %e", errno); \
+ return 1; \
+ } \
+ } while (0)
+#define READ_MSTREAM(BUF,FOUT) \
+ ((((count = ftell(FOUT)), (BUF = (char *)zalloc(count + 1))) && \
+ ((fseek(FOUT, 0L, SEEK_SET) == 0) && !(BUF[count] = '\0')) && \
+ (fread(BUF, 1, count, FOUT) == count)) ? count : (size_t)-1)
+#define CLOSE_MSTREAM(FOUT) fclose(FOUT)
+
+#endif
+
+#define IS_MSTREAM(FOUT) \
+ (FOUT != stdout && \
+ (OPT_ISSET(ops,'z') || OPT_ISSET(ops,'s') || OPT_ISSET(ops,'v')))
+
+ /* Testing EBADF special-cases >&- redirections */
+#define CLOSE_CLEANLY(FOUT) \
+ (IS_MSTREAM(FOUT) ? CLOSE_MSTREAM(FOUT) == 0 : \
+ ((FOUT == stdout) ? (fflush(FOUT) == 0 || errno == EBADF) : \
+ (fclose(FOUT) == 0))) /* implies error for -u on a closed fd */
+
+ Histent ent;
+ mnumber mnumval;
+ double doubleval;
+ int intval;
+ zlong zlongval;
+ zulong zulongval;
+ char *stringval;
+
+ /* Error check option combinations and option arguments */
+
+ if (OPT_ISSET(ops, 'z') +
+ OPT_ISSET(ops, 's') + OPT_ISSET(ops, 'S') +
+ OPT_ISSET(ops, 'v') > 1) {
+ zwarnnam(name, "only one of -s, -S, -v, or -z allowed");
+ return 1;
+ }
+ if ((OPT_ISSET(ops, 'z') | OPT_ISSET(ops, 's') | OPT_ISSET(ops, 'S')) +
+ (OPT_ISSET(ops, 'c') | OPT_ISSET(ops, 'C')) > 1) {
+ zwarnnam(name, "-c or -C not allowed with -s, -S, or -z");
+ return 1;
+ }
+ if ((OPT_ISSET(ops, 'z') | OPT_ISSET(ops, 'v') |
+ OPT_ISSET(ops, 's') | OPT_ISSET(ops, 'S')) +
+ (OPT_ISSET(ops, 'p') | OPT_ISSET(ops, 'u')) > 1) {
+ zwarnnam(name, "-p or -u not allowed with -s, -S, -v, or -z");
+ return 1;
+ }
+ /*
+ if (OPT_ISSET(ops, 'f') &&
+ (OPT_ISSET(ops, 'S') || OPT_ISSET(ops, 'c') || OPT_ISSET(ops, 'C'))) {
+ zwarnnam(name, "-f not allowed with -c, -C, or -S");
+ return 1;
+ }
+ */
+
+ /* -C -- number of columns */
+ if (!fmt && OPT_ISSET(ops,'C')) {
+ char *eptr, *argptr = OPT_ARG(ops,'C');
+ nc = (int)zstrtol(argptr, &eptr, 10);
+ if (*eptr) {
+ zwarnnam(name, "number expected after -%c: %s", 'C', argptr);
+ return 1;
+ }
+ if (nc <= 0) {
+ zwarnnam(name, "invalid number of columns: %s", argptr);
+ return 1;
+ }
+ }
+
+ if (func == BIN_PRINTF) {
+ if (!strcmp(*args, "--") && !*++args) {
+ zwarnnam(name, "not enough arguments");
+ return 1;
+ }
+ fmt = *args++;
+ } else if (func == BIN_ECHO && isset(BSDECHO))
+ ops->ind['E'] = 1;
+ else if (OPT_HASARG(ops,'f'))
+ fmt = OPT_ARG(ops,'f');
+ if (fmt)
+ fmt = getkeystring(fmt, &flen, OPT_ISSET(ops,'b') ? GETKEYS_BINDKEY :
+ GETKEYS_PRINTF_FMT, &fmttrunc);
+
+ first = args;
+
+ /* -m option -- treat the first argument as a pattern and remove
+ * arguments not matching */
+ if (OPT_ISSET(ops,'m')) {
+ Patprog pprog;
+ char **t, **p;
+
+ if (!*args) {
+ zwarnnam(name, "no pattern specified");
+ return 1;
+ }
+ queue_signals();
+ tokenize(*args);
+ if (!(pprog = patcompile(*args, PAT_STATIC, NULL))) {
+ untokenize(*args);
+ zwarnnam(name, "bad pattern: %s", *args);
+ unqueue_signals();
+ return 1;
+ }
+ for (t = p = ++args; *p; p++)
+ if (pattry(pprog, *p))
+ *t++ = *p;
+ *t = NULL;
+ first = args;
+ unqueue_signals();
+ if (fmt && !*args) return 0;
+ }
+ /* compute lengths, and interpret according to -P, -D, -e, etc. */
+ argc = arrlen(args);
+ len = (int *) hcalloc(argc * sizeof(int));
+ for (n = 0; n < argc; n++) {
+ /* first \ sequences */
+ if (fmt ||
+ (!OPT_ISSET(ops,'e') &&
+ (OPT_ISSET(ops,'R') || OPT_ISSET(ops,'r') || OPT_ISSET(ops,'E'))))
+ unmetafy(args[n], &len[n]);
+ else {
+ int escape_how;
+ if (OPT_ISSET(ops,'b'))
+ escape_how = GETKEYS_BINDKEY;
+ else if (func != BIN_ECHO && !OPT_ISSET(ops,'e'))
+ escape_how = GETKEYS_PRINT;
+ else
+ escape_how = GETKEYS_ECHO;
+ args[n] = getkeystring(args[n], &len[n], escape_how, &nnl);
+ if (nnl) {
+ /* If there was a \c escape, make this the last arg. */
+ argc = n + 1;
+ args[argc] = NULL;
+ }
+ }
+ /* -P option -- interpret as a prompt sequence */
+ if (OPT_ISSET(ops,'P')) {
+ /*
+ * promptexpand uses permanent storage: to avoid
+ * messy memory management, stick it on the heap
+ * instead.
+ */
+ char *str = unmetafy(
+ promptexpand(metafy(args[n], len[n], META_NOALLOC),
+ 0, NULL, NULL, NULL),
+ &len[n]);
+ args[n] = dupstrpfx(str, len[n]);
+ free(str);
+ }
+ /* -D option -- interpret as a directory, and use ~ */
+ if (OPT_ISSET(ops,'D')) {
+ Nameddir d;
+
+ queue_signals();
+ /* TODO: finddir takes a metafied file */
+ d = finddir(args[n]);
+ if (d) {
+ int dirlen = strlen(d->dir);
+ char *arg = zhalloc(len[n] - dirlen + strlen(d->node.nam) + 2);
+ sprintf(arg, "~%s%s", d->node.nam, args[n] + dirlen);
+ args[n] = arg;
+ len[n] = strlen(args[n]);
+ }
+ unqueue_signals();
+ }
+ }
+
+ /* -o and -O -- sort the arguments */
+ if (OPT_ISSET(ops,'o') || OPT_ISSET(ops,'O')) {
+ int flags;
+
+ if (fmt && !*args)
+ return 0;
+ flags = OPT_ISSET(ops,'i') ? SORTIT_IGNORING_CASE : 0;
+ if (OPT_ISSET(ops,'O'))
+ flags |= SORTIT_BACKWARDS;
+ strmetasort(args, flags, len);
+ }
+
+ /* -u and -p -- output to other than standard output */
+ if ((OPT_HASARG(ops,'u') || OPT_ISSET(ops,'p')) &&
+ /* rule out conflicting options -- historical precedence */
+ ((!fmt && (OPT_ISSET(ops,'c') || OPT_ISSET(ops,'C'))) ||
+ !(OPT_ISSET(ops, 'z') || OPT_ISSET(ops, 'v') ||
+ OPT_ISSET(ops, 's') || OPT_ISSET(ops, 'S')))) {
+ int fdarg, fd;
+
+ if (OPT_ISSET(ops, 'p')) {
+ fdarg = coprocout;
+ if (fdarg < 0) {
+ zwarnnam(name, "-p: no coprocess");
+ return 1;
+ }
+ } else {
+ char *argptr = OPT_ARG(ops,'u'), *eptr;
+ /* Handle undocumented feature that -up worked */
+ if (!strcmp(argptr, "p")) {
+ fdarg = coprocout;
+ if (fdarg < 0) {
+ zwarnnam(name, "-p: no coprocess");
+ return 1;
+ }
+ } else {
+ fdarg = (int)zstrtol(argptr, &eptr, 10);
+ if (*eptr) {
+ zwarnnam(name, "number expected after -u: %s", argptr);
+ return 1;
+ }
+ }
+ }
+
+ if ((fd = dup(fdarg)) < 0) {
+ zwarnnam(name, "bad file number: %d", fdarg);
+ return 1;
+ }
+ if ((fout = fdopen(fd, "w")) == 0) {
+ close(fd);
+ zwarnnam(name, "bad mode on fd %d", fd);
+ return 1;
+ }
+ }
+
+ if (OPT_ISSET(ops, 'v') ||
+ (fmt && (OPT_ISSET(ops,'z') || OPT_ISSET(ops,'s'))))
+ ASSIGN_MSTREAM(buf,fout);
+
+ /* -c -- output in columns */
+ if (!fmt && (OPT_ISSET(ops,'c') || OPT_ISSET(ops,'C'))) {
+ int l, nr, sc, n, t, i;
+#ifdef MULTIBYTE_SUPPORT
+ int *widths;
+
+ if (isset(MULTIBYTE)) {
+ int *wptr;
+
+ /*
+ * We need the character widths to align output in
+ * columns.
+ */
+ wptr = widths = (int *) zhalloc(argc * sizeof(int));
+ for (i = 0; i < argc && args[i]; i++, wptr++) {
+ int l = len[i], width = 0;
+ char *aptr = args[i];
+ mbstate_t mbs;
+
+ memset(&mbs, 0, sizeof(mbstate_t));
+ while (l > 0) {
+ wchar_t wc;
+ size_t cnt;
+ int wcw;
+
+ /*
+ * Prevent misaligned columns due to escape sequences by
+ * skipping over them. Octals \033 and \233 are the
+ * possible escape characters recognized by ANSI.
+ *
+ * It ought to be possible to do this in the case
+ * of prompt expansion by propagating the information
+ * about escape sequences (currently we strip this
+ * out).
+ */
+ if (*aptr == '\033' || *aptr == '\233') {
+ for (aptr++, l--;
+ l && !isalpha(STOUC(*aptr));
+ aptr++, l--)
+ ;
+ aptr++;
+ l--;
+ continue;
+ }
+
+ cnt = mbrtowc(&wc, aptr, l, &mbs);
+
+ if (cnt == MB_INCOMPLETE || cnt == MB_INVALID)
+ {
+ /* treat as ordinary string */
+ width += l;
+ break;
+ }
+ wcw = WCWIDTH(wc);
+ /* treat unprintable as 0 */
+ if (wcw > 0)
+ width += wcw;
+ /* skip over NUL normally */
+ if (cnt == 0)
+ cnt = 1;
+ aptr += cnt;
+ l -= cnt;
+ }
+ widths[i] = width;
+ }
+ }
+ else
+ widths = len;
+#else
+ int *widths = len;
+#endif
+
+ if (OPT_ISSET(ops,'C')) {
+ /*
+ * n: number of elements
+ * nc: number of columns (above)
+ * nr: number of rows
+ */
+ n = arrlen(args);
+ nr = (n + nc - 1) / nc;
+
+ /*
+ * i: loop counter
+ * l: maximum length seen
+ *
+ * Ignore lengths in last column since they don't affect
+ * the separation.
+ */
+ for (i = l = 0; i < argc; i++) {
+ if (OPT_ISSET(ops, 'a')) {
+ if ((i % nc) == nc - 1)
+ continue;
+ } else {
+ if (i >= nr * (nc - 1))
+ break;
+ }
+ if (l < widths[i])
+ l = widths[i];
+ }
+ sc = l + 2;
+ }
+ else
+ {
+ /*
+ * n: loop counter
+ * l: maximum length seen
+ */
+ for (n = l = 0; n < argc; n++)
+ if (l < widths[n])
+ l = widths[n];
+
+ /*
+ * sc: column width
+ * nc: number of columns (at least one)
+ */
+ sc = l + 2;
+ nc = (zterm_columns + 1) / sc;
+ if (!nc)
+ nc = 1;
+ nr = (n + nc - 1) / nc;
+ }
+
+ if (OPT_ISSET(ops,'a')) /* print across, i.e. columns first */
+ n = 0;
+ for (i = 0; i < nr; i++) {
+ if (OPT_ISSET(ops,'a'))
+ {
+ int ic;
+ for (ic = 0; ic < nc && n < argc; ic++, n++)
+ {
+ fwrite(args[n], len[n], 1, fout);
+ l = widths[n];
+ if (n < argc)
+ for (; l < sc; l++)
+ fputc(' ', fout);
+ }
+ }
+ else
+ {
+ n = i;
+ do {
+ fwrite(args[n], len[n], 1, fout);
+ l = widths[n];
+ for (t = nr; t && n < argc; t--, n++);
+ if (n < argc)
+ for (; l < sc; l++)
+ fputc(' ', fout);
+ } while (n < argc);
+ }
+ fputc(OPT_ISSET(ops,'N') ? '\0' : '\n', fout);
+ }
+ if (IS_MSTREAM(fout) && (rcount = READ_MSTREAM(buf,fout)) == -1)
+ ret = 1;
+ if (!CLOSE_CLEANLY(fout) || ret) {
+ zwarnnam(name, "write error: %e", errno);
+ ret = 1;
+ }
+ if (buf) {
+ /* assert: we must be doing -v at this point */
+ queue_signals();
+ if (ret)
+ free(buf);
+ else
+ setsparam(OPT_ARG(ops, 'v'),
+ metafy(buf, rcount, META_REALLOC));
+ unqueue_signals();
+ }
+ return ret;
+ }
+
+ /* normal output */
+ if (!fmt) {
+ if (OPT_ISSET(ops, 'z') || OPT_ISSET(ops, 'v') ||
+ OPT_ISSET(ops, 's') || OPT_ISSET(ops, 'S')) {
+ /*
+ * We don't want the arguments unmetafied after all.
+ */
+ for (n = 0; n < argc; n++)
+ metafy(args[n], len[n], META_NOALLOC);
+ }
+
+ /* -z option -- push the arguments onto the editing buffer stack */
+ if (OPT_ISSET(ops,'z')) {
+ queue_signals();
+ zpushnode(bufstack, sepjoin(args, NULL, 0));
+ unqueue_signals();
+ return 0;
+ }
+ /* -s option -- add the arguments to the history list */
+ if (OPT_ISSET(ops,'s') || OPT_ISSET(ops,'S')) {
+ int nwords = 0, nlen, iwords;
+ char **pargs = args;
+
+ queue_signals();
+ while (*pargs++)
+ nwords++;
+ if (nwords) {
+ if (OPT_ISSET(ops,'S')) {
+ int wordsize;
+ short *words;
+ if (nwords > 1) {
+ zwarnnam(name, "option -S takes a single argument");
+ unqueue_signals();
+ return 1;
+ }
+ words = NULL;
+ wordsize = 0;
+ histsplitwords(*args, &words, &wordsize, &nwords, 1);
+ ent = prepnexthistent();
+ ent->words = (short *)zalloc(nwords*sizeof(short));
+ memcpy(ent->words, words, nwords*sizeof(short));
+ free(words);
+ ent->nwords = nwords/2;
+ } else {
+ ent = prepnexthistent();
+ ent->words = (short *)zalloc(nwords*2*sizeof(short));
+ ent->nwords = nwords;
+ nlen = iwords = 0;
+ for (pargs = args; *pargs; pargs++) {
+ ent->words[iwords++] = nlen;
+ nlen += strlen(*pargs);
+ ent->words[iwords++] = nlen;
+ nlen++;
+ }
+ }
+ } else {
+ ent = prepnexthistent();
+ ent->words = (short *)NULL;
+ }
+ ent->node.nam = zjoin(args, ' ', 0);
+ ent->stim = ent->ftim = time(NULL);
+ ent->node.flags = 0;
+ addhistnode(histtab, ent->node.nam, ent);
+ unqueue_signals();
+ return 0;
+ }
+
+ if (OPT_HASARG(ops, 'x') || OPT_HASARG(ops, 'X')) {
+ char *eptr;
+ int expand, startpos = 0;
+ int all = OPT_HASARG(ops, 'X');
+ char *xarg = all ? OPT_ARG(ops, 'X') : OPT_ARG(ops, 'x');
+
+ expand = (int)zstrtol(xarg, &eptr, 10);
+ if (*eptr || expand <= 0) {
+ zwarnnam(name, "positive integer expected after -%c: %s", 'x',
+ xarg);
+ return 1;
+ }
+ for (; *args; args++, len++) {
+ startpos = zexpandtabs(*args, *len, expand, startpos, fout,
+ all);
+ if (args[1]) {
+ if (OPT_ISSET(ops, 'l')) {
+ fputc('\n', fout);
+ startpos = 0;
+ } else if (OPT_ISSET(ops,'N')) {
+ fputc('\0', fout);
+ } else {
+ fputc(' ', fout);
+ startpos++;
+ }
+ }
+ }
+ } else {
+ for (; *args; args++, len++) {
+ fwrite(*args, *len, 1, fout);
+ if (args[1])
+ fputc(OPT_ISSET(ops,'l') ? '\n' :
+ OPT_ISSET(ops,'N') ? '\0' : ' ', fout);
+ }
+ }
+ if (!(OPT_ISSET(ops,'n') || nnl ||
+ (OPT_ISSET(ops, 'v') && !OPT_ISSET(ops, 'l'))))
+ fputc(OPT_ISSET(ops,'N') ? '\0' : '\n', fout);
+ if (IS_MSTREAM(fout) && (rcount = READ_MSTREAM(buf,fout)) == -1)
+ ret = 1;
+ if (!CLOSE_CLEANLY(fout) || ret) {
+ zwarnnam(name, "write error: %e", errno);
+ ret = 1;
+ }
+ if (buf) {
+ /* assert: we must be doing -v at this point */
+ queue_signals();
+ if (ret)
+ free(buf);
+ else
+ setsparam(OPT_ARG(ops, 'v'),
+ metafy(buf, rcount, META_REALLOC));
+ unqueue_signals();
+ }
+ return ret;
+ }
+
+ /*
+ * All the remaining code in this function is for printf-style
+ * output (printf itself, or print -f). We still have to handle
+ * special cases of printing to a ZLE buffer or the history, however.
+ */
+
+ if (OPT_ISSET(ops,'v')) {
+ struct value vbuf;
+ char* s = OPT_ARG(ops,'v');
+ Value v = getvalue(&vbuf, &s, 0);
+ visarr = v && PM_TYPE(v->pm->node.flags) == PM_ARRAY;
+ }
+ /* printf style output */
+ *spec = '%';
+ argp = args;
+ do {
+ rcount = count;
+ if (argp > args && visarr) { /* reusing format string */
+ if (!splits)
+ cursplit = splits = (size_t *)zhalloc(sizeof(size_t) *
+ (arrlen(args) / (argp - args) + 1));
+ *cursplit++ = count;
+ }
+ if (maxarg) {
+ first += maxarg;
+ argc -= maxarg;
+ maxarg = 0;
+ }
+ for (c = fmt; c-fmt < flen; c++) {
+ if (*c != '%') {
+ putc(*c, fout);
+ ++count;
+ continue;
+ }
+
+ start = c++;
+ if (*c == '%') {
+ putc('%', fout);
+ ++count;
+ continue;
+ }
+
+ type = prec = -1;
+ width = 0;
+ curarg = NULL;
+ d = spec + 1;
+
+ if (*c >= '1' && *c <= '9') {
+ narg = strtoul(c, &endptr, 0);
+ if (*endptr == '$') {
+ c = endptr + 1;
+ DPUTS(narg <= 0, "specified zero or negative arg");
+ if (narg > argc) {
+ zwarnnam(name, "%d: argument specifier out of range",
+ narg);
+ if (fout != stdout)
+ fclose(fout);
+#ifdef HAVE_OPEN_MEMSTREAM
+ if (buf)
+ free(buf);
+#endif
+ return 1;
+ } else {
+ if (narg > maxarg) maxarg = narg;
+ curarg = *(first + narg - 1);
+ curlen = len[first - args + narg - 1];
+ }
+ }
+ }
+
+ /* copy only one of each flag as spec has finite size */
+ memset(flags, 0, sizeof(flags));
+ while (*c && (flag = strchr(flagch, *c))) {
+ if (!flags[flag - flagch]) {
+ flags[flag - flagch] = 1;
+ *d++ = *c;
+ }
+ c++;
+ }
+
+ if (idigit(*c)) {
+ width = strtoul(c, &endptr, 0);
+ c = endptr;
+ } else if (*c == '*') {
+ if (idigit(*++c)) {
+ narg = strtoul(c, &endptr, 0);
+ if (*endptr == '$') {
+ c = endptr + 1;
+ if (narg > argc || narg <= 0) {
+ zwarnnam(name,
+ "%d: argument specifier out of range",
+ narg);
+ if (fout != stdout)
+ fclose(fout);
+#ifdef HAVE_OPEN_MEMSTREAM
+ if (buf)
+ free(buf);
+#endif
+ return 1;
+ } else {
+ if (narg > maxarg) maxarg = narg;
+ argp = first + narg - 1;
+ }
+ }
+ }
+ if (*argp) {
+ width = (int)mathevali(*argp++);
+ if (errflag) {
+ errflag &= ~ERRFLAG_ERROR;
+ ret = 1;
+ }
+ }
+ }
+ *d++ = '*';
+
+ if (*c == '.') {
+ if (*++c == '*') {
+ if (idigit(*++c)) {
+ narg = strtoul(c, &endptr, 0);
+ if (*endptr == '$') {
+ c = endptr + 1;
+ if (narg > argc || narg <= 0) {
+ zwarnnam(name,
+ "%d: argument specifier out of range",
+ narg);
+ if (fout != stdout)
+ fclose(fout);
+#ifdef HAVE_OPEN_MEMSTREAM
+ if (buf)
+ free(buf);
+#endif
+ return 1;
+ } else {
+ if (narg > maxarg) maxarg = narg;
+ argp = first + narg - 1;
+ }
+ }
+ }
+
+ if (*argp) {
+ prec = (int)mathevali(*argp++);
+ if (errflag) {
+ errflag &= ~ERRFLAG_ERROR;
+ ret = 1;
+ }
+ }
+ } else if (idigit(*c)) {
+ prec = strtoul(c, &endptr, 0);
+ c = endptr;
+ } else
+ prec = 0;
+ if (prec >= 0) *d++ = '.', *d++ = '*';
+ }
+
+ /* ignore any size modifier */
+ if (*c == 'l' || *c == 'L' || *c == 'h') c++;
+
+ if (!curarg && *argp) {
+ curarg = *argp;
+ curlen = len[argp++ - args];
+ }
+ d[1] = '\0';
+ switch (*d = *c) {
+ case 'c':
+ if (curarg)
+ intval = *curarg;
+ else
+ intval = 0;
+ print_val(intval);
+ break;
+ case 's':
+ case 'b':
+ if (curarg) {
+ char *b, *ptr;
+ int lbytes, lchars, lleft;
+#ifdef MULTIBYTE_SUPPORT
+ mbstate_t mbs;
+#endif
+
+ if (*c == 'b') {
+ b = getkeystring(metafy(curarg, curlen, META_USEHEAP),
+ &lbytes,
+ OPT_ISSET(ops,'b') ? GETKEYS_BINDKEY :
+ GETKEYS_PRINTF_ARG, &nnl);
+ } else {
+ b = curarg;
+ lbytes = curlen;
+ }
+ /*
+ * Handle width/precision here and use fwrite so that
+ * nul characters can be output.
+ *
+ * First, examine width of string given that it
+ * may contain multibyte characters. The output
+ * widths are for characters, so we need to count
+ * (in lchars). However, if we need to truncate
+ * the string we need the width in bytes (in lbytes).
+ */
+ ptr = b;
+#ifdef MULTIBYTE_SUPPORT
+ memset(&mbs, 0, sizeof(mbs));
+#endif
+
+ for (lchars = 0, lleft = lbytes; lleft > 0; lchars++) {
+ int chars;
+
+ if (lchars == prec) {
+ /* Truncate at this point. */
+ lbytes = ptr - b;
+ break;
+ }
+#ifdef MULTIBYTE_SUPPORT
+ if (isset(MULTIBYTE)) {
+ chars = mbrlen(ptr, lleft, &mbs);
+ if (chars < 0) {
+ /*
+ * Invalid/incomplete character at this
+ * point. Assume all the rest are a
+ * single byte. That's about the best we
+ * can do.
+ */
+ lchars += lleft;
+ lbytes = (ptr - b) + lleft;
+ break;
+ } else if (chars == 0) {
+ /* NUL, handle as real character */
+ chars = 1;
+ }
+ }
+ else /* use the non-multibyte code below */
+#endif
+ chars = 1; /* compiler can optimise this...*/
+ lleft -= chars;
+ ptr += chars;
+ }
+ if (width > 0 && flags[3]) width = -width;
+ if (width > 0 && lchars < width)
+ count += fprintf(fout, "%*c", width - lchars, ' ');
+ count += fwrite(b, 1, lbytes, fout);
+ if (width < 0 && lchars < -width)
+ count += fprintf(fout, "%*c", -width - lchars, ' ');
+ if (nnl) {
+ /* If the %b arg had a \c escape, truncate the fmt. */
+ flen = c - fmt + 1;
+ fmttrunc = 1;
+ }
+ } else if (width)
+ count += fprintf(fout, "%*c", width, ' ');
+ break;
+ case 'q':
+ stringval = curarg ?
+ quotestring(metafy(curarg, curlen, META_USEHEAP),
+ QT_BACKSLASH_SHOWNULL) : &nullstr;
+ *d = 's';
+ print_val(unmetafy(stringval, &curlen));
+ break;
+ case 'd':
+ case 'i':
+ type=1;
+ break;
+ case 'e':
+ case 'E':
+ case 'f':
+ case 'g':
+ case 'G':
+ type=2;
+ break;
+ case 'o':
+ case 'u':
+ case 'x':
+ case 'X':
+ type=3;
+ break;
+ case 'n':
+ if (curarg) setiparam(curarg, count - rcount);
+ break;
+ default:
+ if (*c) {
+ save = c[1];
+ c[1] = '\0';
+ }
+ zwarnnam(name, "%s: invalid directive", start);
+ if (*c) c[1] = save;
+ /* Why do we care about a clean close here? */
+ if (!CLOSE_CLEANLY(fout))
+ zwarnnam(name, "write error: %e", errno);
+#ifdef HAVE_OPEN_MEMSTREAM
+ if (buf)
+ free(buf);
+#endif
+ return 1;
+ }
+
+ if (type > 0) {
+ if (curarg && (*curarg == '\'' || *curarg == '"' )) {
+ convchar_t cc;
+#ifdef MULTIBYTE_SUPPORT
+ if (isset(MULTIBYTE)) {
+ mb_charinit();
+ (void)mb_metacharlenconv(metafy(curarg+1, curlen-1,
+ META_USEHEAP), &cc);
+ }
+ else
+ cc = WEOF;
+ if (cc == WEOF)
+ cc = (curlen > 1) ? STOUC(curarg[1]) : 0;
+#else
+ cc = (curlen > 1) ? STOUC(curarg[1]) : 0;
+#endif
+ if (type == 2) {
+ doubleval = cc;
+ print_val(doubleval);
+ } else {
+ intval = cc;
+ print_val(intval);
+ }
+ } else {
+ switch (type) {
+ case 1:
+#ifdef ZSH_64_BIT_TYPE
+ *d++ = 'l';
+#endif
+ *d++ = 'l', *d++ = *c, *d = '\0';
+ zlongval = (curarg) ? mathevali(curarg) : 0;
+ if (errflag) {
+ zlongval = 0;
+ errflag &= ~ERRFLAG_ERROR;
+ ret = 1;
+ }
+ print_val(zlongval)
+ break;
+ case 2:
+ if (curarg) {
+ char *eptr;
+ /*
+ * First attempt to parse as a floating
+ * point constant. If we go through
+ * a math evaluation, we can lose
+ * mostly unimportant information
+ * that people in standards organizations
+ * worry about.
+ */
+ doubleval = strtod(curarg, &eptr);
+ /*
+ * If it didn't parse as a constant,
+ * parse it as an expression.
+ */
+ if (*eptr != '\0') {
+ mnumval = matheval(curarg);
+ doubleval = (mnumval.type & MN_FLOAT) ?
+ mnumval.u.d : (double)mnumval.u.l;
+ }
+ } else doubleval = 0;
+ if (errflag) {
+ doubleval = 0;
+ errflag &= ~ERRFLAG_ERROR;
+ ret = 1;
+ }
+ /* force consistent form for Inf/NaN output */
+ if (isnan(doubleval))
+ count += fputs("nan", fout);
+ else if (isinf(doubleval))
+ count += fputs((doubleval < 0.0) ? "-inf" : "inf", fout);
+ else
+ print_val(doubleval)
+ break;
+ case 3:
+#ifdef ZSH_64_BIT_UTYPE
+ *d++ = 'l';
+#endif
+ *d++ = 'l', *d++ = *c, *d = '\0';
+ if (!curarg)
+ zulongval = (zulong)0;
+ else if (!zstrtoul_underscore(curarg, &zulongval))
+ zulongval = mathevali(curarg);
+ if (errflag) {
+ zulongval = 0;
+ errflag &= ~ERRFLAG_ERROR;
+ ret = 1;
+ }
+ print_val(zulongval)
+ }
+ }
+ }
+ if (maxarg && (argp - first > maxarg))
+ maxarg = argp - first;
+ }
+
+ if (maxarg) argp = first + maxarg;
+ /* if there are remaining args, reuse format string */
+ } while (*argp && argp != first && !fmttrunc && !OPT_ISSET(ops,'r'));
+
+ if (IS_MSTREAM(fout)) {
+ queue_signals();
+ if ((rcount = READ_MSTREAM(buf,fout)) == -1) {
+ zwarnnam(name, "i/o error: %e", errno);
+ if (buf)
+ free(buf);
+ } else {
+ if (visarr && splits) {
+ char **arrayval = zshcalloc((cursplit - splits + 2) * sizeof(char *));
+ for (;cursplit >= splits; cursplit--) {
+ int start = cursplit == splits ? 0 : cursplit[-1];
+ arrayval[cursplit - splits] =
+ metafy(buf + start, count - start, META_DUP);
+ count = start;
+ }
+ setaparam(OPT_ARG(ops, 'v'), arrayval);
+ free(buf);
+ } else {
+ stringval = metafy(buf, rcount, META_REALLOC);
+ if (OPT_ISSET(ops,'z')) {
+ zpushnode(bufstack, stringval);
+ } else if (OPT_ISSET(ops,'v')) {
+ setsparam(OPT_ARG(ops, 'v'), stringval);
+ } else {
+ ent = prepnexthistent();
+ ent->node.nam = stringval;
+ ent->stim = ent->ftim = time(NULL);
+ ent->node.flags = 0;
+ ent->words = (short *)NULL;
+ addhistnode(histtab, ent->node.nam, ent);
+ }
+ }
+ }
+ unqueue_signals();
+ }
+
+ if (!CLOSE_CLEANLY(fout))
+ {
+ zwarnnam(name, "write error: %e", errno);
+ ret = 1;
+ }
+ return ret;
+}
+
+/* shift builtin */
+
+/**/
+int
+bin_shift(char *name, char **argv, Options ops, UNUSED(int func))
+{
+ int num = 1, l, ret = 0;
+ char **s;
+
+ /* optional argument can be either numeric or an array */
+ queue_signals();
+ if (*argv && !getaparam(*argv)) {
+ num = mathevali(*argv++);
+ if (errflag) {
+ unqueue_signals();
+ return 1;
+ }
+ }
+
+ if (num < 0) {
+ unqueue_signals();
+ zwarnnam(name, "argument to shift must be non-negative");
+ return 1;
+ }
+
+ if (*argv) {
+ for (; *argv; argv++)
+ if ((s = getaparam(*argv))) {
+ if (arrlen_lt(s, num)) {
+ zwarnnam(name, "shift count must be <= $#");
+ ret++;
+ continue;
+ }
+ if (OPT_ISSET(ops,'p')) {
+ char **s2, **src, **dst;
+ int count;
+ l = arrlen(s);
+ src = s;
+ dst = s2 = (char **)zalloc((l - num + 1) * sizeof(char *));
+ for (count = l - num; count; count--)
+ *dst++ = ztrdup(*src++);
+ *dst = NULL;
+ s = s2;
+ } else {
+ s = zarrdup(s + num);
+ }
+ setaparam(*argv, s);
+ }
+ } else {
+ if (num > (l = arrlen(pparams))) {
+ zwarnnam(name, "shift count must be <= $#");
+ ret = 1;
+ } else {
+ s = zalloc((l - num + 1) * sizeof(char *));
+ if (OPT_ISSET(ops,'p')) {
+ memcpy(s, pparams, (l - num) * sizeof(char *));
+ s[l-num] = NULL;
+ while (num--)
+ zsfree(pparams[l-1-num]);
+ } else {
+ memcpy(s, pparams + num, (l - num + 1) * sizeof(char *));
+ while (num--)
+ zsfree(pparams[num]);
+ }
+ zfree(pparams, (l + 1) * sizeof(char *));
+ pparams = s;
+ }
+ }
+ unqueue_signals();
+ return ret;
+}
+
+/*
+ * Position of getopts option within OPTIND argument with multiple options.
+ */
+
+/**/
+int optcind;
+
+/* getopts: automagical option handling for shell scripts */
+
+/**/
+int
+bin_getopts(UNUSED(char *name), char **argv, UNUSED(Options ops), UNUSED(int func))
+{
+ int lenstr, lenoptstr, quiet, lenoptbuf;
+ char *optstr = unmetafy(*argv++, &lenoptstr), *var = *argv++;
+ char **args = (*argv) ? argv : pparams;
+ char *str, optbuf[2] = " ", *p, opch;
+
+ /* zoptind keeps count of the current argument number. The *
+ * user can set it to zero to start a new option parse. */
+ if (zoptind < 1) {
+ /* first call */
+ zoptind = 1;
+ optcind = 0;
+ }
+ if (arrlen_lt(args, zoptind))
+ /* no more options */
+ return 1;
+
+ /* leading ':' in optstr means don't print an error message */
+ quiet = *optstr == ':';
+ optstr += quiet;
+ lenoptstr -= quiet;
+
+ /* find place in relevant argument */
+ str = unmetafy(dupstring(args[zoptind - 1]), &lenstr);
+ if (!lenstr) /* Definitely not an option. */
+ return 1;
+ if(optcind >= lenstr) {
+ optcind = 0;
+ if(!args[zoptind++])
+ return 1;
+ str = unmetafy(dupstring(args[zoptind - 1]), &lenstr);
+ }
+ if(!optcind) {
+ if(lenstr < 2 || (*str != '-' && *str != '+'))
+ return 1;
+ if(lenstr == 2 && str[0] == '-' && str[1] == '-') {
+ zoptind++;
+ return 1;
+ }
+ optcind++;
+ }
+ opch = str[optcind++];
+ if(str[0] == '+') {
+ optbuf[0] = '+';
+ lenoptbuf = 2;
+ } else
+ lenoptbuf = 1;
+ optbuf[lenoptbuf - 1] = opch;
+
+ /* check for legality */
+ if(opch == ':' || !(p = memchr(optstr, opch, lenoptstr))) {
+ p = "?";
+ err:
+ zsfree(zoptarg);
+ setsparam(var, ztrdup(p));
+ if(quiet) {
+ zoptarg = metafy(optbuf, lenoptbuf, META_DUP);
+ } else {
+ zwarn(*p == '?' ? "bad option: %c%c" :
+ "argument expected after %c%c option",
+ "?-+"[lenoptbuf], opch);
+ zoptarg=ztrdup("");
+ }
+ return 0;
+ }
+
+ /* check for required argument */
+ if(p[1] == ':') {
+ if(optcind == lenstr) {
+ if(!args[zoptind]) {
+ p = ":";
+ goto err;
+ }
+ p = ztrdup(args[zoptind++]);
+ } else
+ p = metafy(str+optcind, lenstr-optcind, META_DUP);
+ /*
+ * Careful: I've just changed the following two lines from
+ * optcind = ztrlen(args[zoptind - 1]);
+ * and it's a rigorous theorem that every change in getopts breaks
+ * something. See zsh-workers/9095 for the bug fixed here.
+ * PWS 2000/05/02
+ */
+ optcind = 0;
+ zoptind++;
+ zsfree(zoptarg);
+ zoptarg = p;
+ } else {
+ zsfree(zoptarg);
+ zoptarg = ztrdup("");
+ }
+
+ setsparam(var, metafy(optbuf, lenoptbuf, META_DUP));
+ return 0;
+}
+
+/* Flag that we should exit the shell as soon as all functions return. */
+/**/
+mod_export int
+exit_pending;
+
+/* Shell level at which we exit if exit_pending */
+/**/
+mod_export int
+exit_level;
+
+/* break, bye, continue, exit, logout, return -- most of these take *
+ * one numeric argument, and the other (logout) is related to return. *
+ * (return is treated as a logout when in a login shell.) */
+
+/**/
+int
+bin_break(char *name, char **argv, UNUSED(Options ops), int func)
+{
+ int num = lastval, nump = 0, implicit;
+
+ /* handle one optional numeric argument */
+ implicit = !*argv;
+ if (*argv) {
+ num = mathevali(*argv++);
+ nump = 1;
+ }
+
+ if (nump > 0 && (func == BIN_CONTINUE || func == BIN_BREAK) && num <= 0) {
+ zerrnam(name, "argument is not positive: %d", num);
+ return 1;
+ }
+
+ switch (func) {
+ case BIN_CONTINUE:
+ if (!loops) { /* continue is only permitted in loops */
+ zerrnam(name, "not in while, until, select, or repeat loop");
+ return 1;
+ }
+ contflag = 1; /* FALLTHROUGH */
+ case BIN_BREAK:
+ if (!loops) { /* break is only permitted in loops */
+ zerrnam(name, "not in while, until, select, or repeat loop");
+ return 1;
+ }
+ breaks = nump ? minimum(num,loops) : 1;
+ break;
+ case BIN_RETURN:
+ if ((isset(INTERACTIVE) && isset(SHINSTDIN))
+ || locallevel || sourcelevel) {
+ retflag = 1;
+ breaks = loops;
+ lastval = num;
+ if (trap_state == TRAP_STATE_PRIMED && trap_return == -2
+ /*
+ * With POSIX, "return" on its own in a trap doesn't
+ * update $? --- we keep the status from before the
+ * trap.
+ */
+ && !(isset(POSIXTRAPS) && implicit)) {
+ trap_state = TRAP_STATE_FORCE_RETURN;
+ trap_return = lastval;
+ }
+ return lastval;
+ }
+ zexit(num, 0); /* else treat return as logout/exit */
+ break;
+ case BIN_LOGOUT:
+ if (unset(LOGINSHELL)) {
+ zerrnam(name, "not login shell");
+ return 1;
+ }
+ /*FALLTHROUGH*/
+ case BIN_EXIT:
+ if (locallevel > forklevel && shell_exiting != -1) {
+ /*
+ * We don't exit directly from functions to allow tidying
+ * up, in particular EXIT traps. We still need to perform
+ * the usual interactive tests to see if we can exit at
+ * all, however.
+ *
+ * If we are forked, we exit the shell at the function depth
+ * at which we became a subshell, hence the comparison.
+ *
+ * If we are already exiting... give this all up as
+ * a bad job.
+ */
+ if (stopmsg || (zexit(0,2), !stopmsg)) {
+ retflag = 1;
+ breaks = loops;
+ exit_pending = (num << 1) | 1;
+ exit_level = locallevel;
+ }
+ } else
+ zexit(num, 0);
+ break;
+ }
+ return 0;
+}
+
+/* we have printed a 'you have stopped (running) jobs.' message */
+
+/**/
+mod_export int stopmsg;
+
+/* check to see if user has jobs running/stopped */
+
+/**/
+static void
+checkjobs(void)
+{
+ int i;
+
+ for (i = 1; i <= maxjob; i++)
+ if (i != thisjob && (jobtab[i].stat & STAT_LOCKED) &&
+ !(jobtab[i].stat & STAT_NOPRINT) &&
+ (isset(CHECKRUNNINGJOBS) || jobtab[i].stat & STAT_STOPPED))
+ break;
+ if (i <= maxjob) {
+ if (jobtab[i].stat & STAT_STOPPED) {
+
+#ifdef USE_SUSPENDED
+ zerr("you have suspended jobs.");
+#else
+ zerr("you have stopped jobs.");
+#endif
+
+ } else
+ zerr("you have running jobs.");
+ stopmsg = 1;
+ }
+}
+
+/*
+ * -1 if the shell is already committed to exit.
+ * positive if zexit() was already called.
+ */
+
+/**/
+int shell_exiting;
+
+/* exit the shell. val is the return value of the shell. *
+ * from_where is
+ * 1 if zexit is called because of a signal
+ * 2 if we can't actually exit yet (e.g. functions need
+ * terminating) but should perform the usual interactive tests.
+ */
+
+/**/
+mod_export void
+zexit(int val, int from_where)
+{
+ /* Don't do anything recursively: see below */
+ if (shell_exiting == -1)
+ return;
+
+ if (isset(MONITOR) && !stopmsg && from_where != 1) {
+ scanjobs(); /* check if jobs need printing */
+ if (isset(CHECKJOBS))
+ checkjobs(); /* check if any jobs are running/stopped */
+ if (stopmsg) {
+ stopmsg = 2;
+ return;
+ }
+ }
+ /* Positive in_exit means we have been here before */
+ if (from_where == 2 || (shell_exiting++ && from_where))
+ return;
+
+ /*
+ * We're now committed to exiting. Set shell_exiting to -1 to
+ * indicate we shouldn't do any recursive processing.
+ */
+ shell_exiting = -1;
+ /*
+ * We want to do all remaining processing regardless of preceding
+ * errors, even user interrupts.
+ */
+ errflag = 0;
+
+ if (isset(MONITOR)) {
+ /* send SIGHUP to any jobs left running */
+ killrunjobs(from_where == 1);
+ }
+ if (isset(RCS) && interact) {
+ if (!nohistsave) {
+ int writeflags = HFILE_USE_OPTIONS;
+ if (from_where == 1)
+ writeflags |= HFILE_NO_REWRITE;
+ saveandpophiststack(1, writeflags);
+ savehistfile(NULL, 1, writeflags);
+ }
+ if (islogin && !subsh) {
+ sourcehome(".zlogout");
+#ifdef GLOBAL_ZLOGOUT
+ if (isset(RCS) && isset(GLOBALRCS))
+ source(GLOBAL_ZLOGOUT);
+#endif
+ }
+ }
+ lastval = val;
+ /*
+ * Now we are committed to exiting any previous state
+ * is irrelevant. Ensure trap can run.
+ */
+ errflag = intrap = 0;
+ if (sigtrapped[SIGEXIT])
+ dotrap(SIGEXIT);
+ callhookfunc("zshexit", NULL, 1, NULL);
+ runhookdef(EXITHOOK, NULL);
+ if (opts[MONITOR] && interact && (SHTTY != -1)) {
+ release_pgrp();
+ }
+ if (mypid != getpid())
+ _exit(val);
+ else
+ exit(val);
+}
+
+/* . (dot), source */
+
+/**/
+int
+bin_dot(char *name, char **argv, UNUSED(Options ops), UNUSED(int func))
+{
+ char **old, *old0 = NULL;
+ int diddot = 0, dotdot = 0;
+ char *s, **t, *enam, *arg0, *buf;
+ struct stat st;
+ enum source_return ret;
+
+ if (!*argv)
+ return 0;
+ old = pparams;
+ /* get arguments for the script */
+ if (argv[1])
+ pparams = zarrdup(argv + 1);
+
+ enam = arg0 = ztrdup(*argv);
+ if (isset(FUNCTIONARGZERO)) {
+ old0 = argzero;
+ argzero = ztrdup(arg0);
+ }
+ s = unmeta(enam);
+ errno = ENOENT;
+ ret = SOURCE_NOT_FOUND;
+ /* for source only, check in current directory first */
+ if (*name != '.' && access(s, F_OK) == 0
+ && stat(s, &st) >= 0 && !S_ISDIR(st.st_mode)) {
+ diddot = 1;
+ ret = source(enam);
+ }
+ if (ret == SOURCE_NOT_FOUND) {
+ /* use a path with / in it */
+ for (s = arg0; *s; s++)
+ if (*s == '/') {
+ if (*arg0 == '.') {
+ if (arg0 + 1 == s)
+ ++diddot;
+ else if (arg0[1] == '.' && arg0 + 2 == s)
+ ++dotdot;
+ }
+ ret = source(arg0);
+ break;
+ }
+ if (!*s || (ret == SOURCE_NOT_FOUND &&
+ isset(PATHDIRS) && diddot < 2 && dotdot == 0)) {
+ pushheap();
+ /* search path for script */
+ for (t = path; *t; t++) {
+ if (!(*t)[0] || ((*t)[0] == '.' && !(*t)[1])) {
+ if (diddot)
+ continue;
+ diddot = 1;
+ buf = dupstring(arg0);
+ } else
+ buf = zhtricat(*t, "/", arg0);
+
+ s = unmeta(buf);
+ if (access(s, F_OK) == 0 && stat(s, &st) >= 0
+ && !S_ISDIR(st.st_mode)) {
+ ret = source(enam = buf);
+ break;
+ }
+ }
+ popheap();
+ }
+ }
+ /* clean up and return */
+ if (argv[1]) {
+ freearray(pparams);
+ pparams = old;
+ }
+ if (ret == SOURCE_NOT_FOUND) {
+ if (isset(POSIXBUILTINS)) {
+ /* hard error in POSIX (we'll exit later) */
+ zerrnam(name, "%e: %s", errno, enam);
+ } else {
+ zwarnnam(name, "%e: %s", errno, enam);
+ }
+ }
+ zsfree(arg0);
+ if (old0) {
+ zsfree(argzero);
+ argzero = old0;
+ }
+ return ret == SOURCE_OK ? lastval : 128 - ret;
+}
+
+/*
+ * common for bin_emulate and bin_eval
+ */
+
+static int
+eval(char **argv)
+{
+ Eprog prog;
+ char *oscriptname = scriptname;
+ int oineval = ineval, fpushed;
+ struct funcstack fstack;
+
+ /*
+ * If EVALLINENO is not set, we use the line number of the
+ * environment and must flag this up to exec.c. Otherwise,
+ * we use a special script name to indicate the special line number.
+ */
+ ineval = !isset(EVALLINENO);
+ if (!ineval) {
+ scriptname = "(eval)";
+ fstack.prev = funcstack;
+ fstack.name = scriptname;
+ fstack.caller = funcstack ? funcstack->name : dupstring(argzero);
+ fstack.lineno = lineno;
+ fstack.tp = FS_EVAL;
+
+ /*
+ * To get file line numbers, we need to know if parent is
+ * the original script/shell or a sourced file, in which
+ * case we use the line number raw, or a function or eval,
+ * in which case we need to deduce where that came from.
+ *
+ * This replicates the logic for working out the information
+ * for $funcfiletrace---eval is similar to an inlined function
+ * call from a tracing perspective.
+ */
+ if (!funcstack || funcstack->tp == FS_SOURCE) {
+ fstack.flineno = fstack.lineno;
+ fstack.filename = fstack.caller;
+ } else {
+ fstack.flineno = funcstack->flineno + lineno;
+ /*
+ * Line numbers in eval start from 1, not zero,
+ * so offset by one to get line in file.
+ */
+ if (funcstack->tp == FS_EVAL)
+ fstack.flineno--;
+ fstack.filename = funcstack->filename;
+ if (!fstack.filename)
+ fstack.filename = "";
+ }
+ funcstack = &fstack;
+
+ fpushed = 1;
+ } else
+ fpushed = 0;
+
+ prog = parse_string(zjoin(argv, ' ', 1), 1);
+ if (prog) {
+ if (wc_code(*prog->prog) != WC_LIST) {
+ /* No code to execute */
+ lastval = 0;
+ } else {
+ execode(prog, 1, 0, "eval");
+
+ if (errflag && !lastval)
+ lastval = errflag;
+ }
+ } else {
+ lastval = 1;
+ }
+
+ if (fpushed)
+ funcstack = funcstack->prev;
+
+ errflag &= ~ERRFLAG_ERROR;
+ scriptname = oscriptname;
+ ineval = oineval;
+
+ return lastval;
+}
+
+/* emulate: set emulation mode and optionally evaluate shell code */
+
+/**/
+int
+bin_emulate(char *nam, char **argv, Options ops, UNUSED(int func))
+{
+ int opt_L = OPT_ISSET(ops, 'L');
+ int opt_R = OPT_ISSET(ops, 'R');
+ int opt_l = OPT_ISSET(ops, 'l');
+ int saveemulation, savehackchar;
+ int ret = 1, new_emulation;
+ unsigned int savepatterns;
+ char saveopts[OPT_SIZE], new_opts[OPT_SIZE];
+ char *cmd = 0;
+ const char *shname = *argv;
+ LinkList optlist;
+ LinkNode optnode;
+ Emulation_options save_sticky;
+ OptIndex *on_ptr, *off_ptr;
+
+ /* without arguments just print current emulation */
+ if (!shname) {
+ if (opt_L || opt_R) {
+ zwarnnam(nam, "not enough arguments");
+ return 1;
+ }
+
+ switch(SHELL_EMULATION()) {
+ case EMULATE_CSH:
+ shname = "csh";
+ break;
+
+ case EMULATE_KSH:
+ shname = "ksh";
+ break;
+
+ case EMULATE_SH:
+ shname = "sh";
+ break;
+
+ default:
+ shname = "zsh";
+ break;
+ }
+
+ printf("%s\n", shname);
+ return 0;
+ }
+
+ /* with single argument set current emulation */
+ if (!argv[1]) {
+ char *cmdopts;
+ if (opt_l) {
+ cmdopts = (char *)zhalloc(OPT_SIZE);
+ memcpy(cmdopts, opts, OPT_SIZE);
+ } else
+ cmdopts = opts;
+ emulate(shname, opt_R, &emulation, cmdopts);
+ if (opt_L)
+ cmdopts[LOCALOPTIONS] = cmdopts[LOCALTRAPS] =
+ cmdopts[LOCALPATTERNS] = 1;
+ if (opt_l) {
+ list_emulate_options(cmdopts, opt_R);
+ return 0;
+ }
+ clearpatterndisables();
+ return 0;
+ }
+
+ if (opt_l) {
+ zwarnnam(nam, "too many arguments for -l");
+ return 1;
+ }
+
+ argv++;
+ memcpy(saveopts, opts, sizeof(opts));
+ memcpy(new_opts, opts, sizeof(opts));
+ savehackchar = keyboardhackchar;
+ emulate(shname, opt_R, &new_emulation, new_opts);
+ optlist = newlinklist();
+ if (parseopts(nam, &argv, new_opts, &cmd, optlist, 0)) {
+ ret = 1;
+ goto restore;
+ }
+
+ /* parseopts() has consumed anything that looks like an option */
+ if (*argv) {
+ zwarnnam(nam, "unknown argument %s", *argv);
+ goto restore;
+ }
+
+ savepatterns = savepatterndisables();
+ /*
+ * All emulations start with an empty set of pattern disables,
+ * hence no special "sticky" behaviour is required.
+ */
+ clearpatterndisables();
+
+ saveemulation = emulation;
+ emulation = new_emulation;
+ memcpy(opts, new_opts, sizeof(opts));
+ /* If "-c command" is given, evaluate command using specified
+ * emulation mode.
+ */
+ if (cmd) {
+ if (opt_L) {
+ zwarnnam(nam, "option -L incompatible with -c");
+ goto restore2;
+ }
+ *--argv = cmd; /* on stack, never free()d, see execbuiltin() */
+ } else {
+ if (opt_L)
+ opts[LOCALOPTIONS] = opts[LOCALTRAPS] = opts[LOCALPATTERNS] = 1;
+ return 0;
+ }
+
+ save_sticky = sticky;
+ sticky = hcalloc(sizeof(*sticky));
+ sticky->emulation = emulation;
+ for (optnode = firstnode(optlist); optnode; incnode(optnode)) {
+ /* Data is index into new_opts */
+ char *optptr = (char *)getdata(optnode);
+ if (*optptr)
+ sticky->n_on_opts++;
+ else
+ sticky->n_off_opts++;
+ }
+ if (sticky->n_on_opts)
+ on_ptr = sticky->on_opts =
+ zhalloc(sticky->n_on_opts * sizeof(*sticky->on_opts));
+ else
+ on_ptr = NULL;
+ if (sticky->n_off_opts)
+ off_ptr = sticky->off_opts = zhalloc(sticky->n_off_opts *
+ sizeof(*sticky->off_opts));
+ else
+ off_ptr = NULL;
+ for (optnode = firstnode(optlist); optnode; incnode(optnode)) {
+ /* Data is index into new_opts */
+ char *optptr = (char *)getdata(optnode);
+ int optno = optptr - new_opts;
+ if (*optptr)
+ *on_ptr++ = optno;
+ else
+ *off_ptr++ = optno;
+ }
+ ret = eval(argv);
+ sticky = save_sticky;
+restore2:
+ emulation = saveemulation;
+ memcpy(opts, saveopts, sizeof(opts));
+ restorepatterndisables(savepatterns);
+restore:
+ keyboardhackchar = savehackchar;
+ inittyptab(); /* restore banghist */
+ return ret;
+}
+
+/* eval: simple evaluation */
+
+/**/
+mod_export int ineval;
+
+/**/
+int
+bin_eval(UNUSED(char *nam), char **argv, UNUSED(Options ops), UNUSED(int func))
+{
+ return eval(argv);
+}
+
+static char *zbuf;
+static int readfd;
+
+/* Read a character from readfd, or from the buffer zbuf. Return EOF on end of
+file/buffer. */
+
+/* read: get a line of input, or (for compctl functions) return some *
+ * useful data about the state of the editing line. The -E and -e *
+ * options mean that the result should be sent to stdout. -e means, *
+ * in addition, that the result should not actually be assigned to *
+ * the specified parameters. */
+
+/**/
+int
+bin_read(char *name, char **args, Options ops, UNUSED(int func))
+{
+ char *reply, *readpmpt;
+ int bsiz, c = 0, gotnl = 0, al = 0, first, nchars = 1, bslash, keys = 0;
+ int haso = 0; /* true if /dev/tty has been opened specially */
+ int isem = !strcmp(term, "emacs"), izle = zleactive;
+ char *buf, *bptr, *firstarg, *zbuforig;
+ LinkList readll = newlinklist();
+ FILE *oshout = NULL;
+ int readchar = -1, val, resettty = 0;
+ struct ttyinfo saveti;
+ char d;
+ long izle_timeout = 0;
+#ifdef MULTIBYTE_SUPPORT
+ wchar_t delim = L'\n', wc;
+ mbstate_t mbs;
+ char *laststart;
+ size_t ret;
+#else
+ char delim = '\n';
+#endif
+
+ if (OPT_HASARG(ops,c='k')) {
+ char *eptr, *optarg = OPT_ARG(ops,c);
+ nchars = (int)zstrtol(optarg, &eptr, 10);
+ if (*eptr) {
+ zwarnnam(name, "number expected after -%c: %s", c, optarg);
+ return 1;
+ }
+ }
+ /* This `*args++ : *args' looks a bit weird, but it works around a bug
+ * in gcc-2.8.1 under DU 4.0. */
+ firstarg = (*args && **args == '?' ? *args++ : *args);
+ reply = *args ? *args++ : OPT_ISSET(ops,'A') ? "reply" : "REPLY";
+
+ if (OPT_ISSET(ops,'A') && *args) {
+ zwarnnam(name, "only one array argument allowed");
+ return 1;
+ }
+
+ /* handle compctl case */
+ if(OPT_ISSET(ops,'l') || OPT_ISSET(ops,'c'))
+ return compctlreadptr(name, args, ops, reply);
+
+ if ((OPT_ISSET(ops,'k') || OPT_ISSET(ops,'q')) &&
+ !OPT_ISSET(ops,'u') && !OPT_ISSET(ops,'p')) {
+ if (!zleactive) {
+ if (SHTTY == -1) {
+ /* need to open /dev/tty specially */
+ if ((SHTTY = open("/dev/tty", O_RDWR|O_NOCTTY)) != -1) {
+ haso = 1;
+ oshout = shout;
+ init_shout();
+ }
+ } else if (!shout) {
+ /* We need an output FILE* on the tty */
+ init_shout();
+ }
+ /* We should have a SHTTY opened by now. */
+ if (SHTTY == -1) {
+ /* Unfortunately, we didn't. */
+ fprintf(stderr, "not interactive and can't open terminal\n");
+ fflush(stderr);
+ return 1;
+ }
+ if (unset(INTERACTIVE))
+ gettyinfo(&shttyinfo);
+ /* attach to the tty */
+ attachtty(mypgrp);
+ if (!isem)
+ setcbreak();
+ readfd = SHTTY;
+ }
+ keys = 1;
+ } else if (OPT_HASARG(ops,'u') && !OPT_ISSET(ops,'p')) {
+ /* -u means take input from the specified file descriptor. */
+ char *eptr, *argptr = OPT_ARG(ops,'u');
+ /* The old code handled -up, but that was never documented. Still...*/
+ if (!strcmp(argptr, "p")) {
+ readfd = coprocin;
+ if (readfd < 0) {
+ zwarnnam(name, "-p: no coprocess");
+ return 1;
+ }
+ } else {
+ readfd = (int)zstrtol(argptr, &eptr, 10);
+ if (*eptr) {
+ zwarnnam(name, "number expected after -%c: %s", 'u', argptr);
+ return 1;
+ }
+ }
+#if 0
+ /* This code is left as a warning to future generations --- pws. */
+ for (readfd = 9; readfd && !OPT_ISSET(ops,readfd + '0'); --readfd);
+#endif
+ izle = 0;
+ } else if (OPT_ISSET(ops,'p')) {
+ readfd = coprocin;
+ if (readfd < 0) {
+ zwarnnam(name, "-p: no coprocess");
+ return 1;
+ }
+ izle = 0;
+ } else
+ readfd = izle = 0;
+
+ if (OPT_ISSET(ops,'s') && SHTTY != -1) {
+ struct ttyinfo ti;
+ gettyinfo(&ti);
+ saveti = ti;
+ resettty = 1;
+#ifdef HAS_TIO
+ ti.tio.c_lflag &= ~ECHO;
+#else
+ ti.sgttyb.sg_flags &= ~ECHO;
+#endif
+ settyinfo(&ti);
+ }
+
+ /* handle prompt */
+ if (firstarg) {
+ for (readpmpt = firstarg;
+ *readpmpt && *readpmpt != '?'; readpmpt++);
+ if (*readpmpt++) {
+ if (keys || isatty(0)) {
+ zputs(readpmpt, (shout ? shout : stderr));
+ fflush(shout ? shout : stderr);
+ }
+ readpmpt[-1] = '\0';
+ }
+ }
+
+ if (OPT_ISSET(ops,'d')) {
+ char *delimstr = OPT_ARG(ops,'d');
+#ifdef MULTIBYTE_SUPPORT
+ wint_t wi;
+
+ if (isset(MULTIBYTE)) {
+ mb_charinit();
+ (void)mb_metacharlenconv(delimstr, &wi);
+ }
+ else
+ wi = WEOF;
+ if (wi != WEOF)
+ delim = (wchar_t)wi;
+ else
+ delim = (wchar_t)((delimstr[0] == Meta) ?
+ delimstr[1] ^ 32 : delimstr[0]);
+#else
+ delim = (delimstr[0] == Meta) ? delimstr[1] ^ 32 : delimstr[0];
+#endif
+ if (SHTTY != -1) {
+ struct ttyinfo ti;
+ gettyinfo(&ti);
+ if (! resettty) {
+ saveti = ti;
+ resettty = 1;
+ }
+#ifdef HAS_TIO
+ ti.tio.c_lflag &= ~ICANON;
+ ti.tio.c_cc[VMIN] = 1;
+ ti.tio.c_cc[VTIME] = 0;
+#else
+ ti.sgttyb.sg_flags |= CBREAK;
+#endif
+ settyinfo(&ti);
+ }
+ }
+ if (OPT_ISSET(ops,'t')) {
+ zlong timeout = 0;
+ if (OPT_HASARG(ops,'t')) {
+ mnumber mn = zero_mnumber;
+ mn = matheval(OPT_ARG(ops,'t'));
+ if (errflag)
+ return 1;
+ if (mn.type == MN_FLOAT) {
+ mn.u.d *= 1e6;
+ timeout = (zlong)mn.u.d;
+ } else {
+ timeout = (zlong)mn.u.l * (zlong)1000000;
+ }
+ }
+ if (izle) {
+ /*
+ * Timeout is in 100ths of a second rather than us.
+ * See calc_timeout() in zle_main for format of this.
+ */
+ timeout = -(timeout/(zlong)10000 + 1L);
+ izle_timeout = (long)timeout;
+#ifdef LONG_MAX
+ /* saturate if range exceeded */
+ if ((zlong)izle_timeout != timeout)
+ izle_timeout = LONG_MAX;
+#endif
+ } else {
+ if (readfd == -1 ||
+ !read_poll(readfd, &readchar, keys && !zleactive,
+ timeout)) {
+ if (keys && !zleactive && !isem)
+ settyinfo(&shttyinfo);
+ else if (resettty && SHTTY != -1)
+ settyinfo(&saveti);
+ if (haso) {
+ fclose(shout);
+ shout = oshout;
+ SHTTY = -1;
+ }
+ return OPT_ISSET(ops,'q') ? 2 : 1;
+ }
+ }
+ }
+
+#ifdef MULTIBYTE_SUPPORT
+ memset(&mbs, 0, sizeof(mbs));
+#endif
+
+ /*
+ * option -k means read only a given number of characters (default 1)
+ * option -q means get one character, and interpret it as a Y or N
+ */
+ if (OPT_ISSET(ops,'k') || OPT_ISSET(ops,'q')) {
+ int eof = 0;
+ /* allocate buffer space for result */
+#ifdef MULTIBYTE_SUPPORT
+ bptr = buf = (char *)zalloc(nchars*MB_CUR_MAX+1);
+#else
+ bptr = buf = (char *)zalloc(nchars+1);
+#endif
+
+ do {
+ if (izle) {
+ zleentry(ZLE_CMD_GET_KEY, izle_timeout, NULL, &val);
+ if (val < 0) {
+ eof = 1;
+ break;
+ }
+ *bptr = (char) val;
+#ifdef MULTIBYTE_SUPPORT
+ if (isset(MULTIBYTE)) {
+ ret = mbrlen(bptr++, 1, &mbs);
+ if (ret == MB_INVALID)
+ memset(&mbs, 0, sizeof(mbs));
+ /* treat invalid as single character */
+ if (ret != MB_INCOMPLETE)
+ nchars--;
+ continue;
+ } else {
+ bptr++;
+ nchars--;
+ }
+#else
+ bptr++;
+ nchars--;
+#endif
+ } else {
+ /* If read returns 0, is end of file */
+ if (readchar >= 0) {
+ *bptr = readchar;
+ val = 1;
+ readchar = -1;
+ } else {
+ while ((val = read(readfd, bptr, nchars)) < 0) {
+ if (errno != EINTR ||
+ errflag || retflag || breaks || contflag)
+ break;
+ }
+ if (val <= 0) {
+ eof = 1;
+ break;
+ }
+ }
+
+#ifdef MULTIBYTE_SUPPORT
+ if (isset(MULTIBYTE)) {
+ while (val > 0) {
+ ret = mbrlen(bptr, val, &mbs);
+ if (ret == MB_INCOMPLETE) {
+ bptr += val;
+ break;
+ } else {
+ if (ret == MB_INVALID) {
+ memset(&mbs, 0, sizeof(mbs));
+ /* treat as single byte */
+ ret = 1;
+ }
+ else if (ret == 0) /* handle null as normal char */
+ ret = 1;
+ else if (ret > (size_t)val) {
+ /* Some mbrlen()s return the full char len */
+ ret = val;
+ }
+ nchars--;
+ val -= ret;
+ bptr += ret;
+ }
+ }
+ continue;
+ }
+#endif
+ /* decrement number of characters read from number required */
+ nchars -= val;
+
+ /* increment pointer past read characters */
+ bptr += val;
+ }
+ } while (nchars > 0);
+
+ if (!izle && !OPT_ISSET(ops,'u') && !OPT_ISSET(ops,'p')) {
+ /* dispose of result appropriately, etc. */
+ if (isem)
+ while (val > 0 && read(SHTTY, &d, 1) == 1 && d != '\n');
+ else {
+ settyinfo(&shttyinfo);
+ resettty = 0;
+ }
+ if (haso) {
+ fclose(shout); /* close(SHTTY) */
+ shout = oshout;
+ SHTTY = -1;
+ }
+ }
+
+ if (OPT_ISSET(ops,'q'))
+ {
+ /*
+ * Keep eof as status but status is now whether we read
+ * 'y' or 'Y'. If we timed out, status is 2.
+ */
+ if (eof)
+ eof = 2;
+ else
+ eof = (bptr - buf != 1 || (buf[0] != 'y' && buf[0] != 'Y'));
+ buf[0] = eof ? 'n' : 'y';
+ bptr = buf + 1;
+ }
+ if (OPT_ISSET(ops,'e') || OPT_ISSET(ops,'E'))
+ fwrite(buf, bptr - buf, 1, stdout);
+ if (!OPT_ISSET(ops,'e'))
+ setsparam(reply, metafy(buf, bptr - buf, META_REALLOC));
+ else
+ zfree(buf, bptr - buf + 1);
+ if (resettty && SHTTY != -1)
+ settyinfo(&saveti);
+ return eof;
+ }
+
+ /* All possible special types of input have been exhausted. Take one line,
+ and assign words to the parameters until they run out. Leftover words go
+ onto the last parameter. If an array is specified, all the words become
+ separate elements of the array. */
+
+ zbuforig = zbuf = (!OPT_ISSET(ops,'z')) ? NULL :
+ (nonempty(bufstack)) ? (char *) getlinknode(bufstack) : ztrdup("");
+ first = 1;
+ bslash = 0;
+ while (*args || (OPT_ISSET(ops,'A') && !gotnl)) {
+ sigset_t s = child_unblock();
+ buf = bptr = (char *)zalloc(bsiz = 64);
+#ifdef MULTIBYTE_SUPPORT
+ laststart = buf;
+ ret = MB_INCOMPLETE;
+#endif
+ /* get input, a character at a time */
+ while (!gotnl) {
+ c = zread(izle, &readchar, izle_timeout);
+ /* \ at the end of a line indicates a continuation *
+ * line, except in raw mode (-r option) */
+#ifdef MULTIBYTE_SUPPORT
+ if (c == EOF) {
+ /* not waiting to be completed any more */
+ ret = 0;
+ break;
+ }
+ *bptr = (char)c;
+ if (isset(MULTIBYTE)) {
+ ret = mbrtowc(&wc, bptr, 1, &mbs);
+ if (!ret) /* NULL */
+ ret = 1;
+ } else {
+ ret = 1;
+ wc = (wchar_t)c;
+ }
+ if (ret != MB_INCOMPLETE) {
+ if (ret == MB_INVALID) {
+ memset(&mbs, 0, sizeof(mbs));
+ /* Treat this as a single character */
+ wc = (wchar_t)c;
+ laststart = bptr;
+ }
+ if (bslash && wc == delim) {
+ bslash = 0;
+ continue;
+ }
+ if (wc == delim)
+ break;
+ /*
+ * `first' is non-zero if any separator we encounter is a
+ * non-whitespace separator, which means that anything
+ * (even an empty string) between, before or after separators
+ * is significant. If it is zero, we have a whitespace
+ * separator, which shouldn't cause extra empty strings to
+ * be emitted. Hence the test for (*buf || first) when
+ * we assign the result of reading a word.
+ */
+ if (!bslash && wcsitype(wc, ISEP)) {
+ if (bptr != buf ||
+ (!(c < 128 && iwsep(c)) && first)) {
+ first |= !(c < 128 && iwsep(c));
+ break;
+ }
+ first |= !(c < 128 && iwsep(c));
+ continue;
+ }
+ bslash = (wc == L'\\' && !bslash && !OPT_ISSET(ops,'r'));
+ if (bslash)
+ continue;
+ first = 0;
+ }
+ if (imeta(STOUC(*bptr))) {
+ bptr[1] = bptr[0] ^ 32;
+ bptr[0] = Meta;
+ bptr += 2;
+ }
+ else
+ bptr++;
+ if (ret != MB_INCOMPLETE)
+ laststart = bptr;
+#else
+ if (c == EOF)
+ break;
+ if (bslash && c == delim) {
+ bslash = 0;
+ continue;
+ }
+ if (c == delim)
+ break;
+ /*
+ * `first' is non-zero if any separator we encounter is a
+ * non-whitespace separator, which means that anything
+ * (even an empty string) between, before or after separators
+ * is significant. If it is zero, we have a whitespace
+ * separator, which shouldn't cause extra empty strings to
+ * be emitted. Hence the test for (*buf || first) when
+ * we assign the result of reading a word.
+ */
+ if (!bslash && isep(c)) {
+ if (bptr != buf || (!iwsep(c) && first)) {
+ first |= !iwsep(c);
+ break;
+ }
+ first |= !iwsep(c);
+ continue;
+ }
+ bslash = c == '\\' && !bslash && !OPT_ISSET(ops,'r');
+ if (bslash)
+ continue;
+ first = 0;
+ if (imeta(c)) {
+ *bptr++ = Meta;
+ *bptr++ = c ^ 32;
+ } else
+ *bptr++ = c;
+#endif
+ /* increase the buffer size, if necessary */
+ if (bptr >= buf + bsiz - 1) {
+ int blen = bptr - buf;
+#ifdef MULTIBYTE_SUPPORT
+ int llen = laststart - buf;
+#endif
+
+ buf = realloc(buf, bsiz *= 2);
+ bptr = buf + blen;
+#ifdef MULTIBYTE_SUPPORT
+ laststart = buf + llen;
+#endif
+ }
+ }
+ signal_setmask(s);
+#ifdef MULTIBYTE_SUPPORT
+ if (c == EOF) {
+ gotnl = 1;
+ *bptr = '\0'; /* see below */
+ } else if (ret == MB_INCOMPLETE) {
+ /*
+ * We can only get here if there is an EOF in the
+ * middle of a character... safest to keep the debris,
+ * I suppose.
+ */
+ *bptr = '\0';
+ } else {
+ if (wc == delim)
+ gotnl = 1;
+ *laststart = '\0';
+ }
+#else
+ if (c == delim || c == EOF)
+ gotnl = 1;
+ *bptr = '\0';
+#endif
+ /* dispose of word appropriately */
+ if (OPT_ISSET(ops,'e') ||
+ /*
+ * When we're doing an array assignment, we'll
+ * handle echoing at that point. In all other
+ * cases (including -A with no assignment)
+ * we'll do it here.
+ */
+ (OPT_ISSET(ops,'E') && !OPT_ISSET(ops,'A'))) {
+ zputs(buf, stdout);
+ putchar('\n');
+ }
+ if (!OPT_ISSET(ops,'e') && (*buf || first || gotnl)) {
+ if (OPT_ISSET(ops,'A')) {
+ addlinknode(readll, buf);
+ al++;
+ } else
+ setsparam(reply, buf);
+ } else
+ free(buf);
+ if (!OPT_ISSET(ops,'A'))
+ reply = *args++;
+ }
+ /* handle EOF */
+ if (c == EOF) {
+ if (readfd == coprocin) {
+ close(coprocin);
+ close(coprocout);
+ coprocin = coprocout = -1;
+ }
+ }
+ /* final assignment (and display) of array parameter */
+ if (OPT_ISSET(ops,'A')) {
+ char **pp, **p = NULL;
+ LinkNode n;
+
+ p = (OPT_ISSET(ops,'e') ? (char **)NULL
+ : (char **)zalloc((al + 1) * sizeof(char *)));
+
+ for (pp = p, n = firstnode(readll); n; incnode(n)) {
+ if (OPT_ISSET(ops,'E')) {
+ zputs((char *) getdata(n), stdout);
+ putchar('\n');
+ }
+ if (p)
+ *pp++ = (char *)getdata(n);
+ else
+ zsfree(getdata(n));
+ }
+ if (p) {
+ *pp++ = NULL;
+ setaparam(reply, p);
+ }
+ if (resettty && SHTTY != -1)
+ settyinfo(&saveti);
+ return c == EOF;
+ }
+ buf = bptr = (char *)zalloc(bsiz = 64);
+#ifdef MULTIBYTE_SUPPORT
+ laststart = buf;
+ ret = MB_INCOMPLETE;
+#endif
+ /* any remaining part of the line goes into one parameter */
+ bslash = 0;
+ if (!gotnl) {
+ sigset_t s = child_unblock();
+ for (;;) {
+ c = zread(izle, &readchar, izle_timeout);
+#ifdef MULTIBYTE_SUPPORT
+ if (c == EOF) {
+ /* not waiting to be completed any more */
+ ret = 0;
+ break;
+ }
+ *bptr = (char)c;
+ if (isset(MULTIBYTE)) {
+ ret = mbrtowc(&wc, bptr, 1, &mbs);
+ if (!ret) /* NULL */
+ ret = 1;
+ } else {
+ ret = 1;
+ wc = (wchar_t)c;
+ }
+ if (ret != MB_INCOMPLETE) {
+ if (ret == MB_INVALID) {
+ memset(&mbs, 0, sizeof(mbs));
+ /* Treat this as a single character */
+ wc = (wchar_t)c;
+ laststart = bptr;
+ }
+ /*
+ * \ at the end of a line introduces a continuation line,
+ * except in raw mode (-r option)
+ */
+ if (bslash && wc == delim) {
+ bslash = 0;
+ continue;
+ }
+ if (wc == delim && !zbuf)
+ break;
+ if (!bslash && bptr == buf && wcsitype(wc, ISEP)) {
+ if (c < 128 && iwsep(c))
+ continue;
+ else if (!first) {
+ first = 1;
+ continue;
+ }
+ }
+ bslash = (wc == L'\\' && !bslash && !OPT_ISSET(ops,'r'));
+ if (bslash)
+ continue;
+ }
+ if (imeta(STOUC(*bptr))) {
+ bptr[1] = bptr[0] ^ 32;
+ bptr[0] = Meta;
+ bptr += 2;
+ }
+ else
+ bptr++;
+ if (ret != MB_INCOMPLETE)
+ laststart = bptr;
+#else
+ /* \ at the end of a line introduces a continuation line, except in
+ raw mode (-r option) */
+ if (bslash && c == delim) {
+ bslash = 0;
+ continue;
+ }
+ if (c == EOF || (c == delim && !zbuf))
+ break;
+ if (!bslash && isep(c) && bptr == buf) {
+ if (iwsep(c))
+ continue;
+ else if (!first) {
+ first = 1;
+ continue;
+ }
+ }
+ bslash = c == '\\' && !bslash && !OPT_ISSET(ops,'r');
+ if (bslash)
+ continue;
+ if (imeta(c)) {
+ *bptr++ = Meta;
+ *bptr++ = c ^ 32;
+ } else
+ *bptr++ = c;
+#endif
+ /* increase the buffer size, if necessary */
+ if (bptr >= buf + bsiz - 1) {
+ int blen = bptr - buf;
+#ifdef MULTIBYTE_SUPPORT
+ int llen = laststart - buf;
+#endif
+
+ buf = realloc(buf, bsiz *= 2);
+ bptr = buf + blen;
+#ifdef MULTIBYTE_SUPPORT
+ laststart = buf + llen;
+#endif
+ }
+ }
+ signal_setmask(s);
+ }
+#ifdef MULTIBYTE_SUPPORT
+ if (ret != MB_INCOMPLETE)
+ bptr = laststart;
+#endif
+ /*
+ * Strip trailing IFS whitespace.
+ * iwsep can only be certain single-byte ASCII bytes, but we
+ * must check the byte isn't metafied.
+ */
+ while (bptr > buf) {
+ if (bptr > buf + 1 && bptr[-2] == Meta) {
+ /* non-ASCII, can't be IWSEP */
+ break;
+ } else if (iwsep(bptr[-1]))
+ bptr--;
+ else
+ break;
+ }
+ *bptr = '\0';
+ if (resettty && SHTTY != -1)
+ settyinfo(&saveti);
+ /* final assignment of reply, etc. */
+ if (OPT_ISSET(ops,'e') || OPT_ISSET(ops,'E')) {
+ zputs(buf, stdout);
+ putchar('\n');
+ }
+ if (!OPT_ISSET(ops,'e'))
+ setsparam(reply, buf);
+ else
+ zsfree(buf);
+ if (zbuforig) {
+ char first = *zbuforig;
+
+ zsfree(zbuforig);
+ if (!first)
+ return 1;
+ } else if (c == EOF) {
+ if (readfd == coprocin) {
+ close(coprocin);
+ close(coprocout);
+ coprocin = coprocout = -1;
+ }
+ return 1;
+ }
+ /*
+ * The following is to ensure a failure to set the parameter
+ * causes a non-zero status return. There are arguments for
+ * turning a non-zero status into errflag more widely.
+ */
+ return errflag;
+}
+
+/**/
+static int
+zread(int izle, int *readchar, long izle_timeout)
+{
+ char cc, retry = 0;
+ int ret;
+
+ if (izle) {
+ int c;
+ zleentry(ZLE_CMD_GET_KEY, izle_timeout, NULL, &c);
+
+ return (c < 0 ? EOF : c);
+ }
+ /* use zbuf if possible */
+ if (zbuf) {
+ /* If zbuf points to anything, it points to the next character in the
+ buffer. This may be a null byte to indicate EOF. If reading from the
+ buffer, move on the buffer pointer. */
+ if (*zbuf == Meta)
+ return zbuf++, STOUC(*zbuf++ ^ 32);
+ else
+ return (*zbuf) ? STOUC(*zbuf++) : EOF;
+ }
+ if (*readchar >= 0) {
+ cc = *readchar;
+ *readchar = -1;
+ return STOUC(cc);
+ }
+ for (;;) {
+ /* read a character from readfd */
+ ret = read(readfd, &cc, 1);
+ switch (ret) {
+ case 1:
+ /* return the character read */
+ return STOUC(cc);
+ case -1:
+#if defined(EAGAIN) || defined(EWOULDBLOCK)
+ if (!retry && readfd == 0 && (
+# ifdef EAGAIN
+ errno == EAGAIN
+# ifdef EWOULDBLOCK
+ ||
+# endif /* EWOULDBLOCK */
+# endif /* EAGAIN */
+# ifdef EWOULDBLOCK
+ errno == EWOULDBLOCK
+# endif /* EWOULDBLOCK */
+ ) && setblock_stdin()) {
+ retry = 1;
+ continue;
+ } else
+#endif /* EAGAIN || EWOULDBLOCK */
+ if (errno == EINTR && !(errflag || retflag || breaks || contflag))
+ continue;
+ break;
+ }
+ return EOF;
+ }
+}
+
+/* holds arguments for testlex() */
+/**/
+char **testargs, **curtestarg;
+
+/* test, [: the old-style general purpose logical expression builtin */
+
+/**/
+void
+testlex(void)
+{
+ if (tok == LEXERR)
+ return;
+
+ tokstr = *(curtestarg = testargs);
+ if (!*testargs) {
+ /* if tok is already zero, reading past the end: error */
+ tok = tok ? NULLTOK : LEXERR;
+ return;
+ } else if (!strcmp(*testargs, "-o"))
+ tok = DBAR;
+ else if (!strcmp(*testargs, "-a"))
+ tok = DAMPER;
+ else if (!strcmp(*testargs, "!"))
+ tok = BANG;
+ else if (!strcmp(*testargs, "("))
+ tok = INPAR;
+ else if (!strcmp(*testargs, ")"))
+ tok = OUTPAR;
+ else
+ tok = STRING;
+ testargs++;
+}
+
+/**/
+int
+bin_test(char *name, char **argv, UNUSED(Options ops), int func)
+{
+ char **s;
+ Eprog prog;
+ struct estate state;
+ int nargs, sense = 0, ret;
+
+ /* if "test" was invoked as "[", it needs a matching "]" *
+ * which is subsequently ignored */
+ if (func == BIN_BRACKET) {
+ for (s = argv; *s; s++);
+ if (s == argv || strcmp(s[-1], "]")) {
+ zwarnnam(name, "']' expected");
+ return 2;
+ }
+ s[-1] = NULL;
+ }
+ /* an empty argument list evaluates to false (1) */
+ if (!*argv)
+ return 1;
+
+ /*
+ * Implement some XSI extensions to POSIX here.
+ * See
+ * http://pubs.opengroup.org/onlinepubs/9699919799/utilities/test.html
+ */
+ nargs = arrlen(argv);
+ if (nargs == 3 || nargs == 4)
+ {
+ /*
+ * As parentheses are an extension, we need to be careful ---
+ * if this is a three-argument expression that could
+ * be a binary operator, prefer that.
+ */
+ if (!strcmp(argv[0], "(") && !strcmp(argv[nargs-1],")") &&
+ (nargs != 3 || !is_cond_binary_op(argv[1]))) {
+ argv[nargs-1] = NULL;
+ argv++;
+ }
+ if (nargs == 4 && !strcmp("!", argv[0])) {
+ sense = 1;
+ argv++;
+ }
+ }
+
+ zcontext_save();
+ testargs = argv;
+ tok = NULLTOK;
+ condlex = testlex;
+ testlex();
+ prog = parse_cond();
+ condlex = zshlex;
+
+ if (errflag) {
+ errflag &= ~ERRFLAG_ERROR;
+ zcontext_restore();
+ return 2;
+ }
+
+ if (!prog || tok == LEXERR) {
+ zwarnnam(name, tokstr ? "parse error" : "argument expected");
+ zcontext_restore();
+ return 2;
+ }
+ zcontext_restore();
+
+ if (*curtestarg) {
+ zwarnnam(name, "too many arguments");
+ return 2;
+ }
+
+ /* syntax is OK, so evaluate */
+
+ state.prog = prog;
+ state.pc = prog->prog;
+ state.strs = prog->strs;
+
+ ret = evalcond(&state, name);
+ if (ret < 2 && sense)
+ ret = ! ret;
+
+ return ret;
+}
+
+/* display a time, provided in units of 1/60s, as minutes and seconds */
+#define pttime(X) printf("%ldm%ld.%02lds",((long) (X))/(60 * clktck),\
+ ((long) (X))/clktck%clktck,\
+ ((long) (X))*100/clktck%100)
+
+/* times: display, in a two-line format, the times provided by times(3) */
+
+/**/
+int
+bin_times(UNUSED(char *name), UNUSED(char **argv), UNUSED(Options ops), UNUSED(int func))
+{
+ struct tms buf;
+ long clktck = get_clktck();
+
+ /* get time accounting information */
+ if (times(&buf) == -1)
+ return 1;
+ pttime(buf.tms_utime); /* user time */
+ putchar(' ');
+ pttime(buf.tms_stime); /* system time */
+ putchar('\n');
+ pttime(buf.tms_cutime); /* user time, children */
+ putchar(' ');
+ pttime(buf.tms_cstime); /* system time, children */
+ putchar('\n');
+ return 0;
+}
+
+/* trap: set/unset signal traps */
+
+/**/
+int
+bin_trap(char *name, char **argv, UNUSED(Options ops), UNUSED(int func))
+{
+ Eprog prog;
+ char *arg, *s;
+ int sig;
+
+ if (*argv && !strcmp(*argv, "--"))
+ argv++;
+
+ /* If given no arguments, list all currently-set traps */
+ if (!*argv) {
+ queue_signals();
+ for (sig = 0; sig < VSIGCOUNT; sig++) {
+ if (sigtrapped[sig] & ZSIG_FUNC) {
+ HashNode hn;
+
+ if ((hn = gettrapnode(sig, 0)))
+ shfunctab->printnode(hn, 0);
+ DPUTS(!hn, "BUG: I did not find any trap functions!");
+ } else if (sigtrapped[sig]) {
+ const char *name = getsigname(sig);
+ if (!siglists[sig])
+ printf("trap -- '' %s\n", name);
+ else {
+ s = getpermtext(siglists[sig], NULL, 0);
+ printf("trap -- ");
+ quotedzputs(s, stdout);
+ printf(" %s\n", name);
+ zsfree(s);
+ }
+ }
+ }
+ unqueue_signals();
+ return 0;
+ }
+
+ /* If we have a signal number, unset the specified *
+ * signals. With only -, remove all traps. */
+ if ((getsignum(*argv) != -1) || (!strcmp(*argv, "-") && argv++)) {
+ if (!*argv) {
+ for (sig = 0; sig < VSIGCOUNT; sig++)
+ unsettrap(sig);
+ } else {
+ for (; *argv; argv++) {
+ sig = getsignum(*argv);
+ if (sig == -1) {
+ zwarnnam(name, "undefined signal: %s", *argv);
+ break;
+ }
+ unsettrap(sig);
+ }
+ }
+ return *argv != NULL;
+ }
+
+ /* Sort out the command to execute on trap */
+ arg = *argv++;
+ if (!*arg)
+ prog = &dummy_eprog;
+ else if (!(prog = parse_string(arg, 1))) {
+ zwarnnam(name, "couldn't parse trap command");
+ return 1;
+ }
+
+ /* set traps */
+ for (; *argv; argv++) {
+ Eprog t;
+ int flags;
+
+ sig = getsignum(*argv);
+ if (sig == -1) {
+ zwarnnam(name, "undefined signal: %s", *argv);
+ break;
+ }
+ if (idigit(**argv) ||
+ !strcmp(sigs[sig], *argv) ||
+ (!strncmp("SIG", *argv, 3) && !strcmp(sigs[sig], *argv+3))) {
+ /* The signal was specified by number or by canonical name (with
+ * or without SIG prefix).
+ */
+ flags = 0;
+ }
+ else {
+ /*
+ * Record that the signal is used under an assumed name.
+ * If we ever have more than one alias per signal this
+ * will need improving.
+ */
+ flags = ZSIG_ALIAS;
+ }
+ t = dupeprog(prog, 0);
+ if (settrap(sig, t, flags))
+ freeeprog(t);
+ }
+ return *argv != NULL;
+}
+
+/**/
+int
+bin_ttyctl(UNUSED(char *name), UNUSED(char **argv), Options ops, UNUSED(int func))
+{
+ if (OPT_ISSET(ops,'f'))
+ ttyfrozen = 1;
+ else if (OPT_ISSET(ops,'u'))
+ ttyfrozen = 0;
+ else
+ printf("tty is %sfrozen\n", ttyfrozen ? "" : "not ");
+ return 0;
+}
+
+/* let -- mathematical evaluation */
+
+/**/
+int
+bin_let(UNUSED(char *name), char **argv, UNUSED(Options ops), UNUSED(int func))
+{
+ mnumber val = zero_mnumber;
+
+ while (*argv)
+ val = matheval(*argv++);
+ /* Errors in math evaluation in let are non-fatal. */
+ errflag &= ~ERRFLAG_ERROR;
+ /* should test for fabs(val.u.d) < epsilon? */
+ return (val.type == MN_INTEGER) ? val.u.l == 0 : val.u.d == 0.0;
+}
+
+/* umask command. umask may be specified as octal digits, or in the *
+ * symbolic form that chmod(1) uses. Well, a subset of it. Remember *
+ * that only the bottom nine bits of umask are used, so there's no *
+ * point allowing the set{u,g}id and sticky bits to be specified. */
+
+/**/
+int
+bin_umask(char *nam, char **args, Options ops, UNUSED(int func))
+{
+ mode_t um;
+ char *s = *args;
+
+ /* Get the current umask. */
+ um = umask(0);
+ umask(um);
+ /* No arguments means to display the current setting. */
+ if (!s) {
+ if (OPT_ISSET(ops,'S')) {
+ char *who = "ugo";
+
+ while (*who) {
+ char *what = "rwx";
+ printf("%c=", *who++);
+ while (*what) {
+ if (!(um & 0400))
+ putchar(*what);
+ um <<= 1;
+ what++;
+ }
+ putchar(*who ? ',' : '\n');
+ }
+ } else {
+ if (um & 0700)
+ putchar('0');
+ printf("%03o\n", (unsigned)um);
+ }
+ return 0;
+ }
+
+ if (idigit(*s)) {
+ /* Simple digital umask. */
+ um = zstrtol(s, &s, 8);
+ if (*s) {
+ zwarnnam(nam, "bad umask");
+ return 1;
+ }
+ } else {
+ /* Symbolic notation -- slightly complicated. */
+ int whomask, umaskop, mask;
+
+ /* More than one symbolic argument may be used at once, each separated
+ by commas. */
+ for (;;) {
+ /* First part of the argument -- who does this apply to?
+ u=owner, g=group, o=other. */
+ whomask = 0;
+ while (*s == 'u' || *s == 'g' || *s == 'o' || *s == 'a')
+ if (*s == 'u')
+ s++, whomask |= 0700;
+ else if (*s == 'g')
+ s++, whomask |= 0070;
+ else if (*s == 'o')
+ s++, whomask |= 0007;
+ else if (*s == 'a')
+ s++, whomask |= 0777;
+ /* Default whomask is everyone. */
+ if (!whomask)
+ whomask = 0777;
+ /* Operation may be +, - or =. */
+ umaskop = (int)*s;
+ if (!(umaskop == '+' || umaskop == '-' || umaskop == '=')) {
+ if (umaskop)
+ zwarnnam(nam, "bad symbolic mode operator: %c", umaskop);
+ else
+ zwarnnam(nam, "bad umask");
+ return 1;
+ }
+ /* Permissions mask -- r=read, w=write, x=execute. */
+ mask = 0;
+ while (*++s && *s != ',')
+ if (*s == 'r')
+ mask |= 0444 & whomask;
+ else if (*s == 'w')
+ mask |= 0222 & whomask;
+ else if (*s == 'x')
+ mask |= 0111 & whomask;
+ else {
+ zwarnnam(nam, "bad symbolic mode permission: %c", *s);
+ return 1;
+ }
+ /* Apply parsed argument to um. */
+ if (umaskop == '+')
+ um &= ~mask;
+ else if (umaskop == '-')
+ um |= mask;
+ else /* umaskop == '=' */
+ um = (um | (whomask)) & ~mask;
+ if (*s == ',')
+ s++;
+ else
+ break;
+ }
+ if (*s) {
+ zwarnnam(nam, "bad character in symbolic mode: %c", *s);
+ return 1;
+ }
+ }
+
+ /* Finally, set the new umask. */
+ umask(um);
+ return 0;
+}
+
+/* Generic builtin for facilities not available on this OS */
+
+/**/
+mod_export int
+bin_notavail(char *nam, UNUSED(char **argv), UNUSED(Options ops), UNUSED(int func))
+{
+ zwarnnam(nam, "not available on this system");
+ return 1;
+}
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/compat.c b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/compat.c
new file mode 100644
index 0000000..7b5c441
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/compat.c
@@ -0,0 +1,742 @@
+/*
+ * compat.c - compatibility routines for the deprived
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+#include "zsh.mdh"
+#include "compat.pro"
+
+/* Return pointer to first occurence of string t *
+ * in string s. Return NULL if not present. */
+
+/**/
+#ifndef HAVE_STRSTR
+
+/**/
+char *
+strstr(const char *s, const char *t)
+{
+ const char *p1, *p2;
+
+ for (; *s; s++) {
+ for (p1 = s, p2 = t; *p2; p1++, p2++)
+ if (*p1 != *p2)
+ break;
+ if (!*p2)
+ return (char *)s;
+ }
+ return NULL;
+}
+
+/**/
+#endif
+
+
+/**/
+#ifndef HAVE_GETHOSTNAME
+
+/**/
+int
+gethostname(char *name, size_t namelen)
+{
+ struct utsname uts;
+
+ uname(&uts);
+ if(strlen(uts.nodename) >= namelen) {
+ errno = EINVAL;
+ return -1;
+ }
+ strcpy(name, uts.nodename);
+ return 0;
+}
+
+/**/
+#endif
+
+
+/**/
+#ifndef HAVE_GETTIMEOFDAY
+
+/**/
+int
+gettimeofday(struct timeval *tv, struct timezone *tz)
+{
+ tv->tv_usec = 0;
+ tv->tv_sec = (long)time((time_t) 0);
+ return 0;
+}
+
+/**/
+#endif
+
+
+/* Provide clock time with nanoseconds */
+
+/**/
+mod_export int
+zgettime(struct timespec *ts)
+{
+ int ret = -1;
+
+#ifdef HAVE_CLOCK_GETTIME
+ struct timespec dts;
+ if (clock_gettime(CLOCK_REALTIME, &dts) < 0) {
+ zwarn("unable to retrieve time: %e", errno);
+ ret--;
+ } else {
+ ret++;
+ ts->tv_sec = (time_t) dts.tv_sec;
+ ts->tv_nsec = (long) dts.tv_nsec;
+ }
+#endif
+
+ if (ret) {
+ struct timeval dtv;
+ struct timezone dtz;
+ gettimeofday(&dtv, &dtz);
+ ret++;
+ ts->tv_sec = (time_t) dtv.tv_sec;
+ ts->tv_nsec = (long) dtv.tv_usec * 1000;
+ }
+
+ return ret;
+}
+
+
+/* compute the difference between two calendar times */
+
+/**/
+#ifndef HAVE_DIFFTIME
+
+/**/
+double
+difftime(time_t t2, time_t t1)
+{
+ return ((double)t2 - (double)t1);
+}
+
+/**/
+#endif
+
+
+/**/
+#ifndef HAVE_STRERROR
+extern char *sys_errlist[];
+
+/* Get error message string associated with a particular *
+ * error number, and returns a pointer to that string. *
+ * This is not a particularly robust version of strerror. */
+
+/**/
+char *
+strerror(int errnum)
+{
+ return (sys_errlist[errnum]);
+}
+
+/**/
+#endif
+
+
+#if 0
+/* pathconf(_PC_PATH_MAX) is not currently useful to zsh. The value *
+ * returned varies depending on a number of factors, e.g. the amount *
+ * of memory available to the operating system at a given time; thus *
+ * it can't be used for buffer allocation, or even as an indication *
+ * of whether an attempt to use or create a given pathname may fail *
+ * at any future time. *
+ * *
+ * The call is also permitted to fail if the argument path is not an *
+ * existing directory, so even to make sense of that one must search *
+ * for a valid directory somewhere in the path and adjust. Even if *
+ * it succeeds, the return value is relative to the input directory, *
+ * and therefore potentially relative to the length of the shortest *
+ * path either to that directory or to our working directory. *
+ * *
+ * Finally, see the note below for glibc; detection of pathconf() is *
+ * not by itself an indication that it works reliably. */
+
+/* The documentation for pathconf() says something like: *
+ * The limit is returned, if one exists. If the system does *
+ * not have a limit for the requested resource, -1 is *
+ * returned, and errno is unchanged. If there is an error, *
+ * -1 is returned, and errno is set to reflect the nature of *
+ * the error. *
+ * *
+ * System calls are not permitted to set errno to 0; but we must (or *
+ * some other flag value) in order to determine that the resource is *
+ * unlimited. What use is leaving errno unchanged? Instead, define *
+ * a wrapper that resets errno to 0 and returns 0 for "the system *
+ * does not have a limit," so that -1 always means a real error. */
+
+/**/
+mod_export long
+zpathmax(char *dir)
+{
+#ifdef HAVE_PATHCONF
+ long pathmax;
+
+ errno = 0;
+ if ((pathmax = pathconf(dir, _PC_PATH_MAX)) >= 0) {
+ /* Some versions of glibc pathconf return a hardwired value! */
+ return pathmax;
+ } else if (errno == EINVAL || errno == ENOENT || errno == ENOTDIR) {
+ /* Work backward to find a directory, until we run out of path. */
+ char *tail = strrchr(dir, '/');
+ while (tail > dir && tail[-1] == '/')
+ --tail;
+ if (tail > dir) {
+ *tail = 0;
+ pathmax = zpathmax(dir);
+ *tail = '/';
+ } else {
+ errno = 0;
+ if (tail)
+ pathmax = pathconf("/", _PC_PATH_MAX);
+ else
+ pathmax = pathconf(".", _PC_PATH_MAX);
+ }
+ if (pathmax > 0) {
+ long taillen = (tail ? strlen(tail) : (strlen(dir) + 1));
+ if (taillen < pathmax)
+ return pathmax - taillen;
+ else
+ errno = ENAMETOOLONG;
+ }
+ }
+ if (errno)
+ return -1;
+ else
+ return 0; /* pathmax should be considered unlimited */
+#else
+ long dirlen = strlen(dir);
+
+ /* The following is wrong if dir is not an absolute path. */
+ return ((long) ((dirlen >= PATH_MAX) ?
+ ((errno = ENAMETOOLONG), -1) :
+ ((errno = 0), PATH_MAX - dirlen)));
+#endif
+}
+#endif /* 0 */
+
+/**/
+#ifdef HAVE_SYSCONF
+/*
+ * This is replaced by a macro from system.h if not HAVE_SYSCONF.
+ * 0 is returned by sysconf if _SC_OPEN_MAX is unavailable;
+ * -1 is returned on error
+ *
+ * Neither of these should happen, but resort to OPEN_MAX rather
+ * than return 0 or -1 just in case.
+ *
+ * We'll limit the open maximum to ZSH_INITIAL_OPEN_MAX to
+ * avoid probing ridiculous numbers of file descriptors.
+ */
+
+/**/
+mod_export long
+zopenmax(void)
+{
+ long openmax;
+
+ if ((openmax = sysconf(_SC_OPEN_MAX)) < 1) {
+ openmax = OPEN_MAX;
+ } else if (openmax > OPEN_MAX) {
+ /* On some systems, "limit descriptors unlimited" or the *
+ * equivalent will set openmax to a huge number. Unless *
+ * there actually is a file descriptor > OPEN_MAX already *
+ * open, nothing in zsh requires the true maximum, and in *
+ * fact it causes inefficiency elsewhere if we report it. *
+ * So, report the maximum of OPEN_MAX or the largest open *
+ * descriptor (is there a better way to find that?). */
+ long i, j = OPEN_MAX;
+ if (openmax > ZSH_INITIAL_OPEN_MAX)
+ openmax = ZSH_INITIAL_OPEN_MAX;
+ for (i = j; i < openmax; i += (errno != EINTR)) {
+ errno = 0;
+ if (fcntl(i, F_GETFL, 0) < 0 &&
+ (errno == EBADF || errno == EINTR))
+ continue;
+ j = i;
+ }
+ openmax = j;
+ }
+
+ return (max_zsh_fd > openmax) ? max_zsh_fd : openmax;
+}
+
+/**/
+#endif
+
+/*
+ * Rationalise the current directory, returning the string.
+ *
+ * If "d" is not NULL, it is used to store information about the
+ * directory. The returned name is also present in d->dirname and is in
+ * permanently allocated memory. The handling of this case depends on
+ * whether the fchdir() system call is available; if it is, it is assumed
+ * the caller is able to restore the current directory. On successfully
+ * identifying the directory the function returns immediately rather
+ * than ascending the hierarchy.
+ *
+ * If "d" is NULL, no assumption about the caller's behaviour is
+ * made. The returned string is in heap memory. This case is
+ * always handled by changing directory up the hierarchy.
+ *
+ * On Cygwin or other systems where USE_GETCWD is defined (at the
+ * time of writing only QNX), we skip all the above and use the
+ * getcwd() system call.
+ */
+
+/**/
+mod_export char *
+zgetdir(struct dirsav *d)
+{
+ char nbuf[PATH_MAX+3];
+ char *buf;
+ int bufsiz, pos;
+ struct stat sbuf;
+ ino_t pino;
+ dev_t pdev;
+#if !defined(__CYGWIN__) && !defined(USE_GETCWD)
+ struct dirent *de;
+ DIR *dir;
+ dev_t dev;
+ ino_t ino;
+ int len;
+#endif
+
+ buf = zhalloc(bufsiz = PATH_MAX+1);
+ pos = bufsiz - 1;
+ buf[pos] = '\0';
+ strcpy(nbuf, "../");
+ if (stat(".", &sbuf) < 0) {
+ return NULL;
+ }
+
+ /* Record the initial inode and device */
+ pino = sbuf.st_ino;
+ pdev = sbuf.st_dev;
+ if (d)
+ d->ino = pino, d->dev = pdev;
+#if !defined(__CYGWIN__) && !defined(USE_GETCWD)
+#ifdef HAVE_FCHDIR
+ else
+#endif
+ holdintr();
+
+ for (;;) {
+ /* Examine the parent of the current directory. */
+ if (stat("..", &sbuf) < 0)
+ break;
+
+ /* Inode and device of curtent directory */
+ ino = pino;
+ dev = pdev;
+ /* Inode and device of current directory's parent */
+ pino = sbuf.st_ino;
+ pdev = sbuf.st_dev;
+
+ /* If they're the same, we've reached the root directory. */
+ if (ino == pino && dev == pdev) {
+ if (!buf[pos])
+ buf[--pos] = '/';
+ if (d) {
+#ifndef HAVE_FCHDIR
+ zchdir(buf + pos);
+ noholdintr();
+#endif
+ return d->dirname = ztrdup(buf + pos);
+ }
+ zchdir(buf + pos);
+ noholdintr();
+ return buf + pos;
+ }
+
+ /* Search the parent for the current directory. */
+ if (!(dir = opendir("..")))
+ break;
+
+ while ((de = readdir(dir))) {
+ char *fn = de->d_name;
+ /* Ignore `.' and `..'. */
+ if (fn[0] == '.' &&
+ (fn[1] == '\0' ||
+ (fn[1] == '.' && fn[2] == '\0')))
+ continue;
+#ifdef HAVE_STRUCT_DIRENT_D_STAT
+ if(de->d_stat.st_dev == dev && de->d_stat.st_ino == ino) {
+ /* Found the directory we're currently in */
+ strncpy(nbuf + 3, fn, PATH_MAX);
+ break;
+ }
+#else /* !HAVE_STRUCT_DIRENT_D_STAT */
+# ifdef HAVE_STRUCT_DIRENT_D_INO
+ if (dev != pdev || (ino_t) de->d_ino == ino)
+# endif /* HAVE_STRUCT_DIRENT_D_INO */
+ {
+ /* Maybe found directory, need to check device & inode */
+ strncpy(nbuf + 3, fn, PATH_MAX);
+ lstat(nbuf, &sbuf);
+ if (sbuf.st_dev == dev && sbuf.st_ino == ino)
+ break;
+ }
+#endif /* !HAVE_STRUCT_DIRENT_D_STAT */
+ }
+ closedir(dir);
+ if (!de)
+ break; /* Not found */
+ /*
+ * We get the "/" free just by copying from nbuf+2 instead
+ * of nbuf+3, which is where we copied the path component.
+ * This means buf[pos] is always a "/".
+ */
+ len = strlen(nbuf + 2);
+ pos -= len;
+ while (pos <= 1) {
+ char *newbuf = zhalloc(2*bufsiz);
+ memcpy(newbuf + bufsiz, buf, bufsiz);
+ buf = newbuf;
+ pos += bufsiz;
+ bufsiz *= 2;
+ }
+ memcpy(buf + pos, nbuf + 2, len);
+#ifdef HAVE_FCHDIR
+ if (d)
+ return d->dirname = ztrdup(buf + pos + 1);
+#endif
+ if (chdir(".."))
+ break;
+ }
+
+ /*
+ * Fix up the directory, if necessary.
+ * We're changing back down the hierarchy, ignore the
+ * "/" at buf[pos].
+ */
+ if (d) {
+#ifndef HAVE_FCHDIR
+ if (buf[pos])
+ zchdir(buf + pos + 1);
+ noholdintr();
+#endif
+ return NULL;
+ }
+
+ if (buf[pos])
+ zchdir(buf + pos + 1);
+ noholdintr();
+
+#else /* __CYGWIN__, USE_GETCWD cases */
+
+ if (!getcwd(buf, bufsiz)) {
+ if (d) {
+ return NULL;
+ }
+ } else {
+ if (d) {
+ return d->dirname = ztrdup(buf);
+ }
+ return buf;
+ }
+#endif
+
+ /*
+ * Something bad happened.
+ * This has been seen when inside a special directory,
+ * such as the Netapp .snapshot directory, that doesn't
+ * appear as a directory entry in the parent directory.
+ * We'll just need our best guess.
+ *
+ * We only get here from zgetcwd(); let that fall back to pwd.
+ */
+
+ return NULL;
+}
+
+/*
+ * Try to find the current directory.
+ * If we couldn't work it out internally, fall back to getcwd().
+ * If it fails, fall back to pwd; if zgetcwd() is being used
+ * to set pwd, pwd should be NULL and we just return ".".
+ */
+
+/**/
+char *
+zgetcwd(void)
+{
+ char *ret = zgetdir(NULL);
+#ifdef HAVE_GETCWD
+ if (!ret) {
+#ifdef GETCWD_CALLS_MALLOC
+ char *cwd = getcwd(NULL, 0);
+ if (cwd) {
+ ret = dupstring(cwd);
+ free(cwd);
+ }
+#else
+ char *cwdbuf = zalloc(PATH_MAX+1);
+ ret = getcwd(cwdbuf, PATH_MAX);
+ if (ret)
+ ret = dupstring(ret);
+ zfree(cwdbuf, PATH_MAX+1);
+#endif /* GETCWD_CALLS_MALLOC */
+ }
+#endif /* HAVE_GETCWD */
+ if (!ret)
+ ret = unmeta(pwd);
+ if (!ret)
+ ret = dupstring(".");
+ return ret;
+}
+
+/*
+ * chdir with arbitrary long pathname. Returns 0 on success, -1 on normal *
+ * failure and -2 when chdir failed and the current directory is lost.
+ *
+ * This is to be treated as if at system level, so dir is unmetafied but
+ * terminated by a NULL.
+ */
+
+/**/
+mod_export int
+zchdir(char *dir)
+{
+ char *s;
+ int currdir = -2;
+
+ for (;;) {
+ if (!*dir || chdir(dir) == 0) {
+#ifdef HAVE_FCHDIR
+ if (currdir >= 0)
+ close(currdir);
+#endif
+ return 0;
+ }
+ if ((errno != ENAMETOOLONG && errno != ENOMEM) ||
+ strlen(dir) < PATH_MAX)
+ break;
+ for (s = dir + PATH_MAX - 1; s > dir && *s != '/'; s--)
+ ;
+ if (s == dir)
+ break;
+#ifdef HAVE_FCHDIR
+ if (currdir == -2)
+ currdir = open(".", O_RDONLY|O_NOCTTY);
+#endif
+ *s = '\0';
+ if (chdir(dir) < 0) {
+ *s = '/';
+ break;
+ }
+#ifndef HAVE_FCHDIR
+ currdir = -1;
+#endif
+ *s = '/';
+ while (*++s == '/')
+ ;
+ dir = s;
+ }
+#ifdef HAVE_FCHDIR
+ if (currdir >= 0) {
+ if (fchdir(currdir) < 0) {
+ close(currdir);
+ return -2;
+ }
+ close(currdir);
+ return -1;
+ }
+#endif
+ return currdir == -2 ? -1 : -2;
+}
+
+/*
+ * How to print out a 64 bit integer. This isn't needed (1) if longs
+ * are 64 bit, since ordinary %ld will work (2) if we couldn't find a
+ * 64 bit type anyway.
+ */
+/**/
+#ifdef ZSH_64_BIT_TYPE
+/**/
+mod_export char *
+output64(zlong val)
+{
+ static char llbuf[DIGBUFSIZE];
+ convbase(llbuf, val, 0);
+ return llbuf;
+}
+/**/
+#endif /* ZSH_64_BIT_TYPE */
+
+/**/
+#ifndef HAVE_STRTOUL
+
+/*
+ * Copyright (c) 1990, 1993
+ * The Regents of the University of California. All rights reserved.
+ *
+ * Redistribution and use in source and binary forms, with or without
+ * modification, are permitted provided that the following conditions
+ * are met:
+ * 1. Redistributions of source code must retain the above copyright
+ * notice, this list of conditions and the following disclaimer.
+ * 2. Redistributions in binary form must reproduce the above copyright
+ * notice, this list of conditions and the following disclaimer in the
+ * documentation and/or other materials provided with the distribution.
+ * 3. Neither the name of the University nor the names of its contributors
+ * may be used to endorse or promote products derived from this software
+ * without specific prior written permission.
+ *
+ * THIS SOFTWARE IS PROVIDED BY THE REGENTS AND CONTRIBUTORS ``AS IS'' AND
+ * ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
+ * IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
+ * ARE DISCLAIMED. IN NO EVENT SHALL THE REGENTS OR CONTRIBUTORS BE LIABLE
+ * FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
+ * DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS
+ * OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION)
+ * HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT
+ * LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY
+ * OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF
+ * SUCH DAMAGE.
+ */
+
+/*
+ * Convert a string to an unsigned long integer.
+ *
+ * Ignores `locale' stuff. Assumes that the upper and lower case
+ * alphabets and digits are each contiguous.
+ */
+
+/**/
+unsigned long
+strtoul(nptr, endptr, base)
+ const char *nptr;
+ char **endptr;
+ int base;
+{
+ const char *s;
+ unsigned long acc, cutoff;
+ int c;
+ int neg, any, cutlim;
+
+ /* endptr may be NULL */
+
+ s = nptr;
+ do {
+ c = (unsigned char) *s++;
+ } while (isspace(c));
+ if (c == '-') {
+ neg = 1;
+ c = *s++;
+ } else {
+ neg = 0;
+ if (c == '+')
+ c = *s++;
+ }
+ if ((base == 0 || base == 16) &&
+ c == '0' && (*s == 'x' || *s == 'X')) {
+ c = s[1];
+ s += 2;
+ base = 16;
+ }
+ if (base == 0)
+ base = c == '0' ? 8 : 10;
+
+ cutoff = ULONG_MAX / (unsigned long)base;
+ cutlim = (int)(ULONG_MAX % (unsigned long)base);
+ for (acc = 0, any = 0;; c = (unsigned char) *s++) {
+ if (isdigit(c))
+ c -= '0';
+ else if (isalpha(c)) {
+ c -= isupper(c) ? 'A' - 10 : 'a' - 10;
+ } else
+ break;
+ if (c >= base)
+ break;
+ if (any < 0)
+ continue;
+ if (acc > cutoff || (acc == cutoff && c > cutlim)) {
+ any = -1;
+ acc = ULONG_MAX;
+ errno = ERANGE;
+ } else {
+ any = 1;
+ acc *= (unsigned long)base;
+ acc += c;
+ }
+ }
+ if (neg && any > 0)
+ acc = -acc;
+ if (endptr != NULL)
+ *endptr = any ? s - 1 : nptr;
+ return (acc);
+}
+
+/**/
+#endif /* HAVE_STRTOUL */
+
+/**/
+#ifdef ENABLE_UNICODE9
+#include "./wcwidth9.h"
+
+/**/
+int
+u9_wcwidth(wchar_t ucs)
+{
+ int w = wcwidth9(ucs);
+ if (w < -1)
+ return 1;
+ return w;
+}
+
+/**/
+int
+u9_iswprint(wint_t ucs)
+{
+ if (ucs == 0)
+ return 0;
+ return wcwidth9(ucs) != -1;
+}
+
+/**/
+#endif /* ENABLE_UNICODE9 */
+
+/**/
+#if defined(__APPLE__) && defined(BROKEN_ISPRINT)
+
+/**/
+int
+isprint_ascii(int c)
+{
+ if (!strcmp(nl_langinfo(CODESET), "UTF-8"))
+ return (c >= 0x20 && c <= 0x7e);
+ else
+ return isprint(c);
+}
+
+/**/
+#endif /* __APPLE__ && BROKEN_ISPRINT */
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/exec.c b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/exec.c
new file mode 100644
index 0000000..615a508
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/exec.c
@@ -0,0 +1,6250 @@
+/*
+ * exec.c - command execution
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+#include "zsh.mdh"
+#include "exec.pro"
+
+/* Flags for last argument of addvars */
+
+enum {
+ /* Export the variable for "VAR=val cmd ..." */
+ ADDVAR_EXPORT = 1 << 0,
+ /* Apply restrictions for variable */
+ ADDVAR_RESTRICT = 1 << 1,
+ /* Variable list is being restored later */
+ ADDVAR_RESTORE = 1 << 2
+};
+
+/* Structure in which to save values around shell function call */
+
+struct funcsave {
+ char opts[OPT_SIZE];
+ char *argv0;
+ int zoptind, lastval, optcind, numpipestats;
+ int *pipestats;
+ char *scriptname;
+ int breaks, contflag, loops, emulation, noerrexit, oflags, restore_sticky;
+ Emulation_options sticky;
+ struct funcstack fstack;
+};
+typedef struct funcsave *Funcsave;
+
+/*
+ * used to suppress ERREXIT and trapping of SIGZERR, SIGEXIT.
+ * Bits from noerrexit_bits.
+ */
+
+/**/
+int noerrexit;
+
+/* used to suppress ERREXIT or ERRRETURN for one occurrence: 0 or 1 */
+
+/**/
+int this_noerrexit;
+
+/*
+ * noerrs = 1: suppress error messages
+ * noerrs = 2: don't set errflag on parse error, either
+ */
+
+/**/
+mod_export int noerrs;
+
+/* do not save history on exec and exit */
+
+/**/
+int nohistsave;
+
+/* error flag: bits from enum errflag_bits */
+
+/**/
+mod_export int errflag;
+
+/*
+ * State of trap return value. Value is from enum trap_state.
+ */
+
+/**/
+int trap_state;
+
+/*
+ * Value associated with return from a trap.
+ * This is only active if we are inside a trap, else its value
+ * is irrelevant. It is initialised to -1 for a function trap and
+ * -2 for a non-function trap and if negative is decremented as
+ * we go deeper into functions and incremented as we come back up.
+ * The value is used to decide if an explicit "return" should cause
+ * a return from the caller of the trap; it does this by setting
+ * trap_return to a status (i.e. a non-negative value).
+ *
+ * In summary, trap_return is
+ * - zero unless we are in a trap
+ * - negative in a trap unless it has triggered. Code uses this
+ * to detect an active trap.
+ * - non-negative in a trap once it was triggered. It should remain
+ * non-negative until restored after execution of the trap.
+ */
+
+/**/
+int trap_return;
+
+/* != 0 if this is a subshell */
+
+/**/
+int subsh;
+
+/* != 0 if we have a return pending */
+
+/**/
+mod_export int retflag;
+
+/**/
+long lastval2;
+
+/* The table of file descriptors. A table element is zero if the *
+ * corresponding fd is not used by the shell. It is greater than *
+ * 1 if the fd is used by a <(...) or >(...) substitution and 1 if *
+ * it is an internal file descriptor which must be closed before *
+ * executing an external command. The first ten elements of the *
+ * table is not used. A table element is set by movefd and cleard *
+ * by zclose. */
+
+/**/
+mod_export unsigned char *fdtable;
+
+/* The allocated size of fdtable */
+
+/**/
+int fdtable_size;
+
+/* The highest fd that marked with nonzero in fdtable */
+
+/**/
+mod_export int max_zsh_fd;
+
+/* input fd from the coprocess */
+
+/**/
+mod_export int coprocin;
+
+/* output fd from the coprocess */
+
+/**/
+mod_export int coprocout;
+
+/* count of file locks recorded in fdtable */
+
+/**/
+int fdtable_flocks;
+
+
+/* != 0 if the line editor is active */
+
+/**/
+mod_export int zleactive;
+
+/* pid of process undergoing 'process substitution' */
+
+/**/
+pid_t cmdoutpid;
+
+/* pid of last process started by <(...), >(...) */
+
+/**/
+mod_export pid_t procsubstpid;
+
+/* exit status of process undergoing 'process substitution' */
+
+/**/
+int cmdoutval;
+
+/*
+ * This is set by an exiting $(...) substitution to indicate we need
+ * to retain the status. We initialize it to zero if we think we need
+ * to reset the status for a command.
+ */
+
+/**/
+int use_cmdoutval;
+
+/* The context in which a shell function is called, see SFC_* in zsh.h. */
+
+/**/
+mod_export int sfcontext;
+
+/* Stack to save some variables before executing a signal handler function */
+
+/**/
+struct execstack *exstack;
+
+/* Stack with names of function calls, 'source' calls, and 'eval' calls
+ * currently active. */
+
+/**/
+mod_export Funcstack funcstack;
+
+#define execerr() \
+ do { \
+ if (!forked) { \
+ redir_err = lastval = 1; \
+ goto done; \
+ } else { \
+ _exit(1); \
+ } \
+ } while (0)
+
+static int doneps4;
+static char *STTYval;
+static char *blank_env[] = { NULL };
+
+/* Execution functions. */
+
+static int (*execfuncs[WC_COUNT-WC_CURSH]) _((Estate, int)) = {
+ execcursh, exectime, NULL /* execfuncdef handled specially */,
+ execfor, execselect,
+ execwhile, execrepeat, execcase, execif, execcond,
+ execarith, execautofn, exectry
+};
+
+/* structure for command builtin for when it is used with -v or -V */
+static struct builtin commandbn =
+ BUILTIN("command", 0, bin_whence, 0, -1, BIN_COMMAND, "pvV", NULL);
+
+/* parse string into a list */
+
+/**/
+mod_export Eprog
+parse_string(char *s, int reset_lineno)
+{
+ Eprog p;
+ zlong oldlineno;
+
+ zcontext_save();
+ inpush(s, INP_LINENO, NULL);
+ strinbeg(0);
+ oldlineno = lineno;
+ if (reset_lineno)
+ lineno = 1;
+ p = parse_list();
+ lineno = oldlineno;
+ if (tok == LEXERR && !lastval)
+ lastval = 1;
+ strinend();
+ inpop();
+ zcontext_restore();
+ return p;
+}
+
+/**/
+#ifdef HAVE_GETRLIMIT
+
+/* the resource limits for the shell and its children */
+
+/**/
+mod_export struct rlimit current_limits[RLIM_NLIMITS], limits[RLIM_NLIMITS];
+
+/**/
+mod_export int
+zsetlimit(int limnum, char *nam)
+{
+ if (limits[limnum].rlim_max != current_limits[limnum].rlim_max ||
+ limits[limnum].rlim_cur != current_limits[limnum].rlim_cur) {
+ if (setrlimit(limnum, limits + limnum)) {
+ if (nam)
+ zwarnnam(nam, "setrlimit failed: %e", errno);
+ limits[limnum] = current_limits[limnum];
+ return -1;
+ }
+ current_limits[limnum] = limits[limnum];
+ }
+ return 0;
+}
+
+/**/
+mod_export int
+setlimits(char *nam)
+{
+ int limnum;
+ int ret = 0;
+
+ for (limnum = 0; limnum < RLIM_NLIMITS; limnum++)
+ if (zsetlimit(limnum, nam))
+ ret++;
+ return ret;
+}
+
+/**/
+#endif /* HAVE_GETRLIMIT */
+
+/* fork and set limits */
+
+/**/
+static pid_t
+zfork(struct timeval *tv)
+{
+ pid_t pid;
+ struct timezone dummy_tz;
+
+ /*
+ * Is anybody willing to explain this test?
+ */
+ if (thisjob != -1 && thisjob >= jobtabsize - 1 && !expandjobtab()) {
+ zerr("job table full");
+ return -1;
+ }
+ if (tv)
+ gettimeofday(tv, &dummy_tz);
+ /*
+ * Queueing signals is necessary on Linux because fork()
+ * manipulates mutexes, leading to deadlock in memory
+ * allocation. We don't expect fork() to be particularly
+ * zippy anyway.
+ */
+ queue_signals();
+ pid = fork();
+ unqueue_signals();
+ if (pid == -1) {
+ zerr("fork failed: %e", errno);
+ return -1;
+ }
+#ifdef HAVE_GETRLIMIT
+ if (!pid)
+ /* set resource limits for the child process */
+ setlimits(NULL);
+#endif
+ return pid;
+}
+
+/*
+ * Allen Edeln gebiet ich Andacht,
+ * Hohen und Niedern von Heimdalls Geschlecht;
+ * Ich will list_pipe's Wirken kuenden
+ * Die aeltesten Sagen, der ich mich entsinne...
+ *
+ * In most shells, if you do something like:
+ *
+ * cat foo | while read a; do grep $a bar; done
+ *
+ * the shell forks and executes the loop in the sub-shell thus created.
+ * In zsh this traditionally executes the loop in the current shell, which
+ * is nice to have if the loop does something to change the shell, like
+ * setting parameters or calling builtins.
+ * Putting the loop in a sub-shell makes life easy, because the shell only
+ * has to put it into the job-structure and then treats it as a normal
+ * process. Suspending and interrupting is no problem then.
+ * Some years ago, zsh either couldn't suspend such things at all, or
+ * it got really messed up when users tried to do it. As a solution, we
+ * implemented the list_pipe-stuff, which has since then become a reason
+ * for many nightmares.
+ * Pipelines like the one above are executed by the functions in this file
+ * which call each other (and sometimes recursively). The one above, for
+ * example would lead to a function call stack roughly like:
+ *
+ * execlist->execpline->execcmd->execwhile->execlist->execpline
+ *
+ * (when waiting for the grep, ignoring execpline2 for now). At this time,
+ * zsh has built two job-table entries for it: one for the cat and one for
+ * the grep. If the user hits ^Z at this point (and jobbing is used), the
+ * shell is notified that the grep was suspended. The list_pipe flag is
+ * used to tell the execpline where it was waiting that it was in a pipeline
+ * with a shell construct at the end (which may also be a shell function or
+ * several other things). When zsh sees the suspended grep, it forks to let
+ * the sub-shell execute the rest of the while loop. The parent shell walks
+ * up in the function call stack to the first execpline. There it has to find
+ * out that it has just forked and then has to add information about the sub-
+ * shell (its pid and the text for it) in the job entry of the cat. The pid
+ * is passed down in the list_pipe_pid variable.
+ * But there is a problem: the suspended grep is a child of the parent shell
+ * and can't be adopted by the sub-shell. So the parent shell also has to
+ * keep the information about this process (more precisely: this pipeline)
+ * by keeping the job table entry it created for it. The fact that there
+ * are two jobs which have to be treated together is remembered by setting
+ * the STAT_SUPERJOB flag in the entry for the cat-job (which now also
+ * contains a process-entry for the whole loop -- the sub-shell) and by
+ * setting STAT_SUBJOB in the job of the grep-job. With that we can keep
+ * sub-jobs from being displayed and we can handle an fg/bg on the super-
+ * job correctly. When the super-job is continued, the shell also wakes up
+ * the sub-job. But then, the grep will exit sometime. Now the parent shell
+ * has to remember not to try to wake it up again (in case of another ^Z).
+ * It also has to wake up the sub-shell (which suspended itself immediately
+ * after creation), so that the rest of the loop is executed by it.
+ * But there is more: when the sub-shell is created, the cat may already
+ * have exited, so we can't put the sub-shell in the process group of it.
+ * In this case, we put the sub-shell in the process group of the parent
+ * shell and in any case, the sub-shell has to put all commands executed
+ * by it into its own process group, because only this way the parent
+ * shell can control them since it only knows the process group of the sub-
+ * shell. Of course, this information is also important when putting a job
+ * in the foreground, where we have to attach its process group to the
+ * controlling tty.
+ * All this is made more difficult because we have to handle return values
+ * correctly. If the grep is signaled, its exit status has to be propagated
+ * back to the parent shell which needs it to set the exit status of the
+ * super-job. And of course, when the grep is signaled (including ^C), the
+ * loop has to be stopped, etc.
+ * The code for all this is distributed over three files (exec.c, jobs.c,
+ * and signals.c) and none of them is a simple one. So, all in all, there
+ * may still be bugs, but considering the complexity (with race conditions,
+ * signal handling, and all that), this should probably be expected.
+ */
+
+/**/
+int list_pipe = 0, simple_pline = 0;
+
+static pid_t list_pipe_pid;
+static struct timeval list_pipe_start;
+static int nowait, pline_level = 0;
+static int list_pipe_child = 0, list_pipe_job;
+static char list_pipe_text[JOBTEXTSIZE];
+
+/* execute a current shell command */
+
+/**/
+static int
+execcursh(Estate state, int do_exec)
+{
+ Wordcode end = state->pc + WC_CURSH_SKIP(state->pc[-1]);
+
+ /* Skip word only used for try/always */
+ state->pc++;
+
+ /*
+ * The test thisjob != -1 was added because sometimes thisjob
+ * can be invalid at this point. The case in question was
+ * in a precmd function after operations involving background
+ * jobs.
+ *
+ * This is because sometimes we bypass job control to execute
+ * very simple functions via execssimple().
+ */
+ if (!list_pipe && thisjob != -1 && thisjob != list_pipe_job &&
+ !hasprocs(thisjob))
+ deletejob(jobtab + thisjob, 0);
+ cmdpush(CS_CURSH);
+ execlist(state, 1, do_exec);
+ cmdpop();
+
+ state->pc = end;
+ this_noerrexit = 1;
+
+ return lastval;
+}
+
+/* execve after handling $_ and #! */
+
+#define POUNDBANGLIMIT 64
+
+/**/
+static int
+zexecve(char *pth, char **argv, char **newenvp)
+{
+ int eno;
+ static char buf[PATH_MAX * 2+1];
+ char **eep;
+
+ unmetafy(pth, NULL);
+ for (eep = argv; *eep; eep++)
+ if (*eep != pth)
+ unmetafy(*eep, NULL);
+ buf[0] = '_';
+ buf[1] = '=';
+ if (*pth == '/')
+ strcpy(buf + 2, pth);
+ else
+ sprintf(buf + 2, "%s/%s", pwd, pth);
+ zputenv(buf);
+#ifndef FD_CLOEXEC
+ closedumps();
+#endif
+
+ if (newenvp == NULL)
+ newenvp = environ;
+ winch_unblock();
+ execve(pth, argv, newenvp);
+
+ /* If the execve returns (which in general shouldn't happen), *
+ * then check for an errno equal to ENOEXEC. This errno is set *
+ * if the process file has the appropriate access permission, *
+ * but has an invalid magic number in its header. */
+ if ((eno = errno) == ENOEXEC || eno == ENOENT) {
+ char execvebuf[POUNDBANGLIMIT + 1], *ptr, *ptr2, *argv0;
+ int fd, ct, t0;
+
+ if ((fd = open(pth, O_RDONLY|O_NOCTTY)) >= 0) {
+ argv0 = *argv;
+ *argv = pth;
+ execvebuf[0] = '\0';
+ ct = read(fd, execvebuf, POUNDBANGLIMIT);
+ close(fd);
+ if (ct >= 0) {
+ if (execvebuf[0] == '#') {
+ if (execvebuf[1] == '!') {
+ for (t0 = 0; t0 != ct; t0++)
+ if (execvebuf[t0] == '\n')
+ break;
+ while (inblank(execvebuf[t0]))
+ execvebuf[t0--] = '\0';
+ execvebuf[POUNDBANGLIMIT] = '\0';
+ for (ptr = execvebuf + 2; *ptr && *ptr == ' '; ptr++);
+ for (ptr2 = ptr; *ptr && *ptr != ' '; ptr++);
+ if (eno == ENOENT) {
+ char *pprog;
+ if (*ptr)
+ *ptr = '\0';
+ if (*ptr2 != '/' &&
+ (pprog = pathprog(ptr2, NULL))) {
+ argv[-2] = ptr2;
+ argv[-1] = ptr + 1;
+ winch_unblock();
+ execve(pprog, argv - 2, newenvp);
+ }
+ zerr("%s: bad interpreter: %s: %e", pth, ptr2,
+ eno);
+ } else if (*ptr) {
+ *ptr = '\0';
+ argv[-2] = ptr2;
+ argv[-1] = ptr + 1;
+ winch_unblock();
+ execve(ptr2, argv - 2, newenvp);
+ } else {
+ argv[-1] = ptr2;
+ winch_unblock();
+ execve(ptr2, argv - 1, newenvp);
+ }
+ } else if (eno == ENOEXEC) {
+ argv[-1] = "sh";
+ winch_unblock();
+ execve("/bin/sh", argv - 1, newenvp);
+ }
+ } else if (eno == ENOEXEC) {
+ for (t0 = 0; t0 != ct; t0++)
+ if (!execvebuf[t0])
+ break;
+ if (t0 == ct) {
+ argv[-1] = "sh";
+ winch_unblock();
+ execve("/bin/sh", argv - 1, newenvp);
+ }
+ }
+ } else
+ eno = errno;
+ *argv = argv0;
+ } else
+ eno = errno;
+ }
+ /* restore the original arguments and path but do not bother with *
+ * null characters as these cannot be passed to external commands *
+ * anyway. So the result is truncated at the first null char. */
+ pth = metafy(pth, -1, META_NOALLOC);
+ for (eep = argv; *eep; eep++)
+ if (*eep != pth)
+ (void) metafy(*eep, -1, META_NOALLOC);
+ return eno;
+}
+
+#define MAXCMDLEN (PATH_MAX*4)
+
+/* test whether we really want to believe the error number */
+
+/**/
+static int
+isgooderr(int e, char *dir)
+{
+ /*
+ * Maybe the directory was unreadable, or maybe it wasn't
+ * even a directory.
+ */
+ return ((e != EACCES || !access(dir, X_OK)) &&
+ e != ENOENT && e != ENOTDIR);
+}
+
+/*
+ * Attempt to handle command not found.
+ * Return 0 if the condition was handled, non-zero otherwise.
+ */
+
+/**/
+static int
+commandnotfound(char *arg0, LinkList args)
+{
+ Shfunc shf = (Shfunc)
+ shfunctab->getnode(shfunctab, "command_not_found_handler");
+
+ if (!shf) {
+ lastval = 127;
+ return 1;
+ }
+
+ pushnode(args, arg0);
+ lastval = doshfunc(shf, args, 1);
+ return 0;
+}
+
+/*
+ * Search the default path for cmd.
+ * pbuf of length plen is the buffer to use.
+ * Return NULL if not found.
+ */
+
+static char *
+search_defpath(char *cmd, char *pbuf, int plen)
+{
+ char *ps = DEFAULT_PATH, *pe = NULL, *s;
+
+ for (ps = DEFAULT_PATH; ps; ps = pe ? pe+1 : NULL) {
+ pe = strchr(ps, ':');
+ if (*ps == '/') {
+ s = pbuf;
+ if (pe) {
+ if (pe - ps >= plen)
+ continue;
+ struncpy(&s, ps, pe-ps);
+ } else {
+ if (strlen(ps) >= plen)
+ continue;
+ strucpy(&s, ps);
+ }
+ *s++ = '/';
+ if ((s - pbuf) + strlen(cmd) >= plen)
+ continue;
+ strucpy(&s, cmd);
+ if (iscom(pbuf))
+ return pbuf;
+ }
+ }
+ return NULL;
+}
+
+/* execute an external command */
+
+/**/
+static void
+execute(LinkList args, int flags, int defpath)
+{
+ Cmdnam cn;
+ char buf[MAXCMDLEN+1], buf2[MAXCMDLEN+1];
+ char *s, *z, *arg0;
+ char **argv, **pp, **newenvp = NULL;
+ int eno = 0, ee;
+
+ arg0 = (char *) peekfirst(args);
+ if (isset(RESTRICTED) && (strchr(arg0, '/') || defpath)) {
+ zerr("%s: restricted", arg0);
+ _exit(1);
+ }
+
+ /* If the parameter STTY is set in the command's environment, *
+ * we first run the stty command with the value of this *
+ * parameter as it arguments. */
+ if ((s = STTYval) && isatty(0) && (GETPGRP() == getpid())) {
+ char *t = tricat("stty", " ", s);
+
+ STTYval = 0; /* this prevents infinite recursion */
+ zsfree(s);
+ execstring(t, 1, 0, "stty");
+ zsfree(t);
+ } else if (s) {
+ STTYval = 0;
+ zsfree(s);
+ }
+
+ /* If ARGV0 is in the commands environment, we use *
+ * that as argv[0] for this external command */
+ if (unset(RESTRICTED) && (z = zgetenv("ARGV0"))) {
+ setdata(firstnode(args), (void *) ztrdup(z));
+ /*
+ * Note we don't do anything with the parameter structure
+ * for ARGV0: that's OK since we're about to exec or exit
+ * on failure.
+ */
+#ifdef USE_SET_UNSET_ENV
+ unsetenv("ARGV0");
+#else
+ delenvvalue(z - 6);
+#endif
+ } else if (flags & BINF_DASH) {
+ /* Else if the pre-command `-' was given, we add `-' *
+ * to the front of argv[0] for this command. */
+ sprintf(buf2, "-%s", arg0);
+ setdata(firstnode(args), (void *) ztrdup(buf2));
+ }
+
+ argv = makecline(args);
+ if (flags & BINF_CLEARENV)
+ newenvp = blank_env;
+
+ /*
+ * Note that we don't close fd's attached to process substitution
+ * here, which should be visible to external processes.
+ */
+ closem(FDT_XTRACE, 0);
+#ifndef FD_CLOEXEC
+ if (SHTTY != -1) {
+ close(SHTTY);
+ SHTTY = -1;
+ }
+#endif
+ child_unblock();
+ if ((int) strlen(arg0) >= PATH_MAX) {
+ zerr("command too long: %s", arg0);
+ _exit(1);
+ }
+ for (s = arg0; *s; s++)
+ if (*s == '/') {
+ int lerrno = zexecve(arg0, argv, newenvp);
+ if (arg0 == s || unset(PATHDIRS) ||
+ (arg0[0] == '.' && (arg0 + 1 == s ||
+ (arg0[1] == '.' && arg0 + 2 == s)))) {
+ zerr("%e: %s", lerrno, arg0);
+ _exit((lerrno == EACCES || lerrno == ENOEXEC) ? 126 : 127);
+ }
+ break;
+ }
+
+ /* for command -p, search the default path */
+ if (defpath) {
+ char pbuf[PATH_MAX+1];
+ char *dptr;
+
+ if (!search_defpath(arg0, pbuf, PATH_MAX)) {
+ if (commandnotfound(arg0, args) == 0)
+ _exit(lastval);
+ zerr("command not found: %s", arg0);
+ _exit(127);
+ }
+
+ ee = zexecve(pbuf, argv, newenvp);
+
+ if ((dptr = strrchr(pbuf, '/')))
+ *dptr = '\0';
+ if (isgooderr(ee, *pbuf ? pbuf : "/"))
+ eno = ee;
+
+ } else {
+
+ if ((cn = (Cmdnam) cmdnamtab->getnode(cmdnamtab, arg0))) {
+ char nn[PATH_MAX+1], *dptr;
+
+ if (cn->node.flags & HASHED)
+ strcpy(nn, cn->u.cmd);
+ else {
+ for (pp = path; pp < cn->u.name; pp++)
+ if (!**pp || (**pp == '.' && (*pp)[1] == '\0')) {
+ ee = zexecve(arg0, argv, newenvp);
+ if (isgooderr(ee, *pp))
+ eno = ee;
+ } else if (**pp != '/') {
+ z = buf;
+ strucpy(&z, *pp);
+ *z++ = '/';
+ strcpy(z, arg0);
+ ee = zexecve(buf, argv, newenvp);
+ if (isgooderr(ee, *pp))
+ eno = ee;
+ }
+ strcpy(nn, cn->u.name ? *(cn->u.name) : "");
+ strcat(nn, "/");
+ strcat(nn, cn->node.nam);
+ }
+ ee = zexecve(nn, argv, newenvp);
+
+ if ((dptr = strrchr(nn, '/')))
+ *dptr = '\0';
+ if (isgooderr(ee, *nn ? nn : "/"))
+ eno = ee;
+ }
+ for (pp = path; *pp; pp++)
+ if (!(*pp)[0] || ((*pp)[0] == '.' && !(*pp)[1])) {
+ ee = zexecve(arg0, argv, newenvp);
+ if (isgooderr(ee, *pp))
+ eno = ee;
+ } else {
+ z = buf;
+ strucpy(&z, *pp);
+ *z++ = '/';
+ strcpy(z, arg0);
+ ee = zexecve(buf, argv, newenvp);
+ if (isgooderr(ee, *pp))
+ eno = ee;
+ }
+ }
+
+ if (eno)
+ zerr("%e: %s", eno, arg0);
+ else if (commandnotfound(arg0, args) == 0)
+ _exit(lastval);
+ else
+ zerr("command not found: %s", arg0);
+ _exit((eno == EACCES || eno == ENOEXEC) ? 126 : 127);
+}
+
+#define RET_IF_COM(X) { if (iscom(X)) return docopy ? dupstring(X) : arg0; }
+
+/*
+ * Get the full pathname of an external command.
+ * If the second argument is zero, return the first argument if found;
+ * if non-zero, return the path using heap memory. (RET_IF_COM(X),
+ * above).
+ * If the third argument is non-zero, use the system default path
+ * instead of the current path.
+ */
+
+/**/
+mod_export char *
+findcmd(char *arg0, int docopy, int default_path)
+{
+ char **pp;
+ char *z, *s, buf[MAXCMDLEN];
+ Cmdnam cn;
+
+ if (default_path)
+ {
+ if (search_defpath(arg0, buf, MAXCMDLEN))
+ return docopy ? dupstring(buf) : arg0;
+ return NULL;
+ }
+ cn = (Cmdnam) cmdnamtab->getnode(cmdnamtab, arg0);
+ if (!cn && isset(HASHCMDS) && !isrelative(arg0))
+ cn = hashcmd(arg0, path);
+ if ((int) strlen(arg0) > PATH_MAX)
+ return NULL;
+ if ((s = strchr(arg0, '/'))) {
+ RET_IF_COM(arg0);
+ if (arg0 == s || unset(PATHDIRS) || !strncmp(arg0, "./", 2) ||
+ !strncmp(arg0, "../", 3)) {
+ return NULL;
+ }
+ }
+ if (cn) {
+ char nn[PATH_MAX+1];
+
+ if (cn->node.flags & HASHED)
+ strcpy(nn, cn->u.cmd);
+ else {
+ for (pp = path; pp < cn->u.name; pp++)
+ if (**pp != '/') {
+ z = buf;
+ if (**pp) {
+ strucpy(&z, *pp);
+ *z++ = '/';
+ }
+ strcpy(z, arg0);
+ RET_IF_COM(buf);
+ }
+ strcpy(nn, cn->u.name ? *(cn->u.name) : "");
+ strcat(nn, "/");
+ strcat(nn, cn->node.nam);
+ }
+ RET_IF_COM(nn);
+ }
+ for (pp = path; *pp; pp++) {
+ z = buf;
+ if (**pp) {
+ strucpy(&z, *pp);
+ *z++ = '/';
+ }
+ strcpy(z, arg0);
+ RET_IF_COM(buf);
+ }
+ return NULL;
+}
+
+/*
+ * Return TRUE if the given path denotes an executable regular file, or a
+ * symlink to one.
+ */
+
+/**/
+int
+iscom(char *s)
+{
+ struct stat statbuf;
+ char *us = unmeta(s);
+
+ return (access(us, X_OK) == 0 && stat(us, &statbuf) >= 0 &&
+ S_ISREG(statbuf.st_mode));
+}
+
+/**/
+int
+isreallycom(Cmdnam cn)
+{
+ char fullnam[MAXCMDLEN];
+
+ if (cn->node.flags & HASHED)
+ strcpy(fullnam, cn->u.cmd);
+ else if (!cn->u.name)
+ return 0;
+ else {
+ strcpy(fullnam, *(cn->u.name));
+ strcat(fullnam, "/");
+ strcat(fullnam, cn->node.nam);
+ }
+ return iscom(fullnam);
+}
+
+/*
+ * Return TRUE if the given path contains a dot or dot-dot component
+ * and does not start with a slash.
+ */
+
+/**/
+int
+isrelative(char *s)
+{
+ if (*s != '/')
+ return 1;
+ for (; *s; s++)
+ if (*s == '.' && s[-1] == '/' &&
+ (s[1] == '/' || s[1] == '\0' ||
+ (s[1] == '.' && (s[2] == '/' || s[2] == '\0'))))
+ return 1;
+ return 0;
+}
+
+/**/
+mod_export Cmdnam
+hashcmd(char *arg0, char **pp)
+{
+ Cmdnam cn;
+ char *s, buf[PATH_MAX+1];
+ char **pq;
+
+ for (; *pp; pp++)
+ if (**pp == '/') {
+ s = buf;
+ struncpy(&s, *pp, PATH_MAX);
+ *s++ = '/';
+ if ((s - buf) + strlen(arg0) >= PATH_MAX)
+ continue;
+ strcpy(s, arg0);
+ if (iscom(buf))
+ break;
+ }
+
+ if (!*pp)
+ return NULL;
+
+ cn = (Cmdnam) zshcalloc(sizeof *cn);
+ cn->node.flags = 0;
+ cn->u.name = pp;
+ cmdnamtab->addnode(cmdnamtab, ztrdup(arg0), cn);
+
+ if (isset(HASHDIRS)) {
+ for (pq = pathchecked; pq <= pp; pq++)
+ hashdir(pq);
+ pathchecked = pp + 1;
+ }
+
+ return cn;
+}
+
+/**/
+int
+forklevel;
+
+/* Arguments to entersubsh() */
+enum {
+ /* Subshell is to be run asynchronously (else synchronously) */
+ ESUB_ASYNC = 0x01,
+ /*
+ * Perform process group and tty handling and clear the
+ * (real) job table, since it won't be any longer valid
+ */
+ ESUB_PGRP = 0x02,
+ /* Don't unset traps */
+ ESUB_KEEPTRAP = 0x04,
+ /* This is only a fake entry to a subshell */
+ ESUB_FAKE = 0x08,
+ /* Release the process group if pid is the shell's process group */
+ ESUB_REVERTPGRP = 0x10,
+ /* Don't handle the MONITOR option even if previously set */
+ ESUB_NOMONITOR = 0x20,
+ /* This is a subshell where job control is allowed */
+ ESUB_JOB_CONTROL = 0x40
+};
+
+/**/
+static void
+entersubsh(int flags)
+{
+ int i, sig, monitor, job_control_ok;
+
+ if (!(flags & ESUB_KEEPTRAP))
+ for (sig = 0; sig < SIGCOUNT; sig++)
+ if (!(sigtrapped[sig] & ZSIG_FUNC))
+ unsettrap(sig);
+ monitor = isset(MONITOR);
+ job_control_ok = monitor && (flags & ESUB_JOB_CONTROL) && isset(POSIXJOBS);
+ if (flags & ESUB_NOMONITOR)
+ opts[MONITOR] = 0;
+ if (!isset(MONITOR)) {
+ if (flags & ESUB_ASYNC) {
+ settrap(SIGINT, NULL, 0);
+ settrap(SIGQUIT, NULL, 0);
+ if (isatty(0)) {
+ close(0);
+ if (open("/dev/null", O_RDWR | O_NOCTTY)) {
+ zerr("can't open /dev/null: %e", errno);
+ _exit(1);
+ }
+ }
+ }
+ } else if (thisjob != -1 && (flags & ESUB_PGRP)) {
+ if (jobtab[list_pipe_job].gleader && (list_pipe || list_pipe_child)) {
+ if (setpgrp(0L, jobtab[list_pipe_job].gleader) == -1 ||
+ killpg(jobtab[list_pipe_job].gleader, 0) == -1) {
+ jobtab[list_pipe_job].gleader =
+ jobtab[thisjob].gleader = (list_pipe_child ? mypgrp : getpid());
+ setpgrp(0L, jobtab[list_pipe_job].gleader);
+ if (!(flags & ESUB_ASYNC))
+ attachtty(jobtab[thisjob].gleader);
+ }
+ }
+ else if (!jobtab[thisjob].gleader ||
+ setpgrp(0L, jobtab[thisjob].gleader) == -1) {
+ /*
+ * This is the standard point at which a newly started
+ * process gets put into the foreground by taking over
+ * the terminal. Note that in normal circumstances we do
+ * this only from the process itself. This only works if
+ * we are still ignoring SIGTTOU at this point; in this
+ * case ignoring the signal has the special effect that
+ * the operation is allowed to work (in addition to not
+ * causing the shell to be suspended).
+ */
+ jobtab[thisjob].gleader = getpid();
+ if (list_pipe_job != thisjob &&
+ !jobtab[list_pipe_job].gleader)
+ jobtab[list_pipe_job].gleader = jobtab[thisjob].gleader;
+ setpgrp(0L, jobtab[thisjob].gleader);
+ if (!(flags & ESUB_ASYNC))
+ attachtty(jobtab[thisjob].gleader);
+ }
+ }
+ if (!(flags & ESUB_FAKE))
+ subsh = 1;
+ /*
+ * Increment the visible parameter ZSH_SUBSHELL even if this
+ * is a fake subshell because we are exec'ing at the end.
+ * Logically this should be equivalent to a real subshell so
+ * we don't hang out the dirty washing.
+ */
+ zsh_subshell++;
+ if ((flags & ESUB_REVERTPGRP) && getpid() == mypgrp)
+ release_pgrp();
+ shout = NULL;
+ if (flags & ESUB_NOMONITOR) {
+ /*
+ * Allowing any form of interactive signalling here is
+ * actively harmful as we are in a context where there is no
+ * control over the process.
+ */
+ signal_ignore(SIGTTOU);
+ signal_ignore(SIGTTIN);
+ signal_ignore(SIGTSTP);
+ } else if (!job_control_ok) {
+ /*
+ * If this process is not going to be doing job control,
+ * we don't want to do special things with the corresponding
+ * signals. If it is, we need to keep the special behaviour:
+ * see note about attachtty() above.
+ */
+ signal_default(SIGTTOU);
+ signal_default(SIGTTIN);
+ signal_default(SIGTSTP);
+ }
+ if (interact) {
+ signal_default(SIGTERM);
+ if (!(sigtrapped[SIGINT] & ZSIG_IGNORED))
+ signal_default(SIGINT);
+ if (!(sigtrapped[SIGPIPE]))
+ signal_default(SIGPIPE);
+ }
+ if (!(sigtrapped[SIGQUIT] & ZSIG_IGNORED))
+ signal_default(SIGQUIT);
+ /*
+ * sigtrapped[sig] == ZSIG_IGNORED for signals that remain ignored,
+ * but other trapped signals are temporarily blocked when intrap,
+ * and must be unblocked before continuing into the subshell. This
+ * is orthogonal to what the default handler for the signal may be.
+ *
+ * Start loop at 1 because 0 is SIGEXIT
+ */
+ if (intrap)
+ for (sig = 1; sig < SIGCOUNT; sig++)
+ if (sigtrapped[sig] && sigtrapped[sig] != ZSIG_IGNORED)
+ signal_unblock(signal_mask(sig));
+ if (!job_control_ok)
+ opts[MONITOR] = 0;
+ opts[USEZLE] = 0;
+ zleactive = 0;
+ /*
+ * If we've saved fd's for later restoring, we're never going
+ * to restore them now, so just close them.
+ */
+ for (i = 10; i <= max_zsh_fd; i++) {
+ if (fdtable[i] & FDT_SAVED_MASK)
+ zclose(i);
+ }
+ if (flags & ESUB_PGRP)
+ clearjobtab(monitor);
+ get_usage();
+ forklevel = locallevel;
+}
+
+/* execute a string */
+
+/**/
+mod_export void
+execstring(char *s, int dont_change_job, int exiting, char *context)
+{
+ Eprog prog;
+
+ pushheap();
+ if (isset(VERBOSE)) {
+ zputs(s, stderr);
+ fputc('\n', stderr);
+ fflush(stderr);
+ }
+ if ((prog = parse_string(s, 0)))
+ execode(prog, dont_change_job, exiting, context);
+ popheap();
+}
+
+/**/
+mod_export void
+execode(Eprog p, int dont_change_job, int exiting, char *context)
+{
+ struct estate s;
+ static int zsh_eval_context_len;
+ int alen;
+
+ if (!zsh_eval_context_len) {
+ zsh_eval_context_len = 16;
+ alen = 0;
+ zsh_eval_context = (char **)zalloc(zsh_eval_context_len *
+ sizeof(*zsh_eval_context));
+ } else {
+ alen = arrlen(zsh_eval_context);
+ if (zsh_eval_context_len == alen + 1) {
+ zsh_eval_context_len *= 2;
+ zsh_eval_context = zrealloc(zsh_eval_context,
+ zsh_eval_context_len *
+ sizeof(*zsh_eval_context));
+ }
+ }
+ zsh_eval_context[alen] = context;
+ zsh_eval_context[alen+1] = NULL;
+
+ s.prog = p;
+ s.pc = p->prog;
+ s.strs = p->strs;
+ useeprog(p); /* Mark as in use */
+
+ execlist(&s, dont_change_job, exiting);
+
+ freeeprog(p); /* Free if now unused */
+
+ /*
+ * zsh_eval_context may have been altered by a recursive
+ * call, but that's OK since we're using the global value.
+ */
+ zsh_eval_context[alen] = NULL;
+}
+
+/* Execute a simplified command. This is used to execute things that
+ * will run completely in the shell, so that we can by-pass all that
+ * nasty job-handling and redirection stuff in execpline and execcmd. */
+
+/**/
+static int
+execsimple(Estate state)
+{
+ wordcode code = *state->pc++;
+ int lv, otj;
+
+ if (errflag)
+ return (lastval = 1);
+
+ if (!isset(EXECOPT))
+ return lastval = 0;
+
+ /* In evaluated traps, don't modify the line number. */
+ if (!IN_EVAL_TRAP() && !ineval && code)
+ lineno = code - 1;
+
+ code = wc_code(*state->pc++);
+
+ /*
+ * Because we're bypassing job control, ensure the called
+ * code doesn't see the current job.
+ */
+ otj = thisjob;
+ thisjob = -1;
+
+ if (code == WC_ASSIGN) {
+ cmdoutval = 0;
+ addvars(state, state->pc - 1, 0);
+ setunderscore("");
+ if (isset(XTRACE)) {
+ fputc('\n', xtrerr);
+ fflush(xtrerr);
+ }
+ lv = (errflag ? errflag : cmdoutval);
+ } else {
+ int q = queue_signal_level();
+ dont_queue_signals();
+ if (code == WC_FUNCDEF)
+ lv = execfuncdef(state, NULL);
+ else
+ lv = (execfuncs[code - WC_CURSH])(state, 0);
+ restore_queue_signals(q);
+ }
+
+ thisjob = otj;
+
+ return lastval = lv;
+}
+
+/* Main routine for executing a list. *
+ * exiting means that the (sub)shell we are in is a definite goner *
+ * after the current list is finished, so we may be able to exec the *
+ * last command directly instead of forking. If dont_change_job is *
+ * nonzero, then restore the current job number after executing the *
+ * list. */
+
+/**/
+void
+execlist(Estate state, int dont_change_job, int exiting)
+{
+ static int donetrap;
+ Wordcode next;
+ wordcode code;
+ int ret, cj, csp, ltype;
+ int old_pline_level, old_list_pipe, old_list_pipe_job;
+ char *old_list_pipe_text;
+ zlong oldlineno;
+ /*
+ * ERREXIT only forces the shell to exit if the last command in a &&
+ * or || fails. This is the case even if an earlier command is a
+ * shell function or other current shell structure, so we have to set
+ * noerrexit here if the sublist is not of type END.
+ */
+ int oldnoerrexit = noerrexit;
+
+ queue_signals();
+
+ cj = thisjob;
+ old_pline_level = pline_level;
+ old_list_pipe = list_pipe;
+ old_list_pipe_job = list_pipe_job;
+ if (*list_pipe_text)
+ old_list_pipe_text = ztrdup(list_pipe_text);
+ else
+ old_list_pipe_text = NULL;
+ oldlineno = lineno;
+
+ if (sourcelevel && unset(SHINSTDIN)) {
+ pline_level = list_pipe = list_pipe_job = 0;
+ *list_pipe_text = '\0';
+ }
+
+ /* Loop over all sets of comands separated by newline, *
+ * semi-colon or ampersand (`sublists'). */
+ code = *state->pc++;
+ if (wc_code(code) != WC_LIST) {
+ /* Empty list; this returns status zero. */
+ lastval = 0;
+ }
+ while (wc_code(code) == WC_LIST && !breaks && !retflag && !errflag) {
+ int donedebug;
+ int this_donetrap = 0;
+ this_noerrexit = 0;
+
+ ltype = WC_LIST_TYPE(code);
+ csp = cmdsp;
+
+ if (!IN_EVAL_TRAP() && !ineval) {
+ /*
+ * Ensure we have a valid line number for debugging,
+ * unless we are in an evaluated trap in which case
+ * we retain the line number from the context.
+ * This was added for DEBUGBEFORECMD but I've made
+ * it unconditional to keep dependencies to a minimum.
+ *
+ * The line number is updated for individual pipelines.
+ * This isn't necessary for debug traps since they only
+ * run once per sublist.
+ */
+ wordcode code2 = *state->pc, lnp1 = 0;
+ if (ltype & Z_SIMPLE) {
+ lnp1 = code2;
+ } else if (wc_code(code2) == WC_SUBLIST) {
+ if (WC_SUBLIST_FLAGS(code2) == WC_SUBLIST_SIMPLE)
+ lnp1 = state->pc[1];
+ else
+ lnp1 = WC_PIPE_LINENO(state->pc[1]);
+ }
+ if (lnp1)
+ lineno = lnp1 - 1;
+ }
+
+ if (sigtrapped[SIGDEBUG] && isset(DEBUGBEFORECMD) && !intrap) {
+ Wordcode pc2 = state->pc;
+ int oerrexit_opt = opts[ERREXIT];
+ Param pm;
+ opts[ERREXIT] = 0;
+ noerrexit = NOERREXIT_EXIT | NOERREXIT_RETURN;
+ if (ltype & Z_SIMPLE) /* skip the line number */
+ pc2++;
+ pm = assignsparam("ZSH_DEBUG_CMD",
+ getpermtext(state->prog, pc2, 0),
+ 0);
+
+ exiting = donetrap;
+ ret = lastval;
+ dotrap(SIGDEBUG);
+ if (!retflag)
+ lastval = ret;
+ donetrap = exiting;
+ noerrexit = oldnoerrexit;
+ /*
+ * Only execute the trap once per sublist, even
+ * if the DEBUGBEFORECMD option changes.
+ */
+ donedebug = isset(ERREXIT) ? 2 : 1;
+ opts[ERREXIT] = oerrexit_opt;
+ if (pm)
+ unsetparam_pm(pm, 0, 1);
+ } else
+ donedebug = intrap ? 1 : 0;
+
+ /* Reset donetrap: this ensures that a trap is only *
+ * called once for each sublist that fails. */
+ donetrap = 0;
+ if (ltype & Z_SIMPLE) {
+ next = state->pc + WC_LIST_SKIP(code);
+ if (donedebug != 2)
+ execsimple(state);
+ state->pc = next;
+ goto sublist_done;
+ }
+
+ /* Loop through code followed by &&, ||, or end of sublist. */
+ code = *state->pc++;
+ if (donedebug == 2) {
+ /* Skip sublist. */
+ while (wc_code(code) == WC_SUBLIST) {
+ state->pc = state->pc + WC_SUBLIST_SKIP(code);
+ if (WC_SUBLIST_TYPE(code) == WC_SUBLIST_END)
+ break;
+ code = *state->pc++;
+ }
+ donetrap = 1;
+ /* yucky but consistent... */
+ goto sublist_done;
+ }
+ while (wc_code(code) == WC_SUBLIST) {
+ int isend = (WC_SUBLIST_TYPE(code) == WC_SUBLIST_END);
+ next = state->pc + WC_SUBLIST_SKIP(code);
+ if (!oldnoerrexit)
+ noerrexit = isend ? 0 : NOERREXIT_EXIT | NOERREXIT_RETURN;
+ if (WC_SUBLIST_FLAGS(code) & WC_SUBLIST_NOT) {
+ /* suppress errexit for "! this_command" */
+ if (isend)
+ this_noerrexit = 1;
+ /* suppress errexit for ! */
+ noerrexit = NOERREXIT_EXIT | NOERREXIT_RETURN;
+ }
+ switch (WC_SUBLIST_TYPE(code)) {
+ case WC_SUBLIST_END:
+ /* End of sublist; just execute, ignoring status. */
+ if (WC_SUBLIST_FLAGS(code) & WC_SUBLIST_SIMPLE)
+ execsimple(state);
+ else
+ execpline(state, code, ltype, (ltype & Z_END) && exiting);
+ state->pc = next;
+ goto sublist_done;
+ break;
+ case WC_SUBLIST_AND:
+ /* If the return code is non-zero, we skip pipelines until *
+ * we find a sublist followed by ORNEXT. */
+ if ((ret = ((WC_SUBLIST_FLAGS(code) & WC_SUBLIST_SIMPLE) ?
+ execsimple(state) :
+ execpline(state, code, Z_SYNC, 0)))) {
+ state->pc = next;
+ code = *state->pc++;
+ next = state->pc + WC_SUBLIST_SKIP(code);
+ while (wc_code(code) == WC_SUBLIST &&
+ WC_SUBLIST_TYPE(code) == WC_SUBLIST_AND) {
+ state->pc = next;
+ code = *state->pc++;
+ next = state->pc + WC_SUBLIST_SKIP(code);
+ }
+ if (wc_code(code) != WC_SUBLIST) {
+ /* We've skipped to the end of the list, not executing *
+ * the final pipeline, so don't perform error handling *
+ * for this sublist. */
+ this_donetrap = 1;
+ goto sublist_done;
+ } else if (WC_SUBLIST_TYPE(code) == WC_SUBLIST_END) {
+ this_donetrap = 1;
+ /*
+ * Treat this in the same way as if we reached
+ * the end of the sublist normally.
+ */
+ state->pc = next;
+ goto sublist_done;
+ }
+ }
+ cmdpush(CS_CMDAND);
+ break;
+ case WC_SUBLIST_OR:
+ /* If the return code is zero, we skip pipelines until *
+ * we find a sublist followed by ANDNEXT. */
+ if (!(ret = ((WC_SUBLIST_FLAGS(code) & WC_SUBLIST_SIMPLE) ?
+ execsimple(state) :
+ execpline(state, code, Z_SYNC, 0)))) {
+ state->pc = next;
+ code = *state->pc++;
+ next = state->pc + WC_SUBLIST_SKIP(code);
+ while (wc_code(code) == WC_SUBLIST &&
+ WC_SUBLIST_TYPE(code) == WC_SUBLIST_OR) {
+ state->pc = next;
+ code = *state->pc++;
+ next = state->pc + WC_SUBLIST_SKIP(code);
+ }
+ if (wc_code(code) != WC_SUBLIST) {
+ /* We've skipped to the end of the list, not executing *
+ * the final pipeline, so don't perform error handling *
+ * for this sublist. */
+ this_donetrap = 1;
+ goto sublist_done;
+ } else if (WC_SUBLIST_TYPE(code) == WC_SUBLIST_END) {
+ this_donetrap = 1;
+ /*
+ * Treat this in the same way as if we reached
+ * the end of the sublist normally.
+ */
+ state->pc = next;
+ goto sublist_done;
+ }
+ }
+ cmdpush(CS_CMDOR);
+ break;
+ }
+ state->pc = next;
+ code = *state->pc++;
+ }
+ state->pc--;
+sublist_done:
+
+ /*
+ * See hairy code near the end of execif() for the
+ * following. "noerrexit " only applies until
+ * we hit execcmd on the way down. We're now
+ * on the way back up, so don't restore it.
+ */
+ if (!(oldnoerrexit & NOERREXIT_UNTIL_EXEC))
+ noerrexit = oldnoerrexit;
+
+ if (sigtrapped[SIGDEBUG] && !isset(DEBUGBEFORECMD) && !donedebug) {
+ /*
+ * Save and restore ERREXIT for consistency with
+ * DEBUGBEFORECMD, even though it's not used.
+ */
+ int oerrexit_opt = opts[ERREXIT];
+ opts[ERREXIT] = 0;
+ noerrexit = NOERREXIT_EXIT | NOERREXIT_RETURN;
+ exiting = donetrap;
+ ret = lastval;
+ dotrap(SIGDEBUG);
+ if (!retflag)
+ lastval = ret;
+ donetrap = exiting;
+ noerrexit = oldnoerrexit;
+ opts[ERREXIT] = oerrexit_opt;
+ }
+
+ cmdsp = csp;
+
+ /* Check whether we are suppressing traps/errexit *
+ * (typically in init scripts) and if we haven't *
+ * already performed them for this sublist. */
+ if (!this_noerrexit && !donetrap && !this_donetrap) {
+ if (sigtrapped[SIGZERR] && lastval &&
+ !(noerrexit & NOERREXIT_EXIT)) {
+ dotrap(SIGZERR);
+ donetrap = 1;
+ }
+ if (lastval) {
+ int errreturn = isset(ERRRETURN) &&
+ (isset(INTERACTIVE) || locallevel || sourcelevel) &&
+ !(noerrexit & NOERREXIT_RETURN);
+ int errexit = (isset(ERREXIT) ||
+ (isset(ERRRETURN) && !errreturn)) &&
+ !(noerrexit & NOERREXIT_EXIT);
+ if (errexit) {
+ if (sigtrapped[SIGEXIT])
+ dotrap(SIGEXIT);
+ if (mypid != getpid())
+ _exit(lastval);
+ else
+ exit(lastval);
+ }
+ if (errreturn) {
+ retflag = 1;
+ breaks = loops;
+ }
+ }
+ }
+ if (ltype & Z_END)
+ break;
+ code = *state->pc++;
+ }
+ pline_level = old_pline_level;
+ list_pipe = old_list_pipe;
+ list_pipe_job = old_list_pipe_job;
+ if (old_list_pipe_text) {
+ strcpy(list_pipe_text, old_list_pipe_text);
+ zsfree(old_list_pipe_text);
+ } else {
+ *list_pipe_text = '\0';
+ }
+ lineno = oldlineno;
+ if (dont_change_job)
+ thisjob = cj;
+
+ if (exiting && sigtrapped[SIGEXIT]) {
+ dotrap(SIGEXIT);
+ /* Make sure this doesn't get executed again. */
+ sigtrapped[SIGEXIT] = 0;
+ }
+
+ unqueue_signals();
+}
+
+/* Execute a pipeline. *
+ * last1 is a flag that this command is the last command in a shell *
+ * that is about to exit, so we can exec instead of forking. It gets *
+ * passed all the way down to execcmd() which actually makes the *
+ * decision. A 0 is always passed if the command is not the last in *
+ * the pipeline. This function assumes that the sublist is not NULL. *
+ * If last1 is zero but the command is at the end of a pipeline, we *
+ * pass 2 down to execcmd(). *
+ */
+
+/**/
+static int
+execpline(Estate state, wordcode slcode, int how, int last1)
+{
+ int ipipe[2], opipe[2];
+ int pj, newjob;
+ int old_simple_pline = simple_pline;
+ int slflags = WC_SUBLIST_FLAGS(slcode);
+ wordcode code = *state->pc++;
+ static int lastwj, lpforked;
+
+ if (wc_code(code) != WC_PIPE)
+ return lastval = (slflags & WC_SUBLIST_NOT) != 0;
+ else if (slflags & WC_SUBLIST_NOT)
+ last1 = 0;
+
+ /* If trap handlers are allowed to run here, they may start another
+ * external job in the middle of us starting this one, which can
+ * result in jobs being reaped before their job table entries have
+ * been initialized, which in turn leads to waiting forever for
+ * jobs that no longer exist. So don't do that.
+ */
+ queue_signals();
+
+ pj = thisjob;
+ ipipe[0] = ipipe[1] = opipe[0] = opipe[1] = 0;
+ child_block();
+
+ /*
+ * Get free entry in job table and initialize it. This is currently
+ * the only call to initjob() (apart from a minor exception in
+ * clearjobtab()), so this is also the only place where we can
+ * expand the job table under us.
+ */
+ if ((thisjob = newjob = initjob()) == -1) {
+ child_unblock();
+ unqueue_signals();
+ return 1;
+ }
+ if (how & Z_TIMED)
+ jobtab[thisjob].stat |= STAT_TIMED;
+
+ if (slflags & WC_SUBLIST_COPROC) {
+ how = Z_ASYNC;
+ if (coprocin >= 0) {
+ zclose(coprocin);
+ zclose(coprocout);
+ }
+ if (mpipe(ipipe) < 0) {
+ coprocin = coprocout = -1;
+ slflags &= ~WC_SUBLIST_COPROC;
+ } else if (mpipe(opipe) < 0) {
+ close(ipipe[0]);
+ close(ipipe[1]);
+ coprocin = coprocout = -1;
+ slflags &= ~WC_SUBLIST_COPROC;
+ } else {
+ coprocin = ipipe[0];
+ coprocout = opipe[1];
+ fdtable[coprocin] = fdtable[coprocout] = FDT_UNUSED;
+ }
+ }
+ /* This used to set list_pipe_pid=0 unconditionally, but in things
+ * like `ls|if true; then sleep 20; cat; fi' where the sleep was
+ * stopped, the top-level execpline() didn't get the pid for the
+ * sub-shell because it was overwritten. */
+ if (!pline_level++) {
+ list_pipe_pid = 0;
+ nowait = 0;
+ simple_pline = (WC_PIPE_TYPE(code) == WC_PIPE_END);
+ list_pipe_job = newjob;
+ }
+ lastwj = lpforked = 0;
+ execpline2(state, code, how, opipe[0], ipipe[1], last1);
+ pline_level--;
+ if (how & Z_ASYNC) {
+ lastwj = newjob;
+
+ if (thisjob == list_pipe_job)
+ list_pipe_job = 0;
+ jobtab[thisjob].stat |= STAT_NOSTTY;
+ if (slflags & WC_SUBLIST_COPROC) {
+ zclose(ipipe[1]);
+ zclose(opipe[0]);
+ }
+ if (how & Z_DISOWN) {
+ pipecleanfilelist(jobtab[thisjob].filelist, 0);
+ deletejob(jobtab + thisjob, 1);
+ thisjob = -1;
+ }
+ else
+ spawnjob();
+ child_unblock();
+ unqueue_signals();
+ /* Executing background code resets shell status */
+ return lastval = 0;
+ } else {
+ if (newjob != lastwj) {
+ Job jn = jobtab + newjob;
+ int updated;
+
+ if (newjob == list_pipe_job && list_pipe_child)
+ _exit(0);
+
+ lastwj = thisjob = newjob;
+
+ if (list_pipe || (pline_level && !(how & Z_TIMED)))
+ jn->stat |= STAT_NOPRINT;
+
+ if (nowait) {
+ if(!pline_level) {
+ int jobsub;
+ struct process *pn, *qn;
+
+ curjob = newjob;
+ DPUTS(!list_pipe_pid, "invalid list_pipe_pid");
+ addproc(list_pipe_pid, list_pipe_text, 0,
+ &list_pipe_start);
+
+ /* If the super-job contains only the sub-shell, the
+ sub-shell is the group leader. */
+ if (!jn->procs->next || lpforked == 2) {
+ jn->gleader = list_pipe_pid;
+ jn->stat |= STAT_SUBLEADER;
+ /*
+ * Pick up any subjob that's still lying around
+ * as it's now our responsibility.
+ * If we find it we're a SUPERJOB.
+ */
+ for (jobsub = 1; jobsub <= maxjob; jobsub++) {
+ Job jnsub = jobtab + jobsub;
+ if (jnsub->stat & STAT_SUBJOB_ORPHANED) {
+ jn->other = jobsub;
+ jn->stat |= STAT_SUPERJOB;
+ jnsub->stat &= ~STAT_SUBJOB_ORPHANED;
+ jnsub->other = list_pipe_pid;
+ }
+ }
+ }
+ for (pn = jobtab[jn->other].procs; pn; pn = pn->next)
+ if (WIFSTOPPED(pn->status))
+ break;
+
+ if (pn) {
+ for (qn = jn->procs; qn->next; qn = qn->next);
+ qn->status = pn->status;
+ }
+
+ jn->stat &= ~(STAT_DONE | STAT_NOPRINT);
+ jn->stat |= STAT_STOPPED | STAT_CHANGED | STAT_LOCKED |
+ STAT_INUSE;
+ printjob(jn, !!isset(LONGLISTJOBS), 1);
+ }
+ else if (newjob != list_pipe_job)
+ deletejob(jn, 0);
+ else
+ lastwj = -1;
+ }
+
+ errbrk_saved = 0;
+ for (; !nowait;) {
+ if (list_pipe_child) {
+ jn->stat |= STAT_NOPRINT;
+ makerunning(jn);
+ }
+ if (!(jn->stat & STAT_LOCKED)) {
+ updated = hasprocs(thisjob);
+ waitjobs(); /* deals with signal queue */
+ child_block();
+ } else
+ updated = 0;
+ if (!updated &&
+ list_pipe_job && hasprocs(list_pipe_job) &&
+ !(jobtab[list_pipe_job].stat & STAT_STOPPED)) {
+ int q = queue_signal_level();
+ child_unblock();
+ child_block();
+ dont_queue_signals();
+ restore_queue_signals(q);
+ }
+ if (list_pipe_child &&
+ jn->stat & STAT_DONE &&
+ lastval2 & 0200)
+ killpg(mypgrp, lastval2 & ~0200);
+ if (!list_pipe_child && !lpforked && !subsh && jobbing &&
+ (list_pipe || last1 || pline_level) &&
+ ((jn->stat & STAT_STOPPED) ||
+ (list_pipe_job && pline_level &&
+ (jobtab[list_pipe_job].stat & STAT_STOPPED)))) {
+ pid_t pid = 0;
+ int synch[2];
+ struct timeval bgtime;
+
+ /*
+ * A pipeline with the shell handling the right
+ * hand side was stopped. We'll fork to allow
+ * it to continue.
+ */
+ if (pipe(synch) < 0 || (pid = zfork(&bgtime)) == -1) {
+ /* Failure */
+ if (pid < 0) {
+ close(synch[0]);
+ close(synch[1]);
+ } else
+ zerr("pipe failed: %e", errno);
+ zleentry(ZLE_CMD_TRASH);
+ fprintf(stderr, "zsh: job can't be suspended\n");
+ fflush(stderr);
+ makerunning(jn);
+ killjb(jn, SIGCONT);
+ thisjob = newjob;
+ }
+ else if (pid) {
+ /*
+ * Parent: job control is here. If the job
+ * started for the RHS of the pipeline is still
+ * around, then its a SUBJOB and the job for
+ * earlier parts of the pipeeline is its SUPERJOB.
+ * The newly forked shell isn't recorded as a
+ * separate job here, just as list_pipe_pid.
+ * If the superjob exits (it may already have
+ * done so, see child branch below), we'll use
+ * list_pipe_pid to form the basis of a
+ * replacement job --- see SUBLEADER code above.
+ */
+ char dummy;
+
+ lpforked =
+ (killpg(jobtab[list_pipe_job].gleader, 0) == -1 ? 2 : 1);
+ list_pipe_pid = pid;
+ list_pipe_start = bgtime;
+ nowait = 1;
+ errflag |= ERRFLAG_ERROR;
+ breaks = loops;
+ close(synch[1]);
+ read_loop(synch[0], &dummy, 1);
+ close(synch[0]);
+ /* If this job has finished, we leave it as a
+ * normal (non-super-) job. */
+ if (!(jn->stat & STAT_DONE)) {
+ jobtab[list_pipe_job].other = newjob;
+ jobtab[list_pipe_job].stat |= STAT_SUPERJOB;
+ jn->stat |= STAT_SUBJOB | STAT_NOPRINT;
+ jn->other = list_pipe_pid; /* see zsh.h */
+ if (hasprocs(list_pipe_job))
+ jn->gleader = jobtab[list_pipe_job].gleader;
+ }
+ if ((list_pipe || last1) && hasprocs(list_pipe_job))
+ killpg(jobtab[list_pipe_job].gleader, SIGSTOP);
+ break;
+ }
+ else {
+ close(synch[0]);
+ entersubsh(ESUB_ASYNC);
+ /*
+ * At this point, we used to attach this process
+ * to the process group of list_pipe_job (the
+ * new superjob) any time that was still available.
+ * That caused problems in at least two
+ * cases because this forked shell was then
+ * suspended with the right hand side of the
+ * pipeline, and the SIGSTOP below suspended
+ * it a second time when it was continued.
+ *
+ * It's therefore not clear entirely why you'd ever
+ * do anything other than the following, but no
+ * doubt we'll find out...
+ */
+ setpgrp(0L, mypgrp = getpid());
+ close(synch[1]);
+ kill(getpid(), SIGSTOP);
+ list_pipe = 0;
+ list_pipe_child = 1;
+ opts[INTERACTIVE] = 0;
+ if (errbrk_saved) {
+ /*
+ * Keep any user interrupt bit in errflag.
+ */
+ errflag = prev_errflag | (errflag & ERRFLAG_INT);
+ breaks = prev_breaks;
+ }
+ break;
+ }
+ }
+ else if (subsh && jn->stat & STAT_STOPPED)
+ thisjob = newjob;
+ else
+ break;
+ }
+ child_unblock();
+ unqueue_signals();
+
+ if (list_pipe && (lastval & 0200) && pj >= 0 &&
+ (!(jn->stat & STAT_INUSE) || (jn->stat & STAT_DONE))) {
+ deletejob(jn, 0);
+ jn = jobtab + pj;
+ if (jn->gleader)
+ killjb(jn, lastval & ~0200);
+ }
+ if (list_pipe_child ||
+ ((jn->stat & STAT_DONE) &&
+ (list_pipe || (pline_level && !(jn->stat & STAT_SUBJOB)))))
+ deletejob(jn, 0);
+ thisjob = pj;
+ }
+ else
+ unqueue_signals();
+ if ((slflags & WC_SUBLIST_NOT) && !errflag)
+ lastval = !lastval;
+ }
+ if (!pline_level)
+ simple_pline = old_simple_pline;
+ return lastval;
+}
+
+/* execute pipeline. This function assumes the `pline' is not NULL. */
+
+/**/
+static void
+execpline2(Estate state, wordcode pcode,
+ int how, int input, int output, int last1)
+{
+ struct execcmd_params eparams;
+
+ if (breaks || retflag)
+ return;
+
+ /* In evaluated traps, don't modify the line number. */
+ if (!IN_EVAL_TRAP() && !ineval && WC_PIPE_LINENO(pcode))
+ lineno = WC_PIPE_LINENO(pcode) - 1;
+
+ if (pline_level == 1) {
+ if ((how & Z_ASYNC) || !sfcontext)
+ strcpy(list_pipe_text,
+ getjobtext(state->prog,
+ state->pc + (WC_PIPE_TYPE(pcode) == WC_PIPE_END ?
+ 0 : 1)));
+ else
+ list_pipe_text[0] = '\0';
+ }
+ if (WC_PIPE_TYPE(pcode) == WC_PIPE_END) {
+ execcmd_analyse(state, &eparams);
+ execcmd_exec(state, &eparams, input, output, how, last1 ? 1 : 2, -1);
+ } else {
+ int pipes[2];
+ int old_list_pipe = list_pipe;
+ Wordcode next = state->pc + (*state->pc);
+
+ ++state->pc;
+ execcmd_analyse(state, &eparams);
+
+ if (mpipe(pipes) < 0) {
+ /* FIXME */
+ }
+
+ addfilelist(NULL, pipes[0]);
+ execcmd_exec(state, &eparams, input, pipes[1], how, 0, pipes[0]);
+ zclose(pipes[1]);
+ state->pc = next;
+
+ /* if another execpline() is invoked because the command is *
+ * a list it must know that we're already in a pipeline */
+ cmdpush(CS_PIPE);
+ list_pipe = 1;
+ execpline2(state, *state->pc++, how, pipes[0], output, last1);
+ list_pipe = old_list_pipe;
+ cmdpop();
+ }
+}
+
+/* make the argv array */
+
+/**/
+static char **
+makecline(LinkList list)
+{
+ LinkNode node;
+ char **argv, **ptr;
+
+ /* A bigger argv is necessary for executing scripts */
+ ptr = argv = 2 + (char **) hcalloc((countlinknodes(list) + 4) *
+ sizeof(char *));
+
+ if (isset(XTRACE)) {
+ if (!doneps4)
+ printprompt4();
+
+ for (node = firstnode(list); node; incnode(node)) {
+ *ptr++ = (char *)getdata(node);
+ quotedzputs(getdata(node), xtrerr);
+ if (nextnode(node))
+ fputc(' ', xtrerr);
+ }
+ fputc('\n', xtrerr);
+ fflush(xtrerr);
+ } else {
+ for (node = firstnode(list); node; incnode(node))
+ *ptr++ = (char *)getdata(node);
+ }
+ *ptr = NULL;
+ return (argv);
+}
+
+/**/
+mod_export void
+untokenize(char *s)
+{
+ if (*s) {
+ int c;
+
+ while ((c = *s++))
+ if (itok(c)) {
+ char *p = s - 1;
+
+ if (c != Nularg)
+ *p++ = ztokens[c - Pound];
+
+ while ((c = *s++)) {
+ if (itok(c)) {
+ if (c != Nularg)
+ *p++ = ztokens[c - Pound];
+ } else
+ *p++ = c;
+ }
+ *p = '\0';
+ break;
+ }
+ }
+}
+
+
+/*
+ * Given a tokenized string, output it to standard output in
+ * such a way that it's clear which tokens are active.
+ * Hence Star becomes an unquoted "*", while a "*" becomes "\*".
+ *
+ * The code here is a kind of amalgamation of the tests in
+ * zshtokenize() and untokenize() with some outputting.
+ */
+
+/**/
+void
+quote_tokenized_output(char *str, FILE *file)
+{
+ char *s = str;
+
+ for (; *s; s++) {
+ switch (*s) {
+ case Meta:
+ putc(*++s ^ 32, file);
+ continue;
+
+ case Nularg:
+ /* Do nothing. I think. */
+ continue;
+
+ case '\\':
+ case '<':
+ case '>':
+ case '(':
+ case '|':
+ case ')':
+ case '^':
+ case '#':
+ case '~':
+ case '[':
+ case ']':
+ case '*':
+ case '?':
+ case '$':
+ case ' ':
+ putc('\\', file);
+ break;
+
+ case '\t':
+ fputs("$'\\t'", file);
+ continue;
+
+ case '\n':
+ fputs("$'\\n'", file);
+ continue;
+
+ case '\r':
+ fputs("$'\\r'", file);
+ continue;
+
+ case '=':
+ if (s == str)
+ putc('\\', file);
+ break;
+
+ default:
+ if (itok(*s)) {
+ putc(ztokens[*s - Pound], file);
+ continue;
+ }
+ break;
+ }
+
+ putc(*s, file);
+ }
+}
+
+/* Check that we can use a parameter for allocating a file descriptor. */
+
+static int
+checkclobberparam(struct redir *f)
+{
+ struct value vbuf;
+ Value v;
+ char *s = f->varid;
+ int fd;
+
+ if (!s)
+ return 1;
+
+ if (!(v = getvalue(&vbuf, &s, 0)))
+ return 1;
+
+ if (v->pm->node.flags & PM_READONLY) {
+ zwarn("can't allocate file descriptor to readonly parameter %s",
+ f->varid);
+ /* don't flag a system error for this */
+ errno = 0;
+ return 0;
+ }
+
+ /*
+ * We can't clobber the value in the parameter if it's
+ * already an opened file descriptor --- that means it's a decimal
+ * integer corresponding to an opened file descriptor,
+ * not merely an expression that evaluates to a file descriptor.
+ */
+ if (!isset(CLOBBER) && (s = getstrvalue(v)) &&
+ (fd = (int)zstrtol(s, &s, 10)) >= 0 && !*s &&
+ fd <= max_zsh_fd && fdtable[fd] == FDT_EXTERNAL) {
+ zwarn("can't clobber parameter %s containing file descriptor %d",
+ f->varid, fd);
+ /* don't flag a system error for this */
+ errno = 0;
+ return 0;
+ }
+ return 1;
+}
+
+/* Open a file for writing redirection */
+
+/**/
+static int
+clobber_open(struct redir *f)
+{
+ struct stat buf;
+ int fd, oerrno;
+
+ /* If clobbering, just open. */
+ if (isset(CLOBBER) || IS_CLOBBER_REDIR(f->type))
+ return open(unmeta(f->name),
+ O_WRONLY | O_CREAT | O_TRUNC | O_NOCTTY, 0666);
+
+ /* If not clobbering, attempt to create file exclusively. */
+ if ((fd = open(unmeta(f->name),
+ O_WRONLY | O_CREAT | O_EXCL | O_NOCTTY, 0666)) >= 0)
+ return fd;
+
+ /* If that fails, we are still allowed to open non-regular files. *
+ * Try opening, and if it's a regular file then close it again *
+ * because we weren't supposed to open it. */
+ oerrno = errno;
+ if ((fd = open(unmeta(f->name), O_WRONLY | O_NOCTTY)) != -1) {
+ if(!fstat(fd, &buf) && !S_ISREG(buf.st_mode))
+ return fd;
+ close(fd);
+ }
+ errno = oerrno;
+ return -1;
+}
+
+/* size of buffer for tee and cat processes */
+#define TCBUFSIZE 4092
+
+/* close an multio (success) */
+
+/**/
+static void
+closemn(struct multio **mfds, int fd, int type)
+{
+ if (fd >= 0 && mfds[fd] && mfds[fd]->ct >= 2) {
+ struct multio *mn = mfds[fd];
+ char buf[TCBUFSIZE];
+ int len, i;
+ pid_t pid;
+ struct timeval bgtime;
+
+ /*
+ * We need to block SIGCHLD in case the process
+ * we are spawning terminates before the job table
+ * is set up to handle it.
+ */
+ child_block();
+ if ((pid = zfork(&bgtime))) {
+ for (i = 0; i < mn->ct; i++)
+ zclose(mn->fds[i]);
+ zclose(mn->pipe);
+ if (pid == -1) {
+ mfds[fd] = NULL;
+ child_unblock();
+ return;
+ }
+ mn->ct = 1;
+ mn->fds[0] = fd;
+ addproc(pid, NULL, 1, &bgtime);
+ child_unblock();
+ return;
+ }
+ /* pid == 0 */
+ child_unblock();
+ closeallelse(mn);
+ if (mn->rflag) {
+ /* tee process */
+ while ((len = read(mn->pipe, buf, TCBUFSIZE)) != 0) {
+ if (len < 0) {
+ if (errno == EINTR)
+ continue;
+ else
+ break;
+ }
+ for (i = 0; i < mn->ct; i++)
+ write_loop(mn->fds[i], buf, len);
+ }
+ } else {
+ /* cat process */
+ for (i = 0; i < mn->ct; i++)
+ while ((len = read(mn->fds[i], buf, TCBUFSIZE)) != 0) {
+ if (len < 0) {
+ if (errno == EINTR)
+ continue;
+ else
+ break;
+ }
+ write_loop(mn->pipe, buf, len);
+ }
+ }
+ _exit(0);
+ } else if (fd >= 0 && type == REDIR_CLOSE)
+ mfds[fd] = NULL;
+}
+
+/* close all the mnodes (failure) */
+
+/**/
+static void
+closemnodes(struct multio **mfds)
+{
+ int i, j;
+
+ for (i = 0; i < 10; i++)
+ if (mfds[i]) {
+ for (j = 0; j < mfds[i]->ct; j++)
+ zclose(mfds[i]->fds[j]);
+ mfds[i] = NULL;
+ }
+}
+
+/**/
+static void
+closeallelse(struct multio *mn)
+{
+ int i, j;
+ long openmax;
+
+ openmax = fdtable_size;
+
+ for (i = 0; i < openmax; i++)
+ if (mn->pipe != i) {
+ for (j = 0; j < mn->ct; j++)
+ if (mn->fds[j] == i)
+ break;
+ if (j == mn->ct)
+ zclose(i);
+ }
+}
+
+/*
+ * A multio is a list of fds associated with a certain fd.
+ * Thus if you do "foo >bar >ble", the multio for fd 1 will have
+ * two fds, the result of open("bar",...), and the result of
+ * open("ble",....).
+ */
+
+/*
+ * Add a fd to an multio. fd1 must be < 10, and may be in any state.
+ * fd2 must be open, and is `consumed' by this function. Note that
+ * fd1 == fd2 is possible, and indicates that fd1 was really closed.
+ * We effectively do `fd2 = movefd(fd2)' at the beginning of this
+ * function, but in most cases we can avoid an extra dup by delaying
+ * the movefd: we only >need< to move it if we're actually doing a
+ * multiple redirection.
+ *
+ * If varid is not NULL, we open an fd above 10 and set the parameter
+ * named varid to that value. fd1 is not used.
+ */
+
+/**/
+static void
+addfd(int forked, int *save, struct multio **mfds, int fd1, int fd2, int rflag,
+ char *varid)
+{
+ int pipes[2];
+
+ if (varid) {
+ /* fd will be over 10, don't touch mfds */
+ fd1 = movefd(fd2);
+ if (fd1 == -1) {
+ zerr("cannot moved fd %d: %e", fd2, errno);
+ return;
+ } else {
+ fdtable[fd1] = FDT_EXTERNAL;
+ setiparam(varid, (zlong)fd1);
+ /*
+ * If setting the parameter failed, close the fd else
+ * it will leak.
+ */
+ if (errflag)
+ zclose(fd1);
+ }
+ } else if (!mfds[fd1] || unset(MULTIOS)) {
+ if(!mfds[fd1]) { /* starting a new multio */
+ mfds[fd1] = (struct multio *) zhalloc(sizeof(struct multio));
+ if (!forked && save[fd1] == -2) {
+ if (fd1 == fd2)
+ save[fd1] = -1;
+ else {
+ int fdN = movefd(fd1);
+ /*
+ * fd1 may already be closed here, so
+ * ignore bad file descriptor error
+ */
+ if (fdN < 0) {
+ if (errno != EBADF) {
+ zerr("cannot duplicate fd %d: %e", fd1, errno);
+ mfds[fd1] = NULL;
+ closemnodes(mfds);
+ return;
+ }
+ } else {
+ DPUTS(fdtable[fdN] != FDT_INTERNAL,
+ "Saved file descriptor not marked as internal");
+ fdtable[fdN] |= FDT_SAVED_MASK;
+ }
+ save[fd1] = fdN;
+ }
+ }
+ }
+ if (!varid)
+ redup(fd2, fd1);
+ mfds[fd1]->ct = 1;
+ mfds[fd1]->fds[0] = fd1;
+ mfds[fd1]->rflag = rflag;
+ } else {
+ if (mfds[fd1]->rflag != rflag) {
+ zerr("file mode mismatch on fd %d", fd1);
+ closemnodes(mfds);
+ return;
+ }
+ if (mfds[fd1]->ct == 1) { /* split the stream */
+ int fdN = movefd(fd1);
+ if (fdN < 0) {
+ zerr("multio failed for fd %d: %e", fd1, errno);
+ closemnodes(mfds);
+ return;
+ }
+ mfds[fd1]->fds[0] = fdN;
+ fdN = movefd(fd2);
+ if (fdN < 0) {
+ zerr("multio failed for fd %d: %e", fd2, errno);
+ closemnodes(mfds);
+ return;
+ }
+ mfds[fd1]->fds[1] = fdN;
+ if (mpipe(pipes) < 0) {
+ zerr("multio failed for fd %d: %e", fd2, errno);
+ closemnodes(mfds);
+ return;
+ }
+ mfds[fd1]->pipe = pipes[1 - rflag];
+ redup(pipes[rflag], fd1);
+ mfds[fd1]->ct = 2;
+ } else { /* add another fd to an already split stream */
+ int fdN;
+ if(!(mfds[fd1]->ct % MULTIOUNIT)) {
+ int new = sizeof(struct multio) + sizeof(int) * mfds[fd1]->ct;
+ int old = new - sizeof(int) * MULTIOUNIT;
+ mfds[fd1] = hrealloc((char *)mfds[fd1], old, new);
+ }
+ if ((fdN = movefd(fd2)) < 0) {
+ zerr("multio failed for fd %d: %e", fd2, errno);
+ closemnodes(mfds);
+ return;
+ }
+ mfds[fd1]->fds[mfds[fd1]->ct++] = fdN;
+ }
+ }
+}
+
+/**/
+static void
+addvars(Estate state, Wordcode pc, int addflags)
+{
+ LinkList vl;
+ int xtr, isstr, htok = 0;
+ char **arr, **ptr, *name;
+ int flags;
+
+ Wordcode opc = state->pc;
+ wordcode ac;
+ local_list1(svl);
+
+ /*
+ * Warn when creating a global without using typeset -g in a
+ * function. Don't do this if there is a list of variables marked
+ * to be restored after the command, since then the assignment
+ * is implicitly scoped.
+ */
+ flags = !(addflags & ADDVAR_RESTORE) ? ASSPM_WARN : 0;
+ xtr = isset(XTRACE);
+ if (xtr) {
+ printprompt4();
+ doneps4 = 1;
+ }
+ state->pc = pc;
+ while (wc_code(ac = *state->pc++) == WC_ASSIGN) {
+ int myflags = flags;
+ name = ecgetstr(state, EC_DUPTOK, &htok);
+ if (htok)
+ untokenize(name);
+ if (WC_ASSIGN_TYPE2(ac) == WC_ASSIGN_INC)
+ myflags |= ASSPM_AUGMENT;
+ if (xtr)
+ fprintf(xtrerr,
+ WC_ASSIGN_TYPE2(ac) == WC_ASSIGN_INC ? "%s+=" : "%s=", name);
+ if ((isstr = (WC_ASSIGN_TYPE(ac) == WC_ASSIGN_SCALAR))) {
+ init_list1(svl, ecgetstr(state, EC_DUPTOK, &htok));
+ vl = &svl;
+ } else {
+ vl = ecgetlist(state, WC_ASSIGN_NUM(ac), EC_DUPTOK, &htok);
+ if (errflag) {
+ state->pc = opc;
+ return;
+ }
+ }
+
+ if (vl && htok) {
+ int prefork_ret = 0;
+ prefork(vl, (isstr ? (PREFORK_SINGLE|PREFORK_ASSIGN) :
+ PREFORK_ASSIGN), &prefork_ret);
+ if (errflag) {
+ state->pc = opc;
+ return;
+ }
+ if (prefork_ret & PREFORK_KEY_VALUE)
+ myflags |= ASSPM_KEY_VALUE;
+ if (!isstr || (isset(GLOBASSIGN) && isstr &&
+ haswilds((char *)getdata(firstnode(vl))))) {
+ globlist(vl, prefork_ret);
+ /* Unset the parameter to force it to be recreated
+ * as either scalar or array depending on how many
+ * matches were found for the glob.
+ */
+ if (isset(GLOBASSIGN) && isstr)
+ unsetparam(name);
+ if (errflag) {
+ state->pc = opc;
+ return;
+ }
+ }
+ }
+ if (isstr && (empty(vl) || !nextnode(firstnode(vl)))) {
+ Param pm;
+ char *val;
+ int allexp;
+
+ if (empty(vl))
+ val = ztrdup("");
+ else {
+ untokenize(peekfirst(vl));
+ val = ztrdup(ugetnode(vl));
+ }
+ if (xtr) {
+ quotedzputs(val, xtrerr);
+ fputc(' ', xtrerr);
+ }
+ if ((addflags & ADDVAR_EXPORT) && !strchr(name, '[')) {
+ if ((addflags & ADDVAR_RESTRICT) && isset(RESTRICTED) &&
+ (pm = (Param) paramtab->removenode(paramtab, name)) &&
+ (pm->node.flags & PM_RESTRICTED)) {
+ zerr("%s: restricted", pm->node.nam);
+ zsfree(val);
+ state->pc = opc;
+ return;
+ }
+ if (strcmp(name, "STTY") == 0) {
+ zsfree(STTYval);
+ STTYval = ztrdup(val);
+ }
+ allexp = opts[ALLEXPORT];
+ opts[ALLEXPORT] = 1;
+ if (isset(KSHARRAYS))
+ unsetparam(name);
+ pm = assignsparam(name, val, myflags);
+ opts[ALLEXPORT] = allexp;
+ } else
+ pm = assignsparam(name, val, myflags);
+ if (errflag) {
+ state->pc = opc;
+ return;
+ }
+ continue;
+ }
+ if (vl) {
+ ptr = arr = (char **) zalloc(sizeof(char *) *
+ (countlinknodes(vl) + 1));
+
+ while (nonempty(vl))
+ *ptr++ = ztrdup((char *) ugetnode(vl));
+ } else
+ ptr = arr = (char **) zalloc(sizeof(char *));
+
+ *ptr = NULL;
+ if (xtr) {
+ fprintf(xtrerr, "( ");
+ for (ptr = arr; *ptr; ptr++) {
+ quotedzputs(*ptr, xtrerr);
+ fputc(' ', xtrerr);
+ }
+ fprintf(xtrerr, ") ");
+ }
+ assignaparam(name, arr, myflags);
+ if (errflag) {
+ state->pc = opc;
+ return;
+ }
+ }
+ state->pc = opc;
+}
+
+/**/
+void
+setunderscore(char *str)
+{
+ queue_signals();
+ if (str && *str) {
+ int l = strlen(str) + 1, nl = (l + 31) & ~31;
+
+ if (nl > underscorelen || (underscorelen - nl) > 64) {
+ zfree(zunderscore, underscorelen);
+ zunderscore = (char *) zalloc(underscorelen = nl);
+ }
+ strcpy(zunderscore, str);
+ underscoreused = l;
+ } else {
+ if (underscorelen > 128) {
+ zfree(zunderscore, underscorelen);
+ zunderscore = (char *) zalloc(underscorelen = 32);
+ }
+ *zunderscore = '\0';
+ underscoreused = 1;
+ }
+ unqueue_signals();
+}
+
+/* These describe the type of expansions that need to be done on the words
+ * used in the thing we are about to execute. They are set in execcmd() and
+ * used in execsubst() which might be called from one of the functions
+ * called from execcmd() (like execfor() and so on). */
+
+static int esprefork, esglob = 1;
+
+/**/
+void
+execsubst(LinkList strs)
+{
+ if (strs) {
+ prefork(strs, esprefork, NULL);
+ if (esglob && !errflag) {
+ LinkList ostrs = strs;
+ globlist(strs, 0);
+ strs = ostrs;
+ }
+ }
+}
+
+/*
+ * Check if a builtin requires an autoload and if so
+ * deal with it. This may return NULL.
+ */
+
+/**/
+static HashNode
+resolvebuiltin(const char *cmdarg, HashNode hn)
+{
+ if (!((Builtin) hn)->handlerfunc) {
+ char *modname = dupstring(((Builtin) hn)->optstr);
+ /*
+ * Ensure the module is loaded and the
+ * feature corresponding to the builtin
+ * is enabled.
+ */
+ (void)ensurefeature(modname, "b:",
+ (hn->flags & BINF_AUTOALL) ? NULL :
+ hn->nam);
+ hn = builtintab->getnode(builtintab, cmdarg);
+ if (!hn) {
+ lastval = 1;
+ zerr("autoloading module %s failed to define builtin: %s",
+ modname, cmdarg);
+ return NULL;
+ }
+ }
+ return hn;
+}
+
+/*
+ * We are about to execute a command at the lowest level of the
+ * hierarchy. Analyse the parameters from the wordcode.
+ */
+
+/**/
+static void
+execcmd_analyse(Estate state, Execcmd_params eparams)
+{
+ wordcode code;
+ int i;
+
+ eparams->beg = state->pc;
+ eparams->redir =
+ (wc_code(*state->pc) == WC_REDIR ? ecgetredirs(state) : NULL);
+ if (wc_code(*state->pc) == WC_ASSIGN) {
+ cmdoutval = 0;
+ eparams->varspc = state->pc;
+ while (wc_code((code = *state->pc)) == WC_ASSIGN)
+ state->pc += (WC_ASSIGN_TYPE(code) == WC_ASSIGN_SCALAR ?
+ 3 : WC_ASSIGN_NUM(code) + 2);
+ } else
+ eparams->varspc = NULL;
+
+ code = *state->pc++;
+
+ eparams->type = wc_code(code);
+ eparams->postassigns = 0;
+
+ /* It would be nice if we could use EC_DUPTOK instead of EC_DUP here.
+ * But for that we would need to check/change all builtins so that
+ * they don't modify their argument strings. */
+ switch (eparams->type) {
+ case WC_SIMPLE:
+ eparams->args = ecgetlist(state, WC_SIMPLE_ARGC(code), EC_DUP,
+ &eparams->htok);
+ eparams->assignspc = NULL;
+ break;
+
+ case WC_TYPESET:
+ eparams->args = ecgetlist(state, WC_TYPESET_ARGC(code), EC_DUP,
+ &eparams->htok);
+ eparams->postassigns = *state->pc++;
+ eparams->assignspc = state->pc;
+ for (i = 0; i < eparams->postassigns; i++) {
+ code = *state->pc;
+ DPUTS(wc_code(code) != WC_ASSIGN,
+ "BUG: miscounted typeset assignments");
+ state->pc += (WC_ASSIGN_TYPE(code) == WC_ASSIGN_SCALAR ?
+ 3 : WC_ASSIGN_NUM(code) + 2);
+ }
+ break;
+
+ default:
+ eparams->args = NULL;
+ eparams->assignspc = NULL;
+ eparams->htok = 0;
+ break;
+ }
+}
+
+/*
+ * Transfer the first node of args to preargs, performing
+ * prefork expansion on the way if necessary.
+ */
+static void execcmd_getargs(LinkList preargs, LinkList args, int expand)
+{
+ if (!firstnode(args)) {
+ return;
+ } else if (expand) {
+ local_list0(svl);
+ init_list0(svl);
+ /* not init_list1, as we need real nodes */
+ addlinknode(&svl, uremnode(args, firstnode(args)));
+ /* Analysing commands, so vanilla options to prefork */
+ prefork(&svl, 0, NULL);
+ joinlists(preargs, &svl);
+ } else {
+ addlinknode(preargs, uremnode(args, firstnode(args)));
+ }
+}
+
+/**/
+static int
+execcmd_fork(Estate state, int how, int type, Wordcode varspc,
+ LinkList *filelistp, char *text, int oautocont,
+ int close_if_forked)
+{
+ pid_t pid;
+ int synch[2], flags;
+ char dummy;
+ struct timeval bgtime;
+
+ child_block();
+
+ if (pipe(synch) < 0) {
+ zerr("pipe failed: %e", errno);
+ return -1;
+ } else if ((pid = zfork(&bgtime)) == -1) {
+ close(synch[0]);
+ close(synch[1]);
+ lastval = 1;
+ errflag |= ERRFLAG_ERROR;
+ return -1;
+ }
+ if (pid) {
+ close(synch[1]);
+ read_loop(synch[0], &dummy, 1);
+ close(synch[0]);
+ if (how & Z_ASYNC) {
+ lastpid = (zlong) pid;
+ } else if (!jobtab[thisjob].stty_in_env && varspc) {
+ /* search for STTY=... */
+ Wordcode p = varspc;
+ wordcode ac;
+
+ while (wc_code(ac = *p) == WC_ASSIGN) {
+ if (!strcmp(ecrawstr(state->prog, p + 1, NULL), "STTY")) {
+ jobtab[thisjob].stty_in_env = 1;
+ break;
+ }
+ p += (WC_ASSIGN_TYPE(ac) == WC_ASSIGN_SCALAR ?
+ 3 : WC_ASSIGN_NUM(ac) + 2);
+ }
+ }
+ addproc(pid, text, 0, &bgtime);
+ if (oautocont >= 0)
+ opts[AUTOCONTINUE] = oautocont;
+ pipecleanfilelist(jobtab[thisjob].filelist, 1);
+ return pid;
+ }
+
+ /* pid == 0 */
+ close(synch[0]);
+ flags = ((how & Z_ASYNC) ? ESUB_ASYNC : 0) | ESUB_PGRP;
+ if ((type != WC_SUBSH) && !(how & Z_ASYNC))
+ flags |= ESUB_KEEPTRAP;
+ if (type == WC_SUBSH && !(how & Z_ASYNC))
+ flags |= ESUB_JOB_CONTROL;
+ *filelistp = jobtab[thisjob].filelist;
+ entersubsh(flags);
+ close(synch[1]);
+ zclose(close_if_forked);
+
+ if (sigtrapped[SIGINT] & ZSIG_IGNORED)
+ holdintr();
+ /*
+ * EXIT traps shouldn't be called even if we forked to run
+ * shell code as this isn't the main shell.
+ */
+ sigtrapped[SIGEXIT] = 0;
+#ifdef HAVE_NICE
+ /* Check if we should run background jobs at a lower priority. */
+ if ((how & Z_ASYNC) && isset(BGNICE))
+ if (nice(5) < 0)
+ zwarn("nice(5) failed: %e", errno);
+#endif /* HAVE_NICE */
+
+ return 0;
+}
+
+/*
+ * Execute a command at the lowest level of the hierarchy.
+ */
+
+/**/
+static void
+execcmd_exec(Estate state, Execcmd_params eparams,
+ int input, int output, int how, int last1, int close_if_forked)
+{
+ HashNode hn = NULL;
+ LinkList filelist = NULL;
+ LinkNode node;
+ Redir fn;
+ struct multio *mfds[10];
+ char *text;
+ int save[10];
+ int fil, dfil, is_cursh, do_exec = 0, redir_err = 0, i;
+ int nullexec = 0, magic_assign = 0, forked = 0, old_lastval;
+ int is_shfunc = 0, is_builtin = 0, is_exec = 0, use_defpath = 0;
+ /* Various flags to the command. */
+ int cflags = 0, orig_cflags = 0, checked = 0, oautocont = -1;
+ FILE *oxtrerr = xtrerr, *newxtrerr = NULL;
+ /*
+ * Retrieve parameters for quick reference (they are unique
+ * to us so we can modify the structure if we want).
+ */
+ LinkList args = eparams->args;
+ LinkList redir = eparams->redir;
+ Wordcode varspc = eparams->varspc;
+ int type = eparams->type;
+ /*
+ * preargs comes from expanding the head of the args list
+ * in order to check for prefix commands.
+ */
+ LinkList preargs;
+
+ doneps4 = 0;
+
+ /*
+ * If assignment but no command get the status from variable
+ * assignment.
+ */
+ old_lastval = lastval;
+ if (!args && varspc)
+ lastval = errflag ? errflag : cmdoutval;
+ /*
+ * If there are arguments, we should reset the status for the
+ * command before execution---unless we are using the result of a
+ * command substitution, which will be indicated by setting
+ * use_cmdoutval to 1. We haven't kicked those off yet, so
+ * there's no race.
+ */
+ use_cmdoutval = !args;
+
+ for (i = 0; i < 10; i++) {
+ save[i] = -2;
+ mfds[i] = NULL;
+ }
+
+ /* If the command begins with `%', then assume it is a *
+ * reference to a job in the job table. */
+ if ((type == WC_SIMPLE || type == WC_TYPESET) && args && nonempty(args) &&
+ *(char *)peekfirst(args) == '%') {
+ if (how & Z_DISOWN) {
+ oautocont = opts[AUTOCONTINUE];
+ opts[AUTOCONTINUE] = 1;
+ }
+ pushnode(args, dupstring((how & Z_DISOWN)
+ ? "disown" : (how & Z_ASYNC) ? "bg" : "fg"));
+ how = Z_SYNC;
+ }
+
+ /* If AUTORESUME is set, the command is SIMPLE, and doesn't have *
+ * any redirections, then check if it matches as a prefix of a *
+ * job currently in the job table. If it does, then we treat it *
+ * as a command to resume this job. */
+ if (isset(AUTORESUME) && type == WC_SIMPLE && (how & Z_SYNC) &&
+ args && nonempty(args) && (!redir || empty(redir)) && !input &&
+ !nextnode(firstnode(args))) {
+ if (unset(NOTIFY))
+ scanjobs();
+ if (findjobnam(peekfirst(args)) != -1)
+ pushnode(args, dupstring("fg"));
+ }
+
+ if ((how & Z_ASYNC) || output) {
+ /*
+ * If running in the background, or not the last command in a
+ * pipeline, we don't need any of the rest of this function to
+ * affect the state in the main shell, so fork immediately.
+ *
+ * In other cases we may need to process the command line
+ * a bit further before we make the decision.
+ */
+ text = getjobtext(state->prog, eparams->beg);
+ switch (execcmd_fork(state, how, type, varspc, &filelist,
+ text, oautocont, close_if_forked)) {
+ case -1:
+ goto fatal;
+ case 0:
+ break;
+ default:
+ return;
+ }
+ last1 = forked = 1;
+ } else
+ text = NULL;
+
+ /* Check if it's a builtin needing automatic MAGIC_EQUALS_SUBST *
+ * handling. Things like typeset need this. We can't detect the *
+ * command if it contains some tokens (e.g. x=ex; ${x}port), so this *
+ * only works in simple cases. has_token() is called to make sure *
+ * this really is a simple case. */
+ if ((type == WC_SIMPLE || type == WC_TYPESET) && args) {
+ /*
+ * preargs contains args that have been expanded by prefork.
+ * Running execcmd_getargs() causes any argument available
+ * in args to be exanded where necessary and transferred to
+ * preargs. We call execcmd_getargs() every time we need to
+ * analyse an argument not available in preargs, though there is
+ * no guarantee a further argument will be available.
+ */
+ preargs = newlinklist();
+ execcmd_getargs(preargs, args, eparams->htok);
+ while (nonempty(preargs)) {
+ char *cmdarg = (char *) peekfirst(preargs);
+ checked = !has_token(cmdarg);
+ if (!checked)
+ break;
+ if (type == WC_TYPESET &&
+ (hn = builtintab->getnode2(builtintab, cmdarg))) {
+ /*
+ * If reserved word for typeset command found (and so
+ * enabled), use regardless of whether builtin is
+ * enabled as we share the implementation.
+ *
+ * Reserved words take precedence over shell functions.
+ */
+ checked = 1;
+ } else if (isset(POSIXBUILTINS) && (cflags & BINF_EXEC)) {
+ /*
+ * POSIX doesn't allow "exec" to operate on builtins
+ * or shell functions.
+ */
+ break;
+ } else {
+ if (!(cflags & (BINF_BUILTIN | BINF_COMMAND)) &&
+ (hn = shfunctab->getnode(shfunctab, cmdarg))) {
+ is_shfunc = 1;
+ break;
+ }
+ if (!(hn = builtintab->getnode(builtintab, cmdarg))) {
+ checked = !(cflags & BINF_BUILTIN);
+ break;
+ }
+ }
+ orig_cflags |= cflags;
+ cflags &= ~BINF_BUILTIN & ~BINF_COMMAND;
+ cflags |= hn->flags;
+ if (!(hn->flags & BINF_PREFIX)) {
+ is_builtin = 1;
+
+ /* autoload the builtin if necessary */
+ if (!(hn = resolvebuiltin(cmdarg, hn))) {
+ if (forked)
+ _exit(lastval);
+ return;
+ }
+ if (type != WC_TYPESET)
+ magic_assign = (hn->flags & BINF_MAGICEQUALS);
+ break;
+ }
+ checked = 0;
+ /*
+ * We usually don't need the argument containing the
+ * precommand modifier itself. Exception: when "command"
+ * will implemented by a call to "whence", in which case
+ * we'll simply re-insert the argument.
+ */
+ uremnode(preargs, firstnode(preargs));
+ if (!firstnode(preargs)) {
+ execcmd_getargs(preargs, args, eparams->htok);
+ if (!firstnode(preargs))
+ break;
+ }
+ if ((cflags & BINF_COMMAND)) {
+ /*
+ * Check for options to "command".
+ * If just -p, this is handled here: use the default
+ * path to execute.
+ * If -v or -V, possibly with -p, dispatch to bin_whence
+ * but with flag to indicate special handling of -p.
+ * Otherwise, just leave marked as BINF_COMMAND
+ * modifier with no additional action.
+ */
+ LinkNode argnode, oldnode, pnode = NULL;
+ char *argdata, *cmdopt;
+ int has_p = 0, has_vV = 0, has_other = 0;
+ argnode = firstnode(preargs);
+ argdata = (char *) getdata(argnode);
+ while (IS_DASH(*argdata)) {
+ /* Just to be definite, stop on single "-", too, */
+ if (!argdata[1] ||
+ (IS_DASH(argdata[1]) && !argdata[2]))
+ break;
+ for (cmdopt = argdata+1; *cmdopt; cmdopt++) {
+ switch (*cmdopt) {
+ case 'p':
+ /*
+ * If we've got this multiple times (command
+ * -p -p) we'll treat the second -p as a
+ * command because we only remove one below.
+ * Don't think that's a big issue, and it's
+ * also traditional behaviour.
+ */
+ has_p = 1;
+ pnode = argnode;
+ break;
+ case 'v':
+ case 'V':
+ has_vV = 1;
+ break;
+ default:
+ has_other = 1;
+ break;
+ }
+ }
+ if (has_other) {
+ /* Don't know how to handle this, so don't */
+ has_p = has_vV = 0;
+ break;
+ }
+
+ oldnode = argnode;
+ argnode = nextnode(argnode);
+ if (!argnode) {
+ execcmd_getargs(preargs, args, eparams->htok);
+ if (!(argnode = nextnode(oldnode)))
+ break;
+ }
+ argdata = (char *) getdata(argnode);
+ }
+ if (has_vV) {
+ /*
+ * Leave everything alone, dispatch to whence.
+ * We need to put the name back in the list.
+ */
+ pushnode(preargs, "command");
+ hn = &commandbn.node;
+ is_builtin = 1;
+ break;
+ } else if (has_p) {
+ /* Use default path */
+ use_defpath = 1;
+ /*
+ * We don't need this node as we're not treating
+ * "command" as a builtin this time.
+ */
+ if (pnode)
+ uremnode(preargs, pnode);
+ }
+ /*
+ * Else just any trailing
+ * end-of-options marker. This can only occur
+ * if we just had -p or something including more
+ * than just -p, -v and -V, in which case we behave
+ * as if this is command [non-option-stuff]. This
+ * isn't a good place for standard option handling.
+ */
+ if (IS_DASH(argdata[0]) && IS_DASH(argdata[1]) && !argdata[2])
+ uremnode(preargs, argnode);
+ } else if (cflags & BINF_EXEC) {
+ /*
+ * Check for compatibility options to exec builtin.
+ * It would be nice to do these more generically,
+ * but currently we don't have a mechanism for
+ * precommand modifiers.
+ */
+ LinkNode argnode = firstnode(preargs), oldnode;
+ char *argdata = (char *) getdata(argnode);
+ char *cmdopt, *exec_argv0 = NULL;
+ /*
+ * Careful here: we want to make sure a final dash
+ * is passed through in order that it still behaves
+ * as a precommand modifier (zsh equivalent of -l).
+ * It has to be last, but I think that's OK since
+ * people aren't likely to mix the option style
+ * with the zsh style.
+ */
+ while (argdata && IS_DASH(*argdata) && strlen(argdata) >= 2) {
+ oldnode = argnode;
+ argnode = nextnode(oldnode);
+ if (!argnode) {
+ execcmd_getargs(preargs, args, eparams->htok);
+ argnode = nextnode(oldnode);
+ }
+ if (!argnode) {
+ zerr("exec requires a command to execute");
+ lastval = 1;
+ errflag |= ERRFLAG_ERROR;
+ goto done;
+ }
+ uremnode(preargs, oldnode);
+ if (IS_DASH(argdata[0]) && IS_DASH(argdata[1]) && !argdata[2])
+ break;
+ for (cmdopt = &argdata[1]; *cmdopt; ++cmdopt) {
+ switch (*cmdopt) {
+ case 'a':
+ /* argument is ARGV0 string */
+ if (cmdopt[1]) {
+ exec_argv0 = cmdopt+1;
+ /* position on last non-NULL character */
+ cmdopt += strlen(cmdopt+1);
+ } else {
+ if (!argnode) {
+ zerr("exec requires a command to execute");
+ lastval = 1;
+ errflag |= ERRFLAG_ERROR;
+ goto done;
+ }
+ if (!nextnode(argnode))
+ execcmd_getargs(preargs, args,
+ eparams->htok);
+ if (!nextnode(argnode)) {
+ zerr("exec flag -a requires a parameter");
+ lastval = 1;
+ errflag |= ERRFLAG_ERROR;
+ goto done;
+ }
+ exec_argv0 = (char *) getdata(argnode);
+ oldnode = argnode;
+ argnode = nextnode(argnode);
+ uremnode(args, oldnode);
+ }
+ break;
+ case 'c':
+ cflags |= BINF_CLEARENV;
+ break;
+ case 'l':
+ cflags |= BINF_DASH;
+ break;
+ default:
+ zerr("unknown exec flag -%c", *cmdopt);
+ lastval = 1;
+ errflag |= ERRFLAG_ERROR;
+ if (forked)
+ _exit(lastval);
+ return;
+ }
+ }
+ if (!argnode)
+ break;
+ argdata = (char *) getdata(argnode);
+ }
+ if (exec_argv0) {
+ char *str, *s;
+ exec_argv0 = dupstring(exec_argv0);
+ remnulargs(exec_argv0);
+ untokenize(exec_argv0);
+ size_t sz = strlen(exec_argv0);
+ str = s = zalloc(5 + 1 + sz + 1);
+ strcpy(s, "ARGV0=");
+ s+=6;
+ strcpy(s, exec_argv0);
+ zputenv(str);
+ }
+ }
+ hn = NULL;
+ if ((cflags & BINF_COMMAND) && unset(POSIXBUILTINS))
+ break;
+ if (!nonempty(preargs))
+ execcmd_getargs(preargs, args, eparams->htok);
+ }
+ } else
+ preargs = NULL;
+
+ /* if we get this far, it is OK to pay attention to lastval again */
+ if (noerrexit & NOERREXIT_UNTIL_EXEC)
+ noerrexit = 0;
+
+ /* Do prefork substitutions.
+ *
+ * Decide if we need "magic" handling of ~'s etc. in
+ * assignment-like arguments.
+ * - If magic_assign is set, we are using a builtin of the
+ * tyepset family, but did not recognise this as a keyword,
+ * so need guess-o-matic behaviour.
+ * - Otherwise, if we did recognise the keyword, we never need
+ * guess-o-matic behaviour as the argument was properly parsed
+ * as such.
+ * - Otherwise, use the behaviour specified by the MAGIC_EQUAL_SUBST
+ * option.
+ */
+ esprefork = (magic_assign ||
+ (isset(MAGICEQUALSUBST) && type != WC_TYPESET)) ?
+ PREFORK_TYPESET : 0;
+
+ if (args) {
+ if (eparams->htok)
+ prefork(args, esprefork, NULL);
+ if (preargs)
+ args = joinlists(preargs, args);
+ }
+
+ if (type == WC_SIMPLE || type == WC_TYPESET) {
+ int unglobbed = 0;
+
+ for (;;) {
+ char *cmdarg;
+
+ if (!(cflags & BINF_NOGLOB))
+ while (!checked && !errflag && args && nonempty(args) &&
+ has_token((char *) peekfirst(args)))
+ zglob(args, firstnode(args), 0);
+ else if (!unglobbed) {
+ for (node = firstnode(args); node; incnode(node))
+ untokenize((char *) getdata(node));
+ unglobbed = 1;
+ }
+
+ /* Current shell should not fork unless the *
+ * exec occurs at the end of a pipeline. */
+ if ((cflags & BINF_EXEC) && last1)
+ do_exec = 1;
+
+ /* Empty command */
+ if (!args || empty(args)) {
+ if (redir && nonempty(redir)) {
+ if (do_exec) {
+ /* Was this "exec < foobar"? */
+ nullexec = 1;
+ break;
+ } else if (varspc) {
+ nullexec = 2;
+ break;
+ } else if (!nullcmd || !*nullcmd || opts[CSHNULLCMD] ||
+ (cflags & BINF_PREFIX)) {
+ zerr("redirection with no command");
+ lastval = 1;
+ errflag |= ERRFLAG_ERROR;
+ if (forked)
+ _exit(lastval);
+ return;
+ } else if (!nullcmd || !*nullcmd || opts[SHNULLCMD]) {
+ if (!args)
+ args = newlinklist();
+ addlinknode(args, dupstring(":"));
+ } else if (readnullcmd && *readnullcmd &&
+ ((Redir) peekfirst(redir))->type == REDIR_READ &&
+ !nextnode(firstnode(redir))) {
+ if (!args)
+ args = newlinklist();
+ addlinknode(args, dupstring(readnullcmd));
+ } else {
+ if (!args)
+ args = newlinklist();
+ addlinknode(args, dupstring(nullcmd));
+ }
+ } else if ((cflags & BINF_PREFIX) && (cflags & BINF_COMMAND)) {
+ lastval = 0;
+ if (forked)
+ _exit(lastval);
+ return;
+ } else {
+ /*
+ * No arguments. Reset the status if there were
+ * arguments before and no command substitution
+ * has provided a status.
+ */
+ if (badcshglob == 1) {
+ zerr("no match");
+ lastval = 1;
+ if (forked)
+ _exit(lastval);
+ return;
+ }
+ cmdoutval = use_cmdoutval ? lastval : 0;
+ if (varspc) {
+ /* Make sure $? is still correct for assignment */
+ lastval = old_lastval;
+ addvars(state, varspc, 0);
+ }
+ if (errflag)
+ lastval = 1;
+ else
+ lastval = cmdoutval;
+ if (isset(XTRACE)) {
+ fputc('\n', xtrerr);
+ fflush(xtrerr);
+ }
+ if (forked)
+ _exit(lastval);
+ return;
+ }
+ } else if (isset(RESTRICTED) && (cflags & BINF_EXEC) && do_exec) {
+ zerrnam("exec", "%s: restricted",
+ (char *) getdata(firstnode(args)));
+ lastval = 1;
+ if (forked)
+ _exit(lastval);
+ return;
+ }
+
+ /*
+ * Quit looking for a command if:
+ * - there was an error; or
+ * - we checked the simple cases needing MAGIC_EQUAL_SUBST; or
+ * - we know we already found a builtin (because either:
+ * - we loaded a builtin from a module, or
+ * - we have determined there are options which would
+ * require us to use the "command" builtin); or
+ * - we aren't using POSIX and so BINF_COMMAND indicates a zsh
+ * precommand modifier is being used in place of the
+ * builtin
+ * - we are using POSIX and this is an EXEC, so we can't
+ * execute a builtin or function.
+ */
+ if (errflag || checked || is_builtin ||
+ (isset(POSIXBUILTINS) ?
+ (cflags & BINF_EXEC) : (cflags & BINF_COMMAND)))
+ break;
+
+ cmdarg = (char *) peekfirst(args);
+ if (!(cflags & (BINF_BUILTIN | BINF_COMMAND)) &&
+ (hn = shfunctab->getnode(shfunctab, cmdarg))) {
+ is_shfunc = 1;
+ break;
+ }
+ if (!(hn = builtintab->getnode(builtintab, cmdarg))) {
+ if (cflags & BINF_BUILTIN) {
+ zwarn("no such builtin: %s", cmdarg);
+ lastval = 1;
+ if (oautocont >= 0)
+ opts[AUTOCONTINUE] = oautocont;
+ if (forked)
+ _exit(lastval);
+ return;
+ }
+ break;
+ }
+ if (!(hn->flags & BINF_PREFIX)) {
+ is_builtin = 1;
+
+ /* autoload the builtin if necessary */
+ if (!(hn = resolvebuiltin(cmdarg, hn))) {
+ if (forked)
+ _exit(lastval);
+ return;
+ }
+ break;
+ }
+ cflags &= ~BINF_BUILTIN & ~BINF_COMMAND;
+ cflags |= hn->flags;
+ uremnode(args, firstnode(args));
+ hn = NULL;
+ }
+ }
+
+ if (errflag) {
+ if (!lastval)
+ lastval = 1;
+ if (oautocont >= 0)
+ opts[AUTOCONTINUE] = oautocont;
+ if (forked)
+ _exit(lastval);
+ return;
+ }
+
+ /* Get the text associated with this command. */
+ if (!text &&
+ (!sfcontext && (jobbing || (how & Z_TIMED))))
+ text = getjobtext(state->prog, eparams->beg);
+
+ /*
+ * Set up special parameter $_
+ * For execfuncdef we may need to take account of an
+ * anonymous function with arguments.
+ */
+ if (type != WC_FUNCDEF)
+ setunderscore((args && nonempty(args)) ?
+ ((char *) getdata(lastnode(args))) : "");
+
+ /* Warn about "rm *" */
+ if (type == WC_SIMPLE && interact && unset(RMSTARSILENT) &&
+ isset(SHINSTDIN) && args && nonempty(args) &&
+ nextnode(firstnode(args)) && !strcmp(peekfirst(args), "rm")) {
+ LinkNode node, next;
+
+ for (node = nextnode(firstnode(args)); node && !errflag; node = next) {
+ char *s = (char *) getdata(node);
+ int l = strlen(s);
+
+ next = nextnode(node);
+ if (s[0] == Star && !s[1]) {
+ if (!checkrmall(pwd)) {
+ errflag |= ERRFLAG_ERROR;
+ break;
+ }
+ } else if (l >= 2 && s[l - 2] == '/' && s[l - 1] == Star) {
+ char t = s[l - 2];
+ int rmall;
+
+ s[l - 2] = 0;
+ rmall = checkrmall(s);
+ s[l - 2] = t;
+
+ if (!rmall) {
+ errflag |= ERRFLAG_ERROR;
+ break;
+ }
+ }
+ }
+ }
+
+ if (type == WC_FUNCDEF) {
+ /*
+ * The first word of a function definition is a list of
+ * names. If this is empty, we're doing an anonymous function:
+ * in that case redirections are handled normally.
+ * If not, it's a function definition: then we don't do
+ * redirections here but pass in the list of redirections to
+ * be stored for recall with the function.
+ */
+ if (*state->pc != 0) {
+ /* Nonymous, don't do redirections here */
+ redir = NULL;
+ }
+ } else if (is_shfunc || type == WC_AUTOFN) {
+ Shfunc shf;
+ if (is_shfunc)
+ shf = (Shfunc)hn;
+ else {
+ shf = loadautofn(state->prog->shf, 1, 0, 0);
+ if (shf)
+ state->prog->shf = shf;
+ else {
+ /*
+ * This doesn't set errflag, so just return now.
+ */
+ lastval = 1;
+ if (oautocont >= 0)
+ opts[AUTOCONTINUE] = oautocont;
+ if (forked)
+ _exit(lastval);
+ return;
+ }
+ }
+ /*
+ * A function definition may have a list of additional
+ * redirections to apply, so retrieve it.
+ */
+ if (shf->redir) {
+ struct estate s;
+ LinkList redir2;
+
+ s.prog = shf->redir;
+ s.pc = shf->redir->prog;
+ s.strs = shf->redir->strs;
+ redir2 = ecgetredirs(&s);
+ if (!redir)
+ redir = redir2;
+ else {
+ while (nonempty(redir2))
+ addlinknode(redir, ugetnode(redir2));
+ }
+ }
+ }
+
+ if (errflag) {
+ lastval = 1;
+ if (oautocont >= 0)
+ opts[AUTOCONTINUE] = oautocont;
+ if (forked)
+ _exit(lastval);
+ return;
+ }
+
+ if ((type == WC_SIMPLE || type == WC_TYPESET) && !nullexec) {
+ char *s;
+ char trycd = (isset(AUTOCD) && isset(SHINSTDIN) &&
+ (!redir || empty(redir)) && args && !empty(args) &&
+ !nextnode(firstnode(args)) && *(char *)peekfirst(args));
+
+ DPUTS((!args || empty(args)), "BUG: empty(args) in exec.c");
+ if (!hn) {
+ /* Resolve external commands */
+ char *cmdarg = (char *) peekfirst(args);
+ char **checkpath = pathchecked;
+ int dohashcmd = isset(HASHCMDS);
+
+ hn = cmdnamtab->getnode(cmdnamtab, cmdarg);
+ if (hn && trycd && !isreallycom((Cmdnam)hn)) {
+ if (!(((Cmdnam)hn)->node.flags & HASHED)) {
+ checkpath = path;
+ dohashcmd = 1;
+ }
+ cmdnamtab->removenode(cmdnamtab, cmdarg);
+ cmdnamtab->freenode(hn);
+ hn = NULL;
+ }
+ if (!hn && dohashcmd && strcmp(cmdarg, "..")) {
+ for (s = cmdarg; *s && *s != '/'; s++);
+ if (!*s)
+ hn = (HashNode) hashcmd(cmdarg, checkpath);
+ }
+ }
+
+ /* If no command found yet, see if it *
+ * is a directory we should AUTOCD to. */
+ if (!hn && trycd && (s = cancd(peekfirst(args)))) {
+ peekfirst(args) = (void *) s;
+ pushnode(args, dupstring("--"));
+ pushnode(args, dupstring("cd"));
+ if ((hn = builtintab->getnode(builtintab, "cd")))
+ is_builtin = 1;
+ }
+ }
+
+ /* This is nonzero if the command is a current shell procedure? */
+ is_cursh = (is_builtin || is_shfunc || nullexec || type >= WC_CURSH);
+
+ /**************************************************************************
+ * Do we need to fork? We need to fork if: *
+ * 1) The command is supposed to run in the background. This *
+ * case is now handled above (forked = 1 here). (or) *
+ * 2) There is no `exec' flag, and either: *
+ * a) This is a builtin or shell function with output piped somewhere. *
+ * b) This is an external command and we can't do a `fake exec'. *
+ * *
+ * A `fake exec' is possible if we have all the following conditions: *
+ * 1) last1 flag is 1. This indicates that the current shell will not *
+ * be needed after the current command. This is typically the case *
+ * when the command is the last stage in a subshell, or is the *
+ * last command after the option `-c'. *
+ * 2) We don't have any traps set. *
+ * 3) We don't have any files to delete. *
+ * *
+ * The condition above for a `fake exec' will also work for a current *
+ * shell command such as a builtin, but doesn't really buy us anything *
+ * (doesn't save us a process), since it is already running in the *
+ * current shell. *
+ **************************************************************************/
+
+ if (!forked) {
+ if (!do_exec &&
+ (((is_builtin || is_shfunc) && output) ||
+ (!is_cursh && (last1 != 1 || nsigtrapped || havefiles() ||
+ fdtable_flocks)))) {
+ switch (execcmd_fork(state, how, type, varspc, &filelist,
+ text, oautocont, close_if_forked)) {
+ case -1:
+ goto fatal;
+ case 0:
+ break;
+ default:
+ return;
+ }
+ forked = 1;
+ } else if (is_cursh) {
+ /* This is a current shell procedure that didn't need to fork. *
+ * This includes current shell procedures that are being exec'ed, *
+ * as well as null execs. */
+ jobtab[thisjob].stat |= STAT_CURSH;
+ if (!jobtab[thisjob].procs)
+ jobtab[thisjob].stat |= STAT_NOPRINT;
+ if (is_builtin)
+ jobtab[thisjob].stat |= STAT_BUILTIN;
+ } else {
+ /* This is an exec (real or fake) for an external command. *
+ * Note that any form of exec means that the subshell is fake *
+ * (but we may be in a subshell already). */
+ is_exec = 1;
+ /*
+ * If we are in a subshell environment anyway, say we're forked,
+ * even if we're actually not forked because we know the
+ * subshell is exiting. This ensures SHLVL reflects the current
+ * shell, and also optimises out any save/restore we'd need to
+ * do if we were returning to the main shell.
+ */
+ if (type == WC_SUBSH)
+ forked = 1;
+ }
+ }
+
+ if ((esglob = !(cflags & BINF_NOGLOB)) && args && eparams->htok) {
+ LinkList oargs = args;
+ globlist(args, 0);
+ args = oargs;
+ }
+ if (errflag) {
+ lastval = 1;
+ goto err;
+ }
+
+ /* Make a copy of stderr for xtrace output before redirecting */
+ fflush(xtrerr);
+ if (isset(XTRACE) && xtrerr == stderr &&
+ (type < WC_SUBSH || type == WC_TIMED)) {
+ if ((newxtrerr = fdopen(movefd(dup(fileno(stderr))), "w"))) {
+ xtrerr = newxtrerr;
+ fdtable[fileno(xtrerr)] = FDT_XTRACE;
+ }
+ }
+
+ /* Add pipeline input/output to mnodes */
+ if (input)
+ addfd(forked, save, mfds, 0, input, 0, NULL);
+ if (output)
+ addfd(forked, save, mfds, 1, output, 1, NULL);
+
+ /* Do process substitutions */
+ if (redir)
+ spawnpipes(redir, nullexec);
+
+ /* Do io redirections */
+ while (redir && nonempty(redir)) {
+ fn = (Redir) ugetnode(redir);
+
+ DPUTS(fn->type == REDIR_HEREDOC || fn->type == REDIR_HEREDOCDASH,
+ "BUG: unexpanded here document");
+ if (fn->type == REDIR_INPIPE) {
+ if (!checkclobberparam(fn) || fn->fd2 == -1) {
+ if (fn->fd2 != -1)
+ zclose(fn->fd2);
+ closemnodes(mfds);
+ fixfds(save);
+ execerr();
+ }
+ addfd(forked, save, mfds, fn->fd1, fn->fd2, 0, fn->varid);
+ } else if (fn->type == REDIR_OUTPIPE) {
+ if (!checkclobberparam(fn) || fn->fd2 == -1) {
+ if (fn->fd2 != -1)
+ zclose(fn->fd2);
+ closemnodes(mfds);
+ fixfds(save);
+ execerr();
+ }
+ addfd(forked, save, mfds, fn->fd1, fn->fd2, 1, fn->varid);
+ } else {
+ int closed;
+ if (fn->type != REDIR_HERESTR && xpandredir(fn, redir))
+ continue;
+ if (errflag) {
+ closemnodes(mfds);
+ fixfds(save);
+ execerr();
+ }
+ if (isset(RESTRICTED) && IS_WRITE_FILE(fn->type)) {
+ zwarn("writing redirection not allowed in restricted mode");
+ execerr();
+ }
+ if (unset(EXECOPT))
+ continue;
+ switch(fn->type) {
+ case REDIR_HERESTR:
+ if (!checkclobberparam(fn))
+ fil = -1;
+ else
+ fil = getherestr(fn);
+ if (fil == -1) {
+ if (errno && errno != EINTR)
+ zwarn("can't create temp file for here document: %e",
+ errno);
+ closemnodes(mfds);
+ fixfds(save);
+ execerr();
+ }
+ addfd(forked, save, mfds, fn->fd1, fil, 0, fn->varid);
+ break;
+ case REDIR_READ:
+ case REDIR_READWRITE:
+ if (!checkclobberparam(fn))
+ fil = -1;
+ else if (fn->type == REDIR_READ)
+ fil = open(unmeta(fn->name), O_RDONLY | O_NOCTTY);
+ else
+ fil = open(unmeta(fn->name),
+ O_RDWR | O_CREAT | O_NOCTTY, 0666);
+ if (fil == -1) {
+ closemnodes(mfds);
+ fixfds(save);
+ if (errno != EINTR)
+ zwarn("%e: %s", errno, fn->name);
+ execerr();
+ }
+ addfd(forked, save, mfds, fn->fd1, fil, 0, fn->varid);
+ /* If this is 'exec < file', read from stdin, *
+ * not terminal, unless `file' is a terminal. */
+ if (nullexec == 1 && fn->fd1 == 0 &&
+ isset(SHINSTDIN) && interact && !zleactive)
+ init_io(NULL);
+ break;
+ case REDIR_CLOSE:
+ if (fn->varid) {
+ char *s = fn->varid, *t;
+ struct value vbuf;
+ Value v;
+ int bad = 0;
+
+ if (!(v = getvalue(&vbuf, &s, 0))) {
+ bad = 1;
+ } else if (v->pm->node.flags & PM_READONLY) {
+ bad = 2;
+ } else {
+ s = getstrvalue(v);
+ if (errflag)
+ bad = 1;
+ else {
+ fn->fd1 = zstrtol(s, &t, 0);
+ if (s == t)
+ bad = 1;
+ else if (*t) {
+ /* Check for base#number format */
+ if (*t == '#' && *s != '0')
+ fn->fd1 = zstrtol(s = t+1, &t, fn->fd1);
+ if (s == t || *t)
+ bad = 1;
+ }
+ if (!bad && fn->fd1 <= max_zsh_fd) {
+ if (fn->fd1 >= 10 &&
+ (fdtable[fn->fd1] & FDT_TYPE_MASK) ==
+ FDT_INTERNAL)
+ bad = 3;
+ }
+ }
+ }
+ if (bad) {
+ const char *bad_msg[] = {
+ "parameter %s does not contain a file descriptor",
+ "can't close file descriptor from readonly parameter %s",
+ "file descriptor %d used by shell, not closed"
+ };
+ if (bad > 2)
+ zwarn(bad_msg[bad-1], fn->fd1);
+ else
+ zwarn(bad_msg[bad-1], fn->varid);
+ execerr();
+ }
+ }
+ /*
+ * Note we may attempt to close an fd beyond max_zsh_fd:
+ * OK as long as we never look in fdtable for it.
+ */
+ closed = 0;
+ if (!forked && fn->fd1 < 10 && save[fn->fd1] == -2) {
+ save[fn->fd1] = movefd(fn->fd1);
+ if (save[fn->fd1] >= 0) {
+ /*
+ * The original fd is now closed, we don't need
+ * to do it below.
+ */
+ closed = 1;
+ }
+ }
+ if (fn->fd1 < 10)
+ closemn(mfds, fn->fd1, REDIR_CLOSE);
+ /*
+ * Only report failures to close file descriptors
+ * if they're under user control as we don't know
+ * what the previous status of others was.
+ */
+ if (!closed && zclose(fn->fd1) < 0 && fn->varid) {
+ zwarn("failed to close file descriptor %d: %e",
+ fn->fd1, errno);
+ }
+ break;
+ case REDIR_MERGEIN:
+ case REDIR_MERGEOUT:
+ if (fn->fd2 < 10)
+ closemn(mfds, fn->fd2, fn->type);
+ if (!checkclobberparam(fn))
+ fil = -1;
+ else if (fn->fd2 > 9 &&
+ /*
+ * If the requested fd is > max_zsh_fd,
+ * the shell doesn't know about it.
+ * Just assume the user knows what they're
+ * doing.
+ */
+ (fn->fd2 <= max_zsh_fd &&
+ ((fdtable[fn->fd2] != FDT_UNUSED &&
+ fdtable[fn->fd2] != FDT_EXTERNAL) ||
+ fn->fd2 == coprocin ||
+ fn->fd2 == coprocout))) {
+ fil = -1;
+ errno = EBADF;
+ } else {
+ int fd = fn->fd2;
+ if(fd == -2)
+ fd = (fn->type == REDIR_MERGEOUT) ? coprocout : coprocin;
+ fil = movefd(dup(fd));
+ }
+ if (fil == -1) {
+ char fdstr[DIGBUFSIZE];
+
+ closemnodes(mfds);
+ fixfds(save);
+ if (fn->fd2 != -2)
+ sprintf(fdstr, "%d", fn->fd2);
+ if (errno)
+ zwarn("%s: %e", fn->fd2 == -2 ? "coprocess" : fdstr,
+ errno);
+ execerr();
+ }
+ addfd(forked, save, mfds, fn->fd1, fil,
+ fn->type == REDIR_MERGEOUT, fn->varid);
+ break;
+ default:
+ if (!checkclobberparam(fn))
+ fil = -1;
+ else if (IS_APPEND_REDIR(fn->type))
+ fil = open(unmeta(fn->name),
+ ((unset(CLOBBER) && unset(APPENDCREATE)) &&
+ !IS_CLOBBER_REDIR(fn->type)) ?
+ O_WRONLY | O_APPEND | O_NOCTTY :
+ O_WRONLY | O_APPEND | O_CREAT | O_NOCTTY, 0666);
+ else
+ fil = clobber_open(fn);
+ if(fil != -1 && IS_ERROR_REDIR(fn->type))
+ dfil = movefd(dup(fil));
+ else
+ dfil = 0;
+ if (fil == -1 || dfil == -1) {
+ if(fil != -1)
+ close(fil);
+ closemnodes(mfds);
+ fixfds(save);
+ if (errno && errno != EINTR)
+ zwarn("%e: %s", errno, fn->name);
+ execerr();
+ }
+ addfd(forked, save, mfds, fn->fd1, fil, 1, fn->varid);
+ if(IS_ERROR_REDIR(fn->type))
+ addfd(forked, save, mfds, 2, dfil, 1, NULL);
+ break;
+ }
+ /* May be error in addfd due to setting parameter. */
+ if (errflag) {
+ closemnodes(mfds);
+ fixfds(save);
+ execerr();
+ }
+ }
+ }
+
+ /* We are done with redirection. close the mnodes, *
+ * spawning tee/cat processes as necessary. */
+ for (i = 0; i < 10; i++)
+ if (mfds[i] && mfds[i]->ct >= 2)
+ closemn(mfds, i, REDIR_CLOSE);
+
+ if (nullexec) {
+ /*
+ * If nullexec is 2, we have variables to add with the redirections
+ * in place. If nullexec is 1, we may have variables but they
+ * need the standard restore logic.
+ */
+ if (varspc) {
+ LinkList restorelist = 0, removelist = 0;
+ if (!isset(POSIXBUILTINS) && nullexec != 2)
+ save_params(state, varspc, &restorelist, &removelist);
+ addvars(state, varspc, 0);
+ if (restorelist)
+ restore_params(restorelist, removelist);
+ }
+ lastval = errflag ? errflag : cmdoutval;
+ if (nullexec == 1) {
+ /*
+ * If nullexec is 1 we specifically *don't* restore the original
+ * fd's before returning.
+ */
+ for (i = 0; i < 10; i++)
+ if (save[i] != -2)
+ zclose(save[i]);
+ goto done;
+ }
+ if (isset(XTRACE)) {
+ fputc('\n', xtrerr);
+ fflush(xtrerr);
+ }
+ } else if (isset(EXECOPT) && !errflag) {
+ int q = queue_signal_level();
+ /*
+ * We delay the entersubsh() to here when we are exec'ing
+ * the current shell (including a fake exec to run a builtin then
+ * exit) in case there is an error return.
+ */
+ if (is_exec) {
+ int flags = ((how & Z_ASYNC) ? ESUB_ASYNC : 0) |
+ ESUB_PGRP | ESUB_FAKE;
+ if (type != WC_SUBSH)
+ flags |= ESUB_KEEPTRAP;
+ if ((do_exec || (type >= WC_CURSH && last1 == 1))
+ && !forked)
+ flags |= ESUB_REVERTPGRP;
+ entersubsh(flags);
+ }
+ if (type == WC_FUNCDEF) {
+ Eprog redir_prog;
+ if (!redir && wc_code(*eparams->beg) == WC_REDIR) {
+ /*
+ * We're not using a redirection from the currently
+ * parsed environment, which is what we'd do for an
+ * anonymous function, but there are redirections we
+ * should store with the new function.
+ */
+ struct estate s;
+
+ s.prog = state->prog;
+ s.pc = eparams->beg;
+ s.strs = state->prog->strs;
+
+ /*
+ * The copy uses the wordcode parsing area, so save and
+ * restore state.
+ */
+ zcontext_save();
+ redir_prog = eccopyredirs(&s);
+ zcontext_restore();
+ } else
+ redir_prog = NULL;
+
+ dont_queue_signals();
+ lastval = execfuncdef(state, redir_prog);
+ restore_queue_signals(q);
+ }
+ else if (type >= WC_CURSH) {
+ if (last1 == 1)
+ do_exec = 1;
+ dont_queue_signals();
+ if (type == WC_AUTOFN) {
+ /*
+ * We pre-loaded this to get any redirs.
+ * So we execuate a simplified function here.
+ */
+ lastval = execautofn_basic(state, do_exec);
+ } else
+ lastval = (execfuncs[type - WC_CURSH])(state, do_exec);
+ restore_queue_signals(q);
+ } else if (is_builtin || is_shfunc) {
+ LinkList restorelist = 0, removelist = 0;
+ int do_save = 0;
+ /* builtin or shell function */
+
+ if (!forked) {
+ if (isset(POSIXBUILTINS)) {
+ /*
+ * If it's a function or special builtin --- save
+ * if it's got "command" in front.
+ * If it's a normal command --- save.
+ */
+ if (is_shfunc || (hn->flags & (BINF_PSPECIAL|BINF_ASSIGN)))
+ do_save = (orig_cflags & BINF_COMMAND);
+ else
+ do_save = 1;
+ } else {
+ /*
+ * Save if it's got "command" in front or it's
+ * not a magic-equals assignment.
+ */
+ if ((cflags & (BINF_COMMAND|BINF_ASSIGN)) || !magic_assign)
+ do_save = 1;
+ }
+ if (do_save && varspc)
+ save_params(state, varspc, &restorelist, &removelist);
+ }
+ if (varspc) {
+ /* Export this if the command is a shell function,
+ * but not if it's a builtin.
+ */
+ int flags = 0;
+ if (is_shfunc)
+ flags |= ADDVAR_EXPORT;
+ if (restorelist)
+ flags |= ADDVAR_RESTORE;
+
+ addvars(state, varspc, flags);
+ if (errflag) {
+ if (restorelist)
+ restore_params(restorelist, removelist);
+ lastval = 1;
+ fixfds(save);
+ goto done;
+ }
+ }
+
+ if (is_shfunc) {
+ /* It's a shell function */
+ pipecleanfilelist(filelist, 0);
+ execshfunc((Shfunc) hn, args);
+ } else {
+ /* It's a builtin */
+ LinkList assigns = (LinkList)0;
+ int postassigns = eparams->postassigns;
+ if (forked)
+ closem(FDT_INTERNAL, 0);
+ if (postassigns) {
+ Wordcode opc = state->pc;
+ state->pc = eparams->assignspc;
+ assigns = newlinklist();
+ while (postassigns--) {
+ int htok;
+ wordcode ac = *state->pc++;
+ char *name = ecgetstr(state, EC_DUPTOK, &htok);
+ Asgment asg;
+ local_list1(svl);
+
+ DPUTS(wc_code(ac) != WC_ASSIGN,
+ "BUG: bad assignment list for typeset");
+ if (htok) {
+ init_list1(svl, name);
+ if (WC_ASSIGN_TYPE(ac) == WC_ASSIGN_SCALAR &&
+ WC_ASSIGN_TYPE2(ac) == WC_ASSIGN_INC) {
+ char *data;
+ /*
+ * Special case: this is a name only, so
+ * it's not required to be a single
+ * expansion. Furthermore, for
+ * consistency with the builtin
+ * interface, it may expand into
+ * scalar assignments:
+ * ass=(one=two three=four)
+ * typeset a=b $ass
+ */
+ /* Unused dummy value for name */
+ (void)ecgetstr(state, EC_DUPTOK, &htok);
+ prefork(&svl, PREFORK_TYPESET, NULL);
+ if (errflag) {
+ state->pc = opc;
+ break;
+ }
+ globlist(&svl, 0);
+ if (errflag) {
+ state->pc = opc;
+ break;
+ }
+ while ((data = ugetnode(&svl))) {
+ char *ptr;
+ asg = (Asgment)zhalloc(sizeof(struct asgment));
+ asg->flags = 0;
+ if ((ptr = strchr(data, '='))) {
+ *ptr++ = '\0';
+ asg->name = data;
+ asg->value.scalar = ptr;
+ } else {
+ asg->name = data;
+ asg->value.scalar = NULL;
+ }
+ uaddlinknode(assigns, &asg->node);
+ }
+ continue;
+ }
+ prefork(&svl, PREFORK_SINGLE, NULL);
+ name = empty(&svl) ? "" :
+ (char *)getdata(firstnode(&svl));
+ }
+ untokenize(name);
+ asg = (Asgment)zhalloc(sizeof(struct asgment));
+ asg->name = name;
+ if (WC_ASSIGN_TYPE(ac) == WC_ASSIGN_SCALAR) {
+ char *val = ecgetstr(state, EC_DUPTOK, &htok);
+ asg->flags = 0;
+ if (WC_ASSIGN_TYPE2(ac) == WC_ASSIGN_INC) {
+ /* Fake assignment, no value */
+ asg->value.scalar = NULL;
+ } else {
+ if (htok) {
+ init_list1(svl, val);
+ prefork(&svl,
+ PREFORK_SINGLE|PREFORK_ASSIGN,
+ NULL);
+ if (errflag) {
+ state->pc = opc;
+ break;
+ }
+ /*
+ * No globassign for typeset
+ * arguments, thank you
+ */
+ val = empty(&svl) ? "" :
+ (char *)getdata(firstnode(&svl));
+ }
+ untokenize(val);
+ asg->value.scalar = val;
+ }
+ } else {
+ asg->flags = ASG_ARRAY;
+ asg->value.array =
+ ecgetlist(state, WC_ASSIGN_NUM(ac),
+ EC_DUPTOK, &htok);
+ if (asg->value.array)
+ {
+ if (!errflag) {
+ int prefork_ret = 0;
+ prefork(asg->value.array, PREFORK_ASSIGN,
+ &prefork_ret);
+ if (errflag) {
+ state->pc = opc;
+ break;
+ }
+ if (prefork_ret & PREFORK_KEY_VALUE)
+ asg->flags |= ASG_KEY_VALUE;
+ globlist(asg->value.array, prefork_ret);
+ }
+ if (errflag) {
+ state->pc = opc;
+ break;
+ }
+ }
+ }
+
+ uaddlinknode(assigns, &asg->node);
+ }
+ state->pc = opc;
+ }
+ dont_queue_signals();
+ if (!errflag) {
+ int ret = execbuiltin(args, assigns, (Builtin) hn);
+ /*
+ * In case of interruption assume builtin status
+ * is less useful than what interrupt set.
+ */
+ if (!(errflag & ERRFLAG_INT))
+ lastval = ret;
+ }
+ if (do_save & BINF_COMMAND)
+ errflag &= ~ERRFLAG_ERROR;
+ restore_queue_signals(q);
+ fflush(stdout);
+ if (save[1] == -2) {
+ if (ferror(stdout)) {
+ zwarn("write error: %e", errno);
+ clearerr(stdout);
+ }
+ } else
+ clearerr(stdout);
+ }
+ if (isset(PRINTEXITVALUE) && isset(SHINSTDIN) &&
+ lastval && !subsh) {
+#if defined(ZLONG_IS_LONG_LONG) && defined(PRINTF_HAS_LLD)
+ fprintf(stderr, "zsh: exit %lld\n", lastval);
+#else
+ fprintf(stderr, "zsh: exit %ld\n", (long)lastval);
+#endif
+ fflush(stderr);
+ }
+
+ if (do_exec) {
+ if (subsh)
+ _exit(lastval);
+
+ /* If we are exec'ing a command, and we are not in a subshell, *
+ * then check if we should save the history file. */
+ if (isset(RCS) && interact && !nohistsave)
+ savehistfile(NULL, 1, HFILE_USE_OPTIONS);
+ exit(lastval);
+ }
+ if (restorelist)
+ restore_params(restorelist, removelist);
+
+ } else {
+ if (!subsh) {
+ /* for either implicit or explicit "exec", decrease $SHLVL
+ * as we're now done as a shell */
+ if (!forked)
+ setiparam("SHLVL", --shlvl);
+
+ /* If we are exec'ing a command, and we are not *
+ * in a subshell, then save the history file. */
+ if (do_exec && isset(RCS) && interact && !nohistsave)
+ savehistfile(NULL, 1, HFILE_USE_OPTIONS);
+ }
+ if (type == WC_SIMPLE || type == WC_TYPESET) {
+ if (varspc) {
+ int addflags = ADDVAR_EXPORT|ADDVAR_RESTRICT;
+ if (forked)
+ addflags |= ADDVAR_RESTORE;
+ addvars(state, varspc, addflags);
+ if (errflag)
+ _exit(1);
+ }
+ closem(FDT_INTERNAL, 0);
+ if (coprocin != -1) {
+ zclose(coprocin);
+ coprocin = -1;
+ }
+ if (coprocout != -1) {
+ zclose(coprocout);
+ coprocout = -1;
+ }
+#ifdef HAVE_GETRLIMIT
+ if (!forked)
+ setlimits(NULL);
+#endif
+ if (how & Z_ASYNC) {
+ zsfree(STTYval);
+ STTYval = 0;
+ }
+ execute(args, cflags, use_defpath);
+ } else { /* ( ... ) */
+ DPUTS(varspc,
+ "BUG: assignment before complex command");
+ list_pipe = 0;
+ pipecleanfilelist(filelist, 0);
+ /* If we're forked (and we should be), no need to return */
+ DPUTS(last1 != 1 && !forked, "BUG: not exiting?");
+ DPUTS(type != WC_SUBSH, "Not sure what we're doing.");
+ /* Skip word only used for try/always blocks */
+ state->pc++;
+ execlist(state, 0, 1);
+ }
+ }
+ }
+
+ err:
+ if (forked) {
+ /*
+ * So what's going on here then? Well, I'm glad you asked.
+ *
+ * If we create multios for use in a subshell we do
+ * this after forking, in this function above. That
+ * means that the current (sub)process is responsible
+ * for clearing them up. However, the processes won't
+ * go away until we have closed the fd's talking to them.
+ * Since we're about to exit the shell there's nothing
+ * to stop us closing all fd's (including the ones 0 to 9
+ * that we usually leave alone).
+ *
+ * Then we wait for any processes. When we forked,
+ * we cleared the jobtable and started a new job just for
+ * any oddments like this, so if there aren't any we won't
+ * need to wait. The result of not waiting is that
+ * the multios haven't flushed the fd's properly, leading
+ * to obscure missing data.
+ *
+ * It would probably be cleaner to ensure that the
+ * parent shell handled multios, but that requires
+ * some architectural changes which are likely to be
+ * hairy.
+ */
+ for (i = 0; i < 10; i++)
+ if (fdtable[i] != FDT_UNUSED)
+ close(i);
+ closem(FDT_UNUSED, 1);
+ if (thisjob != -1)
+ waitjobs();
+ _exit(lastval);
+ }
+ fixfds(save);
+
+ done:
+ if (isset(POSIXBUILTINS) &&
+ (cflags & (BINF_PSPECIAL|BINF_EXEC)) &&
+ !(orig_cflags & BINF_COMMAND)) {
+ /*
+ * For POSIX-compatible behaviour with special
+ * builtins (including exec which we don't usually
+ * classify as a builtin) we treat all errors as fatal.
+ * The "command" builtin is not special so resets this behaviour.
+ */
+ forked |= zsh_subshell;
+ fatal:
+ if (redir_err || errflag) {
+ if (!isset(INTERACTIVE)) {
+ if (forked)
+ _exit(1);
+ else
+ exit(1);
+ }
+ errflag |= ERRFLAG_ERROR;
+ }
+ }
+ if (newxtrerr) {
+ fil = fileno(newxtrerr);
+ fclose(newxtrerr);
+ xtrerr = oxtrerr;
+ zclose(fil);
+ }
+
+ zsfree(STTYval);
+ STTYval = 0;
+ if (oautocont >= 0)
+ opts[AUTOCONTINUE] = oautocont;
+}
+
+/* Arrange to have variables restored. */
+
+/**/
+static void
+save_params(Estate state, Wordcode pc, LinkList *restore_p, LinkList *remove_p)
+{
+ Param pm;
+ char *s;
+ wordcode ac;
+
+ *restore_p = newlinklist();
+ *remove_p = newlinklist();
+
+ while (wc_code(ac = *pc) == WC_ASSIGN) {
+ s = ecrawstr(state->prog, pc + 1, NULL);
+ if ((pm = (Param) paramtab->getnode(paramtab, s))) {
+ Param tpm;
+ if (pm->env)
+ delenv(pm);
+ if (!(pm->node.flags & PM_SPECIAL)) {
+ /*
+ * We used to remove ordinary parameters from the
+ * table, but that meant "HELLO=$HELLO shellfunc"
+ * failed because the expansion of $HELLO hasn't
+ * been done at this point. Instead, copy the
+ * parameter: in this case, we'll insert the
+ * copied parameter straight back into the parameter
+ * table so we want to be sure everything is
+ * properly set up and in permanent memory.
+ */
+ tpm = (Param) zshcalloc(sizeof *tpm);
+ tpm->node.nam = ztrdup(pm->node.nam);
+ copyparam(tpm, pm, 0);
+ pm = tpm;
+ } else if (!(pm->node.flags & PM_READONLY) &&
+ (unset(RESTRICTED) || !(pm->node.flags & PM_RESTRICTED))) {
+ /*
+ * In this case we're just saving parts of
+ * the parameter in a tempory, so use heap allocation
+ * and don't bother copying every detail.
+ */
+ tpm = (Param) hcalloc(sizeof *tpm);
+ tpm->node.nam = pm->node.nam;
+ copyparam(tpm, pm, 1);
+ pm = tpm;
+ }
+ addlinknode(*remove_p, dupstring(s));
+ addlinknode(*restore_p, pm);
+ } else
+ addlinknode(*remove_p, dupstring(s));
+
+ pc += (WC_ASSIGN_TYPE(ac) == WC_ASSIGN_SCALAR ?
+ 3 : WC_ASSIGN_NUM(ac) + 2);
+ }
+}
+
+/* Restore saved parameters after executing a shfunc or builtin */
+
+/**/
+static void
+restore_params(LinkList restorelist, LinkList removelist)
+{
+ Param pm;
+ char *s;
+
+ /* remove temporary parameters */
+ while ((s = (char *) ugetnode(removelist))) {
+ if ((pm = (Param) paramtab->getnode(paramtab, s)) &&
+ !(pm->node.flags & PM_SPECIAL)) {
+ pm->node.flags &= ~PM_READONLY;
+ unsetparam_pm(pm, 0, 0);
+ }
+ }
+
+ if (restorelist) {
+ /* restore saved parameters */
+ while ((pm = (Param) ugetnode(restorelist))) {
+ if (pm->node.flags & PM_SPECIAL) {
+ Param tpm = (Param) paramtab->getnode(paramtab, pm->node.nam);
+
+ DPUTS(!tpm || PM_TYPE(pm->node.flags) != PM_TYPE(tpm->node.flags) ||
+ !(pm->node.flags & PM_SPECIAL),
+ "BUG: in restoring special parameters");
+ if (!pm->env && tpm->env)
+ delenv(tpm);
+ tpm->node.flags = pm->node.flags;
+ switch (PM_TYPE(pm->node.flags)) {
+ case PM_SCALAR:
+ tpm->gsu.s->setfn(tpm, pm->u.str);
+ break;
+ case PM_INTEGER:
+ tpm->gsu.i->setfn(tpm, pm->u.val);
+ break;
+ case PM_EFLOAT:
+ case PM_FFLOAT:
+ tpm->gsu.f->setfn(tpm, pm->u.dval);
+ break;
+ case PM_ARRAY:
+ tpm->gsu.a->setfn(tpm, pm->u.arr);
+ break;
+ case PM_HASHED:
+ tpm->gsu.h->setfn(tpm, pm->u.hash);
+ break;
+ }
+ pm = tpm;
+ } else {
+ paramtab->addnode(paramtab, pm->node.nam, pm);
+ }
+ if ((pm->node.flags & PM_EXPORTED) && ((s = getsparam(pm->node.nam))))
+ addenv(pm, s);
+ }
+ }
+}
+
+/* restore fds after redirecting a builtin */
+
+/**/
+static void
+fixfds(int *save)
+{
+ int old_errno = errno;
+ int i;
+
+ for (i = 0; i != 10; i++)
+ if (save[i] != -2)
+ redup(save[i], i);
+ errno = old_errno;
+}
+
+/*
+ * Close internal shell fds.
+ *
+ * Close any that are marked as used if "how" is FDT_UNUSED, else
+ * close any with the value "how".
+ *
+ * If "all" is zero, we'll skip cases where we need the file
+ * descriptor to be visible externally.
+ */
+
+/**/
+mod_export void
+closem(int how, int all)
+{
+ int i;
+
+ for (i = 10; i <= max_zsh_fd; i++)
+ if (fdtable[i] != FDT_UNUSED &&
+ /*
+ * Process substitution needs to be visible to user;
+ * fd's are explicitly cleaned up by filelist handling.
+ */
+ (all || fdtable[i] != FDT_PROC_SUBST) &&
+ (how == FDT_UNUSED || (fdtable[i] & FDT_TYPE_MASK) == how)) {
+ if (i == SHTTY)
+ SHTTY = -1;
+ zclose(i);
+ }
+}
+
+/* convert here document into a here string */
+
+/**/
+char *
+gethere(char **strp, int typ)
+{
+ char *buf;
+ int bsiz, qt = 0, strip = 0;
+ char *s, *t, *bptr, c;
+ char *str = *strp;
+
+ for (s = str; *s; s++)
+ if (inull(*s)) {
+ qt = 1;
+ break;
+ }
+ str = quotesubst(str);
+ untokenize(str);
+ if (typ == REDIR_HEREDOCDASH) {
+ strip = 1;
+ while (*str == '\t')
+ str++;
+ }
+ *strp = str;
+ bptr = buf = zalloc(bsiz = 256);
+ for (;;) {
+ t = bptr;
+
+ while ((c = hgetc()) == '\t' && strip)
+ ;
+ for (;;) {
+ if (bptr >= buf + bsiz - 2) {
+ ptrdiff_t toff = t - buf;
+ ptrdiff_t bptroff = bptr - buf;
+ char *newbuf = realloc(buf, 2 * bsiz);
+ if (!newbuf) {
+ /* out of memory */
+ zfree(buf, bsiz);
+ return NULL;
+ }
+ buf = newbuf;
+ t = buf + toff;
+ bptr = buf + bptroff;
+ bsiz *= 2;
+ }
+ if (lexstop || c == '\n')
+ break;
+ if (!qt && c == '\\') {
+ *bptr++ = c;
+ c = hgetc();
+ if (c == '\n') {
+ bptr--;
+ c = hgetc();
+ continue;
+ }
+ }
+ *bptr++ = c;
+ c = hgetc();
+ }
+ *bptr = '\0';
+ if (!strcmp(t, str))
+ break;
+ if (lexstop) {
+ t = bptr;
+ break;
+ }
+ *bptr++ = '\n';
+ }
+ *t = '\0';
+ s = buf;
+ buf = dupstring(buf);
+ zfree(s, bsiz);
+ if (!qt) {
+ int ef = errflag;
+
+ parsestr(&buf);
+
+ if (!(errflag & ERRFLAG_ERROR)) {
+ /* Retain any user interrupt error */
+ errflag = ef | (errflag & ERRFLAG_INT);
+ }
+ }
+ return buf;
+}
+
+/* open here string fd */
+
+/**/
+static int
+getherestr(struct redir *fn)
+{
+ char *s, *t;
+ int fd, len;
+
+ t = fn->name;
+ singsub(&t);
+ untokenize(t);
+ unmetafy(t, &len);
+ /*
+ * For real here-strings we append a newline, as if the
+ * string given was a complete command line.
+ *
+ * For here-strings from here documents, we use the original
+ * text exactly.
+ */
+ if (!(fn->flags & REDIRF_FROM_HEREDOC))
+ t[len++] = '\n';
+ if ((fd = gettempfile(NULL, 1, &s)) < 0)
+ return -1;
+ write_loop(fd, t, len);
+ close(fd);
+ fd = open(s, O_RDONLY | O_NOCTTY);
+ unlink(s);
+ return fd;
+}
+
+/*
+ * Test if some wordcode starts with a simple redirection of type
+ * redir_type. If it does, return the name of the file, copied onto
+ * the heap. If it doesn't, return NULL.
+ */
+
+static char *
+simple_redir_name(Eprog prog, int redir_type)
+{
+ Wordcode pc;
+
+ pc = prog->prog;
+ if (prog != &dummy_eprog &&
+ wc_code(pc[0]) == WC_LIST && (WC_LIST_TYPE(pc[0]) & Z_END) &&
+ wc_code(pc[1]) == WC_SUBLIST && !WC_SUBLIST_FLAGS(pc[1]) &&
+ WC_SUBLIST_TYPE(pc[1]) == WC_SUBLIST_END &&
+ wc_code(pc[2]) == WC_PIPE && WC_PIPE_TYPE(pc[2]) == WC_PIPE_END &&
+ wc_code(pc[3]) == WC_REDIR && WC_REDIR_TYPE(pc[3]) == redir_type &&
+ !WC_REDIR_VARID(pc[3]) &&
+ !pc[4] &&
+ wc_code(pc[6]) == WC_SIMPLE && !WC_SIMPLE_ARGC(pc[6])) {
+ return dupstring(ecrawstr(prog, pc + 5, NULL));
+ }
+
+ return NULL;
+}
+
+/* $(...) */
+
+/**/
+LinkList
+getoutput(char *cmd, int qt)
+{
+ Eprog prog;
+ int pipes[2];
+ pid_t pid;
+ char *s;
+
+ int onc = nocomments;
+ nocomments = (interact && unset(INTERACTIVECOMMENTS));
+ prog = parse_string(cmd, 0);
+ nocomments = onc;
+
+ if (!prog)
+ return NULL;
+
+ if ((s = simple_redir_name(prog, REDIR_READ))) {
+ /* $(< word) */
+ int stream;
+ LinkList retval;
+ int readerror;
+
+ singsub(&s);
+ if (errflag)
+ return NULL;
+ untokenize(s);
+ if ((stream = open(unmeta(s), O_RDONLY | O_NOCTTY)) == -1) {
+ zwarn("%e: %s", errno, s);
+ lastval = cmdoutval = 1;
+ return newlinklist();
+ }
+ retval = readoutput(stream, qt, &readerror);
+ if (readerror) {
+ zwarn("error when reading %s: %e", s, readerror);
+ lastval = cmdoutval = 1;
+ }
+ return retval;
+ }
+ if (mpipe(pipes) < 0) {
+ errflag |= ERRFLAG_ERROR;
+ cmdoutpid = 0;
+ return NULL;
+ }
+ child_block();
+ cmdoutval = 0;
+ if ((cmdoutpid = pid = zfork(NULL)) == -1) {
+ /* fork error */
+ zclose(pipes[0]);
+ zclose(pipes[1]);
+ errflag |= ERRFLAG_ERROR;
+ cmdoutpid = 0;
+ child_unblock();
+ return NULL;
+ } else if (pid) {
+ LinkList retval;
+
+ zclose(pipes[1]);
+ retval = readoutput(pipes[0], qt, NULL);
+ fdtable[pipes[0]] = FDT_UNUSED;
+ waitforpid(pid, 0); /* unblocks */
+ lastval = cmdoutval;
+ return retval;
+ }
+ /* pid == 0 */
+ child_unblock();
+ zclose(pipes[0]);
+ redup(pipes[1], 1);
+ entersubsh(ESUB_PGRP|ESUB_NOMONITOR);
+ cmdpush(CS_CMDSUBST);
+ execode(prog, 0, 1, "cmdsubst");
+ cmdpop();
+ close(1);
+ _exit(lastval);
+ zerr("exit returned in child!!");
+ kill(getpid(), SIGKILL);
+ return NULL;
+}
+
+/* read output of command substitution */
+
+/**/
+mod_export LinkList
+readoutput(int in, int qt, int *readerror)
+{
+ LinkList ret;
+ char *buf, *ptr;
+ int bsiz, c, cnt = 0;
+ FILE *fin;
+ int q = queue_signal_level();
+
+ fin = fdopen(in, "r");
+ ret = newlinklist();
+ ptr = buf = (char *) hcalloc(bsiz = 64);
+ /*
+ * We need to be sensitive to SIGCHLD else we can be
+ * stuck forever with important processes unreaped.
+ * The case that triggered this was where the exiting
+ * process is group leader of the foreground process and we need
+ * to reclaim the terminal else ^C doesn't work.
+ */
+ dont_queue_signals();
+ child_unblock();
+ while ((c = fgetc(fin)) != EOF || errno == EINTR) {
+ if (c == EOF) {
+ errno = 0;
+ clearerr(fin);
+ continue;
+ }
+ if (imeta(c)) {
+ *ptr++ = Meta;
+ c ^= 32;
+ cnt++;
+ }
+ if (++cnt >= bsiz) {
+ char *pp;
+ queue_signals();
+ pp = (char *) hcalloc(bsiz *= 2);
+ dont_queue_signals();
+
+ memcpy(pp, buf, cnt - 1);
+ ptr = (buf = pp) + cnt - 1;
+ }
+ *ptr++ = c;
+ }
+ child_block();
+ restore_queue_signals(q);
+ if (readerror)
+ *readerror = ferror(fin) ? errno : 0;
+ fclose(fin);
+ while (cnt && ptr[-1] == '\n')
+ ptr--, cnt--;
+ *ptr = '\0';
+ if (qt) {
+ if (!cnt) {
+ *ptr++ = Nularg;
+ *ptr = '\0';
+ }
+ addlinknode(ret, buf);
+ } else {
+ char **words = spacesplit(buf, 0, 1, 0);
+
+ while (*words) {
+ if (isset(GLOBSUBST))
+ shtokenize(*words);
+ addlinknode(ret, *words++);
+ }
+ }
+ return ret;
+}
+
+/**/
+static Eprog
+parsecmd(char *cmd, char **eptr)
+{
+ char *str;
+ Eprog prog;
+
+ for (str = cmd + 2; *str && *str != Outpar; str++);
+ if (!*str || cmd[1] != Inpar) {
+ /*
+ * This can happen if the expression is being parsed
+ * inside another construct, e.g. as a value within ${..:..} etc.
+ * So print a proper error message instead of the not very
+ * useful but traditional "oops".
+ */
+ char *errstr = dupstrpfx(cmd, 2);
+ untokenize(errstr);
+ zerr("unterminated `%s...)'", errstr);
+ return NULL;
+ }
+ *str = '\0';
+ if (eptr)
+ *eptr = str+1;
+ if (!(prog = parse_string(cmd + 2, 0))) {
+ zerr("parse error in process substitution");
+ return NULL;
+ }
+ return prog;
+}
+
+/* =(...) */
+
+/**/
+char *
+getoutputfile(char *cmd, char **eptr)
+{
+ pid_t pid;
+ char *nam;
+ Eprog prog;
+ int fd;
+ char *s;
+
+ if (thisjob == -1){
+ zerr("process substitution %s cannot be used here", cmd);
+ return NULL;
+ }
+ if (!(prog = parsecmd(cmd, eptr)))
+ return NULL;
+ if (!(nam = gettempname(NULL, 1)))
+ return NULL;
+
+ if ((s = simple_redir_name(prog, REDIR_HERESTR))) {
+ /*
+ * =(<<(...) */
+
+/**/
+char *
+getproc(char *cmd, char **eptr)
+{
+#if !defined(HAVE_FIFOS) && !defined(PATH_DEV_FD)
+ zerr("doesn't look like your system supports FIFOs.");
+ return NULL;
+#else
+ Eprog prog;
+ int out = *cmd == Inang;
+ char *pnam;
+ pid_t pid;
+ struct timeval bgtime;
+
+#ifndef PATH_DEV_FD
+ int fd;
+ if (thisjob == -1) {
+ zerr("process substitution %s cannot be used here", cmd);
+ return NULL;
+ }
+ if (!(pnam = namedpipe()))
+ return NULL;
+ if (!(prog = parsecmd(cmd, eptr)))
+ return NULL;
+ addfilelist(pnam, 0);
+
+ if ((pid = zfork(&bgtime))) {
+ if (pid == -1)
+ return NULL;
+ if (!out)
+ addproc(pid, NULL, 1, &bgtime);
+ procsubstpid = pid;
+ return pnam;
+ }
+ closem(FDT_UNUSED, 0);
+ fd = open(pnam, out ? O_WRONLY | O_NOCTTY : O_RDONLY | O_NOCTTY);
+ if (fd == -1) {
+ zerr("can't open %s: %e", pnam, errno);
+ _exit(1);
+ }
+ entersubsh(ESUB_ASYNC|ESUB_PGRP);
+ redup(fd, out);
+#else /* PATH_DEV_FD */
+ int pipes[2], fd;
+
+ if (thisjob == -1) {
+ zerr("process substitution %s cannot be used here", cmd);
+ return NULL;
+ }
+ pnam = zhalloc(strlen(PATH_DEV_FD) + 1 + DIGBUFSIZE);
+ if (!(prog = parsecmd(cmd, eptr)))
+ return NULL;
+ if (mpipe(pipes) < 0)
+ return NULL;
+ if ((pid = zfork(&bgtime))) {
+ sprintf(pnam, "%s/%d", PATH_DEV_FD, pipes[!out]);
+ zclose(pipes[out]);
+ if (pid == -1)
+ {
+ zclose(pipes[!out]);
+ return NULL;
+ }
+ fd = pipes[!out];
+ fdtable[fd] = FDT_PROC_SUBST;
+ addfilelist(NULL, fd);
+ if (!out)
+ {
+ addproc(pid, NULL, 1, &bgtime);
+ }
+ procsubstpid = pid;
+ return pnam;
+ }
+ entersubsh(ESUB_ASYNC|ESUB_PGRP);
+ redup(pipes[out], out);
+ closem(FDT_UNUSED, 0); /* this closes pipes[!out] as well */
+#endif /* PATH_DEV_FD */
+
+ cmdpush(CS_CMDSUBST);
+ execode(prog, 0, 1, out ? "outsubst" : "insubst");
+ cmdpop();
+ zclose(out);
+ _exit(lastval);
+ return NULL;
+#endif /* HAVE_FIFOS and PATH_DEV_FD not defined */
+}
+
+/*
+ * > >(...) or < <(...) (does not use named pipes)
+ *
+ * If the second argument is 1, this is part of
+ * an "exec < <(...)" or "exec > >(...)" and we shouldn't
+ * wait for the job to finish before continuing.
+ */
+
+/**/
+static int
+getpipe(char *cmd, int nullexec)
+{
+ Eprog prog;
+ int pipes[2], out = *cmd == Inang;
+ pid_t pid;
+ struct timeval bgtime;
+ char *ends;
+
+ if (!(prog = parsecmd(cmd, &ends)))
+ return -1;
+ if (*ends) {
+ zerr("invalid syntax for process substitution in redirection");
+ return -1;
+ }
+ if (mpipe(pipes) < 0)
+ return -1;
+ if ((pid = zfork(&bgtime))) {
+ zclose(pipes[out]);
+ if (pid == -1) {
+ zclose(pipes[!out]);
+ return -1;
+ }
+ if (!nullexec)
+ addproc(pid, NULL, 1, &bgtime);
+ procsubstpid = pid;
+ return pipes[!out];
+ }
+ entersubsh(ESUB_PGRP);
+ redup(pipes[out], out);
+ closem(FDT_UNUSED, 0); /* this closes pipes[!out] as well */
+ cmdpush(CS_CMDSUBST);
+ execode(prog, 0, 1, out ? "outsubst" : "insubst");
+ cmdpop();
+ _exit(lastval);
+ return 0;
+}
+
+/* open pipes with fds >= 10 */
+
+/**/
+static int
+mpipe(int *pp)
+{
+ if (pipe(pp) < 0) {
+ zerr("pipe failed: %e", errno);
+ return -1;
+ }
+ pp[0] = movefd(pp[0]);
+ pp[1] = movefd(pp[1]);
+ return 0;
+}
+
+/*
+ * Do process substitution with redirection
+ *
+ * If the second argument is 1, this is part of
+ * an "exec < <(...)" or "exec > >(...)" and we shouldn't
+ * wait for the job to finish before continuing.
+ * Likewise, we shouldn't wait if we are opening the file
+ * descriptor using the {fd}>>(...) notation since it stays
+ * valid for subsequent commands.
+ */
+
+/**/
+static void
+spawnpipes(LinkList l, int nullexec)
+{
+ LinkNode n;
+ Redir f;
+ char *str;
+
+ n = firstnode(l);
+ for (; n; incnode(n)) {
+ f = (Redir) getdata(n);
+ if (f->type == REDIR_OUTPIPE || f->type == REDIR_INPIPE) {
+ str = f->name;
+ f->fd2 = getpipe(str, nullexec || f->varid);
+ }
+ }
+}
+
+/* evaluate a [[ ... ]] */
+
+/**/
+static int
+execcond(Estate state, UNUSED(int do_exec))
+{
+ int stat;
+
+ state->pc--;
+ if (isset(XTRACE)) {
+ printprompt4();
+ fprintf(xtrerr, "[[");
+ tracingcond++;
+ }
+ cmdpush(CS_COND);
+ stat = evalcond(state, NULL);
+ /*
+ * 2 indicates a syntax error. For compatibility, turn this
+ * into a shell error.
+ */
+ if (stat == 2)
+ errflag |= ERRFLAG_ERROR;
+ cmdpop();
+ if (isset(XTRACE)) {
+ fprintf(xtrerr, " ]]\n");
+ fflush(xtrerr);
+ tracingcond--;
+ }
+ return stat;
+}
+
+/* evaluate a ((...)) arithmetic command */
+
+/**/
+static int
+execarith(Estate state, UNUSED(int do_exec))
+{
+ char *e;
+ mnumber val = zero_mnumber;
+ int htok = 0;
+
+ if (isset(XTRACE)) {
+ printprompt4();
+ fprintf(xtrerr, "((");
+ }
+ cmdpush(CS_MATH);
+ e = ecgetstr(state, EC_DUPTOK, &htok);
+ if (htok)
+ singsub(&e);
+ if (isset(XTRACE))
+ fprintf(xtrerr, " %s", e);
+
+ val = matheval(e);
+
+ cmdpop();
+
+ if (isset(XTRACE)) {
+ fprintf(xtrerr, " ))\n");
+ fflush(xtrerr);
+ }
+ if (errflag) {
+ errflag &= ~ERRFLAG_ERROR;
+ return 2;
+ }
+ /* should test for fabs(val.u.d) < epsilon? */
+ return (val.type == MN_INTEGER) ? val.u.l == 0 : val.u.d == 0.0;
+}
+
+/* perform time ... command */
+
+/**/
+static int
+exectime(Estate state, UNUSED(int do_exec))
+{
+ int jb;
+
+ jb = thisjob;
+ if (WC_TIMED_TYPE(state->pc[-1]) == WC_TIMED_EMPTY) {
+ shelltime();
+ return 0;
+ }
+ execpline(state, *state->pc++, Z_TIMED|Z_SYNC, 0);
+ thisjob = jb;
+ return lastval;
+}
+
+/* Define a shell function */
+
+static const char *const ANONYMOUS_FUNCTION_NAME = "(anon)";
+
+/**/
+static int
+execfuncdef(Estate state, Eprog redir_prog)
+{
+ Shfunc shf;
+ char *s = NULL;
+ int signum, nprg, sbeg, nstrs, npats, len, plen, i, htok = 0, ret = 0;
+ int anon_func = 0;
+ Wordcode beg = state->pc, end;
+ Eprog prog;
+ Patprog *pp;
+ LinkList names;
+
+ end = beg + WC_FUNCDEF_SKIP(state->pc[-1]);
+ names = ecgetlist(state, *state->pc++, EC_DUPTOK, &htok);
+ nprg = end - beg;
+ sbeg = *state->pc++;
+ nstrs = *state->pc++;
+ npats = *state->pc++;
+
+ nprg = (end - state->pc);
+ plen = nprg * sizeof(wordcode);
+ len = plen + (npats * sizeof(Patprog)) + nstrs;
+
+ if (htok && names) {
+ execsubst(names);
+ if (errflag) {
+ state->pc = end;
+ return 1;
+ }
+ }
+
+ DPUTS(!names && redir_prog,
+ "Passing redirection to anon function definition.");
+ while (!names || (s = (char *) ugetnode(names))) {
+ if (!names) {
+ prog = (Eprog) zhalloc(sizeof(*prog));
+ prog->nref = -1; /* on the heap */
+ } else {
+ prog = (Eprog) zalloc(sizeof(*prog));
+ prog->nref = 1; /* allocated from permanent storage */
+ }
+ prog->npats = npats;
+ prog->len = len;
+ if (state->prog->dump || !names) {
+ if (!names) {
+ prog->flags = EF_HEAP;
+ prog->dump = NULL;
+ prog->pats = pp = (Patprog *) zhalloc(npats * sizeof(Patprog));
+ } else {
+ prog->flags = EF_MAP;
+ incrdumpcount(state->prog->dump);
+ prog->dump = state->prog->dump;
+ prog->pats = pp = (Patprog *) zalloc(npats * sizeof(Patprog));
+ }
+ prog->prog = state->pc;
+ prog->strs = state->strs + sbeg;
+ } else {
+ prog->flags = EF_REAL;
+ prog->pats = pp = (Patprog *) zalloc(len);
+ prog->prog = (Wordcode) (prog->pats + npats);
+ prog->strs = (char *) (prog->prog + nprg);
+ prog->dump = NULL;
+ memcpy(prog->prog, state->pc, plen);
+ memcpy(prog->strs, state->strs + sbeg, nstrs);
+ }
+ for (i = npats; i--; pp++)
+ *pp = dummy_patprog1;
+ prog->shf = NULL;
+
+ shf = (Shfunc) zalloc(sizeof(*shf));
+ shf->funcdef = prog;
+ shf->node.flags = 0;
+ /* No dircache here, not a directory */
+ shf->filename = ztrdup(scriptfilename);
+ shf->lineno =
+ (funcstack && (funcstack->tp == FS_FUNC ||
+ funcstack->tp == FS_EVAL)) ?
+ funcstack->flineno + lineno :
+ lineno;
+ /*
+ * redir_prog is permanently allocated --- but if
+ * this function has multiple names we need an additional
+ * one. Original redir_prog used with the last name
+ * because earlier functions are freed in case of duplicate
+ * names.
+ */
+ if (names && nonempty(names) && redir_prog)
+ shf->redir = dupeprog(redir_prog, 0);
+ else {
+ shf->redir = redir_prog;
+ redir_prog = 0;
+ }
+ shfunc_set_sticky(shf);
+
+ if (!names) {
+ /*
+ * Anonymous function, execute immediately.
+ * Function name is "(anon)".
+ */
+ LinkList args;
+
+ anon_func = 1;
+ shf->node.flags |= PM_ANONYMOUS;
+
+ state->pc = end;
+ end += *state->pc++;
+ args = ecgetlist(state, *state->pc++, EC_DUPTOK, &htok);
+
+ if (htok && args) {
+ execsubst(args);
+ if (errflag) {
+ freeeprog(shf->funcdef);
+ if (shf->redir) /* shouldn't be */
+ freeeprog(shf->redir);
+ dircache_set(&shf->filename, NULL);
+ zfree(shf, sizeof(*shf));
+ state->pc = end;
+ return 1;
+ }
+ }
+
+ setunderscore((args && nonempty(args)) ?
+ ((char *) getdata(lastnode(args))) : "");
+
+ if (!args)
+ args = newlinklist();
+ shf->node.nam = (char *) ANONYMOUS_FUNCTION_NAME;
+ pushnode(args, shf->node.nam);
+
+ execshfunc(shf, args);
+ ret = lastval;
+
+ if (isset(PRINTEXITVALUE) && isset(SHINSTDIN) &&
+ lastval) {
+#if defined(ZLONG_IS_LONG_LONG) && defined(PRINTF_HAS_LLD)
+ fprintf(stderr, "zsh: exit %lld\n", lastval);
+#else
+ fprintf(stderr, "zsh: exit %ld\n", (long)lastval);
+#endif
+ fflush(stderr);
+ }
+
+ freeeprog(shf->funcdef);
+ if (shf->redir) /* shouldn't be */
+ freeeprog(shf->redir);
+ dircache_set(&shf->filename, NULL);
+ zfree(shf, sizeof(*shf));
+ break;
+ } else {
+ /* is this shell function a signal trap? */
+ if (!strncmp(s, "TRAP", 4) &&
+ (signum = getsignum(s + 4)) != -1) {
+ if (settrap(signum, NULL, ZSIG_FUNC)) {
+ freeeprog(shf->funcdef);
+ dircache_set(&shf->filename, NULL);
+ zfree(shf, sizeof(*shf));
+ state->pc = end;
+ return 1;
+ }
+
+ /*
+ * Remove the old node explicitly in case it has
+ * an alternative name
+ */
+ removetrapnode(signum);
+ }
+ shfunctab->addnode(shfunctab, ztrdup(s), shf);
+ }
+ }
+ if (!anon_func)
+ setunderscore("");
+ if (redir_prog) {
+ /* For completeness, shouldn't happen */
+ freeeprog(redir_prog);
+ }
+ state->pc = end;
+ return ret;
+}
+
+/* Duplicate a sticky emulation */
+
+/**/
+
+mod_export Emulation_options
+sticky_emulation_dup(Emulation_options src, int useheap)
+{
+ Emulation_options newsticky = useheap ?
+ hcalloc(sizeof(*src)) : zshcalloc(sizeof(*src));
+ newsticky->emulation = src->emulation;
+ if (src->n_on_opts) {
+ size_t sz = src->n_on_opts * sizeof(*src->on_opts);
+ newsticky->n_on_opts = src->n_on_opts;
+ newsticky->on_opts = useheap ? zhalloc(sz) : zalloc(sz);
+ memcpy(newsticky->on_opts, src->on_opts, sz);
+ }
+ if (src->n_off_opts) {
+ size_t sz = src->n_off_opts * sizeof(*src->off_opts);
+ newsticky->n_off_opts = src->n_off_opts;
+ newsticky->off_opts = useheap ? zhalloc(sz) : zalloc(sz);
+ memcpy(newsticky->off_opts, src->off_opts, sz);
+ }
+
+ return newsticky;
+}
+
+/* Set the sticky emulation attributes for a shell function */
+
+/**/
+
+mod_export void
+shfunc_set_sticky(Shfunc shf)
+{
+ if (sticky)
+ shf->sticky = sticky_emulation_dup(sticky, 0);
+ else
+ shf->sticky = NULL;
+}
+
+
+/* Main entry point to execute a shell function. */
+
+/**/
+static void
+execshfunc(Shfunc shf, LinkList args)
+{
+ LinkList last_file_list = NULL;
+ unsigned char *ocs;
+ int ocsp, osfc;
+
+ if (errflag)
+ return;
+
+ /* thisjob may be invalid if we're called via execsimple: see execcursh */
+ if (!list_pipe && thisjob != -1 && thisjob != list_pipe_job &&
+ !hasprocs(thisjob)) {
+ /* Without this deletejob the process table *
+ * would be filled by a recursive function. */
+ last_file_list = jobtab[thisjob].filelist;
+ jobtab[thisjob].filelist = NULL;
+ deletejob(jobtab + thisjob, 0);
+ }
+
+ if (isset(XTRACE)) {
+ LinkNode lptr;
+ printprompt4();
+ if (args)
+ for (lptr = firstnode(args); lptr; incnode(lptr)) {
+ if (lptr != firstnode(args))
+ fputc(' ', xtrerr);
+ quotedzputs((char *)getdata(lptr), xtrerr);
+ }
+ fputc('\n', xtrerr);
+ fflush(xtrerr);
+ }
+ queue_signals();
+ ocs = cmdstack;
+ ocsp = cmdsp;
+ cmdstack = (unsigned char *) zalloc(CMDSTACKSZ);
+ cmdsp = 0;
+ if ((osfc = sfcontext) == SFC_NONE)
+ sfcontext = SFC_DIRECT;
+ xtrerr = stderr;
+
+ doshfunc(shf, args, 0);
+
+ sfcontext = osfc;
+ free(cmdstack);
+ cmdstack = ocs;
+ cmdsp = ocsp;
+
+ if (!list_pipe)
+ deletefilelist(last_file_list, 0);
+ unqueue_signals();
+}
+
+/*
+ * Function to execute the special type of command that represents an
+ * autoloaded shell function. The command structure tells us which
+ * function it is. This function is actually called as part of the
+ * execution of the autoloaded function itself, so when the function
+ * has been autoloaded, its list is just run with no frills.
+ *
+ * There are two cases because if we are doing all-singing, all-dancing
+ * non-simple code we load the shell function early in execcmd() (the
+ * action also present in the non-basic version) to check if
+ * there are redirections that need to be handled at that point.
+ * Then we call execautofn_basic() to do the rest.
+ */
+
+/**/
+static int
+execautofn_basic(Estate state, UNUSED(int do_exec))
+{
+ Shfunc shf;
+ char *oldscriptname, *oldscriptfilename;
+
+ shf = state->prog->shf;
+
+ /*
+ * Probably we didn't know the filename where this function was
+ * defined yet.
+ */
+ if (funcstack && !funcstack->filename)
+ funcstack->filename = getshfuncfile(shf);
+
+ oldscriptname = scriptname;
+ oldscriptfilename = scriptfilename;
+ scriptname = dupstring(shf->node.nam);
+ scriptfilename = getshfuncfile(shf);
+ execode(shf->funcdef, 1, 0, "loadautofunc");
+ scriptname = oldscriptname;
+ scriptfilename = oldscriptfilename;
+
+ return lastval;
+}
+
+/**/
+static int
+execautofn(Estate state, UNUSED(int do_exec))
+{
+ Shfunc shf;
+
+ if (!(shf = loadautofn(state->prog->shf, 1, 0, 0)))
+ return 1;
+
+ state->prog->shf = shf;
+ return execautofn_basic(state, 0);
+}
+
+/*
+ * Helper function to install the source file name of a shell function
+ * just autoloaded.
+ *
+ * We attempt to do this efficiently as the typical case is the
+ * directory part is a well-known directory, which is cached, and
+ * the non-directory part is the same as the node name.
+ */
+
+/**/
+static void
+loadautofnsetfile(Shfunc shf, char *fdir)
+{
+ /*
+ * If shf->filename is already the load directory ---
+ * keep it as we can still use it to get the load file.
+ * This makes autoload with an absolute path particularly efficient.
+ */
+ if (!(shf->node.flags & PM_LOADDIR) ||
+ strcmp(shf->filename, fdir) != 0) {
+ /* Old directory name not useful... */
+ dircache_set(&shf->filename, NULL);
+ if (fdir) {
+ /* ...can still cache directory */
+ shf->node.flags |= PM_LOADDIR;
+ dircache_set(&shf->filename, fdir);
+ } else {
+ /* ...no separate directory part to cache, for some reason. */
+ shf->node.flags &= ~PM_LOADDIR;
+ shf->filename = ztrdup(shf->node.nam);
+ }
+ }
+}
+
+/**/
+Shfunc
+loadautofn(Shfunc shf, int fksh, int autol, int current_fpath)
+{
+ int noalias = noaliases, ksh = 1;
+ Eprog prog;
+ char *fdir; /* Directory path where func found */
+
+ pushheap();
+
+ noaliases = (shf->node.flags & PM_UNALIASED);
+ if (shf->filename && shf->filename[0] == '/' &&
+ (shf->node.flags & PM_LOADDIR))
+ {
+ char *spec_path[2];
+ spec_path[0] = dupstring(shf->filename);
+ spec_path[1] = NULL;
+ prog = getfpfunc(shf->node.nam, &ksh, &fdir, spec_path, 0);
+ if (prog == &dummy_eprog &&
+ (current_fpath || (shf->node.flags & PM_CUR_FPATH)))
+ prog = getfpfunc(shf->node.nam, &ksh, &fdir, NULL, 0);
+ }
+ else
+ prog = getfpfunc(shf->node.nam, &ksh, &fdir, NULL, 0);
+ noaliases = noalias;
+
+ if (ksh == 1) {
+ ksh = fksh;
+ if (ksh == 1)
+ ksh = (shf->node.flags & PM_KSHSTORED) ? 2 :
+ (shf->node.flags & PM_ZSHSTORED) ? 0 : 1;
+ }
+
+ if (prog == &dummy_eprog) {
+ /* We're not actually in the function; decrement locallevel */
+ locallevel--;
+ zwarn("%s: function definition file not found", shf->node.nam);
+ locallevel++;
+ popheap();
+ return NULL;
+ }
+ if (!prog) {
+ popheap();
+ return NULL;
+ }
+ if (ksh == 2 || (ksh == 1 && isset(KSHAUTOLOAD))) {
+ if (autol) {
+ prog->flags |= EF_RUN;
+
+ freeeprog(shf->funcdef);
+ if (prog->flags & EF_MAP)
+ shf->funcdef = prog;
+ else
+ shf->funcdef = dupeprog(prog, 0);
+ shf->node.flags &= ~PM_UNDEFINED;
+ loadautofnsetfile(shf, fdir);
+ } else {
+ VARARR(char, n, strlen(shf->node.nam) + 1);
+ strcpy(n, shf->node.nam);
+ execode(prog, 1, 0, "evalautofunc");
+ shf = (Shfunc) shfunctab->getnode(shfunctab, n);
+ if (!shf || (shf->node.flags & PM_UNDEFINED)) {
+ /* We're not actually in the function; decrement locallevel */
+ locallevel--;
+ zwarn("%s: function not defined by file", n);
+ locallevel++;
+ popheap();
+ return NULL;
+ }
+ }
+ } else {
+ freeeprog(shf->funcdef);
+ if (prog->flags & EF_MAP)
+ shf->funcdef = stripkshdef(prog, shf->node.nam);
+ else
+ shf->funcdef = dupeprog(stripkshdef(prog, shf->node.nam), 0);
+ shf->node.flags &= ~PM_UNDEFINED;
+ loadautofnsetfile(shf, fdir);
+ }
+ popheap();
+
+ return shf;
+}
+
+/*
+ * Check if a sticky emulation differs from the current one.
+ */
+
+/**/
+
+int sticky_emulation_differs(Emulation_options sticky2)
+{
+ /* If no new sticky emulation, not a different emulation */
+ if (!sticky2)
+ return 0;
+ /* If no current sticky emulation, different */
+ if (!sticky)
+ return 1;
+ /* If basic emulation different, different */
+ if (sticky->emulation != sticky2->emulation)
+ return 1;
+ /* If differing numbers of options, different */
+ if (sticky->n_on_opts != sticky2->n_on_opts ||
+ sticky->n_off_opts != sticky2->n_off_opts)
+ return 1;
+ /*
+ * We need to compare option arrays, if non-null.
+ * We made parseopts() create the list of options in option
+ * order to make this easy.
+ */
+ /* If different options turned on, different */
+ if (sticky->n_on_opts &&
+ memcmp(sticky->on_opts, sticky2->on_opts,
+ sticky->n_on_opts * sizeof(*sticky->on_opts)) != 0)
+ return 1;
+ /* If different options turned on, different */
+ if (sticky->n_off_opts &&
+ memcmp(sticky->off_opts, sticky2->off_opts,
+ sticky->n_off_opts * sizeof(*sticky->off_opts)) != 0)
+ return 1;
+ return 0;
+}
+
+/*
+ * execute a shell function
+ *
+ * name is the name of the function
+ *
+ * prog is the code to execute
+ *
+ * doshargs, if set, are parameters to pass to the function,
+ * in which the first element is the function name (even if
+ * FUNCTIONARGZERO is set as this is handled inside this function).
+ *
+ * If noreturnval is nonzero, then reset the current return
+ * value (lastval) to its value before the shell function
+ * was executed. However, in any case return the status value
+ * from the function (i.e. if noreturnval is not set, this
+ * will be the same as lastval).
+ */
+
+/**/
+mod_export int
+doshfunc(Shfunc shfunc, LinkList doshargs, int noreturnval)
+{
+ char **pptab, **x;
+ int ret;
+ char *name = shfunc->node.nam;
+ int flags = shfunc->node.flags;
+ char *fname = dupstring(name);
+ Eprog prog;
+ static int oflags;
+ static int funcdepth;
+ Heap funcheap;
+
+ queue_signals(); /* Lots of memory and global state changes coming */
+
+ NEWHEAPS(funcheap) {
+ /*
+ * Save data in heap rather than on stack to keep recursive
+ * function cost down --- use of heap memory should be efficient
+ * at this point. Saving is not actually massive.
+ */
+ Funcsave funcsave = zhalloc(sizeof(struct funcsave));
+ funcsave->scriptname = scriptname;
+ funcsave->argv0 = NULL;
+ funcsave->breaks = breaks;
+ funcsave->contflag = contflag;
+ funcsave->loops = loops;
+ funcsave->lastval = lastval;
+ funcsave->pipestats = NULL;
+ funcsave->numpipestats = numpipestats;
+ funcsave->noerrexit = noerrexit;
+ if (trap_state == TRAP_STATE_PRIMED)
+ trap_return--;
+ /*
+ * Suppression of ERR_RETURN is turned off in function scope.
+ */
+ noerrexit &= ~NOERREXIT_RETURN;
+ if (noreturnval) {
+ /*
+ * Easiest to use the heap here since we're bracketed
+ * immediately by a pushheap/popheap pair.
+ */
+ size_t bytes = sizeof(int)*numpipestats;
+ funcsave->pipestats = (int *)zhalloc(bytes);
+ memcpy(funcsave->pipestats, pipestats, bytes);
+ }
+
+ starttrapscope();
+ startpatternscope();
+
+ pptab = pparams;
+ if (!(flags & PM_UNDEFINED))
+ scriptname = dupstring(name);
+ funcsave->zoptind = zoptind;
+ funcsave->optcind = optcind;
+ if (!isset(POSIXBUILTINS)) {
+ zoptind = 1;
+ optcind = 0;
+ }
+
+ /* We need to save the current options even if LOCALOPTIONS is *
+ * not currently set. That's because if it gets set in the *
+ * function we need to restore the original options on exit. */
+ memcpy(funcsave->opts, opts, sizeof(opts));
+ funcsave->emulation = emulation;
+ funcsave->sticky = sticky;
+
+ if (sticky_emulation_differs(shfunc->sticky)) {
+ /*
+ * Function is marked for sticky emulation.
+ * Enable it now.
+ *
+ * We deliberately do not do this if the sticky emulation
+ * in effect is the same as that requested. This enables
+ * option setting naturally within emulation environments.
+ * Note that a difference in EMULATE_FULLY (emulate with
+ * or without -R) counts as a different environment.
+ *
+ * This propagates the sticky emulation to subfunctions.
+ */
+ sticky = sticky_emulation_dup(shfunc->sticky, 1);
+ emulation = sticky->emulation;
+ funcsave->restore_sticky = 1;
+ installemulation(emulation, opts);
+ if (sticky->n_on_opts) {
+ OptIndex *onptr;
+ for (onptr = sticky->on_opts;
+ onptr < sticky->on_opts + sticky->n_on_opts;
+ onptr++)
+ opts[*onptr] = 1;
+ }
+ if (sticky->n_off_opts) {
+ OptIndex *offptr;
+ for (offptr = sticky->off_opts;
+ offptr < sticky->off_opts + sticky->n_off_opts;
+ offptr++)
+ opts[*offptr] = 0;
+ }
+ /* All emulations start with pattern disables clear */
+ clearpatterndisables();
+ } else
+ funcsave->restore_sticky = 0;
+
+ if (flags & (PM_TAGGED|PM_TAGGED_LOCAL))
+ opts[XTRACE] = 1;
+ else if (oflags & PM_TAGGED_LOCAL) {
+ if (shfunc->node.nam == ANONYMOUS_FUNCTION_NAME /* pointer comparison */)
+ flags |= PM_TAGGED_LOCAL;
+ else
+ opts[XTRACE] = 0;
+ }
+ if (flags & PM_WARNNESTED)
+ opts[WARNNESTEDVAR] = 1;
+ else if (oflags & PM_WARNNESTED) {
+ if (shfunc->node.nam == ANONYMOUS_FUNCTION_NAME)
+ flags |= PM_WARNNESTED;
+ else
+ opts[WARNNESTEDVAR] = 0;
+ }
+ funcsave->oflags = oflags;
+ /*
+ * oflags is static, because we compare it on the next recursive
+ * call. Hence also we maintain a saved version for restoring
+ * the previous value of oflags after the call.
+ */
+ oflags = flags;
+ opts[PRINTEXITVALUE] = 0;
+ if (doshargs) {
+ LinkNode node;
+
+ node = firstnode(doshargs);
+ pparams = x = (char **) zshcalloc(((sizeof *x) *
+ (1 + countlinknodes(doshargs))));
+ if (isset(FUNCTIONARGZERO)) {
+ funcsave->argv0 = argzero;
+ argzero = ztrdup(getdata(node));
+ }
+ /* first node contains name regardless of option */
+ node = node->next;
+ for (; node; node = node->next, x++)
+ *x = ztrdup(getdata(node));
+ } else {
+ pparams = (char **) zshcalloc(sizeof *pparams);
+ if (isset(FUNCTIONARGZERO)) {
+ funcsave->argv0 = argzero;
+ argzero = ztrdup(argzero);
+ }
+ }
+ ++funcdepth;
+ if (zsh_funcnest >= 0 && funcdepth > zsh_funcnest) {
+ zerr("maximum nested function level reached; increase FUNCNEST?");
+ lastval = 1;
+ goto undoshfunc;
+ }
+ funcsave->fstack.name = dupstring(name);
+ /*
+ * The caller is whatever is immediately before on the stack,
+ * unless we're at the top, in which case it's the script
+ * or interactive shell name.
+ */
+ funcsave->fstack.caller = funcstack ? funcstack->name :
+ dupstring(funcsave->argv0 ? funcsave->argv0 : argzero);
+ funcsave->fstack.lineno = lineno;
+ funcsave->fstack.prev = funcstack;
+ funcsave->fstack.tp = FS_FUNC;
+ funcstack = &funcsave->fstack;
+
+ funcsave->fstack.flineno = shfunc->lineno;
+ funcsave->fstack.filename = getshfuncfile(shfunc);
+
+ prog = shfunc->funcdef;
+ if (prog->flags & EF_RUN) {
+ Shfunc shf;
+
+ prog->flags &= ~EF_RUN;
+
+ runshfunc(prog, NULL, funcsave->fstack.name);
+
+ if (!(shf = (Shfunc) shfunctab->getnode(shfunctab,
+ (name = fname)))) {
+ zwarn("%s: function not defined by file", name);
+ if (noreturnval)
+ errflag |= ERRFLAG_ERROR;
+ else
+ lastval = 1;
+ goto doneshfunc;
+ }
+ prog = shf->funcdef;
+ }
+ runshfunc(prog, wrappers, funcsave->fstack.name);
+ doneshfunc:
+ funcstack = funcsave->fstack.prev;
+ undoshfunc:
+ --funcdepth;
+ if (retflag) {
+ /*
+ * This function is forced to return.
+ */
+ retflag = 0;
+ /*
+ * The calling function isn't necessarily forced to return,
+ * but it should be made sensitive to ERR_EXIT and
+ * ERR_RETURN as the assumptions we made at the end of
+ * constructs within this function no longer apply. If
+ * there are cases where this is not true, they need adding
+ * to C03traps.ztst.
+ */
+ this_noerrexit = 0;
+ breaks = funcsave->breaks;
+ }
+ freearray(pparams);
+ if (funcsave->argv0) {
+ zsfree(argzero);
+ argzero = funcsave->argv0;
+ }
+ pparams = pptab;
+ if (!isset(POSIXBUILTINS)) {
+ zoptind = funcsave->zoptind;
+ optcind = funcsave->optcind;
+ }
+ scriptname = funcsave->scriptname;
+ oflags = funcsave->oflags;
+
+ endpatternscope(); /* before restoring old LOCALPATTERNS */
+
+ if (funcsave->restore_sticky) {
+ /*
+ * If we switched to an emulation environment just for
+ * this function, we interpret the option and emulation
+ * switch as being a firewall between environments.
+ */
+ memcpy(opts, funcsave->opts, sizeof(opts));
+ emulation = funcsave->emulation;
+ sticky = funcsave->sticky;
+ } else if (isset(LOCALOPTIONS)) {
+ /* restore all shell options except PRIVILEGED and RESTRICTED */
+ funcsave->opts[PRIVILEGED] = opts[PRIVILEGED];
+ funcsave->opts[RESTRICTED] = opts[RESTRICTED];
+ memcpy(opts, funcsave->opts, sizeof(opts));
+ emulation = funcsave->emulation;
+ } else {
+ /* just restore a couple. */
+ opts[XTRACE] = funcsave->opts[XTRACE];
+ opts[PRINTEXITVALUE] = funcsave->opts[PRINTEXITVALUE];
+ opts[LOCALOPTIONS] = funcsave->opts[LOCALOPTIONS];
+ opts[LOCALLOOPS] = funcsave->opts[LOCALLOOPS];
+ opts[WARNNESTEDVAR] = funcsave->opts[WARNNESTEDVAR];
+ }
+
+ if (opts[LOCALLOOPS]) {
+ if (contflag)
+ zwarn("`continue' active at end of function scope");
+ if (breaks)
+ zwarn("`break' active at end of function scope");
+ breaks = funcsave->breaks;
+ contflag = funcsave->contflag;
+ loops = funcsave->loops;
+ }
+
+ endtrapscope();
+
+ if (trap_state == TRAP_STATE_PRIMED)
+ trap_return++;
+ ret = lastval;
+ noerrexit = funcsave->noerrexit;
+ if (noreturnval) {
+ lastval = funcsave->lastval;
+ numpipestats = funcsave->numpipestats;
+ memcpy(pipestats, funcsave->pipestats, sizeof(int)*numpipestats);
+ }
+ } OLDHEAPS;
+
+ unqueue_signals();
+
+ /*
+ * Exit with a tidy up.
+ * Only leave if we're at the end of the appropriate function ---
+ * not a nested function. As we usually skip the function body,
+ * the only likely case where we need that second test is
+ * when we have an "always" block. The endparamscope() has
+ * already happened, hence the "+1" here.
+ *
+ * If we are in an exit trap, finish it first... we wouldn't set
+ * exit_pending if we were already in one.
+ */
+ if (exit_pending && exit_level >= locallevel+1 && !in_exit_trap) {
+ if (locallevel > forklevel) {
+ /* Still functions to return: force them to do so. */
+ retflag = 1;
+ breaks = loops;
+ } else {
+ /*
+ * All functions finished: time to exit the shell.
+ * We already did the `stopmsg' test when the
+ * exit command was handled.
+ */
+ stopmsg = 1;
+ zexit(exit_pending >> 1, 0);
+ }
+ }
+
+ return ret;
+}
+
+/* This finally executes a shell function and any function wrappers *
+ * defined by modules. This works by calling the wrapper function which *
+ * in turn has to call back this function with the arguments it gets. */
+
+/**/
+mod_export void
+runshfunc(Eprog prog, FuncWrap wrap, char *name)
+{
+ int cont, ouu;
+ char *ou;
+
+ queue_signals();
+
+ ou = zalloc(ouu = underscoreused);
+ if (ou)
+ memcpy(ou, zunderscore, underscoreused);
+
+ while (wrap) {
+ wrap->module->wrapper++;
+ cont = wrap->handler(prog, wrap->next, name);
+ wrap->module->wrapper--;
+
+ if (!wrap->module->wrapper &&
+ (wrap->module->node.flags & MOD_UNLOAD))
+ unload_module(wrap->module);
+
+ if (!cont) {
+ if (ou)
+ zfree(ou, ouu);
+ unqueue_signals();
+ return;
+ }
+ wrap = wrap->next;
+ }
+ startparamscope();
+ execode(prog, 1, 0, "shfunc"); /* handles signal unqueueing */
+ if (ou) {
+ setunderscore(ou);
+ zfree(ou, ouu);
+ }
+ endparamscope();
+
+ unqueue_signals();
+}
+
+/*
+ * Search fpath for an undefined function. Finds the file, and returns the
+ * list of its contents.
+ *
+ * If test is 0, load the function.
+ *
+ * If test_only is 1, don't load function, just test for it:
+ * Non-null return means function was found
+ *
+ * *fdir points to path at which found (as passed in, not duplicated)
+ */
+
+/**/
+Eprog
+getfpfunc(char *s, int *ksh, char **fdir, char **alt_path, int test_only)
+{
+ char **pp, buf[PATH_MAX+1];
+ off_t len;
+ off_t rlen;
+ char *d;
+ Eprog r;
+ int fd;
+
+ pp = alt_path ? alt_path : fpath;
+ for (; *pp; pp++) {
+ if (strlen(*pp) + strlen(s) + 1 >= PATH_MAX)
+ continue;
+ if (**pp)
+ sprintf(buf, "%s/%s", *pp, s);
+ else
+ strcpy(buf, s);
+ if ((r = try_dump_file(*pp, s, buf, ksh, test_only))) {
+ if (fdir)
+ *fdir = *pp;
+ return r;
+ }
+ unmetafy(buf, NULL);
+ if (!access(buf, R_OK) && (fd = open(buf, O_RDONLY | O_NOCTTY)) != -1) {
+ struct stat st;
+ if (!fstat(fd, &st) && S_ISREG(st.st_mode) &&
+ (len = lseek(fd, 0, 2)) != -1) {
+ if (test_only) {
+ close(fd);
+ if (fdir)
+ *fdir = *pp;
+ return &dummy_eprog;
+ }
+ d = (char *) zalloc(len + 1);
+ lseek(fd, 0, 0);
+ if ((rlen = read(fd, d, len)) >= 0) {
+ char *oldscriptname = scriptname;
+
+ close(fd);
+ d[rlen] = '\0';
+ d = metafy(d, rlen, META_REALLOC);
+
+ scriptname = dupstring(s);
+ r = parse_string(d, 1);
+ scriptname = oldscriptname;
+
+ if (fdir)
+ *fdir = *pp;
+
+ zfree(d, len + 1);
+
+ return r;
+ } else
+ close(fd);
+
+ zfree(d, len + 1);
+ } else
+ close(fd);
+ }
+ }
+ return test_only ? NULL : &dummy_eprog;
+}
+
+/* Handle the most common type of ksh-style autoloading, when doing a *
+ * zsh-style autoload. Given the list read from an autoload file, and the *
+ * name of the function being defined, check to see if the file consists *
+ * entirely of a single definition for that function. If so, use the *
+ * contents of that definition. Otherwise, use the entire file. */
+
+/**/
+Eprog
+stripkshdef(Eprog prog, char *name)
+{
+ Wordcode pc;
+ wordcode code;
+ char *ptr1, *ptr2;
+
+ if (!prog)
+ return NULL;
+ pc = prog->prog;
+ code = *pc++;
+ if (wc_code(code) != WC_LIST ||
+ (WC_LIST_TYPE(code) & (Z_SYNC|Z_END|Z_SIMPLE)) != (Z_SYNC|Z_END|Z_SIMPLE))
+ return prog;
+ pc++;
+ code = *pc++;
+ if (wc_code(code) != WC_FUNCDEF || *pc != 1)
+ return prog;
+
+ /*
+ * See if name of function requested (name) is same as
+ * name of function in word code. name may still have "-"
+ * tokenised. The word code shouldn't, as function names should be
+ * untokenised, but reports say it sometimes does.
+ */
+ ptr1 = name;
+ ptr2 = ecrawstr(prog, pc + 1, NULL);
+ while (*ptr1 && *ptr2) {
+ if (*ptr1 != *ptr2 && *ptr1 != Dash && *ptr1 != '-' &&
+ *ptr2 != Dash && *ptr2 != '-')
+ break;
+ ptr1++;
+ ptr2++;
+ }
+ if (*ptr1 || *ptr2)
+ return prog;
+
+ {
+ Eprog ret;
+ Wordcode end = pc + WC_FUNCDEF_SKIP(code);
+ int sbeg = pc[2], nstrs = pc[3], nprg, npats = pc[4], plen, len, i;
+ Patprog *pp;
+
+ pc += 5;
+
+ nprg = end - pc;
+ plen = nprg * sizeof(wordcode);
+ len = plen + (npats * sizeof(Patprog)) + nstrs;
+
+ if (prog->flags & EF_MAP) {
+ ret = prog;
+ free(prog->pats);
+ ret->pats = pp = (Patprog *) zalloc(npats * sizeof(Patprog));
+ ret->prog = pc;
+ ret->strs = prog->strs + sbeg;
+ } else {
+ ret = (Eprog) zhalloc(sizeof(*ret));
+ ret->flags = EF_HEAP;
+ ret->pats = pp = (Patprog *) zhalloc(len);
+ ret->prog = (Wordcode) (ret->pats + npats);
+ ret->strs = (char *) (ret->prog + nprg);
+ memcpy(ret->prog, pc, plen);
+ memcpy(ret->strs, prog->strs + sbeg, nstrs);
+ ret->dump = NULL;
+ }
+ ret->len = len;
+ ret->npats = npats;
+ for (i = npats; i--; pp++)
+ *pp = dummy_patprog1;
+ ret->shf = NULL;
+
+ return ret;
+ }
+}
+
+/* check to see if AUTOCD applies here */
+
+/**/
+static char *
+cancd(char *s)
+{
+ int nocdpath = s[0] == '.' &&
+ (s[1] == '/' || !s[1] || (s[1] == '.' && (s[2] == '/' || !s[1])));
+ char *t;
+
+ if (*s != '/') {
+ char sbuf[PATH_MAX+1], **cp;
+
+ if (cancd2(s))
+ return s;
+ if (access(unmeta(s), X_OK) == 0)
+ return NULL;
+ if (!nocdpath)
+ for (cp = cdpath; *cp; cp++) {
+ if (strlen(*cp) + strlen(s) + 1 >= PATH_MAX)
+ continue;
+ if (**cp)
+ sprintf(sbuf, "%s/%s", *cp, s);
+ else
+ strcpy(sbuf, s);
+ if (cancd2(sbuf)) {
+ doprintdir = -1;
+ return dupstring(sbuf);
+ }
+ }
+ if ((t = cd_able_vars(s))) {
+ if (cancd2(t)) {
+ doprintdir = -1;
+ return t;
+ }
+ }
+ return NULL;
+ }
+ return cancd2(s) ? s : NULL;
+}
+
+/**/
+static int
+cancd2(char *s)
+{
+ struct stat buf;
+ char *us, *us2 = NULL;
+ int ret;
+
+ /*
+ * If CHASEDOTS and CHASELINKS are not set, we want to rationalize the
+ * path by removing foo/.. combinations in the logical rather than
+ * the physical path. If either is set, we test the physical path.
+ */
+ if (!isset(CHASEDOTS) && !isset(CHASELINKS)) {
+ if (*s != '/')
+ us = tricat(pwd[1] ? pwd : "", "/", s);
+ else
+ us = ztrdup(s);
+ fixdir(us2 = us);
+ } else
+ us = unmeta(s);
+ ret = !(access(us, X_OK) || stat(us, &buf) || !S_ISDIR(buf.st_mode));
+ if (us2)
+ free(us2);
+ return ret;
+}
+
+/**/
+void
+execsave(void)
+{
+ struct execstack *es;
+
+ es = (struct execstack *) zalloc(sizeof(struct execstack));
+ es->list_pipe_pid = list_pipe_pid;
+ es->nowait = nowait;
+ es->pline_level = pline_level;
+ es->list_pipe_child = list_pipe_child;
+ es->list_pipe_job = list_pipe_job;
+ strcpy(es->list_pipe_text, list_pipe_text);
+ es->lastval = lastval;
+ es->noeval = noeval;
+ es->badcshglob = badcshglob;
+ es->cmdoutpid = cmdoutpid;
+ es->cmdoutval = cmdoutval;
+ es->use_cmdoutval = use_cmdoutval;
+ es->procsubstpid = procsubstpid;
+ es->trap_return = trap_return;
+ es->trap_state = trap_state;
+ es->trapisfunc = trapisfunc;
+ es->traplocallevel = traplocallevel;
+ es->noerrs = noerrs;
+ es->this_noerrexit = this_noerrexit;
+ es->underscore = ztrdup(zunderscore);
+ es->next = exstack;
+ exstack = es;
+ noerrs = cmdoutpid = 0;
+}
+
+/**/
+void
+execrestore(void)
+{
+ struct execstack *en = exstack;
+
+ DPUTS(!exstack, "BUG: execrestore() without execsave()");
+
+ queue_signals();
+ exstack = exstack->next;
+
+ list_pipe_pid = en->list_pipe_pid;
+ nowait = en->nowait;
+ pline_level = en->pline_level;
+ list_pipe_child = en->list_pipe_child;
+ list_pipe_job = en->list_pipe_job;
+ strcpy(list_pipe_text, en->list_pipe_text);
+ lastval = en->lastval;
+ noeval = en->noeval;
+ badcshglob = en->badcshglob;
+ cmdoutpid = en->cmdoutpid;
+ cmdoutval = en->cmdoutval;
+ use_cmdoutval = en->use_cmdoutval;
+ procsubstpid = en->procsubstpid;
+ trap_return = en->trap_return;
+ trap_state = en->trap_state;
+ trapisfunc = en->trapisfunc;
+ traplocallevel = en->traplocallevel;
+ noerrs = en->noerrs;
+ this_noerrexit = en->this_noerrexit;
+ setunderscore(en->underscore);
+ zsfree(en->underscore);
+ free(en);
+
+ unqueue_signals();
+}
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/glob.c b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/glob.c
new file mode 100644
index 0000000..ed2c90b
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/glob.c
@@ -0,0 +1,3913 @@
+/*
+ * glob.c - filename generation
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+#include "zsh.mdh"
+#include "glob.pro"
+
+#if defined(OFF_T_IS_64_BIT) && defined(__GNUC__)
+# define ALIGN64 __attribute__((aligned(8)))
+#else
+# define ALIGN64
+#endif
+
+/* flag for CSHNULLGLOB */
+
+typedef struct gmatch *Gmatch;
+
+struct gmatch {
+ /* Metafied file name */
+ char *name;
+ /* Unmetafied file name; embedded nulls can't occur in file names */
+ char *uname;
+ /*
+ * Array of sort strings: one for each GS_EXEC sort type in
+ * the glob qualifiers.
+ */
+ char **sortstrs;
+ off_t size ALIGN64;
+ long atime;
+ long mtime;
+ long ctime;
+ long links;
+ off_t _size ALIGN64;
+ long _atime;
+ long _mtime;
+ long _ctime;
+ long _links;
+#ifdef GET_ST_ATIME_NSEC
+ long ansec;
+ long _ansec;
+#endif
+#ifdef GET_ST_MTIME_NSEC
+ long mnsec;
+ long _mnsec;
+#endif
+#ifdef GET_ST_CTIME_NSEC
+ long cnsec;
+ long _cnsec;
+#endif
+};
+
+#define GS_NAME 1
+#define GS_DEPTH 2
+#define GS_EXEC 4
+
+#define GS_SHIFT_BASE 8
+
+#define GS_SIZE (GS_SHIFT_BASE)
+#define GS_ATIME (GS_SHIFT_BASE << 1)
+#define GS_MTIME (GS_SHIFT_BASE << 2)
+#define GS_CTIME (GS_SHIFT_BASE << 3)
+#define GS_LINKS (GS_SHIFT_BASE << 4)
+
+#define GS_SHIFT 5
+#define GS__SIZE (GS_SIZE << GS_SHIFT)
+#define GS__ATIME (GS_ATIME << GS_SHIFT)
+#define GS__MTIME (GS_MTIME << GS_SHIFT)
+#define GS__CTIME (GS_CTIME << GS_SHIFT)
+#define GS__LINKS (GS_LINKS << GS_SHIFT)
+
+#define GS_DESC (GS_SHIFT_BASE << (2*GS_SHIFT))
+#define GS_NONE (GS_SHIFT_BASE << (2*GS_SHIFT+1))
+
+#define GS_NORMAL (GS_SIZE | GS_ATIME | GS_MTIME | GS_CTIME | GS_LINKS)
+#define GS_LINKED (GS_NORMAL << GS_SHIFT)
+
+/**/
+int badcshglob;
+
+/**/
+int pathpos; /* position in pathbuf (needed by pattern code) */
+
+/*
+ * pathname buffer (needed by pattern code).
+ * It is currently believed the string in here is stored metafied and is
+ * unmetafied temporarily as needed by system calls.
+ */
+
+/**/
+char *pathbuf;
+
+typedef struct stat *Statptr; /* This makes the Ultrix compiler happy. Go figure. */
+
+/* modifier for unit conversions */
+
+#define TT_DAYS 0
+#define TT_HOURS 1
+#define TT_MINS 2
+#define TT_WEEKS 3
+#define TT_MONTHS 4
+#define TT_SECONDS 5
+
+#define TT_BYTES 0
+#define TT_POSIX_BLOCKS 1
+#define TT_KILOBYTES 2
+#define TT_MEGABYTES 3
+#define TT_GIGABYTES 4
+#define TT_TERABYTES 5
+
+
+typedef int (*TestMatchFunc) _((char *, struct stat *, off_t, char *));
+
+struct qual {
+ struct qual *next; /* Next qualifier, must match */
+ struct qual *or; /* Alternative set of qualifiers to match */
+ TestMatchFunc func; /* Function to call to test match */
+ off_t data ALIGN64; /* Argument passed to function */
+ int sense; /* Whether asserting or negating */
+ int amc; /* Flag for which time to test (a, m, c) */
+ int range; /* Whether to test <, > or = (as per signum) */
+ int units; /* Multiplier for time or size, respectively */
+ char *sdata; /* currently only: expression to eval */
+};
+
+/* Prefix, suffix for doing zle trickery */
+
+/**/
+mod_export char *glob_pre, *glob_suf;
+
+/* Element of a glob sort */
+struct globsort {
+ /* Sort type */
+ int tp;
+ /* Sort code to eval, if type is GS_EXEC */
+ char *exec;
+};
+
+/* Maximum entries in sort array */
+#define MAX_SORTS (12)
+
+/* struct to easily save/restore current state */
+
+struct globdata {
+ int gd_pathpos;
+ char *gd_pathbuf;
+
+ int gd_matchsz; /* size of matchbuf */
+ int gd_matchct; /* number of matches found */
+ int gd_pathbufsz; /* size of pathbuf */
+ int gd_pathbufcwd; /* where did we chdir()'ed */
+ Gmatch gd_matchbuf; /* array of matches */
+ Gmatch gd_matchptr; /* &matchbuf[matchct] */
+ char *gd_colonmod; /* colon modifiers in qualifier list */
+
+ /* Qualifiers pertaining to current pattern */
+ struct qual *gd_quals;
+
+ /* Other state values for current pattern */
+ int gd_qualct, gd_qualorct;
+ int gd_range, gd_amc, gd_units;
+ int gd_gf_nullglob, gd_gf_markdirs, gd_gf_noglobdots, gd_gf_listtypes;
+ int gd_gf_numsort;
+ int gd_gf_follow, gd_gf_sorts, gd_gf_nsorts;
+ struct globsort gd_gf_sortlist[MAX_SORTS];
+ LinkList gd_gf_pre_words, gd_gf_post_words;
+
+ char *gd_glob_pre, *gd_glob_suf;
+};
+
+/* The variable with the current globbing state and convenience macros */
+
+static struct globdata curglobdata;
+
+#define matchsz (curglobdata.gd_matchsz)
+#define matchct (curglobdata.gd_matchct)
+#define pathbufsz (curglobdata.gd_pathbufsz)
+#define pathbufcwd (curglobdata.gd_pathbufcwd)
+#define matchbuf (curglobdata.gd_matchbuf)
+#define matchptr (curglobdata.gd_matchptr)
+#define colonmod (curglobdata.gd_colonmod)
+#define quals (curglobdata.gd_quals)
+#define qualct (curglobdata.gd_qualct)
+#define qualorct (curglobdata.gd_qualorct)
+#define g_range (curglobdata.gd_range)
+#define g_amc (curglobdata.gd_amc)
+#define g_units (curglobdata.gd_units)
+#define gf_nullglob (curglobdata.gd_gf_nullglob)
+#define gf_markdirs (curglobdata.gd_gf_markdirs)
+#define gf_noglobdots (curglobdata.gd_gf_noglobdots)
+#define gf_listtypes (curglobdata.gd_gf_listtypes)
+#define gf_numsort (curglobdata.gd_gf_numsort)
+#define gf_follow (curglobdata.gd_gf_follow)
+#define gf_sorts (curglobdata.gd_gf_sorts)
+#define gf_nsorts (curglobdata.gd_gf_nsorts)
+#define gf_sortlist (curglobdata.gd_gf_sortlist)
+#define gf_pre_words (curglobdata.gd_gf_pre_words)
+#define gf_post_words (curglobdata.gd_gf_post_words)
+
+/* and macros for save/restore */
+
+#define save_globstate(N) \
+ do { \
+ queue_signals(); \
+ memcpy(&(N), &curglobdata, sizeof(struct globdata)); \
+ (N).gd_pathpos = pathpos; \
+ (N).gd_pathbuf = pathbuf; \
+ (N).gd_glob_pre = glob_pre; \
+ (N).gd_glob_suf = glob_suf; \
+ pathbuf = NULL; \
+ unqueue_signals(); \
+ } while (0)
+
+#define restore_globstate(N) \
+ do { \
+ queue_signals(); \
+ zfree(pathbuf, pathbufsz); \
+ memcpy(&curglobdata, &(N), sizeof(struct globdata)); \
+ pathpos = (N).gd_pathpos; \
+ pathbuf = (N).gd_pathbuf; \
+ glob_pre = (N).gd_glob_pre; \
+ glob_suf = (N).gd_glob_suf; \
+ unqueue_signals(); \
+ } while (0)
+
+/* pathname component in filename patterns */
+
+struct complist {
+ Complist next;
+ Patprog pat;
+ int closure; /* 1 if this is a (foo/)# */
+ int follow; /* 1 to go thru symlinks */
+};
+
+/* Add a component to pathbuf: This keeps track of how *
+ * far we are into a file name, since each path component *
+ * must be matched separately. */
+
+/**/
+static void
+addpath(char *s, int l)
+{
+ DPUTS(!pathbuf, "BUG: pathbuf not initialised");
+ while (pathpos + l + 1 >= pathbufsz)
+ pathbuf = zrealloc(pathbuf, pathbufsz *= 2);
+ while (l--)
+ pathbuf[pathpos++] = *s++;
+ pathbuf[pathpos++] = '/';
+ pathbuf[pathpos] = '\0';
+}
+
+/* stat the filename s appended to pathbuf. l should be true for lstat, *
+ * false for stat. If st is NULL, the file is only checked for existance. *
+ * s == "" is treated as s == ".". This is necessary since on most systems *
+ * foo/ can be used to reference a non-directory foo. Returns nonzero if *
+ * the file does not exists. */
+
+/**/
+static int
+statfullpath(const char *s, struct stat *st, int l)
+{
+ char buf[PATH_MAX+1];
+
+ DPUTS(strlen(s) + !*s + pathpos - pathbufcwd >= PATH_MAX,
+ "BUG: statfullpath(): pathname too long");
+ strcpy(buf, pathbuf + pathbufcwd);
+ strcpy(buf + pathpos - pathbufcwd, s);
+ if (!*s && *buf) {
+ /*
+ * Don't add the '.' if the path so far is empty, since
+ * then we get bogus empty strings inserted as files.
+ */
+ buf[pathpos - pathbufcwd] = '.';
+ buf[pathpos - pathbufcwd + 1] = '\0';
+ l = 0;
+ }
+ unmetafy(buf, NULL);
+ if (!st) {
+ char lbuf[1];
+ return access(buf, F_OK) && (!l || readlink(buf, lbuf, 1) < 0);
+ }
+ return l ? lstat(buf, st) : stat(buf, st);
+}
+
+/* This may be set by qualifier functions to an array of strings to insert
+ * into the list instead of the original string. */
+
+static char **inserts;
+
+/* add a match to the list */
+
+/**/
+static void
+insert(char *s, int checked)
+{
+ struct stat buf, buf2, *bp;
+ char *news = s;
+ int statted = 0;
+
+ queue_signals();
+ inserts = NULL;
+
+ if (gf_listtypes || gf_markdirs) {
+ /* Add the type marker to the end of the filename */
+ mode_t mode;
+ checked = statted = 1;
+ if (statfullpath(s, &buf, 1)) {
+ unqueue_signals();
+ return;
+ }
+ mode = buf.st_mode;
+ if (gf_follow) {
+ if (!S_ISLNK(mode) || statfullpath(s, &buf2, 0))
+ memcpy(&buf2, &buf, sizeof(buf));
+ statted |= 2;
+ mode = buf2.st_mode;
+ }
+ if (gf_listtypes || S_ISDIR(mode)) {
+ int ll = strlen(s);
+
+ news = (char *) hcalloc(ll + 2);
+ strcpy(news, s);
+ news[ll] = file_type(mode);
+ news[ll + 1] = '\0';
+ }
+ }
+ if (qualct || qualorct) {
+ /* Go through the qualifiers, rejecting the file if appropriate */
+ struct qual *qo, *qn;
+
+ if (!statted && statfullpath(s, &buf, 1)) {
+ unqueue_signals();
+ return;
+ }
+ news = dyncat(pathbuf, news);
+
+ statted = 1;
+ qo = quals;
+ for (qn = qo; qn && qn->func;) {
+ g_range = qn->range;
+ g_amc = qn->amc;
+ g_units = qn->units;
+ if ((qn->sense & 2) && !(statted & 2)) {
+ /* If (sense & 2), we're following links */
+ if (!S_ISLNK(buf.st_mode) || statfullpath(s, &buf2, 0))
+ memcpy(&buf2, &buf, sizeof(buf));
+ statted |= 2;
+ }
+ bp = (qn->sense & 2) ? &buf2 : &buf;
+ /* Reject the file if the function returned zero *
+ * and the sense was positive (sense&1 == 0), or *
+ * vice versa. */
+ if ((!((qn->func) (news, bp, qn->data, qn->sdata))
+ ^ qn->sense) & 1) {
+ /* Try next alternative, or return if there are no more */
+ if (!(qo = qo->or)) {
+ unqueue_signals();
+ return;
+ }
+ qn = qo;
+ continue;
+ }
+ qn = qn->next;
+ }
+ } else if (!checked) {
+ if (statfullpath(s, &buf, 1)) {
+ unqueue_signals();
+ return;
+ }
+ statted = 1;
+ news = dyncat(pathbuf, news);
+ } else
+ news = dyncat(pathbuf, news);
+
+ while (!inserts || (news = dupstring(*inserts++))) {
+ if (colonmod) {
+ /* Handle the remainder of the qualifier: e.g. (:r:s/foo/bar/). */
+ char *mod = colonmod;
+ modify(&news, &mod);
+ }
+ if (!statted && (gf_sorts & GS_NORMAL)) {
+ statfullpath(s, &buf, 1);
+ statted = 1;
+ }
+ if (!(statted & 2) && (gf_sorts & GS_LINKED)) {
+ if (statted) {
+ if (!S_ISLNK(buf.st_mode) || statfullpath(s, &buf2, 0))
+ memcpy(&buf2, &buf, sizeof(buf));
+ } else if (statfullpath(s, &buf2, 0))
+ statfullpath(s, &buf2, 1);
+ statted |= 2;
+ }
+ matchptr->name = news;
+ if (statted & 1) {
+ matchptr->size = buf.st_size;
+ matchptr->atime = buf.st_atime;
+ matchptr->mtime = buf.st_mtime;
+ matchptr->ctime = buf.st_ctime;
+ matchptr->links = buf.st_nlink;
+#ifdef GET_ST_ATIME_NSEC
+ matchptr->ansec = GET_ST_ATIME_NSEC(buf);
+#endif
+#ifdef GET_ST_MTIME_NSEC
+ matchptr->mnsec = GET_ST_MTIME_NSEC(buf);
+#endif
+#ifdef GET_ST_CTIME_NSEC
+ matchptr->cnsec = GET_ST_CTIME_NSEC(buf);
+#endif
+ }
+ if (statted & 2) {
+ matchptr->_size = buf2.st_size;
+ matchptr->_atime = buf2.st_atime;
+ matchptr->_mtime = buf2.st_mtime;
+ matchptr->_ctime = buf2.st_ctime;
+ matchptr->_links = buf2.st_nlink;
+#ifdef GET_ST_ATIME_NSEC
+ matchptr->_ansec = GET_ST_ATIME_NSEC(buf2);
+#endif
+#ifdef GET_ST_MTIME_NSEC
+ matchptr->_mnsec = GET_ST_MTIME_NSEC(buf2);
+#endif
+#ifdef GET_ST_CTIME_NSEC
+ matchptr->_cnsec = GET_ST_CTIME_NSEC(buf2);
+#endif
+ }
+ matchptr++;
+
+ if (++matchct == matchsz) {
+ matchbuf = (Gmatch)zrealloc((char *)matchbuf,
+ sizeof(struct gmatch) * (matchsz *= 2));
+
+ matchptr = matchbuf + matchct;
+ }
+ if (!inserts)
+ break;
+ }
+ unqueue_signals();
+ return;
+}
+
+/* Do the globbing: scanner is called recursively *
+ * with successive bits of the path until we've *
+ * tried all of it. */
+
+/**/
+static void
+scanner(Complist q, int shortcircuit)
+{
+ Patprog p;
+ int closure;
+ int pbcwdsav = pathbufcwd;
+ int errssofar = errsfound;
+ struct dirsav ds;
+
+ if (!q || errflag)
+ return;
+ init_dirsav(&ds);
+
+ if ((closure = q->closure)) {
+ /* (foo/)# - match zero or more dirs */
+ if (q->closure == 2) /* (foo/)## - match one or more dirs */
+ q->closure = 1;
+ else {
+ scanner(q->next, shortcircuit);
+ if (shortcircuit && shortcircuit == matchct)
+ return;
+ }
+ }
+ p = q->pat;
+ /* Now the actual matching for the current path section. */
+ if (p->flags & PAT_PURES) {
+ /*
+ * It's a straight string to the end of the path section.
+ */
+ char *str = (char *)p + p->startoff;
+ int l = p->patmlen;
+
+ if (l + !l + pathpos - pathbufcwd >= PATH_MAX) {
+ int err;
+
+ if (l >= PATH_MAX)
+ return;
+ err = lchdir(unmeta(pathbuf + pathbufcwd), &ds, 0);
+ if (err == -1)
+ return;
+ if (err) {
+ zerr("current directory lost during glob");
+ return;
+ }
+ pathbufcwd = pathpos;
+ }
+ if (q->next) {
+ /* Not the last path section. Just add it to the path. */
+ int oppos = pathpos;
+
+ if (!errflag) {
+ int add = 1;
+
+ if (q->closure && *pathbuf) {
+ if (!strcmp(str, "."))
+ add = 0;
+ else if (!strcmp(str, "..")) {
+ struct stat sc, sr;
+
+ add = (stat("/", &sr) || stat(unmeta(pathbuf), &sc) ||
+ sr.st_ino != sc.st_ino ||
+ sr.st_dev != sc.st_dev);
+ }
+ }
+ if (add) {
+ addpath(str, l);
+ if (!closure || !statfullpath("", NULL, 1)) {
+ scanner((q->closure) ? q : q->next, shortcircuit);
+ if (shortcircuit && shortcircuit == matchct)
+ return;
+ }
+ pathbuf[pathpos = oppos] = '\0';
+ }
+ }
+ } else {
+ if (str[l])
+ str = dupstrpfx(str, l);
+ insert(str, 0);
+ if (shortcircuit && shortcircuit == matchct)
+ return;
+ }
+ } else {
+ /* Do pattern matching on current path section. */
+ char *fn = pathbuf[pathbufcwd] ? unmeta(pathbuf + pathbufcwd) : ".";
+ int dirs = !!q->next;
+ DIR *lock = opendir(fn);
+ char *subdirs = NULL;
+ int subdirlen = 0;
+
+ if (lock == NULL)
+ return;
+ while ((fn = zreaddir(lock, 1)) && !errflag) {
+ /* prefix and suffix are zle trickery */
+ if (!dirs && !colonmod &&
+ ((glob_pre && !strpfx(glob_pre, fn))
+ || (glob_suf && !strsfx(glob_suf, fn))))
+ continue;
+ errsfound = errssofar;
+ if (pattry(p, fn)) {
+ /* if this name matchs the pattern... */
+ if (pbcwdsav == pathbufcwd &&
+ strlen(fn) + pathpos - pathbufcwd >= PATH_MAX) {
+ int err;
+
+ DPUTS(pathpos == pathbufcwd,
+ "BUG: filename longer than PATH_MAX");
+ err = lchdir(unmeta(pathbuf + pathbufcwd), &ds, 0);
+ if (err == -1)
+ break;
+ if (err) {
+ zerr("current directory lost during glob");
+ break;
+ }
+ pathbufcwd = pathpos;
+ }
+ if (dirs) {
+ int l;
+
+ /*
+ * If not the last component in the path:
+ *
+ * If we made an approximation in the new path segment,
+ * then it is possible we made too many errors. For
+ * example, (ab)#(cb)# will match the directory abcb
+ * with one error if allowed to, even though it can
+ * match with none. This will stop later parts of the
+ * path matching, so we need to check by reducing the
+ * maximum number of errors and seeing if the directory
+ * still matches. Luckily, this is not a terribly
+ * common case, since complex patterns typically occur
+ * in the last part of the path which is not affected
+ * by this problem.
+ */
+ if (errsfound > errssofar) {
+ forceerrs = errsfound - 1;
+ while (forceerrs >= errssofar) {
+ errsfound = errssofar;
+ if (!pattry(p, fn))
+ break;
+ forceerrs = errsfound - 1;
+ }
+ errsfound = forceerrs + 1;
+ forceerrs = -1;
+ }
+ if (closure) {
+ /* if matching multiple directories */
+ struct stat buf;
+
+ if (statfullpath(fn, &buf, !q->follow)) {
+ if (errno != ENOENT && errno != EINTR &&
+ errno != ENOTDIR && !errflag) {
+ zwarn("%e: %s", errno, fn);
+ }
+ continue;
+ }
+ if (!S_ISDIR(buf.st_mode))
+ continue;
+ }
+ l = strlen(fn) + 1;
+ subdirs = hrealloc(subdirs, subdirlen, subdirlen + l
+ + sizeof(int));
+ strcpy(subdirs + subdirlen, fn);
+ subdirlen += l;
+ /* store the count of errors made so far, too */
+ memcpy(subdirs + subdirlen, (char *)&errsfound,
+ sizeof(int));
+ subdirlen += sizeof(int);
+ } else {
+ /* if the last filename component, just add it */
+ insert(fn, 1);
+ if (shortcircuit && shortcircuit == matchct) {
+ closedir(lock);
+ return;
+ }
+ }
+ }
+ }
+ closedir(lock);
+ if (subdirs) {
+ int oppos = pathpos;
+
+ for (fn = subdirs; fn < subdirs+subdirlen; ) {
+ int l = strlen(fn);
+ addpath(fn, l);
+ fn += l + 1;
+ memcpy((char *)&errsfound, fn, sizeof(int));
+ fn += sizeof(int);
+ /* scan next level */
+ scanner((q->closure) ? q : q->next, shortcircuit);
+ if (shortcircuit && shortcircuit == matchct)
+ return;
+ pathbuf[pathpos = oppos] = '\0';
+ }
+ hrealloc(subdirs, subdirlen, 0);
+ }
+ }
+ if (pbcwdsav < pathbufcwd) {
+ if (restoredir(&ds))
+ zerr("current directory lost during glob");
+ zsfree(ds.dirname);
+ if (ds.dirfd >= 0)
+ close(ds.dirfd);
+ pathbufcwd = pbcwdsav;
+ }
+ return;
+}
+
+/* This function tokenizes a zsh glob pattern */
+
+/**/
+static Complist
+parsecomplist(char *instr)
+{
+ Patprog p1;
+ Complist l1;
+ char *str;
+ int compflags = gf_noglobdots ? (PAT_FILE|PAT_NOGLD) : PAT_FILE;
+
+ if (instr[0] == Star && instr[1] == Star) {
+ int shortglob = 0;
+ if (instr[2] == '/' || (instr[2] == Star && instr[3] == '/')
+ || (shortglob = isset(GLOBSTARSHORT))) {
+ /* Match any number of directories. */
+ int follow;
+
+ /* with three stars, follow symbolic links */
+ follow = (instr[2] == Star);
+ /*
+ * With GLOBSTARSHORT, leave a star in place for the
+ * pattern inside the directory.
+ */
+ instr += ((shortglob ? 1 : 3) + follow);
+
+ /* Now get the next path component if there is one. */
+ l1 = (Complist) zhalloc(sizeof *l1);
+ if ((l1->next = parsecomplist(instr)) == NULL) {
+ errflag |= ERRFLAG_ERROR;
+ return NULL;
+ }
+ l1->pat = patcompile(NULL, compflags | PAT_ANY, NULL);
+ l1->closure = 1; /* ...zero or more times. */
+ l1->follow = follow;
+ return l1;
+ }
+ }
+
+ /* Parse repeated directories such as (dir/)# and (dir/)## */
+ if (*(str = instr) == zpc_special[ZPC_INPAR] &&
+ !skipparens(Inpar, Outpar, (char **)&str) &&
+ *str == zpc_special[ZPC_HASH] && str[-2] == '/') {
+ instr++;
+ if (!(p1 = patcompile(instr, compflags, &instr)))
+ return NULL;
+ if (instr[0] == '/' && instr[1] == Outpar && instr[2] == Pound) {
+ int pdflag = 0;
+
+ instr += 3;
+ if (*instr == Pound) {
+ pdflag = 1;
+ instr++;
+ }
+ l1 = (Complist) zhalloc(sizeof *l1);
+ l1->pat = p1;
+ /* special case (/)# to avoid infinite recursion */
+ l1->closure = (*((char *)p1 + p1->startoff)) ? 1 + pdflag : 0;
+ l1->follow = 0;
+ l1->next = parsecomplist(instr);
+ return (l1->pat) ? l1 : NULL;
+ }
+ } else {
+ /* parse single path component */
+ if (!(p1 = patcompile(instr, compflags|PAT_FILET, &instr)))
+ return NULL;
+ /* then do the remaining path components */
+ if (*instr == '/' || !*instr) {
+ int ef = *instr == '/';
+
+ l1 = (Complist) zhalloc(sizeof *l1);
+ l1->pat = p1;
+ l1->closure = 0;
+ l1->next = ef ? parsecomplist(instr+1) : NULL;
+ return (ef && !l1->next) ? NULL : l1;
+ }
+ }
+ errflag |= ERRFLAG_ERROR;
+ return NULL;
+}
+
+/* turn a string into a Complist struct: this has path components */
+
+/**/
+static Complist
+parsepat(char *str)
+{
+ long assert;
+ int ignore;
+
+ patcompstart();
+ /*
+ * Check for initial globbing flags, so that they don't form
+ * a bogus path component.
+ */
+ if ((*str == zpc_special[ZPC_INPAR] && str[1] == zpc_special[ZPC_HASH]) ||
+ (*str == zpc_special[ZPC_KSH_AT] && str[1] == Inpar &&
+ str[2] == zpc_special[ZPC_HASH])) {
+ str += (*str == Inpar) ? 2 : 3;
+ if (!patgetglobflags(&str, &assert, &ignore))
+ return NULL;
+ }
+
+ /* Now there is no (#X) in front, we can check the path. */
+ if (!pathbuf)
+ pathbuf = zalloc(pathbufsz = PATH_MAX+1);
+ DPUTS(pathbufcwd, "BUG: glob changed directory");
+ if (*str == '/') { /* pattern has absolute path */
+ str++;
+ pathbuf[0] = '/';
+ pathbuf[pathpos = 1] = '\0';
+ } else /* pattern is relative to pwd */
+ pathbuf[pathpos = 0] = '\0';
+
+ return parsecomplist(str);
+}
+
+/* get number after qualifier */
+
+/**/
+static off_t
+qgetnum(char **s)
+{
+ off_t v = 0;
+
+ if (!idigit(**s)) {
+ zerr("number expected");
+ return 0;
+ }
+ while (idigit(**s))
+ v = v * 10 + *(*s)++ - '0';
+ return v;
+}
+
+/* get mode spec after qualifier */
+
+/**/
+static zlong
+qgetmodespec(char **s)
+{
+ zlong yes = 0, no = 0, val, mask, t;
+ char *p = *s, c, how, end;
+
+ if ((c = *p) == '=' || c == Equals || c == '+' || c == '-' ||
+ c == '?' || c == Quest || (c >= '0' && c <= '7')) {
+ end = 0;
+ c = 0;
+ } else {
+ end = (c == '<' ? '>' :
+ (c == '[' ? ']' :
+ (c == '{' ? '}' :
+ (c == Inang ? Outang :
+ (c == Inbrack ? Outbrack :
+ (c == Inbrace ? Outbrace : c))))));
+ p++;
+ }
+ do {
+ mask = 0;
+ while (((c = *p) == 'u' || c == 'g' || c == 'o' || c == 'a') && end) {
+ switch (c) {
+ case 'o': mask |= 01007; break;
+ case 'g': mask |= 02070; break;
+ case 'u': mask |= 04700; break;
+ case 'a': mask |= 07777; break;
+ }
+ p++;
+ }
+ how = ((c == '+' || c == '-') ? c : '=');
+ if (c == '+' || c == '-' || c == '=' || c == Equals)
+ p++;
+ val = 0;
+ if (mask) {
+ while ((c = *p++) != ',' && c != end) {
+ switch (c) {
+ case 'x': val |= 00111; break;
+ case 'w': val |= 00222; break;
+ case 'r': val |= 00444; break;
+ case 's': val |= 06000; break;
+ case 't': val |= 01000; break;
+ case '0': case '1': case '2': case '3':
+ case '4': case '5': case '6': case '7':
+ t = ((zlong) c - '0');
+ val |= t | (t << 3) | (t << 6);
+ break;
+ default:
+ zerr("invalid mode specification");
+ return 0;
+ }
+ }
+ if (how == '=' || how == '+') {
+ yes |= val & mask;
+ val = ~val;
+ }
+ if (how == '=' || how == '-')
+ no |= val & mask;
+ } else if (!(end && c == end) && c != ',' && c) {
+ t = 07777;
+ while ((c = *p) == '?' || c == Quest ||
+ (c >= '0' && c <= '7')) {
+ if (c == '?' || c == Quest) {
+ t = (t << 3) | 7;
+ val <<= 3;
+ } else {
+ t <<= 3;
+ val = (val << 3) | ((zlong) c - '0');
+ }
+ p++;
+ }
+ if (end && c != end && c != ',') {
+ zerr("invalid mode specification");
+ return 0;
+ }
+ if (how == '=') {
+ yes = (yes & ~t) | val;
+ no = (no & ~t) | (~val & ~t);
+ } else if (how == '+')
+ yes |= val;
+ else
+ no |= val;
+ } else {
+ zerr("invalid mode specification");
+ return 0;
+ }
+ } while (end && c != end);
+
+ *s = p;
+ return ((yes & 07777) | ((no & 07777) << 12));
+}
+
+static int
+gmatchcmp(Gmatch a, Gmatch b)
+{
+ int i;
+ off_t r = 0L;
+ struct globsort *s;
+ char **asortstrp = NULL, **bsortstrp = NULL;
+
+ for (i = gf_nsorts, s = gf_sortlist; i; i--, s++) {
+ switch (s->tp & ~GS_DESC) {
+ case GS_NAME:
+ r = zstrcmp(b->uname, a->uname,
+ gf_numsort ? SORTIT_NUMERICALLY : 0);
+ break;
+ case GS_DEPTH:
+ {
+ char *aptr = a->name, *bptr = b->name;
+ int slasha = 0, slashb = 0;
+ /* Count slashes. Trailing slashes don't count. */
+ while (*aptr && *aptr == *bptr)
+ aptr++, bptr++;
+ /* Like I just said... */
+ if ((!*aptr || !*bptr) && aptr > a->name && aptr[-1] == '/')
+ aptr--, bptr--;
+ if (*aptr)
+ for (; aptr[1]; aptr++)
+ if (*aptr == '/') {
+ slasha = 1;
+ break;
+ }
+ if (*bptr)
+ for (; bptr[1]; bptr++)
+ if (*bptr == '/') {
+ slashb = 1;
+ break;
+ }
+ r = slasha - slashb;
+ }
+ break;
+ case GS_EXEC:
+ if (!asortstrp) {
+ asortstrp = a->sortstrs;
+ bsortstrp = b->sortstrs;
+ } else {
+ asortstrp++;
+ bsortstrp++;
+ }
+ r = zstrcmp(*bsortstrp, *asortstrp,
+ gf_numsort ? SORTIT_NUMERICALLY : 0);
+ break;
+ case GS_SIZE:
+ r = b->size - a->size;
+ break;
+ case GS_ATIME:
+ r = a->atime - b->atime;
+#ifdef GET_ST_ATIME_NSEC
+ if (!r)
+ r = a->ansec - b->ansec;
+#endif
+ break;
+ case GS_MTIME:
+ r = a->mtime - b->mtime;
+#ifdef GET_ST_MTIME_NSEC
+ if (!r)
+ r = a->mnsec - b->mnsec;
+#endif
+ break;
+ case GS_CTIME:
+ r = a->ctime - b->ctime;
+#ifdef GET_ST_CTIME_NSEC
+ if (!r)
+ r = a->cnsec - b->cnsec;
+#endif
+ break;
+ case GS_LINKS:
+ r = b->links - a->links;
+ break;
+ case GS__SIZE:
+ r = b->_size - a->_size;
+ break;
+ case GS__ATIME:
+ r = a->_atime - b->_atime;
+#ifdef GET_ST_ATIME_NSEC
+ if (!r)
+ r = a->_ansec - b->_ansec;
+#endif
+ break;
+ case GS__MTIME:
+ r = a->_mtime - b->_mtime;
+#ifdef GET_ST_MTIME_NSEC
+ if (!r)
+ r = a->_mnsec - b->_mnsec;
+#endif
+ break;
+ case GS__CTIME:
+ r = a->_ctime - b->_ctime;
+#ifdef GET_ST_CTIME_NSEC
+ if (!r)
+ r = a->_cnsec - b->_cnsec;
+#endif
+ break;
+ case GS__LINKS:
+ r = b->_links - a->_links;
+ break;
+ }
+ if (r)
+ return (s->tp & GS_DESC) ?
+ (r < 0L ? 1 : -1) :
+ (r > 0L ? 1 : -1);
+ }
+ return 0;
+}
+
+/*
+ * Duplicate a list of qualifiers using the `next' linkage (not the
+ * `or' linkage). Return the head element and set *last (if last non-NULL)
+ * to point to the last element of the new list. All allocation is on the
+ * heap (or off the heap?)
+ */
+static struct qual *dup_qual_list(struct qual *orig, struct qual **lastp)
+{
+ struct qual *qfirst = NULL, *qlast = NULL;
+
+ while (orig) {
+ struct qual *qnew = (struct qual *)zhalloc(sizeof(struct qual));
+ *qnew = *orig;
+ qnew->next = qnew->or = NULL;
+
+ if (!qfirst)
+ qfirst = qnew;
+ if (qlast)
+ qlast->next = qnew;
+ qlast = qnew;
+
+ orig = orig->next;
+ }
+
+ if (lastp)
+ *lastp = qlast;
+ return qfirst;
+}
+
+
+/*
+ * Get a glob string for execution, following e, P or + qualifiers.
+ * Pointer is character after the e, P or +.
+ */
+
+/**/
+static char *
+glob_exec_string(char **sp)
+{
+ char sav, *tt, *sdata, *s = *sp;
+ int plus;
+
+ if (s[-1] == '+') {
+ plus = 0;
+ tt = itype_end(s, IIDENT, 0);
+ if (tt == s)
+ {
+ zerr("missing identifier after `+'");
+ return NULL;
+ }
+ } else {
+ tt = get_strarg(s, &plus);
+ if (!*tt)
+ {
+ zerr("missing end of string");
+ return NULL;
+ }
+ }
+
+ sav = *tt;
+ *tt = '\0';
+ sdata = dupstring(s + plus);
+ untokenize(sdata);
+ *tt = sav;
+ if (sav)
+ *sp = tt + plus;
+ else
+ *sp = tt;
+
+ return sdata;
+}
+
+/*
+ * Insert a glob match.
+ * If there were words to prepend given by the P glob qualifier, do so.
+ */
+static void
+insert_glob_match(LinkList list, LinkNode next, char *data)
+{
+ if (gf_pre_words) {
+ LinkNode added;
+ for (added = firstnode(gf_pre_words); added; incnode(added)) {
+ next = insertlinknode(list, next, dupstring(getdata(added)));
+ }
+ }
+
+ next = insertlinknode(list, next, data);
+
+ if (gf_post_words) {
+ LinkNode added;
+ for (added = firstnode(gf_post_words); added; incnode(added)) {
+ next = insertlinknode(list, next, dupstring(getdata(added)));
+ }
+ }
+}
+
+/*
+ * Return
+ * 1 if str ends in bare glob qualifiers
+ * 2 if str ends in non-bare glob qualifiers (#q)
+ * 0 otherwise.
+ *
+ * str is the string to check.
+ * sl is its length (to avoid recalculation).
+ * nobareglob is 1 if bare glob qualifiers are not allowed.
+ * *sp, if sp is not null, will be a pointer to the opening parenthesis.
+ */
+
+/**/
+int
+checkglobqual(char *str, int sl, int nobareglob, char **sp)
+{
+ char *s;
+ int paren, ret = 1;
+
+ if (str[sl - 1] != Outpar)
+ return 0;
+
+ /* Check these are really qualifiers, not a set of *
+ * alternatives or exclusions. We can be more *
+ * lenient with an explicit (#q) than with a bare *
+ * set of qualifiers. */
+ paren = 0;
+ for (s = str + sl - 2; *s && (*s != Inpar || paren); s--) {
+ switch (*s) {
+ case Outpar:
+ paren++; /*FALLTHROUGH*/
+ case Bar:
+ if (!zpc_disables[ZPC_BAR])
+ nobareglob = 1;
+ break;
+ case Tilde:
+ if (isset(EXTENDEDGLOB) && !zpc_disables[ZPC_TILDE])
+ nobareglob = 1;
+ break;
+ case Inpar:
+ paren--;
+ break;
+ }
+ if (s == str)
+ break;
+ }
+ if (*s != Inpar)
+ return 0;
+ if (isset(EXTENDEDGLOB) && !zpc_disables[ZPC_HASH] && s[1] == Pound) {
+ if (s[2] != 'q')
+ return 0;
+ ret = 2;
+ } else if (nobareglob)
+ return 0;
+
+ if (sp)
+ *sp = s;
+
+ return ret;
+}
+
+/* Main entry point to the globbing code for filename globbing. *
+ * np points to a node in the list which will be expanded *
+ * into a series of nodes. */
+
+/**/
+void
+zglob(LinkList list, LinkNode np, int nountok)
+{
+ struct qual *qo, *qn, *ql;
+ LinkNode node = prevnode(np);
+ char *str; /* the pattern */
+ int sl; /* length of the pattern */
+ Complist q; /* pattern after parsing */
+ char *ostr = (char *)getdata(np); /* the pattern before the parser */
+ /* chops it up */
+ int first = 0, end = -1; /* index of first match to return */
+ /* and index+1 of the last match */
+ struct globdata saved; /* saved glob state */
+ int nobareglob = !isset(BAREGLOBQUAL);
+ int shortcircuit = 0; /* How many files to match; */
+ /* 0 means no limit */
+
+ if (unset(GLOBOPT) || !haswilds(ostr) || unset(EXECOPT)) {
+ if (!nountok)
+ untokenize(ostr);
+ return;
+ }
+ save_globstate(saved);
+
+ str = dupstring(ostr);
+ uremnode(list, np);
+
+ /* quals will hold the complete list of qualifiers (file static). */
+ quals = NULL;
+ /*
+ * qualct and qualorct indicate we have qualifiers in the last
+ * alternative, or a set of alternatives, respectively. They
+ * are not necessarily an accurate count, however.
+ */
+ qualct = qualorct = 0;
+ /*
+ * colonmod is a concatenated list of all colon modifiers found in
+ * all sets of qualifiers.
+ */
+ colonmod = NULL;
+ /* The gf_* flags are qualifiers which are applied globally. */
+ gf_nullglob = isset(NULLGLOB);
+ gf_markdirs = isset(MARKDIRS);
+ gf_listtypes = gf_follow = 0;
+ gf_noglobdots = unset(GLOBDOTS);
+ gf_numsort = isset(NUMERICGLOBSORT);
+ gf_sorts = gf_nsorts = 0;
+ gf_pre_words = gf_post_words = NULL;
+
+ /* Check for qualifiers */
+ while (!nobareglob ||
+ (isset(EXTENDEDGLOB) && !zpc_disables[ZPC_HASH])) {
+ struct qual *newquals;
+ char *s;
+ int sense, qualsfound;
+ off_t data;
+ char *sdata, *newcolonmod, *ptr;
+ int (*func) _((char *, Statptr, off_t, char *));
+
+ /*
+ * Initialise state variables for current file pattern.
+ * newquals is the root for the linked list of all qualifiers.
+ * qo is the root of the current list of alternatives.
+ * ql is the end of the current alternative where the `next' will go.
+ * qn is the current qualifier node to be added.
+ *
+ * Here is an attempt at a diagram. An `or' is added horizontally
+ * to the top line, a `next' at the bottom of the right hand line.
+ * `qn' is usually NULL unless a new `or' has just been added.
+ *
+ * quals -> x -> x -> qo
+ * | | |
+ * x x x
+ * | |
+ * x ql
+ *
+ * In fact, after each loop the complete set is in the file static
+ * `quals'. Then, if we have a second set of qualifiers, we merge
+ * the lists together. This is only tricky if one or both have an
+ * `or' in them; then we need to distribute over all alternatives.
+ */
+ newquals = qo = qn = ql = NULL;
+
+ sl = strlen(str);
+ if (!(qualsfound = checkglobqual(str, sl, nobareglob, &s)))
+ break;
+
+ /* Real qualifiers found. */
+ nobareglob = 1;
+ sense = 0; /* bit 0 for match (0)/don't match (1) */
+ /* bit 1 for follow links (2), don't (0) */
+ data = 0; /* Any numerical argument required */
+ sdata = NULL; /* Any list argument required */
+ newcolonmod = NULL; /* Contains trailing colon modifiers */
+
+ str[sl-1] = 0;
+ *s++ = 0;
+ if (qualsfound == 2)
+ s += 2;
+ for (ptr = s; *ptr; ptr++)
+ if (*ptr == Dash)
+ *ptr = '-';
+ while (*s && !newcolonmod) {
+ func = (int (*) _((char *, Statptr, off_t, char *)))0;
+ if (*s == ',') {
+ /* A comma separates alternative sets of qualifiers */
+ s++;
+ sense = 0;
+ if (qualct) {
+ qn = (struct qual *)hcalloc(sizeof *qn);
+ qo->or = qn;
+ qo = qn;
+ qualorct++;
+ qualct = 0;
+ ql = NULL;
+ }
+ } else {
+ switch (*s++) {
+ case ':':
+ /* Remaining arguments are history-type *
+ * colon substitutions, handled separately. */
+ newcolonmod = s - 1;
+ untokenize(newcolonmod);
+ if (colonmod) {
+ /* remember we're searching backwards */
+ colonmod = dyncat(newcolonmod, colonmod);
+ } else
+ colonmod = newcolonmod;
+ break;
+ case Hat:
+ case '^':
+ /* Toggle sense: go from positive to *
+ * negative match and vice versa. */
+ sense ^= 1;
+ break;
+ case '-':
+ case Dash:
+ /* Toggle matching of symbolic links */
+ sense ^= 2;
+ break;
+ case '@':
+ /* Match symbolic links */
+ func = qualislnk;
+ break;
+ case Equals:
+ case '=':
+ /* Match sockets */
+ func = qualissock;
+ break;
+ case 'p':
+ /* Match named pipes */
+ func = qualisfifo;
+ break;
+ case '/':
+ /* Match directories */
+ func = qualisdir;
+ break;
+ case '.':
+ /* Match regular files */
+ func = qualisreg;
+ break;
+ case '%':
+ /* Match special files: block, *
+ * character or any device */
+ if (*s == 'b')
+ s++, func = qualisblk;
+ else if (*s == 'c')
+ s++, func = qualischr;
+ else
+ func = qualisdev;
+ break;
+ case Star:
+ /* Match executable plain files */
+ func = qualiscom;
+ break;
+ case 'R':
+ /* Match world-readable files */
+ func = qualflags;
+ data = 0004;
+ break;
+ case 'W':
+ /* Match world-writeable files */
+ func = qualflags;
+ data = 0002;
+ break;
+ case 'X':
+ /* Match world-executable files */
+ func = qualflags;
+ data = 0001;
+ break;
+ case 'A':
+ func = qualflags;
+ data = 0040;
+ break;
+ case 'I':
+ func = qualflags;
+ data = 0020;
+ break;
+ case 'E':
+ func = qualflags;
+ data = 0010;
+ break;
+ case 'r':
+ /* Match files readable by current process */
+ func = qualflags;
+ data = 0400;
+ break;
+ case 'w':
+ /* Match files writeable by current process */
+ func = qualflags;
+ data = 0200;
+ break;
+ case 'x':
+ /* Match files executable by current process */
+ func = qualflags;
+ data = 0100;
+ break;
+ case 's':
+ /* Match setuid files */
+ func = qualflags;
+ data = 04000;
+ break;
+ case 'S':
+ /* Match setgid files */
+ func = qualflags;
+ data = 02000;
+ break;
+ case 't':
+ func = qualflags;
+ data = 01000;
+ break;
+ case 'd':
+ /* Match device files by device number *
+ * (as given by stat's st_dev element). */
+ func = qualdev;
+ data = qgetnum(&s);
+ break;
+ case 'l':
+ /* Match files with the given no. of hard links */
+ func = qualnlink;
+ g_amc = -1;
+ goto getrange;
+ case 'U':
+ /* Match files owned by effective user ID */
+ func = qualuid;
+ data = geteuid();
+ break;
+ case 'G':
+ /* Match files owned by effective group ID */
+ func = qualgid;
+ data = getegid();
+ break;
+ case 'u':
+ /* Match files owned by given user id */
+ func = qualuid;
+ /* either the actual uid... */
+ if (idigit(*s))
+ data = qgetnum(&s);
+ else {
+ /* ... or a user name */
+ char sav, *tt;
+ int arglen;
+
+ /* Find matching delimiters */
+ tt = get_strarg(s, &arglen);
+ if (!*tt) {
+ zerr("missing delimiter for 'u' glob qualifier");
+ data = 0;
+ } else {
+#ifdef USE_GETPWNAM
+ struct passwd *pw;
+ sav = *tt;
+ *tt = '\0';
+
+ if ((pw = getpwnam(s + arglen)))
+ data = pw->pw_uid;
+ else {
+ zerr("unknown username '%s'", s + arglen);
+ data = 0;
+ }
+ *tt = sav;
+#else /* !USE_GETPWNAM */
+ sav = *tt;
+ *tt = '\0';
+ zerr("unable to resolve non-numeric username '%s'", s + arglen);
+ *tt = sav;
+ data = 0;
+#endif /* !USE_GETPWNAM */
+ if (sav)
+ s = tt + arglen;
+ else
+ s = tt;
+ }
+ }
+ break;
+ case 'g':
+ /* Given gid or group id... works like `u' */
+ func = qualgid;
+ /* either the actual gid... */
+ if (idigit(*s))
+ data = qgetnum(&s);
+ else {
+ /* ...or a delimited group name. */
+ char sav, *tt;
+ int arglen;
+
+ tt = get_strarg(s, &arglen);
+ if (!*tt) {
+ zerr("missing delimiter for 'g' glob qualifier");
+ data = 0;
+ } else {
+#ifdef USE_GETGRNAM
+ struct group *gr;
+ sav = *tt;
+ *tt = '\0';
+
+ if ((gr = getgrnam(s + arglen)))
+ data = gr->gr_gid;
+ else {
+ zerr("unknown group");
+ data = 0;
+ }
+ *tt = sav;
+#else /* !USE_GETGRNAM */
+ sav = *tt;
+ zerr("unknown group");
+ data = 0;
+#endif /* !USE_GETGRNAM */
+ if (sav)
+ s = tt + arglen;
+ else
+ s = tt;
+ }
+ }
+ break;
+ case 'f':
+ /* Match modes with chmod-spec. */
+ func = qualmodeflags;
+ data = qgetmodespec(&s);
+ break;
+ case 'F':
+ func = qualnonemptydir;
+ break;
+ case 'M':
+ /* Mark directories with a / */
+ if ((gf_markdirs = !(sense & 1)))
+ gf_follow = sense & 2;
+ break;
+ case 'T':
+ /* Mark types in a `ls -F' type fashion */
+ if ((gf_listtypes = !(sense & 1)))
+ gf_follow = sense & 2;
+ break;
+ case 'N':
+ /* Nullglob: remove unmatched patterns. */
+ gf_nullglob = !(sense & 1);
+ break;
+ case 'D':
+ /* Glob dots: match leading dots implicitly */
+ gf_noglobdots = sense & 1;
+ break;
+ case 'n':
+ /* Numeric glob sort */
+ gf_numsort = !(sense & 1);
+ break;
+ case 'Y':
+ {
+ /* Short circuit: limit number of matches */
+ const char *s_saved = s;
+ shortcircuit = !(sense & 1);
+ if (shortcircuit) {
+ /* Parse the argument. */
+ data = qgetnum(&s);
+ if ((shortcircuit = data) != data) {
+ /* Integer overflow */
+ zerr("value too big: Y%s", s_saved);
+ restore_globstate(saved);
+ return;
+ }
+ }
+ break;
+ }
+ case 'a':
+ /* Access time in given range */
+ g_amc = 0;
+ func = qualtime;
+ goto getrange;
+ case 'm':
+ /* Modification time in given range */
+ g_amc = 1;
+ func = qualtime;
+ goto getrange;
+ case 'c':
+ /* Inode creation time in given range */
+ g_amc = 2;
+ func = qualtime;
+ goto getrange;
+ case 'L':
+ /* File size (Length) in given range */
+ func = qualsize;
+ g_amc = -1;
+ /* Get size multiplier */
+ g_units = TT_BYTES;
+ if (*s == 'p' || *s == 'P')
+ g_units = TT_POSIX_BLOCKS, ++s;
+ else if (*s == 'k' || *s == 'K')
+ g_units = TT_KILOBYTES, ++s;
+ else if (*s == 'm' || *s == 'M')
+ g_units = TT_MEGABYTES, ++s;
+#if defined(ZSH_64_BIT_TYPE) || defined(LONG_IS_64_BIT)
+ else if (*s == 'g' || *s == 'G')
+ g_units = TT_GIGABYTES, ++s;
+ else if (*s == 't' || *s == 'T')
+ g_units = TT_TERABYTES, ++s;
+#endif
+ getrange:
+ /* Get time multiplier */
+ if (g_amc >= 0) {
+ g_units = TT_DAYS;
+ if (*s == 'h')
+ g_units = TT_HOURS, ++s;
+ else if (*s == 'm')
+ g_units = TT_MINS, ++s;
+ else if (*s == 'w')
+ g_units = TT_WEEKS, ++s;
+ else if (*s == 'M')
+ g_units = TT_MONTHS, ++s;
+ else if (*s == 's')
+ g_units = TT_SECONDS, ++s;
+ else if (*s == 'd')
+ ++s;
+ }
+ /* See if it's greater than, equal to, or less than */
+ if ((g_range = *s == '+' ? 1 : IS_DASH(*s) ? -1 : 0))
+ ++s;
+ data = qgetnum(&s);
+ break;
+
+ case 'o':
+ case 'O':
+ {
+ int t;
+ char *send;
+
+ if (gf_nsorts == MAX_SORTS) {
+ zerr("too many glob sort specifiers");
+ restore_globstate(saved);
+ return;
+ }
+
+ /* usually just one character */
+ send = s+1;
+ switch (*s) {
+ case 'n': t = GS_NAME; break;
+ case 'L': t = GS_SIZE; break;
+ case 'l': t = GS_LINKS; break;
+ case 'a': t = GS_ATIME; break;
+ case 'm': t = GS_MTIME; break;
+ case 'c': t = GS_CTIME; break;
+ case 'd': t = GS_DEPTH; break;
+ case 'N': t = GS_NONE; break;
+ case 'e':
+ case '+':
+ {
+ t = GS_EXEC;
+ if ((gf_sortlist[gf_nsorts].exec =
+ glob_exec_string(&send)) == NULL)
+ {
+ restore_globstate(saved);
+ return;
+ }
+ break;
+ }
+ default:
+ zerr("unknown sort specifier");
+ restore_globstate(saved);
+ return;
+ }
+ if ((sense & 2) &&
+ (t & (GS_SIZE|GS_ATIME|GS_MTIME|GS_CTIME|GS_LINKS)))
+ t <<= GS_SHIFT; /* HERE: GS_EXEC? */
+ if (t != GS_EXEC) {
+ if (gf_sorts & t) {
+ zerr("doubled sort specifier");
+ restore_globstate(saved);
+ return;
+ }
+ }
+ gf_sorts |= t;
+ gf_sortlist[gf_nsorts++].tp = t |
+ (((sense & 1) ^ (s[-1] == 'O')) ? GS_DESC : 0);
+ s = send;
+ break;
+ }
+ case '+':
+ case 'e':
+ {
+ char *tt;
+
+ tt = glob_exec_string(&s);
+
+ if (tt == NULL) {
+ data = 0;
+ } else {
+ func = qualsheval;
+ sdata = tt;
+ }
+ break;
+ }
+ case '[':
+ case Inbrack:
+ {
+ char *os = --s;
+ struct value v;
+
+ v.isarr = SCANPM_WANTVALS;
+ v.pm = NULL;
+ v.end = -1;
+ v.flags = 0;
+ if (getindex(&s, &v, 0) || s == os) {
+ zerr("invalid subscript");
+ restore_globstate(saved);
+ return;
+ }
+ first = v.start;
+ end = v.end;
+ break;
+ }
+ case 'P':
+ {
+ char *tt;
+ tt = glob_exec_string(&s);
+
+ if (tt != NULL)
+ {
+ LinkList *words = sense & 1 ? &gf_post_words : &gf_pre_words;
+ if (!*words)
+ *words = newlinklist();
+ addlinknode(*words, tt);
+ }
+ break;
+ }
+ default:
+ untokenize(--s);
+ zerr("unknown file attribute: %c", *s);
+ restore_globstate(saved);
+ return;
+ }
+ }
+ if (func) {
+ /* Requested test is performed by function func */
+ if (!qn)
+ qn = (struct qual *)hcalloc(sizeof *qn);
+ if (ql)
+ ql->next = qn;
+ ql = qn;
+ if (!newquals)
+ newquals = qo = qn;
+ qn->func = func;
+ qn->sense = sense;
+ qn->data = data;
+ qn->sdata = sdata;
+ qn->range = g_range;
+ qn->units = g_units;
+ qn->amc = g_amc;
+
+ qn = NULL;
+ qualct++;
+ }
+ if (errflag) {
+ restore_globstate(saved);
+ return;
+ }
+ }
+
+ if (quals && newquals) {
+ /* Merge previous group of qualifiers with new set. */
+ if (quals->or || newquals->or) {
+ /* The hard case. */
+ struct qual *qorhead = NULL, *qortail = NULL;
+ /*
+ * Distribute in the most trivial way, by creating
+ * all possible combinations of the two sets and chaining
+ * these into one long set of alternatives given
+ * by qorhead and qortail.
+ */
+ for (qn = newquals; qn; qn = qn->or) {
+ for (qo = quals; qo; qo = qo->or) {
+ struct qual *qfirst, *qlast;
+ int islast = !qn->or && !qo->or;
+ /* Generate first set of qualifiers... */
+ if (islast) {
+ /* Last time round: don't bother copying. */
+ qfirst = qn;
+ for (qlast = qfirst; qlast->next;
+ qlast = qlast->next)
+ ;
+ } else
+ qfirst = dup_qual_list(qn, &qlast);
+ /* ... link into new `or' chain ... */
+ if (!qorhead)
+ qorhead = qfirst;
+ if (qortail)
+ qortail->or = qfirst;
+ qortail = qfirst;
+ /* ... and concatenate second set. */
+ qlast->next = islast ? qo : dup_qual_list(qo, NULL);
+ }
+ }
+ quals = qorhead;
+ } else {
+ /*
+ * Easy: we can just chain the qualifiers together.
+ * This is an optimisation; the code above will work, too.
+ * We retain the original left to right ordering --- remember
+ * we are searching for sets of qualifiers from the right.
+ */
+ qn = newquals;
+ for ( ; newquals->next; newquals = newquals->next)
+ ;
+ newquals->next = quals;
+ quals = qn;
+ }
+ } else if (newquals)
+ quals = newquals;
+ }
+ q = parsepat(str);
+ if (!q || errflag) { /* if parsing failed */
+ restore_globstate(saved);
+ if (unset(BADPATTERN)) {
+ if (!nountok)
+ untokenize(ostr);
+ insertlinknode(list, node, ostr);
+ return;
+ }
+ errflag &= ~ERRFLAG_ERROR;
+ zerr("bad pattern: %s", ostr);
+ return;
+ }
+ if (!gf_nsorts) {
+ gf_sortlist[0].tp = gf_sorts = (shortcircuit ? GS_NONE : GS_NAME);
+ gf_nsorts = 1;
+ }
+ /* Initialise receptacle for matched files, *
+ * expanded by insert() where necessary. */
+ matchptr = matchbuf = (Gmatch)zalloc((matchsz = 16) *
+ sizeof(struct gmatch));
+ matchct = 0;
+ pattrystart();
+
+ /* The actual processing takes place here: matches go into *
+ * matchbuf. This is the only top-level call to scanner(). */
+ scanner(q, shortcircuit);
+
+ /* Deal with failures to match depending on options */
+ if (matchct)
+ badcshglob |= 2; /* at least one cmd. line expansion O.K. */
+ else if (!gf_nullglob) {
+ if (isset(CSHNULLGLOB)) {
+ badcshglob |= 1; /* at least one cmd. line expansion failed */
+ } else if (isset(NOMATCH)) {
+ zerr("no matches found: %s", ostr);
+ zfree(matchbuf, 0);
+ restore_globstate(saved);
+ return;
+ } else {
+ /* treat as an ordinary string */
+ untokenize(matchptr->name = dupstring(ostr));
+ matchptr++;
+ matchct = 1;
+ }
+ }
+
+ if (!(gf_sortlist[0].tp & GS_NONE)) {
+ /*
+ * Get the strings to use for sorting by executing
+ * the code chunk. We allow more than one of these.
+ */
+ int nexecs = 0;
+ struct globsort *sortp;
+ struct globsort *lastsortp = gf_sortlist + gf_nsorts;
+ Gmatch gmptr;
+
+ /* First find out if there are any GS_EXECs, counting them. */
+ for (sortp = gf_sortlist; sortp < lastsortp; sortp++)
+ {
+ if (sortp->tp & GS_EXEC)
+ nexecs++;
+ }
+
+ if (nexecs) {
+ Gmatch tmpptr;
+ int iexec = 0;
+
+ /* Yes; allocate enough space for strings for each */
+ for (tmpptr = matchbuf; tmpptr < matchptr; tmpptr++)
+ tmpptr->sortstrs = (char **)zhalloc(nexecs*sizeof(char*));
+
+ /* Loop over each one, incrementing iexec */
+ for (sortp = gf_sortlist; sortp < lastsortp; sortp++)
+ {
+ /* Ignore unless this is a GS_EXEC */
+ if (sortp->tp & GS_EXEC) {
+ Eprog prog;
+
+ if ((prog = parse_string(sortp->exec, 0))) {
+ int ef = errflag, lv = lastval;
+
+ /* Parsed OK, execute for each name */
+ for (tmpptr = matchbuf; tmpptr < matchptr; tmpptr++) {
+ setsparam("REPLY", ztrdup(tmpptr->name));
+ execode(prog, 1, 0, "globsort");
+ if (!errflag)
+ tmpptr->sortstrs[iexec] =
+ dupstring(getsparam("REPLY"));
+ else
+ tmpptr->sortstrs[iexec] = tmpptr->name;
+ }
+
+ /* Retain any user interrupt error status */
+ errflag = ef | (errflag & ERRFLAG_INT);
+ lastval = lv;
+ } else {
+ /* Failed, let's be safe */
+ for (tmpptr = matchbuf; tmpptr < matchptr; tmpptr++)
+ tmpptr->sortstrs[iexec] = tmpptr->name;
+ }
+
+ iexec++;
+ }
+ }
+ }
+
+ /*
+ * Where necessary, create unmetafied version of names
+ * for comparison. If no Meta characters just point
+ * to original string. All on heap.
+ */
+ for (gmptr = matchbuf; gmptr < matchptr; gmptr++)
+ {
+ if (strchr(gmptr->name, Meta))
+ {
+ int dummy;
+ gmptr->uname = dupstring(gmptr->name);
+ unmetafy(gmptr->uname, &dummy);
+ } else {
+ gmptr->uname = gmptr->name;
+ }
+ }
+
+ /* Sort arguments in to lexical (and possibly numeric) order. *
+ * This is reversed to facilitate insertion into the list. */
+ qsort((void *) & matchbuf[0], matchct, sizeof(struct gmatch),
+ (int (*) _((const void *, const void *)))gmatchcmp);
+ }
+
+ if (first < 0) {
+ first += matchct;
+ if (first < 0)
+ first = 0;
+ }
+ if (end < 0)
+ end += matchct + 1;
+ else if (end > matchct)
+ end = matchct;
+ if ((end -= first) > 0) {
+ if (gf_sortlist[0].tp & GS_NONE) {
+ /* Match list was never reversed, so insert back to front. */
+ matchptr = matchbuf + matchct - first - 1;
+ while (end-- > 0) {
+ /* insert matches in the arg list */
+ insert_glob_match(list, node, matchptr->name);
+ matchptr--;
+ }
+ } else {
+ matchptr = matchbuf + matchct - first - end;
+ while (end-- > 0) {
+ /* insert matches in the arg list */
+ insert_glob_match(list, node, matchptr->name);
+ matchptr++;
+ }
+ }
+ } else if (!badcshglob && !isset(NOMATCH) && matchct == 1) {
+ insert_glob_match(list, node, (--matchptr)->name);
+ }
+ zfree(matchbuf, 0);
+
+ restore_globstate(saved);
+}
+
+/* Return the trailing character for marking file types */
+
+/**/
+mod_export char
+file_type(mode_t filemode)
+{
+ if(S_ISBLK(filemode))
+ return '#';
+ else if(S_ISCHR(filemode))
+ return '%';
+ else if(S_ISDIR(filemode))
+ return '/';
+ else if(S_ISFIFO(filemode))
+ return '|';
+ else if(S_ISLNK(filemode))
+ return '@';
+ else if(S_ISREG(filemode))
+ return (filemode & S_IXUGO) ? '*' : ' ';
+ else if(S_ISSOCK(filemode))
+ return '=';
+ else
+ return '?';
+}
+
+/* check to see if str is eligible for brace expansion */
+
+/**/
+mod_export int
+hasbraces(char *str)
+{
+ char *lbr, *mbr, *comma;
+
+ if (isset(BRACECCL)) {
+ /* In this case, any properly formed brace expression *
+ * will match and expand to the characters in between. */
+ int bc, c;
+
+ for (bc = 0; (c = *str); ++str)
+ if (c == Inbrace) {
+ if (!bc && str[1] == Outbrace)
+ *str++ = '{', *str = '}';
+ else
+ bc++;
+ } else if (c == Outbrace) {
+ if (!bc)
+ *str = '}';
+ else if (!--bc)
+ return 1;
+ }
+ return 0;
+ }
+ /* Otherwise we need to look for... */
+ lbr = mbr = comma = NULL;
+ for (;;) {
+ switch (*str++) {
+ case Inbrace:
+ if (!lbr) {
+ if (bracechardots(str-1, NULL, NULL))
+ return 1;
+ lbr = str - 1;
+ if (IS_DASH(*str))
+ str++;
+ while (idigit(*str))
+ str++;
+ if (*str == '.' && str[1] == '.') {
+ str++; str++;
+ if (IS_DASH(*str))
+ str++;
+ while (idigit(*str))
+ str++;
+ if (*str == Outbrace &&
+ (idigit(lbr[1]) || idigit(str[-1])))
+ return 1;
+ else if (*str == '.' && str[1] == '.') {
+ str++; str++;
+ if (IS_DASH(*str))
+ str++;
+ while (idigit(*str))
+ str++;
+ if (*str == Outbrace &&
+ (idigit(lbr[1]) || idigit(str[-1])))
+ return 1;
+ }
+ }
+ } else {
+ char *s = --str;
+
+ if (skipparens(Inbrace, Outbrace, &str)) {
+ *lbr = *s = '{';
+ if (comma)
+ str = comma;
+ if (mbr && mbr < str)
+ str = mbr;
+ lbr = mbr = comma = NULL;
+ } else if (!mbr)
+ mbr = s;
+ }
+ break;
+ case Outbrace:
+ if (!lbr)
+ str[-1] = '}';
+ else if (comma)
+ return 1;
+ else {
+ *lbr = '{';
+ str[-1] = '}';
+ if (mbr)
+ str = mbr;
+ mbr = lbr = NULL;
+ }
+ break;
+ case Comma:
+ if (!lbr)
+ str[-1] = ',';
+ else if (!comma)
+ comma = str - 1;
+ break;
+ case '\0':
+ if (lbr)
+ *lbr = '{';
+ if (!mbr && !comma)
+ return 0;
+ if (comma)
+ str = comma;
+ if (mbr && mbr < str)
+ str = mbr;
+ lbr = mbr = comma = NULL;
+ break;
+ }
+ }
+}
+
+/* expand stuff like >>*.c */
+
+/**/
+int
+xpandredir(struct redir *fn, LinkList redirtab)
+{
+ char *nam;
+ struct redir *ff;
+ int ret = 0;
+ local_list1(fake);
+
+ /* Stick the name in a list... */
+ init_list1(fake, fn->name);
+ /* ...which undergoes all the usual shell expansions */
+ prefork(&fake, isset(MULTIOS) ? 0 : PREFORK_SINGLE, NULL);
+ /* Globbing is only done for multios. */
+ if (!errflag && isset(MULTIOS))
+ globlist(&fake, 0);
+ if (errflag)
+ return 0;
+ if (nonempty(&fake) && !nextnode(firstnode(&fake))) {
+ /* Just one match, the usual case. */
+ char *s = peekfirst(&fake);
+ fn->name = s;
+ untokenize(s);
+ if (fn->type == REDIR_MERGEIN || fn->type == REDIR_MERGEOUT) {
+ if (IS_DASH(s[0]) && !s[1])
+ fn->type = REDIR_CLOSE;
+ else if (s[0] == 'p' && !s[1])
+ fn->fd2 = -2;
+ else {
+ while (idigit(*s))
+ s++;
+ if (!*s && s > fn->name)
+ fn->fd2 = zstrtol(fn->name, NULL, 10);
+ else if (fn->type == REDIR_MERGEIN)
+ zerr("file number expected");
+ else
+ fn->type = REDIR_ERRWRITE;
+ }
+ }
+ } else if (fn->type == REDIR_MERGEIN)
+ zerr("file number expected");
+ else {
+ if (fn->type == REDIR_MERGEOUT)
+ fn->type = REDIR_ERRWRITE;
+ while ((nam = (char *)ugetnode(&fake))) {
+ /* Loop over matches, duplicating the *
+ * redirection for each file found. */
+ ff = (struct redir *) zhalloc(sizeof *ff);
+ *ff = *fn;
+ ff->name = nam;
+ addlinknode(redirtab, ff);
+ ret = 1;
+ }
+ }
+ return ret;
+}
+
+/*
+ * Check for a brace expansion of the form {..}.
+ * On input str must be positioned at an Inbrace, but the sequence
+ * of characters beyond that has not necessarily been checked.
+ * Return 1 if found else 0.
+ *
+ * The other parameters are optionaland if the function returns 1 are
+ * used to return:
+ * - *c1p: the first character in the expansion.
+ * - *c2p: the final character in the expansion.
+ */
+
+/**/
+static int
+bracechardots(char *str, convchar_t *c1p, convchar_t *c2p)
+{
+ convchar_t cstart, cend;
+ char *pnext = str + 1, *pconv, convstr[2];
+ if (itok(*pnext)) {
+ if (*pnext == Inbrace)
+ return 0;
+ convstr[0] = ztokens[*pnext - Pound];
+ convstr[1] = '\0';
+ pconv = convstr;
+ } else
+ pconv = pnext;
+ MB_METACHARINIT();
+ pnext += MB_METACHARLENCONV(pconv, &cstart);
+ if (
+#ifdef MULTIBYTE_SUPPORT
+ cstart == WEOF ||
+#else
+ !cstart ||
+#endif
+ pnext[0] != '.' || pnext[1] != '.')
+ return 0;
+ pnext += 2;
+ if (!*pnext)
+ return 0;
+ if (itok(*pnext)) {
+ if (*pnext == Inbrace)
+ return 0;
+ convstr[0] = ztokens[*pnext - Pound];
+ convstr[1] = '\0';
+ pconv = convstr;
+ } else
+ pconv = pnext;
+ MB_METACHARINIT();
+ pnext += MB_METACHARLENCONV(pconv, &cend);
+ if (
+#ifdef MULTIBYTE_SUPPORT
+ cend == WEOF ||
+#else
+ !cend ||
+#endif
+ *pnext != Outbrace)
+ return 0;
+ if (c1p)
+ *c1p = cstart;
+ if (c2p)
+ *c2p = cend;
+ return 1;
+}
+
+/* brace expansion */
+
+/**/
+mod_export void
+xpandbraces(LinkList list, LinkNode *np)
+{
+ LinkNode node = (*np), last = prevnode(node);
+ char *str = (char *)getdata(node), *str3 = str, *str2;
+ int prev, bc, comma, dotdot;
+
+ for (; *str != Inbrace; str++);
+ /* First, match up braces and see what we have. */
+ for (str2 = str, bc = comma = dotdot = 0; *str2; ++str2)
+ if (*str2 == Inbrace)
+ ++bc;
+ else if (*str2 == Outbrace) {
+ if (--bc == 0)
+ break;
+ } else if (bc == 1) {
+ if (*str2 == Comma)
+ ++comma; /* we have {foo,bar} */
+ else if (*str2 == '.' && str2[1] == '.') {
+ dotdot++; /* we have {num1..num2} */
+ ++str2;
+ }
+ }
+ DPUTS(bc, "BUG: unmatched brace in xpandbraces()");
+ if (!comma && dotdot) {
+ /* Expand range like 0..10 numerically: comma or recursive
+ brace expansion take precedence. */
+ char *dots, *p, *dots2 = NULL;
+ LinkNode olast = last;
+ /* Get the first number of the range */
+ zlong rstart, rend;
+ int err = 0, rev = 0, rincr = 1;
+ int wid1, wid2, wid3, strp;
+ convchar_t cstart, cend;
+
+ if (bracechardots(str, &cstart, &cend)) {
+ int lenalloc;
+ /*
+ * This is a character range.
+ */
+ if (cend < cstart) {
+ convchar_t ctmp = cend;
+ cend = cstart;
+ cstart = ctmp;
+ rev = 1;
+ }
+ uremnode(list, node);
+ strp = str - str3;
+ lenalloc = strp + strlen(str2+1) + 1;
+ do {
+#ifdef MULTIBYTE_SUPPORT
+ char *ncptr;
+ int nclen;
+ mb_charinit();
+ ncptr = wcs_nicechar(cend, NULL, NULL);
+ nclen = strlen(ncptr);
+ p = zhalloc(lenalloc + nclen);
+ memcpy(p, str3, strp);
+ memcpy(p + strp, ncptr, nclen);
+ strcpy(p + strp + nclen, str2 + 1);
+#else
+ p = zhalloc(lenalloc + 1);
+ memcpy(p, str3, strp);
+ sprintf(p + strp, "%c", cend);
+ strcat(p + strp, str2 + 1);
+#endif
+ insertlinknode(list, last, p);
+ if (rev) /* decreasing: add in reverse order. */
+ last = nextnode(last);
+ } while (cend-- > cstart);
+ *np = nextnode(olast);
+ return;
+ }
+
+ /* Get the first number of the range */
+ rstart = zstrtol(str+1,&dots,10);
+ rend = 0;
+ wid1 = (dots - str) - 1;
+ wid2 = (str2 - dots) - 2;
+ wid3 = 0;
+ strp = str - str3;
+
+ if (dots == str + 1 || *dots != '.' || dots[1] != '.')
+ err++;
+ else {
+ /* Get the last number of the range */
+ rend = zstrtol(dots+2,&p,10);
+ if (p == dots+2)
+ err++;
+ /* check for {num1..num2..incr} */
+ if (p != str2) {
+ wid2 = (p - dots) - 2;
+ dots2 = p;
+ if (dotdot == 2 && *p == '.' && p[1] == '.') {
+ rincr = zstrtol(p+2, &p, 10);
+ wid3 = p - dots2 - 2;
+ if (p != str2 || !rincr)
+ err++;
+ } else
+ err++;
+ }
+ }
+ if (!err) {
+ /* If either no. begins with a zero, pad the output with *
+ * zeroes. Otherwise, set min width to 0 to suppress them.
+ * str+1 is the first number in the range, dots+2 the last,
+ * and dots2+2 is the increment if that's given. */
+ /* TODO: sorry about this */
+ int minw = (str[1] == '0' ||
+ (IS_DASH(str[1]) && str[2] == '0'))
+ ? wid1
+ : (dots[2] == '0' ||
+ (IS_DASH(dots[2]) && dots[3] == '0'))
+ ? wid2
+ : (dots2 && (dots2[2] == '0' ||
+ (IS_DASH(dots2[2]) && dots2[3] == '0')))
+ ? wid3
+ : 0;
+ if (rincr < 0) {
+ /* Handle negative increment */
+ rincr = -rincr;
+ rev = !rev;
+ }
+ if (rstart > rend) {
+ /* Handle decreasing ranges correctly. */
+ zlong rt = rend;
+ rend = rstart;
+ rstart = rt;
+ rev = !rev;
+ } else if (rincr > 1) {
+ /* when incr > 1, range is aligned to the highest number of str1,
+ * compensate for this so that it is aligned to the first number */
+ rend -= (rend - rstart) % rincr;
+ }
+ uremnode(list, node);
+ for (; rend >= rstart; rend -= rincr) {
+ /* Node added in at end, so do highest first */
+ p = dupstring(str3);
+#if defined(ZLONG_IS_LONG_LONG) && defined(PRINTF_HAS_LLD)
+ sprintf(p + strp, "%0*lld", minw, rend);
+#else
+ sprintf(p + strp, "%0*ld", minw, (long)rend);
+#endif
+ strcat(p + strp, str2 + 1);
+ insertlinknode(list, last, p);
+ if (rev) /* decreasing: add in reverse order. */
+ last = nextnode(last);
+ }
+ *np = nextnode(olast);
+ return;
+ }
+ }
+ if (!comma && isset(BRACECCL)) { /* {a-mnop} */
+ /* Here we expand each character to a separate node, *
+ * but also ranges of characters like a-m. ccl is a *
+ * set of flags saying whether each character is present; *
+ * the final list is in lexical order. */
+ char ccl[256], *p;
+ unsigned char c1, c2;
+ unsigned int len, pl;
+ int lastch = -1;
+
+ uremnode(list, node);
+ memset(ccl, 0, sizeof(ccl) / sizeof(ccl[0]));
+ for (p = str + 1; p < str2;) {
+ if (itok(c1 = *p++))
+ c1 = ztokens[c1 - STOUC(Pound)];
+ if ((char) c1 == Meta)
+ c1 = 32 ^ *p++;
+ if (itok(c2 = *p))
+ c2 = ztokens[c2 - STOUC(Pound)];
+ if ((char) c2 == Meta)
+ c2 = 32 ^ p[1];
+ if (IS_DASH((char)c1) && lastch >= 0 &&
+ p < str2 && lastch <= (int)c2) {
+ while (lastch < (int)c2)
+ ccl[lastch++] = 1;
+ lastch = -1;
+ } else
+ ccl[lastch = c1] = 1;
+ }
+ pl = str - str3;
+ len = pl + strlen(++str2) + 2;
+ for (p = ccl + 256; p-- > ccl;)
+ if (*p) {
+ c1 = p - ccl;
+ if (imeta(c1)) {
+ str = hcalloc(len + 1);
+ str[pl] = Meta;
+ str[pl+1] = c1 ^ 32;
+ strcpy(str + pl + 2, str2);
+ } else {
+ str = hcalloc(len);
+ str[pl] = c1;
+ strcpy(str + pl + 1, str2);
+ }
+ memcpy(str, str3, pl);
+ insertlinknode(list, last, str);
+ }
+ *np = nextnode(last);
+ return;
+ }
+ prev = str++ - str3;
+ str2++;
+ uremnode(list, node);
+ node = last;
+ /* Finally, normal comma expansion *
+ * str1{foo,bar}str2 -> str1foostr2 str1barstr2. *
+ * Any number of intervening commas is allowed. */
+ for (;;) {
+ char *zz, *str4;
+ int cnt;
+
+ for (str4 = str, cnt = 0; cnt || (*str != Comma && *str !=
+ Outbrace); str++) {
+ if (*str == Inbrace)
+ cnt++;
+ else if (*str == Outbrace)
+ cnt--;
+ DPUTS(!*str, "BUG: illegal brace expansion");
+ }
+ /* Concatenate the string before the braces (str3), the section *
+ * just found (str4) and the text after the braces (str2) */
+ zz = (char *) hcalloc(prev + (str - str4) + strlen(str2) + 1);
+ ztrncpy(zz, str3, prev);
+ strncat(zz, str4, str - str4);
+ strcat(zz, str2);
+ /* and add this text to the argument list. */
+ insertlinknode(list, node, zz);
+ incnode(node);
+ if (*str != Outbrace)
+ str++;
+ else
+ break;
+ }
+ *np = nextnode(last);
+}
+
+/* check to see if a matches b (b is not a filename pattern) */
+
+/**/
+int
+matchpat(char *a, char *b)
+{
+ Patprog p;
+ int ret;
+
+ queue_signals(); /* Protect PAT_STATIC */
+
+ if (!(p = patcompile(b, PAT_STATIC, NULL))) {
+ zerr("bad pattern: %s", b);
+ ret = 0;
+ } else
+ ret = pattry(p, a);
+
+ unqueue_signals();
+
+ return ret;
+}
+
+/* do the ${foo%%bar}, ${foo#bar} stuff */
+/* please do not laugh at this code. */
+
+/* Having found a match in getmatch, decide what part of string
+ * to return. The matched part starts b characters into string imd->ustr
+ * and finishes e characters in: 0 <= b <= e <= imd->ulen on input
+ * (yes, empty matches should work).
+ *
+ * imd->flags is a set of the SUB_* matches defined in zsh.h from
+ * SUB_MATCH onwards; the lower parts are ignored.
+ *
+ * imd->replstr is the replacement string for a substitution
+ *
+ * imd->replstr is metafied and the values put in imd->repllist are metafied.
+ */
+
+/**/
+static char *
+get_match_ret(Imatchdata imd, int b, int e)
+{
+ char buf[80], *r, *p, *rr, *replstr = imd->replstr;
+ int ll = 0, bl = 0, t = 0, add = 0, fl = imd->flags, i;
+
+ /* Account for b and e referring to unmetafied string */
+ for (p = imd->ustr; p < imd->ustr + b; p++)
+ if (imeta(*p))
+ add++;
+ b += add;
+ for (; p < imd->ustr + e; p++)
+ if (imeta(*p))
+ add++;
+ e += add;
+
+ /* Everything now refers to metafied lengths. */
+ if (replstr || (fl & SUB_LIST)) {
+ if (fl & SUB_DOSUBST) {
+ replstr = dupstring(replstr);
+ singsub(&replstr);
+ untokenize(replstr);
+ }
+ if ((fl & (SUB_GLOBAL|SUB_LIST)) && imd->repllist) {
+ /* We are replacing the chunk, just add this to the list */
+ Repldata rd = (Repldata)
+ ((fl & SUB_LIST) ? zalloc(sizeof(*rd)) : zhalloc(sizeof(*rd)));
+ rd->b = b;
+ rd->e = e;
+ rd->replstr = replstr;
+ if (fl & SUB_LIST)
+ zaddlinknode(imd->repllist, rd);
+ else
+ addlinknode(imd->repllist, rd);
+ return imd->mstr;
+ }
+ ll += strlen(replstr);
+ }
+ if (fl & SUB_MATCH) /* matched portion */
+ ll += 1 + (e - b);
+ if (fl & SUB_REST) /* unmatched portion */
+ ll += 1 + (imd->mlen - (e - b));
+ if (fl & SUB_BIND) {
+ /* position of start of matched portion */
+ sprintf(buf, "%d ", MB_METASTRLEN2END(imd->mstr, 0, imd->mstr+b) + 1);
+ ll += (bl = strlen(buf));
+ }
+ if (fl & SUB_EIND) {
+ /* position of end of matched portion */
+ sprintf(buf + bl, "%d ",
+ MB_METASTRLEN2END(imd->mstr, 0, imd->mstr+e) + 1);
+ ll += (bl = strlen(buf));
+ }
+ if (fl & SUB_LEN) {
+ /* length of matched portion */
+ sprintf(buf + bl, "%d ", MB_METASTRLEN2END(imd->mstr+b, 0,
+ imd->mstr+e));
+ ll += (bl = strlen(buf));
+ }
+ if (bl)
+ buf[bl - 1] = '\0';
+
+ rr = r = (char *) hcalloc(ll);
+
+ if (fl & SUB_MATCH) {
+ /* copy matched portion to new buffer */
+ for (i = b, p = imd->mstr + b; i < e; i++)
+ *rr++ = *p++;
+ t = 1;
+ }
+ if (fl & SUB_REST) {
+ /* Copy unmatched portion to buffer. If both portions *
+ * requested, put a space in between (why?) */
+ if (t)
+ *rr++ = ' ';
+ /* there may be unmatched bits at both beginning and end of string */
+ for (i = 0, p = imd->mstr; i < b; i++)
+ *rr++ = *p++;
+ if (replstr)
+ for (p = replstr; *p; )
+ *rr++ = *p++;
+ for (i = e, p = imd->mstr + e; i < imd->mlen; i++)
+ *rr++ = *p++;
+ t = 1;
+ }
+ *rr = '\0';
+ if (bl) {
+ /* if there was a buffer (with a numeric result), add it; *
+ * if there was other stuff too, stick in a space first. */
+ if (t)
+ *rr++ = ' ';
+ strcpy(rr, buf);
+ }
+ return r;
+}
+
+static Patprog
+compgetmatch(char *pat, int *flp, char **replstrp)
+{
+ Patprog p;
+ /*
+ * Flags to pattern compiler: use static buffer since we only
+ * have one pattern at a time; we will try the must-match test ourselves,
+ * so tell the pattern compiler we are scanning.
+ */
+
+ /* int patflags = PAT_STATIC|PAT_SCAN|PAT_NOANCH;*/
+
+ /* Unfortunately, PAT_STATIC doesn't work if we have a replstr with
+ * something like ${x#...} in it which will be singsub()ed below because
+ * that would overwrite the pattern buffer. */
+
+ int patflags = PAT_SCAN|PAT_NOANCH | (*replstrp ? 0 : PAT_STATIC);
+
+ /*
+ * Search is anchored to the end of the string if we want to match
+ * it all, or if we are matching at the end of the string and not
+ * using substrings.
+ */
+ if ((*flp & SUB_ALL) || ((*flp & SUB_END) && !(*flp & SUB_SUBSTR)))
+ patflags &= ~PAT_NOANCH;
+ p = patcompile(pat, patflags, NULL);
+ if (!p) {
+ zerr("bad pattern: %s", pat);
+ return NULL;
+ }
+ if (*replstrp) {
+ if (p->patnpar || (p->globend & GF_MATCHREF)) {
+ /*
+ * Either backreferences or match references, so we
+ * need to re-substitute replstr each time round.
+ */
+ *flp |= SUB_DOSUBST;
+ } else {
+ singsub(replstrp);
+ untokenize(*replstrp);
+ }
+ }
+
+ return p;
+}
+
+/*
+ * This is called from paramsubst to get the match for ${foo#bar} etc.
+ * fl is a set of the SUB_* flags defined in zsh.h
+ * *sp points to the string we have to modify. The n'th match will be
+ * returned in *sp. The heap is used to get memory for the result string.
+ * replstr is the replacement string from a ${.../orig/repl}, in
+ * which case pat is the original.
+ *
+ * n is now ignored unless we are looking for a substring, in
+ * which case the n'th match from the start is counted such that
+ * there is no more than one match from each position.
+ */
+
+/**/
+int
+getmatch(char **sp, char *pat, int fl, int n, char *replstr)
+{
+ Patprog p;
+
+ if (!(p = compgetmatch(pat, &fl, &replstr)))
+ return 1;
+
+ return igetmatch(sp, p, fl, n, replstr, NULL);
+}
+
+/*
+ * This is the corresponding function for array variables.
+ * Matching is done with the same pattern on each element.
+ */
+
+/**/
+void
+getmatcharr(char ***ap, char *pat, int fl, int n, char *replstr)
+{
+ char **arr = *ap, **pp;
+ Patprog p;
+
+ if (!(p = compgetmatch(pat, &fl, &replstr)))
+ return;
+
+ *ap = pp = hcalloc(sizeof(char *) * (arrlen(arr) + 1));
+ while ((*pp = *arr++))
+ if (igetmatch(pp, p, fl, n, replstr, NULL))
+ pp++;
+}
+
+/*
+ * Match against str using pattern pp; return a list of
+ * Repldata matches in the linked list *repllistp; this is
+ * in permanent storage and to be freed by freematchlist()
+ */
+
+/**/
+mod_export int
+getmatchlist(char *str, Patprog p, LinkList *repllistp)
+{
+ char **sp = &str;
+
+ /*
+ * We don't care if we have longest or shortest match, but SUB_LONG
+ * is cheaper since the pattern code does that by default.
+ * We need SUB_GLOBAL to get all matches.
+ * We need SUB_SUBSTR to scan through for substrings.
+ * We need SUB_LIST to activate the special handling of the list
+ * passed in.
+ */
+ return igetmatch(sp, p, SUB_LONG|SUB_GLOBAL|SUB_SUBSTR|SUB_LIST,
+ 0, NULL, repllistp);
+}
+
+static void
+freerepldata(void *ptr)
+{
+ zfree(ptr, sizeof(struct repldata));
+}
+
+/**/
+mod_export void
+freematchlist(LinkList repllist)
+{
+ freelinklist(repllist, freerepldata);
+}
+
+/**/
+static void
+set_pat_start(Patprog p, int offs)
+{
+ /*
+ * If we are messing around with the test string by advancing up
+ * it from the start, we need to tell the pattern matcher that
+ * a start-of-string assertion, i.e. (#s), should fail. Hence
+ * we test whether the offset of the real start of string from
+ * the actual start, passed as offs, is zero.
+ */
+ if (offs)
+ p->flags |= PAT_NOTSTART;
+ else
+ p->flags &= ~PAT_NOTSTART;
+}
+
+/**/
+static void
+set_pat_end(Patprog p, char null_me)
+{
+ /*
+ * If we are messing around with the string by shortening it at the
+ * tail, we need to tell the pattern matcher that an end-of-string
+ * assertion, i.e. (#e), should fail. Hence we test whether
+ * the character null_me about to be zapped is or is not already a null.
+ */
+ if (null_me)
+ p->flags |= PAT_NOTEND;
+ else
+ p->flags &= ~PAT_NOTEND;
+}
+
+/**/
+#ifdef MULTIBYTE_SUPPORT
+
+/*
+ * Increment *tp over character which may be multibyte.
+ * Return number of bytes.
+ * All unmetafied here.
+ */
+
+/**/
+static int iincchar(char **tp, int left)
+{
+ char *t = *tp;
+ int mbclen = mb_charlenconv(t, left, NULL);
+ *tp = t + mbclen;
+
+ return mbclen;
+}
+
+/**/
+static int
+igetmatch(char **sp, Patprog p, int fl, int n, char *replstr,
+ LinkList *repllistp)
+{
+ char *s = *sp, *t, *tmatch, *send;
+ /*
+ * Note that ioff counts (possibly multibyte) characters in the
+ * character set (Meta's are not included), while l counts characters in
+ * the metafied string.
+ *
+ * umlen is a counter for (unmetafied) byte lengths---neither characters
+ * nor raw byte indices; this is simply an optimisation for allocation.
+ * umltot is the full length of the string in this scheme.
+ *
+ * l is the raw string length, used together with any pointers into
+ * the string (typically t).
+ */
+ int ioff, l = strlen(*sp), matched = 1, umltot = ztrlen(*sp);
+ int umlen, nmatches;
+ struct patstralloc patstralloc;
+ struct imatchdata imd;
+
+ (void)patallocstr(p, s, l, umltot, 1, &patstralloc);
+ s = patstralloc.alloced;
+ DPUTS(!s, "forced patallocstr failed");
+ send = s + umltot;
+
+ imd.mstr = *sp;
+ imd.mlen = l;
+ imd.ustr = s;
+ imd.ulen = umltot;
+ imd.flags = fl;
+ imd.replstr = replstr;
+ imd.repllist = NULL;
+
+ /* perform must-match test for complex closures */
+ if (p->mustoff)
+ {
+ char *muststr = (char *)p + p->mustoff;
+
+ matched = 0;
+ if (p->patmlen <= umltot)
+ {
+ for (t = s; t <= send - p->patmlen; t++)
+ {
+ if (!memcmp(muststr, t, p->patmlen)) {
+ matched = 1;
+ break;
+ }
+ }
+ }
+ }
+
+ /* in case we used the prog before... */
+ p->flags &= ~(PAT_NOTSTART|PAT_NOTEND);
+
+ if (fl & SUB_ALL) {
+ int i = matched && pattrylen(p, s, umltot, 0, &patstralloc, 0);
+ if (!i) {
+ /* Perform under no-match conditions */
+ umltot = 0;
+ imd.replstr = NULL;
+ }
+ *sp = get_match_ret(&imd, 0, umltot);
+ if (! **sp && (((fl & SUB_MATCH) && !i) || ((fl & SUB_REST) && i)))
+ return 0;
+ return 1;
+ }
+ if (matched) {
+ /*
+ * The default behaviour is to match at the start; this
+ * is modified by SUB_END and SUB_SUBSTR. SUB_END matches
+ * at the end of the string instead of the start. SUB_SUBSTR
+ * without SUB_END matches substrings searching from the start;
+ * with SUB_END it matches substrings searching from the end.
+ *
+ * The possibilities are further modified by whether we want the
+ * longest (SUB_LONG) or shortest possible match.
+ *
+ * SUB_START is only used in the case where we are also
+ * forcing a match at the end (SUB_END with no SUB_SUBSTR,
+ * with or without SUB_LONG), to indicate we should match
+ * the entire string.
+ */
+ switch (fl & (SUB_END|SUB_LONG|SUB_SUBSTR)) {
+ case 0:
+ case SUB_LONG:
+ /*
+ * Largest/smallest possible match at head of string.
+ * First get the longest match...
+ */
+ if (pattrylen(p, s, umltot, 0, &patstralloc, 0)) {
+ /* patmatchlen returns unmetafied length in this case */
+ int mlen = patmatchlen();
+ if (!(fl & SUB_LONG) && !(p->flags & PAT_PURES)) {
+ send = s + mlen;
+ /*
+ * ... now we know whether it's worth looking for the
+ * shortest, which we do by brute force.
+ */
+ mb_charinit();
+ for (t = s, umlen = 0; t < send; ) {
+ set_pat_end(p, *t);
+ if (pattrylen(p, s, umlen, 0, &patstralloc, 0)) {
+ mlen = patmatchlen();
+ break;
+ }
+ umlen += iincchar(&t, send - t);
+ }
+ }
+ *sp = get_match_ret(&imd, 0, mlen);
+ return 1;
+ }
+ break;
+
+ case SUB_END:
+ /*
+ * Smallest possible match at tail of string.
+ * As we can only be sure we've got wide characters right
+ * when going forwards, we need to match at every point
+ * until we fail and record the last successful match.
+ *
+ * It's important that we return the last successful match
+ * so that match, mbegin, mend and MATCH, MBEGIN, MEND are
+ * correct.
+ */
+ mb_charinit();
+ tmatch = NULL;
+ for (ioff = 0, t = s, umlen = umltot; t < send; ioff++) {
+ set_pat_start(p, t-s);
+ if (pattrylen(p, t, umlen, 0, &patstralloc, ioff))
+ tmatch = t;
+ if (fl & SUB_START)
+ break;
+ umlen -= iincchar(&t, send - t);
+ }
+ if (tmatch) {
+ *sp = get_match_ret(&imd, tmatch - s, umltot);
+ return 1;
+ }
+ if (!(fl & SUB_START) && pattrylen(p, s + umltot, 0, 0,
+ &patstralloc, ioff)) {
+ *sp = get_match_ret(&imd, umltot, umltot);
+ return 1;
+ }
+ break;
+
+ case (SUB_END|SUB_LONG):
+ /* Largest possible match at tail of string: *
+ * move forward along string until we get a match. *
+ * Again there's no optimisation. */
+ mb_charinit();
+ for (ioff = 0, t = s, umlen = umltot; t <= send ; ioff++) {
+ set_pat_start(p, t-s);
+ if (pattrylen(p, t, umlen, 0, &patstralloc, ioff)) {
+ *sp = get_match_ret(&imd, t-s, umltot);
+ return 1;
+ }
+ if (fl & SUB_START)
+ break;
+ if (t == send)
+ break;
+ umlen -= iincchar(&t, send - t);
+ }
+ if (!(fl & SUB_START) && pattrylen(p, send, 0, 0,
+ &patstralloc, ioff)) {
+ *sp = get_match_ret(&imd, umltot, umltot);
+ return 1;
+ }
+ break;
+
+ case SUB_SUBSTR:
+ /* Smallest at start, but matching substrings. */
+ set_pat_start(p, l);
+ if (!(fl & SUB_GLOBAL) &&
+ pattrylen(p, send, 0, 0, &patstralloc, 0) &&
+ !--n) {
+ *sp = get_match_ret(&imd, 0, 0);
+ return 1;
+ } /* fall through */
+ case (SUB_SUBSTR|SUB_LONG):
+ /* longest or smallest at start with substrings */
+ t = s;
+ if (fl & SUB_GLOBAL) {
+ imd.repllist = (fl & SUB_LIST) ? znewlinklist() : newlinklist();
+ if (repllistp)
+ *repllistp = imd.repllist;
+ }
+ ioff = 0; /* offset into string */
+ umlen = umltot;
+ mb_charinit();
+ do {
+ /* loop over all matches for global substitution */
+ matched = 0;
+ for (; t <= send; ioff++) {
+ /* Find the longest match from this position. */
+ set_pat_start(p, t-s);
+ if (pattrylen(p, t, umlen, 0, &patstralloc, ioff)) {
+ char *mpos = t + patmatchlen();
+ if (!(fl & SUB_LONG) && !(p->flags & PAT_PURES)) {
+ char *ptr;
+ int umlen2;
+ /*
+ * If searching for the shortest match,
+ * start with a zero length and increase
+ * it until we reach the longest possible
+ * match, accepting the first successful
+ * match.
+ */
+ for (ptr = t, umlen2 = 0; ptr < mpos;) {
+ set_pat_end(p, *ptr);
+ if (pattrylen(p, t, umlen2, 0,
+ &patstralloc, ioff)) {
+ mpos = t + patmatchlen();
+ break;
+ }
+ umlen2 += iincchar(&ptr, mpos - ptr);
+ }
+ }
+ if (!--n || (n <= 0 && (fl & SUB_GLOBAL))) {
+ *sp = get_match_ret(&imd, t-s, mpos-s);
+ if (mpos == t)
+ mpos += mb_charlenconv(mpos, send - mpos, NULL);
+ }
+ if (!(fl & SUB_GLOBAL)) {
+ if (n) {
+ /*
+ * Looking for a later match: in this case,
+ * we can continue looking for matches from
+ * the next character, even if it overlaps
+ * with what we just found.
+ */
+ umlen -= iincchar(&t, send - t);
+ continue;
+ } else {
+ return 1;
+ }
+ }
+ /*
+ * For a global match, we need to skip the stuff
+ * which is already marked for replacement.
+ */
+ matched = 1;
+ if (t == send)
+ break;
+ while (t < mpos) {
+ ioff++;
+ umlen -= iincchar(&t, send - t);
+ }
+ break;
+ }
+ if (t == send)
+ break;
+ umlen -= iincchar(&t, send - t);
+ }
+ } while (matched && t < send);
+ /*
+ * check if we can match a blank string, if so do it
+ * at the start. Goodness knows if this is a good idea
+ * with global substitution, so it doesn't happen.
+ */
+ set_pat_start(p, l);
+ if ((fl & (SUB_LONG|SUB_GLOBAL)) == SUB_LONG &&
+ pattrylen(p, send, 0, 0, &patstralloc, 0) && !--n) {
+ *sp = get_match_ret(&imd, 0, 0);
+ return 1;
+ }
+ break;
+
+ case (SUB_END|SUB_SUBSTR):
+ case (SUB_END|SUB_LONG|SUB_SUBSTR):
+ /* Longest/shortest at end, matching substrings. */
+ if (!(fl & SUB_LONG)) {
+ set_pat_start(p, l);
+ if (pattrylen(p, send, 0, 0, &patstralloc, umltot) &&
+ !--n) {
+ *sp = get_match_ret(&imd, umltot, umltot);
+ return 1;
+ }
+ }
+ /*
+ * If multibyte characters are present we need to start from the
+ * beginning. This is a bit unpleasant because we can't tell in
+ * advance how many times it will match and from where, so if n is
+ * greater then 1 we will need to count the number of times it
+ * matched and then go through again until we reach the right
+ * point. (Either that or record every single match in a list,
+ * which isn't stupid; it involves more memory management at this
+ * level but less use of the pattern matcher.)
+ */
+ nmatches = 0;
+ tmatch = NULL;
+ mb_charinit();
+ for (ioff = 0, t = s, umlen = umltot; t < send; ioff++) {
+ set_pat_start(p, t-s);
+ if (pattrylen(p, t, umlen, 0, &patstralloc, ioff)) {
+ nmatches++;
+ tmatch = t;
+ }
+ umlen -= iincchar(&t, send - t);
+ }
+ if (nmatches) {
+ char *mpos;
+ if (n > 1) {
+ /*
+ * We need to find the n'th last match.
+ */
+ n = nmatches - n;
+ mb_charinit();
+ for (ioff = 0, t = s, umlen = umltot; t < send; ioff++) {
+ set_pat_start(p, t-s);
+ if (pattrylen(p, t, umlen, 0, &patstralloc, ioff) &&
+ !n--) {
+ tmatch = t;
+ break;
+ }
+ umlen -= iincchar(&t, send - t);
+ }
+ }
+ mpos = tmatch + patmatchlen();
+ /* Look for the shortest match if necessary */
+ if (!(fl & SUB_LONG) && !(p->flags & PAT_PURES)) {
+ for (t = tmatch, umlen = 0; t < mpos; ) {
+ set_pat_end(p, *t);
+ if (pattrylen(p, tmatch, umlen, 0,
+ &patstralloc, ioff)) {
+ mpos = tmatch + patmatchlen();
+ break;
+ }
+ umlen += iincchar(&t, mpos - t);
+ }
+ }
+ *sp = get_match_ret(&imd, tmatch-s, mpos-s);
+ return 1;
+ }
+ set_pat_start(p, l);
+ if ((fl & SUB_LONG) && pattrylen(p, send, 0, 0,
+ &patstralloc, umltot) &&
+ !--n) {
+ *sp = get_match_ret(&imd, umltot, umltot);
+ return 1;
+ }
+ break;
+ }
+ }
+
+ if (imd.repllist && nonempty(imd.repllist)) {
+ /* Put all the bits of a global search and replace together. */
+ LinkNode nd;
+ Repldata rd;
+ int lleft;
+ char *ptr, *start;
+ int i;
+
+ /*
+ * Use metafied string again.
+ * Results from get_match_ret in repllist are all metafied.
+ */
+ s = *sp;
+ if (!(fl & SUB_LIST)) {
+ lleft = 0; /* size of returned string */
+ i = 0; /* start of last chunk we got from *sp */
+ for (nd = firstnode(imd.repllist); nd; incnode(nd)) {
+ rd = (Repldata) getdata(nd);
+ lleft += rd->b - i; /* previous chunk of *sp */
+ lleft += strlen(rd->replstr); /* the replaced bit */
+ i = rd->e; /* start of next chunk of *sp */
+ }
+ lleft += l - i; /* final chunk from *sp */
+ start = t = zhalloc(lleft+1);
+ i = 0;
+ for (nd = firstnode(imd.repllist); nd; incnode(nd)) {
+ rd = (Repldata) getdata(nd);
+ memcpy(t, s + i, rd->b - i);
+ t += rd->b - i;
+ ptr = rd->replstr;
+ while (*ptr)
+ *t++ = *ptr++;
+ i = rd->e;
+ }
+ memcpy(t, s + i, l - i);
+ start[lleft] = '\0';
+ *sp = (char *)start;
+ }
+ return 1;
+ }
+ if (fl & SUB_LIST) { /* safety: don't think this can happen */
+ return 0;
+ }
+
+ /* munge the whole string: no match, so no replstr */
+ imd.replstr = NULL;
+ imd.repllist = NULL;
+ *sp = get_match_ret(&imd, 0, 0);
+ return (fl & SUB_RETFAIL) ? 0 : 1;
+}
+
+/**/
+#else
+
+/*
+ * Increment pointer which may be on a Meta (x is a pointer variable),
+ * returning the incremented value (i.e. like pre-increment).
+ */
+#define METAINC(x) ((x) += (*(x) == Meta) ? 2 : 1)
+
+/**/
+static int
+igetmatch(char **sp, Patprog p, int fl, int n, char *replstr,
+ LinkList *repllistp)
+{
+ char *s = *sp, *t, *send;
+ /*
+ * Note that ioff and uml count characters in the character
+ * set (Meta's are not included), while l counts characters in the
+ * metafied string. umlen is a counter for (unmetafied) character
+ * lengths.
+ */
+ int ioff, l = strlen(*sp), uml = ztrlen(*sp), matched = 1, umlen;
+ struct patstralloc patstralloc;
+ struct imatchdata imd;
+
+ (void)patallocstr(p, s, l, uml, 1, &patstralloc);
+ s = patstralloc.alloced;
+ DPUTS(!s, "forced patallocstr failed");
+ send = s + uml;
+
+ imd.mstr = *sp;
+ imd.mlen = l;
+ imd.ustr = s;
+ imd.ulen = uml;
+ imd.flags = fl;
+ imd.replstr = replstr;
+ imd.repllist = NULL;
+
+ /* perform must-match test for complex closures */
+ if (p->mustoff)
+ {
+ char *muststr = (char *)p + p->mustoff;
+
+ matched = 0;
+ if (p->patmlen <= uml)
+ {
+ for (t = s; t <= send - p->patmlen; t++)
+ {
+ if (!memcmp(muststr, t, p->patmlen)) {
+ matched = 1;
+ break;
+ }
+ }
+ }
+ }
+
+ /* in case we used the prog before... */
+ p->flags &= ~(PAT_NOTSTART|PAT_NOTEND);
+
+ if (fl & SUB_ALL) {
+ int i = matched && pattrylen(p, s, uml, 0, &patstralloc, 0);
+ if (!i)
+ imd.replstr = NULL;
+ *sp = get_match_ret(&imd, 0, i ? l : 0);
+ if (! **sp && (((fl & SUB_MATCH) && !i) || ((fl & SUB_REST) && i)))
+ return 0;
+ return 1;
+ }
+ if (matched) {
+ switch (fl & (SUB_END|SUB_LONG|SUB_SUBSTR)) {
+ case 0:
+ case SUB_LONG:
+ /*
+ * Largest/smallest possible match at head of string.
+ * First get the longest match...
+ */
+ if (pattrylen(p, s, uml, 0, &patstralloc, 0)) {
+ /* patmatchlen returns metafied length, as we need */
+ int mlen = patmatchlen();
+ if (!(fl & SUB_LONG) && !(p->flags & PAT_PURES)) {
+ send = s + mlen;
+ /*
+ * ... now we know whether it's worth looking for the
+ * shortest, which we do by brute force.
+ */
+ for (t = s, umlen = 0; t < s + mlen; METAINC(t), umlen++) {
+ set_pat_end(p, *t);
+ if (pattrylen(p, s, umlen, 0, &patstralloc, 0)) {
+ mlen = patmatchlen();
+ break;
+ }
+ }
+ }
+ *sp = get_match_ret(&imd, 0, mlen);
+ return 1;
+ }
+ break;
+
+ case SUB_END:
+ /* Smallest possible match at tail of string: *
+ * move back down string until we get a match. *
+ * There's no optimization here. */
+ for (ioff = uml, t = send, umlen = 0; t >= s;
+ t--, ioff--, umlen++) {
+ set_pat_start(p, t-s);
+ if (pattrylen(p, t, umlen, 0, &patstralloc, ioff)) {
+ *sp = get_match_ret(&imd, t - s, uml);
+ return 1;
+ }
+ }
+ break;
+
+ case (SUB_END|SUB_LONG):
+ /* Largest possible match at tail of string: *
+ * move forward along string until we get a match. *
+ * Again there's no optimisation. */
+ for (ioff = 0, t = s, umlen = uml; t < send;
+ ioff++, t++, umlen--) {
+ set_pat_start(p, t-s);
+ if (pattrylen(p, t, send - t, umlen, &patstralloc, ioff)) {
+ *sp = get_match_ret(&imd, t-s, uml);
+ return 1;
+ }
+ }
+ break;
+
+ case SUB_SUBSTR:
+ /* Smallest at start, but matching substrings. */
+ set_pat_start(p, l);
+ if (!(fl & SUB_GLOBAL) &&
+ pattrylen(p, send, 0, 0, &patstralloc, 0) && !--n) {
+ *sp = get_match_ret(&imd, 0, 0);
+ return 1;
+ } /* fall through */
+ case (SUB_SUBSTR|SUB_LONG):
+ /* longest or smallest at start with substrings */
+ t = s;
+ if (fl & SUB_GLOBAL) {
+ imd.repllist = newlinklist();
+ if (repllistp)
+ *repllistp = imd.repllist;
+ }
+ ioff = 0; /* offset into string */
+ umlen = uml;
+ do {
+ /* loop over all matches for global substitution */
+ matched = 0;
+ for (; t < send; t++, ioff++, umlen--) {
+ /* Find the longest match from this position. */
+ set_pat_start(p, t-s);
+ if (pattrylen(p, t, send - t, umlen, &patstralloc, ioff)) {
+ char *mpos = t + patmatchlen();
+ if (!(fl & SUB_LONG) && !(p->flags & PAT_PURES)) {
+ char *ptr;
+ int umlen2;
+ for (ptr = t, umlen2 = 0; ptr < mpos;
+ ptr++, umlen2++) {
+ set_pat_end(p, *ptr);
+ if (pattrylen(p, t, ptr - t, umlen2,
+ &patstralloc, ioff)) {
+ mpos = t + patmatchlen();
+ break;
+ }
+ }
+ }
+ if (!--n || (n <= 0 && (fl & SUB_GLOBAL))) {
+ *sp = get_match_ret(&imd, t-s, mpos-s);
+ if (mpos == t)
+ mpos++;
+ }
+ if (!(fl & SUB_GLOBAL)) {
+ if (n) {
+ /*
+ * Looking for a later match: in this case,
+ * we can continue looking for matches from
+ * the next character, even if it overlaps
+ * with what we just found.
+ */
+ continue;
+ } else {
+ return 1;
+ }
+ }
+ /*
+ * For a global match, we need to skip the stuff
+ * which is already marked for replacement.
+ */
+ matched = 1;
+ while (t < mpos) {
+ ioff++;
+ umlen--;
+ t++;
+ }
+ break;
+ }
+ }
+ } while (matched);
+ /*
+ * check if we can match a blank string, if so do it
+ * at the start. Goodness knows if this is a good idea
+ * with global substitution, so it doesn't happen.
+ */
+ set_pat_start(p, l);
+ if ((fl & (SUB_LONG|SUB_GLOBAL)) == SUB_LONG &&
+ pattrylen(p, send, 0, 0, &patstralloc, 0) && !--n) {
+ *sp = get_match_ret(&imd, 0, 0);
+ return 1;
+ }
+ break;
+
+ case (SUB_END|SUB_SUBSTR):
+ case (SUB_END|SUB_LONG|SUB_SUBSTR):
+ /* Longest/shortest at end, matching substrings. */
+ if (!(fl & SUB_LONG)) {
+ set_pat_start(p, l);
+ if (pattrylen(p, send, 0, 0, &patstralloc, uml) && !--n) {
+ *sp = get_match_ret(&imd, uml, uml);
+ return 1;
+ }
+ }
+ for (ioff = uml - 1, t = send - 1, umlen = 1; t >= s;
+ t--, ioff--, umlen++) {
+ set_pat_start(p, t-s);
+ if (pattrylen(p, t, send - t, umlen, &patstralloc, ioff) &&
+ !--n) {
+ /* Found the longest match */
+ char *mpos = t + patmatchlen();
+ if (!(fl & SUB_LONG) && !(p->flags & PAT_PURES)) {
+ char *ptr;
+ int umlen2;
+ for (ptr = t, umlen2 = 0; ptr < mpos;
+ ptr++, umlen2++) {
+ set_pat_end(p, *ptr);
+ if (pattrylen(p, t, umlen2, 0, &patstralloc,
+ ioff)) {
+ mpos = t + patmatchlen();
+ break;
+ }
+ }
+ }
+ *sp = get_match_ret(&imd, t-s, mpos-s);
+ return 1;
+ }
+ }
+ set_pat_start(p, l);
+ if ((fl & SUB_LONG) && pattrylen(p, send, 0, 0,
+ &patstralloc, uml) &&
+ !--n) {
+ *sp = get_match_ret(&imd, uml, uml);
+ return 1;
+ }
+ break;
+ }
+ }
+
+ if (imd.repllist && nonempty(imd.repllist)) {
+ /* Put all the bits of a global search and replace together. */
+ LinkNode nd;
+ Repldata rd;
+ int lleft = 0; /* size of returned string */
+ char *ptr, *start;
+ int i;
+
+ /*
+ * Use metafied string again.
+ * Results from get_match_ret in repllist are all metafied.
+ */
+ s = *sp;
+ i = 0; /* start of last chunk we got from *sp */
+ for (nd = firstnode(imd.repllist); nd; incnode(nd)) {
+ rd = (Repldata) getdata(nd);
+ lleft += rd->b - i; /* previous chunk of *sp */
+ lleft += strlen(rd->replstr); /* the replaced bit */
+ i = rd->e; /* start of next chunk of *sp */
+ }
+ lleft += l - i; /* final chunk from *sp */
+ start = t = zhalloc(lleft+1);
+ i = 0;
+ for (nd = firstnode(imd.repllist); nd; incnode(nd)) {
+ rd = (Repldata) getdata(nd);
+ memcpy(t, s + i, rd->b - i);
+ t += rd->b - i;
+ ptr = rd->replstr;
+ while (*ptr)
+ *t++ = *ptr++;
+ i = rd->e;
+ }
+ memcpy(t, s + i, l - i);
+ start[lleft] = '\0';
+ *sp = (char *)start;
+ return 1;
+ }
+
+ /* munge the whole string: no match, so no replstr */
+ imd.replstr = NULL;
+ imd.repllist = NULL;
+ *sp = get_match_ret(&imd, 0, 0);
+ return 1;
+}
+
+/**/
+#endif /* MULTIBYTE_SUPPORT */
+
+/* blindly turn a string into a tokenised expression without lexing */
+
+/**/
+mod_export void
+tokenize(char *s)
+{
+ zshtokenize(s, 0);
+}
+
+/*
+ * shtokenize is used when we tokenize a string with GLOB_SUBST set.
+ * In that case we need to retain backslashes when we turn the
+ * pattern back into a string, so that the string is not
+ * modified if it failed to match a pattern.
+ *
+ * It may be modified by the effect of SH_GLOB which turns off
+ * various zsh-specific options.
+ */
+
+/**/
+mod_export void
+shtokenize(char *s)
+{
+ int flags = ZSHTOK_SUBST;
+ if (isset(SHGLOB))
+ flags |= ZSHTOK_SHGLOB;
+ zshtokenize(s, flags);
+}
+
+/**/
+static void
+zshtokenize(char *s, int flags)
+{
+ char *t;
+ int bslash = 0;
+
+ for (; *s; s++) {
+ cont:
+ switch (*s) {
+ case Meta:
+ /* skip both Meta and following character */
+ s++;
+ break;
+ case Bnull:
+ case Bnullkeep:
+ case '\\':
+ if (bslash) {
+ s[-1] = (flags & ZSHTOK_SUBST) ? Bnullkeep : Bnull;
+ break;
+ }
+ bslash = 1;
+ continue;
+ case '<':
+ if (flags & ZSHTOK_SHGLOB)
+ break;
+ if (bslash) {
+ s[-1] = (flags & ZSHTOK_SUBST) ? Bnullkeep : Bnull;
+ break;
+ }
+ t = s;
+ while (idigit(*++s));
+ if (!IS_DASH(*s))
+ goto cont;
+ while (idigit(*++s));
+ if (*s != '>')
+ goto cont;
+ *t = Inang;
+ *s = Outang;
+ break;
+ case '(':
+ case '|':
+ case ')':
+ if (flags & ZSHTOK_SHGLOB)
+ break;
+ /*FALLTHROUGH*/
+ case '>':
+ case '^':
+ case '#':
+ case '~':
+ case '[':
+ case ']':
+ case '*':
+ case '?':
+ case '=':
+ case '-':
+ case '!':
+ for (t = ztokens; *t; t++) {
+ if (*t == *s) {
+ if (bslash)
+ s[-1] = (flags & ZSHTOK_SUBST) ? Bnullkeep : Bnull;
+ else
+ *s = (t - ztokens) + Pound;
+ break;
+ }
+ }
+ break;
+ }
+ bslash = 0;
+ }
+}
+
+/* remove unnecessary Nulargs */
+
+/**/
+mod_export void
+remnulargs(char *s)
+{
+ if (*s) {
+ char *o = s, c;
+
+ while ((c = *s++))
+ if (c == Bnullkeep) {
+ /*
+ * An active backslash that needs to be turned back into
+ * a real backslash for output. However, we don't
+ * do that yet since we need to ignore it during
+ * pattern matching.
+ */
+ continue;
+ } else if (inull(c)) {
+ char *t = s - 1;
+
+ while ((c = *s++)) {
+ if (c == Bnullkeep)
+ *t++ = '\\';
+ else if (!inull(c))
+ *t++ = c;
+ }
+ *t = '\0';
+ if (!*o) {
+ o[0] = Nularg;
+ o[1] = '\0';
+ }
+ break;
+ }
+ }
+}
+
+/* qualifier functions: mostly self-explanatory, see glob(). */
+
+/* device number */
+
+/**/
+static int
+qualdev(UNUSED(char *name), struct stat *buf, off_t dv, UNUSED(char *dummy))
+{
+ return (off_t)buf->st_dev == dv;
+}
+
+/* number of hard links to file */
+
+/**/
+static int
+qualnlink(UNUSED(char *name), struct stat *buf, off_t ct, UNUSED(char *dummy))
+{
+ return (g_range < 0 ? buf->st_nlink < ct :
+ g_range > 0 ? buf->st_nlink > ct :
+ buf->st_nlink == ct);
+}
+
+/* user ID */
+
+/**/
+static int
+qualuid(UNUSED(char *name), struct stat *buf, off_t uid, UNUSED(char *dummy))
+{
+ return buf->st_uid == uid;
+}
+
+/* group ID */
+
+/**/
+static int
+qualgid(UNUSED(char *name), struct stat *buf, off_t gid, UNUSED(char *dummy))
+{
+ return buf->st_gid == gid;
+}
+
+/* device special file? */
+
+/**/
+static int
+qualisdev(UNUSED(char *name), struct stat *buf, UNUSED(off_t junk), UNUSED(char *dummy))
+{
+ return S_ISBLK(buf->st_mode) || S_ISCHR(buf->st_mode);
+}
+
+/* block special file? */
+
+/**/
+static int
+qualisblk(UNUSED(char *name), struct stat *buf, UNUSED(off_t junk), UNUSED(char *dummy))
+{
+ return S_ISBLK(buf->st_mode);
+}
+
+/* character special file? */
+
+/**/
+static int
+qualischr(UNUSED(char *name), struct stat *buf, UNUSED(off_t junk), UNUSED(char *dummy))
+{
+ return S_ISCHR(buf->st_mode);
+}
+
+/* directory? */
+
+/**/
+static int
+qualisdir(UNUSED(char *name), struct stat *buf, UNUSED(off_t junk), UNUSED(char *dummy))
+{
+ return S_ISDIR(buf->st_mode);
+}
+
+/* FIFO? */
+
+/**/
+static int
+qualisfifo(UNUSED(char *name), struct stat *buf, UNUSED(off_t junk), UNUSED(char *dummy))
+{
+ return S_ISFIFO(buf->st_mode);
+}
+
+/* symbolic link? */
+
+/**/
+static int
+qualislnk(UNUSED(char *name), struct stat *buf, UNUSED(off_t junk), UNUSED(char *dummy))
+{
+ return S_ISLNK(buf->st_mode);
+}
+
+/* regular file? */
+
+/**/
+static int
+qualisreg(UNUSED(char *name), struct stat *buf, UNUSED(off_t junk), UNUSED(char *dummy))
+{
+ return S_ISREG(buf->st_mode);
+}
+
+/* socket? */
+
+/**/
+static int
+qualissock(UNUSED(char *name), struct stat *buf, UNUSED(off_t junk), UNUSED(char *dummy))
+{
+ return S_ISSOCK(buf->st_mode);
+}
+
+/* given flag is set in mode */
+
+/**/
+static int
+qualflags(UNUSED(char *name), struct stat *buf, off_t mod, UNUSED(char *dummy))
+{
+ return mode_to_octal(buf->st_mode) & mod;
+}
+
+/* mode matches specification */
+
+/**/
+static int
+qualmodeflags(UNUSED(char *name), struct stat *buf, off_t mod, UNUSED(char *dummy))
+{
+ long v = mode_to_octal(buf->st_mode), y = mod & 07777, n = mod >> 12;
+
+ return ((v & y) == y && !(v & n));
+}
+
+/* regular executable file? */
+
+/**/
+static int
+qualiscom(UNUSED(char *name), struct stat *buf, UNUSED(off_t mod), UNUSED(char *dummy))
+{
+ return S_ISREG(buf->st_mode) && (buf->st_mode & S_IXUGO);
+}
+
+/* size in required range? */
+
+/**/
+static int
+qualsize(UNUSED(char *name), struct stat *buf, off_t size, UNUSED(char *dummy))
+{
+#if defined(ZSH_64_BIT_TYPE) || defined(LONG_IS_64_BIT)
+# define QS_CAST_SIZE()
+ zlong scaled = buf->st_size;
+#else
+# define QS_CAST_SIZE() (unsigned long)
+ unsigned long scaled = (unsigned long)buf->st_size;
+#endif
+
+ switch (g_units) {
+ case TT_POSIX_BLOCKS:
+ scaled += 511l;
+ scaled /= 512l;
+ break;
+ case TT_KILOBYTES:
+ scaled += 1023l;
+ scaled /= 1024l;
+ break;
+ case TT_MEGABYTES:
+ scaled += 1048575l;
+ scaled /= 1048576l;
+ break;
+#if defined(ZSH_64_BIT_TYPE) || defined(LONG_IS_64_BIT)
+ case TT_GIGABYTES:
+ scaled += ZLONG_CONST(1073741823);
+ scaled /= ZLONG_CONST(1073741824);
+ break;
+ case TT_TERABYTES:
+ scaled += ZLONG_CONST(1099511627775);
+ scaled /= ZLONG_CONST(1099511627776);
+ break;
+#endif
+ }
+
+ return (g_range < 0 ? scaled < QS_CAST_SIZE() size :
+ g_range > 0 ? scaled > QS_CAST_SIZE() size :
+ scaled == QS_CAST_SIZE() size);
+#undef QS_CAST_SIZE
+}
+
+/* time in required range? */
+
+/**/
+static int
+qualtime(UNUSED(char *name), struct stat *buf, off_t days, UNUSED(char *dummy))
+{
+ time_t now, diff;
+
+ time(&now);
+ diff = now - (g_amc == 0 ? buf->st_atime : g_amc == 1 ? buf->st_mtime :
+ buf->st_ctime);
+ /* handle multipliers indicating units */
+ switch (g_units) {
+ case TT_DAYS:
+ diff /= 86400l;
+ break;
+ case TT_HOURS:
+ diff /= 3600l;
+ break;
+ case TT_MINS:
+ diff /= 60l;
+ break;
+ case TT_WEEKS:
+ diff /= 604800l;
+ break;
+ case TT_MONTHS:
+ diff /= 2592000l;
+ break;
+ }
+
+ return (g_range < 0 ? diff < days :
+ g_range > 0 ? diff > days :
+ diff == days);
+}
+
+/* evaluate a string */
+
+/**/
+static int
+qualsheval(char *name, UNUSED(struct stat *buf), UNUSED(off_t days), char *str)
+{
+ Eprog prog;
+
+ if ((prog = parse_string(str, 0))) {
+ int ef = errflag, lv = lastval, ret;
+ int cshglob = badcshglob;
+
+ unsetparam("reply");
+ setsparam("REPLY", ztrdup(name));
+ badcshglob = 0;
+
+ execode(prog, 1, 0, "globqual");
+
+ if ((ret = lastval))
+ badcshglob |= cshglob;
+ /* Retain any user interrupt error status */
+ errflag = ef | (errflag & ERRFLAG_INT);
+ lastval = lv;
+
+ if (!(inserts = getaparam("reply")) &&
+ !(inserts = gethparam("reply"))) {
+ char *tmp;
+
+ if ((tmp = getsparam("reply")) || (tmp = getsparam("REPLY"))) {
+ static char *tmparr[2];
+
+ tmparr[0] = tmp;
+ tmparr[1] = NULL;
+
+ inserts = tmparr;
+ }
+ }
+
+ return !ret;
+ }
+ return 0;
+}
+
+/**/
+static int
+qualnonemptydir(char *name, struct stat *buf, UNUSED(off_t days), UNUSED(char *str))
+{
+ DIR *dirh;
+ struct dirent *de;
+ int unamelen;
+ char *uname = unmetafy(dupstring(name), &unamelen);
+
+ if (!S_ISDIR(buf->st_mode))
+ return 0;
+
+ if (buf->st_nlink > 2)
+ return 1;
+
+ if (!(dirh = opendir(uname)))
+ return 0;
+
+ while ((de = readdir(dirh))) {
+ if (strcmp(de->d_name, ".") && strcmp(de->d_name, "..")) {
+ closedir(dirh);
+ return 1;
+ }
+ }
+
+ closedir(dirh);
+ return 0;
+}
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/hashtable.c b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/hashtable.c
new file mode 100644
index 0000000..b7baa31
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/hashtable.c
@@ -0,0 +1,1617 @@
+/*
+ * hashtable.c - hash tables
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+#include "../config.h"
+
+#ifdef ZSH_HASH_DEBUG
+# define HASHTABLE_DEBUG_MEMBERS \
+ /* Members of struct hashtable used for debugging hash tables */ \
+ HashTable next, last; /* linked list of all hash tables */ \
+ char *tablename; /* string containing name of the hash table */ \
+ PrintTableStats printinfo; /* pointer to function to print table stats */
+#else /* !ZSH_HASH_DEBUG */
+# define HASHTABLE_DEBUG_MEMBERS
+#endif /* !ZSH_HASH_DEBUG */
+
+#define HASHTABLE_INTERNAL_MEMBERS \
+ ScanStatus scan; /* status of a scan over this hashtable */ \
+ HASHTABLE_DEBUG_MEMBERS
+
+typedef struct scanstatus *ScanStatus;
+
+#include "zsh.mdh"
+#include "hashtable.pro"
+
+/* Structure for recording status of a hashtable scan in progress. When a *
+ * scan starts, the .scan member of the hashtable structure points to one *
+ * of these. That member being non-NULL disables resizing of the *
+ * hashtable (when adding elements). When elements are deleted, the *
+ * contents of this structure is used to make sure the scan won't stumble *
+ * into the deleted element. */
+
+struct scanstatus {
+ int sorted;
+ union {
+ struct {
+ HashNode *hashtab;
+ int ct;
+ } s;
+ HashNode u;
+ } u;
+};
+
+/********************************/
+/* Generic Hash Table functions */
+/********************************/
+
+#ifdef ZSH_HASH_DEBUG
+static HashTable firstht, lastht;
+#endif /* ZSH_HASH_DEBUG */
+
+/* Generic hash function */
+
+/**/
+mod_export unsigned
+hasher(const char *str)
+{
+ unsigned hashval = 0, c;
+
+ while ((c = *((unsigned char *) str++)))
+ hashval += (hashval << 5) + c;
+
+ return hashval;
+}
+
+/* Get a new hash table */
+
+/**/
+mod_export HashTable
+newhashtable(int size, UNUSED(char const *name), UNUSED(PrintTableStats printinfo))
+{
+ HashTable ht;
+
+ ht = (HashTable) zshcalloc(sizeof *ht);
+#ifdef ZSH_HASH_DEBUG
+ ht->next = NULL;
+ if(!firstht)
+ firstht = ht;
+ ht->last = lastht;
+ if(lastht)
+ lastht->next = ht;
+ lastht = ht;
+ ht->printinfo = printinfo ? printinfo : printhashtabinfo;
+ ht->tablename = ztrdup(name);
+#endif /* ZSH_HASH_DEBUG */
+ ht->nodes = (HashNode *) zshcalloc(size * sizeof(HashNode));
+ ht->hsize = size;
+ ht->ct = 0;
+ ht->scan = NULL;
+ ht->scantab = NULL;
+ return ht;
+}
+
+/* Delete a hash table. After this function has been used, any *
+ * existing pointers to the hash table are invalid. */
+
+/**/
+mod_export void
+deletehashtable(HashTable ht)
+{
+ ht->emptytable(ht);
+#ifdef ZSH_HASH_DEBUG
+ if(ht->next)
+ ht->next->last = ht->last;
+ else
+ lastht = ht->last;
+ if(ht->last)
+ ht->last->next = ht->next;
+ else
+ firstht = ht->next;
+ zsfree(ht->tablename);
+#endif /* ZSH_HASH_DEBUG */
+ zfree(ht->nodes, ht->hsize * sizeof(HashNode));
+ zfree(ht, sizeof(*ht));
+}
+
+/* Add a node to a hash table. *
+ * nam is the key to use in hashing. nodeptr points *
+ * to the node to add. If there is already a node in *
+ * the table with the same key, it is first freed, and *
+ * then the new node is added. If the number of nodes *
+ * is now greater than twice the number of hash values, *
+ * the table is then expanded. */
+
+/**/
+mod_export void
+addhashnode(HashTable ht, char *nam, void *nodeptr)
+{
+ HashNode oldnode = addhashnode2(ht, nam, nodeptr);
+ if (oldnode)
+ ht->freenode(oldnode);
+}
+
+/* Add a node to a hash table, returning the old node on replacement. */
+
+/**/
+HashNode
+addhashnode2(HashTable ht, char *nam, void *nodeptr)
+{
+ unsigned hashval;
+ HashNode hn, hp, hq;
+
+ hn = (HashNode) nodeptr;
+ hn->nam = nam;
+
+ hashval = ht->hash(hn->nam) % ht->hsize;
+ hp = ht->nodes[hashval];
+
+ /* check if this is the first node for this hash value */
+ if (!hp) {
+ hn->next = NULL;
+ ht->nodes[hashval] = hn;
+ if (++ht->ct >= ht->hsize * 2 && !ht->scan)
+ expandhashtable(ht);
+ return NULL;
+ }
+
+ /* else check if the first node contains the same key */
+ if (ht->cmpnodes(hp->nam, hn->nam) == 0) {
+ ht->nodes[hashval] = hn;
+ replacing:
+ hn->next = hp->next;
+ if(ht->scan) {
+ if(ht->scan->sorted) {
+ HashNode *hashtab = ht->scan->u.s.hashtab;
+ int i;
+ for(i = ht->scan->u.s.ct; i--; )
+ if(hashtab[i] == hp)
+ hashtab[i] = hn;
+ } else if(ht->scan->u.u == hp)
+ ht->scan->u.u = hn;
+ }
+ return hp;
+ }
+
+ /* else run through the list and check all the keys */
+ hq = hp;
+ hp = hp->next;
+ for (; hp; hq = hp, hp = hp->next) {
+ if (ht->cmpnodes(hp->nam, hn->nam) == 0) {
+ hq->next = hn;
+ goto replacing;
+ }
+ }
+
+ /* else just add it at the front of the list */
+ hn->next = ht->nodes[hashval];
+ ht->nodes[hashval] = hn;
+ if (++ht->ct >= ht->hsize * 2 && !ht->scan)
+ expandhashtable(ht);
+ return NULL;
+}
+
+/* Get an enabled entry in a hash table. *
+ * If successful, it returns a pointer to *
+ * the hashnode. If the node is DISABLED *
+ * or isn't found, it returns NULL */
+
+/**/
+mod_export HashNode
+gethashnode(HashTable ht, const char *nam)
+{
+ unsigned hashval;
+ HashNode hp;
+
+ hashval = ht->hash(nam) % ht->hsize;
+ for (hp = ht->nodes[hashval]; hp; hp = hp->next) {
+ if (ht->cmpnodes(hp->nam, nam) == 0) {
+ if (hp->flags & DISABLED)
+ return NULL;
+ else
+ return hp;
+ }
+ }
+ return NULL;
+}
+
+/* Get an entry in a hash table. It will *
+ * ignore the DISABLED flag and return a *
+ * pointer to the hashnode if found, else *
+ * it returns NULL. */
+
+/**/
+mod_export HashNode
+gethashnode2(HashTable ht, const char *nam)
+{
+ unsigned hashval;
+ HashNode hp;
+
+ hashval = ht->hash(nam) % ht->hsize;
+ for (hp = ht->nodes[hashval]; hp; hp = hp->next) {
+ if (ht->cmpnodes(hp->nam, nam) == 0)
+ return hp;
+ }
+ return NULL;
+}
+
+/* Remove an entry from a hash table. *
+ * If successful, it removes the node from the *
+ * table and returns a pointer to it. If there *
+ * is no such node, then it returns NULL */
+
+/**/
+mod_export HashNode
+removehashnode(HashTable ht, const char *nam)
+{
+ unsigned hashval;
+ HashNode hp, hq;
+
+ hashval = ht->hash(nam) % ht->hsize;
+ hp = ht->nodes[hashval];
+
+ /* if no nodes at this hash value, return NULL */
+ if (!hp)
+ return NULL;
+
+ /* else check if the key in the first one matches */
+ if (ht->cmpnodes(hp->nam, nam) == 0) {
+ ht->nodes[hashval] = hp->next;
+ gotit:
+ ht->ct--;
+ if(ht->scan) {
+ if(ht->scan->sorted) {
+ HashNode *hashtab = ht->scan->u.s.hashtab;
+ int i;
+ for(i = ht->scan->u.s.ct; i--; )
+ if(hashtab[i] == hp)
+ hashtab[i] = NULL;
+ } else if(ht->scan->u.u == hp)
+ ht->scan->u.u = hp->next;
+ }
+ return hp;
+ }
+
+ /* else run through the list and check the rest of the keys */
+ hq = hp;
+ hp = hp->next;
+ for (; hp; hq = hp, hp = hp->next) {
+ if (ht->cmpnodes(hp->nam, nam) == 0) {
+ hq->next = hp->next;
+ goto gotit;
+ }
+ }
+
+ /* else it is not in the list, so return NULL */
+ return NULL;
+}
+
+/* Disable a node in a hash table */
+
+/**/
+void
+disablehashnode(HashNode hn, UNUSED(int flags))
+{
+ hn->flags |= DISABLED;
+}
+
+/* Enable a node in a hash table */
+
+/**/
+void
+enablehashnode(HashNode hn, UNUSED(int flags))
+{
+ hn->flags &= ~DISABLED;
+}
+
+/* Compare two hash table entries by name */
+
+/**/
+static int
+hnamcmp(const void *ap, const void *bp)
+{
+ HashNode a = *(HashNode *)ap;
+ HashNode b = *(HashNode *)bp;
+ return ztrcmp(a->nam, b->nam);
+}
+
+/* Scan the nodes in a hash table and execute scanfunc on nodes based on
+ * the flags that are set/unset. scanflags is passed unchanged to
+ * scanfunc (if executed).
+ *
+ * If sorted != 0, then sort entries of hash table before scanning.
+ * If flags1 > 0, then execute scanfunc on a node only if at least one of
+ * these flags is set.
+ * If flags2 > 0, then execute scanfunc on a node only if all of
+ * these flags are NOT set.
+ * The conditions above for flags1/flags2 must both be true.
+ *
+ * It is safe to add, remove or replace hash table elements from within
+ * the scanfunc. Replaced elements will appear in the scan exactly once,
+ * the new version if it was not scanned before the replacement was made.
+ * Added elements might or might not appear in the scan.
+ *
+ * pprog, if non-NULL, is a pattern that must match the name
+ * of the node.
+ *
+ * The function returns the number of matches, as reduced by pprog, flags1
+ * and flags2.
+ */
+
+/**/
+mod_export int
+scanmatchtable(HashTable ht, Patprog pprog, int sorted,
+ int flags1, int flags2, ScanFunc scanfunc, int scanflags)
+{
+ int match = 0;
+ struct scanstatus st;
+
+ /*
+ * scantab is currently only used by modules to scan
+ * tables where the contents are generated on the fly from
+ * other objects. Note the fact that in this case pprog,
+ * sorted, flags1 and flags2 are ignore.
+ */
+ if (!pprog && ht->scantab) {
+ ht->scantab(ht, scanfunc, scanflags);
+ return ht->ct;
+ }
+ if (sorted) {
+ int i, ct = ht->ct;
+ VARARR(HashNode, hnsorttab, ct);
+ HashNode *htp, hn;
+
+ /*
+ * Because the structure might change under our feet,
+ * we can't apply the flags and the pattern before sorting,
+ * tempting though that is.
+ */
+ for (htp = hnsorttab, i = 0; i < ht->hsize; i++)
+ for (hn = ht->nodes[i]; hn; hn = hn->next)
+ *htp++ = hn;
+ qsort((void *)hnsorttab, ct, sizeof(HashNode), hnamcmp);
+
+ st.sorted = 1;
+ st.u.s.hashtab = hnsorttab;
+ st.u.s.ct = ct;
+ ht->scan = &st;
+
+ for (htp = hnsorttab, i = 0; i < ct; i++, htp++) {
+ if ((!flags1 || ((*htp)->flags & flags1)) &&
+ !((*htp)->flags & flags2) &&
+ (!pprog || pattry(pprog, (*htp)->nam))) {
+ match++;
+ scanfunc(*htp, scanflags);
+ }
+ }
+
+ ht->scan = NULL;
+ } else {
+ int i, hsize = ht->hsize;
+ HashNode *nodes = ht->nodes;
+
+ st.sorted = 0;
+ ht->scan = &st;
+
+ for (i = 0; i < hsize; i++)
+ for (st.u.u = nodes[i]; st.u.u; ) {
+ HashNode hn = st.u.u;
+ st.u.u = st.u.u->next;
+ if ((!flags1 || (hn->flags & flags1)) && !(hn->flags & flags2)
+ && (!pprog || pattry(pprog, hn->nam))) {
+ match++;
+ scanfunc(hn, scanflags);
+ }
+ }
+
+ ht->scan = NULL;
+ }
+
+ return match;
+}
+
+
+/**/
+mod_export int
+scanhashtable(HashTable ht, int sorted, int flags1, int flags2,
+ ScanFunc scanfunc, int scanflags)
+{
+ return scanmatchtable(ht, NULL, sorted, flags1, flags2,
+ scanfunc, scanflags);
+}
+
+/* Expand hash tables when they get too many entries. *
+ * The new size is 4 times the previous size. */
+
+/**/
+static void
+expandhashtable(HashTable ht)
+{
+ struct hashnode **onodes, **ha, *hn, *hp;
+ int i, osize;
+
+ osize = ht->hsize;
+ onodes = ht->nodes;
+
+ ht->hsize = osize * 4;
+ ht->nodes = (HashNode *) zshcalloc(ht->hsize * sizeof(HashNode));
+ ht->ct = 0;
+
+ /* scan through the old list of nodes, and *
+ * rehash them into the new list of nodes */
+ for (i = 0, ha = onodes; i < osize; i++, ha++) {
+ for (hn = *ha; hn;) {
+ hp = hn->next;
+ ht->addnode(ht, hn->nam, hn);
+ hn = hp;
+ }
+ }
+ zfree(onodes, osize * sizeof(HashNode));
+}
+
+/* Empty the hash table and resize it if necessary */
+
+/**/
+static void
+resizehashtable(HashTable ht, int newsize)
+{
+ struct hashnode **ha, *hn, *hp;
+ int i;
+
+ /* free all the hash nodes */
+ ha = ht->nodes;
+ for (i = 0; i < ht->hsize; i++, ha++) {
+ for (hn = *ha; hn;) {
+ hp = hn->next;
+ ht->freenode(hn);
+ hn = hp;
+ }
+ }
+
+ /* If new size desired is different from current size, *
+ * we free it and allocate a new nodes array. */
+ if (ht->hsize != newsize) {
+ zfree(ht->nodes, ht->hsize * sizeof(HashNode));
+ ht->nodes = (HashNode *) zshcalloc(newsize * sizeof(HashNode));
+ ht->hsize = newsize;
+ } else {
+ /* else we just re-zero the current nodes array */
+ memset(ht->nodes, 0, newsize * sizeof(HashNode));
+ }
+
+ ht->ct = 0;
+}
+
+/* Generic method to empty a hash table */
+
+/**/
+mod_export void
+emptyhashtable(HashTable ht)
+{
+ resizehashtable(ht, ht->hsize);
+}
+
+/**/
+#ifdef ZSH_HASH_DEBUG
+
+/* Print info about hash table */
+
+#define MAXDEPTH 7
+
+/**/
+static void
+printhashtabinfo(HashTable ht)
+{
+ HashNode hn;
+ int chainlen[MAXDEPTH + 1];
+ int i, tmpcount, total;
+
+ printf("name of table : %s\n", ht->tablename);
+ printf("size of nodes[] : %d\n", ht->hsize);
+ printf("number of nodes : %d\n\n", ht->ct);
+
+ memset(chainlen, 0, sizeof(chainlen));
+
+ /* count the number of nodes just to be sure */
+ total = 0;
+ for (i = 0; i < ht->hsize; i++) {
+ tmpcount = 0;
+ for (hn = ht->nodes[i]; hn; hn = hn->next)
+ tmpcount++;
+ if (tmpcount >= MAXDEPTH)
+ chainlen[MAXDEPTH]++;
+ else
+ chainlen[tmpcount]++;
+ total += tmpcount;
+ }
+
+ for (i = 0; i < MAXDEPTH; i++)
+ printf("number of hash values with chain of length %d : %4d\n", i, chainlen[i]);
+ printf("number of hash values with chain of length %d+ : %4d\n", MAXDEPTH, chainlen[MAXDEPTH]);
+ printf("total number of nodes : %4d\n", total);
+}
+
+/**/
+int
+bin_hashinfo(UNUSED(char *nam), UNUSED(char **args), UNUSED(Options ops), UNUSED(int func))
+{
+ HashTable ht;
+
+ printf("----------------------------------------------------\n");
+ queue_signals();
+ for(ht = firstht; ht; ht = ht->next) {
+ ht->printinfo(ht);
+ printf("----------------------------------------------------\n");
+ }
+ unqueue_signals();
+ return 0;
+}
+
+/**/
+#endif /* ZSH_HASH_DEBUG */
+
+/********************************/
+/* Command Hash Table Functions */
+/********************************/
+
+/* hash table containing external commands */
+
+/**/
+mod_export HashTable cmdnamtab;
+
+/* how far we've hashed the PATH so far */
+
+/**/
+mod_export char **pathchecked;
+
+/* Create a new command hash table */
+
+/**/
+void
+createcmdnamtable(void)
+{
+ cmdnamtab = newhashtable(201, "cmdnamtab", NULL);
+
+ cmdnamtab->hash = hasher;
+ cmdnamtab->emptytable = emptycmdnamtable;
+ cmdnamtab->filltable = fillcmdnamtable;
+ cmdnamtab->cmpnodes = strcmp;
+ cmdnamtab->addnode = addhashnode;
+ cmdnamtab->getnode = gethashnode2;
+ cmdnamtab->getnode2 = gethashnode2;
+ cmdnamtab->removenode = removehashnode;
+ cmdnamtab->disablenode = NULL;
+ cmdnamtab->enablenode = NULL;
+ cmdnamtab->freenode = freecmdnamnode;
+ cmdnamtab->printnode = printcmdnamnode;
+
+ pathchecked = path;
+}
+
+/**/
+static void
+emptycmdnamtable(HashTable ht)
+{
+ emptyhashtable(ht);
+ pathchecked = path;
+}
+
+/* Add all commands in a given directory *
+ * to the command hashtable. */
+
+/**/
+void
+hashdir(char **dirp)
+{
+ Cmdnam cn;
+ DIR *dir;
+ char *fn, *unmetadir, *pathbuf, *pathptr;
+ int dirlen;
+#if defined(_WIN32) || defined(__CYGWIN__)
+ char *exe;
+#endif /* _WIN32 || _CYGWIN__ */
+
+ if (isrelative(*dirp))
+ return;
+ unmetadir = unmeta(*dirp);
+ if (!(dir = opendir(unmetadir)))
+ return;
+
+ dirlen = strlen(unmetadir);
+ pathbuf = (char *)zalloc(dirlen + PATH_MAX + 2);
+ sprintf(pathbuf, "%s/", unmetadir);
+ pathptr = pathbuf + dirlen + 1;
+
+ while ((fn = zreaddir(dir, 1))) {
+ if (!cmdnamtab->getnode(cmdnamtab, fn)) {
+ char *fname = ztrdup(fn);
+ struct stat statbuf;
+ int add = 0, dummylen;
+
+ unmetafy(fn, &dummylen);
+ if (strlen(fn) > PATH_MAX) {
+ /* Too heavy to do all the allocation */
+ add = 1;
+ } else {
+ strcpy(pathptr, fn);
+ /*
+ * This is the same test as for the glob qualifier for
+ * executable plain files.
+ */
+ if (unset(HASHEXECUTABLESONLY) ||
+ (access(pathbuf, X_OK) == 0 &&
+ stat(pathbuf, &statbuf) == 0 &&
+ S_ISREG(statbuf.st_mode) && (statbuf.st_mode & S_IXUGO)))
+ add = 1;
+ }
+ if (add) {
+ cn = (Cmdnam) zshcalloc(sizeof *cn);
+ cn->node.flags = 0;
+ cn->u.name = dirp;
+ cmdnamtab->addnode(cmdnamtab, fname, cn);
+ } else
+ zsfree(fname);
+ }
+#if defined(_WIN32) || defined(__CYGWIN__)
+ /* Hash foo.exe as foo, since when no real foo exists, foo.exe
+ will get executed by DOS automatically. This quiets
+ spurious corrections when CORRECT or CORRECT_ALL is set. */
+ if ((exe = strrchr(fn, '.')) &&
+ (exe[1] == 'E' || exe[1] == 'e') &&
+ (exe[2] == 'X' || exe[2] == 'x') &&
+ (exe[3] == 'E' || exe[3] == 'e') && exe[4] == 0) {
+ *exe = 0;
+ if (!cmdnamtab->getnode(cmdnamtab, fn)) {
+ cn = (Cmdnam) zshcalloc(sizeof *cn);
+ cn->node.flags = 0;
+ cn->u.name = dirp;
+ cmdnamtab->addnode(cmdnamtab, ztrdup(fn), cn);
+ }
+ }
+#endif /* _WIN32 || __CYGWIN__ */
+ }
+ closedir(dir);
+ zfree(pathbuf, dirlen + PATH_MAX + 2);
+}
+
+/* Go through user's PATH and add everything to *
+ * the command hashtable. */
+
+/**/
+static void
+fillcmdnamtable(UNUSED(HashTable ht))
+{
+ char **pq;
+
+ for (pq = pathchecked; *pq; pq++)
+ hashdir(pq);
+
+ pathchecked = pq;
+}
+
+/**/
+static void
+freecmdnamnode(HashNode hn)
+{
+ Cmdnam cn = (Cmdnam) hn;
+
+ zsfree(cn->node.nam);
+ if (cn->node.flags & HASHED)
+ zsfree(cn->u.cmd);
+
+ zfree(cn, sizeof(struct cmdnam));
+}
+
+/* Print an element of the cmdnamtab hash table (external command) */
+
+/**/
+static void
+printcmdnamnode(HashNode hn, int printflags)
+{
+ Cmdnam cn = (Cmdnam) hn;
+
+ if (printflags & PRINT_WHENCE_WORD) {
+ printf("%s: %s\n", cn->node.nam, (cn->node.flags & HASHED) ?
+ "hashed" : "command");
+ return;
+ }
+
+ if ((printflags & PRINT_WHENCE_CSH) || (printflags & PRINT_WHENCE_SIMPLE)) {
+ if (cn->node.flags & HASHED) {
+ zputs(cn->u.cmd, stdout);
+ putchar('\n');
+ } else {
+ zputs(*(cn->u.name), stdout);
+ putchar('/');
+ zputs(cn->node.nam, stdout);
+ putchar('\n');
+ }
+ return;
+ }
+
+ if (printflags & PRINT_WHENCE_VERBOSE) {
+ if (cn->node.flags & HASHED) {
+ nicezputs(cn->node.nam, stdout);
+ printf(" is hashed to ");
+ nicezputs(cn->u.cmd, stdout);
+ putchar('\n');
+ } else {
+ nicezputs(cn->node.nam, stdout);
+ printf(" is ");
+ nicezputs(*(cn->u.name), stdout);
+ putchar('/');
+ nicezputs(cn->node.nam, stdout);
+ putchar('\n');
+ }
+ return;
+ }
+
+ if (printflags & PRINT_LIST) {
+ printf("hash ");
+
+ if(cn->node.nam[0] == '-')
+ printf("-- ");
+ }
+
+ if (cn->node.flags & HASHED) {
+ quotedzputs(cn->node.nam, stdout);
+ putchar('=');
+ quotedzputs(cn->u.cmd, stdout);
+ putchar('\n');
+ } else {
+ quotedzputs(cn->node.nam, stdout);
+ putchar('=');
+ quotedzputs(*(cn->u.name), stdout);
+ putchar('/');
+ quotedzputs(cn->node.nam, stdout);
+ putchar('\n');
+ }
+}
+
+/***************************************/
+/* Shell Function Hash Table Functions */
+/***************************************/
+
+/* hash table containing the shell functions */
+
+/**/
+mod_export HashTable shfunctab;
+
+/**/
+void
+createshfunctable(void)
+{
+ shfunctab = newhashtable(7, "shfunctab", NULL);
+
+ shfunctab->hash = hasher;
+ shfunctab->emptytable = NULL;
+ shfunctab->filltable = NULL;
+ shfunctab->cmpnodes = strcmp;
+ shfunctab->addnode = addhashnode;
+ shfunctab->getnode = gethashnode;
+ shfunctab->getnode2 = gethashnode2;
+ shfunctab->removenode = removeshfuncnode;
+ shfunctab->disablenode = disableshfuncnode;
+ shfunctab->enablenode = enableshfuncnode;
+ shfunctab->freenode = freeshfuncnode;
+ shfunctab->printnode = printshfuncnode;
+}
+
+/* Remove an entry from the shell function hash table. *
+ * It checks if the function is a signal trap and if so, *
+ * it will disable the trapping of that signal. */
+
+/**/
+static HashNode
+removeshfuncnode(UNUSED(HashTable ht), const char *nam)
+{
+ HashNode hn;
+ int signum;
+
+ if (!strncmp(nam, "TRAP", 4) && (signum = getsignum(nam + 4)) != -1)
+ hn = removetrap(signum);
+ else
+ hn = removehashnode(shfunctab, nam);
+
+ return hn;
+}
+
+/* Disable an entry in the shell function hash table. *
+ * It checks if the function is a signal trap and if so, *
+ * it will disable the trapping of that signal. */
+
+/**/
+static void
+disableshfuncnode(HashNode hn, UNUSED(int flags))
+{
+ hn->flags |= DISABLED;
+ if (!strncmp(hn->nam, "TRAP", 4)) {
+ int signum = getsignum(hn->nam + 4);
+ if (signum != -1) {
+ sigtrapped[signum] &= ~ZSIG_FUNC;
+ unsettrap(signum);
+ }
+ }
+}
+
+/* Re-enable an entry in the shell function hash table. *
+ * It checks if the function is a signal trap and if so, *
+ * it will re-enable the trapping of that signal. */
+
+/**/
+static void
+enableshfuncnode(HashNode hn, UNUSED(int flags))
+{
+ Shfunc shf = (Shfunc) hn;
+
+ shf->node.flags &= ~DISABLED;
+ if (!strncmp(shf->node.nam, "TRAP", 4)) {
+ int signum = getsignum(shf->node.nam + 4);
+ if (signum != -1) {
+ settrap(signum, NULL, ZSIG_FUNC);
+ }
+ }
+}
+
+/**/
+static void
+freeshfuncnode(HashNode hn)
+{
+ Shfunc shf = (Shfunc) hn;
+
+ zsfree(shf->node.nam);
+ if (shf->funcdef)
+ freeeprog(shf->funcdef);
+ if (shf->redir)
+ freeeprog(shf->redir);
+ dircache_set(&shf->filename, NULL);
+ if (shf->sticky) {
+ if (shf->sticky->n_on_opts)
+ zfree(shf->sticky->on_opts,
+ shf->sticky->n_on_opts * sizeof(*shf->sticky->on_opts));
+ if (shf->sticky->n_off_opts)
+ zfree(shf->sticky->off_opts,
+ shf->sticky->n_off_opts * sizeof(*shf->sticky->off_opts));
+ zfree(shf->sticky, sizeof(*shf->sticky));
+ }
+ zfree(shf, sizeof(struct shfunc));
+}
+
+/* Print a shell function */
+
+/**/
+static void
+printshfuncnode(HashNode hn, int printflags)
+{
+ Shfunc f = (Shfunc) hn;
+ char *t = 0;
+
+ if ((printflags & PRINT_NAMEONLY) ||
+ ((printflags & PRINT_WHENCE_SIMPLE) &&
+ !(printflags & PRINT_WHENCE_FUNCDEF))) {
+ zputs(f->node.nam, stdout);
+ putchar('\n');
+ return;
+ }
+
+ if ((printflags & (PRINT_WHENCE_VERBOSE|PRINT_WHENCE_WORD)) &&
+ !(printflags & PRINT_WHENCE_FUNCDEF)) {
+ nicezputs(f->node.nam, stdout);
+ printf((printflags & PRINT_WHENCE_WORD) ? ": function" :
+ (f->node.flags & PM_UNDEFINED) ?
+ " is an autoload shell function" :
+ " is a shell function");
+ if ((printflags & PRINT_WHENCE_VERBOSE) && f->filename) {
+ printf(" from ");
+ quotedzputs(f->filename, stdout);
+ if (f->node.flags & PM_LOADDIR) {
+ printf("/");
+ quotedzputs(f->node.nam, stdout);
+ }
+ }
+ putchar('\n');
+ return;
+ }
+
+ quotedzputs(f->node.nam, stdout);
+ if (f->funcdef || f->node.flags & PM_UNDEFINED) {
+ printf(" () {\n");
+ zoutputtab(stdout);
+ if (f->node.flags & PM_UNDEFINED) {
+ printf("%c undefined\n", hashchar);
+ zoutputtab(stdout);
+ } else
+ t = getpermtext(f->funcdef, NULL, 1);
+ if (f->node.flags & (PM_TAGGED|PM_TAGGED_LOCAL)) {
+ printf("%c traced\n", hashchar);
+ zoutputtab(stdout);
+ }
+ if (!t) {
+ char *fopt = "UtTkzc";
+ int flgs[] = {
+ PM_UNALIASED, PM_TAGGED, PM_TAGGED_LOCAL,
+ PM_KSHSTORED, PM_ZSHSTORED, PM_CUR_FPATH, 0
+ };
+ int fl;;
+
+ zputs("builtin autoload -X", stdout);
+ for (fl=0;fopt[fl];fl++)
+ if (f->node.flags & flgs[fl]) putchar(fopt[fl]);
+ if (f->filename && (f->node.flags & PM_LOADDIR)) {
+ putchar(' ');
+ zputs(f->filename, stdout);
+ }
+ } else {
+ zputs(t, stdout);
+ zsfree(t);
+ if (f->funcdef->flags & EF_RUN) {
+ printf("\n");
+ zoutputtab(stdout);
+ quotedzputs(f->node.nam, stdout);
+ printf(" \"$@\"");
+ }
+ }
+ printf("\n}");
+ } else {
+ printf(" () { }");
+ }
+ if (f->redir) {
+ t = getpermtext(f->redir, NULL, 1);
+ if (t) {
+ zputs(t, stdout);
+ zsfree(t);
+ }
+ }
+
+ putchar('\n');
+}
+
+/*
+ * Wrap scanmatchtable for shell functions with optional
+ * expansion of leading tabs.
+ * expand = 0 is standard: use hard tabs.
+ * expand > 0 uses that many spaces.
+ * expand < 0 uses no identation.
+ *
+ * Note this function and the following two are called with
+ * interrupts queued, so saving and restoring text_expand_tabs
+ * is safe.
+ */
+
+/**/
+mod_export int
+scanmatchshfunc(Patprog pprog, int sorted, int flags1, int flags2,
+ ScanFunc scanfunc, int scanflags, int expand)
+{
+ int ret, save_expand;
+
+ save_expand = text_expand_tabs;
+ text_expand_tabs = expand;
+ ret = scanmatchtable(shfunctab, pprog, sorted, flags1, flags2,
+ scanfunc, scanflags);
+ text_expand_tabs = save_expand;
+
+ return ret;
+}
+
+/* Wrap scanhashtable to expand tabs for shell functions */
+
+/**/
+mod_export int
+scanshfunc(int sorted, int flags1, int flags2,
+ ScanFunc scanfunc, int scanflags, int expand)
+{
+ return scanmatchshfunc(NULL, sorted, flags1, flags2,
+ scanfunc, scanflags, expand);
+}
+
+/* Wrap shfunctab->printnode to expand tabs */
+
+/**/
+mod_export void
+printshfuncexpand(HashNode hn, int printflags, int expand)
+{
+ int save_expand;
+
+ save_expand = text_expand_tabs;
+ text_expand_tabs = expand;
+ shfunctab->printnode(hn, printflags);
+ text_expand_tabs = save_expand;
+}
+
+/*
+ * Get a heap-duplicated name of the shell function, for
+ * use in tracing.
+ */
+
+/**/
+mod_export char *
+getshfuncfile(Shfunc shf)
+{
+ if (shf->node.flags & PM_LOADDIR) {
+ return zhtricat(shf->filename, "/", shf->node.nam);
+ } else if (shf->filename) {
+ return dupstring(shf->filename);
+ } else {
+ return NULL;
+ }
+}
+
+/**************************************/
+/* Reserved Word Hash Table Functions */
+/**************************************/
+
+/* Nodes for reserved word hash table */
+
+static struct reswd reswds[] = {
+ {{NULL, "!", 0}, BANG},
+ {{NULL, "[[", 0}, DINBRACK},
+ {{NULL, "{", 0}, INBRACE},
+ {{NULL, "}", 0}, OUTBRACE},
+ {{NULL, "case", 0}, CASE},
+ {{NULL, "coproc", 0}, COPROC},
+ {{NULL, "declare", 0}, TYPESET},
+ {{NULL, "do", 0}, DOLOOP},
+ {{NULL, "done", 0}, DONE},
+ {{NULL, "elif", 0}, ELIF},
+ {{NULL, "else", 0}, ELSE},
+ {{NULL, "end", 0}, ZEND},
+ {{NULL, "esac", 0}, ESAC},
+ {{NULL, "export", 0}, TYPESET},
+ {{NULL, "fi", 0}, FI},
+ {{NULL, "float", 0}, TYPESET},
+ {{NULL, "for", 0}, FOR},
+ {{NULL, "foreach", 0}, FOREACH},
+ {{NULL, "function", 0}, FUNC},
+ {{NULL, "if", 0}, IF},
+ {{NULL, "integer", 0}, TYPESET},
+ {{NULL, "local", 0}, TYPESET},
+ {{NULL, "nocorrect", 0}, NOCORRECT},
+ {{NULL, "readonly", 0}, TYPESET},
+ {{NULL, "repeat", 0}, REPEAT},
+ {{NULL, "select", 0}, SELECT},
+ {{NULL, "then", 0}, THEN},
+ {{NULL, "time", 0}, TIME},
+ {{NULL, "typeset", 0}, TYPESET},
+ {{NULL, "until", 0}, UNTIL},
+ {{NULL, "while", 0}, WHILE},
+ {{NULL, NULL, 0}, 0}
+};
+
+/* hash table containing the reserved words */
+
+/**/
+mod_export HashTable reswdtab;
+
+/* Build the hash table containing zsh's reserved words. */
+
+/**/
+void
+createreswdtable(void)
+{
+ Reswd rw;
+
+ reswdtab = newhashtable(23, "reswdtab", NULL);
+
+ reswdtab->hash = hasher;
+ reswdtab->emptytable = NULL;
+ reswdtab->filltable = NULL;
+ reswdtab->cmpnodes = strcmp;
+ reswdtab->addnode = addhashnode;
+ reswdtab->getnode = gethashnode;
+ reswdtab->getnode2 = gethashnode2;
+ reswdtab->removenode = NULL;
+ reswdtab->disablenode = disablehashnode;
+ reswdtab->enablenode = enablehashnode;
+ reswdtab->freenode = NULL;
+ reswdtab->printnode = printreswdnode;
+
+ for (rw = reswds; rw->node.nam; rw++)
+ reswdtab->addnode(reswdtab, rw->node.nam, rw);
+}
+
+/* Print a reserved word */
+
+/**/
+static void
+printreswdnode(HashNode hn, int printflags)
+{
+ Reswd rw = (Reswd) hn;
+
+ if (printflags & PRINT_WHENCE_WORD) {
+ printf("%s: reserved\n", rw->node.nam);
+ return;
+ }
+
+ if (printflags & PRINT_WHENCE_CSH) {
+ printf("%s: shell reserved word\n", rw->node.nam);
+ return;
+ }
+
+ if (printflags & PRINT_WHENCE_VERBOSE) {
+ printf("%s is a reserved word\n", rw->node.nam);
+ return;
+ }
+
+ /* default is name only */
+ printf("%s\n", rw->node.nam);
+}
+
+/********************************/
+/* Aliases Hash Table Functions */
+/********************************/
+
+/* hash table containing the aliases */
+
+/**/
+mod_export HashTable aliastab;
+
+/* has table containing suffix aliases */
+
+/**/
+mod_export HashTable sufaliastab;
+
+/* Create new hash tables for aliases */
+
+/**/
+void
+createaliastable(HashTable ht)
+{
+ ht->hash = hasher;
+ ht->emptytable = NULL;
+ ht->filltable = NULL;
+ ht->cmpnodes = strcmp;
+ ht->addnode = addhashnode;
+ ht->getnode = gethashnode;
+ ht->getnode2 = gethashnode2;
+ ht->removenode = removehashnode;
+ ht->disablenode = disablehashnode;
+ ht->enablenode = enablehashnode;
+ ht->freenode = freealiasnode;
+ ht->printnode = printaliasnode;
+}
+
+/**/
+void
+createaliastables(void)
+{
+ /* Table for regular and global aliases */
+
+ aliastab = newhashtable(23, "aliastab", NULL);
+
+ createaliastable(aliastab);
+
+ /* add the default aliases */
+ aliastab->addnode(aliastab, ztrdup("run-help"), createaliasnode(ztrdup("man"), 0));
+ aliastab->addnode(aliastab, ztrdup("which-command"), createaliasnode(ztrdup("whence"), 0));
+
+
+ /* Table for suffix aliases --- make this smaller */
+
+ sufaliastab = newhashtable(11, "sufaliastab", NULL);
+
+ createaliastable(sufaliastab);
+}
+
+/* Create a new alias node */
+
+/**/
+mod_export Alias
+createaliasnode(char *txt, int flags)
+{
+ Alias al;
+
+ al = (Alias) zshcalloc(sizeof *al);
+ al->node.flags = flags;
+ al->text = txt;
+ al->inuse = 0;
+ return al;
+}
+
+/**/
+static void
+freealiasnode(HashNode hn)
+{
+ Alias al = (Alias) hn;
+
+ zsfree(al->node.nam);
+ zsfree(al->text);
+ zfree(al, sizeof(struct alias));
+}
+
+/* Print an alias */
+
+/**/
+static void
+printaliasnode(HashNode hn, int printflags)
+{
+ Alias a = (Alias) hn;
+
+ if (printflags & PRINT_NAMEONLY) {
+ zputs(a->node.nam, stdout);
+ putchar('\n');
+ return;
+ }
+
+ if (printflags & PRINT_WHENCE_WORD) {
+ if (a->node.flags & ALIAS_SUFFIX)
+ printf("%s: suffix alias\n", a->node.nam);
+ else if (a->node.flags & ALIAS_GLOBAL)
+ printf("%s: global alias\n", a->node.nam);
+ else
+ printf("%s: alias\n", a->node.nam);
+ return;
+ }
+
+ if (printflags & PRINT_WHENCE_SIMPLE) {
+ zputs(a->text, stdout);
+ putchar('\n');
+ return;
+ }
+
+ if (printflags & PRINT_WHENCE_CSH) {
+ nicezputs(a->node.nam, stdout);
+ printf(": ");
+ if (a->node.flags & ALIAS_SUFFIX)
+ printf("suffix ");
+ else if (a->node.flags & ALIAS_GLOBAL)
+ printf("globally ");
+ printf ("aliased to ");
+ nicezputs(a->text, stdout);
+ putchar('\n');
+ return;
+ }
+
+ if (printflags & PRINT_WHENCE_VERBOSE) {
+ nicezputs(a->node.nam, stdout);
+ printf(" is a");
+ if (a->node.flags & ALIAS_SUFFIX)
+ printf(" suffix");
+ else if (a->node.flags & ALIAS_GLOBAL)
+ printf(" global");
+ else
+ printf("n");
+ printf(" alias for ");
+ nicezputs(a->text, stdout);
+ putchar('\n');
+ return;
+ }
+
+ if (printflags & PRINT_LIST) {
+ /* Fast fail on unrepresentable values. */
+ if (strchr(a->node.nam, '=')) {
+ zwarn("invalid alias '%s' encountered while printing aliases",
+ a->node.nam);
+ /* ### TODO: Return an error status to the C caller */
+ return;
+ }
+
+ /* Normal path. */
+ printf("alias ");
+ if (a->node.flags & ALIAS_SUFFIX)
+ printf("-s ");
+ else if (a->node.flags & ALIAS_GLOBAL)
+ printf("-g ");
+
+ /* If an alias begins with `-' or `+', then we must output `-- '
+ * first, so that it is not interpreted as an option. */
+ if(a->node.nam[0] == '-' || a->node.nam[0] == '+')
+ printf("-- ");
+ }
+
+ quotedzputs(a->node.nam, stdout);
+ putchar('=');
+ quotedzputs(a->text, stdout);
+
+ putchar('\n');
+}
+
+/*************************************/
+/* History Line Hash Table Functions */
+/*************************************/
+
+/**/
+void
+createhisttable(void)
+{
+ histtab = newhashtable(599, "histtab", NULL);
+
+ histtab->hash = histhasher;
+ histtab->emptytable = emptyhisttable;
+ histtab->filltable = NULL;
+ histtab->cmpnodes = histstrcmp;
+ histtab->addnode = addhistnode;
+ histtab->getnode = gethashnode2;
+ histtab->getnode2 = gethashnode2;
+ histtab->removenode = removehashnode;
+ histtab->disablenode = NULL;
+ histtab->enablenode = NULL;
+ histtab->freenode = freehistnode;
+ histtab->printnode = NULL;
+}
+
+/**/
+unsigned
+histhasher(const char *str)
+{
+ unsigned hashval = 0;
+
+ while (inblank(*str)) str++;
+
+ while (*str) {
+ if (inblank(*str)) {
+ do str++; while (inblank(*str));
+ if (*str)
+ hashval += (hashval << 5) + ' ';
+ }
+ else
+ hashval += (hashval << 5) + *(unsigned char *)str++;
+ }
+ return hashval;
+}
+
+/**/
+void
+emptyhisttable(HashTable ht)
+{
+ emptyhashtable(ht);
+ if (hist_ring)
+ histremovedups();
+}
+
+/* Compare two strings with normalized white-space */
+
+/**/
+int
+histstrcmp(const char *str1, const char *str2)
+{
+ while (inblank(*str1)) str1++;
+ while (inblank(*str2)) str2++;
+ while (*str1 && *str2) {
+ if (inblank(*str1)) {
+ if (!inblank(*str2))
+ break;
+ do str1++; while (inblank(*str1));
+ do str2++; while (inblank(*str2));
+ }
+ else {
+ if (*str1 != *str2)
+ break;
+ str1++;
+ str2++;
+ }
+ }
+ return *str1 - *str2;
+}
+
+/**/
+void
+addhistnode(HashTable ht, char *nam, void *nodeptr)
+{
+ HashNode oldnode = addhashnode2(ht, nam, nodeptr);
+ Histent he = (Histent)nodeptr;
+ if (oldnode && oldnode != (HashNode)nodeptr) {
+ if (he->node.flags & HIST_MAKEUNIQUE
+ || (he->node.flags & HIST_FOREIGN && (Histent)oldnode == he->up)) {
+ (void) addhashnode2(ht, oldnode->nam, oldnode); /* restore hash */
+ he->node.flags |= HIST_DUP;
+ he->node.flags &= ~HIST_MAKEUNIQUE;
+ }
+ else {
+ oldnode->flags |= HIST_DUP;
+ if (hist_ignore_all_dups)
+ freehistnode(oldnode); /* Remove the old dup */
+ }
+ }
+ else
+ he->node.flags &= ~HIST_MAKEUNIQUE;
+}
+
+/**/
+void
+freehistnode(HashNode nodeptr)
+{
+ freehistdata((Histent)nodeptr, 1);
+ zfree(nodeptr, sizeof (struct histent));
+}
+
+/**/
+void
+freehistdata(Histent he, int unlink)
+{
+ if (!he)
+ return;
+
+ if (he == &curline)
+ return;
+
+ if (!(he->node.flags & (HIST_DUP | HIST_TMPSTORE)))
+ removehashnode(histtab, he->node.nam);
+
+ zsfree(he->node.nam);
+ if (he->nwords)
+ zfree(he->words, he->nwords*2*sizeof(short));
+
+ if (unlink) {
+ if (!--histlinect)
+ hist_ring = NULL;
+ else {
+ if (he == hist_ring)
+ hist_ring = hist_ring->up;
+ he->up->down = he->down;
+ he->down->up = he->up;
+ }
+ }
+}
+
+
+/***********************************************************************
+ * Directory name cache mechanism
+ *
+ * The idea of this is that there are various shell structures,
+ * notably functions, that record the directories with which they
+ * are associated. Rather than store the full string each time,
+ * we store a pointer to the same location and count the references.
+ * This is optimised so that retrieval is quick at the expense of
+ * searching the list when setting up the structure, which is a much
+ * rarer operation.
+ *
+ * There is nothing special about the fact that the strings are
+ * directories, except for the assumptions for efficiency that many
+ * structures will point to the same one, and that there are not too
+ * many different directories associated with the shell.
+ **********************************************************************/
+
+struct dircache_entry
+{
+ /* Name of directory in cache */
+ char *name;
+ /* Number of references to it */
+ int refs;
+};
+
+/*
+ * dircache is the cache, of length dircache_size.
+ * dircache_lastentry is the last entry used, an optimisation
+ * for multiple references to the same directory, e.g
+ * "autoload /blah/blah/\*".
+ */
+static struct dircache_entry *dircache, *dircache_lastentry;
+static int dircache_size;
+
+/*
+ * Set *name to point to a cached version of value.
+ * value is copied so may come from any source.
+ *
+ * If value is NULL, look for the existing value of *name (safe if this
+ * too is NULL) and remove a reference to it from the cache. If it's
+ * not found in the cache, it's assumed to be an allocated string and
+ * freed --- this currently occurs for a shell function that's been
+ * loaded as the filename is now a full path, not just a directory,
+ * though we may one day optimise this to a cached directory plus a
+ * name, too. Note --- the function does *not* otherwise check
+ * if *name points to something already cached, so this is
+ * necessary any time *name may already be in the cache.
+ */
+
+/**/
+mod_export void
+dircache_set(char **name, char *value)
+{
+ struct dircache_entry *dcptr, *dcnew;
+
+ if (!value) {
+ if (!*name)
+ return;
+ if (!dircache_size) {
+ zsfree(*name);
+ *name = NULL;
+ return;
+ }
+
+ for (dcptr = dircache; dcptr < dircache + dircache_size; dcptr++)
+ {
+ /* Must be a pointer much, not a string match */
+ if (*name == dcptr->name)
+ {
+ --dcptr->refs;
+ if (!dcptr->refs) {
+ ptrdiff_t ind = dcptr - dircache;
+ zsfree(dcptr->name);
+ --dircache_size;
+
+ if (!dircache_size) {
+ zfree(dircache, sizeof(*dircache));
+ dircache = NULL;
+ dircache_lastentry = NULL;
+ *name = NULL;
+ return;
+ }
+ dcnew = (struct dircache_entry *)
+ zalloc(dircache_size * sizeof(*dcnew));
+ if (ind)
+ memcpy(dcnew, dircache, ind * sizeof(*dcnew));
+ if (ind < dircache_size)
+ memcpy(dcnew + ind, dcptr + 1,
+ (dircache_size - ind) * sizeof(*dcnew));
+ zfree(dircache, (dircache_size+1)*sizeof(*dcnew));
+ dircache = dcnew;
+ dircache_lastentry = NULL;
+ }
+ *name = NULL;
+ return;
+ }
+ }
+ zsfree(*name);
+ *name = NULL;
+ } else {
+ /*
+ * As the function path has been resolved to a particular
+ * location, we'll store it as an absolute path.
+ */
+ if (*value != '/') {
+ value = zhtricat(metafy(zgetcwd(), -1, META_HEAPDUP),
+ "/", value);
+ value = xsymlink(value, 1);
+ }
+ /*
+ * We'll maintain the cache at exactly the right size rather
+ * than overallocating. The rationale here is that typically
+ * we'll get a lot of functions in a small number of directories
+ * so the complexity overhead of maintaining a separate count
+ * isn't really matched by the efficiency gain.
+ */
+ if (dircache_lastentry &&
+ !strcmp(value, dircache_lastentry->name)) {
+ *name = dircache_lastentry->name;
+ ++dircache_lastentry->refs;
+ return;
+ } else if (!dircache_size) {
+ dircache_size = 1;
+ dcptr = dircache =
+ (struct dircache_entry *)zalloc(sizeof(*dircache));
+ } else {
+ for (dcptr = dircache; dcptr < dircache + dircache_size; dcptr++)
+ {
+ if (!strcmp(value, dcptr->name)) {
+ *name = dcptr->name;
+ ++dcptr->refs;
+ return;
+ }
+ }
+ ++dircache_size;
+ dircache = (struct dircache_entry *)
+ zrealloc(dircache, sizeof(*dircache) * dircache_size);
+ dcptr = dircache + dircache_size - 1;
+ }
+ dcptr->name = ztrdup(value);
+ *name = dcptr->name;
+ dcptr->refs = 1;
+ dircache_lastentry = dcptr;
+ }
+}
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/hashtable.h b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/hashtable.h
new file mode 100644
index 0000000..21398e1
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/hashtable.h
@@ -0,0 +1,69 @@
+/*
+ * hashtable.h - header file for hash table handling code
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+/* Builtin function numbers; used by handler functions that handle more *
+ * than one builtin. Note that builtins such as compctl, that are not *
+ * overloaded, don't get a number. */
+
+#define BIN_TYPESET 0
+#define BIN_BG 1
+#define BIN_FG 2
+#define BIN_JOBS 3
+#define BIN_WAIT 4
+#define BIN_DISOWN 5
+#define BIN_BREAK 6
+#define BIN_CONTINUE 7
+#define BIN_EXIT 8
+#define BIN_RETURN 9
+#define BIN_CD 10
+#define BIN_POPD 11
+#define BIN_PUSHD 12
+#define BIN_PRINT 13
+#define BIN_EVAL 14
+#define BIN_SCHED 15
+#define BIN_FC 16
+#define BIN_R 17
+#define BIN_PUSHLINE 18
+#define BIN_LOGOUT 19
+#define BIN_TEST 20
+#define BIN_BRACKET 21
+#define BIN_READONLY 22
+#define BIN_ECHO 23
+#define BIN_DISABLE 24
+#define BIN_ENABLE 25
+#define BIN_PRINTF 26
+#define BIN_COMMAND 27
+#define BIN_UNHASH 28
+#define BIN_UNALIAS 29
+#define BIN_UNFUNCTION 30
+#define BIN_UNSET 31
+
+/* These currently depend on being 0 and 1. */
+#define BIN_SETOPT 0
+#define BIN_UNSETOPT 1
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/init.c b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/init.c
new file mode 100644
index 0000000..e9e6be9
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/init.c
@@ -0,0 +1,1792 @@
+/*
+ * init.c - main loop and initialization routines
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+#include "zsh.mdh"
+
+#include "zshpaths.h"
+#include "zshxmods.h"
+
+#include "init.pro"
+
+#include "version.h"
+
+/**/
+int noexitct = 0;
+
+/* buffer for $_ and its length */
+
+/**/
+char *zunderscore;
+
+/**/
+int underscorelen, underscoreused;
+
+/* what level of sourcing we are at */
+
+/**/
+int sourcelevel;
+
+/* the shell tty fd */
+
+/**/
+mod_export int SHTTY;
+
+/* the FILE attached to the shell tty */
+
+/**/
+mod_export FILE *shout;
+
+/* termcap strings */
+
+/**/
+mod_export char *tcstr[TC_COUNT];
+
+/* lengths of each termcap string */
+
+/**/
+mod_export int tclen[TC_COUNT];
+
+/* Values of the li, co and am entries */
+
+/**/
+int tclines, tccolumns;
+/**/
+mod_export int hasam, hasbw, hasxn, hasye;
+
+/* Value of the Co (max_colors) entry: may not be set */
+
+/**/
+mod_export int tccolours;
+
+/* SIGCHLD mask */
+
+/**/
+mod_export sigset_t sigchld_mask;
+
+/**/
+mod_export struct hookdef zshhooks[] = {
+ HOOKDEF("exit", NULL, HOOKF_ALL),
+ HOOKDEF("before_trap", NULL, HOOKF_ALL),
+ HOOKDEF("after_trap", NULL, HOOKF_ALL),
+};
+
+/* keep executing lists until EOF found */
+
+/**/
+enum loop_return
+loop(int toplevel, int justonce)
+{
+ Eprog prog;
+ int err, non_empty = 0;
+
+ queue_signals();
+ pushheap();
+ if (!toplevel)
+ zcontext_save();
+ for (;;) {
+ freeheap();
+ if (stophist == 3) /* re-entry via preprompt() */
+ hend(NULL);
+ hbegin(1); /* init history mech */
+ if (isset(SHINSTDIN)) {
+ setblock_stdin();
+ if (interact && toplevel) {
+ int hstop = stophist;
+ stophist = 3;
+ /*
+ * Reset all errors including the interrupt error status
+ * immediately, so preprompt runs regardless of what
+ * just happened. We'll reset again below as a
+ * precaution to ensure we get back to the command line
+ * no matter what.
+ */
+ errflag = 0;
+ preprompt();
+ if (stophist != 3)
+ hbegin(1);
+ else
+ stophist = hstop;
+ /*
+ * Reset all errors, including user interupts.
+ * This is what allows ^C in an interactive shell
+ * to return us to the command line.
+ */
+ errflag = 0;
+ }
+ }
+ use_exit_printed = 0;
+ intr(); /* interrupts on */
+ lexinit(); /* initialize lexical state */
+ if (!(prog = parse_event(ENDINPUT))) {
+ /* if we couldn't parse a list */
+ hend(NULL);
+ if ((tok == ENDINPUT && !errflag) ||
+ (tok == LEXERR && (!isset(SHINSTDIN) || !toplevel)) ||
+ justonce)
+ break;
+ if (exit_pending) {
+ /*
+ * Something down there (a ZLE function?) decided
+ * to exit when there was stuff to clear up.
+ * Handle that now.
+ */
+ stopmsg = 1;
+ zexit(exit_pending >> 1, 0);
+ }
+ if (tok == LEXERR && !lastval)
+ lastval = 1;
+ continue;
+ }
+ if (hend(prog)) {
+ enum lextok toksav = tok;
+
+ non_empty = 1;
+ if (toplevel &&
+ (getshfunc("preexec") ||
+ paramtab->getnode(paramtab, "preexec" HOOK_SUFFIX))) {
+ LinkList args;
+ char *cmdstr;
+
+ /*
+ * As we're about to freeheap() or popheap()
+ * anyway, there's no gain in using permanent
+ * storage here.
+ */
+ args = newlinklist();
+ addlinknode(args, "preexec");
+ /* If curline got dumped from the history, we don't know
+ * what the user typed. */
+ if (hist_ring && curline.histnum == curhist)
+ addlinknode(args, hist_ring->node.nam);
+ else
+ addlinknode(args, "");
+ addlinknode(args, dupstring(getjobtext(prog, NULL)));
+ addlinknode(args, cmdstr = getpermtext(prog, NULL, 0));
+
+ callhookfunc("preexec", args, 1, NULL);
+
+ /* The only permanent storage is from getpermtext() */
+ zsfree(cmdstr);
+ /*
+ * Note this does *not* remove a user interrupt error
+ * condition, even though we're at the top level loop:
+ * that would be inconsistent with the case where
+ * we didn't execute a preexec function. This is
+ * an implementation detail that an interrupting user
+ * does't care about.
+ */
+ errflag &= ~ERRFLAG_ERROR;
+ }
+ if (stopmsg) /* unset 'you have stopped jobs' flag */
+ stopmsg--;
+ execode(prog, 0, 0, toplevel ? "toplevel" : "file");
+ tok = toksav;
+ if (toplevel)
+ noexitct = 0;
+ }
+ if (ferror(stderr)) {
+ zerr("write error");
+ clearerr(stderr);
+ }
+ if (subsh) /* how'd we get this far in a subshell? */
+ exit(lastval);
+ if (((!interact || sourcelevel) && errflag) || retflag)
+ break;
+ if (isset(SINGLECOMMAND) && toplevel) {
+ dont_queue_signals();
+ if (sigtrapped[SIGEXIT])
+ dotrap(SIGEXIT);
+ exit(lastval);
+ }
+ if (justonce)
+ break;
+ }
+ err = errflag;
+ if (!toplevel)
+ zcontext_restore();
+ popheap();
+ unqueue_signals();
+
+ if (err)
+ return LOOP_ERROR;
+ if (!non_empty)
+ return LOOP_EMPTY;
+ return LOOP_OK;
+}
+
+static int restricted;
+
+/**/
+static void
+parseargs(char *zsh_name, char **argv, char **runscript, char **cmdptr)
+{
+ char **x;
+ LinkList paramlist;
+ int flags = PARSEARGS_TOPLEVEL;
+ if (**argv == '-')
+ flags |= PARSEARGS_LOGIN;
+
+ argzero = posixzero = *argv++;
+ SHIN = 0;
+
+ /*
+ * parseopts sets up some options after we deal with emulation in
+ * order to be consistent --- the code in parseopts_setemulate() is
+ * matched by code at the end of the present function.
+ */
+
+ if (parseopts(zsh_name, &argv, opts, cmdptr, NULL, flags))
+ exit(1);
+
+ /*
+ * USEZLE remains set if the shell has access to a terminal and
+ * is not reading from some other source as indicated by SHINSTDIN.
+ * SHINSTDIN becomes set below if there is no command argument,
+ * but it is the explicit setting (or not) that matters to USEZLE.
+ * USEZLE may also become unset in init_io() if the shell is not
+ * interactive or the terminal cannot be re-opened read/write.
+ */
+ if (opts[SHINSTDIN])
+ opts[USEZLE] = (opts[USEZLE] && isatty(0));
+
+ paramlist = znewlinklist();
+ if (*argv) {
+ if (unset(SHINSTDIN)) {
+ posixzero = *argv;
+ if (*cmdptr)
+ argzero = *argv;
+ else
+ *runscript = *argv;
+ opts[INTERACTIVE] &= 1;
+ argv++;
+ }
+ while (*argv)
+ zaddlinknode(paramlist, ztrdup(*argv++));
+ } else if (!*cmdptr)
+ opts[SHINSTDIN] = 1;
+ if(isset(SINGLECOMMAND))
+ opts[INTERACTIVE] &= 1;
+ opts[INTERACTIVE] = !!opts[INTERACTIVE];
+ if (opts[MONITOR] == 2)
+ opts[MONITOR] = opts[INTERACTIVE];
+ if (opts[HASHDIRS] == 2)
+ opts[HASHDIRS] = opts[INTERACTIVE];
+ pparams = x = (char **) zshcalloc((countlinknodes(paramlist) + 1) * sizeof(char *));
+
+ while ((*x++ = (char *)getlinknode(paramlist)));
+ free(paramlist);
+ argzero = ztrdup(argzero);
+ posixzero = ztrdup(posixzero);
+}
+
+/* Insert into list in order of pointer value */
+
+/**/
+static void
+parseopts_insert(LinkList optlist, char *base, int optno)
+{
+ LinkNode node;
+ void *ptr = base + (optno < 0 ? -optno : optno);
+
+ for (node = firstnode(optlist); node; incnode(node)) {
+ if (ptr < getdata(node)) {
+ insertlinknode(optlist, prevnode(node), ptr);
+ return;
+ }
+ }
+
+ addlinknode(optlist, ptr);
+}
+
+/*
+ * This sets the global emulation plus the options we traditionally
+ * set immediately after that. This is just for historical consistency
+ * --- I don't think those options actually need to be set here.
+ */
+static void parseopts_setemulate(char *nam, int flags)
+{
+ emulate(nam, 1, &emulation, opts); /* initialises most options */
+ opts[LOGINSHELL] = ((flags & PARSEARGS_LOGIN) != 0);
+ opts[PRIVILEGED] = (getuid() != geteuid() || getgid() != getegid());
+
+ /* There's a bit of trickery with opts[INTERACTIVE] here. It starts *
+ * at a value of 2 (instead of 1) or 0. If it is explicitly set on *
+ * the command line, it goes to 1 or 0. If input is coming from *
+ * somewhere that normally makes the shell non-interactive, we do *
+ * "opts[INTERACTIVE] &= 1", so that only a *default* on state will *
+ * be changed. At the end of the function, a value of 2 gets *
+ * changed to 1. */
+ opts[INTERACTIVE] = isatty(0) ? 2 : 0;
+ /*
+ * MONITOR is similar: we initialise it to 2, and if it's
+ * still 2 at the end, we set it to the value of INTERACTIVE.
+ */
+ opts[MONITOR] = 2; /* may be unset in init_io() */
+ opts[HASHDIRS] = 2; /* same relationship to INTERACTIVE */
+ opts[USEZLE] = 1; /* see below, related to SHINSTDIN */
+ opts[SHINSTDIN] = 0;
+ opts[SINGLECOMMAND] = 0;
+}
+
+/*
+ * Parse shell options.
+ *
+ * If (flags & PARSEARGS_TOPLEVEL):
+ * - we are doing shell initilisation
+ * - nam is the name under which the shell was started
+ * - set up emulation and standard options based on that.
+ * Otherwise:
+ * - nam is a command name
+ * - don't exit on failure.
+ *
+ * If optlist is not NULL, it used to form a list of pointers
+ * into new_opts indicating which options have been changed.
+ */
+
+/**/
+mod_export int
+parseopts(char *nam, char ***argvp, char *new_opts, char **cmdp,
+ LinkList optlist, int flags)
+{
+ int optionbreak = 0;
+ int action, optno;
+ char **argv = *argvp;
+ int toplevel = ((flags & PARSEARGS_TOPLEVEL) != 0u);
+ int emulate_required = toplevel;
+ char *top_emulation = nam;
+
+ *cmdp = 0;
+#define WARN_OPTION(F, S) \
+ do { \
+ if (!toplevel) \
+ zwarnnam(nam, F, S); \
+ else \
+ zerr(F, S); \
+ } while (0)
+#define LAST_OPTION(N) \
+ do { \
+ if (!toplevel) { \
+ if (*argv) \
+ argv++; \
+ goto doneargv; \
+ } else exit(N); \
+ } while(0)
+
+ /* loop through command line options (begins with "-" or "+") */
+ while (!optionbreak && *argv && (**argv == '-' || **argv == '+')) {
+ char *args = *argv;
+ action = (**argv == '-');
+ if (!argv[0][1])
+ *argv = "--";
+ while (*++*argv) {
+ if (**argv == '-') {
+ if (!argv[0][1]) {
+ /* The pseudo-option `--' signifies the end of options. */
+ argv++;
+ goto doneoptions;
+ }
+ if (!toplevel || *argv != args+1 || **argv != '-')
+ goto badoptionstring;
+ /* GNU-style long options */
+ ++*argv;
+ if (!strcmp(*argv, "version")) {
+ printf("zsh %s (%s-%s-%s)\n",
+ ZSH_VERSION, MACHTYPE, VENDOR, OSTYPE);
+ LAST_OPTION(0);
+ }
+ if (!strcmp(*argv, "help")) {
+ printhelp();
+ LAST_OPTION(0);
+ }
+ if (!strcmp(*argv, "emulate")) {
+ ++argv;
+ if (!*argv) {
+ zerr("--emulate: argument required");
+ exit(1);
+ }
+ if (!emulate_required) {
+ zerr("--emulate: must precede other options");
+ exit(1);
+ }
+ top_emulation = *argv;
+ break;
+ }
+ /* `-' characters are allowed in long options */
+ for(args = *argv; *args; args++)
+ if(*args == '-')
+ *args = '_';
+ goto longoptions;
+ }
+
+ if (unset(SHOPTIONLETTERS) && **argv == 'b') {
+ if (emulate_required) {
+ parseopts_setemulate(top_emulation, flags);
+ emulate_required = 0;
+ }
+ /* -b ends options at the end of this argument */
+ optionbreak = 1;
+ } else if (**argv == 'c') {
+ if (emulate_required) {
+ parseopts_setemulate(top_emulation, flags);
+ emulate_required = 0;
+ }
+ /* -c command */
+ *cmdp = *argv;
+ new_opts[INTERACTIVE] &= 1;
+ if (toplevel)
+ scriptname = scriptfilename = ztrdup("zsh");
+ } else if (**argv == 'o') {
+ if (!*++*argv)
+ argv++;
+ if (!*argv) {
+ WARN_OPTION("string expected after -o", NULL);
+ return 1;
+ }
+ longoptions:
+ if (emulate_required) {
+ parseopts_setemulate(top_emulation, flags);
+ emulate_required = 0;
+ }
+ if (!(optno = optlookup(*argv))) {
+ WARN_OPTION("no such option: %s", *argv);
+ return 1;
+ } else if (optno == RESTRICTED && toplevel) {
+ restricted = action;
+ } else if ((optno == EMACSMODE || optno == VIMODE) && !toplevel) {
+ WARN_OPTION("can't change option: %s", *argv);
+ } else {
+ if (dosetopt(optno, action, toplevel, new_opts) &&
+ !toplevel) {
+ WARN_OPTION("can't change option: %s", *argv);
+ } else if (optlist) {
+ parseopts_insert(optlist, new_opts, optno);
+ }
+ }
+ break;
+ } else if (isspace(STOUC(**argv))) {
+ /* zsh's typtab not yet set, have to use ctype */
+ while (*++*argv)
+ if (!isspace(STOUC(**argv))) {
+ badoptionstring:
+ WARN_OPTION("bad option string: '%s'", args);
+ return 1;
+ }
+ break;
+ } else {
+ if (emulate_required) {
+ parseopts_setemulate(top_emulation, flags);
+ emulate_required = 0;
+ }
+ if (!(optno = optlookupc(**argv))) {
+ WARN_OPTION("bad option: -%c", **argv);
+ return 1;
+ } else if (optno == RESTRICTED && toplevel) {
+ restricted = action;
+ } else if ((optno == EMACSMODE || optno == VIMODE) &&
+ !toplevel) {
+ WARN_OPTION("can't change option: %s", *argv);
+ } else {
+ if (dosetopt(optno, action, toplevel, new_opts) &&
+ !toplevel) {
+ WARN_OPTION("can't change option: -%c", **argv);
+ } else if (optlist) {
+ parseopts_insert(optlist, new_opts, optno);
+ }
+ }
+ }
+ }
+ argv++;
+ }
+ doneoptions:
+ if (*cmdp) {
+ if (!*argv) {
+ WARN_OPTION("string expected after -%s", *cmdp);
+ return 1;
+ }
+ *cmdp = *argv++;
+ }
+ doneargv:
+ *argvp = argv;
+ if (emulate_required) {
+ parseopts_setemulate(top_emulation, flags);
+ emulate_required = 0;
+ }
+ return 0;
+}
+
+/**/
+static void
+printhelp(void)
+{
+ printf("Usage: %s [] [ ...]\n", argzero);
+ printf("\nSpecial options:\n");
+ printf(" --help show this message, then exit\n");
+ printf(" --version show zsh version number, then exit\n");
+ if(unset(SHOPTIONLETTERS))
+ printf(" -b end option processing, like --\n");
+ printf(" -c take first argument as a command to execute\n");
+ printf(" -o OPTION set an option by name (see below)\n");
+ printf("\nNormal options are named. An option may be turned on by\n");
+ printf("`-o OPTION', `--OPTION', `+o no_OPTION' or `+-no-OPTION'. An\n");
+ printf("option may be turned off by `-o no_OPTION', `--no-OPTION',\n");
+ printf("`+o OPTION' or `+-OPTION'. Options are listed below only in\n");
+ printf("`--OPTION' or `--no-OPTION' form.\n");
+ printoptionlist();
+}
+
+/**/
+mod_export void
+init_io(char *cmd)
+{
+ static char outbuf[BUFSIZ], errbuf[BUFSIZ];
+
+#ifdef RSH_BUG_WORKAROUND
+ int i;
+#endif
+
+/* stdout, stderr fully buffered */
+#ifdef _IOFBF
+ setvbuf(stdout, outbuf, _IOFBF, BUFSIZ);
+ setvbuf(stderr, errbuf, _IOFBF, BUFSIZ);
+#else
+ setbuffer(stdout, outbuf, BUFSIZ);
+ setbuffer(stderr, errbuf, BUFSIZ);
+#endif
+
+/* This works around a bug in some versions of in.rshd. *
+ * Currently this is not defined by default. */
+#ifdef RSH_BUG_WORKAROUND
+ if (cmd) {
+ for (i = 3; i < 10; i++)
+ close(i);
+ }
+#else
+ (void)cmd;
+#endif
+
+ if (shout) {
+ /*
+ * Check if shout was set to stderr, if so don't close it.
+ * We do this if we are interactive but don't have a
+ * terminal.
+ */
+ if (shout != stderr)
+ fclose(shout);
+ shout = 0;
+ }
+ if (SHTTY != -1) {
+ zclose(SHTTY);
+ SHTTY = -1;
+ }
+
+ /* Send xtrace output to stderr -- see execcmd() */
+ xtrerr = stderr;
+
+ /* Make sure the tty is opened read/write. */
+ if (isatty(0)) {
+ zsfree(ttystrname);
+ if ((ttystrname = ztrdup(ttyname(0)))) {
+ SHTTY = movefd(open(ttystrname, O_RDWR | O_NOCTTY));
+#ifdef TIOCNXCL
+ /*
+ * See if the terminal claims to be busy. If so, and fd 0
+ * is a terminal, try and set non-exclusive use for that.
+ * This is something to do with Solaris over-cleverness.
+ */
+ if (SHTTY == -1 && errno == EBUSY)
+ ioctl(0, TIOCNXCL, 0);
+#endif
+ }
+ /*
+ * xterm, rxvt and probably all terminal emulators except
+ * dtterm on Solaris 2.6 & 7 have a bug. Applications are
+ * unable to open /dev/tty or /dev/pts/
+ * because something in Sun's STREAMS modules doesn't like
+ * it. The open() call fails with EBUSY which is not even
+ * listed as a possibility in the open(2) man page. So we'll
+ * try to outsmart The Company. --
+ *
+ * Presumably there's no harm trying this on any OS, given that
+ * isatty(0) worked but opening the tty didn't. Possibly we won't
+ * get the tty read/write, but it's the best we can do -- pws
+ *
+ * Try both stdin and stdout before trying /dev/tty. -- Bart
+ */
+#if defined(HAVE_FCNTL_H) && defined(F_GETFL)
+#define rdwrtty(fd) ((fcntl(fd, F_GETFL, 0) & O_RDWR) == O_RDWR)
+#else
+#define rdwrtty(fd) 1
+#endif
+ if (SHTTY == -1 && rdwrtty(0)) {
+ SHTTY = movefd(dup(0));
+ }
+ }
+ if (SHTTY == -1 && isatty(1) && rdwrtty(1) &&
+ (SHTTY = movefd(dup(1))) != -1) {
+ zsfree(ttystrname);
+ ttystrname = ztrdup(ttyname(1));
+ }
+ if (SHTTY == -1 &&
+ (SHTTY = movefd(open("/dev/tty", O_RDWR | O_NOCTTY))) != -1) {
+ zsfree(ttystrname);
+ ttystrname = ztrdup(ttyname(SHTTY));
+ }
+ if (SHTTY == -1) {
+ zsfree(ttystrname);
+ ttystrname = ztrdup("");
+ } else {
+#ifdef FD_CLOEXEC
+ long fdflags = fcntl(SHTTY, F_GETFD, 0);
+ if (fdflags != (long)-1) {
+ fdflags |= FD_CLOEXEC;
+ fcntl(SHTTY, F_SETFD, fdflags);
+ }
+#endif
+ if (!ttystrname)
+ ttystrname = ztrdup("/dev/tty");
+ }
+
+ /* We will only use zle if shell is interactive, *
+ * SHTTY != -1, and shout != 0 */
+ if (interact) {
+ init_shout();
+ if(!SHTTY || !shout)
+ opts[USEZLE] = 0;
+ } else
+ opts[USEZLE] = 0;
+
+#ifdef JOB_CONTROL
+ /* If interactive, make sure the shell is in the foreground and is the
+ * process group leader.
+ */
+ mypid = (zlong)getpid();
+ if (opts[MONITOR] && (SHTTY != -1)) {
+ origpgrp = GETPGRP();
+ acquire_pgrp(); /* might also clear opts[MONITOR] */
+ } else
+ opts[MONITOR] = 0;
+#else
+ opts[MONITOR] = 0;
+#endif
+}
+
+/**/
+mod_export void
+init_shout(void)
+{
+ static char shoutbuf[BUFSIZ];
+#if defined(JOB_CONTROL) && defined(TIOCSETD) && defined(NTTYDISC)
+ int ldisc;
+#endif
+
+ if (SHTTY == -1)
+ {
+ /* Since we're interactive, it's nice to have somewhere to write. */
+ shout = stderr;
+ return;
+ }
+
+#if defined(JOB_CONTROL) && defined(TIOCSETD) && defined(NTTYDISC)
+ ldisc = NTTYDISC;
+ ioctl(SHTTY, TIOCSETD, (char *)&ldisc);
+#endif
+
+ /* Associate terminal file descriptor with a FILE pointer */
+ shout = fdopen(SHTTY, "w");
+#ifdef _IOFBF
+ if (shout)
+ setvbuf(shout, shoutbuf, _IOFBF, BUFSIZ);
+#endif
+
+ gettyinfo(&shttyinfo); /* get tty state */
+#if defined(__sgi)
+ if (shttyinfo.tio.c_cc[VSWTCH] <= 0) /* hack for irises */
+ shttyinfo.tio.c_cc[VSWTCH] = CSWTCH;
+#endif
+}
+
+/* names of the termcap strings we want */
+
+static char *tccapnams[TC_COUNT] = {
+ "cl", "le", "LE", "nd", "RI", "up", "UP", "do",
+ "DO", "dc", "DC", "ic", "IC", "cd", "ce", "al", "dl", "ta",
+ "md", "so", "us", "me", "se", "ue", "ch",
+ "ku", "kd", "kl", "kr", "sc", "rc", "bc", "AF", "AB"
+};
+
+/**/
+mod_export char *
+tccap_get_name(int cap)
+{
+ if (cap >= TC_COUNT) {
+#ifdef DEBUG
+ dputs("name of invalid capability %d requested", cap);
+#endif
+ return "";
+ }
+ return tccapnams[cap];
+}
+
+/* Initialise termcap */
+
+/**/
+mod_export int
+init_term(void)
+{
+#ifndef TGETENT_ACCEPTS_NULL
+ static char termbuf[2048]; /* the termcap buffer */
+#endif
+
+ if (!*term) {
+ termflags |= TERM_UNKNOWN;
+ return 0;
+ }
+
+ /* unset zle if using zsh under emacs */
+ if (!strcmp(term, "emacs"))
+ opts[USEZLE] = 0;
+
+#ifdef TGETENT_ACCEPTS_NULL
+ /* If possible, we let tgetent allocate its own termcap buffer */
+ if (tgetent(NULL, term) != TGETENT_SUCCESS)
+#else
+ if (tgetent(termbuf, term) != TGETENT_SUCCESS)
+#endif
+ {
+ if (interact)
+ zerr("can't find terminal definition for %s", term);
+ errflag &= ~ERRFLAG_ERROR;
+ termflags |= TERM_BAD;
+ return 0;
+ } else {
+ char tbuf[1024], *pp;
+ int t0;
+
+ termflags &= ~TERM_BAD;
+ termflags &= ~TERM_UNKNOWN;
+ for (t0 = 0; t0 != TC_COUNT; t0++) {
+ pp = tbuf;
+ zsfree(tcstr[t0]);
+ /* AIX tgetstr() ignores second argument */
+ if (!(pp = tgetstr(tccapnams[t0], &pp)))
+ tcstr[t0] = NULL, tclen[t0] = 0;
+ else {
+ tclen[t0] = strlen(pp);
+ tcstr[t0] = (char *) zalloc(tclen[t0] + 1);
+ memcpy(tcstr[t0], pp, tclen[t0] + 1);
+ }
+ }
+
+ /* check whether terminal has automargin (wraparound) capability */
+ hasam = tgetflag("am");
+ hasbw = tgetflag("bw");
+ hasxn = tgetflag("xn"); /* also check for newline wraparound glitch */
+ hasye = tgetflag("YE"); /* print in last column does carriage return */
+
+ tclines = tgetnum("li");
+ tccolumns = tgetnum("co");
+ tccolours = tgetnum("Co");
+
+ /* if there's no termcap entry for cursor up, use single line mode: *
+ * this is flagged by termflags which is examined in zle_refresh.c *
+ */
+ if (tccan(TCUP))
+ termflags &= ~TERM_NOUP;
+ else {
+ zsfree(tcstr[TCUP]);
+ tcstr[TCUP] = NULL;
+ termflags |= TERM_NOUP;
+ }
+
+ /* most termcaps don't define "bc" because they use \b. */
+ if (!tccan(TCBACKSPACE)) {
+ zsfree(tcstr[TCBACKSPACE]);
+ tcstr[TCBACKSPACE] = ztrdup("\b");
+ tclen[TCBACKSPACE] = 1;
+ }
+
+ /* if there's no termcap entry for cursor left, use backspace. */
+ if (!tccan(TCLEFT)) {
+ zsfree(tcstr[TCLEFT]);
+ tcstr[TCLEFT] = ztrdup(tcstr[TCBACKSPACE]);
+ tclen[TCLEFT] = tclen[TCBACKSPACE];
+ }
+
+ if (tccan(TCSAVECURSOR) && !tccan(TCRESTRCURSOR)) {
+ tclen[TCSAVECURSOR] = 0;
+ zsfree(tcstr[TCSAVECURSOR]);
+ tcstr[TCSAVECURSOR] = NULL;
+ }
+
+ /* if the termcap entry for down is \n, don't use it. */
+ if (tccan(TCDOWN) && tcstr[TCDOWN][0] == '\n') {
+ tclen[TCDOWN] = 0;
+ zsfree(tcstr[TCDOWN]);
+ tcstr[TCDOWN] = NULL;
+ }
+
+ /* if there's no termcap entry for clear, use ^L. */
+ if (!tccan(TCCLEARSCREEN)) {
+ zsfree(tcstr[TCCLEARSCREEN]);
+ tcstr[TCCLEARSCREEN] = ztrdup("\14");
+ tclen[TCCLEARSCREEN] = 1;
+ }
+ rprompt_indent = 1; /* If you change this, update rprompt_indent_unsetfn() */
+ /* The following is an attempt at a heuristic,
+ * but it fails in some cases */
+ /* rprompt_indent = ((hasam && !hasbw) || hasye || !tccan(TCLEFT)); */
+ }
+ return 1;
+}
+
+/* Initialize lots of global variables and hash tables */
+
+/**/
+void
+setupvals(char *cmd, char *runscript, char *zsh_name)
+{
+#ifdef USE_GETPWUID
+ struct passwd *pswd;
+#endif
+ struct timezone dummy_tz;
+ char *ptr;
+ int i, j;
+#if defined(SITEFPATH_DIR) || defined(FPATH_DIR) || defined (ADDITIONAL_FPATH) || defined(FIXED_FPATH_DIR)
+#define FPATH_NEEDS_INIT 1
+ char **fpathptr;
+# if defined(FPATH_DIR) && defined(FPATH_SUBDIRS)
+ char *fpath_subdirs[] = FPATH_SUBDIRS;
+# endif
+# if defined(ADDITIONAL_FPATH)
+ char *more_fndirs[] = ADDITIONAL_FPATH;
+ int more_fndirs_len;
+# endif
+# ifdef FIXED_FPATH_DIR
+# define FIXED_FPATH_LEN 1
+# else
+# define FIXED_FPATH_LEN 0
+# endif
+# ifdef SITEFPATH_DIR
+# define SITE_FPATH_LEN 1
+# else
+# define SITE_FPATH_LEN 0
+# endif
+ int fpathlen = FIXED_FPATH_LEN + SITE_FPATH_LEN;
+#endif
+ int close_fds[10], tmppipe[2];
+
+ /*
+ * Workaround a problem with NIS (in one guise or another) which
+ * grabs file descriptors and keeps them for future reference.
+ * We don't want these to be in the range where the user can
+ * open fd's, i.e. 0 to 9 inclusive. So we make sure all
+ * fd's in that range are in use.
+ */
+ memset(close_fds, 0, 10*sizeof(int));
+ if (pipe(tmppipe) == 0) {
+ /*
+ * Strategy: Make sure we have at least fd 0 open (hence
+ * the pipe). From then on, keep dup'ing until we are
+ * up to 9. If we go over the top, close immediately, else
+ * mark for later closure.
+ */
+ i = -1; /* max fd we have checked */
+ while (i < 9) {
+ /* j is current fd */
+ if (i < tmppipe[0])
+ j = tmppipe[0];
+ else if (i < tmppipe[1])
+ j = tmppipe[1];
+ else {
+ j = dup(0);
+ if (j == -1)
+ break;
+ }
+ if (j < 10)
+ close_fds[j] = 1;
+ else
+ close(j);
+ if (i < j)
+ i = j;
+ }
+ if (i < tmppipe[0])
+ close(tmppipe[0]);
+ if (i < tmppipe[1])
+ close(tmppipe[1]);
+ }
+
+ (void)addhookdefs(NULL, zshhooks, sizeof(zshhooks)/sizeof(*zshhooks));
+
+ init_eprog();
+
+ zero_mnumber.type = MN_INTEGER;
+ zero_mnumber.u.l = 0;
+
+ noeval = 0;
+ curhist = 0;
+ histsiz = DEFAULT_HISTSIZE;
+ inithist();
+
+ cmdstack = (unsigned char *) zalloc(CMDSTACKSZ);
+ cmdsp = 0;
+
+ bangchar = '!';
+ hashchar = '#';
+ hatchar = '^';
+ termflags = TERM_UNKNOWN;
+ curjob = prevjob = coprocin = coprocout = -1;
+ gettimeofday(&shtimer, &dummy_tz); /* init $SECONDS */
+ srand((unsigned int)(shtimer.tv_sec + shtimer.tv_usec)); /* seed $RANDOM */
+
+ /* Set default path */
+ path = (char **) zalloc(sizeof(*path) * 5);
+ path[0] = ztrdup("/bin");
+ path[1] = ztrdup("/usr/bin");
+ path[2] = ztrdup("/usr/ucb");
+ path[3] = ztrdup("/usr/local/bin");
+ path[4] = NULL;
+
+ cdpath = mkarray(NULL);
+ manpath = mkarray(NULL);
+ fignore = mkarray(NULL);
+
+#ifdef FPATH_NEEDS_INIT
+# ifdef FPATH_DIR
+# ifdef FPATH_SUBDIRS
+ fpathlen += sizeof(fpath_subdirs)/sizeof(char *);
+# else /* FPATH_SUBDIRS */
+ fpathlen++;
+# endif /* FPATH_SUBDIRS */
+# endif /* FPATH_DIR */
+# if defined(ADDITIONAL_FPATH)
+ more_fndirs_len = sizeof(more_fndirs)/sizeof(char *);
+ fpathlen += more_fndirs_len;
+# endif /* ADDITONAL_FPATH */
+ fpath = fpathptr = (char **)zalloc((fpathlen+1)*sizeof(char *));
+# ifdef FIXED_FPATH_DIR
+ *fpathptr++ = ztrdup(FIXED_FPATH_DIR);
+ fpathlen--;
+# endif
+# ifdef SITEFPATH_DIR
+ *fpathptr++ = ztrdup(SITEFPATH_DIR);
+ fpathlen--;
+# endif /* SITEFPATH_DIR */
+# if defined(ADDITIONAL_FPATH)
+ for (j = 0; j < more_fndirs_len; j++)
+ *fpathptr++ = ztrdup(more_fndirs[j]);
+# endif
+# ifdef FPATH_DIR
+# ifdef FPATH_SUBDIRS
+# ifdef ADDITIONAL_FPATH
+ for (j = more_fndirs_len; j < fpathlen; j++)
+ *fpathptr++ = tricat(FPATH_DIR, "/", fpath_subdirs[j - more_fndirs_len]);
+# else
+ for (j = 0; j < fpathlen; j++)
+ *fpathptr++ = tricat(FPATH_DIR, "/", fpath_subdirs[j]);
+#endif
+# else
+ *fpathptr++ = ztrdup(FPATH_DIR);
+# endif
+# endif
+ *fpathptr = NULL;
+#else /* FPATH_NEEDS_INIT */
+ fpath = mkarray(NULL);
+#endif /* FPATH_NEEDS_INIT */
+
+ mailpath = mkarray(NULL);
+ watch = mkarray(NULL);
+ psvar = mkarray(NULL);
+ module_path = mkarray(ztrdup(MODULE_DIR));
+ modulestab = newmoduletable(17, "modules");
+ linkedmodules = znewlinklist();
+
+ /* Set default prompts */
+ if(unset(INTERACTIVE)) {
+ prompt = ztrdup("");
+ prompt2 = ztrdup("");
+ } else if (EMULATION(EMULATE_KSH|EMULATE_SH)) {
+ prompt = ztrdup(privasserted() ? "# " : "$ ");
+ prompt2 = ztrdup("> ");
+ } else {
+ prompt = ztrdup("%m%# ");
+ prompt2 = ztrdup("%_> ");
+ }
+ prompt3 = ztrdup("?# ");
+ prompt4 = EMULATION(EMULATE_KSH|EMULATE_SH)
+ ? ztrdup("+ ") : ztrdup("+%N:%i> ");
+ sprompt = ztrdup("zsh: correct '%R' to '%r' [nyae]? ");
+
+ ifs = EMULATION(EMULATE_KSH|EMULATE_SH) ?
+ ztrdup(DEFAULT_IFS_SH) : ztrdup(DEFAULT_IFS);
+ wordchars = ztrdup(DEFAULT_WORDCHARS);
+ postedit = ztrdup("");
+ zunderscore = (char *) zalloc(underscorelen = 32);
+ underscoreused = 1;
+ *zunderscore = '\0';
+
+ zoptarg = ztrdup("");
+ zoptind = 1;
+
+ ppid = (zlong) getppid();
+ mypid = (zlong) getpid();
+ term = ztrdup("");
+
+ nullcmd = ztrdup("cat");
+ readnullcmd = ztrdup(DEFAULT_READNULLCMD);
+
+ /* We cache the uid so we know when to *
+ * recheck the info for `USERNAME' */
+ cached_uid = getuid();
+
+ /* Get password entry and set info for `USERNAME' */
+#ifdef USE_GETPWUID
+ if ((pswd = getpwuid(cached_uid))) {
+ if (EMULATION(EMULATE_ZSH))
+ home = metafy(pswd->pw_dir, -1, META_DUP);
+ cached_username = ztrdup(pswd->pw_name);
+ }
+ else
+#endif /* USE_GETPWUID */
+ {
+ if (EMULATION(EMULATE_ZSH))
+ home = ztrdup("/");
+ cached_username = ztrdup("");
+ }
+
+ /*
+ * Try a cheap test to see if we can initialize `PWD' from `HOME'.
+ * In non-native emulations HOME must come from the environment;
+ * we're not allowed to set it locally.
+ */
+ if (EMULATION(EMULATE_ZSH))
+ ptr = home;
+ else
+ ptr = zgetenv("HOME");
+ if (ptr && ispwd(ptr))
+ pwd = ztrdup(ptr);
+ else if ((ptr = zgetenv("PWD")) && (strlen(ptr) < PATH_MAX) &&
+ (ptr = metafy(ptr, -1, META_STATIC), ispwd(ptr)))
+ pwd = ztrdup(ptr);
+ else {
+ pwd = NULL;
+ pwd = metafy(zgetcwd(), -1, META_DUP);
+ }
+
+ oldpwd = ztrdup(pwd); /* initialize `OLDPWD' = `PWD' */
+
+ inittyptab(); /* initialize the ztypes table */
+ initlextabs(); /* initialize lexing tables */
+
+ createreswdtable(); /* create hash table for reserved words */
+ createaliastables(); /* create hash tables for aliases */
+ createcmdnamtable(); /* create hash table for external commands */
+ createshfunctable(); /* create hash table for shell functions */
+ createbuiltintable(); /* create hash table for builtin commands */
+ createnameddirtable(); /* create hash table for named directories */
+ createparamtable(); /* create parameter hash table */
+
+ condtab = NULL;
+ wrappers = NULL;
+
+#ifdef TIOCGWINSZ
+ adjustwinsize(0);
+#else
+ /* columns and lines are normally zero, unless something different *
+ * was inhereted from the environment. If either of them are zero *
+ * the setiparam calls below set them to the defaults from termcap */
+ setiparam("COLUMNS", zterm_columns);
+ setiparam("LINES", zterm_lines);
+#endif
+
+#ifdef HAVE_GETRLIMIT
+ for (i = 0; i != RLIM_NLIMITS; i++) {
+ getrlimit(i, current_limits + i);
+ limits[i] = current_limits[i];
+ }
+#endif
+
+ breaks = loops = 0;
+ lastmailcheck = time(NULL);
+ locallevel = sourcelevel = 0;
+ sfcontext = SFC_NONE;
+ trap_return = 0;
+ trap_state = TRAP_STATE_INACTIVE;
+ noerrexit = NOERREXIT_EXIT | NOERREXIT_RETURN | NOERREXIT_SIGNAL;
+ nohistsave = 1;
+ dirstack = znewlinklist();
+ bufstack = znewlinklist();
+ hsubl = hsubr = NULL;
+ lastpid = 0;
+
+ get_usage();
+
+ /* Close the file descriptors we opened to block off 0 to 9 */
+ for (i = 0; i < 10; i++)
+ if (close_fds[i])
+ close(i);
+
+ /* Colour sequences for outputting colours in prompts and zle */
+ set_default_colour_sequences();
+
+ if (cmd)
+ setsparam("ZSH_EXECUTION_STRING", ztrdup(cmd));
+ if (runscript)
+ setsparam("ZSH_SCRIPT", ztrdup(runscript));
+ setsparam("ZSH_NAME", ztrdup(zsh_name)); /* NOTE: already metafied early in zsh_main() */
+}
+
+/*
+ * Setup shell input, opening any script file (runscript, may be NULL).
+ * This is deferred until we have a path to search, in case
+ * PATHSCRIPT is set for sh-compatible behaviour.
+ */
+static void
+setupshin(char *runscript)
+{
+ if (runscript) {
+ char *funmeta, *sfname = NULL;
+ struct stat st;
+
+ funmeta = unmeta(runscript);
+ /*
+ * Always search the current directory first.
+ */
+ if (access(funmeta, F_OK) == 0 &&
+ stat(funmeta, &st) >= 0 &&
+ !S_ISDIR(st.st_mode))
+ sfname = runscript;
+ else if (isset(PATHSCRIPT) && !strchr(runscript, '/')) {
+ /*
+ * With the PATHSCRIPT option, search the path if no
+ * path was given in the script name.
+ */
+ funmeta = pathprog(runscript, &sfname);
+ }
+ if (!sfname ||
+ (SHIN = movefd(open(funmeta, O_RDONLY | O_NOCTTY)))
+ == -1) {
+ zerr("can't open input file: %s", runscript);
+ exit(127);
+ }
+ scriptfilename = sfname;
+ sfname = argzero; /* copy to avoid race condition */
+ argzero = ztrdup(runscript);
+ zsfree(sfname); /* argzero ztrdup'd in parseargs */
+ }
+ /*
+ * We only initialise line numbering once there is a script to
+ * read commands from.
+ */
+ lineno = 1;
+ /*
+ * Finish setting up SHIN and its relatives.
+ */
+ bshin = SHIN ? fdopen(SHIN, "r") : stdin;
+ if (isset(SHINSTDIN) && !SHIN && unset(INTERACTIVE)) {
+#ifdef _IONBF
+ setvbuf(stdin, NULL, _IONBF, 0);
+#else
+ setlinebuf(stdin);
+#endif
+ }
+}
+
+/* Initialize signal handling */
+
+/**/
+void
+init_signals(void)
+{
+ if (interact) {
+ int i;
+ signal_setmask(signal_mask(0));
+ for (i=0; i= 10)
+ fclose(bshin);
+ SHIN = movefd(open("/dev/null", O_RDONLY | O_NOCTTY));
+ bshin = fdopen(SHIN, "r");
+ execstring(cmd, 0, 1, "cmdarg");
+ stopmsg = 1;
+ zexit(lastval, 0);
+ }
+
+ if (interact && isset(RCS))
+ readhistfile(NULL, 0, HFILE_USE_OPTIONS);
+}
+
+/*
+ * source a file
+ * Returns one of the SOURCE_* enum values.
+ */
+
+/**/
+mod_export enum source_return
+source(char *s)
+{
+ Eprog prog;
+ int tempfd = -1, fd, cj;
+ zlong oldlineno;
+ int oldshst, osubsh, oloops;
+ FILE *obshin;
+ char *old_scriptname = scriptname, *us;
+ char *old_scriptfilename = scriptfilename;
+ unsigned char *ocs;
+ int ocsp;
+ int otrap_return = trap_return, otrap_state = trap_state;
+ struct funcstack fstack;
+ enum source_return ret = SOURCE_OK;
+
+ if (!s ||
+ (!(prog = try_source_file((us = unmeta(s)))) &&
+ (tempfd = movefd(open(us, O_RDONLY | O_NOCTTY))) == -1)) {
+ return SOURCE_NOT_FOUND;
+ }
+
+ /* save the current shell state */
+ fd = SHIN; /* store the shell input fd */
+ obshin = bshin; /* store file handle for buffered shell input */
+ osubsh = subsh; /* store whether we are in a subshell */
+ cj = thisjob; /* store our current job number */
+ oldlineno = lineno; /* store our current lineno */
+ oloops = loops; /* stored the # of nested loops we are in */
+ oldshst = opts[SHINSTDIN]; /* store current value of this option */
+ ocs = cmdstack;
+ ocsp = cmdsp;
+ cmdstack = (unsigned char *) zalloc(CMDSTACKSZ);
+ cmdsp = 0;
+
+ if (!prog) {
+ SHIN = tempfd;
+ bshin = fdopen(SHIN, "r");
+ }
+ subsh = 0;
+ lineno = 1;
+ loops = 0;
+ dosetopt(SHINSTDIN, 0, 1, opts);
+ scriptname = s;
+ scriptfilename = s;
+
+ if (isset(SOURCETRACE)) {
+ printprompt4();
+ fprintf(xtrerr ? xtrerr : stderr, "\n");
+ }
+
+ /*
+ * The special return behaviour of traps shouldn't
+ * trigger in files sourced from traps; the return
+ * is just a return from the file.
+ */
+ trap_state = TRAP_STATE_INACTIVE;
+
+ sourcelevel++;
+
+ fstack.name = scriptfilename;
+ fstack.caller = funcstack ? funcstack->name :
+ dupstring(old_scriptfilename ? old_scriptfilename : "zsh");
+ fstack.flineno = 0;
+ fstack.lineno = oldlineno;
+ fstack.filename = scriptfilename;
+ fstack.prev = funcstack;
+ fstack.tp = FS_SOURCE;
+ funcstack = &fstack;
+
+ if (prog) {
+ pushheap();
+ errflag &= ~ERRFLAG_ERROR;
+ execode(prog, 1, 0, "filecode");
+ popheap();
+ if (errflag)
+ ret = SOURCE_ERROR;
+ } else {
+ /* loop through the file to be sourced */
+ switch (loop(0, 0))
+ {
+ case LOOP_OK:
+ /* nothing to do but compilers like a complete enum */
+ break;
+
+ case LOOP_EMPTY:
+ /* Empty code resets status */
+ lastval = 0;
+ break;
+
+ case LOOP_ERROR:
+ ret = SOURCE_ERROR;
+ break;
+ }
+ }
+ funcstack = funcstack->prev;
+ sourcelevel--;
+
+ trap_state = otrap_state;
+ trap_return = otrap_return;
+
+ /* restore the current shell state */
+ if (prog)
+ freeeprog(prog);
+ else {
+ fclose(bshin);
+ fdtable[SHIN] = FDT_UNUSED;
+ SHIN = fd; /* the shell input fd */
+ bshin = obshin; /* file handle for buffered shell input */
+ }
+ subsh = osubsh; /* whether we are in a subshell */
+ thisjob = cj; /* current job number */
+ lineno = oldlineno; /* our current lineno */
+ loops = oloops; /* the # of nested loops we are in */
+ dosetopt(SHINSTDIN, oldshst, 1, opts); /* SHINSTDIN option */
+ errflag &= ~ERRFLAG_ERROR;
+ if (!exit_pending)
+ retflag = 0;
+ scriptname = old_scriptname;
+ scriptfilename = old_scriptfilename;
+ zfree(cmdstack, CMDSTACKSZ);
+ cmdstack = ocs;
+ cmdsp = ocsp;
+
+ return ret;
+}
+
+/* Try to source a file in the home directory */
+
+/**/
+void
+sourcehome(char *s)
+{
+ char *h;
+
+ queue_signals();
+ if (EMULATION(EMULATE_SH|EMULATE_KSH) || !(h = getsparam_u("ZDOTDIR"))) {
+ h = home;
+ if (!h) {
+ unqueue_signals();
+ return;
+ }
+ }
+
+ {
+ /* Let source() complain if path is too long */
+ VARARR(char, buf, strlen(h) + strlen(s) + 2);
+ sprintf(buf, "%s/%s", h, s);
+ unqueue_signals();
+ source(buf);
+ }
+}
+
+/**/
+void
+init_bltinmods(void)
+{
+
+#include "bltinmods.list"
+
+ (void)load_module("zsh/main", NULL, 0);
+}
+
+/**/
+mod_export void
+noop_function(void)
+{
+ /* do nothing */
+}
+
+/**/
+mod_export void
+noop_function_int(UNUSED(int nothing))
+{
+ /* do nothing */
+}
+
+/*
+ * ZLE entry point pointer.
+ * No other source file needs to know which modules are linked in.
+ */
+/**/
+mod_export ZleEntryPoint zle_entry_ptr;
+
+/*
+ * State of loading of zle.
+ * 0 = Not loaded, not attempted.
+ * 1 = Loaded successfully
+ * 2 = Failed to load.
+ */
+/**/
+mod_export int zle_load_state;
+
+/**/
+mod_export char *
+zleentry(VA_ALIST1(int cmd))
+VA_DCL
+{
+ char *ret = NULL;
+ va_list ap;
+ VA_DEF_ARG(int cmd);
+
+ VA_START(ap, cmd);
+ VA_GET_ARG(ap, cmd, int);
+
+#if defined(LINKED_XMOD_zshQszle) || defined(UNLINKED_XMOD_zshQszle)
+ /* autoload */
+ switch (zle_load_state) {
+ case 0:
+ /*
+ * Some commands don't require us to load ZLE.
+ * These also have no fallback.
+ */
+ if (cmd != ZLE_CMD_TRASH && cmd != ZLE_CMD_RESET_PROMPT &&
+ cmd != ZLE_CMD_REFRESH)
+ {
+ if (load_module("zsh/zle", NULL, 0) != 1) {
+ (void)load_module("zsh/compctl", NULL, 0);
+ ret = zle_entry_ptr(cmd, ap);
+ /* Don't execute fallback code */
+ cmd = -1;
+ } else {
+ zle_load_state = 2;
+ /* Execute fallback code below */
+ }
+ }
+ break;
+
+ case 1:
+ ret = zle_entry_ptr(cmd, ap);
+ /* Don't execute fallback code */
+ cmd = -1;
+ break;
+
+ case 2:
+ /* Execute fallback code */
+ break;
+ }
+#endif
+
+ switch (cmd) {
+ /*
+ * Only the read command really needs a fallback if zle
+ * is not available. ZLE_CMD_GET_LINE has traditionally
+ * had local code in bufferwords() to do this, but that'
+ * probably only because bufferwords() is part of completion
+ * and so everything to do with it is horribly complicated.
+ */
+ case ZLE_CMD_READ:
+ {
+ char *pptbuf, **lp;
+ int pptlen;
+
+ lp = va_arg(ap, char **);
+
+ pptbuf = unmetafy(promptexpand(lp ? *lp : NULL, 0, NULL, NULL,
+ NULL),
+ &pptlen);
+ write_loop(2, pptbuf, pptlen);
+ free(pptbuf);
+
+ ret = shingetline();
+ break;
+ }
+
+ case ZLE_CMD_GET_LINE:
+ {
+ int *ll, *cs;
+
+ ll = va_arg(ap, int *);
+ cs = va_arg(ap, int *);
+ *ll = *cs = 0;
+ ret = ztrdup("");
+ break;
+ }
+ }
+
+ va_end(ap);
+ return ret;
+}
+
+/* compctl entry point pointers. Similar to the ZLE ones. */
+
+/**/
+mod_export CompctlReadFn compctlreadptr = fallback_compctlread;
+
+/**/
+mod_export int
+fallback_compctlread(char *name, UNUSED(char **args), UNUSED(Options ops), UNUSED(char *reply))
+{
+ zwarnnam(name, "no loaded module provides read for completion context");
+ return 1;
+}
+
+/*
+ * Used by zle to indicate it has already printed a "use 'exit' to exit"
+ * message.
+ */
+/**/
+mod_export int use_exit_printed;
+
+/*
+ * This is real main entry point. This has to be mod_export'ed
+ * so zsh.exe can found it on Cygwin
+ */
+
+/**/
+mod_export int
+zsh_main(UNUSED(int argc), char **argv)
+{
+ char **t, *runscript = NULL, *zsh_name;
+ char *cmd; /* argument to -c */
+ int t0;
+#ifdef USE_LOCALE
+ setlocale(LC_ALL, "");
+#endif
+
+ init_jobs(argv, environ);
+
+ /*
+ * Provisionally set up the type table to allow metafication.
+ * This will be done properly when we have decided if we are
+ * interactive
+ */
+ typtab['\0'] |= IMETA;
+ typtab[STOUC(Meta) ] |= IMETA;
+ typtab[STOUC(Marker)] |= IMETA;
+ for (t0 = (int)STOUC(Pound); t0 <= (int)STOUC(Nularg); t0++)
+ typtab[t0] |= ITOK | IMETA;
+
+ for (t = argv; *t; *t = metafy(*t, -1, META_ALLOC), t++);
+
+ zsh_name = argv[0];
+ do {
+ char *arg0 = zsh_name;
+ if (!(zsh_name = strrchr(arg0, '/')))
+ zsh_name = arg0;
+ else
+ zsh_name++;
+ if (*zsh_name == '-')
+ zsh_name++;
+ if (strcmp(zsh_name, "su") == 0) {
+ char *sh = zgetenv("SHELL");
+ if (sh && *sh && arg0 != sh)
+ zsh_name = sh;
+ else
+ break;
+ } else
+ break;
+ } while (zsh_name);
+
+ fdtable_size = zopenmax();
+ fdtable = zshcalloc(fdtable_size*sizeof(*fdtable));
+ fdtable[0] = fdtable[1] = fdtable[2] = FDT_EXTERNAL;
+
+ createoptiontable();
+ /* sets emulation, LOGINSHELL, PRIVILEGED, ZLE, INTERACTIVE,
+ * SHINSTDIN and SINGLECOMMAND */
+ parseargs(zsh_name, argv, &runscript, &cmd);
+
+ SHTTY = -1;
+ init_io(cmd);
+ setupvals(cmd, runscript, zsh_name);
+
+ init_signals();
+ init_bltinmods();
+ init_builtins();
+ run_init_scripts();
+ setupshin(runscript);
+ init_misc(cmd, zsh_name);
+
+ for (;;) {
+ /*
+ * See if we can free up some of jobtab.
+ * We only do this at top level, because if we are
+ * executing stuff we may refer to them by job pointer.
+ */
+ int errexit = 0;
+ maybeshrinkjobtab();
+
+ do {
+ /* Reset return from top level which gets us back here */
+ retflag = 0;
+ loop(1,0);
+ if (errflag && !interact && !isset(CONTINUEONERROR)) {
+ errexit = 1;
+ break;
+ }
+ } while (tok != ENDINPUT && (tok != LEXERR || isset(SHINSTDIN)));
+ if (tok == LEXERR || errexit) {
+ /* Make sure a fatal error exits with non-zero status */
+ if (!lastval)
+ lastval = 1;
+ stopmsg = 1;
+ zexit(lastval, 0);
+ }
+ if (!(isset(IGNOREEOF) && interact)) {
+#if 0
+ if (interact)
+ fputs(islogin ? "logout\n" : "exit\n", shout);
+#endif
+ zexit(lastval, 0);
+ continue;
+ }
+ noexitct++;
+ if (noexitct >= 10) {
+ stopmsg = 1;
+ zexit(lastval, 0);
+ }
+ /*
+ * Don't print the message if it was already handled by
+ * zle, since that makes special arrangements to keep
+ * the display tidy.
+ */
+ if (!use_exit_printed)
+ zerrnam("zsh", (!islogin) ? "use 'exit' to exit."
+ : "use 'logout' to logout.");
+ }
+}
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/input.c b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/input.c
new file mode 100644
index 0000000..9787ded
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/input.c
@@ -0,0 +1,701 @@
+/*
+ * input.c - read and store lines of input
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+
+/*
+ * This file deals with input buffering, supplying characters to the
+ * history expansion code a character at a time. Input is stored on a
+ * stack, which allows insertion of strings into the input, possibly with
+ * flags marking the end of alias expansion, with minimal copying of
+ * strings. The same stack is used to record the fact that the input
+ * is a history or alias expansion and to store the alias while it is in use.
+ *
+ * Input is taken either from zle, if appropriate, or read directly from
+ * the input file, or may be supplied by some other part of the shell (such
+ * as `eval' or $(...) substitution). In the last case, it should be
+ * supplied by pushing a new level onto the stack, via inpush(input_string,
+ * flag, alias); if the current input really needs to be altered, use
+ * inputsetline(input_string, flag). `Flag' can include or's of INP_FREE
+ * (if the input string is to be freed when used), INP_CONT (if the input
+ * is to continue onto what's already in the input queue), INP_ALIAS
+ * (push supplied alias onto stack) or INP_HIST (ditto, but used to
+ * mark history expansion). `alias' is ignored unless INP_ALIAS or
+ * INP_HIST is supplied. INP_ALIAS is always set if INP_HIST is.
+ *
+ * Note that the input string is itself used as the input buffer: it is not
+ * copied, nor is it every written back to, so using a constant string
+ * should work. Consequently, when passing areas of memory from the heap
+ * it is necessary that that heap last as long as the operation of reading
+ * the string. After the string is read, the stack should be popped with
+ * inpop(), which effectively flushes any unread input as well as restoring
+ * the previous input state.
+ *
+ * The internal flags INP_ALCONT and INP_HISTCONT show that the stack
+ * element was pushed by an alias or history expansion; they should not
+ * be needed elsewhere.
+ *
+ * The global variable inalmore is set to indicate aliases should
+ * continue to be expanded because the last alias expansion ended
+ * in a space. It is only reset after a complete word was read
+ * without expanding a new alias, in exalias().
+ *
+ * PWS 1996/12/10
+ */
+
+#ifdef HAVE_STDIO_H
+#include
+#endif
+
+#include "zsh.mdh"
+#include "input.pro"
+
+/* the shell input fd */
+
+/**/
+int SHIN;
+
+/* buffered shell input for non-interactive shells */
+
+/**/
+FILE *bshin;
+
+/* != 0 means we are reading input from a string */
+
+/**/
+int strin;
+
+/* total # of characters waiting to be read. */
+
+/**/
+mod_export int inbufct;
+
+/* the flags controlling the input routines in input.c: see INP_* in zsh.h */
+
+/**/
+int inbufflags;
+
+static char *inbuf; /* Current input buffer */
+static char *inbufptr; /* Pointer into input buffer */
+static char *inbufpush; /* Character at which to re-push alias */
+static int inbufleft; /* Characters left in current input
+ stack element */
+
+
+ /* Input must be stacked since the input queue is used by
+ * various different parts of the shell.
+ */
+
+struct instacks {
+ char *buf, *bufptr;
+ Alias alias;
+ int bufleft, bufct, flags;
+};
+static struct instacks *instack, *instacktop;
+/*
+ * Input stack size. We need to push the stack for aliases, history
+ * expansion, and reading from internal strings: only if these operations
+ * are nested do we need more than one extra level. Thus we shouldn't need
+ * too much space as a rule. Initially, INSTACK_INITIAL is allocated; if
+ * more is required, an extra INSTACK_EXPAND is added each time.
+ */
+#define INSTACK_INITIAL 4
+#define INSTACK_EXPAND 4
+
+static int instacksz = INSTACK_INITIAL;
+
+/* Read a line from bshin. Convert tokens and *
+ * null characters to Meta c^32 character pairs. */
+
+/**/
+mod_export char *
+shingetline(void)
+{
+ char *line = NULL;
+ int ll = 0;
+ int c;
+ char buf[BUFSIZ];
+ char *p;
+ int q = queue_signal_level();
+
+ p = buf;
+ winch_unblock();
+ dont_queue_signals();
+ for (;;) {
+ /* Can't fgets() here because we need to accept '\0' bytes */
+ do {
+ errno = 0;
+ c = fgetc(bshin);
+ } while (c < 0 && errno == EINTR);
+ if (c < 0 || c == '\n') {
+ winch_block();
+ restore_queue_signals(q);
+ if (c == '\n')
+ *p++ = '\n';
+ if (p > buf) {
+ *p++ = '\0';
+ line = zrealloc(line, ll + (p - buf));
+ memcpy(line + ll, buf, p - buf);
+ }
+ return line;
+ }
+ if (imeta(c)) {
+ *p++ = Meta;
+ *p++ = c ^ 32;
+ } else
+ *p++ = c;
+ if (p >= buf + BUFSIZ - 1) {
+ winch_block();
+ queue_signals();
+ line = zrealloc(line, ll + (p - buf) + 1);
+ memcpy(line + ll, buf, p - buf);
+ ll += p - buf;
+ line[ll] = '\0';
+ p = buf;
+ winch_unblock();
+ dont_queue_signals();
+ }
+ }
+}
+
+/* Get the next character from the input.
+ * Will call inputline() to get a new line where necessary.
+ */
+
+/**/
+int
+ingetc(void)
+{
+ int lastc = ' ';
+
+ if (lexstop)
+ return ' ';
+ for (;;) {
+ if (inbufleft) {
+ inbufleft--;
+ inbufct--;
+ if (itok(lastc = STOUC(*inbufptr++)))
+ continue;
+ if (((inbufflags & INP_LINENO) || !strin) && lastc == '\n')
+ lineno++;
+ break;
+ }
+
+ /*
+ * See if we have reached the end of input
+ * (due to an error, or to reading from a single string).
+ * Check the remaining characters left, since if there aren't
+ * any we don't want to pop the stack---it'll mark any aliases
+ * as not in use before we've finished processing.
+ */
+ if (!inbufct && (strin || errflag)) {
+ lexstop = 1;
+ break;
+ }
+ /* If the next element down the input stack is a continuation of
+ * this, use it.
+ */
+ if (inbufflags & INP_CONT) {
+ inpoptop();
+ continue;
+ }
+ /* As a last resort, get some more input */
+ if (inputline())
+ break;
+ }
+ if (!lexstop)
+ zshlex_raw_add(lastc);
+ return lastc;
+}
+
+/* Read a line from the current command stream and store it as input */
+
+/**/
+static int
+inputline(void)
+{
+ char *ingetcline, **ingetcpmptl = NULL, **ingetcpmptr = NULL;
+ int context = ZLCON_LINE_START;
+
+ /* If reading code interactively, work out the prompts. */
+ if (interact && isset(SHINSTDIN)) {
+ if (!isfirstln) {
+ ingetcpmptl = &prompt2;
+ if (rprompt2)
+ ingetcpmptr = &rprompt2;
+ context = ZLCON_LINE_CONT;
+ }
+ else {
+ ingetcpmptl = &prompt;
+ if (rprompt)
+ ingetcpmptr = &rprompt;
+ }
+ }
+ if (!(interact && isset(SHINSTDIN) && SHTTY != -1 && isset(USEZLE))) {
+ /*
+ * If not using zle, read the line straight from the input file.
+ * Possibly we don't get the whole line at once: in that case,
+ * we get another chunk with the next call to inputline().
+ */
+
+ if (interact && isset(SHINSTDIN)) {
+ /*
+ * We may still be interactive (e.g. running under emacs),
+ * so output a prompt if necessary. We don't know enough
+ * about the input device to be able to handle an rprompt,
+ * though.
+ */
+ char *pptbuf;
+ int pptlen;
+ pptbuf = unmetafy(promptexpand(ingetcpmptl ? *ingetcpmptl : NULL,
+ 0, NULL, NULL, NULL), &pptlen);
+ write_loop(2, pptbuf, pptlen);
+ free(pptbuf);
+ }
+ ingetcline = shingetline();
+ } else {
+ /*
+ * Since we may have to read multiple lines before getting
+ * a complete piece of input, we tell zle not to restore the
+ * original tty settings after reading each chunk. Instead,
+ * this is done when the history mechanism for the current input
+ * terminates, which is not until we have the whole input.
+ * This is supposed to minimise problems on systems that clobber
+ * typeahead when the terminal settings are altered.
+ * pws 1998/03/12
+ */
+ int flags = ZLRF_HISTORY|ZLRF_NOSETTY;
+ if (isset(IGNOREEOF))
+ flags |= ZLRF_IGNOREEOF;
+ ingetcline = zleentry(ZLE_CMD_READ, ingetcpmptl, ingetcpmptr,
+ flags, context);
+ histdone |= HISTFLAG_SETTY;
+ }
+ if (!ingetcline) {
+ return lexstop = 1;
+ }
+ if (errflag) {
+ free(ingetcline);
+ errflag |= ERRFLAG_ERROR;
+ return lexstop = 1;
+ }
+ if (isset(VERBOSE)) {
+ /* Output the whole line read so far. */
+ zputs(ingetcline, stderr);
+ fflush(stderr);
+ }
+ if (keyboardhackchar && *ingetcline &&
+ ingetcline[strlen(ingetcline) - 1] == '\n' &&
+ interact && isset(SHINSTDIN) &&
+ SHTTY != -1 && ingetcline[1])
+ {
+ char *stripptr = ingetcline + strlen(ingetcline) - 2;
+ if (*stripptr == keyboardhackchar) {
+ /* Junk an unwanted character at the end of the line.
+ (key too close to return key) */
+ int ct = 1; /* force odd */
+ char *ptr;
+
+ if (keyboardhackchar == '\'' || keyboardhackchar == '"' ||
+ keyboardhackchar == '`') {
+ /*
+ * for the chars above, also require an odd count before
+ * junking
+ */
+ for (ct = 0, ptr = ingetcline; *ptr; ptr++)
+ if (*ptr == keyboardhackchar)
+ ct++;
+ }
+ if (ct & 1) {
+ stripptr[0] = '\n';
+ stripptr[1] = '\0';
+ }
+ }
+ }
+ isfirstch = 1;
+ if ((inbufflags & INP_APPEND) && inbuf) {
+ /*
+ * We need new input but need to be able to back up
+ * over the old input, so append this line.
+ * Pushing the line onto the stack doesn't have the right
+ * effect.
+ *
+ * This is quite a simple and inefficient fix, but currently
+ * we only need it when backing up over a multi-line $((...
+ * that turned out to be a command substitution rather than
+ * a math substitution, which is a very special case.
+ * So it's not worth rewriting.
+ */
+ char *oinbuf = inbuf;
+ int newlen = strlen(ingetcline);
+ int oldlen = (int)(inbufptr - inbuf) + inbufleft;
+ if (inbufflags & INP_FREE) {
+ inbuf = realloc(inbuf, oldlen + newlen + 1);
+ } else {
+ inbuf = zalloc(oldlen + newlen + 1);
+ memcpy(inbuf, oinbuf, oldlen);
+ }
+ inbufptr += inbuf - oinbuf;
+ strcpy(inbuf + oldlen, ingetcline);
+ free(ingetcline);
+ inbufleft += newlen;
+ inbufct += newlen;
+ inbufflags |= INP_FREE;
+ } else {
+ /* Put this into the input channel. */
+ inputsetline(ingetcline, INP_FREE);
+ }
+
+ return 0;
+}
+
+/*
+ * Put a string in the input queue:
+ * inbuf is only freeable if the flags include INP_FREE.
+ */
+
+/**/
+static void
+inputsetline(char *str, int flags)
+{
+ queue_signals();
+
+ if ((inbufflags & INP_FREE) && inbuf) {
+ free(inbuf);
+ }
+ inbuf = inbufptr = str;
+ inbufleft = strlen(inbuf);
+
+ /*
+ * inbufct must reflect the total number of characters left,
+ * as it used by other parts of the shell, so we need to take account
+ * of whether the input stack continues, and whether there
+ * is an extra space to add on at the end.
+ */
+ if (flags & INP_CONT)
+ inbufct += inbufleft;
+ else
+ inbufct = inbufleft;
+ inbufflags = flags;
+
+ unqueue_signals();
+}
+
+/*
+ * Backup one character of the input.
+ * The last character can always be backed up, provided we didn't just
+ * expand an alias or a history reference.
+ * In fact, the character is ignored and the previous character is used.
+ * (If that's wrong, the bug is in the calling code. Use the #ifdef DEBUG
+ * code to check.)
+ */
+
+/**/
+void
+inungetc(int c)
+{
+ if (!lexstop) {
+ if (inbufptr != inbuf) {
+#ifdef DEBUG
+ /* Just for debugging: enable only if foul play suspected. */
+ if (inbufptr[-1] != (char) c)
+ fprintf(stderr, "Warning: backing up wrong character.\n");
+#endif
+ /* Just decrement the pointer: if it's not the same
+ * character being pushed back, we're in trouble anyway.
+ */
+ inbufptr--;
+ inbufct++;
+ inbufleft++;
+ if (((inbufflags & INP_LINENO) || !strin) && c == '\n')
+ lineno--;
+ }
+ else if (!(inbufflags & INP_CONT)) {
+#ifdef DEBUG
+ /* Just for debugging */
+ fprintf(stderr, "Attempt to inungetc() at start of input.\n");
+#endif
+ zerr("Garbled input at %c (binary file as commands?)", c);
+ return;
+ }
+ else {
+ /*
+ * The character is being backed up from a previous input stack
+ * layer. However, there was an expansion in the middle, so we
+ * can't back up where we want to. Instead, we just push it
+ * onto the input stack as an extra character.
+ */
+ char *cback = (char *)zshcalloc(2);
+ cback[0] = (char) c;
+ inpush(cback, INP_FREE|INP_CONT, NULL);
+ }
+ /* If we are back at the start of a segment,
+ * we may need to restore an alias popped from the stack.
+ * Note this may be a dummy (history expansion) entry.
+ */
+ if (inbufptr == inbufpush &&
+ (inbufflags & (INP_ALCONT|INP_HISTCONT))) {
+ /*
+ * Go back up the stack over all entries which were alias
+ * expansions and were pushed with nothing remaining to read.
+ */
+ do {
+ if (instacktop->alias)
+ instacktop->alias->inuse = 1;
+ instacktop++;
+ } while ((instacktop->flags & (INP_ALCONT|INP_HISTCONT))
+ && !instacktop->bufleft);
+ if (inbufflags & INP_HISTCONT)
+ inbufflags = INP_CONT|INP_ALIAS|INP_HIST;
+ else
+ inbufflags = INP_CONT|INP_ALIAS;
+ inbufleft = 0;
+ inbuf = inbufptr = "";
+ }
+ zshlex_raw_back();
+ }
+}
+
+/* stuff a whole file into the input queue and print it */
+
+/**/
+int
+stuff(char *fn)
+{
+ FILE *in;
+ char *buf;
+ off_t len;
+
+ if (!(in = fopen(unmeta(fn), "r"))) {
+ zerr("can't open %s", fn);
+ return 1;
+ }
+ fseek(in, 0, 2);
+ len = ftell(in);
+ fseek(in, 0, 0);
+ buf = (char *)zalloc(len + 1);
+ if (!(fread(buf, len, 1, in))) {
+ zerr("read error on %s", fn);
+ fclose(in);
+ zfree(buf, len + 1);
+ return 1;
+ }
+ fclose(in);
+ buf[len] = '\0';
+ fwrite(buf, len, 1, stderr);
+ fflush(stderr);
+ inputsetline(metafy(buf, len, META_REALLOC), INP_FREE);
+ return 0;
+}
+
+/* flush input queue */
+
+/**/
+void
+inerrflush(void)
+{
+ while (!lexstop && inbufct)
+ ingetc();
+}
+
+/* Set some new input onto a new element of the input stack */
+
+/**/
+mod_export void
+inpush(char *str, int flags, Alias inalias)
+{
+ if (!instack) {
+ /* Initial stack allocation */
+ instack = (struct instacks *)zalloc(instacksz*sizeof(struct instacks));
+ instacktop = instack;
+ }
+
+ instacktop->buf = inbuf;
+ instacktop->bufptr = inbufptr;
+ instacktop->bufleft = inbufleft;
+ instacktop->bufct = inbufct;
+ inbufflags &= ~(INP_ALCONT|INP_HISTCONT);
+ if (flags & (INP_ALIAS|INP_HIST)) {
+ /*
+ * Text is expansion for history or alias, so continue
+ * back to old level when done. Also mark stack top
+ * as alias continuation so as to back up if necessary,
+ * and mark alias as in use.
+ */
+ flags |= INP_CONT|INP_ALIAS;
+ if (flags & INP_HIST)
+ instacktop->flags = inbufflags | INP_HISTCONT;
+ else
+ instacktop->flags = inbufflags | INP_ALCONT;
+ if ((instacktop->alias = inalias))
+ inalias->inuse = 1;
+ } else {
+ /* If we are continuing an alias expansion, record the alias
+ * expansion in new set of flags (do we need this?)
+ */
+ if (((instacktop->flags = inbufflags) & INP_ALIAS) &&
+ (flags & INP_CONT))
+ flags |= INP_ALIAS;
+ }
+
+ instacktop++;
+ if (instacktop == instack + instacksz) {
+ /* Expand the stack */
+ instack = (struct instacks *)
+ realloc(instack,
+ (instacksz + INSTACK_EXPAND)*sizeof(struct instacks));
+ instacktop = instack + instacksz;
+ instacksz += INSTACK_EXPAND;
+ }
+ /*
+ * We maintain the entry above the highest one with real
+ * text as a flag to inungetc() that it can stop re-pushing the stack.
+ */
+ instacktop->flags = 0;
+
+ inbufpush = inbuf = NULL;
+
+ inputsetline(str, flags);
+}
+
+/* Remove the top element of the stack */
+
+/**/
+static void
+inpoptop(void)
+{
+ if (!lexstop) {
+ inbufflags &= ~(INP_ALCONT|INP_HISTCONT);
+ while (inbufptr > inbuf) {
+ inbufptr--;
+ inbufct++;
+ inbufleft++;
+ /*
+ * As elsewhere in input and history mechanisms:
+ * unwinding aliases and unwinding history have different
+ * implications as aliases are after the lexer while
+ * history is before, but they're both pushed onto
+ * the input stack.
+ */
+ if ((inbufflags & (INP_ALIAS|INP_HIST|INP_RAW_KEEP)) == INP_ALIAS)
+ zshlex_raw_back();
+ }
+ }
+
+ if (inbuf && (inbufflags & INP_FREE))
+ free(inbuf);
+
+ instacktop--;
+
+ inbuf = instacktop->buf;
+ inbufptr = inbufpush = instacktop->bufptr;
+ inbufleft = instacktop->bufleft;
+ inbufct = instacktop->bufct;
+ inbufflags = instacktop->flags;
+
+ if (!(inbufflags & (INP_ALCONT|INP_HISTCONT)))
+ return;
+
+ if (instacktop->alias) {
+ char *t = instacktop->alias->text;
+ /* a real alias: mark it as unused. */
+ instacktop->alias->inuse = 0;
+ if (*t && t[strlen(t) - 1] == ' ') {
+ inalmore = 1;
+ histbackword();
+ }
+ }
+}
+
+/* Remove the top element of the stack and all its continuations. */
+
+/**/
+mod_export void
+inpop(void)
+{
+ int remcont;
+
+ do {
+ remcont = inbufflags & INP_CONT;
+
+ inpoptop();
+ } while (remcont);
+}
+
+/*
+ * Expunge any aliases from the input stack; they shouldn't appear
+ * in the history and need to be flushed explicitly when we encounter
+ * an error.
+ */
+
+/**/
+void
+inpopalias(void)
+{
+ while (inbufflags & INP_ALIAS)
+ inpoptop();
+}
+
+
+/*
+ * Get pointer to remaining string to read.
+ */
+
+/**/
+char *
+ingetptr(void)
+{
+ return inbufptr;
+}
+
+/*
+ * Check if the current input line, including continuations, is
+ * expanding an alias. This does not detect alias expansions that
+ * have been fully processed and popped from the input stack.
+ * If there is an alias, the most recently expanded is returned,
+ * else NULL.
+ */
+
+/**/
+char *input_hasalias(void)
+{
+ int flags = inbufflags;
+ struct instacks *instackptr = instacktop;
+
+ for (;;)
+ {
+ if (!(flags & INP_CONT))
+ break;
+ instackptr--;
+ if (instackptr->alias)
+ return instackptr->alias->node.nam;
+ flags = instackptr->flags;
+ }
+
+ return NULL;
+}
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/jobs.c b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/jobs.c
new file mode 100644
index 0000000..38b3d89
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/jobs.c
@@ -0,0 +1,2894 @@
+/*
+ * jobs.c - job control
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+#include "zsh.mdh"
+#include "jobs.pro"
+
+/* the process group of the shell at startup (equal to mypgprp, except
+ when we started without being process group leader */
+
+/**/
+mod_export pid_t origpgrp;
+
+/* the process group of the shell */
+
+/**/
+mod_export pid_t mypgrp;
+
+/* the job we are working on */
+
+/**/
+mod_export int thisjob;
+
+/* the current job (+) */
+
+/**/
+mod_export int curjob;
+
+/* the previous job (-) */
+
+/**/
+mod_export int prevjob;
+
+/* the job table */
+
+/**/
+mod_export struct job *jobtab;
+
+/* Size of the job table. */
+
+/**/
+mod_export int jobtabsize;
+
+/* The highest numbered job in the jobtable */
+
+/**/
+mod_export int maxjob;
+
+/* If we have entered a subshell, the original shell's job table. */
+static struct job *oldjobtab;
+
+/* The size of that. */
+static int oldmaxjob;
+
+/* shell timings */
+
+/**/
+#ifdef HAVE_GETRUSAGE
+/**/
+static struct rusage child_usage;
+/**/
+#else
+/**/
+static struct tms shtms;
+/**/
+#endif
+
+/* 1 if ttyctl -f has been executed */
+
+/**/
+mod_export int ttyfrozen;
+
+/* Previous values of errflag and breaks if the signal handler had to
+ * change them. And a flag saying if it did that. */
+
+/**/
+int prev_errflag, prev_breaks, errbrk_saved;
+
+/**/
+int numpipestats, pipestats[MAX_PIPESTATS];
+
+/* Diff two timevals for elapsed-time computations */
+
+/**/
+static struct timeval *
+dtime(struct timeval *dt, struct timeval *t1, struct timeval *t2)
+{
+ dt->tv_sec = t2->tv_sec - t1->tv_sec;
+ dt->tv_usec = t2->tv_usec - t1->tv_usec;
+ if (dt->tv_usec < 0) {
+ dt->tv_usec += 1000000.0;
+ dt->tv_sec -= 1.0;
+ }
+ return dt;
+}
+
+/* change job table entry from stopped to running */
+
+/**/
+void
+makerunning(Job jn)
+{
+ Process pn;
+
+ jn->stat &= ~STAT_STOPPED;
+ for (pn = jn->procs; pn; pn = pn->next) {
+#if 0
+ if (WIFSTOPPED(pn->status) &&
+ (!(jn->stat & STAT_SUPERJOB) || pn->next))
+ pn->status = SP_RUNNING;
+#endif
+ if (WIFSTOPPED(pn->status))
+ pn->status = SP_RUNNING;
+ }
+
+ if (jn->stat & STAT_SUPERJOB)
+ makerunning(jobtab + jn->other);
+}
+
+/* Find process and job associated with pid. *
+ * Return 1 if search was successful, else return 0. */
+
+/**/
+int
+findproc(pid_t pid, Job *jptr, Process *pptr, int aux)
+{
+ Process pn;
+ int i;
+
+ *jptr = NULL;
+ *pptr = NULL;
+ for (i = 1; i <= maxjob; i++)
+ {
+ /*
+ * We are only interested in jobs with processes still
+ * marked as live. Careful in case there's an identical
+ * process number in a job we haven't quite got around
+ * to deleting.
+ */
+ if (jobtab[i].stat & STAT_DONE)
+ continue;
+
+ for (pn = aux ? jobtab[i].auxprocs : jobtab[i].procs;
+ pn; pn = pn->next)
+ {
+ /*
+ * Make sure we match a process that's still running.
+ *
+ * When a job contains two pids, one terminated pid and one
+ * running pid, then the condition (jobtab[i].stat &
+ * STAT_DONE) will not stop these pids from being candidates
+ * for the findproc result (which is supposed to be a
+ * RUNNING pid), and if the terminated pid is an identical
+ * process number for the pid identifying the running
+ * process we are trying to find (after pid number
+ * wrapping), then we need to avoid returning the terminated
+ * pid, otherwise the shell would block and wait forever for
+ * the termination of the process which pid we were supposed
+ * to return in a different job.
+ */
+ if (pn->pid == pid) {
+ *pptr = pn;
+ *jptr = jobtab + i;
+ if (pn->status == SP_RUNNING)
+ return 1;
+ }
+ }
+ }
+
+ return (*pptr && *jptr);
+}
+
+/* Does the given job number have any processes? */
+
+/**/
+int
+hasprocs(int job)
+{
+ Job jn;
+
+ if (job < 0) {
+ DPUTS(1, "job number invalid in hasprocs");
+ return 0;
+ }
+ jn = jobtab + job;
+
+ return jn->procs || jn->auxprocs;
+}
+
+/* Find the super-job of a sub-job. */
+
+/**/
+static int
+super_job(int sub)
+{
+ int i;
+
+ for (i = 1; i <= maxjob; i++)
+ if ((jobtab[i].stat & STAT_SUPERJOB) &&
+ jobtab[i].other == sub &&
+ jobtab[i].gleader)
+ return i;
+ return 0;
+}
+
+/**/
+static int
+handle_sub(int job, int fg)
+{
+ /* job: superjob; sj: subjob. */
+ Job jn = jobtab + job, sj = jobtab + jn->other;
+
+ if ((sj->stat & STAT_DONE) || (!sj->procs && !sj->auxprocs)) {
+ struct process *p;
+
+ for (p = sj->procs; p; p = p->next) {
+ if (WIFSIGNALED(p->status)) {
+ if (jn->gleader != mypgrp && jn->procs->next)
+ killpg(jn->gleader, WTERMSIG(p->status));
+ else
+ kill(jn->procs->pid, WTERMSIG(p->status));
+ kill(sj->other, SIGCONT);
+ kill(sj->other, WTERMSIG(p->status));
+ break;
+ }
+ }
+ if (!p) {
+ int cp;
+
+ jn->stat &= ~STAT_SUPERJOB;
+ jn->stat |= STAT_WASSUPER;
+
+ if ((cp = ((WIFEXITED(jn->procs->status) ||
+ WIFSIGNALED(jn->procs->status)) &&
+ killpg(jn->gleader, 0) == -1))) {
+ Process p;
+ for (p = jn->procs; p->next; p = p->next);
+ jn->gleader = p->pid;
+ }
+ /* This deleted the job too early if the parent
+ shell waited for a command in a list that will
+ be executed by the sub-shell (e.g.: if we have
+ `ls|if true;then sleep 20;cat;fi' and ^Z the
+ sleep, the rest will be executed by a sub-shell,
+ but the parent shell gets notified for the
+ sleep.
+ deletejob(sj, 0); */
+ /* If this super-job contains only the sub-shell,
+ we have to attach the tty to its process group
+ now. */
+ if ((fg || thisjob == job) &&
+ (!jn->procs->next || cp || jn->procs->pid != jn->gleader))
+ attachtty(jn->gleader);
+ kill(sj->other, SIGCONT);
+ if (jn->stat & STAT_DISOWN)
+ {
+ deletejob(jn, 1);
+ }
+ }
+ curjob = jn - jobtab;
+ } else if (sj->stat & STAT_STOPPED) {
+ struct process *p;
+
+ jn->stat |= STAT_STOPPED;
+ for (p = jn->procs; p; p = p->next)
+ if (p->status == SP_RUNNING ||
+ (!WIFEXITED(p->status) && !WIFSIGNALED(p->status)))
+ p->status = sj->procs->status;
+ curjob = jn - jobtab;
+ printjob(jn, !!isset(LONGLISTJOBS), 1);
+ return 1;
+ }
+ return 0;
+}
+
+
+/* Get the latest usage information */
+
+/**/
+void
+get_usage(void)
+{
+#ifdef HAVE_GETRUSAGE
+ getrusage(RUSAGE_CHILDREN, &child_usage);
+#else
+ times(&shtms);
+#endif
+}
+
+
+#if !defined HAVE_WAIT3 || !defined HAVE_GETRUSAGE
+/* Update status of process that we have just WAIT'ed for */
+
+/**/
+void
+update_process(Process pn, int status)
+{
+ struct timezone dummy_tz;
+#ifdef HAVE_GETRUSAGE
+ struct timeval childs = child_usage.ru_stime;
+ struct timeval childu = child_usage.ru_utime;
+#else
+ long childs = shtms.tms_cstime;
+ long childu = shtms.tms_cutime;
+#endif
+
+ /* get time-accounting info */
+ get_usage();
+ gettimeofday(&pn->endtime, &dummy_tz); /* record time process exited */
+
+ pn->status = status; /* save the status returned by WAIT */
+#ifdef HAVE_GETRUSAGE
+ dtime(&pn->ti.ru_stime, &childs, &child_usage.ru_stime);
+ dtime(&pn->ti.ru_utime, &childu, &child_usage.ru_utime);
+#else
+ pn->ti.st = shtms.tms_cstime - childs; /* compute process system space time */
+ pn->ti.ut = shtms.tms_cutime - childu; /* compute process user space time */
+#endif
+}
+#endif
+
+/*
+ * Called when the current shell is behaving as if it received
+ * a interactively generated signal (sig).
+ *
+ * As we got the signal or are pretending we did, we need to pretend
+ * anything attached to a CURSH process got it, too.
+ */
+/**/
+void
+check_cursh_sig(int sig)
+{
+ int i, j;
+
+ if (!errflag)
+ return;
+ for (i = 1; i <= maxjob; i++) {
+ if ((jobtab[i].stat & (STAT_CURSH|STAT_DONE)) ==
+ STAT_CURSH) {
+ for (j = 0; j < 2; j++) {
+ Process pn = j ? jobtab[i].auxprocs : jobtab[i].procs;
+ for (; pn; pn = pn->next) {
+ if (pn->status == SP_RUNNING) {
+ kill(pn->pid, sig);
+ }
+ }
+ }
+ }
+ }
+}
+
+/**/
+void
+storepipestats(Job jn, int inforeground, int fixlastval)
+{
+ int i, pipefail = 0, jpipestats[MAX_PIPESTATS];
+ Process p;
+
+ for (p = jn->procs, i = 0; p && i < MAX_PIPESTATS; p = p->next, i++) {
+ jpipestats[i] = (WIFSIGNALED(p->status) ?
+ 0200 | WTERMSIG(p->status) :
+ (WIFSTOPPED(p->status) ?
+ 0200 | WEXITSTATUS(p->status) :
+ WEXITSTATUS(p->status)));
+ if (jpipestats[i])
+ pipefail = jpipestats[i];
+ }
+ if (inforeground) {
+ memcpy(pipestats, jpipestats, sizeof(int)*i);
+ if ((jn->stat & STAT_CURSH) && i < MAX_PIPESTATS)
+ pipestats[i++] = lastval;
+ numpipestats = i;
+ }
+
+ if (fixlastval) {
+ if (jn->stat & STAT_CURSH) {
+ if (!lastval && isset(PIPEFAIL))
+ lastval = pipefail;
+ } else if (isset(PIPEFAIL))
+ lastval = pipefail;
+ }
+}
+
+/* Update status of job, possibly printing it */
+
+/**/
+void
+update_job(Job jn)
+{
+ Process pn;
+ int job;
+ int val = 0, status = 0;
+ int somestopped = 0, inforeground = 0;
+
+ for (pn = jn->auxprocs; pn; pn = pn->next) {
+#ifdef WIFCONTINUED
+ if (WIFCONTINUED(pn->status))
+ pn->status = SP_RUNNING;
+#endif
+ if (pn->status == SP_RUNNING)
+ return;
+ }
+
+ for (pn = jn->procs; pn; pn = pn->next) {
+#ifdef WIFCONTINUED
+ if (WIFCONTINUED(pn->status)) {
+ jn->stat &= ~STAT_STOPPED;
+ pn->status = SP_RUNNING;
+ }
+#endif
+ if (pn->status == SP_RUNNING) /* some processes in this job are running */
+ return; /* so no need to update job table entry */
+ if (WIFSTOPPED(pn->status)) /* some processes are stopped */
+ somestopped = 1; /* so job is not done, but entry needs updating */
+ if (!pn->next) /* last job in pipeline determines exit status */
+ val = (WIFSIGNALED(pn->status) ?
+ 0200 | WTERMSIG(pn->status) :
+ (WIFSTOPPED(pn->status) ?
+ 0200 | WEXITSTATUS(pn->status) :
+ WEXITSTATUS(pn->status)));
+ if (pn->pid == jn->gleader) /* if this process is process group leader */
+ status = pn->status;
+ }
+
+ job = jn - jobtab; /* compute job number */
+
+ if (somestopped) {
+ if (jn->stty_in_env && !jn->ty) {
+ jn->ty = (struct ttyinfo *) zalloc(sizeof(struct ttyinfo));
+ gettyinfo(jn->ty);
+ }
+ if (jn->stat & STAT_STOPPED) {
+ if (jn->stat & STAT_SUBJOB) {
+ /* If we have `cat foo|while read a; grep $a bar;done'
+ * and have hit ^Z, the sub-job is stopped, but the
+ * super-job may still be running, waiting to be stopped
+ * or to exit. So we have to send it a SIGTSTP. */
+ int i;
+
+ if ((i = super_job(job)))
+ killpg(jobtab[i].gleader, SIGTSTP);
+ }
+ return;
+ }
+ }
+ { /* job is done or stopped, remember return value */
+ lastval2 = val;
+ /* If last process was run in the current shell, keep old status
+ * and let it handle its own traps, but always allow the test
+ * for the pgrp.
+ */
+ if (jn->stat & STAT_CURSH)
+ inforeground = 1;
+ else if (job == thisjob) {
+ lastval = val;
+ inforeground = 2;
+ }
+ }
+
+ if (shout && shout != stderr && !ttyfrozen && !jn->stty_in_env &&
+ !zleactive && job == thisjob && !somestopped &&
+ !(jn->stat & STAT_NOSTTY))
+ gettyinfo(&shttyinfo);
+
+ if (isset(MONITOR)) {
+ pid_t pgrp = gettygrp(); /* get process group of tty */
+
+ /* is this job in the foreground of an interactive shell? */
+ if (mypgrp != pgrp && inforeground &&
+ (jn->gleader == pgrp || (pgrp > 1 && kill(-pgrp, 0) == -1))) {
+ if (list_pipe) {
+ if (somestopped || (pgrp > 1 && kill(-pgrp, 0) == -1)) {
+ attachtty(mypgrp);
+ /* check window size and adjust if necessary */
+ adjustwinsize(0);
+ } else {
+ /*
+ * Oh, dear, we're right in the middle of some confusion
+ * of shell jobs on the righthand side of a pipeline, so
+ * it's death to call attachtty() just yet. Mark the
+ * fact in the job, so that the attachtty() will be called
+ * when the job is finally deleted.
+ */
+ jn->stat |= STAT_ATTACH;
+ }
+ /* If we have `foo|while true; (( x++ )); done', and hit
+ * ^C, we have to stop the loop, too. */
+ if ((val & 0200) && inforeground == 1 &&
+ ((val & ~0200) == SIGINT || (val & ~0200) == SIGQUIT)) {
+ if (!errbrk_saved) {
+ errbrk_saved = 1;
+ prev_breaks = breaks;
+ prev_errflag = errflag;
+ }
+ breaks = loops;
+ errflag |= ERRFLAG_INT;
+ inerrflush();
+ }
+ } else {
+ attachtty(mypgrp);
+ /* check window size and adjust if necessary */
+ adjustwinsize(0);
+ }
+ }
+ } else if (list_pipe && (val & 0200) && inforeground == 1 &&
+ ((val & ~0200) == SIGINT || (val & ~0200) == SIGQUIT)) {
+ if (!errbrk_saved) {
+ errbrk_saved = 1;
+ prev_breaks = breaks;
+ prev_errflag = errflag;
+ }
+ breaks = loops;
+ errflag |= ERRFLAG_INT;
+ inerrflush();
+ }
+ if (somestopped && jn->stat & STAT_SUPERJOB)
+ return;
+ jn->stat |= (somestopped) ? STAT_CHANGED | STAT_STOPPED :
+ STAT_CHANGED | STAT_DONE;
+ if (jn->stat & (STAT_DONE|STAT_STOPPED)) {
+ /* This may be redundant with printjob() but note that inforeground
+ * is true here for STAT_CURSH jobs even when job != thisjob, most
+ * likely because thisjob = -1 from exec.c:execsimple() trickery.
+ * However, if we reset lastval here we break it for printjob().
+ */
+ storepipestats(jn, inforeground, 0);
+ }
+ if (!inforeground &&
+ (jn->stat & (STAT_SUBJOB | STAT_DONE)) == (STAT_SUBJOB | STAT_DONE)) {
+ int su;
+
+ if ((su = super_job(jn - jobtab)))
+ handle_sub(su, 0);
+ }
+ if ((jn->stat & (STAT_DONE | STAT_STOPPED)) == STAT_STOPPED) {
+ prevjob = curjob;
+ curjob = job;
+ }
+ if ((isset(NOTIFY) || job == thisjob) && (jn->stat & STAT_LOCKED)) {
+ if (printjob(jn, !!isset(LONGLISTJOBS), 0) &&
+ zleactive)
+ zleentry(ZLE_CMD_REFRESH);
+ }
+ if (sigtrapped[SIGCHLD] && job != thisjob)
+ dotrap(SIGCHLD);
+
+ /* When MONITOR is set, the foreground process runs in a different *
+ * process group from the shell, so the shell will not receive *
+ * terminal signals, therefore we pretend that the shell got *
+ * the signal too. */
+ if (inforeground == 2 && isset(MONITOR) && WIFSIGNALED(status)) {
+ int sig = WTERMSIG(status);
+
+ if (sig == SIGINT || sig == SIGQUIT) {
+ if (sigtrapped[sig]) {
+ dotrap(sig);
+ /* We keep the errflag as set or not by dotrap.
+ * This is to fulfil the promise to carry on
+ * with the jobs if trap returns zero.
+ * Setting breaks = loops ensures a consistent return
+ * status if inside a loop. Maybe the code in loops
+ * should be changed.
+ */
+ if (errflag)
+ breaks = loops;
+ } else {
+ breaks = loops;
+ errflag |= ERRFLAG_INT;
+ }
+ check_cursh_sig(sig);
+ }
+ }
+}
+
+/* set the previous job to something reasonable */
+
+/**/
+static void
+setprevjob(void)
+{
+ int i;
+
+ for (i = maxjob; i; i--)
+ if ((jobtab[i].stat & STAT_INUSE) && (jobtab[i].stat & STAT_STOPPED) &&
+ !(jobtab[i].stat & STAT_SUBJOB) && i != curjob && i != thisjob) {
+ prevjob = i;
+ return;
+ }
+
+ for (i = maxjob; i; i--)
+ if ((jobtab[i].stat & STAT_INUSE) && !(jobtab[i].stat & STAT_SUBJOB) &&
+ i != curjob && i != thisjob) {
+ prevjob = i;
+ return;
+ }
+
+ prevjob = -1;
+}
+
+/**/
+long
+get_clktck(void)
+{
+ static long clktck;
+
+#ifdef _SC_CLK_TCK
+ if (!clktck)
+ /* fetch clock ticks per second from *
+ * sysconf only the first time */
+ clktck = sysconf(_SC_CLK_TCK);
+#else
+# ifdef __NeXT__
+ /* NeXTStep 3.3 defines CLK_TCK wrongly */
+ clktck = 60;
+# else
+# ifdef CLK_TCK
+ clktck = CLK_TCK;
+# else
+# ifdef HZ
+ clktck = HZ;
+# else
+ clktck = 60;
+# endif
+# endif
+# endif
+#endif
+
+ return clktck;
+}
+
+/**/
+static void
+printhhmmss(double secs)
+{
+ int mins = (int) secs / 60;
+ int hours = mins / 60;
+
+ secs -= 60 * mins;
+ mins -= 60 * hours;
+ if (hours)
+ fprintf(stderr, "%d:%02d:%05.2f", hours, mins, secs);
+ else if (mins)
+ fprintf(stderr, "%d:%05.2f", mins, secs);
+ else
+ fprintf(stderr, "%.3f", secs);
+}
+
+static void
+printtime(struct timeval *real, child_times_t *ti, char *desc)
+{
+ char *s;
+ double elapsed_time, user_time, system_time;
+#ifdef HAVE_GETRUSAGE
+ double total_time;
+#endif
+ int percent, desclen;
+
+ if (!desc)
+ {
+ desc = "";
+ desclen = 0;
+ }
+ else
+ {
+ desc = dupstring(desc);
+ unmetafy(desc, &desclen);
+ }
+
+ /* go ahead and compute these, since almost every TIMEFMT will have them */
+ elapsed_time = real->tv_sec + real->tv_usec / 1000000.0;
+
+#ifdef HAVE_GETRUSAGE
+ user_time = ti->ru_utime.tv_sec + ti->ru_utime.tv_usec / 1000000.0;
+ system_time = ti->ru_stime.tv_sec + ti->ru_stime.tv_usec / 1000000.0;
+ total_time = user_time + system_time;
+ percent = 100.0 * total_time
+ / (real->tv_sec + real->tv_usec / 1000000.0);
+#else
+ {
+ long clktck = get_clktck();
+ user_time = ti->ut / (double) clktck;
+ system_time = ti->st / (double) clktck;
+ percent = 100.0 * (ti->ut + ti->st)
+ / (clktck * real->tv_sec + clktck * real->tv_usec / 1000000.0);
+ }
+#endif
+
+ queue_signals();
+ if (!(s = getsparam("TIMEFMT")))
+ s = DEFAULT_TIMEFMT;
+ else
+ s = unmetafy(s, NULL);
+
+ for (; *s; s++)
+ if (*s == '%')
+ switch (*++s) {
+ case 'E':
+ fprintf(stderr, "%4.2fs", elapsed_time);
+ break;
+ case 'U':
+ fprintf(stderr, "%4.2fs", user_time);
+ break;
+ case 'S':
+ fprintf(stderr, "%4.2fs", system_time);
+ break;
+ case 'm':
+ switch (*++s) {
+ case 'E':
+ fprintf(stderr, "%0.fms", elapsed_time * 1000.0);
+ break;
+ case 'U':
+ fprintf(stderr, "%0.fms", user_time * 1000.0);
+ break;
+ case 'S':
+ fprintf(stderr, "%0.fms", system_time * 1000.0);
+ break;
+ default:
+ fprintf(stderr, "%%m");
+ s--;
+ break;
+ }
+ break;
+ case 'u':
+ switch (*++s) {
+ case 'E':
+ fprintf(stderr, "%0.fus", elapsed_time * 1000000.0);
+ break;
+ case 'U':
+ fprintf(stderr, "%0.fus", user_time * 1000000.0);
+ break;
+ case 'S':
+ fprintf(stderr, "%0.fus", system_time * 1000000.0);
+ break;
+ default:
+ fprintf(stderr, "%%u");
+ s--;
+ break;
+ }
+ break;
+ case '*':
+ switch (*++s) {
+ case 'E':
+ printhhmmss(elapsed_time);
+ break;
+ case 'U':
+ printhhmmss(user_time);
+ break;
+ case 'S':
+ printhhmmss(system_time);
+ break;
+ default:
+ fprintf(stderr, "%%*");
+ s--;
+ break;
+ }
+ break;
+ case 'P':
+ fprintf(stderr, "%d%%", percent);
+ break;
+#ifdef HAVE_STRUCT_RUSAGE_RU_NSWAP
+ case 'W':
+ fprintf(stderr, "%ld", ti->ru_nswap);
+ break;
+#endif
+#ifdef HAVE_STRUCT_RUSAGE_RU_IXRSS
+ case 'X':
+ fprintf(stderr, "%ld",
+ total_time ?
+ (long)(ti->ru_ixrss / total_time) :
+ (long)0);
+ break;
+#endif
+#ifdef HAVE_STRUCT_RUSAGE_RU_IDRSS
+ case 'D':
+ fprintf(stderr, "%ld",
+ total_time ?
+ (long) ((ti->ru_idrss
+#ifdef HAVE_STRUCT_RUSAGE_RU_ISRSS
+ + ti->ru_isrss
+#endif
+ ) / total_time) :
+ (long)0);
+ break;
+#endif
+#if defined(HAVE_STRUCT_RUSAGE_RU_IDRSS) || \
+ defined(HAVE_STRUCT_RUSAGE_RU_ISRSS) || \
+ defined(HAVE_STRUCT_RUSAGE_RU_IXRSS)
+ case 'K':
+ /* treat as D if X not available */
+ fprintf(stderr, "%ld",
+ total_time ?
+ (long) ((
+#ifdef HAVE_STRUCT_RUSAGE_RU_IXRSS
+ ti->ru_ixrss
+#else
+ 0
+#endif
+#ifdef HAVE_STRUCT_RUSAGE_RU_IDRSS
+ + ti->ru_idrss
+#endif
+#ifdef HAVE_STRUCT_RUSAGE_RU_ISRSS
+ + ti->ru_isrss
+#endif
+ ) / total_time) :
+ (long)0);
+ break;
+#endif
+#ifdef HAVE_STRUCT_RUSAGE_RU_MAXRSS
+ case 'M':
+ fprintf(stderr, "%ld", ti->ru_maxrss / 1024);
+ break;
+#endif
+#ifdef HAVE_STRUCT_RUSAGE_RU_MAJFLT
+ case 'F':
+ fprintf(stderr, "%ld", ti->ru_majflt);
+ break;
+#endif
+#ifdef HAVE_STRUCT_RUSAGE_RU_MINFLT
+ case 'R':
+ fprintf(stderr, "%ld", ti->ru_minflt);
+ break;
+#endif
+#ifdef HAVE_STRUCT_RUSAGE_RU_INBLOCK
+ case 'I':
+ fprintf(stderr, "%ld", ti->ru_inblock);
+ break;
+#endif
+#ifdef HAVE_STRUCT_RUSAGE_RU_OUBLOCK
+ case 'O':
+ fprintf(stderr, "%ld", ti->ru_oublock);
+ break;
+#endif
+#ifdef HAVE_STRUCT_RUSAGE_RU_MSGRCV
+ case 'r':
+ fprintf(stderr, "%ld", ti->ru_msgrcv);
+ break;
+#endif
+#ifdef HAVE_STRUCT_RUSAGE_RU_MSGSND
+ case 's':
+ fprintf(stderr, "%ld", ti->ru_msgsnd);
+ break;
+#endif
+#ifdef HAVE_STRUCT_RUSAGE_RU_NSIGNALS
+ case 'k':
+ fprintf(stderr, "%ld", ti->ru_nsignals);
+ break;
+#endif
+#ifdef HAVE_STRUCT_RUSAGE_RU_NVCSW
+ case 'w':
+ fprintf(stderr, "%ld", ti->ru_nvcsw);
+ break;
+#endif
+#ifdef HAVE_STRUCT_RUSAGE_RU_NIVCSW
+ case 'c':
+ fprintf(stderr, "%ld", ti->ru_nivcsw);
+ break;
+#endif
+ case 'J':
+ fwrite(desc, sizeof(char), desclen, stderr);
+ break;
+ case '%':
+ putc('%', stderr);
+ break;
+ case '\0':
+ s--;
+ break;
+ default:
+ fprintf(stderr, "%%%c", *s);
+ break;
+ } else
+ putc(*s, stderr);
+ unqueue_signals();
+ putc('\n', stderr);
+ fflush(stderr);
+}
+
+/**/
+static void
+dumptime(Job jn)
+{
+ Process pn;
+ struct timeval dtimeval;
+
+ if (!jn->procs)
+ return;
+ for (pn = jn->procs; pn; pn = pn->next)
+ printtime(dtime(&dtimeval, &pn->bgtime, &pn->endtime), &pn->ti,
+ pn->text);
+}
+
+/* Check whether shell should report the amount of time consumed *
+ * by job. This will be the case if we have preceded the command *
+ * with the keyword time, or if REPORTTIME is non-negative and the *
+ * amount of time consumed by the job is greater than REPORTTIME */
+
+/**/
+static int
+should_report_time(Job j)
+{
+ struct value vbuf;
+ Value v;
+ char *s = "REPORTTIME";
+ int save_errflag = errflag;
+ zlong reporttime = -1;
+#ifdef HAVE_GETRUSAGE
+ char *sm = "REPORTMEMORY";
+ zlong reportmemory = -1;
+#endif
+
+ /* if the time keyword was used */
+ if (j->stat & STAT_TIMED)
+ return 1;
+
+ queue_signals();
+ errflag = 0;
+ if ((v = getvalue(&vbuf, &s, 0)))
+ reporttime = getintvalue(v);
+#ifdef HAVE_GETRUSAGE
+ if ((v = getvalue(&vbuf, &sm, 0)))
+ reportmemory = getintvalue(v);
+#endif
+ errflag = save_errflag;
+ unqueue_signals();
+ if (reporttime < 0
+#ifdef HAVE_GETRUSAGE
+ && reportmemory < 0
+#endif
+ )
+ return 0;
+ /* can this ever happen? */
+ if (!j->procs)
+ return 0;
+ if (zleactive)
+ return 0;
+
+ if (reporttime >= 0)
+ {
+#ifdef HAVE_GETRUSAGE
+ reporttime -= j->procs->ti.ru_utime.tv_sec +
+ j->procs->ti.ru_stime.tv_sec;
+ if (j->procs->ti.ru_utime.tv_usec +
+ j->procs->ti.ru_stime.tv_usec >= 1000000)
+ reporttime--;
+ if (reporttime <= 0)
+ return 1;
+#else
+ {
+ clktck = get_clktck();
+ if ((j->procs->ti.ut + j->procs->ti.st) / clktck >= reporttime)
+ return 1;
+ }
+#endif
+ }
+
+#ifdef HAVE_GETRUSAGE
+ if (reportmemory >= 0 &&
+ j->procs->ti.ru_maxrss / 1024 > reportmemory)
+ return 1;
+#endif
+
+ return 0;
+}
+
+/* !(lng & 3) means jobs *
+ * (lng & 1) means jobs -l *
+ * (lng & 2) means jobs -p
+ * (lng & 4) means jobs -d
+ *
+ * synch = 0 means asynchronous
+ * synch = 1 means synchronous
+ * synch = 2 means called synchronously from jobs
+ * synch = 3 means called synchronously from bg or fg
+ *
+ * Returns 1 if some output was done.
+ *
+ * The function also deletes the job if it was done, even it
+ * is not printed.
+ */
+
+/**/
+int
+printjob(Job jn, int lng, int synch)
+{
+ Process pn;
+ int job, len = 9, sig, sflag = 0, llen;
+ int conted = 0, lineleng = zterm_columns, skip = 0, doputnl = 0;
+ int doneprint = 0, skip_print = 0;
+ FILE *fout = (synch == 2 || !shout) ? stdout : shout;
+
+ if (synch > 1 && oldjobtab != NULL)
+ job = jn - oldjobtab;
+ else
+ job = jn - jobtab;
+ DPUTS3(job < 0 || job > (oldjobtab && synch > 1 ? oldmaxjob : maxjob),
+ "bogus job number, jn = %L, jobtab = %L, oldjobtab = %L",
+ (long)jn, (long)jobtab, (long)oldjobtab);
+
+ if (jn->stat & STAT_NOPRINT) {
+ skip_print = 1;
+ }
+
+ if (lng < 0) {
+ conted = 1;
+ lng = !!isset(LONGLISTJOBS);
+ }
+
+/* find length of longest signame, check to see */
+/* if we really need to print this job */
+
+ for (pn = jn->procs; pn; pn = pn->next) {
+ if (jn->stat & STAT_SUPERJOB &&
+ jn->procs->status == SP_RUNNING && !pn->next)
+ pn->status = SP_RUNNING;
+ if (pn->status != SP_RUNNING) {
+ if (WIFSIGNALED(pn->status)) {
+ sig = WTERMSIG(pn->status);
+ llen = strlen(sigmsg(sig));
+ if (WCOREDUMP(pn->status))
+ llen += 14;
+ if (llen > len)
+ len = llen;
+ if (sig != SIGINT && sig != SIGPIPE)
+ sflag = 1;
+ if (job == thisjob && sig == SIGINT)
+ doputnl = 1;
+ if (isset(PRINTEXITVALUE) && isset(SHINSTDIN)) {
+ sflag = 1;
+ skip_print = 0;
+ }
+ } else if (WIFSTOPPED(pn->status)) {
+ sig = WSTOPSIG(pn->status);
+ if ((int)strlen(sigmsg(sig)) > len)
+ len = strlen(sigmsg(sig));
+ if (job == thisjob && sig == SIGTSTP)
+ doputnl = 1;
+ } else if (isset(PRINTEXITVALUE) && isset(SHINSTDIN) &&
+ WEXITSTATUS(pn->status)) {
+ sflag = 1;
+ skip_print = 0;
+ }
+ }
+ }
+
+ if (skip_print) {
+ if (jn->stat & STAT_DONE) {
+ /* This looks silly, but see update_job() */
+ if (synch <= 1)
+ storepipestats(jn, job == thisjob, job == thisjob);
+ if (should_report_time(jn))
+ dumptime(jn);
+ deletejob(jn, 0);
+ if (job == curjob) {
+ curjob = prevjob;
+ prevjob = job;
+ }
+ if (job == prevjob)
+ setprevjob();
+ }
+ return 0;
+ }
+
+ /*
+ * - Always print if called from jobs
+ * - Otherwise, require MONITOR option ("jobbing") and some
+ * change of state
+ * - also either the shell is interactive or this is synchronous.
+ */
+ if (synch == 2 ||
+ ((interact || synch) && jobbing &&
+ ((jn->stat & STAT_STOPPED) || sflag || job != thisjob))) {
+ int len2, fline = 1;
+ /* POSIX requires just the job text for bg and fg */
+ int plainfmt = (synch == 3) && isset(POSIXJOBS);
+ /* use special format for current job, except in `jobs' */
+ int thisfmt = job == thisjob && synch != 2;
+ Process qn;
+
+ if (!synch)
+ zleentry(ZLE_CMD_TRASH);
+ if (doputnl && !synch) {
+ doneprint = 1;
+ putc('\n', fout);
+ }
+ for (pn = jn->procs; pn;) {
+ len2 = (thisfmt ? 5 : 10) + len; /* 2 spaces */
+ if (lng & 3)
+ qn = pn->next;
+ else
+ for (qn = pn->next; qn; qn = qn->next) {
+ if (qn->status != pn->status)
+ break;
+ if ((int)strlen(qn->text) + len2 + ((qn->next) ? 3 : 0)
+ > lineleng)
+ break;
+ len2 += strlen(qn->text) + 2;
+ }
+ doneprint = 1;
+ if (!plainfmt) {
+ if (!thisfmt || lng) {
+ if (fline)
+ fprintf(fout, "[%ld] %c ",
+ (long)job,
+ (job == curjob) ? '+'
+ : (job == prevjob) ? '-' : ' ');
+ else
+ fprintf(fout, (job > 9) ? " " : " ");
+ } else
+ fprintf(fout, "zsh: ");
+ if (lng & 1)
+ fprintf(fout, "%ld ", (long) pn->pid);
+ else if (lng & 2) {
+ pid_t x = jn->gleader;
+
+ fprintf(fout, "%ld ", (long) x);
+ do
+ skip++;
+ while ((x /= 10));
+ skip++;
+ lng &= ~3;
+ } else
+ fprintf(fout, "%*s", skip, "");
+ if (pn->status == SP_RUNNING) {
+ if (!conted)
+ fprintf(fout, "running%*s", len - 7 + 2, "");
+ else
+ fprintf(fout, "continued%*s", len - 9 + 2, "");
+ }
+ else if (WIFEXITED(pn->status)) {
+ if (WEXITSTATUS(pn->status))
+ fprintf(fout, "exit %-4d%*s", WEXITSTATUS(pn->status),
+ len - 9 + 2, "");
+ else
+ fprintf(fout, "done%*s", len - 4 + 2, "");
+ } else if (WIFSTOPPED(pn->status))
+ fprintf(fout, "%-*s", len + 2,
+ sigmsg(WSTOPSIG(pn->status)));
+ else if (WCOREDUMP(pn->status))
+ fprintf(fout, "%s (core dumped)%*s",
+ sigmsg(WTERMSIG(pn->status)),
+ (int)(len - 14 + 2 -
+ strlen(sigmsg(WTERMSIG(pn->status)))), "");
+ else
+ fprintf(fout, "%-*s", len + 2,
+ sigmsg(WTERMSIG(pn->status)));
+ }
+ for (; pn != qn; pn = pn->next) {
+ char *txt = dupstring(pn->text);
+ int txtlen;
+ unmetafy(txt, &txtlen);
+ fwrite(txt, sizeof(char), txtlen, fout);
+ if (pn->next)
+ fputs(" | ", fout);
+ }
+ putc('\n', fout);
+ fline = 0;
+ }
+ fflush(fout);
+ } else if (doputnl && interact && !synch) {
+ doneprint = 1;
+ putc('\n', fout);
+ fflush(fout);
+ }
+
+ /* print "(pwd now: foo)" messages: with (lng & 4) we are printing
+ * the directory where the job is running, otherwise the current directory
+ */
+
+ if ((lng & 4) || (interact && job == thisjob &&
+ jn->pwd && strcmp(jn->pwd, pwd))) {
+ doneprint = 1;
+ fprintf(fout, "(pwd %s: ", (lng & 4) ? "" : "now");
+ fprintdir(((lng & 4) && jn->pwd) ? jn->pwd : pwd, fout);
+ fprintf(fout, ")\n");
+ fflush(fout);
+ }
+
+ /* delete job if done */
+
+ if (jn->stat & STAT_DONE) {
+ /* This looks silly, but see update_job() */
+ if (synch <= 1)
+ storepipestats(jn, job == thisjob, job == thisjob);
+ if (should_report_time(jn))
+ dumptime(jn);
+ deletejob(jn, 0);
+ if (job == curjob) {
+ curjob = prevjob;
+ prevjob = job;
+ }
+ if (job == prevjob)
+ setprevjob();
+ } else
+ jn->stat &= ~STAT_CHANGED;
+
+ return doneprint;
+}
+
+/* Add a file to be deleted or fd to be closed to the current job */
+
+/**/
+void
+addfilelist(const char *name, int fd)
+{
+ Jobfile jf = (Jobfile)zalloc(sizeof(struct jobfile));
+ LinkList ll = jobtab[thisjob].filelist;
+
+ if (!ll)
+ ll = jobtab[thisjob].filelist = znewlinklist();
+ if (name)
+ {
+ jf->u.name = ztrdup(name);
+ jf->is_fd = 0;
+ }
+ else
+ {
+ jf->u.fd = fd;
+ jf->is_fd = 1;
+ }
+ zaddlinknode(ll, jf);
+}
+
+/* Clean up pipes no longer needed associated with a job */
+
+/**/
+void
+pipecleanfilelist(LinkList filelist, int proc_subst_only)
+{
+ LinkNode node;
+
+ if (!filelist)
+ return;
+ node = firstnode(filelist);
+ while (node) {
+ Jobfile jf = (Jobfile)getdata(node);
+ if (jf->is_fd &&
+ (!proc_subst_only || fdtable[jf->u.fd] == FDT_PROC_SUBST)) {
+ LinkNode next = nextnode(node);
+ zclose(jf->u.fd);
+ (void)remnode(filelist, node);
+ zfree(jf, sizeof(*jf));
+ node = next;
+ } else
+ incnode(node);
+ }
+}
+
+/* Finished with list of files for a job */
+
+/**/
+void
+deletefilelist(LinkList file_list, int disowning)
+{
+ Jobfile jf;
+ if (file_list) {
+ while ((jf = (Jobfile)getlinknode(file_list))) {
+ if (jf->is_fd) {
+ if (!disowning)
+ zclose(jf->u.fd);
+ } else {
+ if (!disowning)
+ unlink(jf->u.name);
+ zsfree(jf->u.name);
+ }
+ zfree(jf, sizeof(*jf));
+ }
+ zfree(file_list, sizeof(struct linklist));
+ }
+}
+
+/**/
+void
+freejob(Job jn, int deleting)
+{
+ struct process *pn, *nx;
+
+ pn = jn->procs;
+ jn->procs = NULL;
+ for (; pn; pn = nx) {
+ nx = pn->next;
+ zfree(pn, sizeof(struct process));
+ }
+
+ pn = jn->auxprocs;
+ jn->auxprocs = NULL;
+ for (; pn; pn = nx) {
+ nx = pn->next;
+ zfree(pn, sizeof(struct process));
+ }
+
+ if (jn->ty)
+ zfree(jn->ty, sizeof(struct ttyinfo));
+ if (jn->pwd)
+ zsfree(jn->pwd);
+ jn->pwd = NULL;
+ if (jn->stat & STAT_WASSUPER) {
+ /* careful in case we shrink and move the job table */
+ int job = jn - jobtab;
+ if (deleting)
+ deletejob(jobtab + jn->other, 0);
+ else
+ freejob(jobtab + jn->other, 0);
+ jn = jobtab + job;
+ }
+ jn->gleader = jn->other = 0;
+ jn->stat = jn->stty_in_env = 0;
+ jn->filelist = NULL;
+ jn->ty = NULL;
+
+ /* Find the new highest job number. */
+ if (maxjob == jn - jobtab) {
+ while (maxjob && !(jobtab[maxjob].stat & STAT_INUSE))
+ maxjob--;
+ }
+}
+
+/*
+ * We are actually finished with this job, rather
+ * than freeing it to make space.
+ *
+ * If "disowning" is set, files associated with the job are not
+ * actually deleted --- and won't be as there is nothing left
+ * to clear up.
+ */
+
+/**/
+void
+deletejob(Job jn, int disowning)
+{
+ deletefilelist(jn->filelist, disowning);
+ if (jn->stat & STAT_ATTACH) {
+ attachtty(mypgrp);
+ adjustwinsize(0);
+ }
+ if (jn->stat & STAT_SUPERJOB) {
+ Job jno = jobtab + jn->other;
+ if (jno->stat & STAT_SUBJOB)
+ jno->stat |= STAT_SUBJOB_ORPHANED;
+ }
+
+ freejob(jn, 1);
+}
+
+/*
+ * Add a process to the current job.
+ * The third argument is 1 if we are adding a process which is not
+ * part of the main pipeline but an auxiliary process used for
+ * handling MULTIOS or process substitution. We will wait for it
+ * but not display job information about it.
+ */
+
+/**/
+void
+addproc(pid_t pid, char *text, int aux, struct timeval *bgtime)
+{
+ Process pn, *pnlist;
+
+ DPUTS(thisjob == -1, "No valid job in addproc.");
+ pn = (Process) zshcalloc(sizeof *pn);
+ pn->pid = pid;
+ if (text)
+ strcpy(pn->text, text);
+ else
+ *pn->text = '\0';
+ pn->status = SP_RUNNING;
+ pn->next = NULL;
+
+ if (!aux)
+ {
+ pn->bgtime = *bgtime;
+ /* if this is the first process we are adding to *
+ * the job, then it's the group leader. */
+ if (!jobtab[thisjob].gleader)
+ jobtab[thisjob].gleader = pid;
+ /* attach this process to end of process list of current job */
+ pnlist = &jobtab[thisjob].procs;
+ }
+ else
+ pnlist = &jobtab[thisjob].auxprocs;
+
+ if (*pnlist) {
+ Process n;
+
+ for (n = *pnlist; n->next; n = n->next);
+ n->next = pn;
+ } else {
+ /* first process for this job */
+ *pnlist = pn;
+ }
+ /* If the first process in the job finished before any others were *
+ * added, maybe STAT_DONE got set incorrectly. This can happen if *
+ * a $(...) was waited for and the last existing job in the *
+ * pipeline was already finished. We need to be very careful that *
+ * there was no call to printjob() between then and now, else *
+ * the job will already have been deleted from the table. */
+ jobtab[thisjob].stat &= ~STAT_DONE;
+}
+
+/* Check if we have files to delete. We need to check this to see *
+ * if it's all right to exec a command without forking in the last *
+ * component of subshells or after the `-c' option. */
+
+/**/
+int
+havefiles(void)
+{
+ int i;
+
+ for (i = 1; i <= maxjob; i++)
+ if (jobtab[i].stat && jobtab[i].filelist)
+ return 1;
+ return 0;
+
+}
+
+/*
+ * Wait for a particular process.
+ * wait_cmd indicates this is from the interactive wait command,
+ * in which case the behaviour is a little different: the command
+ * itself can be interrupted by a trapped signal.
+ */
+
+/**/
+int
+waitforpid(pid_t pid, int wait_cmd)
+{
+ int first = 1, q = queue_signal_level();
+
+ /* child_block() around this loop in case #ifndef WNOHANG */
+ dont_queue_signals();
+ child_block(); /* unblocked in signal_suspend() */
+ queue_traps(wait_cmd);
+
+ /* This function should never be called with a pid that is not a
+ * child of the current shell. Consequently, if kill(0, pid)
+ * fails here with ESRCH, the child has already been reaped. In
+ * the loop body, we expect this to happen in signal_suspend()
+ * via zhandler(), after which this test terminates the loop.
+ */
+ while (!errflag && (kill(pid, 0) >= 0 || errno != ESRCH)) {
+ if (first)
+ first = 0;
+ else if (!wait_cmd)
+ kill(pid, SIGCONT);
+
+ last_signal = -1;
+ signal_suspend(SIGCHLD, wait_cmd);
+ if (last_signal != SIGCHLD && wait_cmd && last_signal >= 0 &&
+ (sigtrapped[last_signal] & ZSIG_TRAPPED)) {
+ /* wait command interrupted, but no error: return */
+ restore_queue_signals(q);
+ return 128 + last_signal;
+ }
+ child_block();
+ }
+ unqueue_traps();
+ child_unblock();
+ restore_queue_signals(q);
+
+ return 0;
+}
+
+/*
+ * Wait for a job to finish.
+ * wait_cmd indicates this is from the wait builtin; see
+ * wait_cmd in waitforpid().
+ */
+
+/**/
+static int
+zwaitjob(int job, int wait_cmd)
+{
+ int q = queue_signal_level();
+ Job jn = jobtab + job;
+
+ child_block(); /* unblocked during signal_suspend() */
+ queue_traps(wait_cmd);
+ dont_queue_signals();
+ if (jn->procs || jn->auxprocs) { /* if any forks were done */
+ jn->stat |= STAT_LOCKED;
+ if (jn->stat & STAT_CHANGED)
+ printjob(jn, !!isset(LONGLISTJOBS), 1);
+ if (jn->filelist) {
+ /*
+ * The main shell is finished with any file descriptors used
+ * for process substitution associated with this job: close
+ * them to indicate to listeners there's no more input.
+ *
+ * Note we can't safely delete temporary files yet as these
+ * are directly visible to other processes. However,
+ * we can't deadlock on the fact that those still exist, so
+ * that's not a problem.
+ */
+ pipecleanfilelist(jn->filelist, 0);
+ }
+ while (!(errflag & ERRFLAG_ERROR) && jn->stat &&
+ !(jn->stat & STAT_DONE) &&
+ !(interact && (jn->stat & STAT_STOPPED))) {
+ signal_suspend(SIGCHLD, wait_cmd);
+ if (last_signal != SIGCHLD && wait_cmd && last_signal >= 0 &&
+ (sigtrapped[last_signal] & ZSIG_TRAPPED))
+ {
+ /* builtin wait interrupted by trapped signal */
+ restore_queue_signals(q);
+ return 128 + last_signal;
+ }
+ /* Commenting this out makes ^C-ing a job started by a function
+ stop the whole function again. But I guess it will stop
+ something else from working properly, we have to find out
+ what this might be. --oberon
+
+ When attempting to separate errors and interrupts, we
+ assumed because of the previous comment it would be OK
+ to remove ERRFLAG_ERROR and leave ERRFLAG_INT set, since
+ that's the one related to ^C. But that doesn't work.
+ There's something more here we don't understand. --pws
+
+ The change above to ignore ERRFLAG_INT in the loop test
+ solves a problem wherein child processes that ignore the
+ INT signal were never waited-for. Clearing the flag here
+ still seems the wrong thing, but perhaps ERRFLAG_INT
+ should be saved and restored around signal_suspend() to
+ prevent it being lost within a signal trap? --Bart
+
+ errflag = 0; */
+
+ if (subsh) {
+ killjb(jn, SIGCONT);
+ jn->stat &= ~STAT_STOPPED;
+ }
+ if (jn->stat & STAT_SUPERJOB)
+ if (handle_sub(jn - jobtab, 1))
+ break;
+ child_block();
+ }
+ } else {
+ deletejob(jn, 0);
+ pipestats[0] = lastval;
+ numpipestats = 1;
+ }
+ restore_queue_signals(q);
+ unqueue_traps();
+ child_unblock();
+
+ return 0;
+}
+
+/* wait for running job to finish */
+
+/**/
+void
+waitjobs(void)
+{
+ Job jn = jobtab + thisjob;
+ DPUTS(thisjob == -1, "No valid job in waitjobs.");
+
+ if (jn->procs || jn->auxprocs)
+ zwaitjob(thisjob, 0);
+ else {
+ deletejob(jn, 0);
+ pipestats[0] = lastval;
+ numpipestats = 1;
+ }
+ thisjob = -1;
+}
+
+/* clear job table when entering subshells */
+
+/**/
+mod_export void
+clearjobtab(int monitor)
+{
+ int i;
+
+ if (isset(POSIXJOBS))
+ oldmaxjob = 0;
+ for (i = 1; i <= maxjob; i++) {
+ /*
+ * See if there is a jobtable worth saving.
+ * We never free the saved version; it only happens
+ * once for each subshell of a shell with job control,
+ * so doesn't create a leak.
+ */
+ if (monitor && !isset(POSIXJOBS) && jobtab[i].stat)
+ oldmaxjob = i+1;
+ else if (jobtab[i].stat & STAT_INUSE)
+ freejob(jobtab + i, 0);
+ }
+
+ if (monitor && oldmaxjob) {
+ int sz = oldmaxjob * sizeof(struct job);
+ if (oldjobtab)
+ free(oldjobtab);
+ oldjobtab = (struct job *)zalloc(sz);
+ memcpy(oldjobtab, jobtab, sz);
+
+ /* Don't report any job we're part of */
+ if (thisjob != -1 && thisjob < oldmaxjob)
+ memset(oldjobtab+thisjob, 0, sizeof(struct job));
+ }
+
+ memset(jobtab, 0, jobtabsize * sizeof(struct job)); /* zero out table */
+ maxjob = 0;
+
+ /*
+ * Although we don't have job control in subshells, we
+ * sometimes needs control structures for other purposes such
+ * as multios. Grab a job for this purpose; any will do
+ * since we've freed them all up (so there's no question
+ * of problems with the job table size here).
+ */
+ thisjob = initjob();
+}
+
+static int initnewjob(int i)
+{
+ jobtab[i].stat = STAT_INUSE;
+ if (jobtab[i].pwd) {
+ zsfree(jobtab[i].pwd);
+ jobtab[i].pwd = NULL;
+ }
+ jobtab[i].gleader = 0;
+
+ if (i > maxjob)
+ maxjob = i;
+
+ return i;
+}
+
+/* Get a free entry in the job table and initialize it. */
+
+/**/
+int
+initjob(void)
+{
+ int i;
+
+ for (i = 1; i <= maxjob; i++)
+ if (!jobtab[i].stat)
+ return initnewjob(i);
+ if (maxjob + 1 < jobtabsize)
+ return initnewjob(maxjob+1);
+
+ if (expandjobtab())
+ return initnewjob(i);
+
+ zerr("job table full or recursion limit exceeded");
+ return -1;
+}
+
+/**/
+void
+setjobpwd(void)
+{
+ int i;
+
+ for (i = 1; i <= maxjob; i++)
+ if (jobtab[i].stat && !jobtab[i].pwd)
+ jobtab[i].pwd = ztrdup(pwd);
+}
+
+/* print pids for & */
+
+/**/
+void
+spawnjob(void)
+{
+ Process pn;
+
+ DPUTS(thisjob == -1, "No valid job in spawnjob.");
+ /* if we are not in a subshell */
+ if (!subsh) {
+ if (curjob == -1 || !(jobtab[curjob].stat & STAT_STOPPED)) {
+ curjob = thisjob;
+ setprevjob();
+ } else if (prevjob == -1 || !(jobtab[prevjob].stat & STAT_STOPPED))
+ prevjob = thisjob;
+ if (jobbing && jobtab[thisjob].procs) {
+ FILE *fout = shout ? shout : stdout;
+ fprintf(fout, "[%d]", thisjob);
+ for (pn = jobtab[thisjob].procs; pn; pn = pn->next)
+ fprintf(fout, " %ld", (long) pn->pid);
+ fprintf(fout, "\n");
+ fflush(fout);
+ }
+ }
+ if (!hasprocs(thisjob))
+ deletejob(jobtab + thisjob, 0);
+ else {
+ jobtab[thisjob].stat |= STAT_LOCKED;
+ pipecleanfilelist(jobtab[thisjob].filelist, 0);
+ }
+ thisjob = -1;
+}
+
+/**/
+void
+shelltime(void)
+{
+ struct timezone dummy_tz;
+ struct timeval dtimeval, now;
+ child_times_t ti;
+#ifndef HAVE_GETRUSAGE
+ struct tms buf;
+#endif
+
+ gettimeofday(&now, &dummy_tz);
+
+#ifdef HAVE_GETRUSAGE
+ getrusage(RUSAGE_SELF, &ti);
+#else
+ times(&buf);
+
+ ti.ut = buf.tms_utime;
+ ti.st = buf.tms_stime;
+#endif
+ printtime(dtime(&dtimeval, &shtimer, &now), &ti, "shell");
+
+#ifdef HAVE_GETRUSAGE
+ getrusage(RUSAGE_CHILDREN, &ti);
+#else
+ ti.ut = buf.tms_cutime;
+ ti.st = buf.tms_cstime;
+#endif
+ printtime(&dtimeval, &ti, "children");
+
+}
+
+/* see if jobs need printing */
+
+/**/
+void
+scanjobs(void)
+{
+ int i;
+
+ for (i = 1; i <= maxjob; i++)
+ if (jobtab[i].stat & STAT_CHANGED)
+ printjob(jobtab + i, !!isset(LONGLISTJOBS), 1);
+}
+
+/**** job control builtins ****/
+
+/* This simple function indicates whether or not s may represent *
+ * a number. It returns true iff s consists purely of digits and *
+ * minuses. Note that minus may appear more than once, and the empty *
+ * string will produce a `true' response. */
+
+/**/
+static int
+isanum(char *s)
+{
+ while (*s == '-' || idigit(*s))
+ s++;
+ return *s == '\0';
+}
+
+/* Make sure we have a suitable current and previous job set. */
+
+/**/
+static void
+setcurjob(void)
+{
+ if (curjob == thisjob ||
+ (curjob != -1 && !(jobtab[curjob].stat & STAT_INUSE))) {
+ curjob = prevjob;
+ setprevjob();
+ if (curjob == thisjob ||
+ (curjob != -1 && !((jobtab[curjob].stat & STAT_INUSE) &&
+ curjob != thisjob))) {
+ curjob = prevjob;
+ setprevjob();
+ }
+ }
+}
+
+/* Convert a job specifier ("%%", "%1", "%foo", "%?bar?", etc.) *
+ * to a job number. */
+
+/**/
+mod_export int
+getjob(const char *s, const char *prog)
+{
+ int jobnum, returnval, mymaxjob;
+ Job myjobtab;
+
+ if (oldjobtab) {
+ myjobtab = oldjobtab;
+ mymaxjob = oldmaxjob;
+ } else {
+ myjobtab= jobtab;
+ mymaxjob = maxjob;
+ }
+
+ /* if there is no %, treat as a name */
+ if (*s != '%')
+ goto jump;
+ s++;
+ /* "%%", "%+" and "%" all represent the current job */
+ if (*s == '%' || *s == '+' || !*s) {
+ if (curjob == -1) {
+ if (prog)
+ zwarnnam(prog, "no current job");
+ returnval = -1;
+ goto done;
+ }
+ returnval = curjob;
+ goto done;
+ }
+ /* "%-" represents the previous job */
+ if (*s == '-') {
+ if (prevjob == -1) {
+ if (prog)
+ zwarnnam(prog, "no previous job");
+ returnval = -1;
+ goto done;
+ }
+ returnval = prevjob;
+ goto done;
+ }
+ /* a digit here means we have a job number */
+ if (idigit(*s)) {
+ jobnum = atoi(s);
+ if (jobnum && jobnum <= mymaxjob && myjobtab[jobnum].stat &&
+ !(myjobtab[jobnum].stat & STAT_SUBJOB) &&
+ /*
+ * If running jobs in a subshell, we are allowed to
+ * refer to the "current" job (it's not really the
+ * current job in the subshell). It's possible we
+ * should reset thisjob to -1 on entering the subshell.
+ */
+ (myjobtab == oldjobtab || jobnum != thisjob)) {
+ returnval = jobnum;
+ goto done;
+ }
+ if (prog)
+ zwarnnam(prog, "%%%s: no such job", s);
+ returnval = -1;
+ goto done;
+ }
+ /* "%?" introduces a search string */
+ if (*s == '?') {
+ struct process *pn;
+
+ for (jobnum = mymaxjob; jobnum >= 0; jobnum--)
+ if (myjobtab[jobnum].stat &&
+ !(myjobtab[jobnum].stat & STAT_SUBJOB) &&
+ jobnum != thisjob)
+ for (pn = myjobtab[jobnum].procs; pn; pn = pn->next)
+ if (strstr(pn->text, s + 1)) {
+ returnval = jobnum;
+ goto done;
+ }
+ if (prog)
+ zwarnnam(prog, "job not found: %s", s);
+ returnval = -1;
+ goto done;
+ }
+ jump:
+ /* anything else is a job name, specified as a string that begins the
+ job's command */
+ if ((jobnum = findjobnam(s)) != -1) {
+ returnval = jobnum;
+ goto done;
+ }
+ /* if we get here, it is because none of the above succeeded and went
+ to done */
+ zwarnnam(prog, "job not found: %s", s);
+ returnval = -1;
+ done:
+ return returnval;
+}
+
+#ifndef HAVE_SETPROCTITLE
+/* For jobs -Z (which modifies the shell's name as seen in ps listings). *
+ * hackzero is the start of the safely writable space, and hackspace is *
+ * its length, excluding a final NUL terminator that will always be left. */
+
+static char *hackzero;
+static int hackspace;
+#endif
+
+
+/* Initialise job handling. */
+
+/**/
+void
+init_jobs(char **argv, char **envp)
+{
+#ifndef HAVE_SETPROCTITLE
+ char *p, *q;
+#endif
+ size_t init_bytes = MAXJOBS_ALLOC*sizeof(struct job);
+
+ /*
+ * Initialise the job table. If this fails, we're in trouble.
+ */
+ jobtab = (struct job *)zalloc(init_bytes);
+ if (!jobtab) {
+ zerr("failed to allocate job table, aborting.");
+ exit(1);
+ }
+ jobtabsize = MAXJOBS_ALLOC;
+ memset(jobtab, 0, init_bytes);
+
+#ifndef HAVE_SETPROCTITLE
+ /*
+ * Initialise the jobs -Z system. The technique is borrowed from
+ * perl: check through the argument and environment space, to see
+ * how many of the strings are in contiguous space. This determines
+ * the value of hackspace.
+ */
+ hackzero = *argv;
+ p = strchr(hackzero, 0);
+ while(*++argv) {
+ q = *argv;
+ if(q != p+1)
+ goto done;
+ p = strchr(q, 0);
+ }
+#if !defined(HAVE_PUTENV) && !defined(USE_SET_UNSET_ENV)
+ for(; *envp; envp++) {
+ q = *envp;
+ if(q != p+1)
+ goto done;
+ p = strchr(q, 0);
+ }
+#endif
+ done:
+ hackspace = p - hackzero;
+#endif
+}
+
+
+/*
+ * We have run out of space in the job table.
+ * Expand it by an additional MAXJOBS_ALLOC slots.
+ */
+
+/*
+ * An arbitrary limit on the absolute maximum size of the job table.
+ * This prevents us taking over the entire universe.
+ * Ought to be a multiple of MAXJOBS_ALLOC, but doesn't need to be.
+ */
+#define MAX_MAXJOBS 1000
+
+/**/
+int
+expandjobtab(void)
+{
+ int newsize = jobtabsize + MAXJOBS_ALLOC;
+ struct job *newjobtab;
+
+ if (newsize > MAX_MAXJOBS)
+ return 0;
+
+ newjobtab = (struct job *)zrealloc(jobtab, newsize * sizeof(struct job));
+ if (!newjobtab)
+ return 0;
+
+ /*
+ * Clear the new section of the table; this is necessary for
+ * the jobs to appear unused.
+ */
+ memset(newjobtab + jobtabsize, 0, MAXJOBS_ALLOC * sizeof(struct job));
+
+ jobtab = newjobtab;
+ jobtabsize = newsize;
+
+ return 1;
+}
+
+
+/*
+ * See if we can reduce the job table. We can if we go over
+ * a MAXJOBS_ALLOC boundary. However, we leave a boundary,
+ * currently 20 jobs, so that we have a place for immediate
+ * expansion and don't play ping pong with the job table size.
+ */
+
+/**/
+void
+maybeshrinkjobtab(void)
+{
+ int jobbound;
+
+ queue_signals();
+ jobbound = maxjob + MAXJOBS_ALLOC - (maxjob % MAXJOBS_ALLOC);
+ if (jobbound < jobtabsize && jobbound > maxjob + 20) {
+ struct job *newjobtab;
+
+ /* Hope this can't fail, but anyway... */
+ newjobtab = (struct job *)zrealloc(jobtab,
+ jobbound*sizeof(struct job));
+
+ if (newjobtab) {
+ jobtab = newjobtab;
+ jobtabsize = jobbound;
+ }
+ }
+ unqueue_signals();
+}
+
+/*
+ * Definitions for the background process stuff recorded below.
+ * This would be more efficient as a hash, but
+ * - that's quite heavyweight for something not needed very often
+ * - we need some kind of ordering as POSIX allows us to limit
+ * the size of the list to the value of _SC_CHILD_MAX and clearly
+ * we want to clear the oldest first
+ * - cases with a long list of background jobs where the user doesn't
+ * wait for a large number, and then does wait for one (the only
+ * inefficient case) are rare
+ * - in the context of waiting for an external process, looping
+ * over a list isn't so very inefficient.
+ * Enough excuses already.
+ */
+
+/* Data in the link list, a key (process ID) / value (exit status) pair. */
+struct bgstatus {
+ pid_t pid;
+ int status;
+};
+typedef struct bgstatus *Bgstatus;
+/* The list of those entries */
+static LinkList bgstatus_list;
+/* Count of entries. Reaches value of _SC_CHILD_MAX and stops. */
+static long bgstatus_count;
+
+/*
+ * Remove and free a bgstatus entry.
+ */
+static void rembgstatus(LinkNode node)
+{
+ zfree(remnode(bgstatus_list, node), sizeof(struct bgstatus));
+ bgstatus_count--;
+}
+
+/*
+ * Record the status of a background process that exited so we
+ * can execute the builtin wait for it.
+ *
+ * We can't execute the wait builtin for something that exited in the
+ * foreground as it's not visible to the user, so don't bother recording.
+ */
+
+/**/
+void
+addbgstatus(pid_t pid, int status)
+{
+ static long child_max;
+ Bgstatus bgstatus_entry;
+
+ if (!child_max) {
+#ifdef _SC_CHILD_MAX
+ child_max = sysconf(_SC_CHILD_MAX);
+ if (!child_max) /* paranoia */
+#endif
+ {
+ /* Be inventive */
+ child_max = 1024L;
+ }
+ }
+
+ if (!bgstatus_list) {
+ bgstatus_list = znewlinklist();
+ /*
+ * We're not always robust about memory failures, but
+ * this is pretty deep in the shell basics to be failing owing
+ * to memory, and a failure to wait is reported loudly, so test
+ * and fail silently here.
+ */
+ if (!bgstatus_list)
+ return;
+ }
+ if (bgstatus_count == child_max) {
+ /* Overflow. List is in order, remove first */
+ rembgstatus(firstnode(bgstatus_list));
+ }
+ bgstatus_entry = (Bgstatus)zalloc(sizeof(*bgstatus_entry));
+ if (!bgstatus_entry) {
+ /* See note above */
+ return;
+ }
+ bgstatus_entry->pid = pid;
+ bgstatus_entry->status = status;
+ if (!zaddlinknode(bgstatus_list, bgstatus_entry)) {
+ zfree(bgstatus_entry, sizeof(*bgstatus_entry));
+ return;
+ }
+ bgstatus_count++;
+}
+
+/*
+ * See if pid has a recorded exit status.
+ * Note we make no guarantee that the PIDs haven't wrapped, so this
+ * may not be the right process.
+ *
+ * This is only used by wait, which must only work on each
+ * pid once, so we need to remove the entry if we find it.
+ */
+
+static int getbgstatus(pid_t pid)
+{
+ LinkNode node;
+ Bgstatus bgstatus_entry;
+
+ if (!bgstatus_list)
+ return -1;
+ for (node = firstnode(bgstatus_list); node; incnode(node)) {
+ bgstatus_entry = (Bgstatus)getdata(node);
+ if (bgstatus_entry->pid == pid) {
+ int status = bgstatus_entry->status;
+ rembgstatus(node);
+ return status;
+ }
+ }
+ return -1;
+}
+
+/* bg, disown, fg, jobs, wait: most of the job control commands are *
+ * here. They all take the same type of argument. Exception: wait can *
+ * take a pid or a job specifier, whereas the others only work on jobs. */
+
+/**/
+int
+bin_fg(char *name, char **argv, Options ops, int func)
+{
+ int job, lng, firstjob = -1, retval = 0, ofunc = func;
+
+ if (OPT_ISSET(ops,'Z')) {
+ int len;
+
+ if(isset(RESTRICTED)) {
+ zwarnnam(name, "-Z is restricted");
+ return 1;
+ }
+ if(!argv[0] || argv[1]) {
+ zwarnnam(name, "-Z requires one argument");
+ return 1;
+ }
+ queue_signals();
+ unmetafy(*argv, &len);
+#ifdef HAVE_SETPROCTITLE
+ setproctitle("%s", *argv);
+#else
+ if(len > hackspace)
+ len = hackspace;
+ memcpy(hackzero, *argv, len);
+ memset(hackzero + len, 0, hackspace - len);
+#endif
+ unqueue_signals();
+ return 0;
+ }
+
+ if (func == BIN_JOBS) {
+ lng = (OPT_ISSET(ops,'l')) ? 1 : (OPT_ISSET(ops,'p')) ? 2 : 0;
+ if (OPT_ISSET(ops,'d'))
+ lng |= 4;
+ } else {
+ lng = !!isset(LONGLISTJOBS);
+ }
+
+ if ((func == BIN_FG || func == BIN_BG) && !jobbing) {
+ /* oops... maybe bg and fg should have been disabled? */
+ zwarnnam(name, "no job control in this shell.");
+ return 1;
+ }
+
+ queue_signals();
+ /*
+ * In case any processes changed state recently, wait for them.
+ * This updates stopped processes (but we should have been
+ * signalled about those, up to inevitable races), and also
+ * continued processes if that feature is available.
+ */
+ wait_for_processes();
+
+ /* If necessary, update job table. */
+ if (unset(NOTIFY))
+ scanjobs();
+
+ if (func != BIN_JOBS || isset(MONITOR) || !oldmaxjob)
+ setcurjob();
+
+ if (func == BIN_JOBS)
+ /* If you immediately type "exit" after "jobs", this *
+ * will prevent zexit from complaining about stopped jobs */
+ stopmsg = 2;
+ if (!*argv) {
+ /* This block handles all of the default cases (no arguments). bg,
+ fg and disown act on the current job, and jobs and wait act on all the
+ jobs. */
+ if (func == BIN_FG || func == BIN_BG || func == BIN_DISOWN) {
+ /* W.r.t. the above comment, we'd better have a current job at this
+ point or else. */
+ if (curjob == -1 || (jobtab[curjob].stat & STAT_NOPRINT)) {
+ zwarnnam(name, "no current job");
+ unqueue_signals();
+ return 1;
+ }
+ firstjob = curjob;
+ } else if (func == BIN_JOBS) {
+ /* List jobs. */
+ struct job *jobptr;
+ int curmaxjob, ignorejob;
+ if (unset(MONITOR) && oldmaxjob) {
+ jobptr = oldjobtab;
+ curmaxjob = oldmaxjob ? oldmaxjob - 1 : 0;
+ ignorejob = 0;
+ } else {
+ jobptr = jobtab;
+ curmaxjob = maxjob;
+ ignorejob = thisjob;
+ }
+ for (job = 0; job <= curmaxjob; job++, jobptr++)
+ if (job != ignorejob && jobptr->stat) {
+ if ((!OPT_ISSET(ops,'r') && !OPT_ISSET(ops,'s')) ||
+ (OPT_ISSET(ops,'r') && OPT_ISSET(ops,'s')) ||
+ (OPT_ISSET(ops,'r') &&
+ !(jobptr->stat & STAT_STOPPED)) ||
+ (OPT_ISSET(ops,'s') && jobptr->stat & STAT_STOPPED))
+ printjob(jobptr, lng, 2);
+ }
+ unqueue_signals();
+ return 0;
+ } else { /* Must be BIN_WAIT, so wait for all jobs */
+ for (job = 0; job <= maxjob; job++)
+ if (job != thisjob && jobtab[job].stat &&
+ !(jobtab[job].stat & STAT_NOPRINT))
+ retval = zwaitjob(job, 1);
+ unqueue_signals();
+ return retval;
+ }
+ }
+
+ /* Defaults have been handled. We now have an argument or two, or three...
+ In the default case for bg, fg and disown, the argument will be provided by
+ the above routine. We now loop over the arguments. */
+ for (; (firstjob != -1) || *argv; (void)(*argv && argv++)) {
+ int stopped, ocj = thisjob, jstat;
+
+ func = ofunc;
+
+ if (func == BIN_WAIT && isanum(*argv)) {
+ /* wait can take a pid; the others can't. */
+ pid_t pid = (long)atoi(*argv);
+ Job j;
+ Process p;
+
+ if (findproc(pid, &j, &p, 0)) {
+ if (j->stat & STAT_STOPPED) {
+ retval = (killjb(j, SIGCONT) != 0);
+ if (retval == 0)
+ makerunning(j);
+ }
+ if (retval == 0) {
+ /*
+ * returns 0 for normal exit, else signal+128
+ * in which case we should return that status.
+ */
+ retval = waitforpid(pid, 1);
+ }
+ if (retval == 0) {
+ if ((retval = getbgstatus(pid)) < 0) {
+ retval = lastval2;
+ }
+ }
+ } else if ((retval = getbgstatus(pid)) < 0) {
+ zwarnnam(name, "pid %d is not a child of this shell", pid);
+ /* presumably lastval2 doesn't tell us a heck of a lot? */
+ retval = 1;
+ }
+ thisjob = ocj;
+ continue;
+ }
+ if (func != BIN_JOBS && oldjobtab != NULL) {
+ zwarnnam(name, "can't manipulate jobs in subshell");
+ unqueue_signals();
+ return 1;
+ }
+ /* The only type of argument allowed now is a job spec. Check it. */
+ job = (*argv) ? getjob(*argv, name) : firstjob;
+ firstjob = -1;
+ if (job == -1) {
+ retval = 1;
+ break;
+ }
+ jstat = oldjobtab ? oldjobtab[job].stat : jobtab[job].stat;
+ if (!(jstat & STAT_INUSE) ||
+ (jstat & STAT_NOPRINT)) {
+ zwarnnam(name, "%s: no such job", *argv);
+ unqueue_signals();
+ return 1;
+ }
+ /* If AUTO_CONTINUE is set (automatically make stopped jobs running
+ * on disown), we actually do a bg and then delete the job table entry. */
+
+ if (isset(AUTOCONTINUE) && func == BIN_DISOWN &&
+ jstat & STAT_STOPPED)
+ func = BIN_BG;
+
+ /* We have a job number. Now decide what to do with it. */
+ switch (func) {
+ case BIN_FG:
+ case BIN_BG:
+ case BIN_WAIT:
+ if (func == BIN_BG) {
+ jobtab[job].stat |= STAT_NOSTTY;
+ jobtab[job].stat &= ~STAT_CURSH;
+ }
+ if ((stopped = (jobtab[job].stat & STAT_STOPPED))) {
+ makerunning(jobtab + job);
+ if (func == BIN_BG) {
+ /* Set $! to indicate this was backgrounded */
+ Process pn = jobtab[job].procs;
+ for (;;) {
+ Process next = pn->next;
+ if (!next) {
+ lastpid = (zlong) pn->pid;
+ break;
+ }
+ pn = next;
+ }
+ }
+ } else if (func == BIN_BG) {
+ /* Silly to bg a job already running. */
+ zwarnnam(name, "job already in background");
+ thisjob = ocj;
+ unqueue_signals();
+ return 1;
+ }
+ /* It's time to shuffle the jobs around! Reset the current job,
+ and pick a sensible secondary job. */
+ if (curjob == job) {
+ curjob = prevjob;
+ prevjob = (func == BIN_BG) ? -1 : job;
+ }
+ if (prevjob == job || prevjob == -1)
+ setprevjob();
+ if (curjob == -1) {
+ curjob = prevjob;
+ setprevjob();
+ }
+ if (func != BIN_WAIT)
+ /* for bg and fg -- show the job we are operating on */
+ printjob(jobtab + job, (stopped) ? -1 : lng, 3);
+ if (func != BIN_BG) { /* fg or wait */
+ if (jobtab[job].pwd && strcmp(jobtab[job].pwd, pwd)) {
+ FILE *fout = (func == BIN_JOBS || !shout) ? stdout : shout;
+ fprintf(fout, "(pwd : ");
+ fprintdir(jobtab[job].pwd, fout);
+ fprintf(fout, ")\n");
+ fflush(fout);
+ }
+ if (func != BIN_WAIT) { /* fg */
+ thisjob = job;
+ if ((jobtab[job].stat & STAT_SUPERJOB) &&
+ ((!jobtab[job].procs->next ||
+ (jobtab[job].stat & STAT_SUBLEADER) ||
+ killpg(jobtab[job].gleader, 0) == -1)) &&
+ jobtab[jobtab[job].other].gleader)
+ attachtty(jobtab[jobtab[job].other].gleader);
+ else
+ attachtty(jobtab[job].gleader);
+ }
+ }
+ if (stopped) {
+ if (func != BIN_BG && jobtab[job].ty)
+ settyinfo(jobtab[job].ty);
+ killjb(jobtab + job, SIGCONT);
+ }
+ if (func == BIN_WAIT)
+ {
+ retval = zwaitjob(job, 1);
+ if (!retval)
+ retval = lastval2;
+ }
+ else if (func != BIN_BG) {
+ /*
+ * HERE: there used not to be an "else" above. How
+ * could it be right to wait for the foreground job
+ * when we've just been told to wait for another
+ * job (and done it)?
+ */
+ waitjobs();
+ retval = lastval2;
+ } else if (ofunc == BIN_DISOWN)
+ deletejob(jobtab + job, 1);
+ break;
+ case BIN_JOBS:
+ printjob(job + (oldjobtab ? oldjobtab : jobtab), lng, 2);
+ break;
+ case BIN_DISOWN:
+ if (jobtab[job].stat & STAT_SUPERJOB) {
+ jobtab[job].stat |= STAT_DISOWN;
+ continue;
+ }
+ if (jobtab[job].stat & STAT_STOPPED) {
+ char buf[20], *pids = "";
+
+ if (jobtab[job].stat & STAT_SUPERJOB) {
+ Process pn;
+
+ for (pn = jobtab[jobtab[job].other].procs; pn; pn = pn->next) {
+ sprintf(buf, " -%d", pn->pid);
+ pids = dyncat(pids, buf);
+ }
+ for (pn = jobtab[job].procs; pn->next; pn = pn->next) {
+ sprintf(buf, " %d", pn->pid);
+ pids = dyncat(pids, buf);
+ }
+ if (!jobtab[jobtab[job].other].procs && pn) {
+ sprintf(buf, " %d", pn->pid);
+ pids = dyncat(pids, buf);
+ }
+ } else {
+ sprintf(buf, " -%d", jobtab[job].gleader);
+ pids = buf;
+ }
+ zwarnnam(name,
+#ifdef USE_SUSPENDED
+ "warning: job is suspended, use `kill -CONT%s' to resume",
+#else
+ "warning: job is stopped, use `kill -CONT%s' to resume",
+#endif
+ pids);
+ }
+ deletejob(jobtab + job, 1);
+ break;
+ }
+ thisjob = ocj;
+ }
+ unqueue_signals();
+ return retval;
+}
+
+static const struct {
+ const char *name;
+ int num;
+} alt_sigs[] = {
+#if defined(SIGCHLD) && defined(SIGCLD)
+#if SIGCHLD == SIGCLD
+ { "CLD", SIGCLD },
+#endif
+#endif
+#if defined(SIGPOLL) && defined(SIGIO)
+#if SIGPOLL == SIGIO
+ { "IO", SIGIO },
+#endif
+#endif
+#if !defined(SIGERR)
+ /*
+ * If SIGERR is not defined by the operating system, use it
+ * as an alias for SIGZERR.
+ */
+ { "ERR", SIGZERR },
+#endif
+ { NULL, 0 }
+};
+
+/* kill: send a signal to a process. The process(es) may be specified *
+ * by job specifier (see above) or pid. A signal, defaulting to *
+ * SIGTERM, may be specified by name or number, preceded by a dash. */
+
+/**/
+int
+bin_kill(char *nam, char **argv, UNUSED(Options ops), UNUSED(int func))
+{
+ int sig = SIGTERM;
+ int returnval = 0;
+
+ /* check for, and interpret, a signal specifier */
+ if (*argv && **argv == '-') {
+ if (idigit((*argv)[1])) {
+ char *endp;
+ /* signal specified by number */
+ sig = zstrtol(*argv + 1, &endp, 10);
+ if (*endp) {
+ zwarnnam(nam, "invalid signal number: %s", *argv);
+ return 1;
+ }
+ } else if ((*argv)[1] != '-' || (*argv)[2]) {
+ char *signame;
+
+ /* with argument "-l" display the list of signal names */
+ if ((*argv)[1] == 'l' && (*argv)[2] == '\0') {
+ if (argv[1]) {
+ while (*++argv) {
+ sig = zstrtol(*argv, &signame, 10);
+ if (signame == *argv) {
+ if (!strncmp(signame, "SIG", 3))
+ signame += 3;
+ for (sig = 1; sig <= SIGCOUNT; sig++)
+ if (!strcasecmp(sigs[sig], signame))
+ break;
+ if (sig > SIGCOUNT) {
+ int i;
+
+ for (i = 0; alt_sigs[i].name; i++)
+ if (!strcasecmp(alt_sigs[i].name, signame))
+ {
+ sig = alt_sigs[i].num;
+ break;
+ }
+ }
+ if (sig > SIGCOUNT) {
+ zwarnnam(nam, "unknown signal: SIG%s",
+ signame);
+ returnval++;
+ } else
+ printf("%d\n", sig);
+ } else {
+ if (*signame) {
+ zwarnnam(nam, "unknown signal: SIG%s",
+ signame);
+ returnval++;
+ } else {
+ if (WIFSIGNALED(sig))
+ sig = WTERMSIG(sig);
+ else if (WIFSTOPPED(sig))
+ sig = WSTOPSIG(sig);
+ if (1 <= sig && sig <= SIGCOUNT)
+ printf("%s\n", sigs[sig]);
+ else
+ printf("%d\n", sig);
+ }
+ }
+ }
+ return returnval;
+ }
+ printf("%s", sigs[1]);
+ for (sig = 2; sig <= SIGCOUNT; sig++)
+ printf(" %s", sigs[sig]);
+ putchar('\n');
+ return 0;
+ }
+
+ if ((*argv)[1] == 'n' && (*argv)[2] == '\0') {
+ char *endp;
+
+ if (!*++argv) {
+ zwarnnam(nam, "-n: argument expected");
+ return 1;
+ }
+ sig = zstrtol(*argv, &endp, 10);
+ if (*endp) {
+ zwarnnam(nam, "invalid signal number: %s", *argv);
+ return 1;
+ }
+ } else {
+ if (!((*argv)[1] == 's' && (*argv)[2] == '\0'))
+ signame = *argv + 1;
+ else if (!(*++argv)) {
+ zwarnnam(nam, "-s: argument expected");
+ return 1;
+ } else
+ signame = *argv;
+ if (!*signame) {
+ zwarnnam(nam, "-: signal name expected");
+ return 1;
+ }
+ signame = casemodify(signame, CASMOD_UPPER);
+ if (!strncmp(signame, "SIG", 3))
+ signame+=3;
+
+ /* check for signal matching specified name */
+ for (sig = 1; sig <= SIGCOUNT; sig++)
+ if (!strcmp(*(sigs + sig), signame))
+ break;
+ if (*signame == '0' && !signame[1])
+ sig = 0;
+ if (sig > SIGCOUNT) {
+ int i;
+
+ for (i = 0; alt_sigs[i].name; i++)
+ if (!strcmp(alt_sigs[i].name, signame))
+ {
+ sig = alt_sigs[i].num;
+ break;
+ }
+ }
+ if (sig > SIGCOUNT) {
+ zwarnnam(nam, "unknown signal: SIG%s", signame);
+ zwarnnam(nam, "type kill -l for a list of signals");
+ return 1;
+ }
+ }
+ }
+ argv++;
+ }
+
+ /* Discard the standard "-" and "--" option breaks */
+ if (*argv && (*argv)[0] == '-' && (!(*argv)[1] || (*argv)[1] == '-'))
+ argv++;
+
+ if (!*argv) {
+ zwarnnam(nam, "not enough arguments");
+ return 1;
+ }
+
+ queue_signals();
+ setcurjob();
+
+ /* Remaining arguments specify processes. Loop over them, and send the
+ signal (number sig) to each process. */
+ for (; *argv; argv++) {
+ if (**argv == '%') {
+ /* job specifier introduced by '%' */
+ int p;
+
+ if ((p = getjob(*argv, nam)) == -1) {
+ returnval++;
+ continue;
+ }
+ if (killjb(jobtab + p, sig) == -1) {
+ zwarnnam("kill", "kill %s failed: %e", *argv, errno);
+ returnval++;
+ continue;
+ }
+ /* automatically update the job table if sending a SIGCONT to a
+ job, and send the job a SIGCONT if sending it a non-stopping
+ signal. */
+ if (jobtab[p].stat & STAT_STOPPED) {
+#ifndef WIFCONTINUED
+ /* With WIFCONTINUED we find this out properly */
+ if (sig == SIGCONT)
+ makerunning(jobtab + p);
+#endif
+ if (sig != SIGKILL && sig != SIGCONT && sig != SIGTSTP
+ && sig != SIGTTOU && sig != SIGTTIN && sig != SIGSTOP)
+ killjb(jobtab + p, SIGCONT);
+ }
+ } else if (!isanum(*argv)) {
+ zwarnnam("kill", "illegal pid: %s", *argv);
+ returnval++;
+ } else {
+ int pid = atoi(*argv);
+ if (kill(pid, sig) == -1) {
+ zwarnnam("kill", "kill %s failed: %e", *argv, errno);
+ returnval++;
+ }
+#ifndef WIFCONTINUED
+ else if (sig == SIGCONT) {
+ Job jn;
+ Process pn;
+ /* With WIFCONTINUED we find this out properly */
+ if (findproc(pid, &jn, &pn, 0)) {
+ if (WIFSTOPPED(pn->status))
+ pn->status = SP_RUNNING;
+ }
+ }
+#endif
+ }
+ }
+ unqueue_signals();
+
+ return returnval < 126 ? returnval : 1;
+}
+/* Get a signal number from a string */
+
+/**/
+mod_export int
+getsignum(const char *s)
+{
+ int x, i;
+
+ /* check for a signal specified by number */
+ x = atoi(s);
+ if (idigit(*s) && x >= 0 && x < VSIGCOUNT)
+ return x;
+
+ /* search for signal by name */
+ if (!strncmp(s, "SIG", 3))
+ s += 3;
+
+ for (i = 0; i < VSIGCOUNT; i++)
+ if (!strcmp(s, sigs[i]))
+ return i;
+
+ for (i = 0; alt_sigs[i].name; i++)
+ {
+ if (!strcmp(s, alt_sigs[i].name))
+ return alt_sigs[i].num;
+ }
+
+ /* no matching signal */
+ return -1;
+}
+
+/* Get the name for a signal. */
+
+/**/
+mod_export const char *
+getsigname(int sig)
+{
+ if (sigtrapped[sig] & ZSIG_ALIAS)
+ {
+ int i;
+ for (i = 0; alt_sigs[i].name; i++)
+ if (sig == alt_sigs[i].num)
+ return alt_sigs[i].name;
+ }
+ else
+ return sigs[sig];
+
+ /* shouldn't reach here */
+#ifdef DEBUG
+ dputs("Bad alias flag for signal");
+#endif
+ return "";
+}
+
+
+/* Get the function node for a trap, taking care about alternative names */
+/**/
+HashNode
+gettrapnode(int sig, int ignoredisable)
+{
+ char fname[20];
+ HashNode hn;
+ HashNode (*getptr)(HashTable ht, const char *name);
+ int i;
+ if (ignoredisable)
+ getptr = shfunctab->getnode2;
+ else
+ getptr = shfunctab->getnode;
+
+ sprintf(fname, "TRAP%s", sigs[sig]);
+ if ((hn = getptr(shfunctab, fname)))
+ return hn;
+
+ for (i = 0; alt_sigs[i].name; i++) {
+ if (alt_sigs[i].num == sig) {
+ sprintf(fname, "TRAP%s", alt_sigs[i].name);
+ if ((hn = getptr(shfunctab, fname)))
+ return hn;
+ }
+ }
+
+ return NULL;
+}
+
+/* Remove a TRAP function under any name for the signal */
+
+/**/
+void
+removetrapnode(int sig)
+{
+ HashNode hn = gettrapnode(sig, 1);
+ if (hn) {
+ shfunctab->removenode(shfunctab, hn->nam);
+ shfunctab->freenode(hn);
+ }
+}
+
+/* Suspend this shell */
+
+/**/
+int
+bin_suspend(char *name, UNUSED(char **argv), Options ops, UNUSED(int func))
+{
+ /* won't suspend a login shell, unless forced */
+ if (islogin && !OPT_ISSET(ops,'f')) {
+ zwarnnam(name, "can't suspend login shell");
+ return 1;
+ }
+ if (jobbing) {
+ /* stop ignoring signals */
+ signal_default(SIGTTIN);
+ signal_default(SIGTSTP);
+ signal_default(SIGTTOU);
+
+ /* Move ourselves back to the process group we came from */
+ release_pgrp();
+ }
+
+ /* suspend ourselves with a SIGTSTP */
+ killpg(origpgrp, SIGTSTP);
+
+ if (jobbing) {
+ acquire_pgrp();
+ /* restore signal handling */
+ signal_ignore(SIGTTOU);
+ signal_ignore(SIGTSTP);
+ signal_ignore(SIGTTIN);
+ }
+ return 0;
+}
+
+/* find a job named s */
+
+/**/
+int
+findjobnam(const char *s)
+{
+ int jobnum;
+
+ for (jobnum = maxjob; jobnum >= 0; jobnum--)
+ if (!(jobtab[jobnum].stat & (STAT_SUBJOB | STAT_NOPRINT)) &&
+ jobtab[jobnum].stat && jobtab[jobnum].procs && jobnum != thisjob &&
+ jobtab[jobnum].procs->text[0] && strpfx(s, jobtab[jobnum].procs->text))
+ return jobnum;
+ return -1;
+}
+
+
+/* make sure we are a process group leader by creating a new process
+ group if necessary */
+
+/**/
+void
+acquire_pgrp(void)
+{
+ long ttpgrp;
+ sigset_t blockset, oldset;
+
+ if ((mypgrp = GETPGRP()) >= 0) {
+ long lastpgrp = mypgrp;
+ sigemptyset(&blockset);
+ sigaddset(&blockset, SIGTTIN);
+ sigaddset(&blockset, SIGTTOU);
+ sigaddset(&blockset, SIGTSTP);
+ oldset = signal_block(blockset);
+ while ((ttpgrp = gettygrp()) != -1 && ttpgrp != mypgrp) {
+ mypgrp = GETPGRP();
+ if (mypgrp == mypid) {
+ if (!interact)
+ break; /* attachtty() will be a no-op, give up */
+ signal_setmask(oldset);
+ attachtty(mypgrp); /* Might generate SIGT* */
+ signal_block(blockset);
+ }
+ if (mypgrp == gettygrp())
+ break;
+ signal_setmask(oldset);
+ if (read(0, NULL, 0) != 0) {} /* Might generate SIGT* */
+ signal_block(blockset);
+ mypgrp = GETPGRP();
+ if (mypgrp == lastpgrp && !interact)
+ break; /* Unlikely that pgrp will ever change */
+ lastpgrp = mypgrp;
+ }
+ if (mypgrp != mypid) {
+ if (setpgrp(0, 0) == 0) {
+ mypgrp = mypid;
+ attachtty(mypgrp);
+ } else
+ opts[MONITOR] = 0;
+ }
+ signal_setmask(oldset);
+ } else
+ opts[MONITOR] = 0;
+}
+
+/* revert back to the process group we came from (before acquire_pgrp) */
+
+/**/
+void
+release_pgrp(void)
+{
+ if (origpgrp != mypgrp) {
+ /* in linux pid namespaces, origpgrp may never have been set */
+ if (origpgrp) {
+ attachtty(origpgrp);
+ setpgrp(0, origpgrp);
+ }
+ mypgrp = origpgrp;
+ }
+}
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/lex.c b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/lex.c
new file mode 100644
index 0000000..44ad880
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/lex.c
@@ -0,0 +1,2203 @@
+/*
+ * lex.c - lexical analysis
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+#include "zsh.mdh"
+#include "lex.pro"
+
+#define LEX_HEAP_SIZE (32)
+
+/* tokens */
+
+/**/
+mod_export char ztokens[] = "#$^*(())$=|{}[]`<>>?~`,-!'\"\\\\";
+
+/* parts of the current token */
+
+/**/
+char *zshlextext;
+/**/
+mod_export char *tokstr;
+/**/
+mod_export enum lextok tok;
+/**/
+mod_export int tokfd;
+
+/*
+ * Line number at which the first character of a token was found.
+ * We always set this in gettok(), which is always called from
+ * zshlex() unless we have reached an error. So it is always
+ * valid when parsing. It is not useful during execution
+ * of the parsed structure.
+ */
+
+/**/
+zlong toklineno;
+
+/* lexical analyzer error flag */
+
+/**/
+mod_export int lexstop;
+
+/* if != 0, this is the first line of the command */
+
+/**/
+mod_export int isfirstln;
+
+/* if != 0, this is the first char of the command (not including white space) */
+
+/**/
+int isfirstch;
+
+/* flag that an alias should be expanded after expansion ending in space */
+
+/**/
+int inalmore;
+
+/*
+ * Don't do spelling correction.
+ * Bit 1 is only valid for the current word. It's
+ * set when we detect a lookahead that stops the word from
+ * needing correction.
+ */
+
+/**/
+int nocorrect;
+
+/*
+ * TBD: the following exported variables are part of the non-interface
+ * with ZLE for completion. They are poorly named and the whole
+ * scheme is incredibly brittle. One piece of robustness is applied:
+ * the variables are only set if LEXFLAGS_ZLE is set. Improvements
+ * should therefore concentrate on areas with this flag set.
+ *
+ * Cursor position and line length in zle when the line is
+ * metafied for access from the main shell.
+ */
+
+/**/
+mod_export int zlemetacs, zlemetall;
+
+/* inwhat says what exactly we are in *
+ * (its value is one of the IN_* things). */
+
+/**/
+mod_export int inwhat;
+
+/* 1 if x added to complete in a blank between words */
+
+/**/
+mod_export int addedx;
+
+/* wb and we hold the beginning/end position of the word we are completing. */
+
+/**/
+mod_export int wb, we;
+
+/**/
+mod_export int wordbeg;
+
+/**/
+mod_export int parbegin;
+
+/**/
+mod_export int parend;
+
+
+/* 1 if aliases should not be expanded */
+
+/**/
+mod_export int noaliases;
+
+/*
+ * If non-zero, we are parsing a line sent to use by the editor, or some
+ * other string that's not part of standard command input (e.g. eval is
+ * part of normal command input).
+ *
+ * Set of bits from LEXFLAGS_*.
+ *
+ * Note that although it is passed into the lexer as an input, the
+ * lexer can set it to zero after finding the word it's searching for.
+ * This only happens if the line being parsed actually does come from
+ * ZLE, and hence the bit LEXFLAGS_ZLE is set.
+ */
+
+/**/
+mod_export int lexflags;
+
+/* don't recognize comments */
+
+/**/
+mod_export int nocomments;
+
+/* add raw input characters while parsing command substitution */
+
+/**/
+int lex_add_raw;
+
+/* variables associated with the above */
+
+static char *tokstr_raw;
+static struct lexbufstate lexbuf_raw;
+
+/* text of punctuation tokens */
+
+/**/
+mod_export char *tokstrings[WHILE + 1] = {
+ NULL, /* NULLTOK 0 */
+ ";", /* SEPER */
+ "\\n", /* NEWLIN */
+ ";", /* SEMI */
+ ";;", /* DSEMI */
+ "&", /* AMPER 5 */
+ "(", /* INPAR */
+ ")", /* OUTPAR */
+ "||", /* DBAR */
+ "&&", /* DAMPER */
+ ">", /* OUTANG 10 */
+ ">|", /* OUTANGBANG */
+ ">>", /* DOUTANG */
+ ">>|", /* DOUTANGBANG */
+ "<", /* INANG */
+ "<>", /* INOUTANG 15 */
+ "<<", /* DINANG */
+ "<<-", /* DINANGDASH */
+ "<&", /* INANGAMP */
+ ">&", /* OUTANGAMP */
+ "&>", /* AMPOUTANG 20 */
+ "&>|", /* OUTANGAMPBANG */
+ ">>&", /* DOUTANGAMP */
+ ">>&|", /* DOUTANGAMPBANG */
+ "<<<", /* TRINANG */
+ "|", /* BAR 25 */
+ "|&", /* BARAMP */
+ "()", /* INOUTPAR */
+ "((", /* DINPAR */
+ "))", /* DOUTPAR */
+ "&|", /* AMPERBANG 30 */
+ ";&", /* SEMIAMP */
+ ";|", /* SEMIBAR */
+};
+
+/* lexical state */
+
+static int dbparens;
+static struct lexbufstate lexbuf = { NULL, 256, 0 };
+
+/* save lexical context */
+
+/**/
+void
+lex_context_save(struct lex_stack *ls, int toplevel)
+{
+ (void)toplevel;
+
+ ls->dbparens = dbparens;
+ ls->isfirstln = isfirstln;
+ ls->isfirstch = isfirstch;
+ ls->lexflags = lexflags;
+
+ ls->tok = tok;
+ ls->tokstr = tokstr;
+ ls->zshlextext = zshlextext;
+ ls->lexbuf = lexbuf;
+ ls->lex_add_raw = lex_add_raw;
+ ls->tokstr_raw = tokstr_raw;
+ ls->lexbuf_raw = lexbuf_raw;
+ ls->lexstop = lexstop;
+ ls->toklineno = toklineno;
+
+ tokstr = zshlextext = lexbuf.ptr = NULL;
+ lexbuf.siz = 256;
+ tokstr_raw = lexbuf_raw.ptr = NULL;
+ lexbuf_raw.siz = lexbuf_raw.len = lex_add_raw = 0;
+}
+
+/* restore lexical context */
+
+/**/
+mod_export void
+lex_context_restore(const struct lex_stack *ls, int toplevel)
+{
+ (void)toplevel;
+
+ dbparens = ls->dbparens;
+ isfirstln = ls->isfirstln;
+ isfirstch = ls->isfirstch;
+ lexflags = ls->lexflags;
+ tok = ls->tok;
+ tokstr = ls->tokstr;
+ zshlextext = ls->zshlextext;
+ lexbuf = ls->lexbuf;
+ lex_add_raw = ls->lex_add_raw;
+ tokstr_raw = ls->tokstr_raw;
+ lexbuf_raw = ls->lexbuf_raw;
+ lexstop = ls->lexstop;
+ toklineno = ls->toklineno;
+}
+
+/**/
+void
+zshlex(void)
+{
+ if (tok == LEXERR)
+ return;
+ do {
+ if (inrepeat_)
+ ++inrepeat_;
+ if (inrepeat_ == 3 && isset(SHORTLOOPS))
+ incmdpos = 1;
+ tok = gettok();
+ } while (tok != ENDINPUT && exalias());
+ nocorrect &= 1;
+ if (tok == NEWLIN || tok == ENDINPUT) {
+ while (hdocs) {
+ struct heredocs *next = hdocs->next;
+ char *doc, *munged_term;
+
+ hwbegin(0);
+ cmdpush(hdocs->type == REDIR_HEREDOC ? CS_HEREDOC : CS_HEREDOCD);
+ munged_term = dupstring(hdocs->str);
+ STOPHIST
+ doc = gethere(&munged_term, hdocs->type);
+ ALLOWHIST
+ cmdpop();
+ hwend();
+ if (!doc) {
+ zerr("here document too large");
+ while (hdocs) {
+ next = hdocs->next;
+ zfree(hdocs, sizeof(struct heredocs));
+ hdocs = next;
+ }
+ tok = LEXERR;
+ break;
+ }
+ setheredoc(hdocs->pc, REDIR_HERESTR, doc, hdocs->str,
+ munged_term);
+ zfree(hdocs, sizeof(struct heredocs));
+ hdocs = next;
+ }
+ }
+ if (tok != NEWLIN)
+ isnewlin = 0;
+ else
+ isnewlin = (inbufct) ? -1 : 1;
+ if (tok == SEMI || (tok == NEWLIN && !(lexflags & LEXFLAGS_NEWLINE)))
+ tok = SEPER;
+}
+
+/**/
+mod_export void
+ctxtlex(void)
+{
+ static int oldpos;
+
+ zshlex();
+ switch (tok) {
+ case SEPER:
+ case NEWLIN:
+ case SEMI:
+ case DSEMI:
+ case SEMIAMP:
+ case SEMIBAR:
+ case AMPER:
+ case AMPERBANG:
+ case INPAR:
+ case INBRACE:
+ case DBAR:
+ case DAMPER:
+ case BAR:
+ case BARAMP:
+ case INOUTPAR:
+ case DOLOOP:
+ case THEN:
+ case ELIF:
+ case ELSE:
+ case DOUTBRACK:
+ incmdpos = 1;
+ break;
+ case STRING:
+ case TYPESET:
+ /* case ENVSTRING: */
+ case ENVARRAY:
+ case OUTPAR:
+ case CASE:
+ case DINBRACK:
+ incmdpos = 0;
+ break;
+
+ default:
+ /* nothing to do, keep compiler happy */
+ break;
+ }
+ if (tok != DINPAR)
+ infor = tok == FOR ? 2 : 0;
+ if (IS_REDIROP(tok) || tok == FOR || tok == FOREACH || tok == SELECT) {
+ inredir = 1;
+ oldpos = incmdpos;
+ incmdpos = 0;
+ } else if (inredir) {
+ incmdpos = oldpos;
+ inredir = 0;
+ }
+}
+
+#define LX1_BKSLASH 0
+#define LX1_COMMENT 1
+#define LX1_NEWLIN 2
+#define LX1_SEMI 3
+#define LX1_AMPER 5
+#define LX1_BAR 6
+#define LX1_INPAR 7
+#define LX1_OUTPAR 8
+#define LX1_INANG 13
+#define LX1_OUTANG 14
+#define LX1_OTHER 15
+
+#define LX2_BREAK 0
+#define LX2_OUTPAR 1
+#define LX2_BAR 2
+#define LX2_STRING 3
+#define LX2_INBRACK 4
+#define LX2_OUTBRACK 5
+#define LX2_TILDE 6
+#define LX2_INPAR 7
+#define LX2_INBRACE 8
+#define LX2_OUTBRACE 9
+#define LX2_OUTANG 10
+#define LX2_INANG 11
+#define LX2_EQUALS 12
+#define LX2_BKSLASH 13
+#define LX2_QUOTE 14
+#define LX2_DQUOTE 15
+#define LX2_BQUOTE 16
+#define LX2_COMMA 17
+#define LX2_DASH 18
+#define LX2_BANG 19
+#define LX2_OTHER 20
+#define LX2_META 21
+
+static unsigned char lexact1[256], lexact2[256], lextok2[256];
+
+/**/
+void
+initlextabs(void)
+{
+ int t0;
+ static char *lx1 = "\\q\n;!&|(){}[]<>";
+ static char *lx2 = ";)|$[]~({}><=\\\'\"`,-!";
+
+ for (t0 = 0; t0 != 256; t0++) {
+ lexact1[t0] = LX1_OTHER;
+ lexact2[t0] = LX2_OTHER;
+ lextok2[t0] = t0;
+ }
+ for (t0 = 0; lx1[t0]; t0++)
+ lexact1[(int)lx1[t0]] = t0;
+ for (t0 = 0; lx2[t0]; t0++)
+ lexact2[(int)lx2[t0]] = t0;
+ lexact2['&'] = LX2_BREAK;
+ lexact2[STOUC(Meta)] = LX2_META;
+ lextok2['*'] = Star;
+ lextok2['?'] = Quest;
+ lextok2['{'] = Inbrace;
+ lextok2['['] = Inbrack;
+ lextok2['$'] = String;
+ lextok2['~'] = Tilde;
+ lextok2['#'] = Pound;
+ lextok2['^'] = Hat;
+}
+
+/* initialize lexical state */
+
+/**/
+void
+lexinit(void)
+{
+ nocorrect = dbparens = lexstop = 0;
+ tok = ENDINPUT;
+}
+
+/* add a char to the string buffer */
+
+/**/
+void
+add(int c)
+{
+ *lexbuf.ptr++ = c;
+ if (lexbuf.siz == ++lexbuf.len) {
+ int newbsiz = lexbuf.siz * 2;
+
+ if (newbsiz > inbufct && inbufct > lexbuf.siz)
+ newbsiz = inbufct;
+
+ tokstr = (char *)hrealloc(tokstr, lexbuf.siz, newbsiz);
+ lexbuf.ptr = tokstr + lexbuf.len;
+ /* len == bsiz, so bptr is at the start of newly allocated memory */
+ memset(lexbuf.ptr, 0, newbsiz - lexbuf.siz);
+ lexbuf.siz = newbsiz;
+ }
+}
+
+#define SETPARBEGIN { \
+ if ((lexflags & LEXFLAGS_ZLE) && !(inbufflags & INP_ALIAS) && \
+ zlemetacs >= zlemetall+1-inbufct) \
+ parbegin = inbufct; \
+ }
+#define SETPAREND { \
+ if ((lexflags & LEXFLAGS_ZLE) && !(inbufflags & INP_ALIAS) && \
+ parbegin != -1 && parend == -1) { \
+ if (zlemetacs >= zlemetall + 1 - inbufct) \
+ parbegin = -1; \
+ else \
+ parend = inbufct; \
+ } \
+ }
+
+enum {
+ CMD_OR_MATH_CMD,
+ CMD_OR_MATH_MATH,
+ CMD_OR_MATH_ERR
+};
+
+/*
+ * Return one of the above. If it couldn't be
+ * parsed as math, but there was no gross error, it's a command.
+ */
+
+static int
+cmd_or_math(int cs_type)
+{
+ int oldlen = lexbuf.len;
+ int c;
+ int oinflags = inbufflags;
+
+ cmdpush(cs_type);
+ inbufflags |= INP_APPEND;
+ c = dquote_parse(')', 0);
+ if (!(oinflags & INP_APPEND))
+ inbufflags &= ~INP_APPEND;
+ cmdpop();
+ *lexbuf.ptr = '\0';
+ if (!c) {
+ /* Successfully parsed, see if it was math */
+ c = hgetc();
+ if (c == ')')
+ return CMD_OR_MATH_MATH; /* yes */
+ hungetc(c);
+ lexstop = 0;
+ c = ')';
+ } else if (lexstop) {
+ /* we haven't got anything to unget */
+ return CMD_OR_MATH_ERR;
+ }
+ /* else unsuccessful: unget the whole thing */
+ hungetc(c);
+ lexstop = 0;
+ while (lexbuf.len > oldlen && !(errflag & ERRFLAG_ERROR)) {
+ lexbuf.len--;
+ hungetc(itok(*--lexbuf.ptr) ?
+ ztokens[*lexbuf.ptr - Pound] : *lexbuf.ptr);
+ }
+ if (errflag)
+ return CMD_OR_MATH_ERR;
+ hungetc('(');
+ return errflag ? CMD_OR_MATH_ERR : CMD_OR_MATH_CMD;
+}
+
+
+/*
+ * Parse either a $(( ... )) or a $(...)
+ * Return the same as cmd_or_math().
+ */
+static int
+cmd_or_math_sub(void)
+{
+ int c = hgetc(), ret;
+
+ if (c == '(') {
+ int lexpos = (int)(lexbuf.ptr - tokstr);
+ add(Inpar);
+ add('(');
+ if ((ret = cmd_or_math(CS_MATHSUBST)) == CMD_OR_MATH_MATH) {
+ tokstr[lexpos] = Inparmath;
+ add(')');
+ return CMD_OR_MATH_MATH;
+ }
+ if (ret == CMD_OR_MATH_ERR)
+ return CMD_OR_MATH_ERR;
+ lexbuf.ptr -= 2;
+ lexbuf.len -= 2;
+ } else {
+ hungetc(c);
+ lexstop = 0;
+ }
+ return skipcomm() ? CMD_OR_MATH_ERR : CMD_OR_MATH_CMD;
+}
+
+/* Check whether we're looking at valid numeric globbing syntax *
+ * (/\<[0-9]*-[0-9]*\>/). Call pointing just after the opening "<". *
+ * Leaves the input in the same place, returning 0 or 1. */
+
+/**/
+static int
+isnumglob(void)
+{
+ int c, ec = '-', ret = 0;
+ int tbs = 256, n = 0;
+ char *tbuf = (char *)zalloc(tbs);
+
+ while(1) {
+ c = hgetc();
+ if(lexstop) {
+ lexstop = 0;
+ break;
+ }
+ tbuf[n++] = c;
+ if(!idigit(c)) {
+ if(c != ec)
+ break;
+ if(ec == '>') {
+ ret = 1;
+ break;
+ }
+ ec = '>';
+ }
+ if(n == tbs)
+ tbuf = (char *)realloc(tbuf, tbs *= 2);
+ }
+ while(n--)
+ hungetc(tbuf[n]);
+ zfree(tbuf, tbs);
+ return ret;
+}
+
+/**/
+static enum lextok
+gettok(void)
+{
+ int c, d;
+ int peekfd = -1;
+ enum lextok peek;
+
+ beginning:
+ tokstr = NULL;
+ while (iblank(c = hgetc()) && !lexstop);
+ toklineno = lineno;
+ if (lexstop)
+ return (errflag) ? LEXERR : ENDINPUT;
+ isfirstln = 0;
+ if ((lexflags & LEXFLAGS_ZLE) && !(inbufflags & INP_ALIAS))
+ wordbeg = inbufct - (qbang && c == bangchar);
+ hwbegin(-1-(qbang && c == bangchar));
+ /* word includes the last character read and possibly \ before ! */
+ if (dbparens) {
+ lexbuf.len = 0;
+ lexbuf.ptr = tokstr = (char *) hcalloc(lexbuf.siz = LEX_HEAP_SIZE);
+ hungetc(c);
+ cmdpush(CS_MATH);
+ c = dquote_parse(infor ? ';' : ')', 0);
+ cmdpop();
+ *lexbuf.ptr = '\0';
+ if (!c && infor) {
+ infor--;
+ return DINPAR;
+ }
+ if (c || (c = hgetc()) != ')') {
+ hungetc(c);
+ return LEXERR;
+ }
+ dbparens = 0;
+ return DOUTPAR;
+ } else if (idigit(c)) { /* handle 1< foo */
+ d = hgetc();
+ if(d == '&') {
+ d = hgetc();
+ if(d == '>') {
+ peekfd = c - '0';
+ hungetc('>');
+ c = '&';
+ } else {
+ hungetc(d);
+ lexstop = 0;
+ hungetc('&');
+ }
+ } else if (d == '>' || d == '<') {
+ peekfd = c - '0';
+ c = d;
+ } else {
+ hungetc(d);
+ lexstop = 0;
+ }
+ }
+
+ /* chars in initial position in word */
+
+ /*
+ * Handle comments. There are some special cases when this
+ * is not normal command input: lexflags implies we are examining
+ * a line lexically without it being used for normal command input.
+ */
+ if (c == hashchar && !nocomments &&
+ (isset(INTERACTIVECOMMENTS) ||
+ ((!lexflags || (lexflags & LEXFLAGS_COMMENTS)) && !expanding &&
+ (!interact || unset(SHINSTDIN) || strin)))) {
+ /* History is handled here to prevent extra *
+ * newlines being inserted into the history. */
+
+ if (lexflags & LEXFLAGS_COMMENTS_KEEP) {
+ lexbuf.len = 0;
+ lexbuf.ptr = tokstr =
+ (char *)hcalloc(lexbuf.siz = LEX_HEAP_SIZE);
+ add(c);
+ }
+ hwabort();
+ while ((c = ingetc()) != '\n' && !lexstop) {
+ hwaddc(c);
+ addtoline(c);
+ if (lexflags & LEXFLAGS_COMMENTS_KEEP)
+ add(c);
+ }
+
+ if (errflag)
+ peek = LEXERR;
+ else {
+ if (lexflags & LEXFLAGS_COMMENTS_KEEP) {
+ *lexbuf.ptr = '\0';
+ if (!lexstop)
+ hungetc(c);
+ peek = STRING;
+ } else {
+ hwend();
+ hwbegin(0);
+ hwaddc('\n');
+ addtoline('\n');
+ /*
+ * If splitting a line and removing comments,
+ * we don't want a newline token since it's
+ * treated specially.
+ */
+ if ((lexflags & LEXFLAGS_COMMENTS_STRIP) && lexstop)
+ peek = ENDINPUT;
+ else
+ peek = NEWLIN;
+ }
+ }
+ return peek;
+ }
+ switch (lexact1[STOUC(c)]) {
+ case LX1_BKSLASH:
+ d = hgetc();
+ if (d == '\n')
+ goto beginning;
+ hungetc(d);
+ lexstop = 0;
+ break;
+ case LX1_NEWLIN:
+ return NEWLIN;
+ case LX1_SEMI:
+ d = hgetc();
+ if(d == ';')
+ return DSEMI;
+ else if(d == '&')
+ return SEMIAMP;
+ else if (d == '|')
+ return SEMIBAR;
+ hungetc(d);
+ lexstop = 0;
+ return SEMI;
+ case LX1_AMPER:
+ d = hgetc();
+ if (d == '&')
+ return DAMPER;
+ else if (d == '!' || d == '|')
+ return AMPERBANG;
+ else if (d == '>') {
+ tokfd = peekfd;
+ d = hgetc();
+ if (d == '!' || d == '|')
+ return OUTANGAMPBANG;
+ else if (d == '>') {
+ d = hgetc();
+ if (d == '!' || d == '|')
+ return DOUTANGAMPBANG;
+ hungetc(d);
+ lexstop = 0;
+ return DOUTANGAMP;
+ }
+ hungetc(d);
+ lexstop = 0;
+ return AMPOUTANG;
+ }
+ hungetc(d);
+ lexstop = 0;
+ return AMPER;
+ case LX1_BAR:
+ d = hgetc();
+ if (d == '|' && !incasepat)
+ return DBAR;
+ else if (d == '&')
+ return BARAMP;
+ hungetc(d);
+ lexstop = 0;
+ return BAR;
+ case LX1_INPAR:
+ d = hgetc();
+ if (d == '(') {
+ if (infor) {
+ dbparens = 1;
+ return DINPAR;
+ }
+ if (incmdpos || (isset(SHGLOB) && !isset(KSHGLOB))) {
+ lexbuf.len = 0;
+ lexbuf.ptr = tokstr = (char *)
+ hcalloc(lexbuf.siz = LEX_HEAP_SIZE);
+ switch (cmd_or_math(CS_MATH)) {
+ case CMD_OR_MATH_MATH:
+ return DINPAR;
+
+ case CMD_OR_MATH_CMD:
+ /*
+ * Not math, so we don't return the contents
+ * as a string in this case.
+ */
+ tokstr = NULL;
+ return INPAR;
+
+ case CMD_OR_MATH_ERR:
+ /*
+ * LEXFLAGS_ACTIVE means we came from bufferwords(),
+ * so we treat as an incomplete math expression
+ */
+ if (lexflags & LEXFLAGS_ACTIVE)
+ tokstr = dyncat("((", tokstr ? tokstr : "");
+ /* fall through */
+
+ default:
+ return LEXERR;
+ }
+ }
+ } else if (d == ')')
+ return INOUTPAR;
+ hungetc(d);
+ lexstop = 0;
+ if (!(isset(SHGLOB) || incond == 1 || incmdpos))
+ break;
+ return INPAR;
+ case LX1_OUTPAR:
+ return OUTPAR;
+ case LX1_INANG:
+ d = hgetc();
+ if (d == '(') {
+ hungetc(d);
+ lexstop = 0;
+ unpeekfd:
+ if(peekfd != -1) {
+ hungetc(c);
+ c = '0' + peekfd;
+ }
+ break;
+ }
+ if (d == '>') {
+ peek = INOUTANG;
+ } else if (d == '<') {
+ int e = hgetc();
+
+ if (e == '(') {
+ hungetc(e);
+ hungetc(d);
+ peek = INANG;
+ } else if (e == '<')
+ peek = TRINANG;
+ else if (e == '-')
+ peek = DINANGDASH;
+ else {
+ hungetc(e);
+ lexstop = 0;
+ peek = DINANG;
+ }
+ } else if (d == '&') {
+ peek = INANGAMP;
+ } else {
+ hungetc(d);
+ if(isnumglob())
+ goto unpeekfd;
+ peek = INANG;
+ }
+ tokfd = peekfd;
+ return peek;
+ case LX1_OUTANG:
+ d = hgetc();
+ if (d == '(') {
+ hungetc(d);
+ goto unpeekfd;
+ } else if (d == '&') {
+ d = hgetc();
+ if (d == '!' || d == '|')
+ peek = OUTANGAMPBANG;
+ else {
+ hungetc(d);
+ lexstop = 0;
+ peek = OUTANGAMP;
+ }
+ } else if (d == '!' || d == '|')
+ peek = OUTANGBANG;
+ else if (d == '>') {
+ d = hgetc();
+ if (d == '&') {
+ d = hgetc();
+ if (d == '!' || d == '|')
+ peek = DOUTANGAMPBANG;
+ else {
+ hungetc(d);
+ lexstop = 0;
+ peek = DOUTANGAMP;
+ }
+ } else if (d == '!' || d == '|')
+ peek = DOUTANGBANG;
+ else if (d == '(') {
+ hungetc(d);
+ hungetc('>');
+ peek = OUTANG;
+ } else {
+ hungetc(d);
+ lexstop = 0;
+ peek = DOUTANG;
+ if (isset(HISTALLOWCLOBBER))
+ hwaddc('|');
+ }
+ } else {
+ hungetc(d);
+ lexstop = 0;
+ peek = OUTANG;
+ if (!incond && isset(HISTALLOWCLOBBER))
+ hwaddc('|');
+ }
+ tokfd = peekfd;
+ return peek;
+ }
+
+ /* we've started a string, now get the *
+ * rest of it, performing tokenization */
+ return gettokstr(c, 0);
+}
+
+/*
+ * Get the remains of a token string. This has two uses.
+ * When called from gettok(), with sub = 0, we have already identified
+ * any interesting initial character and want to get the rest of
+ * what we now know is a string. However, the string may still include
+ * metacharacters and potentially substitutions.
+ *
+ * When called from parse_subst_string() with sub = 1, we are not
+ * fully parsing a command line, merely tokenizing a string.
+ * In this case we always add characters to the parsed string
+ * unless there is a parse error.
+ */
+
+/**/
+static enum lextok
+gettokstr(int c, int sub)
+{
+ int bct = 0, pct = 0, brct = 0, seen_brct = 0, fdpar = 0;
+ int intpos = 1, in_brace_param = 0;
+ int inquote, unmatched = 0;
+ enum lextok peek;
+#ifdef DEBUG
+ int ocmdsp = cmdsp;
+#endif
+
+ peek = STRING;
+ if (!sub) {
+ lexbuf.len = 0;
+ lexbuf.ptr = tokstr = (char *) hcalloc(lexbuf.siz = LEX_HEAP_SIZE);
+ }
+ for (;;) {
+ int act;
+ int e;
+ int inbl = inblank(c);
+
+ if (fdpar && !inbl && c != ')')
+ fdpar = 0;
+
+ if (inbl && !in_brace_param && !pct)
+ act = LX2_BREAK;
+ else {
+ act = lexact2[STOUC(c)];
+ c = lextok2[STOUC(c)];
+ }
+ switch (act) {
+ case LX2_BREAK:
+ if (!in_brace_param && !sub)
+ goto brk;
+ break;
+ case LX2_META:
+ c = hgetc();
+#ifdef DEBUG
+ if (lexstop) {
+ fputs("BUG: input terminated by Meta\n", stderr);
+ fflush(stderr);
+ goto brk;
+ }
+#endif
+ add(Meta);
+ break;
+ case LX2_OUTPAR:
+ if (fdpar) {
+ /* this is a single word `( )', treat as INOUTPAR */
+ add(c);
+ *lexbuf.ptr = '\0';
+ return INOUTPAR;
+ }
+ if ((sub || in_brace_param) && isset(SHGLOB))
+ break;
+ if (!in_brace_param && !pct--) {
+ if (sub) {
+ pct = 0;
+ break;
+ } else
+ goto brk;
+ }
+ c = Outpar;
+ break;
+ case LX2_BAR:
+ if (!pct && !in_brace_param) {
+ if (sub)
+ break;
+ else
+ goto brk;
+ }
+ if (unset(SHGLOB) || (!sub && !in_brace_param))
+ c = Bar;
+ break;
+ case LX2_STRING:
+ e = hgetc();
+ if (e == '[') {
+ cmdpush(CS_MATHSUBST);
+ add(String);
+ add(Inbrack);
+ c = dquote_parse(']', sub);
+ cmdpop();
+ if (c) {
+ peek = LEXERR;
+ goto brk;
+ }
+ c = Outbrack;
+ } else if (e == '(') {
+ add(String);
+ switch (cmd_or_math_sub()) {
+ case CMD_OR_MATH_CMD:
+ c = Outpar;
+ break;
+
+ case CMD_OR_MATH_MATH:
+ c = Outparmath;
+ break;
+
+ default:
+ peek = LEXERR;
+ goto brk;
+ }
+ } else {
+ if (e == '{') {
+ add(c);
+ c = Inbrace;
+ ++bct;
+ cmdpush(CS_BRACEPAR);
+ if (!in_brace_param) {
+ if ((in_brace_param = bct))
+ seen_brct = 0;
+ }
+ } else {
+ hungetc(e);
+ lexstop = 0;
+ }
+ }
+ break;
+ case LX2_INBRACK:
+ if (!in_brace_param) {
+ brct++;
+ seen_brct = 1;
+ }
+ c = Inbrack;
+ break;
+ case LX2_OUTBRACK:
+ if (!in_brace_param)
+ brct--;
+ if (brct < 0)
+ brct = 0;
+ c = Outbrack;
+ break;
+ case LX2_INPAR:
+ if (isset(SHGLOB)) {
+ if (sub || in_brace_param)
+ break;
+ if (incasepat > 0 && !lexbuf.len)
+ return INPAR;
+ if (!isset(KSHGLOB) && lexbuf.len)
+ goto brk;
+ }
+ if (!in_brace_param) {
+ if (!sub) {
+ e = hgetc();
+ hungetc(e);
+ lexstop = 0;
+ /* For command words, parentheses are only
+ * special at the start. But now we're tokenising
+ * the remaining string. So I don't see what
+ * the old incmdpos test here is for.
+ * pws 1999/6/8
+ *
+ * Oh, no.
+ * func1( )
+ * is a valid function definition in [k]sh. The best
+ * thing we can do, without really nasty lookahead tricks,
+ * is break if we find a blank after a parenthesis. At
+ * least this can't happen inside braces or brackets. We
+ * only allow this with SHGLOB (set for both sh and ksh).
+ *
+ * Things like `print @( |foo)' should still
+ * work, because [k]sh don't allow multiple words
+ * in a function definition, so we only do this
+ * in command position.
+ * pws 1999/6/14
+ */
+ if (e == ')' || (isset(SHGLOB) && inblank(e) && !bct &&
+ !brct && !intpos && incmdpos)) {
+ /*
+ * Either a () token, or a command word with
+ * something suspiciously like a ksh function
+ * definition.
+ * The current word isn't spellcheckable.
+ */
+ nocorrect |= 2;
+ goto brk;
+ }
+ }
+ /*
+ * This also handles the [k]sh `foo( )' function definition.
+ * Maintain a variable fdpar, set as long as a single set of
+ * parentheses contains only space. Then if we get to the
+ * closing parenthesis and it is still set, we can assume we
+ * have a function definition. Only do this at the start of
+ * the word, since the (...) must be a separate token.
+ */
+ if (!pct++ && isset(SHGLOB) && intpos && !bct && !brct)
+ fdpar = 1;
+ }
+ c = Inpar;
+ break;
+ case LX2_INBRACE:
+ if (isset(IGNOREBRACES) || sub)
+ c = '{';
+ else {
+ if (!lexbuf.len && incmdpos) {
+ add('{');
+ *lexbuf.ptr = '\0';
+ return STRING;
+ }
+ if (in_brace_param) {
+ cmdpush(CS_BRACE);
+ }
+ bct++;
+ }
+ break;
+ case LX2_OUTBRACE:
+ if ((isset(IGNOREBRACES) || sub) && !in_brace_param)
+ break;
+ if (!bct)
+ break;
+ if (in_brace_param) {
+ cmdpop();
+ }
+ if (bct-- == in_brace_param)
+ in_brace_param = 0;
+ c = Outbrace;
+ break;
+ case LX2_COMMA:
+ if (unset(IGNOREBRACES) && !sub && bct > in_brace_param)
+ c = Comma;
+ break;
+ case LX2_OUTANG:
+ if (in_brace_param || sub)
+ break;
+ e = hgetc();
+ if (e != '(') {
+ hungetc(e);
+ lexstop = 0;
+ goto brk;
+ }
+ add(OutangProc);
+ if (skipcomm()) {
+ peek = LEXERR;
+ goto brk;
+ }
+ c = Outpar;
+ break;
+ case LX2_INANG:
+ if (isset(SHGLOB) && sub)
+ break;
+ e = hgetc();
+ if (!(in_brace_param || sub) && e == '(') {
+ add(Inang);
+ if (skipcomm()) {
+ peek = LEXERR;
+ goto brk;
+ }
+ c = Outpar;
+ break;
+ }
+ hungetc(e);
+ if(isnumglob()) {
+ add(Inang);
+ while ((c = hgetc()) != '>')
+ add(c);
+ c = Outang;
+ break;
+ }
+ lexstop = 0;
+ if (in_brace_param || sub)
+ break;
+ goto brk;
+ case LX2_EQUALS:
+ if (!sub) {
+ if (intpos) {
+ e = hgetc();
+ if (e != '(') {
+ hungetc(e);
+ lexstop = 0;
+ c = Equals;
+ } else {
+ add(Equals);
+ if (skipcomm()) {
+ peek = LEXERR;
+ goto brk;
+ }
+ c = Outpar;
+ }
+ } else if (peek != ENVSTRING &&
+ (incmdpos || intypeset) && !bct && !brct) {
+ char *t = tokstr;
+ if (idigit(*t))
+ while (++t < lexbuf.ptr && idigit(*t));
+ else {
+ int sav = *lexbuf.ptr;
+ *lexbuf.ptr = '\0';
+ t = itype_end(t, IIDENT, 0);
+ if (t < lexbuf.ptr) {
+ skipparens(Inbrack, Outbrack, &t);
+ } else {
+ *lexbuf.ptr = sav;
+ }
+ }
+ if (*t == '+')
+ t++;
+ if (t == lexbuf.ptr) {
+ e = hgetc();
+ if (e == '(') {
+ *lexbuf.ptr = '\0';
+ return ENVARRAY;
+ }
+ hungetc(e);
+ lexstop = 0;
+ peek = ENVSTRING;
+ intpos = 2;
+ } else
+ c = Equals;
+ } else
+ c = Equals;
+ }
+ break;
+ case LX2_BKSLASH:
+ c = hgetc();
+ if (c == '\n') {
+ c = hgetc();
+ if (!lexstop)
+ continue;
+ } else {
+ add(Bnull);
+ if (c == STOUC(Meta)) {
+ c = hgetc();
+#ifdef DEBUG
+ if (lexstop) {
+ fputs("BUG: input terminated by Meta\n", stderr);
+ fflush(stderr);
+ goto brk;
+ }
+#endif
+ add(Meta);
+ }
+ }
+ if (lexstop)
+ goto brk;
+ break;
+ case LX2_QUOTE: {
+ int strquote = (lexbuf.len && lexbuf.ptr[-1] == String);
+
+ add(Snull);
+ cmdpush(CS_QUOTE);
+ for (;;) {
+ STOPHIST
+ while ((c = hgetc()) != '\'' && !lexstop) {
+ if (strquote && c == '\\') {
+ c = hgetc();
+ if (lexstop)
+ break;
+ /*
+ * Mostly we don't need to do anything special
+ * with escape backslashes or closing quotes
+ * inside $'...'; however in completion we
+ * need to be able to strip multiple backslashes
+ * neatly.
+ */
+ if (c == '\\' || c == '\'')
+ add(Bnull);
+ else
+ add('\\');
+ } else if (!sub && isset(CSHJUNKIEQUOTES) && c == '\n') {
+ if (lexbuf.ptr[-1] == '\\')
+ lexbuf.ptr--, lexbuf.len--;
+ else
+ break;
+ }
+ add(c);
+ }
+ ALLOWHIST
+ if (c != '\'') {
+ unmatched = '\'';
+ /* Not an error when called from bufferwords() */
+ if (!(lexflags & LEXFLAGS_ACTIVE))
+ peek = LEXERR;
+ cmdpop();
+ goto brk;
+ }
+ e = hgetc();
+ if (e != '\'' || unset(RCQUOTES) || strquote)
+ break;
+ add(c);
+ }
+ cmdpop();
+ hungetc(e);
+ lexstop = 0;
+ c = Snull;
+ break;
+ }
+ case LX2_DQUOTE:
+ add(Dnull);
+ cmdpush(CS_DQUOTE);
+ c = dquote_parse('"', sub);
+ cmdpop();
+ if (c) {
+ unmatched = '"';
+ /* Not an error when called from bufferwords() */
+ if (!(lexflags & LEXFLAGS_ACTIVE))
+ peek = LEXERR;
+ goto brk;
+ }
+ c = Dnull;
+ break;
+ case LX2_BQUOTE:
+ add(Tick);
+ cmdpush(CS_BQUOTE);
+ SETPARBEGIN
+ inquote = 0;
+ while ((c = hgetc()) != '`' && !lexstop) {
+ if (c == '\\') {
+ c = hgetc();
+ if (c != '\n') {
+ add(c == '`' || c == '\\' || c == '$' ? Bnull : '\\');
+ add(c);
+ }
+ else if (!sub && isset(CSHJUNKIEQUOTES))
+ add(c);
+ } else {
+ if (!sub && isset(CSHJUNKIEQUOTES) && c == '\n') {
+ break;
+ }
+ add(c);
+ if (c == '\'') {
+ if ((inquote = !inquote))
+ STOPHIST
+ else
+ ALLOWHIST
+ }
+ }
+ }
+ if (inquote)
+ ALLOWHIST
+ cmdpop();
+ if (c != '`') {
+ unmatched = '`';
+ /* Not an error when called from bufferwords() */
+ if (!(lexflags & LEXFLAGS_ACTIVE))
+ peek = LEXERR;
+ goto brk;
+ }
+ c = Tick;
+ SETPAREND
+ break;
+ case LX2_DASH:
+ /*
+ * - shouldn't be treated as a special character unless
+ * we're in a pattern. Unfortunately, working out for
+ * sure in complicated expressions whether we're in a
+ * pattern is tricky. So we'll make it special and
+ * turn it back any time we don't need it special.
+ * This is not ideal as it's a lot of work.
+ */
+ c = Dash;
+ break;
+ case LX2_BANG:
+ /*
+ * Same logic as Dash, for ! to perform negation in range.
+ */
+ if (seen_brct)
+ c = Bang;
+ else
+ c = '!';
+ }
+ add(c);
+ c = hgetc();
+ if (intpos)
+ intpos--;
+ if (lexstop)
+ break;
+ }
+ brk:
+ if (errflag) {
+ if (in_brace_param) {
+ while(bct-- >= in_brace_param)
+ cmdpop();
+ }
+ return LEXERR;
+ }
+ hungetc(c);
+ if (unmatched && !(lexflags & LEXFLAGS_ACTIVE))
+ zerr("unmatched %c", unmatched);
+ if (in_brace_param) {
+ while(bct-- >= in_brace_param)
+ cmdpop();
+ zerr("closing brace expected");
+ } else if (unset(IGNOREBRACES) && !sub && lexbuf.len > 1 &&
+ peek == STRING && lexbuf.ptr[-1] == '}' &&
+ lexbuf.ptr[-2] != Bnull) {
+ /* hack to get {foo} command syntax work */
+ lexbuf.ptr--;
+ lexbuf.len--;
+ lexstop = 0;
+ hungetc('}');
+ }
+ *lexbuf.ptr = '\0';
+ DPUTS(cmdsp != ocmdsp, "BUG: gettok: cmdstack changed.");
+ return peek;
+}
+
+
+/*
+ * Parse input as if in double quotes.
+ * endchar is the end character to expect.
+ * sub has got something to do with whether we are doing quoted substitution.
+ * Return non-zero for error (character to unget), else zero
+ */
+
+/**/
+static int
+dquote_parse(char endchar, int sub)
+{
+ int pct = 0, brct = 0, bct = 0, intick = 0, err = 0;
+ int c;
+ int math = endchar == ')' || endchar == ']' || infor;
+ int zlemath = math && zlemetacs > zlemetall + addedx - inbufct;
+
+ while (((c = hgetc()) != endchar || bct ||
+ (math && ((pct > 0) || (brct > 0))) ||
+ intick) && !lexstop) {
+ cont:
+ switch (c) {
+ case '\\':
+ c = hgetc();
+ if (c != '\n') {
+ if (c == '$' || c == '\\' || (c == '}' && !intick && bct) ||
+ c == endchar || c == '`' ||
+ (endchar == ']' && (c == '[' || c == ']' ||
+ c == '(' || c == ')' ||
+ c == '{' || c == '}' ||
+ (c == '"' && sub))))
+ add(Bnull);
+ else {
+ /* lexstop is implicitly handled here */
+ add('\\');
+ goto cont;
+ }
+ } else if (sub || unset(CSHJUNKIEQUOTES) || endchar != '"')
+ continue;
+ break;
+ case '\n':
+ err = !sub && isset(CSHJUNKIEQUOTES) && endchar == '"';
+ break;
+ case '$':
+ if (intick)
+ break;
+ c = hgetc();
+ if (c == '(') {
+ add(Qstring);
+ switch (cmd_or_math_sub()) {
+ case CMD_OR_MATH_CMD:
+ c = Outpar;
+ break;
+
+ case CMD_OR_MATH_MATH:
+ c = Outparmath;
+ break;
+
+ default:
+ err = 1;
+ break;
+ }
+ } else if (c == '[') {
+ add(String);
+ add(Inbrack);
+ cmdpush(CS_MATHSUBST);
+ err = dquote_parse(']', sub);
+ cmdpop();
+ c = Outbrack;
+ } else if (c == '{') {
+ add(Qstring);
+ c = Inbrace;
+ cmdpush(CS_BRACEPAR);
+ bct++;
+ } else if (c == '$')
+ add(Qstring);
+ else {
+ hungetc(c);
+ lexstop = 0;
+ c = Qstring;
+ }
+ break;
+ case '}':
+ if (intick || !bct)
+ break;
+ c = Outbrace;
+ bct--;
+ cmdpop();
+ break;
+ case '`':
+ c = Qtick;
+ if (intick == 2)
+ ALLOWHIST
+ if ((intick = !intick)) {
+ SETPARBEGIN
+ cmdpush(CS_BQUOTE);
+ } else {
+ SETPAREND
+ cmdpop();
+ }
+ break;
+ case '\'':
+ if (!intick)
+ break;
+ if (intick == 1)
+ intick = 2, STOPHIST
+ else
+ intick = 1, ALLOWHIST
+ break;
+ case '(':
+ if (!math || !bct)
+ pct++;
+ break;
+ case ')':
+ if (!math || !bct)
+ err = (!pct-- && math);
+ break;
+ case '[':
+ if (!math || !bct)
+ brct++;
+ break;
+ case ']':
+ if (!math || !bct)
+ err = (!brct-- && math);
+ break;
+ case '"':
+ if (intick || (endchar != '"' && !bct))
+ break;
+ if (bct) {
+ add(Dnull);
+ cmdpush(CS_DQUOTE);
+ err = dquote_parse('"', sub);
+ cmdpop();
+ c = Dnull;
+ } else
+ err = 1;
+ break;
+ }
+ if (err || lexstop)
+ break;
+ add(c);
+ }
+ if (intick == 2)
+ ALLOWHIST
+ if (intick) {
+ cmdpop();
+ }
+ while (bct--)
+ cmdpop();
+ if (lexstop)
+ err = intick || endchar || err;
+ else if (err == 1) {
+ /*
+ * TODO: as far as I can see, this hack is used in gettokstr()
+ * to hungetc() a character on an error. However, I don't
+ * understand what that actually gets us, and we can't guarantee
+ * it's a character anyway, because of the previous test.
+ *
+ * We use the same feature in cmd_or_math where we actually do
+ * need to unget if we decide it's really a command substitution.
+ * We try to handle the other case by testing for lexstop.
+ */
+ err = c;
+ }
+ if (zlemath && zlemetacs <= zlemetall + 1 - inbufct)
+ inwhat = IN_MATH;
+ return err;
+}
+
+/*
+ * Tokenize a string given in s. Parsing is done as in double
+ * quotes. This is usually called before singsub().
+ *
+ * parsestr() is noisier, reporting an error if the parse failed.
+ *
+ * On entry, *s must point to a string allocated from the stack of
+ * exactly the right length, i.e. strlen(*s) + 1, as the string
+ * is used as the lexical token string whose memory management
+ * demands this. Usually the input string will therefore be
+ * the result of an immediately preceding dupstring().
+ */
+
+/**/
+mod_export int
+parsestr(char **s)
+{
+ int err;
+
+ if ((err = parsestrnoerr(s))) {
+ untokenize(*s);
+ if (!(errflag & ERRFLAG_INT)) {
+ if (err > 32 && err < 127)
+ zerr("parse error near `%c'", err);
+ else
+ zerr("parse error");
+ }
+ }
+ return err;
+}
+
+/**/
+mod_export int
+parsestrnoerr(char **s)
+{
+ int l = strlen(*s), err;
+
+ zcontext_save();
+ untokenize(*s);
+ inpush(dupstring(*s), 0, NULL);
+ strinbeg(0);
+ lexbuf.len = 0;
+ lexbuf.ptr = tokstr = *s;
+ lexbuf.siz = l + 1;
+ err = dquote_parse('\0', 1);
+ if (tokstr)
+ *s = tokstr;
+ *lexbuf.ptr = '\0';
+ strinend();
+ inpop();
+ DPUTS(cmdsp, "BUG: parsestr: cmdstack not empty.");
+ zcontext_restore();
+ return err;
+}
+
+/*
+ * Parse a subscript in string s.
+ * sub is passed down to dquote_parse().
+ * endchar is the final character.
+ * Return the next character, or NULL.
+ */
+/**/
+mod_export char *
+parse_subscript(char *s, int sub, int endchar)
+{
+ int l = strlen(s), err, toklen;
+ char *t;
+
+ if (!*s || *s == endchar)
+ return 0;
+ zcontext_save();
+ untokenize(t = dupstring(s));
+ inpush(t, 0, NULL);
+ strinbeg(0);
+ /*
+ * Warning to Future Generations:
+ *
+ * This way of passing the subscript through the lexer is brittle.
+ * Code above this for several layers assumes that when we tokenise
+ * the input it goes into the same place as the original string.
+ * However, the lexer may overwrite later bits of the string or
+ * reallocate it, in particular when expanding aliaes. To get
+ * around this, we copy the string and then copy it back. This is a
+ * bit more robust but still relies on the underlying assumption of
+ * length preservation.
+ */
+ lexbuf.len = 0;
+ lexbuf.ptr = tokstr = dupstring(s);
+ lexbuf.siz = l + 1;
+ err = dquote_parse(endchar, sub);
+ toklen = (int)(lexbuf.ptr - tokstr);
+ DPUTS(toklen > l, "Bad length for parsed subscript");
+ memcpy(s, tokstr, toklen);
+ if (err) {
+ char *strend = s + toklen;
+ err = *strend;
+ *strend = '\0';
+ untokenize(s);
+ *strend = err;
+ s = NULL;
+ } else {
+ s += toklen;
+ }
+ strinend();
+ inpop();
+ DPUTS(cmdsp, "BUG: parse_subscript: cmdstack not empty.");
+ zcontext_restore();
+ return s;
+}
+
+/* Tokenize a string given in s. Parsing is done as if s were a normal *
+ * command-line argument but it may contain separators. This is used *
+ * to parse the right-hand side of ${...%...} substitutions. */
+
+/**/
+mod_export int
+parse_subst_string(char *s)
+{
+ int c, l = strlen(s), err;
+ char *ptr;
+ enum lextok ctok;
+
+ if (!*s || !strcmp(s, nulstring))
+ return 0;
+ zcontext_save();
+ untokenize(s);
+ inpush(dupstring(s), 0, NULL);
+ strinbeg(0);
+ lexbuf.len = 0;
+ lexbuf.ptr = tokstr = s;
+ lexbuf.siz = l + 1;
+ c = hgetc();
+ ctok = gettokstr(c, 1);
+ err = errflag;
+ strinend();
+ inpop();
+ DPUTS(cmdsp, "BUG: parse_subst_string: cmdstack not empty.");
+ zcontext_restore();
+ /* Keep any interrupt error status */
+ errflag = err | (errflag & ERRFLAG_INT);
+ if (ctok == LEXERR) {
+ untokenize(s);
+ return 1;
+ }
+#ifdef DEBUG
+ /*
+ * Historical note: we used to check here for olen (the value of lexbuf.len
+ * before zcontext_restore()) == l, but that's not necessarily the case if
+ * we stripped an RCQUOTE.
+ */
+ if (ctok != STRING || (errflag && !noerrs)) {
+ fprintf(stderr, "Oops. Bug in parse_subst_string: %s\n",
+ errflag ? "errflag" : "ctok != STRING");
+ fflush(stderr);
+ untokenize(s);
+ return 1;
+ }
+#endif
+ /* Check for $'...' quoting. This needs special handling. */
+ for (ptr = s; *ptr; )
+ {
+ if (*ptr == String && ptr[1] == Snull)
+ {
+ char *t;
+ int len, tlen, diff;
+ t = getkeystring(ptr + 2, &len, GETKEYS_DOLLARS_QUOTE, NULL);
+ len += 2;
+ tlen = strlen(t);
+ diff = len - tlen;
+ /*
+ * Yuk.
+ * parse_subst_string() currently handles strings in-place.
+ * That's not so easy to fix without knowing whether
+ * additional memory should come off the heap or
+ * otherwise. So we cheat by copying the unquoted string
+ * into place, unless it's too long. That's not the
+ * normal case, but I'm worried there are pathological
+ * cases with converting metafied multibyte strings.
+ * If someone can prove there aren't I will be very happy.
+ */
+ if (diff < 0) {
+ DPUTS(1, "$'...' subst too long: fix get_parse_string()");
+ return 1;
+ }
+ memcpy(ptr, t, tlen);
+ ptr += tlen;
+ if (diff > 0) {
+ char *dptr = ptr;
+ char *sptr = ptr + diff;
+ while ((*dptr++ = *sptr++))
+ ;
+ }
+ } else
+ ptr++;
+ }
+ return 0;
+}
+
+/* Called below to report word positions. */
+
+/**/
+static void
+gotword(void)
+{
+ int nwe = zlemetall + 1 - inbufct + (addedx == 2 ? 1 : 0);
+ if (zlemetacs <= nwe) {
+ int nwb = zlemetall - wordbeg + addedx;
+ if (zlemetacs >= nwb) {
+ wb = nwb;
+ we = nwe;
+ } else {
+ wb = zlemetacs + addedx;
+ if (we < wb)
+ we = wb;
+ }
+ lexflags = 0;
+ }
+}
+
+/* Check if current lex text matches an alias: 1 if so, else 0 */
+
+static int
+checkalias(void)
+{
+ Alias an;
+
+ if (!zshlextext)
+ return 0;
+
+ if (!noaliases && isset(ALIASESOPT) &&
+ (!isset(POSIXALIASES) ||
+ (tok == STRING && !reswdtab->getnode(reswdtab, zshlextext)))) {
+ char *suf;
+
+ an = (Alias) aliastab->getnode(aliastab, zshlextext);
+ if (an && !an->inuse &&
+ ((an->node.flags & ALIAS_GLOBAL) ||
+ (incmdpos && tok == STRING) || inalmore)) {
+ if (!lexstop) {
+ /*
+ * Tokens that don't require a space after, get one,
+ * because they are treated as if preceded by one.
+ */
+ int c = hgetc();
+ hungetc(c);
+ if (!iblank(c))
+ inpush(" ", INP_ALIAS, 0);
+ }
+ inpush(an->text, INP_ALIAS, an);
+ if (an->text[0] == ' ' && !(an->node.flags & ALIAS_GLOBAL))
+ aliasspaceflag = 1;
+ lexstop = 0;
+ return 1;
+ }
+ if ((suf = strrchr(zshlextext, '.')) && suf[1] &&
+ suf > zshlextext && suf[-1] != Meta &&
+ (an = (Alias)sufaliastab->getnode(sufaliastab, suf+1)) &&
+ !an->inuse && incmdpos) {
+ inpush(dupstring(zshlextext), INP_ALIAS, an);
+ inpush(" ", INP_ALIAS, NULL);
+ inpush(an->text, INP_ALIAS, NULL);
+ lexstop = 0;
+ return 1;
+ }
+ }
+
+ return 0;
+}
+
+/* expand aliases and reserved words */
+
+/**/
+int
+exalias(void)
+{
+ Reswd rw;
+
+ hwend();
+ if (interact && isset(SHINSTDIN) && !strin && incasepat <= 0 &&
+ tok == STRING && !nocorrect && !(inbufflags & INP_ALIAS) &&
+ (isset(CORRECTALL) || (isset(CORRECT) && incmdpos)))
+ spckword(&tokstr, 1, incmdpos, 1);
+
+ if (!tokstr) {
+ zshlextext = tokstrings[tok];
+
+ if (tok == NEWLIN)
+ return 0;
+ return checkalias();
+ } else {
+ VARARR(char, copy, (strlen(tokstr) + 1));
+
+ if (has_token(tokstr)) {
+ char *p, *t;
+
+ zshlextext = p = copy;
+ for (t = tokstr;
+ (*p++ = itok(*t) ? ztokens[*t++ - Pound] : *t++););
+ } else
+ zshlextext = tokstr;
+
+ if ((lexflags & LEXFLAGS_ZLE) && !(inbufflags & INP_ALIAS)) {
+ int zp = lexflags;
+
+ gotword();
+ if ((zp & LEXFLAGS_ZLE) && !lexflags) {
+ if (zshlextext == copy)
+ zshlextext = tokstr;
+ return 0;
+ }
+ }
+
+ if (tok == STRING) {
+ /* Check for an alias */
+ if ((zshlextext != copy || !isset(POSIXALIASES)) && checkalias()) {
+ if (zshlextext == copy)
+ zshlextext = tokstr;
+ return 1;
+ }
+
+ /* Then check for a reserved word */
+ if ((incmdpos ||
+ (unset(IGNOREBRACES) && unset(IGNORECLOSEBRACES) &&
+ zshlextext[0] == '}' && !zshlextext[1])) &&
+ (rw = (Reswd) reswdtab->getnode(reswdtab, zshlextext))) {
+ tok = rw->token;
+ inrepeat_ = (tok == REPEAT);
+ if (tok == DINBRACK)
+ incond = 1;
+ } else if (incond && !strcmp(zshlextext, "]]")) {
+ tok = DOUTBRACK;
+ incond = 0;
+ } else if (incond == 1 && zshlextext[0] == '!' && !zshlextext[1])
+ tok = BANG;
+ }
+ inalmore = 0;
+ if (zshlextext == copy)
+ zshlextext = tokstr;
+ }
+ return 0;
+}
+
+/**/
+void
+zshlex_raw_add(int c)
+{
+ if (!lex_add_raw)
+ return;
+
+ *lexbuf_raw.ptr++ = c;
+ if (lexbuf_raw.siz == ++lexbuf_raw.len) {
+ int newbsiz = lexbuf_raw.siz * 2;
+
+ tokstr_raw = (char *)hrealloc(tokstr_raw, lexbuf_raw.siz, newbsiz);
+ lexbuf_raw.ptr = tokstr_raw + lexbuf_raw.len;
+ memset(lexbuf_raw.ptr, 0, newbsiz - lexbuf_raw.siz);
+ lexbuf_raw.siz = newbsiz;
+ }
+}
+
+/**/
+void
+zshlex_raw_back(void)
+{
+ if (!lex_add_raw)
+ return;
+ lexbuf_raw.ptr--;
+ lexbuf_raw.len--;
+}
+
+/**/
+int
+zshlex_raw_mark(int offset)
+{
+ if (!lex_add_raw)
+ return 0;
+ return lexbuf_raw.len + offset;
+}
+
+/**/
+void
+zshlex_raw_back_to_mark(int mark)
+{
+ if (!lex_add_raw)
+ return;
+ lexbuf_raw.ptr = tokstr_raw + mark;
+ lexbuf_raw.len = mark;
+}
+
+/*
+ * Skip (...) for command-style substitutions: $(...), <(...), >(...)
+ *
+ * In order to ensure we don't stop at closing parentheses with
+ * some other syntactic significance, we'll parse the input until
+ * we find an unmatched closing parenthesis. However, we'll throw
+ * away the result of the parsing and just keep the string we've built
+ * up on the way.
+ */
+
+/**/
+static int
+skipcomm(void)
+{
+#ifdef ZSH_OLD_SKIPCOMM
+ int pct = 1, c, start = 1;
+
+ cmdpush(CS_CMDSUBST);
+ SETPARBEGIN
+ c = Inpar;
+ do {
+ int iswhite;
+ add(c);
+ c = hgetc();
+ if (itok(c) || lexstop)
+ break;
+ iswhite = inblank(c);
+ switch (c) {
+ case '(':
+ pct++;
+ break;
+ case ')':
+ pct--;
+ break;
+ case '\\':
+ add(c);
+ c = hgetc();
+ break;
+ case '\'': {
+ int strquote = lexbuf.ptr[-1] == '$';
+ add(c);
+ STOPHIST
+ while ((c = hgetc()) != '\'' && !lexstop) {
+ if (c == '\\' && strquote) {
+ add(c);
+ c = hgetc();
+ }
+ add(c);
+ }
+ ALLOWHIST
+ break;
+ }
+ case '\"':
+ add(c);
+ while ((c = hgetc()) != '\"' && !lexstop)
+ if (c == '\\') {
+ add(c);
+ add(hgetc());
+ } else
+ add(c);
+ break;
+ case '`':
+ add(c);
+ while ((c = hgetc()) != '`' && !lexstop)
+ if (c == '\\')
+ add(c), add(hgetc());
+ else
+ add(c);
+ break;
+ case '#':
+ if (start) {
+ add(c);
+ while ((c = hgetc()) != '\n' && !lexstop)
+ add(c);
+ iswhite = 1;
+ }
+ break;
+ }
+ start = iswhite;
+ }
+ while (pct);
+ if (!lexstop)
+ SETPAREND
+ cmdpop();
+ return lexstop;
+#else
+ char *new_tokstr;
+ int new_lexstop, new_lex_add_raw;
+ int save_infor = infor;
+ struct lexbufstate new_lexbuf;
+
+ infor = 0;
+ cmdpush(CS_CMDSUBST);
+ SETPARBEGIN
+ add(Inpar);
+
+ new_lex_add_raw = lex_add_raw + 1;
+ if (!lex_add_raw) {
+ /*
+ * We'll combine the string so far with the input
+ * read in for the command substitution. To do this
+ * we'll just propagate the current tokstr etc. as the
+ * variables used for adding raw input, and
+ * ensure we swap those for the real tokstr etc. at the end.
+ *
+ * However, we need to save and restore the rest of the
+ * lexical and parse state as we're effectively parsing
+ * an internal string. Because we're still parsing it from
+ * the original input source (we have to --- we don't know
+ * when to stop inputting it otherwise and can't rely on
+ * the input being recoverable until we've read it) we need
+ * to keep the same history context.
+ */
+ new_tokstr = tokstr;
+ new_lexbuf = lexbuf;
+
+ /*
+ * If we're expanding an alias at this point, we need the whole
+ * remaining text as part of the string for the command in
+ * parentheses, so don't backtrack. This is different from the
+ * usual case where the alias is fully within the command, where
+ * we want the unexpanded text so that it will be expanded
+ * again when the command in the parentheses is executed.
+ *
+ * I never wanted to be a software engineer, you know.
+ */
+ if (inbufflags & INP_ALIAS)
+ inbufflags |= INP_RAW_KEEP;
+ zcontext_save_partial(ZCONTEXT_LEX|ZCONTEXT_PARSE);
+ hist_in_word(1);
+ } else {
+ /*
+ * Set up for nested command subsitution, however
+ * we don't actually need the string until we get
+ * back to the top level and recover the lot.
+ * The $() body just appears empty.
+ *
+ * We do need to propagate the raw variables which would
+ * otherwise by cleared, though.
+ */
+ new_tokstr = tokstr_raw;
+ new_lexbuf = lexbuf_raw;
+
+ zcontext_save_partial(ZCONTEXT_LEX|ZCONTEXT_PARSE);
+ }
+ tokstr_raw = new_tokstr;
+ lexbuf_raw = new_lexbuf;
+ lex_add_raw = new_lex_add_raw;
+ /*
+ * Don't do any ZLE specials down here: they're only needed
+ * when we return the string from the recursive parse.
+ * (TBD: this probably means we should be initialising lexflags
+ * more consistently.)
+ *
+ * Note that in that case we're still using the ZLE line reading
+ * function at the history layer --- this is consistent with the
+ * intention of maintaining the history and input layers across
+ * the recursive parsing.
+ *
+ * Also turn off LEXFLAGS_NEWLINE because this is already skipping
+ * across the entire construct, and parse_event() needs embedded
+ * newlines to be "real" when looking for the OUTPAR token.
+ */
+ lexflags &= ~(LEXFLAGS_ZLE|LEXFLAGS_NEWLINE);
+ dbparens = 0; /* restored by zcontext_restore_partial() */
+
+ if (!parse_event(OUTPAR) || tok != OUTPAR) {
+ if (strin) {
+ /*
+ * Get the rest of the string raw since we don't
+ * know where this token ends.
+ */
+ while (!lexstop)
+ (void)ingetc();
+ } else
+ lexstop = 1;
+ }
+ /* Outpar lexical token gets added in caller if present */
+
+ /*
+ * We're going to keep the full raw input string
+ * as the current token string after popping the stack.
+ */
+ new_tokstr = tokstr_raw;
+ new_lexbuf = lexbuf_raw;
+ /*
+ * We're also going to propagate the lexical state:
+ * if we couldn't parse the command substitution we
+ * can't continue.
+ */
+ new_lexstop = lexstop;
+
+ zcontext_restore_partial(ZCONTEXT_LEX|ZCONTEXT_PARSE);
+
+ if (lex_add_raw) {
+ /*
+ * Keep going, so retain the raw variables.
+ */
+ tokstr_raw = new_tokstr;
+ lexbuf_raw = new_lexbuf;
+ } else {
+ if (!new_lexstop) {
+ /* Ignore the ')' added on input */
+ new_lexbuf.len--;
+ *--new_lexbuf.ptr = '\0';
+ }
+
+ /*
+ * Convince the rest of lex.c we were examining a string
+ * all along.
+ */
+ tokstr = new_tokstr;
+ lexbuf = new_lexbuf;
+ lexstop = new_lexstop;
+ hist_in_word(0);
+ }
+
+ if (!lexstop)
+ SETPAREND
+ cmdpop();
+ infor = save_infor;
+
+ return lexstop;
+#endif
+}
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/loop.c b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/loop.c
new file mode 100644
index 0000000..1013aeb
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/loop.c
@@ -0,0 +1,795 @@
+/*
+ * loop.c - loop execution
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+#include "zsh.mdh"
+#include "loop.pro"
+
+/* # of nested loops we are in */
+
+/**/
+int loops;
+
+/* # of continue levels */
+
+/**/
+mod_export int contflag;
+
+/* # of break levels */
+
+/**/
+mod_export int breaks;
+
+/**/
+int
+execfor(Estate state, int do_exec)
+{
+ Wordcode end, loop;
+ wordcode code = state->pc[-1];
+ int iscond = (WC_FOR_TYPE(code) == WC_FOR_COND), ctok = 0, atok = 0;
+ int last = 0;
+ char *name, *str, *cond = NULL, *advance = NULL;
+ zlong val = 0;
+ LinkList vars = NULL, args = NULL;
+ int old_simple_pline = simple_pline;
+
+ /* See comments in execwhile() */
+ simple_pline = 1;
+
+ end = state->pc + WC_FOR_SKIP(code);
+
+ if (iscond) {
+ str = dupstring(ecgetstr(state, EC_NODUP, NULL));
+ singsub(&str);
+ if (isset(XTRACE)) {
+ char *str2 = dupstring(str);
+ untokenize(str2);
+ printprompt4();
+ fprintf(xtrerr, "%s\n", str2);
+ fflush(xtrerr);
+ }
+ if (!errflag) {
+ matheval(str);
+ }
+ if (errflag) {
+ state->pc = end;
+ simple_pline = old_simple_pline;
+ return 1;
+ }
+ cond = ecgetstr(state, EC_NODUP, &ctok);
+ advance = ecgetstr(state, EC_NODUP, &atok);
+ } else {
+ vars = ecgetlist(state, *state->pc++, EC_NODUP, NULL);
+
+ if (WC_FOR_TYPE(code) == WC_FOR_LIST) {
+ int htok = 0;
+
+ if (!(args = ecgetlist(state, *state->pc++, EC_DUPTOK, &htok))) {
+ state->pc = end;
+ simple_pline = old_simple_pline;
+ return 0;
+ }
+ if (htok) {
+ execsubst(args);
+ if (errflag) {
+ state->pc = end;
+ simple_pline = old_simple_pline;
+ return 1;
+ }
+ }
+ } else {
+ char **x;
+
+ args = newlinklist();
+ for (x = pparams; *x; x++)
+ addlinknode(args, dupstring(*x));
+ }
+ }
+
+ if (!args || empty(args))
+ lastval = 0;
+
+ loops++;
+ pushheap();
+ cmdpush(CS_FOR);
+ loop = state->pc;
+ while (!last) {
+ if (iscond) {
+ if (ctok) {
+ str = dupstring(cond);
+ singsub(&str);
+ } else
+ str = cond;
+ if (!errflag) {
+ while (iblank(*str))
+ str++;
+ if (*str) {
+ if (isset(XTRACE)) {
+ printprompt4();
+ fprintf(xtrerr, "%s\n", str);
+ fflush(xtrerr);
+ }
+ val = mathevali(str);
+ } else
+ val = 1;
+ }
+ if (errflag) {
+ if (breaks)
+ breaks--;
+ lastval = 1;
+ break;
+ }
+ if (!val)
+ break;
+ } else {
+ LinkNode node;
+ int count = 0;
+ for (node = firstnode(vars); node; incnode(node))
+ {
+ name = (char *)getdata(node);
+ if (!args || !(str = (char *) ugetnode(args)))
+ {
+ if (count) {
+ str = "";
+ last = 1;
+ } else
+ break;
+ }
+ if (isset(XTRACE)) {
+ printprompt4();
+ fprintf(xtrerr, "%s=%s\n", name, str);
+ fflush(xtrerr);
+ }
+ setsparam(name, ztrdup(str));
+ count++;
+ }
+ if (!count)
+ break;
+ }
+ state->pc = loop;
+ execlist(state, 1, do_exec && args && empty(args));
+ if (breaks) {
+ breaks--;
+ if (breaks || !contflag)
+ break;
+ contflag = 0;
+ }
+ if (retflag)
+ break;
+ if (iscond && !errflag) {
+ if (atok) {
+ str = dupstring(advance);
+ singsub(&str);
+ } else
+ str = advance;
+ if (isset(XTRACE)) {
+ printprompt4();
+ fprintf(xtrerr, "%s\n", str);
+ fflush(xtrerr);
+ }
+ if (!errflag)
+ matheval(str);
+ }
+ if (errflag) {
+ if (breaks)
+ breaks--;
+ lastval = 1;
+ break;
+ }
+ freeheap();
+ }
+ popheap();
+ cmdpop();
+ loops--;
+ simple_pline = old_simple_pline;
+ state->pc = end;
+ this_noerrexit = 1;
+ return lastval;
+}
+
+/**/
+int
+execselect(Estate state, UNUSED(int do_exec))
+{
+ Wordcode end, loop;
+ wordcode code = state->pc[-1];
+ char *str, *s, *name;
+ LinkNode n;
+ int i, usezle;
+ FILE *inp;
+ size_t more;
+ LinkList args;
+ int old_simple_pline = simple_pline;
+
+ /* See comments in execwhile() */
+ simple_pline = 1;
+
+ end = state->pc + WC_FOR_SKIP(code);
+ name = ecgetstr(state, EC_NODUP, NULL);
+
+ if (WC_SELECT_TYPE(code) == WC_SELECT_PPARAM) {
+ char **x;
+
+ args = newlinklist();
+ for (x = pparams; *x; x++)
+ addlinknode(args, dupstring(*x));
+ } else {
+ int htok = 0;
+
+ if (!(args = ecgetlist(state, *state->pc++, EC_DUPTOK, &htok))) {
+ state->pc = end;
+ simple_pline = old_simple_pline;
+ return 0;
+ }
+ if (htok) {
+ execsubst(args);
+ if (errflag) {
+ state->pc = end;
+ simple_pline = old_simple_pline;
+ return 1;
+ }
+ }
+ }
+ if (!args || empty(args)) {
+ state->pc = end;
+ simple_pline = old_simple_pline;
+ return 0;
+ }
+ loops++;
+
+ pushheap();
+ cmdpush(CS_SELECT);
+ usezle = interact && SHTTY != -1 && isset(USEZLE);
+ inp = fdopen(dup(usezle ? SHTTY : 0), "r");
+ more = selectlist(args, 0);
+ loop = state->pc;
+ for (;;) {
+ for (;;) {
+ if (empty(bufstack)) {
+ if (usezle) {
+ int oef = errflag;
+
+ isfirstln = 1;
+ str = zleentry(ZLE_CMD_READ, &prompt3, NULL,
+ 0, ZLCON_SELECT);
+ if (errflag)
+ str = NULL;
+ /* Keep any user interrupt error status */
+ errflag = oef | (errflag & ERRFLAG_INT);
+ } else {
+ str = promptexpand(prompt3, 0, NULL, NULL, NULL);
+ zputs(str, stderr);
+ free(str);
+ fflush(stderr);
+ str = fgets(zhalloc(256), 256, inp);
+ }
+ } else
+ str = (char *)getlinknode(bufstack);
+ if (!str && !errflag)
+ setsparam("REPLY", ztrdup("")); /* EOF (user pressed Ctrl+D) */
+ if (!str || errflag) {
+ if (breaks)
+ breaks--;
+ fprintf(stderr, "\n");
+ fflush(stderr);
+ goto done;
+ }
+ if ((s = strchr(str, '\n')))
+ *s = '\0';
+ if (*str)
+ break;
+ more = selectlist(args, more);
+ }
+ setsparam("REPLY", ztrdup(str));
+ i = atoi(str);
+ if (!i)
+ str = "";
+ else {
+ for (i--, n = firstnode(args); n && i; incnode(n), i--);
+ if (n)
+ str = (char *) getdata(n);
+ else
+ str = "";
+ }
+ setsparam(name, ztrdup(str));
+ state->pc = loop;
+ execlist(state, 1, 0);
+ freeheap();
+ if (breaks) {
+ breaks--;
+ if (breaks || !contflag)
+ break;
+ contflag = 0;
+ }
+ if (retflag || errflag)
+ break;
+ }
+ done:
+ cmdpop();
+ popheap();
+ fclose(inp);
+ loops--;
+ simple_pline = old_simple_pline;
+ state->pc = end;
+ this_noerrexit = 1;
+ return lastval;
+}
+
+/* And this is used to print select lists. */
+
+/**/
+size_t
+selectlist(LinkList l, size_t start)
+{
+ size_t longest = 1, fct, fw = 0, colsz, t0, t1, ct;
+ char **arr, **ap;
+
+ zleentry(ZLE_CMD_TRASH);
+ arr = hlinklist2array(l, 0);
+ for (ap = arr; *ap; ap++)
+ if (strlen(*ap) > longest)
+ longest = strlen(*ap);
+ t0 = ct = ap - arr;
+ longest++;
+ while (t0)
+ t0 /= 10, longest++;
+ /* to compensate for added ')' */
+ fct = (zterm_columns - 1) / (longest + 3);
+ if (fct == 0)
+ fct = 1;
+ else
+ fw = (zterm_columns - 1) / fct;
+ colsz = (ct + fct - 1) / fct;
+ for (t1 = start; t1 != colsz && t1 - start < zterm_lines - 2; t1++) {
+ ap = arr + t1;
+ do {
+ size_t t2 = strlen(*ap) + 2;
+ int t3;
+
+ fprintf(stderr, "%d) %s", t3 = ap - arr + 1, *ap);
+ while (t3)
+ t2++, t3 /= 10;
+ for (; t2 < fw; t2++)
+ fputc(' ', stderr);
+ for (t0 = colsz; t0 && *ap; t0--, ap++);
+ }
+ while (*ap);
+ fputc('\n', stderr);
+ }
+
+ /* Below is a simple attempt at doing it the Korn Way..
+ ap = arr;
+ t0 = 0;
+ do {
+ t0++;
+ fprintf(stderr,"%d) %s\n",t0,*ap);
+ ap++;
+ }
+ while (*ap);*/
+ fflush(stderr);
+
+ return t1 < colsz ? t1 : 0;
+}
+
+/**/
+int
+execwhile(Estate state, UNUSED(int do_exec))
+{
+ Wordcode end, loop;
+ wordcode code = state->pc[-1];
+ int olderrexit, oldval, isuntil = (WC_WHILE_TYPE(code) == WC_WHILE_UNTIL);
+ int old_simple_pline = simple_pline;
+
+ end = state->pc + WC_WHILE_SKIP(code);
+ olderrexit = noerrexit;
+ oldval = 0;
+ pushheap();
+ cmdpush(isuntil ? CS_UNTIL : CS_WHILE);
+ loops++;
+ loop = state->pc;
+
+ if (loop[0] == WC_END && loop[1] == WC_END) {
+
+ /* This is an empty loop. Make sure the signal handler sets the
+ * flags and then just wait for someone hitting ^C. */
+
+ simple_pline = 1;
+
+ while (!breaks)
+ ;
+ breaks--;
+
+ simple_pline = old_simple_pline;
+ } else
+ for (;;) {
+ state->pc = loop;
+ noerrexit = NOERREXIT_EXIT | NOERREXIT_RETURN;
+
+ /* In case the test condition is a functional no-op,
+ * make sure signal handlers recognize ^C to end the loop. */
+ simple_pline = 1;
+
+ execlist(state, 1, 0);
+
+ simple_pline = old_simple_pline;
+ noerrexit = olderrexit;
+ if (!((lastval == 0) ^ isuntil)) {
+ if (breaks)
+ breaks--;
+ if (!retflag)
+ lastval = oldval;
+ break;
+ }
+ if (retflag)
+ break;
+
+ /* In case the loop body is also a functional no-op,
+ * make sure signal handlers recognize ^C as above. */
+ simple_pline = 1;
+
+ execlist(state, 1, 0);
+
+ simple_pline = old_simple_pline;
+ if (breaks) {
+ breaks--;
+ if (breaks || !contflag)
+ break;
+ contflag = 0;
+ }
+ if (errflag) {
+ lastval = 1;
+ break;
+ }
+ if (retflag)
+ break;
+ freeheap();
+ oldval = lastval;
+ }
+ cmdpop();
+ popheap();
+ loops--;
+ state->pc = end;
+ this_noerrexit = 1;
+ return lastval;
+}
+
+/**/
+int
+execrepeat(Estate state, UNUSED(int do_exec))
+{
+ Wordcode end, loop;
+ wordcode code = state->pc[-1];
+ int count, htok = 0;
+ char *tmp;
+ int old_simple_pline = simple_pline;
+
+ /* See comments in execwhile() */
+ simple_pline = 1;
+
+ end = state->pc + WC_REPEAT_SKIP(code);
+
+ lastval = 0;
+ tmp = ecgetstr(state, EC_DUPTOK, &htok);
+ if (htok)
+ singsub(&tmp);
+ count = mathevali(tmp);
+ if (errflag)
+ return 1;
+ pushheap();
+ cmdpush(CS_REPEAT);
+ loops++;
+ loop = state->pc;
+ while (count-- > 0) {
+ state->pc = loop;
+ execlist(state, 1, 0);
+ freeheap();
+ if (breaks) {
+ breaks--;
+ if (breaks || !contflag)
+ break;
+ contflag = 0;
+ }
+ if (errflag) {
+ lastval = 1;
+ break;
+ }
+ if (retflag)
+ break;
+ }
+ cmdpop();
+ popheap();
+ loops--;
+ simple_pline = old_simple_pline;
+ state->pc = end;
+ this_noerrexit = 1;
+ return lastval;
+}
+
+/**/
+int
+execif(Estate state, int do_exec)
+{
+ Wordcode end, next;
+ wordcode code = state->pc[-1];
+ int olderrexit, s = 0, run = 0;
+
+ olderrexit = noerrexit;
+ end = state->pc + WC_IF_SKIP(code);
+
+ noerrexit |= NOERREXIT_EXIT | NOERREXIT_RETURN;
+ while (state->pc < end) {
+ code = *state->pc++;
+ if (wc_code(code) != WC_IF ||
+ (run = (WC_IF_TYPE(code) == WC_IF_ELSE))) {
+ if (run)
+ run = 2;
+ break;
+ }
+ next = state->pc + WC_IF_SKIP(code);
+ cmdpush(s ? CS_ELIF : CS_IF);
+ execlist(state, 1, 0);
+ cmdpop();
+ if (!lastval) {
+ run = 1;
+ break;
+ }
+ if (retflag)
+ break;
+ s = 1;
+ state->pc = next;
+ }
+
+ if (run) {
+ /* we need to ignore lastval until we reach execcmd() */
+ if (olderrexit)
+ noerrexit = olderrexit;
+ else if (lastval)
+ noerrexit |= NOERREXIT_EXIT | NOERREXIT_RETURN | NOERREXIT_UNTIL_EXEC;
+ else
+ noerrexit &= ~ (NOERREXIT_EXIT | NOERREXIT_RETURN);
+ cmdpush(run == 2 ? CS_ELSE : (s ? CS_ELIFTHEN : CS_IFTHEN));
+ execlist(state, 1, do_exec);
+ cmdpop();
+ } else {
+ noerrexit = olderrexit;
+ if (!retflag)
+ lastval = 0;
+ }
+ state->pc = end;
+ this_noerrexit = 1;
+
+ return lastval;
+}
+
+/**/
+int
+execcase(Estate state, int do_exec)
+{
+ Wordcode end, next;
+ wordcode code = state->pc[-1];
+ char *word, *pat;
+ int npat, save, nalts, ialt, patok, anypatok;
+ Patprog *spprog, pprog;
+
+ end = state->pc + WC_CASE_SKIP(code);
+
+ word = ecgetstr(state, EC_DUP, NULL);
+ singsub(&word);
+ untokenize(word);
+ anypatok = 0;
+
+ cmdpush(CS_CASE);
+ while (state->pc < end) {
+ code = *state->pc++;
+ if (wc_code(code) != WC_CASE)
+ break;
+
+ save = 0;
+ next = state->pc + WC_CASE_SKIP(code);
+ nalts = *state->pc++;
+ ialt = patok = 0;
+
+ if (isset(XTRACE)) {
+ printprompt4();
+ fprintf(xtrerr, "case %s (", word);
+ }
+
+ while (!patok && nalts) {
+ npat = state->pc[1];
+ spprog = state->prog->pats + npat;
+ pprog = NULL;
+ pat = NULL;
+
+ queue_signals();
+
+ if (isset(XTRACE)) {
+ int htok = 0;
+ pat = dupstring(ecrawstr(state->prog, state->pc, &htok));
+ if (htok)
+ singsub(&pat);
+
+ if (ialt++)
+ fprintf(stderr, " | ");
+ quote_tokenized_output(pat, xtrerr);
+ }
+
+ if (*spprog != dummy_patprog1 && *spprog != dummy_patprog2)
+ pprog = *spprog;
+
+ if (!pprog) {
+ if (!pat) {
+ char *opat;
+ int htok = 0;
+
+ pat = dupstring(opat = ecrawstr(state->prog,
+ state->pc, &htok));
+ if (htok)
+ singsub(&pat);
+ save = (!(state->prog->flags & EF_HEAP) &&
+ !strcmp(pat, opat) && *spprog != dummy_patprog2);
+ }
+ if (!(pprog = patcompile(pat, (save ? PAT_ZDUP : PAT_STATIC),
+ NULL)))
+ zerr("bad pattern: %s", pat);
+ else if (save)
+ *spprog = pprog;
+ }
+ if (pprog && pattry(pprog, word))
+ patok = anypatok = 1;
+ state->pc += 2;
+ nalts--;
+
+ unqueue_signals();
+ }
+ state->pc += 2 * nalts;
+ if (isset(XTRACE)) {
+ fprintf(xtrerr, ")\n");
+ fflush(xtrerr);
+ }
+ if (patok) {
+ execlist(state, 1, ((WC_CASE_TYPE(code) == WC_CASE_OR) &&
+ do_exec));
+ while (!retflag && wc_code(code) == WC_CASE &&
+ WC_CASE_TYPE(code) == WC_CASE_AND && state->pc < end) {
+ state->pc = next;
+ code = *state->pc++;
+ next = state->pc + WC_CASE_SKIP(code);
+ nalts = *state->pc++;
+ state->pc += 2 * nalts;
+ execlist(state, 1, ((WC_CASE_TYPE(code) == WC_CASE_OR) &&
+ do_exec));
+ }
+ if (WC_CASE_TYPE(code) != WC_CASE_TESTAND)
+ break;
+ }
+ state->pc = next;
+ }
+ cmdpop();
+
+ state->pc = end;
+
+ if (!anypatok)
+ lastval = 0;
+ this_noerrexit = 1;
+
+ return lastval;
+}
+
+/*
+ * Errflag from `try' block, may be reset in `always' block.
+ * Accessible from an integer parameter, so needs to be a zlong.
+ */
+
+/**/
+zlong
+try_errflag = -1;
+
+/**
+ * Corresponding interrupt error status form `try' block.
+ */
+
+/**/
+zlong
+try_interrupt = -1;
+
+/**/
+zlong
+try_tryflag = 0;
+
+/**/
+int
+exectry(Estate state, int do_exec)
+{
+ Wordcode end, always;
+ int endval;
+ int save_retflag, save_breaks, save_contflag;
+ zlong save_try_errflag, save_try_tryflag, save_try_interrupt;
+
+ end = state->pc + WC_TRY_SKIP(state->pc[-1]);
+ always = state->pc + 1 + WC_TRY_SKIP(*state->pc);
+ state->pc++;
+ pushheap();
+ cmdpush(CS_CURSH);
+
+ /* The :try clause */
+ save_try_tryflag = try_tryflag;
+ try_tryflag = 1;
+
+ execlist(state, 1, do_exec);
+
+ try_tryflag = save_try_tryflag;
+
+ /* Don't record errflag here, may be reset. However, */
+ /* endval should show failure when there is an error. */
+ endval = lastval ? lastval : errflag;
+
+ freeheap();
+
+ cmdpop();
+ cmdpush(CS_ALWAYS);
+
+ /* The always clause. */
+ save_try_errflag = try_errflag;
+ save_try_interrupt = try_interrupt;
+ try_errflag = (zlong)(errflag & ERRFLAG_ERROR);
+ try_interrupt = (zlong)((errflag & ERRFLAG_INT) ? 1 : 0);
+ /* We need to reset all errors to allow the block to execute */
+ errflag = 0;
+ save_retflag = retflag;
+ retflag = 0;
+ save_breaks = breaks;
+ breaks = 0;
+ save_contflag = contflag;
+ contflag = 0;
+
+ state->pc = always;
+ execlist(state, 1, do_exec);
+
+ if (try_errflag)
+ errflag |= ERRFLAG_ERROR;
+ else
+ errflag &= ~ERRFLAG_ERROR;
+ if (try_interrupt)
+ errflag |= ERRFLAG_INT;
+ else
+ errflag &= ~ERRFLAG_INT;
+ try_errflag = save_try_errflag;
+ try_interrupt = save_try_interrupt;
+ if (!retflag)
+ retflag = save_retflag;
+ if (!breaks)
+ breaks = save_breaks;
+ if (!contflag)
+ contflag = save_contflag;
+
+ cmdpop();
+ popheap();
+ state->pc = end;
+
+ return endval;
+}
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/makepro.awk b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/makepro.awk
new file mode 100644
index 0000000..0498c15
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/makepro.awk
@@ -0,0 +1,166 @@
+#
+# makepro.awk - generate prototype lists
+#
+
+BEGIN {
+ aborting = 0
+
+ # arg 1 is the name of the file to process
+ # arg 2 is the name of the subdirectory it is in
+ if(ARGC != 3) {
+ aborting = 1
+ exit 1
+ }
+ name = ARGV[1]
+ gsub(/^.*\//, "", name)
+ gsub(/\.c$/, "", name)
+ name = ARGV[2] "_" name
+ gsub(/\//, "_", name)
+ ARGC--
+
+ printf "E#ifndef have_%s_globals\n", name
+ printf "E#define have_%s_globals\n", name
+ printf "E\n"
+}
+
+# all relevant declarations are preceded by "/**/" on a line by itself
+
+/^\/\*\*\/$/ {
+ # The declaration is on following lines. The interesting part might
+ # be terminated by a `{' (`int foo(void) { }' or `int bar[] = {')
+ # or `;' (`int x;').
+ line = ""
+ isfunc = 0
+ while(1) {
+ if(getline <= 0) {
+ aborting = 1
+ exit 1
+ }
+ if (line == "" && $0 ~ /^[ \t]*#/) {
+ # Directly after the /**/ was a preprocessor line.
+ # Spit it out and re-start the outer loop.
+ printf "E%s\n", $0
+ printf "L%s\n", $0
+ next
+ }
+ gsub(/\t/, " ")
+ line = line " " $0
+ gsub(/\/\*([^*]|\*+[^*\/])*\*+\//, " ", line)
+ if(line ~ /\/\*/)
+ continue
+ # If it is a function definition, note so.
+ if(line ~ /\) *(VA_DCL )*[{].*$/) #}
+ isfunc = 1
+ if(sub(/ *[{;].*$/, "", line)) #}
+ break
+ }
+ if (!match(line, /VA_ALIST/)) {
+ # Put spaces around each identifier.
+ while(match(line, /[^_0-9A-Za-z ][_0-9A-Za-z]/) ||
+ match(line, /[_0-9A-Za-z][^_0-9A-Za-z ]/))
+ line = substr(line, 1, RSTART) " " substr(line, RSTART+1)
+ }
+ # Separate declarations into a type and a list of declarators.
+ # In each declarator, "@{" and "@}" are used in place of parens to
+ # mark function parameter lists, and "@!" is used in place of commas
+ # in parameter lists. "@<" and "@>" are used in place of
+ # non-parameter list parens.
+ gsub(/ _ +/, " _ ", line)
+ while(1) {
+ if(isfunc && match(line, /\([^()]*\)$/))
+ line = substr(line, 1, RSTART-1) " _ (" substr(line, RSTART) ")"
+ else if(match(line, / _ \(\([^,()]*,/))
+ line = substr(line, 1, RSTART+RLENGTH-2) "@!" substr(line, RSTART+RLENGTH)
+ else if(match(line, / _ \(\([^,()]*\)\)/))
+ line = substr(line, 1, RSTART-1) "@{" substr(line, RSTART+5, RLENGTH-7) "@}" substr(line, RSTART+RLENGTH)
+ else if(match(line, /\([^,()]*\)/))
+ line = substr(line, 1, RSTART-1) "@<" substr(line, RSTART+1, RLENGTH-2) "@>" substr(line, RSTART+RLENGTH)
+ else
+ break
+ }
+ sub(/^ */, "", line)
+ match(line, /^((const|enum|mod_export|static|struct|union) +)*([_0-9A-Za-z]+ +|((char|double|float|int|long|short|unsigned|void) +)+)((const|static) +)*/)
+ dtype = substr(line, 1, RLENGTH)
+ sub(/ *$/, "", dtype)
+ if(" " dtype " " ~ / static /)
+ locality = "L"
+ else
+ locality = "E"
+ exported = " " dtype " " ~ / mod_export /
+ line = substr(line, RLENGTH+1) ","
+ # Handle each declarator.
+ if (match(line, /VA_ALIST/)) {
+ # Already has VARARGS handling.
+
+ # Put parens etc. back
+ gsub(/@[{]/, "((", line)
+ gsub(/@}/, "))", line)
+ gsub(/@/, ")", line)
+ gsub(/@!/, ",", line)
+ sub(/,$/, ";", line)
+ gsub(/mod_export/, "mod_import_function", dtype)
+ gsub(/VA_ALIST/, "VA_ALIST_PROTO", line)
+ sub(/ VA_DCL/, "", line)
+
+ if(locality ~ /E/)
+ dtype = "extern " dtype
+
+ if (match(line, /[_0-9A-Za-z]+\(VA_ALIST/))
+ dnam = substr(line, RSTART, RLENGTH-9)
+
+ # If this is exported, add it to the exported symbol list.
+ if (exported)
+ printf "X%s\n", dnam
+
+ printf "%s%s %s\n", locality, dtype, line
+ } else {
+ while(match(line, /^[^,]*,/)) {
+ # Separate out the name from the declarator. Use "@+" and "@-"
+ # to bracket the name within the declarator. Strip off any
+ # initialiser.
+ dcltor = substr(line, 1, RLENGTH-1)
+ line = substr(line, RLENGTH+1)
+ sub(/\=.*$/, "", dcltor)
+ match(dcltor, /^([^_0-9A-Za-z]| const )*/)
+ dcltor = substr(dcltor, 1, RLENGTH) "@+" substr(dcltor, RLENGTH+1)
+ match(dcltor, /^.*@\+[_0-9A-Za-z]+/)
+ dcltor = substr(dcltor, 1, RLENGTH) "@-" substr(dcltor, RLENGTH+1)
+ dnam = dcltor
+ sub(/^.*@\+/, "", dnam)
+ sub(/@-.*$/, "", dnam)
+
+ # Put parens etc. back
+ gsub(/@[{]/, " _((", dcltor)
+ gsub(/@}/, "))", dcltor)
+ gsub(/@/, ")", dcltor)
+ gsub(/@!/, ",", dcltor)
+
+ # If this is exported, add it to the exported symbol list.
+ if(exported)
+ printf "X%s\n", dnam
+
+ # Format the declaration for output
+ dcl = dtype " " dcltor ";"
+ if(locality ~ /E/)
+ dcl = "extern " dcl
+ if(isfunc)
+ gsub(/ mod_export /, " mod_import_function ", dcl)
+ else
+ gsub(/ mod_export /, " mod_import_variable ", dcl)
+ gsub(/@[+-]/, "", dcl)
+ gsub(/ +/, " ", dcl)
+ while(match(dcl, /[^_0-9A-Za-z] ./) || match(dcl, /. [^_0-9A-Za-z]/))
+ dcl = substr(dcl, 1, RSTART) substr(dcl, RSTART+2)
+ printf "%s%s\n", locality, dcl
+ }
+ }
+}
+
+END {
+ if(aborting)
+ exit 1
+ printf "E\n"
+ printf "E#endif /* !have_%s_globals */\n", name
+}
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/mem.c b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/mem.c
new file mode 100644
index 0000000..77e4375
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/mem.c
@@ -0,0 +1,1899 @@
+/*
+ * mem.c - memory management
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+#include "zsh.mdh"
+#include "mem.pro"
+
+/*
+ There are two ways to allocate memory in zsh. The first way is
+ to call zalloc/zshcalloc, which call malloc/calloc directly. It
+ is legal to call realloc() or free() on memory allocated this way.
+ The second way is to call zhalloc/hcalloc, which allocates memory
+ from one of the memory pools on the heap stack. Such memory pools
+ will automatically created when the heap allocation routines are
+ called. To be sure that they are freed at appropriate times
+ one should call pushheap() before one starts using heaps and
+ popheap() after that (when the memory allocated on the heaps since
+ the last pushheap() isn't needed anymore).
+ pushheap() saves the states of all currently allocated heaps and
+ popheap() resets them to the last state saved and destroys the
+ information about that state. If you called pushheap() and
+ allocated some memory on the heaps and then come to a place where
+ you don't need the allocated memory anymore but you still want
+ to allocate memory on the heap, you should call freeheap(). This
+ works like popheap(), only that it doesn't free the information
+ about the heap states (i.e. the heaps are like after the call to
+ pushheap() and you have to call popheap some time later).
+
+ Memory allocated in this way does not have to be freed explicitly;
+ it will all be freed when the pool is destroyed. In fact,
+ attempting to free this memory may result in a core dump.
+
+ If possible, the heaps are allocated using mmap() so that the
+ (*real*) heap isn't filled up with empty zsh heaps. If mmap()
+ is not available and zsh's own allocator is used, we use a simple trick
+ to avoid that: we allocate a large block of memory before allocating
+ a heap pool, this memory is freed again immediately after the pool
+ is allocated. If there are only small blocks on the free list this
+ guarantees that the memory for the pool is at the end of the memory
+ which means that we can give it back to the system when the pool is
+ freed.
+
+ hrealloc(char *p, size_t old, size_t new) is an optimisation
+ with a similar interface to realloc(). Typically the new size
+ will be larger than the old one, since there is no gain in
+ shrinking the allocation (indeed, that will confused hrealloc()
+ since it will forget that the unused space once belonged to this
+ pointer). However, new == 0 is a special case; then if we
+ had to allocate a special heap for this memory it is freed at
+ that point.
+*/
+
+#if defined(HAVE_SYS_MMAN_H) && defined(HAVE_MMAP) && defined(HAVE_MUNMAP)
+
+#include
+
+/*
+ * This definition is designed to enable use of memory mapping on MacOS.
+ * However, performance tests indicate that MacOS mapped regions are
+ * somewhat slower to allocate than memory from malloc(), so whether
+ * using this improves performance depends on details of zhalloc().
+ */
+#if defined(MAP_ANON) && !defined(MAP_ANONYMOUS)
+#define MAP_ANONYMOUS MAP_ANON
+#endif
+
+#if defined(MAP_ANONYMOUS) && defined(MAP_PRIVATE)
+
+#define USE_MMAP 1
+#define MMAP_FLAGS (MAP_ANONYMOUS | MAP_PRIVATE)
+
+#endif
+#endif
+
+#ifdef ZSH_MEM_WARNING
+# ifndef DEBUG
+# define DEBUG 1
+# endif
+#endif
+
+#if defined(ZSH_MEM) && defined(ZSH_MEM_DEBUG)
+
+static int h_m[1025], h_push, h_pop, h_free;
+
+#endif
+
+/* Make sure we align to the longest fundamental type. */
+union mem_align {
+ zlong l;
+ double d;
+};
+
+#define H_ISIZE sizeof(union mem_align)
+#define HEAPSIZE (16384 - H_ISIZE)
+/* Memory available for user data in default arena size */
+#define HEAP_ARENA_SIZE (HEAPSIZE - sizeof(struct heap))
+#define HEAPFREE (16384 - H_ISIZE)
+
+/* Memory available for user data in heap h */
+#define ARENA_SIZEOF(h) ((h)->size - sizeof(struct heap))
+
+/* list of zsh heaps */
+
+static Heap heaps;
+
+/* a heap with free space, not always correct (it will be the last heap
+ * if that was newly allocated but it may also be another one) */
+
+static Heap fheap;
+
+/**/
+#ifdef ZSH_HEAP_DEBUG
+/*
+ * The heap ID we'll allocate next.
+ *
+ * We'll avoid using 0 as that means zero-initialised memory
+ * containing a heap ID is (correctly) marked as invalid.
+ */
+static Heapid next_heap_id = (Heapid)1;
+
+/*
+ * The ID of the heap from which we last allocated heap memory.
+ * In theory, since we carefully avoid allocating heap memory during
+ * interrupts, after any call to zhalloc() or wrappers this should
+ * be the ID of the heap containing the memory just returned.
+ */
+/**/
+mod_export Heapid last_heap_id;
+
+/*
+ * Stack of heaps saved by new_heaps().
+ * Assumes old_heaps() will come along and restore it later
+ * (outputs an error if old_heaps() is called out of sequence).
+ */
+static LinkList heaps_saved;
+
+/*
+ * Debugging verbosity. This must be set from a debugger.
+ * An 'or' of bits from the enum heap_debug_verbosity.
+ */
+static volatile int heap_debug_verbosity;
+
+/*
+ * Generate a heap identifier that's unique up to unsigned integer wrap.
+ *
+ * For the purposes of debugging we won't bother trying to make a
+ * heap_id globally unique, which would require checking all existing
+ * heaps every time we create an ID and still wouldn't do what we
+ * ideally want, which is to make sure the IDs of valid heaps are
+ * different from the IDs of no-longer-valid heaps. Given that,
+ * we'll just assume that if we haven't tracked the problem when the
+ * ID wraps we're out of luck. We could change the type to a long long
+ * if we wanted more room
+ */
+
+static Heapid
+new_heap_id(void)
+{
+ return next_heap_id++;
+}
+
+/**/
+#endif
+
+/* Use new heaps from now on. This returns the old heap-list. */
+
+/**/
+mod_export Heap
+new_heaps(void)
+{
+ Heap h;
+
+ queue_signals();
+ h = heaps;
+
+ fheap = heaps = NULL;
+ unqueue_signals();
+
+#ifdef ZSH_HEAP_DEBUG
+ if (heap_debug_verbosity & HDV_NEW) {
+ fprintf(stderr, "HEAP DEBUG: heap " HEAPID_FMT
+ " saved, new heaps created.\n", h->heap_id);
+ }
+ if (!heaps_saved)
+ heaps_saved = znewlinklist();
+ zpushnode(heaps_saved, h);
+#endif
+ return h;
+}
+
+/* Re-install the old heaps again, freeing the new ones. */
+
+/**/
+mod_export void
+old_heaps(Heap old)
+{
+ Heap h, n;
+
+ queue_signals();
+ for (h = heaps; h; h = n) {
+ n = h->next;
+ DPUTS(h->sp, "BUG: old_heaps() with pushed heaps");
+#ifdef ZSH_HEAP_DEBUG
+ if (heap_debug_verbosity & HDV_FREE) {
+ fprintf(stderr, "HEAP DEBUG: heap " HEAPID_FMT
+ "freed in old_heaps().\n", h->heap_id);
+ }
+#endif
+#ifdef USE_MMAP
+ munmap((void *) h, h->size);
+#else
+ zfree(h, HEAPSIZE);
+#endif
+#ifdef ZSH_VALGRIND
+ VALGRIND_DESTROY_MEMPOOL((char *)h);
+#endif
+ }
+ heaps = old;
+#ifdef ZSH_HEAP_DEBUG
+ if (heap_debug_verbosity & HDV_OLD) {
+ fprintf(stderr, "HEAP DEBUG: heap " HEAPID_FMT
+ "restored.\n", heaps->heap_id);
+ }
+ {
+ Heap myold = heaps_saved ? getlinknode(heaps_saved) : NULL;
+ if (old != myold)
+ {
+ fprintf(stderr, "HEAP DEBUG: invalid old heap " HEAPID_FMT
+ ", expecting " HEAPID_FMT ".\n", old->heap_id,
+ myold->heap_id);
+ }
+ }
+#endif
+ fheap = NULL;
+ unqueue_signals();
+}
+
+/* Temporarily switch to other heaps (or back again). */
+
+/**/
+mod_export Heap
+switch_heaps(Heap new)
+{
+ Heap h;
+
+ queue_signals();
+ h = heaps;
+
+#ifdef ZSH_HEAP_DEBUG
+ if (heap_debug_verbosity & HDV_SWITCH) {
+ fprintf(stderr, "HEAP DEBUG: heap temporarily switched from "
+ HEAPID_FMT " to " HEAPID_FMT ".\n", h->heap_id, new->heap_id);
+ }
+#endif
+ heaps = new;
+ fheap = NULL;
+ unqueue_signals();
+
+ return h;
+}
+
+/* save states of zsh heaps */
+
+/**/
+mod_export void
+pushheap(void)
+{
+ Heap h;
+ Heapstack hs;
+
+ queue_signals();
+
+#if defined(ZSH_MEM) && defined(ZSH_MEM_DEBUG)
+ h_push++;
+#endif
+
+ for (h = heaps; h; h = h->next) {
+ DPUTS(!h->used && h->next, "BUG: empty heap");
+ hs = (Heapstack) zalloc(sizeof(*hs));
+ hs->next = h->sp;
+ h->sp = hs;
+ hs->used = h->used;
+#ifdef ZSH_HEAP_DEBUG
+ hs->heap_id = h->heap_id;
+ h->heap_id = new_heap_id();
+ if (heap_debug_verbosity & HDV_PUSH) {
+ fprintf(stderr, "HEAP DEBUG: heap " HEAPID_FMT " pushed, new id is "
+ HEAPID_FMT ".\n",
+ hs->heap_id, h->heap_id);
+ }
+#endif
+ }
+ unqueue_signals();
+}
+
+/* reset heaps to previous state */
+
+/**/
+mod_export void
+freeheap(void)
+{
+ Heap h, hn, hl = NULL;
+
+ queue_signals();
+
+#if defined(ZSH_MEM) && defined(ZSH_MEM_DEBUG)
+ h_free++;
+#endif
+
+ /*
+ * When pushheap() is called, it sweeps over the entire heaps list of
+ * arenas and marks every one of them with the amount of free space in
+ * that arena at that moment. zhalloc() is then allowed to grab bits
+ * out of any of those arenas that have free space.
+ *
+ * Whenever fheap is NULL here, the loop below sweeps back over the
+ * entire heap list again, resetting the free space in every arena to
+ * the amount stashed by pushheap() and finding the arena with the most
+ * free space to optimize zhalloc()'s next search. When there's a lot
+ * of stuff already on the heap, this is an enormous amount of work,
+ * and performance goes to hell.
+ *
+ * Therefore, we defer freeing the most recently allocated arena until
+ * we reach popheap().
+ *
+ * However, if the arena to which fheap points is unused, we want to
+ * reclaim space in earlier arenas, so we have no choice but to do the
+ * sweep for a new fheap.
+ */
+ if (fheap && !fheap->sp)
+ fheap = NULL; /* We used to do this unconditionally */
+ /*
+ * In other cases, either fheap is already correct, or it has never
+ * been set and this loop will do it, or it'll be reset from scratch
+ * on the next popheap(). So all that's needed here is to pick up
+ * the scan wherever the last pass [or the last popheap()] left off.
+ */
+ for (h = (fheap ? fheap : heaps); h; h = hn) {
+ hn = h->next;
+ if (h->sp) {
+#ifdef ZSH_MEM_DEBUG
+#ifdef ZSH_VALGRIND
+ VALGRIND_MAKE_MEM_UNDEFINED((char *)arena(h) + h->sp->used,
+ h->used - h->sp->used);
+#endif
+ memset(arena(h) + h->sp->used, 0xff, h->used - h->sp->used);
+#endif
+ h->used = h->sp->used;
+ if (!fheap) {
+ if (h->used < ARENA_SIZEOF(h))
+ fheap = h;
+ } else if (ARENA_SIZEOF(h) - h->used >
+ ARENA_SIZEOF(fheap) - fheap->used)
+ fheap = h;
+ hl = h;
+#ifdef ZSH_HEAP_DEBUG
+ /*
+ * As the free makes the heap invalid, give it a new
+ * identifier. We're not popping it, so don't use
+ * the one in the heap stack.
+ */
+ {
+ Heapid new_id = new_heap_id();
+ if (heap_debug_verbosity & HDV_FREE) {
+ fprintf(stderr, "HEAP DEBUG: heap " HEAPID_FMT
+ " freed, new id is " HEAPID_FMT ".\n",
+ h->heap_id, new_id);
+ }
+ h->heap_id = new_id;
+ }
+#endif
+#ifdef ZSH_VALGRIND
+ VALGRIND_MEMPOOL_TRIM((char *)h, (char *)arena(h), h->used);
+#endif
+ } else {
+ if (fheap == h)
+ fheap = NULL;
+ if (h->next) {
+ /* We want to cut this out of the arena list if we can */
+ if (h == heaps)
+ hl = heaps = h->next;
+ else if (hl && hl->next == h)
+ hl->next = h->next;
+ else {
+ DPUTS(hl, "hl->next != h when freeing");
+ hl = h;
+ continue;
+ }
+ h->next = NULL;
+ } else {
+ /* Leave an empty arena at the end until popped */
+ h->used = 0;
+ fheap = hl = h;
+ break;
+ }
+#ifdef USE_MMAP
+ munmap((void *) h, h->size);
+#else
+ zfree(h, HEAPSIZE);
+#endif
+#ifdef ZSH_VALGRIND
+ VALGRIND_DESTROY_MEMPOOL((char *)h);
+#endif
+ }
+ }
+ if (hl)
+ hl->next = NULL;
+ else
+ heaps = fheap = NULL;
+
+ unqueue_signals();
+}
+
+/* reset heap to previous state and destroy state information */
+
+/**/
+mod_export void
+popheap(void)
+{
+ Heap h, hn, hl = NULL;
+ Heapstack hs;
+
+ queue_signals();
+
+#if defined(ZSH_MEM) && defined(ZSH_MEM_DEBUG)
+ h_pop++;
+#endif
+
+ fheap = NULL;
+ for (h = heaps; h; h = hn) {
+ hn = h->next;
+ if ((hs = h->sp)) {
+ h->sp = hs->next;
+#ifdef ZSH_MEM_DEBUG
+#ifdef ZSH_VALGRIND
+ VALGRIND_MAKE_MEM_UNDEFINED((char *)arena(h) + hs->used,
+ h->used - hs->used);
+#endif
+ memset(arena(h) + hs->used, 0xff, h->used - hs->used);
+#endif
+ h->used = hs->used;
+#ifdef ZSH_HEAP_DEBUG
+ if (heap_debug_verbosity & HDV_POP) {
+ fprintf(stderr, "HEAP DEBUG: heap " HEAPID_FMT
+ " popped, old heap was " HEAPID_FMT ".\n",
+ h->heap_id, hs->heap_id);
+ }
+ h->heap_id = hs->heap_id;
+#endif
+#ifdef ZSH_VALGRIND
+ VALGRIND_MEMPOOL_TRIM((char *)h, (char *)arena(h), h->used);
+#endif
+ if (!fheap) {
+ if (h->used < ARENA_SIZEOF(h))
+ fheap = h;
+ } else if (ARENA_SIZEOF(h) - h->used >
+ ARENA_SIZEOF(fheap) - fheap->used)
+ fheap = h;
+ zfree(hs, sizeof(*hs));
+
+ hl = h;
+ } else {
+ if (h->next) {
+ /* We want to cut this out of the arena list if we can */
+ if (h == heaps)
+ hl = heaps = h->next;
+ else if (hl && hl->next == h)
+ hl->next = h->next;
+ else {
+ DPUTS(hl, "hl->next != h when popping");
+ hl = h;
+ continue;
+ }
+ h->next = NULL;
+ } else if (hl == h) /* This is the last arena of all */
+ hl = NULL;
+#ifdef USE_MMAP
+ munmap((void *) h, h->size);
+#else
+ zfree(h, HEAPSIZE);
+#endif
+#ifdef ZSH_VALGRIND
+ VALGRIND_DESTROY_MEMPOOL((char *)h);
+#endif
+ }
+ }
+ if (hl)
+ hl->next = NULL;
+ else
+ heaps = NULL;
+
+ unqueue_signals();
+}
+
+#ifdef USE_MMAP
+/*
+ * Utility function to allocate a heap area of at least *n bytes.
+ * *n will be rounded up to the next page boundary.
+ */
+static Heap
+mmap_heap_alloc(size_t *n)
+{
+ Heap h;
+ static size_t pgsz = 0;
+
+ if (!pgsz) {
+
+#ifdef _SC_PAGESIZE
+ pgsz = sysconf(_SC_PAGESIZE); /* SVR4 */
+#else
+# ifdef _SC_PAGE_SIZE
+ pgsz = sysconf(_SC_PAGE_SIZE); /* HPUX */
+# else
+ pgsz = getpagesize();
+# endif
+#endif
+
+ pgsz--;
+ }
+ *n = (*n + pgsz) & ~pgsz;
+ h = (Heap) mmap(NULL, *n, PROT_READ | PROT_WRITE,
+ MMAP_FLAGS, -1, 0);
+ if (h == ((Heap) -1)) {
+ zerr("fatal error: out of heap memory");
+ exit(1);
+ }
+
+ return h;
+}
+#endif
+
+/* check whether a pointer is within a memory pool */
+
+/**/
+mod_export void *
+zheapptr(void *p)
+{
+ Heap h;
+ queue_signals();
+ for (h = heaps; h; h = h->next)
+ if ((char *)p >= arena(h) &&
+ (char *)p + H_ISIZE < arena(h) + ARENA_SIZEOF(h))
+ break;
+ unqueue_signals();
+ return (h ? p : 0);
+}
+
+/* allocate memory from the current memory pool */
+
+/**/
+mod_export void *
+zhalloc(size_t size)
+{
+ Heap h, hp = NULL;
+ size_t n;
+#ifdef ZSH_VALGRIND
+ size_t req_size = size;
+
+ if (size == 0)
+ return NULL;
+#endif
+
+ size = (size + H_ISIZE - 1) & ~(H_ISIZE - 1);
+
+ queue_signals();
+
+#if defined(ZSH_MEM) && defined(ZSH_MEM_DEBUG)
+ h_m[size < (1024 * H_ISIZE) ? (size / H_ISIZE) : 1024]++;
+#endif
+
+ /* find a heap with enough free space */
+
+ /*
+ * This previously assigned:
+ * h = ((fheap && ARENA_SIZEOF(fheap) >= (size + fheap->used))
+ * ? fheap : heaps);
+ * but we think that nothing upstream of fheap has more free space,
+ * so why start over at heaps just because fheap has too little?
+ */
+ for (h = (fheap ? fheap : heaps); h; h = h->next) {
+ hp = h;
+ if (ARENA_SIZEOF(h) >= (n = size + h->used)) {
+ void *ret;
+
+ h->used = n;
+ ret = arena(h) + n - size;
+ unqueue_signals();
+#ifdef ZSH_HEAP_DEBUG
+ last_heap_id = h->heap_id;
+ if (heap_debug_verbosity & HDV_ALLOC) {
+ fprintf(stderr, "HEAP DEBUG: allocated memory from heap "
+ HEAPID_FMT ".\n", h->heap_id);
+ }
+#endif
+#ifdef ZSH_VALGRIND
+ VALGRIND_MEMPOOL_ALLOC((char *)h, (char *)ret, req_size);
+#endif
+ return ret;
+ }
+ }
+ {
+ /* not found, allocate new heap */
+#if defined(ZSH_MEM) && !defined(USE_MMAP)
+ static int called = 0;
+ void *foo = called ? (void *)malloc(HEAPFREE) : NULL;
+ /* tricky, see above */
+#endif
+
+ n = HEAP_ARENA_SIZE > size ? HEAPSIZE : size + sizeof(*h);
+
+#ifdef USE_MMAP
+ h = mmap_heap_alloc(&n);
+#else
+ h = (Heap) zalloc(n);
+#endif
+
+#if defined(ZSH_MEM) && !defined(USE_MMAP)
+ if (called)
+ zfree(foo, HEAPFREE);
+ called = 1;
+#endif
+
+ h->size = n;
+ h->used = size;
+ h->next = NULL;
+ h->sp = NULL;
+#ifdef ZSH_HEAP_DEBUG
+ h->heap_id = new_heap_id();
+ if (heap_debug_verbosity & HDV_CREATE) {
+ fprintf(stderr, "HEAP DEBUG: create new heap " HEAPID_FMT ".\n",
+ h->heap_id);
+ }
+#endif
+#ifdef ZSH_VALGRIND
+ VALGRIND_CREATE_MEMPOOL((char *)h, 0, 0);
+ VALGRIND_MAKE_MEM_NOACCESS((char *)arena(h),
+ n - ((char *)arena(h)-(char *)h));
+ VALGRIND_MEMPOOL_ALLOC((char *)h, (char *)arena(h), req_size);
+#endif
+
+ DPUTS(hp && hp->next, "failed to find end of chain in zhalloc");
+ if (hp)
+ hp->next = h;
+ else
+ heaps = h;
+ fheap = h;
+
+ unqueue_signals();
+#ifdef ZSH_HEAP_DEBUG
+ last_heap_id = h->heap_id;
+ if (heap_debug_verbosity & HDV_ALLOC) {
+ fprintf(stderr, "HEAP DEBUG: allocated memory from heap "
+ HEAPID_FMT ".\n", h->heap_id);
+ }
+#endif
+ return arena(h);
+ }
+}
+
+/**/
+mod_export void *
+hrealloc(char *p, size_t old, size_t new)
+{
+ Heap h, ph;
+
+#ifdef ZSH_VALGRIND
+ size_t new_req = new;
+#endif
+
+ old = (old + H_ISIZE - 1) & ~(H_ISIZE - 1);
+ new = (new + H_ISIZE - 1) & ~(H_ISIZE - 1);
+
+ if (old == new)
+ return p;
+ if (!old && !p)
+#ifdef ZSH_VALGRIND
+ return zhalloc(new_req);
+#else
+ return zhalloc(new);
+#endif
+
+ /* find the heap with p */
+
+ queue_signals();
+ for (h = heaps, ph = NULL; h; ph = h, h = h->next)
+ if (p >= arena(h) && p < arena(h) + ARENA_SIZEOF(h))
+ break;
+
+ DPUTS(!h, "BUG: hrealloc() called for non-heap memory.");
+ DPUTS(h->sp && arena(h) + h->sp->used > p,
+ "BUG: hrealloc() wants to realloc pushed memory");
+
+ /*
+ * If the end of the old chunk is before the used pointer,
+ * more memory has been zhalloc'ed afterwards.
+ * We can't tell if that's still in use, obviously, since
+ * that's the whole point of heap memory.
+ * We have no choice other than to grab some more memory
+ * somewhere else and copy in the old stuff.
+ */
+ if (p + old < arena(h) + h->used) {
+ if (new > old) {
+#ifdef ZSH_VALGRIND
+ char *ptr = (char *) zhalloc(new_req);
+#else
+ char *ptr = (char *) zhalloc(new);
+#endif
+ memcpy(ptr, p, old);
+#ifdef ZSH_MEM_DEBUG
+ memset(p, 0xff, old);
+#endif
+#ifdef ZSH_VALGRIND
+ VALGRIND_MEMPOOL_FREE((char *)h, (char *)p);
+ /*
+ * zhalloc() marked h,ptr,new as an allocation so we don't
+ * need to do that here.
+ */
+#endif
+ unqueue_signals();
+ return ptr;
+ } else {
+#ifdef ZSH_VALGRIND
+ VALGRIND_MEMPOOL_FREE((char *)h, (char *)p);
+ if (p) {
+ VALGRIND_MEMPOOL_ALLOC((char *)h, (char *)p,
+ new_req);
+ VALGRIND_MAKE_MEM_DEFINED((char *)h, (char *)p);
+ }
+#endif
+ unqueue_signals();
+ return new ? p : NULL;
+ }
+ }
+
+ DPUTS(p + old != arena(h) + h->used, "BUG: hrealloc more than allocated");
+
+ /*
+ * We now know there's nothing afterwards in the heap, now see if
+ * there's nothing before. Then we can reallocate the whole thing.
+ * Otherwise, we need to keep the stuff at the start of the heap,
+ * then allocate a new one too; this is handled below. (This will
+ * guarantee we occupy a full heap next time round, provided we
+ * don't use the heap for anything else.)
+ */
+ if (p == arena(h)) {
+#ifdef ZSH_HEAP_DEBUG
+ Heapid heap_id = h->heap_id;
+#endif
+ /*
+ * Zero new seems to be a special case saying we've finished
+ * with the specially reallocated memory, see scanner() in glob.c.
+ */
+ if (!new) {
+ if (ph)
+ ph->next = h->next;
+ else
+ heaps = h->next;
+ fheap = NULL;
+#ifdef USE_MMAP
+ munmap((void *) h, h->size);
+#else
+ zfree(h, HEAPSIZE);
+#endif
+#ifdef ZSH_VALGRIND
+ VALGRIND_DESTROY_MEMPOOL((char *)h);
+#endif
+ unqueue_signals();
+ return NULL;
+ }
+ if (new > ARENA_SIZEOF(h)) {
+ Heap hnew;
+ /*
+ * Not enough memory in this heap. Allocate a new
+ * one of sufficient size.
+ *
+ * To avoid this happening too often, allocate
+ * chunks in multiples of HEAPSIZE.
+ * (Historical note: there didn't used to be any
+ * point in this since we didn't consistently record
+ * the allocated size of the heap, but now we do.)
+ */
+ size_t n = (new + sizeof(*h) + HEAPSIZE);
+ n -= n % HEAPSIZE;
+ fheap = NULL;
+
+#ifdef USE_MMAP
+ {
+ /*
+ * I don't know any easy portable way of requesting
+ * a mmap'd segment be extended, so simply allocate
+ * a new one and copy.
+ */
+ hnew = mmap_heap_alloc(&n);
+ /* Copy the entire heap, header (with next pointer) included */
+ memcpy(hnew, h, h->size);
+ munmap((void *)h, h->size);
+ }
+#else
+ hnew = (Heap) realloc(h, n);
+#endif
+#ifdef ZSH_VALGRIND
+ VALGRIND_MEMPOOL_FREE((char *)h, p);
+ VALGRIND_DESTROY_MEMPOOL((char *)h);
+ VALGRIND_CREATE_MEMPOOL((char *)hnew, 0, 0);
+ VALGRIND_MEMPOOL_ALLOC((char *)hnew, (char *)arena(hnew),
+ new_req);
+ VALGRIND_MAKE_MEM_DEFINED((char *)hnew, (char *)arena(hnew));
+#endif
+ h = hnew;
+
+ h->size = n;
+ if (ph)
+ ph->next = h;
+ else
+ heaps = h;
+ }
+#ifdef ZSH_VALGRIND
+ else {
+ VALGRIND_MEMPOOL_FREE((char *)h, (char *)p);
+ VALGRIND_MEMPOOL_ALLOC((char *)h, (char *)p, new_req);
+ VALGRIND_MAKE_MEM_DEFINED((char *)h, (char *)p);
+ }
+#endif
+ h->used = new;
+#ifdef ZSH_HEAP_DEBUG
+ h->heap_id = heap_id;
+#endif
+ unqueue_signals();
+ return arena(h);
+ }
+#ifndef USE_MMAP
+ DPUTS(h->used > ARENA_SIZEOF(h), "BUG: hrealloc at invalid address");
+#endif
+ if (h->used + (new - old) <= ARENA_SIZEOF(h)) {
+ h->used += new - old;
+ unqueue_signals();
+#ifdef ZSH_VALGRIND
+ VALGRIND_MEMPOOL_FREE((char *)h, (char *)p);
+ VALGRIND_MEMPOOL_ALLOC((char *)h, (char *)p, new_req);
+ VALGRIND_MAKE_MEM_DEFINED((char *)h, (char *)p);
+#endif
+ return p;
+ } else {
+ char *t = zhalloc(new);
+ memcpy(t, p, old > new ? new : old);
+ h->used -= old;
+#ifdef ZSH_MEM_DEBUG
+ memset(p, 0xff, old);
+#endif
+#ifdef ZSH_VALGRIND
+ VALGRIND_MEMPOOL_FREE((char *)h, (char *)p);
+ /* t already marked as allocated by zhalloc() */
+#endif
+ unqueue_signals();
+ return t;
+ }
+}
+
+/**/
+#ifdef ZSH_HEAP_DEBUG
+/*
+ * Check if heap_id is the identifier of a currently valid heap,
+ * including any heap buried on the stack, or of permanent memory.
+ * Return 0 if so, else 1.
+ *
+ * This gets confused by use of switch_heaps(). That's because so do I.
+ */
+
+/**/
+mod_export int
+memory_validate(Heapid heap_id)
+{
+ Heap h;
+ Heapstack hs;
+ LinkNode node;
+
+ if (heap_id == HEAPID_PERMANENT)
+ return 0;
+
+ queue_signals();
+ for (h = heaps; h; h = h->next) {
+ if (h->heap_id == heap_id) {
+ unqueue_signals();
+ return 0;
+ }
+ for (hs = heaps->sp; hs; hs = hs->next) {
+ if (hs->heap_id == heap_id) {
+ unqueue_signals();
+ return 0;
+ }
+ }
+ }
+
+ if (heaps_saved) {
+ for (node = firstnode(heaps_saved); node; incnode(node)) {
+ for (h = (Heap)getdata(node); h; h = h->next) {
+ if (h->heap_id == heap_id) {
+ unqueue_signals();
+ return 0;
+ }
+ for (hs = heaps->sp; hs; hs = hs->next) {
+ if (hs->heap_id == heap_id) {
+ unqueue_signals();
+ return 0;
+ }
+ }
+ }
+ }
+ }
+
+ unqueue_signals();
+ return 1;
+}
+/**/
+#endif
+
+/* allocate memory from the current memory pool and clear it */
+
+/**/
+mod_export void *
+hcalloc(size_t size)
+{
+ void *ptr;
+
+ ptr = zhalloc(size);
+ memset(ptr, 0, size);
+ return ptr;
+}
+
+/* allocate permanent memory */
+
+/**/
+mod_export void *
+zalloc(size_t size)
+{
+ void *ptr;
+
+ if (!size)
+ size = 1;
+ queue_signals();
+ if (!(ptr = (void *) malloc(size))) {
+ zerr("fatal error: out of memory");
+ exit(1);
+ }
+ unqueue_signals();
+
+ return ptr;
+}
+
+/**/
+mod_export void *
+zshcalloc(size_t size)
+{
+ void *ptr = zalloc(size);
+ if (!size)
+ size = 1;
+ memset(ptr, 0, size);
+ return ptr;
+}
+
+/* This front-end to realloc is used to make sure we have a realloc *
+ * that conforms to POSIX realloc. Older realloc's can fail if *
+ * passed a NULL pointer, but POSIX realloc should handle this. A *
+ * better solution would be for configure to check if realloc is *
+ * POSIX compliant, but I'm not sure how to do that. */
+
+/**/
+mod_export void *
+zrealloc(void *ptr, size_t size)
+{
+ queue_signals();
+ if (ptr) {
+ if (size) {
+ /* Do normal realloc */
+ if (!(ptr = (void *) realloc(ptr, size))) {
+ zerr("fatal error: out of memory");
+ exit(1);
+ }
+ unqueue_signals();
+ return ptr;
+ }
+ else
+ /* If ptr is not NULL, but size is zero, *
+ * then object pointed to is freed. */
+ free(ptr);
+
+ ptr = NULL;
+ } else {
+ /* If ptr is NULL, then behave like malloc */
+ if (!(ptr = (void *) malloc(size))) {
+ zerr("fatal error: out of memory");
+ exit(1);
+ }
+ }
+ unqueue_signals();
+
+ return ptr;
+}
+
+/**/
+#ifdef ZSH_MEM
+
+/*
+ Below is a simple segment oriented memory allocator for systems on
+ which it is better than the system's one. Memory is given in blocks
+ aligned to an integer multiple of sizeof(union mem_align), which will
+ probably be 64-bit as it is the longer of zlong or double. Each block is
+ preceded by a header which contains the length of the data part (in
+ bytes). In allocated blocks only this field of the structure m_hdr is
+ senseful. In free blocks the second field (next) is a pointer to the next
+ free segment on the free list.
+
+ On top of this simple allocator there is a second allocator for small
+ chunks of data. It should be both faster and less space-consuming than
+ using the normal segment mechanism for such blocks.
+ For the first M_NSMALL-1 possible sizes memory is allocated in arrays
+ that can hold M_SNUM blocks. Each array is stored in one segment of the
+ main allocator. In these segments the third field of the header structure
+ (free) contains a pointer to the first free block in the array. The
+ last field (used) gives the number of already used blocks in the array.
+
+ If the macro name ZSH_MEM_DEBUG is defined, some information about the memory
+ usage is stored. This information can than be viewed by calling the
+ builtin `mem' (which is only available if ZSH_MEM_DEBUG is set).
+
+ If ZSH_MEM_WARNING is defined, error messages are printed in case of errors.
+
+ If ZSH_SECURE_FREE is defined, free() checks if the given address is really
+ one that was returned by malloc(), it ignores it if it wasn't (printing
+ an error message if ZSH_MEM_WARNING is also defined).
+*/
+#if !defined(__hpux) && !defined(DGUX) && !defined(__osf__)
+# if defined(_BSD)
+# ifndef HAVE_BRK_PROTO
+ extern int brk _((caddr_t));
+# endif
+# ifndef HAVE_SBRK_PROTO
+ extern caddr_t sbrk _((int));
+# endif
+# else
+# ifndef HAVE_BRK_PROTO
+ extern int brk _((void *));
+# endif
+# ifndef HAVE_SBRK_PROTO
+ extern void *sbrk _((int));
+# endif
+# endif
+#endif
+
+#if defined(_BSD) && !defined(STDC_HEADERS)
+# define FREE_RET_T int
+# define FREE_ARG_T char *
+# define FREE_DO_RET
+# define MALLOC_RET_T char *
+# define MALLOC_ARG_T size_t
+#else
+# define FREE_RET_T void
+# define FREE_ARG_T void *
+# define MALLOC_RET_T void *
+# define MALLOC_ARG_T size_t
+#endif
+
+/* structure for building free list in blocks holding small blocks */
+
+struct m_shdr {
+ struct m_shdr *next; /* next one on free list */
+#ifdef PAD_64_BIT
+ /* dummy to make this 64-bit aligned */
+ struct m_shdr *dummy;
+#endif
+};
+
+struct m_hdr {
+ zlong len; /* length of memory block */
+#if defined(PAD_64_BIT) && !defined(ZSH_64_BIT_TYPE)
+ /* either 1 or 2 zlong's, whichever makes up 64 bits. */
+ zlong dummy1;
+#endif
+ struct m_hdr *next; /* if free: next on free list
+ if block of small blocks: next one with
+ small blocks of same size*/
+ struct m_shdr *free; /* if block of small blocks: free list */
+ zlong used; /* if block of small blocks: number of used
+ blocks */
+#if defined(PAD_64_BIT) && !defined(ZSH_64_BIT_TYPE)
+ zlong dummy2;
+#endif
+};
+
+
+/* alignment for memory blocks */
+
+#define M_ALIGN (sizeof(union mem_align))
+
+/* length of memory header, length of first field of memory header and
+ minimal size of a block left free (if we allocate memory and take a
+ block from the free list that is larger than needed, it must have at
+ least M_MIN extra bytes to be splitted; if it has, the rest is put on
+ the free list) */
+
+#define M_HSIZE (sizeof(struct m_hdr))
+#if defined(PAD_64_BIT) && !defined(ZSH_64_BIT_TYPE)
+# define M_ISIZE (2*sizeof(zlong))
+#else
+# define M_ISIZE (sizeof(zlong))
+#endif
+#define M_MIN (2 * M_ISIZE)
+
+/* M_FREE is the number of bytes that have to be free before memory is
+ * given back to the system
+ * M_KEEP is the number of bytes that will be kept when memory is given
+ * back; note that this has to be less than M_FREE
+ * M_ALLOC is the number of extra bytes to request from the system */
+
+#define M_FREE 32768
+#define M_KEEP 16384
+#define M_ALLOC M_KEEP
+
+/* a pointer to the last free block, a pointer to the free list (the blocks
+ on this list are kept in order - lowest address first) */
+
+static struct m_hdr *m_lfree, *m_free;
+
+/* system's pagesize */
+
+static long m_pgsz = 0;
+
+/* the highest and the lowest valid memory addresses, kept for fast validity
+ checks in free() and to find out if and when we can give memory back to
+ the system */
+
+static char *m_high, *m_low;
+
+/* Management of blocks for small blocks:
+ Such blocks are kept in lists (one list for each of the sizes that are
+ allocated in such blocks). The lists are stored in the m_small array.
+ M_SIDX() calculates the index into this array for a given size. M_SNUM
+ is the size (in small blocks) of such blocks. M_SLEN() calculates the
+ size of the small blocks held in a memory block, given a pointer to the
+ header of it. M_SBLEN() gives the size of a memory block that can hold
+ an array of small blocks, given the size of these small blocks. M_BSLEN()
+ calculates the size of the small blocks held in a memory block, given the
+ length of that block (including the header of the memory block. M_NSMALL
+ is the number of possible block sizes that small blocks should be used
+ for. */
+
+
+#define M_SIDX(S) ((S) / M_ISIZE)
+#define M_SNUM 128
+#define M_SLEN(M) ((M)->len / M_SNUM)
+#if defined(PAD_64_BIT) && !defined(ZSH_64_BIT_TYPE)
+/* Include the dummy in the alignment */
+#define M_SBLEN(S) ((S) * M_SNUM + sizeof(struct m_shdr *) + \
+ 2*sizeof(zlong) + sizeof(struct m_hdr *))
+#define M_BSLEN(S) (((S) - sizeof(struct m_shdr *) - \
+ 2*sizeof(zlong) - sizeof(struct m_hdr *)) / M_SNUM)
+#else
+#define M_SBLEN(S) ((S) * M_SNUM + sizeof(struct m_shdr *) + \
+ sizeof(zlong) + sizeof(struct m_hdr *))
+#define M_BSLEN(S) (((S) - sizeof(struct m_shdr *) - \
+ sizeof(zlong) - sizeof(struct m_hdr *)) / M_SNUM)
+#endif
+#define M_NSMALL 8
+
+static struct m_hdr *m_small[M_NSMALL];
+
+#ifdef ZSH_MEM_DEBUG
+
+static int m_s = 0, m_b = 0;
+static int m_m[1025], m_f[1025];
+
+static struct m_hdr *m_l;
+
+#endif /* ZSH_MEM_DEBUG */
+
+MALLOC_RET_T
+malloc(MALLOC_ARG_T size)
+{
+ struct m_hdr *m, *mp, *mt;
+ long n, s, os = 0;
+#ifndef USE_MMAP
+ struct heap *h, *hp, *hf = NULL, *hfp = NULL;
+#endif
+
+ /* some systems want malloc to return the highest valid address plus one
+ if it is called with an argument of zero.
+
+ TODO: really? Suppose we allocate more memory, so
+ that this is now in bounds, then a more rational application
+ that thinks it can free() anything it malloc'ed, even
+ of zero length, calls free for it? Aren't we in big
+ trouble? Wouldn't it be safer just to allocate some
+ memory anyway?
+
+ If the above comment is really correct, then at least
+ we need to check in free() if we're freeing memory
+ at m_high.
+ */
+
+ if (!size)
+#if 1
+ size = 1;
+#else
+ return (MALLOC_RET_T) m_high;
+#endif
+
+ queue_signals(); /* just queue signals rather than handling them */
+
+ /* first call, get page size */
+
+ if (!m_pgsz) {
+
+#ifdef _SC_PAGESIZE
+ m_pgsz = sysconf(_SC_PAGESIZE); /* SVR4 */
+#else
+# ifdef _SC_PAGE_SIZE
+ m_pgsz = sysconf(_SC_PAGE_SIZE); /* HPUX */
+# else
+ m_pgsz = getpagesize();
+# endif
+#endif
+
+ m_free = m_lfree = NULL;
+ }
+ size = (size + M_ALIGN - 1) & ~(M_ALIGN - 1);
+
+ /* Do we need a small block? */
+
+ if ((s = M_SIDX(size)) && s < M_NSMALL) {
+ /* yep, find a memory block with free small blocks of the
+ appropriate size (if we find it in this list, this means that
+ it has room for at least one more small block) */
+ for (mp = NULL, m = m_small[s]; m && !m->free; mp = m, m = m->next);
+
+ if (m) {
+ /* we found one */
+ struct m_shdr *sh = m->free;
+
+ m->free = sh->next;
+ m->used++;
+
+ /* if all small blocks in this block are allocated, the block is
+ put at the end of the list blocks with small blocks of this
+ size (i.e., we try to keep blocks with free blocks at the
+ beginning of the list, to make the search faster) */
+
+ if (m->used == M_SNUM && m->next) {
+ for (mt = m; mt->next; mt = mt->next);
+
+ mt->next = m;
+ if (mp)
+ mp->next = m->next;
+ else
+ m_small[s] = m->next;
+ m->next = NULL;
+ }
+#ifdef ZSH_MEM_DEBUG
+ m_m[size / M_ISIZE]++;
+#endif
+
+ unqueue_signals();
+ return (MALLOC_RET_T) sh;
+ }
+ /* we still want a small block but there were no block with a free
+ small block of the requested size; so we use the real allocation
+ routine to allocate a block for small blocks of this size */
+ os = size;
+ size = M_SBLEN(size);
+ } else
+ s = 0;
+
+ /* search the free list for an block of at least the requested size */
+ for (mp = NULL, m = m_free; m && m->len < size; mp = m, m = m->next);
+
+#ifndef USE_MMAP
+
+ /* if there is an empty zsh heap at a lower address we steal it and take
+ the memory from it, putting the rest on the free list (remember
+ that the blocks on the free list are ordered) */
+
+ for (hp = NULL, h = heaps; h; hp = h, h = h->next)
+ if (!h->used &&
+ (!hf || h < hf) &&
+ (!m || ((char *)m) > ((char *)h)))
+ hf = h, hfp = hp;
+
+ if (hf) {
+ /* we found such a heap */
+ Heapstack hso, hsn;
+
+ /* delete structures on the list holding the heap states */
+ for (hso = hf->sp; hso; hso = hsn) {
+ hsn = hso->next;
+ zfree(hso, sizeof(*hso));
+ }
+ /* take it from the list of heaps */
+ if (hfp)
+ hfp->next = hf->next;
+ else
+ heaps = hf->next;
+ /* now we simply free it and than search the free list again */
+ zfree(hf, HEAPSIZE);
+
+ for (mp = NULL, m = m_free; m && m->len < size; mp = m, m = m->next);
+ }
+#endif
+ if (!m) {
+ long nal;
+ /* no matching free block was found, we have to request new
+ memory from the system */
+ n = (size + M_HSIZE + M_ALLOC + m_pgsz - 1) & ~(m_pgsz - 1);
+
+ if (((char *)(m = (struct m_hdr *)sbrk(n))) == ((char *)-1)) {
+ DPUTS1(1, "MEM: allocation error at sbrk, size %L.", n);
+ unqueue_signals();
+ return NULL;
+ }
+ if ((nal = ((long)(char *)m) & (M_ALIGN-1))) {
+ if ((char *)sbrk(M_ALIGN - nal) == (char *)-1) {
+ DPUTS(1, "MEM: allocation error at sbrk.");
+ unqueue_signals();
+ return NULL;
+ }
+ m = (struct m_hdr *) ((char *)m + (M_ALIGN - nal));
+ }
+ /* set m_low, for the check in free() */
+ if (!m_low)
+ m_low = (char *)m;
+
+#ifdef ZSH_MEM_DEBUG
+ m_s += n;
+
+ if (!m_l)
+ m_l = m;
+#endif
+
+ /* save new highest address */
+ m_high = ((char *)m) + n;
+
+ /* initialize header */
+ m->len = n - M_ISIZE;
+ m->next = NULL;
+
+ /* put it on the free list and set m_lfree pointing to it */
+ if ((mp = m_lfree))
+ m_lfree->next = m;
+ m_lfree = m;
+ }
+ if ((n = m->len - size) > M_MIN) {
+ /* the block we want to use has more than M_MIN bytes plus the
+ number of bytes that were requested; we split it in two and
+ leave the rest on the free list */
+ struct m_hdr *mtt = (struct m_hdr *)(((char *)m) + M_ISIZE + size);
+
+ mtt->len = n - M_ISIZE;
+ mtt->next = m->next;
+
+ m->len = size;
+
+ /* put the rest on the list */
+ if (m_lfree == m)
+ m_lfree = mtt;
+
+ if (mp)
+ mp->next = mtt;
+ else
+ m_free = mtt;
+ } else if (mp) {
+ /* the block we found wasn't the first one on the free list */
+ if (m == m_lfree)
+ m_lfree = mp;
+ mp->next = m->next;
+ } else {
+ /* it was the first one */
+ m_free = m->next;
+ if (m == m_lfree)
+ m_lfree = m_free;
+ }
+
+ if (s) {
+ /* we are allocating a block that should hold small blocks */
+ struct m_shdr *sh, *shn;
+
+ /* build the free list in this block and set `used' filed */
+ m->free = sh = (struct m_shdr *)(((char *)m) +
+ sizeof(struct m_hdr) + os);
+
+ for (n = M_SNUM - 2; n--; sh = shn)
+ shn = sh->next = sh + s;
+ sh->next = NULL;
+
+ m->used = 1;
+
+ /* put the block on the list of blocks holding small blocks if
+ this size */
+ m->next = m_small[s];
+ m_small[s] = m;
+
+#ifdef ZSH_MEM_DEBUG
+ m_m[os / M_ISIZE]++;
+#endif
+
+ unqueue_signals();
+ return (MALLOC_RET_T) (((char *)m) + sizeof(struct m_hdr));
+ }
+#ifdef ZSH_MEM_DEBUG
+ m_m[m->len < (1024 * M_ISIZE) ? (m->len / M_ISIZE) : 1024]++;
+#endif
+
+ unqueue_signals();
+ return (MALLOC_RET_T) & m->next;
+}
+
+/* this is an internal free(); the second argument may, but need not hold
+ the size of the block the first argument is pointing to; if it is the
+ right size of this block, freeing it will be faster, though; the value
+ 0 for this parameter means: `don't know' */
+
+/**/
+mod_export void
+zfree(void *p, int sz)
+{
+ struct m_hdr *m = (struct m_hdr *)(((char *)p) - M_ISIZE), *mp, *mt = NULL;
+ int i;
+# ifdef DEBUG
+ int osz = sz;
+# endif
+
+#ifdef ZSH_SECURE_FREE
+ sz = 0;
+#else
+ sz = (sz + M_ALIGN - 1) & ~(M_ALIGN - 1);
+#endif
+
+ if (!p)
+ return;
+
+ /* first a simple check if the given address is valid */
+ if (((char *)p) < m_low || ((char *)p) > m_high ||
+ ((long)p) & (M_ALIGN - 1)) {
+ DPUTS(1, "BUG: attempt to free storage at invalid address");
+ return;
+ }
+
+ queue_signals();
+
+ fr_rec:
+
+ if ((i = sz / M_ISIZE) < M_NSMALL || !sz)
+ /* if the given sizes says that it is a small block, find the
+ memory block holding it; we search all blocks with blocks
+ of at least the given size; if the size parameter is zero,
+ this means, that all blocks are searched */
+ for (; i < M_NSMALL; i++) {
+ for (mp = NULL, mt = m_small[i];
+ mt && (((char *)mt) > ((char *)p) ||
+ (((char *)mt) + mt->len) < ((char *)p));
+ mp = mt, mt = mt->next);
+
+ if (mt) {
+ /* we found the block holding the small block */
+ struct m_shdr *sh = (struct m_shdr *)p;
+
+#ifdef ZSH_SECURE_FREE
+ struct m_shdr *sh2;
+
+ /* check if the given address is equal to the address of
+ the first small block plus an integer multiple of the
+ block size */
+ if ((((char *)p) - (((char *)mt) + sizeof(struct m_hdr))) %
+ M_BSLEN(mt->len)) {
+
+ DPUTS(1, "BUG: attempt to free storage at invalid address");
+ unqueue_signals();
+ return;
+ }
+ /* check, if the address is on the (block-intern) free list */
+ for (sh2 = mt->free; sh2; sh2 = sh2->next)
+ if (((char *)p) == ((char *)sh2)) {
+
+ DPUTS(1, "BUG: attempt to free already free storage");
+ unqueue_signals();
+ return;
+ }
+#endif
+ DPUTS(M_BSLEN(mt->len) < osz,
+ "BUG: attempt to free more than allocated.");
+
+#ifdef ZSH_MEM_DEBUG
+ m_f[M_BSLEN(mt->len) / M_ISIZE]++;
+ memset(sh, 0xff, M_BSLEN(mt->len));
+#endif
+
+ /* put the block onto the free list */
+ sh->next = mt->free;
+ mt->free = sh;
+
+ if (--mt->used) {
+ /* if there are still used blocks in this block, we
+ put it at the beginning of the list with blocks
+ holding small blocks of the same size (since we
+ know that there is at least one free block in it,
+ this will make allocation of small blocks faster;
+ it also guarantees that long living memory blocks
+ are preferred over younger ones */
+ if (mp) {
+ mp->next = mt->next;
+ mt->next = m_small[i];
+ m_small[i] = mt;
+ }
+ unqueue_signals();
+ return;
+ }
+ /* if there are no more used small blocks in this
+ block, we free the whole block */
+ if (mp)
+ mp->next = mt->next;
+ else
+ m_small[i] = mt->next;
+
+ m = mt;
+ p = (void *) & m->next;
+
+ break;
+ } else if (sz) {
+ /* if we didn't find a block and a size was given, try it
+ again as if no size were given */
+ sz = 0;
+ goto fr_rec;
+ }
+ }
+#ifdef ZSH_MEM_DEBUG
+ if (!mt)
+ m_f[m->len < (1024 * M_ISIZE) ? (m->len / M_ISIZE) : 1024]++;
+#endif
+
+#ifdef ZSH_SECURE_FREE
+ /* search all memory blocks, if one of them is at the given address */
+ for (mt = (struct m_hdr *)m_low;
+ ((char *)mt) < m_high;
+ mt = (struct m_hdr *)(((char *)mt) + M_ISIZE + mt->len))
+ if (((char *)p) == ((char *)&mt->next))
+ break;
+
+ /* no block was found at the given address */
+ if (((char *)mt) >= m_high) {
+ DPUTS(1, "BUG: attempt to free storage at invalid address");
+ unqueue_signals();
+ return;
+ }
+#endif
+
+ /* see if the block is on the free list */
+ for (mp = NULL, mt = m_free; mt && mt < m; mp = mt, mt = mt->next);
+
+ if (m == mt) {
+ /* it is, ouch! */
+ DPUTS(1, "BUG: attempt to free already free storage");
+ unqueue_signals();
+ return;
+ }
+ DPUTS(m->len < osz, "BUG: attempt to free more than allocated");
+#ifdef ZSH_MEM_DEBUG
+ memset(p, 0xff, m->len);
+#endif
+ if (mt && ((char *)mt) == (((char *)m) + M_ISIZE + m->len)) {
+ /* the block after the one we are freeing is free, we put them
+ together */
+ m->len += mt->len + M_ISIZE;
+ m->next = mt->next;
+
+ if (mt == m_lfree)
+ m_lfree = m;
+ } else
+ m->next = mt;
+
+ if (mp && ((char *)m) == (((char *)mp) + M_ISIZE + mp->len)) {
+ /* the block before the one we are freeing is free, we put them
+ together */
+ mp->len += m->len + M_ISIZE;
+ mp->next = m->next;
+
+ if (m == m_lfree)
+ m_lfree = mp;
+ } else if (mp)
+ /* otherwise, we just put it on the free list */
+ mp->next = m;
+ else {
+ m_free = m;
+ if (!m_lfree)
+ m_lfree = m_free;
+ }
+
+ /* if the block we have just freed was at the end of the process heap
+ and now there is more than one page size of memory, we can give
+ it back to the system (and we do it ;-) */
+ if ((((char *)m_lfree) + M_ISIZE + m_lfree->len) == m_high &&
+ m_lfree->len >= m_pgsz + M_MIN + M_FREE) {
+ long n = (m_lfree->len - M_MIN - M_KEEP) & ~(m_pgsz - 1);
+
+ m_lfree->len -= n;
+#ifdef HAVE_BRK
+ if (brk(m_high -= n) == -1) {
+#else
+ m_high -= n;
+ if (sbrk(-n) == (void *)-1) {
+#endif /* HAVE_BRK */
+ DPUTS(1, "MEM: allocation error at brk.");
+ }
+
+#ifdef ZSH_MEM_DEBUG
+ m_b += n;
+#endif
+ }
+ unqueue_signals();
+}
+
+FREE_RET_T
+free(FREE_ARG_T p)
+{
+ zfree(p, 0); /* 0 means: size is unknown */
+
+#ifdef FREE_DO_RET
+ return 0;
+#endif
+}
+
+/* this one is for strings (and only strings, real strings, real C strings,
+ those that have a zero byte at the end) */
+
+/**/
+mod_export void
+zsfree(char *p)
+{
+ if (p)
+ zfree(p, strlen(p) + 1);
+}
+
+MALLOC_RET_T
+realloc(MALLOC_RET_T p, MALLOC_ARG_T size)
+{
+ struct m_hdr *m = (struct m_hdr *)(((char *)p) - M_ISIZE), *mt;
+ char *r;
+ int i, l = 0;
+
+ /* some system..., see above */
+ if (!p && size) {
+ queue_signals();
+ r = malloc(size);
+ unqueue_signals();
+ return (MALLOC_RET_T) r;
+ }
+
+ /* and some systems even do this... */
+ if (!p || !size)
+ return (MALLOC_RET_T) p;
+
+ queue_signals(); /* just queue signals caught rather than handling them */
+
+ /* check if we are reallocating a small block, if we do, we have
+ to compute the size of the block from the sort of block it is in */
+ for (i = 0; i < M_NSMALL; i++) {
+ for (mt = m_small[i];
+ mt && (((char *)mt) > ((char *)p) ||
+ (((char *)mt) + mt->len) < ((char *)p));
+ mt = mt->next);
+
+ if (mt) {
+ l = M_BSLEN(mt->len);
+ break;
+ }
+ }
+ if (!l)
+ /* otherwise the size of the block is in the memory just before
+ the given address */
+ l = m->len;
+
+ /* now allocate the new block, copy the old contents, and free the
+ old block */
+ r = malloc(size);
+ memcpy(r, (char *)p, (size > l) ? l : size);
+ free(p);
+
+ unqueue_signals();
+ return (MALLOC_RET_T) r;
+}
+
+MALLOC_RET_T
+calloc(MALLOC_ARG_T n, MALLOC_ARG_T size)
+{
+ long l;
+ char *r;
+
+ if (!(l = n * size))
+ return (MALLOC_RET_T) m_high;
+
+ /*
+ * use realloc() (with a NULL `p` argument it behaves exactly the same
+ * as malloc() does) to prevent an infinite loop caused by sibling-call
+ * optimizations (the malloc() call would otherwise be replaced by an
+ * unconditional branch back to line 1719 ad infinitum).
+ */
+ r = realloc(NULL, l);
+
+ memset(r, 0, l);
+
+ return (MALLOC_RET_T) r;
+}
+
+#ifdef ZSH_MEM_DEBUG
+
+/**/
+int
+bin_mem(char *name, char **argv, Options ops, int func)
+{
+ int i, ii, fi, ui, j;
+ struct m_hdr *m, *mf, *ms;
+ char *b, *c, buf[40];
+ long u = 0, f = 0, to, cu;
+
+ queue_signals();
+ if (OPT_ISSET(ops,'v')) {
+ printf("The lower and the upper addresses of the heap. Diff gives\n");
+ printf("the difference between them, i.e. the size of the heap.\n\n");
+ }
+ printf("low mem %ld\t high mem %ld\t diff %ld\n",
+ (long)m_l, (long)m_high, (long)(m_high - ((char *)m_l)));
+
+ if (OPT_ISSET(ops,'v')) {
+ printf("\nThe number of bytes that were allocated using sbrk() and\n");
+ printf("the number of bytes that were given back to the system\n");
+ printf("via brk().\n");
+ }
+ printf("\nsbrk %d\tbrk %d\n", m_s, m_b);
+
+ if (OPT_ISSET(ops,'v')) {
+ printf("\nInformation about the sizes that were allocated or freed.\n");
+ printf("For each size that were used the number of mallocs and\n");
+ printf("frees is shown. Diff gives the difference between these\n");
+ printf("values, i.e. the number of blocks of that size that is\n");
+ printf("currently allocated. Total is the product of size and diff,\n");
+ printf("i.e. the number of bytes that are allocated for blocks of\n");
+ printf("this size. The last field gives the accumulated number of\n");
+ printf("bytes for all sizes.\n");
+ }
+ printf("\nsize\tmalloc\tfree\tdiff\ttotal\tcum\n");
+ for (i = 0, cu = 0; i < 1024; i++)
+ if (m_m[i] || m_f[i]) {
+ to = (long) i * M_ISIZE * (m_m[i] - m_f[i]);
+ printf("%ld\t%d\t%d\t%d\t%ld\t%ld\n",
+ (long)i * M_ISIZE, m_m[i], m_f[i], m_m[i] - m_f[i],
+ to, (cu += to));
+ }
+
+ if (m_m[i] || m_f[i])
+ printf("big\t%d\t%d\t%d\n", m_m[i], m_f[i], m_m[i] - m_f[i]);
+
+ if (OPT_ISSET(ops,'v')) {
+ printf("\nThe list of memory blocks. For each block the following\n");
+ printf("information is shown:\n\n");
+ printf("num\tthe number of this block\n");
+ printf("tnum\tlike num but counted separately for used and free\n");
+ printf("\tblocks\n");
+ printf("addr\tthe address of this block\n");
+ printf("len\tthe length of the block\n");
+ printf("state\tthe state of this block, this can be:\n");
+ printf("\t used\tthis block is used for one big block\n");
+ printf("\t free\tthis block is free\n");
+ printf("\t small\tthis block is used for an array of small blocks\n");
+ printf("cum\tthe accumulated sizes of the blocks, counted\n");
+ printf("\tseparately for used and free blocks\n");
+ printf("\nFor blocks holding small blocks the number of free\n");
+ printf("blocks, the number of used blocks and the size of the\n");
+ printf("blocks is shown. For otherwise used blocks the first few\n");
+ printf("bytes are shown as an ASCII dump.\n");
+ }
+ printf("\nblock list:\nnum\ttnum\taddr\t\tlen\tstate\tcum\n");
+ for (m = m_l, mf = m_free, ii = fi = ui = 1; ((char *)m) < m_high;
+ m = (struct m_hdr *)(((char *)m) + M_ISIZE + m->len), ii++) {
+ for (j = 0, ms = NULL; j < M_NSMALL && !ms; j++)
+ for (ms = m_small[j]; ms; ms = ms->next)
+ if (ms == m)
+ break;
+
+ if (m == mf)
+ buf[0] = '\0';
+ else if (m == ms)
+ sprintf(buf, "%ld %ld %ld", (long)(M_SNUM - ms->used),
+ (long)ms->used,
+ (long)(m->len - sizeof(struct m_hdr)) / M_SNUM + 1);
+
+ else {
+ for (i = 0, b = buf, c = (char *)&m->next; i < 20 && i < m->len;
+ i++, c++)
+ *b++ = (*c >= ' ' && *c < 127) ? *c : '.';
+ *b = '\0';
+ }
+
+ printf("%d\t%d\t%ld\t%ld\t%s\t%ld\t%s\n", ii,
+ (m == mf) ? fi++ : ui++,
+ (long)m, (long)m->len,
+ (m == mf) ? "free" : ((m == ms) ? "small" : "used"),
+ (m == mf) ? (f += m->len) : (u += m->len),
+ buf);
+
+ if (m == mf)
+ mf = mf->next;
+ }
+
+ if (OPT_ISSET(ops,'v')) {
+ printf("\nHere is some information about the small blocks used.\n");
+ printf("For each size the arrays with the number of free and the\n");
+ printf("number of used blocks are shown.\n");
+ }
+ printf("\nsmall blocks:\nsize\tblocks (free/used)\n");
+
+ for (i = 0; i < M_NSMALL; i++)
+ if (m_small[i]) {
+ printf("%ld\t", (long)i * M_ISIZE);
+
+ for (ii = 0, m = m_small[i]; m; m = m->next) {
+ printf("(%ld/%ld) ", (long)(M_SNUM - m->used),
+ (long)m->used);
+ if (!((++ii) & 7))
+ printf("\n\t");
+ }
+ putchar('\n');
+ }
+ if (OPT_ISSET(ops,'v')) {
+ printf("\n\nBelow is some information about the allocation\n");
+ printf("behaviour of the zsh heaps. First the number of times\n");
+ printf("pushheap(), popheap(), and freeheap() were called.\n");
+ }
+ printf("\nzsh heaps:\n\n");
+
+ printf("push %d\tpop %d\tfree %d\n\n", h_push, h_pop, h_free);
+
+ if (OPT_ISSET(ops,'v')) {
+ printf("\nThe next list shows for several sizes the number of times\n");
+ printf("memory of this size were taken from heaps.\n\n");
+ }
+ printf("size\tmalloc\ttotal\n");
+ for (i = 0; i < 1024; i++)
+ if (h_m[i])
+ printf("%ld\t%d\t%ld\n", (long)i * H_ISIZE, h_m[i],
+ (long)i * H_ISIZE * h_m[i]);
+ if (h_m[1024])
+ printf("big\t%d\n", h_m[1024]);
+
+ unqueue_signals();
+ return 0;
+}
+
+#endif
+
+/**/
+#else /* not ZSH_MEM */
+
+/**/
+mod_export void
+zfree(void *p, UNUSED(int sz))
+{
+ free(p);
+}
+
+/**/
+mod_export void
+zsfree(char *p)
+{
+ free(p);
+}
+
+/**/
+#endif
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/mkbltnmlst.sh b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/mkbltnmlst.sh
new file mode 100644
index 0000000..c4611d8
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/mkbltnmlst.sh
@@ -0,0 +1,116 @@
+#! /bin/sh
+#
+# mkbltnmlst.sh: generate boot code for linked-in modules
+#
+# Written by Andrew Main
+#
+
+srcdir=${srcdir-`echo $0|sed 's%/[^/][^/]*$%%'`}
+test "x$srcdir" = "x$0" && srcdir=.
+test "x$srcdir" = "x" && srcdir=.
+CFMOD=${CFMOD-$srcdir/../config.modules}
+
+bin_mods="`grep ' link=static' $CFMOD | sed -e '/^#/d' \
+-e 's/ .*/ /' -e 's/^name=/ /'`"
+
+x_mods="`grep ' load=yes' $CFMOD | sed -e '/^#/d' -e '/ link=no/d' \
+-e 's/ .*/ /' -e 's/^name=/ /'`"
+
+trap "rm -f $1; exit 1" 1 2 15
+
+exec > $1
+
+for x_mod in $x_mods; do
+ modfile="`grep '^name='$x_mod' ' $CFMOD | sed -e 's/^.* modfile=//' \
+ -e 's/ .*//'`"
+ if test "x$modfile" = x; then
+ echo >&2 "WARNING: no name for \`$x_mod' in $CFMOD (ignored)"
+ continue
+ fi
+ case "$bin_mods" in
+ *" $x_mod "*)
+ echo "/* linked-in known module \`$x_mod' */"
+ linked=yes
+ ;;
+ *)
+ echo "#ifdef DYNAMIC"
+ echo "/* non-linked-in known module \`$x_mod' */"
+ linked=no
+ esac
+ unset moddeps autofeatures autofeatures_emu
+ . $srcdir/../$modfile
+ if test "x$autofeatures" != x; then
+ if test "x$autofeatures_emu" != x; then
+ echo " {"
+ echo " char *zsh_features[] = { "
+ for feature in $autofeatures; do
+ echo " \"$feature\","
+ done
+ echo " NULL"
+ echo " }; "
+ echo " char *emu_features[] = { "
+ for feature in $autofeatures_emu; do
+ echo " \"$feature\","
+ done
+ echo " NULL"
+ echo " }; "
+ echo " autofeatures(\"zsh\", \"$x_mod\","
+ echo " EMULATION(EMULATE_ZSH) ? zsh_features : emu_features,"
+ echo " 0, 1);"
+ echo " }"
+ else
+ echo " if (EMULATION(EMULATE_ZSH)) {"
+ echo " char *features[] = { "
+ for feature in $autofeatures; do
+ echo " \"$feature\","
+ done
+ echo " NULL"
+ echo " }; "
+ echo " autofeatures(\"zsh\", \"$x_mod\", features, 0, 1);"
+ echo " }"
+ fi
+ fi
+ for dep in $moddeps; do
+ echo " add_dep(\"$x_mod\", \"$dep\");"
+ done
+ test "x$linked" = xno && echo "#endif"
+done
+
+echo
+done_mods=" "
+for bin_mod in $bin_mods; do
+ q_bin_mod=`echo $bin_mod | sed 's,Q,Qq,g;s,_,Qu,g;s,/,Qs,g'`
+ modfile="`grep '^name='$bin_mod' ' $CFMOD | sed -e 's/^.* modfile=//' \
+ -e 's/ .*//'`"
+ echo "/* linked-in module \`$bin_mod' */"
+ unset moddeps
+ . $srcdir/../$modfile
+ for dep in $moddeps; do
+ # This assumes there are no circular dependencies in the builtin
+ # modules. Better ordering of config.modules would be necessary
+ # to enforce stricter dependency checking.
+ case $bin_mods in
+ *" $dep "*)
+ echo " /* depends on \`$dep' */" ;;
+ *) echo >&2 "ERROR: linked-in module \`$bin_mod' depends on \`$dep'"
+ rm -f $1
+ exit 1 ;;
+ esac
+ done
+ echo " {"
+ echo " extern int setup_${q_bin_mod} _((Module));"
+ echo " extern int boot_${q_bin_mod} _((Module));"
+ echo " extern int features_${q_bin_mod} _((Module,char***));"
+ echo " extern int enables_${q_bin_mod} _((Module,int**));"
+ echo " extern int cleanup_${q_bin_mod} _((Module));"
+ echo " extern int finish_${q_bin_mod} _((Module));"
+ echo
+ echo " register_module(\"$bin_mod\","
+ echo " setup_${q_bin_mod},"
+ echo " features_${q_bin_mod},"
+ echo " enables_${q_bin_mod},"
+ echo " boot_${q_bin_mod},"
+ echo " cleanup_${q_bin_mod}, finish_${q_bin_mod});"
+ echo " }"
+ done_mods="$done_mods$bin_mod "
+done
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/mkmakemod.sh b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/mkmakemod.sh
new file mode 100644
index 0000000..140bf70
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/mkmakemod.sh
@@ -0,0 +1,468 @@
+#!/bin/sh
+#
+# mkmakemod.sh: generate Makefile.in files for module building
+#
+# Options:
+# -m = file is already generated; only build the second stage
+# -i = do not build second stage
+#
+# Args:
+# $1 = subdirectory to look in, relative to $top_srcdir
+# $2 = final output filename, within the $1 directory
+#
+# This script must be run from the top-level build directory, and $top_srcdir
+# must be set correctly in the environment.
+#
+# This looks in $1, and uses all the *.mdd files there. Each .mdd file
+# defines one module. The .mdd file is actually a shell script, which will
+# be sourced. It may define the following shell variables:
+#
+# name name of this module
+# moddeps modules on which this module depends (default none)
+# nozshdep non-empty indicates no dependence on the `zsh/main' pseudo-module
+# alwayslink if non-empty, always link the module into the executable
+# autofeatures features defined by the module, for autoloading
+# autofeatures_emu As autofeatures, but for non-zsh emulation modes
+# objects .o files making up this module (*must* be defined)
+# proto .syms files for this module (default generated from $objects)
+# headers extra headers for this module (default none)
+# hdrdeps extra headers on which the .mdh depends (default none)
+# otherincs extra headers that are included indirectly (default none)
+#
+# The .mdd file may also include a Makefile.in fragment between lines
+# `:<<\Make' and `Make' -- this will be copied into Makemod.in.
+#
+# The resulting Makemod.in knows how to build each module that is defined.
+# For each module it also knows how to build a .mdh file. Each source file
+# should #include the .mdh file for the module it is a part of. The .mdh
+# file #includes the .mdh files for any module dependencies, then each of
+# $headers, and then each .epro (for global declarations). It will
+# be recreated if any of the dependency .mdh files changes, or if any of
+# $headers or $hdrdeps changes. When anything depends on it, all the .epros
+# and $otherincs will be made up to date, but the .mdh file won't actually
+# be rebuilt if those files change.
+#
+# The order of sections of the output file is thus:
+# simple generated macros
+# macros generated from *.mdd
+# included Makemod.in.in
+# rules generated from *.mdd
+# The order dependencies are basically that the generated macros are required
+# in Makemod.in.in, but some of the macros that it creates are needed in the
+# later rules.
+#
+
+# sed script to normalise a pathname
+sed_normalise='
+ s,^,/,
+ s,$,/,
+ :1
+ s,/\./,/,
+ t1
+ :2
+ s,/[^/.][^/]*/\.\./,/,
+ s,/\.[^/.][^/]*/\.\./,/,
+ s,/\.\.[^/][^/]*/\.\./,/,
+ t2
+ s,^/$,.,
+ s,^/,,
+ s,\(.\)/$,\1,
+'
+
+# decide which stages to process
+first_stage=true
+second_stage=true
+if test ."$1" = .-m; then
+ shift
+ first_stage=false
+elif test ."$1" = .-i; then
+ shift
+ second_stage=false
+fi
+
+top_srcdir=`echo $top_srcdir | sed "$sed_normalise"`
+the_subdir=$1
+the_makefile=$2
+
+if $first_stage; then
+
+ dir_top=`echo $the_subdir | sed 's,[^/][^/]*,..,g'`
+
+ trap "rm -f $the_subdir/${the_makefile}.in; exit 1" 1 2 15
+ echo "creating $the_subdir/${the_makefile}.in"
+ exec 3>&1 >$the_subdir/${the_makefile}.in
+ echo "##### ${the_makefile}.in generated automatically by mkmakemod.sh"
+ echo "##### DO NOT EDIT!"
+ echo
+ echo "##### ===== DEFINITIONS ===== #####"
+ echo
+ echo "makefile = ${the_makefile}"
+ echo "dir_top = ${dir_top}"
+ echo "subdir = ${the_subdir}"
+ echo
+
+ bin_mods=`grep link=static ./config.modules | \
+ sed -e '/^#/d' -e 's/ .*/ /' -e 's/^name=/ /'`
+ dyn_mods="`grep link=dynamic ./config.modules | \
+ sed -e '/^#/d' -e 's/ .*/ /' -e 's/^name=/ /'`"
+ module_list="${bin_mods}${dyn_mods}"
+
+ if grep '^#define DYNAMIC ' config.h >/dev/null; then
+ is_dynamic=true
+ else
+ is_dynamic=false
+ fi
+
+ here_mddnames=
+ all_subdirs=
+ all_modobjs=
+ all_modules=
+ all_mdds=
+ all_mdhs=
+ all_proto=
+ lastsub=//
+ for module in $module_list; do
+ modfile="`grep '^name='$module' ' ./config.modules | \
+ sed -e 's/^.* modfile=//' -e 's/ .*//'`"
+ case $modfile in
+ $the_subdir/$lastsub/*) ;;
+ $the_subdir/*/*)
+ lastsub=`echo $modfile | sed 's,^'$the_subdir'/,,;s,/[^/]*$,,'`
+ case "$all_subdirs " in
+ *" $lastsub "* ) ;;
+ * )
+ all_subdirs="$all_subdirs $lastsub"
+ ;;
+ esac
+ ;;
+ $the_subdir/*)
+ mddname=`echo $modfile | sed 's,^.*/,,;s,\.mdd$,,'`
+ here_mddnames="$here_mddnames $mddname"
+ build=$is_dynamic
+ case $is_dynamic@$bin_mods in
+ *" $module "*)
+ build=true
+ all_modobjs="$all_modobjs modobjs.${mddname}" ;;
+ true@*)
+ all_modules="$all_modules ${mddname}.\$(DL_EXT)" ;;
+ esac
+ all_mdds="$all_mdds ${mddname}.mdd"
+ $build && all_mdhs="$all_mdhs ${mddname}.mdh"
+ $build && all_proto="$all_proto proto.${mddname}"
+ ;;
+ esac
+ done
+ echo "MODOBJS =$all_modobjs"
+ echo "MODULES =$all_modules"
+ echo "MDDS =$all_mdds"
+ echo "MDHS =$all_mdhs"
+ echo "PROTOS =$all_proto"
+ echo "SUBDIRS =$all_subdirs"
+ echo
+ echo "ENTRYOBJ = \$(dir_src)/modentry..o"
+ echo "NNTRYOBJ ="
+ echo "ENTRYOPT = -emodentry"
+ echo "NNTRYOPT ="
+ echo
+
+ echo "##### ===== INCLUDING Makemod.in.in ===== #####"
+ echo
+ cat $top_srcdir/Src/Makemod.in.in
+ echo
+
+ case $the_subdir in
+ Src) modobjs_sed= ;;
+ Src/*) modobjs_sed="| sed 's\" \" "`echo $the_subdir | sed 's,^Src/,,'`"/\"g' " ;;
+ *) modobjs_sed="| sed 's\" \" ../$the_subdir/\"g' " ;;
+ esac
+
+ other_mdhs=
+ remote_mdhs=
+ other_exports=
+ remote_exports=
+ other_modules=
+ remote_modules=
+ for mddname in $here_mddnames; do
+
+ unset name moddeps nozshdep alwayslink hasexport
+ unset autofeatures autofeatures_emu
+ unset objects proto headers hdrdeps otherincs
+ . $top_srcdir/$the_subdir/${mddname}.mdd
+ q_name=`echo $name | sed 's,Q,Qq,g;s,_,Qu,g;s,/,Qs,g'`
+ test -n "${moddeps+set}" || moddeps=
+ test -n "$nozshdep" || moddeps="$moddeps zsh/main"
+ test -n "${proto+set}" ||
+ proto=`echo $objects '' | sed 's,\.o ,.syms ,g'`
+
+ dobjects=`echo $objects '' | sed 's,\.o ,..o ,g'`
+ modhdeps=
+ mododeps=
+ exportdeps=
+ imports=
+ q_moddeps=
+ for dep in $moddeps; do
+ depfile="`grep '^name='$dep' ' ./config.modules | \
+ sed -e 's/^.* modfile=//' -e 's/ .*//'`"
+ q_dep=`echo $dep | sed 's,Q,Qq,g;s,_,Qu,g;s,/,Qs,g'`
+ q_moddeps="$q_moddeps $q_dep"
+ eval `echo $depfile | sed 's,/\([^/]*\)\.mdd$,;depbase=\1,;s,^,loc=,'`
+ case "$binmod" in
+ *" $dep "* )
+ dep=zsh/main
+ ;;
+ esac
+
+ case $the_subdir in
+ $loc)
+ mdh="${depbase}.mdh"
+ export="${depbase}.export"
+ case "$dep" in
+ zsh/main )
+ mdll="\$(dir_top)/Src/libzsh-\$(VERSION).\$(DL_EXT) "
+ ;;
+ * )
+ mdll="${depbase}.\$(DL_EXT) "
+ ;;
+ esac
+ ;;
+ $loc/*)
+ mdh="\$(dir_top)/$loc/${depbase}.mdh"
+ case "$other_mdhs " in
+ *" $mdh "*) ;;
+ *) other_mdhs="$other_mdhs $mdh" ;;
+ esac
+ export="\$(dir_top)/$loc/${depbase}.export"
+ case "$other_exports " in
+ *" $export "*) ;;
+ *) other_exports="$other_exports $export" ;;
+ esac
+ case "$dep" in
+ zsh/main )
+ mdll="\$(dir_top)/Src/libzsh-\$(VERSION).\$(DL_EXT) "
+ ;;
+ * )
+ mdll="\$(dir_top)/$loc/${depbase}.\$(DL_EXT) "
+ ;;
+ esac
+ case "$other_modules " in
+ *" $mdll "*) ;;
+ *) other_modules="$other_modules $mdll" ;;
+ esac
+ ;;
+ *)
+ mdh="\$(dir_top)/$loc/${depbase}.mdh"
+ case "$remote_mdhs " in
+ *" $mdh "*) ;;
+ *) remote_mdhs="$remote_mdhs $mdh" ;;
+ esac
+ export="\$(dir_top)/$loc/${depbase}.export"
+ case "$remote_exports " in
+ *" $export "*) ;;
+ *) remote_exports="$remote_exports $export" ;;
+ esac
+ case "$dep" in
+ zsh/main )
+ mdll="\$(dir_top)/Src/libzsh-\$(VERSION).\$(DL_EXT) "
+ ;;
+ * )
+ mdll="\$(dir_top)/$loc/${depbase}.\$(DL_EXT) "
+ ;;
+ esac
+ case "$remote_modules " in
+ *" $mdll "*) ;;
+ *) remote_modules="$remote_modules $mdll" ;;
+ esac
+ ;;
+ esac
+ modhdeps="$modhdeps $mdh"
+ exportdeps="$exportdeps $export"
+ imports="$imports \$(IMPOPT)$export"
+ case "$mododeps " in
+ *" $mdll "* )
+ :
+ ;;
+ * )
+ mododeps="$mododeps $mdll"
+ ;;
+ esac
+ done
+
+ echo "##### ===== DEPENDENCIES GENERATED FROM ${mddname}.mdd ===== #####"
+ echo
+ echo "MODOBJS_${mddname} = $objects"
+ echo "MODDOBJS_${mddname} = $dobjects \$(@E@NTRYOBJ)"
+ echo "SYMS_${mddname} = $proto"
+ echo "EPRO_${mddname} = "`echo $proto '' | sed 's,\.syms ,.epro ,g'`
+ echo "INCS_${mddname} = \$(EPRO_${mddname}) $otherincs"
+ echo "EXPIMP_${mddname} = $imports \$(EXPOPT)$mddname.export"
+ echo "NXPIMP_${mddname} ="
+ echo "LINKMODS_${mddname} = $mododeps"
+ echo "NOLINKMODS_${mddname} = "
+ echo
+ echo "proto.${mddname}: \$(EPRO_${mddname})"
+ echo "\$(SYMS_${mddname}): \$(PROTODEPS)"
+ echo
+ echo "${mddname}.export: \$(SYMS_${mddname})"
+ echo " @( echo '#!'; cat \$(SYMS_${mddname}) | sed -n '/^X/{s/^X//;p;}' | sort -u ) > \$@"
+ echo
+ echo "modobjs.${mddname}: \$(MODOBJS_${mddname})"
+ echo " @echo '' \$(MODOBJS_${mddname}) $modobjs_sed>> \$(dir_src)/stamp-modobjs.tmp"
+ echo
+ if test -z "$alwayslink"; then
+ case " $all_modules" in *" ${mddname}."*)
+ echo "install.modules-here: install.modules.${mddname}"
+ echo "uninstall.modules-here: uninstall.modules.${mddname}"
+ echo
+ ;; esac
+ instsubdir=`echo $name | sed 's,^,/,;s,/[^/]*$,,'`
+ echo "install.modules.${mddname}: ${mddname}.\$(DL_EXT)"
+ echo " \$(SHELL) \$(sdir_top)/mkinstalldirs \$(DESTDIR)\$(MODDIR)${instsubdir}"
+ echo " \$(INSTALL_PROGRAM) \$(STRIPFLAGS) ${mddname}.\$(DL_EXT) \$(DESTDIR)\$(MODDIR)/${name}.\$(DL_EXT)"
+ echo
+ echo "uninstall.modules.${mddname}:"
+ echo " rm -f \$(DESTDIR)\$(MODDIR)/${name}.\$(DL_EXT)"
+ echo
+ echo "${mddname}.\$(DL_EXT): \$(MODDOBJS_${mddname}) ${mddname}.export $exportdeps \$(@LINKMODS@_${mddname})"
+ echo ' rm -f $@'
+ echo " \$(DLLINK) \$(@E@XPIMP_$mddname) \$(@E@NTRYOPT) \$(MODDOBJS_${mddname}) \$(@LINKMODS@_${mddname}) \$(LIBS) "
+ echo
+ fi
+ echo "${mddname}.mdhi: ${mddname}.mdhs \$(INCS_${mddname})"
+ echo " @test -f \$@ || echo 'do not delete this file' > \$@"
+ echo
+ echo "${mddname}.mdhs: ${mddname}.mdd"
+ echo " @\$(MAKE) -f \$(makefile) \$(MAKEDEFS) ${mddname}.mdh.tmp"
+ echo " @if cmp -s ${mddname}.mdh ${mddname}.mdh.tmp; then \\"
+ echo " rm -f ${mddname}.mdh.tmp; \\"
+ echo " echo \"\\\`${mddname}.mdh' is up to date.\"; \\"
+ echo " else \\"
+ echo " mv -f ${mddname}.mdh.tmp ${mddname}.mdh; \\"
+ echo " echo \"Updated \\\`${mddname}.mdh'.\"; \\"
+ echo " fi"
+ echo " echo 'timestamp for ${mddname}.mdh against ${mddname}.mdd' > \$@"
+ echo
+ echo "${mddname}.mdh: ${modhdeps} ${headers} ${hdrdeps} ${mddname}.mdhi"
+ echo " @\$(MAKE) -f \$(makefile) \$(MAKEDEFS) ${mddname}.mdh.tmp"
+ echo " @mv -f ${mddname}.mdh.tmp ${mddname}.mdh"
+ echo " @echo \"Updated \\\`${mddname}.mdh'.\""
+ echo
+ echo "${mddname}.mdh.tmp:"
+ echo " @( \\"
+ echo " echo '#ifndef have_${q_name}_module'; \\"
+ echo " echo '#define have_${q_name}_module'; \\"
+ echo " echo; \\"
+ echo " echo '# ifndef IMPORTING_MODULE_${q_name}'; \\"
+ echo " if test @SHORTBOOTNAMES@ = yes; then \\"
+ echo " echo '# ifndef MODULE'; \\"
+ echo " fi; \\"
+ echo " echo '# define boot_ boot_${q_name}'; \\"
+ echo " echo '# define cleanup_ cleanup_${q_name}'; \\"
+ echo " echo '# define features_ features_${q_name}'; \\"
+ echo " echo '# define enables_ enables_${q_name}'; \\"
+ echo " echo '# define setup_ setup_${q_name}'; \\"
+ echo " echo '# define finish_ finish_${q_name}'; \\"
+ echo " if test @SHORTBOOTNAMES@ = yes; then \\"
+ echo " echo '# endif /* !MODULE */'; \\"
+ echo " fi; \\"
+ echo " echo '# endif /* !IMPORTING_MODULE_${q_name} */'; \\"
+ echo " echo; \\"
+ if test -n "$moddeps"; then (
+ set x $q_moddeps
+ echo " echo '/* Module dependencies */'; \\"
+ for hdep in $modhdeps; do
+ shift
+ echo " echo '# define IMPORTING_MODULE_${1} 1'; \\"
+ echo " echo '# include \"${hdep}\"'; \\"
+ done
+ echo " echo; \\"
+ ) fi
+ if test -n "$headers"; then
+ echo " echo '/* Extra headers for this module */'; \\"
+ echo " for hdr in $headers; do \\"
+ echo " echo '# include \"'\$\$hdr'\"'; \\"
+ echo " done; \\"
+ echo " echo; \\"
+ fi
+ if test -n "$proto"; then
+ echo " echo '# undef mod_import_variable'; \\"
+ echo " echo '# undef mod_import_function'; \\"
+ echo " echo '# if defined(IMPORTING_MODULE_${q_name}) && defined(MODULE)'; \\"
+ echo " echo '# define mod_import_variable @MOD_IMPORT_VARIABLE@'; \\"
+ echo " echo '# define mod_import_function @MOD_IMPORT_FUNCTION@'; \\"
+ echo " echo '# else'; \\"
+ echo " echo '# define mod_import_function'; \\"
+ echo " echo '# define mod_import_variable'; \\"
+ echo " echo '# endif /* IMPORTING_MODULE_${q_name} && MODULE */'; \\"
+ echo " for epro in \$(EPRO_${mddname}); do \\"
+ echo " echo '# include \"'\$\$epro'\"'; \\"
+ echo " done; \\"
+ echo " echo '# undef mod_import_variable'; \\"
+ echo " echo '# define mod_import_variable'; \\"
+ echo " echo '# undef mod_import_variable'; \\"
+ echo " echo '# define mod_import_variable'; \\"
+ echo " echo '# ifndef mod_export'; \\"
+ echo " echo '# define mod_export @MOD_EXPORT@'; \\"
+ echo " echo '# endif /* mod_export */'; \\"
+ echo " echo; \\"
+ fi
+ echo " echo '#endif /* !have_${q_name}_module */'; \\"
+ echo " ) > \$@"
+ echo
+ echo "\$(MODOBJS_${mddname}) \$(MODDOBJS_${mddname}): ${mddname}.mdh"
+ sed -e '/^ *: *<< *\\Make *$/,/^Make$/!d' \
+ -e 's/^ *: *<< *\\Make *$//; /^Make$/d' \
+ < $top_srcdir/$the_subdir/${mddname}.mdd
+ echo
+
+ done
+
+ if test -n "$remote_mdhs$other_mdhs$remote_exports$other_exports$remote_modules$other_modules"; then
+ echo "##### ===== DEPENDENCIES FOR REMOTE MODULES ===== #####"
+ echo
+ for mdh in $remote_mdhs; do
+ echo "$mdh: FORCE"
+ echo " @cd @%@ && \$(MAKE) \$(MAKEDEFS) @%@$mdh"
+ echo
+ done | sed 's,^\(.*\)@%@\(.*\)@%@\(.*\)/\([^/]*\)$,\1\3\2\4,'
+ if test -n "$other_mdhs"; then
+ echo "${other_mdhs}:" | sed 's,^ ,,'
+ echo " false # A. should only happen with make -n"
+ echo
+ fi
+ for export in $remote_exports; do
+ echo "$export: FORCE"
+ echo " @cd @%@ && \$(MAKE) \$(MAKEDEFS) @%@$export"
+ echo
+ done | sed 's,^\(.*\)@%@\(.*\)@%@\(.*\)/\([^/]*\)$,\1\3\2\4,'
+ if test -n "$other_exports"; then
+ echo "${other_exports}:" | sed 's,^ ,,'
+ echo " false # B. should only happen with make -n"
+ echo
+ fi
+ for mdll in $remote_modules; do
+ echo "$mdll: FORCE"
+ echo " @cd @%@ && \$(MAKE) \$(MAKEDEFS) @%@$mdll"
+ echo
+ done | sed 's,^\(.*\)@%@\(.*\)@%@\(.*\)/\([^/]*\)$,\1\3\2\4,'
+ if test -n "$other_modules"; then
+ echo "${other_modules}:" | sed 's,^ ,,'
+ echo " false # C. should only happen with make -n"
+ echo
+ fi
+ fi
+
+ echo "##### End of ${the_makefile}.in"
+
+ exec >&3 3>&-
+
+fi
+
+if $second_stage ; then
+ trap "rm -f $the_subdir/${the_makefile}; exit 1" 1 2 15
+
+ ${CONFIG_SHELL-/bin/sh} ./config.status \
+ --file=$the_subdir/${the_makefile}:$the_subdir/${the_makefile}.in ||
+ exit 1
+fi
+
+exit 0
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/module.c b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/module.c
new file mode 100644
index 0000000..4ae7831
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/module.c
@@ -0,0 +1,3641 @@
+/*
+ * module.c - deal with dynamic modules
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1996-1997 Zoltán Hidvégi
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Zoltán Hidvégi or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Zoltán Hidvégi and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Zoltán Hidvégi and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Zoltán Hidvégi and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ */
+
+#include "zsh.mdh"
+#include "module.pro"
+
+/*
+ * List of linked-in modules.
+ * This is set up at boot and remains for the life of the shell;
+ * entries do not appear in "zmodload" listings.
+ */
+
+/**/
+LinkList linkedmodules;
+
+/* $module_path ($MODULE_PATH) */
+
+/**/
+char **module_path;
+
+/* Hash of modules */
+
+/**/
+mod_export HashTable modulestab;
+
+/*
+ * Bit flags passed as the "flags" argument of a autofeaturefn_t.
+ * Used in other places, such as the final argument to
+ * do_module_features().
+ */
+enum {
+ /*
+ * `-i' option: ignore errors pertaining to redefinitions,
+ * or indicate to do_module_features() that it should be
+ * silent.
+ */
+ FEAT_IGNORE = 0x0001,
+ /* If a condition, condition is infix rather than prefix */
+ FEAT_INFIX = 0x0002,
+ /*
+ * Enable all features in the module when autoloading.
+ * This is the traditional zmodload -a behaviour;
+ * zmodload -Fa only enables features explicitly marked for
+ * autoloading.
+ */
+ FEAT_AUTOALL = 0x0004,
+ /*
+ * Remove feature: alternative to "-X:NAME" used if
+ * X is passed separately from NAME.
+ */
+ FEAT_REMOVE = 0x0008,
+ /*
+ * For do_module_features(). Check that any autoloads
+ * for the module are actually provided.
+ */
+ FEAT_CHECKAUTO = 0x0010
+};
+
+/*
+ * All functions to add or remove autoloadable features fit
+ * the following prototype.
+ *
+ * "module" is the name of the module.
+ *
+ * "feature" is the name of the feature, minus any type prefix.
+ *
+ * "flags" is a set of the bits above.
+ *
+ * The return value is 0 for success, -1 for failure with no
+ * message needed, and one of the following to indicate the calling
+ * function should print a message:
+ *
+ * 1: failed to add [type] `[feature]'
+ * 2: [feature]: no such [type]
+ * 3: [feature]: [type] is already defined
+ */
+typedef int (*autofeaturefn_t)(const char *module, const char *feature,
+ int flags);
+
+/* Bits in the second argument to find_module. */
+enum {
+ /*
+ * Resolve any aliases to the underlying module.
+ */
+ FINDMOD_ALIASP = 0x0001,
+ /*
+ * Create an element for the module in the list if
+ * it is not found.
+ */
+ FINDMOD_CREATE = 0x0002,
+};
+
+static void
+freemodulenode(HashNode hn)
+{
+ Module m = (Module) hn;
+
+ if (m->node.flags & MOD_ALIAS)
+ zsfree(m->u.alias);
+ zsfree(m->node.nam);
+ if (m->autoloads)
+ freelinklist(m->autoloads, freestr);
+ if (m->deps)
+ freelinklist(m->deps, freestr);
+ zfree(m, sizeof(*m));
+}
+
+/* flags argument to printmodulenode */
+enum {
+ /* -L flag, output zmodload commands */
+ PRINTMOD_LIST = 0x0001,
+ /* -e flag */
+ PRINTMOD_EXIST = 0x0002,
+ /* -A flag */
+ PRINTMOD_ALIAS = 0x0004,
+ /* -d flag */
+ PRINTMOD_DEPS = 0x0008,
+ /* -F flag */
+ PRINTMOD_FEATURES = 0x0010,
+ /* -l flag in combination with -L flag */
+ PRINTMOD_LISTALL = 0x0020,
+ /* -a flag */
+ PRINTMOD_AUTO = 0x0040
+};
+
+/* Scan function for printing module details */
+
+static void
+printmodulenode(HashNode hn, int flags)
+{
+ Module m = (Module)hn;
+ /*
+ * If we check for a module loaded under an alias, we
+ * need the name of the alias. We can use it in other
+ * cases, too.
+ */
+ const char *modname = m->node.nam;
+
+ if (flags & PRINTMOD_DEPS) {
+ /*
+ * Print the module's dependencies.
+ */
+ LinkNode n;
+
+ if (!m->deps)
+ return;
+
+ if (flags & PRINTMOD_LIST) {
+ printf("zmodload -d ");
+ if (modname[0] == '-')
+ fputs("-- ", stdout);
+ quotedzputs(modname, stdout);
+ } else {
+ nicezputs(modname, stdout);
+ putchar(':');
+ }
+ for (n = firstnode(m->deps); n; incnode(n)) {
+ putchar(' ');
+ if (flags & PRINTMOD_LIST)
+ quotedzputs((char *) getdata(n), stdout);
+ else
+ nicezputs((char *) getdata(n), stdout);
+ }
+ } else if (flags & PRINTMOD_EXIST) {
+ /*
+ * Just print the module name, provided the module is
+ * present under an alias or otherwise.
+ */
+ if (m->node.flags & MOD_ALIAS) {
+ if (!(flags & PRINTMOD_ALIAS) ||
+ !(m = find_module(m->u.alias, FINDMOD_ALIASP, NULL)))
+ return;
+ }
+ if (!m->u.handle || (m->node.flags & MOD_UNLOAD))
+ return;
+ nicezputs(modname, stdout);
+ } else if (m->node.flags & MOD_ALIAS) {
+ /*
+ * Normal listing, but for aliases.
+ */
+ if (flags & PRINTMOD_LIST) {
+ printf("zmodload -A ");
+ if (modname[0] == '-')
+ fputs("-- ", stdout);
+ quotedzputs(modname, stdout);
+ putchar('=');
+ quotedzputs(m->u.alias, stdout);
+ } else {
+ nicezputs(modname, stdout);
+ fputs(" -> ", stdout);
+ nicezputs(m->u.alias, stdout);
+ }
+ } else if (m->u.handle || (flags & PRINTMOD_AUTO)) {
+ /*
+ * Loaded module.
+ */
+ if (flags & PRINTMOD_LIST) {
+ /*
+ * List with -L format. Possibly we are printing
+ * features, either enables or autoloads.
+ */
+ char **features = NULL;
+ int *enables = NULL;
+ if (flags & PRINTMOD_AUTO) {
+ if (!m->autoloads || !firstnode(m->autoloads))
+ return;
+ } else if (flags & PRINTMOD_FEATURES) {
+ if (features_module(m, &features) ||
+ enables_module(m, &enables) ||
+ !*features)
+ return;
+ }
+ printf("zmodload ");
+ if (flags & PRINTMOD_AUTO) {
+ fputs("-Fa ", stdout);
+ } else if (features)
+ fputs("-F ", stdout);
+ if(modname[0] == '-')
+ fputs("-- ", stdout);
+ quotedzputs(modname, stdout);
+ if (flags & PRINTMOD_AUTO) {
+ LinkNode an;
+ for (an = firstnode(m->autoloads); an; incnode(an)) {
+ putchar(' ');
+ quotedzputs((char *)getdata(an), stdout);
+ }
+ } else if (features) {
+ const char *f;
+ while ((f = *features++)) {
+ int on = *enables++;
+ if (flags & PRINTMOD_LISTALL)
+ printf(" %s", on ? "+" : "-");
+ else if (!on)
+ continue;
+ else
+ putchar(' ');
+ quotedzputs(f, stdout);
+ }
+ }
+ } else /* -l */
+ nicezputs(modname, stdout);
+ } else
+ return;
+ putchar('\n');
+}
+
+/**/
+HashTable
+newmoduletable(int size, char const *name)
+{
+ HashTable ht;
+ ht = newhashtable(size, name, NULL);
+
+ ht->hash = hasher;
+ ht->emptytable = emptyhashtable;
+ ht->filltable = NULL;
+ ht->cmpnodes = strcmp;
+ ht->addnode = addhashnode;
+ /* DISABLED is not supported */
+ ht->getnode = gethashnode2;
+ ht->getnode2 = gethashnode2;
+ ht->removenode = removehashnode;
+ ht->disablenode = NULL;
+ ht->enablenode = NULL;
+ ht->freenode = freemodulenode;
+ ht->printnode = printmodulenode;
+
+ return ht;
+}
+
+/************************************************************************
+ * zsh/main standard module functions
+ ************************************************************************/
+
+/* The `zsh/main' module contains all the base code that can't actually be *
+ * built as a separate module. It is initialised by main(), so there's *
+ * nothing for the boot function to do. */
+
+/**/
+int
+setup_(UNUSED(Module m))
+{
+ return 0;
+}
+
+/**/
+int
+features_(UNUSED(Module m), UNUSED(char ***features))
+{
+ /*
+ * There are lots and lots of features, but they're not
+ * handled here.
+ */
+ return 1;
+}
+
+/**/
+int
+enables_(UNUSED(Module m), UNUSED(int **enables))
+{
+ return 1;
+}
+
+/**/
+int
+boot_(UNUSED(Module m))
+{
+ return 0;
+}
+
+/**/
+int
+cleanup_(UNUSED(Module m))
+{
+ return 0;
+}
+
+/**/
+int
+finish_(UNUSED(Module m))
+{
+ return 0;
+}
+
+
+/************************************************************************
+ * Module utility functions
+ ************************************************************************/
+
+/* This registers a builtin module. */
+
+/**/
+void
+register_module(char *n, Module_void_func setup,
+ Module_features_func features,
+ Module_enables_func enables,
+ Module_void_func boot,
+ Module_void_func cleanup,
+ Module_void_func finish)
+{
+ Linkedmod m;
+
+ m = (Linkedmod) zalloc(sizeof(*m));
+
+ m->name = ztrdup(n);
+ m->setup = setup;
+ m->features = features;
+ m->enables = enables;
+ m->boot = boot;
+ m->cleanup = cleanup;
+ m->finish = finish;
+
+ zaddlinknode(linkedmodules, m);
+}
+
+/* Check if a module is linked in. */
+
+/**/
+Linkedmod
+module_linked(char const *name)
+{
+ LinkNode node;
+
+ for (node = firstnode(linkedmodules); node; incnode(node))
+ if (!strcmp(((Linkedmod) getdata(node))->name, name))
+ return (Linkedmod) getdata(node);
+
+ return NULL;
+}
+
+
+/************************************************************************
+ * Support for the various feature types.
+ * First, builtins.
+ ************************************************************************/
+
+/* addbuiltin() can be used to add a new builtin. It returns zero on *
+ * success, 1 on failure. The only possible type of failure is that *
+ * a builtin with the specified name already exists. An autoloaded *
+ * builtin can be replaced using this function. */
+
+/**/
+static int
+addbuiltin(Builtin b)
+{
+ Builtin bn = (Builtin) builtintab->getnode2(builtintab, b->node.nam);
+ if (bn && (bn->node.flags & BINF_ADDED))
+ return 1;
+ if (bn)
+ builtintab->freenode(builtintab->removenode(builtintab, b->node.nam));
+ builtintab->addnode(builtintab, b->node.nam, b);
+ return 0;
+}
+
+/* Define an autoloadable builtin. It returns 0 on success, or 1 on *
+ * failure. The only possible cause of failure is that a builtin *
+ * with the specified name already exists. */
+
+/**/
+static int
+add_autobin(const char *module, const char *bnam, int flags)
+{
+ Builtin bn;
+ int ret;
+
+ bn = zshcalloc(sizeof(*bn));
+ bn->node.nam = ztrdup(bnam);
+ bn->optstr = ztrdup(module);
+ if (flags & FEAT_AUTOALL)
+ bn->node.flags |= BINF_AUTOALL;
+ if ((ret = addbuiltin(bn))) {
+ builtintab->freenode(&bn->node);
+ if (!(flags & FEAT_IGNORE))
+ return 1;
+ }
+ return 0;
+}
+
+/* Remove the builtin added previously by addbuiltin(). Returns *
+ * zero on succes and -1 if there is no builtin with that name. */
+
+/**/
+int
+deletebuiltin(const char *nam)
+{
+ Builtin bn;
+
+ bn = (Builtin) builtintab->removenode(builtintab, nam);
+ if (!bn)
+ return -1;
+ builtintab->freenode(&bn->node);
+ return 0;
+}
+
+/* Remove an autoloaded added by add_autobin */
+
+/**/
+static int
+del_autobin(UNUSED(const char *module), const char *bnam, int flags)
+{
+ Builtin bn = (Builtin) builtintab->getnode2(builtintab, bnam);
+ if (!bn) {
+ if(!(flags & FEAT_IGNORE))
+ return 2;
+ } else if (bn->node.flags & BINF_ADDED) {
+ if (!(flags & FEAT_IGNORE))
+ return 3;
+ } else
+ deletebuiltin(bnam);
+
+ return 0;
+}
+
+/*
+ * Manipulate a set of builtins. This should be called
+ * via setfeatureenables() (or, usually, via the next level up,
+ * handlefeatures()).
+ *
+ * "nam" is the name of the calling code builtin, probably "zmodload".
+ *
+ * "binl" is the builtin table containing an array of "size" builtins.
+ *
+ * "e" is either NULL, in which case all builtins in the
+ * table are removed, or else an array corresponding to "binl"
+ * with a 1 for builtins that are to be added and a 0 for builtins
+ * that are to be removed. Any builtin already in the appropriate
+ * state is left alone.
+ *
+ * Returns 1 on any error, 0 for success. The recommended way
+ * of handling errors is to compare the enables passed down
+ * with the set retrieved after the error to find what failed.
+ */
+
+/**/
+static int
+setbuiltins(char const *nam, Builtin binl, int size, int *e)
+{
+ int ret = 0, n;
+
+ for(n = 0; n < size; n++) {
+ Builtin b = &binl[n];
+ if (e && *e++) {
+ if (b->node.flags & BINF_ADDED)
+ continue;
+ if (addbuiltin(b)) {
+ zwarnnam(nam,
+ "name clash when adding builtin `%s'", b->node.nam);
+ ret = 1;
+ } else {
+ b->node.flags |= BINF_ADDED;
+ }
+ } else {
+ if (!(b->node.flags & BINF_ADDED))
+ continue;
+ if (deletebuiltin(b->node.nam)) {
+ zwarnnam(nam, "builtin `%s' already deleted", b->node.nam);
+ ret = 1;
+ } else {
+ b->node.flags &= ~BINF_ADDED;
+ }
+ }
+ }
+ return ret;
+}
+
+/*
+ * Add multiple builtins. binl points to a table of `size' builtin
+ * structures. Those for which (.flags & BINF_ADDED) is false are to be
+ * added; that flag is set if they succeed.
+ *
+ * If any fail, an error message is printed, using nam as the leading name.
+ * Returns 0 on success, 1 for any failure.
+ *
+ * This should not be used from a module; instead, use handlefeatures().
+ */
+
+/**/
+mod_export int
+addbuiltins(char const *nam, Builtin binl, int size)
+{
+ int ret = 0, n;
+
+ for(n = 0; n < size; n++) {
+ Builtin b = &binl[n];
+ if(b->node.flags & BINF_ADDED)
+ continue;
+ if(addbuiltin(b)) {
+ zwarnnam(nam, "name clash when adding builtin `%s'", b->node.nam);
+ ret = 1;
+ } else {
+ b->node.flags |= BINF_ADDED;
+ }
+ }
+ return ret;
+}
+
+
+/************************************************************************
+ * Function wrappers.
+ ************************************************************************/
+
+/* The list of function wrappers defined. */
+
+/**/
+FuncWrap wrappers;
+
+/* This adds a definition for a wrapper. Return value is one in case of *
+ * error and zero if all went fine. */
+
+/**/
+mod_export int
+addwrapper(Module m, FuncWrap w)
+{
+ FuncWrap p, q;
+
+ /*
+ * We can't add a wrapper to an alias, since it's supposed
+ * to behave identically to the resolved module. This shouldn't
+ * happen since we usually add wrappers when a real module is
+ * loaded.
+ */
+ if (m->node.flags & MOD_ALIAS)
+ return 1;
+
+ if (w->flags & WRAPF_ADDED)
+ return 1;
+ for (p = wrappers, q = NULL; p; q = p, p = p->next);
+ if (q)
+ q->next = w;
+ else
+ wrappers = w;
+ w->next = NULL;
+ w->flags |= WRAPF_ADDED;
+ w->module = m;
+
+ return 0;
+}
+
+/* This removes the given wrapper definition from the list. Returned is *
+ * one in case of error and zero otherwise. */
+
+/**/
+mod_export int
+deletewrapper(Module m, FuncWrap w)
+{
+ FuncWrap p, q;
+
+ if (m->node.flags & MOD_ALIAS)
+ return 1;
+
+ if (w->flags & WRAPF_ADDED) {
+ for (p = wrappers, q = NULL; p && p != w; q = p, p = p->next);
+
+ if (p) {
+ if (q)
+ q->next = p->next;
+ else
+ wrappers = p->next;
+ p->flags &= ~WRAPF_ADDED;
+
+ return 0;
+ }
+ }
+ return 1;
+}
+
+
+/************************************************************************
+ * Conditions.
+ ************************************************************************/
+
+/* The list of module-defined conditions. */
+
+/**/
+mod_export Conddef condtab;
+
+/* This gets a condition definition with the given name. The first *
+ * argument says if we have to look for an infix condition. The last *
+ * argument is non-zero if we should autoload modules if needed. */
+
+/**/
+Conddef
+getconddef(int inf, const char *name, int autol)
+{
+ Conddef p;
+ int f = 1;
+ char *lookup, *s;
+
+ /* detokenize the Dash to the form encoded in lookup tables */
+ lookup = dupstring(name);
+ if (!lookup)
+ return NULL;
+ for (s = lookup; *s != '\0'; s++) {
+ if (*s == Dash)
+ *s = '-';
+ }
+
+ do {
+ for (p = condtab; p; p = p->next) {
+ if ((!!inf == !!(p->flags & CONDF_INFIX)) &&
+ !strcmp(lookup, p->name))
+ break;
+ }
+ if (autol && p && p->module) {
+ /*
+ * This is a definition for an autoloaded condition; load the
+ * module if we haven't tried that already.
+ */
+ if (f) {
+ (void)ensurefeature(p->module,
+ (p->flags & CONDF_INFIX) ? "C:" : "c:",
+ (p->flags & CONDF_AUTOALL) ? NULL : lookup);
+ f = 0;
+ p = NULL;
+ } else {
+ deleteconddef(p);
+ return NULL;
+ }
+ } else
+ break;
+ } while (!p);
+
+ return p;
+}
+
+/*
+ * This adds the given condition definition. The return value is zero on *
+ * success and 1 on failure. If there is a matching definition for an *
+ * autoloaded condition, it is removed.
+ *
+ * This is used for adding both an autoload definition or
+ * a real condition. In the latter case the caller is responsible
+ * for setting the CONDF_ADDED flag.
+ */
+
+/**/
+static int
+addconddef(Conddef c)
+{
+ Conddef p = getconddef((c->flags & CONDF_INFIX), c->name, 0);
+
+ if (p) {
+ if (!p->module || (p->flags & CONDF_ADDED))
+ return 1;
+ /* There is an autoload definition. */
+
+ deleteconddef(p);
+ }
+ c->next = condtab;
+ condtab = c;
+ return 0;
+}
+
+/* This removes the given condition definition from the list(s). If this *
+ * is a definition for a autoloaded condition, the memory is freed. */
+
+/**/
+int
+deleteconddef(Conddef c)
+{
+ Conddef p, q;
+
+ for (p = condtab, q = NULL; p && p != c; q = p, p = p->next);
+
+ if (p) {
+ if (q)
+ q->next = p->next;
+ else
+ condtab = p->next;
+
+ if (p->module) {
+ /* autoloaded, free it */
+ zsfree(p->name);
+ zsfree(p->module);
+ zfree(p, sizeof(*p));
+ }
+ return 0;
+ }
+ return -1;
+}
+
+/*
+ * Add or remove sets of conditions. The interface is
+ * identical to setbuiltins().
+ */
+
+/**/
+static int
+setconddefs(char const *nam, Conddef c, int size, int *e)
+{
+ int ret = 0;
+
+ while (size--) {
+ if (e && *e++) {
+ if (c->flags & CONDF_ADDED) {
+ c++;
+ continue;
+ }
+ if (addconddef(c)) {
+ zwarnnam(nam, "name clash when adding condition `%s'",
+ c->name);
+ ret = 1;
+ } else {
+ c->flags |= CONDF_ADDED;
+ }
+ } else {
+ if (!(c->flags & CONDF_ADDED)) {
+ c++;
+ continue;
+ }
+ if (deleteconddef(c)) {
+ zwarnnam(nam, "condition `%s' already deleted", c->name);
+ ret = 1;
+ } else {
+ c->flags &= ~CONDF_ADDED;
+ }
+ }
+ c++;
+ }
+ return ret;
+}
+
+/* This adds a definition for autoloading a module for a condition. */
+
+/**/
+static int
+add_autocond(const char *module, const char *cnam, int flags)
+{
+ Conddef c;
+
+ c = (Conddef) zalloc(sizeof(*c));
+
+ c->name = ztrdup(cnam);
+ c->flags = ((flags & FEAT_INFIX) ? CONDF_INFIX : 0);
+ if (flags & FEAT_AUTOALL)
+ c->flags |= CONDF_AUTOALL;
+ c->module = ztrdup(module);
+
+ if (addconddef(c)) {
+ zsfree(c->name);
+ zsfree(c->module);
+ zfree(c, sizeof(*c));
+
+ if (!(flags & FEAT_IGNORE))
+ return 1;
+ }
+ return 0;
+}
+
+/* Remove a condition added with add_autocond */
+
+/**/
+static int
+del_autocond(UNUSED(const char *modnam), const char *cnam, int flags)
+{
+ Conddef cd = getconddef((flags & FEAT_INFIX) ? 1 : 0, cnam, 0);
+
+ if (!cd) {
+ if (!(flags & FEAT_IGNORE)) {
+ return 2;
+ }
+ } else if (cd->flags & CONDF_ADDED) {
+ if (!(flags & FEAT_IGNORE))
+ return 3;
+ } else
+ deleteconddef(cd);
+
+ return 0;
+}
+
+/************************************************************************
+ * Hook functions.
+ ************************************************************************/
+
+/* This list of hook functions defined. */
+
+/**/
+Hookdef hooktab;
+
+/* Find a hook definition given the name. */
+
+/**/
+Hookdef
+gethookdef(char *n)
+{
+ Hookdef p;
+
+ for (p = hooktab; p; p = p->next)
+ if (!strcmp(n, p->name))
+ return p;
+ return NULL;
+}
+
+/* This adds the given hook definition. The return value is zero on *
+ * success and 1 on failure. */
+
+/**/
+int
+addhookdef(Hookdef h)
+{
+ if (gethookdef(h->name))
+ return 1;
+
+ h->next = hooktab;
+ hooktab = h;
+ h->funcs = znewlinklist();
+
+ return 0;
+}
+
+/*
+ * This adds multiple hook definitions. This is like addbuiltins().
+ * This allows a NULL module because we call it from init.c.
+ */
+
+/**/
+mod_export int
+addhookdefs(Module m, Hookdef h, int size)
+{
+ int ret = 0;
+
+ while (size--) {
+ if (addhookdef(h)) {
+ zwarnnam(m ? m->node.nam : NULL,
+ "name clash when adding hook `%s'", h->name);
+ ret = 1;
+ }
+ h++;
+ }
+ return ret;
+}
+
+/* Delete hook definitions. */
+
+/**/
+int
+deletehookdef(Hookdef h)
+{
+ Hookdef p, q;
+
+ for (p = hooktab, q = NULL; p && p != h; q = p, p = p->next);
+
+ if (!p)
+ return 1;
+
+ if (q)
+ q->next = p->next;
+ else
+ hooktab = p->next;
+ freelinklist(p->funcs, NULL);
+ return 0;
+}
+
+/* Remove multiple hook definitions. */
+
+/**/
+mod_export int
+deletehookdefs(UNUSED(Module m), Hookdef h, int size)
+{
+ int ret = 0;
+
+ while (size--) {
+ if (deletehookdef(h))
+ ret = 1;
+ h++;
+ }
+ return ret;
+}
+
+/* Add a function to a hook. */
+
+/**/
+int
+addhookdeffunc(Hookdef h, Hookfn f)
+{
+ zaddlinknode(h->funcs, (void *) f);
+
+ return 0;
+}
+
+/**/
+mod_export int
+addhookfunc(char *n, Hookfn f)
+{
+ Hookdef h = gethookdef(n);
+
+ if (h)
+ return addhookdeffunc(h, f);
+ return 1;
+}
+
+/* Delete a function from a hook. */
+
+/**/
+int
+deletehookdeffunc(Hookdef h, Hookfn f)
+{
+ LinkNode p;
+
+ for (p = firstnode(h->funcs); p; incnode(p))
+ if (f == (Hookfn) getdata(p)) {
+ remnode(h->funcs, p);
+ return 0;
+ }
+ return 1;
+}
+
+/* Delete a hook. */
+
+/**/
+mod_export int
+deletehookfunc(char *n, Hookfn f)
+{
+ Hookdef h = gethookdef(n);
+
+ if (h)
+ return deletehookdeffunc(h, f);
+ return 1;
+}
+
+/* Run the function(s) for a hook. */
+
+/**/
+mod_export int
+runhookdef(Hookdef h, void *d)
+{
+ if (empty(h->funcs)) {
+ if (h->def)
+ return h->def(h, d);
+ return 0;
+ } else if (h->flags & HOOKF_ALL) {
+ LinkNode p;
+ int r;
+
+ for (p = firstnode(h->funcs); p; incnode(p))
+ if ((r = ((Hookfn) getdata(p))(h, d)))
+ return r;
+ if (h->def)
+ return h->def(h, d);
+ return 0;
+ } else
+ return ((Hookfn) getdata(lastnode(h->funcs)))(h, d);
+}
+
+
+
+/************************************************************************
+ * Shell parameters.
+ ************************************************************************/
+
+/*
+ * Check that it's possible to add a parameter. This
+ * requires that either there's no parameter already present,
+ * or it's a global parameter marked for autoloading.
+ *
+ * The special status 2 is to indicate it didn't work but
+ * -i was in use so we didn't print a warning.
+ */
+
+static int
+checkaddparam(const char *nam, int opt_i)
+{
+ Param pm;
+
+ if (!(pm = (Param) gethashnode2(paramtab, nam)))
+ return 0;
+
+ if (pm->level || !(pm->node.flags & PM_AUTOLOAD)) {
+ /*
+ * -i suppresses "it's already that way" warnings,
+ * but not "this can't possibly work" warnings, so we print
+ * the message anyway if there's a local parameter blocking
+ * the parameter we want to add, not if there's a
+ * non-autoloadable parameter already there. This
+ * is consistent with the way add_auto* functions work.
+ */
+ if (!opt_i || !pm->level) {
+ zwarn("Can't add module parameter `%s': %s",
+ nam, pm->level ?
+ "local parameter exists" :
+ "parameter already exists");
+ return 1;
+ }
+ return 2;
+ }
+
+ unsetparam_pm(pm, 0, 1);
+ return 0;
+}
+
+/* This adds the given parameter definition. The return value is zero on *
+ * success and 1 on failure. */
+
+/**/
+int
+addparamdef(Paramdef d)
+{
+ Param pm;
+
+ if (checkaddparam(d->name, 0))
+ return 1;
+
+ if (d->getnfn) {
+ if (!(pm = createspecialhash(d->name, d->getnfn,
+ d->scantfn, d->flags)))
+ return 1;
+ }
+ else if (!(pm = createparam(d->name, d->flags)) &&
+ !(pm = (Param) paramtab->getnode(paramtab, d->name)))
+ return 1;
+
+ d->pm = pm;
+ pm->level = 0;
+ if (d->var)
+ pm->u.data = d->var;
+ if (d->var || d->gsu) {
+ /*
+ * If no get/set/unset class, use the appropriate
+ * variable type, else use the one supplied.
+ */
+ switch (PM_TYPE(pm->node.flags)) {
+ case PM_SCALAR:
+ pm->gsu.s = d->gsu ? (GsuScalar)d->gsu : &varscalar_gsu;
+ break;
+
+ case PM_INTEGER:
+ pm->gsu.i = d->gsu ? (GsuInteger)d->gsu : &varinteger_gsu;
+ break;
+
+ case PM_FFLOAT:
+ case PM_EFLOAT:
+ pm->gsu.f = d->gsu;
+ break;
+
+ case PM_ARRAY:
+ pm->gsu.a = d->gsu ? (GsuArray)d->gsu : &vararray_gsu;
+ break;
+
+ case PM_HASHED:
+ /* hashes may behave like standard hashes */
+ if (d->gsu)
+ pm->gsu.h = (GsuHash)d->gsu;
+ break;
+
+ default:
+ unsetparam_pm(pm, 0, 1);
+ return 1;
+ }
+ }
+
+ return 0;
+}
+
+/* Delete parameters defined. No error checking yet. */
+
+/**/
+int
+deleteparamdef(Paramdef d)
+{
+ Param pm = (Param) paramtab->getnode(paramtab, d->name);
+
+ if (!pm)
+ return 1;
+ if (pm != d->pm) {
+ /*
+ * See if the parameter has been hidden. If so,
+ * bring it to the front to unset it.
+ */
+ Param prevpm, searchpm;
+ for (prevpm = pm, searchpm = pm->old;
+ searchpm;
+ prevpm = searchpm, searchpm = searchpm->old)
+ if (searchpm == d->pm)
+ break;
+
+ if (!searchpm)
+ return 1;
+
+ paramtab->removenode(paramtab, pm->node.nam);
+ prevpm->old = searchpm->old;
+ searchpm->old = pm;
+ paramtab->addnode(paramtab, searchpm->node.nam, searchpm);
+
+ pm = searchpm;
+ }
+ pm->node.flags = (pm->node.flags & ~PM_READONLY) | PM_REMOVABLE;
+ unsetparam_pm(pm, 0, 1);
+ d->pm = NULL;
+ return 0;
+}
+
+/*
+ * Add or remove sets of parameters. The interface is
+ * identical to setbuiltins().
+ */
+
+/**/
+static int
+setparamdefs(char const *nam, Paramdef d, int size, int *e)
+{
+ int ret = 0;
+
+ while (size--) {
+ if (e && *e++) {
+ if (d->pm) {
+ d++;
+ continue;
+ }
+ if (addparamdef(d)) {
+ zwarnnam(nam, "error when adding parameter `%s'", d->name);
+ ret = 1;
+ }
+ } else {
+ if (!d->pm) {
+ d++;
+ continue;
+ }
+ if (deleteparamdef(d)) {
+ zwarnnam(nam, "parameter `%s' already deleted", d->name);
+ ret = 1;
+ }
+ }
+ d++;
+ }
+ return ret;
+}
+
+/* This adds a definition for autoloading a module for a parameter. */
+
+/**/
+static int
+add_autoparam(const char *module, const char *pnam, int flags)
+{
+ Param pm;
+ int ret;
+
+ queue_signals();
+ if ((ret = checkaddparam(pnam, (flags & FEAT_IGNORE)))) {
+ unqueue_signals();
+ /*
+ * checkaddparam() has already printed a message if one was
+ * needed. If it wasn't owing to the presence of -i, ret is 2;
+ * for consistency with other add_auto* functions we return
+ * status 0 to indicate there's already such a parameter and
+ * we've been told not to worry if so.
+ */
+ return ret == 2 ? 0 : -1;
+ }
+
+ pm = setsparam(dupstring(pnam), ztrdup(module));
+
+ pm->node.flags |= PM_AUTOLOAD;
+ if (flags & FEAT_AUTOALL)
+ pm->node.flags |= PM_AUTOALL;
+ unqueue_signals();
+
+ return 0;
+}
+
+/* Remove a parameter added with add_autoparam() */
+
+/**/
+static int
+del_autoparam(UNUSED(const char *modnam), const char *pnam, int flags)
+{
+ Param pm = (Param) gethashnode2(paramtab, pnam);
+
+ if (!pm) {
+ if (!(flags & FEAT_IGNORE))
+ return 2;
+ } else if (!(pm->node.flags & PM_AUTOLOAD)) {
+ if (!(flags & FEAT_IGNORE))
+ return 3;
+ } else
+ unsetparam_pm(pm, 0, 1);
+
+ return 0;
+}
+
+/************************************************************************
+ * Math functions.
+ ************************************************************************/
+
+/* List of math functions. */
+
+/**/
+MathFunc mathfuncs;
+
+/*
+ * Remove a single math function form the list (utility function).
+ * This does not delete a module math function, that's deletemathfunc().
+ */
+
+/**/
+void
+removemathfunc(MathFunc previous, MathFunc current)
+{
+ if (previous)
+ previous->next = current->next;
+ else
+ mathfuncs = current->next;
+
+ zsfree(current->name);
+ zsfree(current->module);
+ zfree(current, sizeof(*current));
+}
+
+/* Find a math function in the list, handling autoload if necessary. */
+
+/**/
+MathFunc
+getmathfunc(const char *name, int autol)
+{
+ MathFunc p, q = NULL;
+
+ for (p = mathfuncs; p; q = p, p = p->next)
+ if (!strcmp(name, p->name)) {
+ if (autol && p->module && !(p->flags & MFF_USERFUNC)) {
+ char *n = dupstring(p->module);
+ int flags = p->flags;
+
+ removemathfunc(q, p);
+
+ (void)ensurefeature(n, "f:", (flags & MFF_AUTOALL) ? NULL :
+ name);
+
+ p = getmathfunc(name, 0);
+ if (!p) {
+ zerr("autoloading module %s failed to define math function: %s", n, name);
+ }
+ }
+ return p;
+ }
+
+ return NULL;
+}
+
+/* Add a single math function */
+
+/**/
+static int
+addmathfunc(MathFunc f)
+{
+ MathFunc p, q = NULL;
+
+ if (f->flags & MFF_ADDED)
+ return 1;
+
+ for (p = mathfuncs; p; q = p, p = p->next)
+ if (!strcmp(f->name, p->name)) {
+ if (p->module && !(p->flags & MFF_USERFUNC)) {
+ /*
+ * Autoloadable, replace.
+ */
+ removemathfunc(q, p);
+ break;
+ }
+ return 1;
+ }
+
+ f->next = mathfuncs;
+ mathfuncs = f;
+
+ return 0;
+}
+
+/* Delete a single math function */
+
+/**/
+mod_export int
+deletemathfunc(MathFunc f)
+{
+ MathFunc p, q;
+
+ for (p = mathfuncs, q = NULL; p && p != f; q = p, p = p->next);
+
+ if (p) {
+ if (q)
+ q->next = f->next;
+ else
+ mathfuncs = f->next;
+
+ /* the following applies to both unloaded and user-defined functions */
+ if (f->module) {
+ zsfree(f->name);
+ zsfree(f->module);
+ zfree(f, sizeof(*f));
+ } else
+ f->flags &= ~MFF_ADDED;
+
+ return 0;
+ }
+ return -1;
+}
+
+/*
+ * Add or remove sets of math functions. The interface is
+ * identical to setbuiltins().
+ */
+
+/**/
+static int
+setmathfuncs(char const *nam, MathFunc f, int size, int *e)
+{
+ int ret = 0;
+
+ while (size--) {
+ if (e && *e++) {
+ if (f->flags & MFF_ADDED) {
+ f++;
+ continue;
+ }
+ if (addmathfunc(f)) {
+ zwarnnam(nam, "name clash when adding math function `%s'",
+ f->name);
+ ret = 1;
+ } else {
+ f->flags |= MFF_ADDED;
+ }
+ } else {
+ if (!(f->flags & MFF_ADDED)) {
+ f++;
+ continue;
+ }
+ if (deletemathfunc(f)) {
+ zwarnnam(nam, "math function `%s' already deleted", f->name);
+ ret = 1;
+ } else {
+ f->flags &= ~MFF_ADDED;
+ }
+ }
+ f++;
+ }
+ return ret;
+}
+
+/* Add an autoload definition for a math function. */
+
+/**/
+static int
+add_automathfunc(const char *module, const char *fnam, int flags)
+{
+ MathFunc f;
+
+ f = (MathFunc) zalloc(sizeof(*f));
+
+ f->name = ztrdup(fnam);
+ f->module = ztrdup(module);
+ f->flags = 0;
+
+ if (addmathfunc(f)) {
+ zsfree(f->name);
+ zsfree(f->module);
+ zfree(f, sizeof(*f));
+
+ if (!(flags & FEAT_IGNORE))
+ return 1;
+ }
+
+ return 0;
+}
+
+/* Remove a math function added with add_automathfunc() */
+
+/**/
+static int
+del_automathfunc(UNUSED(const char *modnam), const char *fnam, int flags)
+{
+ MathFunc f = getmathfunc(fnam, 0);
+
+ if (!f) {
+ if (!(flags & FEAT_IGNORE))
+ return 2;
+ } else if (f->flags & MFF_ADDED) {
+ if (!(flags & FEAT_IGNORE))
+ return 3;
+ } else
+ deletemathfunc(f);
+
+ return 0;
+}
+
+/************************************************************************
+ * Now support for dynamical loading and the fallback functions
+ * we use for loading if dynamical loading is not available.
+ ************************************************************************/
+
+/**/
+#ifdef DYNAMIC
+
+/**/
+#ifdef AIXDYNAMIC
+
+#include
+
+static char *dlerrstr[256];
+
+static void *
+load_and_bind(const char *fn)
+{
+ void *ret = (void *) load((char *) fn, L_NOAUTODEFER, NULL);
+
+ if (ret) {
+ Module m;
+ int i, err = loadbind(0, (void *) addbuiltin, ret);
+ for (i = 0; i < modulestab->hsize && !err; i++) {
+ for (m = (Module)modulestab->nodes[i]; m && !err;
+ m = (Module)m->node.next) {
+ if (!(m->node.flags & MOD_ALIAS) &&
+ m->u.handle && !(m->node.flags & MOD_LINKED))
+ err |= loadbind(0, m->u.handle, ret);
+ }
+ }
+
+ if (err) {
+ loadquery(L_GETMESSAGES, dlerrstr, sizeof(dlerrstr));
+ unload(ret);
+ ret = NULL;
+ }
+ } else
+ loadquery(L_GETMESSAGES, dlerrstr, sizeof(dlerrstr));
+
+ return ret;
+}
+
+#define dlopen(X,Y) load_and_bind(X)
+#define dlclose(X) unload(X)
+#define dlerror() (dlerrstr[0])
+#ifndef HAVE_DLERROR
+# define HAVE_DLERROR 1
+#endif
+
+/**/
+#else
+
+#ifdef HAVE_DLFCN_H
+# if defined(HAVE_DL_H) && defined(HPUX10DYNAMIC)
+# include
+# else
+# include
+# endif
+#else
+# ifdef HAVE_DL_H
+# include
+# define RTLD_LAZY BIND_DEFERRED
+# define RTLD_GLOBAL DYNAMIC_PATH
+# else
+# include
+# include
+# include
+# endif
+#endif
+
+/**/
+#ifdef HPUX10DYNAMIC
+# define dlopen(file,mode) (void *)shl_load((file), (mode), (long) 0)
+# define dlclose(handle) shl_unload((shl_t)(handle))
+
+static
+void *
+hpux_dlsym(void *handle, char *name)
+{
+ void *sym_addr;
+ if (!shl_findsym((shl_t *)&handle, name, TYPE_UNDEFINED, &sym_addr))
+ return sym_addr;
+ return NULL;
+}
+
+# define dlsym(handle,name) hpux_dlsym(handle,name)
+# ifdef HAVE_DLERROR /* paranoia */
+# undef HAVE_DLERROR
+# endif
+#else
+# ifndef HAVE_DLCLOSE
+# define dlclose(X) ((X), 0)
+# endif
+/**/
+#endif
+
+#ifdef DLSYM_NEEDS_UNDERSCORE
+# define STR_SETUP "_setup_"
+# define STR_FEATURES "_features_"
+# define STR_ENABLES "_enables_"
+# define STR_BOOT "_boot_"
+# define STR_CLEANUP "_cleanup_"
+# define STR_FINISH "_finish_"
+#else /* !DLSYM_NEEDS_UNDERSCORE */
+# define STR_SETUP "setup_"
+# define STR_FEATURES "features_"
+# define STR_ENABLES "enables_"
+# define STR_BOOT "boot_"
+# define STR_CLEANUP "cleanup_"
+# define STR_FINISH "finish_"
+#endif /* !DLSYM_NEEDS_UNDERSCORE */
+
+/**/
+#endif /* !AIXDYNAMIC */
+
+#ifndef RTLD_LAZY
+# define RTLD_LAZY 1
+#endif
+#ifndef RTLD_GLOBAL
+# define RTLD_GLOBAL 0
+#endif
+
+/*
+ * Attempt to load a module. This is the lowest level of
+ * zsh function for dynamical modules. Returns the handle
+ * from the dynamic loader.
+ */
+
+/**/
+static void *
+try_load_module(char const *name)
+{
+ char buf[PATH_MAX + 1];
+ char **pp;
+ void *ret = NULL;
+ int l;
+
+ l = 1 + strlen(name) + 1 + strlen(DL_EXT);
+ for (pp = module_path; !ret && *pp; pp++) {
+ if (l + (**pp ? strlen(*pp) : 1) > PATH_MAX)
+ continue;
+ sprintf(buf, "%s/%s.%s", **pp ? *pp : ".", name, DL_EXT);
+ unmetafy(buf, NULL);
+ if (*buf) /* dlopen(NULL) returns a handle to the main binary */
+ ret = dlopen(buf, RTLD_LAZY | RTLD_GLOBAL);
+ }
+
+ return ret;
+}
+
+/*
+ * Load a module, with option to complain or not.
+ * Returns the handle from the dynamic loader.
+ */
+
+/**/
+static void *
+do_load_module(char const *name, int silent)
+{
+ void *ret;
+
+ ret = try_load_module(name);
+ if (!ret && !silent) {
+#ifdef HAVE_DLERROR
+ char *errstr = dlerror();
+ zwarn("failed to load module `%s': %s", name,
+ errstr ? metafy(errstr, -1, META_HEAPDUP) : "empty module path");
+#else
+ zwarn("failed to load module: %s", name);
+#endif
+ }
+ return ret;
+}
+
+/**/
+#else /* !DYNAMIC */
+
+/*
+ * Dummy loader when no dynamic loading available; always fails.
+ */
+
+/**/
+static void *
+do_load_module(char const *name, int silent)
+{
+ if (!silent)
+ zwarn("failed to load module: %s", name);
+
+ return NULL;
+}
+
+/**/
+#endif /* !DYNAMIC */
+
+/*
+ * Find a module in the list.
+ * flags is a set of bits defined in the enum above.
+ * If namep is set, this is set to point to the last alias value resolved,
+ * even if that module was not loaded. or the module name if no aliases.
+ * Hence this is always the physical module to load in a chain of aliases.
+ * Return NULL if the module named is not stored as a structure, or if we were
+ * resolving aliases and the final module named is not stored as a
+ * structure.
+ */
+/**/
+static Module
+find_module(const char *name, int flags, const char **namep)
+{
+ Module m;
+
+ m = (Module)modulestab->getnode2(modulestab, name);
+ if (m) {
+ if ((flags & FINDMOD_ALIASP) && (m->node.flags & MOD_ALIAS)) {
+ if (namep)
+ *namep = m->u.alias;
+ return find_module(m->u.alias, flags, namep);
+ }
+ if (namep)
+ *namep = m->node.nam;
+ return m;
+ }
+ if (!(flags & FINDMOD_CREATE))
+ return NULL;
+ m = zshcalloc(sizeof(*m));
+ modulestab->addnode(modulestab, ztrdup(name), m);
+ return m;
+}
+
+/*
+ * Unlink and free a module node from the linked list.
+ */
+
+/**/
+static void
+delete_module(Module m)
+{
+ modulestab->removenode(modulestab, m->node.nam);
+
+ modulestab->freenode(&m->node);
+}
+
+/*
+ * Return 1 if a module is fully loaded else zero.
+ * A linked module may be marked as unloaded even though
+ * we can't fully unload it; this returns 0 to try to
+ * make that state transparently like an unloaded module.
+ */
+
+/**/
+mod_export int
+module_loaded(const char *name)
+{
+ Module m;
+
+ return ((m = find_module(name, FINDMOD_ALIASP, NULL)) &&
+ m->u.handle &&
+ !(m->node.flags & MOD_UNLOAD));
+}
+
+/*
+ * Setup and cleanup functions: we don't search for aliases here,
+ * since they should have been resolved before we try to load or unload
+ * the module.
+ */
+
+/**/
+#ifdef DYNAMIC
+
+/**/
+#ifdef AIXDYNAMIC
+
+/**/
+static int
+dyn_setup_module(Module m)
+{
+ return ((int (*)_((int,Module, void*))) m->u.handle)(0, m, NULL);
+}
+
+/**/
+static int
+dyn_features_module(Module m, char ***features)
+{
+ return ((int (*)_((int,Module, void*))) m->u.handle)(4, m, features);
+}
+
+/**/
+static int
+dyn_enables_module(Module m, int **enables)
+{
+ return ((int (*)_((int,Module, void*))) m->u.handle)(5, m, enables);
+}
+
+/**/
+static int
+dyn_boot_module(Module m)
+{
+ return ((int (*)_((int,Module, void*))) m->u.handle)(1, m, NULL);
+}
+
+/**/
+static int
+dyn_cleanup_module(Module m)
+{
+ return ((int (*)_((int,Module, void*))) m->u.handle)(2, m, NULL);
+}
+
+/**/
+static int
+dyn_finish_module(Module m)
+{
+ return ((int (*)_((int,Module,void *))) m->u.handle)(3, m, NULL);
+}
+
+/**/
+#else
+
+static Module_generic_func
+module_func(Module m, char *name)
+{
+#ifdef DYNAMIC_NAME_CLASH_OK
+ return (Module_generic_func) dlsym(m->u.handle, name);
+#else /* !DYNAMIC_NAME_CLASH_OK */
+ VARARR(char, buf, strlen(name) + strlen(m->node.nam)*2 + 1);
+ char const *p;
+ char *q;
+ strcpy(buf, name);
+ q = strchr(buf, 0);
+ for(p = m->node.nam; *p; p++) {
+ if(*p == '/') {
+ *q++ = 'Q';
+ *q++ = 's';
+ } else if(*p == '_') {
+ *q++ = 'Q';
+ *q++ = 'u';
+ } else if(*p == 'Q') {
+ *q++ = 'Q';
+ *q++ = 'q';
+ } else
+ *q++ = *p;
+ }
+ *q = 0;
+ return (Module_generic_func) dlsym(m->u.handle, buf);
+#endif /* !DYNAMIC_NAME_CLASH_OK */
+}
+
+/**/
+static int
+dyn_setup_module(Module m)
+{
+ Module_void_func fn = (Module_void_func)module_func(m, STR_SETUP);
+
+ if (fn)
+ return fn(m);
+ zwarnnam(m->node.nam, "no setup function");
+ return 1;
+}
+
+/**/
+static int
+dyn_features_module(Module m, char ***features)
+{
+ Module_features_func fn =
+ (Module_features_func)module_func(m, STR_FEATURES);
+
+ if (fn)
+ return fn(m, features);
+ /* not a user-visible error if no features function */
+ return 1;
+}
+
+/**/
+static int
+dyn_enables_module(Module m, int **enables)
+{
+ Module_enables_func fn = (Module_enables_func)module_func(m, STR_ENABLES);
+
+ if (fn)
+ return fn(m, enables);
+ /* not a user-visible error if no enables function */
+ return 1;
+}
+
+/**/
+static int
+dyn_boot_module(Module m)
+{
+ Module_void_func fn = (Module_void_func)module_func(m, STR_BOOT);
+
+ if(fn)
+ return fn(m);
+ zwarnnam(m->node.nam, "no boot function");
+ return 1;
+}
+
+/**/
+static int
+dyn_cleanup_module(Module m)
+{
+ Module_void_func fn = (Module_void_func)module_func(m, STR_CLEANUP);
+
+ if(fn)
+ return fn(m);
+ zwarnnam(m->node.nam, "no cleanup function");
+ return 1;
+}
+
+/* Note that this function does more than just calling finish_foo(), *
+ * it really unloads the module. */
+
+/**/
+static int
+dyn_finish_module(Module m)
+{
+ Module_void_func fn = (Module_void_func)module_func(m, STR_FINISH);
+ int r;
+
+ if (fn)
+ r = fn(m);
+ else {
+ zwarnnam(m->node.nam, "no finish function");
+ r = 1;
+ }
+ dlclose(m->u.handle);
+ return r;
+}
+
+/**/
+#endif /* !AIXDYNAMIC */
+
+/**/
+static int
+setup_module(Module m)
+{
+ return ((m->node.flags & MOD_LINKED) ?
+ (m->u.linked->setup)(m) : dyn_setup_module(m));
+}
+
+/**/
+static int
+features_module(Module m, char ***features)
+{
+ return ((m->node.flags & MOD_LINKED) ?
+ (m->u.linked->features)(m, features) :
+ dyn_features_module(m, features));
+}
+
+/**/
+static int
+enables_module(Module m, int **enables)
+{
+ return ((m->node.flags & MOD_LINKED) ?
+ (m->u.linked->enables)(m, enables) :
+ dyn_enables_module(m, enables));
+}
+
+/**/
+static int
+boot_module(Module m)
+{
+ return ((m->node.flags & MOD_LINKED) ?
+ (m->u.linked->boot)(m) : dyn_boot_module(m));
+}
+
+/**/
+static int
+cleanup_module(Module m)
+{
+ return ((m->node.flags & MOD_LINKED) ?
+ (m->u.linked->cleanup)(m) : dyn_cleanup_module(m));
+}
+
+/**/
+static int
+finish_module(Module m)
+{
+ return ((m->node.flags & MOD_LINKED) ?
+ (m->u.linked->finish)(m) : dyn_finish_module(m));
+}
+
+/**/
+#else /* !DYNAMIC */
+
+/**/
+static int
+setup_module(Module m)
+{
+ return ((m->node.flags & MOD_LINKED) ? (m->u.linked->setup)(m) : 1);
+}
+
+/**/
+static int
+features_module(Module m, char ***features)
+{
+ return ((m->node.flags & MOD_LINKED) ? (m->u.linked->features)(m, features)
+ : 1);
+}
+
+/**/
+static int
+enables_module(Module m, int **enables)
+{
+ return ((m->node.flags & MOD_LINKED) ? (m->u.linked->enables)(m, enables)
+ : 1);
+}
+
+/**/
+static int
+boot_module(Module m)
+{
+ return ((m->node.flags & MOD_LINKED) ? (m->u.linked->boot)(m) : 1);
+}
+
+/**/
+static int
+cleanup_module(Module m)
+{
+ return ((m->node.flags & MOD_LINKED) ? (m->u.linked->cleanup)(m) : 1);
+}
+
+/**/
+static int
+finish_module(Module m)
+{
+ return ((m->node.flags & MOD_LINKED) ? (m->u.linked->finish)(m) : 1);
+}
+
+/**/
+#endif /* !DYNAMIC */
+
+
+/************************************************************************
+ * Functions called when manipulating modules
+ ************************************************************************/
+
+/*
+ * Set the features for the module, which must be loaded
+ * by now (though may not be fully set up).
+ *
+ * Return 0 for success, 1 for failure, 2 if some features
+ * couldn't be set by the module itself (non-existent features
+ * are tested here and cause 1 to be returned).
+ */
+
+/**/
+static int
+do_module_features(Module m, Feature_enables enablesarr, int flags)
+{
+ char **features;
+ int ret = 0;
+
+ if (features_module(m, &features) == 0) {
+ /*
+ * Features are supported. If we were passed
+ * a NULL array, enable all features, else
+ * enable only the features listed.
+ * (This may in principle be an empty array,
+ * although that's not very pointful.)
+ */
+ int *enables = NULL;
+ if (enables_module(m, &enables)) {
+ /* If features are supported, enables should be, too */
+ if (!(flags & FEAT_IGNORE))
+ zwarn("error getting enabled features for module `%s'",
+ m->node.nam);
+ return 1;
+ }
+
+ if ((flags & FEAT_CHECKAUTO) && m->autoloads) {
+ /*
+ * Check autoloads are available. Since these
+ * have been requested at some other point, they
+ * don't affect the return status unless something
+ * in enablesstr doesn't work.
+ */
+ LinkNode an, nextn;
+ for (an = firstnode(m->autoloads); an; an = nextn) {
+ char *al = (char *)getdata(an), **ptr;
+ /* careful, we can delete the current node */
+ nextn = nextnode(an);
+ for (ptr = features; *ptr; ptr++)
+ if (!strcmp(al, *ptr))
+ break;
+ if (!*ptr) {
+ char *arg[2];
+ if (!(flags & FEAT_IGNORE))
+ zwarn(
+ "module `%s' has no such feature: `%s': autoload cancelled",
+ m->node.nam, al);
+ /*
+ * This shouldn't happen, so it's not worth optimising
+ * the call to autofeatures...
+ */
+ arg[0] = al = dupstring(al);
+ arg[1] = NULL;
+ (void)autofeatures(NULL, m->node.nam, arg, 0,
+ FEAT_IGNORE|FEAT_REMOVE);
+ /*
+ * don't want to try to enable *that*...
+ * expunge it from the enable string.
+ */
+ if (enablesarr) {
+ Feature_enables fep;
+ for (fep = enablesarr; fep->str; fep++) {
+ char *str = fep->str;
+ if (*str == '+' || *str == '-')
+ str++;
+ if (fep->pat ? pattry(fep->pat, al) :
+ !strcmp(al, str)) {
+ /* can't enable it after all, so return 1 */
+ ret = 1;
+ while (fep->str) {
+ fep->str = fep[1].str;
+ fep->pat = fep[1].pat;
+ fep++;
+ }
+ if (!fep->pat)
+ break;
+ }
+ }
+ }
+ }
+ }
+ }
+
+ if (enablesarr) {
+ Feature_enables fep;
+ for (fep = enablesarr; fep->str; fep++) {
+ char **fp, *esp = fep->str;
+ int on = 1, found = 0;
+ if (*esp == '+')
+ esp++;
+ else if (*esp == '-') {
+ on = 0;
+ esp++;
+ }
+ for (fp = features; *fp; fp++)
+ if (fep->pat ? pattry(fep->pat, *fp) : !strcmp(*fp, esp)) {
+ enables[fp - features] = on;
+ found++;
+ if (!fep->pat)
+ break;
+ }
+ if (!found) {
+ if (!(flags & FEAT_IGNORE))
+ zwarn(fep->pat ?
+ "module `%s' has no feature matching: `%s'" :
+ "module `%s' has no such feature: `%s'",
+ m->node.nam, esp);
+ return 1;
+ }
+ }
+ } else {
+ /*
+ * Enable all features. This is used when loading
+ * without using zmodload -F.
+ */
+ int n_features = arrlen(features);
+ int *ep;
+ for (ep = enables; n_features--; ep++)
+ *ep = 1;
+ }
+
+ if (enables_module(m, &enables))
+ return 2;
+ } else if (enablesarr) {
+ if (!(flags & FEAT_IGNORE))
+ zwarn("module `%s' does not support features", m->node.nam);
+ return 1;
+ }
+ /* Else it doesn't support features but we don't care. */
+
+ return ret;
+}
+
+/*
+ * Boot the module, including setting up features.
+ * As we've only just loaded the module, we don't yet
+ * know what features it supports, so we get them passed
+ * as a string.
+ *
+ * Returns 0 if OK, 1 if completely failed, 2 if some features
+ * couldn't be set up.
+ */
+
+/**/
+static int
+do_boot_module(Module m, Feature_enables enablesarr, int silent)
+{
+ int ret = do_module_features(m, enablesarr,
+ silent ? FEAT_IGNORE|FEAT_CHECKAUTO :
+ FEAT_CHECKAUTO);
+
+ if (ret == 1)
+ return 1;
+
+ if (boot_module(m))
+ return 1;
+ return ret;
+}
+
+/*
+ * Cleanup the module.
+ */
+
+/**/
+static int
+do_cleanup_module(Module m)
+{
+ return (m->node.flags & MOD_LINKED) ?
+ (m->u.linked && m->u.linked->cleanup(m)) :
+ (m->u.handle && cleanup_module(m));
+}
+
+/*
+ * Test a module name contains only valid characters: those
+ * allowed in a shell identifier plus slash. Return 1 if so.
+ */
+
+/**/
+static int
+modname_ok(char const *p)
+{
+ do {
+ p = itype_end(p, IIDENT, 0);
+ if (!*p)
+ return 1;
+ } while(*p++ == '/');
+ return 0;
+}
+
+/*
+ * High level function to load a module, encapsulating
+ * all the handling of module functions.
+ *
+ * "*enablesstr" is NULL if the caller is not feature-aware;
+ * then the module should turn on all features. If it
+ * is not NULL it points to an array of features to be
+ * turned on. This function is responsible for testing whether
+ * the module supports those features.
+ *
+ * If "silent" is 1, don't issue warnings for errors.
+ *
+ * Now returns 0 for success (changed post-4.3.4),
+ * 1 for complete failure, 2 if some features couldn't be set.
+ */
+
+/**/
+mod_export int
+load_module(char const *name, Feature_enables enablesarr, int silent)
+{
+ Module m;
+ void *handle = NULL;
+ Linkedmod linked;
+ int set, bootret;
+
+ if (!modname_ok(name)) {
+ if (!silent)
+ zerr("invalid module name `%s'", name);
+ return 1;
+ }
+ /*
+ * The following function call may alter name to the final name in a
+ * chain of aliases. This makes sure the actual module loaded
+ * is the right one.
+ */
+ queue_signals();
+ if (!(m = find_module(name, FINDMOD_ALIASP, &name))) {
+ if (!(linked = module_linked(name)) &&
+ !(handle = do_load_module(name, silent))) {
+ unqueue_signals();
+ return 1;
+ }
+ m = zshcalloc(sizeof(*m));
+ if (handle) {
+ m->u.handle = handle;
+ m->node.flags |= MOD_SETUP;
+ } else {
+ m->u.linked = linked;
+ m->node.flags |= MOD_SETUP | MOD_LINKED;
+ }
+ modulestab->addnode(modulestab, ztrdup(name), m);
+
+ if ((set = setup_module(m)) ||
+ (bootret = do_boot_module(m, enablesarr, silent)) == 1) {
+ if (!set)
+ do_cleanup_module(m);
+ finish_module(m);
+ delete_module(m);
+ unqueue_signals();
+ return 1;
+ }
+ m->node.flags |= MOD_INIT_S | MOD_INIT_B;
+ m->node.flags &= ~MOD_SETUP;
+ unqueue_signals();
+ return bootret;
+ }
+ if (m->node.flags & MOD_SETUP) {
+ unqueue_signals();
+ return 0;
+ }
+ if (m->node.flags & MOD_UNLOAD)
+ m->node.flags &= ~MOD_UNLOAD;
+ else if ((m->node.flags & MOD_LINKED) ? m->u.linked : m->u.handle) {
+ unqueue_signals();
+ return 0;
+ }
+ if (m->node.flags & MOD_BUSY) {
+ unqueue_signals();
+ zerr("circular dependencies for module ;%s", name);
+ return 1;
+ }
+ m->node.flags |= MOD_BUSY;
+ /*
+ * TODO: shouldn't we unload the module if one of
+ * its dependencies fails?
+ */
+ if (m->deps) {
+ LinkNode n;
+ for (n = firstnode(m->deps); n; incnode(n))
+ if (load_module((char *) getdata(n), NULL, silent) == 1) {
+ m->node.flags &= ~MOD_BUSY;
+ unqueue_signals();
+ return 1;
+ }
+ }
+ m->node.flags &= ~MOD_BUSY;
+ if (!m->u.handle) {
+ handle = NULL;
+ if (!(linked = module_linked(name)) &&
+ !(handle = do_load_module(name, silent))) {
+ unqueue_signals();
+ return 1;
+ }
+ if (handle) {
+ m->u.handle = handle;
+ m->node.flags |= MOD_SETUP;
+ } else {
+ m->u.linked = linked;
+ m->node.flags |= MOD_SETUP | MOD_LINKED;
+ }
+ if (setup_module(m)) {
+ finish_module(m);
+ if (handle)
+ m->u.handle = NULL;
+ else
+ m->u.linked = NULL;
+ m->node.flags &= ~MOD_SETUP;
+ unqueue_signals();
+ return 1;
+ }
+ m->node.flags |= MOD_INIT_S;
+ }
+ m->node.flags |= MOD_SETUP;
+ if ((bootret = do_boot_module(m, enablesarr, silent)) == 1) {
+ do_cleanup_module(m);
+ finish_module(m);
+ if (m->node.flags & MOD_LINKED)
+ m->u.linked = NULL;
+ else
+ m->u.handle = NULL;
+ m->node.flags &= ~MOD_SETUP;
+ unqueue_signals();
+ return 1;
+ }
+ m->node.flags |= MOD_INIT_B;
+ m->node.flags &= ~MOD_SETUP;
+ unqueue_signals();
+ return bootret;
+}
+
+/* This ensures that the module with the name given as the first argument
+ * is loaded.
+ * The other argument is the array of features to set. If this is NULL
+ * all features are enabled (even if the module was already loaded).
+ *
+ * If this is non-NULL the module features are set accordingly
+ * whether or not the module is loaded; it is an error if the
+ * module does not support the features passed (even if the feature
+ * is to be turned off) or if the module does not support features
+ * at all.
+ * The return value is 0 if the module was found or loaded
+ * (this changed post-4.3.4, because I got so confused---pws),
+ * 1 if loading failed completely, 2 if some features couldn't be set.
+ *
+ * This function behaves like load_module() except that it
+ * handles the case where the module was already loaded, and
+ * sets features accordingly.
+ */
+
+/**/
+mod_export int
+require_module(const char *module, Feature_enables features, int silent)
+{
+ Module m = NULL;
+ int ret = 0;
+
+ /* Resolve aliases and actual loadable module as for load_module */
+ queue_signals();
+ m = find_module(module, FINDMOD_ALIASP, &module);
+ if (!m || !m->u.handle ||
+ (m->node.flags & MOD_UNLOAD))
+ ret = load_module(module, features, silent);
+ else
+ ret = do_module_features(m, features, 0);
+ unqueue_signals();
+
+ return ret;
+}
+
+/*
+ * Indicate that the module named "name" depends on the module
+ * named "from".
+ */
+
+/**/
+void
+add_dep(const char *name, char *from)
+{
+ LinkNode node;
+ Module m;
+
+ /*
+ * If we were passed an alias, we must resolve it to a final
+ * module name (and maybe add the corresponding struct), since otherwise
+ * we would need to check all modules to see if they happen
+ * to be aliased to the same thing to implement dependencies properly.
+ *
+ * This should mean that an attempt to add an alias which would
+ * have the same name as a module which has dependencies is correctly
+ * rejected, because then the module named already exists as a non-alias.
+ * Better make sure. (There's no problem making a an alias which
+ * *points* to a module with dependencies, of course.)
+ */
+ m = find_module(name, FINDMOD_ALIASP|FINDMOD_CREATE, &name);
+ if (!m->deps)
+ m->deps = znewlinklist();
+ for (node = firstnode(m->deps);
+ node && strcmp((char *) getdata(node), from);
+ incnode(node));
+ if (!node)
+ zaddlinknode(m->deps, ztrdup(from));
+}
+
+/*
+ * Function to be used when scanning the builtins table to
+ * find and print autoloadable builtins.
+ */
+
+/**/
+static void
+autoloadscan(HashNode hn, int printflags)
+{
+ Builtin bn = (Builtin) hn;
+
+ if(bn->node.flags & BINF_ADDED)
+ return;
+ if(printflags & PRINT_LIST) {
+ fputs("zmodload -ab ", stdout);
+ if(bn->optstr[0] == '-')
+ fputs("-- ", stdout);
+ quotedzputs(bn->optstr, stdout);
+ if(strcmp(bn->node.nam, bn->optstr)) {
+ putchar(' ');
+ quotedzputs(bn->node.nam, stdout);
+ }
+ } else {
+ nicezputs(bn->node.nam, stdout);
+ if(strcmp(bn->node.nam, bn->optstr)) {
+ fputs(" (", stdout);
+ nicezputs(bn->optstr, stdout);
+ putchar(')');
+ }
+ }
+ putchar('\n');
+}
+
+
+/************************************************************************
+ * Handling for the zmodload builtin and its various options.
+ ************************************************************************/
+
+/*
+ * Main builtin entry point for zmodload.
+ */
+
+/**/
+int
+bin_zmodload(char *nam, char **args, Options ops, UNUSED(int func))
+{
+ int ops_bcpf = OPT_ISSET(ops,'b') || OPT_ISSET(ops,'c') ||
+ OPT_ISSET(ops,'p') || OPT_ISSET(ops,'f');
+ int ops_au = OPT_ISSET(ops,'a') || OPT_ISSET(ops,'u');
+ int ret = 1, autoopts;
+ /* options only allowed with -F */
+ char *fonly = "lP", *fp;
+
+ if (ops_bcpf && !ops_au) {
+ zwarnnam(nam, "-b, -c, -f, and -p must be combined with -a or -u");
+ return 1;
+ }
+ if (OPT_ISSET(ops,'F') && (ops_bcpf || OPT_ISSET(ops,'u'))) {
+ zwarnnam(nam, "-b, -c, -f, -p and -u cannot be combined with -F");
+ return 1;
+ }
+ if (OPT_ISSET(ops,'A') || OPT_ISSET(ops,'R')) {
+ if (ops_bcpf || ops_au || OPT_ISSET(ops,'d') ||
+ (OPT_ISSET(ops,'R') && OPT_ISSET(ops,'e'))) {
+ zwarnnam(nam, "illegal flags combined with -A or -R");
+ return 1;
+ }
+ if (!OPT_ISSET(ops,'e'))
+ return bin_zmodload_alias(nam, args, ops);
+ }
+ if (OPT_ISSET(ops,'d') && OPT_ISSET(ops,'a')) {
+ zwarnnam(nam, "-d cannot be combined with -a");
+ return 1;
+ }
+ if (OPT_ISSET(ops,'u') && !*args) {
+ zwarnnam(nam, "what do you want to unload?");
+ return 1;
+ }
+ if (OPT_ISSET(ops,'e') && (OPT_ISSET(ops,'I') || OPT_ISSET(ops,'L') ||
+ (OPT_ISSET(ops,'a') && !OPT_ISSET(ops,'F'))
+ || OPT_ISSET(ops,'d') ||
+ OPT_ISSET(ops,'i') || OPT_ISSET(ops,'u'))) {
+ zwarnnam(nam, "-e cannot be combined with other options");
+ /* except -F ... */
+ return 1;
+ }
+ for (fp = fonly; *fp; fp++) {
+ if (OPT_ISSET(ops,STOUC(*fp)) && !OPT_ISSET(ops,'F')) {
+ zwarnnam(nam, "-%c is only allowed with -F", *fp);
+ return 1;
+ }
+ }
+ queue_signals();
+ if (OPT_ISSET(ops, 'F'))
+ ret = bin_zmodload_features(nam, args, ops);
+ else if (OPT_ISSET(ops,'e'))
+ ret = bin_zmodload_exist(nam, args, ops);
+ else if (OPT_ISSET(ops,'d'))
+ ret = bin_zmodload_dep(nam, args, ops);
+ else if ((autoopts = OPT_ISSET(ops, 'b') + OPT_ISSET(ops, 'c') +
+ OPT_ISSET(ops, 'p') + OPT_ISSET(ops, 'f')) ||
+ /* zmodload -a is equivalent to zmodload -ab, annoyingly */
+ OPT_ISSET(ops, 'a')) {
+ if (autoopts > 1) {
+ zwarnnam(nam, "use only one of -b, -c, or -p");
+ ret = 1;
+ } else
+ ret = bin_zmodload_auto(nam, args, ops);
+ } else
+ ret = bin_zmodload_load(nam, args, ops);
+ unqueue_signals();
+
+ return ret;
+}
+
+/* zmodload -A */
+
+/**/
+static int
+bin_zmodload_alias(char *nam, char **args, Options ops)
+{
+ /*
+ * TODO: while it would be too nasty to have aliases, as opposed
+ * to real loadable modules, with dependencies --- just what would
+ * we need to load when, exactly? --- there is in principle no objection
+ * to making it possible to force an alias onto an existing unloaded
+ * module which has dependencies. This would simply transfer
+ * the dependencies down the line to the aliased-to module name.
+ * This is actually useful, since then you can alias zsh/zle=mytestzle
+ * to load another version of zle. But then what happens when the
+ * alias is removed? Do you transfer the dependencies back? And
+ * suppose other names are aliased to the same file? It might be
+ * kettle of fish best left unwormed.
+ */
+ Module m;
+
+ if (!*args) {
+ if (OPT_ISSET(ops,'R')) {
+ zwarnnam(nam, "no module alias to remove");
+ return 1;
+ }
+ scanhashtable(modulestab, 1, MOD_ALIAS, 0,
+ modulestab->printnode,
+ OPT_ISSET(ops,'L') ? PRINTMOD_LIST : 0);
+ return 0;
+ }
+
+ for (; *args; args++) {
+ char *eqpos = strchr(*args, '=');
+ char *aliasname = eqpos ? eqpos+1 : NULL;
+ if (eqpos)
+ *eqpos = '\0';
+ if (!modname_ok(*args)) {
+ zwarnnam(nam, "invalid module name `%s'", *args);
+ return 1;
+ }
+ if (OPT_ISSET(ops,'R')) {
+ if (aliasname) {
+ zwarnnam(nam, "bad syntax for removing module alias: %s",
+ *args);
+ return 1;
+ }
+ m = find_module(*args, 0, NULL);
+ if (m) {
+ if (!(m->node.flags & MOD_ALIAS)) {
+ zwarnnam(nam, "module is not an alias: %s", *args);
+ return 1;
+ }
+ delete_module(m);
+ } else {
+ zwarnnam(nam, "no such module alias: %s", *args);
+ return 1;
+ }
+ } else {
+ if (aliasname) {
+ const char *mname = aliasname;
+ if (!modname_ok(aliasname)) {
+ zwarnnam(nam, "invalid module name `%s'", aliasname);
+ return 1;
+ }
+ do {
+ if (!strcmp(mname, *args)) {
+ zwarnnam(nam, "module alias would refer to itself: %s",
+ *args);
+ return 1;
+ }
+ } while ((m = find_module(mname, 0, NULL))
+ && (m->node.flags & MOD_ALIAS)
+ && (mname = m->u.alias));
+ m = find_module(*args, 0, NULL);
+ if (m) {
+ if (!(m->node.flags & MOD_ALIAS)) {
+ zwarnnam(nam, "module is not an alias: %s", *args);
+ return 1;
+ }
+ zsfree(m->u.alias);
+ } else {
+ m = (Module) zshcalloc(sizeof(*m));
+ m->node.flags = MOD_ALIAS;
+ modulestab->addnode(modulestab, ztrdup(*args), m);
+ }
+ m->u.alias = ztrdup(aliasname);
+ } else {
+ if ((m = find_module(*args, 0, NULL))) {
+ if (m->node.flags & MOD_ALIAS)
+ modulestab->printnode(&m->node,
+ OPT_ISSET(ops,'L') ?
+ PRINTMOD_LIST : 0);
+ else {
+ zwarnnam(nam, "module is not an alias: %s", *args);
+ return 1;
+ }
+ } else {
+ zwarnnam(nam, "no such module alias: %s", *args);
+ return 1;
+ }
+ }
+ }
+ }
+
+ return 0;
+}
+
+/* zmodload -e (without -F) */
+
+/**/
+static int
+bin_zmodload_exist(UNUSED(char *nam), char **args, Options ops)
+{
+ Module m;
+
+ if (!*args) {
+ scanhashtable(modulestab, 1, 0, 0, modulestab->printnode,
+ OPT_ISSET(ops,'A') ? PRINTMOD_EXIST|PRINTMOD_ALIAS :
+ PRINTMOD_EXIST);
+ return 0;
+ } else {
+ int ret = 0;
+
+ for (; !ret && *args; args++) {
+ if (!(m = find_module(*args, FINDMOD_ALIASP, NULL))
+ || !m->u.handle
+ || (m->node.flags & MOD_UNLOAD))
+ ret = 1;
+ }
+ return ret;
+ }
+}
+
+/* zmodload -d */
+
+/**/
+static int
+bin_zmodload_dep(UNUSED(char *nam), char **args, Options ops)
+{
+ Module m;
+ if (OPT_ISSET(ops,'u')) {
+ /* remove dependencies, which can't pertain to aliases */
+ const char *tnam = *args++;
+ m = find_module(tnam, FINDMOD_ALIASP, &tnam);
+ if (!m)
+ return 0;
+ if (*args && m->deps) {
+ do {
+ LinkNode dnode;
+ for (dnode = firstnode(m->deps); dnode; incnode(dnode))
+ if (!strcmp(*args, getdata(dnode))) {
+ zsfree(getdata(dnode));
+ remnode(m->deps, dnode);
+ break;
+ }
+ } while(*++args);
+ if (empty(m->deps)) {
+ freelinklist(m->deps, freestr);
+ m->deps = NULL;
+ }
+ } else {
+ if (m->deps) {
+ freelinklist(m->deps, freestr);
+ m->deps = NULL;
+ }
+ }
+ if (!m->deps && !m->u.handle)
+ delete_module(m);
+ return 0;
+ } else if (!args[0] || !args[1]) {
+ /* list dependencies */
+ int depflags = OPT_ISSET(ops,'L') ?
+ PRINTMOD_DEPS|PRINTMOD_LIST : PRINTMOD_DEPS;
+ if (args[0]) {
+ if ((m = (Module)modulestab->getnode2(modulestab, args[0])))
+ modulestab->printnode(&m->node, depflags);
+ } else {
+ scanhashtable(modulestab, 1, 0, 0, modulestab->printnode,
+ depflags);
+ }
+ return 0;
+ } else {
+ /* add dependencies */
+ int ret = 0;
+ char *tnam = *args++;
+
+ for (; *args; args++)
+ add_dep(tnam, *args);
+ return ret;
+ }
+}
+
+/*
+ * Function for scanning the parameter table to find and print
+ * out autoloadable parameters.
+ */
+
+static void
+printautoparams(HashNode hn, int lon)
+{
+ Param pm = (Param) hn;
+
+ if (pm->node.flags & PM_AUTOLOAD) {
+ if (lon)
+ printf("zmodload -ap %s %s\n", pm->u.str, pm->node.nam);
+ else
+ printf("%s (%s)\n", pm->node.nam, pm->u.str);
+ }
+}
+
+/* zmodload -a/u [bcpf] */
+
+/**/
+static int
+bin_zmodload_auto(char *nam, char **args, Options ops)
+{
+ int fchar, flags;
+ char *modnam;
+
+ if (OPT_ISSET(ops,'c')) {
+ if (!*args) {
+ /* list autoloaded conditions */
+ Conddef p;
+
+ for (p = condtab; p; p = p->next) {
+ if (p->module) {
+ if (OPT_ISSET(ops,'L')) {
+ fputs("zmodload -ac", stdout);
+ if (p->flags & CONDF_INFIX)
+ putchar('I');
+ printf(" %s %s\n", p->module, p->name);
+ } else {
+ if (p->flags & CONDF_INFIX)
+ fputs("infix ", stdout);
+ else
+ fputs("post ", stdout);
+ printf("%s (%s)\n",p->name, p->module);
+ }
+ }
+ }
+ return 0;
+ }
+ fchar = OPT_ISSET(ops,'I') ? 'C' : 'c';
+ } else if (OPT_ISSET(ops,'p')) {
+ if (!*args) {
+ /* list autoloaded parameters */
+ scanhashtable(paramtab, 1, 0, 0, printautoparams,
+ OPT_ISSET(ops,'L'));
+ return 0;
+ }
+ fchar = 'p';
+ } else if (OPT_ISSET(ops,'f')) {
+ if (!*args) {
+ /* list autoloaded math functions */
+ MathFunc p;
+
+ for (p = mathfuncs; p; p = p->next) {
+ if (!(p->flags & MFF_USERFUNC) && p->module) {
+ if (OPT_ISSET(ops,'L')) {
+ fputs("zmodload -af", stdout);
+ printf(" %s %s\n", p->module, p->name);
+ } else
+ printf("%s (%s)\n",p->name, p->module);
+ }
+ }
+ return 0;
+ }
+ fchar = 'f';
+ } else {
+ /* builtins are the default; zmodload -ab or just zmodload -a */
+ if (!*args) {
+ /* list autoloaded builtins */
+ scanhashtable(builtintab, 1, 0, 0,
+ autoloadscan, OPT_ISSET(ops,'L') ? PRINT_LIST : 0);
+ return 0;
+ }
+ fchar = 'b';
+ }
+
+ flags = FEAT_AUTOALL;
+ if (OPT_ISSET(ops,'i'))
+ flags |= FEAT_IGNORE;
+ if (OPT_ISSET(ops,'u')) {
+ /* remove autoload */
+ flags |= FEAT_REMOVE;
+ modnam = NULL;
+ } else {
+ /* add autoload */
+ modnam = *args;
+
+ if (args[1])
+ args++;
+ }
+ return autofeatures(nam, modnam, args, fchar, flags);
+}
+
+/* Backend handler for zmodload -u */
+
+/**/
+int
+unload_module(Module m)
+{
+ int del;
+
+ /*
+ * Only unload the real module, so resolve aliases.
+ */
+ if (m->node.flags & MOD_ALIAS) {
+ m = find_module(m->u.alias, FINDMOD_ALIASP, NULL);
+ if (!m)
+ return 1;
+ }
+ /*
+ * We may need to clean up the module any time setup_ has been
+ * called. After cleanup_ is successful we are no longer in the
+ * booted state (because features etc. are deregistered), so remove
+ * MOD_INIT_B, and also MOD_INIT_S since we won't need to cleanup
+ * again if this succeeded.
+ */
+ if ((m->node.flags & MOD_INIT_S) &&
+ !(m->node.flags & MOD_UNLOAD) &&
+ do_cleanup_module(m))
+ return 1;
+ m->node.flags &= ~(MOD_INIT_B|MOD_INIT_S);
+
+ del = (m->node.flags & MOD_UNLOAD);
+
+ if (m->wrapper) {
+ m->node.flags |= MOD_UNLOAD;
+ return 0;
+ }
+ m->node.flags &= ~MOD_UNLOAD;
+
+ /*
+ * We always need to finish the module (and unload it)
+ * if it is present.
+ */
+ if (m->node.flags & MOD_LINKED) {
+ if (m->u.linked) {
+ m->u.linked->finish(m);
+ m->u.linked = NULL;
+ }
+ } else {
+ if (m->u.handle) {
+ finish_module(m);
+ m->u.handle = NULL;
+ }
+ }
+
+ if (del && m->deps) {
+ /* The module was unloaded delayed, unload all modules *
+ * on which it depended. */
+ LinkNode n;
+
+ for (n = firstnode(m->deps); n; incnode(n)) {
+ Module dm = find_module((char *) getdata(n),
+ FINDMOD_ALIASP, NULL);
+
+ if (dm &&
+ (dm->node.flags & MOD_UNLOAD)) {
+ /* See if this is the only module depending on it. */
+ Module am;
+ int du = 1, i;
+ /* Scan hash table the hard way */
+ for (i = 0; du && i < modulestab->hsize; i++) {
+ for (am = (Module)modulestab->nodes[i]; du && am;
+ am = (Module)am->node.next) {
+ LinkNode sn;
+ /*
+ * Don't scan the module we're unloading;
+ * ignore if no dependencies.
+ */
+ if (am == m || !am->deps)
+ continue;
+ /* Don't scan if not loaded nor linked */
+ if ((am->node.flags & MOD_LINKED) ?
+ !am->u.linked : !am->u.handle)
+ continue;
+ for (sn = firstnode(am->deps); du && sn;
+ incnode(sn)) {
+ if (!strcmp((char *) getdata(sn),
+ dm->node.nam))
+ du = 0;
+ }
+ }
+ }
+ if (du)
+ unload_module(dm);
+ }
+ }
+ }
+ if (m->autoloads && firstnode(m->autoloads)) {
+ /*
+ * Module has autoloadable features. Restore them
+ * so that the module will be reloaded when needed.
+ */
+ autofeatures("zsh", m->node.nam,
+ hlinklist2array(m->autoloads, 0), 0, FEAT_IGNORE);
+ } else if (!m->deps) {
+ delete_module(m);
+ }
+ return 0;
+}
+
+/*
+ * Unload a module by name (modname); nam is the command name.
+ * Optionally don't print some error messages (always print
+ * dependency errors).
+ */
+
+/**/
+int
+unload_named_module(char *modname, char *nam, int silent)
+{
+ const char *mname;
+ Module m;
+ int ret = 0;
+
+ m = find_module(modname, FINDMOD_ALIASP, &mname);
+ if (m) {
+ int i, del = 0;
+ Module dm;
+
+ for (i = 0; i < modulestab->hsize; i++) {
+ for (dm = (Module)modulestab->nodes[i]; dm;
+ dm = (Module)dm->node.next) {
+ LinkNode dn;
+ if (!dm->deps || !dm->u.handle)
+ continue;
+ for (dn = firstnode(dm->deps); dn; incnode(dn)) {
+ if (!strcmp((char *) getdata(dn), mname)) {
+ if (dm->node.flags & MOD_UNLOAD)
+ del = 1;
+ else {
+ zwarnnam(nam, "module %s is in use by another module and cannot be unloaded", mname);
+ return 1;
+ }
+ }
+ }
+ }
+ }
+ if (del)
+ m->wrapper++;
+ if (unload_module(m))
+ ret = 1;
+ if (del)
+ m->wrapper--;
+ } else if (!silent) {
+ zwarnnam(nam, "no such module %s", modname);
+ ret = 1;
+ }
+
+ return ret;
+}
+
+/* zmodload -u without -d */
+
+/**/
+static int
+bin_zmodload_load(char *nam, char **args, Options ops)
+{
+ int ret = 0;
+ if(OPT_ISSET(ops,'u')) {
+ /* unload modules */
+ for(; *args; args++) {
+ if (unload_named_module(*args, nam, OPT_ISSET(ops,'i')))
+ ret = 1;
+ }
+ return ret;
+ } else if(!*args) {
+ /* list modules */
+ scanhashtable(modulestab, 1, 0, MOD_UNLOAD|MOD_ALIAS,
+ modulestab->printnode,
+ OPT_ISSET(ops,'L') ? PRINTMOD_LIST : 0);
+ return 0;
+ } else {
+ /* load modules */
+ for (; *args; args++) {
+ int tmpret = require_module(*args, NULL, OPT_ISSET(ops,'s'));
+ if (tmpret && ret != 1)
+ ret = tmpret;
+ }
+
+ return ret;
+ }
+}
+
+/* zmodload -F */
+
+/**/
+static int
+bin_zmodload_features(const char *nam, char **args, Options ops)
+{
+ int iarg;
+ char *modname = *args;
+ Patprog *patprogs;
+ Feature_enables features, fep;
+
+ if (modname)
+ args++;
+ else if (OPT_ISSET(ops,'L')) {
+ int printflags = PRINTMOD_LIST|PRINTMOD_FEATURES;
+ if (OPT_ISSET(ops,'P')) {
+ zwarnnam(nam, "-P is only allowed with a module name");
+ return 1;
+ }
+ if (OPT_ISSET(ops,'l'))
+ printflags |= PRINTMOD_LISTALL;
+ if (OPT_ISSET(ops,'a'))
+ printflags |= PRINTMOD_AUTO;
+ scanhashtable(modulestab, 1, 0, MOD_ALIAS,
+ modulestab->printnode, printflags);
+ return 0;
+ }
+
+ if (!modname) {
+ zwarnnam(nam, "-F requires a module name");
+ return 1;
+ }
+
+ if (OPT_ISSET(ops,'m')) {
+ char **argp;
+ Patprog *patprogp;
+
+ /* not NULL terminated */
+ patprogp = patprogs =
+ (Patprog *)zhalloc(arrlen(args)*sizeof(Patprog));
+ for (argp = args; *argp; argp++, patprogp++) {
+ char *arg = *argp;
+ if (*arg == '+' || *arg == '-')
+ arg++;
+ tokenize(arg);
+ *patprogp = patcompile(arg, 0, 0);
+ }
+ } else
+ patprogs = NULL;
+
+ if (OPT_ISSET(ops,'l') || OPT_ISSET(ops,'L') || OPT_ISSET(ops,'e')) {
+ /*
+ * With option 'l', list all features one per line with + or -.
+ * With option 'L', list as zmodload statement showing
+ * only options turned on.
+ * With both options, list as zmodload showing options
+ * to be turned both on and off.
+ */
+ Module m;
+ char **features, **fp, **arrset = NULL, **arrp = NULL;
+ int *enables = NULL, *ep;
+ char *param = OPT_ARG_SAFE(ops,'P');
+
+ m = find_module(modname, FINDMOD_ALIASP, NULL);
+ if (OPT_ISSET(ops,'a')) {
+ LinkNode ln;
+ /*
+ * If there are no autoloads defined, return status 1.
+ */
+ if (!m || !m->autoloads)
+ return 1;
+ if (OPT_ISSET(ops,'e')) {
+ for (fp = args; *fp; fp++) {
+ char *fstr = *fp;
+ int sense = 1;
+ if (*fstr == '+')
+ fstr++;
+ else if (*fstr == '-') {
+ fstr++;
+ sense = 0;
+ }
+ if ((linknodebystring(m->autoloads, fstr) != NULL) !=
+ sense)
+ return 1;
+ }
+ return 0;
+ }
+ if (param) {
+ arrp = arrset = (char **)zalloc(sizeof(char*) *
+ (countlinknodes(m->autoloads)+1));
+ } else if (OPT_ISSET(ops,'L')) {
+ printf("zmodload -aF %s%c", m->node.nam,
+ m->autoloads && firstnode(m->autoloads) ? ' ' : '\n');
+ arrp = NULL;
+ }
+ for (ln = firstnode(m->autoloads); ln; incnode(ln)) {
+ char *al = (char *)getdata(ln);
+ if (param)
+ *arrp++ = ztrdup(al);
+ else
+ printf("%s%c", al,
+ OPT_ISSET(ops,'L') && nextnode(ln) ? ' ' : '\n');
+ }
+ if (param) {
+ *arrp = NULL;
+ if (!setaparam(param, arrset))
+ return 1;
+ }
+ return 0;
+ }
+ if (!m || !m->u.handle || (m->node.flags & MOD_UNLOAD)) {
+ if (!OPT_ISSET(ops,'e'))
+ zwarnnam(nam, "module `%s' is not yet loaded", modname);
+ return 1;
+ }
+ if (features_module(m, &features)) {
+ if (!OPT_ISSET(ops,'e'))
+ zwarnnam(nam, "module `%s' does not support features",
+ m->node.nam);
+ return 1;
+ }
+ if (enables_module(m, &enables)) {
+ /* this shouldn't ever happen, so don't silence this error */
+ zwarnnam(nam, "error getting enabled features for module `%s'",
+ m->node.nam);
+ return 1;
+ }
+ for (arrp = args, iarg = 0; *arrp; arrp++, iarg++) {
+ char *arg = *arrp;
+ int on, found = 0;
+ if (*arg == '-') {
+ on = 0;
+ arg++;
+ } else if (*arg == '+') {
+ on = 1;
+ arg++;
+ } else
+ on = -1;
+ for (fp = features, ep = enables; *fp; fp++, ep++) {
+ if (patprogs ? pattry(patprogs[iarg], *fp) :
+ !strcmp(arg, *fp)) {
+ /* for -e, check given state, if any */
+ if (OPT_ISSET(ops,'e') && on != -1 &&
+ on != (*ep & 1))
+ return 1;
+ found++;
+ if (!patprogs)
+ break;
+ }
+ }
+ if (!found) {
+ if (!OPT_ISSET(ops,'e'))
+ zwarnnam(nam, patprogs ?
+ "module `%s' has no feature matching: `%s'" :
+ "module `%s' has no such feature: `%s'",
+ modname, *arrp);
+ return 1;
+ }
+ }
+ if (OPT_ISSET(ops,'e')) /* yep, everything we want exists */
+ return 0;
+ if (param) {
+ int arrlen = 0;
+ for (fp = features, ep = enables; *fp; fp++, ep++) {
+ if (OPT_ISSET(ops, 'L') && !OPT_ISSET(ops, 'l') &&
+ !*ep)
+ continue;
+ if (*args) {
+ char **argp;
+ for (argp = args, iarg = 0; *argp; argp++, iarg++) {
+ char *arg = *argp;
+ /* ignore +/- for consistency */
+ if (*arg == '+' || *arg == '-')
+ arg++;
+ if (patprogs ? pattry(patprogs[iarg], *fp) :
+ !strcmp(*fp, arg))
+ break;
+ }
+ if (!*argp)
+ continue;
+ }
+ arrlen++;
+ }
+ arrp = arrset = zalloc(sizeof(char *) * (arrlen+1));
+ } else if (OPT_ISSET(ops, 'L'))
+ printf("zmodload -F %s ", m->node.nam);
+ for (fp = features, ep = enables; *fp; fp++, ep++) {
+ char *onoff;
+ int term;
+ if (*args) {
+ char **argp;
+ for (argp = args, iarg = 0; *argp; argp++, iarg++) {
+ char *arg = *argp;
+ if (*arg == '+' || *arg == '-')
+ arg++;
+ if (patprogs ? pattry(patprogs[iarg], *fp) :
+ !strcmp(*fp, *argp))
+ break;
+ }
+ if (!*argp)
+ continue;
+ }
+ if (OPT_ISSET(ops, 'L') && !OPT_ISSET(ops, 'l')) {
+ if (!*ep)
+ continue;
+ onoff = "";
+ } else if (*ep) {
+ onoff = "+";
+ } else {
+ onoff = "-";
+ }
+ if (param) {
+ *arrp++ = bicat(onoff, *fp);
+ } else {
+ if (OPT_ISSET(ops, 'L') && fp[1]) {
+ term = ' ';
+ } else {
+ term = '\n';
+ }
+ printf("%s%s%c", onoff, *fp, term);
+ }
+ }
+ if (param) {
+ *arrp = NULL;
+ if (!setaparam(param, arrset))
+ return 1;
+ }
+ return 0;
+ } else if (OPT_ISSET(ops,'P')) {
+ zwarnnam(nam, "-P can only be used with -l or -L");
+ return 1;
+ } else if (OPT_ISSET(ops,'a')) {
+ if (OPT_ISSET(ops,'m')) {
+ zwarnnam(nam, "-m cannot be used with -a");
+ return 1;
+ }
+ /*
+ * With zmodload -aF, we always use the effect of -i.
+ * The thinking is that marking a feature for
+ * autoload is separate from enabling or disabling it.
+ * Arguably we could do this with the zmodload -ab method
+ * but I've kept it there for old time's sake.
+ * The decoupling has meant FEAT_IGNORE/-i also
+ * suppresses an error for attempting to remove an
+ * autoload when the feature is enabled, which used
+ * to be a hard error before.
+ */
+ return autofeatures(nam, modname, args, 0, FEAT_IGNORE);
+ }
+
+ fep = features =
+ (Feature_enables)zhalloc((arrlen(args)+1)*sizeof(*fep));
+
+ while (*args) {
+ fep->str = *args++;
+ fep->pat = patprogs ? *patprogs++ : NULL;
+ fep++;
+ }
+ fep->str = NULL;
+ fep->pat = NULL;
+
+ return require_module(modname, features, OPT_ISSET(ops,'s'));
+}
+
+
+/************************************************************************
+ * Generic feature support.
+ * These functions are designed to be called by modules.
+ ************************************************************************/
+
+/*
+ * Construct a features array out of the list of concrete
+ * features given, leaving space for any abstract features
+ * to be added by the module itself.
+ *
+ * Note the memory is from the heap.
+ */
+
+/**/
+mod_export char **
+featuresarray(UNUSED(Module m), Features f)
+{
+ int bn_size = f->bn_size, cd_size = f->cd_size;
+ int mf_size = f->mf_size, pd_size = f->pd_size;
+ int features_size = bn_size + cd_size + pd_size + mf_size + f->n_abstract;
+ Builtin bnp = f->bn_list;
+ Conddef cdp = f->cd_list;
+ MathFunc mfp = f->mf_list;
+ Paramdef pdp = f->pd_list;
+ char **features = (char **)zhalloc((features_size + 1) * sizeof(char *));
+ char **featurep = features;
+
+ while (bn_size--)
+ *featurep++ = dyncat("b:", (bnp++)->node.nam);
+ while (cd_size--) {
+ *featurep++ = dyncat((cdp->flags & CONDF_INFIX) ? "C:" : "c:",
+ cdp->name);
+ cdp++;
+ }
+ while (mf_size--)
+ *featurep++ = dyncat("f:", (mfp++)->name);
+ while (pd_size--)
+ *featurep++ = dyncat("p:", (pdp++)->name);
+
+ features[features_size] = NULL;
+ return features;
+}
+
+/*
+ * Return the current set of enables for the features in a
+ * module using heap memory. Leave space for abstract
+ * features. The array is not zero terminated.
+ */
+/**/
+mod_export int *
+getfeatureenables(UNUSED(Module m), Features f)
+{
+ int bn_size = f->bn_size, cd_size = f->cd_size;
+ int mf_size = f->mf_size, pd_size = f->pd_size;
+ int features_size = bn_size + cd_size + mf_size + pd_size + f->n_abstract;
+ Builtin bnp = f->bn_list;
+ Conddef cdp = f->cd_list;
+ MathFunc mfp = f->mf_list;
+ Paramdef pdp = f->pd_list;
+ int *enables = zhalloc(sizeof(int) * features_size);
+ int *enablep = enables;
+
+ while (bn_size--)
+ *enablep++ = ((bnp++)->node.flags & BINF_ADDED) ? 1 : 0;
+ while (cd_size--)
+ *enablep++ = ((cdp++)->flags & CONDF_ADDED) ? 1 : 0;
+ while (mf_size--)
+ *enablep++ = ((mfp++)->flags & MFF_ADDED) ? 1 : 0;
+ while (pd_size--)
+ *enablep++ = (pdp++)->pm ? 1 : 0;
+
+ return enables;
+}
+
+/*
+ * Add or remove the concrete features passed in arguments,
+ * depending on the corresponding element of the array e.
+ * If e is NULL, disable everything.
+ * Return 0 for success, 1 for failure; does not attempt
+ * to imitate the return values of addbuiltins() etc.
+ * Any failure in adding a requested feature is an
+ * error.
+ */
+
+/**/
+mod_export int
+setfeatureenables(Module m, Features f, int *e)
+{
+ int ret = 0;
+
+ if (f->bn_size) {
+ if (setbuiltins(m->node.nam, f->bn_list, f->bn_size, e))
+ ret = 1;
+ if (e)
+ e += f->bn_size;
+ }
+ if (f->cd_size) {
+ if (setconddefs(m->node.nam, f->cd_list, f->cd_size, e))
+ ret = 1;
+ if (e)
+ e += f->cd_size;
+ }
+ if (f->mf_size) {
+ if (setmathfuncs(m->node.nam, f->mf_list, f->mf_size, e))
+ ret = 1;
+ if (e)
+ e += f->mf_size;
+ }
+ if (f->pd_size) {
+ if (setparamdefs(m->node.nam, f->pd_list, f->pd_size, e))
+ ret = 1;
+ if (e)
+ e += f->pd_size;
+ }
+ return ret;
+}
+
+/*
+ * Convenient front-end to get or set features which
+ * can be used in a module enables_() function.
+ */
+
+/**/
+mod_export int
+handlefeatures(Module m, Features f, int **enables)
+{
+ if (!enables || *enables)
+ return setfeatureenables(m, f, enables ? *enables : NULL);
+ *enables = getfeatureenables(m, f);
+ return 0;
+}
+
+/*
+ * Ensure module "modname" is providing feature with "prefix"
+ * and "feature" (e.g. "b:", "limit"). If feature is NULL,
+ * ensure all features are loaded (used for compatibility
+ * with the pre-feature autoloading behaviour).
+ *
+ * This will usually be called from the main shell to handle
+ * loading of an autoloadable feature.
+ *
+ * Returns 0 on success, 1 for error in module, 2 for error
+ * setting the feature. However, this isn't actually all
+ * that useful for testing immediately on an autoload since
+ * it could be a failure to autoload a different feature
+ * from the one we want. We could fix this but it's
+ * possible to test other ways.
+ */
+
+/**/
+mod_export int
+ensurefeature(const char *modname, const char *prefix, const char *feature)
+{
+ char *f;
+ struct feature_enables features[2];
+
+ if (!feature)
+ return require_module(modname, NULL, 0);
+ f = dyncat(prefix, feature);
+
+ features[0].str = f;
+ features[0].pat = NULL;
+ features[1].str = NULL;
+ features[1].pat = NULL;
+ return require_module(modname, features, 0);
+}
+
+/*
+ * Add autoloadable features for a given module.
+ */
+
+/**/
+int
+autofeatures(const char *cmdnam, const char *module, char **features,
+ int prefchar, int defflags)
+{
+ int ret = 0, subret;
+ Module defm, m;
+ char **modfeatures = NULL;
+ int *modenables = NULL;
+ if (module) {
+ defm = (Module)find_module(module,
+ FINDMOD_ALIASP|FINDMOD_CREATE, NULL);
+ if ((defm->node.flags & MOD_LINKED) ? defm->u.linked :
+ defm->u.handle) {
+ (void)features_module(defm, &modfeatures);
+ (void)enables_module(defm, &modenables);
+ }
+ } else
+ defm = NULL;
+
+ for (; *features; features++) {
+ char *fnam, *typnam, *feature;
+ int add, fchar, flags = defflags;
+ autofeaturefn_t fn;
+
+ if (prefchar) {
+ /*
+ * "features" is list of bare features with no
+ * type prefix; prefchar gives type character.
+ */
+ add = 1; /* unless overridden by flag */
+ fchar = prefchar;
+ fnam = *features;
+ feature = zhalloc(strlen(fnam) + 3);
+ sprintf(feature, "%c:%s", fchar, fnam);
+ } else {
+ feature = *features;
+ if (*feature == '-') {
+ add = 0;
+ feature++;
+ } else {
+ add = 1;
+ if (*feature == '+')
+ feature++;
+ }
+
+ if (!*feature || feature[1] != ':') {
+ zwarnnam(cmdnam, "bad format for autoloadable feature: `%s'",
+ feature);
+ ret = 1;
+ continue;
+ }
+ fnam = feature + 2;
+ fchar = feature[0];
+ }
+ if (flags & FEAT_REMOVE)
+ add = 0;
+
+ switch (fchar) {
+ case 'b':
+ fn = add ? add_autobin : del_autobin;
+ typnam = "builtin";
+ break;
+
+ case 'C':
+ flags |= FEAT_INFIX;
+ /* FALLTHROUGH */
+ case 'c':
+ fn = add ? add_autocond : del_autocond;
+ typnam = "condition";
+ break;
+
+ case 'f':
+ fn = add ? add_automathfunc : del_automathfunc;
+ typnam = "math function";
+ break;
+
+ case 'p':
+ fn = add ? add_autoparam : del_autoparam;
+ typnam = "parameter";
+ break;
+
+ default:
+ zwarnnam(cmdnam, "bad autoloadable feature type: `%c'",
+ fchar);
+ ret = 1;
+ continue;
+ }
+
+ if (strchr(fnam, '/')) {
+ zwarnnam(cmdnam, "%s: `/' is illegal in a %s", fnam, typnam);
+ ret = 1;
+ continue;
+ }
+
+ if (!module) {
+ /*
+ * Traditional un-autoload syntax doesn't tell us
+ * which module this came from.
+ */
+ int i;
+ for (i = 0, m = NULL; !m && i < modulestab->hsize; i++) {
+ for (m = (Module)modulestab->nodes[i]; m;
+ m = (Module)m->node.next) {
+ if (m->autoloads &&
+ linknodebystring(m->autoloads, feature))
+ break;
+ }
+ }
+ if (!m) {
+ if (!(flags & FEAT_IGNORE)) {
+ ret = 1;
+ zwarnnam(cmdnam, "%s: no such %s", fnam, typnam);
+ }
+ continue;
+ }
+ } else
+ m = defm;
+
+ subret = 0;
+ if (add) {
+ char **ptr;
+ if (modfeatures) {
+ /*
+ * If the module is already available, check that
+ * it does in fact provide the necessary feature.
+ */
+ for (ptr = modfeatures; *ptr; ptr++)
+ if (!strcmp(*ptr, feature))
+ break;
+ if (!*ptr) {
+ zwarnnam(cmdnam, "module `%s' has no such feature: `%s'",
+ m->node.nam, feature);
+ ret = 1;
+ continue;
+ }
+ /*
+ * If the feature is already provided by the module, there's
+ * nothing more to do.
+ */
+ if (modenables[ptr-modfeatures])
+ continue;
+ /*
+ * Otherwise, marking it for autoload will do the
+ * right thing when the feature is eventually used.
+ */
+ }
+ if (!m->autoloads) {
+ m->autoloads = znewlinklist();
+ zaddlinknode(m->autoloads, ztrdup(feature));
+ } else {
+ /* Insert in lexical order */
+ LinkNode ln, prev = (LinkNode)m->autoloads;
+ while ((ln = nextnode(prev))) {
+ int cmp = strcmp(feature, (char *)getdata(ln));
+ if (cmp == 0) {
+ /* Already there. Never an error. */
+ break;
+ }
+ if (cmp < 0) {
+ zinsertlinknode(m->autoloads, prev,
+ ztrdup(feature));
+ break;
+ }
+ prev = ln;
+ }
+ if (!ln)
+ zaddlinknode(m->autoloads, ztrdup(feature));
+ }
+ } else if (m->autoloads) {
+ LinkNode ln;
+ if ((ln = linknodebystring(m->autoloads, feature)))
+ zsfree((char *)remnode(m->autoloads, ln));
+ else {
+ /*
+ * With -i (or zmodload -Fa), removing an autoload
+ * that's not there is not an error.
+ */
+ subret = (flags & FEAT_IGNORE) ? -2 : 2;
+ }
+ }
+
+ if (subret == 0)
+ subret = fn(module, fnam, flags);
+
+ if (subret != 0) {
+ /* -2 indicates not an error, just skip running fn() */
+ if (subret != -2)
+ ret = 1;
+ switch (subret) {
+ case 1:
+ zwarnnam(cmdnam, "failed to add %s `%s'", typnam, fnam);
+ break;
+
+ case 2:
+ zwarnnam(cmdnam, "%s: no such %s", fnam, typnam);
+ break;
+
+ case 3:
+ zwarnnam(cmdnam, "%s: %s is already defined", fnam, typnam);
+ break;
+
+ default:
+ /* no (further) message needed */
+ break;
+ }
+ }
+ }
+
+ return ret;
+}
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/options.c b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/options.c
new file mode 100644
index 0000000..600b649
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/options.c
@@ -0,0 +1,955 @@
+/*
+ * options.c - shell options
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+#include "zsh.mdh"
+#include "options.pro"
+
+/* current emulation (used to decide which set of option letters is used) */
+
+/**/
+mod_export int emulation;
+
+/* current sticky emulation: sticky = NULL means none */
+
+/**/
+mod_export Emulation_options sticky;
+
+/* the options; e.g. if opts[SHGLOB] != 0, SH_GLOB is turned on */
+
+/**/
+mod_export char opts[OPT_SIZE];
+
+/* Option name hash table */
+
+/**/
+mod_export HashTable optiontab;
+
+/* The canonical option name table */
+
+#define OPT_CSH EMULATE_CSH
+#define OPT_KSH EMULATE_KSH
+#define OPT_SH EMULATE_SH
+#define OPT_ZSH EMULATE_ZSH
+
+#define OPT_ALL (OPT_CSH|OPT_KSH|OPT_SH|OPT_ZSH)
+#define OPT_BOURNE (OPT_KSH|OPT_SH)
+#define OPT_BSHELL (OPT_KSH|OPT_SH|OPT_ZSH)
+#define OPT_NONBOURNE (OPT_ALL & ~OPT_BOURNE)
+#define OPT_NONZSH (OPT_ALL & ~OPT_ZSH)
+
+/* option is relevant to emulation */
+#define OPT_EMULATE (EMULATE_UNUSED)
+/* option should never be set by emulate() */
+#define OPT_SPECIAL (EMULATE_UNUSED<<1)
+/* option is an alias to an other option */
+#define OPT_ALIAS (EMULATE_UNUSED<<2)
+
+#define defset(X, my_emulation) (!!((X)->node.flags & my_emulation))
+
+/*
+ * Note that option names should usually be fewer than 20 characters long
+ * to avoid formatting problems.
+ */
+static struct optname optns[] = {
+{{NULL, "aliases", OPT_EMULATE|OPT_ALL}, ALIASESOPT},
+{{NULL, "aliasfuncdef", OPT_EMULATE|OPT_BOURNE}, ALIASFUNCDEF},
+{{NULL, "allexport", OPT_EMULATE}, ALLEXPORT},
+{{NULL, "alwayslastprompt", OPT_ALL}, ALWAYSLASTPROMPT},
+{{NULL, "alwaystoend", 0}, ALWAYSTOEND},
+{{NULL, "appendcreate", OPT_EMULATE|OPT_BOURNE}, APPENDCREATE},
+{{NULL, "appendhistory", OPT_ALL}, APPENDHISTORY},
+{{NULL, "autocd", OPT_EMULATE}, AUTOCD},
+{{NULL, "autocontinue", 0}, AUTOCONTINUE},
+{{NULL, "autolist", OPT_ALL}, AUTOLIST},
+{{NULL, "automenu", OPT_ALL}, AUTOMENU},
+{{NULL, "autonamedirs", 0}, AUTONAMEDIRS},
+{{NULL, "autoparamkeys", OPT_ALL}, AUTOPARAMKEYS},
+{{NULL, "autoparamslash", OPT_ALL}, AUTOPARAMSLASH},
+{{NULL, "autopushd", 0}, AUTOPUSHD},
+{{NULL, "autoremoveslash", OPT_ALL}, AUTOREMOVESLASH},
+{{NULL, "autoresume", 0}, AUTORESUME},
+{{NULL, "badpattern", OPT_EMULATE|OPT_NONBOURNE},BADPATTERN},
+{{NULL, "banghist", OPT_NONBOURNE}, BANGHIST},
+{{NULL, "bareglobqual", OPT_EMULATE|OPT_ZSH}, BAREGLOBQUAL},
+{{NULL, "bashautolist", 0}, BASHAUTOLIST},
+{{NULL, "bashrematch", 0}, BASHREMATCH},
+{{NULL, "beep", OPT_ALL}, BEEP},
+{{NULL, "bgnice", OPT_EMULATE|OPT_NONBOURNE},BGNICE},
+{{NULL, "braceccl", OPT_EMULATE}, BRACECCL},
+{{NULL, "bsdecho", OPT_EMULATE|OPT_SH}, BSDECHO},
+{{NULL, "caseglob", OPT_ALL}, CASEGLOB},
+{{NULL, "casematch", OPT_ALL}, CASEMATCH},
+{{NULL, "cbases", 0}, CBASES},
+{{NULL, "cprecedences", OPT_EMULATE|OPT_NONZSH}, CPRECEDENCES},
+{{NULL, "cdablevars", OPT_EMULATE}, CDABLEVARS},
+{{NULL, "chasedots", OPT_EMULATE}, CHASEDOTS},
+{{NULL, "chaselinks", OPT_EMULATE}, CHASELINKS},
+{{NULL, "checkjobs", OPT_EMULATE|OPT_ZSH}, CHECKJOBS},
+{{NULL, "checkrunningjobs", OPT_EMULATE|OPT_ZSH}, CHECKRUNNINGJOBS},
+{{NULL, "clobber", OPT_EMULATE|OPT_ALL}, CLOBBER},
+{{NULL, "combiningchars", 0}, COMBININGCHARS},
+{{NULL, "completealiases", 0}, COMPLETEALIASES},
+{{NULL, "completeinword", 0}, COMPLETEINWORD},
+{{NULL, "continueonerror", 0}, CONTINUEONERROR},
+{{NULL, "correct", 0}, CORRECT},
+{{NULL, "correctall", 0}, CORRECTALL},
+{{NULL, "cshjunkiehistory", OPT_EMULATE|OPT_CSH}, CSHJUNKIEHISTORY},
+{{NULL, "cshjunkieloops", OPT_EMULATE|OPT_CSH}, CSHJUNKIELOOPS},
+{{NULL, "cshjunkiequotes", OPT_EMULATE|OPT_CSH}, CSHJUNKIEQUOTES},
+{{NULL, "cshnullcmd", OPT_EMULATE|OPT_CSH}, CSHNULLCMD},
+{{NULL, "cshnullglob", OPT_EMULATE|OPT_CSH}, CSHNULLGLOB},
+{{NULL, "debugbeforecmd", OPT_ALL}, DEBUGBEFORECMD},
+{{NULL, "emacs", 0}, EMACSMODE},
+{{NULL, "equals", OPT_EMULATE|OPT_ZSH}, EQUALS},
+{{NULL, "errexit", OPT_EMULATE}, ERREXIT},
+{{NULL, "errreturn", OPT_EMULATE}, ERRRETURN},
+{{NULL, "exec", OPT_ALL}, EXECOPT},
+{{NULL, "extendedglob", OPT_EMULATE}, EXTENDEDGLOB},
+{{NULL, "extendedhistory", OPT_CSH}, EXTENDEDHISTORY},
+{{NULL, "evallineno", OPT_EMULATE|OPT_ZSH}, EVALLINENO},
+{{NULL, "flowcontrol", OPT_ALL}, FLOWCONTROL},
+{{NULL, "forcefloat", 0}, FORCEFLOAT},
+{{NULL, "functionargzero", OPT_EMULATE|OPT_NONBOURNE},FUNCTIONARGZERO},
+{{NULL, "glob", OPT_EMULATE|OPT_ALL}, GLOBOPT},
+{{NULL, "globalexport", OPT_EMULATE|OPT_ZSH}, GLOBALEXPORT},
+{{NULL, "globalrcs", OPT_ALL}, GLOBALRCS},
+{{NULL, "globassign", OPT_EMULATE|OPT_CSH}, GLOBASSIGN},
+{{NULL, "globcomplete", 0}, GLOBCOMPLETE},
+{{NULL, "globdots", OPT_EMULATE}, GLOBDOTS},
+{{NULL, "globstarshort", OPT_EMULATE}, GLOBSTARSHORT},
+{{NULL, "globsubst", OPT_EMULATE|OPT_NONZSH}, GLOBSUBST},
+{{NULL, "hashcmds", OPT_ALL}, HASHCMDS},
+{{NULL, "hashdirs", OPT_ALL}, HASHDIRS},
+{{NULL, "hashexecutablesonly", 0}, HASHEXECUTABLESONLY},
+{{NULL, "hashlistall", OPT_ALL}, HASHLISTALL},
+{{NULL, "histallowclobber", 0}, HISTALLOWCLOBBER},
+{{NULL, "histbeep", OPT_ALL}, HISTBEEP},
+{{NULL, "histexpiredupsfirst",0}, HISTEXPIREDUPSFIRST},
+{{NULL, "histfcntllock", 0}, HISTFCNTLLOCK},
+{{NULL, "histfindnodups", 0}, HISTFINDNODUPS},
+{{NULL, "histignorealldups", 0}, HISTIGNOREALLDUPS},
+{{NULL, "histignoredups", 0}, HISTIGNOREDUPS},
+{{NULL, "histignorespace", 0}, HISTIGNORESPACE},
+{{NULL, "histlexwords", 0}, HISTLEXWORDS},
+{{NULL, "histnofunctions", 0}, HISTNOFUNCTIONS},
+{{NULL, "histnostore", 0}, HISTNOSTORE},
+{{NULL, "histsubstpattern", OPT_EMULATE}, HISTSUBSTPATTERN},
+{{NULL, "histreduceblanks", 0}, HISTREDUCEBLANKS},
+{{NULL, "histsavebycopy", OPT_ALL}, HISTSAVEBYCOPY},
+{{NULL, "histsavenodups", 0}, HISTSAVENODUPS},
+{{NULL, "histverify", 0}, HISTVERIFY},
+{{NULL, "hup", OPT_EMULATE|OPT_ZSH}, HUP},
+{{NULL, "ignorebraces", OPT_EMULATE|OPT_SH}, IGNOREBRACES},
+{{NULL, "ignoreclosebraces", OPT_EMULATE}, IGNORECLOSEBRACES},
+{{NULL, "ignoreeof", 0}, IGNOREEOF},
+{{NULL, "incappendhistory", 0}, INCAPPENDHISTORY},
+{{NULL, "incappendhistorytime", 0}, INCAPPENDHISTORYTIME},
+{{NULL, "interactive", OPT_SPECIAL}, INTERACTIVE},
+{{NULL, "interactivecomments",OPT_BOURNE}, INTERACTIVECOMMENTS},
+{{NULL, "ksharrays", OPT_EMULATE|OPT_BOURNE}, KSHARRAYS},
+{{NULL, "kshautoload", OPT_EMULATE|OPT_BOURNE}, KSHAUTOLOAD},
+{{NULL, "kshglob", OPT_EMULATE|OPT_KSH}, KSHGLOB},
+{{NULL, "kshoptionprint", OPT_EMULATE|OPT_KSH}, KSHOPTIONPRINT},
+{{NULL, "kshtypeset", 0}, KSHTYPESET},
+{{NULL, "kshzerosubscript", 0}, KSHZEROSUBSCRIPT},
+{{NULL, "listambiguous", OPT_ALL}, LISTAMBIGUOUS},
+{{NULL, "listbeep", OPT_ALL}, LISTBEEP},
+{{NULL, "listpacked", 0}, LISTPACKED},
+{{NULL, "listrowsfirst", 0}, LISTROWSFIRST},
+{{NULL, "listtypes", OPT_ALL}, LISTTYPES},
+{{NULL, "localoptions", OPT_EMULATE|OPT_KSH}, LOCALOPTIONS},
+{{NULL, "localloops", OPT_EMULATE}, LOCALLOOPS},
+{{NULL, "localpatterns", OPT_EMULATE}, LOCALPATTERNS},
+{{NULL, "localtraps", OPT_EMULATE|OPT_KSH}, LOCALTRAPS},
+{{NULL, "login", OPT_SPECIAL}, LOGINSHELL},
+{{NULL, "longlistjobs", 0}, LONGLISTJOBS},
+{{NULL, "magicequalsubst", OPT_EMULATE}, MAGICEQUALSUBST},
+{{NULL, "mailwarning", 0}, MAILWARNING},
+{{NULL, "markdirs", 0}, MARKDIRS},
+{{NULL, "menucomplete", 0}, MENUCOMPLETE},
+{{NULL, "monitor", OPT_SPECIAL}, MONITOR},
+{{NULL, "multibyte",
+#ifdef MULTIBYTE_SUPPORT
+ OPT_ALL
+#else
+ 0
+#endif
+ }, MULTIBYTE},
+{{NULL, "multifuncdef", OPT_EMULATE|OPT_ZSH}, MULTIFUNCDEF},
+{{NULL, "multios", OPT_EMULATE|OPT_ZSH}, MULTIOS},
+{{NULL, "nomatch", OPT_EMULATE|OPT_NONBOURNE},NOMATCH},
+{{NULL, "notify", OPT_ZSH}, NOTIFY},
+{{NULL, "nullglob", OPT_EMULATE}, NULLGLOB},
+{{NULL, "numericglobsort", OPT_EMULATE}, NUMERICGLOBSORT},
+{{NULL, "octalzeroes", OPT_EMULATE|OPT_SH}, OCTALZEROES},
+{{NULL, "overstrike", 0}, OVERSTRIKE},
+{{NULL, "pathdirs", OPT_EMULATE}, PATHDIRS},
+{{NULL, "pathscript", OPT_EMULATE|OPT_BOURNE}, PATHSCRIPT},
+{{NULL, "pipefail", OPT_EMULATE}, PIPEFAIL},
+{{NULL, "posixaliases", OPT_EMULATE|OPT_BOURNE}, POSIXALIASES},
+{{NULL, "posixargzero", OPT_EMULATE}, POSIXARGZERO},
+{{NULL, "posixbuiltins", OPT_EMULATE|OPT_BOURNE}, POSIXBUILTINS},
+{{NULL, "posixcd", OPT_EMULATE|OPT_BOURNE}, POSIXCD},
+{{NULL, "posixidentifiers", OPT_EMULATE|OPT_BOURNE}, POSIXIDENTIFIERS},
+{{NULL, "posixjobs", OPT_EMULATE|OPT_BOURNE}, POSIXJOBS},
+{{NULL, "posixstrings", OPT_EMULATE|OPT_BOURNE}, POSIXSTRINGS},
+{{NULL, "posixtraps", OPT_EMULATE|OPT_BOURNE}, POSIXTRAPS},
+{{NULL, "printeightbit", 0}, PRINTEIGHTBIT},
+{{NULL, "printexitvalue", 0}, PRINTEXITVALUE},
+{{NULL, "privileged", OPT_SPECIAL}, PRIVILEGED},
+{{NULL, "promptbang", OPT_KSH}, PROMPTBANG},
+{{NULL, "promptcr", OPT_ALL}, PROMPTCR},
+{{NULL, "promptpercent", OPT_NONBOURNE}, PROMPTPERCENT},
+{{NULL, "promptsp", OPT_ALL}, PROMPTSP},
+{{NULL, "promptsubst", OPT_BOURNE}, PROMPTSUBST},
+{{NULL, "pushdignoredups", OPT_EMULATE}, PUSHDIGNOREDUPS},
+{{NULL, "pushdminus", OPT_EMULATE}, PUSHDMINUS},
+{{NULL, "pushdsilent", 0}, PUSHDSILENT},
+{{NULL, "pushdtohome", OPT_EMULATE}, PUSHDTOHOME},
+{{NULL, "rcexpandparam", OPT_EMULATE}, RCEXPANDPARAM},
+{{NULL, "rcquotes", OPT_EMULATE}, RCQUOTES},
+{{NULL, "rcs", OPT_ALL}, RCS},
+{{NULL, "recexact", 0}, RECEXACT},
+{{NULL, "rematchpcre", 0}, REMATCHPCRE},
+{{NULL, "restricted", OPT_SPECIAL}, RESTRICTED},
+{{NULL, "rmstarsilent", OPT_BOURNE}, RMSTARSILENT},
+{{NULL, "rmstarwait", 0}, RMSTARWAIT},
+{{NULL, "sharehistory", OPT_KSH}, SHAREHISTORY},
+{{NULL, "shfileexpansion", OPT_EMULATE|OPT_BOURNE}, SHFILEEXPANSION},
+{{NULL, "shglob", OPT_EMULATE|OPT_BOURNE}, SHGLOB},
+{{NULL, "shinstdin", OPT_SPECIAL}, SHINSTDIN},
+{{NULL, "shnullcmd", OPT_EMULATE|OPT_BOURNE}, SHNULLCMD},
+{{NULL, "shoptionletters", OPT_EMULATE|OPT_BOURNE}, SHOPTIONLETTERS},
+{{NULL, "shortloops", OPT_EMULATE|OPT_NONBOURNE},SHORTLOOPS},
+{{NULL, "shwordsplit", OPT_EMULATE|OPT_BOURNE}, SHWORDSPLIT},
+{{NULL, "singlecommand", OPT_SPECIAL}, SINGLECOMMAND},
+{{NULL, "singlelinezle", OPT_KSH}, SINGLELINEZLE},
+{{NULL, "sourcetrace", 0}, SOURCETRACE},
+{{NULL, "sunkeyboardhack", 0}, SUNKEYBOARDHACK},
+{{NULL, "transientrprompt", 0}, TRANSIENTRPROMPT},
+{{NULL, "trapsasync", 0}, TRAPSASYNC},
+{{NULL, "typesetsilent", OPT_EMULATE|OPT_BOURNE}, TYPESETSILENT},
+{{NULL, "unset", OPT_EMULATE|OPT_BSHELL}, UNSET},
+{{NULL, "verbose", 0}, VERBOSE},
+{{NULL, "vi", 0}, VIMODE},
+{{NULL, "warncreateglobal", OPT_EMULATE}, WARNCREATEGLOBAL},
+{{NULL, "warnnestedvar", OPT_EMULATE}, WARNNESTEDVAR},
+{{NULL, "xtrace", 0}, XTRACE},
+{{NULL, "zle", OPT_SPECIAL}, USEZLE},
+{{NULL, "braceexpand", OPT_ALIAS}, /* ksh/bash */ -IGNOREBRACES},
+{{NULL, "dotglob", OPT_ALIAS}, /* bash */ GLOBDOTS},
+{{NULL, "hashall", OPT_ALIAS}, /* bash */ HASHCMDS},
+{{NULL, "histappend", OPT_ALIAS}, /* bash */ APPENDHISTORY},
+{{NULL, "histexpand", OPT_ALIAS}, /* bash */ BANGHIST},
+{{NULL, "log", OPT_ALIAS}, /* ksh */ -HISTNOFUNCTIONS},
+{{NULL, "mailwarn", OPT_ALIAS}, /* bash */ MAILWARNING},
+{{NULL, "onecmd", OPT_ALIAS}, /* bash */ SINGLECOMMAND},
+{{NULL, "physical", OPT_ALIAS}, /* ksh/bash */ CHASELINKS},
+{{NULL, "promptvars", OPT_ALIAS}, /* bash */ PROMPTSUBST},
+{{NULL, "stdin", OPT_ALIAS}, /* ksh */ SHINSTDIN},
+{{NULL, "trackall", OPT_ALIAS}, /* ksh */ HASHCMDS},
+{{NULL, "dvorak", 0}, DVORAK},
+{{NULL, NULL, 0}, 0}
+};
+
+/* Option letters */
+
+#define optletters (isset(SHOPTIONLETTERS) ? kshletters : zshletters)
+
+#define FIRST_OPT '0'
+#define LAST_OPT 'y'
+
+static short zshletters[LAST_OPT - FIRST_OPT + 1] = {
+ /* 0 */ CORRECT,
+ /* 1 */ PRINTEXITVALUE,
+ /* 2 */ -BADPATTERN,
+ /* 3 */ -NOMATCH,
+ /* 4 */ GLOBDOTS,
+ /* 5 */ NOTIFY,
+ /* 6 */ BGNICE,
+ /* 7 */ IGNOREEOF,
+ /* 8 */ MARKDIRS,
+ /* 9 */ AUTOLIST,
+ /* : */ 0,
+ /* ; */ 0,
+ /* < */ 0,
+ /* = */ 0,
+ /* > */ 0,
+ /* ? */ 0,
+ /* @ */ 0,
+ /* A */ 0, /* use with set for arrays */
+ /* B */ -BEEP,
+ /* C */ -CLOBBER,
+ /* D */ PUSHDTOHOME,
+ /* E */ PUSHDSILENT,
+ /* F */ -GLOBOPT,
+ /* G */ NULLGLOB,
+ /* H */ RMSTARSILENT,
+ /* I */ IGNOREBRACES,
+ /* J */ AUTOCD,
+ /* K */ -BANGHIST,
+ /* L */ SUNKEYBOARDHACK,
+ /* M */ SINGLELINEZLE,
+ /* N */ AUTOPUSHD,
+ /* O */ CORRECTALL,
+ /* P */ RCEXPANDPARAM,
+ /* Q */ PATHDIRS,
+ /* R */ LONGLISTJOBS,
+ /* S */ RECEXACT,
+ /* T */ CDABLEVARS,
+ /* U */ MAILWARNING,
+ /* V */ -PROMPTCR,
+ /* W */ AUTORESUME,
+ /* X */ LISTTYPES,
+ /* Y */ MENUCOMPLETE,
+ /* Z */ USEZLE,
+ /* [ */ 0,
+ /* \ */ 0,
+ /* ] */ 0,
+ /* ^ */ 0,
+ /* _ */ 0,
+ /* ` */ 0,
+ /* a */ ALLEXPORT,
+ /* b */ 0, /* in non-Bourne shells, end of options */
+ /* c */ 0, /* command follows */
+ /* d */ -GLOBALRCS,
+ /* e */ ERREXIT,
+ /* f */ -RCS,
+ /* g */ HISTIGNORESPACE,
+ /* h */ HISTIGNOREDUPS,
+ /* i */ INTERACTIVE,
+ /* j */ 0,
+ /* k */ INTERACTIVECOMMENTS,
+ /* l */ LOGINSHELL,
+ /* m */ MONITOR,
+ /* n */ -EXECOPT,
+ /* o */ 0, /* long option name follows */
+ /* p */ PRIVILEGED,
+ /* q */ 0,
+ /* r */ RESTRICTED,
+ /* s */ SHINSTDIN,
+ /* t */ SINGLECOMMAND,
+ /* u */ -UNSET,
+ /* v */ VERBOSE,
+ /* w */ CHASELINKS,
+ /* x */ XTRACE,
+ /* y */ SHWORDSPLIT,
+};
+
+static short kshletters[LAST_OPT - FIRST_OPT + 1] = {
+ /* 0 */ 0,
+ /* 1 */ 0,
+ /* 2 */ 0,
+ /* 3 */ 0,
+ /* 4 */ 0,
+ /* 5 */ 0,
+ /* 6 */ 0,
+ /* 7 */ 0,
+ /* 8 */ 0,
+ /* 9 */ 0,
+ /* : */ 0,
+ /* ; */ 0,
+ /* < */ 0,
+ /* = */ 0,
+ /* > */ 0,
+ /* ? */ 0,
+ /* @ */ 0,
+ /* A */ 0,
+ /* B */ 0,
+ /* C */ -CLOBBER,
+ /* D */ 0,
+ /* E */ 0,
+ /* F */ 0,
+ /* G */ 0,
+ /* H */ 0,
+ /* I */ 0,
+ /* J */ 0,
+ /* K */ 0,
+ /* L */ 0,
+ /* M */ 0,
+ /* N */ 0,
+ /* O */ 0,
+ /* P */ 0,
+ /* Q */ 0,
+ /* R */ 0,
+ /* S */ 0,
+ /* T */ TRAPSASYNC,
+ /* U */ 0,
+ /* V */ 0,
+ /* W */ 0,
+ /* X */ MARKDIRS,
+ /* Y */ 0,
+ /* Z */ 0,
+ /* [ */ 0,
+ /* \ */ 0,
+ /* ] */ 0,
+ /* ^ */ 0,
+ /* _ */ 0,
+ /* ` */ 0,
+ /* a */ ALLEXPORT,
+ /* b */ NOTIFY,
+ /* c */ 0,
+ /* d */ 0,
+ /* e */ ERREXIT,
+ /* f */ -GLOBOPT,
+ /* g */ 0,
+ /* h */ 0,
+ /* i */ INTERACTIVE,
+ /* j */ 0,
+ /* k */ 0,
+ /* l */ LOGINSHELL,
+ /* m */ MONITOR,
+ /* n */ -EXECOPT,
+ /* o */ 0,
+ /* p */ PRIVILEGED,
+ /* q */ 0,
+ /* r */ RESTRICTED,
+ /* s */ SHINSTDIN,
+ /* t */ SINGLECOMMAND,
+ /* u */ -UNSET,
+ /* v */ VERBOSE,
+ /* w */ 0,
+ /* x */ XTRACE,
+ /* y */ 0,
+};
+
+/* Initialisation of the option name hash table */
+
+/**/
+static void
+printoptionnode(HashNode hn, int set)
+{
+ Optname on = (Optname) hn;
+ int optno = on->optno;
+
+ if (optno < 0)
+ optno = -optno;
+ if (isset(KSHOPTIONPRINT)) {
+ if (defset(on, emulation))
+ printf("no%-19s %s\n", on->node.nam, isset(optno) ? "off" : "on");
+ else
+ printf("%-21s %s\n", on->node.nam, isset(optno) ? "on" : "off");
+ } else if (set == (isset(optno) ^ defset(on, emulation))) {
+ if (set ^ isset(optno))
+ fputs("no", stdout);
+ puts(on->node.nam);
+ }
+}
+
+/**/
+void
+createoptiontable(void)
+{
+ Optname on;
+
+ optiontab = newhashtable(101, "optiontab", NULL);
+
+ optiontab->hash = hasher;
+ optiontab->emptytable = NULL;
+ optiontab->filltable = NULL;
+ optiontab->cmpnodes = strcmp;
+ optiontab->addnode = addhashnode;
+ optiontab->getnode = gethashnode;
+ optiontab->getnode2 = gethashnode2;
+ optiontab->removenode = NULL;
+ optiontab->disablenode = disablehashnode;
+ optiontab->enablenode = enablehashnode;
+ optiontab->freenode = NULL;
+ optiontab->printnode = printoptionnode;
+
+ for (on = optns; on->node.nam; on++)
+ optiontab->addnode(optiontab, on->node.nam, on);
+}
+
+/* Emulation appropriate to the setemulate function */
+
+static int setemulate_emulation;
+
+/* Option array manipulated within the setemulate function */
+
+/**/
+static char *setemulate_opts;
+
+/* Setting of default options */
+
+/**/
+static void
+setemulate(HashNode hn, int fully)
+{
+ Optname on = (Optname) hn;
+
+ /* Set options: each non-special option is set according to the *
+ * current emulation mode if either it is considered relevant *
+ * to emulation or we are doing a full emulation (as indicated *
+ * by the `fully' parameter). */
+ if (!(on->node.flags & OPT_ALIAS) &&
+ ((fully && !(on->node.flags & OPT_SPECIAL)) ||
+ (on->node.flags & OPT_EMULATE)))
+ setemulate_opts[on->optno] = defset(on, setemulate_emulation);
+}
+
+/**/
+void
+installemulation(int new_emulation, char *new_opts)
+{
+ setemulate_emulation = new_emulation;
+ setemulate_opts = new_opts;
+ scanhashtable(optiontab, 0, 0, 0, setemulate,
+ !!(new_emulation & EMULATE_FULLY));
+}
+
+/**/
+void
+emulate(const char *zsh_name, int fully, int *new_emulation, char *new_opts)
+{
+ char ch = *zsh_name;
+
+ if (ch == 'r')
+ ch = zsh_name[1];
+
+ /* Work out the new emulation mode */
+ if (ch == 'c')
+ *new_emulation = EMULATE_CSH;
+ else if (ch == 'k')
+ *new_emulation = EMULATE_KSH;
+ else if (ch == 's' || ch == 'b')
+ *new_emulation = EMULATE_SH;
+ else
+ *new_emulation = EMULATE_ZSH;
+
+ if (fully)
+ *new_emulation |= EMULATE_FULLY;
+ installemulation(*new_emulation, new_opts);
+
+ if (funcstack && funcstack->tp == FS_FUNC) {
+ /*
+ * We are inside a function. Decide if it's traced.
+ * Pedantic note: the function in the function table isn't
+ * guaranteed to be what we're executing, but it's
+ * close enough.
+ */
+ Shfunc shf = (Shfunc)shfunctab->getnode(shfunctab, funcstack->name);
+ if (shf && (shf->node.flags & (PM_TAGGED|PM_TAGGED_LOCAL))) {
+ /* Tracing is on, so set xtrace */
+ new_opts[XTRACE] = 1;
+ }
+ }
+}
+
+/* setopt, unsetopt */
+
+/**/
+static void
+setoption(HashNode hn, int value)
+{
+ dosetopt(((Optname) hn)->optno, value, 0, opts);
+}
+
+/**/
+int
+bin_setopt(char *nam, char **args, UNUSED(Options ops), int isun)
+{
+ int action, optno, match = 0;
+
+ /* With no arguments or options, display options. */
+ if (!*args) {
+ scanhashtable(optiontab, 1, 0, OPT_ALIAS, optiontab->printnode, !isun);
+ return 0;
+ }
+
+ /* loop through command line options (begins with "-" or "+") */
+ while (*args && (**args == '-' || **args == '+')) {
+ action = (**args == '-') ^ isun;
+ if(!args[0][1])
+ *args = "--";
+ while (*++*args) {
+ if(**args == Meta)
+ *++*args ^= 32;
+ /* The pseudo-option `--' signifies the end of options. */
+ if (**args == '-') {
+ args++;
+ goto doneoptions;
+ } else if (**args == 'o') {
+ if (!*++*args)
+ args++;
+ if (!*args) {
+ zwarnnam(nam, "string expected after -o");
+ inittyptab();
+ return 1;
+ }
+ if(!(optno = optlookup(*args)))
+ zwarnnam(nam, "no such option: %s", *args);
+ else if(dosetopt(optno, action, 0, opts))
+ zwarnnam(nam, "can't change option: %s", *args);
+ break;
+ } else if(**args == 'm') {
+ match = 1;
+ } else {
+ if (!(optno = optlookupc(**args)))
+ zwarnnam(nam, "bad option: -%c", **args);
+ else if(dosetopt(optno, action, 0, opts))
+ zwarnnam(nam, "can't change option: -%c", **args);
+ }
+ }
+ args++;
+ }
+ doneoptions:
+
+ if (!match) {
+ /* Not globbing the arguments -- arguments are simply option names. */
+ while (*args) {
+ if(!(optno = optlookup(*args++)))
+ zwarnnam(nam, "no such option: %s", args[-1]);
+ else if(dosetopt(optno, !isun, 0, opts))
+ zwarnnam(nam, "can't change option: %s", args[-1]);
+ }
+ } else {
+ /* Globbing option (-m) set. */
+ while (*args) {
+ Patprog pprog;
+ char *s, *t;
+
+ t = s = dupstring(*args);
+ while (*t)
+ if (*t == '_')
+ chuck(t);
+ else {
+ /* See comment in optlookup() */
+ if (*t >= 'A' && *t <= 'Z')
+ *t = (*t - 'A') + 'a';
+ t++;
+ }
+
+ /* Expand the current arg. */
+ tokenize(s);
+ if (!(pprog = patcompile(s, PAT_HEAPDUP, NULL))) {
+ zwarnnam(nam, "bad pattern: %s", *args);
+ continue;
+ }
+ /* Loop over expansions. */
+ scanmatchtable(optiontab, pprog, 0, 0, OPT_ALIAS,
+ setoption, !isun);
+ args++;
+ }
+ }
+ inittyptab();
+ return 0;
+}
+
+/* Identify an option name */
+
+/**/
+mod_export int
+optlookup(char const *name)
+{
+ char *s, *t;
+ Optname n;
+
+ s = t = dupstring(name);
+
+ /* exorcise underscores, and change to lowercase */
+ while (*t)
+ if (*t == '_')
+ chuck(t);
+ else {
+ /*
+ * Some locales (in particular tr_TR.UTF-8) may
+ * have non-standard mappings of ASCII characters,
+ * so be careful. Option names must be ASCII so
+ * we don't need to be too clever.
+ */
+ if (*t >= 'A' && *t <= 'Z')
+ *t = (*t - 'A') + 'a';
+ t++;
+ }
+
+ /* look up name in the table */
+ if (s[0] == 'n' && s[1] == 'o' &&
+ (n = (Optname) optiontab->getnode(optiontab, s + 2))) {
+ return -n->optno;
+ } else if ((n = (Optname) optiontab->getnode(optiontab, s)))
+ return n->optno;
+ else
+ return OPT_INVALID;
+}
+
+/* Identify an option letter */
+
+/**/
+int
+optlookupc(char c)
+{
+ if(c < FIRST_OPT || c > LAST_OPT)
+ return 0;
+
+ return optletters[c - FIRST_OPT];
+}
+
+/**/
+static void
+restrictparam(char *nam)
+{
+ Param pm = (Param) paramtab->getnode(paramtab, nam);
+
+ if (pm) {
+ pm->node.flags |= PM_SPECIAL | PM_RESTRICTED;
+ return;
+ }
+ createparam(nam, PM_SCALAR | PM_UNSET | PM_SPECIAL | PM_RESTRICTED);
+}
+
+/* list of restricted parameters which are not otherwise special */
+static char *rparams[] = {
+ "SHELL", "HISTFILE", "LD_LIBRARY_PATH", "LD_AOUT_LIBRARY_PATH",
+ "LD_PRELOAD", "LD_AOUT_PRELOAD", NULL
+};
+
+/* Set or unset an option, as a result of user request. The option *
+ * number may be negative, indicating that the sense is reversed *
+ * from the usual meaning of the option. */
+
+/**/
+mod_export int
+dosetopt(int optno, int value, int force, char *new_opts)
+{
+ if(!optno)
+ return -1;
+ if(optno < 0) {
+ optno = -optno;
+ value = !value;
+ }
+ if (optno == RESTRICTED) {
+ if (isset(RESTRICTED))
+ return value ? 0 : -1;
+ if (value) {
+ char **s;
+
+ for (s = rparams; *s; s++)
+ restrictparam(*s);
+ }
+ } else if(!force && optno == EXECOPT && !value && interact) {
+ /* cannot set noexec when interactive */
+ return -1;
+ } else if(!force && (optno == INTERACTIVE || optno == SHINSTDIN ||
+ optno == SINGLECOMMAND)) {
+ if (new_opts[optno] == value)
+ return 0;
+ /* it is not permitted to change the value of these options */
+ return -1;
+ } else if(!force && optno == USEZLE && value) {
+ /* we require a terminal in order to use ZLE */
+ if(!interact || SHTTY == -1 || !shout)
+ return -1;
+ } else if(optno == PRIVILEGED && !value) {
+ /* unsetting PRIVILEGED causes the shell to make itself unprivileged */
+#ifdef HAVE_SETUID
+ int ignore_err;
+ errno = 0;
+ /*
+ * Set the GID first as if we set the UID to non-privileged it
+ * might be impossible to restore the GID.
+ *
+ * Some OSes (possibly no longer around) have been known to
+ * fail silently the first time, so we attempt the change twice.
+ * If it fails we are guaranteed to pick this up the second
+ * time, so ignore the first time.
+ *
+ * Some versions of gcc make it hard to ignore the results the
+ * first time, hence the following. (These are probably not
+ * systems that require the doubled calls.)
+ */
+ ignore_err = setgid(getgid());
+ (void)ignore_err;
+ ignore_err = setuid(getuid());
+ (void)ignore_err;
+ if (setgid(getgid())) {
+ zwarn("failed to change group ID: %e", errno);
+ return -1;
+ } else if (setuid(getuid())) {
+ zwarn("failed to change user ID: %e", errno);
+ return -1;
+ }
+#else
+ zwarn("setuid not available");
+ return -1;
+#endif /* not HAVE_SETUID */
+#ifdef JOB_CONTROL
+ } else if (!force && optno == MONITOR && value) {
+ if (new_opts[optno] == value)
+ return 0;
+ if (SHTTY != -1) {
+ origpgrp = GETPGRP();
+ acquire_pgrp();
+ } else
+ return -1;
+#else
+ } else if(optno == MONITOR && value) {
+ return -1;
+#endif /* not JOB_CONTROL */
+#ifdef GETPWNAM_FAKED
+ } else if(optno == CDABLEVARS && value) {
+ return -1;
+#endif /* GETPWNAM_FAKED */
+ } else if ((optno == EMACSMODE || optno == VIMODE) && value) {
+ if (sticky && sticky->emulation)
+ return -1;
+ zleentry(ZLE_CMD_SET_KEYMAP, optno);
+ new_opts[(optno == EMACSMODE) ? VIMODE : EMACSMODE] = 0;
+ } else if (optno == SUNKEYBOARDHACK) {
+ /* for backward compatibility */
+ keyboardhackchar = (value ? '`' : '\0');
+ }
+ new_opts[optno] = value;
+ if (optno == BANGHIST || optno == SHINSTDIN)
+ inittyptab();
+ return 0;
+}
+
+/* Function to get value for special parameter `-' */
+
+/**/
+char *
+dashgetfn(UNUSED(Param pm))
+{
+ static char buf[LAST_OPT - FIRST_OPT + 2];
+ char *val = buf;
+ int i;
+
+ for(i = 0; i <= LAST_OPT - FIRST_OPT; i++) {
+ int optno = optletters[i];
+ if(optno && ((optno > 0) ? isset(optno) : unset(-optno)))
+ *val++ = FIRST_OPT + i;
+ }
+ *val = '\0';
+ return buf;
+}
+
+/* print options for set -o/+o */
+
+/**/
+void
+printoptionstates(int hadplus)
+{
+ scanhashtable(optiontab, 1, 0, OPT_ALIAS, printoptionnodestate, hadplus);
+}
+
+/**/
+static void
+printoptionnodestate(HashNode hn, int hadplus)
+{
+ Optname on = (Optname) hn;
+ int optno = on->optno;
+
+ if (hadplus) {
+ printf("set %co %s%s\n",
+ defset(on, emulation) != isset(optno) ? '-' : '+',
+ defset(on, emulation) ? "no" : "",
+ on->node.nam);
+ } else {
+ if (defset(on, emulation))
+ printf("no%-19s %s\n", on->node.nam, isset(optno) ? "off" : "on");
+ else
+ printf("%-21s %s\n", on->node.nam, isset(optno) ? "on" : "off");
+ }
+}
+
+/* Print option list for --help */
+
+/**/
+void
+printoptionlist(void)
+{
+ short *lp;
+ char c;
+
+ printf("\nNamed options:\n");
+ scanhashtable(optiontab, 1, 0, OPT_ALIAS, printoptionlist_printoption, 0);
+ printf("\nOption aliases:\n");
+ scanhashtable(optiontab, 1, OPT_ALIAS, 0, printoptionlist_printoption, 0);
+ printf("\nOption letters:\n");
+ for(lp = optletters, c = FIRST_OPT; c <= LAST_OPT; lp++, c++) {
+ if(!*lp)
+ continue;
+ printf(" -%c ", c);
+ printoptionlist_printequiv(*lp);
+ }
+}
+
+/**/
+static void
+printoptionlist_printoption(HashNode hn, UNUSED(int ignored))
+{
+ Optname on = (Optname) hn;
+
+ if(on->node.flags & OPT_ALIAS) {
+ printf(" --%-19s ", on->node.nam);
+ printoptionlist_printequiv(on->optno);
+ } else
+ printf(" --%s\n", on->node.nam);
+}
+
+/**/
+static void
+printoptionlist_printequiv(int optno)
+{
+ int isneg = optno < 0;
+
+ optno *= (isneg ? -1 : 1);
+ printf(" equivalent to --%s%s\n", isneg ? "no-" : "", optns[optno-1].node.nam);
+}
+
+/**/
+static char *print_emulate_opts;
+
+/**/
+static void
+print_emulate_option(HashNode hn, int fully)
+{
+ Optname on = (Optname) hn;
+
+ if (!(on->node.flags & OPT_ALIAS) &&
+ ((fully && !(on->node.flags & OPT_SPECIAL)) ||
+ (on->node.flags & OPT_EMULATE)))
+ {
+ if (!print_emulate_opts[on->optno])
+ fputs("no", stdout);
+ puts(on->node.nam);
+ }
+}
+
+/*
+ * List the settings of options associated with an emulation
+ */
+
+/**/
+void list_emulate_options(char *cmdopts, int fully)
+{
+ print_emulate_opts = cmdopts;
+ scanhashtable(optiontab, 1, 0, 0, print_emulate_option, fully);
+}
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/params.c b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/params.c
new file mode 100644
index 0000000..a1c299f
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/params.c
@@ -0,0 +1,5884 @@
+/*
+ * params.c - parameters
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+#include "zsh.mdh"
+#include "params.pro"
+
+#include "version.h"
+#ifdef CUSTOM_PATCHLEVEL
+#define ZSH_PATCHLEVEL CUSTOM_PATCHLEVEL
+#else
+#include "patchlevel.h"
+
+#include
+
+/* If removed from the ChangeLog for some reason */
+#ifndef ZSH_PATCHLEVEL
+#define ZSH_PATCHLEVEL "unknown"
+#endif
+#endif
+
+/* what level of localness we are at */
+
+/**/
+mod_export int locallevel;
+
+/* Variables holding values of special parameters */
+
+/**/
+mod_export
+char **pparams, /* $argv */
+ **cdpath, /* $cdpath */
+ **fpath, /* $fpath */
+ **mailpath, /* $mailpath */
+ **manpath, /* $manpath */
+ **psvar, /* $psvar */
+ **watch, /* $watch */
+ **zsh_eval_context; /* $zsh_eval_context */
+/**/
+mod_export
+char **path, /* $path */
+ **fignore; /* $fignore */
+
+/**/
+mod_export
+char *argzero, /* $0 */
+ *posixzero, /* $0 */
+ *home, /* $HOME */
+ *nullcmd, /* $NULLCMD */
+ *oldpwd, /* $OLDPWD */
+ *zoptarg, /* $OPTARG */
+ *prompt, /* $PROMPT */
+ *prompt2, /* $PROMPT2 */
+ *prompt3, /* $PROMPT3 */
+ *prompt4, /* $PROMPT4 */
+ *readnullcmd, /* $READNULLCMD */
+ *rprompt, /* $RPROMPT */
+ *rprompt2, /* $RPROMPT2 */
+ *sprompt, /* $SPROMPT */
+ *wordchars; /* $WORDCHARS */
+/**/
+mod_export
+char *ifs, /* $IFS */
+ *postedit, /* $POSTEDIT */
+ *term, /* $TERM */
+ *zsh_terminfo, /* $TERMINFO */
+ *zsh_terminfodirs, /* $TERMINFO_DIRS */
+ *ttystrname, /* $TTY */
+ *pwd; /* $PWD */
+
+/**/
+mod_export
+zlong lastval, /* $? */
+ mypid, /* $$ */
+ lastpid, /* $! */
+ zterm_columns, /* $COLUMNS */
+ zterm_lines, /* $LINES */
+ rprompt_indent, /* $ZLE_RPROMPT_INDENT */
+ ppid, /* $PPID */
+ zsh_subshell; /* $ZSH_SUBSHELL */
+
+/* $FUNCNEST */
+/**/
+mod_export
+zlong zsh_funcnest =
+#ifdef MAX_FUNCTION_DEPTH
+ MAX_FUNCTION_DEPTH
+#else
+ /* Disabled by default but can be enabled at run time */
+ -1
+#endif
+ ;
+
+/**/
+zlong lineno, /* $LINENO */
+ zoptind, /* $OPTIND */
+ shlvl; /* $SHLVL */
+
+/* $histchars */
+
+/**/
+mod_export unsigned char bangchar;
+/**/
+unsigned char hatchar, hashchar;
+
+/**/
+unsigned char keyboardhackchar = '\0';
+
+/* $SECONDS = now.tv_sec - shtimer.tv_sec
+ * + (now.tv_usec - shtimer.tv_usec) / 1000000.0
+ * (rounded to an integer if the parameter is not set to float) */
+
+/**/
+struct timeval shtimer;
+
+/* 0 if this $TERM setup is usable, otherwise it contains TERM_* flags */
+
+/**/
+mod_export int termflags;
+
+/* Forward declaration */
+
+static void
+rprompt_indent_unsetfn(Param pm, int exp);
+
+/* Standard methods for get/set/unset pointers in parameters */
+
+/**/
+mod_export const struct gsu_scalar stdscalar_gsu =
+{ strgetfn, strsetfn, stdunsetfn };
+/**/
+mod_export const struct gsu_scalar varscalar_gsu =
+{ strvargetfn, strvarsetfn, stdunsetfn };
+/**/
+mod_export const struct gsu_scalar nullsetscalar_gsu =
+{ strgetfn, nullstrsetfn, NULL };
+
+/**/
+mod_export const struct gsu_integer stdinteger_gsu =
+{ intgetfn, intsetfn, stdunsetfn };
+/**/
+mod_export const struct gsu_integer varinteger_gsu =
+{ intvargetfn, intvarsetfn, stdunsetfn };
+/**/
+mod_export const struct gsu_integer nullsetinteger_gsu =
+{ intgetfn, NULL, NULL };
+
+/**/
+mod_export const struct gsu_float stdfloat_gsu =
+{ floatgetfn, floatsetfn, stdunsetfn };
+
+/**/
+mod_export const struct gsu_array stdarray_gsu =
+{ arrgetfn, arrsetfn, stdunsetfn };
+/**/
+mod_export const struct gsu_array vararray_gsu =
+{ arrvargetfn, arrvarsetfn, stdunsetfn };
+
+/**/
+mod_export const struct gsu_hash stdhash_gsu =
+{ hashgetfn, hashsetfn, stdunsetfn };
+/**/
+mod_export const struct gsu_hash nullsethash_gsu =
+{ hashgetfn, nullsethashfn, nullunsetfn };
+
+
+/* Non standard methods (not exported) */
+static const struct gsu_integer pound_gsu =
+{ poundgetfn, nullintsetfn, stdunsetfn };
+static const struct gsu_integer errno_gsu =
+{ errnogetfn, errnosetfn, stdunsetfn };
+static const struct gsu_integer gid_gsu =
+{ gidgetfn, gidsetfn, stdunsetfn };
+static const struct gsu_integer egid_gsu =
+{ egidgetfn, egidsetfn, stdunsetfn };
+static const struct gsu_integer histsize_gsu =
+{ histsizegetfn, histsizesetfn, stdunsetfn };
+static const struct gsu_integer random_gsu =
+{ randomgetfn, randomsetfn, stdunsetfn };
+static const struct gsu_integer savehist_gsu =
+{ savehistsizegetfn, savehistsizesetfn, stdunsetfn };
+static const struct gsu_integer intseconds_gsu =
+{ intsecondsgetfn, intsecondssetfn, stdunsetfn };
+static const struct gsu_float floatseconds_gsu =
+{ floatsecondsgetfn, floatsecondssetfn, stdunsetfn };
+static const struct gsu_integer uid_gsu =
+{ uidgetfn, uidsetfn, stdunsetfn };
+static const struct gsu_integer euid_gsu =
+{ euidgetfn, euidsetfn, stdunsetfn };
+static const struct gsu_integer ttyidle_gsu =
+{ ttyidlegetfn, nullintsetfn, stdunsetfn };
+
+static const struct gsu_scalar argzero_gsu =
+{ argzerogetfn, argzerosetfn, nullunsetfn };
+static const struct gsu_scalar username_gsu =
+{ usernamegetfn, usernamesetfn, stdunsetfn };
+static const struct gsu_scalar dash_gsu =
+{ dashgetfn, nullstrsetfn, stdunsetfn };
+static const struct gsu_scalar histchars_gsu =
+{ histcharsgetfn, histcharssetfn, stdunsetfn };
+static const struct gsu_scalar home_gsu =
+{ homegetfn, homesetfn, stdunsetfn };
+static const struct gsu_scalar term_gsu =
+{ termgetfn, termsetfn, stdunsetfn };
+static const struct gsu_scalar terminfo_gsu =
+{ terminfogetfn, terminfosetfn, stdunsetfn };
+static const struct gsu_scalar terminfodirs_gsu =
+{ terminfodirsgetfn, terminfodirssetfn, stdunsetfn };
+static const struct gsu_scalar wordchars_gsu =
+{ wordcharsgetfn, wordcharssetfn, stdunsetfn };
+static const struct gsu_scalar ifs_gsu =
+{ ifsgetfn, ifssetfn, stdunsetfn };
+static const struct gsu_scalar underscore_gsu =
+{ underscoregetfn, nullstrsetfn, stdunsetfn };
+static const struct gsu_scalar keyboard_hack_gsu =
+{ keyboardhackgetfn, keyboardhacksetfn, stdunsetfn };
+#ifdef USE_LOCALE
+static const struct gsu_scalar lc_blah_gsu =
+{ strgetfn, lcsetfn, stdunsetfn };
+static const struct gsu_scalar lang_gsu =
+{ strgetfn, langsetfn, stdunsetfn };
+static const struct gsu_scalar lc_all_gsu =
+{ strgetfn, lc_allsetfn, stdunsetfn };
+#endif
+
+static const struct gsu_integer varint_readonly_gsu =
+{ intvargetfn, nullintsetfn, stdunsetfn };
+static const struct gsu_integer zlevar_gsu =
+{ intvargetfn, zlevarsetfn, stdunsetfn };
+
+static const struct gsu_scalar colonarr_gsu =
+{ colonarrgetfn, colonarrsetfn, stdunsetfn };
+
+static const struct gsu_integer argc_gsu =
+{ poundgetfn, nullintsetfn, stdunsetfn };
+static const struct gsu_array pipestatus_gsu =
+{ pipestatgetfn, pipestatsetfn, stdunsetfn };
+
+static const struct gsu_integer rprompt_indent_gsu =
+{ intvargetfn, zlevarsetfn, rprompt_indent_unsetfn };
+
+/* Nodes for special parameters for parameter hash table */
+
+#ifdef HAVE_UNION_INIT
+# define BR(X) {X}
+typedef struct param initparam;
+#else
+# define BR(X) X
+typedef struct iparam {
+ struct hashnode *next;
+ char *nam; /* hash data */
+ int flags; /* PM_* flags (defined in zsh.h) */
+ void *value;
+ void *gsu; /* get/set/unset methods */
+ int base; /* output base */
+ int width; /* output field width */
+ char *env; /* location in environment, if exported */
+ char *ename; /* name of corresponding environment var */
+ Param old; /* old struct for use with local */
+ int level; /* if (old != NULL), level of localness */
+} initparam;
+#endif
+
+static initparam special_params[] ={
+#define GSU(X) BR((GsuScalar)(void *)(&(X)))
+#define NULL_GSU BR((GsuScalar)(void *)NULL)
+#define IPDEF1(A,B,C) {{NULL,A,PM_INTEGER|PM_SPECIAL|C},BR(NULL),GSU(B),10,0,NULL,NULL,NULL,0}
+IPDEF1("#", pound_gsu, PM_READONLY),
+IPDEF1("ERRNO", errno_gsu, PM_UNSET),
+IPDEF1("GID", gid_gsu, PM_DONTIMPORT | PM_RESTRICTED),
+IPDEF1("EGID", egid_gsu, PM_DONTIMPORT | PM_RESTRICTED),
+IPDEF1("HISTSIZE", histsize_gsu, PM_RESTRICTED),
+IPDEF1("RANDOM", random_gsu, 0),
+IPDEF1("SAVEHIST", savehist_gsu, PM_RESTRICTED),
+IPDEF1("SECONDS", intseconds_gsu, 0),
+IPDEF1("UID", uid_gsu, PM_DONTIMPORT | PM_RESTRICTED),
+IPDEF1("EUID", euid_gsu, PM_DONTIMPORT | PM_RESTRICTED),
+IPDEF1("TTYIDLE", ttyidle_gsu, PM_READONLY),
+
+#define IPDEF2(A,B,C) {{NULL,A,PM_SCALAR|PM_SPECIAL|C},BR(NULL),GSU(B),0,0,NULL,NULL,NULL,0}
+IPDEF2("USERNAME", username_gsu, PM_DONTIMPORT|PM_RESTRICTED),
+IPDEF2("-", dash_gsu, PM_READONLY),
+IPDEF2("histchars", histchars_gsu, PM_DONTIMPORT),
+IPDEF2("HOME", home_gsu, PM_UNSET),
+IPDEF2("TERM", term_gsu, PM_UNSET),
+IPDEF2("TERMINFO", terminfo_gsu, PM_UNSET),
+IPDEF2("TERMINFO_DIRS", terminfodirs_gsu, PM_UNSET),
+IPDEF2("WORDCHARS", wordchars_gsu, 0),
+IPDEF2("IFS", ifs_gsu, PM_DONTIMPORT | PM_RESTRICTED),
+IPDEF2("_", underscore_gsu, PM_DONTIMPORT),
+IPDEF2("KEYBOARD_HACK", keyboard_hack_gsu, PM_DONTIMPORT),
+IPDEF2("0", argzero_gsu, 0),
+
+#ifdef USE_LOCALE
+# define LCIPDEF(name) IPDEF2(name, lc_blah_gsu, PM_UNSET)
+IPDEF2("LANG", lang_gsu, PM_UNSET),
+IPDEF2("LC_ALL", lc_all_gsu, PM_UNSET),
+# ifdef LC_COLLATE
+LCIPDEF("LC_COLLATE"),
+# endif
+# ifdef LC_CTYPE
+LCIPDEF("LC_CTYPE"),
+# endif
+# ifdef LC_MESSAGES
+LCIPDEF("LC_MESSAGES"),
+# endif
+# ifdef LC_NUMERIC
+LCIPDEF("LC_NUMERIC"),
+# endif
+# ifdef LC_TIME
+LCIPDEF("LC_TIME"),
+# endif
+#endif /* USE_LOCALE */
+
+#define IPDEF4(A,B) {{NULL,A,PM_INTEGER|PM_READONLY|PM_SPECIAL},BR((void *)B),GSU(varint_readonly_gsu),10,0,NULL,NULL,NULL,0}
+IPDEF4("!", &lastpid),
+IPDEF4("$", &mypid),
+IPDEF4("?", &lastval),
+IPDEF4("HISTCMD", &curhist),
+IPDEF4("LINENO", &lineno),
+IPDEF4("PPID", &ppid),
+IPDEF4("ZSH_SUBSHELL", &zsh_subshell),
+
+#define IPDEF5(A,B,F) {{NULL,A,PM_INTEGER|PM_SPECIAL},BR((void *)B),GSU(F),10,0,NULL,NULL,NULL,0}
+#define IPDEF5U(A,B,F) {{NULL,A,PM_INTEGER|PM_SPECIAL|PM_UNSET},BR((void *)B),GSU(F),10,0,NULL,NULL,NULL,0}
+IPDEF5("COLUMNS", &zterm_columns, zlevar_gsu),
+IPDEF5("LINES", &zterm_lines, zlevar_gsu),
+IPDEF5U("ZLE_RPROMPT_INDENT", &rprompt_indent, rprompt_indent_gsu),
+IPDEF5("SHLVL", &shlvl, varinteger_gsu),
+IPDEF5("FUNCNEST", &zsh_funcnest, varinteger_gsu),
+
+/* Don't import internal integer status variables. */
+#define IPDEF6(A,B,F) {{NULL,A,PM_INTEGER|PM_SPECIAL|PM_DONTIMPORT},BR((void *)B),GSU(F),10,0,NULL,NULL,NULL,0}
+IPDEF6("OPTIND", &zoptind, varinteger_gsu),
+IPDEF6("TRY_BLOCK_ERROR", &try_errflag, varinteger_gsu),
+IPDEF6("TRY_BLOCK_INTERRUPT", &try_interrupt, varinteger_gsu),
+
+#define IPDEF7(A,B) {{NULL,A,PM_SCALAR|PM_SPECIAL},BR((void *)B),GSU(varscalar_gsu),0,0,NULL,NULL,NULL,0}
+#define IPDEF7R(A,B) {{NULL,A,PM_SCALAR|PM_SPECIAL|PM_DONTIMPORT_SUID},BR((void *)B),GSU(varscalar_gsu),0,0,NULL,NULL,NULL,0}
+#define IPDEF7U(A,B) {{NULL,A,PM_SCALAR|PM_SPECIAL|PM_UNSET},BR((void *)B),GSU(varscalar_gsu),0,0,NULL,NULL,NULL,0}
+IPDEF7("OPTARG", &zoptarg),
+IPDEF7("NULLCMD", &nullcmd),
+IPDEF7U("POSTEDIT", &postedit),
+IPDEF7("READNULLCMD", &readnullcmd),
+IPDEF7("PS1", &prompt),
+IPDEF7U("RPS1", &rprompt),
+IPDEF7U("RPROMPT", &rprompt),
+IPDEF7("PS2", &prompt2),
+IPDEF7U("RPS2", &rprompt2),
+IPDEF7U("RPROMPT2", &rprompt2),
+IPDEF7("PS3", &prompt3),
+IPDEF7R("PS4", &prompt4),
+IPDEF7("SPROMPT", &sprompt),
+
+#define IPDEF9F(A,B,C,D) {{NULL,A,D|PM_ARRAY|PM_SPECIAL|PM_DONTIMPORT},BR((void *)B),GSU(vararray_gsu),0,0,NULL,C,NULL,0}
+#define IPDEF9(A,B,C) IPDEF9F(A,B,C,0)
+IPDEF9F("*", &pparams, NULL, PM_ARRAY|PM_SPECIAL|PM_DONTIMPORT|PM_READONLY),
+IPDEF9F("@", &pparams, NULL, PM_ARRAY|PM_SPECIAL|PM_DONTIMPORT|PM_READONLY),
+
+/*
+ * This empty row indicates the end of parameters available in
+ * all emulations.
+ */
+{{NULL,NULL,0},BR(NULL),NULL_GSU,0,0,NULL,NULL,NULL,0},
+
+#define IPDEF8(A,B,C,D) {{NULL,A,D|PM_SCALAR|PM_SPECIAL},BR((void *)B),GSU(colonarr_gsu),0,0,NULL,C,NULL,0}
+IPDEF8("CDPATH", &cdpath, "cdpath", 0),
+IPDEF8("FIGNORE", &fignore, "fignore", 0),
+IPDEF8("FPATH", &fpath, "fpath", 0),
+IPDEF8("MAILPATH", &mailpath, "mailpath", 0),
+IPDEF8("WATCH", &watch, "watch", 0),
+IPDEF8("PATH", &path, "path", PM_RESTRICTED),
+IPDEF8("PSVAR", &psvar, "psvar", 0),
+IPDEF8("ZSH_EVAL_CONTEXT", &zsh_eval_context, "zsh_eval_context", PM_READONLY),
+
+/* MODULE_PATH is not imported for security reasons */
+IPDEF8("MODULE_PATH", &module_path, "module_path", PM_DONTIMPORT|PM_RESTRICTED),
+
+#define IPDEF10(A,B) {{NULL,A,PM_ARRAY|PM_SPECIAL},BR(NULL),GSU(B),10,0,NULL,NULL,NULL,0}
+
+/*
+ * The following parameters are not available in sh/ksh compatibility *
+ * mode.
+ */
+
+/* All of these have sh compatible equivalents. */
+IPDEF1("ARGC", argc_gsu, PM_READONLY),
+IPDEF2("HISTCHARS", histchars_gsu, PM_DONTIMPORT),
+IPDEF4("status", &lastval),
+IPDEF7("prompt", &prompt),
+IPDEF7("PROMPT", &prompt),
+IPDEF7("PROMPT2", &prompt2),
+IPDEF7("PROMPT3", &prompt3),
+IPDEF7("PROMPT4", &prompt4),
+IPDEF8("MANPATH", &manpath, "manpath", 0),
+IPDEF9("argv", &pparams, NULL),
+IPDEF9("fignore", &fignore, "FIGNORE"),
+IPDEF9("cdpath", &cdpath, "CDPATH"),
+IPDEF9("fpath", &fpath, "FPATH"),
+IPDEF9("mailpath", &mailpath, "MAILPATH"),
+IPDEF9("manpath", &manpath, "MANPATH"),
+IPDEF9("psvar", &psvar, "PSVAR"),
+IPDEF9("watch", &watch, "WATCH"),
+
+IPDEF9F("zsh_eval_context", &zsh_eval_context, "ZSH_EVAL_CONTEXT", PM_READONLY),
+
+IPDEF9F("module_path", &module_path, "MODULE_PATH", PM_RESTRICTED),
+IPDEF9F("path", &path, "PATH", PM_RESTRICTED),
+
+/* These are known to zsh alone. */
+
+IPDEF10("pipestatus", pipestatus_gsu),
+
+{{NULL,NULL,0},BR(NULL),NULL_GSU,0,0,NULL,NULL,NULL,0},
+};
+
+/*
+ * Alternative versions of colon-separated path parameters for
+ * sh emulation. These don't link to the array versions.
+ */
+static initparam special_params_sh[] = {
+IPDEF8("CDPATH", &cdpath, NULL, 0),
+IPDEF8("FIGNORE", &fignore, NULL, 0),
+IPDEF8("FPATH", &fpath, NULL, 0),
+IPDEF8("MAILPATH", &mailpath, NULL, 0),
+IPDEF8("WATCH", &watch, NULL, 0),
+IPDEF8("PATH", &path, NULL, PM_RESTRICTED),
+IPDEF8("PSVAR", &psvar, NULL, 0),
+IPDEF8("ZSH_EVAL_CONTEXT", &zsh_eval_context, NULL, PM_READONLY),
+
+/* MODULE_PATH is not imported for security reasons */
+IPDEF8("MODULE_PATH", &module_path, NULL, PM_DONTIMPORT|PM_RESTRICTED),
+
+{{NULL,NULL,0},BR(NULL),NULL_GSU,0,0,NULL,NULL,NULL,0},
+};
+
+/*
+ * Special way of referring to the positional parameters. Unlike $*
+ * and $@, this is not readonly. This parameter is not directly
+ * visible in user space.
+ */
+static initparam argvparam_pm = IPDEF9F("", &pparams, NULL, \
+ PM_ARRAY|PM_SPECIAL|PM_DONTIMPORT);
+
+#undef BR
+
+#define IS_UNSET_VALUE(V) \
+ ((V) && (!(V)->pm || ((V)->pm->node.flags & PM_UNSET) || \
+ !(V)->pm->node.nam || !*(V)->pm->node.nam))
+
+static Param argvparam;
+
+/* hash table containing the parameters */
+
+/**/
+mod_export HashTable paramtab, realparamtab;
+
+/**/
+mod_export HashTable
+newparamtable(int size, char const *name)
+{
+ HashTable ht;
+ if (!size)
+ size = 17;
+ ht = newhashtable(size, name, NULL);
+
+ ht->hash = hasher;
+ ht->emptytable = emptyhashtable;
+ ht->filltable = NULL;
+ ht->cmpnodes = strcmp;
+ ht->addnode = addhashnode;
+ ht->getnode = getparamnode;
+ ht->getnode2 = gethashnode2;
+ ht->removenode = removehashnode;
+ ht->disablenode = NULL;
+ ht->enablenode = NULL;
+ ht->freenode = freeparamnode;
+ ht->printnode = printparamnode;
+
+ return ht;
+}
+
+/**/
+static HashNode
+getparamnode(HashTable ht, const char *nam)
+{
+ HashNode hn = gethashnode2(ht, nam);
+ Param pm = (Param) hn;
+
+ if (pm && pm->u.str && (pm->node.flags & PM_AUTOLOAD)) {
+ char *mn = dupstring(pm->u.str);
+
+ (void)ensurefeature(mn, "p:", (pm->node.flags & PM_AUTOALL) ? NULL :
+ nam);
+ hn = gethashnode2(ht, nam);
+ if (!hn) {
+ /*
+ * This used to be a warning, but surely if we allow
+ * stuff to go ahead with the autoload stub with
+ * no error status we're in for all sorts of mayhem?
+ */
+ zerr("autoloading module %s failed to define parameter: %s", mn,
+ nam);
+ }
+ }
+ return hn;
+}
+
+/* Copy a parameter hash table */
+
+static HashTable outtable;
+
+/**/
+static void
+scancopyparams(HashNode hn, UNUSED(int flags))
+{
+ /* Going into a real parameter, so always use permanent storage */
+ Param pm = (Param)hn;
+ Param tpm = (Param) zshcalloc(sizeof *tpm);
+ tpm->node.nam = ztrdup(pm->node.nam);
+ copyparam(tpm, pm, 0);
+ addhashnode(outtable, tpm->node.nam, tpm);
+}
+
+/**/
+HashTable
+copyparamtable(HashTable ht, char *name)
+{
+ HashTable nht = 0;
+ if (ht) {
+ nht = newparamtable(ht->hsize, name);
+ outtable = nht;
+ scanhashtable(ht, 0, 0, 0, scancopyparams, 0);
+ outtable = NULL;
+ }
+ return nht;
+}
+
+/* Flag to freeparamnode to unset the struct */
+
+static int delunset;
+
+/* Function to delete a parameter table. */
+
+/**/
+mod_export void
+deleteparamtable(HashTable t)
+{
+ /* The parameters in the hash table need to be unset *
+ * before being deleted. */
+ int odelunset = delunset;
+ delunset = 1;
+ deletehashtable(t);
+ delunset = odelunset;
+}
+
+static unsigned numparamvals;
+
+/**/
+mod_export void
+scancountparams(UNUSED(HashNode hn), int flags)
+{
+ ++numparamvals;
+ if ((flags & SCANPM_WANTKEYS) && (flags & SCANPM_WANTVALS))
+ ++numparamvals;
+}
+
+static Patprog scanprog;
+static char *scanstr;
+static char **paramvals;
+static Param foundparam;
+
+/**/
+static void
+scanparamvals(HashNode hn, int flags)
+{
+ struct value v;
+ Patprog prog;
+
+ if (numparamvals && !(flags & SCANPM_MATCHMANY) &&
+ (flags & (SCANPM_MATCHVAL|SCANPM_MATCHKEY|SCANPM_KEYMATCH)))
+ return;
+ v.pm = (Param)hn;
+ if ((flags & SCANPM_KEYMATCH)) {
+ char *tmp = dupstring(v.pm->node.nam);
+
+ tokenize(tmp);
+ remnulargs(tmp);
+
+ if (!(prog = patcompile(tmp, 0, NULL)) || !pattry(prog, scanstr))
+ return;
+ } else if ((flags & SCANPM_MATCHKEY) && !pattry(scanprog, v.pm->node.nam)) {
+ return;
+ }
+ foundparam = v.pm;
+ if (flags & SCANPM_WANTKEYS) {
+ paramvals[numparamvals++] = v.pm->node.nam;
+ if (!(flags & (SCANPM_WANTVALS|SCANPM_MATCHVAL)))
+ return;
+ }
+ v.isarr = (PM_TYPE(v.pm->node.flags) & (PM_ARRAY|PM_HASHED));
+ v.flags = 0;
+ v.start = 0;
+ v.end = -1;
+ paramvals[numparamvals] = getstrvalue(&v);
+ if (flags & SCANPM_MATCHVAL) {
+ if (pattry(scanprog, paramvals[numparamvals])) {
+ numparamvals += ((flags & SCANPM_WANTVALS) ? 1 :
+ !(flags & SCANPM_WANTKEYS));
+ } else if (flags & SCANPM_WANTKEYS)
+ --numparamvals; /* Value didn't match, discard key */
+ } else
+ ++numparamvals;
+ foundparam = NULL;
+}
+
+/**/
+char **
+paramvalarr(HashTable ht, int flags)
+{
+ DPUTS((flags & (SCANPM_MATCHKEY|SCANPM_MATCHVAL)) && !scanprog,
+ "BUG: scanning hash without scanprog set");
+ numparamvals = 0;
+ if (ht)
+ scanhashtable(ht, 0, 0, PM_UNSET, scancountparams, flags);
+ paramvals = (char **) zhalloc((numparamvals + 1) * sizeof(char *));
+ if (ht) {
+ numparamvals = 0;
+ scanhashtable(ht, 0, 0, PM_UNSET, scanparamvals, flags);
+ }
+ paramvals[numparamvals] = 0;
+ return paramvals;
+}
+
+/* Return the full array (no indexing) referred to by a Value. *
+ * The array value is cached for the lifetime of the Value. */
+
+/**/
+static char **
+getvaluearr(Value v)
+{
+ if (v->arr)
+ return v->arr;
+ else if (PM_TYPE(v->pm->node.flags) == PM_ARRAY)
+ return v->arr = v->pm->gsu.a->getfn(v->pm);
+ else if (PM_TYPE(v->pm->node.flags) == PM_HASHED) {
+ v->arr = paramvalarr(v->pm->gsu.h->getfn(v->pm), v->isarr);
+ /* Can't take numeric slices of associative arrays */
+ v->start = 0;
+ v->end = numparamvals + 1;
+ return v->arr;
+ } else
+ return NULL;
+}
+
+/* Return whether the variable is set *
+ * checks that array slices are within range *
+ * used for [[ -v ... ]] condition test */
+
+/**/
+int
+issetvar(char *name)
+{
+ struct value vbuf;
+ Value v;
+ int slice;
+ char **arr;
+
+ if (!(v = getvalue(&vbuf, &name, 1)) || *name)
+ return 0; /* no value or more chars after the variable name */
+ if (v->isarr & ~SCANPM_ARRONLY)
+ return v->end > 1; /* for extracted elements, end gives us a count */
+
+ slice = v->start != 0 || v->end != -1;
+ if (PM_TYPE(v->pm->node.flags) != PM_ARRAY || !slice)
+ return !slice && !(v->pm->node.flags & PM_UNSET);
+
+ if (!v->end) /* empty array slice */
+ return 0;
+ /* get the array and check end is within range */
+ if (!(arr = getvaluearr(v)))
+ return 0;
+ return arrlen_ge(arr, v->end < 0 ? - v->end : v->end);
+}
+
+/*
+ * Split environment string into (name, value) pair.
+ * this is used to avoid in-place editing of environment table
+ * that results in core dump on some systems
+ */
+
+static int
+split_env_string(char *env, char **name, char **value)
+{
+ char *str, *tenv;
+
+ if (!env || !name || !value)
+ return 0;
+
+ tenv = strcpy(zhalloc(strlen(env) + 1), env);
+ for (str = tenv; *str && *str != '='; str++) {
+ if (STOUC(*str) >= 128) {
+ /*
+ * We'll ignore environment variables with names not
+ * from the portable character set since we don't
+ * know of a good reason to accept them.
+ */
+ return 0;
+ }
+ }
+ if (str != tenv && *str == '=') {
+ *str = '\0';
+ *name = tenv;
+ *value = str + 1;
+ return 1;
+ } else
+ return 0;
+}
+
+/**
+ * Check parameter flags to see if parameter shouldn't be imported
+ * from environment at start.
+ *
+ * return 1: don't import: 0: ok to import.
+ */
+static int dontimport(int flags)
+{
+ /* If explicitly marked as don't export */
+ if (flags & PM_DONTIMPORT)
+ return 1;
+ /* If value already exported */
+ if (flags & PM_EXPORTED)
+ return 1;
+ /* If security issue when importing and running with some privilege */
+ if ((flags & PM_DONTIMPORT_SUID) && isset(PRIVILEGED))
+ return 1;
+ /* OK to import */
+ return 0;
+}
+
+/* Set up parameter hash table. This will add predefined *
+ * parameter entries as well as setting up parameter table *
+ * entries for environment variables we inherit. */
+
+/**/
+void
+createparamtable(void)
+{
+ Param ip, pm;
+#if !defined(HAVE_PUTENV) && !defined(USE_SET_UNSET_ENV)
+ char **new_environ;
+ int envsize;
+#endif
+#ifndef USE_SET_UNSET_ENV
+ char **envp;
+#endif
+ char **envp2, **sigptr, **t;
+ char buf[50], *str, *iname, *ivalue, *hostnam;
+ int oae = opts[ALLEXPORT];
+#ifdef HAVE_UNAME
+ struct utsname unamebuf;
+ char *machinebuf;
+#endif
+
+ paramtab = realparamtab = newparamtable(151, "paramtab");
+
+ /* Add the special parameters to the hash table */
+ for (ip = special_params; ip->node.nam; ip++)
+ paramtab->addnode(paramtab, ztrdup(ip->node.nam), ip);
+ if (EMULATION(EMULATE_SH|EMULATE_KSH)) {
+ for (ip = special_params_sh; ip->node.nam; ip++)
+ paramtab->addnode(paramtab, ztrdup(ip->node.nam), ip);
+ } else {
+ while ((++ip)->node.nam)
+ paramtab->addnode(paramtab, ztrdup(ip->node.nam), ip);
+ }
+
+ argvparam = (Param) &argvparam_pm;
+
+ noerrs = 2;
+
+ /* Add the standard non-special parameters which have to *
+ * be initialized before we copy the environment variables. *
+ * We don't want to override whatever values the user has *
+ * given them in the environment. */
+ opts[ALLEXPORT] = 0;
+ setiparam("MAILCHECK", 60);
+ setiparam("LOGCHECK", 60);
+ setiparam("KEYTIMEOUT", 40);
+ setiparam("LISTMAX", 100);
+ /*
+ * We used to get the output baud rate here. However, that's
+ * pretty irrelevant to a terminal on an X display and can lead
+ * to unnecessary delays if it's wrong (which it probably is).
+ * Furthermore, even if the output is slow it's very likely
+ * to be because of WAN delays, not covered by the output
+ * baud rate.
+ * So allow the user to set it in the special cases where it's
+ * useful.
+ */
+ setsparam("TMPPREFIX", ztrdup_metafy(DEFAULT_TMPPREFIX));
+ setsparam("TIMEFMT", ztrdup_metafy(DEFAULT_TIMEFMT));
+ setsparam("WATCHFMT", ztrdup_metafy(default_watchfmt));
+
+ hostnam = (char *)zalloc(256);
+ gethostname(hostnam, 256);
+ setsparam("HOST", ztrdup_metafy(hostnam));
+ zfree(hostnam, 256);
+
+ setsparam("LOGNAME",
+ ztrdup_metafy((str = getlogin()) && *str ?
+ str : cached_username));
+
+#if !defined(HAVE_PUTENV) && !defined(USE_SET_UNSET_ENV)
+ /* Copy the environment variables we are inheriting to dynamic *
+ * memory, so we can do mallocs and frees on it. */
+ envsize = sizeof(char *)*(1 + arrlen(environ));
+ new_environ = (char **) zalloc(envsize);
+ memcpy(new_environ, environ, envsize);
+ environ = new_environ;
+#endif
+
+ /* Use heap allocation to avoid many small alloc/free calls */
+ pushheap();
+
+ /* Now incorporate environment variables we are inheriting *
+ * into the parameter hash table. Copy them into dynamic *
+ * memory so that we can free them if needed */
+ for (
+#ifndef USE_SET_UNSET_ENV
+ envp =
+#endif
+ envp2 = environ; *envp2; envp2++) {
+ if (split_env_string(*envp2, &iname, &ivalue)) {
+ if (!idigit(*iname) && isident(iname) && !strchr(iname, '[')) {
+ /*
+ * Parameters that aren't already in the parameter table
+ * aren't special to the shell, so it's always OK to
+ * import. Otherwise, check parameter flags.
+ */
+ if ((!(pm = (Param) paramtab->getnode(paramtab, iname)) ||
+ !dontimport(pm->node.flags)) &&
+ (pm = assignsparam(iname, metafy(ivalue, -1, META_DUP),
+ ASSPM_ENV_IMPORT))) {
+ pm->node.flags |= PM_EXPORTED;
+ if (pm->node.flags & PM_SPECIAL)
+ pm->env = mkenvstr (pm->node.nam,
+ getsparam(pm->node.nam), pm->node.flags);
+ else
+ pm->env = ztrdup(*envp2);
+#ifndef USE_SET_UNSET_ENV
+ *envp++ = pm->env;
+#endif
+ }
+ }
+ }
+ }
+ popheap();
+#ifndef USE_SET_UNSET_ENV
+ *envp = NULL;
+#endif
+ opts[ALLEXPORT] = oae;
+
+ /*
+ * For native emulation we always set the variable home
+ * (see setupvals()).
+ */
+ pm = (Param) paramtab->getnode(paramtab, "HOME");
+ if (EMULATION(EMULATE_ZSH))
+ {
+ pm->node.flags &= ~PM_UNSET;
+ if (!(pm->node.flags & PM_EXPORTED))
+ addenv(pm, home);
+ } else if (!home)
+ pm->node.flags |= PM_UNSET;
+ pm = (Param) paramtab->getnode(paramtab, "LOGNAME");
+ if (!(pm->node.flags & PM_EXPORTED))
+ addenv(pm, pm->u.str);
+ pm = (Param) paramtab->getnode(paramtab, "SHLVL");
+ sprintf(buf, "%d", (int)++shlvl);
+ /* shlvl value in environment needs updating unconditionally */
+ addenv(pm, buf);
+
+ /* Add the standard non-special parameters */
+ set_pwd_env();
+#ifdef HAVE_UNAME
+ if(uname(&unamebuf)) setsparam("CPUTYPE", ztrdup("unknown"));
+ else
+ {
+ machinebuf = ztrdup_metafy(unamebuf.machine);
+ setsparam("CPUTYPE", machinebuf);
+ }
+
+#else
+ setsparam("CPUTYPE", ztrdup_metafy("unknown"));
+#endif
+ setsparam("MACHTYPE", ztrdup_metafy(MACHTYPE));
+ setsparam("OSTYPE", ztrdup_metafy(OSTYPE));
+ setsparam("TTY", ztrdup_metafy(ttystrname));
+ setsparam("VENDOR", ztrdup_metafy(VENDOR));
+ setsparam("ZSH_ARGZERO", ztrdup(posixzero));
+ setsparam("ZSH_VERSION", ztrdup_metafy(ZSH_VERSION));
+ setsparam("ZSH_PATCHLEVEL", ztrdup_metafy(ZSH_PATCHLEVEL));
+ setaparam("signals", sigptr = zalloc((SIGCOUNT+4) * sizeof(char *)));
+ for (t = sigs; (*sigptr++ = ztrdup_metafy(*t++)); );
+
+ noerrs = 0;
+}
+
+/* assign various functions used for non-special parameters */
+
+/**/
+mod_export void
+assigngetset(Param pm)
+{
+ switch (PM_TYPE(pm->node.flags)) {
+ case PM_SCALAR:
+ pm->gsu.s = &stdscalar_gsu;
+ break;
+ case PM_INTEGER:
+ pm->gsu.i = &stdinteger_gsu;
+ break;
+ case PM_EFLOAT:
+ case PM_FFLOAT:
+ pm->gsu.f = &stdfloat_gsu;
+ break;
+ case PM_ARRAY:
+ pm->gsu.a = &stdarray_gsu;
+ break;
+ case PM_HASHED:
+ pm->gsu.h = &stdhash_gsu;
+ break;
+ default:
+ DPUTS(1, "BUG: tried to create param node without valid flag");
+ break;
+ }
+}
+
+/* Create a parameter, so that it can be assigned to. Returns NULL if the *
+ * parameter already exists or can't be created, otherwise returns the *
+ * parameter node. If a parameter of the same name exists in an outer *
+ * scope, it is hidden by a newly created parameter. An already existing *
+ * parameter node at the current level may be `created' and returned *
+ * provided it is unset and not special. If the parameter can't be *
+ * created because it already exists, the PM_UNSET flag is cleared. */
+
+/**/
+mod_export Param
+createparam(char *name, int flags)
+{
+ Param pm, oldpm;
+
+ if (paramtab != realparamtab)
+ flags = (flags & ~PM_EXPORTED) | PM_HASHELEM;
+
+ if (name != nulstring) {
+ oldpm = (Param) (paramtab == realparamtab ?
+ /* gethashnode2() for direct table read */
+ gethashnode2(paramtab, name) :
+ paramtab->getnode(paramtab, name));
+
+ DPUTS(oldpm && oldpm->level > locallevel,
+ "BUG: old local parameter not deleted");
+ if (oldpm && (oldpm->level == locallevel || !(flags & PM_LOCAL))) {
+ if (isset(POSIXBUILTINS) && (oldpm->node.flags & PM_READONLY)) {
+ zerr("read-only variable: %s", name);
+ return NULL;
+ }
+ if ((oldpm->node.flags & PM_RESTRICTED) && isset(RESTRICTED)) {
+ zerr("%s: restricted", name);
+ return NULL;
+ }
+ if (!(oldpm->node.flags & PM_UNSET) ||
+ (oldpm->node.flags & PM_SPECIAL) ||
+ /* POSIXBUILTINS horror: we need to retain 'export' flags */
+ (isset(POSIXBUILTINS) && (oldpm->node.flags & PM_EXPORTED))) {
+ oldpm->node.flags &= ~PM_UNSET;
+ if ((oldpm->node.flags & PM_SPECIAL) && oldpm->ename) {
+ Param altpm =
+ (Param) paramtab->getnode(paramtab, oldpm->ename);
+ if (altpm)
+ altpm->node.flags &= ~PM_UNSET;
+ }
+ return NULL;
+ }
+
+ pm = oldpm;
+ pm->base = pm->width = 0;
+ oldpm = pm->old;
+ } else {
+ pm = (Param) zshcalloc(sizeof *pm);
+ if ((pm->old = oldpm)) {
+ /*
+ * needed to avoid freeing oldpm, but we do take it
+ * out of the environment when it's hidden.
+ */
+ if (oldpm->env)
+ delenv(oldpm);
+ paramtab->removenode(paramtab, name);
+ }
+ paramtab->addnode(paramtab, ztrdup(name), pm);
+ }
+
+ if (isset(ALLEXPORT) && !(flags & PM_HASHELEM))
+ flags |= PM_EXPORTED;
+ } else {
+ pm = (Param) hcalloc(sizeof *pm);
+ pm->node.nam = nulstring;
+ }
+ pm->node.flags = flags & ~PM_LOCAL;
+
+ if(!(pm->node.flags & PM_SPECIAL))
+ assigngetset(pm);
+ return pm;
+}
+
+/* Empty dummy function for special hash parameters. */
+
+/**/
+static void
+shempty(void)
+{
+}
+
+/*
+ * Create a simple special hash parameter.
+ *
+ * This is for hashes added internally --- it's not possible to add
+ * special hashes from shell commands. It's currently used
+ * - by addparamdef() for special parameters in the zsh/parameter
+ * module
+ * - by ztie for special parameters tied to databases.
+ */
+
+/**/
+mod_export Param
+createspecialhash(char *name, GetNodeFunc get, ScanTabFunc scan, int flags)
+{
+ Param pm;
+ HashTable ht;
+
+ if (!(pm = createparam(name, PM_SPECIAL|PM_HASHED|flags)))
+ return NULL;
+
+ /*
+ * If there's an old parameter, we'll put the new one at
+ * the current locallevel, so that the old parameter is
+ * exposed again after leaving the function. Otherwise,
+ * we'll leave it alone. Usually this means the parameter
+ * will stay in place until explicitly unloaded, however
+ * if the parameter was previously unset within a function
+ * we'll inherit the level of that function and follow the
+ * standard convention that the parameter remains local
+ * even if unset.
+ *
+ * These semantics are similar to those of a normal parameter set
+ * within a function without a local definition.
+ */
+ if (pm->old)
+ pm->level = locallevel;
+ pm->gsu.h = (flags & PM_READONLY) ? &stdhash_gsu :
+ &nullsethash_gsu;
+ pm->u.hash = ht = newhashtable(0, name, NULL);
+
+ ht->hash = hasher;
+ ht->emptytable = (TableFunc) shempty;
+ ht->filltable = NULL;
+ ht->addnode = (AddNodeFunc) shempty;
+ ht->getnode = ht->getnode2 = get;
+ ht->removenode = (RemoveNodeFunc) shempty;
+ ht->disablenode = NULL;
+ ht->enablenode = NULL;
+ ht->freenode = (FreeNodeFunc) shempty;
+ ht->printnode = printparamnode;
+ ht->scantab = scan;
+
+ return pm;
+}
+
+
+/*
+ * Copy a parameter
+ *
+ * If fakecopy is set, we are just saving the details of a special
+ * parameter. Otherwise, the result will be used as a real parameter
+ * and we need to do more work.
+ */
+
+/**/
+void
+copyparam(Param tpm, Param pm, int fakecopy)
+{
+ /*
+ * Note that tpm, into which we're copying, may not be in permanent
+ * storage. However, the values themselves are later used directly
+ * to set the parameter, so must be permanently allocated (in accordance
+ * with sets.?fn() usage).
+ */
+ tpm->node.flags = pm->node.flags;
+ tpm->base = pm->base;
+ tpm->width = pm->width;
+ tpm->level = pm->level;
+ if (!fakecopy)
+ tpm->node.flags &= ~PM_SPECIAL;
+ switch (PM_TYPE(pm->node.flags)) {
+ case PM_SCALAR:
+ tpm->u.str = ztrdup(pm->gsu.s->getfn(pm));
+ break;
+ case PM_INTEGER:
+ tpm->u.val = pm->gsu.i->getfn(pm);
+ break;
+ case PM_EFLOAT:
+ case PM_FFLOAT:
+ tpm->u.dval = pm->gsu.f->getfn(pm);
+ break;
+ case PM_ARRAY:
+ tpm->u.arr = zarrdup(pm->gsu.a->getfn(pm));
+ break;
+ case PM_HASHED:
+ tpm->u.hash = copyparamtable(pm->gsu.h->getfn(pm), pm->node.nam);
+ break;
+ }
+ /*
+ * If the value is going to be passed as a real parameter (e.g. this is
+ * called from inside an associative array), we need the gets and sets
+ * functions to be useful.
+ *
+ * In this case we assume the saved parameter is not itself special,
+ * so we just use the standard functions. This is also why we switch off
+ * PM_SPECIAL.
+ */
+ if (!fakecopy)
+ assigngetset(tpm);
+}
+
+/* Return 1 if the string s is a valid identifier, else return 0. */
+
+/**/
+mod_export int
+isident(char *s)
+{
+ char *ss;
+
+ if (!*s) /* empty string is definitely not valid */
+ return 0;
+
+ if (idigit(*s)) {
+ /* If the first character is `s' is a digit, then all must be */
+ for (ss = ++s; *ss; ss++)
+ if (!idigit(*ss))
+ break;
+ } else {
+ /* Find the first character in `s' not in the iident type table */
+ ss = itype_end(s, IIDENT, 0);
+ }
+
+ /* If the next character is not [, then it is *
+ * definitely not a valid identifier. */
+ if (!*ss)
+ return 1;
+ if (s == ss)
+ return 0;
+ if (*ss != '[')
+ return 0;
+
+ /* Require balanced [ ] pairs with something between */
+ if (!(ss = parse_subscript(++ss, 1, ']')))
+ return 0;
+ untokenize(s);
+ return !ss[1];
+}
+
+/*
+ * Parse a single argument to a parameter subscript.
+ * The subscripts starts at *str; *str is updated (input/output)
+ *
+ * *inv is set to indicate if the subscript is reversed (output)
+ * v is the Value for the parameter being accessed (input; note
+ * v->isarr may be modified, and if v is a hash the parameter will
+ * be updated to the element of the hash)
+ * a2 is 1 if this is the second subscript of a range (input)
+ * *w is only set if we need to find the end of a word (input; should
+ * be set to 0 by the caller).
+ *
+ * The final two arguments are to support multibyte characters.
+ * If supplied they are set to the length of the character before
+ * the index position and the one at the index position. If
+ * multibyte characters are not in use they are set to 1 for
+ * consistency. Note they aren't fully handled if a2 is non-zero,
+ * since they aren't needed.
+ *
+ * Returns a raw offset into the value from the start or end (i.e.
+ * after the arithmetic for Meta and possible multibyte characters has
+ * been taken into account). This actually gives the offset *after*
+ * the character in question; subtract *prevcharlen if necessary.
+ */
+
+/**/
+static zlong
+getarg(char **str, int *inv, Value v, int a2, zlong *w,
+ int *prevcharlen, int *nextcharlen, int flags)
+{
+ int hasbeg = 0, word = 0, rev = 0, ind = 0, down = 0, l, i, ishash;
+ int keymatch = 0, needtok = 0, arglen, len, inpar = 0;
+ char *s = *str, *sep = NULL, *t, sav, *d, **ta, **p, *tt, c;
+ zlong num = 1, beg = 0, r = 0, quote_arg = 0;
+ Patprog pprog = NULL;
+
+ /*
+ * If in NO_EXEC mode, the parameters won't be set up properly,
+ * so just pretend everything is a hash for subscript parsing
+ */
+
+ ishash = (unset(EXECOPT) ||
+ (v->pm && PM_TYPE(v->pm->node.flags) == PM_HASHED));
+ if (prevcharlen)
+ *prevcharlen = 1;
+ if (nextcharlen)
+ *nextcharlen = 1;
+
+ /* first parse any subscription flags */
+ if (v->pm && (*s == '(' || *s == Inpar)) {
+ int escapes = 0;
+ int waste;
+ for (s++; *s != ')' && *s != Outpar && s != *str; s++) {
+ switch (*s) {
+ case 'r':
+ rev = 1;
+ keymatch = down = ind = 0;
+ break;
+ case 'R':
+ rev = down = 1;
+ keymatch = ind = 0;
+ break;
+ case 'k':
+ keymatch = ishash;
+ rev = 1;
+ down = ind = 0;
+ break;
+ case 'K':
+ keymatch = ishash;
+ rev = down = 1;
+ ind = 0;
+ break;
+ case 'i':
+ rev = ind = 1;
+ down = keymatch = 0;
+ break;
+ case 'I':
+ rev = ind = down = 1;
+ keymatch = 0;
+ break;
+ case 'w':
+ /* If the parameter is a scalar, then make subscription *
+ * work on a per-word basis instead of characters. */
+ word = 1;
+ break;
+ case 'f':
+ word = 1;
+ sep = "\n";
+ break;
+ case 'e':
+ quote_arg = 1;
+ break;
+ case 'n':
+ t = get_strarg(++s, &arglen);
+ if (!*t)
+ goto flagerr;
+ sav = *t;
+ *t = '\0';
+ num = mathevalarg(s + arglen, &d);
+ if (!num)
+ num = 1;
+ *t = sav;
+ s = t + arglen - 1;
+ break;
+ case 'b':
+ hasbeg = 1;
+ t = get_strarg(++s, &arglen);
+ if (!*t)
+ goto flagerr;
+ sav = *t;
+ *t = '\0';
+ if ((beg = mathevalarg(s + arglen, &d)) > 0)
+ beg--;
+ *t = sav;
+ s = t + arglen - 1;
+ break;
+ case 'p':
+ escapes = 1;
+ break;
+ case 's':
+ /* This gives the string that separates words *
+ * (for use with the `w' flag). */
+ t = get_strarg(++s, &arglen);
+ if (!*t)
+ goto flagerr;
+ sav = *t;
+ *t = '\0';
+ s += arglen;
+ sep = escapes ? getkeystring(s, &waste, GETKEYS_SEP, NULL)
+ : dupstring(s);
+ *t = sav;
+ s = t + arglen - 1;
+ break;
+ default:
+ flagerr:
+ num = 1;
+ word = rev = ind = down = keymatch = 0;
+ sep = NULL;
+ s = *str - 1;
+ }
+ }
+ if (s != *str)
+ s++;
+ }
+ if (num < 0) {
+ down = !down;
+ num = -num;
+ }
+ if (v->isarr & SCANPM_WANTKEYS)
+ *inv = (ind || !(v->isarr & SCANPM_WANTVALS));
+ else if (v->isarr & SCANPM_WANTVALS)
+ *inv = 0;
+ else {
+ if (v->isarr) {
+ if (ind) {
+ v->isarr |= SCANPM_WANTKEYS;
+ v->isarr &= ~SCANPM_WANTVALS;
+ } else if (rev)
+ v->isarr |= SCANPM_WANTVALS;
+ /*
+ * This catches the case where we are using "k" (rather
+ * than "K") on a hash.
+ */
+ if (!down && keymatch && ishash)
+ v->isarr &= ~SCANPM_MATCHMANY;
+ }
+ *inv = ind;
+ }
+
+ for (t = s, i = 0;
+ (c = *t) &&
+ ((c != Outbrack && (ishash || c != ',')) || i || inpar);
+ t++) {
+ /* Untokenize inull() except before brackets and double-quotes */
+ if (inull(c)) {
+ c = t[1];
+ if (c == '[' || c == ']' ||
+ c == '(' || c == ')' ||
+ c == '{' || c == '}') {
+ /* This test handles nested subscripts in hash keys */
+ if (ishash && i)
+ *t = ztokens[*t - Pound];
+ needtok = 1;
+ ++t;
+ } else if (c != '"')
+ *t = ztokens[*t - Pound];
+ continue;
+ }
+ /* Inbrack and Outbrack are probably never found here ... */
+ if (c == '[' || c == Inbrack)
+ i++;
+ else if (c == ']' || c == Outbrack)
+ i--;
+ if (c == '(' || c == Inpar)
+ inpar++;
+ else if (c == ')' || c == Outpar)
+ inpar--;
+ if (ispecial(c))
+ needtok = 1;
+ }
+ if (!c)
+ return 0;
+ *str = tt = t;
+
+ /*
+ * If in NO_EXEC mode, the parameters won't be set up properly,
+ * so there's no additional sanity checking we can do.
+ * Just return 0 now.
+ */
+ if (unset(EXECOPT))
+ return 0;
+
+ s = dupstrpfx(s, t - s);
+
+ /* If we're NOT reverse subscripting, strip the inull()s so brackets *
+ * are not backslashed after parsestr(). Otherwise leave them alone *
+ * so that the brackets will be escaped when we patcompile() or when *
+ * subscript arithmetic is performed (for nested subscripts). */
+ if (ishash && (keymatch || !rev))
+ remnulargs(s);
+ if (needtok) {
+ s = dupstring(s);
+ if (parsestr(&s))
+ return 0;
+ singsub(&s);
+ } else if (rev)
+ remnulargs(s); /* This is probably always a no-op, but ... */
+ if (!rev) {
+ if (ishash) {
+ HashTable ht = v->pm->gsu.h->getfn(v->pm);
+ if (!ht) {
+ if (flags & SCANPM_CHECKING)
+ return 0;
+ ht = newparamtable(17, v->pm->node.nam);
+ v->pm->gsu.h->setfn(v->pm, ht);
+ }
+ untokenize(s);
+ if (!(v->pm = (Param) ht->getnode(ht, s))) {
+ HashTable tht = paramtab;
+ paramtab = ht;
+ v->pm = createparam(s, PM_SCALAR|PM_UNSET);
+ paramtab = tht;
+ }
+ v->isarr = (*inv ? SCANPM_WANTINDEX : 0);
+ v->start = 0;
+ *inv = 0; /* We've already obtained the "index" (key) */
+ *w = v->end = -1;
+ r = isset(KSHARRAYS) ? 1 : 0;
+ } else {
+ r = mathevalarg(s, &s);
+ if (isset(KSHARRAYS) && r >= 0)
+ r++;
+ }
+ if (word && !v->isarr) {
+ s = t = getstrvalue(v);
+ i = wordcount(s, sep, 0);
+ if (r < 0)
+ r += i + 1;
+ if (r < 1)
+ r = 1;
+ if (r > i)
+ r = i;
+ if (!s || !*s)
+ return 0;
+ while ((d = findword(&s, sep)) && --r);
+ if (!d)
+ return 0;
+
+ if (!a2 && *tt != ',')
+ *w = (zlong)(s - t);
+
+ return (a2 ? s : d + 1) - t;
+ } else if (!v->isarr && !word) {
+ int lastcharlen = 1;
+ s = getstrvalue(v);
+ /*
+ * Note for the confused (= pws): the index r we
+ * have so far is that specified by the user. The value
+ * passed back is an offset from the start or end of
+ * the string. Hence it needs correcting at least
+ * for Meta characters and maybe for multibyte characters.
+ */
+ if (r > 0) {
+ zlong nchars = r;
+
+ MB_METACHARINIT();
+ for (t = s; nchars && *t; nchars--)
+ t += (lastcharlen = MB_METACHARLEN(t));
+ /* for consistency, keep any remainder off the end */
+ r = (zlong)(t - s) + nchars;
+ if (prevcharlen && !nchars /* ignore if off the end */)
+ *prevcharlen = lastcharlen;
+ if (nextcharlen && *t)
+ *nextcharlen = MB_METACHARLEN(t);
+ } else if (r == 0) {
+ if (prevcharlen)
+ *prevcharlen = 0;
+ if (nextcharlen && *s) {
+ MB_METACHARINIT();
+ *nextcharlen = MB_METACHARLEN(s);
+ }
+ } else {
+ zlong nchars = (zlong)MB_METASTRLEN(s) + r;
+
+ if (nchars < 0) {
+ /* make sure this isn't valid as a raw pointer */
+ r -= (zlong)strlen(s);
+ } else {
+ MB_METACHARINIT();
+ for (t = s; nchars && *t; nchars--)
+ t += (lastcharlen = MB_METACHARLEN(t));
+ r = - (zlong)strlen(t); /* keep negative */
+ if (prevcharlen)
+ *prevcharlen = lastcharlen;
+ if (nextcharlen && *t)
+ *nextcharlen = MB_METACHARLEN(t);
+ }
+ }
+ }
+ } else {
+ if (!v->isarr && !word && !quote_arg) {
+ l = strlen(s);
+ if (a2) {
+ if (!l || *s != '*') {
+ d = (char *) hcalloc(l + 2);
+ *d = '*';
+ strcpy(d + 1, s);
+ s = d;
+ }
+ } else {
+ if (!l || s[l - 1] != '*' || (l > 1 && s[l - 2] == '\\')) {
+ d = (char *) hcalloc(l + 2);
+ strcpy(d, s);
+ strcat(d, "*");
+ s = d;
+ }
+ }
+ }
+ if (!keymatch) {
+ if (quote_arg) {
+ untokenize(s);
+ /* Scalar (e) needs implicit asterisk tokens */
+ if (!v->isarr && !word) {
+ l = strlen(s);
+ d = (char *) hcalloc(l + 2);
+ if (a2) {
+ *d = Star;
+ strcpy(d + 1, s);
+ } else {
+ strcpy(d, s);
+ d[l] = Star;
+ d[l + 1] = '\0';
+ }
+ s = d;
+ }
+ } else
+ tokenize(s);
+ remnulargs(s);
+ pprog = patcompile(s, 0, NULL);
+ } else
+ pprog = NULL;
+
+ if (v->isarr) {
+ if (ishash) {
+ scanprog = pprog;
+ scanstr = s;
+ if (keymatch)
+ v->isarr |= SCANPM_KEYMATCH;
+ else {
+ if (!pprog)
+ return 1;
+ if (ind)
+ v->isarr |= SCANPM_MATCHKEY;
+ else
+ v->isarr |= SCANPM_MATCHVAL;
+ }
+ if (down)
+ v->isarr |= SCANPM_MATCHMANY;
+ if ((ta = getvaluearr(v)) &&
+ (*ta || ((v->isarr & SCANPM_MATCHMANY) &&
+ (v->isarr & (SCANPM_MATCHKEY | SCANPM_MATCHVAL |
+ SCANPM_KEYMATCH))))) {
+ *inv = (v->flags & VALFLAG_INV) ? 1 : 0;
+ *w = v->end;
+ scanprog = NULL;
+ return 1;
+ }
+ scanprog = NULL;
+ } else
+ ta = getarrvalue(v);
+ if (!ta || !*ta)
+ return !down;
+ len = arrlen(ta);
+ if (beg < 0)
+ beg += len;
+ if (down) {
+ if (beg < 0)
+ return 0;
+ } else if (beg >= len)
+ return len + 1;
+ if (beg >= 0 && beg < len) {
+ if (down) {
+ if (!hasbeg)
+ beg = len - 1;
+ for (r = 1 + beg, p = ta + beg; p >= ta; r--, p--) {
+ if (pprog && pattry(pprog, *p) && !--num)
+ return r;
+ }
+ } else
+ for (r = 1 + beg, p = ta + beg; *p; r++, p++)
+ if (pprog && pattry(pprog, *p) && !--num)
+ return r;
+ }
+ } else if (word) {
+ ta = sepsplit(d = s = getstrvalue(v), sep, 1, 1);
+ len = arrlen(ta);
+ if (beg < 0)
+ beg += len;
+ if (down) {
+ if (beg < 0)
+ return 0;
+ } else if (beg >= len)
+ return len + 1;
+ if (beg >= 0 && beg < len) {
+ if (down) {
+ if (!hasbeg)
+ beg = len - 1;
+ for (r = 1 + beg, p = ta + beg; p >= ta; p--, r--)
+ if (pprog && pattry(pprog, *p) && !--num)
+ break;
+ if (p < ta)
+ return 0;
+ } else {
+ for (r = 1 + beg, p = ta + beg; *p; r++, p++)
+ if (pprog && pattry(pprog, *p) && !--num)
+ break;
+ if (!*p)
+ return 0;
+ }
+ }
+ if (a2)
+ r++;
+ for (i = 0; (t = findword(&d, sep)) && *t; i++)
+ if (!--r) {
+ r = (zlong)(t - s + (a2 ? -1 : 1));
+ if (!a2 && *tt != ',')
+ *w = r + strlen(ta[i]) - 1;
+ return r;
+ }
+ return a2 ? -1 : 0;
+ } else {
+ /* Searching characters */
+ int slen;
+ d = getstrvalue(v);
+ if (!d || !*d)
+ return 0;
+ /*
+ * beg and len are character counts, not raw offsets.
+ * Remember we need to return a raw offset.
+ */
+ len = MB_METASTRLEN(d);
+ slen = strlen(d);
+ if (beg < 0)
+ beg += len;
+ MB_METACHARINIT();
+ if (beg >= 0 && beg < len) {
+ char *de = d + slen;
+
+ if (a2) {
+ /*
+ * Second argument: we don't need to
+ * handle prevcharlen or nextcharlen, but
+ * we do need to handle characters appropriately.
+ */
+ if (down) {
+ int nmatches = 0;
+ char *lastpos = NULL;
+
+ if (!hasbeg)
+ beg = len;
+
+ /*
+ * See below: we have to move forward,
+ * but need to count from the end.
+ */
+ for (t = d, r = 0; r <= beg; r++) {
+ sav = *t;
+ *t = '\0';
+ if (pprog && pattry(pprog, d)) {
+ nmatches++;
+ lastpos = t;
+ }
+ *t = sav;
+ if (t == de)
+ break;
+ t += MB_METACHARLEN(t);
+ }
+
+ if (nmatches >= num) {
+ if (num > 1) {
+ nmatches -= num;
+ MB_METACHARINIT();
+ for (t = d, r = 0; ; r++) {
+ sav = *t;
+ *t = '\0';
+ if (pprog && pattry(pprog, d) &&
+ nmatches-- == 0) {
+ lastpos = t;
+ *t = sav;
+ break;
+ }
+ *t = sav;
+ t += MB_METACHARLEN(t);
+ }
+ }
+ /* else lastpos is already OK */
+
+ return lastpos - d;
+ }
+ } else {
+ /*
+ * This handling of the b flag
+ * gives odd results, but this is the
+ * way it's always worked.
+ */
+ for (t = d; beg && t <= de; beg--)
+ t += MB_METACHARLEN(t);
+ for (;;) {
+ sav = *t;
+ *t = '\0';
+ if (pprog && pattry(pprog, d) && !--num) {
+ *t = sav;
+ /*
+ * This time, don't increment
+ * pointer, since it's already
+ * after everything we matched.
+ */
+ return t - d;
+ }
+ *t = sav;
+ if (t == de)
+ break;
+ t += MB_METACHARLEN(t);
+ }
+ }
+ } else {
+ /*
+ * First argument: this is the only case
+ * where we need prevcharlen and nextcharlen.
+ */
+ int lastcharlen;
+
+ if (down) {
+ int nmatches = 0;
+ char *lastpos = NULL;
+
+ if (!hasbeg)
+ beg = len;
+
+ /*
+ * We can only move forward through
+ * multibyte strings, so record the
+ * matches.
+ * Unfortunately the count num works
+ * from the end, so it's easy to get the
+ * last one but we need to repeat if
+ * we want another one.
+ */
+ for (t = d, r = 0; r <= beg; r++) {
+ if (pprog && pattry(pprog, t)) {
+ nmatches++;
+ lastpos = t;
+ }
+ if (t == de)
+ break;
+ t += MB_METACHARLEN(t);
+ }
+
+ if (nmatches >= num) {
+ if (num > 1) {
+ /*
+ * Need to start again and repeat
+ * to get the right match.
+ */
+ nmatches -= num;
+ MB_METACHARINIT();
+ for (t = d, r = 0; ; r++) {
+ if (pprog && pattry(pprog, t) &&
+ nmatches-- == 0) {
+ lastpos = t;
+ break;
+ }
+ t += MB_METACHARLEN(t);
+ }
+ }
+ /* else lastpos is already OK */
+
+ /* return pointer after matched char */
+ lastpos +=
+ (lastcharlen = MB_METACHARLEN(lastpos));
+ if (prevcharlen)
+ *prevcharlen = lastcharlen;
+ if (nextcharlen)
+ *nextcharlen = MB_METACHARLEN(lastpos);
+ return lastpos - d;
+ }
+
+ for (r = beg + 1, t = d + beg; t >= d; r--, t--) {
+ if (pprog && pattry(pprog, t) &&
+ !--num)
+ return r;
+ }
+ } else {
+ for (t = d; beg && t <= de; beg--)
+ t += MB_METACHARLEN(t);
+ for (;;) {
+ if (pprog && pattry(pprog, t) && !--num) {
+ /* return pointer after matched char */
+ t += (lastcharlen = MB_METACHARLEN(t));
+ if (prevcharlen)
+ *prevcharlen = lastcharlen;
+ if (nextcharlen)
+ *nextcharlen = MB_METACHARLEN(t);
+ return t - d;
+ }
+ if (t == de)
+ break;
+ t += MB_METACHARLEN(t);
+ }
+ }
+ }
+ }
+ return down ? 0 : slen + 1;
+ }
+ }
+ return r;
+}
+
+/*
+ * Parse a subscript.
+ *
+ * pptr: In/Out parameter. On entry, *ptr points to a "[foo]" string. On exit
+ * it will point one past the closing bracket.
+ *
+ * v: In/Out parameter. Its .start and .end members (at least) will be updated
+ * with the parsed indices.
+ *
+ * flags: can be either SCANPM_DQUOTED or zero. Other bits are not used.
+ */
+
+/**/
+int
+getindex(char **pptr, Value v, int flags)
+{
+ int start, end, inv = 0;
+ char *s = *pptr, *tbrack;
+
+ *s++ = '[';
+ /* Error handled after untokenizing */
+ s = parse_subscript(s, flags & SCANPM_DQUOTED, ']');
+ /* Now we untokenize everything except inull() markers so we can check *
+ * for the '*' and '@' special subscripts. The inull()s are removed *
+ * in getarg() after we know whether we're doing reverse indexing. */
+ for (tbrack = *pptr + 1; *tbrack && tbrack != s; tbrack++) {
+ if (inull(*tbrack) && !*++tbrack)
+ break;
+ if (itok(*tbrack)) /* Need to check for Nularg here? */
+ *tbrack = ztokens[*tbrack - Pound];
+ }
+ /* If we reached the end of the string (s == NULL) we have an error */
+ if (*tbrack)
+ *tbrack = Outbrack;
+ else {
+ zerr("invalid subscript");
+ *pptr = tbrack;
+ return 1;
+ }
+ s = *pptr + 1;
+ if ((s[0] == '*' || s[0] == '@') && s + 1 == tbrack) {
+ if ((v->isarr || IS_UNSET_VALUE(v)) && s[0] == '@')
+ v->isarr |= SCANPM_ISVAR_AT;
+ v->start = 0;
+ v->end = -1;
+ s += 2;
+ } else {
+ zlong we = 0, dummy;
+ int startprevlen, startnextlen;
+
+ start = getarg(&s, &inv, v, 0, &we, &startprevlen, &startnextlen,
+ flags);
+
+ if (inv) {
+ if (!v->isarr && start != 0) {
+ char *t, *p;
+ t = getstrvalue(v);
+ /*
+ * Note for the confused (= pws): this is an inverse
+ * offset so at this stage we need to convert from
+ * the immediate offset into the value that we have
+ * into a logical character position.
+ */
+ if (start > 0) {
+ int nstart = 0;
+ char *target = t + start - startprevlen;
+
+ p = t;
+ MB_METACHARINIT();
+ while (*p) {
+ /*
+ * move up characters, counting how many we
+ * found
+ */
+ p += MB_METACHARLEN(p);
+ if (p < target)
+ nstart++;
+ else {
+ if (p == target)
+ nstart++;
+ else
+ p = target; /* pretend we hit exactly */
+ break;
+ }
+ }
+ /* if start was too big, keep the difference */
+ start = nstart + (target - p) + 1;
+ } else {
+ zlong startoff = start + strlen(t);
+#ifdef DEBUG
+ dputs("BUG: can't have negative inverse offsets???");
+#endif
+ if (startoff < 0) {
+ /* invalid: keep index but don't dereference */
+ start = startoff;
+ } else {
+ /* find start in full characters */
+ MB_METACHARINIT();
+ for (p = t; p < t + startoff;)
+ p += MB_METACHARLEN(p);
+ start = - MB_METASTRLEN(p);
+ }
+ }
+ }
+ if (start > 0 && (isset(KSHARRAYS) || (v->pm->node.flags & PM_HASHED)))
+ start--;
+ if (v->isarr != SCANPM_WANTINDEX) {
+ v->flags |= VALFLAG_INV;
+ v->isarr = 0;
+ v->start = start;
+ v->end = start + 1;
+ }
+ if (*s == ',') {
+ zerr("invalid subscript");
+ *tbrack = ']';
+ *pptr = tbrack+1;
+ return 1;
+ }
+ if (s == tbrack)
+ s++;
+ } else {
+ int com;
+
+ if ((com = (*s == ','))) {
+ s++;
+ end = getarg(&s, &inv, v, 1, &dummy, NULL, NULL, flags);
+ } else {
+ end = we ? we : start;
+ }
+ if (start != end)
+ com = 1;
+ /*
+ * Somehow the logic sometimes forces us to use the previous
+ * or next character to what we would expect, which is
+ * why we had to calculate them in getarg().
+ */
+ if (start > 0)
+ start -= startprevlen;
+ else if (start == 0 && end == 0)
+ {
+ /*
+ * Strictly, this range is entirely off the
+ * start of the available index range.
+ * This can't happen with KSH_ARRAYS; we already
+ * altered the start index in getarg().
+ * Are we being strict?
+ */
+ if (isset(KSHZEROSUBSCRIPT)) {
+ /*
+ * We're not.
+ * Treat this as accessing the first element of the
+ * array.
+ */
+ end = startnextlen;
+ } else {
+ /*
+ * We are. Flag that this range is invalid
+ * for setting elements. Set the indexes
+ * to a range that returns empty for other accesses.
+ */
+ v->flags |= VALFLAG_EMPTY;
+ start = -1;
+ com = 1;
+ }
+ }
+ if (s == tbrack) {
+ s++;
+ if (v->isarr && !com &&
+ (!(v->isarr & SCANPM_MATCHMANY) ||
+ !(v->isarr & (SCANPM_MATCHKEY | SCANPM_MATCHVAL |
+ SCANPM_KEYMATCH))))
+ v->isarr = 0;
+ v->start = start;
+ v->end = end;
+ } else
+ s = *pptr;
+ }
+ }
+ *tbrack = ']';
+ *pptr = s;
+ return 0;
+}
+
+
+/**/
+mod_export Value
+getvalue(Value v, char **pptr, int bracks)
+{
+ return fetchvalue(v, pptr, bracks, 0);
+}
+
+/**/
+mod_export Value
+fetchvalue(Value v, char **pptr, int bracks, int flags)
+{
+ char *s, *t, *ie;
+ char sav, c;
+ int ppar = 0;
+
+ s = t = *pptr;
+
+ if (idigit(c = *s)) {
+ if (bracks >= 0)
+ ppar = zstrtol(s, &s, 10);
+ else
+ ppar = *s++ - '0';
+ }
+ else if ((ie = itype_end(s, IIDENT, 0)) != s)
+ s = ie;
+ else if (c == Quest)
+ *s++ = '?';
+ else if (c == Pound)
+ *s++ = '#';
+ else if (c == String)
+ *s++ = '$';
+ else if (c == Qstring)
+ *s++ = '$';
+ else if (c == Star)
+ *s++ = '*';
+ else if (IS_DASH(c))
+ *s++ = '-';
+ else if (c == '#' || c == '?' || c == '$' ||
+ c == '!' || c == '@' || c == '*')
+ s++;
+ else
+ return NULL;
+
+ if ((sav = *s))
+ *s = '\0';
+ if (ppar) {
+ if (v)
+ memset(v, 0, sizeof(*v));
+ else
+ v = (Value) hcalloc(sizeof *v);
+ v->pm = argvparam;
+ v->flags = 0;
+ v->start = ppar - 1;
+ v->end = ppar;
+ if (sav)
+ *s = sav;
+ } else {
+ Param pm;
+ int isvarat;
+
+ isvarat = (t[0] == '@' && !t[1]);
+ pm = (Param) paramtab->getnode(paramtab, *t == '0' ? "0" : t);
+ if (sav)
+ *s = sav;
+ *pptr = s;
+ if (!pm || (pm->node.flags & PM_UNSET))
+ return NULL;
+ if (v)
+ memset(v, 0, sizeof(*v));
+ else
+ v = (Value) hcalloc(sizeof *v);
+ if (PM_TYPE(pm->node.flags) & (PM_ARRAY|PM_HASHED)) {
+ /* Overload v->isarr as the flag bits for hashed arrays. */
+ v->isarr = flags | (isvarat ? SCANPM_ISVAR_AT : 0);
+ /* If no flags were passed, we need something to represent *
+ * `true' yet differ from an explicit WANTVALS. Use a *
+ * special flag for this case. */
+ if (!v->isarr)
+ v->isarr = SCANPM_ARRONLY;
+ }
+ v->pm = pm;
+ v->flags = 0;
+ v->start = 0;
+ v->end = -1;
+ if (bracks > 0 && (*s == '[' || *s == Inbrack)) {
+ if (getindex(&s, v, flags)) {
+ *pptr = s;
+ return v;
+ }
+ } else if (!(flags & SCANPM_ASSIGNING) && v->isarr &&
+ itype_end(t, IIDENT, 1) != t && isset(KSHARRAYS))
+ v->end = 1, v->isarr = 0;
+ }
+ if (!bracks && *s)
+ return NULL;
+ *pptr = s;
+#if 0
+ /*
+ * Check for large subscripts that might be erroneous.
+ * This code is too gross in several ways:
+ * - the limit is completely arbitrary
+ * - the test vetoes operations on existing arrays
+ * - it's not at all clear a general test on large arrays of
+ * this kind is any use.
+ *
+ * Until someone comes up with workable replacement code it's
+ * therefore commented out.
+ */
+ if (v->start > MAX_ARRLEN) {
+ zerr("subscript too %s: %d", "big", v->start + !isset(KSHARRAYS));
+ return NULL;
+ }
+ if (v->start < -MAX_ARRLEN) {
+ zerr("subscript too %s: %d", "small", v->start);
+ return NULL;
+ }
+ if (v->end > MAX_ARRLEN+1) {
+ zerr("subscript too %s: %d", "big", v->end - !!isset(KSHARRAYS));
+ return NULL;
+ }
+ if (v->end < -MAX_ARRLEN) {
+ zerr("subscript too %s: %d", "small", v->end);
+ return NULL;
+ }
+#endif
+ return v;
+}
+
+/**/
+mod_export char *
+getstrvalue(Value v)
+{
+ char *s, **ss;
+ char buf[BDIGBUFSIZE];
+ int len;
+
+ if (!v)
+ return hcalloc(1);
+
+ if ((v->flags & VALFLAG_INV) && !(v->pm->node.flags & PM_HASHED)) {
+ sprintf(buf, "%d", v->start);
+ s = dupstring(buf);
+ return s;
+ }
+
+ switch(PM_TYPE(v->pm->node.flags)) {
+ case PM_HASHED:
+ /* (!v->isarr) should be impossible unless emulating ksh */
+ if (!v->isarr && EMULATION(EMULATE_KSH)) {
+ s = dupstring("[0]");
+ if (getindex(&s, v, 0) == 0)
+ s = getstrvalue(v);
+ return s;
+ } /* else fall through */
+ case PM_ARRAY:
+ ss = getvaluearr(v);
+ if (v->isarr)
+ s = sepjoin(ss, NULL, 1);
+ else {
+ if (v->start < 0)
+ v->start += arrlen(ss);
+ s = (arrlen_le(ss, v->start) || v->start < 0) ?
+ (char *) hcalloc(1) : ss[v->start];
+ }
+ return s;
+ case PM_INTEGER:
+ convbase(buf, v->pm->gsu.i->getfn(v->pm), v->pm->base);
+ s = dupstring(buf);
+ break;
+ case PM_EFLOAT:
+ case PM_FFLOAT:
+ s = convfloat(v->pm->gsu.f->getfn(v->pm),
+ v->pm->base, v->pm->node.flags, NULL);
+ break;
+ case PM_SCALAR:
+ s = v->pm->gsu.s->getfn(v->pm);
+ break;
+ default:
+ s = "";
+ DPUTS(1, "BUG: param node without valid type");
+ break;
+ }
+
+ if (v->flags & VALFLAG_SUBST) {
+ if (v->pm->node.flags & (PM_LEFT|PM_RIGHT_B|PM_RIGHT_Z)) {
+ unsigned int fwidth = v->pm->width ? v->pm->width : MB_METASTRLEN(s);
+ switch (v->pm->node.flags & (PM_LEFT | PM_RIGHT_B | PM_RIGHT_Z)) {
+ char *t, *tend;
+ unsigned int t0;
+
+ case PM_LEFT:
+ case PM_LEFT | PM_RIGHT_Z:
+ t = s;
+ if (v->pm->node.flags & PM_RIGHT_Z)
+ while (*t == '0')
+ t++;
+ else
+ while (iblank(*t))
+ t++;
+ MB_METACHARINIT();
+ for (tend = t, t0 = 0; t0 < fwidth && *tend; t0++)
+ tend += MB_METACHARLEN(tend);
+ /*
+ * t0 is the number of characters from t used,
+ * hence (fwidth - t0) is the number of padding
+ * characters. fwidth is a misnomer: we use
+ * character counts, not character widths.
+ *
+ * (tend - t) is the number of bytes we need
+ * to get fwidth characters or the entire string;
+ * the characters may be multiple bytes.
+ */
+ fwidth -= t0; /* padding chars remaining */
+ t0 = tend - t; /* bytes to copy from string */
+ s = (char *) hcalloc(t0 + fwidth + 1);
+ memcpy(s, t, t0);
+ if (fwidth)
+ memset(s + t0, ' ', fwidth);
+ s[t0 + fwidth] = '\0';
+ break;
+ case PM_RIGHT_B:
+ case PM_RIGHT_Z:
+ case PM_RIGHT_Z | PM_RIGHT_B:
+ {
+ int zero = 1;
+ /* Calculate length in possibly multibyte chars */
+ unsigned int charlen = MB_METASTRLEN(s);
+
+ if (charlen < fwidth) {
+ char *valprefend = s;
+ int preflen;
+ if (v->pm->node.flags & PM_RIGHT_Z) {
+ /*
+ * This is a documented feature: when deciding
+ * whether to pad with zeroes, ignore
+ * leading blanks already in the value;
+ * only look for numbers after that.
+ * Not sure how useful this really is.
+ * It's certainly confusing to code around.
+ */
+ for (t = s; iblank(*t); t++)
+ ;
+ /*
+ * Allow padding after initial minus
+ * for numeric variables.
+ */
+ if ((v->pm->node.flags &
+ (PM_INTEGER|PM_EFLOAT|PM_FFLOAT)) &&
+ *t == '-')
+ t++;
+ /*
+ * Allow padding after initial 0x or
+ * base# for integer variables.
+ */
+ if (v->pm->node.flags & PM_INTEGER) {
+ if (isset(CBASES) &&
+ t[0] == '0' && t[1] == 'x')
+ t += 2;
+ else if ((valprefend = strchr(t, '#')))
+ t = valprefend + 1;
+ }
+ valprefend = t;
+ if (!*t)
+ zero = 0;
+ else if (v->pm->node.flags &
+ (PM_INTEGER|PM_EFLOAT|PM_FFLOAT)) {
+ /* zero always OK */
+ } else if (!idigit(*t))
+ zero = 0;
+ }
+ /* number of characters needed for padding */
+ fwidth -= charlen;
+ /* bytes from original string */
+ t0 = strlen(s);
+ t = (char *) hcalloc(fwidth + t0 + 1);
+ /* prefix guaranteed to be single byte chars */
+ preflen = valprefend - s;
+ memset(t + preflen,
+ (((v->pm->node.flags & PM_RIGHT_B)
+ || !zero) ? ' ' : '0'), fwidth);
+ /*
+ * Copy - or 0x or base# before any padding
+ * zeroes.
+ */
+ if (preflen)
+ memcpy(t, s, preflen);
+ memcpy(t + preflen + fwidth,
+ valprefend, t0 - preflen);
+ t[fwidth + t0] = '\0';
+ s = t;
+ } else {
+ /* Need to skip (charlen - fwidth) chars */
+ for (t0 = charlen - fwidth; t0; t0--)
+ s += MB_METACHARLEN(s);
+ }
+ }
+ break;
+ }
+ }
+ switch (v->pm->node.flags & (PM_LOWER | PM_UPPER)) {
+ case PM_LOWER:
+ s = casemodify(s, CASMOD_LOWER);
+ break;
+ case PM_UPPER:
+ s = casemodify(s, CASMOD_UPPER);
+ break;
+ }
+ }
+ if (v->start == 0 && v->end == -1)
+ return s;
+
+ len = strlen(s);
+ if (v->start < 0) {
+ v->start += len;
+ if (v->start < 0)
+ v->start = 0;
+ }
+ if (v->end < 0) {
+ v->end += len;
+ if (v->end >= 0) {
+ char *eptr = s + v->end;
+ if (*eptr)
+ v->end += MB_METACHARLEN(eptr);
+ }
+ }
+
+ s = (v->start > len) ? dupstring("") :
+ dupstring_wlen(s + v->start, len - v->start);
+
+ if (v->end <= v->start)
+ s[0] = '\0';
+ else if (v->end - v->start <= len - v->start)
+ s[v->end - v->start] = '\0';
+
+ return s;
+}
+
+static char *nular[] = {"", NULL};
+
+/**/
+mod_export char **
+getarrvalue(Value v)
+{
+ char **s;
+
+ if (!v)
+ return arrdup(nular);
+ else if (IS_UNSET_VALUE(v))
+ return arrdup(&nular[1]);
+ if (v->flags & VALFLAG_INV) {
+ char buf[DIGBUFSIZE];
+
+ s = arrdup(nular);
+ sprintf(buf, "%d", v->start);
+ s[0] = dupstring(buf);
+ return s;
+ }
+ s = getvaluearr(v);
+ if (v->start == 0 && v->end == -1)
+ return s;
+ if (v->start < 0)
+ v->start += arrlen(s);
+ if (v->end < 0)
+ v->end += arrlen(s) + 1;
+
+ /* Null if 1) array too short, 2) index still negative */
+ if (v->end <= v->start) {
+ s = arrdup_max(nular, 0);
+ }
+ else if (v->start < 0) {
+ s = arrdup_max(nular, 1);
+ }
+ else if (arrlen_le(s, v->start)) {
+ /* Handle $ary[i,i] consistently for any $i > $#ary
+ * and $ary[i,j] consistently for any $j > $i > $#ary
+ */
+ s = arrdup_max(nular, v->end - (v->start + 1));
+ }
+ else {
+ /* Copy to a point before the end of the source array:
+ * arrdup_max will copy at most v->end - v->start elements,
+ * starting from v->start element. Original code said:
+ * s[v->end - v->start] = NULL
+ * which means that there are exactly the same number of
+ * elements as the value of the above *0-based* index.
+ */
+ s = arrdup_max(s + v->start, v->end - v->start);
+ }
+
+ return s;
+}
+
+/**/
+mod_export zlong
+getintvalue(Value v)
+{
+ if (!v)
+ return 0;
+ if (v->flags & VALFLAG_INV)
+ return v->start;
+ if (v->isarr) {
+ char **arr = getarrvalue(v);
+ if (arr) {
+ char *scal = sepjoin(arr, NULL, 1);
+ return mathevali(scal);
+ } else
+ return 0;
+ }
+ if (PM_TYPE(v->pm->node.flags) == PM_INTEGER)
+ return v->pm->gsu.i->getfn(v->pm);
+ if (v->pm->node.flags & (PM_EFLOAT|PM_FFLOAT))
+ return (zlong)v->pm->gsu.f->getfn(v->pm);
+ return mathevali(getstrvalue(v));
+}
+
+/**/
+mnumber
+getnumvalue(Value v)
+{
+ mnumber mn;
+ mn.type = MN_INTEGER;
+
+
+ if (!v) {
+ mn.u.l = 0;
+ } else if (v->flags & VALFLAG_INV) {
+ mn.u.l = v->start;
+ } else if (v->isarr) {
+ char **arr = getarrvalue(v);
+ if (arr) {
+ char *scal = sepjoin(arr, NULL, 1);
+ return matheval(scal);
+ } else
+ mn.u.l = 0;
+ } else if (PM_TYPE(v->pm->node.flags) == PM_INTEGER) {
+ mn.u.l = v->pm->gsu.i->getfn(v->pm);
+ } else if (v->pm->node.flags & (PM_EFLOAT|PM_FFLOAT)) {
+ mn.type = MN_FLOAT;
+ mn.u.d = v->pm->gsu.f->getfn(v->pm);
+ } else
+ return matheval(getstrvalue(v));
+ return mn;
+}
+
+/**/
+void
+export_param(Param pm)
+{
+ char buf[BDIGBUFSIZE], *val;
+
+ if (PM_TYPE(pm->node.flags) & (PM_ARRAY|PM_HASHED)) {
+#if 0 /* Requires changes elsewhere in params.c and builtin.c */
+ if (EMULATION(EMULATE_KSH) /* isset(KSHARRAYS) */) {
+ struct value v;
+ v.isarr = 1;
+ v.flags = 0;
+ v.start = 0;
+ v.end = -1;
+ val = getstrvalue(&v);
+ } else
+#endif
+ return;
+ } else if (PM_TYPE(pm->node.flags) == PM_INTEGER)
+ convbase(val = buf, pm->gsu.i->getfn(pm), pm->base);
+ else if (pm->node.flags & (PM_EFLOAT|PM_FFLOAT))
+ val = convfloat(pm->gsu.f->getfn(pm), pm->base,
+ pm->node.flags, NULL);
+ else
+ val = pm->gsu.s->getfn(pm);
+
+ addenv(pm, val);
+}
+
+/**/
+mod_export void
+setstrvalue(Value v, char *val)
+{
+ assignstrvalue(v, val, 0);
+}
+
+/**/
+mod_export void
+assignstrvalue(Value v, char *val, int flags)
+{
+ if (unset(EXECOPT))
+ return;
+ if (v->pm->node.flags & PM_READONLY) {
+ zerr("read-only variable: %s", v->pm->node.nam);
+ zsfree(val);
+ return;
+ }
+ if ((v->pm->node.flags & PM_RESTRICTED) && isset(RESTRICTED)) {
+ zerr("%s: restricted", v->pm->node.nam);
+ zsfree(val);
+ return;
+ }
+ if ((v->pm->node.flags & PM_HASHED) &&
+ (v->isarr & (SCANPM_MATCHMANY|SCANPM_ARRONLY))) {
+ zerr("%s: attempt to set slice of associative array", v->pm->node.nam);
+ zsfree(val);
+ return;
+ }
+ if (v->flags & VALFLAG_EMPTY) {
+ zerr("%s: assignment to invalid subscript range", v->pm->node.nam);
+ zsfree(val);
+ return;
+ }
+ v->pm->node.flags &= ~PM_UNSET;
+ switch (PM_TYPE(v->pm->node.flags)) {
+ case PM_SCALAR:
+ if (v->start == 0 && v->end == -1) {
+ v->pm->gsu.s->setfn(v->pm, val);
+ if ((v->pm->node.flags & (PM_LEFT | PM_RIGHT_B | PM_RIGHT_Z)) &&
+ !v->pm->width)
+ v->pm->width = strlen(val);
+ } else {
+ char *z, *x;
+ int zlen, vlen, newsize;
+
+ z = v->pm->gsu.s->getfn(v->pm);
+ zlen = strlen(z);
+
+ if ((v->flags & VALFLAG_INV) && unset(KSHARRAYS))
+ v->start--, v->end--;
+ if (v->start < 0) {
+ v->start += zlen;
+ if (v->start < 0)
+ v->start = 0;
+ }
+ if (v->start > zlen)
+ v->start = zlen;
+ if (v->end < 0) {
+ v->end += zlen;
+ if (v->end < 0) {
+ v->end = 0;
+ } else if (v->end >= zlen) {
+ v->end = zlen;
+ } else {
+#ifdef MULTIBYTE_SUPPORT
+ if (isset(MULTIBYTE)) {
+ v->end += MB_METACHARLEN(z + v->end);
+ } else {
+ v->end++;
+ }
+#else
+ v->end++;
+#endif
+ }
+ }
+ else if (v->end > zlen)
+ v->end = zlen;
+
+ vlen = strlen(val);
+ /* Characters preceding start index +
+ characters of what is assigned +
+ characters following end index */
+ newsize = v->start + vlen + (zlen - v->end);
+
+ /* Does new size differ? */
+ if (newsize != zlen || v->pm->gsu.s->setfn != strsetfn) {
+ x = (char *) zalloc(newsize + 1);
+ strncpy(x, z, v->start);
+ strcpy(x + v->start, val);
+ strcat(x + v->start, z + v->end);
+ v->pm->gsu.s->setfn(v->pm, x);
+ } else {
+ Param pm = v->pm;
+ /* Size doesn't change, can limit actions to only
+ * overwriting bytes in already allocated string */
+ strncpy(z + v->start, val, vlen);
+ /* Implement remainder of strsetfn */
+ if (!(pm->node.flags & PM_HASHELEM) &&
+ ((pm->node.flags & PM_NAMEDDIR) ||
+ isset(AUTONAMEDIRS))) {
+ pm->node.flags |= PM_NAMEDDIR;
+ adduserdir(pm->node.nam, z, 0, 0);
+ }
+ }
+ zsfree(val);
+ }
+ break;
+ case PM_INTEGER:
+ if (val) {
+ zlong ival;
+ if (flags & ASSPM_ENV_IMPORT) {
+ char *ptr;
+ ival = zstrtol_underscore(val, &ptr, 0, 1);
+ } else
+ ival = mathevali(val);
+ v->pm->gsu.i->setfn(v->pm, ival);
+ if ((v->pm->node.flags & (PM_LEFT | PM_RIGHT_B | PM_RIGHT_Z)) &&
+ !v->pm->width)
+ v->pm->width = strlen(val);
+ zsfree(val);
+ }
+ if (!v->pm->base && lastbase != -1)
+ v->pm->base = lastbase;
+ break;
+ case PM_EFLOAT:
+ case PM_FFLOAT:
+ if (val) {
+ mnumber mn;
+ if (flags & ASSPM_ENV_IMPORT) {
+ char *ptr;
+ mn.type = MN_FLOAT;
+ mn.u.d = strtod(val, &ptr);
+ } else
+ mn = matheval(val);
+ v->pm->gsu.f->setfn(v->pm, (mn.type & MN_FLOAT) ? mn.u.d :
+ (double)mn.u.l);
+ if ((v->pm->node.flags & (PM_LEFT | PM_RIGHT_B | PM_RIGHT_Z)) &&
+ !v->pm->width)
+ v->pm->width = strlen(val);
+ zsfree(val);
+ }
+ break;
+ case PM_ARRAY:
+ {
+ char **ss = (char **) zalloc(2 * sizeof(char *));
+
+ ss[0] = val;
+ ss[1] = NULL;
+ setarrvalue(v, ss);
+ }
+ break;
+ case PM_HASHED:
+ {
+ if (foundparam == NULL)
+ {
+ zerr("%s: attempt to set associative array to scalar",
+ v->pm->node.nam);
+ zsfree(val);
+ return;
+ }
+ else
+ foundparam->gsu.s->setfn(foundparam, val);
+ }
+ break;
+ }
+ if ((!v->pm->env && !(v->pm->node.flags & PM_EXPORTED) &&
+ !(isset(ALLEXPORT) && !(v->pm->node.flags & PM_HASHELEM))) ||
+ (v->pm->node.flags & PM_ARRAY) || v->pm->ename)
+ return;
+ export_param(v->pm);
+}
+
+/**/
+void
+setnumvalue(Value v, mnumber val)
+{
+ char buf[BDIGBUFSIZE], *p;
+
+ if (unset(EXECOPT))
+ return;
+ if (v->pm->node.flags & PM_READONLY) {
+ zerr("read-only variable: %s", v->pm->node.nam);
+ return;
+ }
+ if ((v->pm->node.flags & PM_RESTRICTED) && isset(RESTRICTED)) {
+ zerr("%s: restricted", v->pm->node.nam);
+ return;
+ }
+ switch (PM_TYPE(v->pm->node.flags)) {
+ case PM_SCALAR:
+ case PM_ARRAY:
+ if ((val.type & MN_INTEGER) || outputradix) {
+ if (!(val.type & MN_INTEGER))
+ val.u.l = (zlong) val.u.d;
+ p = convbase_underscore(buf, val.u.l, outputradix,
+ outputunderscore);
+ } else
+ p = convfloat_underscore(val.u.d, outputunderscore);
+ setstrvalue(v, ztrdup(p));
+ break;
+ case PM_INTEGER:
+ v->pm->gsu.i->setfn(v->pm, (val.type & MN_INTEGER) ? val.u.l :
+ (zlong) val.u.d);
+ setstrvalue(v, NULL);
+ break;
+ case PM_EFLOAT:
+ case PM_FFLOAT:
+ v->pm->gsu.f->setfn(v->pm, (val.type & MN_INTEGER) ?
+ (double)val.u.l : val.u.d);
+ setstrvalue(v, NULL);
+ break;
+ }
+}
+
+/**/
+mod_export void
+setarrvalue(Value v, char **val)
+{
+ if (unset(EXECOPT))
+ return;
+ if (v->pm->node.flags & PM_READONLY) {
+ zerr("read-only variable: %s", v->pm->node.nam);
+ freearray(val);
+ return;
+ }
+ if ((v->pm->node.flags & PM_RESTRICTED) && isset(RESTRICTED)) {
+ zerr("%s: restricted", v->pm->node.nam);
+ freearray(val);
+ return;
+ }
+ if (!(PM_TYPE(v->pm->node.flags) & (PM_ARRAY|PM_HASHED))) {
+ freearray(val);
+ zerr("%s: attempt to assign array value to non-array",
+ v->pm->node.nam);
+ return;
+ }
+ if (v->flags & VALFLAG_EMPTY) {
+ zerr("%s: assignment to invalid subscript range", v->pm->node.nam);
+ freearray(val);
+ return;
+ }
+
+ if (v->start == 0 && v->end == -1) {
+ if (PM_TYPE(v->pm->node.flags) == PM_HASHED)
+ arrhashsetfn(v->pm, val, 0);
+ else
+ v->pm->gsu.a->setfn(v->pm, val);
+ } else if (v->start == -1 && v->end == 0 &&
+ PM_TYPE(v->pm->node.flags) == PM_HASHED) {
+ arrhashsetfn(v->pm, val, ASSPM_AUGMENT);
+ } else if ((PM_TYPE(v->pm->node.flags) == PM_HASHED)) {
+ freearray(val);
+ zerr("%s: attempt to set slice of associative array",
+ v->pm->node.nam);
+ return;
+ } else {
+ char **const old = v->pm->gsu.a->getfn(v->pm);
+ char **new;
+ char **p, **q, **r; /* index variables */
+ const int pre_assignment_length = arrlen(old);
+ int post_assignment_length;
+ int i;
+
+ q = old;
+
+ if ((v->flags & VALFLAG_INV) && unset(KSHARRAYS)) {
+ if (v->start > 0)
+ v->start--;
+ v->end--;
+ }
+ if (v->start < 0) {
+ v->start += pre_assignment_length;
+ if (v->start < 0)
+ v->start = 0;
+ }
+ if (v->end < 0) {
+ v->end += pre_assignment_length + 1;
+ if (v->end < 0)
+ v->end = 0;
+ }
+ if (v->end < v->start)
+ v->end = v->start;
+
+ post_assignment_length = v->start + arrlen(val);
+ if (v->end < pre_assignment_length) {
+ /*
+ * Allocate room for array elements between the end of the slice `v'
+ * and the original array's end.
+ */
+ post_assignment_length += pre_assignment_length - v->end;
+ }
+
+ if (pre_assignment_length == post_assignment_length
+ && v->pm->gsu.a->setfn == arrsetfn
+ /* ... and isn't something that arrsetfn() treats specially */
+ && 0 == (v->pm->node.flags & (PM_SPECIAL|PM_UNIQUE))
+ && NULL == v->pm->ename)
+ {
+ /* v->start is 0-based */
+ p = old + v->start;
+ for (r = val; *r;) {
+ /* Free previous string */
+ zsfree(*p);
+ /* Give away ownership of the string */
+ *p++ = *r++;
+ }
+ } else {
+ /* arr+=( ... )
+ * arr[${#arr}+x,...]=( ... ) */
+ if (post_assignment_length > pre_assignment_length &&
+ pre_assignment_length <= v->start &&
+ pre_assignment_length > 0 &&
+ v->pm->gsu.a->setfn == arrsetfn)
+ {
+ p = new = (char **) zrealloc(old, sizeof(char *)
+ * (post_assignment_length + 1));
+
+ p += pre_assignment_length; /* after old elements */
+
+ /* Consider 1 < 0, case for a=( 1 ); a[1,..] =
+ * 1 < 1, case for a=( 1 ); a[2,..] = */
+ if (pre_assignment_length < v->start) {
+ for (i = pre_assignment_length; i < v->start; i++) {
+ *p++ = ztrdup("");
+ }
+ }
+
+ for (r = val; *r;) {
+ /* Give away ownership of the string */
+ *p++ = *r++;
+ }
+
+ /* v->end doesn't matter:
+ * a=( 1 2 ); a[4,100]=( a b ); echo "${(q@)a}"
+ * 1 2 '' a b */
+ *p = NULL;
+
+ v->pm->u.arr = NULL;
+ v->pm->gsu.a->setfn(v->pm, new);
+ } else {
+ p = new = (char **) zalloc(sizeof(char *)
+ * (post_assignment_length + 1));
+ for (i = 0; i < v->start; i++)
+ *p++ = i < pre_assignment_length ? ztrdup(*q++) : ztrdup("");
+ for (r = val; *r;) {
+ /* Give away ownership of the string */
+ *p++ = *r++;
+ }
+ if (v->end < pre_assignment_length)
+ for (q = old + v->end; *q;)
+ *p++ = ztrdup(*q++);
+ *p = NULL;
+
+ v->pm->gsu.a->setfn(v->pm, new);
+ }
+
+ DPUTS2(p - new != post_assignment_length, "setarrvalue: wrong allocation: %d 1= %lu",
+ post_assignment_length, (unsigned long)(p - new));
+ }
+
+ /* Ownership of all strings has been
+ * given away, can plainly free */
+ free(val);
+ }
+}
+
+/* Retrieve an integer parameter */
+
+/**/
+mod_export zlong
+getiparam(char *s)
+{
+ struct value vbuf;
+ Value v;
+
+ if (!(v = getvalue(&vbuf, &s, 1)))
+ return 0;
+ return getintvalue(v);
+}
+
+/* Retrieve a numerical parameter, either integer or floating */
+
+/**/
+mnumber
+getnparam(char *s)
+{
+ struct value vbuf;
+ Value v;
+
+ if (!(v = getvalue(&vbuf, &s, 1))) {
+ mnumber mn;
+ mn.type = MN_INTEGER;
+ mn.u.l = 0;
+ return mn;
+ }
+ return getnumvalue(v);
+}
+
+/* Retrieve a scalar (string) parameter */
+
+/**/
+mod_export char *
+getsparam(char *s)
+{
+ struct value vbuf;
+ Value v;
+
+ if (!(v = getvalue(&vbuf, &s, 0)))
+ return NULL;
+ return getstrvalue(v);
+}
+
+/**/
+mod_export char *
+getsparam_u(char *s)
+{
+ if ((s = getsparam(s)))
+ return unmetafy(s, NULL);
+ return s;
+}
+
+/* Retrieve an array parameter */
+
+/**/
+mod_export char **
+getaparam(char *s)
+{
+ struct value vbuf;
+ Value v;
+
+ if (!idigit(*s) && (v = getvalue(&vbuf, &s, 0)) &&
+ PM_TYPE(v->pm->node.flags) == PM_ARRAY)
+ return v->pm->gsu.a->getfn(v->pm);
+ return NULL;
+}
+
+/* Retrieve an assoc array parameter as an array */
+
+/**/
+mod_export char **
+gethparam(char *s)
+{
+ struct value vbuf;
+ Value v;
+
+ if (!idigit(*s) && (v = getvalue(&vbuf, &s, 0)) &&
+ PM_TYPE(v->pm->node.flags) == PM_HASHED)
+ return paramvalarr(v->pm->gsu.h->getfn(v->pm), SCANPM_WANTVALS);
+ return NULL;
+}
+
+/* Retrieve the keys of an assoc array parameter as an array */
+
+/**/
+mod_export char **
+gethkparam(char *s)
+{
+ struct value vbuf;
+ Value v;
+
+ if (!idigit(*s) && (v = getvalue(&vbuf, &s, 0)) &&
+ PM_TYPE(v->pm->node.flags) == PM_HASHED)
+ return paramvalarr(v->pm->gsu.h->getfn(v->pm), SCANPM_WANTKEYS);
+ return NULL;
+}
+
+/*
+ * Function behind WARNCREATEGLOBAL and WARNNESTEDVAR option.
+ *
+ * For WARNNESTEDVAR:
+ * Called when the variable is created.
+ * Apply heuristics to see if this variable was just created
+ * globally but in a local context.
+ *
+ * For WARNNESTEDVAR:
+ * Called when the variable already exists and is set.
+ * Apply heuristics to see if this variable is setting
+ * a variable that was created in a less nested function
+ * or globally.
+ */
+
+/**/
+static void
+check_warn_pm(Param pm, const char *pmtype, int created,
+ int may_warn_about_nested_vars)
+{
+ Funcstack i;
+
+ if (!may_warn_about_nested_vars && !created)
+ return;
+
+ if (created && isset(WARNCREATEGLOBAL)) {
+ if (locallevel <= forklevel || pm->level != 0)
+ return;
+ } else if (!created && isset(WARNNESTEDVAR)) {
+ if (pm->level >= locallevel)
+ return;
+ } else
+ return;
+
+ if (pm->node.flags & PM_SPECIAL)
+ return;
+
+ for (i = funcstack; i; i = i->prev) {
+ if (i->tp == FS_FUNC) {
+ char *msg;
+ DPUTS(!i->name, "funcstack entry with no name");
+ msg = created ?
+ "%s parameter %s created globally in function %s" :
+ "%s parameter %s set in enclosing scope in function %s";
+ zwarn(msg, pmtype, pm->node.nam, i->name);
+ break;
+ }
+ }
+}
+
+/**/
+mod_export Param
+assignsparam(char *s, char *val, int flags)
+{
+ struct value vbuf;
+ Value v;
+ char *t = s;
+ char *ss, *copy, *var;
+ size_t lvar;
+ mnumber lhs, rhs;
+ int sstart, created = 0;
+
+ if (!isident(s)) {
+ zerr("not an identifier: %s", s);
+ zsfree(val);
+ errflag |= ERRFLAG_ERROR;
+ return NULL;
+ }
+ queue_signals();
+ if ((ss = strchr(s, '['))) {
+ *ss = '\0';
+ if (!(v = getvalue(&vbuf, &s, 1))) {
+ createparam(t, PM_ARRAY);
+ created = 1;
+ } else {
+ if (v->pm->node.flags & PM_READONLY) {
+ zerr("read-only variable: %s", v->pm->node.nam);
+ *ss = '[';
+ zsfree(val);
+ unqueue_signals();
+ return NULL;
+ }
+ /*
+ * Parameter defined here is a temporary bogus one.
+ * Don't warn about anything.
+ */
+ flags &= ~ASSPM_WARN;
+ }
+ *ss = '[';
+ v = NULL;
+ } else {
+ if (!(v = getvalue(&vbuf, &s, 1))) {
+ createparam(t, PM_SCALAR);
+ created = 1;
+ } else if ((((v->pm->node.flags & PM_ARRAY) && !(flags & ASSPM_AUGMENT)) ||
+ (v->pm->node.flags & PM_HASHED)) &&
+ !(v->pm->node.flags & (PM_SPECIAL|PM_TIED)) &&
+ unset(KSHARRAYS)) {
+ unsetparam(t);
+ createparam(t, PM_SCALAR);
+ /* not regarded as a new creation */
+ v = NULL;
+ }
+ }
+ if (!v && !(v = getvalue(&vbuf, &t, 1))) {
+ unqueue_signals();
+ zsfree(val);
+ /* errflag |= ERRFLAG_ERROR; */
+ return NULL;
+ }
+ if (flags & ASSPM_WARN)
+ check_warn_pm(v->pm, "scalar", created, 1);
+ if (flags & ASSPM_AUGMENT) {
+ if (v->start == 0 && v->end == -1) {
+ switch (PM_TYPE(v->pm->node.flags)) {
+ case PM_SCALAR:
+ v->start = INT_MAX; /* just append to scalar value */
+ break;
+ case PM_INTEGER:
+ case PM_EFLOAT:
+ case PM_FFLOAT:
+ rhs = matheval(val);
+ lhs = getnumvalue(v);
+ if (lhs.type == MN_FLOAT) {
+ if ((rhs.type) == MN_FLOAT)
+ lhs.u.d = lhs.u.d + rhs.u.d;
+ else
+ lhs.u.d = lhs.u.d + (double)rhs.u.l;
+ } else {
+ if ((rhs.type) == MN_INTEGER)
+ lhs.u.l = lhs.u.l + rhs.u.l;
+ else
+ lhs.u.l = lhs.u.l + (zlong)rhs.u.d;
+ }
+ setnumvalue(v, lhs);
+ unqueue_signals();
+ zsfree(val);
+ return v->pm; /* avoid later setstrvalue() call */
+ case PM_ARRAY:
+ if (unset(KSHARRAYS)) {
+ v->start = arrlen(v->pm->gsu.a->getfn(v->pm));
+ v->end = v->start + 1;
+ } else {
+ /* ksh appends scalar to first element */
+ v->end = 1;
+ goto kshappend;
+ }
+ break;
+ }
+ } else {
+ switch (PM_TYPE(v->pm->node.flags)) {
+ case PM_SCALAR:
+ if (v->end > 0)
+ v->start = v->end;
+ else
+ v->start = v->end = strlen(v->pm->gsu.s->getfn(v->pm)) +
+ v->end + 1;
+ break;
+ case PM_INTEGER:
+ case PM_EFLOAT:
+ case PM_FFLOAT:
+ unqueue_signals();
+ zerr("attempt to add to slice of a numeric variable");
+ zsfree(val);
+ return NULL;
+ case PM_ARRAY:
+ kshappend:
+ /* treat slice as the end element */
+ v->start = sstart = v->end > 0 ? v->end - 1 : v->end;
+ v->isarr = 0;
+ var = getstrvalue(v);
+ v->start = sstart;
+ copy = val;
+ lvar = strlen(var);
+ val = (char *)zalloc(lvar + strlen(val) + 1);
+ strcpy(val, var);
+ strcpy(val + lvar, copy);
+ zsfree(copy);
+ break;
+ }
+ }
+ }
+
+ assignstrvalue(v, val, flags);
+ unqueue_signals();
+ return v->pm;
+}
+
+/**/
+mod_export Param
+setsparam(char *s, char *val)
+{
+ return assignsparam(s, val, ASSPM_WARN);
+}
+
+/**/
+mod_export Param
+assignaparam(char *s, char **val, int flags)
+{
+ struct value vbuf;
+ Value v;
+ char *t = s;
+ char *ss;
+ int created = 0;
+ int may_warn_about_nested_vars = 1;
+
+ if (!isident(s)) {
+ zerr("not an identifier: %s", s);
+ freearray(val);
+ errflag |= ERRFLAG_ERROR;
+ return NULL;
+ }
+ queue_signals();
+ if ((ss = strchr(s, '['))) {
+ *ss = '\0';
+ if (!(v = getvalue(&vbuf, &s, 1))) {
+ createparam(t, PM_ARRAY);
+ created = 1;
+ } else {
+ may_warn_about_nested_vars = 0;
+ }
+ *ss = '[';
+ if (v && PM_TYPE(v->pm->node.flags) == PM_HASHED) {
+ unqueue_signals();
+ zerr("%s: attempt to set slice of associative array",
+ v->pm->node.nam);
+ freearray(val);
+ errflag |= ERRFLAG_ERROR;
+ return NULL;
+ }
+ v = NULL;
+ } else {
+ if (!(v = fetchvalue(&vbuf, &s, 1, SCANPM_ASSIGNING))) {
+ createparam(t, PM_ARRAY);
+ created = 1;
+ } else if (!(PM_TYPE(v->pm->node.flags) & (PM_ARRAY|PM_HASHED)) &&
+ !(v->pm->node.flags & (PM_SPECIAL|PM_TIED))) {
+ int uniq = v->pm->node.flags & PM_UNIQUE;
+ if (flags & ASSPM_AUGMENT) {
+ /* insert old value at the beginning of the val array */
+ char **new;
+ int lv = arrlen(val);
+
+ new = (char **) zalloc(sizeof(char *) * (lv + 2));
+ *new = ztrdup(getstrvalue(v));
+ memcpy(new+1, val, sizeof(char *) * (lv + 1));
+ free(val);
+ val = new;
+ }
+ unsetparam(t);
+ createparam(t, PM_ARRAY | uniq);
+ v = NULL;
+ }
+ }
+ if (!v)
+ if (!(v = fetchvalue(&vbuf, &t, 1, SCANPM_ASSIGNING))) {
+ unqueue_signals();
+ freearray(val);
+ /* errflag |= ERRFLAG_ERROR; */
+ return NULL;
+ }
+
+ if (flags & ASSPM_WARN)
+ check_warn_pm(v->pm, "array", created, may_warn_about_nested_vars);
+
+ /*
+ * At this point, we may have array entries consisting of
+ * - a Marker element --- normally allocated array entry but
+ * with just Marker char and null
+ * - an array index element --- as normal for associative array,
+ * but non-standard for normal array which we handle now.
+ * - a value for the indexed element.
+ * This only applies if the flag ASSPM_KEY_VALUE is passed in,
+ * indicating prefork() detected this syntax.
+ *
+ * For associative arrays we just junk the Marker elements.
+ */
+ if (flags & ASSPM_KEY_VALUE) {
+ char **aptr;
+ if (PM_TYPE(v->pm->node.flags) & PM_ARRAY) {
+ /*
+ * This is an ordinary array with key / value pairs.
+ */
+ int maxlen, origlen, nextind;
+ char **fullval, **origptr;
+ zlong *subscripts = (zlong *)zhalloc(arrlen(val) * sizeof(zlong));
+ zlong *iptr = subscripts;
+ if (flags & ASSPM_AUGMENT) {
+ origptr = v->pm->gsu.a->getfn(v->pm);
+ maxlen = origlen = arrlen(origptr);
+ } else {
+ maxlen = origlen = 0;
+ origptr = NULL;
+ }
+ nextind = 0;
+ for (aptr = val; *aptr; ) {
+ if (**aptr == Marker) {
+ *iptr = mathevali(*++aptr);
+ if (*iptr < 0 ||
+ (!isset(KSHARRAYS) && *iptr == 0)) {
+ unqueue_signals();
+ zerr("bad subscript for direct array assignment: %s", *aptr);
+ freearray(val);
+ return NULL;
+ }
+ if (!isset(KSHARRAYS))
+ --*iptr;
+ nextind = *iptr + 1;
+ ++iptr;
+ aptr += 2;
+ } else {
+ ++nextind;
+ ++aptr;
+ }
+ if (nextind > maxlen)
+ maxlen = nextind;
+ }
+ fullval = zshcalloc((maxlen+1) * sizeof(char *));
+ if (!fullval) {
+ zerr("array too large");
+ freearray(val);
+ return NULL;
+ }
+ fullval[maxlen] = NULL;
+ if (flags & ASSPM_AUGMENT) {
+ char **srcptr = origptr;
+ for (aptr = fullval; aptr <= fullval + origlen; aptr++) {
+ *aptr = ztrdup(*srcptr);
+ srcptr++;
+ }
+ }
+ iptr = subscripts;
+ nextind = 0;
+ for (aptr = val; *aptr; ++aptr) {
+ char *old;
+ if (**aptr == Marker) {
+ int augment = ((*aptr)[1] == '+');
+ zsfree(*aptr);
+ zsfree(*++aptr); /* Index, no longer needed */
+ old = fullval[*iptr];
+ if (augment && old) {
+ fullval[*iptr] = bicat(old, *++aptr);
+ zsfree(*aptr);
+ } else {
+ fullval[*iptr] = *++aptr;
+ }
+ nextind = *iptr + 1;
+ ++iptr;
+ } else {
+ old = fullval[nextind];
+ fullval[nextind] = *aptr;
+ ++nextind;
+ }
+ if (old)
+ zsfree(old);
+ /* aptr now on value in both cases */
+ }
+ if (*aptr) { /* Shouldn't be possible */
+ DPUTS(1, "Extra element in key / value array");
+ zsfree(*aptr);
+ }
+ free(val);
+ for (aptr = fullval; aptr < fullval + maxlen; aptr++) {
+ /*
+ * Remember we don't have sparse arrays but and they're null
+ * terminated --- so any value we don't set has to be an
+ * empty string.
+ */
+ if (!*aptr)
+ *aptr = ztrdup("");
+ }
+ setarrvalue(v, fullval);
+ unqueue_signals();
+ return v->pm;
+ } else if (PM_TYPE(v->pm->node.flags & PM_HASHED)) {
+ /*
+ * We strictly enforce [key]=value syntax for associative
+ * arrays. Marker can only indicate a Marker / key / value
+ * triad; it cannot be there by accident.
+ *
+ * It's too inefficient to strip Markers here, and they
+ * can't be there in the other form --- so just ignore
+ * them willy nilly lower down.
+ */
+ for (aptr = val; *aptr; aptr += 3) {
+ if (**aptr != Marker) {
+ unqueue_signals();
+ freearray(val);
+ zerr("bad [key]=value syntax for associative array");
+ return NULL;
+ }
+ }
+ } else {
+ unqueue_signals();
+ freearray(val);
+ zerr("invalid use of [key]=value assignment syntax");
+ return NULL;
+ }
+ }
+
+ if (flags & ASSPM_AUGMENT) {
+ if (v->start == 0 && v->end == -1) {
+ if (PM_TYPE(v->pm->node.flags) & PM_ARRAY) {
+ v->start = arrlen(v->pm->gsu.a->getfn(v->pm));
+ v->end = v->start + 1;
+ } else if (PM_TYPE(v->pm->node.flags) & PM_HASHED)
+ v->start = -1, v->end = 0;
+ } else {
+ if (v->end > 0)
+ v->start = v->end--;
+ else if (PM_TYPE(v->pm->node.flags) & PM_ARRAY) {
+ v->end = arrlen(v->pm->gsu.a->getfn(v->pm)) + v->end;
+ v->start = v->end + 1;
+ }
+ }
+ }
+
+ setarrvalue(v, val);
+ unqueue_signals();
+ return v->pm;
+}
+
+
+/**/
+mod_export Param
+setaparam(char *s, char **aval)
+{
+ return assignaparam(s, aval, ASSPM_WARN);
+}
+
+/**/
+mod_export Param
+sethparam(char *s, char **val)
+{
+ struct value vbuf;
+ Value v;
+ char *t = s;
+ int checkcreate = 0;
+
+ if (!isident(s)) {
+ zerr("not an identifier: %s", s);
+ freearray(val);
+ errflag |= ERRFLAG_ERROR;
+ return NULL;
+ }
+ if (strchr(s, '[')) {
+ freearray(val);
+ zerr("nested associative arrays not yet supported");
+ errflag |= ERRFLAG_ERROR;
+ return NULL;
+ }
+ if (unset(EXECOPT))
+ return NULL;
+ queue_signals();
+ if (!(v = fetchvalue(&vbuf, &s, 1, SCANPM_ASSIGNING))) {
+ createparam(t, PM_HASHED);
+ checkcreate = 1;
+ } else if (!(PM_TYPE(v->pm->node.flags) & PM_HASHED)) {
+ if (!(v->pm->node.flags & PM_SPECIAL)) {
+ unsetparam(t);
+ /* no WARNCREATEGLOBAL check here as parameter already existed */
+ createparam(t, PM_HASHED);
+ v = NULL;
+ } else {
+ zerr("%s: can't change type of a special parameter", t);
+ unqueue_signals();
+ return NULL;
+ }
+ }
+ if (!v)
+ if (!(v = fetchvalue(&vbuf, &t, 1, SCANPM_ASSIGNING))) {
+ unqueue_signals();
+ /* errflag |= ERRFLAG_ERROR; */
+ return NULL;
+ }
+ check_warn_pm(v->pm, "associative array", checkcreate, 1);
+ setarrvalue(v, val);
+ unqueue_signals();
+ return v->pm;
+}
+
+
+/*
+ * Set a generic shell number, floating point or integer.
+ * Option to warn on setting.
+ */
+
+/**/
+mod_export Param
+assignnparam(char *s, mnumber val, int flags)
+{
+ struct value vbuf;
+ Value v;
+ char *t = s, *ss;
+ Param pm;
+ int was_unset = 0;
+
+ if (!isident(s)) {
+ zerr("not an identifier: %s", s);
+ errflag |= ERRFLAG_ERROR;
+ return NULL;
+ }
+ if (unset(EXECOPT))
+ return NULL;
+ queue_signals();
+ ss = strchr(s, '[');
+ v = getvalue(&vbuf, &s, 1);
+ if (v && (v->pm->node.flags & (PM_ARRAY|PM_HASHED)) &&
+ !(v->pm->node.flags & (PM_SPECIAL|PM_TIED)) &&
+ /*
+ * not sure what KSHARRAYS has got to do with this...
+ * copied this from assignsparam().
+ */
+ unset(KSHARRAYS) && !ss) {
+ unsetparam_pm(v->pm, 0, 1);
+ was_unset = 1;
+ s = t;
+ v = NULL;
+ }
+ if (!v) {
+ /* s has been updated by getvalue, so check again */
+ ss = strchr(s, '[');
+ if (ss)
+ *ss = '\0';
+ pm = createparam(t, ss ? PM_ARRAY :
+ isset(POSIXIDENTIFIERS) ? PM_SCALAR :
+ (val.type & MN_INTEGER) ? PM_INTEGER : PM_FFLOAT);
+ if (!pm)
+ pm = (Param) paramtab->getnode(paramtab, t);
+ DPUTS(!pm, "BUG: parameter not created");
+ if (ss) {
+ *ss = '[';
+ } else if (val.type & MN_INTEGER) {
+ pm->base = outputradix;
+ }
+ if (!(v = getvalue(&vbuf, &t, 1))) {
+ DPUTS(!v, "BUG: value not found for new parameter");
+ /* errflag |= ERRFLAG_ERROR; */
+ unqueue_signals();
+ return NULL;
+ }
+ if (flags & ASSPM_WARN)
+ check_warn_pm(v->pm, "numeric", !was_unset, 1);
+ } else {
+ if (flags & ASSPM_WARN)
+ check_warn_pm(v->pm, "numeric", 0, 1);
+ }
+ setnumvalue(v, val);
+ unqueue_signals();
+ return v->pm;
+}
+
+/*
+ * Set a generic shell number, floating point or integer.
+ * Warn on setting based on option.
+ */
+
+/**/
+mod_export Param
+setnparam(char *s, mnumber val)
+{
+ return assignnparam(s, val, ASSPM_WARN);
+}
+
+/* Simplified interface to assignnparam */
+
+/**/
+mod_export Param
+assigniparam(char *s, zlong val, int flags)
+{
+ mnumber mnval;
+ mnval.type = MN_INTEGER;
+ mnval.u.l = val;
+ return assignnparam(s, mnval, flags);
+}
+
+/* Simplified interface to setnparam */
+
+/**/
+mod_export Param
+setiparam(char *s, zlong val)
+{
+ mnumber mnval;
+ mnval.type = MN_INTEGER;
+ mnval.u.l = val;
+ return assignnparam(s, mnval, ASSPM_WARN);
+}
+
+/*
+ * Set an integer parameter without forcing creation of an integer type.
+ * This is useful if the integer is going to be set to a parmaeter which
+ * would usually be scalar but may not exist.
+ */
+
+/**/
+mod_export Param
+setiparam_no_convert(char *s, zlong val)
+{
+ /*
+ * If the target is already an integer, thisgets converted
+ * back. Low technology rules.
+ */
+ char buf[BDIGBUFSIZE];
+ convbase(buf, val, 10);
+ return assignsparam(s, ztrdup(buf), ASSPM_WARN);
+}
+
+/* Unset a parameter */
+
+/**/
+mod_export void
+unsetparam(char *s)
+{
+ Param pm;
+
+ queue_signals();
+ if ((pm = (Param) (paramtab == realparamtab ?
+ /* getnode2() to avoid autoloading */
+ paramtab->getnode2(paramtab, s) :
+ paramtab->getnode(paramtab, s))))
+ unsetparam_pm(pm, 0, 1);
+ unqueue_signals();
+}
+
+/* Unset a parameter
+ *
+ * altflag: if true, don't remove pm->ename from the environment
+ * exp: See stdunsetfn()
+ */
+
+/**/
+mod_export int
+unsetparam_pm(Param pm, int altflag, int exp)
+{
+ Param oldpm, altpm;
+ char *altremove;
+
+ if ((pm->node.flags & PM_READONLY) && pm->level <= locallevel) {
+ zerr("read-only variable: %s", pm->node.nam);
+ return 1;
+ }
+ if ((pm->node.flags & PM_RESTRICTED) && isset(RESTRICTED)) {
+ zerr("%s: restricted", pm->node.nam);
+ return 1;
+ }
+
+ if (pm->ename && !altflag)
+ altremove = ztrdup(pm->ename);
+ else
+ altremove = NULL;
+
+ if (!(pm->node.flags & PM_UNSET))
+ pm->gsu.s->unsetfn(pm, exp);
+ if (pm->env)
+ delenv(pm);
+
+ /* remove it under its alternate name if necessary */
+ if (altremove) {
+ altpm = (Param) paramtab->getnode(paramtab, altremove);
+ /* tied parameters are at the same local level as each other */
+ oldpm = NULL;
+ while (altpm && altpm->level > pm->level) {
+ /* param under alternate name hidden by a local */
+ oldpm = altpm;
+ altpm = altpm->old;
+ }
+ if (altpm) {
+ if (oldpm && !altpm->level) {
+ oldpm->old = NULL;
+ /* fudge things so removenode isn't called */
+ altpm->level = 1;
+ }
+ unsetparam_pm(altpm, 1, exp);
+ }
+
+ zsfree(altremove);
+ }
+
+ /*
+ * If this was a local variable, we need to keep the old
+ * struct so that it is resurrected at the right level.
+ * This is partly because when an array/scalar value is set
+ * and the parameter used to be the other sort, unsetparam()
+ * is called. Beyond that, there is an ambiguity: should
+ * foo() { local bar; unset bar; } make the global bar
+ * available or not? The following makes the answer "no".
+ *
+ * Some specials, such as those used in zle, still need removing
+ * from the parameter table; they have the PM_REMOVABLE flag.
+ */
+ if ((pm->level && locallevel >= pm->level) ||
+ (pm->node.flags & (PM_SPECIAL|PM_REMOVABLE)) == PM_SPECIAL)
+ return 0;
+
+ /* remove parameter node from table */
+ paramtab->removenode(paramtab, pm->node.nam);
+
+ if (pm->old) {
+ oldpm = pm->old;
+ paramtab->addnode(paramtab, oldpm->node.nam, oldpm);
+ if ((PM_TYPE(oldpm->node.flags) == PM_SCALAR) &&
+ !(pm->node.flags & PM_HASHELEM) &&
+ (oldpm->node.flags & PM_NAMEDDIR) &&
+ oldpm->gsu.s == &stdscalar_gsu)
+ adduserdir(oldpm->node.nam, oldpm->u.str, 0, 0);
+ if (oldpm->node.flags & PM_EXPORTED) {
+ /*
+ * Re-export the old value which we removed in typeset_single().
+ * I don't think we need to test for ALL_EXPORT here, since if
+ * it was used to export the parameter originally the parameter
+ * should still have the PM_EXPORTED flag.
+ */
+ export_param(oldpm);
+ }
+ }
+
+ paramtab->freenode(&pm->node); /* free parameter node */
+
+ return 0;
+}
+
+/* Standard function to unset a parameter. This is mostly delegated to *
+ * the specific set function.
+ *
+ * This could usefully be made type-specific, but then we need
+ * to be more careful when calling the unset method directly.
+ *
+ * The "exp"licit parameter should be nonzero for assignments and the
+ * unset command, and zero for implicit unset (e.g., end of scope).
+ * Currently this is used only by some modules.
+ */
+
+/**/
+mod_export void
+stdunsetfn(Param pm, UNUSED(int exp))
+{
+ switch (PM_TYPE(pm->node.flags)) {
+ case PM_SCALAR:
+ if (pm->gsu.s->setfn)
+ pm->gsu.s->setfn(pm, NULL);
+ break;
+
+ case PM_ARRAY:
+ if (pm->gsu.a->setfn)
+ pm->gsu.a->setfn(pm, NULL);
+ break;
+
+ case PM_HASHED:
+ if (pm->gsu.h->setfn)
+ pm->gsu.h->setfn(pm, NULL);
+ break;
+
+ default:
+ if (!(pm->node.flags & PM_SPECIAL))
+ pm->u.str = NULL;
+ break;
+ }
+ if ((pm->node.flags & (PM_SPECIAL|PM_TIED)) == PM_TIED) {
+ if (pm->ename) {
+ zsfree(pm->ename);
+ pm->ename = NULL;
+ }
+ pm->node.flags &= ~PM_TIED;
+ }
+ pm->node.flags |= PM_UNSET;
+}
+
+/* Function to get value of an integer parameter */
+
+/**/
+mod_export zlong
+intgetfn(Param pm)
+{
+ return pm->u.val;
+}
+
+/* Function to set value of an integer parameter */
+
+/**/
+static void
+intsetfn(Param pm, zlong x)
+{
+ pm->u.val = x;
+}
+
+/* Function to get value of a floating point parameter */
+
+/**/
+static double
+floatgetfn(Param pm)
+{
+ return pm->u.dval;
+}
+
+/* Function to set value of an integer parameter */
+
+/**/
+static void
+floatsetfn(Param pm, double x)
+{
+ pm->u.dval = x;
+}
+
+/* Function to get value of a scalar (string) parameter */
+
+/**/
+mod_export char *
+strgetfn(Param pm)
+{
+ return pm->u.str ? pm->u.str : (char *) hcalloc(1);
+}
+
+/* Function to set value of a scalar (string) parameter */
+
+/**/
+mod_export void
+strsetfn(Param pm, char *x)
+{
+ zsfree(pm->u.str);
+ pm->u.str = x;
+ if (!(pm->node.flags & PM_HASHELEM) &&
+ ((pm->node.flags & PM_NAMEDDIR) || isset(AUTONAMEDIRS))) {
+ pm->node.flags |= PM_NAMEDDIR;
+ adduserdir(pm->node.nam, x, 0, 0);
+ }
+ /* If you update this function, you may need to update the
+ * `Implement remainder of strsetfn' block in assignstrvalue(). */
+}
+
+/* Function to get value of an array parameter */
+
+static char *nullarray = NULL;
+
+/**/
+char **
+arrgetfn(Param pm)
+{
+ return pm->u.arr ? pm->u.arr : &nullarray;
+}
+
+/* Function to set value of an array parameter */
+
+/**/
+mod_export void
+arrsetfn(Param pm, char **x)
+{
+ if (pm->u.arr && pm->u.arr != x)
+ freearray(pm->u.arr);
+ if (pm->node.flags & PM_UNIQUE)
+ uniqarray(x);
+ pm->u.arr = x;
+ /* Arrays tied to colon-arrays may need to fix the environment */
+ if (pm->ename && x)
+ arrfixenv(pm->ename, x);
+ /* If you extend this function, update the list of conditions in
+ * setarrvalue(). */
+}
+
+/* Function to get value of an association parameter */
+
+/**/
+mod_export HashTable
+hashgetfn(Param pm)
+{
+ return pm->u.hash;
+}
+
+/* Function to set value of an association parameter */
+
+/**/
+mod_export void
+hashsetfn(Param pm, HashTable x)
+{
+ if (pm->u.hash && pm->u.hash != x)
+ deleteparamtable(pm->u.hash);
+ pm->u.hash = x;
+}
+
+/* Function to dispose of setting of an unsettable hash */
+
+/**/
+mod_export void
+nullsethashfn(UNUSED(Param pm), HashTable x)
+{
+ deleteparamtable(x);
+}
+
+/* Function to set value of an association parameter using key/value pairs */
+
+/**/
+static void
+arrhashsetfn(Param pm, char **val, int flags)
+{
+ /* Best not to shortcut this by using the existing hash table, *
+ * since that could cause trouble for special hashes. This way, *
+ * it's up to pm->gsu.h->setfn() what to do. */
+ int alen = 0;
+ HashTable opmtab = paramtab, ht = 0;
+ char **aptr;
+ Value v = (Value) hcalloc(sizeof *v);
+ v->end = -1;
+
+ for (aptr = val; *aptr; ++aptr) {
+ if (**aptr != Marker)
+ ++alen;
+ }
+
+ if (alen % 2) {
+ freearray(val);
+ zerr("bad set of key/value pairs for associative array");
+ return;
+ }
+ if (flags & ASSPM_AUGMENT) {
+ ht = paramtab = pm->gsu.h->getfn(pm);
+ }
+ if (alen && (!(flags & ASSPM_AUGMENT) || !paramtab)) {
+ ht = paramtab = newparamtable(17, pm->node.nam);
+ }
+ for (aptr = val; *aptr; ) {
+ int eltflags = 0;
+ if (**aptr == Marker) {
+ /* Either all elements have Marker or none. Checked in caller. */
+ if ((*aptr)[1] == '+') {
+ /* Actually, assignstrvalue currently doesn't handle this... */
+ eltflags = ASSPM_AUGMENT;
+ /* ...so we'll use the trick from setsparam(). */
+ v->start = INT_MAX;
+ } else {
+ v->start = 0;
+ }
+ v->end = -1;
+ zsfree(*aptr++);
+ }
+ /* The parameter name is ztrdup'd... */
+ v->pm = createparam(*aptr, PM_SCALAR|PM_UNSET);
+ /*
+ * createparam() doesn't return anything if the parameter
+ * already existed.
+ */
+ if (!v->pm)
+ v->pm = (Param) paramtab->getnode(paramtab, *aptr);
+ zsfree(*aptr++);
+ /* ...but we can use the value without copying. */
+ assignstrvalue(v, *aptr++, eltflags);
+ }
+ paramtab = opmtab;
+ pm->gsu.h->setfn(pm, ht);
+ free(val); /* not freearray() */
+}
+
+/*
+ * These functions are used as the set function for special parameters that
+ * cannot be set by the user. The set is incomplete as the only such
+ * parameters are scalar and integer.
+ */
+
+/**/
+mod_export void
+nullstrsetfn(UNUSED(Param pm), char *x)
+{
+ zsfree(x);
+}
+
+/**/
+mod_export void
+nullintsetfn(UNUSED(Param pm), UNUSED(zlong x))
+{}
+
+/**/
+mod_export void
+nullunsetfn(UNUSED(Param pm), UNUSED(int exp))
+{}
+
+
+/* Function to get value of generic special integer *
+ * parameter. data is pointer to global variable *
+ * containing the integer value. */
+
+/**/
+mod_export zlong
+intvargetfn(Param pm)
+{
+ return *pm->u.valptr;
+}
+
+/* Function to set value of generic special integer *
+ * parameter. data is pointer to global variable *
+ * where the value is to be stored. */
+
+/**/
+mod_export void
+intvarsetfn(Param pm, zlong x)
+{
+ *pm->u.valptr = x;
+}
+
+/* Function to set value of any ZLE-related integer *
+ * parameter. data is pointer to global variable *
+ * where the value is to be stored. */
+
+/**/
+void
+zlevarsetfn(Param pm, zlong x)
+{
+ zlong *p = pm->u.valptr;
+
+ *p = x;
+ if (p == &zterm_lines || p == &zterm_columns)
+ adjustwinsize(2 + (p == &zterm_columns));
+}
+
+
+/* Implements gsu_integer.unsetfn for ZLE_RPROMPT_INDENT; see stdunsetfn() */
+
+static void
+rprompt_indent_unsetfn(Param pm, int exp)
+{
+ stdunsetfn(pm, exp);
+ rprompt_indent = 1; /* Keep this in sync with init_term() */
+}
+
+/* Function to set value of generic special scalar *
+ * parameter. data is pointer to a character pointer *
+ * representing the scalar (string). */
+
+/**/
+mod_export void
+strvarsetfn(Param pm, char *x)
+{
+ char **q = ((char **)pm->u.data);
+
+ zsfree(*q);
+ *q = x;
+}
+
+/* Function to get value of generic special scalar *
+ * parameter. data is pointer to a character pointer *
+ * representing the scalar (string). */
+
+/**/
+mod_export char *
+strvargetfn(Param pm)
+{
+ char *s = *((char **)pm->u.data);
+
+ if (!s)
+ return hcalloc(1);
+ return s;
+}
+
+/* Function to get value of generic special array *
+ * parameter. data is a pointer to the pointer to *
+ * a pointer (a pointer to a variable length array *
+ * of pointers). */
+
+/**/
+mod_export char **
+arrvargetfn(Param pm)
+{
+ char **arrptr = *((char ***)pm->u.data);
+
+ return arrptr ? arrptr : &nullarray;
+}
+
+/* Function to set value of generic special array parameter. *
+ * data is pointer to a variable length array of pointers which *
+ * represents this array of scalars (strings). If pm->ename is *
+ * non NULL, then it is a colon separated environment variable *
+ * version of this array which will need to be updated. */
+
+/**/
+mod_export void
+arrvarsetfn(Param pm, char **x)
+{
+ char ***dptr = (char ***)pm->u.data;
+
+ if (*dptr != x)
+ freearray(*dptr);
+ if (pm->node.flags & PM_UNIQUE)
+ uniqarray(x);
+ /*
+ * Special tied arrays point to variables accessible in other
+ * ways which need to be set to NULL. We can't do this
+ * with user tied variables since we can leak memory.
+ */
+ if ((pm->node.flags & PM_SPECIAL) && !x)
+ *dptr = mkarray(NULL);
+ else
+ *dptr = x;
+ if (pm->ename) {
+ if (x)
+ arrfixenv(pm->ename, x);
+ else if (*dptr == path)
+ pathchecked = path;
+ }
+}
+
+/**/
+char *
+colonarrgetfn(Param pm)
+{
+ char ***dptr = (char ***)pm->u.data;
+ return *dptr ? zjoin(*dptr, ':', 1) : "";
+}
+
+/**/
+void
+colonarrsetfn(Param pm, char *x)
+{
+ char ***dptr = (char ***)pm->u.data;
+ /*
+ * We have to make sure this is never NULL, since that
+ * can cause problems.
+ */
+ if (*dptr)
+ freearray(*dptr);
+ if (x)
+ *dptr = colonsplit(x, pm->node.flags & PM_UNIQUE);
+ else
+ *dptr = mkarray(NULL);
+ arrfixenv(pm->node.nam, *dptr);
+ zsfree(x);
+}
+
+/**/
+char *
+tiedarrgetfn(Param pm)
+{
+ struct tieddata *dptr = (struct tieddata *)pm->u.data;
+ return *dptr->arrptr ? zjoin(*dptr->arrptr, STOUC(dptr->joinchar), 1) : "";
+}
+
+/**/
+void
+tiedarrsetfn(Param pm, char *x)
+{
+ struct tieddata *dptr = (struct tieddata *)pm->u.data;
+
+ if (*dptr->arrptr)
+ freearray(*dptr->arrptr);
+ if (x) {
+ char sepbuf[3];
+ if (imeta(dptr->joinchar))
+ {
+ sepbuf[0] = Meta;
+ sepbuf[1] = dptr->joinchar ^ 32;
+ sepbuf[2] = '\0';
+ }
+ else
+ {
+ sepbuf[0] = dptr->joinchar;
+ sepbuf[1] = '\0';
+ }
+ *dptr->arrptr = sepsplit(x, sepbuf, 0, 0);
+ if (pm->node.flags & PM_UNIQUE)
+ uniqarray(*dptr->arrptr);
+ zsfree(x);
+ } else
+ *dptr->arrptr = NULL;
+ if (pm->ename)
+ arrfixenv(pm->node.nam, *dptr->arrptr);
+}
+
+/**/
+void
+tiedarrunsetfn(Param pm, UNUSED(int exp))
+{
+ /*
+ * Special unset function because we allocated a struct tieddata
+ * in typeset_single to hold the special data which we now
+ * need to delete.
+ */
+ pm->gsu.s->setfn(pm, NULL);
+ zfree(pm->u.data, sizeof(struct tieddata));
+ /* paranoia -- shouldn't need these, but in case we reuse the struct... */
+ pm->u.data = NULL;
+ zsfree(pm->ename);
+ pm->ename = NULL;
+ pm->node.flags &= ~PM_TIED;
+ pm->node.flags |= PM_UNSET;
+}
+
+/**/
+static void
+simple_arrayuniq(char **x, int freeok)
+{
+ char **t, **p = x;
+ char *hole = "";
+
+ /* Find duplicates and replace them with holes */
+ while (*++p)
+ for (t = x; t < p; t++)
+ if (*t != hole && !strcmp(*p, *t)) {
+ if (freeok)
+ zsfree(*p);
+ *p = hole;
+ break;
+ }
+ /* Swap non-holes into holes in optimal jumps */
+ for (p = t = x; *t != NULL; t++) {
+ if (*t == hole) {
+ while (*p == hole)
+ ++p;
+ if ((*t = *p) != NULL)
+ *p++ = hole;
+ } else if (p == t)
+ p++;
+ }
+ /* Erase all the remaining holes, just in case */
+ while (++t < p)
+ *t = NULL;
+}
+
+/**/
+static void
+arrayuniq_freenode(HashNode hn)
+{
+ (void)hn;
+}
+
+/**/
+HashTable
+newuniqtable(zlong size)
+{
+ HashTable ht = newhashtable((int)size, "arrayuniq", NULL);
+ /* ??? error checking */
+
+ ht->hash = hasher;
+ ht->emptytable = emptyhashtable;
+ ht->filltable = NULL;
+ ht->cmpnodes = strcmp;
+ ht->addnode = addhashnode;
+ ht->getnode = gethashnode2;
+ ht->getnode2 = gethashnode2;
+ ht->removenode = removehashnode;
+ ht->disablenode = disablehashnode;
+ ht->enablenode = enablehashnode;
+ ht->freenode = arrayuniq_freenode;
+ ht->printnode = NULL;
+
+ return ht;
+}
+
+/**/
+static void
+arrayuniq(char **x, int freeok)
+{
+ char **it, **write_it;
+ zlong array_size = arrlen(x);
+ HashTable ht;
+
+ if (array_size == 0)
+ return;
+ if (array_size < 10 || !(ht = newuniqtable(array_size + 1))) {
+ /* fallback to simpler routine */
+ simple_arrayuniq(x, freeok);
+ return;
+ }
+
+ for (it = x, write_it = x; *it;) {
+ if (! gethashnode2(ht, *it)) {
+ HashNode new_node = zhalloc(sizeof(struct hashnode));
+ if (!new_node) {
+ /* Oops, out of heap memory, no way to recover */
+ zerr("out of memory in arrayuniq");
+ break;
+ }
+ (void) addhashnode2(ht, *it, new_node);
+ *write_it = *it;
+ if (it != write_it)
+ *it = NULL;
+ ++write_it;
+ }
+ else {
+ if (freeok)
+ zsfree(*it);
+ *it = NULL;
+ }
+ ++it;
+ }
+
+ deletehashtable(ht);
+}
+
+/**/
+void
+uniqarray(char **x)
+{
+ if (!x || !*x)
+ return;
+ arrayuniq(x, !zheapptr(*x));
+}
+
+/**/
+void
+zhuniqarray(char **x)
+{
+ if (!x || !*x)
+ return;
+ arrayuniq(x, 0);
+}
+
+/* Function to get value of special parameter `#' and `ARGC' */
+
+/**/
+zlong
+poundgetfn(UNUSED(Param pm))
+{
+ return arrlen(pparams);
+}
+
+/* Function to get value for special parameter `RANDOM' */
+
+/**/
+zlong
+randomgetfn(UNUSED(Param pm))
+{
+ return rand() & 0x7fff;
+}
+
+/* Function to set value of special parameter `RANDOM' */
+
+/**/
+void
+randomsetfn(UNUSED(Param pm), zlong v)
+{
+ srand((unsigned int)v);
+}
+
+/* Function to get value for special parameter `SECONDS' */
+
+/**/
+zlong
+intsecondsgetfn(UNUSED(Param pm))
+{
+ struct timeval now;
+ struct timezone dummy_tz;
+
+ gettimeofday(&now, &dummy_tz);
+
+ return (zlong)(now.tv_sec - shtimer.tv_sec -
+ (now.tv_usec < shtimer.tv_usec ? 1 : 0));
+}
+
+/* Function to set value of special parameter `SECONDS' */
+
+/**/
+void
+intsecondssetfn(UNUSED(Param pm), zlong x)
+{
+ struct timeval now;
+ struct timezone dummy_tz;
+ zlong diff;
+
+ gettimeofday(&now, &dummy_tz);
+ diff = (zlong)now.tv_sec - x;
+ shtimer.tv_sec = diff;
+ if ((zlong)shtimer.tv_sec != diff)
+ zwarn("SECONDS truncated on assignment");
+ shtimer.tv_usec = now.tv_usec;
+}
+
+/**/
+double
+floatsecondsgetfn(UNUSED(Param pm))
+{
+ struct timeval now;
+ struct timezone dummy_tz;
+
+ gettimeofday(&now, &dummy_tz);
+
+ return (double)(now.tv_sec - shtimer.tv_sec) +
+ (double)(now.tv_usec - shtimer.tv_usec) / 1000000.0;
+}
+
+/**/
+void
+floatsecondssetfn(UNUSED(Param pm), double x)
+{
+ struct timeval now;
+ struct timezone dummy_tz;
+
+ gettimeofday(&now, &dummy_tz);
+ shtimer.tv_sec = now.tv_sec - (zlong)x;
+ shtimer.tv_usec = now.tv_usec - (zlong)((x - (zlong)x) * 1000000.0);
+}
+
+/**/
+double
+getrawseconds(void)
+{
+ return (double)shtimer.tv_sec + (double)shtimer.tv_usec / 1000000.0;
+}
+
+/**/
+void
+setrawseconds(double x)
+{
+ shtimer.tv_sec = (zlong)x;
+ shtimer.tv_usec = (zlong)((x - (zlong)x) * 1000000.0);
+}
+
+/**/
+int
+setsecondstype(Param pm, int on, int off)
+{
+ int newflags = (pm->node.flags | on) & ~off;
+ int tp = PM_TYPE(newflags);
+ /* Only one of the numeric types is allowed. */
+ if (tp == PM_EFLOAT || tp == PM_FFLOAT)
+ {
+ pm->gsu.f = &floatseconds_gsu;
+ }
+ else if (tp == PM_INTEGER)
+ {
+ pm->gsu.i = &intseconds_gsu;
+ }
+ else
+ return 1;
+ pm->node.flags = newflags;
+ return 0;
+}
+
+/* Function to get value for special parameter `USERNAME' */
+
+/**/
+char *
+usernamegetfn(UNUSED(Param pm))
+{
+ return get_username();
+}
+
+/* Function to set value of special parameter `USERNAME' */
+
+/**/
+void
+usernamesetfn(UNUSED(Param pm), char *x)
+{
+#if defined(HAVE_SETUID) && defined(HAVE_GETPWNAM)
+ struct passwd *pswd;
+
+ if (x && (pswd = getpwnam(x)) && (pswd->pw_uid != cached_uid)) {
+# ifdef USE_INITGROUPS
+ initgroups(x, pswd->pw_gid);
+# endif
+ if (setgid(pswd->pw_gid))
+ zwarn("failed to change group ID: %e", errno);
+ else if (setuid(pswd->pw_uid))
+ zwarn("failed to change user ID: %e", errno);
+ else {
+ zsfree(cached_username);
+ cached_username = ztrdup(pswd->pw_name);
+ cached_uid = pswd->pw_uid;
+ }
+ }
+#endif /* HAVE_SETUID && HAVE_GETPWNAM */
+ zsfree(x);
+}
+
+/* Function to get value for special parameter `UID' */
+
+/**/
+zlong
+uidgetfn(UNUSED(Param pm))
+{
+ return getuid();
+}
+
+/* Function to set value of special parameter `UID' */
+
+/**/
+void
+uidsetfn(UNUSED(Param pm), zlong x)
+{
+#ifdef HAVE_SETUID
+ if (setuid((uid_t)x))
+ zerr("failed to change user ID: %e", errno);
+#endif
+}
+
+/* Function to get value for special parameter `EUID' */
+
+/**/
+zlong
+euidgetfn(UNUSED(Param pm))
+{
+ return geteuid();
+}
+
+/* Function to set value of special parameter `EUID' */
+
+/**/
+void
+euidsetfn(UNUSED(Param pm), zlong x)
+{
+#ifdef HAVE_SETEUID
+ if (seteuid((uid_t)x))
+ zerr("failed to change effective user ID: %e", errno);
+#endif
+}
+
+/* Function to get value for special parameter `GID' */
+
+/**/
+zlong
+gidgetfn(UNUSED(Param pm))
+{
+ return getgid();
+}
+
+/* Function to set value of special parameter `GID' */
+
+/**/
+void
+gidsetfn(UNUSED(Param pm), zlong x)
+{
+#ifdef HAVE_SETUID
+ if (setgid((gid_t)x))
+ zerr("failed to change group ID: %e", errno);
+#endif
+}
+
+/* Function to get value for special parameter `EGID' */
+
+/**/
+zlong
+egidgetfn(UNUSED(Param pm))
+{
+ return getegid();
+}
+
+/* Function to set value of special parameter `EGID' */
+
+/**/
+void
+egidsetfn(UNUSED(Param pm), zlong x)
+{
+#ifdef HAVE_SETEUID
+ if (setegid((gid_t)x))
+ zerr("failed to change effective group ID: %e", errno);
+#endif
+}
+
+/**/
+zlong
+ttyidlegetfn(UNUSED(Param pm))
+{
+ struct stat ttystat;
+
+ if (SHTTY == -1 || fstat(SHTTY, &ttystat))
+ return -1;
+ return time(NULL) - ttystat.st_atime;
+}
+
+/* Function to get value for special parameter `IFS' */
+
+/**/
+char *
+ifsgetfn(UNUSED(Param pm))
+{
+ return ifs;
+}
+
+/* Function to set value of special parameter `IFS' */
+
+/**/
+void
+ifssetfn(UNUSED(Param pm), char *x)
+{
+ zsfree(ifs);
+ ifs = x;
+ inittyptab();
+}
+
+/* Functions to set value of special parameters `LANG' and `LC_*' */
+
+#ifdef USE_LOCALE
+static struct localename {
+ char *name;
+ int category;
+} lc_names[] = {
+#ifdef LC_COLLATE
+ {"LC_COLLATE", LC_COLLATE},
+#endif
+#ifdef LC_CTYPE
+ {"LC_CTYPE", LC_CTYPE},
+#endif
+#ifdef LC_MESSAGES
+ {"LC_MESSAGES", LC_MESSAGES},
+#endif
+#ifdef LC_NUMERIC
+ {"LC_NUMERIC", LC_NUMERIC},
+#endif
+#ifdef LC_TIME
+ {"LC_TIME", LC_TIME},
+#endif
+ {NULL, 0}
+};
+
+/**/
+static void
+setlang(char *x)
+{
+ struct localename *ln;
+ char *x2;
+
+ if ((x2 = getsparam_u("LC_ALL")) && *x2)
+ return;
+
+ /*
+ * Set the global locale to the value passed, but override
+ * this with any non-empty definitions for specific
+ * categories.
+ *
+ * We only use non-empty definitions because empty values aren't
+ * valid as locales; when passed to setlocale() they mean "use the
+ * environment variable", but if that's what we're setting the value
+ * from this is meaningless. So just all $LANG to show through in
+ * that case.
+ */
+ setlocale(LC_ALL, x ? unmeta(x) : "");
+ queue_signals();
+ for (ln = lc_names; ln->name; ln++)
+ if ((x = getsparam_u(ln->name)) && *x)
+ setlocale(ln->category, x);
+ unqueue_signals();
+}
+
+/**/
+void
+lc_allsetfn(Param pm, char *x)
+{
+ strsetfn(pm, x);
+ /*
+ * Treat an empty LC_ALL the same as an unset one,
+ * namely by using LANG as the default locale but overriding
+ * that with any LC_* that are set.
+ */
+ if (!x || !*x) {
+ x = getsparam_u("LANG");
+ if (x && *x) {
+ queue_signals();
+ setlang(x);
+ unqueue_signals();
+ }
+ }
+ else
+ setlocale(LC_ALL, unmeta(x));
+}
+
+/**/
+void
+langsetfn(Param pm, char *x)
+{
+ strsetfn(pm, x);
+ setlang(unmeta(x));
+}
+
+/**/
+void
+lcsetfn(Param pm, char *x)
+{
+ char *x2;
+ struct localename *ln;
+
+ strsetfn(pm, x);
+ if ((x2 = getsparam("LC_ALL")) && *x2)
+ return;
+ queue_signals();
+ /* Treat empty LC_* the same as unset. */
+ if (!x || !*x)
+ x = getsparam("LANG");
+
+ /*
+ * If we've got no non-empty string at this
+ * point (after checking $LANG, too),
+ * we shouldn't bother setting anything.
+ */
+ if (x && *x) {
+ for (ln = lc_names; ln->name; ln++)
+ if (!strcmp(ln->name, pm->node.nam))
+ setlocale(ln->category, unmeta(x));
+ }
+ unqueue_signals();
+}
+#endif /* USE_LOCALE */
+
+/* Function to set value for special parameter `0' */
+
+/**/
+static void
+argzerosetfn(UNUSED(Param pm), char *x)
+{
+ if (x) {
+ if (isset(POSIXARGZERO))
+ zerr("read-only variable: 0");
+ else {
+ zsfree(argzero);
+ argzero = ztrdup(x);
+ }
+ zsfree(x);
+ }
+}
+
+/* Function to get value for special parameter `0' */
+
+/**/
+static char *
+argzerogetfn(UNUSED(Param pm))
+{
+ if (isset(POSIXARGZERO))
+ return posixzero;
+ return argzero;
+}
+
+/* Function to get value for special parameter `HISTSIZE' */
+
+/**/
+zlong
+histsizegetfn(UNUSED(Param pm))
+{
+ return histsiz;
+}
+
+/* Function to set value of special parameter `HISTSIZE' */
+
+/**/
+void
+histsizesetfn(UNUSED(Param pm), zlong v)
+{
+ if ((histsiz = v) < 1)
+ histsiz = 1;
+ resizehistents();
+}
+
+/* Function to get value for special parameter `SAVEHIST' */
+
+/**/
+zlong
+savehistsizegetfn(UNUSED(Param pm))
+{
+ return savehistsiz;
+}
+
+/* Function to set value of special parameter `SAVEHIST' */
+
+/**/
+void
+savehistsizesetfn(UNUSED(Param pm), zlong v)
+{
+ if ((savehistsiz = v) < 0)
+ savehistsiz = 0;
+}
+
+/* Function to set value for special parameter `ERRNO' */
+
+/**/
+void
+errnosetfn(UNUSED(Param pm), zlong x)
+{
+ errno = (int)x;
+ if ((zlong)errno != x)
+ zwarn("errno truncated on assignment");
+}
+
+/* Function to get value for special parameter `ERRNO' */
+
+/**/
+zlong
+errnogetfn(UNUSED(Param pm))
+{
+ return errno;
+}
+
+/* Function to get value for special parameter `KEYBOARD_HACK' */
+
+/**/
+char *
+keyboardhackgetfn(UNUSED(Param pm))
+{
+ static char buf[2];
+
+ buf[0] = keyboardhackchar;
+ buf[1] = '\0';
+ return buf;
+}
+
+
+/* Function to set value of special parameter `KEYBOARD_HACK' */
+
+/**/
+void
+keyboardhacksetfn(UNUSED(Param pm), char *x)
+{
+ if (x) {
+ int len, i;
+
+ unmetafy(x, &len);
+ if (len > 1) {
+ len = 1;
+ zwarn("Only one KEYBOARD_HACK character can be defined"); /* could be changed if needed */
+ }
+ for (i = 0; i < len; i++) {
+ if (!isascii(STOUC(x[i]))) {
+ zwarn("KEYBOARD_HACK can only contain ASCII characters");
+ return;
+ }
+ }
+ keyboardhackchar = len ? STOUC(x[0]) : '\0';
+ free(x);
+ } else
+ keyboardhackchar = '\0';
+}
+
+/* Function to get value for special parameter `histchar' */
+
+/**/
+char *
+histcharsgetfn(UNUSED(Param pm))
+{
+ static char buf[4];
+
+ buf[0] = bangchar;
+ buf[1] = hatchar;
+ buf[2] = hashchar;
+ buf[3] = '\0';
+ return buf;
+}
+
+/* Function to set value of special parameter `histchar' */
+
+/**/
+void
+histcharssetfn(UNUSED(Param pm), char *x)
+{
+ if (x) {
+ int len, i;
+
+ unmetafy(x, &len);
+ if (len > 3)
+ len = 3;
+ for (i = 0; i < len; i++) {
+ if (!isascii(STOUC(x[i]))) {
+ zwarn("HISTCHARS can only contain ASCII characters");
+ return;
+ }
+ }
+ bangchar = len ? STOUC(x[0]) : '\0';
+ hatchar = len > 1 ? STOUC(x[1]) : '\0';
+ hashchar = len > 2 ? STOUC(x[2]) : '\0';
+ free(x);
+ } else {
+ bangchar = '!';
+ hashchar = '#';
+ hatchar = '^';
+ }
+ inittyptab();
+}
+
+/* Function to get value for special parameter `HOME' */
+
+/**/
+char *
+homegetfn(UNUSED(Param pm))
+{
+ return home;
+}
+
+/* Function to set value of special parameter `HOME' */
+
+/**/
+void
+homesetfn(UNUSED(Param pm), char *x)
+{
+ zsfree(home);
+ if (x && isset(CHASELINKS) && (home = xsymlink(x, 0)))
+ zsfree(x);
+ else
+ home = x ? x : ztrdup("");
+ finddir(NULL);
+}
+
+/* Function to get value for special parameter `WORDCHARS' */
+
+/**/
+char *
+wordcharsgetfn(UNUSED(Param pm))
+{
+ return wordchars;
+}
+
+/* Function to set value of special parameter `WORDCHARS' */
+
+/**/
+void
+wordcharssetfn(UNUSED(Param pm), char *x)
+{
+ zsfree(wordchars);
+ wordchars = x;
+ inittyptab();
+}
+
+/* Function to get value for special parameter `_' */
+
+/**/
+char *
+underscoregetfn(UNUSED(Param pm))
+{
+ char *u = dupstring(zunderscore);
+
+ untokenize(u);
+ return u;
+}
+
+/* Function used when we need to reinitialise the terminal */
+
+static void
+term_reinit_from_pm(void)
+{
+ /* If non-interactive, delay setting up term till we need it. */
+ if (unset(INTERACTIVE) || !*term)
+ termflags |= TERM_UNKNOWN;
+ else
+ init_term();
+}
+
+/* Function to get value for special parameter `TERM' */
+
+/**/
+char *
+termgetfn(UNUSED(Param pm))
+{
+ return term;
+}
+
+/* Function to set value of special parameter `TERM' */
+
+/**/
+void
+termsetfn(UNUSED(Param pm), char *x)
+{
+ zsfree(term);
+ term = x ? x : ztrdup("");
+ term_reinit_from_pm();
+}
+
+/* Function to get value of special parameter `TERMINFO' */
+
+/**/
+char *
+terminfogetfn(UNUSED(Param pm))
+{
+ return zsh_terminfo ? zsh_terminfo : dupstring("");
+}
+
+/* Function to set value of special parameter `TERMINFO' */
+
+/**/
+void
+terminfosetfn(Param pm, char *x)
+{
+ zsfree(zsh_terminfo);
+ zsh_terminfo = x;
+
+ /*
+ * terminfo relies on the value being exported before
+ * we reinitialise the terminal. This is a bit inefficient.
+ */
+ if ((pm->node.flags & PM_EXPORTED) && x)
+ addenv(pm, x);
+
+ term_reinit_from_pm();
+}
+
+/* Function to get value of special parameter `TERMINFO_DIRS' */
+
+/**/
+char *
+terminfodirsgetfn(UNUSED(Param pm))
+{
+ return zsh_terminfodirs ? zsh_terminfodirs : dupstring("");
+}
+
+/* Function to set value of special parameter `TERMINFO_DIRS' */
+
+/**/
+void
+terminfodirssetfn(Param pm, char *x)
+{
+ zsfree(zsh_terminfodirs);
+ zsh_terminfodirs = x;
+
+ /*
+ * terminfo relies on the value being exported before
+ * we reinitialise the terminal. This is a bit inefficient.
+ */
+ if ((pm->node.flags & PM_EXPORTED) && x)
+ addenv(pm, x);
+
+ term_reinit_from_pm();
+}
+/* Function to get value for special parameter `pipestatus' */
+
+/**/
+static char **
+pipestatgetfn(UNUSED(Param pm))
+{
+ char **x = (char **) zhalloc((numpipestats + 1) * sizeof(char *));
+ char buf[DIGBUFSIZE], **p;
+ int *q, i;
+
+ for (p = x, q = pipestats, i = numpipestats; i--; p++, q++) {
+ sprintf(buf, "%d", *q);
+ *p = dupstring(buf);
+ }
+ *p = NULL;
+
+ return x;
+}
+
+/* Function to get value for special parameter `pipestatus' */
+
+/**/
+static void
+pipestatsetfn(UNUSED(Param pm), char **x)
+{
+ if (x) {
+ int i;
+
+ for (i = 0; *x && i < MAX_PIPESTATS; i++, x++)
+ pipestats[i] = atoi(*x);
+ numpipestats = i;
+ }
+ else
+ numpipestats = 0;
+}
+
+/**/
+void
+arrfixenv(char *s, char **t)
+{
+ Param pm;
+ int joinchar;
+
+ if (t == path)
+ cmdnamtab->emptytable(cmdnamtab);
+
+ pm = (Param) paramtab->getnode(paramtab, s);
+
+ /*
+ * Only one level of a parameter can be exported. Unless
+ * ALLEXPORT is set, this must be global.
+ */
+
+ if (pm->node.flags & PM_HASHELEM)
+ return;
+
+ if (isset(ALLEXPORT))
+ pm->node.flags |= PM_EXPORTED;
+
+ /*
+ * Do not "fix" parameters that were not exported
+ */
+
+ if (!(pm->node.flags & PM_EXPORTED))
+ return;
+
+ if (pm->node.flags & PM_TIED)
+ joinchar = STOUC(((struct tieddata *)pm->u.data)->joinchar);
+ else
+ joinchar = ':';
+
+ addenv(pm, t ? zjoin(t, joinchar, 1) : "");
+}
+
+
+/**/
+int
+zputenv(char *str)
+{
+ DPUTS(!str, "Attempt to put null string into environment.");
+#ifdef USE_SET_UNSET_ENV
+ /*
+ * If we are using unsetenv() to remove values from the
+ * environment, which is the safe thing to do, we
+ * need to use setenv() to put them there in the first place.
+ * Unfortunately this is a slightly different interface
+ * from what zputenv() assumes.
+ */
+ char *ptr;
+ int ret;
+
+ for (ptr = str; *ptr && STOUC(*ptr) < 128 && *ptr != '='; ptr++)
+ ;
+ if (STOUC(*ptr) >= 128) {
+ /*
+ * Environment variables not in the portable character
+ * set are non-standard and we don't really know of
+ * a use for them.
+ *
+ * We'll disable until someone complains.
+ */
+ return 1;
+ } else if (*ptr) {
+ *ptr = '\0';
+ ret = setenv(str, ptr+1, 1);
+ *ptr = '=';
+ } else {
+ /* safety first */
+ DPUTS(1, "bad environment string");
+ ret = setenv(str, ptr, 1);
+ }
+ return ret;
+#else
+#ifdef HAVE_PUTENV
+ return putenv(str);
+#else
+ char **ep;
+ int num_env;
+
+
+ /* First check if there is already an environment *
+ * variable matching string `name'. */
+ if (findenv(str, &num_env)) {
+ environ[num_env] = str;
+ } else {
+ /* Else we have to make room and add it */
+ num_env = arrlen(environ);
+ environ = (char **) zrealloc(environ, (sizeof(char *)) * (num_env + 2));
+
+ /* Now add it at the end */
+ ep = environ + num_env;
+ *ep = str;
+ *(ep + 1) = NULL;
+ }
+ return 0;
+#endif
+#endif
+}
+
+/**/
+#ifndef USE_SET_UNSET_ENV
+/**/
+static int
+findenv(char *name, int *pos)
+{
+ char **ep, *eq;
+ int nlen;
+
+
+ eq = strchr(name, '=');
+ nlen = eq ? eq - name : (int)strlen(name);
+ for (ep = environ; *ep; ep++)
+ if (!strncmp (*ep, name, nlen) && *((*ep)+nlen) == '=') {
+ if (pos)
+ *pos = ep - environ;
+ return 1;
+ }
+
+ return 0;
+}
+/**/
+#endif
+
+/* Given *name = "foo", it searches the environment for string *
+ * "foo=bar", and returns a pointer to the beginning of "bar" */
+
+/**/
+mod_export char *
+zgetenv(char *name)
+{
+#ifdef HAVE_GETENV
+ return getenv(name);
+#else
+ char **ep, *s, *t;
+
+ for (ep = environ; *ep; ep++) {
+ for (s = *ep, t = name; *s && *s == *t; s++, t++);
+ if (*s == '=' && !*t)
+ return s + 1;
+ }
+ return NULL;
+#endif
+}
+
+/**/
+static void
+copyenvstr(char *s, char *value, int flags)
+{
+ while (*s++) {
+ if ((*s = *value++) == Meta)
+ *s = *value++ ^ 32;
+ if (flags & PM_LOWER)
+ *s = tulower(*s);
+ else if (flags & PM_UPPER)
+ *s = tuupper(*s);
+ }
+}
+
+/**/
+void
+addenv(Param pm, char *value)
+{
+ char *newenv = 0;
+#ifndef USE_SET_UNSET_ENV
+ char *oldenv = 0, *env = 0;
+ int pos;
+
+ /*
+ * First check if there is already an environment
+ * variable matching string `name'.
+ */
+ if (findenv(pm->node.nam, &pos))
+ oldenv = environ[pos];
+#endif
+
+ newenv = mkenvstr(pm->node.nam, value, pm->node.flags);
+ if (zputenv(newenv)) {
+ zsfree(newenv);
+ pm->env = NULL;
+ return;
+ }
+#ifdef USE_SET_UNSET_ENV
+ /*
+ * If we are using setenv/unsetenv to manage the environment,
+ * we simply store the string we created in pm->env since
+ * memory management of the environment is handled entirely
+ * by the system.
+ *
+ * TODO: is this good enough to fix problem cases from
+ * the other branch? If so, we don't actually need to
+ * store pm->env at all, just a flag that the value was set.
+ */
+ if (pm->env)
+ zsfree(pm->env);
+ pm->env = newenv;
+ pm->node.flags |= PM_EXPORTED;
+#else
+ /*
+ * Under Cygwin we must use putenv() to maintain consistency.
+ * Unfortunately, current version (1.1.2) copies argument and may
+ * silently reuse existing environment string. This tries to
+ * check for both cases
+ */
+ if (findenv(pm->node.nam, &pos)) {
+ env = environ[pos];
+ if (env != oldenv)
+ zsfree(oldenv);
+ if (env != newenv)
+ zsfree(newenv);
+ pm->node.flags |= PM_EXPORTED;
+ pm->env = env;
+ return;
+ }
+
+ DPUTS(1, "addenv should never reach the end");
+ pm->env = NULL;
+#endif
+}
+
+
+/* Given strings *name = "foo", *value = "bar", *
+ * return a new string *str = "foo=bar". */
+
+/**/
+static char *
+mkenvstr(char *name, char *value, int flags)
+{
+ char *str, *s = value;
+ int len_name, len_value = 0;
+
+ len_name = strlen(name);
+ if (s)
+ while (*s && (*s++ != Meta || *s++ != 32))
+ len_value++;
+ s = str = (char *) zalloc(len_name + len_value + 2);
+ strcpy(s, name);
+ s += len_name;
+ *s = '=';
+ if (value)
+ copyenvstr(s, value, flags);
+ else
+ *++s = '\0';
+ return str;
+}
+
+/* Given *name = "foo", *value = "bar", add the *
+ * string "foo=bar" to the environment. Return a *
+ * pointer to the location of this new environment *
+ * string. */
+
+
+#ifndef USE_SET_UNSET_ENV
+/**/
+void
+delenvvalue(char *x)
+{
+ char **ep;
+
+ for (ep = environ; *ep; ep++) {
+ if (*ep == x)
+ break;
+ }
+ if (*ep) {
+ for (; (ep[0] = ep[1]); ep++);
+ }
+ zsfree(x);
+}
+#endif
+
+
+/* Delete a pointer from the list of pointers to environment *
+ * variables by shifting all the other pointers up one slot. */
+
+/**/
+void
+delenv(Param pm)
+{
+#ifdef USE_SET_UNSET_ENV
+ unsetenv(pm->node.nam);
+ zsfree(pm->env);
+#else
+ delenvvalue(pm->env);
+#endif
+ pm->env = NULL;
+ /*
+ * Note we don't remove PM_EXPORT from the flags. This
+ * may be asking for trouble but we need to know later
+ * if we restore this parameter to its old value.
+ */
+}
+
+/*
+ * Guts of convbase: this version can return the number of digits
+ * sans any base discriminator.
+ */
+
+/**/
+void
+convbase_ptr(char *s, zlong v, int base, int *ndigits)
+{
+ int digs = 0;
+ zulong x;
+
+ if (v < 0)
+ *s++ = '-', v = -v;
+ if (base >= -1 && base <= 1)
+ base = -10;
+
+ if (base > 0) {
+ if (isset(CBASES) && base == 16)
+ sprintf(s, "0x");
+ else if (isset(CBASES) && base == 8 && isset(OCTALZEROES))
+ sprintf(s, "0");
+ else if (base != 10)
+ sprintf(s, "%d#", base);
+ else
+ *s = 0;
+ s += strlen(s);
+ } else
+ base = -base;
+ for (x = v; x; digs++)
+ x /= base;
+ if (!digs)
+ digs = 1;
+ if (ndigits)
+ *ndigits = digs;
+ s[digs--] = '\0';
+ x = v;
+ while (digs >= 0) {
+ int dig = x % base;
+
+ s[digs--] = (dig < 10) ? '0' + dig : dig - 10 + 'A';
+ x /= base;
+ }
+}
+
+/*
+ * Basic conversion of integer to a string given a base.
+ * If 0 base is 10.
+ * If negative no base discriminator is output.
+ */
+
+/**/
+mod_export void
+convbase(char *s, zlong v, int base)
+{
+ convbase_ptr(s, v, base, NULL);
+}
+
+/*
+ * Add underscores to converted integer for readability with given spacing.
+ * s is as for convbase: at least BDIGBUFSIZE.
+ * If underscores were added, returned value with underscores comes from
+ * heap, else the returned value is s.
+ */
+
+/**/
+char *
+convbase_underscore(char *s, zlong v, int base, int underscore)
+{
+ char *retptr, *sptr, *dptr;
+ int ndigits, nunderscore, mod, len;
+
+ convbase_ptr(s, v, base, &ndigits);
+
+ if (underscore <= 0)
+ return s;
+
+ nunderscore = (ndigits - 1) / underscore;
+ if (!nunderscore)
+ return s;
+ len = strlen(s);
+ retptr = zhalloc(len + nunderscore + 1);
+ mod = 0;
+ memcpy(retptr, s, len - ndigits);
+ sptr = s + len;
+ dptr = retptr + len + nunderscore;
+ /* copy the null */
+ *dptr-- = *sptr--;
+ for (;;) {
+ *dptr = *sptr;
+ if (!--ndigits)
+ break;
+ dptr--;
+ sptr--;
+ if (++mod == underscore) {
+ mod = 0;
+ *dptr-- = '_';
+ }
+ }
+
+ return retptr;
+}
+
+/*
+ * Convert a floating point value for output.
+ * Unlike convbase(), this has its own internal storage and returns
+ * a value from the heap.
+ */
+
+/**/
+char *
+convfloat(double dval, int digits, int flags, FILE *fout)
+{
+ char fmt[] = "%.*e";
+ char *prev_locale, *ret;
+
+ /*
+ * The difficulty with the buffer size is that a %f conversion
+ * prints all digits before the decimal point: with 64 bit doubles,
+ * that's around 310. We can't check without doing some quite
+ * serious floating point operations we'd like to avoid.
+ * Then we are liable to get all the digits
+ * we asked for after the decimal point, or we should at least
+ * bargain for it. So we just allocate 512 + digits. This
+ * should work until somebody decides on 128-bit doubles.
+ */
+ if (!(flags & (PM_EFLOAT|PM_FFLOAT))) {
+ /*
+ * Conversion from a floating point expression without using
+ * a variable. The best bet in this case just seems to be
+ * to use the general %g format with something like the maximum
+ * double precision.
+ */
+ fmt[3] = 'g';
+ if (!digits)
+ digits = 17;
+ } else {
+ if (flags & PM_FFLOAT)
+ fmt[3] = 'f';
+ if (digits <= 0)
+ digits = 10;
+ if (flags & PM_EFLOAT) {
+ /*
+ * Here, we are given the number of significant figures, but
+ * %e wants the number of decimal places (unlike %g)
+ */
+ digits--;
+ }
+ }
+#ifdef USE_LOCALE
+ prev_locale = dupstring(setlocale(LC_NUMERIC, NULL));
+ setlocale(LC_NUMERIC, "POSIX");
+#endif
+ if (fout) {
+ fprintf(fout, fmt, digits, dval);
+ ret = NULL;
+ } else {
+ VARARR(char, buf, 512 + digits);
+ if (isinf(dval))
+ ret = dupstring((dval < 0.0) ? "-Inf" : "Inf");
+ else if (isnan(dval))
+ ret = dupstring("NaN");
+ else {
+ sprintf(buf, fmt, digits, dval);
+ if (!strchr(buf, 'e') && !strchr(buf, '.'))
+ strcat(buf, ".");
+ ret = dupstring(buf);
+ }
+ }
+#ifdef USE_LOCALE
+ if (prev_locale) setlocale(LC_NUMERIC, prev_locale);
+#endif
+ return ret;
+}
+
+/*
+ * convert float to string with basic options but inserting underscores
+ * for readability.
+ */
+
+/**/
+char *convfloat_underscore(double dval, int underscore)
+{
+ int ndigits_int = 0, ndigits_frac = 0, nunderscore, len;
+ char *s, *retptr, *sptr, *dptr;
+
+ s = convfloat(dval, 0, 0, NULL);
+ if (underscore <= 0)
+ return s;
+
+ /*
+ * Count the number of digits before and after the decimal point, if any.
+ */
+ sptr = s;
+ if (*sptr == '-')
+ sptr++;
+ while (idigit(*sptr)) {
+ ndigits_int++;
+ sptr++;
+ }
+ if (*sptr == '.') {
+ sptr++;
+ while (idigit(*sptr)) {
+ ndigits_frac++;
+ sptr++;
+ }
+ }
+
+ /*
+ * Work out how many underscores to insert --- remember we
+ * put them in integer and fractional parts separately.
+ */
+ nunderscore = (ndigits_int-1) / underscore + (ndigits_frac-1) / underscore;
+ if (!nunderscore)
+ return s;
+ len = strlen(s);
+ dptr = retptr = zhalloc(len + nunderscore + 1);
+
+ /*
+ * Insert underscores in integer part.
+ * Grouping starts from the point in both directions.
+ */
+ sptr = s;
+ if (*sptr == '-')
+ *dptr++ = *sptr++;
+ while (ndigits_int) {
+ *dptr++ = *sptr++;
+ if (--ndigits_int && !(ndigits_int % underscore))
+ *dptr++ = '_';
+ }
+ if (ndigits_frac) {
+ /*
+ * Insert underscores in the fractional part.
+ */
+ int mod = 0;
+ /* decimal point, we already checked */
+ *dptr++ = *sptr++;
+ while (ndigits_frac) {
+ *dptr++ = *sptr++;
+ mod++;
+ if (--ndigits_frac && mod == underscore) {
+ *dptr++ = '_';
+ mod = 0;
+ }
+ }
+ }
+ /* Copy exponent and anything else up to null */
+ while ((*dptr++ = *sptr++))
+ ;
+ return retptr;
+}
+
+/* Start a parameter scope */
+
+/**/
+mod_export void
+startparamscope(void)
+{
+ locallevel++;
+}
+
+/* End a parameter scope: delete the parameters local to the scope. */
+
+/**/
+mod_export void
+endparamscope(void)
+{
+ queue_signals();
+ locallevel--;
+ /* This pops anything from a higher locallevel */
+ saveandpophiststack(0, HFILE_USE_OPTIONS);
+ scanhashtable(paramtab, 0, 0, 0, scanendscope, 0);
+ unqueue_signals();
+}
+
+/**/
+static void
+scanendscope(HashNode hn, UNUSED(int flags))
+{
+ Param pm = (Param)hn;
+ if (pm->level > locallevel) {
+ if ((pm->node.flags & (PM_SPECIAL|PM_REMOVABLE)) == PM_SPECIAL) {
+ /*
+ * Removable specials are normal in that they can be removed
+ * to reveal an ordinary parameter beneath. Here we handle
+ * non-removable specials, which were made local by stealth
+ * (see newspecial code in typeset_single()). In fact the
+ * visible pm is always the same struct; the pm->old is
+ * just a place holder for old data and flags.
+ */
+ Param tpm = pm->old;
+
+ if (!strcmp(pm->node.nam, "SECONDS"))
+ {
+ setsecondstype(pm, PM_TYPE(tpm->node.flags), PM_TYPE(pm->node.flags));
+ /*
+ * We restore SECONDS by restoring its raw internal value
+ * that we cached off into tpm->u.dval.
+ */
+ setrawseconds(tpm->u.dval);
+ tpm->node.flags |= PM_NORESTORE;
+ }
+ DPUTS(!tpm || PM_TYPE(pm->node.flags) != PM_TYPE(tpm->node.flags) ||
+ !(tpm->node.flags & PM_SPECIAL),
+ "BUG: in restoring scope of special parameter");
+ pm->old = tpm->old;
+ pm->node.flags = (tpm->node.flags & ~PM_NORESTORE);
+ pm->level = tpm->level;
+ pm->base = tpm->base;
+ pm->width = tpm->width;
+ if (pm->env)
+ delenv(pm);
+
+ if (!(tpm->node.flags & (PM_NORESTORE|PM_READONLY)))
+ switch (PM_TYPE(pm->node.flags)) {
+ case PM_SCALAR:
+ pm->gsu.s->setfn(pm, tpm->u.str);
+ break;
+ case PM_INTEGER:
+ pm->gsu.i->setfn(pm, tpm->u.val);
+ break;
+ case PM_EFLOAT:
+ case PM_FFLOAT:
+ pm->gsu.f->setfn(pm, tpm->u.dval);
+ break;
+ case PM_ARRAY:
+ pm->gsu.a->setfn(pm, tpm->u.arr);
+ break;
+ case PM_HASHED:
+ pm->gsu.h->setfn(pm, tpm->u.hash);
+ break;
+ }
+ zfree(tpm, sizeof(*tpm));
+
+ if (pm->node.flags & PM_EXPORTED)
+ export_param(pm);
+ } else
+ unsetparam_pm(pm, 0, 0);
+ }
+}
+
+
+/**********************************/
+/* Parameter Hash Table Functions */
+/**********************************/
+
+/**/
+void
+freeparamnode(HashNode hn)
+{
+ Param pm = (Param) hn;
+
+ /* The second argument of unsetfn() is used by modules to
+ * differentiate "exp"licit unset from implicit unset, as when
+ * a parameter is going out of scope. It's not clear which
+ * of these applies here, but passing 1 has always worked.
+ */
+ if (delunset)
+ pm->gsu.s->unsetfn(pm, 1);
+ zsfree(pm->node.nam);
+ /* If this variable was tied by the user, ename was ztrdup'd */
+ if (pm->node.flags & PM_TIED)
+ zsfree(pm->ename);
+ zfree(pm, sizeof(struct param));
+}
+
+/* Print a parameter */
+
+enum paramtypes_flags {
+ PMTF_USE_BASE = (1<<0),
+ PMTF_USE_WIDTH = (1<<1),
+ PMTF_TEST_LEVEL = (1<<2)
+};
+
+struct paramtypes {
+ int binflag; /* The relevant PM_FLAG(S) */
+ const char *string; /* String for verbose output */
+ int typeflag; /* Flag for typeset -? */
+ int flags; /* The enum above */
+};
+
+static const struct paramtypes pmtypes[] = {
+ { PM_AUTOLOAD, "undefined", 0, 0},
+ { PM_INTEGER, "integer", 'i', PMTF_USE_BASE},
+ { PM_EFLOAT, "float", 'E', 0},
+ { PM_FFLOAT, "float", 'F', 0},
+ { PM_ARRAY, "array", 'a', 0},
+ { PM_HASHED, "association", 'A', 0},
+ { 0, "local", 0, PMTF_TEST_LEVEL},
+ { PM_LEFT, "left justified", 'L', PMTF_USE_WIDTH},
+ { PM_RIGHT_B, "right justified", 'R', PMTF_USE_WIDTH},
+ { PM_RIGHT_Z, "zero filled", 'Z', PMTF_USE_WIDTH},
+ { PM_LOWER, "lowercase", 'l', 0},
+ { PM_UPPER, "uppercase", 'u', 0},
+ { PM_READONLY, "readonly", 'r', 0},
+ { PM_TAGGED, "tagged", 't', 0},
+ { PM_EXPORTED, "exported", 'x', 0}
+};
+
+#define PMTYPES_SIZE ((int)(sizeof(pmtypes)/sizeof(struct paramtypes)))
+
+static void
+printparamvalue(Param p, int printflags)
+{
+ char *t, **u;
+
+ if (!(printflags & PRINT_KV_PAIR))
+ putchar('=');
+
+ /* How the value is displayed depends *
+ * on the type of the parameter */
+ switch (PM_TYPE(p->node.flags)) {
+ case PM_SCALAR:
+ /* string: simple output */
+ if (p->gsu.s->getfn && (t = p->gsu.s->getfn(p)))
+ quotedzputs(t, stdout);
+ break;
+ case PM_INTEGER:
+ /* integer */
+#ifdef ZSH_64_BIT_TYPE
+ fputs(output64(p->gsu.i->getfn(p)), stdout);
+#else
+ printf("%ld", p->gsu.i->getfn(p));
+#endif
+ break;
+ case PM_EFLOAT:
+ case PM_FFLOAT:
+ /* float */
+ convfloat(p->gsu.f->getfn(p), p->base, p->node.flags, stdout);
+ break;
+ case PM_ARRAY:
+ /* array */
+ if (!(printflags & PRINT_KV_PAIR)) {
+ putchar('(');
+ if (!(printflags & PRINT_LINE))
+ putchar(' ');
+ }
+ u = p->gsu.a->getfn(p);
+ if(*u) {
+ if (printflags & PRINT_LINE) {
+ if (printflags & PRINT_KV_PAIR)
+ printf(" ");
+ else
+ printf("\n ");
+ }
+ quotedzputs(*u++, stdout);
+ while (*u) {
+ if (printflags & PRINT_LINE)
+ printf("\n ");
+ else
+ putchar(' ');
+ quotedzputs(*u++, stdout);
+ }
+ if ((printflags & (PRINT_LINE|PRINT_KV_PAIR)) == PRINT_LINE)
+ putchar('\n');
+ }
+ if (!(printflags & PRINT_KV_PAIR)) {
+ if (!(printflags & PRINT_LINE))
+ putchar(' ');
+ putchar(')');
+ }
+ break;
+ case PM_HASHED:
+ /* association */
+ {
+ HashTable ht;
+ int found = 0;
+ if (!(printflags & PRINT_KV_PAIR)) {
+ putchar('(');
+ if (!(printflags & PRINT_LINE))
+ putchar(' ');
+ }
+ ht = p->gsu.h->getfn(p);
+ if (ht)
+ found = scanhashtable(ht, 1, 0, PM_UNSET,
+ ht->printnode, PRINT_KV_PAIR |
+ (printflags & PRINT_LINE));
+ if (!(printflags & PRINT_KV_PAIR)) {
+ if (found && (printflags & PRINT_LINE))
+ putchar('\n');
+ putchar(')');
+ }
+ }
+ break;
+ }
+ if ((printflags & (PRINT_KV_PAIR|PRINT_LINE)) == PRINT_KV_PAIR)
+ putchar(' ');
+ else if (!(printflags & PRINT_KV_PAIR))
+ putchar('\n');
+}
+
+/**/
+mod_export void
+printparamnode(HashNode hn, int printflags)
+{
+ Param p = (Param) hn;
+
+ if (p->node.flags & PM_UNSET) {
+ if (isset(POSIXBUILTINS) && (p->node.flags & PM_READONLY) &&
+ (printflags & PRINT_TYPESET))
+ {
+ /*
+ * Special POSIX rules: show the parameter as readonly
+ * even though it's unset, but with no value.
+ */
+ printflags |= PRINT_NAMEONLY;
+ }
+ else if (p->node.flags & PM_EXPORTED)
+ printflags |= PRINT_NAMEONLY;
+ else
+ return;
+ }
+ if (p->node.flags & PM_AUTOLOAD)
+ printflags |= PRINT_NAMEONLY;
+
+ if (printflags & PRINT_TYPESET) {
+ if ((p->node.flags & (PM_READONLY|PM_SPECIAL)) ==
+ (PM_READONLY|PM_SPECIAL) ||
+ (p->node.flags & PM_AUTOLOAD)) {
+ /*
+ * It's not possible to restore the state of
+ * these, so don't output.
+ */
+ return;
+ }
+ if (locallevel && p->level >= locallevel) {
+ printf("typeset "); /* printf("local "); */
+ } else if ((p->node.flags & PM_EXPORTED) &&
+ !(p->node.flags & (PM_ARRAY|PM_HASHED))) {
+ printf("export ");
+ } else if (locallevel) {
+ printf("typeset -g ");
+ } else
+ printf("typeset ");
+ }
+
+ /* Print the attributes of the parameter */
+ if (printflags & (PRINT_TYPE|PRINT_TYPESET)) {
+ int doneminus = 0, i;
+ const struct paramtypes *pmptr;
+
+ for (pmptr = pmtypes, i = 0; i < PMTYPES_SIZE; i++, pmptr++) {
+ int doprint = 0;
+ if (pmptr->flags & PMTF_TEST_LEVEL) {
+ if (p->level)
+ doprint = 1;
+ } else if ((pmptr->binflag != PM_EXPORTED || p->level ||
+ (p->node.flags & (PM_LOCAL|PM_ARRAY|PM_HASHED))) &&
+ (p->node.flags & pmptr->binflag))
+ doprint = 1;
+
+ if (doprint) {
+ if (printflags & PRINT_TYPESET) {
+ if (pmptr->typeflag) {
+ if (!doneminus) {
+ putchar('-');
+ doneminus = 1;
+ }
+ putchar(pmptr->typeflag);
+ }
+ } else
+ printf("%s ", pmptr->string);
+ if ((pmptr->flags & PMTF_USE_BASE) && p->base) {
+ printf("%d ", p->base);
+ doneminus = 0;
+ }
+ if ((pmptr->flags & PMTF_USE_WIDTH) && p->width) {
+ printf("%d ", p->width);
+ doneminus = 0;
+ }
+ }
+ }
+ if (doneminus)
+ putchar(' ');
+ }
+
+ if ((printflags & PRINT_NAMEONLY) ||
+ ((p->node.flags & PM_HIDEVAL) && !(printflags & PRINT_INCLUDEVALUE))) {
+ zputs(p->node.nam, stdout);
+ putchar('\n');
+ } else {
+ if (printflags & PRINT_KV_PAIR) {
+ if (printflags & PRINT_LINE)
+ printf("\n ");
+ putchar('[');
+ }
+ quotedzputs(p->node.nam, stdout);
+ if (printflags & PRINT_KV_PAIR)
+ printf("]=");
+
+ printparamvalue(p, printflags);
+ }
+}
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/parse.c b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/parse.c
new file mode 100644
index 0000000..83383f1
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/parse.c
@@ -0,0 +1,3977 @@
+/*
+ * parse.c - parser
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+#include "zsh.mdh"
+#include "parse.pro"
+
+/* != 0 if we are about to read a command word */
+
+/**/
+mod_export int incmdpos;
+
+/**/
+int aliasspaceflag;
+
+/* != 0 if we are in the middle of a [[ ... ]] */
+
+/**/
+mod_export int incond;
+
+/* != 0 if we are after a redirection (for ctxtlex only) */
+
+/**/
+mod_export int inredir;
+
+/*
+ * 1 if we are about to read a case pattern
+ * -1 if we are not quite sure
+ * 0 otherwise
+ */
+
+/**/
+int incasepat;
+
+/* != 0 if we just read a newline */
+
+/**/
+int isnewlin;
+
+/* != 0 if we are after a for keyword */
+
+/**/
+int infor;
+
+/* != 0 if we are after a repeat keyword; if it's nonzero it's a 1-based index
+ * of the current token from the last-seen command position */
+
+/**/
+int inrepeat_; /* trailing underscore because of name clash with Zle/zle_vi.c */
+
+/* != 0 if parsing arguments of typeset etc. */
+
+/**/
+mod_export int intypeset;
+
+/* list of here-documents */
+
+/**/
+struct heredocs *hdocs;
+
+
+#define YYERROR(O) { tok = LEXERR; ecused = (O); return 0; }
+#define YYERRORV(O) { tok = LEXERR; ecused = (O); return; }
+#define COND_ERROR(X,Y) \
+ do { \
+ zwarn(X,Y); \
+ herrflush(); \
+ if (noerrs != 2) \
+ errflag |= ERRFLAG_ERROR; \
+ YYERROR(ecused) \
+ } while(0)
+
+
+/*
+ * Word code.
+ *
+ * The parser now produces word code, reducing memory consumption compared
+ * to the nested structs we had before.
+ *
+ * Word code layout:
+ *
+ * WC_END
+ * - end of program code
+ *
+ * WC_LIST
+ * - data contains type (sync, ...)
+ * - followed by code for this list
+ * - if not (type & Z_END), followed by next WC_LIST
+ *
+ * WC_SUBLIST
+ * - data contains type (&&, ||, END) and flags (coprog, not)
+ * - followed by code for sublist
+ * - if not (type == END), followed by next WC_SUBLIST
+ *
+ * WC_PIPE
+ * - data contains type (end, mid) and LINENO
+ * - if not (type == END), followed by offset to next WC_PIPE
+ * - followed by command
+ * - if not (type == END), followed by next WC_PIPE
+ *
+ * WC_REDIR
+ * - must precede command-code (or WC_ASSIGN)
+ * - data contains type (<, >, ...)
+ * - followed by fd1 and name from struct redir
+ * - for the extended form {var}>... where the fd is assigned
+ * to var, there is an extra item to contain var
+ *
+ * WC_ASSIGN
+ * - data contains type (scalar, array) and number of array-elements
+ * - followed by name and value
+ * Note variant for WC_TYPESET assignments: WC_ASSIGN_INC indicates
+ * a name with no equals, not an =+ which isn't valid here.
+ *
+ * WC_SIMPLE
+ * - data contains the number of arguments (plus command)
+ * - followed by strings
+ *
+ * WC_TYPESET
+ * Variant of WC_SIMPLE used when TYPESET reserved word found.
+ * - data contains the number of string arguments (plus command)
+ * - followed by strings
+ * - followed by number of assignments
+ * - followed by assignments if non-zero number.
+ *
+ * WC_SUBSH
+ * - data unused
+ * - followed by list
+ *
+ * WC_CURSH
+ * - data unused
+ * - followed by list
+ *
+ * WC_TIMED
+ * - data contains type (followed by pipe or not)
+ * - if (type == PIPE), followed by pipe
+ *
+ * WC_FUNCDEF
+ * - data contains offset to after body
+ * - followed by number of names
+ * - followed by names
+ * - followed by offset to first string
+ * - followed by length of string table
+ * - followed by number of patterns for body
+ * - followed by codes for body
+ * - followed by strings for body
+ *
+ * WC_FOR
+ * - data contains type (list, ...) and offset to after body
+ * - if (type == COND), followed by init, cond, advance expressions
+ * - else if (type == PPARAM), followed by param name
+ * - else if (type == LIST), followed by param name, num strings, strings
+ * - followed by body
+ *
+ * WC_SELECT
+ * - data contains type (list, ...) and offset to after body
+ * - if (type == PPARAM), followed by param name
+ * - else if (type == LIST), followed by param name, num strings, strings
+ * - followed by body
+ *
+ * WC_WHILE
+ * - data contains type (while, until) and offset to after body
+ * - followed by condition
+ * - followed by body
+ *
+ * WC_REPEAT
+ * - data contains offset to after body
+ * - followed by number-string
+ * - followed by body
+ *
+ * WC_CASE
+ * - first CASE is always of type HEAD, data contains offset to esac
+ * - after that CASEs of type OR (;;), AND (;&) and TESTAND (;|),
+ * data is offset to next case
+ * - each OR/AND/TESTAND case is followed by pattern, pattern-number, list
+ *
+ * WC_IF
+ * - first IF is of type HEAD, data contains offset to fi
+ * - after that IFs of type IF, ELIF, ELSE, data is offset to next
+ * - each non-HEAD is followed by condition (only IF, ELIF) and body
+ *
+ * WC_COND
+ * - data contains type
+ * - if (type == AND/OR), data contains offset to after this one,
+ * followed by two CONDs
+ * - else if (type == NOT), followed by COND
+ * - else if (type == MOD), followed by name and strings
+ * - else if (type == MODI), followed by name, left, right
+ * - else if (type == STR[N]EQ), followed by left, right, pattern-number
+ * - else if (has two args) followed by left, right
+ * - else followed by string
+ *
+ * WC_ARITH
+ * - followed by string (there's only one)
+ *
+ * WC_AUTOFN
+ * - only used by the autoload builtin
+ *
+ * Lists and sublists may also be simplified, indicated by the presence
+ * of the Z_SIMPLE or WC_SUBLIST_SIMPLE flags. In this case they are only
+ * followed by a slot containing the line number, not by a WC_SUBLIST or
+ * WC_PIPE, respectively. The real advantage of simplified lists and
+ * sublists is that they can be executed faster, see exec.c. In the
+ * parser, the test if a list can be simplified is done quite simply
+ * by passing a int* around which gets set to non-zero if the thing
+ * just parsed is `cmplx', i.e. may need to be run by forking or
+ * some such.
+ *
+ * In each of the above, strings are encoded as one word code. For empty
+ * strings this is the bit pattern 11x, the lowest bit is non-zero if the
+ * string contains tokens and zero otherwise (this is true for the other
+ * ways to encode strings, too). For short strings (one to three
+ * characters), this is the marker 01x with the 24 bits above that
+ * containing the characters. Longer strings are encoded as the offset
+ * into the strs character array stored in the eprog struct shifted by
+ * two and ored with the bit pattern 0x.
+ * The ecstrcode() function that adds the code for a string uses a simple
+ * binary tree of strings already added so that long strings are encoded
+ * only once.
+ *
+ * Note also that in the eprog struct the pattern, code, and string
+ * arrays all point to the same memory block.
+ *
+ *
+ * To make things even faster in future versions, we could not only
+ * test if the strings contain tokens, but instead what kind of
+ * expansions need to be done on strings. In the execution code we
+ * could then use these flags for a specialized version of prefork()
+ * to avoid a lot of string parsing and some more string duplication.
+ */
+
+/**/
+int eclen, ecused, ecnpats;
+/**/
+Wordcode ecbuf;
+/**/
+Eccstr ecstrs;
+/**/
+int ecsoffs, ecssub, ecnfunc;
+
+#define EC_INIT_SIZE 256
+#define EC_DOUBLE_THRESHOLD 32768
+#define EC_INCREMENT 1024
+
+/* save parse context */
+
+/**/
+void
+parse_context_save(struct parse_stack *ps, int toplevel)
+{
+ (void)toplevel;
+
+ ps->incmdpos = incmdpos;
+ ps->aliasspaceflag = aliasspaceflag;
+ ps->incond = incond;
+ ps->inredir = inredir;
+ ps->incasepat = incasepat;
+ ps->isnewlin = isnewlin;
+ ps->infor = infor;
+ ps->inrepeat_ = inrepeat_;
+ ps->intypeset = intypeset;
+
+ ps->hdocs = hdocs;
+ ps->eclen = eclen;
+ ps->ecused = ecused;
+ ps->ecnpats = ecnpats;
+ ps->ecbuf = ecbuf;
+ ps->ecstrs = ecstrs;
+ ps->ecsoffs = ecsoffs;
+ ps->ecssub = ecssub;
+ ps->ecnfunc = ecnfunc;
+ ecbuf = NULL;
+ hdocs = NULL;
+}
+
+/* restore parse context */
+
+/**/
+void
+parse_context_restore(const struct parse_stack *ps, int toplevel)
+{
+ (void)toplevel;
+
+ if (ecbuf)
+ zfree(ecbuf, eclen);
+
+ incmdpos = ps->incmdpos;
+ aliasspaceflag = ps->aliasspaceflag;
+ incond = ps->incond;
+ inredir = ps->inredir;
+ incasepat = ps->incasepat;
+ isnewlin = ps->isnewlin;
+ infor = ps->infor;
+ inrepeat_ = ps->inrepeat_;
+ intypeset = ps->intypeset;
+
+ hdocs = ps->hdocs;
+ eclen = ps->eclen;
+ ecused = ps->ecused;
+ ecnpats = ps->ecnpats;
+ ecbuf = ps->ecbuf;
+ ecstrs = ps->ecstrs;
+ ecsoffs = ps->ecsoffs;
+ ecssub = ps->ecssub;
+ ecnfunc = ps->ecnfunc;
+
+ errflag &= ~ERRFLAG_ERROR;
+}
+
+/* Adjust pointers in here-doc structs. */
+
+static void
+ecadjusthere(int p, int d)
+{
+ struct heredocs *h;
+
+ for (h = hdocs; h; h = h->next)
+ if (h->pc >= p)
+ h->pc += d;
+}
+
+/* Insert n free code-slots at position p. */
+
+static void
+ecispace(int p, int n)
+{
+ int m;
+
+ if ((eclen - ecused) < n) {
+ int a = (eclen < EC_DOUBLE_THRESHOLD ? eclen : EC_INCREMENT);
+
+ if (n > a) a = n;
+
+ ecbuf = (Wordcode) zrealloc((char *) ecbuf, (eclen + a) * sizeof(wordcode));
+ eclen += a;
+ }
+ if ((m = ecused - p) > 0)
+ memmove(ecbuf + p + n, ecbuf + p, m * sizeof(wordcode));
+ ecused += n;
+ ecadjusthere(p, n);
+}
+
+/* Add one wordcode. */
+
+static int
+ecadd(wordcode c)
+{
+ if ((eclen - ecused) < 1) {
+ int a = (eclen < EC_DOUBLE_THRESHOLD ? eclen : EC_INCREMENT);
+
+ ecbuf = (Wordcode) zrealloc((char *) ecbuf, (eclen + a) * sizeof(wordcode));
+ eclen += a;
+ }
+ ecbuf[ecused] = c;
+
+ return ecused++;
+}
+
+/* Delete a wordcode. */
+
+static void
+ecdel(int p)
+{
+ int n = ecused - p - 1;
+
+ if (n > 0)
+ memmove(ecbuf + p, ecbuf + p + 1, n * sizeof(wordcode));
+ ecused--;
+ ecadjusthere(p, -1);
+}
+
+/* Build the wordcode for a string. */
+
+static wordcode
+ecstrcode(char *s)
+{
+ int l, t;
+
+ unsigned val = hasher(s);
+
+ if ((l = strlen(s) + 1) && l <= 4) {
+ t = has_token(s);
+ wordcode c = (t ? 3 : 2);
+ switch (l) {
+ case 4: c |= ((wordcode) STOUC(s[2])) << 19;
+ case 3: c |= ((wordcode) STOUC(s[1])) << 11;
+ case 2: c |= ((wordcode) STOUC(s[0])) << 3; break;
+ case 1: c = (t ? 7 : 6); break;
+ }
+ return c;
+ } else {
+ Eccstr p, *pp;
+ int cmp;
+
+ for (pp = &ecstrs; (p = *pp); ) {
+ if (!(cmp = p->nfunc - ecnfunc) && !(cmp = (((signed)p->hashval) - ((signed)val))) && !(cmp = strcmp(p->str, s))) {
+ return p->offs;
+ }
+ pp = (cmp < 0 ? &(p->left) : &(p->right));
+ }
+
+ t = has_token(s);
+
+ p = *pp = (Eccstr) zhalloc(sizeof(*p));
+ p->left = p->right = 0;
+ p->offs = ((ecsoffs - ecssub) << 2) | (t ? 1 : 0);
+ p->aoffs = ecsoffs;
+ p->str = s;
+ p->nfunc = ecnfunc;
+ p->hashval = val;
+ ecsoffs += l;
+
+ return p->offs;
+ }
+}
+
+#define ecstr(S) ecadd(ecstrcode(S))
+
+#define par_save_list(C) \
+ do { \
+ int eu = ecused; \
+ par_list(C); \
+ if (eu == ecused) ecadd(WCB_END()); \
+ } while (0)
+#define par_save_list1(C) \
+ do { \
+ int eu = ecused; \
+ par_list1(C); \
+ if (eu == ecused) ecadd(WCB_END()); \
+ } while (0)
+
+
+/**/
+mod_export void
+init_parse_status(void)
+{
+ /*
+ * These variables are currently declared by the parser, so we
+ * initialise them here. Possibly they are more naturally declared
+ * by the lexical anaylser; however, as they are used for signalling
+ * between the two it's a bit ambiguous. We clear them when
+ * using the lexical analyser for strings as well as here.
+ */
+ incasepat = incond = inredir = infor = intypeset = 0;
+ inrepeat_ = 0;
+ incmdpos = 1;
+}
+
+/* Initialise wordcode buffer. */
+
+/**/
+void
+init_parse(void)
+{
+ queue_signals();
+
+ if (ecbuf) zfree(ecbuf, eclen);
+
+ ecbuf = (Wordcode) zalloc((eclen = EC_INIT_SIZE) * sizeof(wordcode));
+ ecused = 0;
+ ecstrs = NULL;
+ ecsoffs = ecnpats = 0;
+ ecssub = 0;
+ ecnfunc = 0;
+
+ init_parse_status();
+
+ unqueue_signals();
+}
+
+/* Build eprog. */
+
+/* careful: copy_ecstr is from arg1 to arg2, unlike memcpy */
+
+static void
+copy_ecstr(Eccstr s, char *p)
+{
+ while (s) {
+ memcpy(p + s->aoffs, s->str, strlen(s->str) + 1);
+ copy_ecstr(s->left, p);
+ s = s->right;
+ }
+}
+
+static Eprog
+bld_eprog(int heap)
+{
+ Eprog ret;
+ int l;
+
+ queue_signals();
+
+ ecadd(WCB_END());
+
+ ret = heap ? (Eprog) zhalloc(sizeof(*ret)) : (Eprog) zalloc(sizeof(*ret));
+ ret->len = ((ecnpats * sizeof(Patprog)) +
+ (ecused * sizeof(wordcode)) +
+ ecsoffs);
+ ret->npats = ecnpats;
+ ret->nref = heap ? -1 : 1;
+ ret->pats = heap ? (Patprog *) zhalloc(ret->len) :
+ (Patprog *) zshcalloc(ret->len);
+ ret->prog = (Wordcode) (ret->pats + ecnpats);
+ ret->strs = (char *) (ret->prog + ecused);
+ ret->shf = NULL;
+ ret->flags = heap ? EF_HEAP : EF_REAL;
+ ret->dump = NULL;
+ for (l = 0; l < ecnpats; l++)
+ ret->pats[l] = dummy_patprog1;
+ memcpy(ret->prog, ecbuf, ecused * sizeof(wordcode));
+ copy_ecstr(ecstrs, ret->strs);
+
+ zfree(ecbuf, eclen);
+ ecbuf = NULL;
+
+ unqueue_signals();
+
+ return ret;
+}
+
+/**/
+mod_export int
+empty_eprog(Eprog p)
+{
+ return (!p || !p->prog || *p->prog == WCB_END());
+}
+
+static void
+clear_hdocs(void)
+{
+ struct heredocs *p, *n;
+
+ for (p = hdocs; p; p = n) {
+ n = p->next;
+ zfree(p, sizeof(struct heredocs));
+ }
+ hdocs = NULL;
+}
+
+/*
+ * event : ENDINPUT
+ * | SEPER
+ * | sublist [ SEPER | AMPER | AMPERBANG ]
+ *
+ * cmdsubst indicates our event is part of a command-style
+ * substitution terminated by the token indicationg, usual closing
+ * parenthesis. In other cases endtok is ENDINPUT.
+ */
+
+/**/
+Eprog
+parse_event(int endtok)
+{
+ tok = ENDINPUT;
+ incmdpos = 1;
+ aliasspaceflag = 0;
+ zshlex();
+ init_parse();
+
+ if (!par_event(endtok)) {
+ clear_hdocs();
+ return NULL;
+ }
+ if (endtok != ENDINPUT) {
+ /* don't need to build an eprog for this */
+ return &dummy_eprog;
+ }
+ return bld_eprog(1);
+}
+
+/**/
+int
+par_event(int endtok)
+{
+ int r = 0, p, c = 0;
+
+ while (tok == SEPER) {
+ if (isnewlin > 0 && endtok == ENDINPUT)
+ return 0;
+ zshlex();
+ }
+ if (tok == ENDINPUT)
+ return 0;
+ if (tok == endtok)
+ return 1;
+
+ p = ecadd(0);
+
+ if (par_sublist(&c)) {
+ if (tok == ENDINPUT || tok == endtok) {
+ set_list_code(p, Z_SYNC, c);
+ r = 1;
+ } else if (tok == SEPER) {
+ set_list_code(p, Z_SYNC, c);
+ if (isnewlin <= 0 || endtok != ENDINPUT)
+ zshlex();
+ r = 1;
+ } else if (tok == AMPER) {
+ set_list_code(p, Z_ASYNC, c);
+ zshlex();
+ r = 1;
+ } else if (tok == AMPERBANG) {
+ set_list_code(p, (Z_ASYNC | Z_DISOWN), c);
+ zshlex();
+ r = 1;
+ }
+ }
+ if (!r) {
+ tok = LEXERR;
+ if (errflag) {
+ yyerror(0);
+ ecused--;
+ return 0;
+ }
+ yyerror(1);
+ herrflush();
+ if (noerrs != 2)
+ errflag |= ERRFLAG_ERROR;
+ ecused--;
+ return 0;
+ } else {
+ int oec = ecused;
+
+ if (!par_event(endtok)) {
+ ecused = oec;
+ ecbuf[p] |= wc_bdata(Z_END);
+ return errflag ? 0 : 1;
+ }
+ }
+ return 1;
+}
+
+/**/
+mod_export Eprog
+parse_list(void)
+{
+ int c = 0;
+
+ tok = ENDINPUT;
+ init_parse();
+ zshlex();
+ par_list(&c);
+ if (tok != ENDINPUT) {
+ clear_hdocs();
+ tok = LEXERR;
+ yyerror(0);
+ return NULL;
+ }
+ return bld_eprog(1);
+}
+
+/*
+ * This entry point is only used for bin_test, our attempt to
+ * provide compatibility with /bin/[ and /bin/test. Hence
+ * at this point condlex should always be set to testlex.
+ */
+
+/**/
+mod_export Eprog
+parse_cond(void)
+{
+ init_parse();
+
+ if (!par_cond()) {
+ clear_hdocs();
+ return NULL;
+ }
+ return bld_eprog(1);
+}
+
+/* This adds a list wordcode. The important bit about this is that it also
+ * tries to optimise this to a Z_SIMPLE list code. */
+
+/**/
+static void
+set_list_code(int p, int type, int cmplx)
+{
+ if (!cmplx && (type == Z_SYNC || type == (Z_SYNC | Z_END)) &&
+ WC_SUBLIST_TYPE(ecbuf[p + 1]) == WC_SUBLIST_END) {
+ int ispipe = !(WC_SUBLIST_FLAGS(ecbuf[p + 1]) & WC_SUBLIST_SIMPLE);
+ ecbuf[p] = WCB_LIST((type | Z_SIMPLE), ecused - 2 - p);
+ ecdel(p + 1);
+ if (ispipe)
+ ecbuf[p + 1] = WC_PIPE_LINENO(ecbuf[p + 1]);
+ } else
+ ecbuf[p] = WCB_LIST(type, 0);
+}
+
+/* The same for sublists. */
+
+/**/
+static void
+set_sublist_code(int p, int type, int flags, int skip, int cmplx)
+{
+ if (cmplx)
+ ecbuf[p] = WCB_SUBLIST(type, flags, skip);
+ else {
+ ecbuf[p] = WCB_SUBLIST(type, (flags | WC_SUBLIST_SIMPLE), skip);
+ ecbuf[p + 1] = WC_PIPE_LINENO(ecbuf[p + 1]);
+ }
+}
+
+/*
+ * list : { SEPER } [ sublist [ { SEPER | AMPER | AMPERBANG } list ] ]
+ */
+
+/**/
+static void
+par_list(int *cmplx)
+{
+ int p, lp = -1, c;
+
+ rec:
+
+ while (tok == SEPER)
+ zshlex();
+
+ p = ecadd(0);
+ c = 0;
+
+ if (par_sublist(&c)) {
+ *cmplx |= c;
+ if (tok == SEPER || tok == AMPER || tok == AMPERBANG) {
+ if (tok != SEPER)
+ *cmplx = 1;
+ set_list_code(p, ((tok == SEPER) ? Z_SYNC :
+ (tok == AMPER) ? Z_ASYNC :
+ (Z_ASYNC | Z_DISOWN)), c);
+ incmdpos = 1;
+ do {
+ zshlex();
+ } while (tok == SEPER);
+ lp = p;
+ goto rec;
+ } else
+ set_list_code(p, (Z_SYNC | Z_END), c);
+ } else {
+ ecused--;
+ if (lp >= 0)
+ ecbuf[lp] |= wc_bdata(Z_END);
+ }
+}
+
+/**/
+static void
+par_list1(int *cmplx)
+{
+ int p = ecadd(0), c = 0;
+
+ if (par_sublist(&c)) {
+ set_list_code(p, (Z_SYNC | Z_END), c);
+ *cmplx |= c;
+ } else
+ ecused--;
+}
+
+/*
+ * sublist : sublist2 [ ( DBAR | DAMPER ) { SEPER } sublist ]
+ */
+
+/**/
+static int
+par_sublist(int *cmplx)
+{
+ int f, p, c = 0;
+
+ p = ecadd(0);
+
+ if ((f = par_sublist2(&c)) != -1) {
+ int e = ecused;
+
+ *cmplx |= c;
+ if (tok == DBAR || tok == DAMPER) {
+ enum lextok qtok = tok;
+ int sl;
+
+ cmdpush(tok == DBAR ? CS_CMDOR : CS_CMDAND);
+ zshlex();
+ while (tok == SEPER)
+ zshlex();
+ sl = par_sublist(cmplx);
+ set_sublist_code(p, (sl ? (qtok == DBAR ?
+ WC_SUBLIST_OR : WC_SUBLIST_AND) :
+ WC_SUBLIST_END),
+ f, (e - 1 - p), c);
+ cmdpop();
+ } else {
+ if (tok == AMPER || tok == AMPERBANG) {
+ c = 1;
+ *cmplx |= c;
+ }
+ set_sublist_code(p, WC_SUBLIST_END, f, (e - 1 - p), c);
+ }
+ return 1;
+ } else {
+ ecused--;
+ return 0;
+ }
+}
+
+/*
+ * sublist2 : [ COPROC | BANG ] pline
+ */
+
+/**/
+static int
+par_sublist2(int *cmplx)
+{
+ int f = 0;
+
+ if (tok == COPROC) {
+ *cmplx = 1;
+ f |= WC_SUBLIST_COPROC;
+ zshlex();
+ } else if (tok == BANG) {
+ *cmplx = 1;
+ f |= WC_SUBLIST_NOT;
+ zshlex();
+ }
+ if (!par_pline(cmplx) && !f)
+ return -1;
+
+ return f;
+}
+
+/*
+ * pline : cmd [ ( BAR | BARAMP ) { SEPER } pline ]
+ */
+
+/**/
+static int
+par_pline(int *cmplx)
+{
+ int p;
+ zlong line = toklineno;
+
+ p = ecadd(0);
+
+ if (!par_cmd(cmplx, 0)) {
+ ecused--;
+ return 0;
+ }
+ if (tok == BAR) {
+ *cmplx = 1;
+ cmdpush(CS_PIPE);
+ zshlex();
+ while (tok == SEPER)
+ zshlex();
+ ecbuf[p] = WCB_PIPE(WC_PIPE_MID, (line >= 0 ? line + 1 : 0));
+ ecispace(p + 1, 1);
+ ecbuf[p + 1] = ecused - 1 - p;
+ if (!par_pline(cmplx)) {
+ tok = LEXERR;
+ }
+ cmdpop();
+ return 1;
+ } else if (tok == BARAMP) {
+ int r;
+
+ for (r = p + 1; wc_code(ecbuf[r]) == WC_REDIR;
+ r += WC_REDIR_WORDS(ecbuf[r]));
+
+ ecispace(r, 3);
+ ecbuf[r] = WCB_REDIR(REDIR_MERGEOUT);
+ ecbuf[r + 1] = 2;
+ ecbuf[r + 2] = ecstrcode("1");
+
+ *cmplx = 1;
+ cmdpush(CS_ERRPIPE);
+ zshlex();
+ while (tok == SEPER)
+ zshlex();
+ ecbuf[p] = WCB_PIPE(WC_PIPE_MID, (line >= 0 ? line + 1 : 0));
+ ecispace(p + 1, 1);
+ ecbuf[p + 1] = ecused - 1 - p;
+ if (!par_pline(cmplx)) {
+ tok = LEXERR;
+ }
+ cmdpop();
+ return 1;
+ } else {
+ ecbuf[p] = WCB_PIPE(WC_PIPE_END, (line >= 0 ? line + 1 : 0));
+ return 1;
+ }
+}
+
+/*
+ * cmd : { redir } ( for | case | if | while | repeat |
+ * subsh | funcdef | time | dinbrack | dinpar | simple ) { redir }
+ *
+ * zsh_construct is passed through to par_subsh(), q.v.
+ */
+
+/**/
+static int
+par_cmd(int *cmplx, int zsh_construct)
+{
+ int r, nr = 0;
+
+ r = ecused;
+
+ if (IS_REDIROP(tok)) {
+ *cmplx = 1;
+ while (IS_REDIROP(tok)) {
+ nr += par_redir(&r, NULL);
+ }
+ }
+ switch (tok) {
+ case FOR:
+ cmdpush(CS_FOR);
+ par_for(cmplx);
+ cmdpop();
+ break;
+ case FOREACH:
+ cmdpush(CS_FOREACH);
+ par_for(cmplx);
+ cmdpop();
+ break;
+ case SELECT:
+ *cmplx = 1;
+ cmdpush(CS_SELECT);
+ par_for(cmplx);
+ cmdpop();
+ break;
+ case CASE:
+ cmdpush(CS_CASE);
+ par_case(cmplx);
+ cmdpop();
+ break;
+ case IF:
+ par_if(cmplx);
+ break;
+ case WHILE:
+ cmdpush(CS_WHILE);
+ par_while(cmplx);
+ cmdpop();
+ break;
+ case UNTIL:
+ cmdpush(CS_UNTIL);
+ par_while(cmplx);
+ cmdpop();
+ break;
+ case REPEAT:
+ cmdpush(CS_REPEAT);
+ par_repeat(cmplx);
+ cmdpop();
+ break;
+ case INPAR:
+ *cmplx = 1;
+ cmdpush(CS_SUBSH);
+ par_subsh(cmplx, zsh_construct);
+ cmdpop();
+ break;
+ case INBRACE:
+ cmdpush(CS_CURSH);
+ par_subsh(cmplx, zsh_construct);
+ cmdpop();
+ break;
+ case FUNC:
+ cmdpush(CS_FUNCDEF);
+ par_funcdef(cmplx);
+ cmdpop();
+ break;
+ case DINBRACK:
+ cmdpush(CS_COND);
+ par_dinbrack();
+ cmdpop();
+ break;
+ case DINPAR:
+ ecadd(WCB_ARITH());
+ ecstr(tokstr);
+ zshlex();
+ break;
+ case TIME:
+ {
+ static int inpartime = 0;
+
+ if (!inpartime) {
+ *cmplx = 1;
+ inpartime = 1;
+ par_time();
+ inpartime = 0;
+ break;
+ }
+ }
+ tok = STRING;
+ /* fall through */
+ default:
+ {
+ int sr;
+
+ if (!(sr = par_simple(cmplx, nr))) {
+ if (!nr)
+ return 0;
+ } else {
+ /* Take account of redirections */
+ if (sr > 1) {
+ *cmplx = 1;
+ r += sr - 1;
+ }
+ }
+ }
+ break;
+ }
+ if (IS_REDIROP(tok)) {
+ *cmplx = 1;
+ while (IS_REDIROP(tok))
+ (void)par_redir(&r, NULL);
+ }
+ incmdpos = 1;
+ incasepat = 0;
+ incond = 0;
+ intypeset = 0;
+ return 1;
+}
+
+/*
+ * for : ( FOR DINPAR expr SEMI expr SEMI expr DOUTPAR |
+ * ( FOR[EACH] | SELECT ) name ( "in" wordlist | INPAR wordlist OUTPAR ) )
+ * { SEPER } ( DO list DONE | INBRACE list OUTBRACE | list ZEND | list1 )
+ */
+
+/**/
+static void
+par_for(int *cmplx)
+{
+ int oecused = ecused, csh = (tok == FOREACH), p, sel = (tok == SELECT);
+ int type;
+
+ p = ecadd(0);
+
+ incmdpos = 0;
+ infor = tok == FOR ? 2 : 0;
+ zshlex();
+ if (tok == DINPAR) {
+ zshlex();
+ if (tok != DINPAR)
+ YYERRORV(oecused);
+ ecstr(tokstr);
+ zshlex();
+ if (tok != DINPAR)
+ YYERRORV(oecused);
+ ecstr(tokstr);
+ zshlex();
+ if (tok != DOUTPAR)
+ YYERRORV(oecused);
+ ecstr(tokstr);
+ infor = 0;
+ incmdpos = 1;
+ zshlex();
+ type = WC_FOR_COND;
+ } else {
+ int np = 0, n, posix_in, ona = noaliases, onc = nocorrect;
+ infor = 0;
+ if (tok != STRING || !isident(tokstr))
+ YYERRORV(oecused);
+ if (!sel)
+ np = ecadd(0);
+ n = 0;
+ incmdpos = 1;
+ noaliases = nocorrect = 1;
+ for (;;) {
+ n++;
+ ecstr(tokstr);
+ zshlex();
+ if (tok != STRING || !strcmp(tokstr, "in") || sel)
+ break;
+ if (!isident(tokstr) || errflag)
+ {
+ noaliases = ona;
+ nocorrect = onc;
+ YYERRORV(oecused);
+ }
+ }
+ noaliases = ona;
+ nocorrect = onc;
+ if (!sel)
+ ecbuf[np] = n;
+ posix_in = isnewlin;
+ while (isnewlin)
+ zshlex();
+ if (tok == STRING && !strcmp(tokstr, "in")) {
+ incmdpos = 0;
+ zshlex();
+ np = ecadd(0);
+ n = par_wordlist();
+ if (tok != SEPER)
+ YYERRORV(oecused);
+ ecbuf[np] = n;
+ type = (sel ? WC_SELECT_LIST : WC_FOR_LIST);
+ } else if (!posix_in && tok == INPAR) {
+ incmdpos = 0;
+ zshlex();
+ np = ecadd(0);
+ n = par_nl_wordlist();
+ if (tok != OUTPAR)
+ YYERRORV(oecused);
+ ecbuf[np] = n;
+ incmdpos = 1;
+ zshlex();
+ type = (sel ? WC_SELECT_LIST : WC_FOR_LIST);
+ } else
+ type = (sel ? WC_SELECT_PPARAM : WC_FOR_PPARAM);
+ }
+ incmdpos = 1;
+ while (tok == SEPER)
+ zshlex();
+ if (tok == DOLOOP) {
+ zshlex();
+ par_save_list(cmplx);
+ if (tok != DONE)
+ YYERRORV(oecused);
+ incmdpos = 0;
+ zshlex();
+ } else if (tok == INBRACE) {
+ zshlex();
+ par_save_list(cmplx);
+ if (tok != OUTBRACE)
+ YYERRORV(oecused);
+ incmdpos = 0;
+ zshlex();
+ } else if (csh || isset(CSHJUNKIELOOPS)) {
+ par_save_list(cmplx);
+ if (tok != ZEND)
+ YYERRORV(oecused);
+ incmdpos = 0;
+ zshlex();
+ } else if (unset(SHORTLOOPS)) {
+ YYERRORV(oecused);
+ } else
+ par_save_list1(cmplx);
+
+ ecbuf[p] = (sel ?
+ WCB_SELECT(type, ecused - 1 - p) :
+ WCB_FOR(type, ecused - 1 - p));
+}
+
+/*
+ * case : CASE STRING { SEPER } ( "in" | INBRACE )
+ { { SEPER } STRING { BAR STRING } OUTPAR
+ list [ DSEMI | SEMIAMP | SEMIBAR ] }
+ { SEPER } ( "esac" | OUTBRACE )
+ */
+
+/**/
+static void
+par_case(int *cmplx)
+{
+ int oecused = ecused, brflag, p, pp, palts, type, nalts;
+ int ona, onc;
+
+ p = ecadd(0);
+
+ incmdpos = 0;
+ zshlex();
+ if (tok != STRING)
+ YYERRORV(oecused);
+ ecstr(tokstr);
+
+ incmdpos = 1;
+ ona = noaliases;
+ onc = nocorrect;
+ noaliases = nocorrect = 1;
+ zshlex();
+ while (tok == SEPER)
+ zshlex();
+ if (!(tok == STRING && !strcmp(tokstr, "in")) && tok != INBRACE)
+ {
+ noaliases = ona;
+ nocorrect = onc;
+ YYERRORV(oecused);
+ }
+ brflag = (tok == INBRACE);
+ incasepat = 1;
+ incmdpos = 0;
+ noaliases = ona;
+ nocorrect = onc;
+ zshlex();
+
+ for (;;) {
+ char *str;
+ int skip_zshlex;
+
+ while (tok == SEPER)
+ zshlex();
+ if (tok == OUTBRACE)
+ break;
+ if (tok == INPAR)
+ zshlex();
+ if (tok == BAR) {
+ str = dupstring("");
+ skip_zshlex = 1;
+ } else {
+ if (tok != STRING)
+ YYERRORV(oecused);
+ if (!strcmp(tokstr, "esac"))
+ break;
+ str = dupstring(tokstr);
+ skip_zshlex = 0;
+ }
+ type = WC_CASE_OR;
+ pp = ecadd(0);
+ palts = ecadd(0);
+ nalts = 0;
+ /*
+ * Hack here.
+ *
+ * [Pause for astonished hubbub to subside.]
+ *
+ * The next token we get may be
+ * - ")" or "|" if we're looking at an honest-to-god
+ * "case" pattern, either because there's no opening
+ * parenthesis, or because SH_GLOB is set and we
+ * managed to grab an initial "(" to mark the start
+ * of the case pattern.
+ * - Something else --- we don't care what --- because
+ * we're parsing a complete "(...)" as a complete
+ * zsh pattern. In that case, we treat this as a
+ * single instance of a case pattern but we pretend
+ * we're doing proper case parsing --- in which the
+ * parentheses and bar are in different words from
+ * the string, so may be separated by whitespace.
+ * So we quietly massage the whitespace and hope
+ * no one noticed. This is horrible, but it's
+ * unfortunately too difficult to combine traditional
+ * zsh patterns with a properly parsed case pattern
+ * without generating incompatibilities which aren't
+ * all that popular (I've discovered).
+ * - We can also end up with something other than ")" or "|"
+ * just because we're looking at garbage.
+ *
+ * Because of the second case, what happens next might
+ * be the start of the command after the pattern, so we
+ * need to treat it as in command position. Luckily
+ * this doesn't affect our ability to match a | or ) as
+ * these are valid on command lines.
+ */
+ incasepat = -1;
+ incmdpos = 1;
+ if (!skip_zshlex)
+ zshlex();
+ for (;;) {
+ if (tok == OUTPAR) {
+ ecstr(str);
+ ecadd(ecnpats++);
+ nalts++;
+
+ incasepat = 0;
+ incmdpos = 1;
+ zshlex();
+ break;
+ } else if (tok == BAR) {
+ ecstr(str);
+ ecadd(ecnpats++);
+ nalts++;
+
+ incasepat = 1;
+ incmdpos = 0;
+ } else {
+ if (!nalts && str[0] == Inpar) {
+ int pct = 0, sl;
+ char *s;
+
+ for (s = str; *s; s++) {
+ if (*s == Inpar)
+ pct++;
+ if (!pct)
+ break;
+ if (pct == 1) {
+ if (*s == Bar || *s == Inpar)
+ while (iblank(s[1]))
+ chuck(s+1);
+ if (*s == Bar || *s == Outpar)
+ while (iblank(s[-1]) &&
+ (s < str + 1 || s[-2] != Meta))
+ chuck(--s);
+ }
+ if (*s == Outpar)
+ pct--;
+ }
+ if (*s || pct || s == str)
+ YYERRORV(oecused);
+ /* Simplify pattern by removing surrounding (...) */
+ sl = strlen(str);
+ DPUTS(*str != Inpar || str[sl - 1] != Outpar,
+ "BUG: strange case pattern");
+ str[sl - 1] = '\0';
+ chuck(str);
+ ecstr(str);
+ ecadd(ecnpats++);
+ nalts++;
+ break;
+ }
+ YYERRORV(oecused);
+ }
+
+ zshlex();
+ switch (tok) {
+ case STRING:
+ /* Normal case */
+ str = dupstring(tokstr);
+ zshlex();
+ break;
+
+ case OUTPAR:
+ case BAR:
+ /* Empty string */
+ str = dupstring("");
+ break;
+
+ default:
+ /* Oops. */
+ YYERRORV(oecused);
+ break;
+ }
+ }
+ incasepat = 0;
+ par_save_list(cmplx);
+ if (tok == SEMIAMP)
+ type = WC_CASE_AND;
+ else if (tok == SEMIBAR)
+ type = WC_CASE_TESTAND;
+ ecbuf[pp] = WCB_CASE(type, ecused - 1 - pp);
+ ecbuf[palts] = nalts;
+ if ((tok == ESAC && !brflag) || (tok == OUTBRACE && brflag))
+ break;
+ if (tok != DSEMI && tok != SEMIAMP && tok != SEMIBAR)
+ YYERRORV(oecused);
+ incasepat = 1;
+ incmdpos = 0;
+ zshlex();
+ }
+ incmdpos = 1;
+ incasepat = 0;
+ zshlex();
+
+ ecbuf[p] = WCB_CASE(WC_CASE_HEAD, ecused - 1 - p);
+}
+
+/*
+ * if : { ( IF | ELIF ) { SEPER } ( INPAR list OUTPAR | list )
+ { SEPER } ( THEN list | INBRACE list OUTBRACE | list1 ) }
+ [ FI | ELSE list FI | ELSE { SEPER } INBRACE list OUTBRACE ]
+ (you get the idea...?)
+ */
+
+/**/
+static void
+par_if(int *cmplx)
+{
+ int oecused = ecused, p, pp, type, usebrace = 0;
+ enum lextok xtok;
+ unsigned char nc;
+
+ p = ecadd(0);
+
+ for (;;) {
+ xtok = tok;
+ cmdpush(xtok == IF ? CS_IF : CS_ELIF);
+ if (xtok == FI) {
+ incmdpos = 0;
+ zshlex();
+ break;
+ }
+ zshlex();
+ if (xtok == ELSE)
+ break;
+ while (tok == SEPER)
+ zshlex();
+ if (!(xtok == IF || xtok == ELIF)) {
+ cmdpop();
+ YYERRORV(oecused);
+ }
+ pp = ecadd(0);
+ type = (xtok == IF ? WC_IF_IF : WC_IF_ELIF);
+ par_save_list(cmplx);
+ incmdpos = 1;
+ if (tok == ENDINPUT) {
+ cmdpop();
+ YYERRORV(oecused);
+ }
+ while (tok == SEPER)
+ zshlex();
+ xtok = FI;
+ nc = cmdstack[cmdsp - 1] == CS_IF ? CS_IFTHEN : CS_ELIFTHEN;
+ if (tok == THEN) {
+ usebrace = 0;
+ cmdpop();
+ cmdpush(nc);
+ zshlex();
+ par_save_list(cmplx);
+ ecbuf[pp] = WCB_IF(type, ecused - 1 - pp);
+ incmdpos = 1;
+ cmdpop();
+ } else if (tok == INBRACE) {
+ usebrace = 1;
+ cmdpop();
+ cmdpush(nc);
+ zshlex();
+ par_save_list(cmplx);
+ if (tok != OUTBRACE) {
+ cmdpop();
+ YYERRORV(oecused);
+ }
+ ecbuf[pp] = WCB_IF(type, ecused - 1 - pp);
+ /* command word (else) allowed to follow immediately */
+ zshlex();
+ incmdpos = 1;
+ if (tok == SEPER)
+ break;
+ cmdpop();
+ } else if (unset(SHORTLOOPS)) {
+ cmdpop();
+ YYERRORV(oecused);
+ } else {
+ cmdpop();
+ cmdpush(nc);
+ par_save_list1(cmplx);
+ ecbuf[pp] = WCB_IF(type, ecused - 1 - pp);
+ incmdpos = 1;
+ break;
+ }
+ }
+ cmdpop();
+ if (xtok == ELSE || tok == ELSE) {
+ pp = ecadd(0);
+ cmdpush(CS_ELSE);
+ while (tok == SEPER)
+ zshlex();
+ if (tok == INBRACE && usebrace) {
+ zshlex();
+ par_save_list(cmplx);
+ if (tok != OUTBRACE) {
+ cmdpop();
+ YYERRORV(oecused);
+ }
+ } else {
+ par_save_list(cmplx);
+ if (tok != FI) {
+ cmdpop();
+ YYERRORV(oecused);
+ }
+ }
+ incmdpos = 0;
+ ecbuf[pp] = WCB_IF(WC_IF_ELSE, ecused - 1 - pp);
+ zshlex();
+ cmdpop();
+ }
+ ecbuf[p] = WCB_IF(WC_IF_HEAD, ecused - 1 - p);
+}
+
+/*
+ * while : ( WHILE | UNTIL ) ( INPAR list OUTPAR | list ) { SEPER }
+ ( DO list DONE | INBRACE list OUTBRACE | list ZEND )
+ */
+
+/**/
+static void
+par_while(int *cmplx)
+{
+ int oecused = ecused, p;
+ int type = (tok == UNTIL ? WC_WHILE_UNTIL : WC_WHILE_WHILE);
+
+ p = ecadd(0);
+ zshlex();
+ par_save_list(cmplx);
+ incmdpos = 1;
+ while (tok == SEPER)
+ zshlex();
+ if (tok == DOLOOP) {
+ zshlex();
+ par_save_list(cmplx);
+ if (tok != DONE)
+ YYERRORV(oecused);
+ incmdpos = 0;
+ zshlex();
+ } else if (tok == INBRACE) {
+ zshlex();
+ par_save_list(cmplx);
+ if (tok != OUTBRACE)
+ YYERRORV(oecused);
+ incmdpos = 0;
+ zshlex();
+ } else if (isset(CSHJUNKIELOOPS)) {
+ par_save_list(cmplx);
+ if (tok != ZEND)
+ YYERRORV(oecused);
+ zshlex();
+ } else if (unset(SHORTLOOPS)) {
+ YYERRORV(oecused);
+ } else
+ par_save_list1(cmplx);
+
+ ecbuf[p] = WCB_WHILE(type, ecused - 1 - p);
+}
+
+/*
+ * repeat : REPEAT STRING { SEPER } ( DO list DONE | list1 )
+ */
+
+/**/
+static void
+par_repeat(int *cmplx)
+{
+ /* ### what to do about inrepeat_ here? */
+ int oecused = ecused, p;
+
+ p = ecadd(0);
+
+ incmdpos = 0;
+ zshlex();
+ if (tok != STRING)
+ YYERRORV(oecused);
+ ecstr(tokstr);
+ incmdpos = 1;
+ zshlex();
+ while (tok == SEPER)
+ zshlex();
+ if (tok == DOLOOP) {
+ zshlex();
+ par_save_list(cmplx);
+ if (tok != DONE)
+ YYERRORV(oecused);
+ incmdpos = 0;
+ zshlex();
+ } else if (tok == INBRACE) {
+ zshlex();
+ par_save_list(cmplx);
+ if (tok != OUTBRACE)
+ YYERRORV(oecused);
+ incmdpos = 0;
+ zshlex();
+ } else if (isset(CSHJUNKIELOOPS)) {
+ par_save_list(cmplx);
+ if (tok != ZEND)
+ YYERRORV(oecused);
+ zshlex();
+ } else if (unset(SHORTLOOPS)) {
+ YYERRORV(oecused);
+ } else
+ par_save_list1(cmplx);
+
+ ecbuf[p] = WCB_REPEAT(ecused - 1 - p);
+}
+
+/*
+ * subsh : INPAR list OUTPAR |
+ * INBRACE list OUTBRACE [ "always" INBRACE list OUTBRACE ]
+ *
+ * With zsh_construct non-zero, we're doing a zsh special in which
+ * the following token is not considered in command position. This
+ * is used for arguments of anonymous functions.
+ */
+
+/**/
+static void
+par_subsh(int *cmplx, int zsh_construct)
+{
+ enum lextok otok = tok;
+ int oecused = ecused, p, pp;
+
+ p = ecadd(0);
+ /* Extra word only needed for always block */
+ pp = ecadd(0);
+ zshlex();
+ par_list(cmplx);
+ ecadd(WCB_END());
+ if (tok != ((otok == INPAR) ? OUTPAR : OUTBRACE))
+ YYERRORV(oecused);
+ incmdpos = !zsh_construct;
+ zshlex();
+
+ /* Optional always block. No intervening SEPERs allowed. */
+ if (otok == INBRACE && tok == STRING && !strcmp(tokstr, "always")) {
+ ecbuf[pp] = WCB_TRY(ecused - 1 - pp);
+ incmdpos = 1;
+ do {
+ zshlex();
+ } while (tok == SEPER);
+
+ if (tok != INBRACE)
+ YYERRORV(oecused);
+ cmdpop();
+ cmdpush(CS_ALWAYS);
+
+ zshlex();
+ par_save_list(cmplx);
+ while (tok == SEPER)
+ zshlex();
+
+ incmdpos = 1;
+
+ if (tok != OUTBRACE)
+ YYERRORV(oecused);
+ zshlex();
+ ecbuf[p] = WCB_TRY(ecused - 1 - p);
+ } else {
+ ecbuf[p] = (otok == INPAR ? WCB_SUBSH(ecused - 1 - p) :
+ WCB_CURSH(ecused - 1 - p));
+ }
+}
+
+/*
+ * funcdef : FUNCTION wordlist [ INOUTPAR ] { SEPER }
+ * ( list1 | INBRACE list OUTBRACE )
+ */
+
+/**/
+static void
+par_funcdef(int *cmplx)
+{
+ int oecused = ecused, num = 0, onp, p, c = 0;
+ int so, oecssub = ecssub;
+ zlong oldlineno = lineno;
+
+ lineno = 0;
+ nocorrect = 1;
+ incmdpos = 0;
+ zshlex();
+
+ p = ecadd(0);
+ ecadd(0);
+
+ while (tok == STRING) {
+ if ((*tokstr == Inbrace || *tokstr == '{') &&
+ !tokstr[1]) {
+ tok = INBRACE;
+ break;
+ }
+ ecstr(tokstr);
+ num++;
+ zshlex();
+ }
+ ecadd(0);
+ ecadd(0);
+ ecadd(0);
+
+ nocorrect = 0;
+ incmdpos = 1;
+ if (tok == INOUTPAR)
+ zshlex();
+ while (tok == SEPER)
+ zshlex();
+
+ ecnfunc++;
+ ecssub = so = ecsoffs;
+ onp = ecnpats;
+ ecnpats = 0;
+
+ if (tok == INBRACE) {
+ zshlex();
+ par_list(&c);
+ if (tok != OUTBRACE) {
+ lineno += oldlineno;
+ ecnpats = onp;
+ ecssub = oecssub;
+ YYERRORV(oecused);
+ }
+ if (num == 0) {
+ /* Anonymous function, possibly with arguments */
+ incmdpos = 0;
+ }
+ zshlex();
+ } else if (unset(SHORTLOOPS)) {
+ lineno += oldlineno;
+ ecnpats = onp;
+ ecssub = oecssub;
+ YYERRORV(oecused);
+ } else
+ par_list1(&c);
+
+ ecadd(WCB_END());
+ ecbuf[p + num + 2] = so - oecssub;
+ ecbuf[p + num + 3] = ecsoffs - so;
+ ecbuf[p + num + 4] = ecnpats;
+ ecbuf[p + 1] = num;
+
+ ecnpats = onp;
+ ecssub = oecssub;
+ ecnfunc++;
+
+ ecbuf[p] = WCB_FUNCDEF(ecused - 1 - p);
+
+ if (num == 0) {
+ /* Unnamed function */
+ int parg = ecadd(0);
+ ecadd(0);
+ while (tok == STRING) {
+ ecstr(tokstr);
+ num++;
+ zshlex();
+ }
+ if (num > 0)
+ *cmplx = 1;
+ ecbuf[parg] = ecused - parg; /*?*/
+ ecbuf[parg+1] = num;
+ }
+ lineno += oldlineno;
+}
+
+/*
+ * time : TIME sublist2
+ */
+
+/**/
+static void
+par_time(void)
+{
+ int p, f, c = 0;
+
+ zshlex();
+
+ p = ecadd(0);
+ ecadd(0);
+ if ((f = par_sublist2(&c)) < 0) {
+ ecused--;
+ ecbuf[p] = WCB_TIMED(WC_TIMED_EMPTY);
+ } else {
+ ecbuf[p] = WCB_TIMED(WC_TIMED_PIPE);
+ set_sublist_code(p + 1, WC_SUBLIST_END, f, ecused - 2 - p, c);
+ }
+}
+
+/*
+ * dinbrack : DINBRACK cond DOUTBRACK
+ */
+
+/**/
+static void
+par_dinbrack(void)
+{
+ int oecused = ecused;
+
+ incond = 1;
+ incmdpos = 0;
+ zshlex();
+ par_cond();
+ if (tok != DOUTBRACK)
+ YYERRORV(oecused);
+ incond = 0;
+ incmdpos = 1;
+ zshlex();
+}
+
+/*
+ * simple : { COMMAND | EXEC | NOGLOB | NOCORRECT | DASH }
+ { STRING | ENVSTRING | ENVARRAY wordlist OUTPAR | redir }
+ [ INOUTPAR { SEPER } ( list1 | INBRACE list OUTBRACE ) ]
+ *
+ * Returns 0 if no code, else 1 plus the number of code words
+ * used up by redirections.
+ */
+
+/**/
+static int
+par_simple(int *cmplx, int nr)
+{
+ int oecused = ecused, isnull = 1, r, argc = 0, p, isfunc = 0, sr = 0;
+ int c = *cmplx, nrediradd, assignments = 0, ppost = 0, is_typeset = 0;
+ char *hasalias = input_hasalias();
+ wordcode postassigns = 0;
+
+ r = ecused;
+ for (;;) {
+ if (tok == NOCORRECT) {
+ *cmplx = c = 1;
+ nocorrect = 1;
+ } else if (tok == ENVSTRING) {
+ char *ptr, *name, *str;
+
+ name = tokstr;
+ for (ptr = tokstr;
+ *ptr && *ptr != Inbrack && *ptr != '=' && *ptr != '+';
+ ptr++);
+ if (*ptr == Inbrack) skipparens(Inbrack, Outbrack, &ptr);
+ if (*ptr == '+') {
+ *ptr++ = '\0';
+ ecadd(WCB_ASSIGN(WC_ASSIGN_SCALAR, WC_ASSIGN_INC, 0));
+ } else
+ ecadd(WCB_ASSIGN(WC_ASSIGN_SCALAR, WC_ASSIGN_NEW, 0));
+
+ if (*ptr == '=') {
+ *ptr = '\0';
+ str = ptr + 1;
+ } else
+ equalsplit(tokstr, &str);
+ for (ptr = str; *ptr; ptr++) {
+ /*
+ * We can't treat this as "simple" if it contains
+ * expansions that require process subsitution, since then
+ * we need process handling.
+ */
+ if (ptr[1] == Inpar &&
+ (*ptr == Equals || *ptr == Inang || *ptr == OutangProc)) {
+ *cmplx = 1;
+ break;
+ }
+ }
+ ecstr(name);
+ ecstr(str);
+ isnull = 0;
+ assignments = 1;
+ } else if (tok == ENVARRAY) {
+ int oldcmdpos = incmdpos, n, type2;
+
+ /*
+ * We consider array setting cmplx because it can
+ * contain process substitutions, which need a valid job.
+ */
+ *cmplx = c = 1;
+ p = ecadd(0);
+ incmdpos = 0;
+ if ((type2 = strlen(tokstr) - 1) && tokstr[type2] == '+') {
+ tokstr[type2] = '\0';
+ type2 = WC_ASSIGN_INC;
+ } else
+ type2 = WC_ASSIGN_NEW;
+ ecstr(tokstr);
+ cmdpush(CS_ARRAY);
+ zshlex();
+ n = par_nl_wordlist();
+ ecbuf[p] = WCB_ASSIGN(WC_ASSIGN_ARRAY, type2, n);
+ cmdpop();
+ if (tok != OUTPAR)
+ YYERROR(oecused);
+ incmdpos = oldcmdpos;
+ isnull = 0;
+ assignments = 1;
+ } else if (IS_REDIROP(tok)) {
+ *cmplx = c = 1;
+ nr += par_redir(&r, NULL);
+ continue;
+ } else
+ break;
+ zshlex();
+ if (!hasalias)
+ hasalias = input_hasalias();
+ }
+ if (tok == AMPER || tok == AMPERBANG)
+ YYERROR(oecused);
+
+ p = ecadd(WCB_SIMPLE(0));
+
+ for (;;) {
+ if (tok == STRING || tok == TYPESET) {
+ int redir_var = 0;
+
+ *cmplx = 1;
+ incmdpos = 0;
+
+ if (tok == TYPESET)
+ intypeset = is_typeset = 1;
+
+ if (!isset(IGNOREBRACES) && *tokstr == Inbrace)
+ {
+ /* Look for redirs of the form {var}>file etc. */
+ char *eptr = tokstr + strlen(tokstr) - 1;
+ char *ptr = eptr;
+
+ if (*ptr == Outbrace && ptr > tokstr + 1)
+ {
+ if (itype_end(tokstr+1, IIDENT, 0) >= ptr)
+ {
+ char *toksave = tokstr;
+ char *idstring = dupstrpfx(tokstr+1, eptr-tokstr-1);
+ redir_var = 1;
+ zshlex();
+ if (!hasalias)
+ hasalias = input_hasalias();
+
+ if (IS_REDIROP(tok) && tokfd == -1)
+ {
+ *cmplx = c = 1;
+ nrediradd = par_redir(&r, idstring);
+ p += nrediradd;
+ sr += nrediradd;
+ }
+ else
+ {
+ ecstr(toksave);
+ argc++;
+ }
+ }
+ }
+ }
+
+ if (!redir_var)
+ {
+ if (postassigns) {
+ /*
+ * We're in the variable part of a typeset,
+ * but this doesn't have an assignment.
+ * We'll parse it as if it does, but mark
+ * it specially with WC_ASSIGN_INC.
+ */
+ postassigns++;
+ ecadd(WCB_ASSIGN(WC_ASSIGN_SCALAR, WC_ASSIGN_INC, 0));
+ ecstr(tokstr);
+ ecstr(""); /* TBD can possibly optimise out */
+ } else {
+ ecstr(tokstr);
+ argc++;
+ }
+ zshlex();
+ if (!hasalias)
+ hasalias = input_hasalias();
+ }
+ } else if (IS_REDIROP(tok)) {
+ *cmplx = c = 1;
+ nrediradd = par_redir(&r, NULL);
+ p += nrediradd;
+ if (ppost)
+ ppost += nrediradd;
+ sr += nrediradd;
+ } else if (tok == ENVSTRING) {
+ char *ptr, *name, *str;
+
+ if (!postassigns++)
+ ppost = ecadd(0);
+
+ name = tokstr;
+ for (ptr = tokstr; *ptr && *ptr != Inbrack && *ptr != '=' && *ptr != '+';
+ ptr++);
+ if (*ptr == Inbrack) skipparens(Inbrack, Outbrack, &ptr);
+ ecadd(WCB_ASSIGN(WC_ASSIGN_SCALAR, WC_ASSIGN_NEW, 0));
+
+ if (*ptr == '=') {
+ *ptr = '\0';
+ str = ptr + 1;
+ } else
+ equalsplit(tokstr, &str);
+ ecstr(name);
+ ecstr(str);
+ zshlex();
+ if (!hasalias)
+ hasalias = input_hasalias();
+ } else if (tok == ENVARRAY) {
+ int n, parr;
+
+ if (!postassigns++)
+ ppost = ecadd(0);
+
+ parr = ecadd(0);
+ ecstr(tokstr);
+ cmdpush(CS_ARRAY);
+ /*
+ * Careful here: this must be the typeset case,
+ * but we need to tell the lexer not to look
+ * for assignments until we've finished the
+ * present one.
+ */
+ intypeset = 0;
+ zshlex();
+ n = par_nl_wordlist();
+ ecbuf[parr] = WCB_ASSIGN(WC_ASSIGN_ARRAY, WC_ASSIGN_NEW, n);
+ cmdpop();
+ intypeset = 1;
+ if (tok != OUTPAR)
+ YYERROR(oecused);
+ zshlex();
+ } else if (tok == INOUTPAR) {
+ zlong oldlineno = lineno;
+ int onp, so, oecssub = ecssub;
+
+ /* Error if too many function definitions at once */
+ if (!isset(MULTIFUNCDEF) && argc > 1)
+ YYERROR(oecused);
+ /* Error if preceding assignments */
+ if (assignments || postassigns)
+ YYERROR(oecused);
+ if (hasalias && !isset(ALIASFUNCDEF) && argc &&
+ hasalias != input_hasalias()) {
+ zwarn("defining function based on alias `%s'", hasalias);
+ YYERROR(oecused);
+ }
+
+ *cmplx = c;
+ lineno = 0;
+ incmdpos = 1;
+ cmdpush(CS_FUNCDEF);
+ zshlex();
+ while (tok == SEPER)
+ zshlex();
+
+ ecispace(p + 1, 1);
+ ecbuf[p + 1] = argc;
+ ecadd(0);
+ ecadd(0);
+ ecadd(0);
+
+ ecnfunc++;
+ ecssub = so = ecsoffs;
+ onp = ecnpats;
+ ecnpats = 0;
+
+ if (tok == INBRACE) {
+ int c = 0;
+
+ zshlex();
+ par_list(&c);
+ if (tok != OUTBRACE) {
+ cmdpop();
+ lineno += oldlineno;
+ ecnpats = onp;
+ ecssub = oecssub;
+ YYERROR(oecused);
+ }
+ if (argc == 0) {
+ /* Anonymous function, possibly with arguments */
+ incmdpos = 0;
+ }
+ zshlex();
+ } else {
+ int ll, sl, c = 0;
+
+ ll = ecadd(0);
+ sl = ecadd(0);
+ (void)ecadd(WCB_PIPE(WC_PIPE_END, 0));
+
+ if (!par_cmd(&c, argc == 0)) {
+ cmdpop();
+ YYERROR(oecused);
+ }
+ if (argc == 0) {
+ /*
+ * Anonymous function, possibly with arguments.
+ * N.B. for cmplx structures in particular
+ * ( ... ) we rely on lower level code doing this
+ * to get the immediately following word (the
+ * first token after the ")" has already been
+ * read).
+ */
+ incmdpos = 0;
+ }
+
+ set_sublist_code(sl, WC_SUBLIST_END, 0, ecused - 1 - sl, c);
+ set_list_code(ll, (Z_SYNC | Z_END), c);
+ }
+ cmdpop();
+
+ ecadd(WCB_END());
+ ecbuf[p + argc + 2] = so - oecssub;
+ ecbuf[p + argc + 3] = ecsoffs - so;
+ ecbuf[p + argc + 4] = ecnpats;
+
+ ecnpats = onp;
+ ecssub = oecssub;
+ ecnfunc++;
+
+ ecbuf[p] = WCB_FUNCDEF(ecused - 1 - p);
+
+ if (argc == 0) {
+ /* Unnamed function */
+ int parg = ecadd(0);
+ ecadd(0);
+ while (tok == STRING || IS_REDIROP(tok)) {
+ if (tok == STRING)
+ {
+ ecstr(tokstr);
+ argc++;
+ zshlex();
+ } else {
+ *cmplx = c = 1;
+ nrediradd = par_redir(&r, NULL);
+ p += nrediradd;
+ if (ppost)
+ ppost += nrediradd;
+ sr += nrediradd;
+ parg += nrediradd;
+ }
+ }
+ if (argc > 0)
+ *cmplx = 1;
+ ecbuf[parg] = ecused - parg; /*?*/
+ ecbuf[parg+1] = argc;
+ }
+ lineno += oldlineno;
+
+ isfunc = 1;
+ isnull = 0;
+ break;
+ } else
+ break;
+ isnull = 0;
+ }
+ if (isnull && !(sr + nr)) {
+ ecused = p;
+ return 0;
+ }
+ incmdpos = 1;
+ intypeset = 0;
+
+ if (!isfunc) {
+ if (is_typeset) {
+ ecbuf[p] = WCB_TYPESET(argc);
+ if (postassigns)
+ ecbuf[ppost] = postassigns;
+ else
+ ecadd(0);
+ } else
+ ecbuf[p] = WCB_SIMPLE(argc);
+ }
+
+ return sr + 1;
+}
+
+/*
+ * redir : ( OUTANG | ... | TRINANG ) STRING
+ *
+ * Return number of code words required for redirection
+ */
+
+static int redirtab[TRINANG - OUTANG + 1] = {
+ REDIR_WRITE,
+ REDIR_WRITENOW,
+ REDIR_APP,
+ REDIR_APPNOW,
+ REDIR_READ,
+ REDIR_READWRITE,
+ REDIR_HEREDOC,
+ REDIR_HEREDOCDASH,
+ REDIR_MERGEIN,
+ REDIR_MERGEOUT,
+ REDIR_ERRWRITE,
+ REDIR_ERRWRITENOW,
+ REDIR_ERRAPP,
+ REDIR_ERRAPPNOW,
+ REDIR_HERESTR,
+};
+
+/**/
+static int
+par_redir(int *rp, char *idstring)
+{
+ int r = *rp, type, fd1, oldcmdpos, oldnc, ncodes;
+ char *name;
+
+ oldcmdpos = incmdpos;
+ incmdpos = 0;
+ oldnc = nocorrect;
+ if (tok != INANG && tok != INOUTANG)
+ nocorrect = 1;
+ type = redirtab[tok - OUTANG];
+ fd1 = tokfd;
+ zshlex();
+ if (tok != STRING && tok != ENVSTRING)
+ YYERROR(ecused);
+ incmdpos = oldcmdpos;
+ nocorrect = oldnc;
+
+ /* assign default fd */
+ if (fd1 == -1)
+ fd1 = IS_READFD(type) ? 0 : 1;
+
+ name = tokstr;
+
+ switch (type) {
+ case REDIR_HEREDOC:
+ case REDIR_HEREDOCDASH: {
+ /* <<[-] name */
+ struct heredocs **hd;
+ int htype = type;
+
+ /*
+ * Add two here for the string to remember the HERE
+ * terminator in raw and munged form.
+ */
+ if (idstring)
+ {
+ type |= REDIR_VARID_MASK;
+ ncodes = 6;
+ }
+ else
+ ncodes = 5;
+
+ /* If we ever to change the number of codes, we have to change
+ * the definition of WC_REDIR_WORDS. */
+ ecispace(r, ncodes);
+ *rp = r + ncodes;
+ ecbuf[r] = WCB_REDIR(type | REDIR_FROM_HEREDOC_MASK);
+ ecbuf[r + 1] = fd1;
+
+ /*
+ * r + 2: the HERE string we recover
+ * r + 3: the HERE document terminator, raw
+ * r + 4: the HERE document terminator, munged
+ */
+ if (idstring)
+ ecbuf[r + 5] = ecstrcode(idstring);
+
+ for (hd = &hdocs; *hd; hd = &(*hd)->next)
+ ;
+ *hd = zalloc(sizeof(struct heredocs));
+ (*hd)->next = NULL;
+ (*hd)->type = htype;
+ (*hd)->pc = r;
+ (*hd)->str = tokstr;
+
+ zshlex();
+ return ncodes;
+ }
+ case REDIR_WRITE:
+ case REDIR_WRITENOW:
+ if (tokstr[0] == OutangProc && tokstr[1] == Inpar)
+ /* > >(...) */
+ type = REDIR_OUTPIPE;
+ else if (tokstr[0] == Inang && tokstr[1] == Inpar)
+ YYERROR(ecused);
+ break;
+ case REDIR_READ:
+ if (tokstr[0] == Inang && tokstr[1] == Inpar)
+ /* < <(...) */
+ type = REDIR_INPIPE;
+ else if (tokstr[0] == OutangProc && tokstr[1] == Inpar)
+ YYERROR(ecused);
+ break;
+ case REDIR_READWRITE:
+ if ((tokstr[0] == Inang || tokstr[0] == OutangProc) &&
+ tokstr[1] == Inpar)
+ type = tokstr[0] == Inang ? REDIR_INPIPE : REDIR_OUTPIPE;
+ break;
+ }
+ zshlex();
+
+ /* If we ever to change the number of codes, we have to change
+ * the definition of WC_REDIR_WORDS. */
+ if (idstring)
+ {
+ type |= REDIR_VARID_MASK;
+ ncodes = 4;
+ }
+ else
+ ncodes = 3;
+
+ ecispace(r, ncodes);
+ *rp = r + ncodes;
+ ecbuf[r] = WCB_REDIR(type);
+ ecbuf[r + 1] = fd1;
+ ecbuf[r + 2] = ecstrcode(name);
+ if (idstring)
+ ecbuf[r + 3] = ecstrcode(idstring);
+
+ return ncodes;
+}
+
+/**/
+void
+setheredoc(int pc, int type, char *str, char *termstr, char *munged_termstr)
+{
+ ecbuf[pc] = WCB_REDIR(type | REDIR_FROM_HEREDOC_MASK);
+ ecbuf[pc + 2] = ecstrcode(str);
+ ecbuf[pc + 3] = ecstrcode(termstr);
+ ecbuf[pc + 4] = ecstrcode(munged_termstr);
+}
+
+/*
+ * wordlist : { STRING }
+ */
+
+/**/
+static int
+par_wordlist(void)
+{
+ int num = 0;
+ while (tok == STRING) {
+ ecstr(tokstr);
+ num++;
+ zshlex();
+ }
+ return num;
+}
+
+/*
+ * nl_wordlist : { STRING | SEPER }
+ */
+
+/**/
+static int
+par_nl_wordlist(void)
+{
+ int num = 0;
+
+ while (tok == STRING || tok == SEPER) {
+ if (tok != SEPER) {
+ ecstr(tokstr);
+ num++;
+ }
+ zshlex();
+ }
+ return num;
+}
+
+/*
+ * condlex is zshlex for normal parsing, but is altered to allow
+ * the test builtin to use par_cond.
+ */
+
+/**/
+void (*condlex) _((void)) = zshlex;
+
+/*
+ * cond : cond_1 { SEPER } [ DBAR { SEPER } cond ]
+ */
+
+#define COND_SEP() (tok == SEPER && condlex != testlex && *zshlextext != ';')
+
+/**/
+static int
+par_cond(void)
+{
+ int p = ecused, r;
+
+ r = par_cond_1();
+ while (COND_SEP())
+ condlex();
+ if (tok == DBAR) {
+ condlex();
+ while (COND_SEP())
+ condlex();
+ ecispace(p, 1);
+ par_cond();
+ ecbuf[p] = WCB_COND(COND_OR, ecused - 1 - p);
+ return 1;
+ }
+ return r;
+}
+
+/*
+ * cond_1 : cond_2 { SEPER } [ DAMPER { SEPER } cond_1 ]
+ */
+
+/**/
+static int
+par_cond_1(void)
+{
+ int r, p = ecused;
+
+ r = par_cond_2();
+ while (COND_SEP())
+ condlex();
+ if (tok == DAMPER) {
+ condlex();
+ while (COND_SEP())
+ condlex();
+ ecispace(p, 1);
+ par_cond_1();
+ ecbuf[p] = WCB_COND(COND_AND, ecused - 1 - p);
+ return 1;
+ }
+ return r;
+}
+
+/*
+ * Return 1 if condition matches. This also works for non-elided options.
+ *
+ * input is test string, may begin - or Dash.
+ * cond is condition following the -.
+ */
+static int check_cond(const char *input, const char *cond)
+{
+ if (!IS_DASH(input[0]))
+ return 0;
+ return !strcmp(input + 1, cond);
+}
+
+/*
+ * cond_2 : BANG cond_2
+ | INPAR { SEPER } cond_2 { SEPER } OUTPAR
+ | STRING STRING STRING
+ | STRING STRING
+ | STRING ( INANG | OUTANG ) STRING
+ */
+
+/**/
+static int
+par_cond_2(void)
+{
+ char *s1, *s2, *s3;
+ int dble = 0;
+ int n_testargs = (condlex == testlex) ? arrlen(testargs) + 1 : 0;
+
+ if (n_testargs) {
+ /* See the description of test in POSIX 1003.2 */
+ if (tok == NULLTOK)
+ /* no arguments: false */
+ return par_cond_double(dupstring("-n"), dupstring(""));
+ if (n_testargs == 1) {
+ /* one argument: [ foo ] is equivalent to [ -n foo ] */
+ s1 = tokstr;
+ condlex();
+ /* ksh behavior: [ -t ] means [ -t 1 ]; bash disagrees */
+ if (unset(POSIXBUILTINS) && check_cond(s1, "t"))
+ return par_cond_double(s1, dupstring("1"));
+ return par_cond_double(dupstring("-n"), s1);
+ }
+ if (n_testargs > 2) {
+ /* three arguments: if the second argument is a binary operator, *
+ * perform that binary test on the first and the third argument */
+ if (!strcmp(*testargs, "=") ||
+ !strcmp(*testargs, "==") ||
+ !strcmp(*testargs, "!=") ||
+ (IS_DASH(**testargs) && get_cond_num(*testargs + 1) >= 0)) {
+ s1 = tokstr;
+ condlex();
+ s2 = tokstr;
+ condlex();
+ s3 = tokstr;
+ condlex();
+ return par_cond_triple(s1, s2, s3);
+ }
+ }
+ /*
+ * We fall through here on any non-numeric infix operator
+ * or any other time there are at least two arguments.
+ */
+ } else
+ while (COND_SEP())
+ condlex();
+ if (tok == BANG) {
+ /*
+ * In "test" compatibility mode, "! -a ..." and "! -o ..."
+ * are treated as "[string] [and] ..." and "[string] [or] ...".
+ */
+ if (!(n_testargs > 1 && (check_cond(*testargs, "a") ||
+ check_cond(*testargs, "o"))))
+ {
+ condlex();
+ ecadd(WCB_COND(COND_NOT, 0));
+ return par_cond_2();
+ }
+ }
+ if (tok == INPAR) {
+ int r;
+
+ condlex();
+ while (COND_SEP())
+ condlex();
+ r = par_cond();
+ while (COND_SEP())
+ condlex();
+ if (tok != OUTPAR)
+ YYERROR(ecused);
+ condlex();
+ return r;
+ }
+ s1 = tokstr;
+ dble = (s1 && IS_DASH(*s1)
+ && (!n_testargs
+ || strspn(s1+1, "abcdefghknoprstuvwxzLONGS") == 1)
+ && !s1[2]);
+ if (tok != STRING) {
+ /* Check first argument for [[ STRING ]] re-interpretation */
+ if (s1 /* tok != DOUTBRACK && tok != DAMPER && tok != DBAR */
+ && tok != LEXERR && (!dble || n_testargs)) {
+ do condlex(); while (COND_SEP());
+ return par_cond_double(dupstring("-n"), s1);
+ } else
+ YYERROR(ecused);
+ }
+ condlex();
+ if (n_testargs == 2 && tok != STRING && tokstr && IS_DASH(s1[0])) {
+ /*
+ * Something like "test -z" followed by a token.
+ * We'll turn the token into a string (we've also
+ * checked it does have a string representation).
+ */
+ tok = STRING;
+ } else
+ while (COND_SEP())
+ condlex();
+ if (tok == INANG || tok == OUTANG) {
+ enum lextok xtok = tok;
+ do condlex(); while (COND_SEP());
+ if (tok != STRING)
+ YYERROR(ecused);
+ s3 = tokstr;
+ do condlex(); while (COND_SEP());
+ ecadd(WCB_COND((xtok == INANG ? COND_STRLT : COND_STRGTR), 0));
+ ecstr(s1);
+ ecstr(s3);
+ return 1;
+ }
+ if (tok != STRING) {
+ /*
+ * Check second argument in case semantics e.g. [ = -a = ]
+ * mean we have to go back and fix up the first one
+ */
+ if (tok != LEXERR) {
+ if (!dble || n_testargs)
+ return par_cond_double(dupstring("-n"), s1);
+ else
+ return par_cond_multi(s1, newlinklist());
+ } else
+ YYERROR(ecused);
+ }
+ s2 = tokstr;
+ if (!n_testargs)
+ dble = (s2 && IS_DASH(*s2) && !s2[2]);
+ incond++; /* parentheses do globbing */
+ do condlex(); while (COND_SEP());
+ incond--; /* parentheses do grouping */
+ if (tok == STRING && !dble) {
+ s3 = tokstr;
+ do condlex(); while (COND_SEP());
+ if (tok == STRING) {
+ LinkList l = newlinklist();
+
+ addlinknode(l, s2);
+ addlinknode(l, s3);
+
+ while (tok == STRING) {
+ addlinknode(l, tokstr);
+ do condlex(); while (COND_SEP());
+ }
+ return par_cond_multi(s1, l);
+ } else
+ return par_cond_triple(s1, s2, s3);
+ } else
+ return par_cond_double(s1, s2);
+}
+
+/**/
+static int
+par_cond_double(char *a, char *b)
+{
+ if (!IS_DASH(a[0]) || !a[1])
+ COND_ERROR("parse error: condition expected: %s", a);
+ else if (!a[2] && strspn(a+1, "abcdefgknoprstuvwxzhLONGS") == 1) {
+ ecadd(WCB_COND(a[1], 0));
+ ecstr(b);
+ } else {
+ ecadd(WCB_COND(COND_MOD, 1));
+ ecstr(a);
+ ecstr(b);
+ }
+ return 1;
+}
+
+/**/
+static int
+get_cond_num(char *tst)
+{
+ static char *condstrs[] =
+ {
+ "nt", "ot", "ef", "eq", "ne", "lt", "gt", "le", "ge", NULL
+ };
+ int t0;
+
+ for (t0 = 0; condstrs[t0]; t0++)
+ if (!strcmp(condstrs[t0], tst))
+ return t0;
+ return -1;
+}
+
+/**/
+static int
+par_cond_triple(char *a, char *b, char *c)
+{
+ int t0;
+
+ if ((b[0] == Equals || b[0] == '=') && !b[1]) {
+ ecadd(WCB_COND(COND_STREQ, 0));
+ ecstr(a);
+ ecstr(c);
+ ecadd(ecnpats++);
+ } else if ((b[0] == Equals || b[0] == '=') &&
+ (b[1] == Equals || b[1] == '=') && !b[2]) {
+ ecadd(WCB_COND(COND_STRDEQ, 0));
+ ecstr(a);
+ ecstr(c);
+ ecadd(ecnpats++);
+ } else if (b[0] == '!' && (b[1] == Equals || b[1] == '=') && !b[2]) {
+ ecadd(WCB_COND(COND_STRNEQ, 0));
+ ecstr(a);
+ ecstr(c);
+ ecadd(ecnpats++);
+ } else if ((b[0] == Equals || b[0] == '=') &&
+ (b[1] == '~' || b[1] == Tilde) && !b[2]) {
+ /* We become an implicit COND_MODI but do not provide the first
+ * item, it's skipped */
+ ecadd(WCB_COND(COND_REGEX, 0));
+ ecstr(a);
+ ecstr(c);
+ } else if (IS_DASH(b[0])) {
+ if ((t0 = get_cond_num(b + 1)) > -1) {
+ ecadd(WCB_COND(t0 + COND_NT, 0));
+ ecstr(a);
+ ecstr(c);
+ } else {
+ ecadd(WCB_COND(COND_MODI, 0));
+ ecstr(b);
+ ecstr(a);
+ ecstr(c);
+ }
+ } else if (IS_DASH(a[0]) && a[1]) {
+ ecadd(WCB_COND(COND_MOD, 2));
+ ecstr(a);
+ ecstr(b);
+ ecstr(c);
+ } else
+ COND_ERROR("condition expected: %s", b);
+
+ return 1;
+}
+
+/**/
+static int
+par_cond_multi(char *a, LinkList l)
+{
+ if (!IS_DASH(a[0]) || !a[1])
+ COND_ERROR("condition expected: %s", a);
+ else {
+ LinkNode n;
+
+ ecadd(WCB_COND(COND_MOD, countlinknodes(l)));
+ ecstr(a);
+ for (n = firstnode(l); n; incnode(n))
+ ecstr((char *) getdata(n));
+ }
+ return 1;
+}
+
+/**/
+static void
+yyerror(int noerr)
+{
+ int t0;
+ char *t;
+
+ if ((t = dupstring(zshlextext)))
+ untokenize(t);
+
+ for (t0 = 0; t0 != 20; t0++)
+ if (!t || !t[t0] || t[t0] == '\n')
+ break;
+ if (!(histdone & HISTFLAG_NOEXEC) && !(errflag & ERRFLAG_INT)) {
+ if (t0 == 20)
+ zwarn("parse error near `%l...'", t, 20);
+ else if (t0)
+ zwarn("parse error near `%l'", t, t0);
+ else
+ zwarn("parse error");
+ }
+ if (!noerr && noerrs != 2)
+ errflag |= ERRFLAG_ERROR;
+}
+
+/*
+ * Duplicate a programme list, on the heap if heap is 1, else
+ * in permanent storage.
+ *
+ * Be careful in case p is the Eprog for a function which will
+ * later be autoloaded. The shf element of the returned Eprog
+ * must be set appropriately by the caller. (Normally we create
+ * the Eprog in this case by using mkautofn.)
+ */
+
+/**/
+mod_export Eprog
+dupeprog(Eprog p, int heap)
+{
+ Eprog r;
+ int i;
+ Patprog *pp;
+
+ if (p == &dummy_eprog)
+ return p;
+
+ r = (heap ? (Eprog) zhalloc(sizeof(*r)) : (Eprog) zalloc(sizeof(*r)));
+ r->flags = (heap ? EF_HEAP : EF_REAL) | (p->flags & EF_RUN);
+ r->dump = NULL;
+ r->len = p->len;
+ r->npats = p->npats;
+ /*
+ * If Eprog is on the heap, reference count is not valid.
+ * Otherwise, initialise reference count to 1 so that a freeeprog()
+ * will delete it if it is not in use.
+ */
+ r->nref = heap ? -1 : 1;
+ pp = r->pats = (heap ? (Patprog *) hcalloc(r->len) :
+ (Patprog *) zshcalloc(r->len));
+ r->prog = (Wordcode) (r->pats + r->npats);
+ r->strs = ((char *) r->prog) + (p->strs - ((char *) p->prog));
+ memcpy(r->prog, p->prog, r->len - (p->npats * sizeof(Patprog)));
+ r->shf = NULL;
+
+ for (i = r->npats; i--; pp++)
+ *pp = dummy_patprog1;
+
+ return r;
+}
+
+
+/*
+ * Pair of functions to mark an Eprog as in use, and to delete it
+ * when it is no longer in use, by means of the reference count in
+ * then nref element.
+ *
+ * If nref is negative, the Eprog is on the heap and is never freed.
+ */
+
+/* Increase the reference count of an Eprog so it won't be deleted. */
+
+/**/
+mod_export void
+useeprog(Eprog p)
+{
+ if (p && p != &dummy_eprog && p->nref >= 0)
+ p->nref++;
+}
+
+/* Free an Eprog if we have finished with it */
+
+/**/
+mod_export void
+freeeprog(Eprog p)
+{
+ int i;
+ Patprog *pp;
+
+ if (p && p != &dummy_eprog) {
+ /* paranoia */
+ DPUTS(p->nref > 0 && (p->flags & EF_HEAP), "Heap EPROG has nref > 0");
+ DPUTS(p->nref < 0 && !(p->flags & EF_HEAP), "Real EPROG has nref < 0");
+ DPUTS(p->nref < -1, "Uninitialised EPROG nref");
+#ifdef MAX_FUNCTION_DEPTH
+ DPUTS(zsh_funcnest >=0 && p->nref > zsh_funcnest + 10,
+ "Overlarge EPROG nref");
+#endif
+ if (p->nref > 0 && !--p->nref) {
+ for (i = p->npats, pp = p->pats; i--; pp++)
+ freepatprog(*pp);
+ if (p->dump) {
+ decrdumpcount(p->dump);
+ zfree(p->pats, p->npats * sizeof(Patprog));
+ } else
+ zfree(p->pats, p->len);
+ zfree(p, sizeof(*p));
+ }
+ }
+}
+
+/**/
+char *
+ecgetstr(Estate s, int dup, int *tokflag)
+{
+ static char buf[4];
+ wordcode c = *s->pc++;
+ char *r;
+
+ if (c == 6 || c == 7)
+ r = "";
+ else if (c & 2) {
+ buf[0] = (char) ((c >> 3) & 0xff);
+ buf[1] = (char) ((c >> 11) & 0xff);
+ buf[2] = (char) ((c >> 19) & 0xff);
+ buf[3] = '\0';
+ r = dupstring(buf);
+ dup = EC_NODUP;
+ } else {
+ r = s->strs + (c >> 2);
+ }
+ if (tokflag)
+ *tokflag = (c & 1);
+
+ /*** Since function dump files are mapped read-only, avoiding to
+ * to duplicate strings when they don't contain tokens may fail
+ * when one of the many utility functions happens to write to
+ * one of the strings (without really modifying it).
+ * If that happens to you and you don't feel like debugging it,
+ * just change the line below to:
+ *
+ * return (dup ? dupstring(r) : r);
+ */
+
+ return ((dup == EC_DUP || (dup && (c & 1))) ? dupstring(r) : r);
+}
+
+/**/
+char *
+ecrawstr(Eprog p, Wordcode pc, int *tokflag)
+{
+ static char buf[4];
+ wordcode c = *pc;
+
+ if (c == 6 || c == 7) {
+ if (tokflag)
+ *tokflag = (c & 1);
+ return "";
+ } else if (c & 2) {
+ buf[0] = (char) ((c >> 3) & 0xff);
+ buf[1] = (char) ((c >> 11) & 0xff);
+ buf[2] = (char) ((c >> 19) & 0xff);
+ buf[3] = '\0';
+ if (tokflag)
+ *tokflag = (c & 1);
+ return buf;
+ } else {
+ if (tokflag)
+ *tokflag = (c & 1);
+ return p->strs + (c >> 2);
+ }
+}
+
+/**/
+char **
+ecgetarr(Estate s, int num, int dup, int *tokflag)
+{
+ char **ret, **rp;
+ int tf = 0, tmp = 0;
+
+ ret = rp = (char **) zhalloc((num + 1) * sizeof(char *));
+
+ while (num--) {
+ *rp++ = ecgetstr(s, dup, &tmp);
+ tf |= tmp;
+ }
+ *rp = NULL;
+ if (tokflag)
+ *tokflag = tf;
+
+ return ret;
+}
+
+/**/
+LinkList
+ecgetlist(Estate s, int num, int dup, int *tokflag)
+{
+ if (num) {
+ LinkList ret;
+ int i, tf = 0, tmp = 0;
+
+ ret = newsizedlist(num);
+ for (i = 0; i < num; i++) {
+ setsizednode(ret, i, ecgetstr(s, dup, &tmp));
+ tf |= tmp;
+ }
+ if (tokflag)
+ *tokflag = tf;
+ return ret;
+ }
+ if (tokflag)
+ *tokflag = 0;
+ return NULL;
+}
+
+/**/
+LinkList
+ecgetredirs(Estate s)
+{
+ LinkList ret = newlinklist();
+ wordcode code = *s->pc++;
+
+ while (wc_code(code) == WC_REDIR) {
+ Redir r = (Redir) zhalloc(sizeof(*r));
+
+ r->type = WC_REDIR_TYPE(code);
+ r->fd1 = *s->pc++;
+ r->name = ecgetstr(s, EC_DUP, NULL);
+ if (WC_REDIR_FROM_HEREDOC(code)) {
+ r->flags = REDIRF_FROM_HEREDOC;
+ r->here_terminator = ecgetstr(s, EC_DUP, NULL);
+ r->munged_here_terminator = ecgetstr(s, EC_DUP, NULL);
+ } else {
+ r->flags = 0;
+ r->here_terminator = NULL;
+ r->munged_here_terminator = NULL;
+ }
+ if (WC_REDIR_VARID(code))
+ r->varid = ecgetstr(s, EC_DUP, NULL);
+ else
+ r->varid = NULL;
+
+ addlinknode(ret, r);
+
+ code = *s->pc++;
+ }
+ s->pc--;
+
+ return ret;
+}
+
+/*
+ * Copy the consecutive set of redirections in the state at s.
+ * Return NULL if none, else an Eprog consisting only of the
+ * redirections from permanently allocated memory.
+ *
+ * s is left in the state ready for whatever follows the redirections.
+ */
+
+/**/
+Eprog
+eccopyredirs(Estate s)
+{
+ Wordcode pc = s->pc;
+ wordcode code = *pc;
+ int ncode, ncodes = 0, r;
+
+ if (wc_code(code) != WC_REDIR)
+ return NULL;
+
+ init_parse();
+
+ while (wc_code(code) == WC_REDIR) {
+#ifdef DEBUG
+ int type = WC_REDIR_TYPE(code);
+#endif
+
+ DPUTS(type == REDIR_HEREDOC || type == REDIR_HEREDOCDASH,
+ "unexpanded here document");
+
+ if (WC_REDIR_FROM_HEREDOC(code))
+ ncode = 5;
+ else
+ ncode = 3;
+ if (WC_REDIR_VARID(code))
+ ncode++;
+ pc += ncode;
+ ncodes += ncode;
+ code = *pc;
+ }
+ r = ecused;
+ ecispace(r, ncodes);
+
+ code = *s->pc;
+ while (wc_code(code) == WC_REDIR) {
+ s->pc++;
+
+ ecbuf[r++] = code;
+ /* fd1 */
+ ecbuf[r++] = *s->pc++;
+ /* name or HERE string */
+ /* No DUP needed as we'll copy into Eprog immediately below */
+ ecbuf[r++] = ecstrcode(ecgetstr(s, EC_NODUP, NULL));
+ if (WC_REDIR_FROM_HEREDOC(code))
+ {
+ /* terminator, raw */
+ ecbuf[r++] = ecstrcode(ecgetstr(s, EC_NODUP, NULL));
+ /* terminator, munged */
+ ecbuf[r++] = ecstrcode(ecgetstr(s, EC_NODUP, NULL));
+ }
+ if (WC_REDIR_VARID(code))
+ ecbuf[r++] = ecstrcode(ecgetstr(s, EC_NODUP, NULL));
+
+ code = *s->pc;
+ }
+
+ /* bld_eprog() appends a useful WC_END marker */
+ return bld_eprog(0);
+}
+
+/**/
+mod_export struct eprog dummy_eprog;
+
+static wordcode dummy_eprog_code;
+
+/**/
+void
+init_eprog(void)
+{
+ dummy_eprog_code = WCB_END();
+ dummy_eprog.len = sizeof(wordcode);
+ dummy_eprog.prog = &dummy_eprog_code;
+ dummy_eprog.strs = NULL;
+}
+
+/* Code for function dump files.
+ *
+ * Dump files consist of a header and the function bodies (the wordcode
+ * plus the string table) and that twice: once for the byte-order of the
+ * host the file was created on and once for the other byte-order. The
+ * header describes where the beginning of the `other' version is and it
+ * is up to the shell reading the file to decide which version it needs.
+ * This is done by checking if the first word is FD_MAGIC (then the
+ * shell reading the file has the same byte order as the one that created
+ * the file) or if it is FD_OMAGIC, then the `other' version has to be
+ * read.
+ * The header is the magic number, a word containing the flags (if the
+ * file should be mapped or read and if this header is the `other' one),
+ * the version string in a field of 40 characters and the descriptions
+ * for the functions in the dump file.
+ *
+ * NOTES:
+ * - This layout has to be kept; everything after it may be changed.
+ * - When incompatible changes are made, the FD_MAGIC and FD_OMAGIC
+ * numbers have to be changed.
+ *
+ * Each description consists of a struct fdhead followed by the name,
+ * aligned to sizeof(wordcode) (i.e. 4 bytes).
+ */
+
+#include "version.h"
+
+#define FD_EXT ".zwc"
+#define FD_MINMAP 4096
+
+#define FD_PRELEN 12
+#define FD_MAGIC 0x04050607
+#define FD_OMAGIC 0x07060504
+
+#define FDF_MAP 1
+#define FDF_OTHER 2
+
+typedef struct fdhead *FDHead;
+
+struct fdhead {
+ wordcode start; /* offset to function definition */
+ wordcode len; /* length of wordcode/strings */
+ wordcode npats; /* number of patterns needed */
+ wordcode strs; /* offset to strings */
+ wordcode hlen; /* header length (incl. name) */
+ wordcode flags; /* flags and offset to name tail */
+};
+
+#define fdheaderlen(f) (((Wordcode) (f))[FD_PRELEN])
+
+#define fdmagic(f) (((Wordcode) (f))[0])
+#define fdsetbyte(f,i,v) \
+ ((((unsigned char *) (((Wordcode) (f)) + 1))[i]) = ((unsigned char) (v)))
+#define fdbyte(f,i) ((wordcode) (((unsigned char *) (((Wordcode) (f)) + 1))[i]))
+#define fdflags(f) fdbyte(f, 0)
+#define fdsetflags(f,v) fdsetbyte(f, 0, v)
+#define fdother(f) (fdbyte(f, 1) + (fdbyte(f, 2) << 8) + (fdbyte(f, 3) << 16))
+#define fdsetother(f, o) \
+ do { \
+ fdsetbyte(f, 1, ((o) & 0xff)); \
+ fdsetbyte(f, 2, (((o) >> 8) & 0xff)); \
+ fdsetbyte(f, 3, (((o) >> 16) & 0xff)); \
+ } while (0)
+#define fdversion(f) ((char *) ((f) + 2))
+
+#define firstfdhead(f) ((FDHead) (((Wordcode) (f)) + FD_PRELEN))
+#define nextfdhead(f) ((FDHead) (((Wordcode) (f)) + (f)->hlen))
+
+#define fdhflags(f) (((FDHead) (f))->flags)
+#define fdhtail(f) (((FDHead) (f))->flags >> 2)
+#define fdhbldflags(f,t) ((f) | ((t) << 2))
+
+#define FDHF_KSHLOAD 1
+#define FDHF_ZSHLOAD 2
+
+#define fdname(f) ((char *) (((FDHead) (f)) + 1))
+
+/* This is used when building wordcode files. */
+
+typedef struct wcfunc *WCFunc;
+
+struct wcfunc {
+ char *name;
+ Eprog prog;
+ int flags;
+};
+
+/* Try to find the description for the given function name. */
+
+static FDHead
+dump_find_func(Wordcode h, char *name)
+{
+ FDHead n, e = (FDHead) (h + fdheaderlen(h));
+
+ for (n = firstfdhead(h); n < e; n = nextfdhead(n))
+ if (!strcmp(name, fdname(n) + fdhtail(n)))
+ return n;
+
+ return NULL;
+}
+
+/**/
+int
+bin_zcompile(char *nam, char **args, Options ops, UNUSED(int func))
+{
+ int map, flags, ret;
+ char *dump;
+
+ if ((OPT_ISSET(ops,'k') && OPT_ISSET(ops,'z')) ||
+ (OPT_ISSET(ops,'R') && OPT_ISSET(ops,'M')) ||
+ (OPT_ISSET(ops,'c') &&
+ (OPT_ISSET(ops,'U') || OPT_ISSET(ops,'k') || OPT_ISSET(ops,'z'))) ||
+ (!(OPT_ISSET(ops,'c') || OPT_ISSET(ops,'a')) && OPT_ISSET(ops,'m'))) {
+ zwarnnam(nam, "illegal combination of options");
+ return 1;
+ }
+ if ((OPT_ISSET(ops,'c') || OPT_ISSET(ops,'a')) && isset(KSHAUTOLOAD))
+ zwarnnam(nam, "functions will use zsh style autoloading");
+
+ flags = (OPT_ISSET(ops,'k') ? FDHF_KSHLOAD :
+ (OPT_ISSET(ops,'z') ? FDHF_ZSHLOAD : 0));
+
+ if (OPT_ISSET(ops,'t')) {
+ Wordcode f;
+
+ if (!*args) {
+ zwarnnam(nam, "too few arguments");
+ return 1;
+ }
+ if (!(f = load_dump_header(nam, (strsfx(FD_EXT, *args) ? *args :
+ dyncat(*args, FD_EXT)), 1)))
+ return 1;
+
+ if (args[1]) {
+ for (args++; *args; args++)
+ if (!dump_find_func(f, *args))
+ return 1;
+ return 0;
+ } else {
+ FDHead h, e = (FDHead) (f + fdheaderlen(f));
+
+ printf("zwc file (%s) for zsh-%s\n",
+ ((fdflags(f) & FDF_MAP) ? "mapped" : "read"), fdversion(f));
+ for (h = firstfdhead(f); h < e; h = nextfdhead(h))
+ printf("%s\n", fdname(h));
+ return 0;
+ }
+ }
+ if (!*args) {
+ zwarnnam(nam, "too few arguments");
+ return 1;
+ }
+ map = (OPT_ISSET(ops,'M') ? 2 : (OPT_ISSET(ops,'R') ? 0 : 1));
+
+ if (!args[1] && !(OPT_ISSET(ops,'c') || OPT_ISSET(ops,'a'))) {
+ queue_signals();
+ ret = build_dump(nam, dyncat(*args, FD_EXT), args, OPT_ISSET(ops,'U'),
+ map, flags);
+ unqueue_signals();
+ return ret;
+ }
+ dump = (strsfx(FD_EXT, *args) ? *args : dyncat(*args, FD_EXT));
+
+ queue_signals();
+ ret = ((OPT_ISSET(ops,'c') || OPT_ISSET(ops,'a')) ?
+ build_cur_dump(nam, dump, args + 1, OPT_ISSET(ops,'m'), map,
+ (OPT_ISSET(ops,'c') ? 1 : 0) |
+ (OPT_ISSET(ops,'a') ? 2 : 0)) :
+ build_dump(nam, dump, args + 1, OPT_ISSET(ops,'U'), map, flags));
+ unqueue_signals();
+
+ return ret;
+}
+
+/* Load the header of a dump file. Returns NULL if the file isn't a
+ * valid dump file. */
+
+/**/
+static Wordcode
+load_dump_header(char *nam, char *name, int err)
+{
+ int fd, v = 1;
+ wordcode buf[FD_PRELEN + 1];
+
+ if ((fd = open(name, O_RDONLY)) < 0) {
+ if (err)
+ zwarnnam(nam, "can't open zwc file: %s", name);
+ return NULL;
+ }
+ if (read(fd, buf, (FD_PRELEN + 1) * sizeof(wordcode)) !=
+ ((FD_PRELEN + 1) * sizeof(wordcode)) ||
+ (v = (fdmagic(buf) != FD_MAGIC && fdmagic(buf) != FD_OMAGIC)) ||
+ strcmp(fdversion(buf), ZSH_VERSION)) {
+ if (err) {
+ if (!v) {
+ zwarnnam(nam, "zwc file has wrong version (zsh-%s): %s",
+ fdversion(buf), name);
+ } else
+ zwarnnam(nam, "invalid zwc file: %s" , name);
+ }
+ close(fd);
+ return NULL;
+ } else {
+ int len;
+ Wordcode head;
+
+ if (fdmagic(buf) == FD_MAGIC) {
+ len = fdheaderlen(buf) * sizeof(wordcode);
+ head = (Wordcode) zhalloc(len);
+ }
+ else {
+ int o = fdother(buf);
+
+ if (lseek(fd, o, 0) == -1 ||
+ read(fd, buf, (FD_PRELEN + 1) * sizeof(wordcode)) !=
+ ((FD_PRELEN + 1) * sizeof(wordcode))) {
+ zwarnnam(nam, "invalid zwc file: %s" , name);
+ close(fd);
+ return NULL;
+ }
+ len = fdheaderlen(buf) * sizeof(wordcode);
+ head = (Wordcode) zhalloc(len);
+ }
+ memcpy(head, buf, (FD_PRELEN + 1) * sizeof(wordcode));
+
+ len -= (FD_PRELEN + 1) * sizeof(wordcode);
+ if (read(fd, head + (FD_PRELEN + 1), len) != len) {
+ close(fd);
+ zwarnnam(nam, "invalid zwc file: %s" , name);
+ return NULL;
+ }
+ close(fd);
+ return head;
+ }
+}
+
+/* Swap the bytes in a wordcode. */
+
+static void
+fdswap(Wordcode p, int n)
+{
+ wordcode c;
+
+ for (; n--; p++) {
+ c = *p;
+ *p = (((c & 0xff) << 24) |
+ ((c & 0xff00) << 8) |
+ ((c & 0xff0000) >> 8) |
+ ((c & 0xff000000) >> 24));
+ }
+}
+
+/* Write a dump file. */
+
+static void
+write_dump(int dfd, LinkList progs, int map, int hlen, int tlen)
+{
+ LinkNode node;
+ WCFunc wcf;
+ int other = 0, ohlen, tmp;
+ wordcode pre[FD_PRELEN];
+ char *tail, *n;
+ struct fdhead head;
+ Eprog prog;
+
+ if (map == 1)
+ map = (tlen >= FD_MINMAP);
+
+ memset(pre, 0, sizeof(wordcode) * FD_PRELEN);
+
+ for (ohlen = hlen; ; hlen = ohlen) {
+ fdmagic(pre) = (other ? FD_OMAGIC : FD_MAGIC);
+ fdsetflags(pre, ((map ? FDF_MAP : 0) | other));
+ fdsetother(pre, tlen);
+ strcpy(fdversion(pre), ZSH_VERSION);
+ write_loop(dfd, (char *)pre, FD_PRELEN * sizeof(wordcode));
+
+ for (node = firstnode(progs); node; incnode(node)) {
+ wcf = (WCFunc) getdata(node);
+ n = wcf->name;
+ prog = wcf->prog;
+ head.start = hlen;
+ hlen += (prog->len - (prog->npats * sizeof(Patprog)) +
+ sizeof(wordcode) - 1) / sizeof(wordcode);
+ head.len = prog->len - (prog->npats * sizeof(Patprog));
+ head.npats = prog->npats;
+ head.strs = prog->strs - ((char *) prog->prog);
+ head.hlen = (sizeof(struct fdhead) / sizeof(wordcode)) +
+ (strlen(n) + sizeof(wordcode)) / sizeof(wordcode);
+ if ((tail = strrchr(n, '/')))
+ tail++;
+ else
+ tail = n;
+ head.flags = fdhbldflags(wcf->flags, (tail - n));
+ if (other)
+ fdswap((Wordcode) &head, sizeof(head) / sizeof(wordcode));
+ write_loop(dfd, (char *)&head, sizeof(head));
+ tmp = strlen(n) + 1;
+ write_loop(dfd, n, tmp);
+ if ((tmp &= (sizeof(wordcode) - 1)))
+ write_loop(dfd, (char *)&head, sizeof(wordcode) - tmp);
+ }
+ for (node = firstnode(progs); node; incnode(node)) {
+ prog = ((WCFunc) getdata(node))->prog;
+ tmp = (prog->len - (prog->npats * sizeof(Patprog)) +
+ sizeof(wordcode) - 1) / sizeof(wordcode);
+ if (other)
+ fdswap(prog->prog, (((Wordcode) prog->strs) - prog->prog));
+ write_loop(dfd, (char *)prog->prog, tmp * sizeof(wordcode));
+ }
+ if (other)
+ break;
+ other = FDF_OTHER;
+ }
+}
+
+/**/
+static int
+build_dump(char *nam, char *dump, char **files, int ali, int map, int flags)
+{
+ int dfd, fd, hlen, tlen, flen, ona = noaliases;
+ LinkList progs;
+ char *file;
+ Eprog prog;
+ WCFunc wcf;
+
+ if (!strsfx(FD_EXT, dump))
+ dump = dyncat(dump, FD_EXT);
+
+ unlink(dump);
+ if ((dfd = open(dump, O_WRONLY|O_CREAT, 0444)) < 0) {
+ zwarnnam(nam, "can't write zwc file: %s", dump);
+ return 1;
+ }
+ progs = newlinklist();
+ noaliases = ali;
+
+ for (hlen = FD_PRELEN, tlen = 0; *files; files++) {
+ struct stat st;
+
+ if (check_cond(*files, "k")) {
+ flags = (flags & ~(FDHF_KSHLOAD | FDHF_ZSHLOAD)) | FDHF_KSHLOAD;
+ continue;
+ } else if (check_cond(*files, "z")) {
+ flags = (flags & ~(FDHF_KSHLOAD | FDHF_ZSHLOAD)) | FDHF_ZSHLOAD;
+ continue;
+ }
+ if ((fd = open(*files, O_RDONLY)) < 0 ||
+ fstat(fd, &st) != 0 || !S_ISREG(st.st_mode) ||
+ (flen = lseek(fd, 0, 2)) == -1) {
+ if (fd >= 0)
+ close(fd);
+ close(dfd);
+ zwarnnam(nam, "can't open file: %s", *files);
+ noaliases = ona;
+ unlink(dump);
+ return 1;
+ }
+ file = (char *) zalloc(flen + 1);
+ file[flen] = '\0';
+ lseek(fd, 0, 0);
+ if (read(fd, file, flen) != flen) {
+ close(fd);
+ close(dfd);
+ zfree(file, flen);
+ zwarnnam(nam, "can't read file: %s", *files);
+ noaliases = ona;
+ unlink(dump);
+ return 1;
+ }
+ close(fd);
+ file = metafy(file, flen, META_REALLOC);
+
+ if (!(prog = parse_string(file, 1)) || errflag) {
+ errflag &= ~ERRFLAG_ERROR;
+ close(dfd);
+ zfree(file, flen);
+ zwarnnam(nam, "can't read file: %s", *files);
+ noaliases = ona;
+ unlink(dump);
+ return 1;
+ }
+ zfree(file, flen);
+
+ wcf = (WCFunc) zhalloc(sizeof(*wcf));
+ wcf->name = *files;
+ wcf->prog = prog;
+ wcf->flags = ((prog->flags & EF_RUN) ? FDHF_KSHLOAD : flags);
+ addlinknode(progs, wcf);
+
+ flen = (strlen(*files) + sizeof(wordcode)) / sizeof(wordcode);
+ hlen += (sizeof(struct fdhead) / sizeof(wordcode)) + flen;
+
+ tlen += (prog->len - (prog->npats * sizeof(Patprog)) +
+ sizeof(wordcode) - 1) / sizeof(wordcode);
+ }
+ noaliases = ona;
+
+ tlen = (tlen + hlen) * sizeof(wordcode);
+
+ write_dump(dfd, progs, map, hlen, tlen);
+
+ close(dfd);
+
+ return 0;
+}
+
+static int
+cur_add_func(char *nam, Shfunc shf, LinkList names, LinkList progs,
+ int *hlen, int *tlen, int what)
+{
+ Eprog prog;
+ WCFunc wcf;
+
+ if (shf->node.flags & PM_UNDEFINED) {
+ int ona = noaliases;
+
+ if (!(what & 2)) {
+ zwarnnam(nam, "function is not loaded: %s", shf->node.nam);
+ return 1;
+ }
+ noaliases = (shf->node.flags & PM_UNALIASED);
+ if (!(prog = getfpfunc(shf->node.nam, NULL, NULL, NULL, 0)) ||
+ prog == &dummy_eprog) {
+ noaliases = ona;
+ zwarnnam(nam, "can't load function: %s", shf->node.nam);
+ return 1;
+ }
+ if (prog->dump)
+ prog = dupeprog(prog, 1);
+ noaliases = ona;
+ } else {
+ if (!(what & 1)) {
+ zwarnnam(nam, "function is already loaded: %s", shf->node.nam);
+ return 1;
+ }
+ prog = dupeprog(shf->funcdef, 1);
+ }
+ wcf = (WCFunc) zhalloc(sizeof(*wcf));
+ wcf->name = shf->node.nam;
+ wcf->prog = prog;
+ wcf->flags = ((prog->flags & EF_RUN) ? FDHF_KSHLOAD : FDHF_ZSHLOAD);
+ addlinknode(progs, wcf);
+ addlinknode(names, shf->node.nam);
+
+ *hlen += ((sizeof(struct fdhead) / sizeof(wordcode)) +
+ ((strlen(shf->node.nam) + sizeof(wordcode)) / sizeof(wordcode)));
+ *tlen += (prog->len - (prog->npats * sizeof(Patprog)) +
+ sizeof(wordcode) - 1) / sizeof(wordcode);
+
+ return 0;
+}
+
+/**/
+static int
+build_cur_dump(char *nam, char *dump, char **names, int match, int map,
+ int what)
+{
+ int dfd, hlen, tlen;
+ LinkList progs, lnames;
+ Shfunc shf = NULL;
+
+ if (!strsfx(FD_EXT, dump))
+ dump = dyncat(dump, FD_EXT);
+
+ unlink(dump);
+ if ((dfd = open(dump, O_WRONLY|O_CREAT, 0444)) < 0) {
+ zwarnnam(nam, "can't write zwc file: %s", dump);
+ return 1;
+ }
+ progs = newlinklist();
+ lnames = newlinklist();
+
+ hlen = FD_PRELEN;
+ tlen = 0;
+
+ if (!*names) {
+ int i;
+ HashNode hn;
+
+ for (i = 0; i < shfunctab->hsize; i++)
+ for (hn = shfunctab->nodes[i]; hn; hn = hn->next)
+ if (cur_add_func(nam, (Shfunc) hn, lnames, progs,
+ &hlen, &tlen, what)) {
+ errflag &= ~ERRFLAG_ERROR;
+ close(dfd);
+ unlink(dump);
+ return 1;
+ }
+ } else if (match) {
+ char *pat;
+ Patprog pprog;
+ int i;
+ HashNode hn;
+
+ for (; *names; names++) {
+ tokenize(pat = dupstring(*names));
+ /* Signal-safe here, caller queues signals */
+ if (!(pprog = patcompile(pat, PAT_STATIC, NULL))) {
+ zwarnnam(nam, "bad pattern: %s", *names);
+ close(dfd);
+ unlink(dump);
+ return 1;
+ }
+ for (i = 0; i < shfunctab->hsize; i++)
+ for (hn = shfunctab->nodes[i]; hn; hn = hn->next)
+ if (!linknodebydatum(lnames, hn->nam) &&
+ pattry(pprog, hn->nam) &&
+ cur_add_func(nam, (Shfunc) hn, lnames, progs,
+ &hlen, &tlen, what)) {
+ errflag &= ~ERRFLAG_ERROR;
+ close(dfd);
+ unlink(dump);
+ return 1;
+ }
+ }
+ } else {
+ for (; *names; names++) {
+ if (errflag ||
+ !(shf = (Shfunc) shfunctab->getnode(shfunctab, *names))) {
+ zwarnnam(nam, "unknown function: %s", *names);
+ errflag &= ~ERRFLAG_ERROR;
+ close(dfd);
+ unlink(dump);
+ return 1;
+ }
+ if (cur_add_func(nam, shf, lnames, progs, &hlen, &tlen, what)) {
+ errflag &= ~ERRFLAG_ERROR;
+ close(dfd);
+ unlink(dump);
+ return 1;
+ }
+ }
+ }
+ if (empty(progs)) {
+ zwarnnam(nam, "no functions");
+ errflag &= ~ERRFLAG_ERROR;
+ close(dfd);
+ unlink(dump);
+ return 1;
+ }
+ tlen = (tlen + hlen) * sizeof(wordcode);
+
+ write_dump(dfd, progs, map, hlen, tlen);
+
+ close(dfd);
+
+ return 0;
+}
+
+/**/
+#if defined(HAVE_SYS_MMAN_H) && defined(HAVE_MMAP) && defined(HAVE_MUNMAP)
+
+#include
+
+/**/
+#if defined(MAP_SHARED) && defined(PROT_READ)
+
+/**/
+#define USE_MMAP 1
+
+/**/
+#endif
+/**/
+#endif
+
+/**/
+#ifdef USE_MMAP
+
+/* List of dump files mapped. */
+
+static FuncDump dumps;
+
+/**/
+static int
+zwcstat(char *filename, struct stat *buf)
+{
+ if (stat(filename, buf)) {
+#ifdef HAVE_FSTAT
+ FuncDump f;
+
+ for (f = dumps; f; f = f->next) {
+ if (!strncmp(filename, f->filename, strlen(f->filename)) &&
+ !fstat(f->fd, buf))
+ return 0;
+ }
+#endif
+ return 1;
+ } else return 0;
+}
+
+/* Load a dump file (i.e. map it). */
+
+static void
+load_dump_file(char *dump, struct stat *sbuf, int other, int len)
+{
+ FuncDump d;
+ Wordcode addr;
+ int fd, off, mlen;
+
+ if (other) {
+ static size_t pgsz = 0;
+
+ if (!pgsz) {
+
+#ifdef _SC_PAGESIZE
+ pgsz = sysconf(_SC_PAGESIZE); /* SVR4 */
+#else
+# ifdef _SC_PAGE_SIZE
+ pgsz = sysconf(_SC_PAGE_SIZE); /* HPUX */
+# else
+ pgsz = getpagesize();
+# endif
+#endif
+
+ pgsz--;
+ }
+ off = len & ~pgsz;
+ mlen = len + (len - off);
+ } else {
+ off = 0;
+ mlen = len;
+ }
+ if ((fd = open(dump, O_RDONLY)) < 0)
+ return;
+
+ fd = movefd(fd);
+ if (fd == -1)
+ return;
+
+ if ((addr = (Wordcode) mmap(NULL, mlen, PROT_READ, MAP_SHARED, fd, off)) ==
+ ((Wordcode) -1)) {
+ close(fd);
+ return;
+ }
+ d = (FuncDump) zalloc(sizeof(*d));
+ d->next = dumps;
+ dumps = d;
+ d->dev = sbuf->st_dev;
+ d->ino = sbuf->st_ino;
+ d->fd = fd;
+#ifdef FD_CLOEXEC
+ fcntl(fd, F_SETFD, FD_CLOEXEC);
+#endif
+ d->map = addr + (other ? (len - off) / sizeof(wordcode) : 0);
+ d->addr = addr;
+ d->len = len;
+ d->count = 0;
+ d->filename = ztrdup(dump);
+}
+
+#else
+
+#define zwcstat(f, b) (!!stat(f, b))
+
+/**/
+#endif
+
+/* Try to load a function from one of the possible wordcode files for it.
+ * The first argument is a element of $fpath, the second one is the name
+ * of the function searched and the last one is the possible name for the
+ * uncompiled function file (/). */
+
+/**/
+Eprog
+try_dump_file(char *path, char *name, char *file, int *ksh, int test_only)
+{
+ Eprog prog;
+ struct stat std, stc, stn;
+ int rd, rc, rn;
+ char *dig, *wc;
+
+ if (strsfx(FD_EXT, path)) {
+ queue_signals();
+ prog = check_dump_file(path, NULL, name, ksh, test_only);
+ unqueue_signals();
+ return prog;
+ }
+ dig = dyncat(path, FD_EXT);
+ wc = dyncat(file, FD_EXT);
+
+ rd = zwcstat(dig, &std);
+ rc = stat(wc, &stc);
+ rn = stat(file, &stn);
+
+ /* See if there is a digest file for the directory, it is younger than
+ * both the uncompiled function file and its compiled version (or they
+ * don't exist) and the digest file contains the definition for the
+ * function. */
+ queue_signals();
+ if (!rd &&
+ (rc || std.st_mtime >= stc.st_mtime) &&
+ (rn || std.st_mtime >= stn.st_mtime) &&
+ (prog = check_dump_file(dig, &std, name, ksh, test_only))) {
+ unqueue_signals();
+ return prog;
+ }
+ /* No digest file. Now look for the per-function compiled file. */
+ if (!rc &&
+ (rn || stc.st_mtime >= stn.st_mtime) &&
+ (prog = check_dump_file(wc, &stc, name, ksh, test_only))) {
+ unqueue_signals();
+ return prog;
+ }
+ /* No compiled file for the function. The caller (getfpfunc() will
+ * check if the directory contains the uncompiled file for it. */
+ unqueue_signals();
+ return NULL;
+}
+
+/* Almost the same, but for sourced files. */
+
+/**/
+Eprog
+try_source_file(char *file)
+{
+ Eprog prog;
+ struct stat stc, stn;
+ int rc, rn;
+ char *wc, *tail;
+
+ if ((tail = strrchr(file, '/')))
+ tail++;
+ else
+ tail = file;
+
+ if (strsfx(FD_EXT, file)) {
+ queue_signals();
+ prog = check_dump_file(file, NULL, tail, NULL, 0);
+ unqueue_signals();
+ return prog;
+ }
+ wc = dyncat(file, FD_EXT);
+
+ rc = stat(wc, &stc);
+ rn = stat(file, &stn);
+
+ queue_signals();
+ if (!rc && (rn || stc.st_mtime >= stn.st_mtime) &&
+ (prog = check_dump_file(wc, &stc, tail, NULL, 0))) {
+ unqueue_signals();
+ return prog;
+ }
+ unqueue_signals();
+ return NULL;
+}
+
+/* See if `file' names a wordcode dump file and that contains the
+ * definition for the function `name'. If so, return an eprog for it. */
+
+/**/
+static Eprog
+check_dump_file(char *file, struct stat *sbuf, char *name, int *ksh,
+ int test_only)
+{
+ int isrec = 0;
+ Wordcode d;
+ FDHead h;
+ FuncDump f;
+ struct stat lsbuf;
+
+ if (!sbuf) {
+ if (zwcstat(file, &lsbuf))
+ return NULL;
+ sbuf = &lsbuf;
+ }
+
+#ifdef USE_MMAP
+
+ rec:
+
+#endif
+
+ d = NULL;
+
+#ifdef USE_MMAP
+
+ for (f = dumps; f; f = f->next)
+ if (f->dev == sbuf->st_dev && f->ino == sbuf->st_ino) {
+ d = f->map;
+ break;
+ }
+
+#else
+
+ f = NULL;
+
+#endif
+
+ if (!f && (isrec || !(d = load_dump_header(NULL, file, 0))))
+ return NULL;
+
+ if ((h = dump_find_func(d, name))) {
+ /* Found the name. If the file is already mapped, return the eprog,
+ * otherwise map it and just go up. */
+ if (test_only)
+ {
+ /* This is all we need. Just return dummy. */
+ return &dummy_eprog;
+ }
+
+#ifdef USE_MMAP
+
+ if (f) {
+ Eprog prog = (Eprog) zalloc(sizeof(*prog));
+ Patprog *pp;
+ int np;
+
+ prog->flags = EF_MAP;
+ prog->len = h->len;
+ prog->npats = np = h->npats;
+ prog->nref = 1; /* allocated from permanent storage */
+ prog->pats = pp = (Patprog *) zalloc(np * sizeof(Patprog));
+ prog->prog = f->map + h->start;
+ prog->strs = ((char *) prog->prog) + h->strs;
+ prog->shf = NULL;
+ prog->dump = f;
+
+ incrdumpcount(f);
+
+ while (np--)
+ *pp++ = dummy_patprog1;
+
+ if (ksh)
+ *ksh = ((fdhflags(h) & FDHF_KSHLOAD) ? 2 :
+ ((fdhflags(h) & FDHF_ZSHLOAD) ? 0 : 1));
+
+ return prog;
+ } else if (fdflags(d) & FDF_MAP) {
+ load_dump_file(file, sbuf, (fdflags(d) & FDF_OTHER), fdother(d));
+ isrec = 1;
+ goto rec;
+ } else
+
+#endif
+
+ {
+ Eprog prog;
+ Patprog *pp;
+ int np, fd, po = h->npats * sizeof(Patprog);
+
+ if ((fd = open(file, O_RDONLY)) < 0 ||
+ lseek(fd, ((h->start * sizeof(wordcode)) +
+ ((fdflags(d) & FDF_OTHER) ? fdother(d) : 0)), 0) < 0) {
+ if (fd >= 0)
+ close(fd);
+ return NULL;
+ }
+ d = (Wordcode) zalloc(h->len + po);
+
+ if (read(fd, ((char *) d) + po, h->len) != (int)h->len) {
+ close(fd);
+ zfree(d, h->len);
+
+ return NULL;
+ }
+ close(fd);
+
+ prog = (Eprog) zalloc(sizeof(*prog));
+
+ prog->flags = EF_REAL;
+ prog->len = h->len + po;
+ prog->npats = np = h->npats;
+ prog->nref = 1; /* allocated from permanent storage */
+ prog->pats = pp = (Patprog *) d;
+ prog->prog = (Wordcode) (((char *) d) + po);
+ prog->strs = ((char *) prog->prog) + h->strs;
+ prog->shf = NULL;
+ prog->dump = f;
+
+ while (np--)
+ *pp++ = dummy_patprog1;
+
+ if (ksh)
+ *ksh = ((fdhflags(h) & FDHF_KSHLOAD) ? 2 :
+ ((fdhflags(h) & FDHF_ZSHLOAD) ? 0 : 1));
+
+ return prog;
+ }
+ }
+ return NULL;
+}
+
+#ifdef USE_MMAP
+
+/* Increment the reference counter for a dump file. */
+
+/**/
+void
+incrdumpcount(FuncDump f)
+{
+ f->count++;
+}
+
+/**/
+static void
+freedump(FuncDump f)
+{
+ munmap((void *) f->addr, f->len);
+ zclose(f->fd);
+ zsfree(f->filename);
+ zfree(f, sizeof(*f));
+}
+
+/* Decrement the reference counter for a dump file. If zero, unmap the file. */
+
+/**/
+void
+decrdumpcount(FuncDump f)
+{
+ f->count--;
+ if (!f->count) {
+ FuncDump p, q;
+
+ for (q = NULL, p = dumps; p && p != f; q = p, p = p->next);
+ if (p) {
+ if (q)
+ q->next = p->next;
+ else
+ dumps = p->next;
+ freedump(f);
+ }
+ }
+}
+
+#ifndef FD_CLOEXEC
+/**/
+mod_export void
+closedumps(void)
+{
+ while (dumps) {
+ FuncDump p = dumps->next;
+ freedump(dumps);
+ dumps = p;
+ }
+}
+#endif
+
+#else
+
+void
+incrdumpcount(FuncDump f)
+{
+}
+
+void
+decrdumpcount(FuncDump f)
+{
+}
+
+#ifndef FD_CLOEXEC
+/**/
+mod_export void
+closedumps(void)
+{
+}
+#endif
+
+#endif
+
+/**/
+int
+dump_autoload(char *nam, char *file, int on, Options ops, int func)
+{
+ Wordcode h;
+ FDHead n, e;
+ Shfunc shf;
+ int ret = 0;
+
+ if (!strsfx(FD_EXT, file))
+ file = dyncat(file, FD_EXT);
+
+ if (!(h = load_dump_header(nam, file, 1)))
+ return 1;
+
+ for (n = firstfdhead(h), e = (FDHead) (h + fdheaderlen(h)); n < e;
+ n = nextfdhead(n)) {
+ shf = (Shfunc) zshcalloc(sizeof *shf);
+ shf->node.flags = on;
+ shf->funcdef = mkautofn(shf);
+ shf->sticky = NULL;
+ shfunctab->addnode(shfunctab, ztrdup(fdname(n) + fdhtail(n)), shf);
+ if (OPT_ISSET(ops,'X') && eval_autoload(shf, shf->node.nam, ops, func))
+ ret = 1;
+ }
+ return ret;
+}
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/pattern.c b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/pattern.c
new file mode 100644
index 0000000..737f5cd
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/pattern.c
@@ -0,0 +1,4336 @@
+/*
+ * pattern.c - pattern matching
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1999 Peter Stephenson
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Peter Stephenson or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Peter Stephenson and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Peter Stephenson and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Peter Stephenson and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ * Pattern matching code derived from the regexp library by Henry
+ * Spencer, which has the following copyright.
+ *
+ * Copyright (c) 1986 by University of Toronto.
+ * Written by Henry Spencer. Not derived from licensed software.
+ *
+ * Permission is granted to anyone to use this software for any
+ * purpose on any computer system, and to redistribute it freely,
+ * subject to the following restrictions:
+ *
+ * 1. The author is not responsible for the consequences of use of
+ * this software, no matter how awful, even if they arise
+ * from defects in it.
+ *
+ * 2. The origin of this software must not be misrepresented, either
+ * by explicit claim or by omission.
+ *
+ * 3. Altered versions must be plainly marked as such, and must not
+ * be misrepresented as being the original software.
+ *
+ * Eagle-eyed readers will notice this is an altered version. Incredibly
+ * sharp-eyed readers might even find bits that weren't altered.
+ *
+ *
+ * And I experienced a sense that, like certain regular
+ * expressions, seemed to match the day from beginning to end, so
+ * that I did not need to identify the parenthesised subexpression
+ * that told of dawn, nor the group of characters that indicated
+ * the moment when my grandfather returned home with news of
+ * Swann's departure for Paris; and the whole length of the month
+ * of May, as if matched by a closure, fitted into the buffer of my
+ * life with no sign of overflowing, turning the days, like a
+ * procession of insects that could consist of this or that
+ * species, into a random and unstructured repetition of different
+ * sequences, anchored from the first day of the month to the last
+ * in the same fashion as the weeks when I knew I would not see
+ * Gilberte and would search in vain for any occurrences of the
+ * string in the avenue of hawthorns by Tansonville, without my
+ * having to delimit explicitly the start or finish of the pattern.
+ *
+ * M. Proust, "In Search of Lost Files",
+ * bk I, "The Walk by Bourne's Place".
+ */
+
+#include "zsh.mdh"
+
+/*
+ * The following union is used mostly for alignment purposes.
+ * Normal nodes are longs, while certain nodes take a char * as an argument;
+ * here we make sure that they both work out to the same length.
+ * The compiled regexp we construct consists of upats stuck together;
+ * anything else to be added (strings, numbers) is stuck after and
+ * then aligned to a whole number of upat units.
+ *
+ * Note also that offsets are in terms of the sizes of these things.
+ */
+union upat {
+ long l;
+ unsigned char *p;
+};
+
+typedef union upat *Upat;
+
+#include "pattern.pro"
+
+/* Number of active parenthesized expressions allowed in backreferencing */
+#define NSUBEXP 9
+
+/* definition number opnd? meaning */
+#define P_END 0x00 /* no End of program. */
+#define P_EXCSYNC 0x01 /* no Test if following exclude already failed */
+#define P_EXCEND 0x02 /* no Test if exclude matched orig branch */
+#define P_BACK 0x03 /* no Match "", "next" ptr points backward. */
+#define P_EXACTLY 0x04 /* lstr Match this string. */
+#define P_NOTHING 0x05 /* no Match empty string. */
+#define P_ONEHASH 0x06 /* node Match this (simple) thing 0 or more times. */
+#define P_TWOHASH 0x07 /* node Match this (simple) thing 1 or more times. */
+#define P_GFLAGS 0x08 /* long Match nothing and set globbing flags */
+#define P_ISSTART 0x09 /* no Match start of string. */
+#define P_ISEND 0x0a /* no Match end of string. */
+#define P_COUNTSTART 0x0b /* no Initialise P_COUNT */
+#define P_COUNT 0x0c /* 3*long uc* node Match a number of repetitions */
+/* numbered so we can test bit 5 for a branch */
+#define P_BRANCH 0x20 /* node Match this alternative, or the next... */
+#define P_WBRANCH 0x21 /* uc* node P_BRANCH, but match at least 1 char */
+/* excludes are also branches, but have bit 4 set, too */
+#define P_EXCLUDE 0x30 /* uc* node Exclude this from previous branch */
+#define P_EXCLUDP 0x31 /* uc* node Exclude, using full file path so far */
+/* numbered so we can test bit 6 so as not to match initial '.' */
+#define P_ANY 0x40 /* no Match any one character. */
+#define P_ANYOF 0x41 /* str Match any character in this string. */
+#define P_ANYBUT 0x42 /* str Match any character not in this string. */
+#define P_STAR 0x43 /* no Match any set of characters. */
+#define P_NUMRNG 0x44 /* zr, zr Match a numeric range. */
+#define P_NUMFROM 0x45 /* zr Match a number >= X */
+#define P_NUMTO 0x46 /* zr Match a number <= X */
+#define P_NUMANY 0x47 /* no Match any set of decimal digits */
+/* spaces left for P_OPEN+n,... for backreferences */
+#define P_OPEN 0x80 /* no Mark this point in input as start of n. */
+#define P_CLOSE 0x90 /* no Analogous to OPEN. */
+/*
+ * no no argument
+ * zr the range type zrange_t: may be zlong or unsigned long
+ * char a single char
+ * uc* a pointer to unsigned char, used at run time and initialised
+ * to NULL.
+ * str null-terminated, metafied string
+ * lstr length as long then string, not null-terminated, unmetafied.
+ */
+
+/*
+ * Notes on usage:
+ * P_WBRANCH: This works like a branch and is used in complex closures,
+ * to ensure we don't succeed on a zero-length match of the pattern,
+ * since that would cause an infinite loop. We do this by recording
+ * the positions where we have already tried to match. See the
+ * P_WBRANCH test in patmatch().
+ *
+ * P_ANY, P_ANYOF: the operand is a null terminated
+ * string. Normal characters match as expected. Characters
+ * in the range Meta+PP_ALPHA..Meta+PP_UNKWN do the appropriate
+ * Posix range tests. This relies on imeta returning true for these
+ * characters. We treat unknown POSIX ranges as never matching.
+ * PP_RANGE means the next two (possibly metafied) characters form
+ * the limits of a range to test; it's too much like hard work to
+ * expand the range.
+ *
+ * P_EXCLUDE, P_EXCSYNC, PEXCEND: P_EXCLUDE appears in the pattern like
+ * P_BRANCH, but applies to the immediately preceding branch. The code in
+ * the corresponding branch is followed by a P_EXCSYNC, which simply
+ * acts as a marker that a P_EXCLUDE comes next. The P_EXCLUDE
+ * has a pointer to char embeded in it, which works
+ * like P_WBRANCH: if we get to the P_EXCSYNC, and we already matched
+ * up to the same position, fail. Thus we are forced to backtrack
+ * on closures in the P_BRANCH if the first attempt was excluded.
+ * Corresponding to P_EXCSYNC in the original branch, there is a
+ * P_EXCEND in the exclusion. If we get to this point, and we did
+ * *not* match in the original branch, the exclusion itself fails,
+ * otherwise it succeeds since we know the tail already matches,
+ * so P_EXCEND is the end of the exclusion test.
+ * The whole sorry mess looks like this, where the upper lines
+ * show the linkage of the branches, and the lower shows the linkage
+ * of their pattern arguments.
+ *
+ * --------------------- ----------------------
+ * ^ v ^ v
+ * ( :apat-> :excpat-> ) tail
+ * ^
+ * | |
+ * --------------------------------------
+ *
+ * P_EXCLUDP: this behaves exactly like P_EXCLUDE, with the sole exception
+ * that we prepend the path so far to the exclude pattern. This is
+ * for top level file globs, e.g. ** / *.c~*foo.c
+ * ^ I had to leave this space
+ * P_NUM*: zl is a zlong if that is 64-bit, else an unsigned long.
+ *
+ * P_COUNTSTART, P_COUNT: a P_COUNTSTART flags the start of a quantified
+ * closure (#cN,M) and is used to initialise the count. Executing
+ * the pattern leads back to the P_COUNT, while the next links of the
+ * P_COUNTSTART and P_COUNT lead to the tail of the pattern:
+ *
+ * ----------------
+ * v ^
+ * pattern tail
+ * v v ^
+ * ------------------------
+ */
+
+#define P_OP(p) ((p)->l & 0xff)
+#define P_NEXT(p) ((p)->l >> 8)
+#define P_OPERAND(p) ((p) + 1)
+#define P_ISBRANCH(p) ((p)->l & 0x20)
+#define P_ISEXCLUDE(p) (((p)->l & 0x30) == 0x30)
+#define P_NOTDOT(p) ((p)->l & 0x40)
+
+/* Specific to lstr type, i.e. P_EXACTLY. */
+#define P_LS_LEN(p) ((p)[1].l) /* can be used as lvalue */
+#define P_LS_STR(p) ((char *)((p) + 2))
+
+/* Specific to P_COUNT: arguments as offset in nodes from operator */
+#define P_CT_CURRENT (1) /* Current count */
+#define P_CT_MIN (2) /* Minimum count */
+#define P_CT_MAX (3) /* Maximum count, -1 for none */
+#define P_CT_PTR (4) /* Pointer to last match start */
+#define P_CT_OPERAND (5) /* Operand of P_COUNT */
+
+/* Flags needed when pattern is executed */
+#define P_SIMPLE 0x01 /* Simple enough to be #/## operand. */
+#define P_HSTART 0x02 /* Starts with # or ##'d pattern. */
+#define P_PURESTR 0x04 /* Can be matched with a strcmp */
+
+#if defined(ZSH_64_BIT_TYPE) || defined(LONG_IS_64_BIT)
+typedef zlong zrange_t;
+#define ZRANGE_T_IS_SIGNED (1)
+#define ZRANGE_MAX ZLONG_MAX
+#else
+typedef unsigned long zrange_t;
+#define ZRANGE_MAX ULONG_MAX
+#endif
+
+#ifdef MULTIBYTE_SUPPORT
+/*
+ * Handle a byte that's not part of a valid character.
+ *
+ * This range in Unicode is recommended for purposes of this
+ * kind as it corresponds to invalid characters.
+ *
+ * Note that this strictly only works if wchar_t represents
+ * Unicode code points, which isn't necessarily true; however,
+ * converting an invalid character into an unknown format is
+ * a bit tricky...
+ */
+#define WCHAR_INVALID(ch) \
+ ((wchar_t) (0xDC00 + STOUC(ch)))
+#endif /* MULTIBYTE_SUPPORT */
+
+/*
+ * Array of characters corresponding to zpc_chars enum, which it must match.
+ */
+static const char zpc_chars[ZPC_COUNT] = {
+ '/', '\0', Bar, Outpar, Tilde, Inpar, Quest, Star, Inbrack, Inang,
+ Hat, Pound, Bnullkeep, Quest, Star, '+', Bang, '!', '@'
+};
+
+/*
+ * Corresponding strings used in enable/disable -p.
+ * NULL means no way of turning this on or off.
+ */
+/**/
+mod_export const char *zpc_strings[ZPC_COUNT] = {
+ NULL, NULL, "|", NULL, "~", "(", "?", "*", "[", "<",
+ "^", "#", NULL, "?(", "*(", "+(", "!(", "\\!(", "@("
+};
+
+/*
+ * Corresponding array of pattern disables as set by the user
+ * using "disable -p".
+ */
+/**/
+mod_export char zpc_disables[ZPC_COUNT];
+
+/*
+ * Stack of saved (compressed) zpc_disables for function scope.
+ */
+
+static struct zpc_disables_save *zpc_disables_stack;
+
+/*
+ * Characters which terminate a simple string (ZPC_COUNT) or
+ * an entire pattern segment (the first ZPC_SEG_COUNT).
+ * Each entry is either the corresponding character in zpc_chars
+ * or Marker which is guaranteed not to match a character in a
+ * pattern we are compiling.
+ *
+ * The complete list indicates characters that are special, so e.g.
+ * (testchar == special[ZPC_TILDE]) succeeds only if testchar is a Tilde
+ * *and* Tilde is currently special.
+ */
+
+/**/
+char zpc_special[ZPC_COUNT];
+
+/* Default size for pattern buffer */
+#define P_DEF_ALLOC 256
+
+/* Flags used in compilation */
+static char *patstart, *patparse; /* input pointers */
+static int patnpar; /* () count */
+static char *patcode; /* point of code emission */
+static long patsize; /* size of code */
+static char *patout; /* start of code emission string */
+static long patalloc; /* size allocated for same */
+
+/* Flags used in both compilation and execution */
+static int patflags; /* flags passed down to patcompile */
+static int patglobflags; /* globbing flags & approx */
+
+/*
+ * Increment pointer to metafied multibyte string.
+ */
+#ifdef MULTIBYTE_SUPPORT
+typedef wint_t patint_t;
+
+#define PEOF WEOF
+
+#define METACHARINC(x) ((void)metacharinc(&x))
+
+/*
+ * TODO: the shiftstate isn't well handled; we don't guarantee
+ * to maintain it properly between characters. If we don't
+ * need it we should use mbtowc() instead.
+ */
+static mbstate_t shiftstate;
+
+/*
+ * Multibyte version: it's (almost) as easy to return the
+ * value as not, so do so since we sometimes need it..
+ */
+static wchar_t
+metacharinc(char **x)
+{
+ char *inptr = *x;
+ char inchar;
+ size_t ret = MB_INVALID;
+ wchar_t wc;
+
+ /*
+ * Cheat if the top bit isn't set. This is second-guessing
+ * the library, but we know for sure that if the character
+ * set doesn't have the property that all bytes with the 8th
+ * bit clear are single characters then we are stuffed.
+ */
+ if (!(patglobflags & GF_MULTIBYTE) || !(STOUC(*inptr) & 0x80))
+ {
+ if (itok(*inptr))
+ inchar = ztokens[*inptr++ - Pound];
+ else if (*inptr == Meta) {
+ inptr++;
+ inchar = *inptr++ ^ 32;
+ } else {
+ inchar = *inptr++;
+ }
+ *x = inptr;
+ return (wchar_t)STOUC(inchar);
+ }
+
+ while (*inptr) {
+ if (itok(*inptr))
+ inchar = ztokens[*inptr++ - Pound];
+ else if (*inptr == Meta) {
+ inptr++;
+ inchar = *inptr++ ^ 32;
+ } else {
+ inchar = *inptr++;
+ }
+ ret = mbrtowc(&wc, &inchar, 1, &shiftstate);
+
+ if (ret == MB_INVALID)
+ break;
+ if (ret == MB_INCOMPLETE)
+ continue;
+ *x = inptr;
+ return wc;
+ }
+
+ /* Error. */
+ /* Reset the shift state for next time. */
+ memset(&shiftstate, 0, sizeof(shiftstate));
+ return WCHAR_INVALID(*(*x)++);
+}
+
+#else
+typedef int patint_t;
+
+#define PEOF EOF
+
+#define METACHARINC(x) ((void)((x) += (*(x) == Meta) ? 2 : 1))
+#endif
+
+/*
+ * Return unmetafied char from string (x is any char *).
+ * Used with MULTIBYTE_SUPPORT if the GF_MULTIBYTE is not
+ * in effect.
+ */
+#define UNMETA(x) (*(x) == Meta ? (x)[1] ^ 32 : *(x))
+
+/* Add n more characters, ensuring there is enough space. */
+
+enum {
+ PA_NOALIGN = 1,
+ PA_UNMETA = 2
+};
+
+/**/
+static void
+patadd(char *add, int ch, long n, int paflags)
+{
+ /* Make sure everything gets aligned unless we get PA_NOALIGN. */
+ long newpatsize = patsize + n;
+ if (!(paflags & PA_NOALIGN))
+ newpatsize = (newpatsize + sizeof(union upat) - 1) &
+ ~(sizeof(union upat) - 1);
+ if (patalloc < newpatsize) {
+ long newpatalloc =
+ 2*(newpatsize > patalloc ? newpatsize : patalloc);
+ patout = (char *)zrealloc((char *)patout, newpatalloc);
+ patcode = patout + patsize;
+ patalloc = newpatalloc;
+ }
+ patsize = newpatsize;
+ if (add) {
+ if (paflags & PA_UNMETA) {
+ /*
+ * Unmetafy and untokenize the string as we go.
+ * The Meta characters in add aren't counted in n.
+ */
+ while (n--) {
+ if (itok(*add))
+ *patcode++ = ztokens[*add++ - Pound];
+ else if (*add == Meta) {
+ add++;
+ *patcode++ = *add++ ^ 32;
+ } else {
+ *patcode++ = *add++;
+ }
+ }
+ } else {
+ while (n--)
+ *patcode++ = *add++;
+ }
+ } else
+ *patcode++ = ch;
+ patcode = patout + patsize;
+}
+
+static long rn_offs;
+/* operates on pointers to union upat, returns a pointer */
+#define PATNEXT(p) ((rn_offs = P_NEXT(p)) ? \
+ (P_OP(p) == P_BACK) ? \
+ ((p)-rn_offs) : ((p)+rn_offs) : NULL)
+
+/*
+ * Set up zpc_special with characters that end a string segment.
+ * "Marker" cannot occur in the pattern we are compiling so
+ * is used to mark "invalid".
+ */
+static void
+patcompcharsset(void)
+{
+ char *spp, *disp;
+ int i;
+
+ /* Initialise enabled special characters */
+ memcpy(zpc_special, zpc_chars, ZPC_COUNT);
+ /* Apply user disables from disable -p */
+ for (i = 0, spp = zpc_special, disp = zpc_disables;
+ i < ZPC_COUNT;
+ i++, spp++, disp++) {
+ if (*disp)
+ *spp = Marker;
+ }
+
+ if (!isset(EXTENDEDGLOB)) {
+ /* Extended glob characters are not active */
+ zpc_special[ZPC_TILDE] = zpc_special[ZPC_HAT] =
+ zpc_special[ZPC_HASH] = Marker;
+ }
+ if (!isset(KSHGLOB)) {
+ /*
+ * Ksh glob characters are not active.
+ * * and ? are shared with normal globbing, but for their
+ * use here we are looking for a following Inpar.
+ */
+ zpc_special[ZPC_KSH_QUEST] = zpc_special[ZPC_KSH_STAR] =
+ zpc_special[ZPC_KSH_PLUS] = zpc_special[ZPC_KSH_BANG] =
+ zpc_special[ZPC_KSH_BANG2] = zpc_special[ZPC_KSH_AT] = Marker;
+ }
+ /*
+ * Note that if we are using KSHGLOB, then we test for a following
+ * Inpar, not zpc_special[ZPC_INPAR]: the latter makes an Inpar on
+ * its own active. The zpc_special[ZPC_KSH_*] followed by any old Inpar
+ * discriminate ksh globbing.
+ */
+ if (isset(SHGLOB)) {
+ /*
+ * Grouping and numeric ranges are not valid.
+ * We do allow alternation, however; it's needed for
+ * "case". This may not be entirely consistent.
+ *
+ * Don't disable Outpar: we may need to match the end of KSHGLOB
+ * parentheses and it would be difficult to tell them apart.
+ */
+ zpc_special[ZPC_INPAR] = zpc_special[ZPC_INANG] = Marker;
+ }
+}
+
+/* Called before parsing a set of file matchs to initialize flags */
+
+/**/
+void
+patcompstart(void)
+{
+ patcompcharsset();
+ if (isset(CASEGLOB))
+ patglobflags = 0;
+ else
+ patglobflags = GF_IGNCASE;
+ if (isset(MULTIBYTE))
+ patglobflags |= GF_MULTIBYTE;
+}
+
+/*
+ * Top level pattern compilation subroutine
+ * exp is a null-terminated, metafied string.
+ * inflags is an or of some PAT_* flags.
+ * endexp, if non-null, is set to a pointer to the end of the
+ * part of exp which was compiled. This is used when
+ * compiling patterns for directories which must be
+ * matched recursively.
+ */
+
+/**/
+mod_export Patprog
+patcompile(char *exp, int inflags, char **endexp)
+{
+ int flags = 0;
+ long len = 0;
+ long startoff;
+ Upat pscan;
+ char *lng, *strp = NULL;
+ Patprog p;
+
+ queue_signals();
+
+ startoff = sizeof(struct patprog);
+ /* Ensure alignment of start of program string */
+ startoff = (startoff + sizeof(union upat) - 1) & ~(sizeof(union upat) - 1);
+
+ /* Allocate reasonable sized chunk if none, reduce size if too big */
+ if (patalloc != P_DEF_ALLOC)
+ patout = (char *)zrealloc(patout, patalloc = P_DEF_ALLOC);
+ patcode = patout + startoff;
+ patsize = patcode - patout;
+ patstart = patparse = exp;
+ /*
+ * Note global patnpar numbers parentheses 1..9, while patnpar
+ * in struct is actual count of parentheses.
+ */
+ patnpar = 1;
+ patflags = inflags & ~(PAT_PURES|PAT_HAS_EXCLUDP);
+
+ if (!(patflags & PAT_FILE)) {
+ patcompcharsset();
+ zpc_special[ZPC_SLASH] = Marker;
+ remnulargs(patparse);
+ if (isset(MULTIBYTE))
+ patglobflags = GF_MULTIBYTE;
+ else
+ patglobflags = 0;
+ }
+ if (patflags & PAT_LCMATCHUC)
+ patglobflags |= GF_LCMATCHUC;
+ /*
+ * Have to be set now, since they get updated during compilation.
+ */
+ ((Patprog)patout)->globflags = patglobflags;
+
+ if (!(patflags & PAT_ANY)) {
+ /* Look for a really pure string, with no tokens at all. */
+ if (!(patglobflags & ~GF_MULTIBYTE)
+#ifdef __CYGWIN__
+ /*
+ * If the OS treats files case-insensitively and we
+ * are looking at files, we don't need to use pattern
+ * matching to find the file.
+ */
+ || (!(patglobflags & ~GF_IGNCASE) && (patflags & PAT_FILE))
+#endif
+ )
+ {
+ /*
+ * Waah! I wish I understood this.
+ * Empty metafied strings have an initial Nularg.
+ * This never corresponds to a real character in
+ * a glob pattern or string, so skip it.
+ */
+ if (*exp == Nularg)
+ exp++;
+ for (strp = exp; *strp &&
+ (!(patflags & PAT_FILE) || *strp != '/') && !itok(*strp);
+ strp++)
+ ;
+ }
+ if (!strp || (*strp && *strp != '/')) {
+ /* No, do normal compilation. */
+ strp = NULL;
+ if (patcompswitch(0, &flags) == 0) {
+ unqueue_signals();
+ return NULL;
+ }
+ } else {
+ /*
+ * Yes, copy the string, and skip compilation altogether.
+ * Null terminate for the benefit of globbing.
+ * Leave metafied both for globbing and for our own
+ * efficiency.
+ */
+ patparse = strp;
+ len = strp - exp;
+ patadd(exp, 0, len + 1, 0);
+ patout[startoff + len] = '\0';
+ patflags |= PAT_PURES;
+ }
+ }
+
+ /* end of compilation: safe to use pointers */
+ p = (Patprog)patout;
+ p->startoff = startoff;
+ p->patstartch = '\0';
+ p->globend = patglobflags;
+ p->flags = patflags;
+ p->mustoff = 0;
+ p->size = patsize;
+ p->patmlen = len;
+ p->patnpar = patnpar-1;
+
+ if (!strp) {
+ pscan = (Upat)(patout + startoff);
+
+ if (!(patflags & PAT_ANY) && P_OP(PATNEXT(pscan)) == P_END) {
+ /* only one top level choice */
+ pscan = P_OPERAND(pscan);
+
+ if (flags & P_PURESTR) {
+ /*
+ * The pattern can be matched with a simple strncmp/strcmp.
+ * Careful in case we've overwritten the node for the next ptr.
+ */
+ char *dst = patout + startoff;
+ Upat next;
+ p->flags |= PAT_PURES;
+ for (; pscan; pscan = next) {
+ next = PATNEXT(pscan);
+ if (P_OP(pscan) == P_EXACTLY) {
+ char *opnd = P_LS_STR(pscan), *mtest;
+ long oplen = P_LS_LEN(pscan), ilen;
+ int nmeta = 0;
+ /*
+ * Unfortunately we unmetafied the string
+ * and we need to put any metacharacters
+ * back now we know it's a pure string.
+ * This shouldn't happen too often, it's
+ * just that there are some cases such
+ * as . and .. in files where we really
+ * need a pure string even if there are
+ * pattern characters flying around.
+ */
+ for (mtest = opnd, ilen = oplen; ilen;
+ mtest++, ilen--)
+ if (imeta(*mtest))
+ nmeta++;
+ if (nmeta) {
+ patadd(NULL, 0, nmeta, 0);
+ p = (Patprog)patout;
+ opnd = dupstring_wlen(opnd, oplen);
+ dst = patout + startoff;
+ }
+
+ while (oplen--) {
+ if (imeta(*opnd)) {
+ *dst++ = Meta;
+ *dst++ = *opnd++ ^ 32;
+ } else {
+ *dst++ = *opnd++;
+ }
+ }
+ /* Only one string in a PAT_PURES, so now done. */
+ break;
+ }
+ }
+ p->size = dst - patout;
+ /* patmlen is really strlen. We don't need a null. */
+ p->patmlen = p->size - startoff;
+ } else {
+ /* starting point info */
+ if (P_OP(pscan) == P_EXACTLY && !p->globflags &&
+ P_LS_LEN(pscan))
+ p->patstartch = *P_LS_STR(pscan);
+ /*
+ * Find the longest literal string in something expensive.
+ * This is itself not all that cheap if we have
+ * case-insensitive matching or approximation, so don't.
+ */
+ if ((flags & P_HSTART) && !p->globflags) {
+ lng = NULL;
+ len = 0;
+ for (; pscan; pscan = PATNEXT(pscan))
+ if (P_OP(pscan) == P_EXACTLY &&
+ P_LS_LEN(pscan) >= len) {
+ lng = P_LS_STR(pscan);
+ len = P_LS_LEN(pscan);
+ }
+ if (lng) {
+ p->mustoff = lng - patout;
+ p->patmlen = len;
+ }
+ }
+ }
+ }
+ }
+
+ /*
+ * The pattern was compiled in a fixed buffer: unless told otherwise,
+ * we stick the compiled pattern on the heap. This is necessary
+ * for files where we will often be compiling multiple segments at once.
+ * But if we get the ZDUP flag we always put it in zalloc()ed memory.
+ */
+ if (patflags & PAT_ZDUP) {
+ Patprog newp = (Patprog)zalloc(patsize);
+ memcpy((char *)newp, (char *)p, patsize);
+ p = newp;
+ } else if (!(patflags & PAT_STATIC)) {
+ Patprog newp = (Patprog)zhalloc(patsize);
+ memcpy((char *)newp, (char *)p, patsize);
+ p = newp;
+ }
+
+ if (endexp)
+ *endexp = patparse;
+
+ unqueue_signals();
+ return p;
+}
+
+/*
+ * Main body or parenthesized subexpression in pattern
+ * Parenthesis (and any ksh_glob gubbins) will have been removed.
+ */
+
+/**/
+static long
+patcompswitch(int paren, int *flagp)
+{
+ long starter, br, ender, excsync = 0;
+ int parno = 0;
+ int flags, gfchanged = 0;
+ long savglobflags = (long)patglobflags;
+ Upat ptr;
+
+ *flagp = 0;
+
+ if (paren && (patglobflags & GF_BACKREF) && patnpar <= NSUBEXP) {
+ /*
+ * parenthesized: make an open node.
+ * We can only refer to the first nine parentheses.
+ * For any others, we just use P_OPEN on its own; there's
+ * no gain in arbitrarily limiting the number of parentheses.
+ */
+ parno = patnpar++;
+ starter = patnode(P_OPEN + parno);
+ } else
+ starter = 0;
+
+ br = patnode(P_BRANCH);
+ if (!patcompbranch(&flags, paren))
+ return 0;
+ if (patglobflags != (int)savglobflags)
+ gfchanged++;
+ if (starter)
+ pattail(starter, br);
+ else
+ starter = br;
+
+ *flagp |= flags & (P_HSTART|P_PURESTR);
+
+ while (*patparse == zpc_chars[ZPC_BAR] ||
+ (*patparse == zpc_special[ZPC_TILDE] &&
+ (patparse[1] == '/' ||
+ !memchr(zpc_special, patparse[1], ZPC_SEG_COUNT)))) {
+ int tilde = *patparse++ == zpc_special[ZPC_TILDE];
+ long gfnode = 0, newbr;
+
+ *flagp &= ~P_PURESTR;
+
+ if (tilde) {
+ union upat up;
+ /* excsync remembers the P_EXCSYNC node before a chain of
+ * exclusions: all point back to this. only the
+ * original (non-excluded) branch gets a trailing P_EXCSYNC.
+ */
+ if (!excsync) {
+ excsync = patnode(P_EXCSYNC);
+ patoptail(br, excsync);
+ }
+ /*
+ * By default, approximations are turned off in exclusions:
+ * we need to do this here as otherwise the code compiling
+ * the exclusion doesn't know if the flags have really
+ * changed if the error count gets restored.
+ */
+ patglobflags &= ~0xff;
+ if (!(patflags & PAT_FILET) || paren) {
+ br = patnode(P_EXCLUDE);
+ } else {
+ /*
+ * At top level (paren == 0) in a file glob !(patflags
+ * &PAT_FILET) do the exclusion prepending the file path
+ * so far. We need to flag this to avoid unnecessarily
+ * copying the path.
+ */
+ br = patnode(P_EXCLUDP);
+ patflags |= PAT_HAS_EXCLUDP;
+ }
+ up.p = NULL;
+ patadd((char *)&up, 0, sizeof(up), 0);
+ /* / is not treated as special if we are at top level */
+ if (!paren && zpc_special[ZPC_SLASH] == '/') {
+ tilde++;
+ zpc_special[ZPC_SLASH] = Marker;
+ }
+ } else {
+ excsync = 0;
+ br = patnode(P_BRANCH);
+ /*
+ * The position of the following statements means globflags
+ * set in the main branch carry over to the exclusion.
+ */
+ if (!paren) {
+ patglobflags = 0;
+ if (((Patprog)patout)->globflags) {
+ /*
+ * If at top level, we need to reinitialize flags to zero,
+ * since (#i)foo|bar only applies to foo and we stuck
+ * the #i into the global flags.
+ * We could have done it so that they only got set in the
+ * first branch, but it's quite convenient having any
+ * global flags set in the header and not buried in the
+ * pattern. (Or maybe it isn't and we should
+ * forget this bit and always stick in an explicit GFLAGS
+ * statement instead of using the header.)
+ * Also, this can't happen for file globs where there are
+ * no top-level |'s.
+ *
+ * No gfchanged, as nothing to follow branch at top
+ * level.
+ */
+ union upat up;
+ gfnode = patnode(P_GFLAGS);
+ up.l = patglobflags;
+ patadd((char *)&up, 0, sizeof(union upat), 0);
+ }
+ } else {
+ patglobflags = (int)savglobflags;
+ }
+ }
+ newbr = patcompbranch(&flags, paren);
+ if (tilde == 2) {
+ /* restore special treatment of / */
+ zpc_special[ZPC_SLASH] = '/';
+ }
+ if (!newbr)
+ return 0;
+ if (gfnode)
+ pattail(gfnode, newbr);
+ if (!tilde && patglobflags != (int)savglobflags)
+ gfchanged++;
+ pattail(starter, br);
+ if (excsync)
+ patoptail(br, patnode(P_EXCEND));
+ *flagp |= flags & P_HSTART;
+ }
+
+ /*
+ * Make a closing node, hooking it to the end.
+ * Note that we can't optimize P_NOTHING out here, since another
+ * branch at that point would indicate the current choices continue,
+ * which they don't.
+ */
+ ender = patnode(paren ? parno ? P_CLOSE+parno : P_NOTHING : P_END);
+ pattail(starter, ender);
+
+ /*
+ * Hook the tails of the branches to the closing node,
+ * except for exclusions which terminate where they are.
+ */
+ for (ptr = (Upat)patout + starter; ptr; ptr = PATNEXT(ptr))
+ if (!P_ISEXCLUDE(ptr))
+ patoptail(ptr-(Upat)patout, ender);
+
+ /* check for proper termination */
+ if ((paren && *patparse++ != Outpar) ||
+ (!paren && *patparse &&
+ !((patflags & PAT_FILE) && *patparse == '/')))
+ return 0;
+
+ if (paren && gfchanged) {
+ /*
+ * Restore old values of flags when leaving parentheses.
+ * gfchanged detects a change in any branch (except exclusions
+ * which are separate), since we need to emit this even if
+ * a later branch happened to put the flags back.
+ */
+ pattail(ender, patnode(P_GFLAGS));
+ patglobflags = (int)savglobflags;
+ patadd((char *)&savglobflags, 0, sizeof(long), 0);
+ }
+
+ return starter;
+}
+
+/*
+ * Compile something ended by Bar, Outpar, Tilde, or end of string.
+ * Note the BRANCH or EXCLUDE tag must already have been omitted:
+ * this returns the position of the operand of that.
+ */
+
+/**/
+static long
+patcompbranch(int *flagp, int paren)
+{
+ long chain, latest = 0, starter;
+ int flags = 0;
+
+ *flagp = P_PURESTR;
+
+ starter = chain = 0;
+ while (!memchr(zpc_special, *patparse, ZPC_SEG_COUNT) ||
+ (*patparse == zpc_special[ZPC_TILDE] && patparse[1] != '/' &&
+ memchr(zpc_special, patparse[1], ZPC_SEG_COUNT))) {
+ if ((*patparse == zpc_special[ZPC_INPAR] &&
+ patparse[1] == zpc_special[ZPC_HASH]) ||
+ (*patparse == zpc_special[ZPC_KSH_AT] && patparse[1] == Inpar &&
+ patparse[2] == zpc_special[ZPC_HASH])) {
+ /* Globbing flags. */
+ char *pp1 = patparse;
+ int oldglobflags = patglobflags, ignore;
+ long assert;
+ patparse += (*patparse == '@') ? 3 : 2;
+ if (!patgetglobflags(&patparse, &assert, &ignore))
+ return 0;
+ if (!ignore) {
+ if (assert) {
+ /*
+ * Start/end assertion looking like flags, but
+ * actually handled as a normal node
+ */
+ latest = patnode(assert);
+ flags = 0;
+ } else {
+ if (pp1 == patstart) {
+ /* Right at start of pattern, the simplest case.
+ * Put them into the flags and don't emit anything.
+ */
+ ((Patprog)patout)->globflags = patglobflags;
+ continue;
+ } else if (!*patparse) {
+ /* Right at the end, so just leave the flags for
+ * the next Patprog in the chain to pick up.
+ */
+ break;
+ }
+ /*
+ * Otherwise, we have to stick them in as a pattern
+ * matching nothing.
+ */
+ if (oldglobflags != patglobflags) {
+ /* Flags changed */
+ union upat up;
+ latest = patnode(P_GFLAGS);
+ up.l = patglobflags;
+ patadd((char *)&up, 0, sizeof(union upat), 0);
+ } else {
+ /* No effect. */
+ continue;
+ }
+ }
+ } else if (!*patparse)
+ break;
+ else
+ continue;
+ } else if (*patparse == zpc_special[ZPC_HAT]) {
+ /*
+ * ^pat: anything but pat. For proper backtracking,
+ * etc., we turn this into (*~pat), except without the
+ * parentheses.
+ */
+ patparse++;
+ latest = patcompnot(0, &flags);
+ } else
+ latest = patcomppiece(&flags, paren);
+ if (!latest)
+ return 0;
+ if (!starter)
+ starter = latest;
+ if (!(flags & P_PURESTR))
+ *flagp &= ~P_PURESTR;
+ if (!chain)
+ *flagp |= flags & P_HSTART;
+ else
+ pattail(chain, latest);
+ chain = latest;
+ }
+ /* check if there was nothing in the loop, i.e. () */
+ if (!chain)
+ starter = patnode(P_NOTHING);
+
+ return starter;
+}
+
+/* get glob flags, return 1 for success, 0 for failure */
+
+/**/
+int
+patgetglobflags(char **strp, long *assertp, int *ignore)
+{
+ char *nptr, *ptr = *strp;
+ zlong ret;
+
+ *assertp = 0;
+ *ignore = 1;
+ /* (#X): assumes we are still positioned on the first X */
+ for (; *ptr && *ptr != Outpar; ptr++) {
+ if (*ptr == 'q') {
+ /* Glob qualifiers, ignored in pattern code */
+ while (*ptr && *ptr != Outpar)
+ ptr++;
+ break;
+ } else {
+ *ignore = 0;
+ switch (*ptr) {
+ case 'a':
+ /* Approximate matching, max no. of errors follows */
+ ret = zstrtol(++ptr, &nptr, 10);
+ /*
+ * We can't have more than 254, because we need 255 to
+ * mark 254 errors in wbranch and exclude sync strings
+ * (hypothetically --- hope no-one tries it).
+ */
+ if (ret < 0 || ret > 254 || ptr == nptr)
+ return 0;
+ patglobflags = (patglobflags & ~0xff) | (ret & 0xff);
+ ptr = nptr-1;
+ break;
+
+ case 'l':
+ /* Lowercase in pattern matches lower or upper in target */
+ patglobflags = (patglobflags & ~GF_IGNCASE) | GF_LCMATCHUC;
+ break;
+
+ case 'i':
+ /* Fully case insensitive */
+ patglobflags = (patglobflags & ~GF_LCMATCHUC) | GF_IGNCASE;
+ break;
+
+ case 'I':
+ /* Restore case sensitivity */
+ patglobflags &= ~(GF_LCMATCHUC|GF_IGNCASE);
+ break;
+
+ case 'b':
+ /* Make backreferences */
+ patglobflags |= GF_BACKREF;
+ break;
+
+ case 'B':
+ /* Don't make backreferences */
+ patglobflags &= ~GF_BACKREF;
+ break;
+
+ case 'm':
+ /* Make references to complete match */
+ patglobflags |= GF_MATCHREF;
+ break;
+
+ case 'M':
+ /* Don't */
+ patglobflags &= ~GF_MATCHREF;
+ break;
+
+ case 's':
+ *assertp = P_ISSTART;
+ break;
+
+ case 'e':
+ *assertp = P_ISEND;
+ break;
+
+ case 'u':
+ patglobflags |= GF_MULTIBYTE;
+ break;
+
+ case 'U':
+ patglobflags &= ~GF_MULTIBYTE;
+ break;
+
+ default:
+ return 0;
+ }
+ }
+ }
+ if (*ptr != Outpar)
+ return 0;
+ /* Start/end assertions must appear on their own. */
+ if (*assertp && (*strp)[1] != Outpar)
+ return 0;
+ *strp = ptr + 1;
+ return 1;
+}
+
+
+static const char *colon_stuffs[] = {
+ "alpha", "alnum", "ascii", "blank", "cntrl", "digit", "graph",
+ "lower", "print", "punct", "space", "upper", "xdigit", "IDENT",
+ "IFS", "IFSSPACE", "WORD", "INCOMPLETE", "INVALID", NULL
+};
+
+/*
+ * Handle the guts of a [:stuff:] character class element.
+ * start is the beginning of "stuff" and len is its length.
+ * This code is exported for the benefit of completion matching.
+ */
+
+/**/
+mod_export int
+range_type(char *start, int len)
+{
+ const char **csp;
+
+ for (csp = colon_stuffs; *csp; csp++) {
+ if (strlen(*csp) == len && !strncmp(start, *csp, len))
+ return (csp - colon_stuffs) + PP_FIRST;
+ }
+
+ return PP_UNKWN;
+}
+
+
+/*
+ * Convert the contents of a [...] or [^...] expression (just the
+ * ... part) back into a string. This is used by compfiles -p/-P
+ * for some reason. The compiled form (a metafied string) is
+ * passed in rangestr.
+ *
+ * If outstr is non-NULL the compiled form is placed there. It
+ * must be sufficiently long. A terminating NULL is appended.
+ *
+ * Return the length required, not including the terminating NULL.
+ *
+ * TODO: this is non-multibyte for now. It will need to be defined
+ * appropriately with MULTIBYTE_SUPPORT when the completion matching
+ * code catches up.
+ */
+
+/**/
+mod_export int
+pattern_range_to_string(char *rangestr, char *outstr)
+{
+ int len = 0;
+
+ while (*rangestr) {
+ if (imeta(STOUC(*rangestr))) {
+ int swtype = STOUC(*rangestr) - STOUC(Meta);
+
+ if (swtype == 0) {
+ /* Ordindary metafied character */
+ if (outstr)
+ {
+ *outstr++ = Meta;
+ *outstr++ = rangestr[1] ^ 32;
+ }
+ len += 2;
+ rangestr += 2;
+ } else if (swtype == PP_RANGE) {
+ /* X-Y range */
+ int i;
+
+ for (i = 0; i < 2; i++) {
+ if (*rangestr == Meta) {
+ if (outstr) {
+ *outstr++ = Meta;
+ *outstr++ = rangestr[1];
+ }
+ len += 2;
+ rangestr += 2;
+ } else {
+ if (outstr)
+ *outstr++ = *rangestr;
+ len++;
+ rangestr++;
+ }
+
+ if (i == 0) {
+ if (outstr)
+ *outstr++ = '-';
+ len++;
+ }
+ }
+ } else if (swtype >= PP_FIRST && swtype <= PP_LAST) {
+ /* [:stuff:]; we need to output [: and :] */
+ const char *found = colon_stuffs[swtype - PP_FIRST];
+ int newlen = strlen(found);
+ if (outstr) {
+ strcpy(outstr, "[:");
+ outstr += 2;
+ memcpy(outstr, found, newlen);
+ outstr += newlen;
+ strcpy(outstr, ":]");
+ outstr += 2;
+ }
+ len += newlen + 4;
+ rangestr++;
+ } else {
+ /* shouldn't happen */
+ DPUTS(1, "BUG: unknown PP_ code in pattern range");
+ rangestr++;
+ }
+ } else {
+ /* ordinary character, guaranteed no Meta handling needed */
+ if (outstr)
+ *outstr++ = *rangestr;
+ len++;
+ rangestr++;
+ }
+ }
+
+ if (outstr)
+ *outstr = '\0';
+ return len;
+}
+
+/*
+ * compile a chunk such as a literal string or a [...] followed
+ * by a possible hash operator
+ */
+
+/**/
+static long
+patcomppiece(int *flagp, int paren)
+{
+ long starter = 0, next, op, opnd;
+ int flags, flags2, kshchar, len, ch, patch, nmeta;
+ int hash, count;
+ union upat up;
+ char *nptr, *str0, *ptr, *patprev;
+ zrange_t from, to;
+ char *charstart;
+
+ flags = 0;
+ str0 = patprev = patparse;
+ for (;;) {
+ /*
+ * Check if we have a string. First, we need to make sure
+ * the string doesn't introduce a ksh-like parenthesized expression.
+ */
+ kshchar = '\0';
+ if (*patparse && patparse[1] == Inpar) {
+ if (*patparse == zpc_special[ZPC_KSH_PLUS])
+ kshchar = STOUC('+');
+ else if (*patparse == zpc_special[ZPC_KSH_BANG])
+ kshchar = STOUC('!');
+ else if (*patparse == zpc_special[ZPC_KSH_BANG2])
+ kshchar = STOUC('!');
+ else if (*patparse == zpc_special[ZPC_KSH_AT])
+ kshchar = STOUC('@');
+ else if (*patparse == zpc_special[ZPC_KSH_STAR])
+ kshchar = STOUC('*');
+ else if (*patparse == zpc_special[ZPC_KSH_QUEST])
+ kshchar = STOUC('?');
+ }
+
+ /*
+ * If '(' is disabled as a pattern char, allow ')' as
+ * an ordinary string character if there are no parentheses to
+ * close. Don't allow it otherwise, it changes the syntax.
+ */
+ if (zpc_special[ZPC_INPAR] != Marker || *patparse != Outpar ||
+ paren) {
+ /*
+ * End of string (or no string at all) if ksh-type parentheses,
+ * or special character, unless that character is a tilde and
+ * the character following is an end-of-segment character. Thus
+ * tildes are not special if there is nothing following to
+ * be excluded.
+ *
+ * Don't look for X()-style kshglobs at this point; we've
+ * checked above for the case with parentheses and we don't
+ * want to match without parentheses.
+ */
+ if (kshchar ||
+ (memchr(zpc_special, *patparse, ZPC_NO_KSH_GLOB) &&
+ (*patparse != zpc_special[ZPC_TILDE] ||
+ patparse[1] == '/' ||
+ !memchr(zpc_special, patparse[1], ZPC_SEG_COUNT)))) {
+ break;
+ }
+ }
+
+ /* Remember the previous character for backtracking */
+ patprev = patparse;
+ METACHARINC(patparse);
+ }
+
+ if (patparse > str0) {
+ long slen = patparse - str0;
+ int morelen;
+
+ /* Ordinary string: cancel kshchar lookahead */
+ kshchar = '\0';
+ /*
+ * Assume it matches a simple string until we find otherwise.
+ */
+ flags |= P_PURESTR;
+ DPUTS(patparse == str0, "BUG: matched nothing in patcomppiece.");
+ /* more than one character matched? */
+ morelen = (patprev > str0);
+ /*
+ * If we have more than one character, a following hash
+ * or (#c...) only applies to the last, so backtrack one character.
+ */
+ if ((*patparse == zpc_special[ZPC_HASH] ||
+ (*patparse == zpc_special[ZPC_INPAR] &&
+ patparse[1] == zpc_special[ZPC_HASH] &&
+ patparse[2] == 'c') ||
+ (*patparse == zpc_special[ZPC_KSH_AT] &&
+ patparse[1] == Inpar &&
+ patparse[2] == zpc_special[ZPC_HASH] &&
+ patparse[3] == 'c')) && morelen)
+ patparse = patprev;
+ /*
+ * If len is 1, we can't have an active # following, so doesn't
+ * matter that we don't make X in `XX#' simple.
+ */
+ if (!morelen)
+ flags |= P_SIMPLE;
+ starter = patnode(P_EXACTLY);
+
+ /* Get length of string without metafication. */
+ nmeta = 0;
+ /* inherited from domatch, but why, exactly? */
+ if (*str0 == Nularg)
+ str0++;
+ for (ptr = str0; ptr < patparse; ptr++) {
+ if (*ptr == Meta) {
+ nmeta++;
+ ptr++;
+ }
+ }
+ slen = (patparse - str0) - nmeta;
+ /* First add length, which is a long */
+ patadd((char *)&slen, 0, sizeof(long), 0);
+ /*
+ * Then the string, not null terminated.
+ * Unmetafy and untokenize; pass the final length,
+ * which is what we need to allocate, i.e. not including
+ * a count for each Meta in the string.
+ */
+ patadd(str0, 0, slen, PA_UNMETA);
+ nptr = P_LS_STR((Upat)patout + starter);
+ /*
+ * It's much simpler to turn off pure string mode for
+ * any case-insensitive or approximate matching; usually,
+ * that is correct, or they wouldn't have been turned on.
+ * However, we need to make sure we match a "." or ".."
+ * in a file name as a pure string. There's a minor bug
+ * that this will also apply to something like
+ * ..(#a1).. (i.e. the (#a1) has no effect), but if you're
+ * going to write funny patterns, you get no sympathy from me.
+ */
+ if (patglobflags &
+#ifdef __CYGWIN__
+ /*
+ * As above: don't use pattern matching for files
+ * just because of case insensitivity if file system
+ * is known to be case insensitive.
+ *
+ * This is known to be necessary in at least one case:
+ * if "mount -c /" is in effect, so that drives appear
+ * directly under / instead of the usual /cygdrive, they
+ * aren't shown by readdir(). So it's vital we don't use
+ * globbing to find "/c", since that'll fail.
+ */
+ ((patflags & PAT_FILE) ?
+ (0xFF|GF_LCMATCHUC) :
+ (0xFF|GF_LCMATCHUC|GF_IGNCASE))
+#else
+ (0xFF|GF_LCMATCHUC|GF_IGNCASE)
+#endif
+ ) {
+ if (!(patflags & PAT_FILE))
+ flags &= ~P_PURESTR;
+ else if (!(nptr[0] == '.' &&
+ (slen == 1 || (nptr[1] == '.' && slen == 2))))
+ flags &= ~P_PURESTR;
+ }
+ } else {
+ if (kshchar)
+ patparse++;
+
+ patch = *patparse;
+ METACHARINC(patparse);
+ switch(patch) {
+ case Quest:
+ DPUTS(zpc_special[ZPC_QUEST] == Marker,
+ "Treating '?' as pattern character although disabled");
+ flags |= P_SIMPLE;
+ starter = patnode(P_ANY);
+ break;
+ case Star:
+ DPUTS(zpc_special[ZPC_STAR] == Marker,
+ "Treating '*' as pattern character although disabled");
+ /* kshchar is used as a sign that we can't have #'s. */
+ kshchar = -1;
+ starter = patnode(P_STAR);
+ break;
+ case Inbrack:
+ DPUTS(zpc_special[ZPC_INBRACK] == Marker,
+ "Treating '[' as pattern character although disabled");
+ flags |= P_SIMPLE;
+ if (*patparse == Hat || *patparse == Bang) {
+ patparse++;
+ starter = patnode(P_ANYBUT);
+ } else
+ starter = patnode(P_ANYOF);
+ /*
+ * []...] means match a "]" or other included characters.
+ * However, to be a bit helpful and for compatibility
+ * with other shells, don't take in that sense if
+ * there's no further "]". That's still imperfect,
+ * but it's all we can do --- we're required to
+ * treat [$var]*[$var]with empty var as [ ... ]
+ * containing "]*[".
+ */
+ if (*patparse == Outbrack && strchr(patparse+1, Outbrack)) {
+ patparse++;
+ patadd(NULL, ']', 1, PA_NOALIGN);
+ }
+ while (*patparse && *patparse != Outbrack) {
+ /* Meta is not a token */
+ if (*patparse == Inbrack && patparse[1] == ':' &&
+ (nptr = strchr(patparse+2, ':')) &&
+ nptr[1] == Outbrack) {
+ /* Posix range. */
+ patparse += 2;
+ len = nptr - patparse;
+ ch = range_type(patparse, len);
+ patparse = nptr + 2;
+ if (ch != PP_UNKWN)
+ patadd(NULL, STOUC(Meta) + ch, 1, PA_NOALIGN);
+ continue;
+ }
+ charstart = patparse;
+ METACHARINC(patparse);
+
+ if (*patparse == Dash && patparse[1] &&
+ patparse[1] != Outbrack) {
+ patadd(NULL, STOUC(Meta)+PP_RANGE, 1, PA_NOALIGN);
+ if (itok(*charstart)) {
+ patadd(0, STOUC(ztokens[*charstart - Pound]), 1,
+ PA_NOALIGN);
+ } else {
+ patadd(charstart, 0, patparse-charstart, PA_NOALIGN);
+ }
+ charstart = ++patparse; /* skip Dash token */
+ METACHARINC(patparse);
+ }
+ if (itok(*charstart)) {
+ patadd(0, STOUC(ztokens[*charstart - Pound]), 1,
+ PA_NOALIGN);
+ } else {
+ patadd(charstart, 0, patparse-charstart, PA_NOALIGN);
+ }
+ }
+ if (*patparse != Outbrack)
+ return 0;
+ patparse++;
+ /* terminate null string and fix alignment */
+ patadd(NULL, 0, 1, 0);
+ break;
+ case Inpar:
+ DPUTS(!kshchar && zpc_special[ZPC_INPAR] == Marker,
+ "Treating '(' as pattern character although disabled");
+ DPUTS(isset(SHGLOB) && !kshchar,
+ "Treating bare '(' as pattern character with SHGLOB");
+ if (kshchar == '!') {
+ /* This is nasty, we should really either handle all
+ * kshglobbing below or here. But most of the
+ * others look like non-ksh patterns, while this one
+ * doesn't, so we handle it here and leave the rest.
+ * We treat it like an extendedglob ^, except that
+ * it goes into parentheses.
+ *
+ * If we did do kshglob here, we could support
+ * the old behaviour that things like !(foo)##
+ * work, but it makes the code more complicated at
+ * the expense of allowing the user to do things
+ * they shouldn't.
+ */
+ if (!(starter = patcompnot(1, &flags2)))
+ return 0;
+ } else if (!(starter = patcompswitch(1, &flags2)))
+ return 0;
+ flags |= flags2 & P_HSTART;
+ break;
+ case Inang:
+ /* Numeric glob */
+ DPUTS(zpc_special[ZPC_INANG] == Marker,
+ "Treating '<' as pattern character although disabled");
+ DPUTS(isset(SHGLOB), "Treating <..> as numeric range with SHGLOB");
+ len = 0; /* beginning present 1, end present 2 */
+ if (idigit(*patparse)) {
+ from = (zrange_t) zstrtol((char *)patparse,
+ (char **)&nptr, 10);
+ patparse = nptr;
+ len |= 1;
+ }
+ DPUTS(!IS_DASH(*patparse), "BUG: - missing from numeric glob");
+ patparse++;
+ if (idigit(*patparse)) {
+ to = (zrange_t) zstrtol((char *)patparse,
+ (char **)&nptr, 10);
+ patparse = nptr;
+ len |= 2;
+ }
+ if (*patparse != Outang)
+ return 0;
+ patparse++;
+ switch(len) {
+ case 3:
+ starter = patnode(P_NUMRNG);
+ patadd((char *)&from, 0, sizeof(from), 0);
+ patadd((char *)&to, 0, sizeof(to), 0);
+ break;
+ case 2:
+ starter = patnode(P_NUMTO);
+ patadd((char *)&to, 0, sizeof(to), 0);
+ break;
+ case 1:
+ starter = patnode(P_NUMFROM);
+ patadd((char *)&from, 0, sizeof(from), 0);
+ break;
+ case 0:
+ starter = patnode(P_NUMANY);
+ break;
+ }
+ /* This can't be simple, because it isn't.
+ * Mention in manual that matching digits with [...]
+ * is more efficient.
+ */
+ break;
+ case Pound:
+ DPUTS(zpc_special[ZPC_HASH] == Marker,
+ "Treating '#' as pattern character although disabled");
+ DPUTS(!isset(EXTENDEDGLOB), "BUG: # not treated as string");
+ /*
+ * A hash here is an error; it should follow something
+ * repeatable.
+ */
+ return 0;
+ break;
+ case Bnullkeep:
+ /*
+ * Marker for restoring a backslash in output:
+ * does not match a character.
+ */
+ next = patcomppiece(flagp, paren);
+ /*
+ * Can't match a pure string since we need to do this
+ * as multiple chunks.
+ */
+ *flagp &= ~P_PURESTR;
+ return next;
+ break;
+#ifdef DEBUG
+ default:
+ dputs("BUG: character not handled in patcomppiece");
+ return 0;
+ break;
+#endif
+ }
+ }
+
+ count = 0;
+ if (!(hash = (*patparse == zpc_special[ZPC_HASH])) &&
+ !(count = ((*patparse == zpc_special[ZPC_INPAR] &&
+ patparse[1] == zpc_special[ZPC_HASH] &&
+ patparse[2] == 'c') ||
+ (*patparse == zpc_special[ZPC_KSH_AT] &&
+ patparse[1] == Inpar &&
+ patparse[2] == zpc_special[ZPC_HASH] &&
+ patparse[3] == 'c'))) &&
+ (kshchar <= 0 || kshchar == '@' || kshchar == '!')) {
+ *flagp = flags;
+ return starter;
+ }
+
+ /* too much at once doesn't currently work */
+ if (kshchar && (hash || count))
+ return 0;
+
+ if (kshchar == '*') {
+ op = P_ONEHASH;
+ *flagp = P_HSTART;
+ } else if (kshchar == '+') {
+ op = P_TWOHASH;
+ *flagp = P_HSTART;
+ } else if (kshchar == '?') {
+ op = 0;
+ *flagp = 0;
+ } else if (count) {
+ op = P_COUNT;
+ patparse += 3;
+ *flagp = P_HSTART;
+ } else if (*++patparse == zpc_special[ZPC_HASH]) {
+ op = P_TWOHASH;
+ patparse++;
+ *flagp = P_HSTART;
+ } else {
+ op = P_ONEHASH;
+ *flagp = P_HSTART;
+ }
+
+ /*
+ * Note optimizations with pointers into P_NOTHING branches: some
+ * should logically point to next node after current piece.
+ *
+ * Backtracking is also encoded in a slightly obscure way: the
+ * code emitted ensures we test the non-empty branch of complex
+ * patterns before the empty branch on each repetition. Hence
+ * each time we fail on a non-empty branch, we try the empty branch,
+ * which is equivalent to backtracking.
+ */
+ if (op == P_COUNT) {
+ /* (#cN,M) */
+ union upat countargs[P_CT_OPERAND];
+ char *opp = patparse;
+
+ countargs[0].l = P_COUNT;
+ countargs[P_CT_CURRENT].l = 0L;
+ countargs[P_CT_MIN].l = (long)zstrtol(patparse, &patparse, 10);
+ if (patparse == opp) {
+ /* missing number treated as zero */
+ countargs[P_CT_MIN].l = 0L;
+ }
+ if (*patparse != ',' && *patparse != Comma) {
+ /* either max = min or error */
+ if (*patparse != Outpar)
+ return 0;
+ countargs[P_CT_MAX].l = countargs[P_CT_MIN].l;
+ } else {
+ opp = ++patparse;
+ countargs[P_CT_MAX].l = (long)zstrtol(patparse, &patparse, 10);
+ if (*patparse != Outpar)
+ return 0;
+ if (patparse == opp) {
+ /* missing number treated as infinity: record as -1 */
+ countargs[P_CT_MAX].l = -1L;
+ }
+ }
+ patparse++;
+ countargs[P_CT_PTR].p = NULL;
+ /* Mark this chain as a min/max count... */
+ patinsert(P_COUNTSTART, starter, (char *)countargs, sizeof(countargs));
+ /*
+ * The next of the operand is a loop back to the P_COUNT. This is
+ * how we get recursion for the count. We don't loop back to
+ * the P_COUNTSTART; that's used for initialising the count
+ * and saving and restoring the count for any enclosing use
+ * of the match.
+ */
+ opnd = P_OPERAND(starter) + P_CT_OPERAND;
+ pattail(opnd, patnode(P_BACK));
+ pattail(opnd, P_OPERAND(starter));
+ /*
+ * The next of the counter operators is what follows the
+ * closure.
+ * This handles matching of the tail.
+ */
+ next = patnode(P_NOTHING);
+ pattail(starter, next);
+ pattail(P_OPERAND(starter), next);
+ } else if ((flags & P_SIMPLE) && (op == P_ONEHASH || op == P_TWOHASH) &&
+ P_OP((Upat)patout+starter) == P_ANY) {
+ /* Optimize ?# to *. Silly thing to do, since who would use
+ * use ?# ? But it makes the later code shorter.
+ */
+ Upat uptr = (Upat)patout + starter;
+ if (op == P_TWOHASH) {
+ /* ?## becomes ?* */
+ uptr->l = (uptr->l & ~0xff) | P_ANY;
+ pattail(starter, patnode(P_STAR));
+ } else {
+ uptr->l = (uptr->l & ~0xff) | P_STAR;
+ }
+ } else if ((flags & P_SIMPLE) && op && !(patglobflags & 0xff)) {
+ /* Simplify, but not if we need to look for approximations. */
+ patinsert(op, starter, NULL, 0);
+ } else if (op == P_ONEHASH) {
+ /* Emit x# as (x&|), where & means "self". */
+ up.p = NULL;
+ patinsert(P_WBRANCH, starter, (char *)&up, sizeof(up));
+ /* Either x */
+ patoptail(starter, patnode(P_BACK)); /* and loop */
+ patoptail(starter, starter); /* back */
+ pattail(starter, patnode(P_BRANCH)); /* or */
+ pattail(starter, patnode(P_NOTHING)); /* null. */
+ } else if (op == P_TWOHASH) {
+ /* Emit x## as x(&|) where & means "self". */
+ next = patnode(P_WBRANCH); /* Either */
+ up.p = NULL;
+ patadd((char *)&up, 0, sizeof(up), 0);
+ pattail(starter, next);
+ pattail(patnode(P_BACK), starter); /* loop back */
+ pattail(next, patnode(P_BRANCH)); /* or */
+ pattail(starter, patnode(P_NOTHING)); /* null. */
+ } else if (kshchar == '?') {
+ /* Emit ?(x) as (x|) */
+ patinsert(P_BRANCH, starter, NULL, 0); /* Either x */
+ pattail(starter, patnode(P_BRANCH)); /* or */
+ next = patnode(P_NOTHING); /* null */
+ pattail(starter, next);
+ patoptail(starter, next);
+ }
+ if (*patparse == zpc_special[ZPC_HASH])
+ return 0;
+
+ return starter;
+}
+
+/*
+ * Turn a ^foo (paren = 0) or !(foo) (paren = 1) into *~foo with
+ * parentheses if necessary. As you see, that's really quite easy.
+ */
+
+/**/
+static long
+patcompnot(int paren, int *flagsp)
+{
+ union upat up;
+ long excsync, br, excl, n, starter;
+ int dummy;
+
+ /* Here, we're matching a star at the start. */
+ *flagsp = P_HSTART;
+
+ starter = patnode(P_BRANCH);
+ br = patnode(P_STAR);
+ excsync = patnode(P_EXCSYNC);
+ pattail(br, excsync);
+ pattail(starter, excl = patnode(P_EXCLUDE));
+ up.p = NULL;
+ patadd((char *)&up, 0, sizeof(up), 0);
+ if (!(br = (paren ? patcompswitch(1, &dummy) : patcompbranch(&dummy, 0))))
+ return 0;
+ pattail(br, patnode(P_EXCEND));
+ n = patnode(P_NOTHING); /* just so much easier */
+ pattail(excsync, n);
+ pattail(excl, n);
+
+ return starter;
+}
+
+/* Emit a node */
+
+/**/
+static long
+patnode(long op)
+{
+ long starter = (Upat)patcode - (Upat)patout;
+ union upat up;
+
+ up.l = op;
+ patadd((char *)&up, 0, sizeof(union upat), 0);
+ return starter;
+}
+
+/*
+ * insert an operator in front of an already emitted operand:
+ * we relocate the operand. there had better be nothing else after.
+ */
+
+/**/
+static void
+patinsert(long op, int opnd, char *xtra, int sz)
+{
+ char *src, *dst, *opdst;
+ union upat buf, *lptr;
+
+ buf.l = 0;
+ patadd((char *)&buf, 0, sizeof(buf), 0);
+ if (sz)
+ patadd(xtra, 0, sz, 0);
+ src = patcode - sizeof(union upat) - sz;
+ dst = patcode;
+ opdst = patout + opnd * sizeof(union upat);
+ while (src > opdst)
+ *--dst = *--src;
+
+ /* A cast can't be an lvalue */
+ lptr = (Upat)opdst;
+ lptr->l = op;
+ opdst += sizeof(union upat);
+ while (sz--)
+ *opdst++ = *xtra++;
+}
+
+/* set the 'next' pointer at the end of a node chain */
+
+/**/
+static void
+pattail(long p, long val)
+{
+ Upat scan, temp;
+ long offset;
+
+ scan = (Upat)patout + p;
+ for (;;) {
+ if (!(temp = PATNEXT(scan)))
+ break;
+ scan = temp;
+ }
+
+ offset = (P_OP(scan) == P_BACK)
+ ? (scan - (Upat)patout) - val : val - (scan - (Upat)patout);
+
+ scan->l |= offset << 8;
+}
+
+/* do pattail, but on operand of first argument; nop if operandless */
+
+/**/
+static void
+patoptail(long p, long val)
+{
+ Upat ptr = (Upat)patout + p;
+ int op = P_OP(ptr);
+ if (!p || !P_ISBRANCH(ptr))
+ return;
+ if (op == P_BRANCH)
+ pattail(P_OPERAND(p), val);
+ else
+ pattail(P_OPERAND(p) + 1, val);
+}
+
+
+/*
+ * Run a pattern.
+ */
+struct rpat {
+ char *patinstart; /* Start of input string */
+ char *patinend; /* End of input string */
+ char *patinput; /* String input pointer */
+ char *patinpath; /* Full path for use with ~ exclusions */
+ int patinlen; /* Length of last successful match.
+ * Includes count of Meta characters.
+ */
+
+ char *patbeginp[NSUBEXP]; /* Pointer to backref beginnings */
+ char *patendp[NSUBEXP]; /* Pointer to backref ends */
+ int parsfound; /* parentheses (with backrefs) found */
+
+ int globdots; /* Glob initial dots? */
+};
+
+static struct rpat pattrystate;
+
+#define patinstart (pattrystate.patinstart)
+#define patinend (pattrystate.patinend)
+#define patinput (pattrystate.patinput)
+#define patinpath (pattrystate.patinpath)
+#define patinlen (pattrystate.patinlen)
+#define patbeginp (pattrystate.patbeginp)
+#define patendp (pattrystate.patendp)
+#define parsfound (pattrystate.parsfound)
+#define globdots (pattrystate.globdots)
+
+
+/*
+ * Character functions operating on unmetafied strings.
+ */
+#ifdef MULTIBYTE_SUPPORT
+
+/* Get a character from the start point in a string */
+#define CHARREF(x, y) charref((x), (y), (int *)NULL)
+static wchar_t
+charref(char *x, char *y, int *zmb_ind)
+{
+ wchar_t wc;
+ size_t ret;
+
+ if (!(patglobflags & GF_MULTIBYTE) || !(STOUC(*x) & 0x80))
+ return (wchar_t) STOUC(*x);
+
+ ret = mbrtowc(&wc, x, y-x, &shiftstate);
+
+ if (ret == MB_INVALID || ret == MB_INCOMPLETE) {
+ /* Error. */
+ /* Reset the shift state for next time. */
+ memset(&shiftstate, 0, sizeof(shiftstate));
+ if (zmb_ind)
+ *zmb_ind = (ret == MB_INVALID) ? ZMB_INVALID : ZMB_INCOMPLETE;
+ return WCHAR_INVALID(*x);
+ }
+
+ if (zmb_ind)
+ *zmb_ind = ZMB_VALID;
+ return wc;
+}
+
+/* Get a pointer to the next character */
+#define CHARNEXT(x, y) charnext((x), (y))
+static char *
+charnext(char *x, char *y)
+{
+ wchar_t wc;
+ size_t ret;
+
+ if (!(patglobflags & GF_MULTIBYTE) || !(STOUC(*x) & 0x80))
+ return x + 1;
+
+ ret = mbrtowc(&wc, x, y-x, &shiftstate);
+
+ if (ret == MB_INVALID || ret == MB_INCOMPLETE) {
+ /* Error. Treat as single byte. */
+ /* Reset the shift state for next time. */
+ memset(&shiftstate, 0, sizeof(shiftstate));
+ return x + 1;
+ }
+
+ /* Nulls here are normal characters */
+ return x + (ret ? ret : 1);
+}
+
+/* Increment a pointer past the current character. */
+#define CHARINC(x, y) ((x) = charnext((x), (y)))
+
+
+/* Get a character and increment */
+#define CHARREFINC(x, y, z) charrefinc(&(x), (y), (z))
+static wchar_t
+charrefinc(char **x, char *y, int *z)
+{
+ wchar_t wc;
+ size_t ret;
+
+ if (!(patglobflags & GF_MULTIBYTE) || !(STOUC(**x) & 0x80))
+ return (wchar_t) STOUC(*(*x)++);
+
+ ret = mbrtowc(&wc, *x, y-*x, &shiftstate);
+
+ if (ret == MB_INVALID || ret == MB_INCOMPLETE) {
+ /* Error. Treat as single byte, but flag. */
+ *z = 1;
+ /* Reset the shift state for next time. */
+ memset(&shiftstate, 0, sizeof(shiftstate));
+ return WCHAR_INVALID(*(*x)++);
+ }
+
+ /* Nulls here are normal characters */
+ *x += ret ? ret : 1;
+
+ return wc;
+}
+
+
+/*
+ * Counter the number of characters between two pointers, smaller first
+ *
+ * This is used when setting values in parameters, so we obey
+ * the MULTIBYTE option (even if it's been overridden locally).
+ */
+#define CHARSUB(x,y) charsub(x, y)
+static ptrdiff_t
+charsub(char *x, char *y)
+{
+ ptrdiff_t res = 0;
+ size_t ret;
+ wchar_t wc;
+
+ if (!isset(MULTIBYTE))
+ return y - x;
+
+ while (x < y) {
+ ret = mbrtowc(&wc, x, y-x, &shiftstate);
+
+ if (ret == MB_INVALID || ret == MB_INCOMPLETE) {
+ /* Error. Treat remainder as single characters */
+ return res + (y - x);
+ }
+
+ /* Treat nulls as normal characters */
+ if (!ret)
+ ret = 1;
+ res++;
+ x += ret;
+ }
+
+ return res;
+}
+
+#else /* no MULTIBYTE_SUPPORT */
+
+/* Get a character from the start point in a string */
+#define CHARREF(x, y) (STOUC(*(x)))
+/* Get a pointer to the next character */
+#define CHARNEXT(x, y) ((x)+1)
+/* Increment a pointer past the current character. */
+#define CHARINC(x, y) ((x)++)
+/* Get a character and increment */
+#define CHARREFINC(x, y, z) (STOUC(*(x)++))
+/* Counter the number of characters between two pointers, smaller first */
+#define CHARSUB(x,y) ((y) - (x))
+
+#endif /* MULTIBYTE_SUPPORT */
+
+/*
+ * The following need to be accessed in the globbing scanner for
+ * a multi-component file path. See horror story in glob.c.
+ */
+/**/
+int errsfound; /* Total error count so far */
+
+/**/
+int forceerrs; /* Forced maximum error count */
+
+/**/
+void
+pattrystart(void)
+{
+ forceerrs = -1;
+ errsfound = 0;
+}
+
+/*
+ * Fix up string length stuff.
+ *
+ * If we call patallocstr() with "force" to set things up early, it's
+ * done there, else it's done in pattryrefs(). The reason for the
+ * difference is in the latter case we may not be relying on
+ * patallocstr() having an effect.
+ */
+
+/**/
+static void
+patmungestring(char **string, int *stringlen, int *unmetalenin)
+{
+ /*
+ * Special signalling of empty tokenised string.
+ */
+ if (*stringlen > 0 && **string == Nularg) {
+ (*string)++;
+ /*
+ * If we don't have an unmetafied length
+ * and need it (we may not) we'll get it later.
+ */
+ if (*unmetalenin > 0)
+ (*unmetalenin)--;
+ if (*stringlen > 0)
+ (*stringlen)--;
+ }
+
+ /* Ensure we have a metafied length */
+ if (*stringlen < 0)
+ *stringlen = strlen(*string);
+}
+
+/*
+ * Allocate memeory for pattern match. Note this is specific to use
+ * of pattern *and* trial string.
+ *
+ * Unmetafy a trial string for use in pattern matching, if needed.
+ *
+ * If it is needed, returns a heap allocated string; if not needed,
+ * returns NULL.
+ *
+ * prog is the pattern to be executed.
+ * string is the metafied trial string.
+ * stringlen is it's length; it will be calculated if it's negative
+ * (this is a simple strlen()).
+ * unmetalen is the unmetafied length of the string, may be -1.
+ * force is 1 if we always unmetafy: this is useful if we are going
+ * to try again with different versions of the string. If this is
+ * called from pattryrefs() we don't force unmetafication as it won't
+ * be optimal. This option should be used if the resulting
+ * patstralloc is going to be passed to pattrylen() / pattryrefs().
+ * In patstralloc (supplied by caller, must last until last pattry is done)
+ * unmetalen is the unmetafied length of the string; it will be
+ * calculated if the input value is negative.
+ * unmetalenp is the umetafied length of a path segment preceeding
+ * the trial string needed for file mananagement; it is calculated as
+ * needed so does not need to be initialised.
+ * alloced is the memory allocated on the heap --- same as return value from
+ * function.
+ */
+/**/
+mod_export
+char *patallocstr(Patprog prog, char *string, int stringlen, int unmetalen,
+ int force, Patstralloc patstralloc)
+{
+ int needfullpath;
+
+ if (force)
+ patmungestring(&string, &stringlen, &unmetalen);
+
+ /*
+ * For a top-level ~-exclusion, we will need the full
+ * path to exclude, so copy the path so far and append the
+ * current test string.
+ */
+ needfullpath = (prog->flags & PAT_HAS_EXCLUDP) && pathpos;
+
+ /* Get the length of the full string when unmetafied. */
+ if (unmetalen < 0)
+ patstralloc->unmetalen = ztrsub(string + stringlen, string);
+ else
+ patstralloc->unmetalen = unmetalen;
+ if (needfullpath) {
+ patstralloc->unmetalenp = ztrsub(pathbuf + pathpos, pathbuf);
+ if (!patstralloc->unmetalenp)
+ needfullpath = 0;
+ } else
+ patstralloc->unmetalenp = 0;
+ /* Initialise cache area */
+ patstralloc->progstrunmeta = NULL;
+ patstralloc->progstrunmetalen = 0;
+
+ DPUTS(needfullpath && (prog->flags & (PAT_PURES|PAT_ANY)),
+ "rum sort of file exclusion");
+ /*
+ * Partly for efficiency, and partly for the convenience of
+ * globbing, we don't unmetafy pure string patterns, and
+ * there's no reason to if the pattern is just a *.
+ */
+ if (force ||
+ (!(prog->flags & (PAT_PURES|PAT_ANY))
+ && (needfullpath || patstralloc->unmetalen != stringlen))) {
+ /*
+ * We need to copy if we need to prepend the path so far
+ * (in which case we copy both chunks), or if we have
+ * Meta characters.
+ */
+ char *dst, *ptr;
+ int i, icopy, ncopy;
+
+ dst = patstralloc->alloced =
+ zhalloc(patstralloc->unmetalen + patstralloc->unmetalenp);
+
+ if (needfullpath) {
+ /* loop twice, copy path buffer first time */
+ ptr = pathbuf;
+ ncopy = patstralloc->unmetalenp;
+ } else {
+ /* just loop once, copy string with unmetafication */
+ ptr = string;
+ ncopy = patstralloc->unmetalen;
+ }
+ for (icopy = 0; icopy < 2; icopy++) {
+ for (i = 0; i < ncopy; i++) {
+ if (*ptr == Meta) {
+ ptr++;
+ *dst++ = *ptr++ ^ 32;
+ } else {
+ *dst++ = *ptr++;
+ }
+ }
+ if (!needfullpath)
+ break;
+ /* next time append test string to path so far */
+ ptr = string;
+ ncopy = patstralloc->unmetalen;
+ }
+ }
+ else
+ {
+ patstralloc->alloced = NULL;
+ }
+
+ return patstralloc->alloced;
+}
+
+
+/*
+ * Test prog against null-terminated, metafied string.
+ */
+
+/**/
+mod_export int
+pattry(Patprog prog, char *string)
+{
+ return pattryrefs(prog, string, -1, -1, NULL, 0, NULL, NULL, NULL);
+}
+
+/*
+ * Test prog against string of given length, no null termination
+ * but still metafied at this point. offset gives an offset
+ * to include in reported match indices
+ */
+
+/**/
+mod_export int
+pattrylen(Patprog prog, char *string, int len, int unmetalen,
+ Patstralloc patstralloc, int offset)
+{
+ return pattryrefs(prog, string, len, unmetalen, patstralloc, offset,
+ NULL, NULL, NULL);
+}
+
+/*
+ * Test prog against string with given lengths. The input
+ * string is metafied; stringlen is the raw string length, and
+ * unmetalen the number of characters in the original string (some
+ * of which may now be metafied). Either value may be -1
+ * to indicate a null-terminated string which will be counted. Note
+ * there may be a severe penalty for this if a lot of matching is done
+ * on one string.
+ *
+ * If patstralloc is not NULL it is used to optimise unmetafication
+ * of a trial string that may be passed (or any substring may be passed) to
+ * pattryrefs multiple times or the same pattern (N.B. so patstralloc
+ * depends on both prog *and* the trial string). This should only be
+ * done if there is no path prefix (pathpos == 0) as otherwise the path
+ * buffer and unmetafied string may not match. To do this,
+ * patallocstr() is callled (use force = 1 to ensure it is alway
+ * unmetafied); paststralloc points to existing storage. Memory is
+ * on the heap.
+ *
+ * patstralloc->alloced and patstralloc->unmetalen contain the
+ * unmetafied string and its length. In that case, the rules for the
+ * earlier arguments change:
+ * - string is an unmetafied string
+ * - stringlen is its unmetafied (i.e. actual) length
+ * - unmetalenin is not used.
+ * string and stringlen may refer to arbitrary substrings of
+ * patstralloc->alloced without any internal modification to patstralloc.
+ *
+ * patoffset is the position in the original string (not seen by
+ * the pattern module) at which we are trying to match.
+ * This is added in to the positions recorded in patbeginp and patendp
+ * when we are looking for substrings. Currently this only happens
+ * in the parameter substitution code. It refers to a real character
+ * offset, i.e. is already in the form ready for presentation to the
+ * general public --- this is necessary as we don't have the
+ * information to convert it down here.
+ *
+ * Note this is a character offset, i.e. a single possibly metafied and
+ * possibly multibyte character counts as 1.
+ *
+ * The last three arguments are used to report the positions for the
+ * backreferences. On entry, *nump should contain the maximum number
+ * of positions to report. In this case the match, mbegin, mend
+ * arrays are not altered.
+ *
+ * If nump is NULL but endp is not NULL, then *endp is set to the
+ * end position of the match, taking into account patinstart.
+ */
+
+/**/
+mod_export int
+pattryrefs(Patprog prog, char *string, int stringlen, int unmetalenin,
+ Patstralloc patstralloc, int patoffset,
+ int *nump, int *begp, int *endp)
+{
+ int i, maxnpos = 0, ret;
+ int origlen;
+ char **sp, **ep, *ptr;
+ char *progstr = (char *)prog + prog->startoff;
+ struct patstralloc patstralloc_struct;
+
+ if (nump) {
+ maxnpos = *nump;
+ *nump = 0;
+ }
+
+ if (!patstralloc)
+ patmungestring(&string, &stringlen, &unmetalenin);
+ origlen = stringlen;
+
+ if (patstralloc) {
+ DPUTS(!patstralloc->alloced,
+ "External unmetafy didn't actually unmetafy.");
+ DPUTS(patstralloc->unmetalenp,
+ "Ooh-err: pathpos with external unmetafy. I have bad vibes.");
+ patinpath = NULL;
+ patinstart = string;
+ /* stringlen is unmetafied length; unmetalenin is ignored */
+ } else {
+ patstralloc = &patstralloc_struct;
+ if (patallocstr(prog, string, stringlen, unmetalenin, 0, patstralloc)) {
+ patinstart = patstralloc->alloced + patstralloc->unmetalenp;
+ stringlen = patstralloc->unmetalen;
+ } else
+ patinstart = string;
+ if (patstralloc->unmetalenp)
+ patinpath = patstralloc->alloced;
+ else
+ patinpath = NULL;
+ }
+
+ patflags = prog->flags;
+ patinend = patinstart + stringlen;
+ /*
+ * From now on we do not require NULL termination of
+ * the test string. There should also be no more references
+ * to the variable string.
+ */
+
+ if (prog->flags & (PAT_PURES|PAT_ANY)) {
+ /*
+ * Either we are testing against a pure string,
+ * or we can match anything at all.
+ */
+ int pstrlen;
+ char *pstr;
+ if (patstralloc->alloced)
+ {
+ /*
+ * Unmetafied; we need pattern sring that's also unmetafied.
+ * We'll cache it in the patstralloc structure.
+ * Note it's on the heap.
+ */
+ if (!patstralloc->progstrunmeta)
+ {
+ patstralloc->progstrunmeta =
+ dupstrpfx(progstr, (int)prog->patmlen);
+ unmetafy(patstralloc->progstrunmeta,
+ &patstralloc->progstrunmetalen);
+ }
+ pstr = patstralloc->progstrunmeta;
+ pstrlen = patstralloc->progstrunmetalen;
+ }
+ else
+ {
+ /* Metafied. */
+ pstr = progstr;
+ pstrlen = (int)prog->patmlen;
+ }
+ if (prog->flags & PAT_ANY) {
+ /*
+ * Optimisation for a single "*": always matches
+ * (except for no_glob_dots, see below).
+ */
+ ret = 1;
+ } else {
+ /*
+ * Testing a pure string. See if initial
+ * components match.
+ */
+ int lendiff = stringlen - pstrlen;
+ if (lendiff < 0) {
+ /* No, the pattern string is too long. */
+ ret = 0;
+ } else if (!memcmp(pstr, patinstart, pstrlen)) {
+ /*
+ * Initial component matches. Matches either
+ * if lengths are the same or we are not anchored
+ * to the end of the string.
+ */
+ ret = !lendiff || (prog->flags & PAT_NOANCH);
+ } else {
+ /* No match. */
+ ret = 0;
+ }
+ }
+ if (ret) {
+ /*
+ * For files, we won't match initial "."s unless
+ * glob_dots is set.
+ */
+ if ((prog->flags & PAT_NOGLD) && *patinstart == '.') {
+ ret = 0;
+ } else {
+ /*
+ * Remember the length in case used for ${..#..} etc.
+ * In this case, we didn't unmetafy the pattern string
+ * In the orignal structure, but it might be unmetafied
+ * for use with an unmetafied test string.
+ */
+ patinlen = pstrlen;
+ /* if matching files, must update globbing flags */
+ patglobflags = prog->globend;
+
+ if ((patglobflags & GF_MATCHREF) &&
+ !(patflags & PAT_FILE)) {
+ char *str;
+ int mlen;
+
+ if (patstralloc->alloced) {
+ /*
+ * Unmetafied: pstrlen contains unmetafied
+ * length in bytes.
+ */
+ str = metafy(patinstart, pstrlen, META_DUP);
+ mlen = CHARSUB(patinstart, patinstart + pstrlen);
+ } else {
+ str = ztrduppfx(patinstart, patinlen);
+ /*
+ * Count the characters. We're not using CHARSUB()
+ * because the string is still metafied.
+ */
+ MB_METACHARINIT();
+ mlen = MB_METASTRLEN2END(patinstart, 0,
+ patinstart + patinlen);
+ }
+
+ setsparam("MATCH", str);
+ setiparam("MBEGIN",
+ (zlong)(patoffset + !isset(KSHARRAYS)));
+ setiparam("MEND",
+ (zlong)(mlen + patoffset +
+ !isset(KSHARRAYS) - 1));
+ }
+ }
+ }
+ } else {
+ /*
+ * Test for a `must match' string, unless we're scanning for a match
+ * in which case we don't need to do this each time.
+ */
+ ret = 1;
+ if (!(prog->flags & PAT_SCAN) && prog->mustoff)
+ {
+ char *testptr; /* start pointer into test string */
+ char *teststop; /* last point from which we can match */
+ char *patptr = (char *)prog + prog->mustoff;
+ int patlen = prog->patmlen;
+ int found = 0;
+
+ if (patlen > stringlen) {
+ /* Too long, can't match. */
+ ret = 0;
+ } else {
+ teststop = patinend - patlen;
+
+ for (testptr = patinstart; testptr <= teststop; testptr++)
+ {
+ if (!memcmp(testptr, patptr, patlen)) {
+ found = 1;
+ break;
+ }
+ }
+
+ if (!found)
+ ret = 0;
+ }
+ }
+ if (!ret)
+ return 0;
+
+ patglobflags = prog->globflags;
+ if (!(patflags & PAT_FILE)) {
+ forceerrs = -1;
+ errsfound = 0;
+ }
+ globdots = !(patflags & PAT_NOGLD);
+ parsfound = 0;
+
+ patinput = patinstart;
+
+ if (patmatch((Upat)progstr)) {
+ /*
+ * we were lazy and didn't save the globflags if an exclusion
+ * failed, so set it now
+ */
+ patglobflags = prog->globend;
+
+ /*
+ * Record length of successful match, including Meta
+ * characters. Do it here so that patmatchlen() can return
+ * it even if we delete the pattern strings.
+ */
+ patinlen = patinput - patinstart;
+ /*
+ * Optimization: if we didn't find any Meta characters
+ * to begin with, we don't need to look for them now.
+ *
+ * For patstralloc pased in, we want the unmetafied length.
+ */
+ if (patstralloc == &patstralloc_struct &&
+ patstralloc->unmetalen != origlen) {
+ for (ptr = patinstart; ptr < patinput; ptr++)
+ if (imeta(*ptr))
+ patinlen++;
+ }
+
+ /*
+ * Should we clear backreferences and matches on a failed
+ * match?
+ */
+ if ((patglobflags & GF_MATCHREF) && !(patflags & PAT_FILE)) {
+ /*
+ * m flag: for global match. This carries no overhead
+ * in the pattern matching part.
+ *
+ * Remember the test pattern is already unmetafied.
+ */
+ char *str;
+ int mlen = CHARSUB(patinstart, patinput);
+
+ str = metafy(patinstart, patinput - patinstart, META_DUP);
+ setsparam("MATCH", str);
+ setiparam("MBEGIN", (zlong)(patoffset + !isset(KSHARRAYS)));
+ setiparam("MEND",
+ (zlong)(mlen + patoffset +
+ !isset(KSHARRAYS) - 1));
+ }
+ if (prog->patnpar && nump) {
+ /*
+ * b flag: for backreferences using parentheses. Reported
+ * directly.
+ */
+ *nump = prog->patnpar;
+
+ sp = patbeginp;
+ ep = patendp;
+
+ for (i = 0; i < prog->patnpar && i < maxnpos; i++) {
+ if (parsfound & (1 << i)) {
+ if (begp)
+ *begp++ = CHARSUB(patinstart, *sp) + patoffset;
+ if (endp)
+ *endp++ = CHARSUB(patinstart, *ep) + patoffset
+ - 1;
+ } else {
+ if (begp)
+ *begp++ = -1;
+ if (endp)
+ *endp++ = -1;
+ }
+
+ sp++;
+ ep++;
+ }
+ } else if (prog->patnpar && !(patflags & PAT_FILE)) {
+ /*
+ * b flag: for backreferences using parentheses.
+ */
+ int palen = prog->patnpar+1;
+ char **matcharr, **mbeginarr, **mendarr;
+ char numbuf[DIGBUFSIZE];
+
+ matcharr = zshcalloc(palen*sizeof(char *));
+ mbeginarr = zshcalloc(palen*sizeof(char *));
+ mendarr = zshcalloc(palen*sizeof(char *));
+
+ sp = patbeginp;
+ ep = patendp;
+
+ for (i = 0; i < prog->patnpar; i++) {
+ if (parsfound & (1 << i)) {
+ matcharr[i] = metafy(*sp, *ep - *sp, META_DUP);
+ /*
+ * mbegin and mend give indexes into the string
+ * in the standard notation, i.e. respecting
+ * KSHARRAYS, and with the end index giving
+ * the last character, not one beyond.
+ * For example, foo=foo; [[ $foo = (f)oo ]] gives
+ * (without KSHARRAYS) indexes 1 and 1, which
+ * corresponds to indexing as ${foo[1,1]}.
+ */
+ sprintf(numbuf, "%ld",
+ (long)(CHARSUB(patinstart, *sp) +
+ patoffset +
+ !isset(KSHARRAYS)));
+ mbeginarr[i] = ztrdup(numbuf);
+ sprintf(numbuf, "%ld",
+ (long)(CHARSUB(patinstart, *ep) +
+ patoffset +
+ !isset(KSHARRAYS) - 1));
+ mendarr[i] = ztrdup(numbuf);
+ } else {
+ /* Pattern wasn't set: either it was in an
+ * unmatched branch, or a hashed parenthesis
+ * that didn't match at all.
+ */
+ matcharr[i] = ztrdup("");
+ mbeginarr[i] = ztrdup("-1");
+ mendarr[i] = ztrdup("-1");
+ }
+ sp++;
+ ep++;
+ }
+ setaparam("match", matcharr);
+ setaparam("mbegin", mbeginarr);
+ setaparam("mend", mendarr);
+ }
+
+ if (!nump && endp) {
+ /*
+ * We just need the overall end position.
+ */
+ *endp = CHARSUB(patinstart, patinput) + patoffset;
+ }
+
+ ret = 1;
+ } else
+ ret = 0;
+ }
+
+ return ret;
+}
+
+/*
+ * Return length of previous succesful match. This is
+ * in metafied bytes, i.e. includes a count of Meta characters,
+ * unless the match was done on an unmetafied string using
+ * a patstralloc stuct, in which case it, too is unmetafed.
+ * Unusual and futile attempt at modular encapsulation.
+ */
+
+/**/
+int
+patmatchlen(void)
+{
+ return patinlen;
+}
+
+/*
+ * Match literal characters with case insensitivity test: the first
+ * comes from the input string, the second the current pattern.
+ */
+#ifdef MULTIBYTE_SUPPORT
+#define ISUPPER(x) iswupper(x)
+#define ISLOWER(x) iswlower(x)
+#define TOUPPER(x) towupper(x)
+#define TOLOWER(x) towlower(x)
+#define ISDIGIT(x) iswdigit(x)
+#else
+#define ISUPPER(x) isupper(x)
+#define ISLOWER(x) islower(x)
+#define TOUPPER(x) toupper(x)
+#define TOLOWER(x) tolower(x)
+#define ISDIGIT(x) idigit(x)
+#endif
+#define CHARMATCH(chin, chpa) (chin == chpa || \
+ ((patglobflags & GF_IGNCASE) ? \
+ ((ISUPPER(chin) ? TOLOWER(chin) : chin) == \
+ (ISUPPER(chpa) ? TOLOWER(chpa) : chpa)) : \
+ (patglobflags & GF_LCMATCHUC) ? \
+ (ISLOWER(chpa) && TOUPPER(chpa) == chin) : 0))
+
+/*
+ * The same but caching an expression from the first argument,
+ * Requires local charmatch_cache definition.
+ */
+#define CHARMATCH_EXPR(expr, chpa) \
+ (charmatch_cache = (expr), CHARMATCH(charmatch_cache, chpa))
+
+/*
+ * exactpos is used to remember how far down an exact string we have
+ * matched, if we are doing approximation and can therefore redo from
+ * the same point; we never need to otherwise.
+ *
+ * exactend is a pointer to the end of the string, which isn't
+ * null-terminated.
+ */
+static char *exactpos, *exactend;
+
+/*
+ * Main matching routine.
+ *
+ * Testing the tail end of a match is usually done by recursion, but
+ * we try to eliminate that in favour of looping for simple cases.
+ */
+
+/**/
+static int
+patmatch(Upat prog)
+{
+ /* Current and next nodes */
+ Upat scan = prog, next, opnd;
+ char *start, *save, *chrop, *chrend, *compend;
+ int savglobflags, op, no, min, fail = 0, saverrsfound;
+ zrange_t from, to, comp;
+ patint_t nextch;
+ int q = queue_signal_level();
+
+ /*
+ * To avoid overhead of saving state if there are no queued signals
+ * waiting, we pierce the signals.h veil and examine queue state.
+ */
+#define check_for_signals() do if (queue_front != queue_rear) { \
+ int savpatflags = patflags, savpatglobflags = patglobflags; \
+ char *savexactpos = exactpos, *savexactend = exactend; \
+ struct rpat savpattrystate = pattrystate; \
+ dont_queue_signals(); \
+ restore_queue_signals(q); \
+ exactpos = savexactpos; \
+ exactend = savexactend; \
+ patflags = savpatflags; \
+ patglobflags = savpatglobflags; \
+ pattrystate = savpattrystate; \
+ } while (0)
+
+ check_for_signals();
+
+ while (scan && !errflag) {
+ next = PATNEXT(scan);
+
+ if (!globdots && P_NOTDOT(scan) && patinput == patinstart &&
+ patinput < patinend && *patinput == '.')
+ return 0;
+
+ switch (P_OP(scan)) {
+ case P_ANY:
+ if (patinput == patinend)
+ fail = 1;
+ else
+ CHARINC(patinput, patinend);
+ break;
+ case P_EXACTLY:
+ /*
+ * acts as nothing if *chrop is null: this is used by
+ * approx code.
+ */
+ if (exactpos) {
+ chrop = exactpos;
+ chrend = exactend;
+ } else {
+ chrop = P_LS_STR(scan);
+ chrend = chrop + P_LS_LEN(scan);
+ }
+ exactpos = NULL;
+ while (chrop < chrend && patinput < patinend) {
+ char *savpatinput = patinput;
+ char *savchrop = chrop;
+ int badin = 0, badpa = 0;
+ /*
+ * Care with character matching:
+ * We do need to convert the character to wide
+ * representation if possible, because we may need
+ * to do case transformation. However, we should
+ * be careful in case one, but not the other, wasn't
+ * representable in the current locale---in that
+ * case they don't match even if the returned
+ * values (one properly converted, one raw) are
+ * the same.
+ */
+ patint_t chin = CHARREFINC(patinput, patinend, &badin);
+ patint_t chpa = CHARREFINC(chrop, chrend, &badpa);
+ if (!CHARMATCH(chin, chpa) || badin != badpa) {
+ fail = 1;
+ patinput = savpatinput;
+ chrop = savchrop;
+ break;
+ }
+ }
+ if (chrop < chrend) {
+ exactpos = chrop;
+ exactend = chrend;
+ fail = 1;
+ }
+ break;
+ case P_ANYOF:
+ case P_ANYBUT:
+ if (patinput == patinend)
+ fail = 1;
+ else {
+#ifdef MULTIBYTE_SUPPORT
+ int zmb_ind;
+ wchar_t cr = charref(patinput, patinend, &zmb_ind);
+ char *scanop = (char *)P_OPERAND(scan);
+ if (patglobflags & GF_MULTIBYTE) {
+ if (mb_patmatchrange(scanop, cr, zmb_ind, NULL, NULL) ^
+ (P_OP(scan) == P_ANYOF))
+ fail = 1;
+ else
+ CHARINC(patinput, patinend);
+ } else if (patmatchrange(scanop, (int)cr, NULL, NULL) ^
+ (P_OP(scan) == P_ANYOF))
+ fail = 1;
+ else
+ CHARINC(patinput, patinend);
+#else
+ if (patmatchrange((char *)P_OPERAND(scan),
+ CHARREF(patinput, patinend), NULL, NULL) ^
+ (P_OP(scan) == P_ANYOF))
+ fail = 1;
+ else
+ CHARINC(patinput, patinend);
+#endif
+ }
+ break;
+ case P_NUMRNG:
+ case P_NUMFROM:
+ case P_NUMTO:
+ /*
+ * To do this properly, we really have to treat numbers as
+ * closures: that's so things like <1-1000>33 will
+ * match 633 (they didn't up to 3.1.6). To avoid making this
+ * too inefficient, we see if there's an exact match next:
+ * if there is, and it's not a digit, we return 1 after
+ * the first attempt.
+ */
+ op = P_OP(scan);
+ start = (char *)P_OPERAND(scan);
+ from = to = 0;
+ if (op != P_NUMTO) {
+#ifdef ZSH_64_BIT_TYPE
+ /* We can't rely on pointer alignment being good enough. */
+ memcpy((char *)&from, start, sizeof(zrange_t));
+#else
+ from = *((zrange_t *) start);
+#endif
+ start += sizeof(zrange_t);
+ }
+ if (op != P_NUMFROM) {
+#ifdef ZSH_64_BIT_TYPE
+ memcpy((char *)&to, start, sizeof(zrange_t));
+#else
+ to = *((zrange_t *) start);
+#endif
+ }
+ start = compend = patinput;
+ comp = 0;
+ while (patinput < patinend && idigit(*patinput)) {
+ int out_of_range = 0;
+ int digit = *patinput - '0';
+ if (comp > ZRANGE_MAX / (zlong)10) {
+ out_of_range = 1;
+ } else {
+ zrange_t c10 = comp ? comp * 10 : 0;
+ if (ZRANGE_MAX - c10 < digit) {
+ out_of_range = 1;
+ } else {
+ comp = c10;
+ comp += digit;
+ }
+ }
+ patinput++;
+ compend++;
+
+ if (out_of_range ||
+ (comp & ((zrange_t)1 << (sizeof(comp)*8 -
+#ifdef ZRANGE_T_IS_SIGNED
+ 2
+#else
+ 1
+#endif
+ )))) {
+ /*
+ * Out of range (allowing for signedness, which
+ * we need if we are using zlongs).
+ * This is as far as we can go.
+ * If we're doing a range "from", skip all the
+ * remaining numbers. Otherwise, we can't
+ * match beyond the previous point anyway.
+ * Leave the pointer to the last calculated
+ * position (compend) where it was before.
+ */
+ if (op == P_NUMFROM) {
+ while (patinput < patinend && idigit(*patinput))
+ patinput++;
+ }
+ }
+ }
+ save = patinput;
+ no = 0;
+ while (patinput > start) {
+ /* if already too small, no power on earth can save it */
+ if (comp < from && patinput <= compend)
+ break;
+ if ((op == P_NUMFROM || comp <= to) && patmatch(next)) {
+ return 1;
+ }
+ if (!no && P_OP(next) == P_EXACTLY &&
+ (!P_LS_LEN(next) ||
+ !idigit(STOUC(*P_LS_STR(next)))) &&
+ !(patglobflags & 0xff))
+ return 0;
+ patinput = --save;
+ no++;
+ /*
+ * With a range start and an unrepresentable test
+ * number, we just back down the test string without
+ * changing the number until we get to a representable
+ * one.
+ */
+ if (patinput < compend)
+ comp /= 10;
+ }
+ patinput = start;
+ fail = 1;
+ break;
+ case P_NUMANY:
+ /* This is <->: any old set of digits, don't bother comparing */
+ start = patinput;
+ while (patinput < patinend && idigit(*patinput))
+ patinput++;
+ save = patinput;
+ no = 0;
+ while (patinput > start) {
+ if (patmatch(next))
+ return 1;
+ if (!no && P_OP(next) == P_EXACTLY &&
+ (!P_LS_LEN(next) ||
+ !idigit(*P_LS_STR(next))) &&
+ !(patglobflags & 0xff))
+ return 0;
+ patinput = --save;
+ no++;
+ }
+ patinput = start;
+ fail = 1;
+ break;
+ case P_NOTHING:
+ break;
+ case P_BACK:
+ break;
+ case P_GFLAGS:
+ patglobflags = P_OPERAND(scan)->l;
+ break;
+ case P_OPEN:
+ case P_OPEN+1:
+ case P_OPEN+2:
+ case P_OPEN+3:
+ case P_OPEN+4:
+ case P_OPEN+5:
+ case P_OPEN+6:
+ case P_OPEN+7:
+ case P_OPEN+8:
+ case P_OPEN+9:
+ no = P_OP(scan) - P_OPEN;
+ save = patinput;
+
+ if (patmatch(next)) {
+ /*
+ * Don't set patbeginp if some later invocation of
+ * the same parentheses already has.
+ */
+ if (no && !(parsfound & (1 << (no - 1)))) {
+ patbeginp[no-1] = save;
+ parsfound |= 1 << (no - 1);
+ }
+ return 1;
+ } else
+ return 0;
+ break;
+ case P_CLOSE:
+ case P_CLOSE+1:
+ case P_CLOSE+2:
+ case P_CLOSE+3:
+ case P_CLOSE+4:
+ case P_CLOSE+5:
+ case P_CLOSE+6:
+ case P_CLOSE+7:
+ case P_CLOSE+8:
+ case P_CLOSE+9:
+ no = P_OP(scan) - P_CLOSE;
+ save = patinput;
+
+ if (patmatch(next)) {
+ if (no && !(parsfound & (1 << (no + 15)))) {
+ patendp[no-1] = save;
+ parsfound |= 1 << (no + 15);
+ }
+ return 1;
+ } else
+ return 0;
+ break;
+ case P_EXCSYNC:
+ /* See the P_EXCLUDE code below for where syncptr comes from */
+ {
+ unsigned char *syncptr;
+ Upat after;
+ after = P_OPERAND(scan);
+ DPUTS(!P_ISEXCLUDE(after),
+ "BUG: EXCSYNC not followed by EXCLUDE.");
+ DPUTS(!P_OPERAND(after)->p,
+ "BUG: EXCSYNC not handled by EXCLUDE");
+ syncptr = P_OPERAND(after)->p + (patinput - patinstart);
+ /*
+ * If we already matched from here, this time we fail.
+ * See WBRANCH code for story about error count.
+ */
+ if (*syncptr && errsfound + 1 >= *syncptr)
+ return 0;
+ /*
+ * Else record that we (possibly) matched this time.
+ * No harm if we don't: then the previous test will just
+ * short cut the attempted match that is bound to fail.
+ * We never try to exclude something that has already
+ * failed anyway.
+ */
+ *syncptr = errsfound + 1;
+ }
+ break;
+ case P_EXCEND:
+ /*
+ * This is followed by a P_EXCSYNC, but only in the P_EXCLUDE
+ * branch. Actually, we don't bother following it: all we
+ * need to know is that we successfully matched so far up
+ * to the end of the asserted pattern; the endpoint
+ * in the target string is nulled out.
+ */
+ if (!(fail = (patinput < patinend)))
+ return 1;
+ break;
+ case P_BRANCH:
+ case P_WBRANCH:
+ /* P_EXCLUDE shouldn't occur without a P_BRANCH */
+ if (!P_ISBRANCH(next)) {
+ /* no choice, avoid recursion */
+ DPUTS(P_OP(scan) == P_WBRANCH,
+ "BUG: WBRANCH with no alternative.");
+ next = P_OPERAND(scan);
+ } else {
+ do {
+ save = patinput;
+ savglobflags = patglobflags;
+ saverrsfound = errsfound;
+ if (P_ISEXCLUDE(next)) {
+ /*
+ * The strategy is to test the asserted pattern,
+ * recording via P_EXCSYNC how far the part to
+ * be excluded matched. We then set the
+ * length of the test string to that
+ * point and see if the exclusion as far as
+ * P_EXCEND also matches that string.
+ * We need to keep testing the asserted pattern
+ * by backtracking, since the first attempt
+ * may be excluded while a later attempt may not.
+ * For this we keep a pointer just after
+ * the P_EXCLUDE which is tested by the P_EXCSYNC
+ * to see if we matched there last time, in which
+ * case we fail. If there is nothing to backtrack
+ * over, that doesn't matter: we should fail anyway.
+ * The pointer also tells us where the asserted
+ * pattern matched for use by the exclusion.
+ *
+ * It's hard to allocate space for this
+ * beforehand since we may need to do it
+ * recursively.
+ *
+ * P.S. in case you were wondering, this code
+ * is horrible.
+ */
+ Upat syncstrp;
+ char *origpatinend;
+ unsigned char *oldsyncstr;
+ char *matchpt = NULL;
+ int ret, savglobdots, matchederrs = 0;
+ int savparsfound = parsfound;
+ DPUTS(P_OP(scan) == P_WBRANCH,
+ "BUG: excluded WBRANCH");
+ syncstrp = P_OPERAND(next);
+ /*
+ * Unlike WBRANCH, each test at the same exclude
+ * sync point (due to an external loop) is separate,
+ * i.e testing (foo~bar)# is no different from
+ * (foo~bar)(foo~bar)... from the exclusion point
+ * of view, so we use a different sync string.
+ */
+ oldsyncstr = syncstrp->p;
+ syncstrp->p = (unsigned char *)
+ zshcalloc((patinend - patinstart) + 1);
+ origpatinend = patinend;
+ while ((ret = patmatch(P_OPERAND(scan)))) {
+ unsigned char *syncpt;
+ char *savpatinstart;
+ int savforce = forceerrs;
+ int savpatflags = patflags, synclen;
+ forceerrs = -1;
+ savglobdots = globdots;
+ matchederrs = errsfound;
+ matchpt = patinput; /* may not be end */
+ globdots = 1; /* OK to match . first */
+ /* Find the point where the scan
+ * matched the part to be excluded: because
+ * of backtracking, the one
+ * most recently matched will be the first.
+ * (Luckily, backtracking is done after all
+ * possibilities for approximation have been
+ * checked.)
+ */
+ for (syncpt = syncstrp->p; !*syncpt; syncpt++)
+ ;
+ synclen = syncpt - syncstrp->p;
+ if (patinstart + synclen != patinend) {
+ /*
+ * Temporarily mark the string as
+ * ending at this point.
+ */
+ DPUTS(patinstart + synclen > matchpt,
+ "BUG: EXCSYNC failed");
+
+ patinend = patinstart + synclen;
+ /*
+ * If this isn't really the end of the string,
+ * remember this for the (#e) assertion.
+ */
+ patflags |= PAT_NOTEND;
+ }
+ savpatinstart = patinstart;
+ next = PATNEXT(scan);
+ while (next && P_ISEXCLUDE(next)) {
+ patinput = save;
+ /*
+ * turn off approximations in exclusions:
+ * note we keep remaining patglobflags
+ * set by asserted branch (or previous
+ * excluded branches, for consistency).
+ */
+ patglobflags &= ~0xff;
+ errsfound = 0;
+ opnd = P_OPERAND(next) + 1;
+ if (P_OP(next) == P_EXCLUDP && patinpath) {
+ /*
+ * Top level exclusion with a file,
+ * applies to whole path so add the
+ * segments already matched.
+ * We copied these in front of the
+ * test pattern, so patinend doesn't
+ * need moving.
+ */
+ DPUTS(patinput != patinstart,
+ "BUG: not at start excluding path");
+ patinput = patinstart = patinpath;
+ }
+ if (patmatch(opnd)) {
+ ret = 0;
+ /*
+ * Another subtlety: if we exclude the
+ * match, any parentheses just found
+ * become invalidated.
+ */
+ parsfound = savparsfound;
+ }
+ if (patinpath) {
+ patinput = savpatinstart +
+ (patinput - patinstart);
+ patinstart = savpatinstart;
+ }
+ if (!ret)
+ break;
+ next = PATNEXT(next);
+ }
+ /*
+ * Restore original end position.
+ */
+ patinend = origpatinend;
+ patflags = savpatflags;
+ globdots = savglobdots;
+ forceerrs = savforce;
+ if (ret)
+ break;
+ patinput = save;
+ patglobflags = savglobflags;
+ errsfound = saverrsfound;
+ }
+ zfree((char *)syncstrp->p,
+ (patinend - patinstart) + 1);
+ syncstrp->p = oldsyncstr;
+ if (ret) {
+ patinput = matchpt;
+ errsfound = matchederrs;
+ return 1;
+ }
+ while ((scan = PATNEXT(scan)) &&
+ P_ISEXCLUDE(scan))
+ ;
+ } else {
+ int ret = 1, pfree = 0;
+ Upat ptrp = NULL;
+ unsigned char *ptr;
+ if (P_OP(scan) == P_WBRANCH) {
+ /*
+ * This is where we make sure that we are not
+ * repeatedly matching zero-length strings in
+ * a closure, which would cause an infinite loop,
+ * and also remove exponential behaviour in
+ * backtracking nested closures.
+ * The P_WBRANCH operator leaves a space for a
+ * uchar *, initialized to NULL, which is
+ * turned into a string the same length as the
+ * target string. Every time we match from a
+ * particular point in the target string, we
+ * stick a 1 at the corresponding point here.
+ * If we come round to the same branch again, and
+ * there is already a 1, then the test fails.
+ */
+ opnd = P_OPERAND(scan);
+ ptrp = opnd++;
+ if (!ptrp->p) {
+ ptrp->p = (unsigned char *)
+ zshcalloc((patinend - patinstart) + 1);
+ pfree = 1;
+ }
+ ptr = ptrp->p + (patinput - patinstart);
+
+ /*
+ * Without approximation, this is just a
+ * single bit test. With approximation, we
+ * need to know how many errors there were
+ * last time we made the test. If errsfound
+ * is now smaller than it was, hence we can
+ * make more approximations in the remaining
+ * code, we continue with the test.
+ * (This is why the max number of errors is
+ * 254, not 255.)
+ */
+ if (*ptr && errsfound + 1 >= *ptr)
+ ret = 0;
+ *ptr = errsfound + 1;
+ } else
+ opnd = P_OPERAND(scan);
+ if (ret)
+ ret = patmatch(opnd);
+ if (pfree) {
+ zfree((char *)ptrp->p,
+ (patinend - patinstart) + 1);
+ ptrp->p = NULL;
+ }
+ if (ret)
+ return 1;
+ scan = PATNEXT(scan);
+ }
+ patinput = save;
+ patglobflags = savglobflags;
+ errsfound = saverrsfound;
+ DPUTS(P_OP(scan) == P_WBRANCH,
+ "BUG: WBRANCH not first choice.");
+ next = PATNEXT(scan);
+ } while (scan && P_ISBRANCH(scan));
+ return 0;
+ }
+ break;
+ case P_STAR:
+ /* Handle specially for speed, although really P_ONEHASH+P_ANY */
+ while (P_OP(next) == P_STAR) {
+ /*
+ * If there's another * following we can optimise it
+ * out. Chains of *'s can give pathologically bad
+ * performance.
+ */
+ scan = next;
+ next = PATNEXT(scan);
+ }
+ /*FALLTHROUGH*/
+ case P_ONEHASH:
+ case P_TWOHASH:
+ /*
+ * This is just simple cases, matching one character.
+ * With approximations, we still handle * this way, since
+ * no approximation is ever necessary, but other closures
+ * are handled by the more complicated branching method
+ */
+ op = P_OP(scan);
+ /* Note that no counts possibly metafied characters */
+ start = patinput;
+ {
+ char *lastcharstart;
+ /*
+ * Array to record the start of characters for
+ * backtracking.
+ */
+ VARARR(char, charstart, patinend-patinput);
+ memset(charstart, 0, patinend-patinput);
+
+ if (op == P_STAR) {
+ for (no = 0; patinput < patinend;
+ CHARINC(patinput, patinend))
+ {
+ charstart[patinput-start] = 1;
+ no++;
+ }
+ /* simple optimization for reasonably common case */
+ if (P_OP(next) == P_END)
+ return 1;
+ } else {
+ DPUTS(patglobflags & 0xff,
+ "BUG: wrong backtracking with approximation.");
+ if (!globdots && P_NOTDOT(P_OPERAND(scan)) &&
+ patinput == patinstart && patinput < patinend &&
+ CHARREF(patinput, patinend) == ZWC('.'))
+ return 0;
+ no = patrepeat(P_OPERAND(scan), charstart);
+ }
+ min = (op == P_TWOHASH) ? 1 : 0;
+ /*
+ * Lookahead to avoid useless matches. This is not possible
+ * with approximation.
+ */
+ if (P_OP(next) == P_EXACTLY && P_LS_LEN(next) &&
+ !(patglobflags & 0xff)) {
+ char *nextop = P_LS_STR(next);
+#ifdef MULTIBYTE_SUPPORT
+ /* else second argument of CHARREF isn't used */
+ int nextlen = P_LS_LEN(next);
+#endif
+ /*
+ * If that P_EXACTLY is last (common in simple patterns,
+ * such as *.c), then it can be only be matched at one
+ * point in the test string, so record that.
+ */
+ if (P_OP(PATNEXT(next)) == P_END &&
+ !(patflags & PAT_NOANCH)) {
+ int ptlen = patinend - patinput;
+ int lenmatch = patinend -
+ (min ? CHARNEXT(start, patinend) : start);
+ /* Are we in the right range? */
+ if (P_LS_LEN(next) > lenmatch ||
+ P_LS_LEN(next) < ptlen)
+ return 0;
+ /* Yes, just position appropriately and test. */
+ patinput += ptlen - P_LS_LEN(next);
+ /*
+ * Here we will need to be careful that patinput is not
+ * in the middle of a multibyte character.
+ */
+ /* Continue loop with P_EXACTLY test. */
+ break;
+ }
+ nextch = CHARREF(nextop, nextop + nextlen);
+ } else
+ nextch = PEOF;
+ savglobflags = patglobflags;
+ saverrsfound = errsfound;
+ lastcharstart = charstart + (patinput - start);
+ if (no >= min) {
+ for (;;) {
+ patint_t charmatch_cache;
+ if (nextch == PEOF ||
+ (patinput < patinend &&
+ CHARMATCH_EXPR(CHARREF(patinput, patinend),
+ nextch))) {
+ if (patmatch(next))
+ return 1;
+ }
+ if (--no < min)
+ break;
+ /* find start of previous full character */
+ while (!*--lastcharstart)
+ DPUTS(lastcharstart < charstart,
+ "lastcharstart invalid");
+ patinput = start + (lastcharstart-charstart);
+ patglobflags = savglobflags;
+ errsfound = saverrsfound;
+ }
+ }
+ }
+ /*
+ * As with branches, the patmatch(next) stuff for *
+ * handles approximation, so we don't need to try
+ * anything here.
+ */
+ return 0;
+ case P_ISSTART:
+ if (patinput != patinstart || (patflags & PAT_NOTSTART))
+ fail = 1;
+ break;
+ case P_ISEND:
+ if (patinput < patinend || (patflags & PAT_NOTEND))
+ fail = 1;
+ break;
+ case P_COUNTSTART:
+ {
+ /*
+ * Save and restore the current count and the
+ * start pointer in case the pattern has been
+ * executed by a previous repetition of a
+ * closure.
+ */
+ long *curptr = &P_OPERAND(scan)[P_CT_CURRENT].l;
+ long savecount = *curptr;
+ unsigned char *saveptr = scan[P_CT_PTR].p;
+ int ret;
+
+ *curptr = 0L;
+ ret = patmatch(P_OPERAND(scan));
+ *curptr = savecount;
+ scan[P_CT_PTR].p = saveptr;
+ return ret;
+ }
+ case P_COUNT:
+ {
+ /* (#cN,M): execution is relatively straightforward */
+ long cur = scan[P_CT_CURRENT].l;
+ long min = scan[P_CT_MIN].l;
+ long max = scan[P_CT_MAX].l;
+
+ if (cur && cur >= min &&
+ (unsigned char *)patinput == scan[P_CT_PTR].p) {
+ /*
+ * Not at the first attempt to match so
+ * the previous attempt managed zero length.
+ * We can do this indefinitely so there's
+ * no point in going on. Simply try to
+ * match the remainder of the pattern.
+ */
+ return patmatch(next);
+ }
+ scan[P_CT_PTR].p = (unsigned char *)patinput;
+
+ if (max < 0 || cur < max) {
+ char *patinput_thistime = patinput;
+ scan[P_CT_CURRENT].l = cur + 1;
+ if (patmatch(scan + P_CT_OPERAND))
+ return 1;
+ scan[P_CT_CURRENT].l = cur;
+ patinput = patinput_thistime;
+ }
+ if (cur < min)
+ return 0;
+ return patmatch(next);
+ }
+ case P_END:
+ if (!(fail = (patinput < patinend && !(patflags & PAT_NOANCH))))
+ return 1;
+ break;
+#ifdef DEBUG
+ default:
+ dputs("BUG: bad operand in patmatch.");
+ return 0;
+ break;
+#endif
+ }
+
+ if (fail) {
+ if (errsfound < (patglobflags & 0xff) &&
+ (forceerrs == -1 || errsfound < forceerrs)) {
+ /*
+ * Approximation code. There are four possibilities
+ *
+ * 1. omit character from input string
+ * 2. transpose characters in input and pattern strings
+ * 3. omit character in both input and pattern strings
+ * 4. omit character from pattern string.
+ *
+ * which we try in that order.
+ *
+ * Of these, 2, 3 and 4 require an exact match string
+ * (P_EXACTLY) while 1, 2 and 3 require that we not
+ * have reached the end of the input string.
+ *
+ * Note in each case after making the approximation we
+ * need to retry the *same* pattern; this is what
+ * requires exactpos, a slightly doleful way of
+ * communicating with the exact character matcher.
+ */
+ char *savexact = exactpos;
+ save = patinput;
+ savglobflags = patglobflags;
+ saverrsfound = ++errsfound;
+ fail = 0;
+
+ DPUTS(P_OP(scan) != P_EXACTLY && exactpos,
+ "BUG: non-exact match has set exactpos");
+
+ /* Try omitting a character from the input string */
+ if (patinput < patinend) {
+ CHARINC(patinput, patinend);
+ /* If we are not on an exact match, then this is
+ * our last gasp effort, so we can optimize out
+ * the recursive call.
+ */
+ if (P_OP(scan) != P_EXACTLY)
+ continue;
+ if (patmatch(scan))
+ return 1;
+ }
+
+ if (P_OP(scan) == P_EXACTLY) {
+ char *nextexact = savexact;
+ DPUTS(!savexact,
+ "BUG: exact match has not set exactpos");
+ CHARINC(nextexact, exactend);
+
+ if (save < patinend) {
+ char *nextin = save;
+ CHARINC(nextin, patinend);
+ patglobflags = savglobflags;
+ errsfound = saverrsfound;
+ exactpos = savexact;
+
+ /*
+ * Try swapping two characters in patinput and
+ * exactpos
+ */
+ if (save < patinend && nextin < patinend &&
+ nextexact < exactend) {
+ patint_t cin0 = CHARREF(save, patinend);
+ patint_t cpa0 = CHARREF(exactpos, exactend);
+ patint_t cin1 = CHARREF(nextin, patinend);
+ patint_t cpa1 = CHARREF(nextexact, exactend);
+
+ if (CHARMATCH(cin0, cpa1) &&
+ CHARMATCH(cin1, cpa0)) {
+ patinput = nextin;
+ CHARINC(patinput, patinend);
+ exactpos = nextexact;
+ CHARINC(exactpos, exactend);
+ if (patmatch(scan))
+ return 1;
+
+ patglobflags = savglobflags;
+ errsfound = saverrsfound;
+ }
+ }
+
+ /*
+ * Try moving up both strings.
+ */
+ patinput = nextin;
+ exactpos = nextexact;
+ if (patmatch(scan))
+ return 1;
+
+ patinput = save;
+ patglobflags = savglobflags;
+ errsfound = saverrsfound;
+ exactpos = savexact;
+ }
+
+ DPUTS(exactpos == exactend, "approximating too far");
+ /*
+ * Try moving up the exact match pattern.
+ * This must be the last attempt, so just loop
+ * instead of calling recursively.
+ */
+ CHARINC(exactpos, exactend);
+ continue;
+ }
+ }
+ exactpos = NULL;
+ return 0;
+ }
+
+ scan = next;
+
+ /* Allow handlers to run once per loop */
+ check_for_signals();
+ }
+
+ return 0;
+}
+
+
+/**/
+#ifdef MULTIBYTE_SUPPORT
+
+/*
+ * See if character ch matches a pattern range specification.
+ * The null-terminated specification is in range; the test
+ * character is in ch.
+ *
+ * zmb is one of the enum defined above charref(), for indicating
+ * incomplete or invalid multibyte characters.
+ *
+ * indptr is used by completion matching, which is why this
+ * function is exported. If indptr is not NULL we set *indptr
+ * to the index of the character in the range string, adjusted
+ * in the case of "A-B" ranges such that A would count as its
+ * normal index (say IA), B would count as IA + (B-A), and any
+ * character within the range as appropriate. We're not strictly
+ * guaranteed this fits within a wint_t, but if this is Unicode
+ * in 32 bits we have a fair amount of distance left over.
+ *
+ * mtp is used in the same circumstances. *mtp returns the match type:
+ * 0 for a standard character, else the PP_ index. It's not
+ * useful if the match failed.
+ */
+
+/**/
+mod_export int
+mb_patmatchrange(char *range, wchar_t ch, int zmb_ind, wint_t *indptr, int *mtp)
+{
+ wchar_t r1, r2;
+
+ if (indptr)
+ *indptr = 0;
+ /*
+ * Careful here: unlike other strings, range is a NULL-terminated,
+ * metafied string, because we need to treat the Posix and hyphenated
+ * ranges specially.
+ */
+ while (*range) {
+ if (imeta(STOUC(*range))) {
+ int swtype = STOUC(*range++) - STOUC(Meta);
+ if (mtp)
+ *mtp = swtype;
+ switch (swtype) {
+ case 0:
+ /* ordinary metafied character */
+ range--;
+ if (metacharinc(&range) == ch)
+ return 1;
+ break;
+ case PP_ALPHA:
+ if (iswalpha(ch))
+ return 1;
+ break;
+ case PP_ALNUM:
+ if (iswalnum(ch))
+ return 1;
+ break;
+ case PP_ASCII:
+ if ((ch & ~0x7f) == 0)
+ return 1;
+ break;
+ case PP_BLANK:
+#if !defined(HAVE_ISWBLANK) && !defined(iswblank)
+/*
+ * iswblank() is GNU and C99. There's a remote chance that some
+ * systems still don't support it (but would support the other ones
+ * if MULTIBYTE_SUPPORT is enabled).
+ */
+#define iswblank(c) (c == L' ' || c == L'\t')
+#endif
+ if (iswblank(ch))
+ return 1;
+ break;
+ case PP_CNTRL:
+ if (iswcntrl(ch))
+ return 1;
+ break;
+ case PP_DIGIT:
+ if (iswdigit(ch))
+ return 1;
+ break;
+ case PP_GRAPH:
+ if (iswgraph(ch))
+ return 1;
+ break;
+ case PP_LOWER:
+ if (iswlower(ch))
+ return 1;
+ break;
+ case PP_PRINT:
+ if (WC_ISPRINT(ch))
+ return 1;
+ break;
+ case PP_PUNCT:
+ if (iswpunct(ch))
+ return 1;
+ break;
+ case PP_SPACE:
+ if (iswspace(ch))
+ return 1;
+ break;
+ case PP_UPPER:
+ if (iswupper(ch))
+ return 1;
+ break;
+ case PP_XDIGIT:
+ if (iswxdigit(ch))
+ return 1;
+ break;
+ case PP_IDENT:
+ if (wcsitype(ch, IIDENT))
+ return 1;
+ break;
+ case PP_IFS:
+ if (wcsitype(ch, ISEP))
+ return 1;
+ break;
+ case PP_IFSSPACE:
+ /* must be ASCII space character */
+ if (ch < 128 && iwsep((int)ch))
+ return 1;
+ break;
+ case PP_WORD:
+ if (wcsitype(ch, IWORD))
+ return 1;
+ break;
+ case PP_RANGE:
+ r1 = metacharinc(&range);
+ r2 = metacharinc(&range);
+ if (r1 <= ch && ch <= r2) {
+ if (indptr)
+ *indptr += ch - r1;
+ return 1;
+ }
+ /* Careful not to screw up counting with bogus range */
+ if (indptr && r1 < r2) {
+ /*
+ * This gets incremented again below to get
+ * us past the range end. This is correct.
+ */
+ *indptr += r2 - r1;
+ }
+ break;
+ case PP_INCOMPLETE:
+ if (zmb_ind == ZMB_INCOMPLETE)
+ return 1;
+ break;
+ case PP_INVALID:
+ if (zmb_ind == ZMB_INVALID)
+ return 1;
+ break;
+ case PP_UNKWN:
+ DPUTS(1, "BUG: unknown posix range passed through.\n");
+ break;
+ default:
+ DPUTS(1, "BUG: unknown metacharacter in range.");
+ break;
+ }
+ } else if (metacharinc(&range) == ch) {
+ if (mtp)
+ *mtp = 0;
+ return 1;
+ }
+ if (indptr)
+ (*indptr)++;
+ }
+ return 0;
+}
+
+
+/*
+ * This is effectively the reverse of mb_patmatchrange().
+ * Given a range descriptor of the same form, and an index into it,
+ * try to determine the character that is matched. If the index
+ * points to a [:...:] generic style match, set chr to WEOF and
+ * return the type in mtp instead. Return 1 if successful, 0 if
+ * there was no corresponding index. Note all pointer arguments
+ * must be non-null.
+ */
+
+/**/
+mod_export int
+mb_patmatchindex(char *range, wint_t ind, wint_t *chr, int *mtp)
+{
+ wchar_t r1, r2, rchr;
+ wint_t rdiff;
+
+ *chr = WEOF;
+ *mtp = 0;
+
+ while (*range) {
+ if (imeta(STOUC(*range))) {
+ int swtype = STOUC(*range++) - STOUC(Meta);
+ switch (swtype) {
+ case 0:
+ range--;
+ rchr = metacharinc(&range);
+ if (!ind) {
+ *chr = (wint_t) rchr;
+ return 1;
+ }
+ break;
+
+ case PP_ALPHA:
+ case PP_ALNUM:
+ case PP_ASCII:
+ case PP_BLANK:
+ case PP_CNTRL:
+ case PP_DIGIT:
+ case PP_GRAPH:
+ case PP_LOWER:
+ case PP_PRINT:
+ case PP_PUNCT:
+ case PP_SPACE:
+ case PP_UPPER:
+ case PP_XDIGIT:
+ case PP_IDENT:
+ case PP_IFS:
+ case PP_IFSSPACE:
+ case PP_WORD:
+ case PP_INCOMPLETE:
+ case PP_INVALID:
+ if (!ind) {
+ *mtp = swtype;
+ return 1;
+ }
+ break;
+
+ case PP_RANGE:
+ r1 = metacharinc(&range);
+ r2 = metacharinc(&range);
+ rdiff = (wint_t)r2 - (wint_t)r1;
+ if (rdiff >= ind) {
+ *chr = (wint_t)r1 + ind;
+ return 1;
+ }
+ /* note the extra decrement to ind below */
+ ind -= rdiff;
+ break;
+ case PP_UNKWN:
+ DPUTS(1, "BUG: unknown posix range passed through.\n");
+ break;
+ default:
+ DPUTS(1, "BUG: unknown metacharacter in range.");
+ break;
+ }
+ } else {
+ rchr = metacharinc(&range);
+ if (!ind) {
+ *chr = (wint_t)rchr;
+ return 1;
+ }
+ }
+ if (!ind--)
+ break;
+ }
+
+ /* No corresponding index. */
+ return 0;
+}
+
+/**/
+#endif /* MULTIBYTE_SUPPORT */
+
+/*
+ * Identical function to mb_patmatchrange() above for single-byte
+ * characters.
+ */
+
+/**/
+mod_export int
+patmatchrange(char *range, int ch, int *indptr, int *mtp)
+{
+ int r1, r2;
+
+ if (indptr)
+ *indptr = 0;
+ /*
+ * Careful here: unlike other strings, range is a NULL-terminated,
+ * metafied string, because we need to treat the Posix and hyphenated
+ * ranges specially.
+ */
+ for (; *range; range++) {
+ if (imeta(STOUC(*range))) {
+ int swtype = STOUC(*range) - STOUC(Meta);
+ if (mtp)
+ *mtp = swtype;
+ switch (swtype) {
+ case 0:
+ if (STOUC(*++range ^ 32) == ch)
+ return 1;
+ break;
+ case PP_ALPHA:
+ if (isalpha(ch))
+ return 1;
+ break;
+ case PP_ALNUM:
+ if (isalnum(ch))
+ return 1;
+ break;
+ case PP_ASCII:
+ if ((ch & ~0x7f) == 0)
+ return 1;
+ break;
+ case PP_BLANK:
+#if !defined(HAVE_ISBLANK) && !defined(isblank)
+/*
+ * isblank() is GNU and C99. There's a remote chance that some
+ * systems still don't support it.
+ */
+#define isblank(c) (c == ' ' || c == '\t')
+#endif
+ if (isblank(ch))
+ return 1;
+ break;
+ case PP_CNTRL:
+ if (iscntrl(ch))
+ return 1;
+ break;
+ case PP_DIGIT:
+ if (isdigit(ch))
+ return 1;
+ break;
+ case PP_GRAPH:
+ if (isgraph(ch))
+ return 1;
+ break;
+ case PP_LOWER:
+ if (islower(ch))
+ return 1;
+ break;
+ case PP_PRINT:
+ if (ZISPRINT(ch))
+ return 1;
+ break;
+ case PP_PUNCT:
+ if (ispunct(ch))
+ return 1;
+ break;
+ case PP_SPACE:
+ if (isspace(ch))
+ return 1;
+ break;
+ case PP_UPPER:
+ if (isupper(ch))
+ return 1;
+ break;
+ case PP_XDIGIT:
+ if (isxdigit(ch))
+ return 1;
+ break;
+ case PP_IDENT:
+ if (iident(ch))
+ return 1;
+ break;
+ case PP_IFS:
+ if (isep(ch))
+ return 1;
+ break;
+ case PP_IFSSPACE:
+ if (iwsep(ch))
+ return 1;
+ break;
+ case PP_WORD:
+ if (iword(ch))
+ return 1;
+ break;
+ case PP_RANGE:
+ range++;
+ r1 = STOUC(UNMETA(range));
+ METACHARINC(range);
+ r2 = STOUC(UNMETA(range));
+ if (*range == Meta)
+ range++;
+ if (r1 <= ch && ch <= r2) {
+ if (indptr)
+ *indptr += ch - r1;
+ return 1;
+ }
+ if (indptr && r1 < r2)
+ *indptr += r2 - r1;
+ break;
+ case PP_INCOMPLETE:
+ case PP_INVALID:
+ /* Never true if not in multibyte mode */
+ break;
+ case PP_UNKWN:
+ DPUTS(1, "BUG: unknown posix range passed through.\n");
+ break;
+ default:
+ DPUTS(1, "BUG: unknown metacharacter in range.");
+ break;
+ }
+ } else if (STOUC(*range) == ch) {
+ if (mtp)
+ *mtp = 0;
+ return 1;
+ }
+ if (indptr)
+ (*indptr)++;
+ }
+ return 0;
+}
+
+
+/**/
+#ifndef MULTIBYTE_SUPPORT
+
+/*
+ * Identical function to mb_patmatchindex() above for single-byte
+ * characters. Here -1 represents a character that needs a special type.
+ *
+ * Unlike patmatchrange, we only need this in ZLE, which always
+ * uses MULTIBYTE_SUPPORT if compiled in; hence we don't use
+ * this function in that case.
+ */
+
+/**/
+mod_export int
+patmatchindex(char *range, int ind, int *chr, int *mtp)
+{
+ int r1, r2, rdiff, rchr;
+
+ *chr = -1;
+ *mtp = 0;
+
+ for (; *range; range++) {
+ if (imeta(STOUC(*range))) {
+ int swtype = STOUC(*range) - STOUC(Meta);
+ switch (swtype) {
+ case 0:
+ /* ordinary metafied character */
+ rchr = STOUC(*++range) ^ 32;
+ if (!ind) {
+ *chr = rchr;
+ return 1;
+ }
+ break;
+
+ case PP_ALPHA:
+ case PP_ALNUM:
+ case PP_ASCII:
+ case PP_BLANK:
+ case PP_CNTRL:
+ case PP_DIGIT:
+ case PP_GRAPH:
+ case PP_LOWER:
+ case PP_PRINT:
+ case PP_PUNCT:
+ case PP_SPACE:
+ case PP_UPPER:
+ case PP_XDIGIT:
+ case PP_IDENT:
+ case PP_IFS:
+ case PP_IFSSPACE:
+ case PP_WORD:
+ case PP_INCOMPLETE:
+ case PP_INVALID:
+ if (!ind) {
+ *mtp = swtype;
+ return 1;
+ }
+ break;
+
+ case PP_RANGE:
+ range++;
+ r1 = STOUC(UNMETA(range));
+ METACHARINC(range);
+ r2 = STOUC(UNMETA(range));
+ if (*range == Meta)
+ range++;
+ rdiff = r2 - r1;
+ if (rdiff >= ind) {
+ *chr = r1 + ind;
+ return 1;
+ }
+ /* note the extra decrement to ind below */
+ ind -= rdiff;
+ break;
+ case PP_UNKWN:
+ DPUTS(1, "BUG: unknown posix range passed through.\n");
+ break;
+ default:
+ DPUTS(1, "BUG: unknown metacharacter in range.");
+ break;
+ }
+ } else {
+ if (!ind) {
+ *chr = STOUC(*range);
+ return 1;
+ }
+ }
+ if (!ind--)
+ break;
+ }
+
+ /* No corresponding index. */
+ return 0;
+}
+
+/**/
+#endif /* MULTIBYTE_SUPPORT */
+
+/*
+ * Repeatedly match something simple and say how many times.
+ * charstart is an array parallel to that starting at patinput
+ * and records the start of (possibly multibyte) characters
+ * to aid in later backtracking.
+ */
+
+/**/
+static int patrepeat(Upat p, char *charstart)
+{
+ int count = 0;
+ patint_t tch, charmatch_cache;
+ char *scan, *opnd;
+
+ scan = patinput;
+ opnd = (char *)P_OPERAND(p);
+
+ switch(P_OP(p)) {
+#ifdef DEBUG
+ case P_ANY:
+ dputs("BUG: ?# did not get optimized to *");
+ return 0;
+ break;
+#endif
+ case P_EXACTLY:
+ DPUTS(P_LS_LEN(p) != 1, "closure following more than one character");
+ tch = CHARREF(P_LS_STR(p), P_LS_STR(p) + P_LS_LEN(p));
+ while (scan < patinend &&
+ CHARMATCH_EXPR(CHARREF(scan, patinend), tch)) {
+ charstart[scan-patinput] = 1;
+ count++;
+ CHARINC(scan, patinend);
+ }
+ break;
+ case P_ANYOF:
+ case P_ANYBUT:
+ while (scan < patinend) {
+#ifdef MULTIBYTE_SUPPORT
+ int zmb_ind;
+ wchar_t cr = charref(scan, patinend, &zmb_ind);
+ if (patglobflags & GF_MULTIBYTE) {
+ if (mb_patmatchrange(opnd, cr, zmb_ind, NULL, NULL) ^
+ (P_OP(p) == P_ANYOF))
+ break;
+ } else if (patmatchrange(opnd, (int)cr, NULL, NULL) ^
+ (P_OP(p) == P_ANYOF))
+ break;
+#else
+ if (patmatchrange(opnd, CHARREF(scan, patinend), NULL, NULL) ^
+ (P_OP(p) == P_ANYOF))
+ break;
+#endif
+ charstart[scan-patinput] = 1;
+ count++;
+ CHARINC(scan, patinend);
+ }
+ break;
+#ifdef DEBUG
+ default:
+ dputs("BUG: something very strange is happening in patrepeat");
+ return 0;
+ break;
+#endif
+ }
+
+ patinput = scan;
+ return count;
+}
+
+/* Free a patprog. */
+
+/**/
+mod_export void
+freepatprog(Patprog prog)
+{
+ if (prog && prog != dummy_patprog1 && prog != dummy_patprog2)
+ zfree(prog, prog->size);
+}
+
+/* Disable or reenable a pattern character */
+
+/**/
+int
+pat_enables(const char *cmd, char **patp, int enable)
+{
+ int ret = 0;
+ const char **stringp;
+ char *disp;
+
+ if (!*patp) {
+ int done = 0;
+ for (stringp = zpc_strings, disp = zpc_disables;
+ stringp < zpc_strings + ZPC_COUNT;
+ stringp++, disp++) {
+ if (!*stringp)
+ continue;
+ if (enable ? *disp : !*disp)
+ continue;
+ if (done)
+ putc(' ', stdout);
+ printf("'%s'", *stringp);
+ done = 1;
+ }
+ if (done)
+ putc('\n', stdout);
+ return 0;
+ }
+
+ for (; *patp; patp++) {
+ for (stringp = zpc_strings, disp = zpc_disables;
+ stringp < zpc_strings + ZPC_COUNT;
+ stringp++, disp++) {
+ if (*stringp && !strcmp(*stringp, *patp)) {
+ *disp = (char)!enable;
+ break;
+ }
+ }
+ if (stringp == zpc_strings + ZPC_COUNT) {
+ zerrnam(cmd, "invalid pattern: %s", *patp);
+ ret = 1;
+ }
+ }
+
+ return ret;
+}
+
+/*
+ * Save the current state of pattern disables, returning the saved value.
+ */
+
+/**/
+unsigned int
+savepatterndisables(void)
+{
+ unsigned int disables, bit;
+ char *disp;
+
+ disables = 0;
+ for (bit = 1, disp = zpc_disables;
+ disp < zpc_disables + ZPC_COUNT;
+ bit <<= 1, disp++) {
+ if (*disp)
+ disables |= bit;
+ }
+ return disables;
+}
+
+/*
+ * Function scope saving pattern enables.
+ */
+
+/**/
+void
+startpatternscope(void)
+{
+ Zpc_disables_save newdis;
+
+ newdis = (Zpc_disables_save)zalloc(sizeof(*newdis));
+ newdis->next = zpc_disables_stack;
+ newdis->disables = savepatterndisables();
+
+ zpc_disables_stack = newdis;
+}
+
+/*
+ * Restore completely the state of pattern disables.
+ */
+
+/**/
+void
+restorepatterndisables(unsigned int disables)
+{
+ char *disp;
+ unsigned int bit;
+
+ for (bit = 1, disp = zpc_disables;
+ disp < zpc_disables + ZPC_COUNT;
+ bit <<= 1, disp++) {
+ if (disables & bit)
+ *disp = 1;
+ else
+ *disp = 0;
+ }
+}
+
+/*
+ * Function scope to restore pattern enables if localpatterns is turned on.
+ */
+
+/**/
+void
+endpatternscope(void)
+{
+ Zpc_disables_save olddis;
+
+ olddis = zpc_disables_stack;
+ zpc_disables_stack = olddis->next;
+
+ if (isset(LOCALPATTERNS))
+ restorepatterndisables(olddis->disables);
+
+ zfree(olddis, sizeof(*olddis));
+}
+
+/* Reinitialise pattern disables */
+
+/**/
+void
+clearpatterndisables(void)
+{
+ memset(zpc_disables, 0, ZPC_COUNT);
+}
+
+
+/* Check to see if str is eligible for filename generation. */
+
+/**/
+mod_export int
+haswilds(char *str)
+{
+ char *start;
+
+ /* `[' and `]' are legal even if bad patterns are usually not. */
+ if ((*str == Inbrack || *str == Outbrack) && !str[1])
+ return 0;
+
+ /* If % is immediately followed by ?, then that ? is *
+ * not treated as a wildcard. This is so you don't have *
+ * to escape job references such as %?foo. */
+ if (str[0] == '%' && str[1] == Quest)
+ str[1] = '?';
+
+ /*
+ * Note that at this point zpc_special has not been set up.
+ */
+ start = str;
+ for (; *str; str++) {
+ switch (*str) {
+ case Inpar:
+ if ((!isset(SHGLOB) && !zpc_disables[ZPC_INPAR]) ||
+ (str > start && isset(KSHGLOB) &&
+ ((str[-1] == Quest && !zpc_disables[ZPC_KSH_QUEST]) ||
+ (str[-1] == Star && !zpc_disables[ZPC_KSH_STAR]) ||
+ (str[-1] == '+' && !zpc_disables[ZPC_KSH_PLUS]) ||
+ (str[-1] == Bang && !zpc_disables[ZPC_KSH_BANG]) ||
+ (str[-1] == '!' && !zpc_disables[ZPC_KSH_BANG2]) ||
+ (str[-1] == '@' && !zpc_disables[ZPC_KSH_AT]))))
+ return 1;
+ break;
+
+ case Bar:
+ if (!zpc_disables[ZPC_BAR])
+ return 1;
+ break;
+
+ case Star:
+ if (!zpc_disables[ZPC_STAR])
+ return 1;
+ break;
+
+ case Inbrack:
+ if (!zpc_disables[ZPC_INBRACK])
+ return 1;
+ break;
+
+ case Inang:
+ if (!zpc_disables[ZPC_INANG])
+ return 1;
+ break;
+
+ case Quest:
+ if (!zpc_disables[ZPC_QUEST])
+ return 1;
+ break;
+
+ case Pound:
+ if (isset(EXTENDEDGLOB) && !zpc_disables[ZPC_HASH])
+ return 1;
+ break;
+
+ case Hat:
+ if (isset(EXTENDEDGLOB) && !zpc_disables[ZPC_HAT])
+ return 1;
+ break;
+ }
+ }
+ return 0;
+}
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/prompt.c b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/prompt.c
new file mode 100644
index 0000000..959ed8e
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/prompt.c
@@ -0,0 +1,2046 @@
+/*
+ * prompt.c - construct zsh prompts
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+#include "zsh.mdh"
+#include "prompt.pro"
+
+/* text attribute mask */
+
+/**/
+mod_export unsigned txtattrmask;
+
+/* the command stack for use with %_ in prompts */
+
+/**/
+unsigned char *cmdstack;
+/**/
+int cmdsp;
+
+/* parser states, for %_ */
+
+static char *cmdnames[CS_COUNT] = {
+ "for", "while", "repeat", "select",
+ "until", "if", "then", "else",
+ "elif", "math", "cond", "cmdor",
+ "cmdand", "pipe", "errpipe", "foreach",
+ "case", "function", "subsh", "cursh",
+ "array", "quote", "dquote", "bquote",
+ "cmdsubst", "mathsubst", "elif-then", "heredoc",
+ "heredocd", "brace", "braceparam", "always",
+};
+
+
+struct buf_vars;
+
+struct buf_vars {
+/* Previous set of prompt variables on the stack. */
+
+ struct buf_vars *last;
+
+/* The buffer into which an expanded and metafied prompt is being written, *
+ * and its size. */
+
+ char *buf;
+ int bufspc;
+
+/* bp is the pointer to the current position in the buffer, where the next *
+ * character will be added. */
+
+ char *bp;
+
+/* Position of the start of the current line in the buffer */
+
+ char *bufline;
+
+/* bp1 is an auxiliary pointer into the buffer, which when non-NULL is *
+ * moved whenever the buffer is reallocated. It is used when data is *
+ * being temporarily held in the buffer. */
+
+ char *bp1;
+
+/* The format string, for %-expansion. */
+
+ char *fm;
+
+/* Non-zero if truncating the current segment of the buffer. */
+
+ int truncwidth;
+
+/* Current level of nesting of %{ / %} sequences. */
+
+ int dontcount;
+
+/* Level of %{ / %} surrounding a truncation segment. */
+
+ int trunccount;
+
+/* Strings to use for %r and %R (for the spelling prompt). */
+
+ char *rstring, *Rstring;
+};
+
+typedef struct buf_vars *Buf_vars;
+
+/* The currently active prompt output variables */
+static Buf_vars bv;
+
+/*
+ * Expand path p; maximum is npath segments where 0 means the whole path.
+ * If tilde is 1, try and find a named directory to use.
+ */
+
+static void
+promptpath(char *p, int npath, int tilde)
+{
+ char *modp = p;
+ Nameddir nd;
+
+ if (tilde && ((nd = finddir(p))))
+ modp = tricat("~", nd->node.nam, p + strlen(nd->dir));
+
+ if (npath) {
+ char *sptr;
+ if (npath > 0) {
+ for (sptr = modp + strlen(modp); sptr > modp; sptr--) {
+ if (*sptr == '/' && !--npath) {
+ sptr++;
+ break;
+ }
+ }
+ if (*sptr == '/' && sptr[1] && sptr != modp)
+ sptr++;
+ stradd(sptr);
+ } else {
+ char cbu;
+ for (sptr = modp+1; *sptr; sptr++)
+ if (*sptr == '/' && !++npath)
+ break;
+ cbu = *sptr;
+ *sptr = 0;
+ stradd(modp);
+ *sptr = cbu;
+ }
+ } else
+ stradd(modp);
+
+ if (p != modp)
+ zsfree(modp);
+}
+
+/*
+ * Perform prompt expansion on a string, putting the result in a
+ * permanently-allocated string. If ns is non-zero, this string
+ * may have embedded Inpar and Outpar, which indicate a toggling
+ * between spacing and non-spacing parts of the prompt, and
+ * Nularg, which (in a non-spacing sequence) indicates a
+ * `glitch' space.
+ *
+ * txtchangep gives an integer controlling the attributes of
+ * the prompt. This is for use in zle to maintain the attributes
+ * consistenly. Other parts of the shell should not need to use it.
+ */
+
+/**/
+mod_export char *
+promptexpand(char *s, int ns, char *rs, char *Rs, unsigned int *txtchangep)
+{
+ struct buf_vars new_vars;
+
+ if(!s)
+ return ztrdup("");
+
+ if ((termflags & TERM_UNKNOWN) && (unset(INTERACTIVE)))
+ init_term();
+
+ if (isset(PROMPTSUBST)) {
+ int olderr = errflag;
+ int oldval = lastval;
+
+ s = dupstring(s);
+ if (!parsestr(&s))
+ singsub(&s);
+ /*
+ * We don't need the special Nularg hack here and we're
+ * going to be using Nularg for other things.
+ */
+ if (*s == Nularg && s[1] == '\0')
+ *s = '\0';
+
+ /*
+ * Ignore errors and status change in prompt substitution.
+ * However, keep any user interrupt error that occurred.
+ */
+ errflag = olderr | (errflag & ERRFLAG_INT);
+ lastval = oldval;
+ }
+
+ memset(&new_vars, 0, sizeof(new_vars));
+ new_vars.last = bv;
+ bv = &new_vars;
+
+ new_vars.rstring = rs;
+ new_vars.Rstring = Rs;
+ new_vars.fm = s;
+ new_vars.bufspc = 256;
+ new_vars.bp = new_vars.bufline = new_vars.buf = zshcalloc(new_vars.bufspc);
+ new_vars.bp1 = NULL;
+ new_vars.truncwidth = 0;
+
+ putpromptchar(1, '\0', txtchangep);
+ addbufspc(2);
+ if (new_vars.dontcount)
+ *new_vars.bp++ = Outpar;
+ *new_vars.bp = '\0';
+ if (!ns) {
+ /* If zero, Inpar, Outpar and Nularg should be removed. */
+ for (new_vars.bp = new_vars.buf; *new_vars.bp; ) {
+ if (*new_vars.bp == Meta)
+ new_vars.bp += 2;
+ else if (*new_vars.bp == Inpar || *new_vars.bp == Outpar ||
+ *new_vars.bp == Nularg)
+ chuck(new_vars.bp);
+ else
+ new_vars.bp++;
+ }
+ }
+
+ bv = new_vars.last;
+
+ return new_vars.buf;
+}
+
+/* Parse the argument for %F and %K */
+static int
+parsecolorchar(int arg, int is_fg)
+{
+ if (bv->fm[1] == '{') {
+ char *ep;
+ bv->fm += 2; /* skip over F{ */
+ if ((ep = strchr(bv->fm, '}'))) {
+ char oc = *ep, *col, *coll;
+ *ep = '\0';
+ /* expand the contents of the argument so you can use
+ * %v for example */
+ coll = col = promptexpand(bv->fm, 0, NULL, NULL, NULL);
+ *ep = oc;
+ arg = match_colour((const char **)&coll, is_fg, 0);
+ free(col);
+ bv->fm = ep;
+ } else {
+ arg = match_colour((const char **)&bv->fm, is_fg, 0);
+ if (*bv->fm != '}')
+ bv->fm--;
+ }
+ } else
+ arg = match_colour(NULL, 1, arg);
+ return arg;
+}
+
+/* Perform %- and !-expansion as required on a section of the prompt. The *
+ * section is ended by an instance of endchar. If doprint is 0, the valid *
+ * % sequences are merely skipped over, and nothing is stored. */
+
+/**/
+static int
+putpromptchar(int doprint, int endchar, unsigned int *txtchangep)
+{
+ char *ss, *hostnam;
+ int t0, arg, test, sep, j, numjobs, len;
+ struct tm *tm;
+ struct timespec ts;
+ time_t timet;
+ Nameddir nd;
+
+ for (; *bv->fm && *bv->fm != endchar; bv->fm++) {
+ arg = 0;
+ if (*bv->fm == '%' && isset(PROMPTPERCENT)) {
+ int minus = 0;
+ bv->fm++;
+ if (*bv->fm == '-') {
+ minus = 1;
+ bv->fm++;
+ }
+ if (idigit(*bv->fm)) {
+ arg = zstrtol(bv->fm, &bv->fm, 10);
+ if (minus)
+ arg *= -1;
+ } else if (minus)
+ arg = -1;
+ if (*bv->fm == '(') {
+ int tc, otruncwidth;
+
+ if (idigit(*++bv->fm)) {
+ arg = zstrtol(bv->fm, &bv->fm, 10);
+ } else if (arg < 0) {
+ /* negative numbers don't make sense here */
+ arg *= -1;
+ }
+ test = 0;
+ ss = pwd;
+ switch (tc = *bv->fm) {
+ case 'c':
+ case '.':
+ case '~':
+ if ((nd = finddir(ss))) {
+ arg--;
+ ss += strlen(nd->dir);
+ } /*FALLTHROUGH*/
+ case '/':
+ case 'C':
+ /* `/' gives 0, `/any' gives 1, etc. */
+ if (*ss && *ss++ == '/' && *ss)
+ arg--;
+ for (; *ss; ss++)
+ if (*ss == '/')
+ arg--;
+ if (arg <= 0)
+ test = 1;
+ break;
+ case 't':
+ case 'T':
+ case 'd':
+ case 'D':
+ case 'w':
+ timet = time(NULL);
+ tm = localtime(&timet);
+ switch (tc) {
+ case 't':
+ test = (arg == tm->tm_min);
+ break;
+ case 'T':
+ test = (arg == tm->tm_hour);
+ break;
+ case 'd':
+ test = (arg == tm->tm_mday);
+ break;
+ case 'D':
+ test = (arg == tm->tm_mon);
+ break;
+ case 'w':
+ test = (arg == tm->tm_wday);
+ break;
+ }
+ break;
+ case '?':
+ if (lastval == arg)
+ test = 1;
+ break;
+ case '#':
+ if (geteuid() == (uid_t)arg)
+ test = 1;
+ break;
+ case 'g':
+ if (getegid() == (gid_t)arg)
+ test = 1;
+ break;
+ case 'j':
+ for (numjobs = 0, j = 1; j <= maxjob; j++)
+ if (jobtab[j].stat && jobtab[j].procs &&
+ !(jobtab[j].stat & STAT_NOPRINT)) numjobs++;
+ if (numjobs >= arg)
+ test = 1;
+ break;
+ case 'l':
+ *bv->bp = '\0';
+ countprompt(bv->bufline, &t0, 0, 0);
+ if (minus)
+ t0 = zterm_columns - t0;
+ if (t0 >= arg)
+ test = 1;
+ break;
+ case 'e':
+ {
+ Funcstack fsptr = funcstack;
+ test = arg;
+ while (fsptr && test > 0) {
+ test--;
+ fsptr = fsptr->prev;
+ }
+ test = !test;
+ }
+ break;
+ case 'L':
+ if (shlvl >= arg)
+ test = 1;
+ break;
+ case 'S':
+ if (time(NULL) - shtimer.tv_sec >= arg)
+ test = 1;
+ break;
+ case 'v':
+ if (arrlen_ge(psvar, arg))
+ test = 1;
+ break;
+ case 'V':
+ if (psvar && *psvar && arrlen_ge(psvar, arg)) {
+ if (*psvar[(arg ? arg : 1) - 1])
+ test = 1;
+ }
+ break;
+ case '_':
+ test = (cmdsp >= arg);
+ break;
+ case '!':
+ test = privasserted();
+ break;
+ default:
+ test = -1;
+ break;
+ }
+ if (!*bv->fm || !(sep = *++bv->fm))
+ return 0;
+ bv->fm++;
+ /* Don't do the current truncation until we get back */
+ otruncwidth = bv->truncwidth;
+ bv->truncwidth = 0;
+ if (!putpromptchar(test == 1 && doprint, sep,
+ txtchangep) || !*++bv->fm ||
+ !putpromptchar(test == 0 && doprint, ')',
+ txtchangep)) {
+ bv->truncwidth = otruncwidth;
+ return 0;
+ }
+ bv->truncwidth = otruncwidth;
+ continue;
+ }
+ if (!doprint)
+ switch(*bv->fm) {
+ case '[':
+ while(idigit(*++bv->fm));
+ while(*++bv->fm != ']');
+ continue;
+ case '<':
+ while(*++bv->fm != '<');
+ continue;
+ case '>':
+ while(*++bv->fm != '>');
+ continue;
+ case 'D':
+ if(bv->fm[1]=='{')
+ while(*++bv->fm != '}');
+ continue;
+ default:
+ continue;
+ }
+ switch (*bv->fm) {
+ case '~':
+ promptpath(pwd, arg, 1);
+ break;
+ case 'd':
+ case '/':
+ promptpath(pwd, arg, 0);
+ break;
+ case 'c':
+ case '.':
+ promptpath(pwd, arg ? arg : 1, 1);
+ break;
+ case 'C':
+ promptpath(pwd, arg ? arg : 1, 0);
+ break;
+ case 'N':
+ promptpath(scriptname ? scriptname : argzero, arg, 0);
+ break;
+ case 'h':
+ case '!':
+ addbufspc(DIGBUFSIZE);
+ convbase(bv->bp, curhist, 10);
+ bv->bp += strlen(bv->bp);
+ break;
+ case 'j':
+ for (numjobs = 0, j = 1; j <= maxjob; j++)
+ if (jobtab[j].stat && jobtab[j].procs &&
+ !(jobtab[j].stat & STAT_NOPRINT)) numjobs++;
+ addbufspc(DIGBUFSIZE);
+ sprintf(bv->bp, "%d", numjobs);
+ bv->bp += strlen(bv->bp);
+ break;
+ case 'M':
+ queue_signals();
+ if ((hostnam = getsparam("HOST")))
+ stradd(hostnam);
+ unqueue_signals();
+ break;
+ case 'm':
+ if (!arg)
+ arg++;
+ queue_signals();
+ if (!(hostnam = getsparam("HOST"))) {
+ unqueue_signals();
+ break;
+ }
+ if (arg < 0) {
+ for (ss = hostnam + strlen(hostnam); ss > hostnam; ss--)
+ if (ss[-1] == '.' && !++arg)
+ break;
+ stradd(ss);
+ } else {
+ for (ss = hostnam; *ss; ss++)
+ if (*ss == '.' && !--arg)
+ break;
+ stradd(*ss ? dupstrpfx(hostnam, ss - hostnam) : hostnam);
+ }
+ unqueue_signals();
+ break;
+ case 'S':
+ txtchangeset(txtchangep, TXTSTANDOUT, TXTNOSTANDOUT);
+ txtset(TXTSTANDOUT);
+ tsetcap(TCSTANDOUTBEG, TSC_PROMPT);
+ break;
+ case 's':
+ txtchangeset(txtchangep, TXTNOSTANDOUT, TXTSTANDOUT);
+ txtunset(TXTSTANDOUT);
+ tsetcap(TCSTANDOUTEND, TSC_PROMPT|TSC_DIRTY);
+ break;
+ case 'B':
+ txtchangeset(txtchangep, TXTBOLDFACE, TXTNOBOLDFACE);
+ txtset(TXTBOLDFACE);
+ tsetcap(TCBOLDFACEBEG, TSC_PROMPT|TSC_DIRTY);
+ break;
+ case 'b':
+ txtchangeset(txtchangep, TXTNOBOLDFACE, TXTBOLDFACE);
+ txtunset(TXTBOLDFACE);
+ tsetcap(TCALLATTRSOFF, TSC_PROMPT|TSC_DIRTY);
+ break;
+ case 'U':
+ txtchangeset(txtchangep, TXTUNDERLINE, TXTNOUNDERLINE);
+ txtset(TXTUNDERLINE);
+ tsetcap(TCUNDERLINEBEG, TSC_PROMPT);
+ break;
+ case 'u':
+ txtchangeset(txtchangep, TXTNOUNDERLINE, TXTUNDERLINE);
+ txtunset(TXTUNDERLINE);
+ tsetcap(TCUNDERLINEEND, TSC_PROMPT|TSC_DIRTY);
+ break;
+ case 'F':
+ arg = parsecolorchar(arg, 1);
+ if (arg >= 0 && !(arg & TXTNOFGCOLOUR)) {
+ txtchangeset(txtchangep, arg & TXT_ATTR_FG_ON_MASK,
+ TXTNOFGCOLOUR | TXT_ATTR_FG_COL_MASK);
+ txtunset(TXT_ATTR_FG_COL_MASK);
+ txtset(arg & TXT_ATTR_FG_ON_MASK);
+ set_colour_attribute(arg, COL_SEQ_FG, TSC_PROMPT);
+ break;
+ }
+ /* else FALLTHROUGH */
+ case 'f':
+ txtchangeset(txtchangep, TXTNOFGCOLOUR, TXT_ATTR_FG_ON_MASK);
+ txtunset(TXT_ATTR_FG_ON_MASK);
+ set_colour_attribute(TXTNOFGCOLOUR, COL_SEQ_FG, TSC_PROMPT);
+ break;
+ case 'K':
+ arg = parsecolorchar(arg, 0);
+ if (arg >= 0 && !(arg & TXTNOBGCOLOUR)) {
+ txtchangeset(txtchangep, arg & TXT_ATTR_BG_ON_MASK,
+ TXTNOBGCOLOUR | TXT_ATTR_BG_COL_MASK);
+ txtunset(TXT_ATTR_BG_COL_MASK);
+ txtset(arg & TXT_ATTR_BG_ON_MASK);
+ set_colour_attribute(arg, COL_SEQ_BG, TSC_PROMPT);
+ break;
+ }
+ /* else FALLTHROUGH */
+ case 'k':
+ txtchangeset(txtchangep, TXTNOBGCOLOUR, TXT_ATTR_BG_ON_MASK);
+ txtunset(TXT_ATTR_BG_ON_MASK);
+ set_colour_attribute(TXTNOBGCOLOUR, COL_SEQ_BG, TSC_PROMPT);
+ break;
+ case '[':
+ if (idigit(*++bv->fm))
+ arg = zstrtol(bv->fm, &bv->fm, 10);
+ if (!prompttrunc(arg, ']', doprint, endchar, txtchangep))
+ return *bv->fm;
+ break;
+ case '<':
+ case '>':
+ /* Test (minus) here so -0 means "at the right margin" */
+ if (minus) {
+ *bv->bp = '\0';
+ countprompt(bv->bufline, &t0, 0, 0);
+ arg = zterm_columns - t0 + arg;
+ if (arg <= 0)
+ arg = 1;
+ }
+ if (!prompttrunc(arg, *bv->fm, doprint, endchar, txtchangep))
+ return *bv->fm;
+ break;
+ case '{': /*}*/
+ if (!bv->dontcount++) {
+ addbufspc(1);
+ *bv->bp++ = Inpar;
+ }
+ if (arg <= 0)
+ break;
+ /* else */
+ /* FALLTHROUGH */
+ case 'G':
+ if (arg > 0) {
+ addbufspc(arg);
+ while (arg--)
+ *bv->bp++ = Nularg;
+ } else {
+ addbufspc(1);
+ *bv->bp++ = Nularg;
+ }
+ break;
+ case /*{*/ '}':
+ if (bv->trunccount && bv->trunccount >= bv->dontcount)
+ return *bv->fm;
+ if (bv->dontcount && !--bv->dontcount) {
+ addbufspc(1);
+ *bv->bp++ = Outpar;
+ }
+ break;
+ case 't':
+ case '@':
+ case 'T':
+ case '*':
+ case 'w':
+ case 'W':
+ case 'D':
+ {
+ char *tmfmt, *dd, *tmbuf = NULL;
+
+ switch (*bv->fm) {
+ case 'T':
+ tmfmt = "%K:%M";
+ break;
+ case '*':
+ tmfmt = "%K:%M:%S";
+ break;
+ case 'w':
+ tmfmt = "%a %f";
+ break;
+ case 'W':
+ tmfmt = "%m/%d/%y";
+ break;
+ case 'D':
+ if (bv->fm[1] == '{' /*}*/) {
+ for (ss = bv->fm + 2; *ss && *ss != /*{*/ '}'; ss++)
+ if(*ss == '\\' && ss[1])
+ ss++;
+ dd = tmfmt = tmbuf = zalloc(ss - bv->fm);
+ for (ss = bv->fm + 2; *ss && *ss != /*{*/ '}';
+ ss++) {
+ if(*ss == '\\' && ss[1])
+ ss++;
+ *dd++ = *ss;
+ }
+ *dd = 0;
+ bv->fm = ss - !*ss;
+ if (!*tmfmt) {
+ free(tmbuf);
+ continue;
+ }
+ } else
+ tmfmt = "%y-%m-%d";
+ break;
+ default:
+ tmfmt = "%l:%M%p";
+ break;
+ }
+ zgettime(&ts);
+ tm = localtime(&ts.tv_sec);
+ /*
+ * Hack because strftime won't say how
+ * much space it actually needs. Try to add it
+ * a few times until it works. Some formats don't
+ * actually have a length, so we could go on for
+ * ever.
+ */
+ for(j = 0, t0 = strlen(tmfmt)*8; j < 3; j++, t0*=2) {
+ addbufspc(t0);
+ if ((len = ztrftime(bv->bp, t0, tmfmt, tm, ts.tv_nsec))
+ >= 0)
+ break;
+ }
+ /* There is enough room for this because addbufspc(t0)
+ * allocates room for t0 * 2 bytes. */
+ if (len >= 0)
+ metafy(bv->bp, len, META_NOALLOC);
+ bv->bp += strlen(bv->bp);
+ zsfree(tmbuf);
+ break;
+ }
+ case 'n':
+ stradd(get_username());
+ break;
+ case 'l':
+ if (*ttystrname) {
+ ss = (strncmp(ttystrname, "/dev/tty", 8) ?
+ ttystrname + 5 : ttystrname + 8);
+ stradd(ss);
+ } else
+ stradd("()");
+ break;
+ case 'y':
+ if (*ttystrname) {
+ ss = (strncmp(ttystrname, "/dev/", 5) ?
+ ttystrname : ttystrname + 5);
+ stradd(ss);
+ } else
+ stradd("()");
+ break;
+ case 'L':
+ addbufspc(DIGBUFSIZE);
+#if defined(ZLONG_IS_LONG_LONG) && defined(PRINTF_HAS_LLD)
+ sprintf(bv->bp, "%lld", shlvl);
+#else
+ sprintf(bv->bp, "%ld", (long)shlvl);
+#endif
+ bv->bp += strlen(bv->bp);
+ break;
+ case '?':
+ addbufspc(DIGBUFSIZE);
+#if defined(ZLONG_IS_LONG_LONG) && defined(PRINTF_HAS_LLD)
+ sprintf(bv->bp, "%lld", lastval);
+#else
+ sprintf(bv->bp, "%ld", (long)lastval);
+#endif
+ bv->bp += strlen(bv->bp);
+ break;
+ case '%':
+ case ')':
+ addbufspc(1);
+ *bv->bp++ = *bv->fm;
+ break;
+ case '#':
+ addbufspc(1);
+ *bv->bp++ = privasserted() ? '#' : '%';
+ break;
+ case 'v':
+ if (!arg)
+ arg = 1;
+ else if (arg < 0)
+ arg += arrlen(psvar) + 1;
+ if (arg > 0 && arrlen_ge(psvar, arg))
+ stradd(psvar[arg - 1]);
+ break;
+ case 'E':
+ tsetcap(TCCLEAREOL, TSC_PROMPT);
+ break;
+ case '^':
+ if (cmdsp) {
+ if (arg >= 0) {
+ if (arg > cmdsp || arg == 0)
+ arg = cmdsp;
+ for (t0 = cmdsp - 1; arg--; t0--) {
+ stradd(cmdnames[cmdstack[t0]]);
+ if (arg) {
+ addbufspc(1);
+ *bv->bp++=' ';
+ }
+ }
+ } else {
+ arg = -arg;
+ if (arg > cmdsp)
+ arg = cmdsp;
+ for (t0 = arg - 1; arg--; t0--) {
+ stradd(cmdnames[cmdstack[t0]]);
+ if (arg) {
+ addbufspc(1);
+ *bv->bp++=' ';
+ }
+ }
+ }
+ }
+ break;
+ case '_':
+ if (cmdsp) {
+ if (arg >= 0) {
+ if (arg > cmdsp || arg == 0)
+ arg = cmdsp;
+ for (t0 = cmdsp - arg; arg--; t0++) {
+ stradd(cmdnames[cmdstack[t0]]);
+ if (arg) {
+ addbufspc(1);
+ *bv->bp++=' ';
+ }
+ }
+ } else {
+ arg = -arg;
+ if (arg > cmdsp)
+ arg = cmdsp;
+ for (t0 = 0; arg--; t0++) {
+ stradd(cmdnames[cmdstack[t0]]);
+ if (arg) {
+ addbufspc(1);
+ *bv->bp++=' ';
+ }
+ }
+ }
+ }
+ break;
+ case 'r':
+ if(bv->rstring)
+ stradd(bv->rstring);
+ break;
+ case 'R':
+ if(bv->Rstring)
+ stradd(bv->Rstring);
+ break;
+ case 'e':
+ {
+ int depth = 0;
+ Funcstack fsptr = funcstack;
+ while (fsptr) {
+ depth++;
+ fsptr = fsptr->prev;
+ }
+ addbufspc(DIGBUFSIZE);
+ sprintf(bv->bp, "%d", depth);
+ bv->bp += strlen(bv->bp);
+ break;
+ }
+ case 'I':
+ if (funcstack && funcstack->tp != FS_SOURCE &&
+ !IN_EVAL_TRAP()) {
+ /*
+ * We're in a function or an eval with
+ * EVALLINENO. Calculate the line number in
+ * the file.
+ */
+ zlong flineno = lineno + funcstack->flineno;
+ /* take account of eval line nos. starting at 1 */
+ if (funcstack->tp == FS_EVAL)
+ lineno--;
+ addbufspc(DIGBUFSIZE);
+#if defined(ZLONG_IS_LONG_LONG) && defined(PRINTF_HAS_LLD)
+ sprintf(bv->bp, "%lld", flineno);
+#else
+ sprintf(bv->bp, "%ld", (long)flineno);
+#endif
+ bv->bp += strlen(bv->bp);
+ break;
+ }
+ /* else we're in a file and lineno is already correct */
+ /* FALLTHROUGH */
+ case 'i':
+ addbufspc(DIGBUFSIZE);
+#if defined(ZLONG_IS_LONG_LONG) && defined(PRINTF_HAS_LLD)
+ sprintf(bv->bp, "%lld", lineno);
+#else
+ sprintf(bv->bp, "%ld", (long)lineno);
+#endif
+ bv->bp += strlen(bv->bp);
+ break;
+ case 'x':
+ if (funcstack && funcstack->tp != FS_SOURCE &&
+ !IN_EVAL_TRAP())
+ promptpath(funcstack->filename ? funcstack->filename : "",
+ arg, 0);
+ else
+ promptpath(scriptfilename ? scriptfilename : argzero,
+ arg, 0);
+ break;
+ case '\0':
+ return 0;
+ case Meta:
+ bv->fm++;
+ break;
+ }
+ } else if(*bv->fm == '!' && isset(PROMPTBANG)) {
+ if(doprint) {
+ if(bv->fm[1] == '!') {
+ bv->fm++;
+ addbufspc(1);
+ pputc('!');
+ } else {
+ addbufspc(DIGBUFSIZE);
+ convbase(bv->bp, curhist, 10);
+ bv->bp += strlen(bv->bp);
+ }
+ }
+ } else {
+ char c = *bv->fm == Meta ? *++bv->fm ^ 32 : *bv->fm;
+
+ if (doprint) {
+ addbufspc(1);
+ pputc(c);
+ }
+ }
+ }
+
+ return *bv->fm;
+}
+
+/* pputc adds a character to the buffer, metafying. There must *
+ * already be space. */
+
+/**/
+static void
+pputc(char c)
+{
+ if (imeta(c)) {
+ *bv->bp++ = Meta;
+ c ^= 32;
+ }
+ *bv->bp++ = c;
+ if (c == '\n' && !bv->dontcount)
+ bv->bufline = bv->bp;
+}
+
+/* Make sure there is room for `need' more characters in the buffer. */
+
+/**/
+static void
+addbufspc(int need)
+{
+ need *= 2; /* for metafication */
+ if((bv->bp - bv->buf) + need > bv->bufspc) {
+ int bo = bv->bp - bv->buf;
+ int bo1 = bv->bp1 ? bv->bp1 - bv->buf : -1;
+ ptrdiff_t bufline_off = bv->bufline ? bv->bufline - bv->buf : -1;
+
+ if(need & 255)
+ need = (need | 255) + 1;
+ bv->buf = realloc(bv->buf, bv->bufspc += need);
+ memset(bv->buf + bv->bufspc - need, 0, need);
+ bv->bp = bv->buf + bo;
+ if(bo1 != -1)
+ bv->bp1 = bv->buf + bo1;
+ if (bufline_off != -1)
+ bv->bufline = bv->buf + bufline_off;
+ }
+}
+
+/* stradd() adds a metafied string to the prompt, *
+ * in a visible representation. */
+
+/**/
+void
+stradd(char *d)
+{
+#ifdef MULTIBYTE_SUPPORT
+ char *ums, *ups;
+ int upslen, eol = 0;
+ mbstate_t mbs;
+
+ memset(&mbs, 0, sizeof mbs);
+ ums = ztrdup(d);
+ ups = unmetafy(ums, &upslen);
+
+ /*
+ * We now have a raw string of possibly multibyte characters.
+ * Read each character one by one.
+ */
+ while (upslen > 0) {
+ wchar_t cc;
+ char *pc;
+ size_t cnt = eol ? MB_INVALID : mbrtowc(&cc, ups, upslen, &mbs);
+
+ switch (cnt) {
+ case MB_INCOMPLETE:
+ eol = 1;
+ /* FALL THROUGH */
+ case MB_INVALID:
+ /* Bad character. Take the next byte on its own. */
+ pc = nicechar(*ups);
+ cnt = 1;
+ memset(&mbs, 0, sizeof mbs);
+ break;
+ case 0:
+ cnt = 1;
+ /* FALL THROUGH */
+ default:
+ /* Take full wide character in one go */
+ mb_charinit();
+ pc = wcs_nicechar(cc, NULL, NULL);
+ break;
+ }
+ /* Keep output as metafied string. */
+ addbufspc(strlen(pc));
+
+ upslen -= cnt;
+ ups += cnt;
+
+ /* Put printed representation into the buffer */
+ while (*pc)
+ *bv->bp++ = *pc++;
+ }
+
+ free(ums);
+#else
+ char *ps, *pc;
+ addbufspc(niceztrlen(d));
+ /* This loop puts the nice representation of the string into the
+ * prompt buffer. */
+ for (ps = d; *ps; ps++) {
+ for (pc = nicechar(*ps == Meta ? *++ps^32 : *ps); *pc; pc++)
+ *bv->bp++ = *pc;
+ }
+#endif
+}
+
+/* tsetcap(), among other things, can write a termcap string into the buffer. */
+
+/**/
+mod_export void
+tsetcap(int cap, int flags)
+{
+ if (tccan(cap) && !isset(SINGLELINEZLE) &&
+ !(termflags & (TERM_NOUP|TERM_BAD|TERM_UNKNOWN))) {
+ switch (flags & TSC_OUTPUT_MASK) {
+ case TSC_RAW:
+ tputs(tcstr[cap], 1, putraw);
+ break;
+ case 0:
+ default:
+ tputs(tcstr[cap], 1, putshout);
+ break;
+ case TSC_PROMPT:
+ if (!bv->dontcount) {
+ addbufspc(1);
+ *bv->bp++ = Inpar;
+ }
+ tputs(tcstr[cap], 1, putstr);
+ if (!bv->dontcount) {
+ int glitch = 0;
+
+ if (cap == TCSTANDOUTBEG || cap == TCSTANDOUTEND)
+ glitch = tgetnum("sg");
+ else if (cap == TCUNDERLINEBEG || cap == TCUNDERLINEEND)
+ glitch = tgetnum("ug");
+ if(glitch < 0)
+ glitch = 0;
+ addbufspc(glitch + 1);
+ while(glitch--)
+ *bv->bp++ = Nularg;
+ *bv->bp++ = Outpar;
+ }
+ break;
+ }
+
+ if (flags & TSC_DIRTY) {
+ flags &= ~TSC_DIRTY;
+ if (txtisset(TXTBOLDFACE) && cap != TCBOLDFACEBEG)
+ tsetcap(TCBOLDFACEBEG, flags);
+ if (txtisset(TXTSTANDOUT))
+ tsetcap(TCSTANDOUTBEG, flags);
+ if (txtisset(TXTUNDERLINE))
+ tsetcap(TCUNDERLINEBEG, flags);
+ if (txtisset(TXTFGCOLOUR))
+ set_colour_attribute(txtattrmask, COL_SEQ_FG, TSC_PROMPT);
+ if (txtisset(TXTBGCOLOUR))
+ set_colour_attribute(txtattrmask, COL_SEQ_BG, TSC_PROMPT);
+ }
+ }
+}
+
+/**/
+int
+putstr(int d)
+{
+ addbufspc(1);
+ pputc(d);
+ return 0;
+}
+
+/*
+ * Count height etc. of a prompt string returned by promptexpand().
+ * This depends on the current terminal width, and tabs and
+ * newlines require nontrivial processing.
+ * Passing `overf' as -1 means to ignore columns (absolute width).
+ *
+ * If multibyte is enabled, take account of multibyte characters
+ * by locating them and finding out their screen width.
+ */
+
+/**/
+mod_export void
+countprompt(char *str, int *wp, int *hp, int overf)
+{
+ int w = 0, h = 1;
+ int s = 1;
+#ifdef MULTIBYTE_SUPPORT
+ int wcw, multi = 0;
+ char inchar;
+ mbstate_t mbs;
+ wchar_t wc;
+
+ memset(&mbs, 0, sizeof(mbs));
+#endif
+
+ for (; *str; str++) {
+ if (w > zterm_columns && overf >= 0) {
+ w = 0;
+ h++;
+ }
+ /*
+ * Input string should be metafied, so tokens in it should
+ * be real tokens, even if there are multibyte characters.
+ */
+ if (*str == Inpar)
+ s = 0;
+ else if (*str == Outpar)
+ s = 1;
+ else if (*str == Nularg)
+ w++;
+ else if (s) {
+ if (*str == Meta) {
+#ifdef MULTIBYTE_SUPPORT
+ inchar = *++str ^ 32;
+#else
+ str++;
+#endif
+ } else {
+#ifdef MULTIBYTE_SUPPORT
+ /*
+ * Don't look for tab or newline in the middle
+ * of a multibyte character. Otherwise, we are
+ * relying on the character set being an extension
+ * of ASCII so it's safe to test a single byte.
+ */
+ if (!multi) {
+#endif
+ if (*str == '\t') {
+ w = (w | 7) + 1;
+ continue;
+ } else if (*str == '\n') {
+ w = 0;
+ h++;
+ continue;
+ }
+#ifdef MULTIBYTE_SUPPORT
+ }
+
+ inchar = *str;
+#endif
+ }
+
+#ifdef MULTIBYTE_SUPPORT
+ switch (mbrtowc(&wc, &inchar, 1, &mbs)) {
+ case MB_INCOMPLETE:
+ /* Character is incomplete -- keep looking. */
+ multi = 1;
+ break;
+ case MB_INVALID:
+ memset(&mbs, 0, sizeof mbs);
+ /* Invalid character: assume single width. */
+ multi = 0;
+ w++;
+ break;
+ case 0:
+ multi = 0;
+ break;
+ default:
+ /*
+ * If the character isn't printable, WCWIDTH() returns
+ * -1. We assume width 1.
+ */
+ wcw = WCWIDTH(wc);
+ if (wcw >= 0)
+ w += wcw;
+ else
+ w++;
+ multi = 0;
+ break;
+ }
+#else
+ w++;
+#endif
+ }
+ }
+ /*
+ * multi may still be set if we were in the middle of the character.
+ * This isn't easy to handle generally; just assume there's no
+ * output.
+ */
+ if(w >= zterm_columns && overf >= 0) {
+ if (!overf || w > zterm_columns) {
+ w = 0;
+ h++;
+ }
+ }
+ if(wp)
+ *wp = w;
+ if(hp)
+ *hp = h;
+}
+
+/**/
+static int
+prompttrunc(int arg, int truncchar, int doprint, int endchar,
+ unsigned int *txtchangep)
+{
+ if (arg > 0) {
+ char ch = *bv->fm, *ptr, *truncstr;
+ int truncatleft = ch == '<';
+ int w = bv->bp - bv->buf;
+
+ /*
+ * If there is already a truncation active, return so that
+ * can be finished, backing up so that the new truncation
+ * can be started afterwards.
+ */
+ if (bv->truncwidth) {
+ while (*--bv->fm != '%')
+ ;
+ bv->fm--;
+ return 0;
+ }
+
+ bv->truncwidth = arg;
+ if (*bv->fm != ']')
+ bv->fm++;
+ while (*bv->fm && *bv->fm != truncchar) {
+ if (*bv->fm == '\\' && bv->fm[1])
+ ++bv->fm;
+ addbufspc(1);
+ *bv->bp++ = *bv->fm++;
+ }
+ if (!*bv->fm)
+ return 0;
+ if (bv->bp - bv->buf == w && truncchar == ']') {
+ addbufspc(1);
+ *bv->bp++ = '<';
+ }
+ ptr = bv->buf + w; /* addbufspc() may have realloc()'d bv->buf */
+ /*
+ * Now:
+ * bv->buf is the start of the output prompt buffer
+ * ptr is the start of the truncation string
+ * bv->bp is the end of the truncation string
+ */
+ truncstr = ztrduppfx(ptr, bv->bp - ptr);
+
+ bv->bp = ptr;
+ w = bv->bp - bv->buf;
+ bv->fm++;
+ bv->trunccount = bv->dontcount;
+ putpromptchar(doprint, endchar, txtchangep);
+ bv->trunccount = 0;
+ ptr = bv->buf + w; /* putpromptchar() may have realloc()'d */
+ *bv->bp = '\0';
+ /*
+ * Now:
+ * ptr is the start of the truncation string and also
+ * where we need to start putting any truncated output
+ * bv->bp is the end of the string we have just added, which
+ * may need truncating.
+ */
+
+ /*
+ * w below is screen width if multibyte support is enabled
+ * (note that above it was a raw string pointer difference).
+ * It's the full width of the string we may need to truncate.
+ *
+ * bv->truncwidth has come from the user, so we interpret this
+ * as a screen width, too.
+ */
+ countprompt(ptr, &w, 0, -1);
+ if (w > bv->truncwidth) {
+ /*
+ * We need to truncate. t points to the truncation string
+ * -- which is inserted literally, without nice
+ * representation. twidth is its printing width, and maxwidth
+ * is the amount of the main string that we want to keep.
+ * Note that if the truncation string is longer than the
+ * truncation length (twidth > bv->truncwidth), the truncation
+ * string is used in full.
+ */
+ char *t = truncstr;
+ int fullen = bv->bp - ptr;
+ int twidth, maxwidth;
+ int ntrunc = strlen(t);
+
+ twidth = MB_METASTRWIDTH(t);
+ if (twidth < bv->truncwidth) {
+ maxwidth = bv->truncwidth - twidth;
+ /*
+ * It's not safe to assume there are no invisible substrings
+ * just because the width is less than the full string
+ * length since there may be multibyte characters.
+ */
+ addbufspc(ntrunc+1);
+ /* may have realloc'd */
+ ptr = bv->bp - fullen;
+
+ if (truncatleft) {
+ /*
+ * To truncate at the left, selectively copy
+ * maxwidth bytes from the main prompt, preceded
+ * by the truncation string in full.
+ *
+ * We're overwriting the string containing the
+ * text to be truncated, so copy it. We've
+ * just ensured there's sufficient space at the
+ * end of the prompt string.
+ *
+ * Pointer into text to be truncated.
+ */
+ char *fulltextptr, *fulltext;
+ int remw;
+#ifdef MULTIBYTE_SUPPORT
+ mbstate_t mbs;
+ memset(&mbs, 0, sizeof mbs);
+#endif
+
+ fulltextptr = fulltext = ptr + ntrunc;
+ memmove(fulltext, ptr, fullen);
+ fulltext[fullen] = '\0';
+
+ /* Copy the truncstr into place. */
+ while (*t)
+ *ptr++ = *t++;
+
+ /*
+ * Find the point in the text at which we should
+ * start copying, i.e. when the remaining width
+ * is less than or equal to the maximum width.
+ */
+ remw = w;
+ while (remw > maxwidth && *fulltextptr) {
+ if (*fulltextptr == Inpar) {
+ /*
+ * Text marked as invisible: copy
+ * regardless, since we don't know what
+ * this does. It only affects the width
+ * if there are Nularg's present.
+ * However, even in that case we
+ * can't break the sequence down, so
+ * we still loop over the entire group.
+ */
+ for (;;) {
+ *ptr++ = *fulltextptr;
+ if (*fulltextptr == '\0' ||
+ *fulltextptr++ == Outpar)
+ break;
+ if (fulltextptr[-1] == Nularg)
+ remw--;
+ }
+ } else {
+#ifdef MULTIBYTE_SUPPORT
+ /*
+ * Normal text: build up a multibyte character.
+ */
+ char inchar;
+ wchar_t cc;
+ int wcw;
+
+ /*
+ * careful: string is still metafied (we
+ * need that because we don't know a
+ * priori when to stop and the resulting
+ * string must be metafied).
+ */
+ if (*fulltextptr == Meta)
+ inchar = *++fulltextptr ^ 32;
+ else
+ inchar = *fulltextptr;
+ fulltextptr++;
+ switch (mbrtowc(&cc, &inchar, 1, &mbs)) {
+ case MB_INCOMPLETE:
+ /* Incomplete multibyte character. */
+ break;
+ case MB_INVALID:
+ /* Reset invalid state. */
+ memset(&mbs, 0, sizeof mbs);
+ /* FALL THROUGH */
+ case 0:
+ /* Assume a single-byte character. */
+ remw--;
+ break;
+ default:
+ wcw = WCWIDTH(cc);
+ if (wcw >= 0)
+ remw -= wcw;
+ else
+ remw--;
+ break;
+ }
+#else
+ /* Single byte character */
+ if (*fulltextptr == Meta)
+ fulltextptr++;
+ fulltextptr++;
+ remw--;
+#endif
+ }
+ }
+
+ /*
+ * Now simply copy the rest of the text. Still
+ * metafied, so this is easy.
+ */
+ while (*fulltextptr)
+ *ptr++ = *fulltextptr++;
+ /* Mark the end of copying */
+ bv->bp = ptr;
+ } else {
+ /*
+ * Truncating at the right is easier: just leave
+ * enough characters until we have reached the
+ * maximum width.
+ */
+ char *skiptext = ptr;
+#ifdef MULTIBYTE_SUPPORT
+ mbstate_t mbs;
+ memset(&mbs, 0, sizeof mbs);
+#endif
+
+ while (maxwidth > 0 && *skiptext) {
+ if (*skiptext == Inpar) {
+ /* see comment on left truncation above */
+ for (;;) {
+ if (*skiptext == '\0' ||
+ *skiptext++ == Outpar)
+ break;
+ if (skiptext[-1] == Nularg)
+ maxwidth--;
+ }
+ } else {
+#ifdef MULTIBYTE_SUPPORT
+ char inchar;
+ wchar_t cc;
+ int wcw;
+
+ if (*skiptext == Meta)
+ inchar = *++skiptext ^ 32;
+ else
+ inchar = *skiptext;
+ skiptext++;
+ switch (mbrtowc(&cc, &inchar, 1, &mbs)) {
+ case MB_INCOMPLETE:
+ /* Incomplete character. */
+ break;
+ case MB_INVALID:
+ /* Reset invalid state. */
+ memset(&mbs, 0, sizeof mbs);
+ /* FALL THROUGH */
+ case 0:
+ /* Assume a single-byte character. */
+ maxwidth--;
+ break;
+ default:
+ wcw = WCWIDTH(cc);
+ if (wcw >= 0)
+ maxwidth -= wcw;
+ else
+ maxwidth--;
+ break;
+ }
+#else
+ if (*skiptext == Meta)
+ skiptext++;
+ skiptext++;
+ maxwidth--;
+#endif
+ }
+ }
+ /*
+ * We don't need the visible text from now on,
+ * but we'd better copy any invisible bits.
+ * History dictates that these go after the
+ * truncation string. This is sensible since
+ * they may, for example, turn off an effect which
+ * should apply to all text at this point.
+ *
+ * Copy the truncstr.
+ */
+ ptr = skiptext;
+ while (*t)
+ *ptr++ = *t++;
+ bv->bp = ptr;
+ if (*skiptext) {
+ /* Move remaining text so we don't overwrite it */
+ memmove(bv->bp, skiptext, strlen(skiptext)+1);
+ skiptext = bv->bp;
+
+ /*
+ * Copy anything we want, updating bv->bp
+ */
+ while (*skiptext) {
+ if (*skiptext == Inpar) {
+ for (;;) {
+ *bv->bp++ = *skiptext;
+ if (*skiptext == Outpar ||
+ *skiptext == '\0')
+ break;
+ skiptext++;
+ }
+ }
+ else
+ skiptext++;
+ }
+ }
+ }
+ } else {
+ /* Just copy truncstr; no other text appears. */
+ while (*t)
+ *ptr++ = *t++;
+ bv->bp = ptr;
+ }
+ *bv->bp = '\0';
+ }
+ zsfree(truncstr);
+ bv->truncwidth = 0;
+ /*
+ * We may have returned early from the previous putpromptchar *
+ * because we found another truncation following this one. *
+ * In that case we need to do the rest now. *
+ */
+ if (!*bv->fm)
+ return 0;
+ if (*bv->fm != endchar) {
+ bv->fm++;
+ /*
+ * With bv->truncwidth set to zero, we always reach endchar *
+ * (or the terminating NULL) this time round. *
+ */
+ if (!putpromptchar(doprint, endchar, txtchangep))
+ return 0;
+ }
+ /* Now we have to trick it into matching endchar again */
+ bv->fm--;
+ } else {
+ if (*bv->fm != endchar)
+ bv->fm++;
+ while(*bv->fm && *bv->fm != truncchar) {
+ if (*bv->fm == '\\' && bv->fm[1])
+ bv->fm++;
+ bv->fm++;
+ }
+ if (bv->truncwidth || !*bv->fm)
+ return 0;
+ }
+ return 1;
+}
+
+/**/
+void
+cmdpush(int cmdtok)
+{
+ if (cmdsp >= 0 && cmdsp < CMDSTACKSZ)
+ cmdstack[cmdsp++] = (unsigned char)cmdtok;
+}
+
+/**/
+void
+cmdpop(void)
+{
+ if (cmdsp <= 0) {
+ DPUTS(1, "BUG: cmdstack empty");
+ fflush(stderr);
+ } else
+ cmdsp--;
+}
+
+
+/*****************************************************************************
+ * Utilities dealing with colour and other forms of highlighting.
+ *
+ * These are shared by prompts and by zle, so it's easiest to have them
+ * in the main shell.
+ *****************************************************************************/
+
+/* Defines standard ANSI colour names in index order */
+static const char *ansi_colours[] = {
+ "black", "red", "green", "yellow", "blue", "magenta", "cyan", "white",
+ "default", NULL
+};
+
+/* Defines the available types of highlighting */
+struct highlight {
+ const char *name;
+ int mask_on;
+ int mask_off;
+};
+
+static const struct highlight highlights[] = {
+ { "none", 0, TXT_ATTR_ON_MASK },
+ { "bold", TXTBOLDFACE, 0 },
+ { "standout", TXTSTANDOUT, 0 },
+ { "underline", TXTUNDERLINE, 0 },
+ { NULL, 0, 0 }
+};
+
+/*
+ * Return index of ANSI colour for which *teststrp is an abbreviation.
+ * Any non-alphabetic character ends the abbreviation.
+ * 8 is the special value for default (note this is *not* the
+ * right sequence for default which is typically 9).
+ * -1 is failure.
+ */
+
+static int
+match_named_colour(const char **teststrp)
+{
+ const char *teststr = *teststrp, *end, **cptr;
+ int len;
+
+ for (end = teststr; ialpha(*end); end++)
+ ;
+ len = end - teststr;
+ *teststrp = end;
+
+ for (cptr = ansi_colours; *cptr; cptr++) {
+ if (!strncmp(teststr, *cptr, len))
+ return cptr - ansi_colours;
+ }
+
+ return -1;
+}
+
+/*
+ * Match just the colour part of a highlight specification.
+ * If teststrp is NULL, use the already parsed numeric colour.
+ * Return the attributes to set in the attribute variable.
+ * Return -1 for out of range. Does not check the character
+ * following the colour specification.
+ */
+
+/**/
+mod_export int
+match_colour(const char **teststrp, int is_fg, int colour)
+{
+ int shft, on, named = 0, tc;
+
+ if (teststrp) {
+ if ((named = ialpha(**teststrp))) {
+ colour = match_named_colour(teststrp);
+ if (colour == 8) {
+ /* default */
+ return is_fg ? TXTNOFGCOLOUR : TXTNOBGCOLOUR;
+ }
+ }
+ else
+ colour = (int)zstrtol(*teststrp, (char **)teststrp, 10);
+ }
+ if (colour < 0 || colour >= 256)
+ return -1;
+ if (is_fg) {
+ shft = TXT_ATTR_FG_COL_SHIFT;
+ on = TXTFGCOLOUR;
+ tc = TCFGCOLOUR;
+ } else {
+ shft = TXT_ATTR_BG_COL_SHIFT;
+ on = TXTBGCOLOUR;
+ tc = TCBGCOLOUR;
+ }
+ /*
+ * Try termcap for numbered characters if posible.
+ * Don't for named characters, since our best bet
+ * of getting the names right is with ANSI sequences.
+ */
+ if (!named && tccan(tc)) {
+ if (tccolours >= 0 && colour >= tccolours) {
+ /*
+ * Out of range of termcap colours.
+ * Can we assume ANSI colours work?
+ */
+ if (colour > 7)
+ return -1; /* No. */
+ } else {
+ /*
+ * We can handle termcap colours and the number
+ * is in range, so use termcap.
+ */
+ on |= is_fg ? TXT_ATTR_FG_TERMCAP :
+ TXT_ATTR_BG_TERMCAP;
+ }
+ }
+ return on | (colour << shft);
+}
+
+/*
+ * Match a set of highlights in the given teststr.
+ * Set *on_var to reflect the values found.
+ */
+
+/**/
+mod_export void
+match_highlight(const char *teststr, int *on_var)
+{
+ int found = 1;
+
+ *on_var = 0;
+ while (found && *teststr) {
+ const struct highlight *hl;
+
+ found = 0;
+ if (strpfx("fg=", teststr) || strpfx("bg=", teststr)) {
+ int is_fg = (teststr[0] == 'f'), atr;
+
+ teststr += 3;
+ atr = match_colour(&teststr, is_fg, 0);
+ if (*teststr == ',')
+ teststr++;
+ else if (*teststr)
+ break;
+ found = 1;
+ /* skip out of range colours but keep scanning attributes */
+ if (atr >= 0)
+ *on_var |= atr;
+ } else {
+ for (hl = highlights; hl->name; hl++) {
+ if (strpfx(hl->name, teststr)) {
+ const char *val = teststr + strlen(hl->name);
+
+ if (*val == ',')
+ val++;
+ else if (*val)
+ break;
+
+ *on_var |= hl->mask_on;
+ *on_var &= ~hl->mask_off;
+ teststr = val;
+ found = 1;
+ }
+ }
+ }
+ }
+}
+
+/*
+ * Count or output a string for colour information: used
+ * by output_highlight().
+ */
+
+static int
+output_colour(int colour, int fg_bg, int use_tc, char *buf)
+{
+ int atrlen = 3, len;
+ char *ptr = buf;
+ if (buf) {
+ strcpy(ptr, fg_bg == COL_SEQ_FG ? "fg=" : "bg=");
+ ptr += 3;
+ }
+ /* colour should only be > 7 if using termcap but let's be safe */
+ if (use_tc || colour > 7) {
+ char digbuf[DIGBUFSIZE];
+ sprintf(digbuf, "%d", colour);
+ len = strlen(digbuf);
+ atrlen += len;
+ if (buf)
+ strcpy(ptr, digbuf);
+ } else {
+ len = strlen(ansi_colours[colour]);
+ atrlen += len;
+ if (buf)
+ strcpy(ptr, ansi_colours[colour]);
+ }
+
+ return atrlen;
+}
+
+/*
+ * Count the length needed for outputting highlighting information
+ * as a string based on the bits for the attributes.
+ *
+ * If buf is not NULL, output the strings into the buffer, too.
+ * As conventional with strings, the allocated length should be
+ * at least the returned value plus 1 for the NUL byte.
+ */
+
+/**/
+mod_export int
+output_highlight(int atr, char *buf)
+{
+ const struct highlight *hp;
+ int atrlen = 0, len;
+ char *ptr = buf;
+
+ if (atr & TXTFGCOLOUR) {
+ len = output_colour(txtchangeget(atr, TXT_ATTR_FG_COL),
+ COL_SEQ_FG,
+ (atr & TXT_ATTR_FG_TERMCAP),
+ ptr);
+ atrlen += len;
+ if (buf)
+ ptr += len;
+ }
+ if (atr & TXTBGCOLOUR) {
+ if (atrlen) {
+ atrlen++;
+ if (buf) {
+ strcpy(ptr, ",");
+ ptr++;
+ }
+ }
+ len = output_colour(txtchangeget(atr, TXT_ATTR_BG_COL),
+ COL_SEQ_BG,
+ (atr & TXT_ATTR_BG_TERMCAP),
+ ptr);
+ atrlen += len;
+ if (buf)
+ ptr += len;
+ }
+ for (hp = highlights; hp->name; hp++) {
+ if (hp->mask_on & atr) {
+ if (atrlen) {
+ atrlen++;
+ if (buf) {
+ strcpy(ptr, ",");
+ ptr++;
+ }
+ }
+ len = strlen(hp->name);
+ atrlen += len;
+ if (buf) {
+ strcpy(ptr, hp->name);
+ ptr += len;
+ }
+ }
+ }
+
+ if (atrlen == 0) {
+ if (buf)
+ strcpy(ptr, "none");
+ return 4;
+ }
+ return atrlen;
+}
+
+/* Structure and array for holding special colour terminal sequences */
+
+/* Start of escape sequence for foreground colour */
+#define TC_COL_FG_START "\033[3"
+/* End of escape sequence for foreground colour */
+#define TC_COL_FG_END "m"
+/* Code to reset foreground colour */
+#define TC_COL_FG_DEFAULT "9"
+
+/* Start of escape sequence for background colour */
+#define TC_COL_BG_START "\033[4"
+/* End of escape sequence for background colour */
+#define TC_COL_BG_END "m"
+/* Code to reset background colour */
+#define TC_COL_BG_DEFAULT "9"
+
+struct colour_sequences {
+ char *start; /* Escape sequence start */
+ char *end; /* Escape sequence terminator */
+ char *def; /* Code to reset default colour */
+};
+static struct colour_sequences fg_bg_sequences[2];
+
+/*
+ * We need a buffer for colour sequence composition. It may
+ * vary depending on the sequences set. However, it's inefficient
+ * allocating it separately every time we send a colour sequence,
+ * so do it once per refresh.
+ */
+static char *colseq_buf;
+
+/*
+ * Count how often this has been allocated, for recursive usage.
+ */
+static int colseq_buf_allocs;
+
+/**/
+void
+set_default_colour_sequences(void)
+{
+ fg_bg_sequences[COL_SEQ_FG].start = ztrdup(TC_COL_FG_START);
+ fg_bg_sequences[COL_SEQ_FG].end = ztrdup(TC_COL_FG_END);
+ fg_bg_sequences[COL_SEQ_FG].def = ztrdup(TC_COL_FG_DEFAULT);
+
+ fg_bg_sequences[COL_SEQ_BG].start = ztrdup(TC_COL_BG_START);
+ fg_bg_sequences[COL_SEQ_BG].end = ztrdup(TC_COL_BG_END);
+ fg_bg_sequences[COL_SEQ_BG].def = ztrdup(TC_COL_BG_DEFAULT);
+}
+
+static void
+set_colour_code(char *str, char **var)
+{
+ char *keyseq;
+ int len;
+
+ zsfree(*var);
+ keyseq = getkeystring(str, &len, GETKEYS_BINDKEY, NULL);
+ *var = metafy(keyseq, len, META_DUP);
+}
+
+/* Allocate buffer for colour code composition */
+
+/**/
+mod_export void
+allocate_colour_buffer(void)
+{
+ char **atrs;
+ int lenfg, lenbg, len;
+
+ if (colseq_buf_allocs++)
+ return;
+
+ atrs = getaparam("zle_highlight");
+ if (atrs) {
+ for (; *atrs; atrs++) {
+ if (strpfx("fg_start_code:", *atrs)) {
+ set_colour_code(*atrs + 14, &fg_bg_sequences[COL_SEQ_FG].start);
+ } else if (strpfx("fg_default_code:", *atrs)) {
+ set_colour_code(*atrs + 16, &fg_bg_sequences[COL_SEQ_FG].def);
+ } else if (strpfx("fg_end_code:", *atrs)) {
+ set_colour_code(*atrs + 12, &fg_bg_sequences[COL_SEQ_FG].end);
+ } else if (strpfx("bg_start_code:", *atrs)) {
+ set_colour_code(*atrs + 14, &fg_bg_sequences[COL_SEQ_BG].start);
+ } else if (strpfx("bg_default_code:", *atrs)) {
+ set_colour_code(*atrs + 16, &fg_bg_sequences[COL_SEQ_BG].def);
+ } else if (strpfx("bg_end_code:", *atrs)) {
+ set_colour_code(*atrs + 12, &fg_bg_sequences[COL_SEQ_BG].end);
+ }
+ }
+ }
+
+ lenfg = strlen(fg_bg_sequences[COL_SEQ_FG].def);
+ /* always need 1 character for non-default code */
+ if (lenfg < 1)
+ lenfg = 1;
+ lenfg += strlen(fg_bg_sequences[COL_SEQ_FG].start) +
+ strlen(fg_bg_sequences[COL_SEQ_FG].end);
+
+ lenbg = strlen(fg_bg_sequences[COL_SEQ_BG].def);
+ /* always need 1 character for non-default code */
+ if (lenbg < 1)
+ lenbg = 1;
+ lenbg += strlen(fg_bg_sequences[COL_SEQ_BG].start) +
+ strlen(fg_bg_sequences[COL_SEQ_BG].end);
+
+ len = lenfg > lenbg ? lenfg : lenbg;
+ colseq_buf = (char *)zalloc(len+1);
+}
+
+/* Free the colour buffer previously allocated. */
+
+/**/
+mod_export void
+free_colour_buffer(void)
+{
+ if (--colseq_buf_allocs)
+ return;
+
+ DPUTS(!colseq_buf, "Freeing colour sequence buffer without alloc");
+ /* Free buffer for colour code composition */
+ free(colseq_buf);
+ colseq_buf = NULL;
+}
+
+/*
+ * Handle outputting of a colour for prompts or zle.
+ * colour is the numeric colour, 0 to 255 (or less if termcap
+ * says fewer are supported).
+ * fg_bg indicates if we're changing the foreground or background.
+ * tc indicates the termcap code to use, if appropriate.
+ * def indicates if we're resetting the default colour.
+ * use_termcap indicates if we should use termcap to output colours.
+ * flags is either 0 or TSC_PROMPT.
+ */
+
+/**/
+mod_export void
+set_colour_attribute(int atr, int fg_bg, int flags)
+{
+ char *ptr;
+ int do_free, is_prompt = (flags & TSC_PROMPT) ? 1 : 0;
+ int colour, tc, def, use_termcap;
+
+ if (fg_bg == COL_SEQ_FG) {
+ colour = txtchangeget(atr, TXT_ATTR_FG_COL);
+ tc = TCFGCOLOUR;
+ def = txtchangeisset(atr, TXTNOFGCOLOUR);
+ use_termcap = txtchangeisset(atr, TXT_ATTR_FG_TERMCAP);
+ } else {
+ colour = txtchangeget(atr, TXT_ATTR_BG_COL);
+ tc = TCBGCOLOUR;
+ def = txtchangeisset(atr, TXTNOBGCOLOUR);
+ use_termcap = txtchangeisset(atr, TXT_ATTR_BG_TERMCAP);
+ }
+
+ /*
+ * If we're not restoring the default, and either have a
+ * colour value that is too large for ANSI, or have been told
+ * to use the termcap sequence, try to use the termcap sequence.
+ *
+ * We have already sanitised the values we allow from the
+ * highlighting variables, so much of this shouldn't be
+ * necessary at this point, but we might as well be safe.
+ */
+ if (!def && (colour > 7 || use_termcap)) {
+ /*
+ * We can if it's available, and either we couldn't get
+ * the maximum number of colours, or the colour is in range.
+ */
+ if (tccan(tc) && (tccolours < 0 || colour < tccolours))
+ {
+ if (is_prompt)
+ {
+ if (!bv->dontcount) {
+ addbufspc(1);
+ *bv->bp++ = Inpar;
+ }
+ tputs(tgoto(tcstr[tc], colour, colour), 1, putstr);
+ if (!bv->dontcount) {
+ addbufspc(1);
+ *bv->bp++ = Outpar;
+ }
+ } else {
+ tputs(tgoto(tcstr[tc], colour, colour), 1, putshout);
+ }
+ /* That worked. */
+ return;
+ }
+ /*
+ * Nope, that didn't work.
+ * If 0 to 7, assume standard ANSI works, otherwise it won't.
+ */
+ if (colour > 7)
+ return;
+ }
+
+ if ((do_free = (colseq_buf == NULL))) {
+ /* This can happen when moving the cursor in trashzle() */
+ allocate_colour_buffer();
+ }
+
+ strcpy(colseq_buf, fg_bg_sequences[fg_bg].start);
+
+ ptr = colseq_buf + strlen(colseq_buf);
+ if (def) {
+ strcpy(ptr, fg_bg_sequences[fg_bg].def);
+ while (*ptr)
+ ptr++;
+ } else
+ *ptr++ = colour + '0';
+ strcpy(ptr, fg_bg_sequences[fg_bg].end);
+
+ if (is_prompt) {
+ if (!bv->dontcount) {
+ addbufspc(1);
+ *bv->bp++ = Inpar;
+ }
+ tputs(colseq_buf, 1, putstr);
+ if (!bv->dontcount) {
+ addbufspc(1);
+ *bv->bp++ = Outpar;
+ }
+ } else
+ tputs(colseq_buf, 1, putshout);
+
+ if (do_free)
+ free_colour_buffer();
+}
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/prototypes.h b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/prototypes.h
new file mode 100644
index 0000000..e3db4f5
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/prototypes.h
@@ -0,0 +1,134 @@
+/*
+ * prototypes.h - prototypes header file
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+#ifndef HAVE_STDLIB_H
+char *malloc _((size_t));
+char *realloc _((void *, size_t));
+char *calloc _((size_t, size_t));
+#endif
+
+#if !(defined(USES_TERMCAP_H) || defined(USES_TERM_H))
+/*
+ * These prototypes are only used where we don't have the
+ * headers. In some cases they need tweaking.
+ * TBD: we'd much prefer to get hold of the header where
+ * these are defined.
+ */
+#ifdef _AIX
+#define TC_CONST const
+#else
+#define TC_CONST
+#endif
+extern int tgetent _((char *bp, TC_CONST char *name));
+extern int tgetnum _((char *id));
+extern int tgetflag _((char *id));
+extern char *tgetstr _((char *id, char **area));
+extern int tputs _((TC_CONST char *cp, int affcnt, int (*outc) (int)));
+#undef TC_CONST
+#endif
+
+/*
+ * Some systems that do have termcap headers nonetheless don't
+ * declare tgoto, so we detect if that is missing separately.
+ */
+#ifdef TGOTO_PROTO_MISSING
+char *tgoto(const char *cap, int col, int row);
+#endif
+
+/* MISSING PROTOTYPES FOR VARIOUS OPERATING SYSTEMS */
+
+#if defined(__hpux) && defined(_HPUX_SOURCE) && !defined(_XPG4_EXTENDED)
+# define SELECT_ARG_2_T int *
+#else
+# define SELECT_ARG_2_T fd_set *
+#endif
+
+#ifdef __osf__
+char *mktemp _((char *));
+#endif
+
+#if defined(__osf__) && defined(__alpha) && defined(__GNUC__)
+/* Digital cc does not need these prototypes, gcc does need them */
+# ifndef HAVE_IOCTL_PROTO
+int ioctl _((int d, unsigned long request, void *argp));
+# endif
+# ifndef HAVE_MKNOD_PROTO
+int mknod _((const char *pathname, int mode, dev_t device));
+# endif
+int nice _((int increment));
+int select _((int nfds, fd_set * readfds, fd_set * writefds, fd_set * exceptfds, struct timeval *timeout));
+#endif
+
+#if defined(DGUX) && defined(__STDC__)
+/* Just plain missing. */
+extern int getrlimit _((int resource, struct rlimit *rlp));
+extern int setrlimit _((int resource, const struct rlimit *rlp));
+extern int getrusage _((int who, struct rusage *rusage));
+extern int gettimeofday _((struct timeval *tv, struct timezone *tz));
+extern int wait3 _((union wait *wait_status, int options, struct rusage *rusage));
+extern int getdomainname _((char *name, int maxlength));
+extern int select _((int nfds, fd_set * readfds, fd_set * writefds, fd_set * exceptfds, struct timeval *timeout));
+#endif /* DGUX and __STDC__ */
+
+#ifdef __NeXT__
+extern pid_t getppid(void);
+#endif
+
+#if defined(__sun__) && !defined(__SVR4) /* SunOS */
+extern char *strerror _((int errnum));
+#endif
+
+/**************************************************/
+/*** prototypes for functions built in compat.c ***/
+#ifndef HAVE_STRSTR
+extern char *strstr _((const char *s, const char *t));
+#endif
+
+#ifndef HAVE_GETHOSTNAME
+extern int gethostname _((char *name, size_t namelen));
+#endif
+
+#ifndef HAVE_GETTIMEOFDAY
+extern int gettimeofday _((struct timeval *tv, struct timezone *tz));
+#endif
+
+#ifndef HAVE_DIFFTIME
+extern double difftime _((time_t t2, time_t t1));
+#endif
+
+#ifndef HAVE_STRERROR
+extern char *strerror _((int errnum));
+#endif
+
+/*** end of prototypes for functions in compat.c ***/
+/***************************************************/
+
+#ifndef HAVE_MEMMOVE
+extern void bcopy _((const void *, void *, size_t));
+#endif
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/signals.c b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/signals.c
new file mode 100644
index 0000000..20c6fdf
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/signals.c
@@ -0,0 +1,1479 @@
+/*
+ * signals.c - signals handling code
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+#include "zsh.mdh"
+#include "signals.pro"
+
+/* Array describing the state of each signal: an element contains *
+ * 0 for the default action or some ZSIG_* flags ored together. */
+
+/**/
+mod_export int sigtrapped[VSIGCOUNT];
+
+/*
+ * Trap programme lists for each signal.
+ *
+ * If (sigtrapped[sig] & ZSIG_FUNC) is set, this isn't used.
+ * The corresponding shell function is used instead.
+ *
+ * Otherwise, if sigtrapped[sig] is not zero, this is NULL when a signal
+ * is to be ignored, and if not NULL contains the programme list to be
+ * eval'd.
+ */
+
+/**/
+mod_export Eprog siglists[VSIGCOUNT];
+
+/* Total count of trapped signals */
+
+/**/
+mod_export int nsigtrapped;
+
+/* Running an exit trap? */
+
+/**/
+int in_exit_trap;
+
+/*
+ * Flag that exit trap has been set in POSIX mode.
+ * The setter's expectation is therefore that it is run
+ * on programme exit, not function exit.
+ */
+
+/**/
+static int exit_trap_posix;
+
+/* Variables used by signal queueing */
+
+/**/
+mod_export int queueing_enabled, queue_front, queue_rear;
+/**/
+mod_export int signal_queue[MAX_QUEUE_SIZE];
+/**/
+mod_export sigset_t signal_mask_queue[MAX_QUEUE_SIZE];
+#ifdef DEBUG
+/**/
+mod_export int queue_in;
+#endif
+
+/* Variables used by trap queueing */
+
+/**/
+mod_export int trap_queueing_enabled, trap_queue_front, trap_queue_rear;
+/**/
+mod_export int trap_queue[MAX_QUEUE_SIZE];
+
+/* This is only used on machines that don't understand signal sets. *
+ * On SYSV machines this will represent the signals that are blocked *
+ * (held) using sighold. On machines which can't block signals at *
+ * all, we will simulate this by ignoring them and remembering them *
+ * in this variable. */
+#if !defined(POSIX_SIGNALS) && !defined(BSD_SIGNALS)
+static sigset_t blocked_set;
+#endif
+
+#ifdef POSIX_SIGNALS
+# define signal_jmp_buf sigjmp_buf
+# define signal_setjmp(b) sigsetjmp((b),1)
+# define signal_longjmp(b,n) siglongjmp((b),(n))
+#else
+# define signal_jmp_buf jmp_buf
+# define signal_setjmp(b) setjmp(b)
+# define signal_longjmp(b,n) longjmp((b),(n))
+#endif
+
+#ifdef NO_SIGNAL_BLOCKING
+# define signal_process(sig) signal_ignore(sig)
+# define signal_reset(sig) install_handler(sig)
+#else
+# define signal_process(sig) ;
+# define signal_reset(sig) ;
+#endif
+
+/* Install signal handler for given signal. *
+ * If possible, we want to make sure that interrupted *
+ * system calls are not restarted. */
+
+/**/
+mod_export void
+install_handler(int sig)
+{
+#ifdef POSIX_SIGNALS
+ struct sigaction act;
+
+ act.sa_handler = (SIGNAL_HANDTYPE) zhandler;
+ sigemptyset(&act.sa_mask); /* only block sig while in handler */
+ act.sa_flags = 0;
+# ifdef SA_INTERRUPT /* SunOS 4.x */
+ if (interact)
+ act.sa_flags |= SA_INTERRUPT; /* make sure system calls are not restarted */
+# endif
+ sigaction(sig, &act, (struct sigaction *)NULL);
+#else
+# ifdef BSD_SIGNALS
+ struct sigvec vec;
+
+ vec.sv_handler = (SIGNAL_HANDTYPE) zhandler;
+ vec.sv_mask = sigmask(sig); /* mask out this signal while in handler */
+# ifdef SV_INTERRUPT
+ vec.sv_flags = SV_INTERRUPT; /* make sure system calls are not restarted */
+# endif
+ sigvec(sig, &vec, (struct sigvec *)NULL);
+# else
+# ifdef SYSV_SIGNALS
+ /* we want sigset rather than signal because it will *
+ * block sig while in handler. signal usually doesn't */
+ sigset(sig, zhandler);
+# else /* NO_SIGNAL_BLOCKING (bummer) */
+ signal(sig, zhandler);
+
+# endif /* SYSV_SIGNALS */
+# endif /* BSD_SIGNALS */
+#endif /* POSIX_SIGNALS */
+}
+
+/* enable ^C interrupts */
+
+/**/
+mod_export void
+intr(void)
+{
+ if (interact)
+ install_handler(SIGINT);
+}
+
+/* disable ^C interrupts */
+
+#if 0 /**/
+void
+nointr(void)
+{
+ if (interact)
+ signal_ignore(SIGINT);
+}
+#endif
+
+/* temporarily block ^C interrupts */
+
+/**/
+mod_export void
+holdintr(void)
+{
+ if (interact)
+ signal_block(signal_mask(SIGINT));
+}
+
+/* release ^C interrupts */
+
+/**/
+mod_export void
+noholdintr(void)
+{
+ if (interact)
+ signal_unblock(signal_mask(SIGINT));
+}
+
+/* create a signal mask containing *
+ * only the given signal */
+
+/**/
+mod_export sigset_t
+signal_mask(int sig)
+{
+ sigset_t set;
+
+ sigemptyset(&set);
+ if (sig)
+ sigaddset(&set, sig);
+ return set;
+}
+
+/* Block the signals in the given signal *
+ * set. Return the old signal set. */
+
+/**/
+#ifndef BSD_SIGNALS
+
+/**/
+mod_export sigset_t
+signal_block(sigset_t set)
+{
+ sigset_t oset;
+
+#ifdef POSIX_SIGNALS
+ sigprocmask(SIG_BLOCK, &set, &oset);
+
+#else
+# ifdef SYSV_SIGNALS
+ int i;
+
+ oset = blocked_set;
+ for (i = 1; i <= NSIG; ++i) {
+ if (sigismember(&set, i) && !sigismember(&blocked_set, i)) {
+ sigaddset(&blocked_set, i);
+ sighold(i);
+ }
+ }
+# else /* NO_SIGNAL_BLOCKING */
+/* We will just ignore signals if the system doesn't have *
+ * the ability to block them. */
+ int i;
+
+ oset = blocked_set;
+ for (i = 1; i <= NSIG; ++i) {
+ if (sigismember(&set, i) && !sigismember(&blocked_set, i)) {
+ sigaddset(&blocked_set, i);
+ signal_ignore(i);
+ }
+ }
+# endif /* SYSV_SIGNALS */
+#endif /* POSIX_SIGNALS */
+
+ return oset;
+}
+
+/**/
+#endif /* BSD_SIGNALS */
+
+/* Unblock the signals in the given signal *
+ * set. Return the old signal set. */
+
+/**/
+mod_export sigset_t
+signal_unblock(sigset_t set)
+{
+ sigset_t oset;
+
+#ifdef POSIX_SIGNALS
+ sigprocmask(SIG_UNBLOCK, &set, &oset);
+#else
+# ifdef BSD_SIGNALS
+ sigfillset(&oset);
+ oset = sigsetmask(oset);
+ sigsetmask(oset & ~set);
+# else
+# ifdef SYSV_SIGNALS
+ int i;
+
+ oset = blocked_set;
+ for (i = 1; i <= NSIG; ++i) {
+ if (sigismember(&set, i) && sigismember(&blocked_set, i)) {
+ sigdelset(&blocked_set, i);
+ sigrelse(i);
+ }
+ }
+# else /* NO_SIGNAL_BLOCKING */
+/* On systems that can't block signals, we are just ignoring them. So *
+ * to unblock signals, we just reenable the signal handler for them. */
+ int i;
+
+ oset = blocked_set;
+ for (i = 1; i <= NSIG; ++i) {
+ if (sigismember(&set, i) && sigismember(&blocked_set, i)) {
+ sigdelset(&blocked_set, i);
+ install_handler(i);
+ }
+ }
+# endif /* SYSV_SIGNALS */
+# endif /* BSD_SIGNALS */
+#endif /* POSIX_SIGNALS */
+
+ return oset;
+}
+
+/* set the process signal mask to *
+ * be the given signal mask */
+
+/**/
+mod_export sigset_t
+signal_setmask(sigset_t set)
+{
+ sigset_t oset;
+
+#ifdef POSIX_SIGNALS
+ sigprocmask(SIG_SETMASK, &set, &oset);
+#else
+# ifdef BSD_SIGNALS
+ oset = sigsetmask(set);
+# else
+# ifdef SYSV_SIGNALS
+ int i;
+
+ oset = blocked_set;
+ for (i = 1; i <= NSIG; ++i) {
+ if (sigismember(&set, i) && !sigismember(&blocked_set, i)) {
+ sigaddset(&blocked_set, i);
+ sighold(i);
+ } else if (!sigismember(&set, i) && sigismember(&blocked_set, i)) {
+ sigdelset(&blocked_set, i);
+ sigrelse(i);
+ }
+ }
+# else /* NO_SIGNAL_BLOCKING */
+ int i;
+
+ oset = blocked_set;
+ for (i = 1; i < NSIG; ++i) {
+ if (sigismember(&set, i) && !sigismember(&blocked_set, i)) {
+ sigaddset(&blocked_set, i);
+ signal_ignore(i);
+ } else if (!sigismember(&set, i) && sigismember(&blocked_set, i)) {
+ sigdelset(&blocked_set, i);
+ install_handler(i);
+ }
+ }
+# endif /* SYSV_SIGNALS */
+# endif /* BSD_SIGNALS */
+#endif /* POSIX_SIGNALS */
+
+ return oset;
+}
+
+#if defined(NO_SIGNAL_BLOCKING)
+static int suspend_longjmp = 0;
+static signal_jmp_buf suspend_jmp_buf;
+#endif
+
+/**/
+int
+signal_suspend(UNUSED(int sig), int wait_cmd)
+{
+ int ret;
+
+#if defined(POSIX_SIGNALS) || defined(BSD_SIGNALS)
+ sigset_t set;
+# if defined(POSIX_SIGNALS) && defined(BROKEN_POSIX_SIGSUSPEND)
+ sigset_t oset;
+# endif
+
+ sigemptyset(&set);
+
+ /* SIGINT from the terminal driver needs to interrupt "wait"
+ * and to cause traps to fire, but otherwise should not be
+ * handled by the shell until after any foreground job has
+ * a chance to decide whether to exit on that signal.
+ */
+ if (!(wait_cmd || isset(TRAPSASYNC) ||
+ (sigtrapped[SIGINT] & ~ZSIG_IGNORED)))
+ sigaddset(&set, SIGINT);
+#endif /* POSIX_SIGNALS || BSD_SIGNALS */
+
+#ifdef POSIX_SIGNALS
+# ifdef BROKEN_POSIX_SIGSUSPEND
+ sigprocmask(SIG_SETMASK, &set, &oset);
+ ret = pause();
+ sigprocmask(SIG_SETMASK, &oset, NULL);
+# else /* not BROKEN_POSIX_SIGSUSPEND */
+ ret = sigsuspend(&set);
+# endif /* BROKEN_POSIX_SIGSUSPEND */
+#else /* not POSIX_SIGNALS */
+# ifdef BSD_SIGNALS
+ ret = sigpause(set);
+# else
+# ifdef SYSV_SIGNALS
+ ret = sigpause(sig);
+
+# else /* NO_SIGNAL_BLOCKING */
+ /* need to use signal_longjmp to make this race-free *
+ * between the child_unblock() and pause() */
+ if (signal_setjmp(suspend_jmp_buf) == 0) {
+ suspend_longjmp = 1; /* we want to signal_longjmp after catching signal */
+ child_unblock(); /* do we need to do wait_cmd stuff as well? */
+ ret = pause();
+ }
+ suspend_longjmp = 0; /* turn off using signal_longjmp since we are past *
+ * the pause() function. */
+# endif /* SYSV_SIGNALS */
+# endif /* BSD_SIGNALS */
+#endif /* POSIX_SIGNALS */
+
+ return ret;
+}
+
+/* last signal we handled: race prone, or what? */
+/**/
+int last_signal;
+
+/*
+ * Wait for any processes that have changed state.
+ *
+ * The main use for this is in the SIGCHLD handler. However,
+ * we also use it to pick up status changes of jobs when
+ * updating jobs.
+ */
+/**/
+void
+wait_for_processes(void)
+{
+ /* keep WAITING until no more child processes to reap */
+ for (;;) {
+ /* save the errno, since WAIT may change it */
+ int old_errno = errno;
+ int status;
+ Job jn;
+ Process pn;
+ pid_t pid;
+ pid_t *procsubpid = &cmdoutpid;
+ int *procsubval = &cmdoutval;
+ int cont = 0;
+ struct execstack *es = exstack;
+
+ /*
+ * Reap the child process.
+ * If we want usage information, we need to use wait3.
+ */
+#if defined(HAVE_WAIT3) || defined(HAVE_WAITPID)
+# ifdef WCONTINUED
+# define WAITFLAGS (WNOHANG|WUNTRACED|WCONTINUED)
+# else
+# define WAITFLAGS (WNOHANG|WUNTRACED)
+# endif
+#endif
+#ifdef HAVE_WAIT3
+# ifdef HAVE_GETRUSAGE
+ struct rusage ru;
+
+ pid = wait3((void *)&status, WAITFLAGS, &ru);
+# else
+ pid = wait3((void *)&status, WAITFLAGS, NULL);
+# endif
+#else
+# ifdef HAVE_WAITPID
+ pid = waitpid(-1, &status, WAITFLAGS);
+# else
+ pid = wait(&status);
+# endif
+#endif
+
+ if (!pid) /* no more children to reap */
+ break;
+
+ /* check if child returned was from process substitution */
+ for (;;) {
+ if (pid == *procsubpid) {
+ *procsubpid = 0;
+ if (WIFSIGNALED(status))
+ *procsubval = (0200 | WTERMSIG(status));
+ else
+ *procsubval = WEXITSTATUS(status);
+ use_cmdoutval = 1;
+ get_usage();
+ cont = 1;
+ break;
+ }
+ if (!es)
+ break;
+ procsubpid = &es->cmdoutpid;
+ procsubval = &es->cmdoutval;
+ es = es->next;
+ }
+ if (cont)
+ continue;
+
+ /* check for WAIT error */
+ if (pid == -1) {
+ if (errno != ECHILD)
+ zerr("wait failed: %e", errno);
+ /* WAIT changed errno, so restore the original */
+ errno = old_errno;
+ break;
+ }
+
+ /* This is necessary to be sure queueing_enabled > 0 when
+ * we enter printjob() from update_job(), so that we don't
+ * decrement to zero in should_report_time() and improperly
+ * run other handlers in the middle of processing this one */
+ queue_signals();
+
+ /*
+ * Find the process and job containing this pid and
+ * update it.
+ */
+ if (findproc(pid, &jn, &pn, 0)) {
+ if (((jn->stat & STAT_BUILTIN) ||
+ (list_pipe &&
+ (thisjob == -1 ||
+ (jobtab[thisjob].stat & STAT_BUILTIN)))) &&
+ WIFSTOPPED(status) && WSTOPSIG(status) == SIGTSTP) {
+ killjb(jn, SIGCONT);
+ zwarn("job can't be suspended");
+ } else {
+#if defined(HAVE_WAIT3) && defined(HAVE_GETRUSAGE)
+ struct timezone dummy_tz;
+ gettimeofday(&pn->endtime, &dummy_tz);
+#ifdef WIFCONTINUED
+ if (WIFCONTINUED(status))
+ pn->status = SP_RUNNING;
+ else
+#endif
+ pn->status = status;
+ pn->ti = ru;
+#else
+ update_process(pn, status);
+#endif
+ if (WIFEXITED(status) &&
+ pn->pid == jn->gleader &&
+ killpg(pn->pid, 0) == -1) {
+ jn->gleader = 0;
+ if (!(jn->stat & STAT_NOSTTY)) {
+ /*
+ * This PID was in control of the terminal;
+ * reclaim terminal now it has exited.
+ * It's still possible some future forked
+ * process of this job will become group
+ * leader, however.
+ */
+ attachtty(mypgrp);
+ }
+ }
+ }
+ update_job(jn);
+ } else if (findproc(pid, &jn, &pn, 1)) {
+ pn->status = status;
+ update_job(jn);
+ } else {
+ /* If not found, update the shell record of time spent by
+ * children in sub processes anyway: otherwise, this
+ * will get added on to the next found process that
+ * terminates.
+ */
+ get_usage();
+ }
+ /*
+ * Accumulate a list of older jobs. We only do this for
+ * background jobs, which is something in the job table
+ * that's not marked as in the current shell or as shell builtin
+ * and is not equal to the current foreground job.
+ */
+ if (jn && !(jn->stat & (STAT_CURSH|STAT_BUILTIN)) &&
+ jn - jobtab != thisjob) {
+ int val = (WIFSIGNALED(status) ?
+ 0200 | WTERMSIG(status) :
+ (WIFSTOPPED(status) ?
+ 0200 | WEXITSTATUS(status) :
+ WEXITSTATUS(status)));
+ addbgstatus(pid, val);
+ }
+
+ unqueue_signals();
+ }
+}
+
+/* the signal handler */
+
+/**/
+mod_export void
+zhandler(int sig)
+{
+ sigset_t newmask, oldmask;
+
+#if defined(NO_SIGNAL_BLOCKING)
+ int do_jump;
+ signal_jmp_buf jump_to;
+#endif
+
+ last_signal = sig;
+ signal_process(sig);
+
+ sigfillset(&newmask);
+ /* Block all signals temporarily */
+ oldmask = signal_block(newmask);
+
+#if defined(NO_SIGNAL_BLOCKING)
+ /* do we need to longjmp to signal_suspend */
+ do_jump = suspend_longjmp;
+ /* In case a SIGCHLD somehow arrives */
+ suspend_longjmp = 0;
+
+ /* Traps can cause nested signal_suspend() */
+ if (sig == SIGCHLD) {
+ if (do_jump) {
+ /* Copy suspend_jmp_buf */
+ jump_to = suspend_jmp_buf;
+ }
+ }
+#endif
+
+ /* Are we queueing signals now? */
+ if (queueing_enabled) {
+ int temp_rear = ++queue_rear % MAX_QUEUE_SIZE;
+
+ DPUTS(temp_rear == queue_front, "BUG: signal queue full");
+ /* Make sure it's not full (extremely unlikely) */
+ if (temp_rear != queue_front) {
+ /* ok, not full, so add to queue */
+ queue_rear = temp_rear;
+ /* save signal caught */
+ signal_queue[queue_rear] = sig;
+ /* save current signal mask */
+ signal_mask_queue[queue_rear] = oldmask;
+ }
+ signal_reset(sig);
+ return;
+ }
+
+ /* Reset signal mask, signal traps ok now */
+ signal_setmask(oldmask);
+
+ switch (sig) {
+ case SIGCHLD:
+ wait_for_processes();
+ break;
+
+ case SIGPIPE:
+ if (!handletrap(SIGPIPE)) {
+ if (!interact)
+ _exit(SIGPIPE);
+ else if (!isatty(SHTTY)) {
+ stopmsg = 1;
+ zexit(SIGPIPE, 1);
+ }
+ }
+ break;
+
+ case SIGHUP:
+ if (!handletrap(SIGHUP)) {
+ stopmsg = 1;
+ zexit(SIGHUP, 1);
+ }
+ break;
+
+ case SIGINT:
+ if (!handletrap(SIGINT)) {
+ if ((isset(PRIVILEGED) || isset(RESTRICTED)) &&
+ isset(INTERACTIVE) && (noerrexit & NOERREXIT_SIGNAL))
+ zexit(SIGINT, 1);
+ if (list_pipe || chline || simple_pline) {
+ breaks = loops;
+ errflag |= ERRFLAG_INT;
+ inerrflush();
+ check_cursh_sig(SIGINT);
+ }
+ lastval = 128 + SIGINT;
+ }
+ break;
+
+#ifdef SIGWINCH
+ case SIGWINCH:
+ adjustwinsize(1); /* check window size and adjust */
+ (void) handletrap(SIGWINCH);
+ break;
+#endif
+
+ case SIGALRM:
+ if (!handletrap(SIGALRM)) {
+ int idle = ttyidlegetfn(NULL);
+ int tmout = getiparam("TMOUT");
+ if (idle >= 0 && idle < tmout)
+ alarm(tmout - idle);
+ else {
+ /*
+ * We want to exit now.
+ * Cancel all errors, including a user interrupt
+ * which is now redundant.
+ */
+ errflag = noerrs = 0;
+ zwarn("timeout");
+ stopmsg = 1;
+ zexit(SIGALRM, 1);
+ }
+ }
+ break;
+
+ default:
+ (void) handletrap(sig);
+ break;
+ } /* end of switch(sig) */
+
+ signal_reset(sig);
+
+/* This is used to make signal_suspend() race-free */
+#if defined(NO_SIGNAL_BLOCKING)
+ if (do_jump)
+ signal_longjmp(jump_to, 1);
+#endif
+
+} /* handler */
+
+
+/* SIGHUP any jobs left running */
+
+/**/
+void
+killrunjobs(int from_signal)
+{
+ int i, killed = 0;
+
+ if (unset(HUP))
+ return;
+ for (i = 1; i <= maxjob; i++)
+ if ((from_signal || i != thisjob) && (jobtab[i].stat & STAT_LOCKED) &&
+ !(jobtab[i].stat & STAT_NOPRINT) &&
+ !(jobtab[i].stat & STAT_STOPPED)) {
+ if (jobtab[i].gleader != getpid() &&
+ killpg(jobtab[i].gleader, SIGHUP) != -1)
+ killed++;
+ }
+ if (killed)
+ zwarn("warning: %d jobs SIGHUPed", killed);
+}
+
+
+/* send a signal to a job (simply involves kill if monitoring is on) */
+
+/**/
+int
+killjb(Job jn, int sig)
+{
+ Process pn;
+ int err = 0;
+
+ if (jobbing) {
+ if (jn->stat & STAT_SUPERJOB) {
+ if (sig == SIGCONT) {
+ for (pn = jobtab[jn->other].procs; pn; pn = pn->next)
+ if (killpg(pn->pid, sig) == -1)
+ if (kill(pn->pid, sig) == -1 && errno != ESRCH)
+ err = -1;
+
+ /*
+ * Note this does not kill the last process,
+ * which is assumed to be the one controlling the
+ * subjob, i.e. the forked zsh that was originally
+ * list_pipe_pid...
+ */
+ for (pn = jn->procs; pn->next; pn = pn->next)
+ if (kill(pn->pid, sig) == -1 && errno != ESRCH)
+ err = -1;
+
+ /*
+ * ...we only continue that once the external processes
+ * currently associated with the subjob are finished.
+ */
+ if (!jobtab[jn->other].procs && pn)
+ if (kill(pn->pid, sig) == -1 && errno != ESRCH)
+ err = -1;
+
+ return err;
+ }
+ if (killpg(jobtab[jn->other].gleader, sig) == -1 && errno != ESRCH)
+ err = -1;
+
+ if (killpg(jn->gleader, sig) == -1 && errno != ESRCH)
+ err = -1;
+
+ return err;
+ }
+ else
+ return killpg(jn->gleader, sig);
+ }
+ for (pn = jn->procs; pn; pn = pn->next) {
+ /*
+ * Do not kill this job's process if it's already dead as its
+ * pid could have been reused by the system.
+ * As the PID doesn't exist don't return an error.
+ */
+ if (pn->status == SP_RUNNING || WIFSTOPPED(pn->status)) {
+ /*
+ * kill -0 on a job is pointless. We still call kill() for each process
+ * in case the user cares about it but we ignore its outcome.
+ */
+ if ((err = kill(pn->pid, sig)) == -1 && errno != ESRCH && sig != 0)
+ return -1;
+ }
+ }
+ return err;
+}
+
+/*
+ * List for saving traps. We don't usually have that many traps
+ * at once, so just use a linked list.
+ */
+struct savetrap {
+ int sig, flags, local, posix;
+ void *list;
+};
+
+static LinkList savetraps;
+static int dontsavetrap;
+
+/*
+ * Save the current trap by copying it. This does nothing to
+ * the existing value of sigtrapped or siglists.
+ */
+
+static void
+dosavetrap(int sig, int level)
+{
+ struct savetrap *st;
+ st = (struct savetrap *)zalloc(sizeof(*st));
+ st->sig = sig;
+ st->local = level;
+ st->posix = (sig == SIGEXIT) ? exit_trap_posix : 0;
+ if ((st->flags = sigtrapped[sig]) & ZSIG_FUNC) {
+ /*
+ * Get the old function: this assumes we haven't added
+ * the new one yet.
+ */
+ Shfunc shf, newshf = NULL;
+ if ((shf = (Shfunc)gettrapnode(sig, 1))) {
+ /* Copy the node for saving */
+ newshf = (Shfunc) zshcalloc(sizeof(*newshf));
+ newshf->node.nam = ztrdup(shf->node.nam);
+ newshf->node.flags = shf->node.flags;
+ newshf->funcdef = dupeprog(shf->funcdef, 0);
+ if (shf->node.flags & PM_LOADDIR) {
+ dircache_set(&newshf->filename, shf->filename);
+ } else {
+ newshf->filename = ztrdup(shf->filename);
+ }
+ if (shf->sticky) {
+ newshf->sticky = sticky_emulation_dup(shf->sticky, 0);
+ } else
+ newshf->sticky = 0;
+ if (shf->node.flags & PM_UNDEFINED)
+ newshf->funcdef->shf = newshf;
+ }
+#ifdef DEBUG
+ else dputs("BUG: no function present with function trap flag set.");
+#endif
+ DPUTS(siglists[sig], "BUG: function signal has eval list, too.");
+ st->list = newshf;
+ } else if (sigtrapped[sig]) {
+ st->list = siglists[sig] ? dupeprog(siglists[sig], 0) : NULL;
+ } else {
+ DPUTS(siglists[sig], "BUG: siglists not null for untrapped signal");
+ st->list = NULL;
+ }
+ if (!savetraps)
+ savetraps = znewlinklist();
+ /*
+ * Put this at the front of the list
+ */
+ zinsertlinknode(savetraps, (LinkNode)savetraps, st);
+}
+
+
+/*
+ * Set a trap: note this does not handle manipulation of
+ * the function table for TRAPNAL functions.
+ *
+ * sig is the signal number.
+ *
+ * l is the list to be eval'd for a trap defined with the "trap"
+ * builtin and should be NULL for a function trap.
+ *
+ * flags includes any additional flags to be or'd into sigtrapped[sig],
+ * in particular ZSIG_FUNC; the basic flags will be assigned within
+ * settrap.
+ */
+
+/**/
+mod_export int
+settrap(int sig, Eprog l, int flags)
+{
+ if (sig == -1)
+ return 1;
+ if (jobbing && (sig == SIGTTOU || sig == SIGTSTP || sig == SIGTTIN)) {
+ zerr("can't trap SIG%s in interactive shells", sigs[sig]);
+ return 1;
+ }
+
+ /*
+ * Call unsettrap() unconditionally, to make sure trap is saved
+ * if necessary.
+ */
+ queue_signals();
+ unsettrap(sig);
+
+ DPUTS((flags & ZSIG_FUNC) && l,
+ "BUG: trap function has passed eval list, too");
+ siglists[sig] = l;
+ if (!(flags & ZSIG_FUNC) && empty_eprog(l)) {
+ sigtrapped[sig] = ZSIG_IGNORED;
+ if (sig && sig <= SIGCOUNT &&
+#ifdef SIGWINCH
+ sig != SIGWINCH &&
+#endif
+ sig != SIGCHLD)
+ signal_ignore(sig);
+ } else {
+ nsigtrapped++;
+ sigtrapped[sig] = ZSIG_TRAPPED;
+ if (sig && sig <= SIGCOUNT &&
+#ifdef SIGWINCH
+ sig != SIGWINCH &&
+#endif
+ sig != SIGCHLD)
+ install_handler(sig);
+ }
+ sigtrapped[sig] |= flags;
+ /*
+ * Note that introducing the locallevel does not affect whether
+ * sigtrapped[sig] is zero or not, i.e. a test without a mask
+ * works just the same.
+ */
+ if (sig == SIGEXIT) {
+ /* Make POSIX behaviour of EXIT trap sticky */
+ exit_trap_posix = isset(POSIXTRAPS);
+ /* POSIX exit traps are not local. */
+ if (!exit_trap_posix)
+ sigtrapped[sig] |= (locallevel << ZSIG_SHIFT);
+ }
+ else
+ sigtrapped[sig] |= (locallevel << ZSIG_SHIFT);
+ unqueue_signals();
+ return 0;
+}
+
+/**/
+void
+unsettrap(int sig)
+{
+ HashNode hn;
+
+ queue_signals();
+ hn = removetrap(sig);
+ if (hn)
+ shfunctab->freenode(hn);
+ unqueue_signals();
+}
+
+/**/
+HashNode
+removetrap(int sig)
+{
+ int trapped;
+
+ if (sig == -1 ||
+ (jobbing && (sig == SIGTTOU || sig == SIGTSTP || sig == SIGTTIN)))
+ return NULL;
+
+ queue_signals();
+ trapped = sigtrapped[sig];
+ /*
+ * Note that we save the trap here even if there isn't an existing
+ * one, to aid in removing this one. However, if there's
+ * already one at the current locallevel we just overwrite it.
+ *
+ * Note we save EXIT traps based on the *current* setting of
+ * POSIXTRAPS --- so if there is POSIX EXIT trap set but
+ * we are in native mode it can be saved, replaced by a function
+ * trap, and then restored.
+ */
+ if (!dontsavetrap &&
+ (sig == SIGEXIT ? !isset(POSIXTRAPS) : isset(LOCALTRAPS)) &&
+ locallevel &&
+ (!trapped || locallevel > (sigtrapped[sig] >> ZSIG_SHIFT)))
+ dosavetrap(sig, locallevel);
+
+ if (!trapped) {
+ unqueue_signals();
+ return NULL;
+ }
+ if (sigtrapped[sig] & ZSIG_TRAPPED)
+ nsigtrapped--;
+ sigtrapped[sig] = 0;
+ if (sig == SIGINT && interact) {
+ /* PWS 1995/05/16: added test for interactive, also noholdintr() *
+ * as subshells ignoring SIGINT have it blocked from delivery */
+ intr();
+ noholdintr();
+ } else if (sig == SIGHUP)
+ install_handler(sig);
+ else if (sig == SIGPIPE && interact && !forklevel)
+ install_handler(sig);
+ else if (sig && sig <= SIGCOUNT &&
+#ifdef SIGWINCH
+ sig != SIGWINCH &&
+#endif
+ sig != SIGCHLD)
+ signal_default(sig);
+ if (sig == SIGEXIT)
+ exit_trap_posix = 0;
+
+ /*
+ * At this point we free the appropriate structs. If we don't
+ * want that to happen then either the function should already have been
+ * removed from shfunctab, or the entry in siglists should have been set
+ * to NULL. This is no longer necessary for saving traps as that
+ * copies the structures, so here we are remove the originals.
+ * That causes a little inefficiency, but a good deal more reliability.
+ */
+ if (trapped & ZSIG_FUNC) {
+ HashNode node = gettrapnode(sig, 1);
+
+ /*
+ * As in dosavetrap(), don't call removeshfuncnode() because
+ * that calls back into unsettrap();
+ */
+ if (node)
+ removehashnode(shfunctab, node->nam);
+ unqueue_signals();
+
+ return node;
+ } else if (siglists[sig]) {
+ freeeprog(siglists[sig]);
+ siglists[sig] = NULL;
+ }
+ unqueue_signals();
+
+ return NULL;
+}
+
+/**/
+void
+starttrapscope(void)
+{
+ /* No special SIGEXIT behaviour inside another trap. */
+ if (intrap)
+ return;
+
+ /*
+ * SIGEXIT needs to be restored at the current locallevel,
+ * so give it the next higher one. dosavetrap() is called
+ * automatically where necessary.
+ */
+ if (sigtrapped[SIGEXIT] && !exit_trap_posix) {
+ locallevel++;
+ unsettrap(SIGEXIT);
+ locallevel--;
+ }
+}
+
+/*
+ * Reset traps after the end of a function: must be called after
+ * endparamscope() so that the locallevel has been decremented.
+ */
+
+/**/
+void
+endtrapscope(void)
+{
+ LinkNode ln;
+ struct savetrap *st;
+ int exittr = 0;
+ void *exitfn = NULL;
+
+ /*
+ * Remember the exit trap, but don't run it until
+ * after all the other traps have been put back.
+ * Don't do this inside another trap.
+ */
+ if (!intrap &&
+ !exit_trap_posix && (exittr = sigtrapped[SIGEXIT])) {
+ if (exittr & ZSIG_FUNC) {
+ exitfn = removehashnode(shfunctab, "TRAPEXIT");
+ } else {
+ exitfn = siglists[SIGEXIT];
+ siglists[SIGEXIT] = NULL;
+ }
+ if (sigtrapped[SIGEXIT] & ZSIG_TRAPPED)
+ nsigtrapped--;
+ sigtrapped[SIGEXIT] = 0;
+ }
+
+ if (savetraps) {
+ while ((ln = firstnode(savetraps)) &&
+ (st = (struct savetrap *) ln->dat) &&
+ st->local > locallevel) {
+ int sig = st->sig;
+
+ remnode(savetraps, ln);
+
+ if (st->flags && (st->list != NULL)) {
+ /* prevent settrap from saving this */
+ dontsavetrap++;
+ if (st->flags & ZSIG_FUNC)
+ settrap(sig, NULL, ZSIG_FUNC);
+ else
+ settrap(sig, (Eprog) st->list, 0);
+ if (sig == SIGEXIT)
+ exit_trap_posix = st->posix;
+ dontsavetrap--;
+ /*
+ * counting of nsigtrapped should presumably be handled
+ * in settrap...
+ */
+ DPUTS((sigtrapped[sig] ^ st->flags) & ZSIG_TRAPPED,
+ "BUG: settrap didn't restore correct ZSIG_TRAPPED");
+ if ((sigtrapped[sig] = st->flags) & ZSIG_FUNC)
+ shfunctab->addnode(shfunctab, ((Shfunc)st->list)->node.nam,
+ (Shfunc) st->list);
+ } else if (sigtrapped[sig]) {
+ /*
+ * Don't restore the old state if someone has set a
+ * POSIX-style exit trap --- allow this to propagate.
+ */
+ if (sig != SIGEXIT || !exit_trap_posix)
+ unsettrap(sig);
+ }
+
+ zfree(st, sizeof(*st));
+ }
+ }
+
+ if (exittr) {
+ /*
+ * We already made sure this wasn't set as a POSIX exit trap.
+ * We respect the user's intention when the trap in question
+ * was set.
+ */
+ dotrapargs(SIGEXIT, &exittr, exitfn);
+ if (exittr & ZSIG_FUNC)
+ shfunctab->freenode((HashNode)exitfn);
+ else
+ freeeprog(exitfn);
+ }
+ DPUTS(!locallevel && savetraps && firstnode(savetraps),
+ "BUG: still saved traps outside all function scope");
+}
+
+
+/*
+ * Decide whether a trap needs handling.
+ * If so, see if the trap should be run now or queued.
+ * Return 1 if the trap has been or will be handled.
+ * This only needs to be called in place of dotrap() in the
+ * signal handler, since it's only while waiting for children
+ * to exit that we queue traps.
+ */
+/**/
+static int
+handletrap(int sig)
+{
+ if (!sigtrapped[sig])
+ return 0;
+
+ if (trap_queueing_enabled)
+ {
+ /* Code borrowed from signal queueing */
+ int temp_rear = ++trap_queue_rear % MAX_QUEUE_SIZE;
+
+ DPUTS(temp_rear == trap_queue_front, "BUG: trap queue full");
+ /* If queue is not full... */
+ if (temp_rear != trap_queue_front) {
+ trap_queue_rear = temp_rear;
+ trap_queue[trap_queue_rear] = sig;
+ }
+ return 1;
+ }
+
+ dotrap(sig);
+
+ if (sig == SIGALRM)
+ {
+ int tmout;
+ /*
+ * Reset the alarm.
+ * It seems slightly more natural to do this when the
+ * trap is run, rather than when it's queued, since
+ * the user doesn't see the latter.
+ */
+ if ((tmout = getiparam("TMOUT")))
+ alarm(tmout);
+ }
+
+ return 1;
+}
+
+
+/*
+ * Queue traps if they shouldn't be run asynchronously, i.e.
+ * we're not in the wait builtin and TRAPSASYNC isn't set, when
+ * waiting for children to exit.
+ *
+ * Note that unlike signal queuing this should only be called
+ * in single matching pairs and can't be nested. It is
+ * only needed when waiting for a job or process to finish.
+ *
+ * There is presumably a race setting this up: we shouldn't be running
+ * traps between forking a foreground process and this point, either.
+ */
+/**/
+void
+queue_traps(int wait_cmd)
+{
+ if (!isset(TRAPSASYNC) && !wait_cmd) {
+ /*
+ * Traps need to be handled synchronously, so
+ * enable queueing.
+ */
+ trap_queueing_enabled = 1;
+ }
+}
+
+
+/*
+ * Disable trap queuing and run the traps.
+ */
+/**/
+void
+unqueue_traps(void)
+{
+ trap_queueing_enabled = 0;
+ while (trap_queue_front != trap_queue_rear) {
+ trap_queue_front = (trap_queue_front + 1) % MAX_QUEUE_SIZE;
+ (void) handletrap(trap_queue[trap_queue_front]);
+ }
+}
+
+
+/* Execute a trap function for a given signal, possibly
+ * with non-standard sigtrapped & siglists values
+ */
+
+/* Are we already executing a trap? */
+/**/
+int intrap;
+
+/* Is the current trap a function? */
+
+/**/
+int trapisfunc;
+
+/*
+ * If the current trap is not a function, at what function depth
+ * did the trap get called?
+ */
+/**/
+int traplocallevel;
+
+/*
+ * sig is the signal number.
+ * *sigtr is the value to be taken as the field in sigtrapped (since
+ * that may have changed by this point if we are exiting).
+ * sigfn is an Eprog with a non-function eval list, or a Shfunc
+ * with a function trap. It may be NULL with an ignored signal.
+ */
+
+/**/
+static void
+dotrapargs(int sig, int *sigtr, void *sigfn)
+{
+ LinkList args;
+ char *name, num[4];
+ int obreaks = breaks;
+ int oretflag = retflag;
+ int olastval = lastval;
+ int isfunc;
+ int traperr, new_trap_state, new_trap_return;
+
+ /* if signal is being ignored or the trap function *
+ * is NULL, then return *
+ * *
+ * Also return if errflag is set. In fact, the code in the *
+ * function will test for this, but this way we keep status flags *
+ * intact without working too hard. Special cases (e.g. calling *
+ * a trap for SIGINT after the error flag was set) are handled *
+ * by the calling code. (PWS 1995/06/08). *
+ * *
+ * This test is now replicated in dotrap(). */
+ if ((*sigtr & ZSIG_IGNORED) || !sigfn || errflag)
+ return;
+
+ /*
+ * Never execute special (synchronous) traps inside other traps.
+ * This can cause unexpected code execution when more than one
+ * of these is set.
+ *
+ * The down side is that it's harder to debug traps. I don't think
+ * that's a big issue.
+ */
+ if (intrap) {
+ switch (sig) {
+ case SIGEXIT:
+ case SIGDEBUG:
+ case SIGZERR:
+ return;
+ }
+ }
+
+ queue_signals(); /* Any time we manage memory or global state */
+
+ intrap++;
+ *sigtr |= ZSIG_IGNORED;
+
+ zcontext_save();
+ /* execsave will save the old trap_return and trap_state */
+ execsave();
+ breaks = retflag = 0;
+ traplocallevel = locallevel;
+ runhookdef(BEFORETRAPHOOK, NULL);
+ if (*sigtr & ZSIG_FUNC) {
+ int osc = sfcontext, old_incompfunc = incompfunc;
+ HashNode hn = gettrapnode(sig, 0);
+
+ args = znewlinklist();
+ /*
+ * In case of multiple names, try to get
+ * a hint of the name in use from the function table.
+ * In special cases, e.g. EXIT traps, the function
+ * has already been removed. Then it's OK to
+ * use the standard name.
+ */
+ if (hn) {
+ name = ztrdup(hn->nam);
+ } else {
+ name = (char *) zalloc(5 + strlen(sigs[sig]));
+ sprintf(name, "TRAP%s", sigs[sig]);
+ }
+ zaddlinknode(args, name);
+ sprintf(num, "%d", sig);
+ zaddlinknode(args, num);
+
+ trap_return = -1; /* incremented by doshfunc */
+ trap_state = TRAP_STATE_PRIMED;
+ trapisfunc = isfunc = 1;
+
+ sfcontext = SFC_SIGNAL;
+ incompfunc = 0;
+ doshfunc((Shfunc)sigfn, args, 1); /* manages signal queueing */
+ sfcontext = osc;
+ incompfunc= old_incompfunc;
+ freelinklist(args, (FreeFunc) NULL);
+ zsfree(name);
+ } else {
+ trap_return = -2; /* not incremented, used at current level */
+ trap_state = TRAP_STATE_PRIMED;
+ trapisfunc = isfunc = 0;
+
+ execode((Eprog)sigfn, 1, 0, "trap"); /* manages signal queueing */
+ }
+ runhookdef(AFTERTRAPHOOK, NULL);
+
+ traperr = errflag;
+
+ /* Grab values before they are restored */
+ new_trap_state = trap_state;
+ new_trap_return = trap_return;
+
+ execrestore();
+ zcontext_restore();
+
+ if (new_trap_state == TRAP_STATE_FORCE_RETURN &&
+ /* zero return from function isn't special */
+ !(isfunc && new_trap_return == 0)) {
+ if (isfunc) {
+ breaks = loops;
+ /*
+ * For SIGINT we behave the same as the default behaviour
+ * i.e. we set the error bit indicating an interrupt.
+ * We do this with SIGQUIT, too, even though we don't
+ * handle SIGQUIT by default. That's to try to make
+ * it behave a bit more like its normal behaviour when
+ * the trap handler has told us that's what it wants.
+ */
+ if (sig == SIGINT || sig == SIGQUIT)
+ errflag |= ERRFLAG_INT;
+ else
+ errflag |= ERRFLAG_ERROR;
+ }
+ lastval = new_trap_return;
+ /* return triggered */
+ retflag = 1;
+ } else {
+ if (traperr && !EMULATION(EMULATE_SH))
+ lastval = 1;
+ else {
+ /*
+ * With no explicit forced return, we keep the
+ * lastval from before the trap ran.
+ */
+ lastval = olastval;
+ }
+ if (try_tryflag) {
+ if (traperr)
+ errflag |= ERRFLAG_ERROR;
+ else
+ errflag &= ~ERRFLAG_ERROR;
+ }
+ breaks += obreaks;
+ /* return not triggered: restore old flag */
+ retflag = oretflag;
+ if (breaks > loops)
+ breaks = loops;
+ }
+
+ /*
+ * If zle was running while the trap was executed, see if we
+ * need to restore the display.
+ */
+ if (zleactive && resetneeded)
+ zleentry(ZLE_CMD_REFRESH);
+
+ if (*sigtr != ZSIG_IGNORED)
+ *sigtr &= ~ZSIG_IGNORED;
+ intrap--;
+
+ unqueue_signals();
+}
+
+/* Standard call to execute a trap for a given signal. */
+
+/**/
+void
+dotrap(int sig)
+{
+ void *funcprog;
+ int q = queue_signal_level();
+
+ if (sigtrapped[sig] & ZSIG_FUNC) {
+ HashNode hn = gettrapnode(sig, 0);
+ if (hn)
+ funcprog = hn;
+ else {
+#ifdef DEBUG
+ dputs("BUG: running function trap which has escaped.");
+#endif
+ funcprog = NULL;
+ }
+ } else
+ funcprog = siglists[sig];
+
+ /*
+ * Copied from dotrapargs().
+ * (In fact, the gain from duplicating this appears to be virtually
+ * zero. Not sure why it's here.)
+ */
+ if ((sigtrapped[sig] & ZSIG_IGNORED) || !funcprog || errflag)
+ return;
+
+ dont_queue_signals();
+
+ if (sig == SIGEXIT)
+ ++in_exit_trap;
+
+ dotrapargs(sig, sigtrapped+sig, funcprog);
+
+ if (sig == SIGEXIT)
+ --in_exit_trap;
+
+ restore_queue_signals(q);
+}
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/signals.h b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/signals.h
new file mode 100644
index 0000000..41ac88c
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/signals.h
@@ -0,0 +1,142 @@
+/*
+ * signals.h - header file for signals handling code
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+#define SIGNAL_HANDTYPE void (*)_((int))
+
+#ifndef HAVE_KILLPG
+# define killpg(pgrp,sig) kill(-(pgrp),sig)
+#endif
+
+#define SIGZERR (SIGCOUNT+1)
+#define SIGDEBUG (SIGCOUNT+2)
+#define VSIGCOUNT (SIGCOUNT+3)
+#define SIGEXIT 0
+
+#ifdef SV_BSDSIG
+# define SV_INTERRUPT SV_BSDSIG
+#endif
+
+/* If not a POSIX machine, then we create our *
+ * own POSIX style signal sets functions. */
+#ifndef POSIX_SIGNALS
+# define sigemptyset(s) (*(s) = 0)
+# if NSIG == 32
+# define sigfillset(s) (*(s) = ~(sigset_t)0, 0)
+# else
+# define sigfillset(s) (*(s) = (1 << NSIG) - 1, 0)
+# endif
+# define sigaddset(s,n) (*(s) |= (1 << ((n) - 1)), 0)
+# define sigdelset(s,n) (*(s) &= ~(1 << ((n) - 1)), 0)
+# define sigismember(s,n) ((*(s) & (1 << ((n) - 1))) != 0)
+#endif /* ifndef POSIX_SIGNALS */
+
+#define child_block() signal_block(sigchld_mask)
+#define child_unblock() signal_unblock(sigchld_mask)
+
+#ifdef SIGWINCH
+# define winch_block() signal_block(signal_mask(SIGWINCH))
+# define winch_unblock() signal_unblock(signal_mask(SIGWINCH))
+#else
+# define winch_block() 0
+# define winch_unblock() 0
+#endif
+
+/* ignore a signal */
+#define signal_ignore(S) signal(S, SIG_IGN)
+
+/* return a signal to it default action */
+#define signal_default(S) signal(S, SIG_DFL)
+
+/* Use a circular queue to save signals caught during *
+ * critical sections of code. You call queue_signals to *
+ * start queueing, and unqueue_signals to process the *
+ * queue and stop queueing. Since the kernel doesn't *
+ * queue signals, it is probably overkill for zsh to do *
+ * this, but it shouldn't hurt anything to do it anyway. */
+
+#define MAX_QUEUE_SIZE 128
+
+#define run_queued_signals() do { \
+ while (queue_front != queue_rear) { /* while signals in queue */ \
+ sigset_t oset; \
+ queue_front = (queue_front + 1) % MAX_QUEUE_SIZE; \
+ oset = signal_setmask(signal_mask_queue[queue_front]); \
+ zhandler(signal_queue[queue_front]); /* handle queued signal */ \
+ signal_setmask(oset); \
+ } \
+} while (0)
+
+#ifdef DEBUG
+
+#define queue_signals() (queue_in++, queueing_enabled++)
+
+#define unqueue_signals() do { \
+ DPUTS(!queueing_enabled, "BUG: unqueue_signals called but not queueing"); \
+ --queue_in; \
+ if (!--queueing_enabled) run_queued_signals(); \
+} while (0)
+
+#define dont_queue_signals() do { \
+ queue_in = queueing_enabled; \
+ queueing_enabled = 0; \
+ run_queued_signals(); \
+} while (0)
+
+#define restore_queue_signals(q) do { \
+ DPUTS2(queueing_enabled && queue_in != q, \
+ "BUG: q = %d != queue_in = %d", q, queue_in); \
+ queue_in = (queueing_enabled = (q)); \
+} while (0)
+
+#else /* !DEBUG */
+
+#define queue_signals() (queueing_enabled++)
+
+#define unqueue_signals() do { \
+ if (!--queueing_enabled) run_queued_signals(); \
+} while (0)
+
+#define dont_queue_signals() do { \
+ queueing_enabled = 0; \
+ run_queued_signals(); \
+} while (0)
+
+#define restore_queue_signals(q) (queueing_enabled = (q))
+
+#endif /* DEBUG */
+
+#define queue_signal_level() queueing_enabled
+
+#ifdef BSD_SIGNALS
+#define signal_block(S) sigblock(S)
+#else
+extern sigset_t signal_block _((sigset_t));
+#endif /* BSD_SIGNALS */
+
+extern sigset_t signal_unblock _((sigset_t));
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/signames1.awk b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/signames1.awk
new file mode 100644
index 0000000..27d21ac
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/signames1.awk
@@ -0,0 +1,19 @@
+# This is an awk script which finds out what the possibilities for
+# the signal names are, and dumps them out so that cpp can turn them
+# into numbers. Since we don't need to decide here what the
+# real signals are, we can afford to be generous about definitions,
+# in case the definitions are in terms of other definitions.
+# However, we need to avoid definitions with parentheses, which will
+# mess up the syntax.
+BEGIN { printf "#include \n\n" }
+
+/^[\t ]*#[\t ]*define[\t _]*SIG[A-Z][A-Z0-9]*[\t ][\t ]*[^(\t ]/ {
+ sigindex = index($0, "SIG")
+ sigtail = substr($0, sigindex, 80)
+ split(sigtail, tmp)
+ signam = substr(tmp[1], 4, 20)
+ if (substr($0, sigindex-1, 1) == "_")
+ printf("XXNAMES XXSIG%s _SIG%s\n", signam, signam)
+ else
+ printf("XXNAMES XXSIG%s SIG%s\n", signam, signam)
+}
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/signames2.awk b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/signames2.awk
new file mode 100644
index 0000000..4d15681
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/signames2.awk
@@ -0,0 +1,106 @@
+#
+# {g,n}awk script to generate signames.c
+# This version relies on the previous output of the preprocessor
+# on sigtmp.c, sigtmp.out, which is in turn generated by signames1.awk.
+#
+# NB: On SunOS 4.1.3 - user-functions don't work properly, also \" problems
+# Without 0 + hacks some nawks compare numbers as strings
+#
+/^[\t ]*XXNAMES XXSIG[A-Z][A-Z0-9]*[\t ][\t ]*[1-9][0-9]*/ {
+ sigindex = index($0, "SIG")
+ sigtail = substr($0, sigindex, 80)
+ split(sigtail, tmp)
+ signam = substr(tmp[1], 4, 20)
+ signum = tmp[2]
+ if (signam == "CHLD" && sig[signum] == "CLD") sig[signum] = ""
+ if (signam == "POLL" && sig[signum] == "IO") sig[signum] = ""
+ if (sig[signum] == "") {
+ sig[signum] = signam
+ if (0 + max < 0 + signum && signum < 60)
+ max = signum
+ if (signam == "ABRT") { msg[signum] = "abort" }
+ if (signam == "ALRM") { msg[signum] = "alarm" }
+ if (signam == "BUS") { msg[signum] = "bus error" }
+ if (signam == "CHLD") { msg[signum] = "death of child" }
+ if (signam == "CLD") { msg[signum] = "death of child" }
+ if (signam == "CONT") { msg[signum] = "continued" }
+ if (signam == "EMT") { msg[signum] = "EMT instruction" }
+ if (signam == "FPE") { msg[signum] = "floating point exception" }
+ if (signam == "HUP") { msg[signum] = "hangup" }
+ if (signam == "ILL") { msg[signum] = "illegal hardware instruction" }
+ if (signam == "INFO") { msg[signum] = "status request from keyboard" }
+ if (signam == "INT") { msg[signum] = "interrupt" }
+ if (signam == "IO") { msg[signum] = "i/o ready" }
+ if (signam == "IOT") { msg[signum] = "IOT instruction" }
+ if (signam == "KILL") { msg[signum] = "killed" }
+ if (signam == "LOST") { msg[signum] = "resource lost" }
+ if (signam == "PIPE") { msg[signum] = "broken pipe" }
+ if (signam == "POLL") { msg[signum] = "pollable event occurred" }
+ if (signam == "PROF") { msg[signum] = "profile signal" }
+ if (signam == "PWR") { msg[signum] = "power fail" }
+ if (signam == "QUIT") { msg[signum] = "quit" }
+ if (signam == "SEGV") { msg[signum] = "segmentation fault" }
+ if (signam == "SYS") { msg[signum] = "invalid system call" }
+ if (signam == "TERM") { msg[signum] = "terminated" }
+ if (signam == "TRAP") { msg[signum] = "trace trap" }
+ if (signam == "URG") { msg[signum] = "urgent condition" }
+ if (signam == "USR1") { msg[signum] = "user-defined signal 1" }
+ if (signam == "USR2") { msg[signum] = "user-defined signal 2" }
+ if (signam == "VTALRM") { msg[signum] = "virtual time alarm" }
+ if (signam == "WINCH") { msg[signum] = "window size changed" }
+ if (signam == "XCPU") { msg[signum] = "cpu limit exceeded" }
+ if (signam == "XFSZ") { msg[signum] = "file size limit exceeded" }
+ }
+}
+
+END {
+ ps = "%s"
+ ifdstr = sprintf("# ifdef USE_SUSPENDED\n\t%csuspended%s%c,\n%s else\n\t%cstopped%s%c,\n# endif\n", 34, ps, 34, "#", 34, ps, 34)
+
+ printf "/** signames.c **/\n"
+ printf "/** architecture-customized signames.c for zsh **/\n"
+ printf "\n"
+ printf "#define SIGCOUNT\t%d\n", max
+ printf "\n"
+ printf "#include %czsh.mdh%c\n", 34, 34
+ printf "\n"
+ printf "/**/\n"
+ printf "#define sigmsg(sig) ((sig) <= SIGCOUNT ? sig_msg[sig]"
+ printf " : %c%s%c)", 34, "unknown signal", 34
+ printf "\n"
+ printf "/**/\n"
+ printf "mod_export char *sig_msg[SIGCOUNT+2] = {\n"
+ printf "\t%c%s%c,\n", 34, "done", 34
+
+ for (i = 1; i <= 0 + max; i++)
+ if (msg[i] == "") {
+ if (sig[i] == "")
+ printf("\t%c%c,\n", 34, 34)
+ else if (sig[i] == "STOP")
+ printf ifdstr, " (signal)", " (signal)"
+ else if (sig[i] == "TSTP")
+ printf ifdstr, "", ""
+ else if (sig[i] == "TTIN")
+ printf ifdstr, " (tty input)", " (tty input)"
+ else if (sig[i] == "TTOU")
+ printf ifdstr, " (tty output)", " (tty output)"
+ else
+ printf("\t%cSIG%s%c,\n", 34, sig[i], 34)
+ } else
+ printf("\t%c%s%c,\n", 34, msg[i], 34)
+ print "\tNULL"
+ print "};"
+ print ""
+ print "/**/"
+ printf "char *sigs[SIGCOUNT+4] = {\n"
+ printf("\t%cEXIT%c,\n", 34, 34)
+ for (i = 1; i <= 0 + max; i++)
+ if (sig[i] == "")
+ printf("\t%c%d%c,\n", 34, i, 34)
+ else
+ printf("\t%c%s%c,\n", 34, sig[i], 34)
+ printf("\t%cZERR%c,\n", 34, 34)
+ printf("\t%cDEBUG%c,\n", 34, 34)
+ print "\tNULL"
+ print "};"
+}
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/string.c b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/string.c
new file mode 100644
index 0000000..9e14ef9
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/string.c
@@ -0,0 +1,213 @@
+/*
+ * string.c - string manipulation
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 2000 Peter Stephenson
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Peter Stephenson or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Peter Stephenson and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Peter Stephenson and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Peter Stephenson and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ */
+
+#include "zsh.mdh"
+
+/**/
+mod_export char *
+dupstring(const char *s)
+{
+ char *t;
+
+ if (!s)
+ return NULL;
+ t = (char *) zhalloc(strlen((char *)s) + 1);
+ strcpy(t, s);
+ return t;
+}
+
+/* Duplicate string on heap when length is known */
+
+/**/
+mod_export char *
+dupstring_wlen(const char *s, unsigned len)
+{
+ char *t;
+
+ if (!s)
+ return NULL;
+ t = (char *) zhalloc(len + 1);
+ memcpy(t, s, len);
+ t[len] = '\0';
+ return t;
+}
+
+/* Duplicate string on heap, returning length of string */
+
+/**/
+mod_export char *
+dupstring_glen(const char *s, unsigned *len_ret)
+{
+ char *t;
+
+ if (!s)
+ return NULL;
+ t = (char *) zhalloc((*len_ret = strlen((char *)s)) + 1);
+ strcpy(t, s);
+ return t;
+}
+
+/**/
+mod_export char *
+ztrdup(const char *s)
+{
+ char *t;
+
+ if (!s)
+ return NULL;
+ t = (char *)zalloc(strlen((char *)s) + 1);
+ strcpy(t, s);
+ return t;
+}
+
+/**/
+#ifdef MULTIBYTE_SUPPORT
+/**/
+mod_export wchar_t *
+wcs_ztrdup(const wchar_t *s)
+{
+ wchar_t *t;
+
+ if (!s)
+ return NULL;
+ t = (wchar_t *)zalloc(sizeof(wchar_t) * (wcslen((wchar_t *)s) + 1));
+ wcscpy(t, s);
+ return t;
+}
+/**/
+#endif /* MULTIBYTE_SUPPORT */
+
+
+/* concatenate s1, s2, and s3 in dynamically allocated buffer */
+
+/**/
+mod_export char *
+tricat(char const *s1, char const *s2, char const *s3)
+{
+ /* This version always uses permanently-allocated space. */
+ char *ptr;
+ size_t l1 = strlen(s1);
+ size_t l2 = strlen(s2);
+
+ ptr = (char *)zalloc(l1 + l2 + strlen(s3) + 1);
+ strcpy(ptr, s1);
+ strcpy(ptr + l1, s2);
+ strcpy(ptr + l1 + l2, s3);
+ return ptr;
+}
+
+/**/
+mod_export char *
+zhtricat(char const *s1, char const *s2, char const *s3)
+{
+ char *ptr;
+ size_t l1 = strlen(s1);
+ size_t l2 = strlen(s2);
+
+ ptr = (char *)zhalloc(l1 + l2 + strlen(s3) + 1);
+ strcpy(ptr, s1);
+ strcpy(ptr + l1, s2);
+ strcpy(ptr + l1 + l2, s3);
+ return ptr;
+}
+
+/* concatenate s1 and s2 in dynamically allocated buffer */
+
+/**/
+mod_export char *
+dyncat(const char *s1, const char *s2)
+{
+ /* This version always uses space from the current heap. */
+ char *ptr;
+ size_t l1 = strlen(s1);
+
+ ptr = (char *)zhalloc(l1 + strlen(s2) + 1);
+ strcpy(ptr, s1);
+ strcpy(ptr + l1, s2);
+ return ptr;
+}
+
+/**/
+mod_export char *
+bicat(const char *s1, const char *s2)
+{
+ /* This version always uses permanently-allocated space. */
+ char *ptr;
+ size_t l1 = strlen(s1);
+
+ ptr = (char *)zalloc(l1 + strlen(s2) + 1);
+ strcpy(ptr, s1);
+ strcpy(ptr + l1, s2);
+ return ptr;
+}
+
+/* like dupstring(), but with a specified length */
+
+/**/
+mod_export char *
+dupstrpfx(const char *s, int len)
+{
+ char *r = zhalloc(len + 1);
+
+ memcpy(r, s, len);
+ r[len] = '\0';
+ return r;
+}
+
+/**/
+mod_export char *
+ztrduppfx(const char *s, int len)
+{
+ /* This version always uses permanently-allocated space. */
+ char *r = zalloc(len + 1);
+
+ memcpy(r, s, len);
+ r[len] = '\0';
+ return r;
+}
+
+/* Append a string to an allocated string, reallocating to make room. */
+
+/**/
+mod_export char *
+appstr(char *base, char const *append)
+{
+ return strcat(realloc(base, strlen(base) + strlen(append) + 1), append);
+}
+
+/* Return a pointer to the last character of a string,
+ unless the string is empty. */
+
+/**/
+mod_export char *
+strend(char *str)
+{
+ if (*str == '\0')
+ return str;
+ return str + strlen (str) - 1;
+}
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/utils.c b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/utils.c
new file mode 100644
index 0000000..075d272
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/utils.c
@@ -0,0 +1,7520 @@
+/*
+ * utils.c - miscellaneous utilities
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+#include "zsh.mdh"
+#include "utils.pro"
+
+/* name of script being sourced */
+
+/**/
+mod_export char *scriptname; /* is sometimes a function name */
+
+/* filename of script or other file containing code source e.g. autoload */
+
+/**/
+mod_export char *scriptfilename;
+
+/* != 0 if we are in a new style completion function */
+
+/**/
+mod_export int incompfunc;
+
+#ifdef MULTIBYTE_SUPPORT
+struct widechar_array {
+ wchar_t *chars;
+ size_t len;
+};
+typedef struct widechar_array *Widechar_array;
+
+/*
+ * The wordchars variable turned into a wide character array.
+ * This is much more convenient for testing.
+ */
+static struct widechar_array wordchars_wide;
+
+/*
+ * The same for the separators (IFS) array.
+ */
+static struct widechar_array ifs_wide;
+
+/* Function to set one of the above from the multibyte array */
+
+static void
+set_widearray(char *mb_array, Widechar_array wca)
+{
+ if (wca->chars) {
+ free(wca->chars);
+ wca->chars = NULL;
+ }
+ wca->len = 0;
+
+ if (!isset(MULTIBYTE))
+ return;
+
+ if (mb_array) {
+ VARARR(wchar_t, tmpwcs, strlen(mb_array));
+ wchar_t *wcptr = tmpwcs;
+ wint_t wci;
+
+ mb_charinit();
+ while (*mb_array) {
+ int mblen;
+
+ if (STOUC(*mb_array) <= 0x7f) {
+ mb_array++;
+ *wcptr++ = (wchar_t)*mb_array;
+ continue;
+ }
+
+ mblen = mb_metacharlenconv(mb_array, &wci);
+
+ if (!mblen)
+ break;
+ /* No good unless all characters are convertible */
+ if (wci == WEOF)
+ return;
+ *wcptr++ = (wchar_t)wci;
+#ifdef DEBUG
+ /*
+ * This generates a warning from the compiler (and is
+ * indeed useless) if chars are unsigned. It's
+ * extreme paranoia anyway.
+ */
+ if (wcptr[-1] < 0)
+ fprintf(stderr, "BUG: Bad cast to wchar_t\n");
+#endif
+ mb_array += mblen;
+ }
+
+ wca->len = wcptr - tmpwcs;
+ wca->chars = (wchar_t *)zalloc(wca->len * sizeof(wchar_t));
+ wmemcpy(wca->chars, tmpwcs, wca->len);
+ }
+}
+#endif
+
+
+/* Print an error
+
+ The following functions use the following printf-like format codes
+ (implemented by zerrmsg()):
+
+ Code Argument types Prints
+ %s const char * C string (null terminated)
+ %l const char *, int C string of given length (null not required)
+ %L long decimal value
+ %d int decimal value
+ %% (none) literal '%'
+ %c int character at that codepoint
+ %e int strerror() message (argument is typically 'errno')
+ */
+
+static void
+zwarning(const char *cmd, const char *fmt, va_list ap)
+{
+ if (isatty(2))
+ zleentry(ZLE_CMD_TRASH);
+
+ char *prefix = scriptname ? scriptname : (argzero ? argzero : "");
+
+ if (cmd) {
+ if (unset(SHINSTDIN) || locallevel) {
+ nicezputs(prefix, stderr);
+ fputc((unsigned char)':', stderr);
+ }
+ nicezputs(cmd, stderr);
+ fputc((unsigned char)':', stderr);
+ } else {
+ /*
+ * scriptname is set when sourcing scripts, so that we get the
+ * correct name instead of the generic name of whatever
+ * program/script is running. It's also set in shell functions,
+ * so test locallevel, too.
+ */
+ nicezputs((isset(SHINSTDIN) && !locallevel) ? "zsh" : prefix, stderr);
+ fputc((unsigned char)':', stderr);
+ }
+
+ zerrmsg(stderr, fmt, ap);
+}
+
+
+/**/
+mod_export void
+zerr(VA_ALIST1(const char *fmt))
+VA_DCL
+{
+ va_list ap;
+ VA_DEF_ARG(const char *fmt);
+
+ if (errflag || noerrs) {
+ if (noerrs < 2)
+ errflag |= ERRFLAG_ERROR;
+ return;
+ }
+ errflag |= ERRFLAG_ERROR;
+
+ VA_START(ap, fmt);
+ VA_GET_ARG(ap, fmt, const char *);
+ zwarning(NULL, fmt, ap);
+ va_end(ap);
+}
+
+/**/
+mod_export void
+zerrnam(VA_ALIST2(const char *cmd, const char *fmt))
+VA_DCL
+{
+ va_list ap;
+ VA_DEF_ARG(const char *cmd);
+ VA_DEF_ARG(const char *fmt);
+
+ if (errflag || noerrs)
+ return;
+ errflag |= ERRFLAG_ERROR;
+
+ VA_START(ap, fmt);
+ VA_GET_ARG(ap, cmd, const char *);
+ VA_GET_ARG(ap, fmt, const char *);
+ zwarning(cmd, fmt, ap);
+ va_end(ap);
+}
+
+/**/
+mod_export void
+zwarn(VA_ALIST1(const char *fmt))
+VA_DCL
+{
+ va_list ap;
+ VA_DEF_ARG(const char *fmt);
+
+ if (errflag || noerrs)
+ return;
+
+ VA_START(ap, fmt);
+ VA_GET_ARG(ap, fmt, const char *);
+ zwarning(NULL, fmt, ap);
+ va_end(ap);
+}
+
+/**/
+mod_export void
+zwarnnam(VA_ALIST2(const char *cmd, const char *fmt))
+VA_DCL
+{
+ va_list ap;
+ VA_DEF_ARG(const char *cmd);
+ VA_DEF_ARG(const char *fmt);
+
+ if (errflag || noerrs)
+ return;
+
+ VA_START(ap, fmt);
+ VA_GET_ARG(ap, cmd, const char *);
+ VA_GET_ARG(ap, fmt, const char *);
+ zwarning(cmd, fmt, ap);
+ va_end(ap);
+}
+
+
+#ifdef DEBUG
+
+/**/
+mod_export void
+dputs(VA_ALIST1(const char *message))
+VA_DCL
+{
+ char *filename;
+ FILE *file;
+ va_list ap;
+ VA_DEF_ARG(const char *message);
+
+ VA_START(ap, message);
+ VA_GET_ARG(ap, message, const char *);
+ if ((filename = getsparam_u("ZSH_DEBUG_LOG")) != NULL &&
+ (file = fopen(filename, "a")) != NULL) {
+ zerrmsg(file, message, ap);
+ fclose(file);
+ } else
+ zerrmsg(stderr, message, ap);
+ va_end(ap);
+}
+
+#endif /* DEBUG */
+
+#ifdef __CYGWIN__
+/*
+ * This works around an occasional problem with dllwrap on Cygwin, seen
+ * on at least two installations. It fails to find the last symbol
+ * exported in alphabetical order (in our case zwarnnam). Until this is
+ * properly categorised and fixed we add a dummy symbol at the end.
+ */
+mod_export void
+zz_plural_z_alpha(void)
+{
+}
+#endif
+
+/**/
+void
+zerrmsg(FILE *file, const char *fmt, va_list ap)
+{
+ const char *str;
+ int num;
+#ifdef DEBUG
+ long lnum;
+#endif
+#ifdef HAVE_STRERROR_R
+#define ERRBUFSIZE (80)
+ int olderrno;
+ char errbuf[ERRBUFSIZE];
+#endif
+ char *errmsg;
+
+ if ((unset(SHINSTDIN) || locallevel) && lineno) {
+#if defined(ZLONG_IS_LONG_LONG) && defined(PRINTF_HAS_LLD)
+ fprintf(file, "%lld: ", lineno);
+#else
+ fprintf(file, "%ld: ", (long)lineno);
+#endif
+ } else
+ fputc((unsigned char)' ', file);
+
+ while (*fmt)
+ if (*fmt == '%') {
+ fmt++;
+ switch (*fmt++) {
+ case 's':
+ str = va_arg(ap, const char *);
+ nicezputs(str, file);
+ break;
+ case 'l': {
+ char *s;
+ str = va_arg(ap, const char *);
+ num = va_arg(ap, int);
+ num = metalen(str, num);
+ s = zhalloc(num + 1);
+ memcpy(s, str, num);
+ s[num] = '\0';
+ nicezputs(s, file);
+ break;
+ }
+#ifdef DEBUG
+ case 'L':
+ lnum = va_arg(ap, long);
+ fprintf(file, "%ld", lnum);
+ break;
+#endif
+ case 'd':
+ num = va_arg(ap, int);
+ fprintf(file, "%d", num);
+ break;
+ case '%':
+ putc('%', file);
+ break;
+ case 'c':
+ num = va_arg(ap, int);
+#ifdef MULTIBYTE_SUPPORT
+ mb_charinit();
+ zputs(wcs_nicechar(num, NULL, NULL), file);
+#else
+ zputs(nicechar(num), file);
+#endif
+ break;
+ case 'e':
+ /* print the corresponding message for this errno */
+ num = va_arg(ap, int);
+ if (num == EINTR) {
+ fputs("interrupt\n", file);
+ errflag |= ERRFLAG_ERROR;
+ return;
+ }
+ errmsg = strerror(num);
+ /* If the message is not about I/O problems, it looks better *
+ * if we uncapitalize the first letter of the message */
+ if (num == EIO)
+ fputs(errmsg, file);
+ else {
+ fputc(tulower(errmsg[0]), file);
+ fputs(errmsg + 1, file);
+ }
+ break;
+ /* When adding format codes, update the comment above zwarning(). */
+ }
+ } else {
+ putc(*fmt == Meta ? *++fmt ^ 32 : *fmt, file);
+ fmt++;
+ }
+ putc('\n', file);
+ fflush(file);
+}
+
+/*
+ * Wrapper for setupterm() and del_curterm().
+ * These are called from terminfo.c and termcap.c.
+ */
+static int term_count; /* reference count of cur_term */
+
+/**/
+mod_export void
+zsetupterm(void)
+{
+#ifdef HAVE_SETUPTERM
+ int errret;
+
+ DPUTS(term_count < 0 || (term_count > 0 && !cur_term),
+ "inconsistent term_count and/or cur_term");
+ /*
+ * Just because we can't set up the terminal doesn't
+ * mean the modules hasn't booted---TERM may change,
+ * and it should be handled dynamically---so ignore errors here.
+ */
+ if (term_count++ == 0)
+ (void)setupterm((char *)0, 1, &errret);
+#endif
+}
+
+/**/
+mod_export void
+zdeleteterm(void)
+{
+#ifdef HAVE_SETUPTERM
+ DPUTS(term_count < 1 || !cur_term,
+ "inconsistent term_count and/or cur_term");
+ if (--term_count == 0)
+ del_curterm(cur_term);
+#endif
+}
+
+/* Output a single character, for the termcap routines. *
+ * This is used instead of putchar since it can be a macro. */
+
+/**/
+mod_export int
+putraw(int c)
+{
+ putc(c, stdout);
+ return 0;
+}
+
+/* Output a single character, for the termcap routines. */
+
+/**/
+mod_export int
+putshout(int c)
+{
+ putc(c, shout);
+ return 0;
+}
+
+#ifdef MULTIBYTE_SUPPORT
+/*
+ * Turn a character into a visible representation thereof. The visible
+ * string is put together in a static buffer, and this function returns
+ * a pointer to it. Printable characters stand for themselves, DEL is
+ * represented as "^?", newline and tab are represented as "\n" and
+ * "\t", and normal control characters are represented in "^C" form.
+ * Characters with bit 7 set, if unprintable, are represented as "\M-"
+ * followed by the visible representation of the character with bit 7
+ * stripped off. Tokens are interpreted, rather than being treated as
+ * literal characters.
+ *
+ * Note that the returned string is metafied, so that it must be
+ * treated like any other zsh internal string (and not, for example,
+ * output directly).
+ *
+ * This function is used even if MULTIBYTE_SUPPORT is defined: we
+ * use it as a fallback in case we couldn't identify a wide character
+ * in a multibyte string.
+ */
+
+/**/
+mod_export char *
+nicechar_sel(int c, int quotable)
+{
+ static char buf[10];
+ char *s = buf;
+ c &= 0xff;
+ if (ZISPRINT(c))
+ goto done;
+ if (c & 0x80) {
+ if (isset(PRINTEIGHTBIT))
+ goto done;
+ *s++ = '\\';
+ *s++ = 'M';
+ *s++ = '-';
+ c &= 0x7f;
+ if(ZISPRINT(c))
+ goto done;
+ }
+ if (c == 0x7f) {
+ if (quotable) {
+ *s++ = '\\';
+ *s++ = 'C';
+ *s++ = '-';
+ } else
+ *s++ = '^';
+ c = '?';
+ } else if (c == '\n') {
+ *s++ = '\\';
+ c = 'n';
+ } else if (c == '\t') {
+ *s++ = '\\';
+ c = 't';
+ } else if (c < 0x20) {
+ if (quotable) {
+ *s++ = '\\';
+ *s++ = 'C';
+ *s++ = '-';
+ } else
+ *s++ = '^';
+ c += 0x40;
+ }
+ done:
+ /*
+ * The resulting string is still metafied, so check if
+ * we are returning a character in the range that needs metafication.
+ * This can't happen if the character is printed "nicely", so
+ * this results in a maximum of two bytes total (plus the null).
+ */
+ if (imeta(c)) {
+ *s++ = Meta;
+ *s++ = c ^ 32;
+ } else
+ *s++ = c;
+ *s = 0;
+ return buf;
+}
+
+/**/
+mod_export char *
+nicechar(int c)
+{
+ return nicechar_sel(c, 0);
+}
+
+#else /* MULTIBYTE_SUPPORT */
+
+/**/
+mod_export char *
+nicechar(int c)
+{
+ static char buf[10];
+ char *s = buf;
+ c &= 0xff;
+ if (ZISPRINT(c))
+ goto done;
+ if (c & 0x80) {
+ if (isset(PRINTEIGHTBIT))
+ goto done;
+ *s++ = '\\';
+ *s++ = 'M';
+ *s++ = '-';
+ c &= 0x7f;
+ if(ZISPRINT(c))
+ goto done;
+ }
+ if (c == 0x7f) {
+ *s++ = '\\';
+ *s++ = 'C';
+ *s++ = '-';
+ c = '?';
+ } else if (c == '\n') {
+ *s++ = '\\';
+ c = 'n';
+ } else if (c == '\t') {
+ *s++ = '\\';
+ c = 't';
+ } else if (c < 0x20) {
+ *s++ = '\\';
+ *s++ = 'C';
+ *s++ = '-';
+ c += 0x40;
+ }
+ done:
+ /*
+ * The resulting string is still metafied, so check if
+ * we are returning a character in the range that needs metafication.
+ * This can't happen if the character is printed "nicely", so
+ * this results in a maximum of two bytes total (plus the null).
+ */
+ if (imeta(c)) {
+ *s++ = Meta;
+ *s++ = c ^ 32;
+ } else
+ *s++ = c;
+ *s = 0;
+ return buf;
+}
+
+#endif /* MULTIBYTE_SUPPORT */
+
+/*
+ * Return 1 if nicechar() would reformat this character.
+ */
+
+/**/
+mod_export int
+is_nicechar(int c)
+{
+ c &= 0xff;
+ if (ZISPRINT(c))
+ return 0;
+ if (c & 0x80)
+ return !isset(PRINTEIGHTBIT);
+ return (c == 0x7f || c == '\n' || c == '\t' || c < 0x20);
+}
+
+/**/
+#ifdef MULTIBYTE_SUPPORT
+static mbstate_t mb_shiftstate;
+
+/*
+ * Initialise multibyte state: called before a sequence of
+ * wcs_nicechar(), mb_metacharlenconv(), or
+ * mb_charlenconv().
+ */
+
+/**/
+mod_export void
+mb_charinit(void)
+{
+ memset(&mb_shiftstate, 0, sizeof(mb_shiftstate));
+}
+
+/*
+ * The number of bytes we need to allocate for a "nice" representation
+ * of a multibyte character.
+ *
+ * We double MB_CUR_MAX to take account of the fact that
+ * we may need to metafy. In fact the representation probably
+ * doesn't allow every character to be in the meta range, but
+ * we don't need to be too pedantic.
+ *
+ * The 12 is for the output of a UCS-4 code; we don't actually
+ * need this at the same time as MB_CUR_MAX, but again it's
+ * not worth calculating more exactly.
+ */
+#define NICECHAR_MAX (12 + 2*MB_CUR_MAX)
+/*
+ * Input a wide character. Output a printable representation,
+ * which is a metafied multibyte string. With widthp return
+ * the printing width.
+ *
+ * swide, if non-NULL, is used to help the completion code, which needs
+ * to know the printing width of the each part of the representation.
+ * *swide is set to the part of the returned string where the wide
+ * character starts. Any string up to that point is ASCII characters,
+ * so the width of it is (*swide - ). Anything left is
+ * a single wide character corresponding to the remaining width.
+ * Either the initial ASCII part or the wide character part may be empty
+ * (but not both). (Note the complication that the wide character
+ * part may contain metafied characters.)
+ *
+ * The caller needs to call mb_charinit() before the first call, to
+ * set up the multibyte shift state for a range of characters.
+ */
+
+/**/
+mod_export char *
+wcs_nicechar_sel(wchar_t c, size_t *widthp, char **swidep, int quotable)
+{
+ static char *buf;
+ static int bufalloc = 0, newalloc;
+ char *s, *mbptr;
+ int ret = 0;
+ VARARR(char, mbstr, MB_CUR_MAX);
+
+ /*
+ * We want buf to persist beyond the return. MB_CUR_MAX and hence
+ * NICECHAR_MAX may not be constant, so we have to allocate this at
+ * run time. (We could probably get away with just allocating a
+ * large buffer, in practice.) For efficiency, only reallocate if
+ * we really need to, since this function will be called frequently.
+ */
+ newalloc = NICECHAR_MAX;
+ if (bufalloc != newalloc)
+ {
+ bufalloc = newalloc;
+ buf = (char *)zrealloc(buf, bufalloc);
+ }
+
+ s = buf;
+ if (!WC_ISPRINT(c) && (c < 0x80 || !isset(PRINTEIGHTBIT))) {
+ if (c == 0x7f) {
+ if (quotable) {
+ *s++ = '\\';
+ *s++ = 'C';
+ *s++ = '-';
+ } else
+ *s++ = '^';
+ c = '?';
+ } else if (c == L'\n') {
+ *s++ = '\\';
+ c = 'n';
+ } else if (c == L'\t') {
+ *s++ = '\\';
+ c = 't';
+ } else if (c < 0x20) {
+ if (quotable) {
+ *s++ = '\\';
+ *s++ = 'C';
+ *s++ = '-';
+ } else
+ *s++ = '^';
+ c += 0x40;
+ } else if (c >= 0x80) {
+ ret = -1;
+ }
+ }
+
+ if (ret != -1)
+ ret = wcrtomb(mbstr, c, &mb_shiftstate);
+
+ if (ret == -1) {
+ memset(&mb_shiftstate, 0, sizeof(mb_shiftstate));
+ /*
+ * Can't or don't want to convert character: use UCS-2 or
+ * UCS-4 code in print escape format.
+ *
+ * This comparison fails and generates a compiler warning
+ * if wchar_t is 16 bits, but the code is still correct.
+ */
+ if (c >= 0x10000) {
+ sprintf(buf, "\\U%.8x", (unsigned int)c);
+ if (widthp)
+ *widthp = 10;
+ } else if (c >= 0x100) {
+ sprintf(buf, "\\u%.4x", (unsigned int)c);
+ if (widthp)
+ *widthp = 6;
+ } else {
+ strcpy(buf, nicechar((int)c));
+ /*
+ * There may be metafied characters from nicechar(),
+ * so compute width and end position independently.
+ */
+ if (widthp)
+ *widthp = ztrlen(buf);
+ if (swidep)
+ *swidep = buf + strlen(buf);
+ return buf;
+ }
+ if (swidep)
+ *swidep = widthp ? buf + *widthp : buf;
+ return buf;
+ }
+
+ if (widthp) {
+ int wcw = WCWIDTH(c);
+ *widthp = (s - buf);
+ if (wcw >= 0)
+ *widthp += wcw;
+ else
+ (*widthp)++;
+ }
+ if (swidep)
+ *swidep = s;
+ for (mbptr = mbstr; ret; s++, mbptr++, ret--) {
+ DPUTS(s >= buf + NICECHAR_MAX,
+ "BUG: buffer too small in wcs_nicechar");
+ if (imeta(*mbptr)) {
+ *s++ = Meta;
+ DPUTS(s >= buf + NICECHAR_MAX,
+ "BUG: buffer too small for metafied char in wcs_nicechar");
+ *s = *mbptr ^ 32;
+ } else {
+ *s = *mbptr;
+ }
+ }
+ *s = 0;
+ return buf;
+}
+
+/**/
+mod_export char *
+wcs_nicechar(wchar_t c, size_t *widthp, char **swidep)
+{
+ return wcs_nicechar_sel(c, widthp, swidep, 0);
+}
+
+/*
+ * Return 1 if wcs_nicechar() would reformat this character for display.
+ */
+
+/**/
+mod_export int is_wcs_nicechar(wchar_t c)
+{
+ if (!WC_ISPRINT(c) && (c < 0x80 || !isset(PRINTEIGHTBIT))) {
+ if (c == 0x7f || c == L'\n' || c == L'\t' || c < 0x20)
+ return 1;
+ if (c >= 0x80) {
+ return (c >= 0x100);
+ }
+ }
+ return 0;
+}
+
+/**/
+mod_export int
+zwcwidth(wint_t wc)
+{
+ int wcw;
+ /* assume a single-byte character if not valid */
+ if (wc == WEOF || unset(MULTIBYTE))
+ return 1;
+ wcw = WCWIDTH(wc);
+ /* if not printable, assume width 1 */
+ if (wcw < 0)
+ return 1;
+ return wcw;
+}
+
+/**/
+#endif /* MULTIBYTE_SUPPORT */
+
+/*
+ * Search the path for prog and return the file name.
+ * The returned value is unmetafied and in the unmeta storage
+ * area (N.B. should be duplicated if not used immediately and not
+ * equal to *namep).
+ *
+ * If namep is not NULL, *namep is set to the metafied programme
+ * name, which is in heap storage.
+ */
+/**/
+char *
+pathprog(char *prog, char **namep)
+{
+ char **pp, ppmaxlen = 0, *buf, *funmeta;
+ struct stat st;
+
+ for (pp = path; *pp; pp++)
+ {
+ int len = strlen(*pp);
+ if (len > ppmaxlen)
+ ppmaxlen = len;
+ }
+ buf = zhalloc(ppmaxlen + strlen(prog) + 2);
+ for (pp = path; *pp; pp++) {
+ sprintf(buf, "%s/%s", *pp, prog);
+ funmeta = unmeta(buf);
+ if (access(funmeta, F_OK) == 0 &&
+ stat(funmeta, &st) >= 0 &&
+ !S_ISDIR(st.st_mode)) {
+ if (namep)
+ *namep = buf;
+ return funmeta;
+ }
+ }
+
+ return NULL;
+}
+
+/* get a symlink-free pathname for s relative to PWD */
+
+/**/
+char *
+findpwd(char *s)
+{
+ char *t;
+
+ if (*s == '/')
+ return xsymlink(s, 0);
+ s = tricat((pwd[1]) ? pwd : "", "/", s);
+ t = xsymlink(s, 0);
+ zsfree(s);
+ return t;
+}
+
+/* Check whether a string contains the *
+ * name of the present directory. */
+
+/**/
+int
+ispwd(char *s)
+{
+ struct stat sbuf, tbuf;
+
+ /* POSIX: environment PWD must be absolute */
+ if (*s != '/')
+ return 0;
+
+ if (stat((s = unmeta(s)), &sbuf) == 0 && stat(".", &tbuf) == 0)
+ if (sbuf.st_dev == tbuf.st_dev && sbuf.st_ino == tbuf.st_ino) {
+ /* POSIX: No element of $PWD may be "." or ".." */
+ while (*s) {
+ if (s[0] == '.' &&
+ (!s[1] || s[1] == '/' ||
+ (s[1] == '.' && (!s[2] || s[2] == '/'))))
+ break;
+ while (*s++ != '/' && *s)
+ continue;
+ }
+ return !*s;
+ }
+ return 0;
+}
+
+static char xbuf[PATH_MAX*2+1];
+
+/**/
+static char **
+slashsplit(char *s)
+{
+ char *t, **r, **q;
+ int t0;
+
+ if (!*s)
+ return (char **) zshcalloc(sizeof(char *));
+
+ for (t = s, t0 = 0; *t; t++)
+ if (*t == '/')
+ t0++;
+ q = r = (char **) zalloc(sizeof(char *) * (t0 + 2));
+
+ while ((t = strchr(s, '/'))) {
+ *q++ = ztrduppfx(s, t - s);
+ while (*t == '/')
+ t++;
+ if (!*t) {
+ *q = NULL;
+ return r;
+ }
+ s = t;
+ }
+ *q++ = ztrdup(s);
+ *q = NULL;
+ return r;
+}
+
+/* expands symlinks and .. or . expressions */
+
+/**/
+static int
+xsymlinks(char *s, int full)
+{
+ char **pp, **opp;
+ char xbuf2[PATH_MAX*3+1], xbuf3[PATH_MAX*2+1];
+ int t0, ret = 0;
+ zulong xbuflen = strlen(xbuf), pplen;
+
+ opp = pp = slashsplit(s);
+ for (; xbuflen < sizeof(xbuf) && *pp && ret >= 0; pp++) {
+ if (!strcmp(*pp, "."))
+ continue;
+ if (!strcmp(*pp, "..")) {
+ char *p;
+
+ if (!strcmp(xbuf, "/"))
+ continue;
+ if (!*xbuf)
+ continue;
+ p = xbuf + xbuflen;
+ while (*--p != '/')
+ xbuflen--;
+ *p = '\0';
+ /* The \0 isn't included in the length */
+ xbuflen--;
+ continue;
+ }
+ /* Includes null byte. */
+ pplen = strlen(*pp) + 1;
+ if (xbuflen + pplen + 1 > sizeof(xbuf2)) {
+ *xbuf = 0;
+ ret = -1;
+ break;
+ }
+ memcpy(xbuf2, xbuf, xbuflen);
+ xbuf2[xbuflen] = '/';
+ memcpy(xbuf2 + xbuflen + 1, *pp, pplen);
+ t0 = readlink(unmeta(xbuf2), xbuf3, PATH_MAX);
+ if (t0 == -1) {
+ if ((xbuflen += pplen) < sizeof(xbuf)) {
+ strcat(xbuf, "/");
+ strcat(xbuf, *pp);
+ } else {
+ *xbuf = 0;
+ ret = -1;
+ break;
+ }
+ } else {
+ ret = 1;
+ metafy(xbuf3, t0, META_NOALLOC);
+ if (!full) {
+ /*
+ * If only one expansion requested, ensure the
+ * full path is in xbuf.
+ */
+ zulong len = xbuflen;
+ if (*xbuf3 == '/')
+ strcpy(xbuf, xbuf3);
+ else if ((len += strlen(xbuf3) + 1) < sizeof(xbuf)) {
+ strcpy(xbuf + xbuflen, "/");
+ strcpy(xbuf + xbuflen + 1, xbuf3);
+ } else {
+ *xbuf = 0;
+ ret = -1;
+ break;
+ }
+
+ while (*++pp) {
+ zulong newlen = len + strlen(*pp) + 1;
+ if (newlen < sizeof(xbuf)) {
+ strcpy(xbuf + len, "/");
+ strcpy(xbuf + len + 1, *pp);
+ len = newlen;
+ } else {
+ *xbuf = 01;
+ ret = -1;
+ break;
+ }
+ }
+ /*
+ * No need to update xbuflen, we're finished
+ * the expansion (for now).
+ */
+ break;
+ }
+ if (*xbuf3 == '/') {
+ strcpy(xbuf, "");
+ if (xsymlinks(xbuf3 + 1, 1) < 0)
+ ret = -1;
+ else
+ xbuflen = strlen(xbuf);
+ } else
+ if (xsymlinks(xbuf3, 1) < 0)
+ ret = -1;
+ else
+ xbuflen = strlen(xbuf);
+ }
+ }
+ freearray(opp);
+ return ret;
+}
+
+/*
+ * expand symlinks in s, and remove other weird things:
+ * note that this always expands symlinks.
+ *
+ * 'heap' indicates whether to malloc() or allocate on the heap.
+ */
+
+/**/
+char *
+xsymlink(char *s, int heap)
+{
+ if (*s != '/')
+ return NULL;
+ *xbuf = '\0';
+ if (xsymlinks(s + 1, 1) < 0)
+ zwarn("path expansion failed, using root directory");
+ if (!*xbuf)
+ return heap ? dupstring("/") : ztrdup("/");
+ return heap ? dupstring(xbuf) : ztrdup(xbuf);
+}
+
+/**/
+void
+print_if_link(char *s, int all)
+{
+ if (*s == '/') {
+ *xbuf = '\0';
+ if (all) {
+ char *start = s + 1;
+ char xbuflink[PATH_MAX+1];
+ for (;;) {
+ if (xsymlinks(start, 0) > 0) {
+ printf(" -> ");
+ zputs(*xbuf ? xbuf : "/", stdout);
+ if (!*xbuf)
+ break;
+ strcpy(xbuflink, xbuf);
+ start = xbuflink + 1;
+ *xbuf = '\0';
+ } else {
+ break;
+ }
+ }
+ } else {
+ if (xsymlinks(s + 1, 1) > 0)
+ printf(" -> "), zputs(*xbuf ? xbuf : "/", stdout);
+ }
+ }
+}
+
+/* print a directory */
+
+/**/
+void
+fprintdir(char *s, FILE *f)
+{
+ Nameddir d = finddir(s);
+
+ if (!d)
+ fputs(unmeta(s), f);
+ else {
+ putc('~', f);
+ fputs(unmeta(d->node.nam), f);
+ fputs(unmeta(s + strlen(d->dir)), f);
+ }
+}
+
+/*
+ * Substitute a directory using a name.
+ * If there is none, return the original argument.
+ *
+ * At this level all strings involved are metafied.
+ */
+
+/**/
+char *
+substnamedir(char *s)
+{
+ Nameddir d = finddir(s);
+
+ if (!d)
+ return quotestring(s, QT_BACKSLASH);
+ return zhtricat("~", d->node.nam, quotestring(s + strlen(d->dir),
+ QT_BACKSLASH));
+}
+
+
+/* Returns the current username. It caches the username *
+ * and uid to try to avoid requerying the password files *
+ * or NIS/NIS+ database. */
+
+/**/
+uid_t cached_uid;
+/**/
+char *cached_username;
+
+/**/
+char *
+get_username(void)
+{
+#ifdef HAVE_GETPWUID
+ struct passwd *pswd;
+ uid_t current_uid;
+
+ current_uid = getuid();
+ if (current_uid != cached_uid) {
+ cached_uid = current_uid;
+ zsfree(cached_username);
+ if ((pswd = getpwuid(current_uid)))
+ cached_username = ztrdup(pswd->pw_name);
+ else
+ cached_username = ztrdup("");
+ }
+#else /* !HAVE_GETPWUID */
+ cached_uid = getuid();
+#endif /* !HAVE_GETPWUID */
+ return cached_username;
+}
+
+/* static variables needed by finddir(). */
+
+static char *finddir_full;
+static Nameddir finddir_last;
+static int finddir_best;
+
+/* ScanFunc used by finddir(). */
+
+/**/
+static void
+finddir_scan(HashNode hn, UNUSED(int flags))
+{
+ Nameddir nd = (Nameddir) hn;
+
+ if(nd->diff > finddir_best && !dircmp(nd->dir, finddir_full)
+ && !(nd->node.flags & ND_NOABBREV)) {
+ finddir_last=nd;
+ finddir_best=nd->diff;
+ }
+}
+
+/*
+ * See if a path has a named directory as its prefix.
+ * If passed a NULL argument, it will invalidate any
+ * cached information.
+ *
+ * s here is metafied.
+ */
+
+/**/
+Nameddir
+finddir(char *s)
+{
+ static struct nameddir homenode = { {NULL, "", 0}, NULL, 0 };
+ static int ffsz;
+ char **ares;
+ int len;
+
+ /* Invalidate directory cache if argument is NULL. This is called *
+ * whenever a node is added to or removed from the hash table, and *
+ * whenever the value of $HOME changes. (On startup, too.) */
+ if (!s) {
+ homenode.dir = home ? home : "";
+ homenode.diff = home ? strlen(home) : 0;
+ if(homenode.diff==1)
+ homenode.diff = 0;
+ if(!finddir_full)
+ finddir_full = zalloc(ffsz = PATH_MAX+1);
+ finddir_full[0] = 0;
+ return finddir_last = NULL;
+ }
+
+#if 0
+ /*
+ * It's not safe to use the cache while we have function
+ * transformations, and it's not clear it's worth the
+ * complexity of guessing here whether subst_string_by_hook
+ * is going to turn up the goods.
+ */
+ if (!strcmp(s, finddir_full) && *finddir_full)
+ return finddir_last;
+#endif
+
+ if ((int)strlen(s) >= ffsz) {
+ free(finddir_full);
+ finddir_full = zalloc(ffsz = strlen(s) * 2);
+ }
+ strcpy(finddir_full, s);
+ finddir_best=0;
+ finddir_last=NULL;
+ finddir_scan(&homenode.node, 0);
+ scanhashtable(nameddirtab, 0, 0, 0, finddir_scan, 0);
+
+ ares = subst_string_by_hook("zsh_directory_name", "d", finddir_full);
+ if (ares && arrlen_ge(ares, 2) &&
+ (len = (int)zstrtol(ares[1], NULL, 10)) > finddir_best) {
+ /* better duplicate this string since it's come from REPLY */
+ finddir_last = (Nameddir)hcalloc(sizeof(struct nameddir));
+ finddir_last->node.nam = zhtricat("[", dupstring(ares[0]), "]");
+ finddir_last->dir = dupstrpfx(finddir_full, len);
+ finddir_last->diff = len - strlen(finddir_last->node.nam);
+ finddir_best = len;
+ }
+
+ return finddir_last;
+}
+
+/* add a named directory */
+
+/**/
+mod_export void
+adduserdir(char *s, char *t, int flags, int always)
+{
+ Nameddir nd;
+ char *eptr;
+
+ /* We don't maintain a hash table in non-interactive shells. */
+ if (!interact)
+ return;
+
+ /* The ND_USERNAME flag means that this possible hash table *
+ * entry is derived from a passwd entry. Such entries are *
+ * subordinate to explicitly generated entries. */
+ if ((flags & ND_USERNAME) && nameddirtab->getnode2(nameddirtab, s))
+ return;
+
+ /* Normal parameter assignments generate calls to this function, *
+ * with always==0. Unless the AUTO_NAME_DIRS option is set, we *
+ * don't let such assignments actually create directory names. *
+ * Instead, a reference to the parameter as a directory name can *
+ * cause the actual creation of the hash table entry. */
+ if (!always && unset(AUTONAMEDIRS) &&
+ !nameddirtab->getnode2(nameddirtab, s))
+ return;
+
+ if (!t || *t != '/' || strlen(t) >= PATH_MAX) {
+ /* We can't use this value as a directory, so simply remove *
+ * the corresponding entry in the hash table, if any. */
+ HashNode hn = nameddirtab->removenode(nameddirtab, s);
+
+ if(hn)
+ nameddirtab->freenode(hn);
+ return;
+ }
+
+ /* add the name */
+ nd = (Nameddir) zshcalloc(sizeof *nd);
+ nd->node.flags = flags;
+ eptr = t + strlen(t);
+ while (eptr > t && eptr[-1] == '/')
+ eptr--;
+ if (eptr == t) {
+ /*
+ * Don't abbreviate multiple slashes at the start of a
+ * named directory, since these are sometimes used for
+ * special purposes.
+ */
+ nd->dir = metafy(t, -1, META_DUP);
+ } else
+ nd->dir = metafy(t, eptr - t, META_DUP);
+ /* The variables PWD and OLDPWD are not to be displayed as ~PWD etc. */
+ if (!strcmp(s, "PWD") || !strcmp(s, "OLDPWD"))
+ nd->node.flags |= ND_NOABBREV;
+ nameddirtab->addnode(nameddirtab, metafy(s, -1, META_DUP), nd);
+}
+
+/* Get a named directory: this function can cause a directory name *
+ * to be added to the hash table, if it isn't there already. */
+
+/**/
+char *
+getnameddir(char *name)
+{
+ Param pm;
+ char *str;
+ Nameddir nd;
+
+ /* Check if it is already in the named directory table */
+ if ((nd = (Nameddir) nameddirtab->getnode(nameddirtab, name)))
+ return dupstring(nd->dir);
+
+ /* Check if there is a scalar parameter with this name whose value *
+ * begins with a `/'. If there is, add it to the hash table and *
+ * return the new value. */
+ if ((pm = (Param) paramtab->getnode(paramtab, name)) &&
+ (PM_TYPE(pm->node.flags) == PM_SCALAR) &&
+ (str = getsparam(name)) && *str == '/') {
+ pm->node.flags |= PM_NAMEDDIR;
+ adduserdir(name, str, 0, 1);
+ return str;
+ }
+
+#ifdef HAVE_GETPWNAM
+ {
+ /* Retrieve an entry from the password table/database for this user. */
+ struct passwd *pw;
+ if ((pw = getpwnam(name))) {
+ char *dir = isset(CHASELINKS) ? xsymlink(pw->pw_dir, 0)
+ : ztrdup(pw->pw_dir);
+ if (dir) {
+ adduserdir(name, dir, ND_USERNAME, 1);
+ str = dupstring(dir);
+ zsfree(dir);
+ return str;
+ } else
+ return dupstring(pw->pw_dir);
+ }
+ }
+#endif /* HAVE_GETPWNAM */
+
+ /* There are no more possible sources of directory names, so give up. */
+ return NULL;
+}
+
+/*
+ * Compare directories. Both are metafied.
+ */
+
+/**/
+static int
+dircmp(char *s, char *t)
+{
+ if (s) {
+ for (; *s == *t; s++, t++)
+ if (!*s)
+ return 0;
+ if (!*s && *t == '/')
+ return 0;
+ }
+ return 1;
+}
+
+/*
+ * Extra functions to call before displaying the prompt.
+ * The data is a Prepromptfn.
+ */
+
+static LinkList prepromptfns;
+
+/* Add a function to the list of pre-prompt functions. */
+
+/**/
+mod_export void
+addprepromptfn(voidvoidfnptr_t func)
+{
+ Prepromptfn ppdat = (Prepromptfn)zalloc(sizeof(struct prepromptfn));
+ ppdat->func = func;
+ if (!prepromptfns)
+ prepromptfns = znewlinklist();
+ zaddlinknode(prepromptfns, ppdat);
+}
+
+/* Remove a function from the list of pre-prompt functions. */
+
+/**/
+mod_export void
+delprepromptfn(voidvoidfnptr_t func)
+{
+ LinkNode ln;
+
+ for (ln = firstnode(prepromptfns); ln; ln = nextnode(ln)) {
+ Prepromptfn ppdat = (Prepromptfn)getdata(ln);
+ if (ppdat->func == func) {
+ (void)remnode(prepromptfns, ln);
+ zfree(ppdat, sizeof(struct prepromptfn));
+ return;
+ }
+ }
+#ifdef DEBUG
+ dputs("BUG: failed to delete node from prepromptfns");
+#endif
+}
+
+/*
+ * Functions to call at a particular time even if not at
+ * the prompt. This is handled by zle. The data is a
+ * Timedfn. The functions must be in time order, but this
+ * is enforced by addtimedfn().
+ *
+ * Note on debugging: the code in sched.c currently assumes it's
+ * the only user of timedfns for the purposes of checking whether
+ * there's a function on the list. If this becomes no longer the case,
+ * the DPUTS() tests in sched.c need rewriting.
+ */
+
+/**/
+mod_export LinkList timedfns;
+
+/* Add a function to the list of timed functions. */
+
+/**/
+mod_export void
+addtimedfn(voidvoidfnptr_t func, time_t when)
+{
+ Timedfn tfdat = (Timedfn)zalloc(sizeof(struct timedfn));
+ tfdat->func = func;
+ tfdat->when = when;
+
+ if (!timedfns) {
+ timedfns = znewlinklist();
+ zaddlinknode(timedfns, tfdat);
+ } else {
+ LinkNode ln = firstnode(timedfns);
+
+ /*
+ * Insert the new element in the linked list. We do
+ * rather too much work here since the standard
+ * functions insert after a given node, whereas we
+ * want to insert the new data before the first element
+ * with a greater time.
+ *
+ * In practice, the only use of timed functions is
+ * sched, which only adds the one function; so this
+ * whole branch isn't used beyond the following block.
+ */
+ if (!ln) {
+ zaddlinknode(timedfns, tfdat);
+ return;
+ }
+ for (;;) {
+ Timedfn tfdat2;
+ LinkNode next = nextnode(ln);
+ if (!next) {
+ zaddlinknode(timedfns, tfdat);
+ return;
+ }
+ tfdat2 = (Timedfn)getdata(next);
+ if (when < tfdat2->when) {
+ zinsertlinknode(timedfns, ln, tfdat);
+ return;
+ }
+ ln = next;
+ }
+ }
+}
+
+/*
+ * Delete a function from the list of timed functions.
+ * Note that if the function apperas multiple times only
+ * the first occurrence will be removed.
+ *
+ * Note also that when zle calls the function it does *not*
+ * automatically delete the entry from the list. That must
+ * be done by the function called. This is recommended as otherwise
+ * the function will keep being called immediately. (It just so
+ * happens this "feature" fits in well with the only current use
+ * of timed functions.)
+ */
+
+/**/
+mod_export void
+deltimedfn(voidvoidfnptr_t func)
+{
+ LinkNode ln;
+
+ for (ln = firstnode(timedfns); ln; ln = nextnode(ln)) {
+ Timedfn ppdat = (Timedfn)getdata(ln);
+ if (ppdat->func == func) {
+ (void)remnode(timedfns, ln);
+ zfree(ppdat, sizeof(struct timedfn));
+ return;
+ }
+ }
+#ifdef DEBUG
+ dputs("BUG: failed to delete node from timedfns");
+#endif
+}
+
+/* the last time we checked mail */
+
+/**/
+time_t lastmailcheck;
+
+/* the last time we checked the people in the WATCH variable */
+
+/**/
+time_t lastwatch;
+
+/*
+ * Call a function given by "name" with optional arguments
+ * "lnklist". If these are present the first argument is the function name.
+ *
+ * If "arrayp" is not zero, we also look through
+ * the array "name"_functions and execute functions found there.
+ *
+ * If "retval" is not NULL, the return value of the first hook function to
+ * return non-zero is stored in *"retval". The return value is not otherwise
+ * available as the calling context is restored.
+ *
+ * Returns 0 if at least one function was called (regardless of that function's
+ * exit status), and 1 otherwise.
+ */
+
+/**/
+mod_export int
+callhookfunc(char *name, LinkList lnklst, int arrayp, int *retval)
+{
+ Shfunc shfunc;
+ /*
+ * Save stopmsg, since user doesn't get a chance to respond
+ * to a list of jobs generated in a hook.
+ */
+ int osc = sfcontext, osm = stopmsg, stat = 1, ret = 0;
+ int old_incompfunc = incompfunc;
+
+ sfcontext = SFC_HOOK;
+ incompfunc = 0;
+
+ if ((shfunc = getshfunc(name))) {
+ ret = doshfunc(shfunc, lnklst, 1);
+ stat = 0;
+ }
+
+ if (arrayp) {
+ char **arrptr;
+ int namlen = strlen(name);
+ VARARR(char, arrnam, namlen + HOOK_SUFFIX_LEN);
+ memcpy(arrnam, name, namlen);
+ memcpy(arrnam + namlen, HOOK_SUFFIX, HOOK_SUFFIX_LEN);
+
+ if ((arrptr = getaparam(arrnam))) {
+ arrptr = arrdup(arrptr);
+ for (; *arrptr; arrptr++) {
+ if ((shfunc = getshfunc(*arrptr))) {
+ int newret = doshfunc(shfunc, lnklst, 1);
+ if (!ret)
+ ret = newret;
+ stat = 0;
+ }
+ }
+ }
+ }
+
+ sfcontext = osc;
+ stopmsg = osm;
+ incompfunc = old_incompfunc;
+
+ if (retval)
+ *retval = ret;
+ return stat;
+}
+
+/* do pre-prompt stuff */
+
+/**/
+void
+preprompt(void)
+{
+ static time_t lastperiodic;
+ time_t currentmailcheck;
+ LinkNode ln;
+ zlong period = getiparam("PERIOD");
+ zlong mailcheck = getiparam("MAILCHECK");
+
+ /*
+ * Handle any pending window size changes before we compute prompts,
+ * then block them again to avoid interrupts during prompt display.
+ */
+ winch_unblock();
+ winch_block();
+
+ if (isset(PROMPTSP) && isset(PROMPTCR) && !use_exit_printed && shout) {
+ /* The PROMPT_SP heuristic will move the prompt down to a new line
+ * if there was any dangling output on the line (assuming the terminal
+ * has automatic margins, but we try even if hasam isn't set).
+ * Unfortunately it interacts badly with ZLE displaying message
+ * when ^D has been pressed. So just disable PROMPT_SP logic in
+ * this case */
+ char *eolmark = getsparam("PROMPT_EOL_MARK");
+ char *str;
+ int percents = opts[PROMPTPERCENT], w = 0;
+ if (!eolmark)
+ eolmark = "%B%S%#%s%b";
+ opts[PROMPTPERCENT] = 1;
+ str = promptexpand(eolmark, 1, NULL, NULL, NULL);
+ countprompt(str, &w, 0, -1);
+ opts[PROMPTPERCENT] = percents;
+ zputs(str, shout);
+ fprintf(shout, "%*s\r%*s\r", (int)zterm_columns - w - !hasxn,
+ "", w, "");
+ fflush(shout);
+ free(str);
+ }
+
+ /* If NOTIFY is not set, then check for completed *
+ * jobs before we print the prompt. */
+ if (unset(NOTIFY))
+ scanjobs();
+ if (errflag)
+ return;
+
+ /* If a shell function named "precmd" exists, *
+ * then execute it. */
+ callhookfunc("precmd", NULL, 1, NULL);
+ if (errflag)
+ return;
+
+ /* If 1) the parameter PERIOD exists, 2) a hook function for *
+ * "periodic" exists, 3) it's been greater than PERIOD since we *
+ * executed any such hook, then execute it now. */
+ if (period && ((zlong)time(NULL) > (zlong)lastperiodic + period) &&
+ !callhookfunc("periodic", NULL, 1, NULL))
+ lastperiodic = time(NULL);
+ if (errflag)
+ return;
+
+ /* If WATCH is set, then check for the *
+ * specified login/logout events. */
+ if (watch) {
+ if ((int) difftime(time(NULL), lastwatch) > getiparam("LOGCHECK")) {
+ dowatch();
+ lastwatch = time(NULL);
+ }
+ }
+ if (errflag)
+ return;
+
+ /* Check mail */
+ currentmailcheck = time(NULL);
+ if (mailcheck &&
+ (zlong) difftime(currentmailcheck, lastmailcheck) > mailcheck) {
+ char *mailfile;
+
+ if (mailpath && *mailpath && **mailpath)
+ checkmailpath(mailpath);
+ else {
+ queue_signals();
+ if ((mailfile = getsparam("MAIL")) && *mailfile) {
+ char *x[2];
+
+ x[0] = mailfile;
+ x[1] = NULL;
+ checkmailpath(x);
+ }
+ unqueue_signals();
+ }
+ lastmailcheck = currentmailcheck;
+ }
+
+ if (prepromptfns) {
+ for(ln = firstnode(prepromptfns); ln; ln = nextnode(ln)) {
+ Prepromptfn ppnode = (Prepromptfn)getdata(ln);
+ ppnode->func();
+ }
+ }
+}
+
+/**/
+static void
+checkmailpath(char **s)
+{
+ struct stat st;
+ char *v, *u, c;
+
+ while (*s) {
+ for (v = *s; *v && *v != '?'; v++);
+ c = *v;
+ *v = '\0';
+ if (c != '?')
+ u = NULL;
+ else
+ u = v + 1;
+ if (**s == 0) {
+ *v = c;
+ zerr("empty MAILPATH component: %s", *s);
+ } else if (mailstat(unmeta(*s), &st) == -1) {
+ if (errno != ENOENT)
+ zerr("%e: %s", errno, *s);
+ } else if (S_ISDIR(st.st_mode)) {
+ LinkList l;
+ DIR *lock = opendir(unmeta(*s));
+ char buf[PATH_MAX * 2 + 1], **arr, **ap;
+ int buflen, ct = 1;
+
+ if (lock) {
+ char *fn;
+
+ pushheap();
+ l = newlinklist();
+ while ((fn = zreaddir(lock, 1)) && !errflag) {
+ if (u)
+ buflen = snprintf(buf, sizeof(buf), "%s/%s?%s", *s, fn, u);
+ else
+ buflen = snprintf(buf, sizeof(buf), "%s/%s", *s, fn);
+ if (buflen < 0 || buflen >= (int)sizeof(buf))
+ continue;
+ addlinknode(l, dupstring(buf));
+ ct++;
+ }
+ closedir(lock);
+ ap = arr = (char **) zhalloc(ct * sizeof(char *));
+
+ while ((*ap++ = (char *)ugetnode(l)));
+ checkmailpath(arr);
+ popheap();
+ }
+ } else if (shout) {
+ if (st.st_size && st.st_atime <= st.st_mtime &&
+ st.st_mtime >= lastmailcheck) {
+ if (!u) {
+ fprintf(shout, "You have new mail.\n");
+ fflush(shout);
+ } else {
+ char *usav;
+ int uusav = underscoreused;
+
+ usav = zalloc(underscoreused);
+
+ if (usav)
+ memcpy(usav, zunderscore, underscoreused);
+
+ setunderscore(*s);
+
+ u = dupstring(u);
+ if (!parsestr(&u)) {
+ singsub(&u);
+ zputs(u, shout);
+ fputc('\n', shout);
+ fflush(shout);
+ }
+ if (usav) {
+ setunderscore(usav);
+ zfree(usav, uusav);
+ }
+ }
+ }
+ if (isset(MAILWARNING) && st.st_atime > st.st_mtime &&
+ st.st_atime > lastmailcheck && st.st_size) {
+ fprintf(shout, "The mail in %s has been read.\n", unmeta(*s));
+ fflush(shout);
+ }
+ }
+ *v = c;
+ s++;
+ }
+}
+
+/* This prints the XTRACE prompt. */
+
+/**/
+FILE *xtrerr = 0;
+
+/**/
+void
+printprompt4(void)
+{
+ if (!xtrerr)
+ xtrerr = stderr;
+ if (prompt4) {
+ int l, t = opts[XTRACE];
+ char *s = dupstring(prompt4);
+
+ opts[XTRACE] = 0;
+ unmetafy(s, &l);
+ s = unmetafy(promptexpand(metafy(s, l, META_NOALLOC),
+ 0, NULL, NULL, NULL), &l);
+ opts[XTRACE] = t;
+
+ fprintf(xtrerr, "%s", s);
+ free(s);
+ }
+}
+
+/**/
+mod_export void
+freestr(void *a)
+{
+ zsfree(a);
+}
+
+/**/
+mod_export void
+gettyinfo(struct ttyinfo *ti)
+{
+ if (SHTTY != -1) {
+#ifdef HAVE_TERMIOS_H
+# ifdef HAVE_TCGETATTR
+ if (tcgetattr(SHTTY, &ti->tio) == -1)
+# else
+ if (ioctl(SHTTY, TCGETS, &ti->tio) == -1)
+# endif
+ zerr("bad tcgets: %e", errno);
+#else
+# ifdef HAVE_TERMIO_H
+ ioctl(SHTTY, TCGETA, &ti->tio);
+# else
+ ioctl(SHTTY, TIOCGETP, &ti->sgttyb);
+ ioctl(SHTTY, TIOCLGET, &ti->lmodes);
+ ioctl(SHTTY, TIOCGETC, &ti->tchars);
+ ioctl(SHTTY, TIOCGLTC, &ti->ltchars);
+# endif
+#endif
+ }
+}
+
+/**/
+mod_export void
+settyinfo(struct ttyinfo *ti)
+{
+ if (SHTTY != -1) {
+#ifdef HAVE_TERMIOS_H
+# ifdef HAVE_TCGETATTR
+# ifndef TCSADRAIN
+# define TCSADRAIN 1 /* XXX Princeton's include files are screwed up */
+# endif
+ while (tcsetattr(SHTTY, TCSADRAIN, &ti->tio) == -1 && errno == EINTR)
+ ;
+# else
+ while (ioctl(SHTTY, TCSETS, &ti->tio) == -1 && errno == EINTR)
+ ;
+# endif
+ /* zerr("settyinfo: %e",errno);*/
+#else
+# ifdef HAVE_TERMIO_H
+ ioctl(SHTTY, TCSETA, &ti->tio);
+# else
+ ioctl(SHTTY, TIOCSETN, &ti->sgttyb);
+ ioctl(SHTTY, TIOCLSET, &ti->lmodes);
+ ioctl(SHTTY, TIOCSETC, &ti->tchars);
+ ioctl(SHTTY, TIOCSLTC, &ti->ltchars);
+# endif
+#endif
+ }
+}
+
+/* the default tty state */
+
+/**/
+mod_export struct ttyinfo shttyinfo;
+
+/* != 0 if we need to call resetvideo() */
+
+/**/
+mod_export int resetneeded;
+
+#ifdef TIOCGWINSZ
+/* window size changed */
+
+/**/
+mod_export int winchanged;
+#endif
+
+static int
+adjustlines(int signalled)
+{
+ int oldlines = zterm_lines;
+
+#ifdef TIOCGWINSZ
+ if (signalled || zterm_lines <= 0)
+ zterm_lines = shttyinfo.winsize.ws_row;
+ else
+ shttyinfo.winsize.ws_row = zterm_lines;
+#endif /* TIOCGWINSZ */
+ if (zterm_lines <= 0) {
+ DPUTS(signalled && zterm_lines < 0,
+ "BUG: Impossible TIOCGWINSZ rows");
+ zterm_lines = tclines > 0 ? tclines : 24;
+ }
+
+ if (zterm_lines > 2)
+ termflags &= ~TERM_SHORT;
+ else
+ termflags |= TERM_SHORT;
+
+ return (zterm_lines != oldlines);
+}
+
+static int
+adjustcolumns(int signalled)
+{
+ int oldcolumns = zterm_columns;
+
+#ifdef TIOCGWINSZ
+ if (signalled || zterm_columns <= 0)
+ zterm_columns = shttyinfo.winsize.ws_col;
+ else
+ shttyinfo.winsize.ws_col = zterm_columns;
+#endif /* TIOCGWINSZ */
+ if (zterm_columns <= 0) {
+ DPUTS(signalled && zterm_columns < 0,
+ "BUG: Impossible TIOCGWINSZ cols");
+ zterm_columns = tccolumns > 0 ? tccolumns : 80;
+ }
+
+ if (zterm_columns > 2)
+ termflags &= ~TERM_NARROW;
+ else
+ termflags |= TERM_NARROW;
+
+ return (zterm_columns != oldcolumns);
+}
+
+/* check the size of the window and adjust if necessary. *
+ * The value of from: *
+ * 0: called from update_job or setupvals *
+ * 1: called from the SIGWINCH handler *
+ * 2: called from the LINES parameter callback *
+ * 3: called from the COLUMNS parameter callback */
+
+/**/
+void
+adjustwinsize(int from)
+{
+ static int getwinsz = 1;
+#ifdef TIOCGWINSZ
+ int ttyrows = shttyinfo.winsize.ws_row;
+ int ttycols = shttyinfo.winsize.ws_col;
+#endif
+ int resetzle = 0;
+
+ if (getwinsz || from == 1) {
+#ifdef TIOCGWINSZ
+ if (SHTTY == -1)
+ return;
+ if (ioctl(SHTTY, TIOCGWINSZ, (char *)&shttyinfo.winsize) == 0) {
+ resetzle = (ttyrows != shttyinfo.winsize.ws_row ||
+ ttycols != shttyinfo.winsize.ws_col);
+ if (from == 0 && resetzle && ttyrows && ttycols)
+ from = 1; /* Signal missed while a job owned the tty? */
+ ttyrows = shttyinfo.winsize.ws_row;
+ ttycols = shttyinfo.winsize.ws_col;
+ } else {
+ /* Set to value from environment on failure */
+ shttyinfo.winsize.ws_row = zterm_lines;
+ shttyinfo.winsize.ws_col = zterm_columns;
+ resetzle = (from == 1);
+ }
+#else
+ resetzle = from == 1;
+#endif /* TIOCGWINSZ */
+ } /* else
+ return; */
+
+ switch (from) {
+ case 0:
+ case 1:
+ getwinsz = 0;
+ /* Calling setiparam() here calls this function recursively, but *
+ * because we've already called adjustlines() and adjustcolumns() *
+ * here, recursive calls are no-ops unless a signal intervenes. *
+ * The commented "else return;" above might be a safe shortcut, *
+ * but I'm concerned about what happens on race conditions; e.g., *
+ * suppose the user resizes his xterm during `eval $(resize)'? */
+ if (adjustlines(from) && zgetenv("LINES"))
+ setiparam("LINES", zterm_lines);
+ if (adjustcolumns(from) && zgetenv("COLUMNS"))
+ setiparam("COLUMNS", zterm_columns);
+ getwinsz = 1;
+ break;
+ case 2:
+ resetzle = adjustlines(0);
+ break;
+ case 3:
+ resetzle = adjustcolumns(0);
+ break;
+ }
+
+#ifdef TIOCGWINSZ
+ if (interact && from >= 2 &&
+ (shttyinfo.winsize.ws_row != ttyrows ||
+ shttyinfo.winsize.ws_col != ttycols)) {
+ /* shttyinfo.winsize is already set up correctly */
+ /* ioctl(SHTTY, TIOCSWINSZ, (char *)&shttyinfo.winsize); */
+ }
+#endif /* TIOCGWINSZ */
+
+ if (zleactive && resetzle) {
+#ifdef TIOCGWINSZ
+ winchanged =
+#endif /* TIOCGWINSZ */
+ resetneeded = 1;
+ zleentry(ZLE_CMD_RESET_PROMPT);
+ zleentry(ZLE_CMD_REFRESH);
+ }
+}
+
+/*
+ * Ensure the fdtable is large enough for fd, and that the
+ * maximum fd is set appropriately.
+ */
+static void
+check_fd_table(int fd)
+{
+ if (fd <= max_zsh_fd)
+ return;
+
+ if (fd >= fdtable_size) {
+ int old_size = fdtable_size;
+ while (fd >= fdtable_size)
+ fdtable = zrealloc(fdtable,
+ (fdtable_size *= 2)*sizeof(*fdtable));
+ memset(fdtable + old_size, 0,
+ (fdtable_size - old_size) * sizeof(*fdtable));
+ }
+ max_zsh_fd = fd;
+}
+
+/* Move a fd to a place >= 10 and mark the new fd in fdtable. If the fd *
+ * is already >= 10, it is not moved. If it is invalid, -1 is returned. */
+
+/**/
+mod_export int
+movefd(int fd)
+{
+ if(fd != -1 && fd < 10) {
+#ifdef F_DUPFD
+ int fe = fcntl(fd, F_DUPFD, 10);
+#else
+ int fe = movefd(dup(fd));
+#endif
+ /*
+ * To close or not to close if fe is -1?
+ * If it is -1, we haven't moved the fd, so if we close
+ * it we lose it; but we're probably not going to be able
+ * to use it in situ anyway. So probably better to avoid a leak.
+ */
+ zclose(fd);
+ fd = fe;
+ }
+ if(fd != -1) {
+ check_fd_table(fd);
+ fdtable[fd] = FDT_INTERNAL;
+ }
+ return fd;
+}
+
+/*
+ * Move fd x to y. If x == -1, fd y is closed.
+ * Returns y for success, -1 for failure.
+ */
+
+/**/
+mod_export int
+redup(int x, int y)
+{
+ int ret = y;
+
+ if(x < 0)
+ zclose(y);
+ else if (x != y) {
+ if (dup2(x, y) == -1) {
+ ret = -1;
+ } else {
+ check_fd_table(y);
+ fdtable[y] = fdtable[x];
+ if (fdtable[y] == FDT_FLOCK || fdtable[y] == FDT_FLOCK_EXEC)
+ fdtable[y] = FDT_INTERNAL;
+ }
+ /*
+ * Closing any fd to the locked file releases the lock.
+ * This isn't expected to happen, it's here for completeness.
+ */
+ if (fdtable[x] == FDT_FLOCK)
+ fdtable_flocks--;
+ zclose(x);
+ }
+
+ return ret;
+}
+
+/*
+ * Add an fd opened ithin a module.
+ *
+ * fdt is the type of the fd; see the FDT_ definitions in zsh.h.
+ * The most likely falures are:
+ *
+ * FDT_EXTERNAL: the fd can be used within the shell for normal I/O but
+ * it will not be closed automatically or by normal shell syntax.
+ *
+ * FDT_MODULE: as FDT_EXTERNAL, but it can only be closed by the module
+ * (which should included zclose() as part of the sequence), not by
+ * the standard shell syntax for closing file descriptors.
+ *
+ * FDT_INTERNAL: fd is treated like others created by the shell for
+ * internal use; it can be closed and will be closed by the shell if it
+ * exec's or performs an exec with a fork optimised out.
+ *
+ * Safe if fd is -1 to indicate failure.
+ */
+/**/
+mod_export void
+addmodulefd(int fd, int fdt)
+{
+ if (fd >= 0) {
+ check_fd_table(fd);
+ fdtable[fd] = fdt;
+ }
+}
+
+/**/
+
+/*
+ * Indicate that an fd has a file lock; if cloexec is 1 it will be closed
+ * on exec.
+ * The fd should already be known to fdtable (e.g. by movefd).
+ * Note the fdtable code doesn't care what sort of lock
+ * is used; this simply prevents the main shell exiting prematurely
+ * when it holds a lock.
+ */
+
+/**/
+mod_export void
+addlockfd(int fd, int cloexec)
+{
+ if (cloexec) {
+ if (fdtable[fd] != FDT_FLOCK)
+ fdtable_flocks++;
+ fdtable[fd] = FDT_FLOCK;
+ } else {
+ fdtable[fd] = FDT_FLOCK_EXEC;
+ }
+}
+
+/* Close the given fd, and clear it from fdtable. */
+
+/**/
+mod_export int
+zclose(int fd)
+{
+ if (fd >= 0) {
+ /*
+ * Careful: we allow closing of arbitrary fd's, beyond
+ * max_zsh_fd. In that case we don't try anything clever.
+ */
+ if (fd <= max_zsh_fd) {
+ if (fdtable[fd] == FDT_FLOCK)
+ fdtable_flocks--;
+ fdtable[fd] = FDT_UNUSED;
+ while (max_zsh_fd > 0 && fdtable[max_zsh_fd] == FDT_UNUSED)
+ max_zsh_fd--;
+ if (fd == coprocin)
+ coprocin = -1;
+ if (fd == coprocout)
+ coprocout = -1;
+ }
+ return close(fd);
+ }
+ return -1;
+}
+
+/*
+ * Close an fd returning 0 if used for locking; return -1 if it isn't.
+ */
+
+/**/
+mod_export int
+zcloselockfd(int fd)
+{
+ if (fd > max_zsh_fd)
+ return -1;
+ if (fdtable[fd] != FDT_FLOCK && fdtable[fd] != FDT_FLOCK_EXEC)
+ return -1;
+ zclose(fd);
+ return 0;
+}
+
+#ifdef HAVE__MKTEMP
+extern char *_mktemp(char *);
+#endif
+
+/* Get a unique filename for use as a temporary file. If "prefix" is
+ * NULL, the name is relative to $TMPPREFIX; If it is non-NULL, the
+ * unique suffix includes a prefixed '.' for improved readability. If
+ * "use_heap" is true, we allocate the returned name on the heap.
+ * The string passed as "prefix" is expected to be metafied. */
+
+/**/
+mod_export char *
+gettempname(const char *prefix, int use_heap)
+{
+ char *ret, *suffix = prefix ? ".XXXXXX" : "XXXXXX";
+
+ queue_signals();
+ if (!prefix && !(prefix = getsparam("TMPPREFIX")))
+ prefix = DEFAULT_TMPPREFIX;
+ if (use_heap)
+ ret = dyncat(unmeta(prefix), suffix);
+ else
+ ret = bicat(unmeta(prefix), suffix);
+
+#ifdef HAVE__MKTEMP
+ /* Zsh uses mktemp() safely, so silence the warnings */
+ ret = (char *) _mktemp(ret);
+#else
+ ret = (char *) mktemp(ret);
+#endif
+ unqueue_signals();
+
+ return ret;
+}
+
+/* The gettempfile() "prefix" is expected to be metafied, see hist.c
+ * and gettempname(). */
+
+/**/
+mod_export int
+gettempfile(const char *prefix, int use_heap, char **tempname)
+{
+ char *fn;
+ int fd;
+ mode_t old_umask;
+#if HAVE_MKSTEMP
+ char *suffix = prefix ? ".XXXXXX" : "XXXXXX";
+
+ queue_signals();
+ old_umask = umask(0177);
+ if (!prefix && !(prefix = getsparam("TMPPREFIX")))
+ prefix = DEFAULT_TMPPREFIX;
+ if (use_heap)
+ fn = dyncat(unmeta(prefix), suffix);
+ else
+ fn = bicat(unmeta(prefix), suffix);
+
+ fd = mkstemp(fn);
+ if (fd < 0) {
+ if (!use_heap)
+ free(fn);
+ fn = NULL;
+ }
+#else
+ int failures = 0;
+
+ queue_signals();
+ old_umask = umask(0177);
+ do {
+ if (!(fn = gettempname(prefix, use_heap))) {
+ fd = -1;
+ break;
+ }
+ if ((fd = open(fn, O_RDWR | O_CREAT | O_EXCL, 0600)) >= 0)
+ break;
+ if (!use_heap)
+ free(fn);
+ fn = NULL;
+ } while (errno == EEXIST && ++failures < 16);
+#endif
+ *tempname = fn;
+
+ umask(old_umask);
+ unqueue_signals();
+ return fd;
+}
+
+/* Check if a string contains a token */
+
+/**/
+mod_export int
+has_token(const char *s)
+{
+ while(*s)
+ if(itok(*s++))
+ return 1;
+ return 0;
+}
+
+/* Delete a character in a string */
+
+/**/
+mod_export void
+chuck(char *str)
+{
+ while ((str[0] = str[1]))
+ str++;
+}
+
+/**/
+mod_export int
+tulower(int c)
+{
+ c &= 0xff;
+ return (isupper(c) ? tolower(c) : c);
+}
+
+/**/
+mod_export int
+tuupper(int c)
+{
+ c &= 0xff;
+ return (islower(c) ? toupper(c) : c);
+}
+
+/* copy len chars from t into s, and null terminate */
+
+/**/
+void
+ztrncpy(char *s, char *t, int len)
+{
+ while (len--)
+ *s++ = *t++;
+ *s = '\0';
+}
+
+/* copy t into *s and update s */
+
+/**/
+mod_export void
+strucpy(char **s, char *t)
+{
+ char *u = *s;
+
+ while ((*u++ = *t++));
+ *s = u - 1;
+}
+
+/**/
+mod_export void
+struncpy(char **s, char *t, int n)
+{
+ char *u = *s;
+
+ while (n-- && (*u = *t++))
+ u++;
+ *s = u;
+ if (n > 0) /* just one null-byte will do, unlike strncpy(3) */
+ *u = '\0';
+}
+
+/* Return the number of elements in an array of pointers. *
+ * It doesn't count the NULL pointer at the end. */
+
+/**/
+mod_export int
+arrlen(char **s)
+{
+ int count;
+
+ for (count = 0; *s; s++, count++);
+ return count;
+}
+
+/* Return TRUE iff arrlen(s) >= lower_bound, but more efficiently. */
+
+/**/
+mod_export char
+arrlen_ge(char **s, unsigned lower_bound)
+{
+ while (lower_bound--)
+ if (!*s++)
+ return 0 /* FALSE */;
+
+ return 1 /* TRUE */;
+}
+
+/* Return TRUE iff arrlen(s) > lower_bound, but more efficiently. */
+
+/**/
+mod_export char
+arrlen_gt(char **s, unsigned lower_bound)
+{
+ return arrlen_ge(s, 1+lower_bound);
+}
+
+/* Return TRUE iff arrlen(s) <= upper_bound, but more efficiently. */
+
+/**/
+mod_export char
+arrlen_le(char **s, unsigned upper_bound)
+{
+ return arrlen_lt(s, 1+upper_bound);
+}
+
+/* Return TRUE iff arrlen(s) < upper_bound, but more efficiently. */
+
+/**/
+mod_export char
+arrlen_lt(char **s, unsigned upper_bound)
+{
+ return !arrlen_ge(s, upper_bound);
+}
+
+/* Skip over a balanced pair of parenthesis. */
+
+/**/
+mod_export int
+skipparens(char inpar, char outpar, char **s)
+{
+ int level;
+
+ if (**s != inpar)
+ return -1;
+
+ for (level = 1; *++*s && level;)
+ if (**s == inpar)
+ ++level;
+ else if (**s == outpar)
+ --level;
+
+ return level;
+}
+
+/**/
+mod_export zlong
+zstrtol(const char *s, char **t, int base)
+{
+ return zstrtol_underscore(s, t, base, 0);
+}
+
+/* Convert string to zlong (see zsh.h). This function (without the z) *
+ * is contained in the ANSI standard C library, but a lot of them seem *
+ * to be broken. */
+
+/**/
+mod_export zlong
+zstrtol_underscore(const char *s, char **t, int base, int underscore)
+{
+ const char *inp, *trunc = NULL;
+ zulong calc = 0, newcalc = 0;
+ int neg;
+
+ while (inblank(*s))
+ s++;
+
+ if ((neg = IS_DASH(*s)))
+ s++;
+ else if (*s == '+')
+ s++;
+
+ if (!base) {
+ if (*s != '0')
+ base = 10;
+ else if (*++s == 'x' || *s == 'X')
+ base = 16, s++;
+ else if (*s == 'b' || *s == 'B')
+ base = 2, s++;
+ else
+ base = 8;
+ }
+ inp = s;
+ if (base < 2 || base > 36) {
+ zerr("invalid base (must be 2 to 36 inclusive): %d", base);
+ return (zlong)0;
+ } else if (base <= 10) {
+ for (; (*s >= '0' && *s < ('0' + base)) ||
+ (underscore && *s == '_'); s++) {
+ if (trunc || *s == '_')
+ continue;
+ newcalc = calc * base + *s - '0';
+ if (newcalc < calc)
+ {
+ trunc = s;
+ continue;
+ }
+ calc = newcalc;
+ }
+ } else {
+ for (; idigit(*s) || (*s >= 'a' && *s < ('a' + base - 10))
+ || (*s >= 'A' && *s < ('A' + base - 10))
+ || (underscore && *s == '_'); s++) {
+ if (trunc || *s == '_')
+ continue;
+ newcalc = calc*base + (idigit(*s) ? (*s - '0') : (*s & 0x1f) + 9);
+ if (newcalc < calc)
+ {
+ trunc = s;
+ continue;
+ }
+ calc = newcalc;
+ }
+ }
+
+ /*
+ * Special case: check for a number that was just too long for
+ * signed notation.
+ * Extra special case: the lowest negative number would trigger
+ * the first test, but is actually representable correctly.
+ * This is a 1 in the top bit, all others zero, so test for
+ * that explicitly.
+ */
+ if (!trunc && (zlong)calc < 0 &&
+ (!neg || calc & ~((zulong)1 << (8*sizeof(zulong)-1))))
+ {
+ trunc = s - 1;
+ calc /= base;
+ }
+
+ if (trunc)
+ zwarn("number truncated after %d digits: %s", (int)(trunc - inp), inp);
+
+ if (t)
+ *t = (char *)s;
+ return neg ? -(zlong)calc : (zlong)calc;
+}
+
+/*
+ * If s represents a complete unsigned integer (and nothing else)
+ * return 1 and set retval to the value. Otherwise return 0.
+ *
+ * Underscores are always allowed.
+ *
+ * Sensitive to OCTAL_ZEROES.
+ */
+
+/**/
+mod_export int
+zstrtoul_underscore(const char *s, zulong *retval)
+{
+ zulong calc = 0, newcalc = 0, base;
+
+ if (*s == '+')
+ s++;
+
+ if (*s != '0')
+ base = 10;
+ else if (*++s == 'x' || *s == 'X')
+ base = 16, s++;
+ else if (*s == 'b' || *s == 'B')
+ base = 2, s++;
+ else
+ base = isset(OCTALZEROES) ? 8 : 10;
+ if (base <= 10) {
+ for (; (*s >= '0' && *s < ('0' + base)) ||
+ *s == '_'; s++) {
+ if (*s == '_')
+ continue;
+ newcalc = calc * base + *s - '0';
+ if (newcalc < calc)
+ {
+ return 0;
+ }
+ calc = newcalc;
+ }
+ } else {
+ for (; idigit(*s) || (*s >= 'a' && *s < ('a' + base - 10))
+ || (*s >= 'A' && *s < ('A' + base - 10))
+ || *s == '_'; s++) {
+ if (*s == '_')
+ continue;
+ newcalc = calc*base + (idigit(*s) ? (*s - '0') : (*s & 0x1f) + 9);
+ if (newcalc < calc)
+ {
+ return 0;
+ }
+ calc = newcalc;
+ }
+ }
+
+ if (*s)
+ return 0;
+ *retval = calc;
+ return 1;
+}
+
+/**/
+mod_export int
+setblock_fd(int turnonblocking, int fd, long *modep)
+{
+#ifdef O_NDELAY
+# ifdef O_NONBLOCK
+# define NONBLOCK (O_NDELAY|O_NONBLOCK)
+# else /* !O_NONBLOCK */
+# define NONBLOCK O_NDELAY
+# endif /* !O_NONBLOCK */
+#else /* !O_NDELAY */
+# ifdef O_NONBLOCK
+# define NONBLOCK O_NONBLOCK
+# else /* !O_NONBLOCK */
+# define NONBLOCK 0
+# endif /* !O_NONBLOCK */
+#endif /* !O_NDELAY */
+
+#if NONBLOCK
+ struct stat st;
+
+ if (!fstat(fd, &st) && !S_ISREG(st.st_mode)) {
+ *modep = fcntl(fd, F_GETFL, 0);
+ if (*modep != -1) {
+ if (!turnonblocking) {
+ /* We want to know if blocking was off */
+ if ((*modep & NONBLOCK) ||
+ !fcntl(fd, F_SETFL, *modep | NONBLOCK))
+ return 1;
+ } else if ((*modep & NONBLOCK) &&
+ !fcntl(fd, F_SETFL, *modep & ~NONBLOCK)) {
+ /* Here we want to know if the state changed */
+ return 1;
+ }
+ }
+ } else
+#endif /* NONBLOCK */
+ *modep = -1;
+ return 0;
+
+#undef NONBLOCK
+}
+
+/**/
+int
+setblock_stdin(void)
+{
+ long mode;
+ return setblock_fd(1, 0, &mode);
+}
+
+/*
+ * Check for pending input on fd. If polltty is set, we may need to
+ * use termio to look for input. As a final resort, go to non-blocking
+ * input and try to read a character, which in this case will be
+ * returned in *readchar.
+ *
+ * Note that apart from setting (and restoring) non-blocking input,
+ * this function does not change the input mode. The calling function
+ * should have set cbreak mode if necessary.
+ *
+ * fd may be -1 to sleep until the timeout in microseconds. This is a
+ * fallback for old systems that don't have nanosleep(). Some very old
+ * systems might not have select: get with it, daddy-o.
+ */
+
+/**/
+mod_export int
+read_poll(int fd, int *readchar, int polltty, zlong microseconds)
+{
+ int ret = -1;
+ long mode = -1;
+ char c;
+#ifdef HAVE_SELECT
+ fd_set foofd;
+ struct timeval expire_tv;
+#else
+#ifdef FIONREAD
+ int val;
+#endif
+#endif
+#ifdef HAS_TIO
+ struct ttyinfo ti;
+#endif
+
+ if (fd < 0 || (polltty && !isatty(fd)))
+ polltty = 0; /* no tty to poll */
+
+#if defined(HAS_TIO) && !defined(__CYGWIN__)
+ /*
+ * Under Solaris, at least, reading from the terminal in non-canonical
+ * mode requires that we use the VMIN mechanism to poll. Any attempt
+ * to check any other way, or to set the terminal to non-blocking mode
+ * and poll that way, fails; it will just for canonical mode input.
+ * We should probably use this mechanism if the user has set non-canonical
+ * mode, in which case testing here for isatty() and ~ICANON would be
+ * better than testing whether bin_read() set it, but for now we've got
+ * enough problems.
+ *
+ * Under Cygwin, you won't be surprised to here, this mechanism,
+ * although present, doesn't work, and we *have* to use ordinary
+ * non-blocking reads to find out if there is a character present
+ * in non-canonical mode.
+ *
+ * I am assuming Solaris is nearer the UNIX norm. This is not necessarily
+ * as plausible as it sounds, but it seems the right way to guess.
+ * pws 2000/06/26
+ */
+ if (polltty && fd >= 0) {
+ gettyinfo(&ti);
+ if ((polltty = ti.tio.c_cc[VMIN])) {
+ ti.tio.c_cc[VMIN] = 0;
+ /* termios timeout is 10ths of a second */
+ ti.tio.c_cc[VTIME] = (int) (microseconds / (zlong)100000);
+ settyinfo(&ti);
+ }
+ }
+#else
+ polltty = 0;
+#endif
+#ifdef HAVE_SELECT
+ expire_tv.tv_sec = (int) (microseconds / (zlong)1000000);
+ expire_tv.tv_usec = microseconds % (zlong)1000000;
+ FD_ZERO(&foofd);
+ if (fd > -1) {
+ FD_SET(fd, &foofd);
+ ret = select(fd+1, (SELECT_ARG_2_T) &foofd, NULL, NULL, &expire_tv);
+ } else
+ ret = select(0, NULL, NULL, NULL, &expire_tv);
+#else
+ if (fd < 0) {
+ /* OK, can't do that. Just quietly sleep for a second. */
+ sleep(1);
+ return 1;
+ }
+#ifdef FIONREAD
+ if (ioctl(fd, FIONREAD, (char *) &val) == 0)
+ ret = (val > 0);
+#endif
+#endif
+
+ if (fd >= 0 && ret < 0 && !errflag) {
+ /*
+ * Final attempt: set non-blocking read and try to read a character.
+ * Praise Bill, this works under Cygwin (nothing else seems to).
+ */
+ if ((polltty || setblock_fd(0, fd, &mode)) && read(fd, &c, 1) > 0) {
+ *readchar = c;
+ ret = 1;
+ }
+ if (mode != -1)
+ fcntl(fd, F_SETFL, mode);
+ }
+#ifdef HAS_TIO
+ if (polltty) {
+ ti.tio.c_cc[VMIN] = 1;
+ ti.tio.c_cc[VTIME] = 0;
+ settyinfo(&ti);
+ }
+#endif
+ return (ret > 0);
+}
+
+/*
+ * Sleep for the given number of microseconds --- must be within
+ * range of a long at the moment, but this is only used for
+ * limited internal purposes.
+ */
+
+/**/
+int
+zsleep(long us)
+{
+#ifdef HAVE_NANOSLEEP
+ struct timespec sleeptime;
+
+ sleeptime.tv_sec = (time_t)us / (time_t)1000000;
+ sleeptime.tv_nsec = (us % 1000000L) * 1000L;
+ for (;;) {
+ struct timespec rem;
+ int ret = nanosleep(&sleeptime, &rem);
+
+ if (ret == 0)
+ return 1;
+ else if (errno != EINTR)
+ return 0;
+ sleeptime = rem;
+ }
+#else
+ int dummy;
+ return read_poll(-1, &dummy, 0, us);
+#endif
+}
+
+/**
+ * Sleep for time (fairly) randomly up to max_us microseconds.
+ * Don't let the wallclock time extend beyond end_time.
+ * Return 1 if that seemed to work, else 0.
+ *
+ * For best results max_us should be a multiple of 2**16 or large
+ * enough that it doesn't matter.
+ */
+
+/**/
+int
+zsleep_random(long max_us, time_t end_time)
+{
+ long r;
+ time_t now = time(NULL);
+
+ /*
+ * Randomish backoff. Doesn't need to be fundamentally
+ * unpredictable, just probably unlike the value another
+ * exiting shell is using. On some systems the bottom 16
+ * bits aren't that random but the use here doesn't
+ * really care.
+ */
+ r = (long)(rand() & 0xFFFF);
+ /*
+ * Turn this into a fraction of sleep_us. Again, this
+ * doesn't need to be particularly accurate and the base time
+ * is sufficient that we can do the division first and not
+ * worry about the range.
+ */
+ r = (max_us >> 16) * r;
+ /*
+ * Don't sleep beyond timeout.
+ * Not that important as timeout is ridiculously long, but
+ * if there's an interface, interface to it...
+ */
+ while (r && now + (time_t)(r / 1000000) > end_time)
+ r >>= 1;
+ if (r) /* pedantry */
+ return zsleep(r);
+ return 0;
+}
+
+/**/
+int
+checkrmall(char *s)
+{
+ DIR *rmd;
+ int count = 0;
+ if (!shout)
+ return 1;
+ if (*s != '/') {
+ if (pwd[1])
+ s = zhtricat(pwd, "/", s);
+ else
+ s = dyncat("/", s);
+ }
+ const int max_count = 100;
+ if ((rmd = opendir(unmeta(s)))) {
+ int ignoredots = !isset(GLOBDOTS);
+ char *fname;
+
+ while ((fname = zreaddir(rmd, 1))) {
+ if (ignoredots && *fname == '.')
+ continue;
+ count++;
+ if (count > max_count)
+ break;
+ }
+ closedir(rmd);
+ }
+ if (count > max_count)
+ fprintf(shout, "zsh: sure you want to delete more than %d files in ",
+ max_count);
+ else if (count == 1)
+ fprintf(shout, "zsh: sure you want to delete the only file in ");
+ else if (count > 0)
+ fprintf(shout, "zsh: sure you want to delete all %d files in ",
+ count);
+ else {
+ /* We don't know how many files the glob will expand to; see 41707. */
+ fprintf(shout, "zsh: sure you want to delete all the files in ");
+ }
+ nicezputs(s, shout);
+ if(isset(RMSTARWAIT)) {
+ fputs("? (waiting ten seconds)", shout);
+ fflush(shout);
+ zbeep();
+ sleep(10);
+ fputc('\n', shout);
+ }
+ if (errflag)
+ return 0;
+ fputs(" [yn]? ", shout);
+ fflush(shout);
+ zbeep();
+ return (getquery("ny", 1) == 'y');
+}
+
+/**/
+mod_export ssize_t
+read_loop(int fd, char *buf, size_t len)
+{
+ ssize_t got = len;
+
+ while (1) {
+ ssize_t ret = read(fd, buf, len);
+ if (ret == len)
+ break;
+ if (ret <= 0) {
+ if (ret < 0) {
+ if (errno == EINTR)
+ continue;
+ if (fd != SHTTY)
+ zwarn("read failed: %e", errno);
+ }
+ return ret;
+ }
+ buf += ret;
+ len -= ret;
+ }
+
+ return got;
+}
+
+/**/
+mod_export ssize_t
+write_loop(int fd, const char *buf, size_t len)
+{
+ ssize_t wrote = len;
+
+ while (1) {
+ ssize_t ret = write(fd, buf, len);
+ if (ret == len)
+ break;
+ if (ret < 0) {
+ if (errno == EINTR)
+ continue;
+ if (fd != SHTTY)
+ zwarn("write failed: %e", errno);
+ return -1;
+ }
+ buf += ret;
+ len -= ret;
+ }
+
+ return wrote;
+}
+
+static int
+read1char(int echo)
+{
+ char c;
+ int q = queue_signal_level();
+
+ dont_queue_signals();
+ while (read(SHTTY, &c, 1) != 1) {
+ if (errno != EINTR || errflag || retflag || breaks || contflag) {
+ restore_queue_signals(q);
+ return -1;
+ }
+ }
+ restore_queue_signals(q);
+ if (echo)
+ write_loop(SHTTY, &c, 1);
+ return STOUC(c);
+}
+
+/**/
+mod_export int
+noquery(int purge)
+{
+ int val = 0;
+
+#ifdef FIONREAD
+ char c;
+
+ ioctl(SHTTY, FIONREAD, (char *)&val);
+ if (purge) {
+ for (; val; val--) {
+ if (read(SHTTY, &c, 1) != 1) {
+ /* Do nothing... */
+ }
+ }
+ }
+#endif
+
+ return val;
+}
+
+/**/
+int
+getquery(char *valid_chars, int purge)
+{
+ int c, d, nl = 0;
+ int isem = !strcmp(term, "emacs");
+ struct ttyinfo ti;
+
+ attachtty(mypgrp);
+
+ gettyinfo(&ti);
+#ifdef HAS_TIO
+ ti.tio.c_lflag &= ~ECHO;
+ if (!isem) {
+ ti.tio.c_lflag &= ~ICANON;
+ ti.tio.c_cc[VMIN] = 1;
+ ti.tio.c_cc[VTIME] = 0;
+ }
+#else
+ ti.sgttyb.sg_flags &= ~ECHO;
+ if (!isem)
+ ti.sgttyb.sg_flags |= CBREAK;
+#endif
+ settyinfo(&ti);
+
+ if (noquery(purge)) {
+ if (!isem)
+ settyinfo(&shttyinfo);
+ write_loop(SHTTY, "n\n", 2);
+ return 'n';
+ }
+
+ while ((c = read1char(0)) >= 0) {
+ if (c == 'Y')
+ c = 'y';
+ else if (c == 'N')
+ c = 'n';
+ if (!valid_chars)
+ break;
+ if (c == '\n') {
+ c = *valid_chars;
+ nl = 1;
+ break;
+ }
+ if (strchr(valid_chars, c)) {
+ nl = 1;
+ break;
+ }
+ zbeep();
+ }
+ if (c >= 0) {
+ char buf = (char)c;
+ write_loop(SHTTY, &buf, 1);
+ }
+ if (nl)
+ write_loop(SHTTY, "\n", 1);
+
+ if (isem) {
+ if (c != '\n')
+ while ((d = read1char(1)) >= 0 && d != '\n');
+ } else {
+ if (c != '\n' && !valid_chars) {
+#ifdef MULTIBYTE_SUPPORT
+ if (isset(MULTIBYTE) && c >= 0) {
+ /*
+ * No waiting for a valid character, and no draining;
+ * we should ensure we haven't stopped in the middle
+ * of a multibyte character.
+ */
+ mbstate_t mbs;
+ char cc = (char)c;
+ memset(&mbs, 0, sizeof(mbs));
+ for (;;) {
+ size_t ret = mbrlen(&cc, 1, &mbs);
+
+ if (ret != MB_INCOMPLETE)
+ break;
+ c = read1char(1);
+ if (c < 0)
+ break;
+ cc = (char)c;
+ }
+ }
+#endif
+ write_loop(SHTTY, "\n", 1);
+ }
+ }
+ settyinfo(&shttyinfo);
+ return c;
+}
+
+static int d;
+static char *guess, *best;
+static Patprog spckpat, spnamepat;
+
+/**/
+static void
+spscan(HashNode hn, UNUSED(int scanflags))
+{
+ int nd;
+
+ if (spckpat && pattry(spckpat, hn->nam))
+ return;
+
+ nd = spdist(hn->nam, guess, (int) strlen(guess) / 4 + 1);
+ if (nd <= d) {
+ best = hn->nam;
+ d = nd;
+ }
+}
+
+/* spellcheck a word */
+/* fix s ; if hist is nonzero, fix the history list too */
+
+/**/
+mod_export void
+spckword(char **s, int hist, int cmd, int ask)
+{
+ char *t, *correct_ignore;
+ char ic = '\0';
+ int preflen = 0;
+ int autocd = cmd && isset(AUTOCD) && strcmp(*s, ".") && strcmp(*s, "..");
+
+ if ((histdone & HISTFLAG_NOEXEC) || **s == '-' || **s == '%')
+ return;
+ if (!strcmp(*s, "in"))
+ return;
+ if (!(*s)[0] || !(*s)[1])
+ return;
+ if (cmd) {
+ if (shfunctab->getnode(shfunctab, *s) ||
+ builtintab->getnode(builtintab, *s) ||
+ cmdnamtab->getnode(cmdnamtab, *s) ||
+ aliastab->getnode(aliastab, *s) ||
+ reswdtab->getnode(reswdtab, *s))
+ return;
+ else if (isset(HASHLISTALL)) {
+ cmdnamtab->filltable(cmdnamtab);
+ if (cmdnamtab->getnode(cmdnamtab, *s))
+ return;
+ }
+ }
+ t = *s;
+ if (*t == Tilde || *t == Equals || *t == String)
+ t++;
+ for (; *t; t++)
+ if (itok(*t))
+ return;
+ best = NULL;
+ for (t = *s; *t; t++)
+ if (*t == '/')
+ break;
+ if (**s == Tilde && !*t)
+ return;
+
+ if ((correct_ignore = getsparam("CORRECT_IGNORE")) != NULL) {
+ tokenize(correct_ignore = dupstring(correct_ignore));
+ remnulargs(correct_ignore);
+ spckpat = patcompile(correct_ignore, 0, NULL);
+ } else
+ spckpat = NULL;
+
+ if ((correct_ignore = getsparam("CORRECT_IGNORE_FILE")) != NULL) {
+ tokenize(correct_ignore = dupstring(correct_ignore));
+ remnulargs(correct_ignore);
+ spnamepat = patcompile(correct_ignore, 0, NULL);
+ } else
+ spnamepat = NULL;
+
+ if (**s == String && !*t) {
+ guess = *s + 1;
+ if (itype_end(guess, IIDENT, 1) == guess)
+ return;
+ ic = String;
+ d = 100;
+ scanhashtable(paramtab, 1, 0, 0, spscan, 0);
+ } else if (**s == Equals) {
+ if (*t)
+ return;
+ if (hashcmd(guess = *s + 1, pathchecked))
+ return;
+ d = 100;
+ ic = Equals;
+ scanhashtable(aliastab, 1, 0, 0, spscan, 0);
+ scanhashtable(cmdnamtab, 1, 0, 0, spscan, 0);
+ } else {
+ guess = *s;
+ if (*guess == Tilde || *guess == String) {
+ int ne;
+ ic = *guess;
+ if (!*++t)
+ return;
+ guess = dupstring(guess);
+ ne = noerrs;
+ noerrs = 2;
+ singsub(&guess);
+ noerrs = ne;
+ if (!guess)
+ return;
+ preflen = strlen(guess) - strlen(t);
+ }
+ if (access(unmeta(guess), F_OK) == 0)
+ return;
+ best = spname(guess);
+ if (!*t && cmd) {
+ if (hashcmd(guess, pathchecked))
+ return;
+ d = 100;
+ scanhashtable(reswdtab, 1, 0, 0, spscan, 0);
+ scanhashtable(aliastab, 1, 0, 0, spscan, 0);
+ scanhashtable(shfunctab, 1, 0, 0, spscan, 0);
+ scanhashtable(builtintab, 1, 0, 0, spscan, 0);
+ scanhashtable(cmdnamtab, 1, 0, 0, spscan, 0);
+ if (autocd) {
+ char **pp;
+ for (pp = cdpath; *pp; pp++) {
+ char bestcd[PATH_MAX + 1];
+ int thisdist;
+ /* Less than d here, instead of less than or equal *
+ * as used in spscan(), so that an autocd is chosen *
+ * only when it is better than anything so far, and *
+ * so we prefer directories earlier in the cdpath. */
+ if ((thisdist = mindist(*pp, *s, bestcd, 1)) < d) {
+ best = dupstring(bestcd);
+ d = thisdist;
+ }
+ }
+ }
+ }
+ }
+ if (errflag)
+ return;
+ if (best && (int)strlen(best) > 1 && strcmp(best, guess)) {
+ int x;
+ if (ic) {
+ char *u;
+ if (preflen) {
+ /* do not correct the result of an expansion */
+ if (strncmp(guess, best, preflen))
+ return;
+ /* replace the temporarily expanded prefix with the original */
+ u = (char *) zhalloc(t - *s + strlen(best + preflen) + 1);
+ strncpy(u, *s, t - *s);
+ strcpy(u + (t - *s), best + preflen);
+ } else {
+ u = (char *) zhalloc(strlen(best) + 2);
+ *u = '\0';
+ strcpy(u + 1, best);
+ }
+ best = u;
+ guess = *s;
+ *guess = *best = ztokens[ic - Pound];
+ }
+ if (ask) {
+ if (noquery(0)) {
+ x = 'n';
+ } else if (shout) {
+ char *pptbuf;
+ pptbuf = promptexpand(sprompt, 0, best, guess, NULL);
+ zputs(pptbuf, shout);
+ free(pptbuf);
+ fflush(shout);
+ zbeep();
+ x = getquery("nyae", 0);
+ if (cmd && x == 'n')
+ pathchecked = path;
+ } else
+ x = 'n';
+ } else
+ x = 'y';
+ if (x == 'y') {
+ *s = dupstring(best);
+ if (hist)
+ hwrep(best);
+ } else if (x == 'a') {
+ histdone |= HISTFLAG_NOEXEC;
+ } else if (x == 'e') {
+ histdone |= HISTFLAG_NOEXEC | HISTFLAG_RECALL;
+ }
+ if (ic)
+ **s = ic;
+ }
+}
+
+/*
+ * Helper for ztrftime. Called with a pointer to the length left
+ * in the buffer, and a new string length to decrement from that.
+ * Returns 0 if the new length fits, 1 otherwise. We assume a terminating
+ * NUL and return 1 if that doesn't fit.
+ */
+
+static int
+ztrftimebuf(int *bufsizeptr, int decr)
+{
+ if (*bufsizeptr <= decr)
+ return 1;
+ *bufsizeptr -= decr;
+ return 0;
+}
+
+/*
+ * Like the system function, this returns the number of characters
+ * copied, not including the terminating NUL. This may be zero
+ * if the string didn't fit.
+ *
+ * As an extension, try to detect an error in strftime --- typically
+ * not enough memory --- and return -1. Not guaranteed to be portable,
+ * since the strftime() interface doesn't make any guarantees about
+ * the state of the buffer if it returns zero.
+ *
+ * fmt is metafied, but we need to unmetafy it on the fly to
+ * pass into strftime / combine with the output from strftime.
+ * The return value in buf is not metafied.
+ */
+
+/**/
+mod_export int
+ztrftime(char *buf, int bufsize, char *fmt, struct tm *tm, long nsec)
+{
+ int hr12;
+#ifdef HAVE_STRFTIME
+ int decr;
+ char *fmtstart;
+#else
+ static char *astr[] =
+ {"Sun", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat"};
+ static char *estr[] =
+ {"Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul",
+ "Aug", "Sep", "Oct", "Nov", "Dec"};
+#endif
+ char *origbuf = buf;
+
+
+ while (*fmt) {
+ if (*fmt == Meta) {
+ int chr = fmt[1] ^ 32;
+ if (ztrftimebuf(&bufsize, 1))
+ return -1;
+ *buf++ = chr;
+ fmt += 2;
+ } else if (*fmt == '%') {
+ int strip;
+ int digs = 3;
+
+#ifdef HAVE_STRFTIME
+ fmtstart =
+#endif
+ fmt++;
+
+ if (*fmt == '-') {
+ strip = 1;
+ fmt++;
+ } else
+ strip = 0;
+ if (idigit(*fmt)) {
+ /* Digit --- only useful with . */
+ char *dstart = fmt;
+ char *dend = fmt+1;
+ while (idigit(*dend))
+ dend++;
+ if (*dend == '.') {
+ fmt = dend;
+ digs = atoi(dstart);
+ }
+ }
+ /*
+ * Assume this format will take up at least two
+ * characters. Not always true, but if that matters
+ * we are so close to the edge it's not a big deal.
+ * Fix up some longer cases specially when we get to them.
+ */
+ if (ztrftimebuf(&bufsize, 2))
+ return -1;
+#ifdef HAVE_STRFTIME
+ /* Our internal handling doesn't handle padding and other gnu extensions,
+ * so here we detect them and pass over to strftime(). We don't want
+ * to do this unconditionally though, as we have some extensions that
+ * strftime() doesn't have (%., %f, %L and %K) */
+morefmt:
+ if (!((fmt - fmtstart == 1) || (fmt - fmtstart == 2 && strip) || *fmt == '.')) {
+ while (*fmt && strchr("OE^#_-0123456789", *fmt))
+ fmt++;
+ if (*fmt) {
+ fmt++;
+ goto strftimehandling;
+ }
+ }
+#endif
+ switch (*fmt++) {
+ case '.':
+ if (ztrftimebuf(&bufsize, digs))
+ return -1;
+ if (digs > 9)
+ digs = 9;
+ if (digs < 9) {
+ int trunc;
+ for (trunc = 8 - digs; trunc; trunc--)
+ nsec /= 10;
+ nsec = (nsec + 8) / 10;
+ }
+ sprintf(buf, "%0*ld", digs, nsec);
+ buf += digs;
+ break;
+ case '\0':
+ /* Guard against premature end of string */
+ *buf++ = '%';
+ fmt--;
+ break;
+ case 'f':
+ strip = 1;
+ /* FALLTHROUGH */
+ case 'e':
+ if (tm->tm_mday > 9)
+ *buf++ = '0' + tm->tm_mday / 10;
+ else if (!strip)
+ *buf++ = ' ';
+ *buf++ = '0' + tm->tm_mday % 10;
+ break;
+ case 'K':
+ strip = 1;
+ /* FALLTHROUGH */
+ case 'H':
+ case 'k':
+ if (tm->tm_hour > 9)
+ *buf++ = '0' + tm->tm_hour / 10;
+ else if (!strip) {
+ if (fmt[-1] == 'H')
+ *buf++ = '0';
+ else
+ *buf++ = ' ';
+ }
+ *buf++ = '0' + tm->tm_hour % 10;
+ break;
+ case 'L':
+ strip = 1;
+ /* FALLTHROUGH */
+ case 'l':
+ hr12 = tm->tm_hour % 12;
+ if (hr12 == 0)
+ hr12 = 12;
+ if (hr12 > 9)
+ *buf++ = '1';
+ else if (!strip)
+ *buf++ = ' ';
+
+ *buf++ = '0' + (hr12 % 10);
+ break;
+ case 'd':
+ if (tm->tm_mday > 9 || !strip)
+ *buf++ = '0' + tm->tm_mday / 10;
+ *buf++ = '0' + tm->tm_mday % 10;
+ break;
+ case 'm':
+ if (tm->tm_mon > 8 || !strip)
+ *buf++ = '0' + (tm->tm_mon + 1) / 10;
+ *buf++ = '0' + (tm->tm_mon + 1) % 10;
+ break;
+ case 'M':
+ if (tm->tm_min > 9 || !strip)
+ *buf++ = '0' + tm->tm_min / 10;
+ *buf++ = '0' + tm->tm_min % 10;
+ break;
+ case 'N':
+ if (ztrftimebuf(&bufsize, 9))
+ return -1;
+ sprintf(buf, "%09ld", nsec);
+ buf += 9;
+ break;
+ case 'S':
+ if (tm->tm_sec > 9 || !strip)
+ *buf++ = '0' + tm->tm_sec / 10;
+ *buf++ = '0' + tm->tm_sec % 10;
+ break;
+ case 'y':
+ if (tm->tm_year > 9 || !strip)
+ *buf++ = '0' + (tm->tm_year / 10) % 10;
+ *buf++ = '0' + tm->tm_year % 10;
+ break;
+#ifndef HAVE_STRFTIME
+ case 'Y':
+ {
+ int year, digits, testyear;
+ year = tm->tm_year + 1900;
+ digits = 1;
+ testyear = year;
+ while (testyear > 9) {
+ digits++;
+ testyear /= 10;
+ }
+ if (ztrftimebuf(&bufsize, digits))
+ return -1;
+ sprintf(buf, "%d", year);
+ buf += digits;
+ break;
+ }
+ case 'a':
+ if (ztrftimebuf(&bufsize, strlen(astr[tm->tm_wday]) - 2))
+ return -1;
+ strucpy(&buf, astr[tm->tm_wday]);
+ break;
+ case 'b':
+ if (ztrftimebuf(&bufsize, strlen(estr[tm->tm_mon]) - 2))
+ return -1;
+ strucpy(&buf, estr[tm->tm_mon]);
+ break;
+ case 'p':
+ *buf++ = (tm->tm_hour > 11) ? 'p' : 'a';
+ *buf++ = 'm';
+ break;
+ default:
+ *buf++ = '%';
+ if (fmt[-1] != '%')
+ *buf++ = fmt[-1];
+#else
+ case 'E':
+ case 'O':
+ case '^':
+ case '#':
+ case '_':
+ case '-':
+ case '0': case '1': case '2': case '3': case '4':
+ case '5': case '6': case '7': case '8': case '9':
+ goto morefmt;
+strftimehandling:
+ default:
+ /*
+ * Remember we've already allowed for two characters
+ * in the accounting in bufsize (but nowhere else).
+ */
+ {
+ char origchar = fmt[-1];
+ int size = fmt - fmtstart;
+ char *tmp, *last;
+ tmp = zhalloc(size + 1);
+ strncpy(tmp, fmtstart, size);
+ last = fmt-1;
+ if (*last == Meta) {
+ /*
+ * This is for consistency in counting:
+ * a metafiable character isn't actually
+ * a valid strftime descriptor.
+ *
+ * Previous characters were explicitly checked,
+ * so can't be metafied.
+ */
+ *last = *++fmt ^ 32;
+ }
+ tmp[size] = '\0';
+ *buf = '\1';
+ if (!strftime(buf, bufsize + 2, tmp, tm))
+ {
+ /*
+ * Some locales don't have strings for
+ * AM/PM, so empty output is valid.
+ */
+ if (*buf || (origchar != 'p' && origchar != 'P')) {
+ if (*buf) {
+ buf[0] = '\0';
+ return -1;
+ }
+ return 0;
+ }
+ }
+ decr = strlen(buf);
+ buf += decr;
+ bufsize -= decr - 2;
+ }
+#endif
+ break;
+ }
+ } else {
+ if (ztrftimebuf(&bufsize, 1))
+ return -1;
+ *buf++ = *fmt++;
+ }
+ }
+ *buf = '\0';
+ return buf - origbuf;
+}
+
+/**/
+mod_export char *
+zjoin(char **arr, int delim, int heap)
+{
+ int len = 0;
+ char **s, *ret, *ptr;
+
+ for (s = arr; *s; s++)
+ len += strlen(*s) + 1 + (imeta(delim) ? 1 : 0);
+ if (!len)
+ return heap? "" : ztrdup("");
+ ptr = ret = (char *) (heap ? zhalloc(len) : zalloc(len));
+ for (s = arr; *s; s++) {
+ strucpy(&ptr, *s);
+ if (imeta(delim)) {
+ *ptr++ = Meta;
+ *ptr++ = delim ^ 32;
+ }
+ else
+ *ptr++ = delim;
+ }
+ ptr[-1 - (imeta(delim) ? 1 : 0)] = '\0';
+ return ret;
+}
+
+/* Split a string containing a colon separated list *
+ * of items into an array of strings. */
+
+/**/
+mod_export char **
+colonsplit(char *s, int uniq)
+{
+ int ct;
+ char *t, **ret, **ptr, **p;
+
+ for (t = s, ct = 0; *t; t++) /* count number of colons */
+ if (*t == ':')
+ ct++;
+ ptr = ret = (char **) zalloc(sizeof(char *) * (ct + 2));
+
+ t = s;
+ do {
+ s = t;
+ /* move t to point at next colon */
+ for (; *t && *t != ':'; t++);
+ if (uniq)
+ for (p = ret; p < ptr; p++)
+ if ((int)strlen(*p) == t - s && ! strncmp(*p, s, t - s))
+ goto cont;
+ *ptr = (char *) zalloc((t - s) + 1);
+ ztrncpy(*ptr++, s, t - s);
+ cont: ;
+ }
+ while (*t++);
+ *ptr = NULL;
+ return ret;
+}
+
+/**/
+static int
+skipwsep(char **s)
+{
+ char *t = *s;
+ int i = 0;
+
+ /*
+ * Don't need to handle mutlibyte characters, they can't
+ * be IWSEP. Do need to check for metafication.
+ */
+ while (*t && iwsep(*t == Meta ? t[1] ^ 32 : *t)) {
+ if (*t == Meta)
+ t++;
+ t++;
+ i++;
+ }
+ *s = t;
+ return i;
+}
+
+/*
+ * haven't worked out what allownull does; it's passed down from
+ * sepsplit but all the cases it's used are either 0 or 1 without
+ * a comment. it seems to be something to do with the `nulstring'
+ * which i think is some kind of a metafication thing, so probably
+ * allownull's value is associated with whether we are using
+ * metafied strings.
+ * see findsep() below for handling of `quote' argument
+ */
+
+/**/
+mod_export char **
+spacesplit(char *s, int allownull, int heap, int quote)
+{
+ char *t, **ret, **ptr;
+ int l = sizeof(*ret) * (wordcount(s, NULL, -!allownull) + 1);
+ char *(*dup)(const char *) = (heap ? dupstring : ztrdup);
+
+ /* ### TODO: s/calloc/alloc/ */
+ ptr = ret = (char **) (heap ? hcalloc(l) : zshcalloc(l));
+
+ if (quote) {
+ /*
+ * we will be stripping quoted separators by hacking string,
+ * so make sure it's hackable.
+ */
+ s = dupstring(s);
+ }
+
+ t = s;
+ skipwsep(&s);
+ MB_METACHARINIT();
+ if (*s && itype_end(s, ISEP, 1) != s)
+ *ptr++ = dup(allownull ? "" : nulstring);
+ else if (!allownull && t != s)
+ *ptr++ = dup("");
+ while (*s) {
+ char *iend = itype_end(s, ISEP, 1);
+ if (iend != s) {
+ s = iend;
+ skipwsep(&s);
+ }
+ else if (quote && *s == '\\') {
+ s++;
+ skipwsep(&s);
+ }
+ t = s;
+ (void)findsep(&s, NULL, quote);
+ if (s > t || allownull) {
+ *ptr = (char *) (heap ? zhalloc((s - t) + 1) :
+ zalloc((s - t) + 1));
+ ztrncpy(*ptr++, t, s - t);
+ } else
+ *ptr++ = dup(nulstring);
+ t = s;
+ skipwsep(&s);
+ }
+ if (!allownull && t != s)
+ *ptr++ = dup("");
+ *ptr = NULL;
+ return ret;
+}
+
+/*
+ * Find a separator. Return 0 if already at separator, 1 if separator
+ * found later, else -1. (Historical note: used to return length into
+ * string but this is all that is necessary and is less ambiguous with
+ * multibyte characters around.)
+ *
+ * *s is the string we are looking along, which will be updated
+ * to the point we have got to.
+ *
+ * sep is a possibly multicharacter separator to look for. If NULL,
+ * use normal separator characters. If *sep is NULL, split on individual
+ * characters.
+ *
+ * quote is a flag that '\' should not be treated as a separator.
+ * in this case we need to be able to strip the backslash directly
+ * in the string, so the calling function must have sent us something
+ * modifiable. currently this only works for sep == NULL. also in
+ * in this case only, we need to turn \\ into \.
+ */
+
+/**/
+static int
+findsep(char **s, char *sep, int quote)
+{
+ /*
+ */
+ int i, ilen;
+ char *t, *tt;
+ convchar_t c;
+
+ MB_METACHARINIT();
+ if (!sep) {
+ for (t = *s; *t; t += ilen) {
+ if (quote && *t == '\\') {
+ if (t[1] == '\\') {
+ chuck(t);
+ ilen = 1;
+ continue;
+ } else {
+ ilen = MB_METACHARLENCONV(t+1, &c);
+ if (WC_ZISTYPE(c, ISEP)) {
+ chuck(t);
+ /* then advance over new character, length ilen */
+ } else {
+ /* treat *t (backslash) as normal byte */
+ if (isep(*t))
+ break;
+ ilen = 1;
+ }
+ }
+ } else {
+ ilen = MB_METACHARLENCONV(t, &c);
+ if (WC_ZISTYPE(c, ISEP))
+ break;
+ }
+ }
+ i = (t > *s);
+ *s = t;
+ return i;
+ }
+ if (!sep[0]) {
+ /*
+ * NULL separator just means advance past first character,
+ * if any.
+ */
+ if (**s) {
+ *s += MB_METACHARLEN(*s);
+ return 1;
+ }
+ return -1;
+ }
+ for (i = 0; **s; i++) {
+ /*
+ * The following works for multibyte characters by virtue of
+ * the fact that sep may be a string (and we don't care how
+ * it divides up, we need to match all of it).
+ */
+ for (t = sep, tt = *s; *t && *tt && *t == *tt; t++, tt++);
+ if (!*t)
+ return (i > 0);
+ *s += MB_METACHARLEN(*s);
+ }
+ return -1;
+}
+
+/**/
+char *
+findword(char **s, char *sep)
+{
+ char *r, *t;
+ int sl;
+
+ if (!**s)
+ return NULL;
+
+ if (sep) {
+ sl = strlen(sep);
+ r = *s;
+ while (! findsep(s, sep, 0)) {
+ r = *s += sl;
+ }
+ return r;
+ }
+ MB_METACHARINIT();
+ for (t = *s; *t; t += sl) {
+ convchar_t c;
+ sl = MB_METACHARLENCONV(t, &c);
+ if (!WC_ZISTYPE(c, ISEP))
+ break;
+ }
+ *s = t;
+ (void)findsep(s, sep, 0);
+ return t;
+}
+
+/**/
+int
+wordcount(char *s, char *sep, int mul)
+{
+ int r, sl, c;
+
+ if (sep) {
+ r = 1;
+ sl = strlen(sep);
+ for (; (c = findsep(&s, sep, 0)) >= 0; s += sl)
+ if ((c || mul) && (sl || *(s + sl)))
+ r++;
+ } else {
+ char *t = s;
+
+ r = 0;
+ if (mul <= 0)
+ skipwsep(&s);
+ if ((*s && itype_end(s, ISEP, 1) != s) ||
+ (mul < 0 && t != s))
+ r++;
+ for (; *s; r++) {
+ char *ie = itype_end(s, ISEP, 1);
+ if (ie != s) {
+ s = ie;
+ if (mul <= 0)
+ skipwsep(&s);
+ }
+ (void)findsep(&s, NULL, 0);
+ t = s;
+ if (mul <= 0)
+ skipwsep(&s);
+ }
+ if (mul < 0 && t != s)
+ r++;
+ }
+ return r;
+}
+
+/**/
+mod_export char *
+sepjoin(char **s, char *sep, int heap)
+{
+ char *r, *p, **t;
+ int l, sl;
+ char sepbuf[2];
+
+ if (!*s)
+ return heap ? "" : ztrdup("");
+ if (!sep) {
+ /* optimise common case that ifs[0] is space */
+ if (ifs && *ifs != ' ') {
+ MB_METACHARINIT();
+ sep = dupstrpfx(ifs, MB_METACHARLEN(ifs));
+ } else {
+ p = sep = sepbuf;
+ *p++ = ' ';
+ *p = '\0';
+ }
+ }
+ sl = strlen(sep);
+ for (t = s, l = 1 - sl; *t; l += strlen(*t) + sl, t++);
+ r = p = (char *) (heap ? zhalloc(l) : zalloc(l));
+ t = s;
+ while (*t) {
+ strucpy(&p, *t);
+ if (*++t)
+ strucpy(&p, sep);
+ }
+ *p = '\0';
+ return r;
+}
+
+/**/
+char **
+sepsplit(char *s, char *sep, int allownull, int heap)
+{
+ int n, sl;
+ char *t, *tt, **r, **p;
+
+ /* Null string? Treat as empty string. */
+ if (s[0] == Nularg && !s[1])
+ s++;
+
+ if (!sep)
+ return spacesplit(s, allownull, heap, 0);
+
+ sl = strlen(sep);
+ n = wordcount(s, sep, 1);
+ r = p = (char **) (heap ? zhalloc((n + 1) * sizeof(char *)) :
+ zalloc((n + 1) * sizeof(char *)));
+
+ for (t = s; n--;) {
+ tt = t;
+ (void)findsep(&t, sep, 0);
+ *p = (char *) (heap ? zhalloc(t - tt + 1) :
+ zalloc(t - tt + 1));
+ strncpy(*p, tt, t - tt);
+ (*p)[t - tt] = '\0';
+ p++;
+ t += sl;
+ }
+ *p = NULL;
+
+ return r;
+}
+
+/* Get the definition of a shell function */
+
+/**/
+mod_export Shfunc
+getshfunc(char *nam)
+{
+ return (Shfunc) shfunctab->getnode(shfunctab, nam);
+}
+
+/*
+ * Call the function func to substitute string orig by setting
+ * the parameter reply.
+ * Return the array from reply, or NULL if the function returned
+ * non-zero status.
+ * The returned value comes directly from the parameter and
+ * so should be used before there is any chance of that
+ * being changed or unset.
+ * If arg1 is not NULL, it is used as an initial argument to
+ * the function, with the original string as the second argument.
+ */
+
+/**/
+char **
+subst_string_by_func(Shfunc func, char *arg1, char *orig)
+{
+ int osc = sfcontext, osm = stopmsg, old_incompfunc = incompfunc;
+ LinkList l = newlinklist();
+ char **ret;
+
+ addlinknode(l, func->node.nam);
+ if (arg1)
+ addlinknode(l, arg1);
+ addlinknode(l, orig);
+ sfcontext = SFC_SUBST;
+ incompfunc = 0;
+
+ if (doshfunc(func, l, 1))
+ ret = NULL;
+ else
+ ret = getaparam("reply");
+
+ sfcontext = osc;
+ stopmsg = osm;
+ incompfunc = old_incompfunc;
+ return ret;
+}
+
+/**
+ * Front end to subst_string_by_func to use hook-like logic.
+ * name can refer to a function, and name + "_hook" can refer
+ * to an array containing a list of functions. The functions
+ * are tried in order until one returns success.
+ */
+/**/
+char **
+subst_string_by_hook(char *name, char *arg1, char *orig)
+{
+ Shfunc func;
+ char **ret = NULL;
+
+ if ((func = getshfunc(name))) {
+ ret = subst_string_by_func(func, arg1, orig);
+ }
+
+ if (!ret) {
+ char **arrptr;
+ int namlen = strlen(name);
+ VARARR(char, arrnam, namlen + HOOK_SUFFIX_LEN);
+ memcpy(arrnam, name, namlen);
+ memcpy(arrnam + namlen, HOOK_SUFFIX, HOOK_SUFFIX_LEN);
+
+ if ((arrptr = getaparam(arrnam))) {
+ /* Guard against internal modification of the array */
+ arrptr = arrdup(arrptr);
+ for (; *arrptr; arrptr++) {
+ if ((func = getshfunc(*arrptr))) {
+ ret = subst_string_by_func(func, arg1, orig);
+ if (ret)
+ break;
+ }
+ }
+ }
+ }
+
+ return ret;
+}
+
+/**/
+mod_export char **
+mkarray(char *s)
+{
+ char **t = (char **) zalloc((s) ? (2 * sizeof s) : (sizeof s));
+
+ if ((*t = s))
+ t[1] = NULL;
+ return t;
+}
+
+/**/
+mod_export char **
+hmkarray(char *s)
+{
+ char **t = (char **) zhalloc((s) ? (2 * sizeof s) : (sizeof s));
+
+ if ((*t = s))
+ t[1] = NULL;
+ return t;
+}
+
+/**/
+mod_export void
+zbeep(void)
+{
+ char *vb;
+ queue_signals();
+ if ((vb = getsparam_u("ZBEEP"))) {
+ int len;
+ vb = getkeystring(vb, &len, GETKEYS_BINDKEY, NULL);
+ write_loop(SHTTY, vb, len);
+ } else if (isset(BEEP))
+ write_loop(SHTTY, "\07", 1);
+ unqueue_signals();
+}
+
+/**/
+mod_export void
+freearray(char **s)
+{
+ char **t = s;
+
+ DPUTS(!s, "freearray() with zero argument");
+
+ while (*s)
+ zsfree(*s++);
+ free(t);
+}
+
+/**/
+int
+equalsplit(char *s, char **t)
+{
+ for (; *s && *s != '='; s++);
+ if (*s == '=') {
+ *s++ = '\0';
+ *t = s;
+ return 1;
+ }
+ return 0;
+}
+
+
+/* the ztypes table */
+
+/**/
+mod_export short int typtab[256];
+static int typtab_flags = 0;
+
+/* initialize the ztypes table */
+
+/**/
+void
+inittyptab(void)
+{
+ int t0;
+ char *s;
+
+ if (!(typtab_flags & ZTF_INIT)) {
+ typtab_flags = ZTF_INIT;
+ if (interact && isset(SHINSTDIN))
+ typtab_flags |= ZTF_INTERACT;
+ }
+
+ queue_signals();
+
+ memset(typtab, 0, sizeof(typtab));
+ for (t0 = 0; t0 != 32; t0++)
+ typtab[t0] = typtab[t0 + 128] = ICNTRL;
+ typtab[127] = ICNTRL;
+ for (t0 = '0'; t0 <= '9'; t0++)
+ typtab[t0] = IDIGIT | IALNUM | IWORD | IIDENT | IUSER;
+ for (t0 = 'a'; t0 <= 'z'; t0++)
+ typtab[t0] = typtab[t0 - 'a' + 'A'] = IALPHA | IALNUM | IIDENT | IUSER | IWORD;
+#ifndef MULTIBYTE_SUPPORT
+ /*
+ * This really doesn't seem to me the right thing to do when
+ * we have multibyte character support... it was a hack to assume
+ * eight bit characters `worked' for some values of work before
+ * we could test for them properly. I'm not 100% convinced
+ * having IIDENT here is a good idea at all, but this code
+ * should disappear into history...
+ */
+ for (t0 = 0240; t0 != 0400; t0++)
+ typtab[t0] = IALPHA | IALNUM | IIDENT | IUSER | IWORD;
+#endif
+ /* typtab['.'] |= IIDENT; */ /* Allow '.' in variable names - broken */
+ typtab['_'] = IIDENT | IUSER;
+ typtab['-'] = typtab['.'] = typtab[STOUC(Dash)] = IUSER;
+ typtab[' '] |= IBLANK | INBLANK;
+ typtab['\t'] |= IBLANK | INBLANK;
+ typtab['\n'] |= INBLANK;
+ typtab['\0'] |= IMETA;
+ typtab[STOUC(Meta) ] |= IMETA;
+ typtab[STOUC(Marker)] |= IMETA;
+ for (t0 = (int)STOUC(Pound); t0 <= (int)STOUC(LAST_NORMAL_TOK); t0++)
+ typtab[t0] |= ITOK | IMETA;
+ for (t0 = (int)STOUC(Snull); t0 <= (int)STOUC(Nularg); t0++)
+ typtab[t0] |= ITOK | IMETA | INULL;
+ for (s = ifs ? ifs : EMULATION(EMULATE_KSH|EMULATE_SH) ?
+ DEFAULT_IFS_SH : DEFAULT_IFS; *s; s++) {
+ int c = STOUC(*s == Meta ? *++s ^ 32 : *s);
+#ifdef MULTIBYTE_SUPPORT
+ if (!isascii(c)) {
+ /* see comment for wordchars below */
+ continue;
+ }
+#endif
+ if (inblank(c)) {
+ if (s[1] == c)
+ s++;
+ else
+ typtab[c] |= IWSEP;
+ }
+ typtab[c] |= ISEP;
+ }
+ for (s = wordchars ? wordchars : DEFAULT_WORDCHARS; *s; s++) {
+ int c = STOUC(*s == Meta ? *++s ^ 32 : *s);
+#ifdef MULTIBYTE_SUPPORT
+ if (!isascii(c)) {
+ /*
+ * If we have support for multibyte characters, we don't
+ * handle non-ASCII characters here; instead, we turn
+ * wordchars into a wide character array.
+ * (We may actually have a single-byte 8-bit character set,
+ * but it works the same way.)
+ */
+ continue;
+ }
+#endif
+ typtab[c] |= IWORD;
+ }
+#ifdef MULTIBYTE_SUPPORT
+ set_widearray(wordchars, &wordchars_wide);
+ set_widearray(ifs ? ifs : EMULATION(EMULATE_KSH|EMULATE_SH) ?
+ DEFAULT_IFS_SH : DEFAULT_IFS, &ifs_wide);
+#endif
+ for (s = SPECCHARS; *s; s++)
+ typtab[STOUC(*s)] |= ISPECIAL;
+ if (typtab_flags & ZTF_SP_COMMA)
+ typtab[STOUC(',')] |= ISPECIAL;
+ if (isset(BANGHIST) && bangchar && (typtab_flags & ZTF_INTERACT)) {
+ typtab_flags |= ZTF_BANGCHAR;
+ typtab[bangchar] |= ISPECIAL;
+ } else
+ typtab_flags &= ~ZTF_BANGCHAR;
+ for (s = PATCHARS; *s; s++)
+ typtab[STOUC(*s)] |= IPATTERN;
+
+ unqueue_signals();
+}
+
+/**/
+mod_export void
+makecommaspecial(int yesno)
+{
+ if (yesno != 0) {
+ typtab_flags |= ZTF_SP_COMMA;
+ typtab[STOUC(',')] |= ISPECIAL;
+ } else {
+ typtab_flags &= ~ZTF_SP_COMMA;
+ typtab[STOUC(',')] &= ~ISPECIAL;
+ }
+}
+
+/**/
+mod_export void
+makebangspecial(int yesno)
+{
+ /* Name and call signature for congruence with makecommaspecial(),
+ * but in this case when yesno is nonzero we defer to the state
+ * saved by inittyptab().
+ */
+ if (yesno == 0) {
+ typtab[bangchar] &= ~ISPECIAL;
+ } else if (typtab_flags & ZTF_BANGCHAR) {
+ typtab[bangchar] |= ISPECIAL;
+ }
+}
+
+
+/**/
+#ifdef MULTIBYTE_SUPPORT
+/* A wide-character version of the iblank() macro. */
+/**/
+mod_export int
+wcsiblank(wint_t wc)
+{
+ if (iswspace(wc) && wc != L'\n')
+ return 1;
+ return 0;
+}
+
+/*
+ * zistype macro extended to support wide characters.
+ * Works for IIDENT, IWORD, IALNUM, ISEP.
+ * We don't need this for IWSEP because that only applies to
+ * a fixed set of ASCII characters.
+ * Note here that use of multibyte mode is not tested:
+ * that's because for ZLE this is unconditional,
+ * not dependent on the option. The caller must decide.
+ */
+
+/**/
+mod_export int
+wcsitype(wchar_t c, int itype)
+{
+ int len;
+ mbstate_t mbs;
+ VARARR(char, outstr, MB_CUR_MAX);
+
+ if (!isset(MULTIBYTE))
+ return zistype(c, itype);
+
+ /*
+ * Strategy: the shell requires that the multibyte representation
+ * be an extension of ASCII. So see if converting the character
+ * produces an ASCII character. If it does, use zistype on that.
+ * If it doesn't, use iswalnum on the original character.
+ * If that fails, resort to the appropriate wide character array.
+ */
+ memset(&mbs, 0, sizeof(mbs));
+ len = wcrtomb(outstr, c, &mbs);
+
+ if (len == 0) {
+ /* NULL is special */
+ return zistype(0, itype);
+ } else if (len == 1 && isascii(outstr[0])) {
+ return zistype(outstr[0], itype);
+ } else {
+ switch (itype) {
+ case IIDENT:
+ if (!isset(POSIXIDENTIFIERS))
+ return 0;
+ return iswalnum(c);
+
+ case IWORD:
+ if (iswalnum(c))
+ return 1;
+ /*
+ * If we are handling combining characters, any punctuation
+ * characters with zero width needs to be considered part of
+ * a word. If we are not handling combining characters then
+ * logically they are still part of the word, even if they
+ * don't get displayed properly, so always do this.
+ */
+ if (IS_COMBINING(c))
+ return 1;
+ return !!wmemchr(wordchars_wide.chars, c, wordchars_wide.len);
+
+ case ISEP:
+ return !!wmemchr(ifs_wide.chars, c, ifs_wide.len);
+
+ default:
+ return iswalnum(c);
+ }
+ }
+}
+
+/**/
+#endif
+
+
+/*
+ * Find the end of a set of characters in the set specified by itype;
+ * one of IALNUM, IIDENT, IWORD or IUSER. For non-ASCII characters, we assume
+ * alphanumerics are part of the set, with the exception that
+ * identifiers are not treated that way if POSIXIDENTIFIERS is set.
+ *
+ * See notes above for identifiers.
+ * Returns the same pointer as passed if not on an identifier character.
+ * If "once" is set, just test the first character, i.e. (outptr !=
+ * inptr) tests whether the first character is valid in an identifier.
+ *
+ * Currently this is only called with itype IIDENT, IUSER or ISEP.
+ */
+
+/**/
+mod_export char *
+itype_end(const char *ptr, int itype, int once)
+{
+#ifdef MULTIBYTE_SUPPORT
+ if (isset(MULTIBYTE) &&
+ (itype != IIDENT || !isset(POSIXIDENTIFIERS))) {
+ mb_charinit();
+ while (*ptr) {
+ int len;
+ if (itok(*ptr)) {
+ /* Not untokenised yet --- can happen in raw command line */
+ len = 1;
+ if (!zistype(*ptr,itype))
+ break;
+ } else {
+ wint_t wc;
+ len = mb_metacharlenconv(ptr, &wc);
+
+ if (!len)
+ break;
+
+ if (wc == WEOF) {
+ /* invalid, treat as single character */
+ int chr = STOUC(*ptr == Meta ? ptr[1] ^ 32 : *ptr);
+ /* in this case non-ASCII characters can't match */
+ if (chr > 127 || !zistype(chr,itype))
+ break;
+ } else if (len == 1 && isascii(*ptr)) {
+ /* ASCII: can't be metafied, use standard test */
+ if (!zistype(*ptr,itype))
+ break;
+ } else {
+ /*
+ * Valid non-ASCII character.
+ */
+ switch (itype) {
+ case IWORD:
+ if (!iswalnum(wc) &&
+ !wmemchr(wordchars_wide.chars, wc,
+ wordchars_wide.len))
+ return (char *)ptr;
+ break;
+
+ case ISEP:
+ if (!wmemchr(ifs_wide.chars, wc, ifs_wide.len))
+ return (char *)ptr;
+ break;
+
+ default:
+ if (!iswalnum(wc))
+ return (char *)ptr;
+ }
+ }
+ }
+ ptr += len;
+
+ if (once)
+ break;
+ }
+ } else
+#endif
+ for (;;) {
+ int chr = STOUC(*ptr == Meta ? ptr[1] ^ 32 : *ptr);
+ if (!zistype(chr,itype))
+ break;
+ ptr += (*ptr == Meta) ? 2 : 1;
+
+ if (once)
+ break;
+ }
+
+ /*
+ * Nasty. The first argument is const char * because we
+ * don't modify it here. However, we really want to pass
+ * back the same type as was passed down, to allow idioms like
+ * p = itype_end(p, IIDENT, 0);
+ * So returning a const char * isn't really the right thing to do.
+ * Without having two different functions the following seems
+ * to be the best we can do.
+ */
+ return (char *)ptr;
+}
+
+/**/
+mod_export char **
+arrdup(char **s)
+{
+ char **x, **y;
+
+ y = x = (char **) zhalloc(sizeof(char *) * (arrlen(s) + 1));
+
+ while ((*x++ = dupstring(*s++)));
+
+ return y;
+}
+
+/* Duplicate at most max elements of the array s with heap memory */
+
+/**/
+mod_export char **
+arrdup_max(char **s, unsigned max)
+{
+ char **x, **y, **send;
+ int len = 0;
+
+ if (max)
+ len = arrlen(s);
+
+ /* Limit has sense only if not equal to len */
+ if (max > len)
+ max = len;
+
+ y = x = (char **) zhalloc(sizeof(char *) * (max + 1));
+
+ send = s + max;
+ while (s < send)
+ *x++ = dupstring(*s++);
+ *x = NULL;
+
+ return y;
+}
+
+/**/
+mod_export char **
+zarrdup(char **s)
+{
+ char **x, **y;
+
+ y = x = (char **) zalloc(sizeof(char *) * (arrlen(s) + 1));
+
+ while ((*x++ = ztrdup(*s++)));
+
+ return y;
+}
+
+/**/
+#ifdef MULTIBYTE_SUPPORT
+/**/
+mod_export wchar_t **
+wcs_zarrdup(wchar_t **s)
+{
+ wchar_t **x, **y;
+
+ y = x = (wchar_t **) zalloc(sizeof(wchar_t *) * (arrlen((char **)s) + 1));
+
+ while ((*x++ = wcs_ztrdup(*s++)));
+
+ return y;
+}
+/**/
+#endif /* MULTIBYTE_SUPPORT */
+
+/**/
+static char *
+spname(char *oldname)
+{
+ char *p, spnameguess[PATH_MAX + 1], spnamebest[PATH_MAX + 1];
+ static char newname[PATH_MAX + 1];
+ char *new = newname, *old = oldname;
+ int bestdist = 0, thisdist, thresh, maxthresh = 0;
+
+ /* This loop corrects each directory component of the path, stopping *
+ * when any correction distance would exceed the distance threshold. *
+ * NULL is returned only if the first component cannot be corrected; *
+ * otherwise a copy of oldname with a corrected prefix is returned. *
+ * Rationale for this, if there ever was any, has been forgotten. */
+ for (;;) {
+ while (*old == '/') {
+ if (new >= newname + sizeof(newname) - 1)
+ return NULL;
+ *new++ = *old++;
+ }
+ *new = '\0';
+ if (*old == '\0')
+ return newname;
+ p = spnameguess;
+ for (; *old != '/' && *old != '\0'; old++)
+ if (p < spnameguess + PATH_MAX)
+ *p++ = *old;
+ *p = '\0';
+ /* Every component is allowed a single distance 2 correction or two *
+ * distance 1 corrections. Longer ones get additional corrections. */
+ thresh = (int)(p - spnameguess) / 4 + 1;
+ if (thresh < 3)
+ thresh = 3;
+ else if (thresh > 100)
+ thresh = 100;
+ thisdist = mindist(newname, spnameguess, spnamebest, *old == '/');
+ if (thisdist >= thresh) {
+ /* The next test is always true, except for the first path *
+ * component. We could initialize bestdist to some large *
+ * constant instead, and then compare to that constant here, *
+ * because an invariant is that we've never exceeded the *
+ * threshold for any component so far; but I think that looks *
+ * odd to the human reader, and we may make use of the total *
+ * distance for all corrections at some point in the future. */
+ if (bestdist < maxthresh) {
+ struncpy(&new, spnameguess, sizeof(newname) - (new - newname));
+ struncpy(&new, old, sizeof(newname) - (new - newname));
+ return (new >= newname + sizeof(newname) -1) ? NULL : newname;
+ } else
+ return NULL;
+ } else {
+ maxthresh = bestdist + thresh;
+ bestdist += thisdist;
+ }
+ for (p = spnamebest; (*new = *p++);) {
+ if (new >= newname + sizeof(newname) - 1)
+ return NULL;
+ new++;
+ }
+ }
+}
+
+/**/
+static int
+mindist(char *dir, char *mindistguess, char *mindistbest, int wantdir)
+{
+ int mindistd, nd;
+ DIR *dd;
+ char *fn;
+ char *buf;
+ struct stat st;
+ size_t dirlen;
+
+ if (dir[0] == '\0')
+ dir = ".";
+ mindistd = 100;
+
+ if (!(buf = zalloc((dirlen = strlen(dir)) + strlen(mindistguess) + 2)))
+ return 0;
+ sprintf(buf, "%s/%s", dir, mindistguess);
+
+ if (stat(unmeta(buf), &st) == 0 && (!wantdir || S_ISDIR(st.st_mode))) {
+ strcpy(mindistbest, mindistguess);
+ free(buf);
+ return 0;
+ }
+
+ if ((dd = opendir(unmeta(dir)))) {
+ while ((fn = zreaddir(dd, 0))) {
+ if (spnamepat && pattry(spnamepat, fn))
+ continue;
+ nd = spdist(fn, mindistguess,
+ (int)strlen(mindistguess) / 4 + 1);
+ if (nd <= mindistd) {
+ if (wantdir) {
+ if (!(buf = zrealloc(buf, dirlen + strlen(fn) + 2)))
+ continue;
+ sprintf(buf, "%s/%s", dir, fn);
+ if (stat(unmeta(buf), &st) != 0 || !S_ISDIR(st.st_mode))
+ continue;
+ }
+ strcpy(mindistbest, fn);
+ mindistd = nd;
+ if (mindistd == 0)
+ break;
+ }
+ }
+ closedir(dd);
+ }
+ free(buf);
+ return mindistd;
+}
+
+/**/
+static int
+spdist(char *s, char *t, int thresh)
+{
+ /* TODO: Correction for non-ASCII and multibyte-input keyboards. */
+ char *p, *q;
+ const char qwertykeymap[] =
+ "\n\n\n\n\n\n\n\n\n\n\n\n\n\n\
+\t1234567890-=\t\
+\tqwertyuiop[]\t\
+\tasdfghjkl;'\n\t\
+\tzxcvbnm,./\t\t\t\
+\n\n\n\n\n\n\n\n\n\n\n\n\n\n\
+\t!@#$%^&*()_+\t\
+\tQWERTYUIOP{}\t\
+\tASDFGHJKL:\"\n\t\
+\tZXCVBNM<>?\n\n\t\
+\n\n\n\n\n\n\n\n\n\n\n\n\n\n";
+ const char dvorakkeymap[] =
+ "\n\n\n\n\n\n\n\n\n\n\n\n\n\n\
+\t1234567890[]\t\
+\t',.pyfgcrl/=\t\
+\taoeuidhtns-\n\t\
+\t;qjkxbmwvz\t\t\t\
+\n\n\n\n\n\n\n\n\n\n\n\n\n\n\
+\t!@#$%^&*(){}\t\
+\t\"<>PYFGCRL?+\t\
+\tAOEUIDHTNS_\n\t\
+\t:QJKXBMWVZ\n\n\t\
+\n\n\n\n\n\n\n\n\n\n\n\n\n\n";
+ const char *keymap;
+ if ( isset( DVORAK ) )
+ keymap = dvorakkeymap;
+ else
+ keymap = qwertykeymap;
+
+ if (!strcmp(s, t))
+ return 0;
+ /* any number of upper/lower mistakes allowed (dist = 1) */
+ for (p = s, q = t; *p && tulower(*p) == tulower(*q); p++, q++);
+ if (!*p && !*q)
+ return 1;
+ if (!thresh)
+ return 200;
+ for (p = s, q = t; *p && *q; p++, q++)
+ if (*p == *q)
+ continue; /* don't consider "aa" transposed, ash */
+ else if (p[1] == q[0] && q[1] == p[0]) /* transpositions */
+ return spdist(p + 2, q + 2, thresh - 1) + 1;
+ else if (p[1] == q[0]) /* missing letter */
+ return spdist(p + 1, q + 0, thresh - 1) + 2;
+ else if (p[0] == q[1]) /* missing letter */
+ return spdist(p + 0, q + 1, thresh - 1) + 2;
+ else if (*p != *q)
+ break;
+ if ((!*p && strlen(q) == 1) || (!*q && strlen(p) == 1))
+ return 2;
+ for (p = s, q = t; *p && *q; p++, q++)
+ if (p[0] != q[0] && p[1] == q[1]) {
+ int t0;
+ char *z;
+
+ /* mistyped letter */
+
+ if (!(z = strchr(keymap, p[0])) || *z == '\n' || *z == '\t')
+ return spdist(p + 1, q + 1, thresh - 1) + 1;
+ t0 = z - keymap;
+ if (*q == keymap[t0 - 15] || *q == keymap[t0 - 14] ||
+ *q == keymap[t0 - 13] ||
+ *q == keymap[t0 - 1] || *q == keymap[t0 + 1] ||
+ *q == keymap[t0 + 13] || *q == keymap[t0 + 14] ||
+ *q == keymap[t0 + 15])
+ return spdist(p + 1, q + 1, thresh - 1) + 2;
+ return 200;
+ } else if (*p != *q)
+ break;
+ return 200;
+}
+
+/* set cbreak mode, or the equivalent */
+
+/**/
+void
+setcbreak(void)
+{
+ struct ttyinfo ti;
+
+ ti = shttyinfo;
+#ifdef HAS_TIO
+ ti.tio.c_lflag &= ~ICANON;
+ ti.tio.c_cc[VMIN] = 1;
+ ti.tio.c_cc[VTIME] = 0;
+#else
+ ti.sgttyb.sg_flags |= CBREAK;
+#endif
+ settyinfo(&ti);
+}
+
+/* give the tty to some process */
+
+/**/
+mod_export void
+attachtty(pid_t pgrp)
+{
+ static int ep = 0;
+
+ if (jobbing && interact) {
+#ifdef HAVE_TCSETPGRP
+ if (SHTTY != -1 && tcsetpgrp(SHTTY, pgrp) == -1 && !ep)
+#else
+# if ardent
+ if (SHTTY != -1 && setpgrp() == -1 && !ep)
+# else
+ int arg = pgrp;
+
+ if (SHTTY != -1 && ioctl(SHTTY, TIOCSPGRP, &arg) == -1 && !ep)
+# endif
+#endif
+ {
+ if (pgrp != mypgrp && kill(-pgrp, 0) == -1)
+ attachtty(mypgrp);
+ else {
+ if (errno != ENOTTY)
+ {
+ zwarn("can't set tty pgrp: %e", errno);
+ fflush(stderr);
+ }
+ opts[MONITOR] = 0;
+ ep = 1;
+ }
+ }
+ }
+}
+
+/* get the process group associated with the tty */
+
+/**/
+pid_t
+gettygrp(void)
+{
+ pid_t arg;
+
+ if (SHTTY == -1)
+ return -1;
+
+#ifdef HAVE_TCSETPGRP
+ arg = tcgetpgrp(SHTTY);
+#else
+ ioctl(SHTTY, TIOCGPGRP, &arg);
+#endif
+
+ return arg;
+}
+
+
+/* Escape tokens and null characters. Buf is the string which should be *
+ * escaped. len is the length of the string. If len is -1, buf should be *
+ * null terminated. If len is non-negative and the third parameter is not *
+ * META_DUP, buf should point to an at least len+1 long memory area. The *
+ * return value points to the quoted string. If the given string does not *
+ * contain any special character which should be quoted and the third *
+ * parameter is not META_(HEAP|)DUP, buf is returned unchanged (a *
+ * terminating null character is appended to buf if necessary). Otherwise *
+ * the third `heap' argument determines the method used to allocate space *
+ * for the result. It can have the following values: *
+ * META_REALLOC: use zrealloc on buf *
+ * META_HREALLOC: use hrealloc on buf *
+ * META_USEHEAP: get memory from the heap. This leaves buf unchanged. *
+ * META_NOALLOC: buf points to a memory area which is long enough to hold *
+ * the quoted form, just quote it and return buf. *
+ * META_STATIC: store the quoted string in a static area. The original *
+ * string should be at most PATH_MAX long. *
+ * META_ALLOC: allocate memory for the new string with zalloc(). *
+ * META_DUP: leave buf unchanged and allocate space for the return *
+ * value even if buf does not contains special characters *
+ * META_HEAPDUP: same as META_DUP, but uses the heap */
+
+/**/
+mod_export char *
+metafy(char *buf, int len, int heap)
+{
+ int meta = 0;
+ char *t, *p, *e;
+ static char mbuf[PATH_MAX*2+1];
+
+ if (len == -1) {
+ for (e = buf, len = 0; *e; len++)
+ if (imeta(*e++))
+ meta++;
+ } else
+ for (e = buf; e < buf + len;)
+ if (imeta(*e++))
+ meta++;
+
+ if (meta || heap == META_DUP || heap == META_HEAPDUP) {
+ switch (heap) {
+ case META_REALLOC:
+ buf = zrealloc(buf, len + meta + 1);
+ break;
+ case META_HREALLOC:
+ buf = hrealloc(buf, len, len + meta + 1);
+ break;
+ case META_ALLOC:
+ case META_DUP:
+ buf = memcpy(zalloc(len + meta + 1), buf, len);
+ break;
+ case META_USEHEAP:
+ case META_HEAPDUP:
+ buf = memcpy(zhalloc(len + meta + 1), buf, len);
+ break;
+ case META_STATIC:
+#ifdef DEBUG
+ if (len > PATH_MAX) {
+ fprintf(stderr, "BUG: len = %d > PATH_MAX in metafy\n", len);
+ fflush(stderr);
+ }
+#endif
+ buf = memcpy(mbuf, buf, len);
+ break;
+#ifdef DEBUG
+ case META_NOALLOC:
+ break;
+ default:
+ fprintf(stderr, "BUG: metafy called with invalid heap value\n");
+ fflush(stderr);
+ break;
+#endif
+ }
+ p = buf + len;
+ e = t = buf + len + meta;
+ while (meta) {
+ if (imeta(*--t = *--p)) {
+ *t-- ^= 32;
+ *t = Meta;
+ meta--;
+ }
+ }
+ }
+ *e = '\0';
+ return buf;
+}
+
+
+/*
+ * Duplicate a string, metafying it as we go.
+ *
+ * Typically, this is used only for strings imported from outside
+ * zsh, as strings internally are either already metafied or passed
+ * around with an associated length.
+ */
+/**/
+mod_export char *
+ztrdup_metafy(const char *s)
+{
+ /* To mimic ztrdup() behaviour */
+ if (!s)
+ return NULL;
+ /*
+ * metafy() does lots of different things, so the pointer
+ * isn't const. Using it with META_DUP should be safe.
+ */
+ return metafy((char *)s, -1, META_DUP);
+}
+
+
+/*
+ * Take a null-terminated, metafied string in s into a literal
+ * representation by converting in place. The length is in *len
+ * len is non-NULL; if len is NULL, you don't know the length of
+ * the final string, but if it's to be supplied to some system
+ * routine that always uses NULL termination, such as a filename
+ * interpreter, that doesn't matter. Note the NULL termination
+ * is always copied for purposes of that kind.
+ */
+
+/**/
+mod_export char *
+unmetafy(char *s, int *len)
+{
+ char *p, *t;
+
+ for (p = s; *p && *p != Meta; p++);
+ for (t = p; (*t = *p++);)
+ if (*t++ == Meta && *p)
+ t[-1] = *p++ ^ 32;
+ if (len)
+ *len = t - s;
+ return s;
+}
+
+/* Return the character length of a metafied substring, given the *
+ * unmetafied substring length. */
+
+/**/
+mod_export int
+metalen(const char *s, int len)
+{
+ int mlen = len;
+
+ while (len--) {
+ if (*s++ == Meta) {
+ mlen++;
+ s++;
+ }
+ }
+ return mlen;
+}
+
+/*
+ * This function converts a zsh internal string to a form which can be
+ * passed to a system call as a filename. The result is stored in a
+ * single static area, sized to fit. If there is no Meta character
+ * the original string is returned.
+ */
+
+/**/
+mod_export char *
+unmeta(const char *file_name)
+{
+ static char *fn;
+ static int sz;
+ char *p;
+ const char *t;
+ int newsz, meta;
+
+ if (!file_name)
+ return NULL;
+
+ meta = 0;
+ for (t = file_name; *t; t++) {
+ if (*t == Meta)
+ meta = 1;
+ }
+ if (!meta) {
+ /*
+ * don't need allocation... free if it's long, see below
+ */
+ if (sz > 4 * PATH_MAX) {
+ zfree(fn, sz);
+ fn = NULL;
+ sz = 0;
+ }
+ return (char *) file_name;
+ }
+
+ newsz = (t - file_name) + 1;
+ /*
+ * Optimisation: don't resize if we don't have to.
+ * We need a new allocation if
+ * - nothing was allocated before
+ * - the new string is larger than the old one
+ * - the old string was larger than an arbitrary limit but the
+ * new string isn't so that we free up significant space by resizing.
+ */
+ if (!fn || newsz > sz || (sz > 4 * PATH_MAX && newsz <= 4 * PATH_MAX))
+ {
+ if (fn)
+ zfree(fn, sz);
+ sz = newsz;
+ fn = (char *)zalloc(sz);
+ if (!fn) {
+ sz = 0;
+ /*
+ * will quite likely crash in the caller anyway...
+ */
+ return NULL;
+ }
+ }
+
+ for (t = file_name, p = fn; *t; p++)
+ if ((*p = *t++) == Meta && *t)
+ *p = *t++ ^ 32;
+ *p = '\0';
+ return fn;
+}
+
+/*
+ * Unmetafy just one character and store the number of bytes it occupied.
+ */
+/**/
+mod_export convchar_t
+unmeta_one(const char *in, int *sz)
+{
+ convchar_t wc;
+ int newsz;
+#ifdef MULTIBYTE_SUPPORT
+ mbstate_t wstate;
+#endif
+
+ if (!sz)
+ sz = &newsz;
+ *sz = 0;
+
+ if (!in || !*in)
+ return 0;
+
+#ifdef MULTIBYTE_SUPPORT
+ memset(&wstate, 0, sizeof(wstate));
+ *sz = mb_metacharlenconv_r(in, &wc, &wstate);
+#else
+ if (in[0] == Meta) {
+ *sz = 2;
+ wc = STOUC(in[1] ^ 32);
+ } else {
+ *sz = 1;
+ wc = STOUC(in[0]);
+ }
+#endif
+ return wc;
+}
+
+/*
+ * Unmetafy and compare two strings, comparing unsigned character values.
+ * "a\0" sorts after "a".
+ *
+ * Currently this is only used in hash table sorting, where the
+ * keys are names of hash nodes and where we don't use strcoll();
+ * it's not clear if that's right but it does guarantee the ordering
+ * of shell structures on output.
+ *
+ * As we don't use strcoll(), it seems overkill to convert multibyte
+ * characters to wide characters for comparison every time. In the case
+ * of UTF-8, Unicode ordering is preserved when sorted raw, and for
+ * other character sets we rely on an extension of ASCII so the result,
+ * while it may not be correct, is at least rational.
+ */
+
+/**/
+int
+ztrcmp(char const *s1, char const *s2)
+{
+ int c1, c2;
+
+ while(*s1 && *s1 == *s2) {
+ s1++;
+ s2++;
+ }
+
+ if(!(c1 = *s1))
+ c1 = -1;
+ else if(c1 == STOUC(Meta))
+ c1 = *++s1 ^ 32;
+ if(!(c2 = *s2))
+ c2 = -1;
+ else if(c2 == STOUC(Meta))
+ c2 = *++s2 ^ 32;
+
+ if(c1 == c2)
+ return 0;
+ else if(c1 < c2)
+ return -1;
+ else
+ return 1;
+}
+
+/* Return the unmetafied length of a metafied string. */
+
+/**/
+mod_export int
+ztrlen(char const *s)
+{
+ int l;
+
+ for (l = 0; *s; l++) {
+ if (*s++ == Meta) {
+#ifdef DEBUG
+ if (! *s) {
+ fprintf(stderr, "BUG: unexpected end of string in ztrlen()\n");
+ break;
+ } else
+#endif
+ s++;
+ }
+ }
+ return l;
+}
+
+#ifndef MULTIBYTE_SUPPORT
+/*
+ * ztrlen() but with explicit end point for non-null-terminated
+ * segments. eptr may not be NULL.
+ */
+
+/**/
+mod_export int
+ztrlenend(char const *s, char const *eptr)
+{
+ int l;
+
+ for (l = 0; s < eptr; l++) {
+ if (*s++ == Meta) {
+#ifdef DEBUG
+ if (! *s) {
+ fprintf(stderr,
+ "BUG: unexpected end of string in ztrlenend()\n");
+ break;
+ } else
+#endif
+ s++;
+ }
+ }
+ return l;
+}
+
+#endif /* MULTIBYTE_SUPPORT */
+
+/* Subtract two pointers in a metafied string. */
+
+/**/
+mod_export int
+ztrsub(char const *t, char const *s)
+{
+ int l = t - s;
+
+ while (s != t) {
+ if (*s++ == Meta) {
+#ifdef DEBUG
+ if (! *s || s == t)
+ fprintf(stderr, "BUG: substring ends in the middle of a metachar in ztrsub()\n");
+ else
+#endif
+ s++;
+ l--;
+ }
+ }
+ return l;
+}
+
+/*
+ * Wrapper for readdir().
+ *
+ * If ignoredots is true, skip the "." and ".." entries.
+ *
+ * When __APPLE__ is defined, recode dirent names from UTF-8-MAC to UTF-8.
+ *
+ * Return the dirent's name, metafied.
+ */
+
+/**/
+mod_export char *
+zreaddir(DIR *dir, int ignoredots)
+{
+ struct dirent *de;
+#if defined(HAVE_ICONV) && defined(__APPLE__)
+ static iconv_t conv_ds = (iconv_t)0;
+ static char *conv_name = 0;
+ char *conv_name_ptr, *orig_name_ptr;
+ size_t conv_name_len, orig_name_len;
+#endif
+
+ do {
+ de = readdir(dir);
+ if(!de)
+ return NULL;
+ } while(ignoredots && de->d_name[0] == '.' &&
+ (!de->d_name[1] || (de->d_name[1] == '.' && !de->d_name[2])));
+
+#if defined(HAVE_ICONV) && defined(__APPLE__)
+ if (!conv_ds)
+ conv_ds = iconv_open("UTF-8", "UTF-8-MAC");
+ if (conv_ds != (iconv_t)(-1)) {
+ /* Force initial state in case re-using conv_ds */
+ (void) iconv(conv_ds, 0, &orig_name_len, 0, &conv_name_len);
+
+ orig_name_ptr = de->d_name;
+ orig_name_len = strlen(de->d_name);
+ conv_name = zrealloc(conv_name, orig_name_len+1);
+ conv_name_ptr = conv_name;
+ conv_name_len = orig_name_len;
+ if (iconv(conv_ds,
+ &orig_name_ptr, &orig_name_len,
+ &conv_name_ptr, &conv_name_len) != (size_t)(-1) &&
+ orig_name_len == 0) {
+ /* Completely converted, metafy and return */
+ *conv_name_ptr = '\0';
+ return metafy(conv_name, -1, META_STATIC);
+ }
+ /* Error, or conversion incomplete, keep the original name */
+ }
+#endif
+
+ return metafy(de->d_name, -1, META_STATIC);
+}
+
+/* Unmetafy and output a string. Tokens are skipped. */
+
+/**/
+mod_export int
+zputs(char const *s, FILE *stream)
+{
+ int c;
+
+ while (*s) {
+ if (*s == Meta)
+ c = *++s ^ 32;
+ else if(itok(*s)) {
+ s++;
+ continue;
+ } else
+ c = *s;
+ s++;
+ if (fputc(c, stream) < 0)
+ return EOF;
+ }
+ return 0;
+}
+
+#ifndef MULTIBYTE_SUPPORT
+/* Create a visibly-represented duplicate of a string. */
+
+/**/
+mod_export char *
+nicedup(char const *s, int heap)
+{
+ int c, len = strlen(s) * 5 + 1;
+ VARARR(char, buf, len);
+ char *p = buf, *n;
+
+ while ((c = *s++)) {
+ if (itok(c)) {
+ if (c <= Comma)
+ c = ztokens[c - Pound];
+ else
+ continue;
+ }
+ if (c == Meta)
+ c = *s++ ^ 32;
+ /* The result here is metafied */
+ n = nicechar(c);
+ while(*n)
+ *p++ = *n++;
+ }
+ *p = '\0';
+ return heap ? dupstring(buf) : ztrdup(buf);
+}
+#endif
+
+/**/
+mod_export char *
+nicedupstring(char const *s)
+{
+ return nicedup(s, 1);
+}
+
+
+#ifndef MULTIBYTE_SUPPORT
+/* Unmetafy and output a string, displaying special characters readably. */
+
+/**/
+mod_export int
+nicezputs(char const *s, FILE *stream)
+{
+ int c;
+
+ while ((c = *s++)) {
+ if (itok(c)) {
+ if (c <= Comma)
+ c = ztokens[c - Pound];
+ else
+ continue;
+ }
+ if (c == Meta)
+ c = *s++ ^ 32;
+ if(zputs(nicechar(c), stream) < 0)
+ return EOF;
+ }
+ return 0;
+}
+
+
+/* Return the length of the visible representation of a metafied string. */
+
+/**/
+mod_export size_t
+niceztrlen(char const *s)
+{
+ size_t l = 0;
+ int c;
+
+ while ((c = *s++)) {
+ if (itok(c)) {
+ if (c <= Comma)
+ c = ztokens[c - Pound];
+ else
+ continue;
+ }
+ if (c == Meta)
+ c = *s++ ^ 32;
+ l += strlen(nicechar(c));
+ }
+ return l;
+}
+#endif
+
+
+/**/
+#ifdef MULTIBYTE_SUPPORT
+/*
+ * Version of both nicezputs() and niceztrlen() for use with multibyte
+ * characters. Input is a metafied string; output is the screen width of
+ * the string.
+ *
+ * If the FILE * is not NULL, output to that, too.
+ *
+ * If outstrp is not NULL, set *outstrp to a zalloc'd version of
+ * the output (still metafied).
+ *
+ * If flags contains NICEFLAG_HEAP, use the heap for *outstrp, else
+ * zalloc.
+ * If flags contsins NICEFLAG_QUOTE, the output is going to be within
+ * $'...', so quote "'" and "\" with a backslash.
+ */
+
+/**/
+mod_export size_t
+mb_niceformat(const char *s, FILE *stream, char **outstrp, int flags)
+{
+ size_t l = 0, newl;
+ int umlen, outalloc, outleft, eol = 0;
+ wchar_t c;
+ char *ums, *ptr, *fmt, *outstr, *outptr;
+ mbstate_t mbs;
+
+ if (outstrp) {
+ outleft = outalloc = 5 * strlen(s);
+ outptr = outstr = zalloc(outalloc);
+ } else {
+ outleft = outalloc = 0;
+ outptr = outstr = NULL;
+ }
+
+ ums = ztrdup(s);
+ /*
+ * is this necessary at this point? niceztrlen does this
+ * but it's used in lots of places. however, one day this may
+ * be, too.
+ */
+ untokenize(ums);
+ ptr = unmetafy(ums, ¨en);
+
+ memset(&mbs, 0, sizeof mbs);
+ while (umlen > 0) {
+ size_t cnt = eol ? MB_INVALID : mbrtowc(&c, ptr, umlen, &mbs);
+
+ switch (cnt) {
+ case MB_INCOMPLETE:
+ eol = 1;
+ /* FALL THROUGH */
+ case MB_INVALID:
+ /* The byte didn't convert, so output it as a \M-... sequence. */
+ fmt = nicechar_sel(*ptr, flags & NICEFLAG_QUOTE);
+ newl = strlen(fmt);
+ cnt = 1;
+ /* Get mbs out of its undefined state. */
+ memset(&mbs, 0, sizeof mbs);
+ break;
+ case 0:
+ /* Careful: converting '\0' returns 0, but a '\0' is a
+ * real character for us, so we should consume 1 byte. */
+ cnt = 1;
+ /* FALL THROUGH */
+ default:
+ if (c == L'\'' && (flags & NICEFLAG_QUOTE)) {
+ fmt = "\\'";
+ newl = 2;
+ }
+ else if (c == L'\\' && (flags & NICEFLAG_QUOTE)) {
+ fmt = "\\\\";
+ newl = 2;
+ }
+ else
+ fmt = wcs_nicechar_sel(c, &newl, NULL, flags & NICEFLAG_QUOTE);
+ break;
+ }
+
+ umlen -= cnt;
+ ptr += cnt;
+ l += newl;
+
+ if (stream)
+ zputs(fmt, stream);
+ if (outstr) {
+ /* Append to output string */
+ int outlen = strlen(fmt);
+ if (outlen >= outleft) {
+ /* Reallocate to twice the length */
+ int outoffset = outptr - outstr;
+
+ outleft += outalloc;
+ outalloc *= 2;
+ outstr = zrealloc(outstr, outalloc);
+ outptr = outstr + outoffset;
+ }
+ memcpy(outptr, fmt, outlen);
+ /* Update start position */
+ outptr += outlen;
+ /* Update available bytes */
+ outleft -= outlen;
+ }
+ }
+
+ free(ums);
+ if (outstrp) {
+ *outptr = '\0';
+ /* Use more efficient storage for returned string */
+ if (flags & NICEFLAG_NODUP)
+ *outstrp = outstr;
+ else {
+ *outstrp = (flags & NICEFLAG_HEAP) ? dupstring(outstr) :
+ ztrdup(outstr);
+ free(outstr);
+ }
+ }
+
+ return l;
+}
+
+/*
+ * Return 1 if mb_niceformat() would reformat this string, else 0.
+ */
+
+/**/
+mod_export int
+is_mb_niceformat(const char *s)
+{
+ int umlen, eol = 0, ret = 0;
+ wchar_t c;
+ char *ums, *ptr;
+ mbstate_t mbs;
+
+ ums = ztrdup(s);
+ untokenize(ums);
+ ptr = unmetafy(ums, ¨en);
+
+ memset(&mbs, 0, sizeof mbs);
+ while (umlen > 0) {
+ size_t cnt = eol ? MB_INVALID : mbrtowc(&c, ptr, umlen, &mbs);
+
+ switch (cnt) {
+ case MB_INCOMPLETE:
+ eol = 1;
+ /* FALL THROUGH */
+ case MB_INVALID:
+ /* The byte didn't convert, so output it as a \M-... sequence. */
+ if (is_nicechar(*ptr)) {
+ ret = 1;
+ break;
+ }
+ cnt = 1;
+ /* Get mbs out of its undefined state. */
+ memset(&mbs, 0, sizeof mbs);
+ break;
+ case 0:
+ /* Careful: converting '\0' returns 0, but a '\0' is a
+ * real character for us, so we should consume 1 byte. */
+ cnt = 1;
+ /* FALL THROUGH */
+ default:
+ if (is_wcs_nicechar(c))
+ ret = 1;
+ break;
+ }
+
+ if (ret)
+ break;
+
+ umlen -= cnt;
+ ptr += cnt;
+ }
+
+ free(ums);
+
+ return ret;
+}
+
+/* ztrdup multibyte string with nice formatting */
+
+/**/
+mod_export char *
+nicedup(const char *s, int heap)
+{
+ char *retstr;
+
+ (void)mb_niceformat(s, NULL, &retstr, heap ? NICEFLAG_HEAP : 0);
+
+ return retstr;
+}
+
+
+/*
+ * The guts of mb_metacharlenconv(). This version assumes we are
+ * processing a true multibyte character string without tokens, and
+ * takes the shift state as an argument.
+ */
+
+/**/
+mod_export int
+mb_metacharlenconv_r(const char *s, wint_t *wcp, mbstate_t *mbsp)
+{
+ size_t ret = MB_INVALID;
+ char inchar;
+ const char *ptr;
+ wchar_t wc;
+
+ if (STOUC(*s) <= 0x7f) {
+ if (wcp)
+ *wcp = (wint_t)*s;
+ return 1;
+ }
+
+ for (ptr = s; *ptr; ) {
+ if (*ptr == Meta) {
+ inchar = *++ptr ^ 32;
+ DPUTS(!*ptr,
+ "BUG: unexpected end of string in mb_metacharlen()\n");
+ } else if (imeta(*ptr)) {
+ /*
+ * As this is metafied input, this is a token --- this
+ * can't be a part of the string. It might be
+ * something on the end of an unbracketed parameter
+ * reference, for example.
+ */
+ break;
+ } else
+ inchar = *ptr;
+ ptr++;
+ ret = mbrtowc(&wc, &inchar, 1, mbsp);
+
+ if (ret == MB_INVALID)
+ break;
+ if (ret == MB_INCOMPLETE)
+ continue;
+ if (wcp)
+ *wcp = wc;
+ return ptr - s;
+ }
+
+ if (wcp)
+ *wcp = WEOF;
+ /* No valid multibyte sequence */
+ memset(mbsp, 0, sizeof(*mbsp));
+ if (ptr > s) {
+ return 1 + (*s == Meta); /* Treat as single byte character */
+ } else
+ return 0; /* Probably shouldn't happen */
+}
+
+/*
+ * Length of metafied string s which contains the next multibyte
+ * character; single (possibly metafied) character if string is not null
+ * but character is not valid (e.g. possibly incomplete at end of string).
+ * Returned value is guaranteed not to reach beyond the end of the
+ * string (assuming correct metafication).
+ *
+ * If wcp is not NULL, the converted wide character is stored there.
+ * If no conversion could be done WEOF is used.
+ */
+
+/**/
+mod_export int
+mb_metacharlenconv(const char *s, wint_t *wcp)
+{
+ if (!isset(MULTIBYTE) || STOUC(*s) <= 0x7f) {
+ /* treat as single byte, possibly metafied */
+ if (wcp)
+ *wcp = (wint_t)(*s == Meta ? s[1] ^ 32 : *s);
+ return 1 + (*s == Meta);
+ }
+ /*
+ * We have to handle tokens here, since we may be looking
+ * through a tokenized input. Obviously this isn't
+ * a valid multibyte character, so just return WEOF
+ * and let the caller handle it as a single character.
+ *
+ * TODO: I've a sneaking suspicion we could do more here
+ * to prevent the caller always needing to handle invalid
+ * characters specially, but sometimes it may need to know.
+ */
+ if (itok(*s)) {
+ if (wcp)
+ *wcp = WEOF;
+ return 1;
+ }
+
+ return mb_metacharlenconv_r(s, wcp, &mb_shiftstate);
+}
+
+/*
+ * Total number of multibyte characters in metafied string s.
+ * Same answer as iterating mb_metacharlen() and counting calls
+ * until end of string.
+ *
+ * If width is 1, return total character width rather than number.
+ * If width is greater than 1, return 1 if character has non-zero width,
+ * else 0.
+ *
+ * Ends if either *ptr is '\0', the normal case (eptr may be NULL for
+ * this), or ptr is eptr (i.e. *eptr is where the null would be if null
+ * terminated) for strings not delimited by nulls --- note these are
+ * still metafied.
+ */
+
+/**/
+mod_export int
+mb_metastrlenend(char *ptr, int width, char *eptr)
+{
+ char inchar, *laststart;
+ size_t ret;
+ wchar_t wc;
+ int num, num_in_char, complete;
+
+ if (!isset(MULTIBYTE) || MB_CUR_MAX == 1)
+ return eptr ? (int)(eptr - ptr) : ztrlen(ptr);
+
+ laststart = ptr;
+ ret = MB_INVALID;
+ num = num_in_char = 0;
+ complete = 1;
+
+ memset(&mb_shiftstate, 0, sizeof(mb_shiftstate));
+ while (*ptr && !(eptr && ptr >= eptr)) {
+ if (*ptr == Meta)
+ inchar = *++ptr ^ 32;
+ else
+ inchar = *ptr;
+ ptr++;
+
+ if (complete && STOUC(inchar) <= STOUC(0x7f)) {
+ /*
+ * We rely on 7-bit US-ASCII as a subset, so skip
+ * multibyte handling if we have such a character.
+ */
+ num++;
+ laststart = ptr;
+ num_in_char = 0;
+ continue;
+ }
+
+ ret = mbrtowc(&wc, &inchar, 1, &mb_shiftstate);
+
+ if (ret == MB_INCOMPLETE) {
+ /*
+ * "num_in_char" is only used for incomplete characters.
+ * The assumption is that we will output all trailing octets
+ * that form part of an incomplete character as a single
+ * character (of single width) if we don't get a complete
+ * character. This is purely pragmatic --- I'm not aware
+ * of a standard way of dealing with incomplete characters.
+ *
+ * If we do get a complete character, num_in_char
+ * becomes irrelevant and is set to zero
+ *
+ * This is in contrast to "num" which counts the characters
+ * or widths in complete characters. The two are summed,
+ * so we don't count characters twice.
+ */
+ num_in_char++;
+ complete = 0;
+ } else {
+ if (ret == MB_INVALID) {
+ /* Reset, treat as single character */
+ memset(&mb_shiftstate, 0, sizeof(mb_shiftstate));
+ ptr = laststart + (*laststart == Meta) + 1;
+ num++;
+ } else if (width) {
+ /*
+ * Returns -1 if not a printable character. We
+ * turn this into 0.
+ */
+ int wcw = WCWIDTH(wc);
+ if (wcw > 0) {
+ if (width == 1)
+ num += wcw;
+ else
+ num++;
+ }
+ } else
+ num++;
+ laststart = ptr;
+ num_in_char = 0;
+ complete = 1;
+ }
+ }
+
+ /* If incomplete, treat remainder as trailing single character */
+ return num + (num_in_char ? 1 : 0);
+}
+
+/*
+ * The equivalent of mb_metacharlenconv_r() for
+ * strings that aren't metafied and hence have
+ * explicit lengths.
+ */
+
+/**/
+mod_export int
+mb_charlenconv_r(const char *s, int slen, wint_t *wcp, mbstate_t *mbsp)
+{
+ size_t ret = MB_INVALID;
+ char inchar;
+ const char *ptr;
+ wchar_t wc;
+
+ if (slen && STOUC(*s) <= 0x7f) {
+ if (wcp)
+ *wcp = (wint_t)*s;
+ return 1;
+ }
+
+ for (ptr = s; slen; ) {
+ inchar = *ptr;
+ ptr++;
+ slen--;
+ ret = mbrtowc(&wc, &inchar, 1, mbsp);
+
+ if (ret == MB_INVALID)
+ break;
+ if (ret == MB_INCOMPLETE)
+ continue;
+ if (wcp)
+ *wcp = wc;
+ return ptr - s;
+ }
+
+ if (wcp)
+ *wcp = WEOF;
+ /* No valid multibyte sequence */
+ memset(mbsp, 0, sizeof(*mbsp));
+ if (ptr > s) {
+ return 1; /* Treat as single byte character */
+ } else
+ return 0; /* Probably shouldn't happen */
+}
+
+/*
+ * The equivalent of mb_metacharlenconv() for
+ * strings that aren't metafied and hence have
+ * explicit lengths;
+ */
+
+/**/
+mod_export int
+mb_charlenconv(const char *s, int slen, wint_t *wcp)
+{
+ if (!isset(MULTIBYTE) || STOUC(*s) <= 0x7f) {
+ if (wcp)
+ *wcp = (wint_t)*s;
+ return 1;
+ }
+
+ return mb_charlenconv_r(s, slen, wcp, &mb_shiftstate);
+}
+
+/**/
+#else
+
+/* Simple replacement for mb_metacharlenconv */
+
+/**/
+mod_export int
+metacharlenconv(const char *x, int *c)
+{
+ /*
+ * Here we don't use STOUC() on the chars since they
+ * may be compared against other chars and this will fail
+ * if chars are signed and the high bit is set.
+ */
+ if (*x == Meta) {
+ if (c)
+ *c = x[1] ^ 32;
+ return 2;
+ }
+ if (c)
+ *c = (char)*x;
+ return 1;
+}
+
+/* Simple replacement for mb_charlenconv */
+
+/**/
+mod_export int
+charlenconv(const char *x, int len, int *c)
+{
+ if (!len) {
+ if (c)
+ *c = '\0';
+ return 0;
+ }
+
+ if (c)
+ *c = (char)*x;
+ return 1;
+}
+
+/**/
+#endif /* MULTIBYTE_SUPPORT */
+
+/*
+ * Expand tabs to given width, with given starting position on line.
+ * len is length of unmetafied string in bytes.
+ * Output to fout.
+ * Return the end position on the line, i.e. if this is 0 modulo width
+ * the next character is aligned with a tab stop.
+ *
+ * If all is set, all tabs are expanded, else only leading tabs.
+ */
+
+/**/
+mod_export int
+zexpandtabs(const char *s, int len, int width, int startpos, FILE *fout,
+ int all)
+{
+ int at_start = 1;
+
+#ifdef MULTIBYTE_SUPPORT
+ mbstate_t mbs;
+ size_t ret;
+ wchar_t wc;
+
+ memset(&mbs, 0, sizeof(mbs));
+#endif
+
+ while (len) {
+ if (*s == '\t') {
+ if (all || at_start) {
+ s++;
+ len--;
+ if (width <= 0 || !(startpos % width)) {
+ /* always output at least one space */
+ fputc(' ', fout);
+ startpos++;
+ }
+ if (width <= 0)
+ continue; /* paranoia */
+ while (startpos % width) {
+ fputc(' ', fout);
+ startpos++;
+ }
+ } else {
+ /*
+ * Leave tab alone.
+ * Guess width to apply... we might get this wrong.
+ * This is only needed if there's a following string
+ * that needs tabs expanding, which is unusual.
+ */
+ startpos += width - startpos % width;
+ s++;
+ len--;
+ fputc('\t', fout);
+ }
+ continue;
+ } else if (*s == '\n' || *s == '\r') {
+ fputc(*s, fout);
+ s++;
+ len--;
+ startpos = 0;
+ at_start = 1;
+ continue;
+ }
+
+ at_start = 0;
+#ifdef MULTIBYTE_SUPPORT
+ if (isset(MULTIBYTE)) {
+ const char *sstart = s;
+ ret = mbrtowc(&wc, s, len, &mbs);
+ if (ret == MB_INVALID) {
+ /* Assume single character per character */
+ memset(&mbs, 0, sizeof(mbs));
+ s++;
+ len--;
+ } else if (ret == MB_INCOMPLETE) {
+ /* incomplete at end --- assume likewise, best we've got */
+ s++;
+ len--;
+ } else {
+ s += ret;
+ len -= (int)ret;
+ }
+ if (ret == MB_INVALID || ret == MB_INCOMPLETE) {
+ startpos++;
+ } else {
+ int wcw = WCWIDTH(wc);
+ if (wcw > 0) /* paranoia */
+ startpos += wcw;
+ }
+ fwrite(sstart, s - sstart, 1, fout);
+
+ continue;
+ }
+#endif /* MULTIBYTE_SUPPORT */
+ fputc(*s, fout);
+ s++;
+ len--;
+ startpos++;
+ }
+
+ return startpos;
+}
+
+/* check for special characters in the string */
+
+/**/
+mod_export int
+hasspecial(char const *s)
+{
+ for (; *s; s++) {
+ if (ispecial(*s == Meta ? *++s ^ 32 : *s))
+ return 1;
+ }
+ return 0;
+}
+
+
+static char *
+addunprintable(char *v, const char *u, const char *uend)
+{
+ for (; u < uend; u++) {
+ /*
+ * Just do this byte by byte; there's no great
+ * advantage in being clever with multibyte
+ * characters if we don't think they're printable.
+ */
+ int c;
+ if (*u == Meta)
+ c = STOUC(*++u ^ 32);
+ else
+ c = STOUC(*u);
+ switch (c) {
+ case '\0':
+ *v++ = '\\';
+ *v++ = '0';
+ if ('0' <= u[1] && u[1] <= '7') {
+ *v++ = '0';
+ *v++ = '0';
+ }
+ break;
+
+ case '\007': *v++ = '\\'; *v++ = 'a'; break;
+ case '\b': *v++ = '\\'; *v++ = 'b'; break;
+ case '\f': *v++ = '\\'; *v++ = 'f'; break;
+ case '\n': *v++ = '\\'; *v++ = 'n'; break;
+ case '\r': *v++ = '\\'; *v++ = 'r'; break;
+ case '\t': *v++ = '\\'; *v++ = 't'; break;
+ case '\v': *v++ = '\\'; *v++ = 'v'; break;
+
+ default:
+ *v++ = '\\';
+ *v++ = '0' + ((c >> 6) & 7);
+ *v++ = '0' + ((c >> 3) & 7);
+ *v++ = '0' + (c & 7);
+ break;
+ }
+ }
+
+ return v;
+}
+
+/*
+ * Quote the string s and return the result as a string from the heap.
+ *
+ * The last argument is a QT_ value defined in zsh.h other than QT_NONE.
+ *
+ * Most quote styles other than backslash assume the quotes are to
+ * be added outside quotestring(). QT_SINGLE_OPTIONAL is different:
+ * the single quotes are only added where necessary, so the
+ * whole expression is handled here.
+ *
+ * The string may be metafied and contain tokens.
+ */
+
+/**/
+mod_export char *
+quotestring(const char *s, int instring)
+{
+ const char *u;
+ char *v;
+ int alloclen;
+ char *buf;
+ int shownull = 0;
+ /*
+ * quotesub is used with QT_SINGLE_OPTIONAL.
+ * quotesub = 0: mechanism not active
+ * quotesub = 1: mechanism pending, no "'" yet;
+ * needs adding at quotestart.
+ * quotesub = 2: mechanism active, added opening "'"; need
+ * closing "'".
+ */
+ int quotesub = 0, slen;
+ char *quotestart;
+ convchar_t cc;
+ const char *uend;
+
+ slen = strlen(s);
+ switch (instring)
+ {
+ case QT_BACKSLASH_SHOWNULL:
+ shownull = 1;
+ instring = QT_BACKSLASH;
+ /*FALLTHROUGH*/
+ case QT_BACKSLASH:
+ /*
+ * With QT_BACKSLASH we may need to use $'\300' stuff.
+ * Keep memory usage within limits by allocating temporary
+ * storage and using heap for correct size at end.
+ */
+ alloclen = slen * 7 + 1;
+ break;
+
+ case QT_BACKSLASH_PATTERN:
+ alloclen = slen * 2 + 1;
+ break;
+
+ case QT_SINGLE_OPTIONAL:
+ /*
+ * Here, we may need to add single quotes.
+ * Always show empty strings.
+ */
+ alloclen = slen * 4 + 3;
+ quotesub = shownull = 1;
+ break;
+
+ default:
+ alloclen = slen * 4 + 1;
+ break;
+ }
+ if (!*s && shownull)
+ alloclen += 2; /* for '' */
+
+ quotestart = v = buf = zshcalloc(alloclen);
+
+ DPUTS(instring < QT_BACKSLASH || instring == QT_BACKTICK ||
+ instring > QT_BACKSLASH_PATTERN,
+ "BUG: bad quote type in quotestring");
+ u = s;
+ if (instring == QT_DOLLARS) {
+ /*
+ * The only way to get Nularg here is when
+ * it is placeholding for the empty string?
+ */
+ if (inull(*u))
+ u++;
+ /*
+ * As we test for printability here we need to be able
+ * to look for multibyte characters.
+ */
+ MB_METACHARINIT();
+ while (*u) {
+ uend = u + MB_METACHARLENCONV(u, &cc);
+
+ if (
+#ifdef MULTIBYTE_SUPPORT
+ cc != WEOF &&
+#endif
+ WC_ISPRINT(cc)) {
+ switch (cc) {
+ case ZWC('\\'):
+ case ZWC('\''):
+ *v++ = '\\';
+ break;
+
+ default:
+ if (isset(BANGHIST) && cc == (wchar_t)bangchar)
+ *v++ = '\\';
+ break;
+ }
+ while (u < uend)
+ *v++ = *u++;
+ } else {
+ /* Not printable */
+ v = addunprintable(v, u, uend);
+ u = uend;
+ }
+ }
+ } else if (instring == QT_BACKSLASH_PATTERN) {
+ while (*u) {
+ if (ipattern(*u))
+ *v++ = '\\';
+ *v++ = *u++;
+ }
+ } else {
+ if (shownull) {
+ /* We can't show an empty string with just backslash quoting. */
+ if (!*u) {
+ *v++ = '\'';
+ *v++ = '\'';
+ }
+ }
+ /*
+ * Here there are syntactic special characters, so
+ * we start by going through bytewise.
+ */
+ while (*u) {
+ int dobackslash = 0;
+ if (*u == Tick || *u == Qtick) {
+ char c = *u++;
+
+ *v++ = c;
+ while (*u && *u != c)
+ *v++ = *u++;
+ *v++ = c;
+ if (*u)
+ u++;
+ continue;
+ } else if ((*u == Qstring || *u == '$') && u[1] == '\'' &&
+ instring == QT_DOUBLE) {
+ /*
+ * We don't need to quote $'...' inside a double-quoted
+ * string. This is largely cosmetic; it looks neater
+ * if we don't but it doesn't do any harm since the
+ * \ is stripped.
+ */
+ *v++ = *u++;
+ } else if ((*u == String || *u == Qstring) &&
+ (u[1] == Inpar || u[1] == Inbrack || u[1] == Inbrace)) {
+ char c = (u[1] == Inpar ? Outpar : (u[1] == Inbrace ?
+ Outbrace : Outbrack));
+ char beg = *u;
+ int level = 0;
+
+ *v++ = *u++;
+ *v++ = *u++;
+ while (*u && (*u != c || level)) {
+ if (*u == beg)
+ level++;
+ else if (*u == c)
+ level--;
+ *v++ = *u++;
+ }
+ if (*u)
+ *v++ = *u++;
+ continue;
+ }
+ else if (ispecial(*u) &&
+ ((*u != '=' && *u != '~') ||
+ u == s ||
+ (isset(MAGICEQUALSUBST) &&
+ (u[-1] == '=' || u[-1] == ':')) ||
+ (*u == '~' && isset(EXTENDEDGLOB))) &&
+ (instring == QT_BACKSLASH ||
+ instring == QT_SINGLE_OPTIONAL ||
+ (isset(BANGHIST) && *u == (char)bangchar &&
+ instring != QT_SINGLE) ||
+ (instring == QT_DOUBLE &&
+ (*u == '$' || *u == '`' || *u == '\"' || *u == '\\')) ||
+ (instring == QT_SINGLE && *u == '\''))) {
+ if (instring == QT_SINGLE_OPTIONAL) {
+ if (quotesub == 1) {
+ /*
+ * We haven't yet had to quote at the start.
+ */
+ if (*u == '\'') {
+ /*
+ * We don't need to.
+ */
+ *v++ = '\\';
+ } else {
+ /*
+ * It's now time to add quotes.
+ */
+ if (v > quotestart)
+ {
+ char *addq;
+
+ for (addq = v; addq > quotestart; addq--)
+ *addq = addq[-1];
+ }
+ *quotestart = '\'';
+ v++;
+ quotesub = 2;
+ }
+ *v++ = *u++;
+ /*
+ * Next place to start quotes is here.
+ */
+ quotestart = v;
+ } else if (*u == '\'') {
+ if (unset(RCQUOTES)) {
+ *v++ = '\'';
+ *v++ = '\\';
+ *v++ = '\'';
+ /* Don't restart quotes unless we need them */
+ quotesub = 1;
+ quotestart = v;
+ } else {
+ /* simplest just to use '' always */
+ *v++ = '\'';
+ *v++ = '\'';
+ }
+ /* dealt with */
+ u++;
+ } else {
+ /* else already quoting, just add */
+ *v++ = *u++;
+ }
+ continue;
+ } else if (*u == '\n' ||
+ (instring == QT_SINGLE && *u == '\'')) {
+ if (*u == '\n') {
+ *v++ = '$';
+ *v++ = '\'';
+ *v++ = '\\';
+ *v++ = 'n';
+ *v++ = '\'';
+ } else if (unset(RCQUOTES)) {
+ *v++ = '\'';
+ if (*u == '\'')
+ *v++ = '\\';
+ *v++ = *u;
+ *v++ = '\'';
+ } else
+ *v++ = '\'', *v++ = '\'';
+ u++;
+ continue;
+ } else {
+ /*
+ * We'll need a backslash, but don't add it
+ * yet since if the character isn't printable
+ * we'll have to upgrade it to $'...'.
+ */
+ dobackslash = 1;
+ }
+ }
+
+ if (itok(*u) || instring != QT_BACKSLASH) {
+ /* Needs to be passed straight through. */
+ if (dobackslash)
+ *v++ = '\\';
+ if (*u == Inparmath) {
+ /*
+ * Already syntactically quoted: don't
+ * add more.
+ */
+ int inmath = 1;
+ *v++ = *u++;
+ for (;;) {
+ char uc = *u;
+ *v++ = *u++;
+ if (uc == '\0')
+ break;
+ else if (uc == Outparmath && !--inmath)
+ break;
+ else if (uc == Inparmath)
+ ++inmath;
+ }
+ } else
+ *v++ = *u++;
+ continue;
+ }
+
+ /*
+ * Now check if the output is unprintable in the
+ * current character set.
+ */
+ uend = u + MB_METACHARLENCONV(u, &cc);
+ if (
+#ifdef MULTIBYTE_SUPPORT
+ cc != WEOF &&
+#endif
+ WC_ISPRINT(cc)) {
+ if (dobackslash)
+ *v++ = '\\';
+ while (u < uend) {
+ if (*u == Meta)
+ *v++ = *u++;
+ *v++ = *u++;
+ }
+ } else {
+ /* Not printable */
+ *v++ = '$';
+ *v++ = '\'';
+ v = addunprintable(v, u, uend);
+ *v++ = '\'';
+ u = uend;
+ }
+ }
+ }
+ if (quotesub == 2)
+ *v++ = '\'';
+ *v = '\0';
+
+ v = dupstring(buf);
+ zfree(buf, alloclen);
+ return v;
+}
+
+/*
+ * Unmetafy and output a string, quoted if it contains special
+ * characters.
+ *
+ * If stream is NULL, return the same output with any allocation on the
+ * heap.
+ */
+
+/**/
+mod_export char *
+quotedzputs(char const *s, FILE *stream)
+{
+ int inquote = 0, c;
+ char *outstr, *ptr;
+
+ /* check for empty string */
+ if(!*s) {
+ if (!stream)
+ return dupstring("''");
+ fputs("''", stream);
+ return NULL;
+ }
+
+#ifdef MULTIBYTE_SUPPORT
+ if (is_mb_niceformat(s)) {
+ if (stream) {
+ fputs("$'", stream);
+ mb_niceformat(s, stream, NULL, NICEFLAG_QUOTE);
+ fputc('\'', stream);
+ return NULL;
+ } else {
+ char *substr;
+ mb_niceformat(s, NULL, &substr, NICEFLAG_QUOTE|NICEFLAG_NODUP);
+ outstr = (char *)zhalloc(4 + strlen(substr));
+ sprintf(outstr, "$'%s'", substr);
+ free(substr);
+ return outstr;
+ }
+ }
+#endif /* MULTIBYTE_SUPPORT */
+
+ if (!hasspecial(s)) {
+ if (stream) {
+ zputs(s, stream);
+ return NULL;
+ } else {
+ return dupstring(s);
+ }
+ }
+
+ if (!stream) {
+ const char *cptr;
+ int l = strlen(s) + 2;
+ for (cptr = s; *cptr; cptr++) {
+ if (*cptr == Meta)
+ cptr++;
+ else if (*cptr == '\'')
+ l += isset(RCQUOTES) ? 1 : 3;
+ }
+ ptr = outstr = zhalloc(l + 1);
+ } else {
+ ptr = outstr = NULL;
+ }
+ if (isset(RCQUOTES)) {
+ /* use rc-style quotes-within-quotes for the whole string */
+ if (stream) {
+ if (fputc('\'', stream) < 0)
+ return NULL;
+ } else
+ *ptr++ = '\'';
+ while(*s) {
+ if (*s == Dash)
+ c = '-';
+ else if (*s == Meta)
+ c = *++s ^ 32;
+ else
+ c = *s;
+ s++;
+ if (c == '\'') {
+ if (stream) {
+ if (fputc('\'', stream) < 0)
+ return NULL;
+ } else
+ *ptr++ = '\'';
+ } else if (c == '\n' && isset(CSHJUNKIEQUOTES)) {
+ if (stream) {
+ if (fputc('\\', stream) < 0)
+ return NULL;
+ } else
+ *ptr++ = '\\';
+ }
+ if (stream) {
+ if (fputc(c, stream) < 0)
+ return NULL;
+ } else {
+ if (imeta(c)) {
+ *ptr++ = Meta;
+ *ptr++ = c ^ 32;
+ } else
+ *ptr++ = c;
+ }
+ }
+ if (stream) {
+ if (fputc('\'', stream) < 0)
+ return NULL;
+ } else
+ *ptr++ = '\'';
+ } else {
+ /* use Bourne-style quoting, avoiding empty quoted strings */
+ while (*s) {
+ if (*s == Dash)
+ c = '-';
+ else if (*s == Meta)
+ c = *++s ^ 32;
+ else
+ c = *s;
+ s++;
+ if (c == '\'') {
+ if (inquote) {
+ if (stream) {
+ if (putc('\'', stream) < 0)
+ return NULL;
+ } else
+ *ptr++ = '\'';
+ inquote=0;
+ }
+ if (stream) {
+ if (fputs("\\'", stream) < 0)
+ return NULL;
+ } else {
+ *ptr++ = '\\';
+ *ptr++ = '\'';
+ }
+ } else {
+ if (!inquote) {
+ if (stream) {
+ if (fputc('\'', stream) < 0)
+ return NULL;
+ } else
+ *ptr++ = '\'';
+ inquote=1;
+ }
+ if (c == '\n' && isset(CSHJUNKIEQUOTES)) {
+ if (stream) {
+ if (fputc('\\', stream) < 0)
+ return NULL;
+ } else
+ *ptr++ = '\\';
+ }
+ if (stream) {
+ if (fputc(c, stream) < 0)
+ return NULL;
+ } else {
+ if (imeta(c)) {
+ *ptr++ = Meta;
+ *ptr++ = c ^ 32;
+ } else
+ *ptr++ = c;
+ }
+ }
+ }
+ if (inquote) {
+ if (stream) {
+ if (fputc('\'', stream) < 0)
+ return NULL;
+ } else
+ *ptr++ = '\'';
+ }
+ }
+ if (!stream)
+ *ptr++ = '\0';
+
+ return outstr;
+}
+
+/* Double-quote a metafied string. */
+
+/**/
+mod_export char *
+dquotedztrdup(char const *s)
+{
+ int len = strlen(s) * 4 + 2;
+ char *buf = zalloc(len);
+ char *p = buf, *ret;
+
+ if(isset(CSHJUNKIEQUOTES)) {
+ int inquote = 0;
+
+ while(*s) {
+ int c = *s++;
+
+ if (c == Meta)
+ c = *s++ ^ 32;
+ switch(c) {
+ case '"':
+ case '$':
+ case '`':
+ if(inquote) {
+ *p++ = '"';
+ inquote = 0;
+ }
+ *p++ = '\\';
+ *p++ = c;
+ break;
+ default:
+ if(!inquote) {
+ *p++ = '"';
+ inquote = 1;
+ }
+ if(c == '\n')
+ *p++ = '\\';
+ *p++ = c;
+ break;
+ }
+ }
+ if (inquote)
+ *p++ = '"';
+ } else {
+ int pending = 0;
+
+ *p++ = '"';
+ while(*s) {
+ int c = *s++;
+
+ if (c == Meta)
+ c = *s++ ^ 32;
+ switch(c) {
+ case '\\':
+ if(pending)
+ *p++ = '\\';
+ *p++ = '\\';
+ pending = 1;
+ break;
+ case '"':
+ case '$':
+ case '`':
+ if(pending)
+ *p++ = '\\';
+ *p++ = '\\';
+ /* FALL THROUGH */
+ default:
+ *p++ = c;
+ pending = 0;
+ break;
+ }
+ }
+ if(pending)
+ *p++ = '\\';
+ *p++ = '"';
+ }
+ ret = metafy(buf, p - buf, META_DUP);
+ zfree(buf, len);
+ return ret;
+}
+
+/* Unmetafy and output a string, double quoting it in its entirety. */
+
+#if 0 /**/
+int
+dquotedzputs(char const *s, FILE *stream)
+{
+ char *d = dquotedztrdup(s);
+ int ret = zputs(d, stream);
+
+ zsfree(d);
+ return ret;
+}
+#endif
+
+# if defined(HAVE_NL_LANGINFO) && defined(CODESET) && !defined(__STDC_ISO_10646__)
+/* Convert a character from UCS4 encoding to UTF-8 */
+
+static size_t
+ucs4toutf8(char *dest, unsigned int wval)
+{
+ size_t len;
+
+ if (wval < 0x80)
+ len = 1;
+ else if (wval < 0x800)
+ len = 2;
+ else if (wval < 0x10000)
+ len = 3;
+ else if (wval < 0x200000)
+ len = 4;
+ else if (wval < 0x4000000)
+ len = 5;
+ else
+ len = 6;
+
+ switch (len) { /* falls through except to the last case */
+ case 6: dest[5] = (wval & 0x3f) | 0x80; wval >>= 6;
+ case 5: dest[4] = (wval & 0x3f) | 0x80; wval >>= 6;
+ case 4: dest[3] = (wval & 0x3f) | 0x80; wval >>= 6;
+ case 3: dest[2] = (wval & 0x3f) | 0x80; wval >>= 6;
+ case 2: dest[1] = (wval & 0x3f) | 0x80; wval >>= 6;
+ *dest = wval | ((0xfc << (6 - len)) & 0xfc);
+ break;
+ case 1: *dest = wval;
+ }
+
+ return len;
+}
+#endif
+
+
+/*
+ * The following only occurs once or twice in the code, but in different
+ * places depending how character set conversion is implemented.
+ */
+#define CHARSET_FAILED() \
+ if (how & GETKEY_DOLLAR_QUOTE) { \
+ while ((*tdest++ = *++s)) { \
+ if (how & GETKEY_UPDATE_OFFSET) { \
+ if (s - sstart > *misc) \
+ (*misc)++; \
+ } \
+ if (*s == Snull) { \
+ *len = (s - sstart) + 1; \
+ *tdest = '\0'; \
+ return buf; \
+ } \
+ } \
+ *len = tdest - buf; \
+ return buf; \
+ } \
+ *t = '\0'; \
+ *len = t - buf; \
+ return buf
+
+/*
+ * Decode a key string, turning it into the literal characters.
+ * The value returned is a newly allocated string from the heap.
+ *
+ * The length is returned in *len. This is usually the length of
+ * the final unmetafied string. The exception is the case of
+ * a complete GETKEY_DOLLAR_QUOTE conversion where *len is the
+ * length of the input string which has been used (up to and including
+ * the terminating single quote); as the final string is metafied and
+ * NULL-terminated its length is not required. If both GETKEY_DOLLAR_QUOTE
+ * and GETKEY_UPDATE_OFFSET are present in "how", the string is not
+ * expected to be terminated (this is used in completion to parse
+ * a partial $'...'-quoted string) and the length passed back is
+ * that of the converted string. Note in both cases that this is a length
+ * in bytes (i.e. the same as given by a raw pointer difference), not
+ * characters, which may occupy multiple bytes.
+ *
+ * how is a set of bits from the GETKEY_ values defined in zsh.h;
+ * not all combinations of bits are useful. Callers will typically
+ * use one of the GETKEYS_ values which define sets of bits.
+ * Note, for example that:
+ * - GETKEY_SINGLE_CHAR must not be combined with GETKEY_DOLLAR_QUOTE.
+ * - GETKEY_UPDATE_OFFSET is only allowed if GETKEY_DOLLAR_QUOTE is
+ * also present.
+ *
+ * *misc is used for various purposes:
+ * - If GETKEY_BACKSLASH_MINUS is set, it indicates the presence
+ * of \- in the input.
+ * - If GETKEY_BACKSLASH_C is set, it indicates the presence
+ * of \c in the input.
+ * - If GETKEY_UPDATE_OFFSET is set, it is set on input to some
+ * mystical completion offset and is updated to a new offset based
+ * on the converted characters. All Hail the Completion System
+ * [makes the mystic completion system runic sign in the air].
+ *
+ * The return value is unmetafied unless GETKEY_DOLLAR_QUOTE is
+ * in use.
+ */
+
+/**/
+mod_export char *
+getkeystring(char *s, int *len, int how, int *misc)
+{
+ char *buf, tmp[1];
+ char *t, *tdest = NULL, *u = NULL, *sstart = s, *tbuf = NULL;
+ char svchar = '\0';
+ int meta = 0, control = 0, ignoring = 0;
+ int i;
+#if defined(HAVE_WCHAR_H) && defined(HAVE_WCTOMB) && defined(__STDC_ISO_10646__)
+ wint_t wval;
+ int count;
+#else
+ unsigned int wval;
+# if defined(HAVE_NL_LANGINFO) && defined(CODESET)
+# if defined(HAVE_ICONV)
+ iconv_t cd;
+ char inbuf[4];
+ size_t inbytes, outbytes;
+# endif
+ size_t count;
+# endif
+#endif
+
+ DPUTS((how & GETKEY_UPDATE_OFFSET) &&
+ (how & ~(GETKEYS_DOLLARS_QUOTE|GETKEY_UPDATE_OFFSET)),
+ "BUG: offset updating in getkeystring only supported with $'.");
+ DPUTS((how & (GETKEY_DOLLAR_QUOTE|GETKEY_SINGLE_CHAR)) ==
+ (GETKEY_DOLLAR_QUOTE|GETKEY_SINGLE_CHAR),
+ "BUG: incompatible options in getkeystring");
+
+ if (how & GETKEY_SINGLE_CHAR)
+ t = buf = tmp;
+ else {
+ /* Length including terminating NULL */
+ int maxlen = 1;
+ /*
+ * We're not necessarily guaranteed the output string will
+ * be no longer than the input with \u and \U when output
+ * characters need to be metafied. As this is the only
+ * case where the string can get longer (?I think),
+ * include it in the allocation length here but don't
+ * bother taking account of other factors.
+ */
+ for (t = s; *t; t++) {
+ if (*t == '\\') {
+ if (!t[1]) {
+ maxlen++;
+ break;
+ }
+ if (t[1] == 'u' || t[1] == 'U')
+ maxlen += MB_CUR_MAX * 2;
+ else
+ maxlen += 2;
+ /* skip the backslash and the following character */
+ t++;
+ } else
+ maxlen++;
+ }
+ if (how & GETKEY_DOLLAR_QUOTE) {
+ /*
+ * We're going to unmetafy into a new string, but
+ * to get a proper metafied input we're going to metafy
+ * into an intermediate buffer. This is necessary if we have
+ * \u and \U's with multiple metafied bytes. We can't
+ * simply remetafy the entire string because there may
+ * be tokens (indeed, we know there are lexical nulls floating
+ * around), so we have to be aware character by character
+ * what we are converting.
+ *
+ * In this case, buf is the final buffer (as usual),
+ * but t points into a temporary buffer that just has
+ * to be long enough to hold the result of one escape
+ * code transformation. We count this is a full multibyte
+ * character (MB_CUR_MAX) with every character metafied
+ * (*2) plus a little bit of fuzz (for e.g. the odd backslash).
+ */
+ buf = tdest = zhalloc(maxlen);
+ t = tbuf = zhalloc(MB_CUR_MAX * 3 + 1);
+ } else {
+ t = buf = zhalloc(maxlen);
+ }
+ }
+ for (; *s; s++) {
+ if (*s == '\\' && s[1]) {
+ int miscadded;
+ if ((how & GETKEY_UPDATE_OFFSET) && s - sstart < *misc) {
+ (*misc)--;
+ miscadded = 1;
+ } else
+ miscadded = 0;
+ switch (*++s) {
+ case 'a':
+#ifdef __STDC__
+ *t++ = '\a';
+#else
+ *t++ = '\07';
+#endif
+ break;
+ case 'n':
+ *t++ = '\n';
+ break;
+ case 'b':
+ *t++ = '\b';
+ break;
+ case 't':
+ *t++ = '\t';
+ break;
+ case 'v':
+ *t++ = '\v';
+ break;
+ case 'f':
+ *t++ = '\f';
+ break;
+ case 'r':
+ *t++ = '\r';
+ break;
+ case 'E':
+ if (!(how & GETKEY_EMACS)) {
+ *t++ = '\\', s--;
+ if (miscadded)
+ (*misc)++;
+ continue;
+ }
+ /* FALL THROUGH */
+ case 'e':
+ *t++ = '\033';
+ break;
+ case 'M':
+ /* HERE: GETKEY_UPDATE_OFFSET */
+ if (how & GETKEY_EMACS) {
+ if (s[1] == '-')
+ s++;
+ meta = 1 + control; /* preserve the order of ^ and meta */
+ } else {
+ if (miscadded)
+ (*misc)++;
+ *t++ = '\\', s--;
+ }
+ continue;
+ case 'C':
+ /* HERE: GETKEY_UPDATE_OFFSET */
+ if (how & GETKEY_EMACS) {
+ if (s[1] == '-')
+ s++;
+ control = 1;
+ } else {
+ if (miscadded)
+ (*misc)++;
+ *t++ = '\\', s--;
+ }
+ continue;
+ case Meta:
+ if (miscadded)
+ (*misc)++;
+ *t++ = '\\', s--;
+ break;
+ case '-':
+ if (how & GETKEY_BACKSLASH_MINUS) {
+ *misc = 1;
+ break;
+ }
+ goto def;
+ case 'c':
+ if (how & GETKEY_BACKSLASH_C) {
+ *misc = 1;
+ *t = '\0';
+ *len = t - buf;
+ return buf;
+ }
+ goto def;
+ case 'U':
+ if ((how & GETKEY_UPDATE_OFFSET) && s - sstart < *misc)
+ (*misc) -= 4;
+ /* FALLTHROUGH */
+ case 'u':
+ if ((how & GETKEY_UPDATE_OFFSET) && s - sstart < *misc) {
+ (*misc) -= 6; /* HERE don't really believe this */
+ /*
+ * We've now adjusted the offset for all the input
+ * characters, so we need to add for each
+ * byte of output below.
+ */
+ }
+ wval = 0;
+ for (i=(*s == 'u' ? 4 : 8); i>0; i--) {
+ if (*++s && idigit(*s))
+ wval = wval * 16 + (*s - '0');
+ else if (*s && ((*s >= 'a' && *s <= 'f') ||
+ (*s >= 'A' && *s <= 'F')))
+ wval = wval * 16 + (*s & 0x1f) + 9;
+ else {
+ s--;
+ break;
+ }
+ }
+ if (how & GETKEY_SINGLE_CHAR) {
+ *misc = wval;
+ return s+1;
+ }
+#if defined(HAVE_WCHAR_H) && defined(HAVE_WCTOMB) && defined(__STDC_ISO_10646__)
+ count = wctomb(t, (wchar_t)wval);
+ if (count == -1) {
+ zerr("character not in range");
+ CHARSET_FAILED();
+ }
+ if ((how & GETKEY_UPDATE_OFFSET) && s - sstart < *misc)
+ (*misc) += count;
+ t += count;
+# else
+# if defined(HAVE_NL_LANGINFO) && defined(CODESET)
+ if (!strcmp(nl_langinfo(CODESET), "UTF-8")) {
+ count = ucs4toutf8(t, wval);
+ t += count;
+ if ((how & GETKEY_UPDATE_OFFSET) && s - sstart < *misc)
+ (*misc) += count;
+ } else {
+# ifdef HAVE_ICONV
+ ICONV_CONST char *inptr = inbuf;
+ const char *codesetstr = nl_langinfo(CODESET);
+ inbytes = 4;
+ outbytes = 6;
+ /* store value in big endian form */
+ for (i=3;i>=0;i--) {
+ inbuf[i] = wval & 0xff;
+ wval >>= 8;
+ }
+
+ /*
+ * If the code set isn't handled, we'd better
+ * assume it's US-ASCII rather than just failing
+ * hopelessly. Solaris has a weird habit of
+ * returning 646. This is handled by the
+ * native iconv(), but not by GNU iconv; what's
+ * more, some versions of the native iconv don't
+ * handle standard names like ASCII.
+ *
+ * This should only be a problem if there's a
+ * mismatch between the NLS and the iconv in use,
+ * which probably only means if libiconv is in use.
+ * We checked at configure time if our libraries
+ * pulled in _libiconv_version, which should be
+ * a good test.
+ *
+ * It shouldn't ever be NULL, but while we're
+ * being paranoid...
+ */
+#ifdef ICONV_FROM_LIBICONV
+ if (!codesetstr || !*codesetstr)
+ codesetstr = "US-ASCII";
+#endif
+ cd = iconv_open(codesetstr, "UCS-4BE");
+#ifdef ICONV_FROM_LIBICONV
+ if (cd == (iconv_t)-1 && !strcmp(codesetstr, "646")) {
+ codesetstr = "US-ASCII";
+ cd = iconv_open(codesetstr, "UCS-4BE");
+ }
+#endif
+ if (cd == (iconv_t)-1) {
+ zerr("cannot do charset conversion (iconv failed)");
+ CHARSET_FAILED();
+ }
+ count = iconv(cd, &inptr, &inbytes, &t, &outbytes);
+ iconv_close(cd);
+ if (count == (size_t)-1) {
+ zerr("character not in range");
+ CHARSET_FAILED();
+ }
+ if ((how & GETKEY_UPDATE_OFFSET) && s - sstart < *misc)
+ (*misc) += count;
+# else
+ zerr("cannot do charset conversion (iconv not available)");
+ CHARSET_FAILED();
+# endif
+ }
+# else
+ zerr("cannot do charset conversion (NLS not supported)");
+ CHARSET_FAILED();
+# endif
+# endif
+ if (how & GETKEY_DOLLAR_QUOTE) {
+ char *t2;
+ for (t2 = tbuf; t2 < t; t2++) {
+ if (imeta(*t2)) {
+ *tdest++ = Meta;
+ *tdest++ = *t2 ^ 32;
+ } else
+ *tdest++ = *t2;
+ }
+ /* reset temporary buffer after handling */
+ t = tbuf;
+ }
+ continue;
+ case '\'':
+ case '\\':
+ if (how & GETKEY_DOLLAR_QUOTE) {
+ /*
+ * Usually \' and \\ will have the initial
+ * \ turned into a Bnull, however that's not
+ * necessarily the case when called from
+ * completion.
+ */
+ *t++ = *s;
+ break;
+ }
+ /* FALLTHROUGH */
+ default:
+ def:
+ /* HERE: GETKEY_UPDATE_OFFSET? */
+ if ((idigit(*s) && *s < '8') || *s == 'x') {
+ if (!(how & GETKEY_OCTAL_ESC)) {
+ if (*s == '0')
+ s++;
+ else if (*s != 'x') {
+ *t++ = '\\', s--;
+ continue;
+ }
+ }
+ if (s[1] && s[2] && s[3]) {
+ svchar = s[3];
+ s[3] = '\0';
+ u = s;
+ }
+ *t++ = zstrtol(s + (*s == 'x'), &s,
+ (*s == 'x') ? 16 : 8);
+ if ((how & GETKEY_PRINTF_PERCENT) && t[-1] == '%')
+ *t++ = '%';
+ if (svchar) {
+ u[3] = svchar;
+ svchar = '\0';
+ }
+ s--;
+ } else {
+ if (!(how & GETKEY_EMACS) && *s != '\\') {
+ if (miscadded)
+ (*misc)++;
+ *t++ = '\\';
+ }
+ *t++ = *s;
+ }
+ break;
+ }
+ } else if ((how & GETKEY_DOLLAR_QUOTE) && *s == Snull) {
+ /* return length to following character */
+ *len = (s - sstart) + 1;
+ *tdest = '\0';
+ return buf;
+ } else if (*s == '^' && !control && (how & GETKEY_CTRL) && s[1]) {
+ control = 1;
+ continue;
+#ifdef MULTIBYTE_SUPPORT
+ } else if ((how & GETKEY_SINGLE_CHAR) &&
+ isset(MULTIBYTE) && STOUC(*s) > 127) {
+ wint_t wc;
+ int len;
+ len = mb_metacharlenconv(s, &wc);
+ if (wc != WEOF) {
+ *misc = (int)wc;
+ return s + len;
+ }
+#endif
+
+ } else if (*s == Meta)
+ *t++ = *++s ^ 32;
+ else {
+ if (itok(*s)) {
+ /*
+ * We need to be quite careful here. We haven't
+ * necessarily got an input stream with all tokens
+ * removed, so the majority of tokens need passing
+ * through untouched and without Meta handling.
+ * However, me may need to handle tokenized
+ * backslashes.
+ */
+ if (meta || control) {
+ /*
+ * Presumably we should be using meta or control
+ * on the character representing the token.
+ *
+ * Special case: $'\M-\\' where the token is a Bnull.
+ * This time we dump the Bnull since we're
+ * replacing the whole thing. The lexer
+ * doesn't know about the meta or control modifiers.
+ */
+ if ((how & GETKEY_DOLLAR_QUOTE) && *s == Bnull)
+ *t++ = *++s;
+ else
+ *t++ = ztokens[*s - Pound];
+ } else if (how & GETKEY_DOLLAR_QUOTE) {
+ /*
+ * We don't want to metafy this, it's a real
+ * token.
+ */
+ *tdest++ = *s;
+ if (*s == Bnull) {
+ /*
+ * Bnull is a backslash which quotes a couple
+ * of special characters that always appear
+ * literally next. See strquote handling
+ * in gettokstr() in lex.c. We need
+ * to retain the Bnull (as above) so that quote
+ * handling in completion can tell where the
+ * backslash was.
+ */
+ *tdest++ = *++s;
+ }
+ /* reset temporary buffer, now handled */
+ t = tbuf;
+ continue;
+ } else
+ *t++ = *s;
+ } else
+ *t++ = *s;
+ }
+ if (meta == 2) {
+ t[-1] |= 0x80;
+ meta = 0;
+ }
+ if (control) {
+ if (t[-1] == '?')
+ t[-1] = 0x7f;
+ else
+ t[-1] &= 0x9f;
+ control = 0;
+ }
+ if (meta) {
+ t[-1] |= 0x80;
+ meta = 0;
+ }
+ if (how & GETKEY_DOLLAR_QUOTE) {
+ char *t2;
+ for (t2 = tbuf; t2 < t; t2++) {
+ /*
+ * In POSIX mode, an embedded NULL is discarded and
+ * terminates processing. It just does, that's why.
+ */
+ if (isset(POSIXSTRINGS)) {
+ if (*t2 == '\0')
+ ignoring = 1;
+ if (ignoring)
+ break;
+ }
+ if (imeta(*t2)) {
+ *tdest++ = Meta;
+ *tdest++ = *t2 ^ 32;
+ } else {
+ *tdest++ = *t2;
+ }
+ }
+ /*
+ * Reset use of temporary buffer.
+ */
+ t = tbuf;
+ }
+ if ((how & GETKEY_SINGLE_CHAR) && t != tmp) {
+ *misc = STOUC(tmp[0]);
+ return s + 1;
+ }
+ }
+ /*
+ * When called from completion, where we use GETKEY_UPDATE_OFFSET to
+ * update the index into the metafied editor line, we don't necessarily
+ * have the end of a $'...' quotation, else we should do.
+ */
+ DPUTS((how & (GETKEY_DOLLAR_QUOTE|GETKEY_UPDATE_OFFSET)) ==
+ GETKEY_DOLLAR_QUOTE, "BUG: unterminated $' substitution");
+ *t = '\0';
+ if (how & GETKEY_DOLLAR_QUOTE)
+ *tdest = '\0';
+ if (how & GETKEY_SINGLE_CHAR)
+ *misc = 0;
+ else
+ *len = ((how & GETKEY_DOLLAR_QUOTE) ? tdest : t) - buf;
+ return buf;
+}
+
+/* Return non-zero if s is a prefix of t. */
+
+/**/
+mod_export int
+strpfx(const char *s, const char *t)
+{
+ while (*s && *s == *t)
+ s++, t++;
+ return !*s;
+}
+
+/* Return non-zero if s is a suffix of t. */
+
+/**/
+mod_export int
+strsfx(char *s, char *t)
+{
+ int ls = strlen(s), lt = strlen(t);
+
+ if (ls <= lt)
+ return !strcmp(t + lt - ls, s);
+ return 0;
+}
+
+/**/
+static int
+upchdir(int n)
+{
+ char buf[PATH_MAX+1];
+ char *s;
+ int err = -1;
+
+ while (n > 0) {
+ for (s = buf; s < buf + PATH_MAX - 4 && n--; )
+ *s++ = '.', *s++ = '.', *s++ = '/';
+ s[-1] = '\0';
+ if (chdir(buf))
+ return err;
+ err = -2;
+ }
+ return 0;
+}
+
+/*
+ * Initialize a "struct dirsav".
+ * The structure will be set to the directory we want to save
+ * the first time we change to a different directory.
+ */
+
+/**/
+mod_export void
+init_dirsav(Dirsav d)
+{
+ d->ino = d->dev = 0;
+ d->dirname = NULL;
+ d->dirfd = d->level = -1;
+}
+
+/*
+ * Change directory, without following symlinks. Returns 0 on success, -1
+ * on failure. Sets errno to ENOTDIR if any symlinks are encountered. If
+ * fchdir() fails, or the current directory is unreadable, we might end up
+ * in an unwanted directory in case of failure.
+ *
+ * path is an unmetafied but null-terminated string, as needed by system
+ * calls.
+ */
+
+/**/
+mod_export int
+lchdir(char const *path, struct dirsav *d, int hard)
+{
+ char const *pptr;
+ int level;
+ struct stat st1;
+ struct dirsav ds;
+#ifdef HAVE_LSTAT
+ char buf[PATH_MAX + 1], *ptr;
+ int err;
+ struct stat st2;
+#endif
+#ifdef HAVE_FCHDIR
+ int close_dir = 0;
+#endif
+
+ if (!d) {
+ init_dirsav(&ds);
+ d = &ds;
+ }
+#ifdef HAVE_LSTAT
+ if ((*path == '/' || !hard) &&
+ (d != &ds || hard)){
+#else
+ if (*path == '/') {
+#endif
+ level = -1;
+#ifndef HAVE_FCHDIR
+ if (!d->dirname)
+ zgetdir(d);
+#endif
+ } else {
+ level = 0;
+ if (!d->dev && !d->ino) {
+ stat(".", &st1);
+ d->dev = st1.st_dev;
+ d->ino = st1.st_ino;
+ }
+ }
+
+#ifdef HAVE_LSTAT
+ if (!hard)
+#endif
+ {
+ if (d != &ds) {
+ for (pptr = path; *pptr; level++) {
+ while (*pptr && *pptr++ != '/');
+ while (*pptr == '/')
+ pptr++;
+ }
+ d->level = level;
+ }
+ return zchdir((char *) path);
+ }
+
+#ifdef HAVE_LSTAT
+#ifdef HAVE_FCHDIR
+ if (d->dirfd < 0) {
+ close_dir = 1;
+ if ((d->dirfd = open(".", O_RDONLY | O_NOCTTY)) < 0 &&
+ zgetdir(d) && *d->dirname != '/')
+ d->dirfd = open("..", O_RDONLY | O_NOCTTY);
+ }
+#endif
+ if (*path == '/')
+ if (chdir("/") < 0)
+ zwarn("failed to chdir(/): %e", errno);
+ for(;;) {
+ while(*path == '/')
+ path++;
+ if(!*path) {
+ if (d == &ds)
+ zsfree(ds.dirname);
+ else
+ d->level = level;
+#ifdef HAVE_FCHDIR
+ if (d->dirfd >=0 && close_dir) {
+ close(d->dirfd);
+ d->dirfd = -1;
+ }
+#endif
+ return 0;
+ }
+ for(pptr = path; *++pptr && *pptr != '/'; ) ;
+ if(pptr - path > PATH_MAX) {
+ err = ENAMETOOLONG;
+ break;
+ }
+ for(ptr = buf; path != pptr; )
+ *ptr++ = *path++;
+ *ptr = 0;
+ if(lstat(buf, &st1)) {
+ err = errno;
+ break;
+ }
+ if(!S_ISDIR(st1.st_mode)) {
+ err = ENOTDIR;
+ break;
+ }
+ if(chdir(buf)) {
+ err = errno;
+ break;
+ }
+ if (level >= 0)
+ level++;
+ if(lstat(".", &st2)) {
+ err = errno;
+ break;
+ }
+ if(st1.st_dev != st2.st_dev || st1.st_ino != st2.st_ino) {
+ err = ENOTDIR;
+ break;
+ }
+ }
+ if (restoredir(d)) {
+ int restoreerr = errno;
+ int i;
+ /*
+ * Failed to restore the directory.
+ * Just be definite, cd to root and report the result.
+ */
+ for (i = 0; i < 2; i++) {
+ const char *cdest;
+ if (i)
+ cdest = "/";
+ else {
+ if (!home)
+ continue;
+ cdest = home;
+ }
+ zsfree(pwd);
+ pwd = ztrdup(cdest);
+ if (chdir(pwd) == 0)
+ break;
+ }
+ if (i == 2)
+ zerr("lost current directory, failed to cd to /: %e", errno);
+ else
+ zerr("lost current directory: %e: changed to `%s'", restoreerr,
+ pwd);
+ if (d == &ds)
+ zsfree(ds.dirname);
+#ifdef HAVE_FCHDIR
+ if (d->dirfd >=0 && close_dir) {
+ close(d->dirfd);
+ d->dirfd = -1;
+ }
+#endif
+ errno = err;
+ return -2;
+ }
+ if (d == &ds)
+ zsfree(ds.dirname);
+#ifdef HAVE_FCHDIR
+ if (d->dirfd >=0 && close_dir) {
+ close(d->dirfd);
+ d->dirfd = -1;
+ }
+#endif
+ errno = err;
+ return -1;
+#endif /* HAVE_LSTAT */
+}
+
+/**/
+mod_export int
+restoredir(struct dirsav *d)
+{
+ int err = 0;
+ struct stat sbuf;
+
+ if (d->dirname && *d->dirname == '/')
+ return chdir(d->dirname);
+#ifdef HAVE_FCHDIR
+ if (d->dirfd >= 0) {
+ if (!fchdir(d->dirfd)) {
+ if (!d->dirname) {
+ return 0;
+ } else if (chdir(d->dirname)) {
+ close(d->dirfd);
+ d->dirfd = -1;
+ err = -2;
+ }
+ } else {
+ close(d->dirfd);
+ d->dirfd = err = -1;
+ }
+ } else
+#endif
+ if (d->level > 0)
+ err = upchdir(d->level);
+ else if (d->level < 0)
+ err = -1;
+ if (d->dev || d->ino) {
+ stat(".", &sbuf);
+ if (sbuf.st_ino != d->ino || sbuf.st_dev != d->dev)
+ err = -2;
+ }
+ return err;
+}
+
+
+/* Check whether the shell is running with privileges in effect. *
+ * This is the case if EITHER the euid is zero, OR (if the system *
+ * supports POSIX.1e (POSIX.6) capability sets) the process' *
+ * Effective or Inheritable capability sets are non-empty. */
+
+/**/
+int
+privasserted(void)
+{
+ if(!geteuid())
+ return 1;
+#ifdef HAVE_CAP_GET_PROC
+ {
+ cap_t caps = cap_get_proc();
+ if(caps) {
+ /* POSIX doesn't define a way to test whether a capability set *
+ * is empty or not. Typical. I hope this is conforming... */
+ cap_flag_value_t val;
+ cap_value_t n;
+ for(n = 0; !cap_get_flag(caps, n, CAP_EFFECTIVE, &val); n++)
+ if(val) {
+ cap_free(caps);
+ return 1;
+ }
+ }
+ cap_free(caps);
+ }
+#endif /* HAVE_CAP_GET_PROC */
+ return 0;
+}
+
+/**/
+mod_export int
+mode_to_octal(mode_t mode)
+{
+ int m = 0;
+
+ if(mode & S_ISUID)
+ m |= 04000;
+ if(mode & S_ISGID)
+ m |= 02000;
+ if(mode & S_ISVTX)
+ m |= 01000;
+ if(mode & S_IRUSR)
+ m |= 00400;
+ if(mode & S_IWUSR)
+ m |= 00200;
+ if(mode & S_IXUSR)
+ m |= 00100;
+ if(mode & S_IRGRP)
+ m |= 00040;
+ if(mode & S_IWGRP)
+ m |= 00020;
+ if(mode & S_IXGRP)
+ m |= 00010;
+ if(mode & S_IROTH)
+ m |= 00004;
+ if(mode & S_IWOTH)
+ m |= 00002;
+ if(mode & S_IXOTH)
+ m |= 00001;
+ return m;
+}
+
+#ifdef MAILDIR_SUPPORT
+/*
+ * Stat a file. If it's a maildir, check all messages
+ * in the maildir and present the grand total as a file.
+ * The fields in the 'struct stat' are from the mail directory.
+ * The following fields are emulated:
+ *
+ * st_nlink always 1
+ * st_size total number of bytes in all files
+ * st_blocks total number of messages
+ * st_atime access time of newest file in maildir
+ * st_mtime modify time of newest file in maildir
+ * st_mode S_IFDIR changed to S_IFREG
+ *
+ * This is good enough for most mail-checking applications.
+ */
+
+/**/
+int
+mailstat(char *path, struct stat *st)
+{
+ DIR *dd;
+ struct dirent *fn;
+ struct stat st_ret, st_tmp;
+ static struct stat st_ret_last;
+ char *dir, *file = 0;
+ int i;
+ time_t atime = 0, mtime = 0;
+ size_t plen = strlen(path), dlen;
+
+ /* First see if it's a directory. */
+ if ((i = stat(path, st)) != 0 || !S_ISDIR(st->st_mode))
+ return i;
+
+ st_ret = *st;
+ st_ret.st_nlink = 1;
+ st_ret.st_size = 0;
+ st_ret.st_blocks = 0;
+ st_ret.st_mode &= ~S_IFDIR;
+ st_ret.st_mode |= S_IFREG;
+
+ /* See if cur/ is present */
+ dir = appstr(ztrdup(path), "/cur");
+ if (stat(dir, &st_tmp) || !S_ISDIR(st_tmp.st_mode)) return 0;
+ st_ret.st_atime = st_tmp.st_atime;
+
+ /* See if tmp/ is present */
+ dir[plen] = 0;
+ dir = appstr(dir, "/tmp");
+ if (stat(dir, &st_tmp) || !S_ISDIR(st_tmp.st_mode)) return 0;
+ st_ret.st_mtime = st_tmp.st_mtime;
+
+ /* And new/ */
+ dir[plen] = 0;
+ dir = appstr(dir, "/new");
+ if (stat(dir, &st_tmp) || !S_ISDIR(st_tmp.st_mode)) return 0;
+ st_ret.st_mtime = st_tmp.st_mtime;
+
+#if THERE_IS_EXACTLY_ONE_MAILDIR_IN_MAILPATH
+ {
+ static struct stat st_new_last;
+ /* Optimization - if new/ didn't change, nothing else did. */
+ if (st_tmp.st_dev == st_new_last.st_dev &&
+ st_tmp.st_ino == st_new_last.st_ino &&
+ st_tmp.st_atime == st_new_last.st_atime &&
+ st_tmp.st_mtime == st_new_last.st_mtime) {
+ *st = st_ret_last;
+ return 0;
+ }
+ st_new_last = st_tmp;
+ }
+#endif
+
+ /* Loop over new/ and cur/ */
+ for (i = 0; i < 2; i++) {
+ dir[plen] = 0;
+ dir = appstr(dir, i ? "/cur" : "/new");
+ if ((dd = opendir(dir)) == NULL) {
+ zsfree(file);
+ zsfree(dir);
+ return 0;
+ }
+ dlen = strlen(dir) + 1; /* include the "/" */
+ while ((fn = readdir(dd)) != NULL) {
+ if (fn->d_name[0] == '.')
+ continue;
+ if (file) {
+ file[dlen] = 0;
+ file = appstr(file, fn->d_name);
+ } else {
+ file = tricat(dir, "/", fn->d_name);
+ }
+ if (stat(file, &st_tmp) != 0)
+ continue;
+ st_ret.st_size += st_tmp.st_size;
+ st_ret.st_blocks++;
+ if (st_tmp.st_atime != st_tmp.st_mtime &&
+ st_tmp.st_atime > atime)
+ atime = st_tmp.st_atime;
+ if (st_tmp.st_mtime > mtime)
+ mtime = st_tmp.st_mtime;
+ }
+ closedir(dd);
+ }
+ zsfree(file);
+ zsfree(dir);
+
+ if (atime) st_ret.st_atime = atime;
+ if (mtime) st_ret.st_mtime = mtime;
+
+ *st = st_ret_last = st_ret;
+ return 0;
+}
+#endif
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/wcwidth9.h b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/wcwidth9.h
new file mode 100644
index 0000000..448f548
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/wcwidth9.h
@@ -0,0 +1,1325 @@
+#ifndef WCWIDTH9_H
+#define WCWIDTH9_H
+
+#include
+#include
+
+struct wcwidth9_interval {
+ long first;
+ long last;
+};
+
+static const struct wcwidth9_interval wcwidth9_private[] = {
+ {0x00e000, 0x00f8ff},
+ {0x0f0000, 0x0ffffd},
+ {0x100000, 0x10fffd},
+};
+
+static const struct wcwidth9_interval wcwidth9_nonprint[] = {
+ {0x0000, 0x001f},
+ {0x007f, 0x009f},
+ {0x00ad, 0x00ad},
+ {0x070f, 0x070f},
+ {0x180b, 0x180e},
+ {0x200b, 0x200f},
+ {0x2028, 0x2029},
+ {0x202a, 0x202e},
+ {0x206a, 0x206f},
+ {0xd800, 0xdfff},
+ {0xfeff, 0xfeff},
+ {0xfff9, 0xfffb},
+ {0xfffe, 0xffff},
+};
+
+static const struct wcwidth9_interval wcwidth9_combining[] = {
+ {0x0300, 0x036f},
+ {0x0483, 0x0489},
+ {0x0591, 0x05bd},
+ {0x05bf, 0x05bf},
+ {0x05c1, 0x05c2},
+ {0x05c4, 0x05c5},
+ {0x05c7, 0x05c7},
+ {0x0610, 0x061a},
+ {0x064b, 0x065f},
+ {0x0670, 0x0670},
+ {0x06d6, 0x06dc},
+ {0x06df, 0x06e4},
+ {0x06e7, 0x06e8},
+ {0x06ea, 0x06ed},
+ {0x0711, 0x0711},
+ {0x0730, 0x074a},
+ {0x07a6, 0x07b0},
+ {0x07eb, 0x07f3},
+ {0x0816, 0x0819},
+ {0x081b, 0x0823},
+ {0x0825, 0x0827},
+ {0x0829, 0x082d},
+ {0x0859, 0x085b},
+ {0x08d4, 0x08e1},
+ {0x08e3, 0x0903},
+ {0x093a, 0x093c},
+ {0x093e, 0x094f},
+ {0x0951, 0x0957},
+ {0x0962, 0x0963},
+ {0x0981, 0x0983},
+ {0x09bc, 0x09bc},
+ {0x09be, 0x09c4},
+ {0x09c7, 0x09c8},
+ {0x09cb, 0x09cd},
+ {0x09d7, 0x09d7},
+ {0x09e2, 0x09e3},
+ {0x0a01, 0x0a03},
+ {0x0a3c, 0x0a3c},
+ {0x0a3e, 0x0a42},
+ {0x0a47, 0x0a48},
+ {0x0a4b, 0x0a4d},
+ {0x0a51, 0x0a51},
+ {0x0a70, 0x0a71},
+ {0x0a75, 0x0a75},
+ {0x0a81, 0x0a83},
+ {0x0abc, 0x0abc},
+ {0x0abe, 0x0ac5},
+ {0x0ac7, 0x0ac9},
+ {0x0acb, 0x0acd},
+ {0x0ae2, 0x0ae3},
+ {0x0b01, 0x0b03},
+ {0x0b3c, 0x0b3c},
+ {0x0b3e, 0x0b44},
+ {0x0b47, 0x0b48},
+ {0x0b4b, 0x0b4d},
+ {0x0b56, 0x0b57},
+ {0x0b62, 0x0b63},
+ {0x0b82, 0x0b82},
+ {0x0bbe, 0x0bc2},
+ {0x0bc6, 0x0bc8},
+ {0x0bca, 0x0bcd},
+ {0x0bd7, 0x0bd7},
+ {0x0c00, 0x0c03},
+ {0x0c3e, 0x0c44},
+ {0x0c46, 0x0c48},
+ {0x0c4a, 0x0c4d},
+ {0x0c55, 0x0c56},
+ {0x0c62, 0x0c63},
+ {0x0c81, 0x0c83},
+ {0x0cbc, 0x0cbc},
+ {0x0cbe, 0x0cc4},
+ {0x0cc6, 0x0cc8},
+ {0x0cca, 0x0ccd},
+ {0x0cd5, 0x0cd6},
+ {0x0ce2, 0x0ce3},
+ {0x0d01, 0x0d03},
+ {0x0d3e, 0x0d44},
+ {0x0d46, 0x0d48},
+ {0x0d4a, 0x0d4d},
+ {0x0d57, 0x0d57},
+ {0x0d62, 0x0d63},
+ {0x0d82, 0x0d83},
+ {0x0dca, 0x0dca},
+ {0x0dcf, 0x0dd4},
+ {0x0dd6, 0x0dd6},
+ {0x0dd8, 0x0ddf},
+ {0x0df2, 0x0df3},
+ {0x0e31, 0x0e31},
+ {0x0e34, 0x0e3a},
+ {0x0e47, 0x0e4e},
+ {0x0eb1, 0x0eb1},
+ {0x0eb4, 0x0eb9},
+ {0x0ebb, 0x0ebc},
+ {0x0ec8, 0x0ecd},
+ {0x0f18, 0x0f19},
+ {0x0f35, 0x0f35},
+ {0x0f37, 0x0f37},
+ {0x0f39, 0x0f39},
+ {0x0f3e, 0x0f3f},
+ {0x0f71, 0x0f84},
+ {0x0f86, 0x0f87},
+ {0x0f8d, 0x0f97},
+ {0x0f99, 0x0fbc},
+ {0x0fc6, 0x0fc6},
+ {0x102b, 0x103e},
+ {0x1056, 0x1059},
+ {0x105e, 0x1060},
+ {0x1062, 0x1064},
+ {0x1067, 0x106d},
+ {0x1071, 0x1074},
+ {0x1082, 0x108d},
+ {0x108f, 0x108f},
+ {0x109a, 0x109d},
+ {0x135d, 0x135f},
+ {0x1712, 0x1714},
+ {0x1732, 0x1734},
+ {0x1752, 0x1753},
+ {0x1772, 0x1773},
+ {0x17b4, 0x17d3},
+ {0x17dd, 0x17dd},
+ {0x180b, 0x180d},
+ {0x1885, 0x1886},
+ {0x18a9, 0x18a9},
+ {0x1920, 0x192b},
+ {0x1930, 0x193b},
+ {0x1a17, 0x1a1b},
+ {0x1a55, 0x1a5e},
+ {0x1a60, 0x1a7c},
+ {0x1a7f, 0x1a7f},
+ {0x1ab0, 0x1abe},
+ {0x1b00, 0x1b04},
+ {0x1b34, 0x1b44},
+ {0x1b6b, 0x1b73},
+ {0x1b80, 0x1b82},
+ {0x1ba1, 0x1bad},
+ {0x1be6, 0x1bf3},
+ {0x1c24, 0x1c37},
+ {0x1cd0, 0x1cd2},
+ {0x1cd4, 0x1ce8},
+ {0x1ced, 0x1ced},
+ {0x1cf2, 0x1cf4},
+ {0x1cf8, 0x1cf9},
+ {0x1dc0, 0x1df5},
+ {0x1dfb, 0x1dff},
+ {0x20d0, 0x20f0},
+ {0x2cef, 0x2cf1},
+ {0x2d7f, 0x2d7f},
+ {0x2de0, 0x2dff},
+ {0x302a, 0x302f},
+ {0x3099, 0x309a},
+ {0xa66f, 0xa672},
+ {0xa674, 0xa67d},
+ {0xa69e, 0xa69f},
+ {0xa6f0, 0xa6f1},
+ {0xa802, 0xa802},
+ {0xa806, 0xa806},
+ {0xa80b, 0xa80b},
+ {0xa823, 0xa827},
+ {0xa880, 0xa881},
+ {0xa8b4, 0xa8c5},
+ {0xa8e0, 0xa8f1},
+ {0xa926, 0xa92d},
+ {0xa947, 0xa953},
+ {0xa980, 0xa983},
+ {0xa9b3, 0xa9c0},
+ {0xa9e5, 0xa9e5},
+ {0xaa29, 0xaa36},
+ {0xaa43, 0xaa43},
+ {0xaa4c, 0xaa4d},
+ {0xaa7b, 0xaa7d},
+ {0xaab0, 0xaab0},
+ {0xaab2, 0xaab4},
+ {0xaab7, 0xaab8},
+ {0xaabe, 0xaabf},
+ {0xaac1, 0xaac1},
+ {0xaaeb, 0xaaef},
+ {0xaaf5, 0xaaf6},
+ {0xabe3, 0xabea},
+ {0xabec, 0xabed},
+ {0xfb1e, 0xfb1e},
+ {0xfe00, 0xfe0f},
+ {0xfe20, 0xfe2f},
+ {0x101fd, 0x101fd},
+ {0x102e0, 0x102e0},
+ {0x10376, 0x1037a},
+ {0x10a01, 0x10a03},
+ {0x10a05, 0x10a06},
+ {0x10a0c, 0x10a0f},
+ {0x10a38, 0x10a3a},
+ {0x10a3f, 0x10a3f},
+ {0x10ae5, 0x10ae6},
+ {0x11000, 0x11002},
+ {0x11038, 0x11046},
+ {0x1107f, 0x11082},
+ {0x110b0, 0x110ba},
+ {0x11100, 0x11102},
+ {0x11127, 0x11134},
+ {0x11173, 0x11173},
+ {0x11180, 0x11182},
+ {0x111b3, 0x111c0},
+ {0x111ca, 0x111cc},
+ {0x1122c, 0x11237},
+ {0x1123e, 0x1123e},
+ {0x112df, 0x112ea},
+ {0x11300, 0x11303},
+ {0x1133c, 0x1133c},
+ {0x1133e, 0x11344},
+ {0x11347, 0x11348},
+ {0x1134b, 0x1134d},
+ {0x11357, 0x11357},
+ {0x11362, 0x11363},
+ {0x11366, 0x1136c},
+ {0x11370, 0x11374},
+ {0x11435, 0x11446},
+ {0x114b0, 0x114c3},
+ {0x115af, 0x115b5},
+ {0x115b8, 0x115c0},
+ {0x115dc, 0x115dd},
+ {0x11630, 0x11640},
+ {0x116ab, 0x116b7},
+ {0x1171d, 0x1172b},
+ {0x11c2f, 0x11c36},
+ {0x11c38, 0x11c3f},
+ {0x11c92, 0x11ca7},
+ {0x11ca9, 0x11cb6},
+ {0x16af0, 0x16af4},
+ {0x16b30, 0x16b36},
+ {0x16f51, 0x16f7e},
+ {0x16f8f, 0x16f92},
+ {0x1bc9d, 0x1bc9e},
+ {0x1d165, 0x1d169},
+ {0x1d16d, 0x1d172},
+ {0x1d17b, 0x1d182},
+ {0x1d185, 0x1d18b},
+ {0x1d1aa, 0x1d1ad},
+ {0x1d242, 0x1d244},
+ {0x1da00, 0x1da36},
+ {0x1da3b, 0x1da6c},
+ {0x1da75, 0x1da75},
+ {0x1da84, 0x1da84},
+ {0x1da9b, 0x1da9f},
+ {0x1daa1, 0x1daaf},
+ {0x1e000, 0x1e006},
+ {0x1e008, 0x1e018},
+ {0x1e01b, 0x1e021},
+ {0x1e023, 0x1e024},
+ {0x1e026, 0x1e02a},
+ {0x1e8d0, 0x1e8d6},
+ {0x1e944, 0x1e94a},
+ {0xe0100, 0xe01ef},
+};
+
+static const struct wcwidth9_interval wcwidth9_doublewidth[] = {
+ {0x1100, 0x115f},
+ {0x231a, 0x231b},
+ {0x2329, 0x232a},
+ {0x23e9, 0x23ec},
+ {0x23f0, 0x23f0},
+ {0x23f3, 0x23f3},
+ {0x25fd, 0x25fe},
+ {0x2614, 0x2615},
+ {0x2648, 0x2653},
+ {0x267f, 0x267f},
+ {0x2693, 0x2693},
+ {0x26a1, 0x26a1},
+ {0x26aa, 0x26ab},
+ {0x26bd, 0x26be},
+ {0x26c4, 0x26c5},
+ {0x26ce, 0x26ce},
+ {0x26d4, 0x26d4},
+ {0x26ea, 0x26ea},
+ {0x26f2, 0x26f3},
+ {0x26f5, 0x26f5},
+ {0x26fa, 0x26fa},
+ {0x26fd, 0x26fd},
+ {0x2705, 0x2705},
+ {0x270a, 0x270b},
+ {0x2728, 0x2728},
+ {0x274c, 0x274c},
+ {0x274e, 0x274e},
+ {0x2753, 0x2755},
+ {0x2757, 0x2757},
+ {0x2795, 0x2797},
+ {0x27b0, 0x27b0},
+ {0x27bf, 0x27bf},
+ {0x2b1b, 0x2b1c},
+ {0x2b50, 0x2b50},
+ {0x2b55, 0x2b55},
+ {0x2e80, 0x2e99},
+ {0x2e9b, 0x2ef3},
+ {0x2f00, 0x2fd5},
+ {0x2ff0, 0x2ffb},
+ {0x3000, 0x303e},
+ {0x3041, 0x3096},
+ {0x3099, 0x30ff},
+ {0x3105, 0x312d},
+ {0x3131, 0x318e},
+ {0x3190, 0x31ba},
+ {0x31c0, 0x31e3},
+ {0x31f0, 0x321e},
+ {0x3220, 0x3247},
+ {0x3250, 0x32fe},
+ {0x3300, 0x4dbf},
+ {0x4e00, 0xa48c},
+ {0xa490, 0xa4c6},
+ {0xa960, 0xa97c},
+ {0xac00, 0xd7a3},
+ {0xf900, 0xfaff},
+ {0xfe10, 0xfe19},
+ {0xfe30, 0xfe52},
+ {0xfe54, 0xfe66},
+ {0xfe68, 0xfe6b},
+ {0xff01, 0xff60},
+ {0xffe0, 0xffe6},
+ {0x16fe0, 0x16fe0},
+ {0x17000, 0x187ec},
+ {0x18800, 0x18af2},
+ {0x1b000, 0x1b001},
+ {0x1f004, 0x1f004},
+ {0x1f0cf, 0x1f0cf},
+ {0x1f18e, 0x1f18e},
+ {0x1f191, 0x1f19a},
+ {0x1f200, 0x1f202},
+ {0x1f210, 0x1f23b},
+ {0x1f240, 0x1f248},
+ {0x1f250, 0x1f251},
+ {0x1f300, 0x1f320},
+ {0x1f32d, 0x1f335},
+ {0x1f337, 0x1f37c},
+ {0x1f37e, 0x1f393},
+ {0x1f3a0, 0x1f3ca},
+ {0x1f3cf, 0x1f3d3},
+ {0x1f3e0, 0x1f3f0},
+ {0x1f3f4, 0x1f3f4},
+ {0x1f3f8, 0x1f43e},
+ {0x1f440, 0x1f440},
+ {0x1f442, 0x1f4fc},
+ {0x1f4ff, 0x1f53d},
+ {0x1f54b, 0x1f54e},
+ {0x1f550, 0x1f567},
+ {0x1f57a, 0x1f57a},
+ {0x1f595, 0x1f596},
+ {0x1f5a4, 0x1f5a4},
+ {0x1f5fb, 0x1f64f},
+ {0x1f680, 0x1f6c5},
+ {0x1f6cc, 0x1f6cc},
+ {0x1f6d0, 0x1f6d2},
+ {0x1f6eb, 0x1f6ec},
+ {0x1f6f4, 0x1f6f6},
+ {0x1f910, 0x1f91e},
+ {0x1f920, 0x1f927},
+ {0x1f930, 0x1f930},
+ {0x1f933, 0x1f93e},
+ {0x1f940, 0x1f94b},
+ {0x1f950, 0x1f95e},
+ {0x1f980, 0x1f991},
+ {0x1f9c0, 0x1f9c0},
+ {0x20000, 0x2fffd},
+ {0x30000, 0x3fffd},
+};
+
+static const struct wcwidth9_interval wcwidth9_ambiguous[] = {
+ {0x00a1, 0x00a1},
+ {0x00a4, 0x00a4},
+ {0x00a7, 0x00a8},
+ {0x00aa, 0x00aa},
+ {0x00ad, 0x00ae},
+ {0x00b0, 0x00b4},
+ {0x00b6, 0x00ba},
+ {0x00bc, 0x00bf},
+ {0x00c6, 0x00c6},
+ {0x00d0, 0x00d0},
+ {0x00d7, 0x00d8},
+ {0x00de, 0x00e1},
+ {0x00e6, 0x00e6},
+ {0x00e8, 0x00ea},
+ {0x00ec, 0x00ed},
+ {0x00f0, 0x00f0},
+ {0x00f2, 0x00f3},
+ {0x00f7, 0x00fa},
+ {0x00fc, 0x00fc},
+ {0x00fe, 0x00fe},
+ {0x0101, 0x0101},
+ {0x0111, 0x0111},
+ {0x0113, 0x0113},
+ {0x011b, 0x011b},
+ {0x0126, 0x0127},
+ {0x012b, 0x012b},
+ {0x0131, 0x0133},
+ {0x0138, 0x0138},
+ {0x013f, 0x0142},
+ {0x0144, 0x0144},
+ {0x0148, 0x014b},
+ {0x014d, 0x014d},
+ {0x0152, 0x0153},
+ {0x0166, 0x0167},
+ {0x016b, 0x016b},
+ {0x01ce, 0x01ce},
+ {0x01d0, 0x01d0},
+ {0x01d2, 0x01d2},
+ {0x01d4, 0x01d4},
+ {0x01d6, 0x01d6},
+ {0x01d8, 0x01d8},
+ {0x01da, 0x01da},
+ {0x01dc, 0x01dc},
+ {0x0251, 0x0251},
+ {0x0261, 0x0261},
+ {0x02c4, 0x02c4},
+ {0x02c7, 0x02c7},
+ {0x02c9, 0x02cb},
+ {0x02cd, 0x02cd},
+ {0x02d0, 0x02d0},
+ {0x02d8, 0x02db},
+ {0x02dd, 0x02dd},
+ {0x02df, 0x02df},
+ {0x0300, 0x036f},
+ {0x0391, 0x03a1},
+ {0x03a3, 0x03a9},
+ {0x03b1, 0x03c1},
+ {0x03c3, 0x03c9},
+ {0x0401, 0x0401},
+ {0x0410, 0x044f},
+ {0x0451, 0x0451},
+ {0x2010, 0x2010},
+ {0x2013, 0x2016},
+ {0x2018, 0x2019},
+ {0x201c, 0x201d},
+ {0x2020, 0x2022},
+ {0x2024, 0x2027},
+ {0x2030, 0x2030},
+ {0x2032, 0x2033},
+ {0x2035, 0x2035},
+ {0x203b, 0x203b},
+ {0x203e, 0x203e},
+ {0x2074, 0x2074},
+ {0x207f, 0x207f},
+ {0x2081, 0x2084},
+ {0x20ac, 0x20ac},
+ {0x2103, 0x2103},
+ {0x2105, 0x2105},
+ {0x2109, 0x2109},
+ {0x2113, 0x2113},
+ {0x2116, 0x2116},
+ {0x2121, 0x2122},
+ {0x2126, 0x2126},
+ {0x212b, 0x212b},
+ {0x2153, 0x2154},
+ {0x215b, 0x215e},
+ {0x2160, 0x216b},
+ {0x2170, 0x2179},
+ {0x2189, 0x2189},
+ {0x2190, 0x2199},
+ {0x21b8, 0x21b9},
+ {0x21d2, 0x21d2},
+ {0x21d4, 0x21d4},
+ {0x21e7, 0x21e7},
+ {0x2200, 0x2200},
+ {0x2202, 0x2203},
+ {0x2207, 0x2208},
+ {0x220b, 0x220b},
+ {0x220f, 0x220f},
+ {0x2211, 0x2211},
+ {0x2215, 0x2215},
+ {0x221a, 0x221a},
+ {0x221d, 0x2220},
+ {0x2223, 0x2223},
+ {0x2225, 0x2225},
+ {0x2227, 0x222c},
+ {0x222e, 0x222e},
+ {0x2234, 0x2237},
+ {0x223c, 0x223d},
+ {0x2248, 0x2248},
+ {0x224c, 0x224c},
+ {0x2252, 0x2252},
+ {0x2260, 0x2261},
+ {0x2264, 0x2267},
+ {0x226a, 0x226b},
+ {0x226e, 0x226f},
+ {0x2282, 0x2283},
+ {0x2286, 0x2287},
+ {0x2295, 0x2295},
+ {0x2299, 0x2299},
+ {0x22a5, 0x22a5},
+ {0x22bf, 0x22bf},
+ {0x2312, 0x2312},
+ {0x2460, 0x24e9},
+ {0x24eb, 0x254b},
+ {0x2550, 0x2573},
+ {0x2580, 0x258f},
+ {0x2592, 0x2595},
+ {0x25a0, 0x25a1},
+ {0x25a3, 0x25a9},
+ {0x25b2, 0x25b3},
+ {0x25b6, 0x25b7},
+ {0x25bc, 0x25bd},
+ {0x25c0, 0x25c1},
+ {0x25c6, 0x25c8},
+ {0x25cb, 0x25cb},
+ {0x25ce, 0x25d1},
+ {0x25e2, 0x25e5},
+ {0x25ef, 0x25ef},
+ {0x2605, 0x2606},
+ {0x2609, 0x2609},
+ {0x260e, 0x260f},
+ {0x261c, 0x261c},
+ {0x261e, 0x261e},
+ {0x2640, 0x2640},
+ {0x2642, 0x2642},
+ {0x2660, 0x2661},
+ {0x2663, 0x2665},
+ {0x2667, 0x266a},
+ {0x266c, 0x266d},
+ {0x266f, 0x266f},
+ {0x269e, 0x269f},
+ {0x26bf, 0x26bf},
+ {0x26c6, 0x26cd},
+ {0x26cf, 0x26d3},
+ {0x26d5, 0x26e1},
+ {0x26e3, 0x26e3},
+ {0x26e8, 0x26e9},
+ {0x26eb, 0x26f1},
+ {0x26f4, 0x26f4},
+ {0x26f6, 0x26f9},
+ {0x26fb, 0x26fc},
+ {0x26fe, 0x26ff},
+ {0x273d, 0x273d},
+ {0x2776, 0x277f},
+ {0x2b56, 0x2b59},
+ {0x3248, 0x324f},
+ {0xe000, 0xf8ff},
+ {0xfe00, 0xfe0f},
+ {0xfffd, 0xfffd},
+ {0x1f100, 0x1f10a},
+ {0x1f110, 0x1f12d},
+ {0x1f130, 0x1f169},
+ {0x1f170, 0x1f18d},
+ {0x1f18f, 0x1f190},
+ {0x1f19b, 0x1f1ac},
+ {0xe0100, 0xe01ef},
+ {0xf0000, 0xffffd},
+ {0x100000, 0x10fffd},
+};
+
+static const struct wcwidth9_interval wcwidth9_emoji_width[] = {
+ {0x1f1e6, 0x1f1ff},
+ {0x1f321, 0x1f321},
+ {0x1f324, 0x1f32c},
+ {0x1f336, 0x1f336},
+ {0x1f37d, 0x1f37d},
+ {0x1f396, 0x1f397},
+ {0x1f399, 0x1f39b},
+ {0x1f39e, 0x1f39f},
+ {0x1f3cb, 0x1f3ce},
+ {0x1f3d4, 0x1f3df},
+ {0x1f3f3, 0x1f3f5},
+ {0x1f3f7, 0x1f3f7},
+ {0x1f43f, 0x1f43f},
+ {0x1f441, 0x1f441},
+ {0x1f4fd, 0x1f4fd},
+ {0x1f549, 0x1f54a},
+ {0x1f56f, 0x1f570},
+ {0x1f573, 0x1f579},
+ {0x1f587, 0x1f587},
+ {0x1f58a, 0x1f58d},
+ {0x1f590, 0x1f590},
+ {0x1f5a5, 0x1f5a5},
+ {0x1f5a8, 0x1f5a8},
+ {0x1f5b1, 0x1f5b2},
+ {0x1f5bc, 0x1f5bc},
+ {0x1f5c2, 0x1f5c4},
+ {0x1f5d1, 0x1f5d3},
+ {0x1f5dc, 0x1f5de},
+ {0x1f5e1, 0x1f5e1},
+ {0x1f5e3, 0x1f5e3},
+ {0x1f5e8, 0x1f5e8},
+ {0x1f5ef, 0x1f5ef},
+ {0x1f5f3, 0x1f5f3},
+ {0x1f5fa, 0x1f5fa},
+ {0x1f6cb, 0x1f6cf},
+ {0x1f6e0, 0x1f6e5},
+ {0x1f6e9, 0x1f6e9},
+ {0x1f6f0, 0x1f6f0},
+ {0x1f6f3, 0x1f6f3},
+};
+
+static const struct wcwidth9_interval wcwidth9_not_assigned[] = {
+ {0x0378, 0x0379},
+ {0x0380, 0x0383},
+ {0x038b, 0x038b},
+ {0x038d, 0x038d},
+ {0x03a2, 0x03a2},
+ {0x0530, 0x0530},
+ {0x0557, 0x0558},
+ {0x0560, 0x0560},
+ {0x0588, 0x0588},
+ {0x058b, 0x058c},
+ {0x0590, 0x0590},
+ {0x05c8, 0x05cf},
+ {0x05eb, 0x05ef},
+ {0x05f5, 0x05ff},
+ {0x061d, 0x061d},
+ {0x070e, 0x070e},
+ {0x074b, 0x074c},
+ {0x07b2, 0x07bf},
+ {0x07fb, 0x07ff},
+ {0x082e, 0x082f},
+ {0x083f, 0x083f},
+ {0x085c, 0x085d},
+ {0x085f, 0x089f},
+ {0x08b5, 0x08b5},
+ {0x08be, 0x08d3},
+ {0x0984, 0x0984},
+ {0x098d, 0x098e},
+ {0x0991, 0x0992},
+ {0x09a9, 0x09a9},
+ {0x09b1, 0x09b1},
+ {0x09b3, 0x09b5},
+ {0x09ba, 0x09bb},
+ {0x09c5, 0x09c6},
+ {0x09c9, 0x09ca},
+ {0x09cf, 0x09d6},
+ {0x09d8, 0x09db},
+ {0x09de, 0x09de},
+ {0x09e4, 0x09e5},
+ {0x09fc, 0x0a00},
+ {0x0a04, 0x0a04},
+ {0x0a0b, 0x0a0e},
+ {0x0a11, 0x0a12},
+ {0x0a29, 0x0a29},
+ {0x0a31, 0x0a31},
+ {0x0a34, 0x0a34},
+ {0x0a37, 0x0a37},
+ {0x0a3a, 0x0a3b},
+ {0x0a3d, 0x0a3d},
+ {0x0a43, 0x0a46},
+ {0x0a49, 0x0a4a},
+ {0x0a4e, 0x0a50},
+ {0x0a52, 0x0a58},
+ {0x0a5d, 0x0a5d},
+ {0x0a5f, 0x0a65},
+ {0x0a76, 0x0a80},
+ {0x0a84, 0x0a84},
+ {0x0a8e, 0x0a8e},
+ {0x0a92, 0x0a92},
+ {0x0aa9, 0x0aa9},
+ {0x0ab1, 0x0ab1},
+ {0x0ab4, 0x0ab4},
+ {0x0aba, 0x0abb},
+ {0x0ac6, 0x0ac6},
+ {0x0aca, 0x0aca},
+ {0x0ace, 0x0acf},
+ {0x0ad1, 0x0adf},
+ {0x0ae4, 0x0ae5},
+ {0x0af2, 0x0af8},
+ {0x0afa, 0x0b00},
+ {0x0b04, 0x0b04},
+ {0x0b0d, 0x0b0e},
+ {0x0b11, 0x0b12},
+ {0x0b29, 0x0b29},
+ {0x0b31, 0x0b31},
+ {0x0b34, 0x0b34},
+ {0x0b3a, 0x0b3b},
+ {0x0b45, 0x0b46},
+ {0x0b49, 0x0b4a},
+ {0x0b4e, 0x0b55},
+ {0x0b58, 0x0b5b},
+ {0x0b5e, 0x0b5e},
+ {0x0b64, 0x0b65},
+ {0x0b78, 0x0b81},
+ {0x0b84, 0x0b84},
+ {0x0b8b, 0x0b8d},
+ {0x0b91, 0x0b91},
+ {0x0b96, 0x0b98},
+ {0x0b9b, 0x0b9b},
+ {0x0b9d, 0x0b9d},
+ {0x0ba0, 0x0ba2},
+ {0x0ba5, 0x0ba7},
+ {0x0bab, 0x0bad},
+ {0x0bba, 0x0bbd},
+ {0x0bc3, 0x0bc5},
+ {0x0bc9, 0x0bc9},
+ {0x0bce, 0x0bcf},
+ {0x0bd1, 0x0bd6},
+ {0x0bd8, 0x0be5},
+ {0x0bfb, 0x0bff},
+ {0x0c04, 0x0c04},
+ {0x0c0d, 0x0c0d},
+ {0x0c11, 0x0c11},
+ {0x0c29, 0x0c29},
+ {0x0c3a, 0x0c3c},
+ {0x0c45, 0x0c45},
+ {0x0c49, 0x0c49},
+ {0x0c4e, 0x0c54},
+ {0x0c57, 0x0c57},
+ {0x0c5b, 0x0c5f},
+ {0x0c64, 0x0c65},
+ {0x0c70, 0x0c77},
+ {0x0c84, 0x0c84},
+ {0x0c8d, 0x0c8d},
+ {0x0c91, 0x0c91},
+ {0x0ca9, 0x0ca9},
+ {0x0cb4, 0x0cb4},
+ {0x0cba, 0x0cbb},
+ {0x0cc5, 0x0cc5},
+ {0x0cc9, 0x0cc9},
+ {0x0cce, 0x0cd4},
+ {0x0cd7, 0x0cdd},
+ {0x0cdf, 0x0cdf},
+ {0x0ce4, 0x0ce5},
+ {0x0cf0, 0x0cf0},
+ {0x0cf3, 0x0d00},
+ {0x0d04, 0x0d04},
+ {0x0d0d, 0x0d0d},
+ {0x0d11, 0x0d11},
+ {0x0d3b, 0x0d3c},
+ {0x0d45, 0x0d45},
+ {0x0d49, 0x0d49},
+ {0x0d50, 0x0d53},
+ {0x0d64, 0x0d65},
+ {0x0d80, 0x0d81},
+ {0x0d84, 0x0d84},
+ {0x0d97, 0x0d99},
+ {0x0db2, 0x0db2},
+ {0x0dbc, 0x0dbc},
+ {0x0dbe, 0x0dbf},
+ {0x0dc7, 0x0dc9},
+ {0x0dcb, 0x0dce},
+ {0x0dd5, 0x0dd5},
+ {0x0dd7, 0x0dd7},
+ {0x0de0, 0x0de5},
+ {0x0df0, 0x0df1},
+ {0x0df5, 0x0e00},
+ {0x0e3b, 0x0e3e},
+ {0x0e5c, 0x0e80},
+ {0x0e83, 0x0e83},
+ {0x0e85, 0x0e86},
+ {0x0e89, 0x0e89},
+ {0x0e8b, 0x0e8c},
+ {0x0e8e, 0x0e93},
+ {0x0e98, 0x0e98},
+ {0x0ea0, 0x0ea0},
+ {0x0ea4, 0x0ea4},
+ {0x0ea6, 0x0ea6},
+ {0x0ea8, 0x0ea9},
+ {0x0eac, 0x0eac},
+ {0x0eba, 0x0eba},
+ {0x0ebe, 0x0ebf},
+ {0x0ec5, 0x0ec5},
+ {0x0ec7, 0x0ec7},
+ {0x0ece, 0x0ecf},
+ {0x0eda, 0x0edb},
+ {0x0ee0, 0x0eff},
+ {0x0f48, 0x0f48},
+ {0x0f6d, 0x0f70},
+ {0x0f98, 0x0f98},
+ {0x0fbd, 0x0fbd},
+ {0x0fcd, 0x0fcd},
+ {0x0fdb, 0x0fff},
+ {0x10c6, 0x10c6},
+ {0x10c8, 0x10cc},
+ {0x10ce, 0x10cf},
+ {0x1249, 0x1249},
+ {0x124e, 0x124f},
+ {0x1257, 0x1257},
+ {0x1259, 0x1259},
+ {0x125e, 0x125f},
+ {0x1289, 0x1289},
+ {0x128e, 0x128f},
+ {0x12b1, 0x12b1},
+ {0x12b6, 0x12b7},
+ {0x12bf, 0x12bf},
+ {0x12c1, 0x12c1},
+ {0x12c6, 0x12c7},
+ {0x12d7, 0x12d7},
+ {0x1311, 0x1311},
+ {0x1316, 0x1317},
+ {0x135b, 0x135c},
+ {0x137d, 0x137f},
+ {0x139a, 0x139f},
+ {0x13f6, 0x13f7},
+ {0x13fe, 0x13ff},
+ {0x169d, 0x169f},
+ {0x16f9, 0x16ff},
+ {0x170d, 0x170d},
+ {0x1715, 0x171f},
+ {0x1737, 0x173f},
+ {0x1754, 0x175f},
+ {0x176d, 0x176d},
+ {0x1771, 0x1771},
+ {0x1774, 0x177f},
+ {0x17de, 0x17df},
+ {0x17ea, 0x17ef},
+ {0x17fa, 0x17ff},
+ {0x180f, 0x180f},
+ {0x181a, 0x181f},
+ {0x1878, 0x187f},
+ {0x18ab, 0x18af},
+ {0x18f6, 0x18ff},
+ {0x191f, 0x191f},
+ {0x192c, 0x192f},
+ {0x193c, 0x193f},
+ {0x1941, 0x1943},
+ {0x196e, 0x196f},
+ {0x1975, 0x197f},
+ {0x19ac, 0x19af},
+ {0x19ca, 0x19cf},
+ {0x19db, 0x19dd},
+ {0x1a1c, 0x1a1d},
+ {0x1a5f, 0x1a5f},
+ {0x1a7d, 0x1a7e},
+ {0x1a8a, 0x1a8f},
+ {0x1a9a, 0x1a9f},
+ {0x1aae, 0x1aaf},
+ {0x1abf, 0x1aff},
+ {0x1b4c, 0x1b4f},
+ {0x1b7d, 0x1b7f},
+ {0x1bf4, 0x1bfb},
+ {0x1c38, 0x1c3a},
+ {0x1c4a, 0x1c4c},
+ {0x1c89, 0x1cbf},
+ {0x1cc8, 0x1ccf},
+ {0x1cf7, 0x1cf7},
+ {0x1cfa, 0x1cff},
+ {0x1df6, 0x1dfa},
+ {0x1f16, 0x1f17},
+ {0x1f1e, 0x1f1f},
+ {0x1f46, 0x1f47},
+ {0x1f4e, 0x1f4f},
+ {0x1f58, 0x1f58},
+ {0x1f5a, 0x1f5a},
+ {0x1f5c, 0x1f5c},
+ {0x1f5e, 0x1f5e},
+ {0x1f7e, 0x1f7f},
+ {0x1fb5, 0x1fb5},
+ {0x1fc5, 0x1fc5},
+ {0x1fd4, 0x1fd5},
+ {0x1fdc, 0x1fdc},
+ {0x1ff0, 0x1ff1},
+ {0x1ff5, 0x1ff5},
+ {0x1fff, 0x1fff},
+ {0x2065, 0x2065},
+ {0x2072, 0x2073},
+ {0x208f, 0x208f},
+ {0x209d, 0x209f},
+ {0x20bf, 0x20cf},
+ {0x20f1, 0x20ff},
+ {0x218c, 0x218f},
+ {0x23ff, 0x23ff},
+ {0x2427, 0x243f},
+ {0x244b, 0x245f},
+ {0x2b74, 0x2b75},
+ {0x2b96, 0x2b97},
+ {0x2bba, 0x2bbc},
+ {0x2bc9, 0x2bc9},
+ {0x2bd2, 0x2beb},
+ {0x2bf0, 0x2bff},
+ {0x2c2f, 0x2c2f},
+ {0x2c5f, 0x2c5f},
+ {0x2cf4, 0x2cf8},
+ {0x2d26, 0x2d26},
+ {0x2d28, 0x2d2c},
+ {0x2d2e, 0x2d2f},
+ {0x2d68, 0x2d6e},
+ {0x2d71, 0x2d7e},
+ {0x2d97, 0x2d9f},
+ {0x2da7, 0x2da7},
+ {0x2daf, 0x2daf},
+ {0x2db7, 0x2db7},
+ {0x2dbf, 0x2dbf},
+ {0x2dc7, 0x2dc7},
+ {0x2dcf, 0x2dcf},
+ {0x2dd7, 0x2dd7},
+ {0x2ddf, 0x2ddf},
+ {0x2e45, 0x2e7f},
+ {0x2e9a, 0x2e9a},
+ {0x2ef4, 0x2eff},
+ {0x2fd6, 0x2fef},
+ {0x2ffc, 0x2fff},
+ {0x3040, 0x3040},
+ {0x3097, 0x3098},
+ {0x3100, 0x3104},
+ {0x312e, 0x3130},
+ {0x318f, 0x318f},
+ {0x31bb, 0x31bf},
+ {0x31e4, 0x31ef},
+ {0x321f, 0x321f},
+ {0x32ff, 0x32ff},
+ {0x4db6, 0x4dbf},
+ {0x9fd6, 0x9fff},
+ {0xa48d, 0xa48f},
+ {0xa4c7, 0xa4cf},
+ {0xa62c, 0xa63f},
+ {0xa6f8, 0xa6ff},
+ {0xa7af, 0xa7af},
+ {0xa7b8, 0xa7f6},
+ {0xa82c, 0xa82f},
+ {0xa83a, 0xa83f},
+ {0xa878, 0xa87f},
+ {0xa8c6, 0xa8cd},
+ {0xa8da, 0xa8df},
+ {0xa8fe, 0xa8ff},
+ {0xa954, 0xa95e},
+ {0xa97d, 0xa97f},
+ {0xa9ce, 0xa9ce},
+ {0xa9da, 0xa9dd},
+ {0xa9ff, 0xa9ff},
+ {0xaa37, 0xaa3f},
+ {0xaa4e, 0xaa4f},
+ {0xaa5a, 0xaa5b},
+ {0xaac3, 0xaada},
+ {0xaaf7, 0xab00},
+ {0xab07, 0xab08},
+ {0xab0f, 0xab10},
+ {0xab17, 0xab1f},
+ {0xab27, 0xab27},
+ {0xab2f, 0xab2f},
+ {0xab66, 0xab6f},
+ {0xabee, 0xabef},
+ {0xabfa, 0xabff},
+ {0xd7a4, 0xd7af},
+ {0xd7c7, 0xd7ca},
+ {0xd7fc, 0xd7ff},
+ {0xfa6e, 0xfa6f},
+ {0xfada, 0xfaff},
+ {0xfb07, 0xfb12},
+ {0xfb18, 0xfb1c},
+ {0xfb37, 0xfb37},
+ {0xfb3d, 0xfb3d},
+ {0xfb3f, 0xfb3f},
+ {0xfb42, 0xfb42},
+ {0xfb45, 0xfb45},
+ {0xfbc2, 0xfbd2},
+ {0xfd40, 0xfd4f},
+ {0xfd90, 0xfd91},
+ {0xfdc8, 0xfdef},
+ {0xfdfe, 0xfdff},
+ {0xfe1a, 0xfe1f},
+ {0xfe53, 0xfe53},
+ {0xfe67, 0xfe67},
+ {0xfe6c, 0xfe6f},
+ {0xfe75, 0xfe75},
+ {0xfefd, 0xfefe},
+ {0xff00, 0xff00},
+ {0xffbf, 0xffc1},
+ {0xffc8, 0xffc9},
+ {0xffd0, 0xffd1},
+ {0xffd8, 0xffd9},
+ {0xffdd, 0xffdf},
+ {0xffe7, 0xffe7},
+ {0xffef, 0xfff8},
+ {0xfffe, 0xffff},
+ {0x1000c, 0x1000c},
+ {0x10027, 0x10027},
+ {0x1003b, 0x1003b},
+ {0x1003e, 0x1003e},
+ {0x1004e, 0x1004f},
+ {0x1005e, 0x1007f},
+ {0x100fb, 0x100ff},
+ {0x10103, 0x10106},
+ {0x10134, 0x10136},
+ {0x1018f, 0x1018f},
+ {0x1019c, 0x1019f},
+ {0x101a1, 0x101cf},
+ {0x101fe, 0x1027f},
+ {0x1029d, 0x1029f},
+ {0x102d1, 0x102df},
+ {0x102fc, 0x102ff},
+ {0x10324, 0x1032f},
+ {0x1034b, 0x1034f},
+ {0x1037b, 0x1037f},
+ {0x1039e, 0x1039e},
+ {0x103c4, 0x103c7},
+ {0x103d6, 0x103ff},
+ {0x1049e, 0x1049f},
+ {0x104aa, 0x104af},
+ {0x104d4, 0x104d7},
+ {0x104fc, 0x104ff},
+ {0x10528, 0x1052f},
+ {0x10564, 0x1056e},
+ {0x10570, 0x105ff},
+ {0x10737, 0x1073f},
+ {0x10756, 0x1075f},
+ {0x10768, 0x107ff},
+ {0x10806, 0x10807},
+ {0x10809, 0x10809},
+ {0x10836, 0x10836},
+ {0x10839, 0x1083b},
+ {0x1083d, 0x1083e},
+ {0x10856, 0x10856},
+ {0x1089f, 0x108a6},
+ {0x108b0, 0x108df},
+ {0x108f3, 0x108f3},
+ {0x108f6, 0x108fa},
+ {0x1091c, 0x1091e},
+ {0x1093a, 0x1093e},
+ {0x10940, 0x1097f},
+ {0x109b8, 0x109bb},
+ {0x109d0, 0x109d1},
+ {0x10a04, 0x10a04},
+ {0x10a07, 0x10a0b},
+ {0x10a14, 0x10a14},
+ {0x10a18, 0x10a18},
+ {0x10a34, 0x10a37},
+ {0x10a3b, 0x10a3e},
+ {0x10a48, 0x10a4f},
+ {0x10a59, 0x10a5f},
+ {0x10aa0, 0x10abf},
+ {0x10ae7, 0x10aea},
+ {0x10af7, 0x10aff},
+ {0x10b36, 0x10b38},
+ {0x10b56, 0x10b57},
+ {0x10b73, 0x10b77},
+ {0x10b92, 0x10b98},
+ {0x10b9d, 0x10ba8},
+ {0x10bb0, 0x10bff},
+ {0x10c49, 0x10c7f},
+ {0x10cb3, 0x10cbf},
+ {0x10cf3, 0x10cf9},
+ {0x10d00, 0x10e5f},
+ {0x10e7f, 0x10fff},
+ {0x1104e, 0x11051},
+ {0x11070, 0x1107e},
+ {0x110c2, 0x110cf},
+ {0x110e9, 0x110ef},
+ {0x110fa, 0x110ff},
+ {0x11135, 0x11135},
+ {0x11144, 0x1114f},
+ {0x11177, 0x1117f},
+ {0x111ce, 0x111cf},
+ {0x111e0, 0x111e0},
+ {0x111f5, 0x111ff},
+ {0x11212, 0x11212},
+ {0x1123f, 0x1127f},
+ {0x11287, 0x11287},
+ {0x11289, 0x11289},
+ {0x1128e, 0x1128e},
+ {0x1129e, 0x1129e},
+ {0x112aa, 0x112af},
+ {0x112eb, 0x112ef},
+ {0x112fa, 0x112ff},
+ {0x11304, 0x11304},
+ {0x1130d, 0x1130e},
+ {0x11311, 0x11312},
+ {0x11329, 0x11329},
+ {0x11331, 0x11331},
+ {0x11334, 0x11334},
+ {0x1133a, 0x1133b},
+ {0x11345, 0x11346},
+ {0x11349, 0x1134a},
+ {0x1134e, 0x1134f},
+ {0x11351, 0x11356},
+ {0x11358, 0x1135c},
+ {0x11364, 0x11365},
+ {0x1136d, 0x1136f},
+ {0x11375, 0x113ff},
+ {0x1145a, 0x1145a},
+ {0x1145c, 0x1145c},
+ {0x1145e, 0x1147f},
+ {0x114c8, 0x114cf},
+ {0x114da, 0x1157f},
+ {0x115b6, 0x115b7},
+ {0x115de, 0x115ff},
+ {0x11645, 0x1164f},
+ {0x1165a, 0x1165f},
+ {0x1166d, 0x1167f},
+ {0x116b8, 0x116bf},
+ {0x116ca, 0x116ff},
+ {0x1171a, 0x1171c},
+ {0x1172c, 0x1172f},
+ {0x11740, 0x1189f},
+ {0x118f3, 0x118fe},
+ {0x11900, 0x11abf},
+ {0x11af9, 0x11bff},
+ {0x11c09, 0x11c09},
+ {0x11c37, 0x11c37},
+ {0x11c46, 0x11c4f},
+ {0x11c6d, 0x11c6f},
+ {0x11c90, 0x11c91},
+ {0x11ca8, 0x11ca8},
+ {0x11cb7, 0x11fff},
+ {0x1239a, 0x123ff},
+ {0x1246f, 0x1246f},
+ {0x12475, 0x1247f},
+ {0x12544, 0x12fff},
+ {0x1342f, 0x143ff},
+ {0x14647, 0x167ff},
+ {0x16a39, 0x16a3f},
+ {0x16a5f, 0x16a5f},
+ {0x16a6a, 0x16a6d},
+ {0x16a70, 0x16acf},
+ {0x16aee, 0x16aef},
+ {0x16af6, 0x16aff},
+ {0x16b46, 0x16b4f},
+ {0x16b5a, 0x16b5a},
+ {0x16b62, 0x16b62},
+ {0x16b78, 0x16b7c},
+ {0x16b90, 0x16eff},
+ {0x16f45, 0x16f4f},
+ {0x16f7f, 0x16f8e},
+ {0x16fa0, 0x16fdf},
+ {0x16fe1, 0x16fff},
+ {0x187ed, 0x187ff},
+ {0x18af3, 0x1afff},
+ {0x1b002, 0x1bbff},
+ {0x1bc6b, 0x1bc6f},
+ {0x1bc7d, 0x1bc7f},
+ {0x1bc89, 0x1bc8f},
+ {0x1bc9a, 0x1bc9b},
+ {0x1bca4, 0x1cfff},
+ {0x1d0f6, 0x1d0ff},
+ {0x1d127, 0x1d128},
+ {0x1d1e9, 0x1d1ff},
+ {0x1d246, 0x1d2ff},
+ {0x1d357, 0x1d35f},
+ {0x1d372, 0x1d3ff},
+ {0x1d455, 0x1d455},
+ {0x1d49d, 0x1d49d},
+ {0x1d4a0, 0x1d4a1},
+ {0x1d4a3, 0x1d4a4},
+ {0x1d4a7, 0x1d4a8},
+ {0x1d4ad, 0x1d4ad},
+ {0x1d4ba, 0x1d4ba},
+ {0x1d4bc, 0x1d4bc},
+ {0x1d4c4, 0x1d4c4},
+ {0x1d506, 0x1d506},
+ {0x1d50b, 0x1d50c},
+ {0x1d515, 0x1d515},
+ {0x1d51d, 0x1d51d},
+ {0x1d53a, 0x1d53a},
+ {0x1d53f, 0x1d53f},
+ {0x1d545, 0x1d545},
+ {0x1d547, 0x1d549},
+ {0x1d551, 0x1d551},
+ {0x1d6a6, 0x1d6a7},
+ {0x1d7cc, 0x1d7cd},
+ {0x1da8c, 0x1da9a},
+ {0x1daa0, 0x1daa0},
+ {0x1dab0, 0x1dfff},
+ {0x1e007, 0x1e007},
+ {0x1e019, 0x1e01a},
+ {0x1e022, 0x1e022},
+ {0x1e025, 0x1e025},
+ {0x1e02b, 0x1e7ff},
+ {0x1e8c5, 0x1e8c6},
+ {0x1e8d7, 0x1e8ff},
+ {0x1e94b, 0x1e94f},
+ {0x1e95a, 0x1e95d},
+ {0x1e960, 0x1edff},
+ {0x1ee04, 0x1ee04},
+ {0x1ee20, 0x1ee20},
+ {0x1ee23, 0x1ee23},
+ {0x1ee25, 0x1ee26},
+ {0x1ee28, 0x1ee28},
+ {0x1ee33, 0x1ee33},
+ {0x1ee38, 0x1ee38},
+ {0x1ee3a, 0x1ee3a},
+ {0x1ee3c, 0x1ee41},
+ {0x1ee43, 0x1ee46},
+ {0x1ee48, 0x1ee48},
+ {0x1ee4a, 0x1ee4a},
+ {0x1ee4c, 0x1ee4c},
+ {0x1ee50, 0x1ee50},
+ {0x1ee53, 0x1ee53},
+ {0x1ee55, 0x1ee56},
+ {0x1ee58, 0x1ee58},
+ {0x1ee5a, 0x1ee5a},
+ {0x1ee5c, 0x1ee5c},
+ {0x1ee5e, 0x1ee5e},
+ {0x1ee60, 0x1ee60},
+ {0x1ee63, 0x1ee63},
+ {0x1ee65, 0x1ee66},
+ {0x1ee6b, 0x1ee6b},
+ {0x1ee73, 0x1ee73},
+ {0x1ee78, 0x1ee78},
+ {0x1ee7d, 0x1ee7d},
+ {0x1ee7f, 0x1ee7f},
+ {0x1ee8a, 0x1ee8a},
+ {0x1ee9c, 0x1eea0},
+ {0x1eea4, 0x1eea4},
+ {0x1eeaa, 0x1eeaa},
+ {0x1eebc, 0x1eeef},
+ {0x1eef2, 0x1efff},
+ {0x1f02c, 0x1f02f},
+ {0x1f094, 0x1f09f},
+ {0x1f0af, 0x1f0b0},
+ {0x1f0c0, 0x1f0c0},
+ {0x1f0d0, 0x1f0d0},
+ {0x1f0f6, 0x1f0ff},
+ {0x1f10d, 0x1f10f},
+ {0x1f12f, 0x1f12f},
+ {0x1f16c, 0x1f16f},
+ {0x1f1ad, 0x1f1e5},
+ {0x1f203, 0x1f20f},
+ {0x1f23c, 0x1f23f},
+ {0x1f249, 0x1f24f},
+ {0x1f252, 0x1f2ff},
+ {0x1f6d3, 0x1f6df},
+ {0x1f6ed, 0x1f6ef},
+ {0x1f6f7, 0x1f6ff},
+ {0x1f774, 0x1f77f},
+ {0x1f7d5, 0x1f7ff},
+ {0x1f80c, 0x1f80f},
+ {0x1f848, 0x1f84f},
+ {0x1f85a, 0x1f85f},
+ {0x1f888, 0x1f88f},
+ {0x1f8ae, 0x1f90f},
+ {0x1f91f, 0x1f91f},
+ {0x1f928, 0x1f92f},
+ {0x1f931, 0x1f932},
+ {0x1f93f, 0x1f93f},
+ {0x1f94c, 0x1f94f},
+ {0x1f95f, 0x1f97f},
+ {0x1f992, 0x1f9bf},
+ {0x1f9c1, 0x1ffff},
+ {0x2a6d7, 0x2a6ff},
+ {0x2b735, 0x2b73f},
+ {0x2b81e, 0x2b81f},
+ {0x2cea2, 0x2f7ff},
+ {0x2fa1e, 0xe0000},
+ {0xe0002, 0xe001f},
+ {0xe0080, 0xe00ff},
+ {0xe01f0, 0xeffff},
+ {0xffffe, 0xfffff},
+};
+
+#define WCWIDTH9_ARRAY_SIZE(arr) ((sizeof(arr)/sizeof((arr)[0])) / ((size_t)(!(sizeof(arr) % sizeof((arr)[0])))))
+
+static inline bool wcwidth9_intable(const struct wcwidth9_interval *table, size_t n_items, int c) {
+ int mid, bot, top;
+
+ if (c < table[0].first) {
+ return false;
+ }
+
+ bot = 0;
+ top = (int)(n_items - 1);
+ while (top >= bot) {
+ mid = (bot + top) / 2;
+
+ if (table[mid].last < c) {
+ bot = mid + 1;
+ } else if (table[mid].first > c) {
+ top = mid - 1;
+ } else {
+ return true;
+ }
+ }
+
+ return false;
+}
+
+static inline int wcwidth9(int c) {
+ if (c == 0) {
+ return 0;
+ }
+ if (c < 0|| c > 0x10ffff) {
+ return -1;
+ }
+
+ if (wcwidth9_intable(wcwidth9_nonprint, WCWIDTH9_ARRAY_SIZE(wcwidth9_nonprint), c)) {
+ return -1;
+ }
+
+ if (wcwidth9_intable(wcwidth9_combining, WCWIDTH9_ARRAY_SIZE(wcwidth9_combining), c)) {
+ return 0;
+ }
+
+ if (wcwidth9_intable(wcwidth9_not_assigned, WCWIDTH9_ARRAY_SIZE(wcwidth9_not_assigned), c)) {
+ return -1;
+ }
+
+ if (wcwidth9_intable(wcwidth9_private, WCWIDTH9_ARRAY_SIZE(wcwidth9_private), c)) {
+ return -3;
+ }
+
+ if (wcwidth9_intable(wcwidth9_ambiguous, WCWIDTH9_ARRAY_SIZE(wcwidth9_ambiguous), c)) {
+ return -2;
+ }
+
+ if (wcwidth9_intable(wcwidth9_doublewidth, WCWIDTH9_ARRAY_SIZE(wcwidth9_doublewidth), c)) {
+ return 2;
+ }
+
+ if (wcwidth9_intable(wcwidth9_emoji_width, WCWIDTH9_ARRAY_SIZE(wcwidth9_emoji_width), c)) {
+ return 2;
+ }
+
+ return 1;
+}
+
+#endif /* WCWIDTH9_H */
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/zsh.h b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/zsh.h
new file mode 100644
index 0000000..8e7f20b
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/zsh.h
@@ -0,0 +1,3305 @@
+/*
+ * zsh.h - standard header file
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+/* A few typical macros */
+#define minimum(a,b) ((a) < (b) ? (a) : (b))
+
+/*
+ * Our longest integer type: will be a 64 bit either if long already is,
+ * or if we found some alternative such as long long.
+ */
+#ifdef ZSH_64_BIT_TYPE
+typedef ZSH_64_BIT_TYPE zlong;
+#if defined(ZLONG_IS_LONG_LONG) && defined(LLONG_MAX)
+#define ZLONG_MAX LLONG_MAX
+#else
+#ifdef ZLONG_IS_LONG_64
+#define ZLONG_MAX LONG_MAX
+#else
+/* umm... */
+#define ZLONG_MAX ((zlong)9223372036854775807)
+#endif
+#endif
+#ifdef ZSH_64_BIT_UTYPE
+typedef ZSH_64_BIT_UTYPE zulong;
+#else
+typedef unsigned zlong zulong;
+#endif
+#else
+typedef long zlong;
+typedef unsigned long zulong;
+#define ZLONG_MAX LONG_MAX
+#endif
+
+/*
+ * Work out how to define large integer constants that will fit
+ * in a zlong.
+ */
+#if defined(ZSH_64_BIT_TYPE) || defined(LONG_IS_64_BIT)
+/* We have some 64-bit type */
+#ifdef LONG_IS_64_BIT
+/* It's long */
+#define ZLONG_CONST(x) x ## l
+#else
+/* It's long long */
+#ifdef ZLONG_IS_LONG_LONG
+#define ZLONG_CONST(x) x ## ll
+#else
+/*
+ * There's some 64-bit type, but we don't know what it is.
+ * We'll just cast it and hope the compiler does the right thing.
+ */
+#define ZLONG_CONST(x) ((zlong)x)
+#endif
+#endif
+#else
+/* We're stuck with long */
+#define ZLONG_CONST(x) (x ## l)
+#endif
+
+/*
+ * Double float support requires 64-bit alignment, so if longs and
+ * pointers are less we need to pad out.
+ */
+#ifndef LONG_IS_64_BIT
+# define PAD_64_BIT 1
+#endif
+
+/* math.c */
+typedef struct {
+ union {
+ zlong l;
+ double d;
+ } u;
+ int type;
+} mnumber;
+
+#define MN_INTEGER 1 /* mnumber is integer */
+#define MN_FLOAT 2 /* mnumber is floating point */
+#define MN_UNSET 4 /* mnumber not yet retrieved */
+
+typedef struct mathfunc *MathFunc;
+typedef mnumber (*NumMathFunc)(char *, int, mnumber *, int);
+typedef mnumber (*StrMathFunc)(char *, char *, int);
+
+struct mathfunc {
+ MathFunc next;
+ char *name;
+ int flags; /* MFF_* flags defined below */
+ NumMathFunc nfunc;
+ StrMathFunc sfunc;
+ char *module;
+ int minargs;
+ int maxargs;
+ int funcid;
+};
+
+/* Math function takes a string argument */
+#define MFF_STR 1
+/* Math function has been loaded from library */
+#define MFF_ADDED 2
+/* Math function is implemented by a shell function */
+#define MFF_USERFUNC 4
+/* When autoloading, enable all features in module */
+#define MFF_AUTOALL 8
+
+
+#define NUMMATHFUNC(name, func, min, max, id) \
+ { NULL, name, 0, func, NULL, NULL, min, max, id }
+#define STRMATHFUNC(name, func, id) \
+ { NULL, name, MFF_STR, NULL, func, NULL, 0, 0, id }
+
+/* Character tokens are sometimes casted to (unsigned char)'s. *
+ * Unfortunately, some compilers don't correctly cast signed to *
+ * unsigned promotions; i.e. (int)(unsigned char)((char) -1) evaluates *
+ * to -1, instead of 255 like it should. We circumvent the troubles *
+ * of such shameful delinquency by casting to a larger unsigned type *
+ * then back down to unsigned char. */
+
+#ifdef BROKEN_SIGNED_TO_UNSIGNED_CASTING
+# define STOUC(X) ((unsigned char)(unsigned short)(X))
+#else
+# define STOUC(X) ((unsigned char)(X))
+#endif
+
+/* Meta together with the character following Meta denotes the character *
+ * which is the exclusive or of 32 and the character following Meta. *
+ * This is used to represent characters which otherwise has special *
+ * meaning for zsh. These are the characters for which the imeta() test *
+ * is true: the null character, and the characters from Meta to Marker. */
+
+#define Meta ((char) 0x83)
+
+/* Note that the fourth character in DEFAULT_IFS is Meta *
+ * followed by a space which denotes the null character. */
+
+#define DEFAULT_IFS " \t\n\203 "
+
+/* As specified in the standard (POSIX 2008) */
+
+#define DEFAULT_IFS_SH " \t\n"
+
+/*
+ * Character tokens.
+ * These should match the characters in ztokens, defined in lex.c
+ */
+#define Pound ((char) 0x84)
+#define String ((char) 0x85)
+#define Hat ((char) 0x86)
+#define Star ((char) 0x87)
+#define Inpar ((char) 0x88)
+#define Inparmath ((char) 0x89)
+#define Outpar ((char) 0x8a)
+#define Outparmath ((char) 0x8b)
+#define Qstring ((char) 0x8c)
+#define Equals ((char) 0x8d)
+#define Bar ((char) 0x8e)
+#define Inbrace ((char) 0x8f)
+#define Outbrace ((char) 0x90)
+#define Inbrack ((char) 0x91)
+#define Outbrack ((char) 0x92)
+#define Tick ((char) 0x93)
+#define Inang ((char) 0x94)
+#define Outang ((char) 0x95)
+#define OutangProc ((char) 0x96)
+#define Quest ((char) 0x97)
+#define Tilde ((char) 0x98)
+#define Qtick ((char) 0x99)
+#define Comma ((char) 0x9a)
+#define Dash ((char) 0x9b) /* Only in patterns */
+#define Bang ((char) 0x9c) /* Only in patterns */
+/*
+ * Marks the last of the group above.
+ * Remaining tokens are even more special.
+ */
+#define LAST_NORMAL_TOK Bang
+/*
+ * Null arguments: placeholders for single and double quotes
+ * and backslashes.
+ */
+#define Snull ((char) 0x9d)
+#define Dnull ((char) 0x9e)
+#define Bnull ((char) 0x9f)
+/*
+ * Backslash which will be returned to "\" instead of being stripped
+ * when we turn the string into a printable format.
+ */
+#define Bnullkeep ((char) 0xa0)
+/*
+ * Null argument that does not correspond to any character.
+ * This should be last as it does not appear in ztokens and
+ * is used to initialise the IMETA type in inittyptab().
+ */
+#define Nularg ((char) 0xa1)
+
+/*
+ * Take care to update the use of IMETA appropriately when adding
+ * tokens here.
+ */
+/*
+ * Marker is used in the following special circumstances:
+ * - In paramsubst for rc_expand_param.
+ * - In pattern character arrays as guaranteed not to mark a character in
+ * a string.
+ * - In assignments with the ASSPM_KEY_VALUE flag set in order to
+ * mark that there is a key / value pair following. If this
+ * comes from [key]=value the Marker is followed by a null;
+ * if from [key]+=value the Marker is followed by a '+' then a null.
+ * All the above are local uses --- any case where the Marker has
+ * escaped beyond the context in question is an error.
+ */
+#define Marker ((char) 0xa2)
+
+/* chars that need to be quoted if meant literally */
+
+#define SPECCHARS "#$^*()=|{}[]`<>?~;&\n\t \\\'\""
+
+/* chars that need to be quoted for pattern matching */
+
+#define PATCHARS "#^*()|[]<>?~\\"
+
+/*
+ * Check for a possibly tokenized dash.
+ *
+ * A dash only needs to be a token in a character range, [a-z], but
+ * it's difficult in general to ensure that. So it's turned into
+ * a token at the usual point in the lexer. However, we need
+ * to check for a literal dash at many points.
+ */
+#define IS_DASH(x) ((x) == '-' || (x) == Dash)
+
+/*
+ * Types of quote. This is used in various places, so care needs
+ * to be taken when changing them. (Oooh, don't you look surprised.)
+ * - Passed to quotestring() to indicate style. This is the ultimate
+ * destiny of most of the other uses of members of the enum.
+ * - In paramsubst(), to count q's in parameter substitution.
+ * - In the completion code, where we maintain a stack of quotation types.
+ */
+enum {
+ /*
+ * No quote. Not a valid quote, but useful in the substitution
+ * and completion code to indicate we're not doing any quoting.
+ */
+ QT_NONE,
+ /* Backslash: \ */
+ QT_BACKSLASH,
+ /* Single quote: ' */
+ QT_SINGLE,
+ /* Double quote: " */
+ QT_DOUBLE,
+ /* Print-style quote: $' */
+ QT_DOLLARS,
+ /*
+ * Backtick: `
+ * Not understood by many parts of the code; here for a convenience
+ * in those cases where we need to represent a complete set.
+ */
+ QT_BACKTICK,
+ /*
+ * Single quotes, but the default is not to quote unless necessary.
+ * This is only useful as an argument to quotestring().
+ */
+ QT_SINGLE_OPTIONAL,
+ /*
+ * Only quote pattern characters.
+ * ${(b)foo} guarantees that ${~foo} matches the string
+ * contained in foo.
+ */
+ QT_BACKSLASH_PATTERN,
+ /*
+ * As QT_BACKSLASH, but a NULL string is shown as ''.
+ */
+ QT_BACKSLASH_SHOWNULL,
+ /*
+ * Quoting as produced by quotedzputs(), used for human
+ * readability of parameter values.
+ */
+ QT_QUOTEDZPUTS
+};
+
+#define QT_IS_SINGLE(x) ((x) == QT_SINGLE || (x) == QT_SINGLE_OPTIONAL)
+
+/*
+ * Lexical tokens: unlike the character tokens above, these never
+ * appear in strings and don't necessarily represent a single character.
+ */
+
+enum lextok {
+ NULLTOK, /* 0 */
+ SEPER,
+ NEWLIN,
+ SEMI,
+ DSEMI,
+ AMPER, /* 5 */
+ INPAR,
+ OUTPAR,
+ DBAR,
+ DAMPER,
+ OUTANG, /* 10 */
+ OUTANGBANG,
+ DOUTANG,
+ DOUTANGBANG,
+ INANG,
+ INOUTANG, /* 15 */
+ DINANG,
+ DINANGDASH,
+ INANGAMP,
+ OUTANGAMP,
+ AMPOUTANG, /* 20 */
+ OUTANGAMPBANG,
+ DOUTANGAMP,
+ DOUTANGAMPBANG,
+ TRINANG,
+ BAR, /* 25 */
+ BARAMP,
+ INOUTPAR,
+ DINPAR,
+ DOUTPAR,
+ AMPERBANG, /* 30 */
+ SEMIAMP,
+ SEMIBAR,
+ DOUTBRACK,
+ STRING,
+ ENVSTRING, /* 35 */
+ ENVARRAY,
+ ENDINPUT,
+ LEXERR,
+
+ /* Tokens for reserved words */
+ BANG, /* ! */
+ DINBRACK, /* [[ */ /* 40 */
+ INBRACE, /* { */
+ OUTBRACE, /* } */
+ CASE, /* case */
+ COPROC, /* coproc */
+ DOLOOP, /* do */ /* 45 */
+ DONE, /* done */
+ ELIF, /* elif */
+ ELSE, /* else */
+ ZEND, /* end */
+ ESAC, /* esac */ /* 50 */
+ FI, /* fi */
+ FOR, /* for */
+ FOREACH, /* foreach */
+ FUNC, /* function */
+ IF, /* if */ /* 55 */
+ NOCORRECT, /* nocorrect */
+ REPEAT, /* repeat */
+ SELECT, /* select */
+ THEN, /* then */
+ TIME, /* time */ /* 60 */
+ UNTIL, /* until */
+ WHILE, /* while */
+ TYPESET /* typeset or similar */
+};
+
+/* Redirection types. If you modify this, you may also have to modify *
+ * redirtab in parse.c and getredirs() in text.c and the IS_* macros *
+ * below. */
+
+enum {
+ REDIR_WRITE, /* > */
+ REDIR_WRITENOW, /* >| */
+ REDIR_APP, /* >> */
+ REDIR_APPNOW, /* >>| */
+ REDIR_ERRWRITE, /* &>, >& */
+ REDIR_ERRWRITENOW, /* >&| */
+ REDIR_ERRAPP, /* >>& */
+ REDIR_ERRAPPNOW, /* >>&| */
+ REDIR_READWRITE, /* <> */
+ REDIR_READ, /* < */
+ REDIR_HEREDOC, /* << */
+ REDIR_HEREDOCDASH, /* <<- */
+ REDIR_HERESTR, /* <<< */
+ REDIR_MERGEIN, /* <&n */
+ REDIR_MERGEOUT, /* >&n */
+ REDIR_CLOSE, /* >&-, <&- */
+ REDIR_INPIPE, /* < <(...) */
+ REDIR_OUTPIPE /* > >(...) */
+};
+#define REDIR_TYPE_MASK (0x1f)
+/* Redir using {var} syntax */
+#define REDIR_VARID_MASK (0x20)
+/* Mark here-string that came from a here-document */
+#define REDIR_FROM_HEREDOC_MASK (0x40)
+
+#define IS_WRITE_FILE(X) ((X)>=REDIR_WRITE && (X)<=REDIR_READWRITE)
+#define IS_APPEND_REDIR(X) (IS_WRITE_FILE(X) && ((X) & 2))
+#define IS_CLOBBER_REDIR(X) (IS_WRITE_FILE(X) && ((X) & 1))
+#define IS_ERROR_REDIR(X) ((X)>=REDIR_ERRWRITE && (X)<=REDIR_ERRAPPNOW)
+#define IS_READFD(X) (((X)>=REDIR_READWRITE && (X)<=REDIR_MERGEIN) || (X)==REDIR_INPIPE)
+#define IS_REDIROP(X) ((X)>=OUTANG && (X)<=TRINANG)
+
+/*
+ * Values for the fdtable array. They say under what circumstances
+ * the fd will be close. The fdtable is an unsigned char, so these are
+ * #define's rather than an enum.
+ */
+/* Entry not used. */
+#define FDT_UNUSED 0
+/*
+ * Entry used internally by the shell, should not be visible to other
+ * processes.
+ */
+#define FDT_INTERNAL 1
+/*
+ * Entry visible to other processes, for example created using
+ * the {varid}> file syntax.
+ */
+#define FDT_EXTERNAL 2
+/*
+ * Entry visible to other processes but controlled by a module.
+ * The difference from FDT_EXTERNAL is that closing this using
+ * standard fd syntax will fail as there is some tidying up that
+ * needs to be done by the module's own mechanism.
+ */
+#define FDT_MODULE 3
+/*
+ * Entry used by output from the XTRACE option.
+ */
+#define FDT_XTRACE 4
+/*
+ * Entry used for file locking.
+ */
+#define FDT_FLOCK 5
+/*
+ * As above, but the fd is not marked for closing on exec,
+ * so the shell can still exec the last process.
+ */
+#define FDT_FLOCK_EXEC 6
+/*
+ * Entry used by a process substition.
+ * This marker is not tested internally as we associated the file
+ * descriptor with a job for closing.
+ *
+ * This is not used unless PATH_DEV_FD is defined.
+ */
+#define FDT_PROC_SUBST 7
+/*
+ * Mask to get the basic FDT type.
+ */
+#define FDT_TYPE_MASK 15
+
+/*
+ * Bit flag that fd is saved for later restoration.
+ * Currently this is only use with FDT_INTERNAL. We use this fact so as
+ * not to have to mask checks against other types.
+ */
+#define FDT_SAVED_MASK 16
+
+/* Flags for input stack */
+#define INP_FREE (1<<0) /* current buffer can be free'd */
+#define INP_ALIAS (1<<1) /* expanding alias or history */
+#define INP_HIST (1<<2) /* expanding history */
+#define INP_CONT (1<<3) /* continue onto previously stacked input */
+#define INP_ALCONT (1<<4) /* stack is continued from alias expn. */
+#define INP_HISTCONT (1<<5) /* stack is continued from history expn. */
+#define INP_LINENO (1<<6) /* update line number */
+#define INP_APPEND (1<<7) /* Append new lines to allow backup */
+#define INP_RAW_KEEP (1<<8) /* Input needed in raw mode even if alias */
+
+/* Flags for metafy */
+#define META_REALLOC 0
+#define META_USEHEAP 1
+#define META_STATIC 2
+#define META_DUP 3
+#define META_ALLOC 4
+#define META_NOALLOC 5
+#define META_HEAPDUP 6
+#define META_HREALLOC 7
+
+/* Context to save and restore (bit fields) */
+enum {
+ /* History mechanism */
+ ZCONTEXT_HIST = (1<<0),
+ /* Lexical analyser */
+ ZCONTEXT_LEX = (1<<1),
+ /* Parser */
+ ZCONTEXT_PARSE = (1<<2)
+};
+
+/**************************/
+/* Abstract types for zsh */
+/**************************/
+
+typedef struct alias *Alias;
+typedef struct asgment *Asgment;
+typedef struct builtin *Builtin;
+typedef struct cmdnam *Cmdnam;
+typedef struct complist *Complist;
+typedef struct conddef *Conddef;
+typedef struct dirsav *Dirsav;
+typedef struct emulation_options *Emulation_options;
+typedef struct execcmd_params *Execcmd_params;
+typedef struct features *Features;
+typedef struct feature_enables *Feature_enables;
+typedef struct funcstack *Funcstack;
+typedef struct funcwrap *FuncWrap;
+typedef struct hashnode *HashNode;
+typedef struct hashtable *HashTable;
+typedef struct heap *Heap;
+typedef struct heapstack *Heapstack;
+typedef struct histent *Histent;
+typedef struct hookdef *Hookdef;
+typedef struct imatchdata *Imatchdata;
+typedef struct jobfile *Jobfile;
+typedef struct job *Job;
+typedef struct linkedmod *Linkedmod;
+typedef struct linknode *LinkNode;
+typedef union linkroot *LinkList;
+typedef struct module *Module;
+typedef struct nameddir *Nameddir;
+typedef struct options *Options;
+typedef struct optname *Optname;
+typedef struct param *Param;
+typedef struct paramdef *Paramdef;
+typedef struct patstralloc *Patstralloc;
+typedef struct patprog *Patprog;
+typedef struct prepromptfn *Prepromptfn;
+typedef struct process *Process;
+typedef struct redir *Redir;
+typedef struct reswd *Reswd;
+typedef struct shfunc *Shfunc;
+typedef struct timedfn *Timedfn;
+typedef struct value *Value;
+
+/********************************/
+/* Definitions for linked lists */
+/********************************/
+
+/* linked list abstract data type */
+
+struct linknode {
+ LinkNode next;
+ LinkNode prev;
+ void *dat;
+};
+
+struct linklist {
+ LinkNode first;
+ LinkNode last;
+ int flags;
+};
+
+union linkroot {
+ struct linklist list;
+ struct linknode node;
+};
+
+/* Macros for manipulating link lists */
+
+#define firstnode(X) ((X)->list.first)
+#define lastnode(X) ((X)->list.last)
+#define peekfirst(X) (firstnode(X)->dat)
+#define peeklast(X) (lastnode(X)->dat)
+#define addlinknode(X,Y) insertlinknode(X,lastnode(X),Y)
+#define zaddlinknode(X,Y) zinsertlinknode(X,lastnode(X),Y)
+#define uaddlinknode(X,Y) uinsertlinknode(X,lastnode(X),Y)
+#define empty(X) (firstnode(X) == NULL)
+#define nonempty(X) (firstnode(X) != NULL)
+#define getaddrdata(X) (&((X)->dat))
+#define getdata(X) ((X)->dat)
+#define setdata(X,Y) ((X)->dat = (Y))
+#define nextnode(X) ((X)->next)
+#define prevnode(X) ((X)->prev)
+#define pushnode(X,Y) insertlinknode(X,&(X)->node,Y)
+#define zpushnode(X,Y) zinsertlinknode(X,&(X)->node,Y)
+#define incnode(X) (X = nextnode(X))
+#define decnode(X) (X = prevnode(X))
+#define firsthist() (hist_ring? hist_ring->down->histnum : curhist)
+#define setsizednode(X,Y,Z) (firstnode(X)[(Y)].dat = (void *) (Z))
+
+/* stack allocated linked lists */
+
+#define local_list0(N) union linkroot N
+#define init_list0(N) \
+ do { \
+ (N).list.first = NULL; \
+ (N).list.last = &(N).node; \
+ (N).list.flags = 0; \
+ } while (0)
+#define local_list1(N) union linkroot N; struct linknode __n0
+#define init_list1(N,V0) \
+ do { \
+ (N).list.first = &__n0; \
+ (N).list.last = &__n0; \
+ (N).list.flags = 0; \
+ __n0.next = NULL; \
+ __n0.prev = &(N).node; \
+ __n0.dat = (void *) (V0); \
+ } while (0)
+
+/*************************************/
+/* Specific elements of linked lists */
+/*************************************/
+
+typedef void (*voidvoidfnptr_t) _((void));
+
+/*
+ * Element of the prepromptfns list.
+ */
+struct prepromptfn {
+ voidvoidfnptr_t func;
+};
+
+
+/*
+ * Element of the timedfns list.
+ */
+struct timedfn {
+ voidvoidfnptr_t func;
+ time_t when;
+};
+
+/********************************/
+/* Definitions for syntax trees */
+/********************************/
+
+/* These are control flags that are passed *
+ * down the execution pipeline. */
+#define Z_TIMED (1<<0) /* pipeline is being timed */
+#define Z_SYNC (1<<1) /* run this sublist synchronously (;) */
+#define Z_ASYNC (1<<2) /* run this sublist asynchronously (&) */
+#define Z_DISOWN (1<<3) /* run this sublist without job control (&|) */
+/* (1<<4) is used for Z_END, see the wordcode definitions */
+/* (1<<5) is used for Z_SIMPLE, see the wordcode definitions */
+
+/*
+ * Condition types.
+ *
+ * Careful when changing these: both cond_binary_ops in text.c and
+ * condstr in cond.c depend on these. (The zsh motto is "two instances
+ * are better than one". Or something.)
+ */
+
+#define COND_NOT 0
+#define COND_AND 1
+#define COND_OR 2
+#define COND_STREQ 3
+#define COND_STRDEQ 4
+#define COND_STRNEQ 5
+#define COND_STRLT 6
+#define COND_STRGTR 7
+#define COND_NT 8
+#define COND_OT 9
+#define COND_EF 10
+#define COND_EQ 11
+#define COND_NE 12
+#define COND_LT 13
+#define COND_GT 14
+#define COND_LE 15
+#define COND_GE 16
+#define COND_REGEX 17
+#define COND_MOD 18
+#define COND_MODI 19
+
+typedef int (*CondHandler) _((char **, int));
+
+struct conddef {
+ Conddef next; /* next in list */
+ char *name; /* the condition name */
+ int flags; /* see CONDF_* below */
+ CondHandler handler; /* handler function */
+ int min; /* minimum number of strings */
+ int max; /* maximum number of strings */
+ int condid; /* for overloading handler functions */
+ char *module; /* module to autoload */
+};
+
+/* Condition is an infix */
+#define CONDF_INFIX 1
+/* Condition has been loaded from library */
+#define CONDF_ADDED 2
+/* When autoloading, enable all features in library */
+#define CONDF_AUTOALL 4
+
+#define CONDDEF(name, flags, handler, min, max, condid) \
+ { NULL, name, flags, handler, min, max, condid, NULL }
+
+/* Flags for redirections */
+
+enum {
+ /* Mark a here-string that came from a here-document */
+ REDIRF_FROM_HEREDOC = 1
+};
+
+/* tree element for redirection lists */
+
+struct redir {
+ int type;
+ int flags;
+ int fd1, fd2;
+ char *name;
+ char *varid;
+ char *here_terminator;
+ char *munged_here_terminator;
+};
+
+/* The number of fds space is allocated for *
+ * each time a multio must increase in size. */
+#define MULTIOUNIT 8
+
+/* A multio is a list of fds associated with a certain fd. *
+ * Thus if you do "foo >bar >ble", the multio for fd 1 will have *
+ * two fds, the result of open("bar",...), and the result of *
+ * open("ble",....). */
+
+/* structure used for multiple i/o redirection */
+/* one for each fd open */
+
+struct multio {
+ int ct; /* # of redirections on this fd */
+ int rflag; /* 0 if open for reading, 1 if open for writing */
+ int pipe; /* fd of pipe if ct > 1 */
+ int fds[MULTIOUNIT]; /* list of src/dests redirected to/from this fd */
+};
+
+/* lvalue for variable assignment/expansion */
+
+struct value {
+ int isarr;
+ Param pm; /* parameter node */
+ int flags; /* flags defined below */
+ int start; /* first element of array slice, or -1 */
+ int end; /* 1-rel last element of array slice, or -1 */
+ char **arr; /* cache for hash turned into array */
+};
+
+enum {
+ VALFLAG_INV = 0x0001, /* We are performing inverse subscripting */
+ VALFLAG_EMPTY = 0x0002, /* Subscripted range is empty */
+ VALFLAG_SUBST = 0x0004 /* Substitution, so apply padding, case flags */
+};
+
+#define MAX_ARRLEN 262144
+
+/********************************************/
+/* Definitions for word code */
+/********************************************/
+
+typedef unsigned int wordcode;
+typedef wordcode *Wordcode;
+
+typedef struct funcdump *FuncDump;
+typedef struct eprog *Eprog;
+
+struct funcdump {
+ FuncDump next; /* next in list */
+ dev_t dev; /* device */
+ ino_t ino; /* indoe number */
+ int fd; /* file descriptor */
+ Wordcode map; /* pointer to header */
+ Wordcode addr; /* mapped region */
+ int len; /* length */
+ int count; /* reference count */
+ char *filename;
+};
+
+/*
+ * A note on the use of reference counts in Eprogs.
+ *
+ * When an Eprog is created, nref is set to -1 if the Eprog is on the
+ * heap; then no attempt is ever made to free it. (This information is
+ * already present in EF_HEAP; we use the redundancy for debugging
+ * checks.)
+ *
+ * Otherwise, nref is initialised to 1. Calling freeprog() decrements
+ * nref and frees the Eprog if the count is now zero. When the Eprog
+ * is in use, we call useeprog() at the start and freeprog() at the
+ * end to increment and decrement the reference counts. If an attempt
+ * is made to free the Eprog from within, this will then take place
+ * when execution is finished, typically in the call to freeeprog()
+ * in execode(). If the Eprog was on the heap, neither useeprog()
+ * nor freeeprog() has any effect.
+ */
+struct eprog {
+ int flags; /* EF_* below */
+ int len; /* total block length */
+ int npats; /* Patprog cache size */
+ int nref; /* number of references: delete when zero */
+ Patprog *pats; /* the memory block, the patterns */
+ Wordcode prog; /* memory block ctd, the code */
+ char *strs; /* memory block ctd, the strings */
+ Shfunc shf; /* shell function for autoload */
+ FuncDump dump; /* dump file this is in */
+};
+
+#define EF_REAL 1
+#define EF_HEAP 2
+#define EF_MAP 4
+#define EF_RUN 8
+
+typedef struct estate *Estate;
+
+struct estate {
+ Eprog prog; /* the eprog executed */
+ Wordcode pc; /* program counter, current pos */
+ char *strs; /* strings from prog */
+};
+
+typedef struct eccstr *Eccstr;
+
+struct eccstr {
+ Eccstr left, right;
+ char *str;
+ wordcode offs, aoffs;
+ int nfunc;
+ int hashval;
+};
+
+#define EC_NODUP 0
+#define EC_DUP 1
+#define EC_DUPTOK 2
+
+#define WC_CODEBITS 5
+
+#define wc_code(C) ((C) & ((wordcode) ((1 << WC_CODEBITS) - 1)))
+#define wc_data(C) ((C) >> WC_CODEBITS)
+#define wc_bdata(D) ((D) << WC_CODEBITS)
+#define wc_bld(C,D) (((wordcode) (C)) | (((wordcode) (D)) << WC_CODEBITS))
+
+#define WC_END 0
+#define WC_LIST 1
+#define WC_SUBLIST 2
+#define WC_PIPE 3
+#define WC_REDIR 4
+#define WC_ASSIGN 5
+#define WC_SIMPLE 6
+#define WC_TYPESET 7
+#define WC_SUBSH 8
+#define WC_CURSH 9
+#define WC_TIMED 10
+#define WC_FUNCDEF 11
+#define WC_FOR 12
+#define WC_SELECT 13
+#define WC_WHILE 14
+#define WC_REPEAT 15
+#define WC_CASE 16
+#define WC_IF 17
+#define WC_COND 18
+#define WC_ARITH 19
+#define WC_AUTOFN 20
+#define WC_TRY 21
+
+/* increment as necessary */
+#define WC_COUNT 22
+
+#define WCB_END() wc_bld(WC_END, 0)
+
+#define WC_LIST_TYPE(C) wc_data(C)
+#define Z_END (1<<4)
+#define Z_SIMPLE (1<<5)
+#define WC_LIST_FREE (6) /* Next bit available in integer */
+#define WC_LIST_SKIP(C) (wc_data(C) >> WC_LIST_FREE)
+#define WCB_LIST(T,O) wc_bld(WC_LIST, ((T) | ((O) << WC_LIST_FREE)))
+
+#define WC_SUBLIST_TYPE(C) (wc_data(C) & ((wordcode) 3))
+#define WC_SUBLIST_END 0
+#define WC_SUBLIST_AND 1
+#define WC_SUBLIST_OR 2
+#define WC_SUBLIST_FLAGS(C) (wc_data(C) & ((wordcode) 0x1c))
+#define WC_SUBLIST_COPROC 4
+#define WC_SUBLIST_NOT 8
+#define WC_SUBLIST_SIMPLE 16
+#define WC_SUBLIST_FREE (5) /* Next bit available in integer */
+#define WC_SUBLIST_SKIP(C) (wc_data(C) >> WC_SUBLIST_FREE)
+#define WCB_SUBLIST(T,F,O) wc_bld(WC_SUBLIST, \
+ ((T) | (F) | ((O) << WC_SUBLIST_FREE)))
+
+#define WC_PIPE_TYPE(C) (wc_data(C) & ((wordcode) 1))
+#define WC_PIPE_END 0
+#define WC_PIPE_MID 1
+#define WC_PIPE_LINENO(C) (wc_data(C) >> 1)
+#define WCB_PIPE(T,L) wc_bld(WC_PIPE, ((T) | ((L) << 1)))
+
+#define WC_REDIR_TYPE(C) ((int)(wc_data(C) & REDIR_TYPE_MASK))
+#define WC_REDIR_VARID(C) ((int)(wc_data(C) & REDIR_VARID_MASK))
+#define WC_REDIR_FROM_HEREDOC(C) ((int)(wc_data(C) & REDIR_FROM_HEREDOC_MASK))
+#define WCB_REDIR(T) wc_bld(WC_REDIR, (T))
+/* Size of redir is 4 words if REDIR_VARID_MASK is set, else 3 */
+#define WC_REDIR_WORDS(C) \
+ ((WC_REDIR_VARID(C) ? 4 : 3) + \
+ (WC_REDIR_FROM_HEREDOC(C) ? 2 : 0))
+
+#define WC_ASSIGN_TYPE(C) (wc_data(C) & ((wordcode) 1))
+#define WC_ASSIGN_TYPE2(C) ((wc_data(C) & ((wordcode) 2)) >> 1)
+#define WC_ASSIGN_SCALAR 0
+#define WC_ASSIGN_ARRAY 1
+#define WC_ASSIGN_NEW 0
+/*
+ * In normal assignment, this indicate += to append.
+ * In assignment following a typeset, where that's not allowed,
+ * we overload this to indicate a variable without an
+ * assignment.
+ */
+#define WC_ASSIGN_INC 1
+#define WC_ASSIGN_NUM(C) (wc_data(C) >> 2)
+#define WCB_ASSIGN(T,A,N) wc_bld(WC_ASSIGN, ((T) | ((A) << 1) | ((N) << 2)))
+
+#define WC_SIMPLE_ARGC(C) wc_data(C)
+#define WCB_SIMPLE(N) wc_bld(WC_SIMPLE, (N))
+
+#define WC_TYPESET_ARGC(C) wc_data(C)
+#define WCB_TYPESET(N) wc_bld(WC_TYPESET, (N))
+
+#define WC_SUBSH_SKIP(C) wc_data(C)
+#define WCB_SUBSH(O) wc_bld(WC_SUBSH, (O))
+
+#define WC_CURSH_SKIP(C) wc_data(C)
+#define WCB_CURSH(O) wc_bld(WC_CURSH, (O))
+
+#define WC_TIMED_TYPE(C) wc_data(C)
+#define WC_TIMED_EMPTY 0
+#define WC_TIMED_PIPE 1
+#define WCB_TIMED(T) wc_bld(WC_TIMED, (T))
+
+#define WC_FUNCDEF_SKIP(C) wc_data(C)
+#define WCB_FUNCDEF(O) wc_bld(WC_FUNCDEF, (O))
+
+#define WC_FOR_TYPE(C) (wc_data(C) & 3)
+#define WC_FOR_PPARAM 0
+#define WC_FOR_LIST 1
+#define WC_FOR_COND 2
+#define WC_FOR_SKIP(C) (wc_data(C) >> 2)
+#define WCB_FOR(T,O) wc_bld(WC_FOR, ((T) | ((O) << 2)))
+
+#define WC_SELECT_TYPE(C) (wc_data(C) & 1)
+#define WC_SELECT_PPARAM 0
+#define WC_SELECT_LIST 1
+#define WC_SELECT_SKIP(C) (wc_data(C) >> 1)
+#define WCB_SELECT(T,O) wc_bld(WC_SELECT, ((T) | ((O) << 1)))
+
+#define WC_WHILE_TYPE(C) (wc_data(C) & 1)
+#define WC_WHILE_WHILE 0
+#define WC_WHILE_UNTIL 1
+#define WC_WHILE_SKIP(C) (wc_data(C) >> 1)
+#define WCB_WHILE(T,O) wc_bld(WC_WHILE, ((T) | ((O) << 1)))
+
+#define WC_REPEAT_SKIP(C) wc_data(C)
+#define WCB_REPEAT(O) wc_bld(WC_REPEAT, (O))
+
+#define WC_TRY_SKIP(C) wc_data(C)
+#define WCB_TRY(O) wc_bld(WC_TRY, (O))
+
+#define WC_CASE_TYPE(C) (wc_data(C) & 7)
+#define WC_CASE_HEAD 0
+#define WC_CASE_OR 1
+#define WC_CASE_AND 2
+#define WC_CASE_TESTAND 3
+#define WC_CASE_FREE (3) /* Next bit available in integer */
+#define WC_CASE_SKIP(C) (wc_data(C) >> WC_CASE_FREE)
+#define WCB_CASE(T,O) wc_bld(WC_CASE, ((T) | ((O) << WC_CASE_FREE)))
+
+#define WC_IF_TYPE(C) (wc_data(C) & 3)
+#define WC_IF_HEAD 0
+#define WC_IF_IF 1
+#define WC_IF_ELIF 2
+#define WC_IF_ELSE 3
+#define WC_IF_SKIP(C) (wc_data(C) >> 2)
+#define WCB_IF(T,O) wc_bld(WC_IF, ((T) | ((O) << 2)))
+
+#define WC_COND_TYPE(C) (wc_data(C) & 127)
+#define WC_COND_SKIP(C) (wc_data(C) >> 7)
+#define WCB_COND(T,O) wc_bld(WC_COND, ((T) | ((O) << 7)))
+
+#define WCB_ARITH() wc_bld(WC_ARITH, 0)
+
+#define WCB_AUTOFN() wc_bld(WC_AUTOFN, 0)
+
+/********************************************/
+/* Definitions for job table and job control */
+/********************************************/
+
+/* Entry in filelist linked list in job table */
+
+struct jobfile {
+ /* Record to be deleted or closed */
+ union {
+ char *name; /* Name of file to delete */
+ int fd; /* File descriptor to close */
+ } u;
+ /* Discriminant */
+ int is_fd;
+};
+
+/* entry in the job table */
+
+struct job {
+ pid_t gleader; /* process group leader of this job */
+ pid_t other; /* subjob id (SUPERJOB)
+ * or subshell pid (SUBJOB) */
+ int stat; /* see STATs below */
+ char *pwd; /* current working dir of shell when *
+ * this job was spawned */
+ struct process *procs; /* list of processes */
+ struct process *auxprocs; /* auxiliary processes e.g multios */
+ LinkList filelist; /* list of files to delete when done */
+ /* elements are struct jobfile */
+ int stty_in_env; /* if STTY=... is present */
+ struct ttyinfo *ty; /* the modes specified by STTY */
+};
+
+#define STAT_CHANGED (0x0001) /* status changed and not reported */
+#define STAT_STOPPED (0x0002) /* all procs stopped or exited */
+#define STAT_TIMED (0x0004) /* job is being timed */
+#define STAT_DONE (0x0008) /* job is done */
+#define STAT_LOCKED (0x0010) /* shell is finished creating this job, */
+ /* may be deleted from job table */
+#define STAT_NOPRINT (0x0020) /* job was killed internally, */
+ /* we don't want to show that */
+#define STAT_INUSE (0x0040) /* this job entry is in use */
+#define STAT_SUPERJOB (0x0080) /* job has a subjob */
+#define STAT_SUBJOB (0x0100) /* job is a subjob */
+#define STAT_WASSUPER (0x0200) /* was a super-job, sub-job needs to be */
+ /* deleted */
+#define STAT_CURSH (0x0400) /* last command is in current shell */
+#define STAT_NOSTTY (0x0800) /* the tty settings are not inherited */
+ /* from this job when it exits. */
+#define STAT_ATTACH (0x1000) /* delay reattaching shell to tty */
+#define STAT_SUBLEADER (0x2000) /* is super-job, but leader is sub-shell */
+
+#define STAT_BUILTIN (0x4000) /* job at tail of pipeline is a builtin */
+#define STAT_SUBJOB_ORPHANED (0x8000)
+ /* STAT_SUBJOB with STAT_SUPERJOB exited */
+#define STAT_DISOWN (0x10000) /* STAT_SUPERJOB with disown pending */
+
+#define SP_RUNNING -1 /* fake status for jobs currently running */
+
+struct timeinfo {
+ long ut; /* user space time */
+ long st; /* system space time */
+};
+
+#define JOBTEXTSIZE 80
+
+/* Size to initialise the job table to, and to increment it by when needed. */
+#define MAXJOBS_ALLOC (50)
+
+/* node in job process lists */
+
+#ifdef HAVE_GETRUSAGE
+typedef struct rusage child_times_t;
+#else
+typedef struct timeinfo child_times_t;
+#endif
+
+struct process {
+ struct process *next;
+ pid_t pid; /* process id */
+ char text[JOBTEXTSIZE]; /* text to print when 'jobs' is run */
+ int status; /* return code from waitpid/wait3() */
+ child_times_t ti;
+ struct timeval bgtime; /* time job was spawned */
+ struct timeval endtime; /* time job exited */
+};
+
+struct execstack {
+ struct execstack *next;
+
+ pid_t list_pipe_pid;
+ int nowait;
+ int pline_level;
+ int list_pipe_child;
+ int list_pipe_job;
+ char list_pipe_text[JOBTEXTSIZE];
+ int lastval;
+ int noeval;
+ int badcshglob;
+ pid_t cmdoutpid;
+ int cmdoutval;
+ int use_cmdoutval;
+ pid_t procsubstpid;
+ int trap_return;
+ int trap_state;
+ int trapisfunc;
+ int traplocallevel;
+ int noerrs;
+ int this_noerrexit;
+ char *underscore;
+};
+
+struct heredocs {
+ struct heredocs *next;
+ int type;
+ int pc;
+ char *str;
+};
+
+struct dirsav {
+ int dirfd, level;
+ char *dirname;
+ dev_t dev;
+ ino_t ino;
+};
+
+#define MAX_PIPESTATS 256
+
+/*******************************/
+/* Definitions for Hash Tables */
+/*******************************/
+
+typedef void *(*VFunc) _((void *));
+typedef void (*FreeFunc) _((void *));
+
+typedef unsigned (*HashFunc) _((const char *));
+typedef void (*TableFunc) _((HashTable));
+/*
+ * Note that this is deliberately "char *", not "const char *",
+ * since the AddNodeFunc is passed a pointer to a string that
+ * will be stored and later freed.
+ */
+typedef void (*AddNodeFunc) _((HashTable, char *, void *));
+typedef HashNode (*GetNodeFunc) _((HashTable, const char *));
+typedef HashNode (*RemoveNodeFunc) _((HashTable, const char *));
+typedef void (*FreeNodeFunc) _((HashNode));
+typedef int (*CompareFunc) _((const char *, const char *));
+
+/* type of function that is passed to *
+ * scanhashtable or scanmatchtable */
+typedef void (*ScanFunc) _((HashNode, int));
+typedef void (*ScanTabFunc) _((HashTable, ScanFunc, int));
+
+typedef void (*PrintTableStats) _((HashTable));
+
+/* hash table for standard open hashing */
+
+struct hashtable {
+ /* HASHTABLE DATA */
+ int hsize; /* size of nodes[] (number of hash values) */
+ int ct; /* number of elements */
+ HashNode *nodes; /* array of size hsize */
+ void *tmpdata;
+
+ /* HASHTABLE METHODS */
+ HashFunc hash; /* pointer to hash function for this table */
+ TableFunc emptytable; /* pointer to function to empty table */
+ TableFunc filltable; /* pointer to function to fill table */
+ CompareFunc cmpnodes; /* pointer to function to compare two nodes */
+ AddNodeFunc addnode; /* pointer to function to add new node */
+ GetNodeFunc getnode; /* pointer to function to get an enabled node */
+ GetNodeFunc getnode2; /* pointer to function to get node */
+ /* (getnode2 will ignore DISABLED flag) */
+ RemoveNodeFunc removenode; /* pointer to function to delete a node */
+ ScanFunc disablenode; /* pointer to function to disable a node */
+ ScanFunc enablenode; /* pointer to function to enable a node */
+ FreeNodeFunc freenode; /* pointer to function to free a node */
+ ScanFunc printnode; /* pointer to function to print a node */
+ ScanTabFunc scantab; /* pointer to function to scan table */
+
+#ifdef HASHTABLE_INTERNAL_MEMBERS
+ HASHTABLE_INTERNAL_MEMBERS /* internal use in hashtable.c */
+#endif
+};
+
+/* generic hash table node */
+
+struct hashnode {
+ HashNode next; /* next in hash chain */
+ char *nam; /* hash key */
+ int flags; /* various flags */
+};
+
+/* The flag to disable nodes in a hash table. Currently *
+ * you can disable builtins, shell functions, aliases and *
+ * reserved words. */
+#define DISABLED (1<<0)
+
+/* node in shell option table */
+
+struct optname {
+ struct hashnode node;
+ int optno; /* option number */
+};
+
+/* node in shell reserved word hash table (reswdtab) */
+
+struct reswd {
+ struct hashnode node;
+ int token; /* corresponding lexer token */
+};
+
+/* node in alias hash table (aliastab) */
+
+struct alias {
+ struct hashnode node;
+ char *text; /* expansion of alias */
+ int inuse; /* alias is being expanded */
+};
+
+/* bit 0 of flags is the DISABLED flag */
+/* is this alias global? */
+#define ALIAS_GLOBAL (1<<1)
+/* is this an alias for suffix handling? */
+#define ALIAS_SUFFIX (1<<2)
+
+/* structure for foo=bar assignments */
+
+struct asgment {
+ struct linknode node;
+ char *name;
+ int flags;
+ union {
+ char *scalar;
+ LinkList array;
+ } value;
+};
+
+/* Flags for flags element of asgment */
+enum {
+ /* Array value */
+ ASG_ARRAY = 1,
+ /* Key / value array pair */
+ ASG_KEY_VALUE = 2
+};
+
+/*
+ * Assignment is array?
+ */
+#define ASG_ARRAYP(asg) ((asg)->flags & ASG_ARRAY)
+
+/*
+ * Assignment has value?
+ * If the assignment is an arrray, then it certainly has a value --- we
+ * can only tell if there's an expicit assignment.
+ */
+
+#define ASG_VALUEP(asg) (ASG_ARRAYP(asg) || \
+ ((asg)->value.scalar != (char *)0))
+
+/* node in command path hash table (cmdnamtab) */
+
+struct cmdnam {
+ struct hashnode node;
+ union {
+ char **name; /* full pathname for external commands */
+ char *cmd; /* file name for hashed commands */
+ }
+ u;
+};
+
+/* flag for nodes explicitly added to *
+ * cmdnamtab with hash builtin */
+#define HASHED (1<<1)
+
+/* node in shell function hash table (shfunctab) */
+
+struct shfunc {
+ struct hashnode node;
+ char *filename; /* Name of file located in.
+ For not yet autoloaded file, name
+ of explicit directory, if not NULL. */
+ zlong lineno; /* line number in above file */
+ Eprog funcdef; /* function definition */
+ Eprog redir; /* redirections to apply */
+ Emulation_options sticky; /* sticky emulation definitions, if any */
+};
+
+/* Shell function context types. */
+
+#define SFC_NONE 0 /* no function running */
+#define SFC_DIRECT 1 /* called directly from the user */
+#define SFC_SIGNAL 2 /* signal handler */
+#define SFC_HOOK 3 /* one of the special functions */
+#define SFC_WIDGET 4 /* user defined widget */
+#define SFC_COMPLETE 5 /* called from completion code */
+#define SFC_CWIDGET 6 /* new style completion widget */
+#define SFC_SUBST 7 /* used to perform substitution task */
+
+/* tp in funcstack */
+
+enum {
+ FS_SOURCE,
+ FS_FUNC,
+ FS_EVAL
+};
+
+/* node in function stack */
+
+struct funcstack {
+ Funcstack prev; /* previous in stack */
+ char *name; /* name of function/sourced file called */
+ char *filename; /* file function resides in */
+ char *caller; /* name of caller */
+ zlong flineno; /* line number in file */
+ zlong lineno; /* line offset from beginning of function */
+ int tp; /* type of entry: sourced file, func, eval */
+};
+
+/* node in list of function call wrappers */
+
+typedef int (*WrapFunc) _((Eprog, FuncWrap, char *));
+
+struct funcwrap {
+ FuncWrap next;
+ int flags;
+ WrapFunc handler;
+ Module module;
+};
+
+#define WRAPF_ADDED 1
+
+#define WRAPDEF(func) \
+ { NULL, 0, func, NULL }
+
+/*
+ * User-defined hook arrays
+ */
+
+/* Name appended to function name to get hook array */
+#define HOOK_SUFFIX "_functions"
+/* Length of that including NUL byte */
+#define HOOK_SUFFIX_LEN 11
+
+/* node in builtin command hash table (builtintab) */
+
+/*
+ * Handling of options.
+ *
+ * Option strings are standard in that a trailing `:' indicates
+ * a mandatory argument. In addition, `::' indicates an optional
+ * argument which must immediately follow the option letter if it is present.
+ * `:%' indicates an optional numeric argument which may follow
+ * the option letter or be in the next word; the only test is
+ * that the next character is a digit, and no actual conversion is done.
+ */
+
+#define MAX_OPS 128
+
+/* Macros taking struct option * and char argument */
+/* Option was set as -X */
+#define OPT_MINUS(ops,c) ((ops)->ind[c] & 1)
+/* Option was set as +X */
+#define OPT_PLUS(ops,c) ((ops)->ind[c] & 2)
+/*
+ * Option was set any old how, maybe including an argument
+ * (cheap test when we don't care). Some bits of code
+ * expect this to be 1 or 0.
+ */
+#define OPT_ISSET(ops,c) ((ops)->ind[c] != 0)
+/* Option has an argument */
+#define OPT_HASARG(ops,c) ((ops)->ind[c] > 3)
+/* The argument for the option; not safe if it doesn't have one */
+#define OPT_ARG(ops,c) ((ops)->args[((ops)->ind[c] >> 2) - 1])
+/* Ditto, but safely returns NULL if there is no argument. */
+#define OPT_ARG_SAFE(ops,c) (OPT_HASARG(ops,c) ? OPT_ARG(ops,c) : NULL)
+
+struct options {
+ unsigned char ind[MAX_OPS];
+ char **args;
+ int argscount, argsalloc;
+};
+
+/* Flags to parseargs() */
+
+enum {
+ PARSEARGS_TOPLEVEL = 0x1, /* Call to initialise shell */
+ PARSEARGS_LOGIN = 0x2 /* Shell is login shell */
+};
+
+
+/*
+ * Handler arguments are: builtin name, null-terminated argument
+ * list excluding command name, option structure, the funcid element from the
+ * builtin structure.
+ */
+
+typedef int (*HandlerFunc) _((char *, char **, Options, int));
+typedef int (*HandlerFuncAssign) _((char *, char **, LinkList, Options, int));
+#define NULLBINCMD ((HandlerFunc) 0)
+
+struct builtin {
+ struct hashnode node;
+ HandlerFunc handlerfunc; /* pointer to function that executes this builtin */
+ int minargs; /* minimum number of arguments */
+ int maxargs; /* maximum number of arguments, or -1 for no limit */
+ int funcid; /* xbins (see above) for overloaded handlerfuncs */
+ char *optstr; /* string of legal options */
+ char *defopts; /* options set by default for overloaded handlerfuncs */
+};
+
+#define BUILTIN(name, flags, handler, min, max, funcid, optstr, defopts) \
+ { { NULL, name, flags }, handler, min, max, funcid, optstr, defopts }
+#define BIN_PREFIX(name, flags) \
+ BUILTIN(name, flags | BINF_PREFIX, NULLBINCMD, 0, 0, 0, NULL, NULL)
+
+/* builtin flags */
+/* DISABLE IS DEFINED AS (1<<0) */
+#define BINF_PLUSOPTS (1<<1) /* +xyz legal */
+#define BINF_PRINTOPTS (1<<2)
+#define BINF_ADDED (1<<3) /* is in the builtins hash table */
+#define BINF_MAGICEQUALS (1<<4) /* needs automatic MAGIC_EQUAL_SUBST substitution */
+#define BINF_PREFIX (1<<5)
+#define BINF_DASH (1<<6)
+#define BINF_BUILTIN (1<<7)
+#define BINF_COMMAND (1<<8)
+#define BINF_EXEC (1<<9)
+#define BINF_NOGLOB (1<<10)
+#define BINF_PSPECIAL (1<<11)
+/* Builtin option handling */
+#define BINF_SKIPINVALID (1<<12) /* Treat invalid option as argument */
+#define BINF_KEEPNUM (1<<13) /* `[-+]NUM' can be an option */
+#define BINF_SKIPDASH (1<<14) /* Treat `-' as argument (maybe `+') */
+#define BINF_DASHDASHVALID (1<<15) /* Handle `--' even if SKIPINVALD */
+#define BINF_CLEARENV (1<<16) /* new process started with cleared env */
+#define BINF_AUTOALL (1<<17) /* autoload all features at once */
+ /*
+ * Handles options itself. This is only useful if the option string for a
+ * builtin with an empty option string. It is used to indicate that "--"
+ * does not terminate options.
+ */
+#define BINF_HANDLES_OPTS (1<<18)
+/*
+ * Handles the assignement interface. The argv list actually contains
+ * two nested litsts, the first of normal arguments, and the second of
+ * assignment structures.
+ */
+#define BINF_ASSIGN (1<<19)
+
+/**
+ * Parameters passed to execcmd().
+ * These are not opaque --- they are also used by the pipeline manager.
+ */
+struct execcmd_params {
+ LinkList args; /* All command prefixes, arguments & options */
+ LinkList redir; /* Redirections */
+ Wordcode beg; /* The code at the start of the command */
+ Wordcode varspc; /* The code for assignment parsed as such */
+ Wordcode assignspc; /* The code for assignment parsed as typeset */
+ int type; /* The WC_* type of the command */
+ int postassigns; /* The number of assignspc assiguments */
+ int htok; /* tokens in parameter list */
+};
+
+struct module {
+ struct hashnode node;
+ union {
+ void *handle;
+ Linkedmod linked;
+ char *alias;
+ } u;
+ LinkList autoloads;
+ LinkList deps;
+ int wrapper;
+};
+
+/* We are in the process of loading the module */
+#define MOD_BUSY (1<<0)
+/*
+ * We are in the process of unloading the module.
+ * Note this is not needed to indicate a module is actually
+ * unloaded: for that, the handle (or linked pointer) is set to NULL.
+ */
+#define MOD_UNLOAD (1<<1)
+/* We are in the process of setting up the module */
+#define MOD_SETUP (1<<2)
+/* Module is statically linked into the main binary */
+#define MOD_LINKED (1<<3)
+/* Module setup has been carried out (and module has not been finished) */
+#define MOD_INIT_S (1<<4)
+/* Module boot has been carried out (and module has not been finished) */
+#define MOD_INIT_B (1<<5)
+/* Module record is an alias */
+#define MOD_ALIAS (1<<6)
+
+typedef int (*Module_generic_func) _((void));
+typedef int (*Module_void_func) _((Module));
+typedef int (*Module_features_func) _((Module, char ***));
+typedef int (*Module_enables_func) _((Module, int **));
+
+struct linkedmod {
+ char *name;
+ Module_void_func setup;
+ Module_features_func features;
+ Module_enables_func enables;
+ Module_void_func boot;
+ Module_void_func cleanup;
+ Module_void_func finish;
+};
+
+/*
+ * Structure combining all the concrete features available in
+ * a module and with space for information about abstract features.
+ */
+struct features {
+ /* List of builtins provided by the module and the size thereof */
+ Builtin bn_list;
+ int bn_size;
+ /* List of conditions provided by the module and the size thereof */
+ Conddef cd_list;
+ int cd_size;
+ /* List of math functions provided by the module and the size thereof */
+ MathFunc mf_list;
+ int mf_size;
+ /* List of parameters provided by the module and the size thereof */
+ Paramdef pd_list;
+ int pd_size;
+ /* Number of abstract features */
+ int n_abstract;
+};
+
+/*
+ * Structure describing enables for one feature.
+ */
+struct feature_enables {
+ /* String feature to enable (N.B. no leading +/- allowed) */
+ char *str;
+ /* Optional compiled pattern for str sans +/-, NULL for string match */
+ Patprog pat;
+};
+
+/* C-function hooks */
+
+typedef int (*Hookfn) _((Hookdef, void *));
+
+struct hookdef {
+ Hookdef next;
+ char *name;
+ Hookfn def;
+ int flags;
+ LinkList funcs;
+};
+
+#define HOOKF_ALL 1
+
+#define HOOKDEF(name, func, flags) { NULL, name, (Hookfn) func, flags, NULL }
+
+/*
+ * Types used in pattern matching. Most of these longs could probably
+ * happily be ints.
+ */
+
+struct patprog {
+ long startoff; /* length before start of programme */
+ long size; /* total size from start of struct */
+ long mustoff; /* offset to string that must be present */
+ long patmlen; /* length of pure string or longest match */
+ int globflags; /* globbing flags to set at start */
+ int globend; /* globbing flags set after finish */
+ int flags; /* PAT_* flags */
+ int patnpar; /* number of active parentheses */
+ char patstartch;
+};
+
+struct patstralloc {
+ int unmetalen; /* Unmetafied length of trial string */
+ int unmetalenp; /* Unmetafied length of path prefix.
+ If 0, no path prefix. */
+ char *alloced; /* Allocated string, may be NULL */
+ char *progstrunmeta; /* Unmetafied pure string in pattern, cached */
+ int progstrunmetalen; /* Length of the foregoing */
+};
+
+/* Flags used in pattern matchers (Patprog) and passed down to patcompile */
+
+#define PAT_HEAPDUP 0x0000 /* Dummy flag for default behavior */
+#define PAT_FILE 0x0001 /* Pattern is a file name */
+#define PAT_FILET 0x0002 /* Pattern is top level file, affects ~ */
+#define PAT_ANY 0x0004 /* Match anything (cheap "*") */
+#define PAT_NOANCH 0x0008 /* Not anchored at end */
+#define PAT_NOGLD 0x0010 /* Don't glob dots */
+#define PAT_PURES 0x0020 /* Pattern is a pure string: set internally */
+#define PAT_STATIC 0x0040 /* Don't copy pattern to heap as per default */
+#define PAT_SCAN 0x0080 /* Scanning, so don't try must-match test */
+#define PAT_ZDUP 0x0100 /* Copy pattern in real memory */
+#define PAT_NOTSTART 0x0200 /* Start of string is not real start */
+#define PAT_NOTEND 0x0400 /* End of string is not real end */
+#define PAT_HAS_EXCLUDP 0x0800 /* (internal): top-level path1~path2. */
+#define PAT_LCMATCHUC 0x1000 /* equivalent to setting (#l) */
+
+/**
+ * Indexes into the array of active pattern characters.
+ * This must match the array zpc_chars in pattern.c.
+ */
+enum zpc_chars {
+ /*
+ * These characters both terminate a pattern segment and
+ * a pure string segment.
+ */
+ ZPC_SLASH, /* / active as file separator */
+ ZPC_NULL, /* \0 as string terminator */
+ ZPC_BAR, /* | for "or" */
+ ZPC_OUTPAR, /* ) for grouping */
+ ZPC_TILDE, /* ~ for exclusion (extended glob) */
+ ZPC_SEG_COUNT, /* No. of the above characters */
+ /*
+ * These characters terminate a pure string segment.
+ */
+ ZPC_INPAR = ZPC_SEG_COUNT, /* ( for grouping */
+ ZPC_QUEST, /* ? as wildcard */
+ ZPC_STAR, /* * as wildcard */
+ ZPC_INBRACK, /* [ for character class */
+ ZPC_INANG, /* < for numeric glob */
+ ZPC_HAT, /* ^ for exclusion (extended glob) */
+ ZPC_HASH, /* # for repetition (extended glob) */
+ ZPC_BNULLKEEP, /* Special backslashed null not removed */
+ /*
+ * These characters are only valid before a parenthesis
+ */
+ ZPC_NO_KSH_GLOB,
+ ZPC_KSH_QUEST = ZPC_NO_KSH_GLOB, /* ? for ?(...) in KSH_GLOB */
+ ZPC_KSH_STAR, /* * for *(...) in KSH_GLOB */
+ ZPC_KSH_PLUS, /* + for +(...) in KSH_GLOB */
+ ZPC_KSH_BANG, /* ! for !(...) in KSH_GLOB */
+ ZPC_KSH_BANG2, /* ! for !(...) in KSH_GLOB, untokenised */
+ ZPC_KSH_AT, /* @ for @(...) in KSH_GLOB */
+ ZPC_COUNT /* Number of special chararacters */
+};
+
+/*
+ * Structure to save disables special characters for function scope.
+ */
+struct zpc_disables_save {
+ struct zpc_disables_save *next;
+ /*
+ * Bit vector of ZPC_COUNT disabled characters.
+ * We'll live dangerously and assume ZPC_COUNT is no greater
+ * than the number of bits in an unsigned int.
+ */
+ unsigned int disables;
+};
+
+typedef struct zpc_disables_save *Zpc_disables_save;
+
+/*
+ * Special match types used in character classes. These
+ * are represented as tokens, with Meta added. The character
+ * class is represented as a metafied string, with only these
+ * tokens special. Note that an active leading "!" or "^" for
+ * negation is not part of the string but is flagged in the
+ * surrounding context.
+ *
+ * These types are also used in character and equivalence classes
+ * in completion matching.
+ *
+ * This must be kept ordered by the array colon_stuffs in pattern.c.
+ */
+/* Special value for first definition */
+#define PP_FIRST 1
+/* POSIX-defined types: [:alpha:] etc. */
+#define PP_ALPHA 1
+#define PP_ALNUM 2
+#define PP_ASCII 3
+#define PP_BLANK 4
+#define PP_CNTRL 5
+#define PP_DIGIT 6
+#define PP_GRAPH 7
+#define PP_LOWER 8
+#define PP_PRINT 9
+#define PP_PUNCT 10
+#define PP_SPACE 11
+#define PP_UPPER 12
+#define PP_XDIGIT 13
+/* Zsh additions: [:IDENT:] etc. */
+#define PP_IDENT 14
+#define PP_IFS 15
+#define PP_IFSSPACE 16
+#define PP_WORD 17
+#define PP_INCOMPLETE 18
+#define PP_INVALID 19
+/* Special value for last definition */
+#define PP_LAST 19
+
+/* Unknown type. Not used in a valid token. */
+#define PP_UNKWN 20
+/* Range: token followed by the (possibly multibyte) start and end */
+#define PP_RANGE 21
+
+/*
+ * Argument to get_match_ret() in glob.c
+ */
+struct imatchdata {
+ /* Metafied trial string */
+ char *mstr;
+ /* Its length */
+ int mlen;
+ /* Unmetafied string */
+ char *ustr;
+ /* Its length */
+ int ulen;
+ /* Flags (SUB_*) */
+ int flags;
+ /* Replacement string (metafied) */
+ char *replstr;
+ /*
+ * List of bits of matches to concatenate with replacement string.
+ * The data is a struct repldata. It is not used in cases like
+ * ${...//#foo/bar} even though SUB_GLOBAL is set, since the match
+ * is anchored. It goes on the heap.
+ */
+ LinkList repllist;
+};
+
+/* Globbing flags: lower 8 bits gives approx count */
+#define GF_LCMATCHUC 0x0100
+#define GF_IGNCASE 0x0200
+#define GF_BACKREF 0x0400
+#define GF_MATCHREF 0x0800
+#define GF_MULTIBYTE 0x1000 /* Use multibyte if supported by build */
+
+enum {
+ /* Valid multibyte character from charref */
+ ZMB_VALID,
+ /* Incomplete multibyte character from charref */
+ ZMB_INCOMPLETE,
+ /* Invalid multibyte character charref */
+ ZMB_INVALID
+};
+
+/* Dummy Patprog pointers. Used mainly in executable code, but the
+ * pattern code needs to know about it, too. */
+
+#define dummy_patprog1 ((Patprog) 1)
+#define dummy_patprog2 ((Patprog) 2)
+
+/* standard node types for get/set/unset union in parameter */
+
+/*
+ * note non-standard const in pointer declaration: structures are
+ * assumed to be read-only.
+ */
+typedef const struct gsu_scalar *GsuScalar;
+typedef const struct gsu_integer *GsuInteger;
+typedef const struct gsu_float *GsuFloat;
+typedef const struct gsu_array *GsuArray;
+typedef const struct gsu_hash *GsuHash;
+
+struct gsu_scalar {
+ char *(*getfn) _((Param));
+ void (*setfn) _((Param, char *));
+ void (*unsetfn) _((Param, int));
+};
+
+struct gsu_integer {
+ zlong (*getfn) _((Param));
+ void (*setfn) _((Param, zlong));
+ void (*unsetfn) _((Param, int));
+};
+
+struct gsu_float {
+ double (*getfn) _((Param));
+ void (*setfn) _((Param, double));
+ void (*unsetfn) _((Param, int));
+};
+
+struct gsu_array {
+ char **(*getfn) _((Param));
+ void (*setfn) _((Param, char **));
+ void (*unsetfn) _((Param, int));
+};
+
+struct gsu_hash {
+ HashTable (*getfn) _((Param));
+ void (*setfn) _((Param, HashTable));
+ void (*unsetfn) _((Param, int));
+};
+
+
+/* node used in parameter hash table (paramtab) */
+
+struct param {
+ struct hashnode node;
+
+ /* the value of this parameter */
+ union {
+ void *data; /* used by special parameter functions */
+ char **arr; /* value if declared array (PM_ARRAY) */
+ char *str; /* value if declared string (PM_SCALAR) */
+ zlong val; /* value if declared integer (PM_INTEGER) */
+ zlong *valptr; /* value if special pointer to integer */
+ double dval; /* value if declared float
+ (PM_EFLOAT|PM_FFLOAT) */
+ HashTable hash; /* value if declared assoc (PM_HASHED) */
+ } u;
+
+ /*
+ * get/set/unset methods.
+ *
+ * Unlike the data union, this points to a single instance
+ * for every type (although there are special types, e.g.
+ * tied arrays have a different gsu_scalar struct from the
+ * normal one). It's really a poor man's vtable.
+ */
+ union {
+ GsuScalar s;
+ GsuInteger i;
+ GsuFloat f;
+ GsuArray a;
+ GsuHash h;
+ } gsu;
+
+ int base; /* output base or floating point prec */
+ int width; /* field width */
+ char *env; /* location in environment, if exported */
+ char *ename; /* name of corresponding environment var */
+ Param old; /* old struct for use with local */
+ int level; /* if (old != NULL), level of localness */
+};
+
+/* structure stored in struct param's u.data by tied arrays */
+struct tieddata {
+ char ***arrptr; /* pointer to corresponding array */
+ int joinchar; /* character used to join arrays */
+};
+
+/* flags for parameters */
+
+/* parameter types */
+#define PM_SCALAR 0 /* scalar */
+#define PM_ARRAY (1<<0) /* array */
+#define PM_INTEGER (1<<1) /* integer */
+#define PM_EFLOAT (1<<2) /* double with %e output */
+#define PM_FFLOAT (1<<3) /* double with %f output */
+#define PM_HASHED (1<<4) /* association */
+
+#define PM_TYPE(X) \
+ (X & (PM_SCALAR|PM_INTEGER|PM_EFLOAT|PM_FFLOAT|PM_ARRAY|PM_HASHED))
+
+#define PM_LEFT (1<<5) /* left justify, remove leading blanks */
+#define PM_RIGHT_B (1<<6) /* right justify, fill with leading blanks */
+#define PM_RIGHT_Z (1<<7) /* right justify, fill with leading zeros */
+#define PM_LOWER (1<<8) /* all lower case */
+
+/* The following are the same since they *
+ * both represent -u option to typeset */
+#define PM_UPPER (1<<9) /* all upper case */
+#define PM_UNDEFINED (1<<9) /* undefined (autoloaded) shell function */
+
+#define PM_READONLY (1<<10) /* readonly */
+#define PM_TAGGED (1<<11) /* tagged */
+#define PM_EXPORTED (1<<12) /* exported */
+#define PM_ABSPATH_USED (1<<12) /* (function): loaded using absolute path */
+
+/* The following are the same since they *
+ * both represent -U option to typeset */
+#define PM_UNIQUE (1<<13) /* remove duplicates */
+#define PM_UNALIASED (1<<13) /* do not expand aliases when autoloading */
+
+#define PM_HIDE (1<<14) /* Special behaviour hidden by local */
+#define PM_CUR_FPATH (1<<14) /* (function): can use $fpath with filename */
+#define PM_HIDEVAL (1<<15) /* Value not shown in `typeset' commands */
+#define PM_WARNNESTED (1<<15) /* (function): non-recursive WARNNESTEDVAR */
+#define PM_TIED (1<<16) /* array tied to colon-path or v.v. */
+#define PM_TAGGED_LOCAL (1<<16) /* (function): non-recursive PM_TAGGED */
+
+#define PM_KSHSTORED (1<<17) /* function stored in ksh form */
+#define PM_ZSHSTORED (1<<18) /* function stored in zsh form */
+
+/* Remaining flags do not correspond directly to command line arguments */
+#define PM_DONTIMPORT_SUID (1<<19) /* do not import if running setuid */
+#define PM_LOADDIR (1<<19) /* (function) filename gives load directory */
+#define PM_SINGLE (1<<20) /* special can only have a single instance */
+#define PM_ANONYMOUS (1<<20) /* (function) anonymous function */
+#define PM_LOCAL (1<<21) /* this parameter will be made local */
+#define PM_SPECIAL (1<<22) /* special builtin parameter */
+#define PM_DONTIMPORT (1<<23) /* do not import this variable */
+#define PM_RESTRICTED (1<<24) /* cannot be changed in restricted mode */
+#define PM_UNSET (1<<25) /* has null value */
+#define PM_REMOVABLE (1<<26) /* special can be removed from paramtab */
+#define PM_AUTOLOAD (1<<27) /* autoloaded from module */
+#define PM_NORESTORE (1<<28) /* do not restore value of local special */
+#define PM_AUTOALL (1<<28) /* autoload all features in module
+ * when loading: valid only if PM_AUTOLOAD
+ * is also present.
+ */
+#define PM_HASHELEM (1<<29) /* is a hash-element */
+#define PM_NAMEDDIR (1<<30) /* has a corresponding nameddirtab entry */
+
+/* The option string corresponds to the first of the variables above */
+#define TYPESET_OPTSTR "aiEFALRZlurtxUhHTkz"
+
+/* These typeset options take an optional numeric argument */
+#define TYPESET_OPTNUM "LRZiEF"
+
+/* Flags for extracting elements of arrays and associative arrays */
+#define SCANPM_WANTVALS (1<<0) /* Return value includes hash values */
+#define SCANPM_WANTKEYS (1<<1) /* Return value includes hash keys */
+#define SCANPM_WANTINDEX (1<<2) /* Return value includes array index */
+#define SCANPM_MATCHKEY (1<<3) /* Subscript matched against key */
+#define SCANPM_MATCHVAL (1<<4) /* Subscript matched against value */
+#define SCANPM_MATCHMANY (1<<5) /* Subscript matched repeatedly, return all */
+#define SCANPM_ASSIGNING (1<<6) /* Assigning whole array/hash */
+#define SCANPM_KEYMATCH (1<<7) /* keys of hash treated as patterns */
+#define SCANPM_DQUOTED (1<<8) /* substitution was double-quoted
+ * (only used for testing early end of
+ * subscript)
+ */
+#define SCANPM_ARRONLY (1<<9) /* value is array but we don't
+ * necessarily want to match multiple
+ * elements
+ */
+#define SCANPM_CHECKING (1<<10) /* Check if set, no need to create */
+/* "$foo[@]"-style substitution
+ * Only sign bit is significant
+ */
+#define SCANPM_ISVAR_AT ((int)(((unsigned int)-1)<<15))
+
+/*
+ * Flags for doing matches inside parameter substitutions, i.e.
+ * ${...#...} and friends. This could be an enum, but so
+ * could a lot of other things.
+ */
+
+#define SUB_END 0x0001 /* match end instead of beginning, % or %% */
+#define SUB_LONG 0x0002 /* % or # doubled, get longest match */
+#define SUB_SUBSTR 0x0004 /* match a substring */
+#define SUB_MATCH 0x0008 /* include the matched portion */
+#define SUB_REST 0x0010 /* include the unmatched portion */
+#define SUB_BIND 0x0020 /* index of beginning of string */
+#define SUB_EIND 0x0040 /* index of end of string */
+#define SUB_LEN 0x0080 /* length of match */
+#define SUB_ALL 0x0100 /* match complete string */
+#define SUB_GLOBAL 0x0200 /* global substitution ${..//all/these} */
+#define SUB_DOSUBST 0x0400 /* replacement string needs substituting */
+#define SUB_RETFAIL 0x0800 /* return status 0 if no match */
+#define SUB_START 0x1000 /* force match at start with SUB_END
+ * and no SUB_SUBSTR */
+#define SUB_LIST 0x2000 /* no substitution, return list of matches */
+
+/*
+ * Structure recording multiple matches inside a test string.
+ * b and e are the beginning and end of the match.
+ * replstr is the replacement string, if any.
+ */
+struct repldata {
+ int b, e; /* beginning and end of chunk to replace */
+ char *replstr; /* replacement string to use */
+};
+typedef struct repldata *Repldata;
+
+/*
+ * Flags to zshtokenize.
+ */
+enum {
+ /* Do glob substitution */
+ ZSHTOK_SUBST = 0x0001,
+ /* Use sh-style globbing */
+ ZSHTOK_SHGLOB = 0x0002
+};
+
+/* Flags as the second argument to prefork */
+enum {
+ /* argument handled like typeset foo=bar */
+ PREFORK_TYPESET = 0x01,
+ /* argument handled like the RHS of foo=bar */
+ PREFORK_ASSIGN = 0x02,
+ /* single word substitution */
+ PREFORK_SINGLE = 0x04,
+ /* explicitly split nested substitution */
+ PREFORK_SPLIT = 0x08,
+ /* SHWORDSPLIT in parameter expn */
+ PREFORK_SHWORDSPLIT = 0x10,
+ /* SHWORDSPLIT forced off in nested subst */
+ PREFORK_NOSHWORDSPLIT = 0x20,
+ /* Prefork is part of a parameter subexpression */
+ PREFORK_SUBEXP = 0x40,
+ /* Prefork detected an assignment list with [key]=value syntax,
+ * Only used on return from prefork, not meaningful passed down.
+ * Also used as flag to globlist.
+ */
+ PREFORK_KEY_VALUE = 0x80,
+ /* No untokenise: used only as flag to globlist */
+ PREFORK_NO_UNTOK = 0x100
+};
+
+/*
+ * Bit flags passed back from multsub() to paramsubst().
+ * Some flags go from a nested parmsubst() through the enclosing
+ * stringsubst() and prefork().
+ */
+enum {
+ /*
+ * Set if the string had whitespace at the start
+ * that should cause word splitting against any preceeding string.
+ */
+ MULTSUB_WS_AT_START = 1,
+ /*
+ * Set if the string had whitespace at the end
+ * that should cause word splitting against any following string.
+ */
+ MULTSUB_WS_AT_END = 2,
+ /*
+ * Set by nested paramsubst() to indicate the return
+ * value is a parameter name, rather than a value.
+ */
+ MULTSUB_PARAM_NAME = 4
+};
+
+/*
+ * Structure for adding parameters in a module.
+ * The flags should declare the type; note PM_SCALAR is zero.
+ *
+ * Special hashes are recognized by getnfn so the PM_HASHED
+ * is optional. These get slightly non-standard attention:
+ * the function createspecialhash is used to create them.
+ *
+ * The get/set/unset attribute may be NULL; in that case the
+ * parameter is assigned methods suitable for handling the
+ * tie variable var, if that is not NULL, else standard methods.
+ *
+ * pm is set when the parameter is added to the parameter table
+ * and serves as a flag that the parameter has been added.
+ */
+struct paramdef {
+ char *name;
+ int flags;
+ void *var; /* tied internal variable, if any */
+ const void *gsu; /* get/set/unset structure, if special */
+ GetNodeFunc getnfn; /* function to get node, if special hash */
+ ScanTabFunc scantfn; /* function to scan table, if special hash */
+ Param pm; /* structure inserted into param table */
+};
+
+/*
+ * Shorthand for common uses of adding parameters, with no special
+ * hash properties.
+ */
+#define PARAMDEF(name, flags, var, gsu) \
+ { name, flags, (void *) var, (void *) gsu, \
+ NULL, NULL, NULL \
+ }
+/*
+ * Note that the following definitions are appropriate for defining
+ * parameters that reference a variable (var). Hence the get/set/unset
+ * methods used will assume var needs dereferencing to get the value.
+ */
+#define INTPARAMDEF(name, var) \
+ { name, PM_INTEGER, (void *) var, NULL, NULL, NULL, NULL }
+#define STRPARAMDEF(name, var) \
+ { name, PM_SCALAR, (void *) var, NULL, NULL, NULL, NULL }
+#define ARRPARAMDEF(name, var) \
+ { name, PM_ARRAY, (void *) var, NULL, NULL, NULL, NULL }
+/*
+ * The following is appropriate for a module function that behaves
+ * in a special fashion. Parameters used in a module that don't
+ * have special behaviour shouldn't be declared in a table but
+ * should just be added with the standard parameter functions.
+ *
+ * These parameters are not marked as removable, since they
+ * shouldn't be loaded as local parameters, unlike the special
+ * Zle parameters that are added and removed on each call to Zle.
+ * We add the PM_REMOVABLE flag when removing the feature corresponding
+ * to the parameter.
+ */
+#define SPECIALPMDEF(name, flags, gsufn, getfn, scanfn) \
+ { name, flags | PM_SPECIAL | PM_HIDE | PM_HIDEVAL, \
+ NULL, gsufn, getfn, scanfn, NULL }
+
+/*
+ * Flags for assignsparam and assignaparam.
+ */
+enum {
+ /* Add to rather than override value */
+ ASSPM_AUGMENT = 1 << 0,
+ /* Test for warning if creating global variable in function */
+ ASSPM_WARN_CREATE = 1 << 1,
+ /* Test for warning if using nested variable in function */
+ ASSPM_WARN_NESTED = 1 << 2,
+ ASSPM_WARN = (ASSPM_WARN_CREATE|ASSPM_WARN_NESTED),
+ /* Import from environment, so exercise care evaluating value */
+ ASSPM_ENV_IMPORT = 1 << 3,
+ /* Array is key / value pairs.
+ * This is normal for associative arrays but variant behaviour for
+ * normal arrays.
+ */
+ ASSPM_KEY_VALUE = 1 << 4
+};
+
+/* node for named directory hash table (nameddirtab) */
+
+struct nameddir {
+ struct hashnode node;
+ char *dir; /* the directory in full */
+ int diff; /* strlen(.dir) - strlen(.nam) */
+};
+
+/* flags for named directories */
+/* DISABLED is defined (1<<0) */
+#define ND_USERNAME (1<<1) /* nam is actually a username */
+#define ND_NOABBREV (1<<2) /* never print as abbrev (PWD or OLDPWD) */
+
+/* Storage for single group/name mapping */
+typedef struct {
+ /* Name of group */
+ char *name;
+ /* Group identifier */
+ gid_t gid;
+} groupmap;
+typedef groupmap *Groupmap;
+
+/* Storage for a set of group/name mappings */
+typedef struct {
+ /* The set of name to gid mappings */
+ Groupmap array;
+ /* A count of the valid entries in groupmap. */
+ int num;
+} groupset;
+typedef groupset *Groupset;
+
+/* flags for controlling printing of hash table nodes */
+#define PRINT_NAMEONLY (1<<0)
+#define PRINT_TYPE (1<<1)
+#define PRINT_LIST (1<<2)
+#define PRINT_KV_PAIR (1<<3)
+#define PRINT_INCLUDEVALUE (1<<4)
+#define PRINT_TYPESET (1<<5)
+#define PRINT_LINE (1<<6)
+
+/* flags for printing for the whence builtin */
+#define PRINT_WHENCE_CSH (1<<7)
+#define PRINT_WHENCE_VERBOSE (1<<8)
+#define PRINT_WHENCE_SIMPLE (1<<9)
+#define PRINT_WHENCE_FUNCDEF (1<<10)
+#define PRINT_WHENCE_WORD (1<<11)
+
+/* Return values from loop() */
+
+enum loop_return {
+ /* Loop executed OK */
+ LOOP_OK,
+ /* Loop executed no code */
+ LOOP_EMPTY,
+ /* Loop encountered an error */
+ LOOP_ERROR
+};
+
+/* Return values from source() */
+
+enum source_return {
+ /* Source ran OK */
+ SOURCE_OK = 0,
+ /* File not found */
+ SOURCE_NOT_FOUND = 1,
+ /* Internal error sourcing file */
+ SOURCE_ERROR = 2
+};
+
+enum noerrexit_bits {
+ /* Suppress ERR_EXIT and traps: global */
+ NOERREXIT_EXIT = 1,
+ /* Suppress ERR_RETURN: per function call */
+ NOERREXIT_RETURN = 2,
+ /* NOERREXIT only needed on way down */
+ NOERREXIT_UNTIL_EXEC = 4,
+ /* Force exit on SIGINT */
+ NOERREXIT_SIGNAL = 8
+};
+
+/***********************************/
+/* Definitions for history control */
+/***********************************/
+
+/* history entry */
+
+struct histent {
+ struct hashnode node;
+
+ Histent up; /* previous line (moving upward) */
+ Histent down; /* next line (moving downward) */
+ char *zle_text; /* the edited history line,
+ * a metafied, NULL-terminated string,
+ * i.e the same format as the original
+ * entry
+ */
+ time_t stim; /* command started time (datestamp) */
+ time_t ftim; /* command finished time */
+ short *words; /* Position of words in history */
+ /* line: as pairs of start, end */
+ int nwords; /* Number of words in history line */
+ zlong histnum; /* A sequential history number */
+};
+
+#define HIST_MAKEUNIQUE 0x00000001 /* Kill this new entry if not unique */
+#define HIST_OLD 0x00000002 /* Command is already written to disk*/
+#define HIST_READ 0x00000004 /* Command was read back from disk*/
+#define HIST_DUP 0x00000008 /* Command duplicates a later line */
+#define HIST_FOREIGN 0x00000010 /* Command came from another shell */
+#define HIST_TMPSTORE 0x00000020 /* Kill when user enters another cmd */
+#define HIST_NOWRITE 0x00000040 /* Keep internally but don't write */
+
+#define GETHIST_UPWARD (-1)
+#define GETHIST_DOWNWARD 1
+#define GETHIST_EXACT 0
+
+/* Parts of the code where history expansion is disabled *
+ * should be within a pair of STOPHIST ... ALLOWHIST */
+
+#define STOPHIST (stophist += 4);
+#define ALLOWHIST (stophist -= 4);
+
+#define HISTFLAG_DONE 1
+#define HISTFLAG_NOEXEC 2
+#define HISTFLAG_RECALL 4
+#define HISTFLAG_SETTY 8
+
+#define HFILE_APPEND 0x0001
+#define HFILE_SKIPOLD 0x0002
+#define HFILE_SKIPDUPS 0x0004
+#define HFILE_SKIPFOREIGN 0x0008
+#define HFILE_FAST 0x0010
+#define HFILE_NO_REWRITE 0x0020
+#define HFILE_USE_OPTIONS 0x8000
+
+/*
+ * Flags argument to bufferwords() used
+ * also by lexflags variable.
+ */
+/*
+ * Kick the lexer into special string-analysis
+ * mode without parsing. Any bit set in
+ * the flags has this effect, but this
+ * has otherwise all the default effects.
+ */
+#define LEXFLAGS_ACTIVE 0x0001
+/*
+ * Being used from zle. This is slightly more intrusive
+ * (=> grotesquely non-modular) than use from within
+ * the main shell, so it's a separate flag.
+ */
+#define LEXFLAGS_ZLE 0x0002
+/*
+ * Parse comments and treat each comment as a single string
+ */
+#define LEXFLAGS_COMMENTS_KEEP 0x0004
+/*
+ * Parse comments and strip them.
+ */
+#define LEXFLAGS_COMMENTS_STRIP 0x0008
+/*
+ * Either of the above
+ */
+#define LEXFLAGS_COMMENTS (LEXFLAGS_COMMENTS_KEEP|LEXFLAGS_COMMENTS_STRIP)
+/*
+ * Treat newlines as whitespace
+ */
+#define LEXFLAGS_NEWLINE 0x0010
+
+/******************************************/
+/* Definitions for programable completion */
+/******************************************/
+
+/* Nothing special. */
+#define IN_NOTHING 0
+/* In command position. */
+#define IN_CMD 1
+/* In a mathematical environment. */
+#define IN_MATH 2
+/* In a condition. */
+#define IN_COND 3
+/* In a parameter assignment (e.g. `foo=bar'). */
+#define IN_ENV 4
+/* In a parameter name in an assignment. */
+#define IN_PAR 5
+
+
+/******************************/
+/* Definition for zsh options */
+/******************************/
+
+/* Possible values of emulation */
+
+#define EMULATE_CSH (1<<1) /* C shell */
+#define EMULATE_KSH (1<<2) /* Korn shell */
+#define EMULATE_SH (1<<3) /* Bourne shell */
+#define EMULATE_ZSH (1<<4) /* `native' mode */
+
+/* Test for a shell emulation. Use this rather than emulation directly. */
+#define EMULATION(X) (emulation & (X))
+
+/* Return only base shell emulation field. */
+#define SHELL_EMULATION() (emulation & ((1<<5)-1))
+
+/* Additional flags */
+
+#define EMULATE_FULLY (1<<5) /* "emulate -R" in effect */
+/*
+ * Higher bits are used in options.c, record lowest unused bit...
+ */
+#define EMULATE_UNUSED (1<<6)
+
+/* option indices */
+
+enum {
+ OPT_INVALID,
+ ALIASESOPT,
+ ALIASFUNCDEF,
+ ALLEXPORT,
+ ALWAYSLASTPROMPT,
+ ALWAYSTOEND,
+ APPENDHISTORY,
+ AUTOCD,
+ AUTOCONTINUE,
+ AUTOLIST,
+ AUTOMENU,
+ AUTONAMEDIRS,
+ AUTOPARAMKEYS,
+ AUTOPARAMSLASH,
+ AUTOPUSHD,
+ AUTOREMOVESLASH,
+ AUTORESUME,
+ BADPATTERN,
+ BANGHIST,
+ BAREGLOBQUAL,
+ BASHAUTOLIST,
+ BASHREMATCH,
+ BEEP,
+ BGNICE,
+ BRACECCL,
+ BSDECHO,
+ CASEGLOB,
+ CASEMATCH,
+ CBASES,
+ CDABLEVARS,
+ CHASEDOTS,
+ CHASELINKS,
+ CHECKJOBS,
+ CHECKRUNNINGJOBS,
+ CLOBBER,
+ APPENDCREATE,
+ COMBININGCHARS,
+ COMPLETEALIASES,
+ COMPLETEINWORD,
+ CORRECT,
+ CORRECTALL,
+ CONTINUEONERROR,
+ CPRECEDENCES,
+ CSHJUNKIEHISTORY,
+ CSHJUNKIELOOPS,
+ CSHJUNKIEQUOTES,
+ CSHNULLCMD,
+ CSHNULLGLOB,
+ DEBUGBEFORECMD,
+ EMACSMODE,
+ EQUALS,
+ ERREXIT,
+ ERRRETURN,
+ EXECOPT,
+ EXTENDEDGLOB,
+ EXTENDEDHISTORY,
+ EVALLINENO,
+ FLOWCONTROL,
+ FORCEFLOAT,
+ FUNCTIONARGZERO,
+ GLOBOPT,
+ GLOBALEXPORT,
+ GLOBALRCS,
+ GLOBASSIGN,
+ GLOBCOMPLETE,
+ GLOBDOTS,
+ GLOBSTARSHORT,
+ GLOBSUBST,
+ HASHCMDS,
+ HASHDIRS,
+ HASHEXECUTABLESONLY,
+ HASHLISTALL,
+ HISTALLOWCLOBBER,
+ HISTBEEP,
+ HISTEXPIREDUPSFIRST,
+ HISTFCNTLLOCK,
+ HISTFINDNODUPS,
+ HISTIGNOREALLDUPS,
+ HISTIGNOREDUPS,
+ HISTIGNORESPACE,
+ HISTLEXWORDS,
+ HISTNOFUNCTIONS,
+ HISTNOSTORE,
+ HISTREDUCEBLANKS,
+ HISTSAVEBYCOPY,
+ HISTSAVENODUPS,
+ HISTSUBSTPATTERN,
+ HISTVERIFY,
+ HUP,
+ IGNOREBRACES,
+ IGNORECLOSEBRACES,
+ IGNOREEOF,
+ INCAPPENDHISTORY,
+ INCAPPENDHISTORYTIME,
+ INTERACTIVE,
+ INTERACTIVECOMMENTS,
+ KSHARRAYS,
+ KSHAUTOLOAD,
+ KSHGLOB,
+ KSHOPTIONPRINT,
+ KSHTYPESET,
+ KSHZEROSUBSCRIPT,
+ LISTAMBIGUOUS,
+ LISTBEEP,
+ LISTPACKED,
+ LISTROWSFIRST,
+ LISTTYPES,
+ LOCALLOOPS,
+ LOCALOPTIONS,
+ LOCALPATTERNS,
+ LOCALTRAPS,
+ LOGINSHELL,
+ LONGLISTJOBS,
+ MAGICEQUALSUBST,
+ MAILWARNING,
+ MARKDIRS,
+ MENUCOMPLETE,
+ MONITOR,
+ MULTIBYTE,
+ MULTIFUNCDEF,
+ MULTIOS,
+ NOMATCH,
+ NOTIFY,
+ NULLGLOB,
+ NUMERICGLOBSORT,
+ OCTALZEROES,
+ OVERSTRIKE,
+ PATHDIRS,
+ PATHSCRIPT,
+ PIPEFAIL,
+ POSIXALIASES,
+ POSIXARGZERO,
+ POSIXBUILTINS,
+ POSIXCD,
+ POSIXIDENTIFIERS,
+ POSIXJOBS,
+ POSIXSTRINGS,
+ POSIXTRAPS,
+ PRINTEIGHTBIT,
+ PRINTEXITVALUE,
+ PRIVILEGED,
+ PROMPTBANG,
+ PROMPTCR,
+ PROMPTPERCENT,
+ PROMPTSP,
+ PROMPTSUBST,
+ PUSHDIGNOREDUPS,
+ PUSHDMINUS,
+ PUSHDSILENT,
+ PUSHDTOHOME,
+ RCEXPANDPARAM,
+ RCQUOTES,
+ RCS,
+ RECEXACT,
+ REMATCHPCRE,
+ RESTRICTED,
+ RMSTARSILENT,
+ RMSTARWAIT,
+ SHAREHISTORY,
+ SHFILEEXPANSION,
+ SHGLOB,
+ SHINSTDIN,
+ SHNULLCMD,
+ SHOPTIONLETTERS,
+ SHORTLOOPS,
+ SHWORDSPLIT,
+ SINGLECOMMAND,
+ SINGLELINEZLE,
+ SOURCETRACE,
+ SUNKEYBOARDHACK,
+ TRANSIENTRPROMPT,
+ TRAPSASYNC,
+ TYPESETSILENT,
+ UNSET,
+ VERBOSE,
+ VIMODE,
+ WARNCREATEGLOBAL,
+ WARNNESTEDVAR,
+ XTRACE,
+ USEZLE,
+ DVORAK,
+ OPT_SIZE
+};
+
+/*
+ * Size required to fit an option number.
+ * If OPT_SIZE goes above 256 this will need to expand.
+ */
+typedef unsigned char OptIndex;
+
+#undef isset
+#define isset(X) (opts[X])
+#define unset(X) (!opts[X])
+
+#define interact (isset(INTERACTIVE))
+#define jobbing (isset(MONITOR))
+#define islogin (isset(LOGINSHELL))
+
+/*
+ * Record of emulation and options that need to be set
+ * for a full "emulate".
+ */
+struct emulation_options {
+ /* The emulation itself */
+ int emulation;
+ /* The number of options in on_opts. */
+ int n_on_opts;
+ /* The number of options in off_opts. */
+ int n_off_opts;
+ /*
+ * Array of options to be turned on.
+ * Only options specified explicitly in the emulate command
+ * are recorded. Null if n_on_opts is zero.
+ */
+ OptIndex *on_opts;
+ /* Array of options to be turned off, similar. */
+ OptIndex *off_opts;
+};
+
+/***********************************************/
+/* Definitions for terminal and display control */
+/***********************************************/
+
+/* tty state structure */
+
+struct ttyinfo {
+#ifdef HAVE_TERMIOS_H
+ struct termios tio;
+#else
+# ifdef HAVE_TERMIO_H
+ struct termio tio;
+# else
+ struct sgttyb sgttyb;
+ int lmodes;
+ struct tchars tchars;
+ struct ltchars ltchars;
+# endif
+#endif
+#ifdef TIOCGWINSZ
+ struct winsize winsize;
+#endif
+};
+
+#ifndef __INTERIX
+/* defines for whether tabs expand to spaces */
+#if defined(HAVE_TERMIOS_H) || defined(HAVE_TERMIO_H)
+#define SGTTYFLAG shttyinfo.tio.c_oflag
+#else /* we're using sgtty */
+#define SGTTYFLAG shttyinfo.sgttyb.sg_flags
+#endif
+# ifdef TAB3
+#define SGTABTYPE TAB3
+# else
+# ifdef OXTABS
+#define SGTABTYPE OXTABS
+# else
+# ifdef XTABS
+#define SGTABTYPE XTABS
+# endif
+# endif
+# endif
+#endif
+
+/* flags for termflags */
+
+#define TERM_BAD 0x01 /* terminal has extremely basic capabilities */
+#define TERM_UNKNOWN 0x02 /* unknown terminal type */
+#define TERM_NOUP 0x04 /* terminal has no up capability */
+#define TERM_SHORT 0x08 /* terminal is < 3 lines high */
+#define TERM_NARROW 0x10 /* terminal is < 3 columns wide */
+
+/* interesting termcap strings */
+
+#define TCCLEARSCREEN 0
+#define TCLEFT 1
+#define TCMULTLEFT 2
+#define TCRIGHT 3
+#define TCMULTRIGHT 4
+#define TCUP 5
+#define TCMULTUP 6
+#define TCDOWN 7
+#define TCMULTDOWN 8
+#define TCDEL 9
+#define TCMULTDEL 10
+#define TCINS 11
+#define TCMULTINS 12
+#define TCCLEAREOD 13
+#define TCCLEAREOL 14
+#define TCINSLINE 15
+#define TCDELLINE 16
+#define TCNEXTTAB 17
+#define TCBOLDFACEBEG 18
+#define TCSTANDOUTBEG 19
+#define TCUNDERLINEBEG 20
+#define TCALLATTRSOFF 21
+#define TCSTANDOUTEND 22
+#define TCUNDERLINEEND 23
+#define TCHORIZPOS 24
+#define TCUPCURSOR 25
+#define TCDOWNCURSOR 26
+#define TCLEFTCURSOR 27
+#define TCRIGHTCURSOR 28
+#define TCSAVECURSOR 29
+#define TCRESTRCURSOR 30
+#define TCBACKSPACE 31
+#define TCFGCOLOUR 32
+#define TCBGCOLOUR 33
+#define TC_COUNT 34
+
+#define tccan(X) (tclen[X])
+
+/*
+ * Text attributes for displaying in ZLE
+ */
+
+#define TXTBOLDFACE 0x0001
+#define TXTSTANDOUT 0x0002
+#define TXTUNDERLINE 0x0004
+#define TXTFGCOLOUR 0x0008
+#define TXTBGCOLOUR 0x0010
+
+#define TXT_ATTR_ON_MASK 0x001F
+
+#define txtisset(X) (txtattrmask & (X))
+#define txtset(X) (txtattrmask |= (X))
+#define txtunset(X) (txtattrmask &= ~(X))
+
+#define TXTNOBOLDFACE 0x0020
+#define TXTNOSTANDOUT 0x0040
+#define TXTNOUNDERLINE 0x0080
+#define TXTNOFGCOLOUR 0x0100
+#define TXTNOBGCOLOUR 0x0200
+
+#define TXT_ATTR_OFF_MASK 0x03E0
+/* Bits to shift off right to get on */
+#define TXT_ATTR_OFF_ON_SHIFT 5
+#define TXT_ATTR_OFF_FROM_ON(attr) \
+ (((attr) & TXT_ATTR_ON_MASK) << TXT_ATTR_OFF_ON_SHIFT)
+#define TXT_ATTR_ON_FROM_OFF(attr) \
+ (((attr) & TXT_ATTR_OFF_MASK) >> TXT_ATTR_OFF_ON_SHIFT)
+/*
+ * Indicates to zle_refresh.c that the character entry is an
+ * index into the list of multiword symbols.
+ */
+#define TXT_MULTIWORD_MASK 0x0400
+
+/* Mask for colour to use in foreground */
+#define TXT_ATTR_FG_COL_MASK 0x000FF000
+/* Bits to shift the foreground colour */
+#define TXT_ATTR_FG_COL_SHIFT (12)
+/* Mask for colour to use in background */
+#define TXT_ATTR_BG_COL_MASK 0x0FF00000
+/* Bits to shift the background colour */
+#define TXT_ATTR_BG_COL_SHIFT (20)
+
+/* Flag to use termcap AF sequence to set colour, if available */
+#define TXT_ATTR_FG_TERMCAP 0x10000000
+/* Flag to use termcap AB sequence to set colour, if available */
+#define TXT_ATTR_BG_TERMCAP 0x20000000
+
+/* Things to turn on, including values for the colour elements */
+#define TXT_ATTR_ON_VALUES_MASK \
+ (TXT_ATTR_ON_MASK|TXT_ATTR_FG_COL_MASK|TXT_ATTR_BG_COL_MASK|\
+ TXT_ATTR_FG_TERMCAP|TXT_ATTR_BG_TERMCAP)
+
+/* Mask out everything to do with setting a foreground colour */
+#define TXT_ATTR_FG_ON_MASK \
+ (TXTFGCOLOUR|TXT_ATTR_FG_COL_MASK|TXT_ATTR_FG_TERMCAP)
+
+/* Mask out everything to do with setting a background colour */
+#define TXT_ATTR_BG_ON_MASK \
+ (TXTBGCOLOUR|TXT_ATTR_BG_COL_MASK|TXT_ATTR_BG_TERMCAP)
+
+/* Mask out everything to do with activating colours */
+#define TXT_ATTR_COLOUR_ON_MASK \
+ (TXT_ATTR_FG_ON_MASK|TXT_ATTR_BG_ON_MASK)
+
+#define txtchangeisset(T,X) ((T) & (X))
+#define txtchangeget(T,A) (((T) & A ## _MASK) >> A ## _SHIFT)
+#define txtchangeset(T, X, Y) ((void)(T && (*T &= ~(Y), *T |= (X))))
+
+/*
+ * For outputting sequences to change colour: specify foreground
+ * or background.
+ */
+#define COL_SEQ_FG (0)
+#define COL_SEQ_BG (1)
+#define COL_SEQ_COUNT (2)
+
+/*
+ * Flags to testcap() and set_colour_attribute (which currently only
+ * handles TSC_PROMPT).
+ */
+enum {
+ /* Raw output: use stdout rather than shout */
+ TSC_RAW = 0x0001,
+ /* Output to current prompt buffer: only used when assembling prompt */
+ TSC_PROMPT = 0x0002,
+ /* Mask to get the output mode */
+ TSC_OUTPUT_MASK = 0x0003,
+ /* Change needs reset of other attributes */
+ TSC_DIRTY = 0x0004
+};
+
+/****************************************/
+/* Definitions for the %_ prompt escape */
+/****************************************/
+
+#define CMDSTACKSZ 256
+
+#define CS_FOR 0
+#define CS_WHILE 1
+#define CS_REPEAT 2
+#define CS_SELECT 3
+#define CS_UNTIL 4
+#define CS_IF 5
+#define CS_IFTHEN 6
+#define CS_ELSE 7
+#define CS_ELIF 8
+#define CS_MATH 9
+#define CS_COND 10
+#define CS_CMDOR 11
+#define CS_CMDAND 12
+#define CS_PIPE 13
+#define CS_ERRPIPE 14
+#define CS_FOREACH 15
+#define CS_CASE 16
+#define CS_FUNCDEF 17
+#define CS_SUBSH 18
+#define CS_CURSH 19
+#define CS_ARRAY 20
+#define CS_QUOTE 21
+#define CS_DQUOTE 22
+#define CS_BQUOTE 23
+#define CS_CMDSUBST 24
+#define CS_MATHSUBST 25
+#define CS_ELIFTHEN 26
+#define CS_HEREDOC 27
+#define CS_HEREDOCD 28
+#define CS_BRACE 29
+#define CS_BRACEPAR 30
+#define CS_ALWAYS 31
+
+/* Increment as necessary */
+#define CS_COUNT 32
+
+/*********************
+ * Memory management *
+ *********************/
+
+/*
+ * A Heapid is a type for identifying, uniquely up to the point where
+ * the count of new identifiers wraps. all heaps that are or
+ * (importantly) have been valid. Each valid heap is given an
+ * identifier, and every time we push a heap we save the old identifier
+ * and give the heap a new identifier so that when the heap is popped
+ * or freed we can spot anything using invalid memory from the popped
+ * heap.
+ *
+ * We could make this unsigned long long if we wanted a big range.
+ */
+typedef unsigned int Heapid;
+
+#ifdef ZSH_HEAP_DEBUG
+
+/* printf format specifier corresponding to Heapid */
+#define HEAPID_FMT "%x"
+
+/* Marker that memory is permanently allocated */
+#define HEAPID_PERMANENT (UINT_MAX)
+
+/*
+ * Heap debug verbosity.
+ * Bits to be 'or'ed into the variable also called heap_debug_verbosity.
+ */
+enum heap_debug_verbosity {
+ /* Report when we push a heap */
+ HDV_PUSH = 0x01,
+ /* Report when we pop a heap */
+ HDV_POP = 0x02,
+ /* Report when we create a new heap from which to allocate */
+ HDV_CREATE = 0x04,
+ /* Report every time we free a complete heap */
+ HDV_FREE = 0x08,
+ /* Report when we temporarily install a new set of heaps */
+ HDV_NEW = 0x10,
+ /* Report when we restore an old set of heaps */
+ HDV_OLD = 0x20,
+ /* Report when we temporarily switch heaps */
+ HDV_SWITCH = 0x40,
+ /*
+ * Report every time we allocate memory from the heap.
+ * This is very verbose, and arguably not very useful: we
+ * would expect to allocate memory from a heap we create.
+ * For much debugging heap_debug_verbosity = 0x7f should be sufficient.
+ */
+ HDV_ALLOC = 0x80
+};
+
+#define HEAP_ERROR(heap_id) \
+ fprintf(stderr, "%s:%d: HEAP DEBUG: invalid heap: " HEAPID_FMT ".\n", \
+ __FILE__, __LINE__, heap_id)
+#endif
+
+/* heappush saves the current heap state using this structure */
+
+struct heapstack {
+ struct heapstack *next; /* next one in list for this heap */
+ size_t used;
+#ifdef ZSH_HEAP_DEBUG
+ Heapid heap_id;
+#endif
+};
+
+/* A zsh heap. */
+
+struct heap {
+ struct heap *next; /* next one */
+ size_t size; /* size of heap */
+ size_t used; /* bytes used from the heap */
+ struct heapstack *sp; /* used by pushheap() to save the value used */
+
+#ifdef ZSH_HEAP_DEBUG
+ unsigned int heap_id;
+#endif
+
+/* Uncomment the following if the struct needs padding to 64-bit size. */
+/* Make sure sizeof(heap) is a multiple of 8
+#if defined(PAD_64_BIT) && !defined(__GNUC__)
+ size_t dummy;
+#endif
+*/
+#define arena(X) ((char *) (X) + sizeof(struct heap))
+}
+#if defined(PAD_64_BIT) && defined(__GNUC__)
+ __attribute__ ((aligned (8)))
+#endif
+;
+
+# define NEWHEAPS(h) do { Heap _switch_oldheaps = h = new_heaps(); do
+# define OLDHEAPS while (0); old_heaps(_switch_oldheaps); } while (0);
+
+# define SWITCHHEAPS(o, h) do { o = switch_heaps(h); do
+# define SWITCHBACKHEAPS(o) while (0); switch_heaps(o); } while (0);
+
+/****************/
+/* Debug macros */
+/****************/
+
+#ifdef DEBUG
+#define STRINGIFY_LITERAL(x) # x
+#define STRINGIFY(x) STRINGIFY_LITERAL(x)
+#define ERRMSG(x) (__FILE__ ":" STRINGIFY(__LINE__) ": " x)
+# define DPUTS(X,Y) if (!(X)) {;} else dputs(ERRMSG(Y))
+# define DPUTS1(X,Y,Z1) if (!(X)) {;} else dputs(ERRMSG(Y), Z1)
+# define DPUTS2(X,Y,Z1,Z2) if (!(X)) {;} else dputs(ERRMSG(Y), Z1, Z2)
+# define DPUTS3(X,Y,Z1,Z2,Z3) if (!(X)) {;} else dputs(ERRMSG(Y), Z1, Z2, Z3)
+#else
+# define DPUTS(X,Y)
+# define DPUTS1(X,Y,Z1)
+# define DPUTS2(X,Y,Z1,Z2)
+# define DPUTS3(X,Y,Z1,Z2,Z3)
+#endif
+
+/**************************/
+/* Signal handling macros */
+/**************************/
+
+/* These used in the sigtrapped[] array */
+
+#define ZSIG_TRAPPED (1<<0) /* Signal is trapped */
+#define ZSIG_IGNORED (1<<1) /* Signal is ignored */
+#define ZSIG_FUNC (1<<2) /* Trap is a function, not an eval list */
+/* Mask to get the above flags */
+#define ZSIG_MASK (ZSIG_TRAPPED|ZSIG_IGNORED|ZSIG_FUNC)
+/* No. of bits to shift local level when storing in sigtrapped */
+#define ZSIG_ALIAS (1<<3) /* Trap is stored under an alias */
+#define ZSIG_SHIFT 4
+
+/*
+ * State of traps, stored in trap_state.
+ */
+enum trap_state {
+ /* Traps are not active; trap_return is not useful. */
+ TRAP_STATE_INACTIVE,
+ /*
+ * Traps are set but haven't triggered; trap_return gives
+ * minus function depth.
+ */
+ TRAP_STATE_PRIMED,
+ /*
+ * Trap has triggered to force a return; trap_return givens
+ * return value.
+ */
+ TRAP_STATE_FORCE_RETURN
+};
+
+#define IN_EVAL_TRAP() \
+ (intrap && !trapisfunc && traplocallevel == locallevel)
+
+/*
+ * Bits in the errflag variable.
+ */
+enum errflag_bits {
+ /*
+ * Standard internal error bit.
+ */
+ ERRFLAG_ERROR = 1,
+ /*
+ * User interrupt.
+ */
+ ERRFLAG_INT = 2,
+ /*
+ * Hard error --- return to top-level prompt in interactive
+ * shell. In non-interactive shell we'll typically already
+ * have exited. This is reset by "errflag = 0" in
+ * loop(toplevel = 1, ...).
+ */
+ ERRFLAG_HARD = 4
+};
+
+/***********/
+/* Sorting */
+/***********/
+
+typedef int (*CompareFn) _((const void *, const void *));
+
+enum {
+ SORTIT_ANYOLDHOW = 0, /* Defaults */
+ SORTIT_IGNORING_CASE = 1,
+ SORTIT_NUMERICALLY = 2,
+ SORTIT_BACKWARDS = 4,
+ /*
+ * Ignore backslashes that quote another character---which may
+ * be another backslash; the second backslash is active.
+ */
+ SORTIT_IGNORING_BACKSLASHES = 8,
+ /*
+ * Ignored by strmetasort(); used by paramsubst() to indicate
+ * there is some sorting to do.
+ */
+ SORTIT_SOMEHOW = 16,
+};
+
+/*
+ * Element of array passed to qsort().
+ */
+struct sortelt {
+ /* The original string. */
+ char *orig;
+ /* The string used for comparison. */
+ const char *cmp;
+ /*
+ * The length of the string if passed down to the sort algorithm.
+ * Used to sort the lengths together with the strings.
+ */
+ int origlen;
+ /*
+ * The length of the string, if needed, else -1.
+ * The length is only needed if there are embededded nulls.
+ */
+ int len;
+};
+
+typedef struct sortelt *SortElt;
+
+/*********************************************************/
+/* Structures to save and restore for individual modules */
+/*********************************************************/
+
+/* History */
+struct hist_stack {
+ int histactive;
+ int histdone;
+ int stophist;
+ int hlinesz;
+ zlong defev;
+ char *hline;
+ char *hptr;
+ short *chwords;
+ int chwordlen;
+ int chwordpos;
+ int (*hgetc) _((void));
+ void (*hungetc) _((int));
+ void (*hwaddc) _((int));
+ void (*hwbegin) _((int));
+ void (*hwabort) _((void));
+ void (*hwend) _((void));
+ void (*addtoline) _((int));
+ unsigned char *cstack;
+ int csp;
+ int hist_keep_comment;
+};
+
+/*
+ * State of a lexical token buffer.
+ *
+ * It would be neater to include the pointer to the start of the buffer,
+ * however the current code structure means that the standard instance
+ * of this, tokstr, is visible in lots of places, so that's not
+ * convenient.
+ */
+
+struct lexbufstate {
+ /*
+ * Next character to be added.
+ * Set to NULL when the buffer is to be visible from elsewhere.
+ */
+ char *ptr;
+ /* Allocated buffer size */
+ int siz;
+ /* Length in use */
+ int len;
+};
+
+/* Lexical analyser */
+struct lex_stack {
+ int dbparens;
+ int isfirstln;
+ int isfirstch;
+ int lexflags;
+ enum lextok tok;
+ char *tokstr;
+ char *zshlextext;
+ struct lexbufstate lexbuf;
+ int lex_add_raw;
+ char *tokstr_raw;
+ struct lexbufstate lexbuf_raw;
+ int lexstop;
+ zlong toklineno;
+};
+
+/* Parser */
+struct parse_stack {
+ struct heredocs *hdocs;
+
+ int incmdpos;
+ int aliasspaceflag;
+ int incond;
+ int inredir;
+ int incasepat;
+ int isnewlin;
+ int infor;
+ int inrepeat_;
+ int intypeset;
+
+ int eclen, ecused, ecnpats;
+ Wordcode ecbuf;
+ Eccstr ecstrs;
+ int ecsoffs, ecssub, ecnfunc;
+};
+
+/************************/
+/* Flags to casemodifiy */
+/************************/
+
+enum {
+ CASMOD_NONE, /* dummy for tests */
+ CASMOD_UPPER,
+ CASMOD_LOWER,
+ CASMOD_CAPS
+};
+
+/*******************************************/
+/* Flags to third argument of getkeystring */
+/*******************************************/
+
+/*
+ * By default handles some subset of \-escapes. The following bits
+ * turn on extra features.
+ */
+enum {
+ /*
+ * Handle octal where the first digit is non-zero e.g. \3, \33, \333
+ * Otherwise \0333 etc. is handled, i.e. one of \0123 or \123 will
+ * work, but not both.
+ */
+ GETKEY_OCTAL_ESC = (1 << 0),
+ /*
+ * Handle Emacs-like key sequences \C-x etc.
+ * Also treat \E like \e and use backslashes to escape the
+ * next character if not special, i.e. do all the things we
+ * don't do with the echo builtin.
+ */
+ GETKEY_EMACS = (1 << 1),
+ /* Handle ^X etc. */
+ GETKEY_CTRL = (1 << 2),
+ /* Handle \c (uses misc arg to getkeystring()) */
+ GETKEY_BACKSLASH_C = (1 << 3),
+ /* Do $'...' quoting (len arg to getkeystring() not used) */
+ GETKEY_DOLLAR_QUOTE = (1 << 4),
+ /* Handle \- (uses misc arg to getkeystring()) */
+ GETKEY_BACKSLASH_MINUS = (1 << 5),
+ /* Parse only one character (len arg to getkeystring() not used) */
+ GETKEY_SINGLE_CHAR = (1 << 6),
+ /*
+ * If beyond offset in misc arg, add 1 to it for each character removed.
+ * Yes, I know that doesn't seem to make much sense.
+ * It's for use in completion, comprenez?
+ */
+ GETKEY_UPDATE_OFFSET = (1 << 7),
+ /*
+ * When replacing numeric escapes for printf format strings, % -> %%
+ */
+ GETKEY_PRINTF_PERCENT = (1 << 8)
+};
+
+/*
+ * Standard combinations used within the shell.
+ * Note GETKEYS_... instead of GETKEY_...: this is important in some cases.
+ */
+/* echo builtin */
+#define GETKEYS_ECHO (GETKEY_BACKSLASH_C)
+/* printf format string: \123 -> S, \0123 -> NL 3, \045 -> %% */
+#define GETKEYS_PRINTF_FMT \
+ (GETKEY_OCTAL_ESC|GETKEY_BACKSLASH_C|GETKEY_PRINTF_PERCENT)
+/* printf argument: \123 -> \123, \0123 -> S */
+#define GETKEYS_PRINTF_ARG (GETKEY_BACKSLASH_C)
+/* Full print without -e */
+#define GETKEYS_PRINT (GETKEY_OCTAL_ESC|GETKEY_BACKSLASH_C|GETKEY_EMACS)
+/* bindkey */
+#define GETKEYS_BINDKEY (GETKEY_OCTAL_ESC|GETKEY_EMACS|GETKEY_CTRL)
+/* $'...' */
+#define GETKEYS_DOLLARS_QUOTE (GETKEY_OCTAL_ESC|GETKEY_EMACS|GETKEY_DOLLAR_QUOTE)
+/* Single character for math processing */
+#define GETKEYS_MATH \
+ (GETKEY_OCTAL_ESC|GETKEY_EMACS|GETKEY_CTRL|GETKEY_SINGLE_CHAR)
+/* Used to process separators etc. with print-style escapes */
+#define GETKEYS_SEP (GETKEY_OCTAL_ESC|GETKEY_EMACS)
+/* Used for suffix removal */
+#define GETKEYS_SUFFIX \
+ (GETKEY_OCTAL_ESC|GETKEY_EMACS|GETKEY_CTRL|GETKEY_BACKSLASH_MINUS)
+
+/**********************************/
+/* Flags to third argument of zle */
+/**********************************/
+
+#define ZLRF_HISTORY 0x01 /* OK to access the history list */
+#define ZLRF_NOSETTY 0x02 /* Don't set tty before return */
+#define ZLRF_IGNOREEOF 0x04 /* Ignore an EOF from the keyboard */
+
+/***************************/
+/* Context of zleread call */
+/***************************/
+
+enum {
+ ZLCON_LINE_START, /* Command line at PS1 */
+ ZLCON_LINE_CONT, /* Command line at PS2 */
+ ZLCON_SELECT, /* Select loop */
+ ZLCON_VARED /* Vared command */
+};
+
+/****************/
+/* Entry points */
+/****************/
+
+/* compctl entry point pointers */
+
+typedef int (*CompctlReadFn) _((char *, char **, Options, char *));
+
+/* ZLE entry point pointer */
+
+typedef char * (*ZleEntryPoint)(int cmd, va_list ap);
+
+/* Commands to pass to entry point */
+
+enum {
+ ZLE_CMD_GET_LINE,
+ ZLE_CMD_READ,
+ ZLE_CMD_ADD_TO_LINE,
+ ZLE_CMD_TRASH,
+ ZLE_CMD_RESET_PROMPT,
+ ZLE_CMD_REFRESH,
+ ZLE_CMD_SET_KEYMAP,
+ ZLE_CMD_GET_KEY,
+ ZLE_CMD_SET_HIST_LINE
+};
+
+/***************************************/
+/* Hooks in core. */
+/***************************************/
+
+#define EXITHOOK (zshhooks + 0)
+#define BEFORETRAPHOOK (zshhooks + 1)
+#define AFTERTRAPHOOK (zshhooks + 2)
+
+#ifdef MULTIBYTE_SUPPORT
+/* Final argument to mb_niceformat() */
+enum {
+ NICEFLAG_HEAP = 1, /* Heap allocation where needed */
+ NICEFLAG_QUOTE = 2, /* Result will appear in $'...' */
+ NICEFLAG_NODUP = 4, /* Leave allocated */
+};
+
+/* Metafied input */
+#define nicezputs(str, outs) (void)mb_niceformat((str), (outs), NULL, 0)
+#define MB_METACHARINIT() mb_charinit()
+typedef wint_t convchar_t;
+#define MB_METACHARLENCONV(str, cp) mb_metacharlenconv((str), (cp))
+#define MB_METACHARLEN(str) mb_metacharlenconv(str, NULL)
+#define MB_METASTRLEN(str) mb_metastrlenend(str, 0, NULL)
+#define MB_METASTRWIDTH(str) mb_metastrlenend(str, 1, NULL)
+#define MB_METASTRLEN2(str, widthp) mb_metastrlenend(str, widthp, NULL)
+#define MB_METASTRLEN2END(str, widthp, eptr) \
+ mb_metastrlenend(str, widthp, eptr)
+
+/* Unmetafined input */
+#define MB_CHARINIT() mb_charinit()
+#define MB_CHARLENCONV(str, len, cp) mb_charlenconv((str), (len), (cp))
+#define MB_CHARLEN(str, len) mb_charlenconv((str), (len), NULL)
+
+/*
+ * We replace broken implementations with one that uses Unicode
+ * characters directly as wide characters. In principle this is only
+ * likely to work if __STDC_ISO_10646__ is defined, since that's pretty
+ * much what the definition tells us. However, we happen to know this
+ * works on MacOS which doesn't define that.
+ */
+#ifdef ENABLE_UNICODE9
+#define WCWIDTH(wc) u9_wcwidth(wc)
+#else
+#define WCWIDTH(wc) wcwidth(wc)
+#endif
+/*
+ * Note WCWIDTH_WINT() takes wint_t, typically as a convchar_t.
+ * It's written to use the wint_t from mb_metacharlenconv() without
+ * further tests.
+ *
+ * This version has a non-multibyte definition that simply returns
+ * 1. We never expose WCWIDTH() in the non-multibyte world since
+ * it's just a proxy for wcwidth() itself.
+ */
+#define WCWIDTH_WINT(wc) zwcwidth(wc)
+
+#define MB_INCOMPLETE ((size_t)-2)
+#define MB_INVALID ((size_t)-1)
+
+/*
+ * MB_CUR_MAX is the maximum number of bytes that a single wide
+ * character will convert into. We use it to keep strings
+ * sufficiently long. It should always be defined, but if it isn't
+ * just assume we are using Unicode which requires 6 characters.
+ * (Note that it's not necessarily defined to a constant.)
+ */
+#ifndef MB_CUR_MAX
+#define MB_CUR_MAX 6
+#endif
+
+/* Convert character or string to wide character or string */
+#define ZWC(c) L ## c
+#define ZWS(s) L ## s
+
+/*
+ * Test for a combining character.
+ *
+ * wc is assumed to be a wchar_t (i.e. we don't need zwcwidth).
+ *
+ * Pedantic note: in Unicode, a combining character need not be
+ * zero length. However, we are concerned here about display;
+ * we simply need to know whether the character will be displayed
+ * on top of another one. We use "combining character" in this
+ * sense throughout the shell. I am not aware of a way of
+ * detecting the Unicode trait in standard libraries.
+ */
+#define IS_COMBINING(wc) (wc != 0 && WCWIDTH(wc) == 0)
+/*
+ * Test for the base of a combining character.
+ *
+ * We assume a combining character can be successfully displayed with
+ * any non-space printable character, which is what a graphic character
+ * is, as long as it has non-zero width. We need to avoid all forms of
+ * space because the shell will split words on any whitespace.
+ */
+#define IS_BASECHAR(wc) (iswgraph(wc) && WCWIDTH(wc) > 0)
+
+#else /* not MULTIBYTE_SUPPORT */
+
+#define MB_METACHARINIT()
+typedef int convchar_t;
+#define MB_METACHARLENCONV(str, cp) metacharlenconv((str), (cp))
+#define MB_METACHARLEN(str) (*(str) == Meta ? 2 : 1)
+#define MB_METASTRLEN(str) ztrlen(str)
+#define MB_METASTRWIDTH(str) ztrlen(str)
+#define MB_METASTRLEN2(str, widthp) ztrlen(str)
+#define MB_METASTRLEN2END(str, widthp, eptr) ztrlenend(str, eptr)
+
+#define MB_CHARINIT()
+#define MB_CHARLENCONV(str, len, cp) charlenconv((str), (len), (cp))
+#define MB_CHARLEN(str, len) ((len) ? 1 : 0)
+
+#define WCWIDTH_WINT(c) (1)
+
+/* Leave character or string as is. */
+#define ZWC(c) c
+#define ZWS(s) s
+
+#endif /* MULTIBYTE_SUPPORT */
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/zsh.mdd b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/zsh.mdd
new file mode 100644
index 0000000..d95f5d5
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/zsh.mdd
@@ -0,0 +1,147 @@
+name=zsh/main
+link=static
+load=yes
+# load=static should replace use of alwayslink
+functions='Functions/Chpwd/* Functions/Exceptions/* Functions/Math/* Functions/Misc/* Functions/MIME/* Functions/Prompts/* Functions/VCS_Info/* Functions/VCS_Info/Backends/*'
+
+nozshdep=1
+alwayslink=1
+
+# autofeatures not specified because of alwayslink
+
+objects="signames.o builtin.o module.o lex.o exec.o mem.o \
+string.o parse.o hashtable.o init.o input.o loop.o utils.o params.o options.o \
+signals.o pattern.o prompt.o compat.o jobs.o glob.o"
+
+headers="../config.h zsh_system.h zsh.h sigcount.h signals.h \
+prototypes.h hashtable.h ztype.h"
+hdrdeps="zshcurses.h zshterm.h"
+
+:<<\Make
+@CONFIG_MK@
+
+# If we're using gcc as the preprocessor, get rid of the additional
+# lines generated by the preprocessor as they can confuse the script.
+# We don't need these in other cases either, but can't necessarily rely
+# on the option to remove them being the same.
+signames.c: signames1.awk signames2.awk ../config.h @SIGNAL_H@
+ $(AWK) -f $(sdir)/signames1.awk @SIGNAL_H@ >sigtmp.c
+ case "`$(CPP) --version &1`" in \
+ *"Free Software Foundation"*) \
+ $(CPP) -P sigtmp.c >sigtmp.out;; \
+ *) \
+ $(CPP) sigtmp.c >sigtmp.out;; \
+ esac
+ $(AWK) -f $(sdir)/signames2.awk sigtmp.out > $@
+ rm -f sigtmp.c sigtmp.out
+
+sigcount.h: signames.c
+ grep 'define.*SIGCOUNT' signames.c > $@
+
+init.o: bltinmods.list zshpaths.h zshxmods.h
+
+init.o params.o parse.o: version.h
+
+params.o: patchlevel.h
+
+version.h: $(sdir_top)/Config/version.mk zshcurses.h zshterm.h
+ echo '#define ZSH_VERSION "'$(VERSION)'"' > $@
+
+patchlevel.h: FORCE
+ @if [ -f $(sdir)/$@.release ]; then \
+ cp -f $(sdir)/$@.release $@; \
+ else \
+ echo '#define ZSH_PATCHLEVEL "'`cd $(sdir) && git describe --tags --long`'"' > $@.tmp; \
+ cmp $@ $@.tmp >/dev/null 2>&1 && rm -f $@.tmp || mv $@.tmp $@; \
+ fi
+FORCE:
+
+zshcurses.h: ../config.h
+ @if test x$(ZSH_CURSES_H) != x; then \
+ echo "#include <$(ZSH_CURSES_H)>" >zshcurses.h; \
+ else \
+ echo >zshcurses.h; \
+ fi
+
+zshterm.h: ../config.h
+ @if test x$(ZSH_TERM_H) != x; then \
+ echo "#include <$(ZSH_TERM_H)>" >zshterm.h; \
+ else \
+ echo >zshterm.h; \
+ fi
+
+zshpaths.h: Makemod $(CONFIG_INCS)
+ @echo '#define MODULE_DIR "'$(MODDIR)'"' > zshpaths.h.tmp
+ @if test x$(sitescriptdir) != xno; then \
+ echo '#define SITESCRIPT_DIR "'$(sitescriptdir)'"' >> zshpaths.h.tmp; \
+ fi
+ @if test x$(scriptdir) != xno; then \
+ echo '#define SCRIPT_DIR "'$(scriptdir)'"' >> zshpaths.h.tmp; \
+ fi
+ @if test x$(sitefndir) != xno; then \
+ echo '#define SITEFPATH_DIR "'$(sitefndir)'"' >> zshpaths.h.tmp; \
+ fi
+ @if test x$(fixed_sitefndir) != x; then \
+ echo '#define FIXED_FPATH_DIR "'$(fixed_sitefndir)'"' >> zshpaths.h.tmp; \
+ fi
+ @if test x$(fndir) != xno; then \
+ echo '#define FPATH_DIR "'$(fndir)'"' >> zshpaths.h.tmp; \
+ if test x$(FUNCTIONS_SUBDIRS) != x && \
+ test x$(FUNCTIONS_SUBDIRS) != xno; then \
+ fpath_tmp="`grep ' functions=.' \
+ $(dir_top)/config.modules | sed -e '/^#/d' -e '/ link=no/d' \
+ -e 's/^.* functions=//'`"; \
+ fpath_tmp=`for f in $$fpath_tmp; do \
+ echo $$f | sed -e 's%^Functions/%%' -e 's%/[^/]*$$%%' -e 's%/\*%%'; \
+ done | grep -v Scripts | sort | uniq`; \
+ fpath_tmp=`echo $$fpath_tmp | sed 's/ /\", \"/g'`; \
+ echo "#define FPATH_SUBDIRS { \"$$fpath_tmp\" }" \
+ >>zshpaths.h.tmp; \
+ fi; \
+ fi
+ @if test x$(additionalfpath) != x; then \
+ fpath_tmp="`echo $(additionalfpath) | sed -e 's:,:\", \":g'`"; \
+ echo "#define ADDITIONAL_FPATH { \"$$fpath_tmp\" }" >> zshpaths.h.tmp; \
+ fi
+ @if cmp -s zshpaths.h zshpaths.h.tmp; then \
+ rm -f zshpaths.h.tmp; \
+ echo "\`zshpaths.h' is up to date." ; \
+ else \
+ mv -f zshpaths.h.tmp zshpaths.h; \
+ echo "Updated \`zshpaths.h'." ; \
+ fi
+
+bltinmods.list: modules.stamp mkbltnmlst.sh $(dir_top)/config.modules
+ srcdir='$(sdir)' CFMOD='$(dir_top)/config.modules' \
+ $(SHELL) $(sdir)/mkbltnmlst.sh $@
+
+zshxmods.h: $(dir_top)/config.modules
+ @echo "Creating \`$@'."
+ @( \
+ for q_mod in `grep ' load=yes' $(dir_top)/config.modules | \
+ grep ' link=static' | sed -e '/^#/d' -e 's/ .*//' \
+ -e 's/^name=//' -e 's,Q,Qq,g;s,_,Qu,g;s,/,Qs,g'`; do \
+ test x$q_mod = xzshQsmain && continue; \
+ echo "#define LINKED_XMOD_$$q_mod 1"; \
+ done; \
+ for q_mod in `grep ' load=yes' $(dir_top)/config.modules | \
+ grep ' link=dynamic' | sed -e '/^#/d' -e 's/ .*//' \
+ -e 's/^name=//' -e 's,Q,Qq,g;s,_,Qu,g;s,/,Qs,g'`; do \
+ test x$q_mod = x && continue; \
+ echo "#ifdef DYNAMIC"; \
+ echo "# define UNLINKED_XMOD_$$q_mod 1"; \
+ echo "#endif"; \
+ done; \
+ ) > $@
+
+clean-here: clean.zsh
+clean.zsh:
+ rm -f sigcount.h signames.c bltinmods.list version.h zshpaths.h zshxmods.h
+
+# This is not properly part of this module, but it is built as if it were.
+main.o: main.c zsh.mdh main.epro
+ $(CC) -c -I. -I$(sdir_top)/Src $(CPPFLAGS) $(DEFS) $(CFLAGS) -o $@ $(sdir)/main.c
+
+main.syms: $(PROTODEPS)
+proto.zsh: main.epro
+Make
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/zsh.rc b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/zsh.rc
new file mode 100644
index 0000000..93c82ba
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/zsh.rc
@@ -0,0 +1,8 @@
+// Use this file as follows
+//
+// myapp.exe : myapp.o myapp.res
+// gcc -mwindows myapp.o myapp.res -o $@
+//
+// myapp.res : myapp.rc resource.h
+// windres $< -O coff -o $@
+IDR_MAINFRAME ICON DISCARDABLE "zsh.ico"
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/zsh_system.h b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/zsh_system.h
new file mode 100644
index 0000000..8289ee9
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/zsh_system.h
@@ -0,0 +1,900 @@
+/*
+ * system.h - system configuration header file
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+#if 0
+/*
+ * Setting _XPG_IV here is actually wrong and is not needed
+ * with currently supported versions (5.43C20 and above)
+ */
+#ifdef sinix
+# define _XPG_IV 1
+#endif
+#endif
+
+#if defined(__linux) || defined(__GNU__) || defined(__GLIBC__) || defined(LIBC_MUSL) || defined(__CYGWIN__)
+/*
+ * Turn on numerous extensions.
+ * This is in order to get the functions for manipulating /dev/ptmx.
+ */
+#define _GNU_SOURCE 1
+#endif
+#ifdef LIBC_MUSL
+#define _POSIX_C_SOURCE 200809L
+#endif
+
+/* NeXT has half-implemented POSIX support *
+ * which currently fools configure */
+#ifdef __NeXT__
+# undef HAVE_TERMIOS_H
+# undef HAVE_SYS_UTSNAME_H
+#endif
+
+#ifndef ZSH_NO_XOPEN
+# ifdef ZSH_CURSES_SOURCE
+# define _XOPEN_SOURCE_EXTENDED 1
+# else
+# ifdef MULTIBYTE_SUPPORT
+/*
+ * Needed for wcwidth() which is part of XSI.
+ * Various other uses of the interface mean we can't get away with just
+ * _XOPEN_SOURCE.
+ */
+# define _XOPEN_SOURCE_EXTENDED 1
+# endif /* MULTIBYTE_SUPPORT */
+# endif /* ZSH_CURSES_SOURCE */
+#endif /* ZSH_NO_XOPEN */
+
+/*
+ * Solaris by default zeroes all elements of the tm structure in
+ * strptime(). Unfortunately that gives us no way of telling whether
+ * the tm_isdst element has been set from the input pattern. If it
+ * hasn't we want it to be -1 (undetermined) on input to mktime(). So
+ * we stop strptime() zeroing the struct tm and instead set all the
+ * elements ourselves.
+ *
+ * This is likely to be harmless everywhere else.
+ */
+#define _STRPTIME_DONTZERO
+
+#ifdef PROTOTYPES
+# define _(Args) Args
+#else
+# define _(Args) ()
+#endif
+
+#ifndef HAVE_ALLOCA
+# define alloca zhalloc
+#else
+# ifdef __GNUC__
+# define alloca __builtin_alloca
+# else
+# if HAVE_ALLOCA_H
+# include
+# else
+# ifdef _AIX
+ # pragma alloca
+# else
+# ifndef alloca
+char *alloca _((size_t));
+# endif
+# endif
+# endif
+# endif
+#endif
+
+/*
+ * libc.h in an optional package for Debian Linux is broken (it
+ * defines dup() as a synonym for dup2(), which has a different
+ * number of arguments), so just include it for next.
+ */
+#ifdef __NeXT__
+# ifdef HAVE_LIBC_H
+# include
+# endif
+#endif
+
+#ifdef HAVE_SYS_TYPES_H
+# include
+#endif
+
+#ifdef HAVE_UNISTD_H
+# include
+#endif
+
+#ifdef HAVE_STDDEF_H
+/*
+ * Seen on Solaris 8 with gcc: stddef defines offsetof, which clashes
+ * with system.h's definition of the symbol unless we include this
+ * first. Otherwise, this will be hooked in by wchar.h, too late
+ * for comfort.
+ */
+#include
+#endif
+
+#include
+#include
+#include
+#include
+#include
+
+#ifdef HAVE_PWD_H
+# include
+#endif
+
+#ifdef HAVE_GRP_H
+# include
+#endif
+
+#ifdef HAVE_DIRENT_H
+# include
+#else /* !HAVE_DIRENT_H */
+# ifdef HAVE_SYS_NDIR_H
+# include
+# endif
+# ifdef HAVE_SYS_DIR_H
+# include
+# endif
+# ifdef HAVE_NDIR_H
+# include
+# endif
+# define dirent direct
+# undef HAVE_STRUCT_DIRENT_D_INO
+# undef HAVE_STRUCT_DIRENT_D_STAT
+# ifdef HAVE_STRUCT_DIRECT_D_INO
+# define HAVE_STRUCT_DIRENT_D_INO HAVE_STRUCT_DIRECT_D_INO
+# endif
+# ifdef HAVE_STRUCT_DIRECT_D_STAT
+# define HAVE_STRUCT_DIRENT_D_STAT HAVE_STRUCT_DIRECT_D_STAT
+# endif
+#endif /* !HAVE_DIRENT_H */
+
+#ifdef HAVE_STDLIB_H
+# ifdef ZSH_MEM
+ /* malloc and calloc are macros in GNU's stdlib.h unless the
+ * the __MALLOC_0_RETURNS_NULL macro is defined */
+# define __MALLOC_0_RETURNS_NULL
+# endif
+# include
+#endif
+
+/*
+ * Stuff with variable arguments. We use definitions to make the
+ * same code work with varargs (the original K&R-style, just to
+ * be maximally compatible) and stdarg (which all modern systems
+ * should have).
+ *
+ * Ideally this should somehow be merged with the tricks performed
+ * with "_" in makepro.awk, but I don't understand makepro.awk.
+ * Currently we simply rely on the fact that makepro.awk has been
+ * hacked to leave alone argument lists that already contains VA_ALIST
+ * except for removing the VA_DCL and turning VA_ALIST into VA_ALIST_PROTO.
+ */
+#ifdef HAVE_STDARG_H
+# include
+# define VA_ALIST1(x) x, ...
+# define VA_ALIST2(x,y) x, y, ...
+# define VA_ALIST_PROTO1(x) VA_ALIST1(x)
+# define VA_ALIST_PROTO2(x,y) VA_ALIST2(x,y)
+# define VA_DCL
+# define VA_DEF_ARG(x)
+# define VA_START(ap,x) va_start(ap, x)
+# define VA_GET_ARG(ap,x,t)
+#else
+# if HAVE_VARARGS_H
+# include
+# define VA_ALIST1(x) va_alist
+# define VA_ALIST2(x,y) va_alist
+/*
+ * In prototypes, assume K&R form and remove the variable list.
+ * This is about the best we can do without second-guessing the way
+ * varargs works on this system. The _ trick should be able to
+ * do this for us but we've turned it off here.
+ */
+# define VA_ALIST_PROTO1(x)
+# define VA_ALIST_PROTO2(x,y)
+# define VA_DCL va_dcl
+# define VA_DEF_ARG(x) x
+# define VA_START(ap,x) va_start(ap);
+# define VA_GET_ARG(ap,x,t) (x = va_arg(ap, t))
+# else
+# error "Your system has neither stdarg.h or varargs.h."
+# endif
+#endif
+
+#ifdef HAVE_ERRNO_H
+# include
+#endif
+
+#ifdef TIME_WITH_SYS_TIME
+# include
+# include
+#else
+# ifdef HAVE_SYS_TIME_H
+# include
+# else
+# include
+# endif
+#endif
+
+/* This is needed by some old SCO unices */
+#if !defined(HAVE_STRUCT_TIMEZONE) && !defined(ZSH_OOT_MODULE)
+struct timezone {
+ int tz_minuteswest;
+ int tz_dsttime;
+};
+#endif
+
+/* Used to provide compatibility with clock_gettime() */
+#if !defined(HAVE_STRUCT_TIMESPEC) && !defined(ZSH_OOT_MODULE)
+struct timespec {
+ time_t tv_sec;
+ long tv_nsec;
+};
+#endif
+
+/* There's more than one non-standard way to get at this data */
+#if !defined(HAVE_STRUCT_DIRENT_D_INO) && defined(HAVE_STRUCT_DIRENT_D_STAT)
+# define d_ino d_stat.st_ino
+# define HAVE_STRUCT_DIRENT_D_INO HAVE_STRUCT_DIRENT_D_STAT
+#endif /* !HAVE_STRUCT_DIRENT_D_INO && HAVE_STRUCT_DIRENT_D_STAT */
+
+/* Sco needs the following include for struct utimbuf *
+ * which is strange considering we do not use that *
+ * anywhere in the code */
+#ifdef __sco
+# include
+#endif
+
+#ifdef HAVE_SYS_TIMES_H
+# include
+#endif
+
+#if STDC_HEADERS || HAVE_STRING_H
+# include
+/* An ANSI string.h and pre-ANSI memory.h might conflict. */
+# if !STDC_HEADERS && HAVE_MEMORY_H
+# include
+# endif /* not STDC_HEADERS and HAVE_MEMORY_H */
+#else /* not STDC_HEADERS and not HAVE_STRING_H */
+# include
+/* memory.h and strings.h conflict on some systems. */
+#endif /* not STDC_HEADERS and not HAVE_STRING_H */
+
+#ifdef HAVE_LOCALE_H
+# include
+#endif
+
+#ifdef HAVE_LIMITS_H
+# include
+#endif
+
+#ifdef USE_STACK_ALLOCATION
+#ifdef HAVE_VARIABLE_LENGTH_ARRAYS
+# define VARARR(X,Y,Z) X (Y)[Z]
+#else
+# define VARARR(X,Y,Z) X *(Y) = (X *) alloca(sizeof(X) * (Z))
+#endif
+#else
+# define VARARR(X,Y,Z) X *(Y) = (X *) zhalloc(sizeof(X) * (Z))
+#endif
+
+/* we should handle unlimited sizes from pathconf(_PC_PATH_MAX) */
+/* but this is too much trouble */
+#ifndef PATH_MAX
+# ifdef MAXPATHLEN
+# define PATH_MAX MAXPATHLEN
+# else
+# ifdef _POSIX_PATH_MAX
+# define PATH_MAX _POSIX_PATH_MAX
+# else
+ /* so we will just pick something */
+# define PATH_MAX 1024
+# endif
+# endif
+#endif
+
+/*
+ * The number of file descriptors we'll allocate initially.
+ * We will reallocate later if necessary.
+ */
+#define ZSH_INITIAL_OPEN_MAX 64
+#ifndef OPEN_MAX
+# ifdef NOFILE
+# define OPEN_MAX NOFILE
+# else
+ /* so we will just pick something */
+# define OPEN_MAX ZSH_INITIAL_OPEN_MAX
+# endif
+#endif
+#ifndef HAVE_SYSCONF
+# define zopenmax() ((long) (OPEN_MAX > ZSH_INITIAL_OPEN_MAX ? \
+ ZSH_INITIAL_OPEN_MAX : OPEN_MAX))
+#endif
+
+#ifdef HAVE_FCNTL_H
+# include
+#else
+# include
+#endif
+
+/* The following will only be defined if is POSIX. *
+ * So we don't have to worry about union wait. But some machines *
+ * (NeXT) include from other include files, so we *
+ * need to undef and then redefine the wait macros if *
+ * is not POSIX. */
+
+#ifdef HAVE_SYS_WAIT_H
+# include
+#else
+# undef WIFEXITED
+# undef WEXITSTATUS
+# undef WIFSIGNALED
+# undef WTERMSIG
+# undef WCOREDUMP
+# undef WIFSTOPPED
+# undef WSTOPSIG
+#endif
+
+/* missing macros for wait/waitpid/wait3 */
+#ifndef WIFEXITED
+# define WIFEXITED(X) (((X)&0377)==0)
+#endif
+#ifndef WEXITSTATUS
+# define WEXITSTATUS(X) (((X)>>8)&0377)
+#endif
+#ifndef WIFSIGNALED
+# define WIFSIGNALED(X) (((X)&0377)!=0&&((X)&0377)!=0177)
+#endif
+#ifndef WTERMSIG
+# define WTERMSIG(X) ((X)&0177)
+#endif
+#ifndef WCOREDUMP
+# define WCOREDUMP(X) ((X)&0200)
+#endif
+#ifndef WIFSTOPPED
+# define WIFSTOPPED(X) (((X)&0377)==0177)
+#endif
+#ifndef WSTOPSIG
+# define WSTOPSIG(X) (((X)>>8)&0377)
+#endif
+
+#ifdef HAVE_SYS_SELECT_H
+# ifndef TIME_H_SELECT_H_CONFLICTS
+# include
+# endif
+#elif defined(SELECT_IN_SYS_SOCKET_H)
+# include
+#endif
+
+#if defined(__APPLE__) && defined(HAVE_SELECT)
+/*
+ * Prefer select() to poll() on MacOS X since poll() is known
+ * to be problematic in 10.4
+ */
+#undef HAVE_POLL
+#undef HAVE_POLL_H
+#endif
+
+#ifdef HAVE_SYS_FILIO_H
+# include
+#endif
+
+#ifdef HAVE_TERMIOS_H
+# ifdef __sco
+ /* termios.h includes sys/termio.h instead of sys/termios.h; *
+ * hence the declaration for struct termios is missing */
+# include
+# else
+# include
+# endif
+# ifdef _POSIX_VDISABLE
+# define VDISABLEVAL _POSIX_VDISABLE
+# else
+# define VDISABLEVAL 0
+# endif
+# define HAS_TIO 1
+#else /* not TERMIOS */
+# ifdef HAVE_TERMIO_H
+# include
+# define VDISABLEVAL -1
+# define HAS_TIO 1
+# else /* not TERMIOS and TERMIO */
+# include
+# endif /* HAVE_TERMIO_H */
+#endif /* HAVE_TERMIOS_H */
+
+#if defined(GWINSZ_IN_SYS_IOCTL) || defined(IOCTL_IN_SYS_IOCTL)
+# include
+#endif
+#ifdef WINSIZE_IN_PTEM
+# include
+# include
+#endif
+
+#ifdef HAVE_SYS_PARAM_H
+# include
+#endif
+
+#ifdef HAVE_SYS_UTSNAME_H
+# include
+#endif
+
+#define DEFAULT_WORDCHARS "*?_-.[]~=/&;!#$%^(){}<>"
+#define DEFAULT_TIMEFMT "%J %U user %S system %P cpu %*E total"
+
+/* Posix getpgrp takes no argument, while the BSD version *
+ * takes the process ID as an argument */
+#ifdef GETPGRP_VOID
+# define GETPGRP() getpgrp()
+#else
+# define GETPGRP() getpgrp(0)
+#endif
+
+#ifndef HAVE_GETLOGIN
+# define getlogin() cuserid(NULL)
+#endif
+
+#ifdef HAVE_SETPGID
+# define setpgrp setpgid
+#endif
+
+/* can we set the user/group id of a process */
+
+#ifndef HAVE_SETUID
+# ifdef HAVE_SETREUID
+# define setuid(X) setreuid(X,X)
+# define setgid(X) setregid(X,X)
+# define HAVE_SETUID
+# endif
+#endif
+
+/* can we set the effective user/group id of a process */
+
+#ifndef HAVE_SETEUID
+# ifdef HAVE_SETREUID
+# define seteuid(X) setreuid(-1,X)
+# define setegid(X) setregid(-1,X)
+# define HAVE_SETEUID
+# else
+# ifdef HAVE_SETRESUID
+# define seteuid(X) setresuid(-1,X,-1)
+# define setegid(X) setresgid(-1,X,-1)
+# define HAVE_SETEUID
+# endif
+# endif
+#endif
+
+#ifdef HAVE_SYS_RESOURCE_H
+# include
+# if defined(__hpux) && !defined(RLIMIT_CPU)
+/* HPUX does have the BSD rlimits in the kernel. Officially they are *
+ * unsupported but quite a few of them like RLIMIT_CORE seem to work. *
+ * All the following are in the but made visible *
+ * only for the kernel. */
+# define RLIMIT_CPU 0
+# define RLIMIT_FSIZE 1
+# define RLIMIT_DATA 2
+# define RLIMIT_STACK 3
+# define RLIMIT_CORE 4
+# define RLIMIT_RSS 5
+# define RLIMIT_NOFILE 6
+# define RLIMIT_OPEN_MAX RLIMIT_NOFILE
+# define RLIM_NLIMITS 7
+# define RLIM_INFINITY 0x7fffffff
+# endif
+#endif
+
+/* we use the SVR4 constant instead of the BSD one */
+#if !defined(RLIMIT_NOFILE) && defined(RLIMIT_OFILE)
+# define RLIMIT_NOFILE RLIMIT_OFILE
+#endif
+#if !defined(RLIMIT_VMEM) && defined(RLIMIT_AS)
+# define RLIMIT_VMEM RLIMIT_AS
+#endif
+
+#ifdef HAVE_SYS_CAPABILITY_H
+# include
+#endif
+
+/* DIGBUFSIZ is the length of a buffer which can hold the -LONG_MAX-1 *
+ * (or with ZSH_64_BIT_TYPE maybe -LONG_LONG_MAX-1) *
+ * converted to printable decimal form including the sign and the *
+ * terminating null character. Below 0.30103 > lg 2. *
+ * BDIGBUFSIZE is for a number converted to printable binary form. */
+#define DIGBUFSIZE ((int)(((sizeof(zlong) * 8) - 1) * 30103/100000) + 3)
+#define BDIGBUFSIZE ((int)((sizeof(zlong) * 8) + 4))
+
+/* If your stat macros are broken, we will *
+ * just undefine them. */
+
+#ifdef STAT_MACROS_BROKEN
+# undef S_ISBLK
+# undef S_ISCHR
+# undef S_ISDIR
+# undef S_ISDOOR
+# undef S_ISFIFO
+# undef S_ISLNK
+# undef S_ISMPB
+# undef S_ISMPC
+# undef S_ISNWK
+# undef S_ISOFD
+# undef S_ISOFL
+# undef S_ISREG
+# undef S_ISSOCK
+#endif /* STAT_MACROS_BROKEN. */
+
+/* If you are missing the stat macros, we *
+ * define our own */
+
+#ifndef S_IFMT
+# define S_IFMT 0170000
+#endif
+
+#if !defined(S_ISBLK) && defined(S_IFBLK)
+# define S_ISBLK(m) (((m) & S_IFMT) == S_IFBLK)
+#endif
+#if !defined(S_ISCHR) && defined(S_IFCHR)
+# define S_ISCHR(m) (((m) & S_IFMT) == S_IFCHR)
+#endif
+#if !defined(S_ISDIR) && defined(S_IFDIR)
+# define S_ISDIR(m) (((m) & S_IFMT) == S_IFDIR)
+#endif
+#if !defined(S_ISDOOR) && defined(S_IFDOOR) /* Solaris */
+# define S_ISDOOR(m) (((m) & S_IFMT) == S_IFDOOR)
+#endif
+#if !defined(S_ISFIFO) && defined(S_IFIFO)
+# define S_ISFIFO(m) (((m) & S_IFMT) == S_IFIFO)
+#endif
+#if !defined(S_ISLNK) && defined(S_IFLNK)
+# define S_ISLNK(m) (((m) & S_IFMT) == S_IFLNK)
+#endif
+#if !defined(S_ISMPB) && defined(S_IFMPB) /* V7 */
+# define S_ISMPB(m) (((m) & S_IFMT) == S_IFMPB)
+#endif
+#if !defined(S_ISMPC) && defined(S_IFMPC) /* V7 */
+# define S_ISMPC(m) (((m) & S_IFMT) == S_IFMPC)
+#endif
+#if !defined(S_ISNWK) && defined(S_IFNWK) /* HP/UX */
+# define S_ISNWK(m) (((m) & S_IFMT) == S_IFNWK)
+#endif
+#if !defined(S_ISOFD) && defined(S_IFOFD) /* Cray */
+# define S_ISOFD(m) (((m) & S_IFMT) == S_IFOFD)
+#endif
+#if !defined(S_ISOFL) && defined(S_IFOFL) /* Cray */
+# define S_ISOFL(m) (((m) & S_IFMT) == S_IFOFL)
+#endif
+#if !defined(S_ISREG) && defined(S_IFREG)
+# define S_ISREG(m) (((m) & S_IFMT) == S_IFREG)
+#endif
+#if !defined(S_ISSOCK) && defined(S_IFSOCK)
+# define S_ISSOCK(m) (((m) & S_IFMT) == S_IFSOCK)
+#endif
+
+/* We will pretend to have all file types on any system. */
+
+#ifndef S_ISBLK
+# define S_ISBLK(m) ((void)(m), 0)
+#endif
+#ifndef S_ISCHR
+# define S_ISCHR(m) ((void)(m), 0)
+#endif
+#ifndef S_ISDIR
+# define S_ISDIR(m) ((void)(m), 0)
+#endif
+#ifndef S_ISDOOR
+# define S_ISDOOR(m) ((void)(m), 0)
+#endif
+#ifndef S_ISFIFO
+# define S_ISFIFO(m) ((void)(m), 0)
+#endif
+#ifndef S_ISLNK
+# define S_ISLNK(m) ((void)(m), 0)
+#endif
+#ifndef S_ISMPB
+# define S_ISMPB(m) ((void)(m), 0)
+#endif
+#ifndef S_ISMPC
+# define S_ISMPC(m) ((void)(m), 0)
+#endif
+#ifndef S_ISNWK
+# define S_ISNWK(m) ((void)(m), 0)
+#endif
+#ifndef S_ISOFD
+# define S_ISOFD(m) ((void)(m), 0)
+#endif
+#ifndef S_ISOFL
+# define S_ISOFL(m) ((void)(m), 0)
+#endif
+#ifndef S_ISREG
+# define S_ISREG(m) ((void)(m), 0)
+#endif
+#ifndef S_ISSOCK
+# define S_ISSOCK(m) ((void)(m), 0)
+#endif
+
+/* file mode permission bits */
+
+#ifndef S_ISUID
+# define S_ISUID 04000
+#endif
+#ifndef S_ISGID
+# define S_ISGID 02000
+#endif
+#ifndef S_ISVTX
+# define S_ISVTX 01000
+#endif
+#ifndef S_IRUSR
+# define S_IRUSR 00400
+#endif
+#ifndef S_IWUSR
+# define S_IWUSR 00200
+#endif
+#ifndef S_IXUSR
+# define S_IXUSR 00100
+#endif
+#ifndef S_IRGRP
+# define S_IRGRP 00040
+#endif
+#ifndef S_IWGRP
+# define S_IWGRP 00020
+#endif
+#ifndef S_IXGRP
+# define S_IXGRP 00010
+#endif
+#ifndef S_IROTH
+# define S_IROTH 00004
+#endif
+#ifndef S_IWOTH
+# define S_IWOTH 00002
+#endif
+#ifndef S_IXOTH
+# define S_IXOTH 00001
+#endif
+#ifndef S_IRWXU
+# define S_IRWXU (S_IRUSR|S_IWUSR|S_IXUSR)
+#endif
+#ifndef S_IRWXG
+# define S_IRWXG (S_IRGRP|S_IWGRP|S_IXGRP)
+#endif
+#ifndef S_IRWXO
+# define S_IRWXO (S_IROTH|S_IWOTH|S_IXOTH)
+#endif
+#ifndef S_IRUGO
+# define S_IRUGO (S_IRUSR|S_IRGRP|S_IROTH)
+#endif
+#ifndef S_IWUGO
+# define S_IWUGO (S_IWUSR|S_IWGRP|S_IWOTH)
+#endif
+#ifndef S_IXUGO
+# define S_IXUGO (S_IXUSR|S_IXGRP|S_IXOTH)
+#endif
+
+#ifndef HAVE_LSTAT
+# define lstat stat
+#endif
+
+#ifndef HAVE_READLINK
+# define readlink(PATH, BUF, BUFSZ) \
+ ((void)(PATH), (void)(BUF), (void)(BUFSZ), errno = ENOSYS, -1)
+#endif
+
+#ifndef F_OK /* missing macros for access() */
+# define F_OK 0
+# define X_OK 1
+# define W_OK 2
+# define R_OK 4
+#endif
+
+#ifndef HAVE_LCHOWN
+# define lchown chown
+#endif
+
+#ifndef HAVE_MEMCPY
+# define memcpy memmove
+#endif
+
+#ifndef HAVE_MEMMOVE
+# ifndef memmove
+static char *zmmv;
+# define memmove(dest, src, len) (bcopy((src), zmmv = (dest), (len)), zmmv)
+# endif
+#endif
+
+#ifndef offsetof
+# define offsetof(TYPE, MEM) ((char *)&((TYPE *)0)->MEM - (char *)(TYPE *)0)
+#endif
+
+extern char **environ;
+
+/*
+ * We always need setenv and unsetenv in pairs, because
+ * we don't know how to do memory management on the values set.
+ */
+#if defined(HAVE_SETENV) && defined(HAVE_UNSETENV) && !defined(__APPLE__)
+# define USE_SET_UNSET_ENV
+#endif
+
+
+/* These variables are sometimes defined in, *
+ * and needed by, the termcap library. */
+#if MUST_DEFINE_OSPEED
+extern char PC, *BC, *UP;
+extern short ospeed;
+#endif
+
+#ifndef O_NOCTTY
+# define O_NOCTTY 0
+#endif
+
+#ifdef _LARGEFILE_SOURCE
+#ifdef HAVE_FSEEKO
+#define fseek fseeko
+#endif
+#ifdef HAVE_FTELLO
+#define ftell ftello
+#endif
+#endif
+
+/* Can't support job control without working tcsetgrp() */
+#ifdef BROKEN_TCSETPGRP
+#undef JOB_CONTROL
+#endif /* BROKEN_TCSETPGRP */
+
+#ifdef BROKEN_KILL_ESRCH
+#undef ESRCH
+#define ESRCH EINVAL
+#endif /* BROKEN_KILL_ESRCH */
+
+/* Can we do locale stuff? */
+#undef USE_LOCALE
+#if defined(CONFIG_LOCALE) && defined(HAVE_SETLOCALE) && defined(LC_ALL)
+# define USE_LOCALE 1
+#endif /* CONFIG_LOCALE && HAVE_SETLOCALE && LC_ALL */
+
+#ifndef MAILDIR_SUPPORT
+#define mailstat(X,Y) stat(X,Y)
+#endif
+
+#ifdef __CYGWIN__
+# include
+# define IS_DIRSEP(c) ((c) == '/' || (c) == '\\')
+#else
+# define IS_DIRSEP(c) ((c) == '/')
+#endif
+
+#if defined(__GNUC__) && (!defined(__APPLE__) || defined(__clang__))
+/* Does the OS X port of gcc still gag on __attribute__? */
+#define UNUSED(x) x __attribute__((__unused__))
+#else
+#define UNUSED(x) x
+#endif
+
+/*
+ * The MULTIBYTE_SUPPORT configure-define specifies that we want to enable
+ * complete Unicode conversion between wide characters and multibyte strings.
+ */
+#if defined MULTIBYTE_SUPPORT \
+ || (defined HAVE_WCHAR_H && defined HAVE_WCTOMB && defined __STDC_ISO_10646__)
+/*
+ * If MULTIBYTE_SUPPORT is not defined, these includes provide a subset of
+ * Unicode support that makes the \u and \U printf escape sequences work.
+ */
+
+#if defined(__hpux) && !defined(_INCLUDE__STDC_A1_SOURCE)
+#define _INCLUDE__STDC_A1_SOURCE
+#endif
+
+# include
+# include
+#endif
+#ifdef HAVE_LANGINFO_H
+# include
+# ifdef HAVE_ICONV
+# include
+# endif
+#endif
+
+#if defined(HAVE_INITGROUPS) && !defined(DISABLE_DYNAMIC_NSS)
+# define USE_INITGROUPS
+#endif
+
+#if defined(HAVE_GETGRGID) && !defined(DISABLE_DYNAMIC_NSS)
+# define USE_GETGRGID
+#endif
+
+#if defined(HAVE_GETGRNAM) && !defined(DISABLE_DYNAMIC_NSS)
+# define USE_GETGRNAM
+#endif
+
+#if defined(HAVE_GETPWENT) && !defined(DISABLE_DYNAMIC_NSS)
+# define USE_GETPWENT
+#endif
+
+#if defined(HAVE_GETPWNAM) && !defined(DISABLE_DYNAMIC_NSS)
+# define USE_GETPWNAM
+#endif
+
+#if defined(HAVE_GETPWUID) && !defined(DISABLE_DYNAMIC_NSS)
+# define USE_GETPWUID
+#endif
+
+#ifdef HAVE_STRUCT_STAT_ST_ATIM_TV_NSEC
+# define GET_ST_ATIME_NSEC(st) (st).st_atim.tv_nsec
+#elif HAVE_STRUCT_STAT_ST_ATIMESPEC_TV_NSEC
+# define GET_ST_ATIME_NSEC(st) (st).st_atimespec.tv_nsec
+#elif HAVE_STRUCT_STAT_ST_ATIMENSEC
+# define GET_ST_ATIME_NSEC(st) (st).st_atimensec
+#endif
+#ifdef HAVE_STRUCT_STAT_ST_MTIM_TV_NSEC
+# define GET_ST_MTIME_NSEC(st) (st).st_mtim.tv_nsec
+#elif HAVE_STRUCT_STAT_ST_MTIMESPEC_TV_NSEC
+# define GET_ST_MTIME_NSEC(st) (st).st_mtimespec.tv_nsec
+#elif HAVE_STRUCT_STAT_ST_MTIMENSEC
+# define GET_ST_MTIME_NSEC(st) (st).st_mtimensec
+#endif
+#ifdef HAVE_STRUCT_STAT_ST_CTIM_TV_NSEC
+# define GET_ST_CTIME_NSEC(st) (st).st_ctim.tv_nsec
+#elif HAVE_STRUCT_STAT_ST_CTIMESPEC_TV_NSEC
+# define GET_ST_CTIME_NSEC(st) (st).st_ctimespec.tv_nsec
+#elif HAVE_STRUCT_STAT_ST_CTIMENSEC
+# define GET_ST_CTIME_NSEC(st) (st).st_ctimensec
+#endif
+
+#if defined(HAVE_TGETENT) && !defined(ZSH_NO_TERM_HANDLING)
+# if defined(ZSH_HAVE_CURSES_H) && defined(ZSH_HAVE_TERM_H)
+# define USES_TERM_H 1
+# else
+# ifdef HAVE_TERMCAP_H
+# define USES_TERMCAP_H 1
+# endif
+# endif
+
+# ifdef USES_TERM_H
+# ifdef HAVE_TERMIO_H
+# include
+# endif
+# ifdef ZSH_HAVE_CURSES_H
+# include "zshcurses.h"
+# endif
+# include "zshterm.h"
+# else
+# ifdef USES_TERMCAP_H
+# include
+# endif
+# endif
+#endif
+
+#ifdef HAVE_SRAND_DETERMINISTIC
+# define srand srand_deterministic
+#endif
+
+#ifdef ZSH_VALGRIND
+# include "valgrind/valgrind.h"
+# include "valgrind/memcheck.h"
+#endif
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/ztype.h b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/ztype.h
new file mode 100644
index 0000000..ae72367
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Src/ztype.h
@@ -0,0 +1,89 @@
+/*
+ * ztype.h - character classification macros
+ *
+ * This file is part of zsh, the Z shell.
+ *
+ * Copyright (c) 1992-1997 Paul Falstad
+ * All rights reserved.
+ *
+ * Permission is hereby granted, without written agreement and without
+ * license or royalty fees, to use, copy, modify, and distribute this
+ * software and to distribute modified versions of this software for any
+ * purpose, provided that the above copyright notice and the following
+ * two paragraphs appear in all copies of this software.
+ *
+ * In no event shall Paul Falstad or the Zsh Development Group be liable
+ * to any party for direct, indirect, special, incidental, or consequential
+ * damages arising out of the use of this software and its documentation,
+ * even if Paul Falstad and the Zsh Development Group have been advised of
+ * the possibility of such damage.
+ *
+ * Paul Falstad and the Zsh Development Group specifically disclaim any
+ * warranties, including, but not limited to, the implied warranties of
+ * merchantability and fitness for a particular purpose. The software
+ * provided hereunder is on an "as is" basis, and Paul Falstad and the
+ * Zsh Development Group have no obligation to provide maintenance,
+ * support, updates, enhancements, or modifications.
+ *
+ */
+
+#define IDIGIT (1 << 0)
+#define IALNUM (1 << 1)
+#define IBLANK (1 << 2)
+#define INBLANK (1 << 3)
+#define ITOK (1 << 4)
+#define ISEP (1 << 5)
+#define IALPHA (1 << 6)
+#define IIDENT (1 << 7)
+#define IUSER (1 << 8)
+#define ICNTRL (1 << 9)
+#define IWORD (1 << 10)
+#define ISPECIAL (1 << 11)
+#define IMETA (1 << 12)
+#define IWSEP (1 << 13)
+#define INULL (1 << 14)
+#define IPATTERN (1 << 15)
+#define zistype(X,Y) (typtab[STOUC(X)] & Y)
+#define idigit(X) zistype(X,IDIGIT)
+#define ialnum(X) zistype(X,IALNUM)
+#define iblank(X) zistype(X,IBLANK) /* blank, not including \n */
+#define inblank(X) zistype(X,INBLANK) /* blank or \n */
+#define itok(X) zistype(X,ITOK)
+#define isep(X) zistype(X,ISEP)
+#define ialpha(X) zistype(X,IALPHA)
+#define iident(X) zistype(X,IIDENT)
+#define iuser(X) zistype(X,IUSER) /* username char */
+#define icntrl(X) zistype(X,ICNTRL)
+#define iword(X) zistype(X,IWORD)
+#define ispecial(X) zistype(X,ISPECIAL)
+#define imeta(X) zistype(X,IMETA)
+#define iwsep(X) zistype(X,IWSEP)
+#define inull(X) zistype(X,INULL)
+#define ipattern(X) zistype(X,IPATTERN)
+
+/*
+ * Bit flags for typtab_flags --- preserved after
+ * shell initialisation.
+ */
+#define ZTF_INIT (0x0001) /* One-off initialisation done */
+#define ZTF_INTERACT (0x0002) /* Shell interative and reading from stdin */
+#define ZTF_SP_COMMA (0x0004) /* Treat comma as a special characters */
+#define ZTF_BANGCHAR (0x0008) /* Treat bangchar as a special character */
+
+#ifdef MULTIBYTE_SUPPORT
+#define WC_ZISTYPE(X,Y) wcsitype((X),(Y))
+# ifdef ENABLE_UNICODE9
+# define WC_ISPRINT(X) u9_iswprint(X)
+# else
+# define WC_ISPRINT(X) iswprint(X)
+# endif
+#else
+#define WC_ZISTYPE(X,Y) zistype((X),(Y))
+#define WC_ISPRINT(X) isprint(X)
+#endif
+
+#if defined(__APPLE__) && defined(BROKEN_ISPRINT)
+#define ZISPRINT(c) isprint_ascii(c)
+#else
+#define ZISPRINT(c) isprint(c)
+#endif
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/.cvsignore b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/.cvsignore
new file mode 100644
index 0000000..855d729
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/.cvsignore
@@ -0,0 +1,3 @@
+Makefile
+*.tmp
+*.swp
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/.distfiles b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/.distfiles
new file mode 100644
index 0000000..f03668b
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/.distfiles
@@ -0,0 +1,2 @@
+DISTFILES_SRC='
+'
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/A01grammar.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/A01grammar.ztst
new file mode 100644
index 0000000..e4b6870
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/A01grammar.ztst
@@ -0,0 +1,790 @@
+#
+# This file contains tests corresponding to the `Shell Grammar' texinfo node.
+#
+
+%prep
+
+ mkdir basic.tmp && cd basic.tmp
+
+ touch foo bar
+ echo "'" >unmatched_quote.txt
+
+%test
+#
+# Tests for `Simple Commands and Pipelines'
+#
+
+ # Test skipping early to ensure we run the remainder...
+ if [[ -n $ZTST_test_skip ]]; then
+ ZTST_skip="Test system verification for skipping"
+ else
+ print "This is standard output"
+ print "This is standard error" >&2
+ false
+ fi
+1:Test skipping if ZTST_test_skip is set
+>This is standard output
+?This is standard error
+
+ echo foo | cat | sed 's/foo/bar/'
+0:Basic pipeline handling
+>bar
+
+ false | true
+0:Exit status of pipeline with builtins (true)
+
+ true | false
+1:Exit status of pipeline with builtins (false)
+
+ false
+ $nonexistent_variable
+0:Executing command that evaluates to empty resets status
+
+ false
+ sleep 1 &
+ print $?
+ # a tidy test is a happy test
+ wait $!
+0:Starting background command resets status
+>0
+
+ false
+ . /dev/null
+0:Sourcing empty file resets status
+
+ fn() { local foo; read foo; print $foo; }
+ coproc fn
+ print -p coproc test output
+ read -p bar
+ print $bar
+0:Basic coprocess handling
+>coproc test output
+
+ true | false && print true || print false
+0:Basic sublist (i)
+>false
+
+ false | true && print true || print false
+0:Basic sublist (ii)
+>true
+
+ (cd /NonExistentDirectory >&/dev/null) || print false
+0:Basic subshell list with error
+>false
+
+ { cd /NonExistentDirectory >&/dev/null } || print false
+0:Basic current shell list with error
+>false
+
+#
+# Tests for `Precommand Modifiers'
+#
+ - $ZTST_testdir/../Src/zsh -fc "[[ \$0 = \"-$ZTST_testdir/../Src/zsh\" ]]"
+0:`-' precommand modifier
+
+ echo f*
+ noglob echo f*
+0:`noglob' precommand modifier
+>foo
+>f*
+
+ (exec /bin/sh; echo bar)
+0:`exec' precommand modifier
+
+ (exec -l $ZTST_testdir/../Src/zsh -fc 'echo $0' | sed 's%/.*/%%' )
+0:`exec' with -l option
+>-zsh
+
+ (exec -a /bin/SPLATTER /bin/sh -c 'echo $0')
+0:`exec' with -a option
+>/bin/SPLATTER
+
+ (exec -a/bin/SPLOOSH /bin/sh -c 'echo $0')
+0:`exec' with -a option, no space
+>/bin/SPLOOSH
+
+ (export FOO=bar; exec -c /bin/sh -c 'echo x${FOO}x')
+0:`exec' with -c option
+>xx
+
+ cat() { echo Function cat executed; }
+ command cat && unfunction cat
+0:`command' precommand modifier
+External command cat executed
+
+ command -pv cat
+ command -pv echo
+ command -p -V cat
+ command -p -V -- echo
+0:command -p in combination
+*>*/cat
+>echo
+>cat is /*/cat
+>echo is a shell builtin
+
+ cd() { echo Not cd at all; }
+ builtin cd . && unfunction cd
+0:`builtin' precommand modifier
+
+#
+# Tests for `Complex Commands'
+#
+
+ if true; then
+ print true-1
+ elif true; then
+ print true-2
+ else
+ print false
+ fi
+0:`if ...' (i)
+>true-1
+
+ if false; then
+ print true-1
+ elif true; then
+ print true-2
+ else
+ print false
+ fi
+0:`if ...' (ii)
+>true-2
+
+ if false; then
+ print true-1
+ elif false; then
+ print true-2
+ else
+ print false
+ fi
+0:`if ...' (iii)
+>false
+
+ if true;
+ :
+ fi
+1d:`if ...' (iv)
+?(eval):3: parse error near `fi'
+
+ for name in word to term; do
+ print $name
+ done
+0:`for' loop
+>word
+>to
+>term
+
+ for name
+ in word to term; do
+ print $name
+ done
+0:`for' loop with newline before in keyword
+>word
+>to
+>term
+
+ for (( name = 0; name < 3; name++ )); do
+ print $name
+ done
+0:arithmetic `for' loop
+>0
+>1
+>2
+
+ for (( $(true); ; )); do break; done
+ for (( ; $(true); )); do break; done
+ for (( ; ; $(true) )); do break; done
+ for (( ; $((1)); )); do break; done
+0:regression test, nested cmdsubst in arithmetic `for' loop
+
+ for keyvar valvar in key1 val1 key2 val2; do
+ print key=$keyvar val=$valvar
+ done
+0:enhanced `for' syntax with two loop variables
+>key=key1 val=val1
+>key=key2 val=val2
+
+ for keyvar valvar stuffvar in keyA valA stuffA keyB valB stuffB; do
+ print key=$keyvar val=$valvar stuff=$stuffvar
+ done
+0:enhanced `for' syntax with three loop variables
+>key=keyA val=valA stuff=stuffA
+>key=keyB val=valB stuff=stuffB
+
+ for in in in in in stop; do
+ print in=$in
+ done
+0:compatibility of enhanced `for' syntax with standard syntax
+>in=in
+>in=in
+>in=in
+>in=stop
+
+ name=0
+ while (( name < 3 )); do
+ print $name
+ (( name++ ))
+ done
+0:`while' loop
+>0
+>1
+>2
+
+ name=0
+ until (( name == 3 )); do
+ print $name
+ (( name++ ))
+ done
+0:`until' loop
+>0
+>1
+>2
+
+ repeat 3 do
+ echo over and over
+ done
+0:`repeat' loop
+>over and over
+>over and over
+>over and over
+
+ word=Trinity
+ case $word in
+ Michaelmas) print 0
+ ;;
+ Hilary) print 1
+ ;;
+ Trinity) print 2
+ ;;
+ *) print 3
+ ;;
+ esac
+0:`case', old syntax
+>2
+
+ word=Trinity
+ case $word in
+ (Michaelmas) print 0
+ ;;
+ (Hilary) print 1
+ ;;
+ (Trinity) print 2
+ ;;
+ (*) print 3
+ ;;
+ esac
+0:`case', new syntax
+>2
+
+ word=Hilary
+ case $word in
+ (Michaelmas) print 0
+ ;;
+ (Hilary) print 1
+ ;&
+ (Trinity) print 2
+ ;&
+ (*) print 3
+ ;;
+ esac
+0:`case', new syntax, cascaded
+>1
+>2
+>3
+
+ case whatever in
+ (*) print yeah, right ;&
+ esac
+ print but well
+0:'case', redundant final ";&"
+>yeah, right
+>but well
+
+## Select now reads from stdin if the shell is not interactive.
+## Its own output goes to stderr.
+ (COLUMNS=80 LINES=3
+ PS3="input> "
+ select name in one two three; do
+ print $name
+ done)
+0:`select' loop
+<2
+?1) one 2) two 3) three
+?input> input>
+>two
+
+ function name1 name2 () { print This is $0; }
+ name2
+ name1 name2() { print This is still $0; }
+ name2
+0:`function' keyword
+>This is name2
+>This is still name2
+
+ (time cat) >&/dev/null
+0:`time' keyword (status only)
+
+ if [[ -f foo && -d . && -n $ZTST_testdir ]]; then
+ true
+ else
+ false
+ fi
+0:basic [[ ... ]] test
+
+#
+# Current shell execution with try/always form.
+# We put those with errors in subshells so that any unhandled error doesn't
+# propagate.
+#
+
+ {
+ print The try block.
+ } always {
+ print The always block.
+ }
+ print After the always block.
+0:Basic `always' syntax
+>The try block.
+>The always block.
+>After the always block.
+
+ ({
+ print Position one.
+ print ${*this is an error*}
+ print Position two.
+ } always {
+ if (( TRY_BLOCK_ERROR )); then
+ print An error occurred.
+ else
+ print No error occurred.
+ fi
+ }
+ print Position three)
+1:Always block with error not reset
+>Position one.
+>An error occurred.
+?(eval):3: bad substitution
+
+ ({
+ print Stelle eins.
+ print ${*voici une erreur}
+ print Posizione due.
+ } always {
+ if (( TRY_BLOCK_ERROR )); then
+ print Erratum factum est. Retro ponetur.
+ (( TRY_BLOCK_ERROR = 0 ))
+ else
+ print unray touay foay anguageslay
+ fi
+ }
+ print Status after always block is $?.)
+0:Always block with error reset
+>Stelle eins.
+>Erratum factum est. Retro ponetur.
+>Status after always block is 1.
+?(eval):3: bad substitution
+
+ fn() { { return } always { echo always 1 }; echo not executed }
+ fn
+ fn() { { echo try 2 } always { return }; echo not executed }
+ fn
+0:Always block interaction with return
+>always 1
+>try 2
+
+# Outputting of structures from the wordcode is distinctly non-trivial,
+# we probably ought to have more like the following...
+ fn1() { { echo foo; } }
+ fn2() { { echo foo; } always { echo bar; } }
+ fn3() { ( echo foo; ) }
+ functions fn1 fn2 fn3
+0:Output of syntactic structures with and without always blocks
+>fn1 () {
+> {
+> echo foo
+> }
+>}
+>fn2 () {
+> {
+> echo foo
+> } always {
+> echo bar
+> }
+>}
+>fn3 () {
+> (
+> echo foo
+> )
+>}
+
+
+#
+# Tests for `Alternate Forms For Complex Commands'
+#
+
+ if (true) { print true-1 } elif (true) { print true-2 } else { print false }
+ if (false) { print true-1 } elif (true) { print true-2 } else { print false }
+ if (false) { print true-1 } elif (false) { print true-2 } else { print false }
+0:Alternate `if' with braces
+>true-1
+>true-2
+>false
+
+ if { true } print true
+ if { false } print false
+0:Short form of `if'
+>true
+
+ eval "if"
+1:Short form of `if' can't be too short
+?(eval):1: parse error near `if'
+
+ for name ( word1 word2 word3 ) print $name
+0:Form of `for' with parentheses.
+>word1
+>word2
+>word3
+
+ for name in alpha beta gamma; print $name
+0:Short form of `for'
+>alpha
+>beta
+>gamma
+
+ for (( val = 2; val < 10; val *= val )) print $val
+0:Short arithmetic `for'
+>2
+>4
+
+ foreach name ( verbiage words periphrasis )
+ print $name
+ end
+0:Csh-like `for'
+>verbiage
+>words
+>periphrasis
+
+# see comment with braces used in if loops
+ val=0;
+ while (( val < 2 )) { print $((val++)); }
+0:Alternative `while'
+>0
+>1
+
+ val=2;
+ until (( val == 0 )) { print $((val--)); }
+0:Alternative `until'
+>2
+>1
+
+ repeat 3 print Hip hip hooray
+0:Short `repeat'
+>Hip hip hooray
+>Hip hip hooray
+>Hip hip hooray
+
+ case bravo {
+ (alpha) print schmalpha
+ ;;
+ (bravo) print schmavo
+ ;;
+ (charlie) print schmarlie
+ ;;
+ }
+0:`case' with braces
+>schmavo
+
+ for word in artichoke bladderwort chrysanthemum Zanzibar
+ case $word in
+ (*der*) print $word contains the forbidden incantation der
+ ;;
+ (a*) print $word begins with a
+ ;&
+ ([[:upper:]]*) print $word either begins with a or an upper case letter
+ ;|
+ ([[:lower:]]*) print $word begins with a lower case letter
+ ;|
+ (*e*) print $word contains an e
+ ;;
+ esac
+0:`case' with mixed ;& and ;|
+>artichoke begins with a
+>artichoke either begins with a or an upper case letter
+>artichoke begins with a lower case letter
+>artichoke contains an e
+>bladderwort contains the forbidden incantation der
+>chrysanthemum begins with a lower case letter
+>chrysanthemum contains an e
+>Zanzibar either begins with a or an upper case letter
+
+ print -u $ZTST_fd 'This test hangs the shell when it fails...'
+ name=0
+# The number 4375 here is chosen to produce more than 16384 bytes of output
+ while (( name < 4375 )); do
+ print -n $name
+ (( name++ ))
+ done < /dev/null | { read name; print done }
+0:Bug regression: `while' loop with redirection and pipeline
+>done
+
+# This used to be buggy and print X at the end of each iteration.
+ for f in 1 2 3 4; do
+ print $f || break
+ done && print X
+0:Handling of ||'s and &&'s with a for loop in between
+>1
+>2
+>3
+>4
+>X
+
+# Same bug for &&, used to print `no' at the end of each iteration
+ for f in 1 2 3 4; do
+ false && print strange
+ done || print no
+0:Handling of &&'s and ||'s with a for loop in between
+>no
+
+ $ZTST_testdir/../Src/zsh -f unmatched_quote.txt
+1:Parse error with file causes non-zero exit status
+?unmatched_quote.txt:2: unmatched '
+
+ $ZTST_testdir/../Src/zsh -f value
+>not#comment
+
+ . ./nonexistent
+127: Attempt to "." non-existent file.
+?(eval):.:1: no such file or directory: ./nonexistent
+
+ echo '[[' >bad_syntax
+ . ./bad_syntax
+126: Attempt to "." file with bad syntax.
+?./bad_syntax:2: parse error near `\n'
+# `
+
+ echo 'false' >dot_false
+ . ./dot_false
+ print $?
+ echo 'true' >dot_true
+ . ./dot_true
+ print $?
+0:Last status of successfully executed "." file is retained
+>1
+>0
+
+ echo 'echo $?' >dot_status
+ false
+ . ./dot_status
+0:"." file sees status from previous command
+>1
+
+ mkdir test_path_script
+ print "#!/bin/sh\necho Found the script." >test_path_script/myscript
+ chmod u+x test_path_script/myscript
+ path=($PWD/test_path_script $path)
+ export PATH
+ $ZTST_testdir/../Src/zsh -f -o pathscript myscript
+0:PATHSCRIPT option
+>Found the script.
+
+ $ZTST_testdir/../Src/zsh -f myscript
+127q:PATHSCRIPT option not used.
+?$ZTST_testdir/../Src/zsh: can't open input file: myscript
+# '
+
+ $ZTST_testdir/../Src/zsh -fc 'echo $0; echo $1' myargzero myargone
+0:$0 is traditionally if bizarrely set to the first argument with -c
+>myargzero
+>myargone
+
+ (setopt shglob
+ eval '
+ if ! (echo success1); then echo failure1; fi
+ if !(echo success2); then echo failure2; fi
+ print -l one two | while(read foo)do(print read it)done
+ ')
+0:Parentheses in shglob
+>success1
+>success2
+>read it
+>read it
+
+ (
+ mywrap() { echo BEGIN; true; echo END }
+ mytest() { { exit 3 } always { mywrap }; print Exited before this }
+ mytest
+ print Exited before this, too
+ )
+3:Exit and always block with functions: simple
+>BEGIN
+>END
+
+ (
+ mytrue() { echo mytrue; return 0 }
+ mywrap() { echo BEGIN; mytrue; echo END }
+ mytest() { { exit 4 } always { mywrap }; print Exited before this }
+ mytest
+ print Exited before this, too
+ )
+4:Exit and always block with functions: nested
+>BEGIN
+>mytrue
+>END
+
+ (emulate sh -c '
+ fn() {
+ case $1 in
+ ( one | two | three )
+ print Matched $1
+ ;;
+ ( fo* | fi* | si* )
+ print Pattern matched $1
+ ;;
+ ( []x | a[b]* )
+ print Character class matched $1
+ ;;
+ esac
+ }
+ '
+ which fn
+ fn one
+ fn two
+ fn three
+ fn four
+ fn five
+ fn six
+ fn abecedinarian
+ fn xylophone)
+0: case word handling in sh emulation (SH_GLOB parentheses)
+>fn () {
+> case $1 in
+> (one | two | three) print Matched $1 ;;
+> (fo* | fi* | si*) print Pattern matched $1 ;;
+> ([]x | a[b]*) print Character class matched $1 ;;
+> esac
+>}
+>Matched one
+>Matched two
+>Matched three
+>Pattern matched four
+>Pattern matched five
+>Pattern matched six
+>Character class matched abecedinarian
+
+ case grumph in
+ ( no | (grumph) )
+ print 1 OK
+ ;;
+ esac
+ case snruf in
+ ( fleer | (|snr(|[au]f)) )
+ print 2 OK
+ ;;
+ esac
+0: case patterns within words
+>1 OK
+>2 OK
+
+ case horrible in
+ ([a-m])(|[n-z])rr(|ib(um|le|ah)))
+ print It worked
+ ;;
+ esac
+ case "a string with separate words" in
+ (*with separate*))
+ print That worked, too
+ ;;
+ esac
+0:Unbalanced parentheses and spaces with zsh pattern
+>It worked
+>That worked, too
+
+ case horrible in
+ (([a-m])(|[n-z])rr(|ib(um|le|ah)))
+ print It worked
+ ;;
+ esac
+ case "a string with separate words" in
+ (*with separate*)
+ print That worked, too
+ ;;
+ esac
+0:Balanced parentheses and spaces with zsh pattern
+>It worked
+>That worked, too
+
+ fn() {
+ typeset ac_file="the else branch"
+ case $ac_file in
+ *.$ac_ext | *.xcoff | *.tds | *.d | *.pdb | *.xSYM | *.bb | *.bbg | *.map | *.inf | *.dSYM | *.o | *.obj ) ;;
+ *.* ) break;;
+ *)
+ ;;
+ esac
+ print Stuff here
+ }
+ which fn
+ fn
+0:Long case with parsed alternatives turned back into text
+>fn () {
+> typeset ac_file="the else branch"
+> case $ac_file in
+> (*.$ac_ext | *.xcoff | *.tds | *.d | *.pdb | *.xSYM | *.bb | *.bbg | *.map | *.inf | *.dSYM | *.o | *.obj) ;;
+> (*.*) break ;;
+> (*) ;;
+> esac
+> print Stuff here
+>}
+>Stuff here
+
+ (exit 37)
+ case $? in
+ (37) echo $?
+ ;;
+ esac
+0:case retains exit status for execution of cases
+>37
+
+ false
+ case stuff in
+ (nomatch) foo
+ ;;
+ esac
+ echo $?
+0:case sets exit status to zero if no patterns are matched
+>0
+
+ case match in
+ (match) true; false; (exit 37)
+ ;;
+ esac
+ echo $?
+0:case keeps exit status of last command executed in compound-list
+>37
+
+ x=1
+ x=2 | echo $x
+ echo $x
+0:Assignment-only current shell commands in LHS of pipelin
+>1
+>1
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/A02alias.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/A02alias.ztst
new file mode 100644
index 0000000..e68e93e
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/A02alias.ztst
@@ -0,0 +1,139 @@
+# To get the "command not found" message when aliasing is suppressed
+# we need, er, a command that isn't found.
+# The other aliases are only ever used as aliases.
+
+%prep
+ alias ThisCommandDefinitelyDoesNotExist=echo
+
+ alias -g bar=echo
+
+ alias '\bar=echo'
+
+%test
+ ThisCommandDefinitelyDoesNotExist ThisCommandDefinitelyDoesNotExist
+0:Basic aliasing
+>ThisCommandDefinitelyDoesNotExist
+
+ bar bar
+0:Global aliasing
+>echo
+
+ \ThisCommandDefinitelyDoesNotExist ThisCommandDefinitelyDoesNotExist
+127:Not aliasing
+?(eval):1: command not found: ThisCommandDefinitelyDoesNotExist
+
+ \bar \bar
+0:Aliasing with a backslash
+>bar
+
+ (alias '!=echo This command has the argument'
+ eval 'print Without
+ ! true'
+ setopt posixaliases
+ eval 'print With
+ ! true')
+1:POSIX_ALIASES option
+>Without
+>This command has the argument true
+>With
+
+ print -u $ZTST_fd 'This test hangs the shell when it fails...'
+ alias cat='LC_ALL=C cat'
+ cat <(echo foo | cat)
+0:Alias expansion works at the end of parsed strings
+>foo
+
+ alias -g '&&=(){ return $?; } && '
+ alias not_the_print_command=print
+ eval 'print This is output
+ && print And so is this
+ && { print And this too; false; }
+ && print But not this
+ && print Nor this
+ true
+ && not_the_print_command And aliases are expanded'
+0:We can now alias special tokens. Woo hoo.
+>This is output
+>And so is this
+>And this too
+>And aliases are expanded
+
+ $ZTST_testdir/../Src/zsh -fis <<<'
+ unsetopt PROMPT_SP
+ PROMPT="" PS2="" PS3="" PS4="" RPS1="" RPS2=""
+ exec 2>&1
+ alias \{=echo
+ { begin
+ {end
+ fc -l -2' 2>/dev/null
+0:Aliasing reserved tokens
+>begin
+>end
+*>*5*{ begin
+*>*6*{end
+
+ $ZTST_testdir/../Src/zsh -fis <<<'
+ unsetopt PROMPT_SP
+ PROMPT="" PS2="" PS3="" PS4="" RPS1="" RPS2=""
+ exec 2>&1
+ alias -g S=\"
+ echo S a string S "
+ fc -l -1' 2>/dev/null
+0:Global aliasing quotes
+> a string S
+*>*5*echo S a string S "
+# "
+# Note there is a trailing space on the "> a string S " line
+
+ (
+ unalias -a
+ alias
+ )
+0:unalias -a
+
+ alias -s foo=print
+ type bar.foo; type -w bar.foo
+ unalias -as
+0:unalias -as
+>foo is a suffix alias for print
+>foo: suffix alias
+
+ aliases[x=y]=z
+ alias -L | grep x=y
+ echo $pipestatus[1]
+0:printing invalid aliases warns
+>0
+?(eval):2: invalid alias 'x=y' encountered while printing aliases
+# Currently, 'alias -L' returns 0 in this case. Perhaps it should return 1.
+
+ alias -s mysuff='print -r "You said it.";'
+ eval 'thingummy.mysuff'
+127:No endless loop with suffix alias in command position
+>You said it.
+?(eval):1: command not found: thingummy.mysuff
+
+ alias +x; alias -z
+1:error message has the correct sign
+?(eval):alias:1: bad option: +x
+?(eval):alias:1: bad option: -z
+
+ # Usual issue that aliases aren't expanded until we
+ # trigger a new parse...
+ (alias badalias=notacommand
+ eval 'badalias() { print does not work; }')
+1:ALIAS_FUNC_DEF off by default.
+?(eval):1: defining function based on alias `badalias'
+?(eval):1: parse error near `()'
+
+ (alias goodalias=isafunc
+ setopt ALIAS_FUNC_DEF
+ eval 'goodalias() { print does now work; }'
+ isafunc)
+0:ALIAS_FUNC_DEF causes the icky behaviour to be avaliable
+>does now work
+
+ (alias thisisokthough='thisworks() { print That worked; }'
+ eval thisisokthough
+ thisworks)
+0:NO_ALIAS_FUNC_DEF works if the alias is a complete definition
+>That worked
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/A03quoting.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/A03quoting.ztst
new file mode 100644
index 0000000..da3ce35
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/A03quoting.ztst
@@ -0,0 +1,80 @@
+%test
+ print 'single quotes' "double quotes" `echo backquotes`
+0:Simple use of quotes
+>single quotes double quotes backquotes
+
+ foo=text
+ print -r '$foo\\\' "$foo\$foo\\\"\``echo bar`\`\"" `print -r $foo\\\``
+0:Quoting inside quotes
+>$foo\\\ text$foo\"`bar`" text`
+
+ print -r $'\'ut queant laxis\'\n"resonare fibris"'
+0:$'-style quotes
+>'ut queant laxis'
+>"resonare fibris"
+
+ print -r $'\'a \\\' is \'a backslash\' is \'a \\\''
+0:$'-style quotes with backslashed backslashes
+>'a \' is 'a backslash' is 'a \'
+
+ chars=$(print -r $'BS\\MBS\M-\\')
+ for (( i = 1; i <= $#chars; i++ )); do
+ char=$chars[$i]
+ print $(( [#16] #char ))
+ done
+0:$'-style quote with metafied backslash
+>16#42
+>16#53
+>16#5C
+>16#4D
+>16#42
+>16#53
+>16#DC
+
+ print -r ''''
+ setopt rcquotes
+# We need to set rcquotes here for the next example since it is
+# needed while parsing.
+0:No RC_QUOTES with single quotes
+>
+
+ print -r ''''
+ unsetopt rcquotes
+0:Yes RC_QUOTES with single quotes
+>'
+# ' Deconfuse Emacs quoting rules
+
+ print '<\u0041>'
+ printf '%s\n' $'<\u0042>'
+ print '<\u0043>'
+ printf '%s\n' $'<\u0044>'
+0:\u in both print and printf
+>
+>
+>
+>
+
+ null1="$(print -r a$'b\0c'd)"
+ null2="$(setopt posixstrings; print -r a$'b\0c'd)"
+ for string in $null1 $null2; do
+ print ":"
+ for (( i = 1; i <= $#string; i++ )); do
+ char=$string[$i]
+ print $(( [#16] #char ))
+ done
+ done
+0:Embedded null characters in $'...' strings.
+>:
+>16#61
+>16#62
+>16#0
+>16#63
+>16#64
+>:
+>16#61
+>16#62
+>16#64
+
+ () { print $# } '' "" $''
+0:$'' should not be elided, in common with other empty quotes
+>3
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/A04redirect.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/A04redirect.ztst
new file mode 100644
index 0000000..d7fe22f
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/A04redirect.ztst
@@ -0,0 +1,588 @@
+# Tests corresponding to the `Redirection' texinfo node.
+
+%prep
+ mkdir redir.tmp && cd redir.tmp
+
+ myfd=99
+ (echo >&$myfd) 2>msg
+ bad_fd_msg="${$(redir && cat redir
+0:'>' and '<' redirection
+>This is file redir
+
+ rm -f redir
+ print 'This is still file redir' <>redir >&0 && cat <>redir
+0:'<>' redirection
+>This is still file redir
+
+ rm -f redir
+ print 'With a bar' >|redir && cat redir
+0:'>|' redirection
+>With a bar
+
+ rm -f redir
+ print 'With a bang' >!redir && cat redir
+0:'>!' redirection
+>With a bang
+
+ rm -f redir
+ print 'Line 1' >>redir && print 'Line 2' >>redir && cat redir
+0:'>>' redirection
+>Line 1
+>Line 2
+
+ rm -f redir
+ print 'Line a' >>|redir && print 'Line b' >>!redir
+0:'>>|' and '>>!' redirection
+
+ foo=bar
+ cat <<' HERE'
+ $foo
+ HERE
+ eval "$(print 'cat < $foo
+>bar
+
+ cat <<-HERE
+# note tabs at the start of the following lines
+ $foo$foo
+ HERE
+0:Here-documents stripping tabs
+>barbar
+
+ cat <<-$'$HERE '`$(THERE) `'$((AND)) '"\EVERYWHERE" #
+# tabs again. sorry about the max miller.
+ Here's a funny thing. Here is a funny thing.
+ I went home last night. There's a funny thing.
+ Man walks into a $foo. Ouch, it's an iron $foo.
+ $HERE `$(THERE) `$((AND)) \EVERYWHERE
+0:Here-documents don't perform shell expansion on the initial word
+>Here's a funny thing. Here is a funny thing.
+>I went home last night. There's a funny thing.
+>Man walks into a $foo. Ouch, it's an iron $foo.
+
+ cat <<-$'\x45\x4e\x44\t\x44\x4f\x43'
+# tabs again
+ This message is unfathomable.
+ END DOC
+0:Here-documents do perform $'...' expansion on the initial word
+>This message is unfathomable.
+
+ cat <<<"This is a line with a $foo in it"
+0:'<<<' redirection
+>This is a line with a bar in it
+
+ cat <<<$'a\nb\nc'
+0:here-strings with $'...' quoting
+>a
+>b
+>c
+
+# The following tests check that output of parsed here-documents works.
+# This isn't completely trivial because we convert the here-documents
+# internally to here-strings. So we check again that we can output
+# the reevaluated here-strings correctly. Hence there are three slightly
+# different stages. We don't care how the output actually looks, so
+# we don't test that.
+ heretest() {
+ print First line
+ cat <<-HERE
+ $foo$foo met celeste 'but with extra' "stuff to test quoting"
+ HERE
+ print Last line
+ }
+ heretest
+ eval "$(functions heretest)"
+ heretest
+ eval "$(functions heretest)"
+ heretest
+0:Re-evaluation of function output with here document, unquoted
+>First line
+>barbar met celeste 'but with extra' "stuff to test quoting"
+>Last line
+>First line
+>barbar met celeste 'but with extra' "stuff to test quoting"
+>Last line
+>First line
+>barbar met celeste 'but with extra' "stuff to test quoting"
+>Last line
+
+ heretest() {
+ print First line
+ cat <<' HERE'
+ $foo$foo met celeste 'but with extra' "stuff to test quoting"
+ HERE
+ print Last line
+ }
+ heretest
+ eval "$(functions heretest)"
+ heretest
+ eval "$(functions heretest)"
+ heretest
+0:Re-evaluation of function output with here document, quoted
+>First line
+> $foo$foo met celeste 'but with extra' "stuff to test quoting"
+>Last line
+>First line
+> $foo$foo met celeste 'but with extra' "stuff to test quoting"
+>Last line
+>First line
+> $foo$foo met celeste 'but with extra' "stuff to test quoting"
+>Last line
+
+ read -r line <<' HERE'
+ HERE
+1:No input, not even newline, from empty here document.
+
+ #
+ # exec tests: perform these in subshells so if they fail the
+ # shell won't exit.
+ #
+ (exec 3>redir && print hello >&3 && print goodbye >&3 && cat redir)
+0:'>&' redirection
+>hello
+>goodbye
+
+ (exec 3hello
+>goodbye
+
+ ({exec 3<&- } 2>/dev/null
+ exec 3<&-
+ read foo <&-)
+1:'<&-' redirection with numeric fd (no error message on failure)
+
+ (exec {varid}<&0
+ exec {varid}<&-
+ print About to close a second time >&2
+ read {varid}<&-)
+1:'<&-' redirection with fd in variable (error message on failure)
+?About to close a second time
+*?\(eval\):*: failed to close file descriptor *
+
+ print foo >&-
+0:'>&-' redirection
+
+ (exec >&-
+ print foo)
+0:'>&-' with attempt to use closed fd
+*?\(eval\):2: write error:*
+
+ fn() { local foo; read foo; print $foo; }
+ coproc fn
+ print test output >&p
+ read bar <&p
+ print $bar
+0:'>&p' and '<&p' redirection
+>test output
+
+ ( print Output; print Error >& 2 ) >&errout && cat errout
+0:'>&FILE' handling
+>Output
+>Error
+
+ rm -f errout
+ ( print Output2; print Error2 >& 2 ) &>errout && cat errout
+0:'&>FILE' handling
+>Output2
+>Error2
+
+ rm -f errout
+ ( print Output3; print Error3 >& 2 ) >&|errout && cat errout
+ ( print Output4; print Error4 >& 2 ) >&!errout && cat errout
+ ( print Output5; print Error5 >& 2 ) &>|errout && cat errout
+ ( print Output6; print Error6 >& 2 ) &>!errout &&
+ ( print Output7; print Error7 >& 2 ) >>&errout &&
+ ( print Output8; print Error8 >& 2 ) &>>errout &&
+ ( print Output9; print Error9 >& 2 ) >>&|errout &&
+ ( print Output10; print Error10 >& 2 ) &>>|errout &&
+ ( print Output11; print Error11 >& 2 ) >>&!errout &&
+ ( print Output12; print Error12 >& 2 ) &>>!errout && cat errout
+0:'>&|', '>&!', '&>|', '&>!' redirection
+>Output3
+>Error3
+>Output4
+>Error4
+>Output5
+>Error5
+>Output6
+>Error6
+>Output7
+>Error7
+>Output8
+>Error8
+>Output9
+>Error9
+>Output10
+>Error10
+>Output11
+>Error11
+>Output12
+>Error12
+
+ rm -f errout
+ ( print Output; print Error 1>&2 ) 1>errout 2>&1 && cat errout
+0:'Combining > with >& (1)'
+>Output
+>Error
+
+ rm -f errout
+ ( print Output; print Error 1>&2 ) 2>&1 1>errout && print errout: &&
+ cat errout
+0:'Combining > with >& (2)'
+>Error
+>errout:
+>Output
+
+ rm -f errout
+ print doo be doo be doo >foo >bar
+ print "foo: $(foo: doo be doo be doo
+>bar: doo be doo be doo
+
+ rm -f foo bar
+ print dont be dont be dont >foo | sed 's/dont/wont/g' >bar
+0:setup file+pipe multio
+
+ print "foo: $(foo: dont be dont be dont
+>bar: wont be wont be wont
+
+ rm -f *
+ touch out1 out2
+ print All files >*
+ print *
+ print "out1: $(out1 out2
+>out1: All files
+>out2: All files
+
+ print This is out1 >out1
+ print This is out2 >out2
+0:setup multio for input
+
+# Currently, This is out1
+>This is out2
+
+ cat out1 | sed s/out/bout/ This is bout1
+>This is bout2
+
+ unset NULLCMD
+ >out1
+1:null redir with NULLCMD unset
+?(eval):2: redirection with no command
+
+ echo this should still work >out1
+ print "$(this should still work
+
+ READNULLCMD=cat
+ print cat input >out1
+ out1
+ [[ ! -s out1 ]] || print out1 is not empty
+0:null redir with NULLCMD=:
+out1
+ cat input
+
+ NULLCMD=cat
+ >out1
+ cat out1
+0:null redir with NULLCMD=cat
+input
+
+ (myfd=
+ exec {myfd}>logfile
+ if [[ -z $myfd ]]; then
+ print "Ooops, failed to set myfd to a file descriptor." >&2
+ else
+ print This is my logfile. >&$myfd
+ print Examining contents of logfile...
+ cat logfile
+ fi)
+0:Using {fdvar}> syntax to open a new file descriptor
+>Examining contents of logfile...
+>This is my logfile.
+
+ (setopt noclobber
+ exec {myfd}>logfile2
+ echo $myfd
+ exec {myfd}>logfile3) | read myfd
+ (( ! ${pipestatus[1]} ))
+1q:NO_CLOBBER prevents overwriting parameter with allocated fd
+?(eval):4: can't clobber parameter myfd containing file descriptor $myfd
+
+ (setopt noclobber
+ exec {myfd}>logfile2b
+ print First open >&$myfd
+ rm -f logfile2b # prevent normal file no_clobberation
+ myotherfd="${myfd}+0"
+ exec {myotherfd}>logfile2b
+ print Overwritten >&$myotherfd)
+ cat logfile2b
+0:NO_CLOBBER doesn't complain about any other expression
+>Overwritten
+
+ (exec {myfd}>logfile4
+ echo $myfd
+ exec {myfd}>&-
+ print This message should disappear >&$myfd) | read myfd
+ (( ! ${pipestatus[1]} ))
+1q:Closing file descriptor using brace syntax
+?(eval):4: $myfd:$bad_fd_msg
+
+ typeset -r myfd
+ echo This should not appear {myfd}>nologfile
+1:Error opening file descriptor using readonly variable
+?(eval):2: can't allocate file descriptor to readonly parameter myfd
+
+ (typeset +r myfd
+ exec {myfd}>newlogfile
+ typeset -r myfd
+ exec {myfd}>&-)
+1:Error closing file descriptor using readonly variable
+?(eval):4: can't close file descriptor from readonly parameter myfd
+
+# This tests the here-string to filename optimisation; we can't
+# test that it's actually being optimised, but we can test that it
+# still works.
+ cat =(<<<$'This string has been replaced\nby a file containing it.\n')
+0:Optimised here-string to filename
+>This string has been replaced
+>by a file containing it.
+
+ print This f$'\x69'le contains d$'\x61'ta. >redirfile
+ print redirection:
+ catoutfile
+ print output:
+ cat outfile
+ print append:
+ cat>>outfileredirection:
+>output:
+>This file contains data.
+>append:
+>more output:
+>This file contains data.
+>This file contains data.
+
+ $ZTST_testdir/../Src/zsh -fc 'exec >/nonexistent/nonexistent
+ echo output'
+0:failed exec redir, no POSIX_BUILTINS
+>output
+?zsh:1: no such file or directory: /nonexistent/nonexistent
+
+ $ZTST_testdir/../Src/zsh -f -o POSIX_BUILTINS -c '
+ exec >/nonexistent/nonexistent
+ echo output'
+1:failed exec redir, POSIX_BUILTINS
+?zsh:2: no such file or directory: /nonexistent/nonexistent
+
+ $ZTST_testdir/../Src/zsh -f -o POSIX_BUILTINS -c '
+ set >/nonexistent/nonexistent
+ echo output'
+1:failed special builtin redir, POSIX_BUILTINS
+?zsh:2: no such file or directory: /nonexistent/nonexistent
+
+ $ZTST_testdir/../Src/zsh -f -o POSIX_BUILTINS -c '
+ command set >/nonexistent/nonexistent
+ echo output'
+0:failed special builtin redir with command prefix, POSIX_BUILTINS
+>output
+?zsh:2: no such file or directory: /nonexistent/nonexistent
+
+ $ZTST_testdir/../Src/zsh -f -o POSIX_BUILTINS -c '
+ echo >/nonexistent/nonexistent
+ echo output'
+0:failed unspecial builtin redir, POSIX_BUILTINS
+>output
+?zsh:2: no such file or directory: /nonexistent/nonexistent
+
+ $ZTST_testdir/../Src/zsh -f -o POSIX_BUILTINS -c '
+ . /nonexistent/nonexistent
+ echo output'
+1:failed dot, POSIX_BUILTINS
+?zsh:.:2: no such file or directory: /nonexistent/nonexistent
+
+ $ZTST_testdir/../Src/zsh -f -c '
+ . /nonexistent/nonexistent
+ echo output'
+0:failed dot, NO_POSIX_BUILTINS
+>output
+?zsh:.:2: no such file or directory: /nonexistent/nonexistent
+
+ $ZTST_testdir/../Src/zsh -f -o CONTINUE_ON_ERROR <<<'
+ readonly foo
+ foo=bar set output
+ echo output'
+0:failed assignment on posix special, CONTINUE_ON_ERROR
+>output
+?zsh: read-only variable: foo
+
+ $ZTST_testdir/../Src/zsh -f <<<'
+ readonly foo
+ foo=bar set output
+ echo output'
+1:failed assignment on posix special, NO_CONTINUE_ON_ERROR
+?zsh: read-only variable: foo
+
+ $ZTST_testdir/../Src/zsh -f -o CONTINUE_ON_ERROR <<<'
+ readonly foo
+ foo=bar echo output
+ echo output'
+0:failed assignment on non-posix-special, CONTINUE_ON_ERROR
+>output
+?zsh: read-only variable: foo
+
+ [input1
+ () {
+ local var
+ read var
+ print I just read $var
+ } output1
+ print Nothing output yet
+ cat output1
+0:anonymous function redirections are applied immediately
+>Nothing output yet
+>I just read any old rubbish
+
+ redirfn() {
+ local var
+ read var
+ print I want to tell you about $var
+ print Also, this might be an error >&2
+ } output2 2>&1
+ print something I heard on the radio >input2
+ redirfn
+ print No output until after this
+ cat output2
+0:redirections with normal function definition
+>No output until after this
+>I want to tell you about something I heard on the radio
+>Also, this might be an error
+
+ which redirfn
+0:text output of function with redirections
+>redirfn () {
+> local var
+> read var
+> print I want to tell you about $var
+> print Also, this might be an error >&2
+>} < input2 > output2 2>&1
+
+ 1func 2func 3func() { print Ich heisse $0 } >output3
+ for i in 1 2 3; do
+ f=${i}func
+ print Running $f
+ $f
+ cat output3
+ unfunction $f
+ done
+0:multiply named functions with redirection
+>Running 1func
+>Ich heisse 1func
+>Running 2func
+>Ich heisse 2func
+>Running 3func
+>Ich heisse 3func
+
+ redirfn2() { print The latest output; } >&3
+ redirfn2 3>output4
+ print No output yet
+ cat output4
+0:Redirections in both function definition and command line
+>No output yet
+>The latest output
+
+# This relies on the fact that the test harness always loads
+# the zsh/parameter module.
+ print $functions[redirfn]
+0:Output from $functions[] for definition with redirection
+>{
+> local var
+> read var
+> print I want to tell you about $var
+> print Also, this might be an error >&2
+>} < input2 > output2 2>&1
+
+ noredirfn() { print This rather boring function has no redirection.; }
+ print $functions[noredirfn]
+0:Output from $functions[] for definition with no redirection
+> print This rather boring function has no redirection.
+
+ (x=43
+ x=$(print This should appear, really >&2; print Not used) exec >test.log
+ print x=$x)
+ cat test.log
+0:Assignment with exec used for redirection: no POSIX_BUILTINS
+>x=43
+?This should appear, really
+
+ (setopt POSIX_BUILTINS
+ x=45
+ x=$(print This should appear, too >&2; print And this) exec >test.log
+ print x=$x)
+ cat test.log
+0:Assignment with exec used for redirection: POSIX_BUILTINS
+>x=And this
+?This should appear, too
+
+ fn-two-heres() {
+# tabs below
+ cat <<-x <<-y
+ foo
+ x
+ bar
+ y
+ }
+ which -x2 fn-two-heres
+ fn-two-heres
+ eval "$(which -x2 fn-two-heres)"
+ fn-two-heres
+ print $functions[fn-two-heres]
+0:Two here-documents in a line are shown correctly.
+>fn-two-heres () {
+> cat <foo
+>x
+>bar
+>y
+>}
+>foo
+>bar
+>foo
+>bar
+> cat <foo
+>x
+>bar
+>y
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/A05execution.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/A05execution.ztst
new file mode 100644
index 0000000..0804691
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/A05execution.ztst
@@ -0,0 +1,312 @@
+%prep
+
+ storepath=($path)
+
+ mkdir command.tmp command.tmp/dir1 command.tmp/dir2
+
+ cd command.tmp
+
+ print '#!/bin/sh\necho This is top' >tstcmd
+
+ print '#!/bin/sh\necho This is dir1' >dir1/tstcmd
+
+ print '#!/bin/sh\necho This is dir2' >dir2/tstcmd
+
+ chmod 755 tstcmd dir1/tstcmd dir2/tstcmd
+
+%test
+ ./tstcmd
+0:./prog execution
+>This is top
+
+ path=($ZTST_testdir/command.tmp/dir1
+ $ZTST_testdir/command.tmp/dir2
+ .)
+ tstcmd
+ path=($storepath)
+0:path (1)
+>This is dir1
+
+ path=(. command.tmp/dir{1,2})
+ tstcmd
+ path=($storepath)
+0:path (2)
+>This is top
+
+ functst() { print $# arguments:; print -l $*; }
+ functst "Eines Morgens" "als Gregor Samsa"
+ functst ""
+ functst "aus unr�higen Tr�umen erwachte"
+ foo="fand er sich in seinem Bett"
+ bar=
+ rod="zu einem ungeheuren Ungeziefer verwandelt."
+ functst $foo $bar $rod
+# set up alias for next test
+ alias foo='print This is alias one'
+0:function argument passing
+>2 arguments:
+>Eines Morgens
+>als Gregor Samsa
+>1 arguments:
+>
+>1 arguments:
+>aus unr�higen Tr�umen erwachte
+>2 arguments:
+>fand er sich in seinem Bett
+>zu einem ungeheuren Ungeziefer verwandelt.
+
+ alias foo='print This is alias two'
+ fn() { foo; }
+ fn
+0:Aliases in functions
+>This is alias one
+
+ foo='Global foo'
+ traptst() { local foo="Local foo"; trap 'print $foo' EXIT; }
+ traptst
+0:EXIT trap environment
+>Global foo
+
+ functst() { return 0; print Ha ha; return 1; }
+ functst
+0:return (1)
+
+ functst() { return 1; print Ho ho; return 0; }
+ functst
+1:return (2)
+
+ unfunction functst
+ fpath=(.)
+ print "print This is functst." >functst
+ autoload functst
+ functst
+0:autoloading (1)
+>This is functst.
+
+ unfunction functst
+ print "functst() { print This, too, is functst; }; print Hello." >functst
+ typeset -fu functst
+ functst
+ functst
+0:autoloading with initialization
+>Hello.
+>This, too, is functst
+
+ unfunction functst
+ print "print Yet another version" >functst
+ functst() { autoload -X; }
+ functst
+0:autoloading via -X
+>Yet another version
+
+ chpwd() { print Changed to $PWD; }
+ cd .
+ unfunction chpwd
+0q:chpwd
+>Changed to $ZTST_testdir/command.tmp
+
+ chpwd() { print chpwd: changed to $PWD; }
+ chpwdfn1() { print chpwdfn1: changed to $PWD; }
+ chpwdfn2() { print chpwdfn2: changed to $PWD; }
+ chpwd_functions=(chpwdfn1 '' chpwdnonexistentfn chpwdfn2)
+ cd .
+ unfunction chpwd
+ unset chpwd_functions
+0q:chpwd_functions
+>chpwd: changed to $ZTST_testdir/command.tmp
+>chpwdfn1: changed to $ZTST_testdir/command.tmp
+>chpwdfn2: changed to $ZTST_testdir/command.tmp
+
+# Hard to test periodic, precmd and preexec non-interactively.
+
+ fn() { TRAPEXIT() { print Exit; }; }
+ fn
+0:TRAPEXIT
+>Exit
+
+ unsetopt DEBUG_BEFORE_CMD
+ unfunction fn
+ print 'TRAPDEBUG() {
+ print Line $LINENO
+ }
+ :
+ unfunction TRAPDEBUG
+ ' > fn
+ autoload fn
+ fn
+ rm fn
+0:TRAPDEBUG
+>Line 1
+>Line 1
+
+ unsetopt DEBUG_BEFORE_CMD
+ unfunction fn
+ print 'trap '\''print Line $LINENO'\'' DEBUG
+ :
+ trap - DEBUG
+ ' > fn
+ autoload fn
+ fn
+ rm fn
+0:trap DEBUG
+>Line 1
+>Line 2
+
+ TRAPZERR() { print Command failed; }
+ true
+ false
+ true
+ false
+ unfunction TRAPZERR
+0:TRAPZERR
+>Command failed
+>Command failed
+
+ trap 'print Command failed again.' ZERR
+ true
+ false
+ true
+ false
+ trap - ZERR
+0:trap ZERR
+>Command failed again.
+>Command failed again.
+
+ false
+ sleep 1000 &
+ print $?
+ kill $!
+0:Status reset by starting a backgrounded command
+>0
+
+ { setopt MONITOR } 2>/dev/null
+ [[ -o MONITOR ]] || print -u $ZTST_fd 'Unable to change MONITOR option'
+ repeat 2048; do (return 2 |
+ return 1 |
+ while true; do
+ false
+ break
+ done;
+ print "${pipestatus[@]}")
+ ZTST_hashmark
+ done | sort | uniq -c | sed 's/^ *//'
+0:Check whether '$pipestatus[]' behaves.
+>2048 2 1 0
+F:This test checks for a bug in '$pipestatus[]' handling. If it breaks then
+F:the bug is still there or it reappeared. See workers-29973 for details.
+
+ { setopt MONITOR } 2>/dev/null
+ externFunc() { awk >/dev/null 2>&1; true; }
+ false | true | false | true | externFunc
+ echo $pipestatus
+0:Check $pipestatus with a known difficult case
+>1 0 1 0 0
+F:This similar test was triggering a reproducible failure with pipestatus.
+
+ { unsetopt MONITOR } 2>/dev/null
+ coproc { read -et 5 || { print -u $ZTST_fd KILLED; kill -HUP -$$ } }
+ print -u $ZTST_fd 'This test takes 5 seconds to fail...'
+ { printf "%d\n" {1..20000} } 2>/dev/null | ( read -e )
+ hang(){ printf "%d\n" {2..20000} | cat }; hang 2>/dev/null | ( read -e )
+ print -p done
+ read -et 6 -p
+0:Bug regression: piping a shell construct to an external process may hang
+>1
+>2
+>done
+F:This test checks for a file descriptor leak that could cause the left
+F:side of a pipe to block on write after the right side has exited
+
+ { setopt MONITOR } 2>/dev/null
+ if [[ -o MONITOR ]]
+ then
+ ( while :; do print "This is a line"; done ) | () : &
+ sleep 1
+ jobs -l
+ else
+ print -u $ZTST_fd "Skipping pipe leak test, requires MONITOR option"
+ print "[0] 0 0"
+ fi
+0:Bug regression: piping to anonymous function; piping to backround function
+*>\[<->\] <-> <->
+F:This test checks for two different bugs, a parser segfault piping to an
+F:anonymous function, and a descriptor leak when backgrounding a pipeline
+
+ print "autoload_redir() { print Autoloaded ksh style; } >autoload.log" >autoload_redir
+ autoload -Uk autoload_redir
+ autoload_redir
+ print No output yet
+ cat autoload.log
+ functions autoload_redir
+0:
+>No output yet
+>Autoloaded ksh style
+>autoload_redir () {
+> print Autoloaded ksh style
+>} > autoload.log
+
+# This tests that we record the status of processes that have already exited
+# for when we wait for them.
+#
+# Actually, we don't guarantee here that the jobs have already exited, but
+# the order of the waits means it's highly likely we do need to recall a
+# previous status, barring accidents which shouldn't happen very often. In
+# other words, we rely on the test working repeatedly rather than just
+# once. The monitor option is irrelevant to the logic, so we'll make
+# our job easier by turning it off.
+ { unsetopt MONITOR } 2>/dev/null
+ (exit 1) &
+ one=$!
+ (exit 2) &
+ two=$!
+ (exit 3) &
+ three=$!
+ wait $three
+ print $?
+ wait $two
+ print $?
+ wait $one
+ print $?
+0:The status of recently exited background jobs is recorded
+>3
+>2
+>1
+
+# Regression test for workers/34060 (patch in 34065)
+ setopt ERR_EXIT NULL_GLOB
+ if false; then :; else echo if:$?; fi
+ if false; then :; else for x in _*_; do :; done; echo for:$?; fi
+0:False "if" condition handled correctly by "for" loops with ERR_EXIT
+>if:1
+>for:0
+
+# Regression test for workers/34065 (uses setopt from preceding test)
+ select x; do :; done; echo $?
+ select x in; do :; done; echo $?
+ select x in _*_; do :; done; echo $?
+ unsetopt ERR_EXIT NULL_GLOB
+0:The status of "select" is zero when the loop body does not execute
+>0
+>0
+>0
+
+# Regression test for workers/36392
+ print -u $ZTST_fd 'This test takes 3 seconds and hangs the shell when it fails...'
+ callfromchld() { true && { print CHLD } }
+ TRAPCHLD() { callfromchld }
+ sleep 2 & sleep 3; print OK
+0:Background job exit does not affect reaping foreground job
+>CHLD
+>OK
+
+# Regression test for workers/39839 and workers/39844
+ () { if return 11; then :; fi }; echo $?
+ () { while return 13; do :; done }; echo $?
+ () { until return 17; do :; done }; echo $?
+ () { until false; do return 19; done }; echo $?
+0:"return" in "if" or "while" conditional
+>11
+>13
+>17
+>19
+
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/A06assign.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/A06assign.ztst
new file mode 100644
index 0000000..bf39aee
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/A06assign.ztst
@@ -0,0 +1,631 @@
+# Tests of parameter assignments
+
+%prep
+ mkdir assign.tmp && cd assign.tmp
+
+ touch tmpfile1 tmpfile2
+
+%test
+
+ typeset -A assoc
+ assoc=(one 1 two 2 odd)
+1:assign to association with odd no. of values
+?(eval):2: bad set of key/value pairs for associative array
+
+# tests of array element assignment
+
+ array=(1 2 3 4 5)
+ array[1]=42
+ print $array
+0:Replacement of array element
+>42 2 3 4 5
+
+ array=(1 2 3 4 5)
+ array[1]=(42 43)
+ print $array
+0:Replacement of array element with array
+>42 43 2 3 4 5
+
+ array=(1 2 3 4 5)
+ array[1,2]=(42 43)
+ print $array
+0:Replacement of start of array
+>42 43 3 4 5
+
+ array=(1 2 3 4 5)
+ array[1,4]=(42 43)
+ print $array
+0:Replacement of start of array with shorter slice
+>42 43 5
+
+ array=(1 2 3 4 5)
+ array[1,6]=(42 43)
+ print $array
+0:Replacement of array by extending slice
+>42 43
+
+ array=(1 2 3 4 5)
+ array[3]=(42 43)
+ print $array
+0:Replacement of middle element with array
+>1 2 42 43 4 5
+
+ array=(1 2 3 4 5)
+ array[3,4]=(42 43 44)
+ print $array
+0:Replacement of slice in middle
+>1 2 42 43 44 5
+
+ array=(1 2 3 4 5)
+ array[7,8]=(42 43)
+ print $array
+ # check that [6] was left empty...
+ array[6]=41
+ print $array
+0:Appending by replacing elements off the end
+>1 2 3 4 5 42 43
+>1 2 3 4 5 41 42 43
+
+ array=(1 2 3 4 5)
+ array[-1]=42
+ print $array
+0:Replacement of last element of array, negative indices
+>1 2 3 4 42
+
+ array=(1 2 3 4 5)
+ array[-1]=(42 43)
+ print $array
+0:Replacement of last element of array with array, negative indices
+>1 2 3 4 42 43
+
+ array=(1 2 3 4 5)
+ array[-3,-2]=(42 43 44)
+ print $array
+0:Replacement of middle of array, negative indices
+>1 2 42 43 44 5
+
+ array=(1 2 3 4 5)
+ array[-5,-1]=(42 43)
+ print $array
+0:Replacement of entire array, negative indices
+>42 43
+
+ array=(1 2 3 4 5)
+ array[-7,-1]=(42 43)
+ print $array
+0:Replacement of more than entire array, negative indices
+>42 43
+
+ array=(1 2 3 4 5)
+ array[-7]=42
+ print $array
+0:Replacement of element off start of array.
+>42 1 2 3 4 5
+
+ array=(1 2 3 4 5)
+ array[-7]=42
+ array[-6]=43
+ print $array
+0:Replacement off start doesn't leave gaps. Hope this is right.
+>43 1 2 3 4 5
+
+ array=(1 2 3 4 5)
+ array[1,-1]=(42 43)
+ print $array
+ array[-3,3]=(1 2 3 4 5)
+ print $array
+0:Replacement of entire array, mixed indices
+>42 43
+>1 2 3 4 5
+
+ array=(1 2 3 4 5)
+ array[-7,7]=(42 43)
+ print $array
+0:Replacement of more than entire array, mixed indices
+>42 43
+
+ array=(1 2 3 4 5)
+ array[3,-2]=(42 43 44)
+ print $array
+ array[-3,5]=(100 99)
+ print $array
+0:Replacement of slice in middle, mixed indices
+>1 2 42 43 44 5
+>1 2 42 100 99 5
+
+# tests of var+=scalar
+
+ s+=foo
+ echo $s
+0:append scalar to unset scalar
+>foo
+
+ s=foo
+ s+=bar
+ echo $s
+0:append to scalar
+>foobar
+
+ set -- a b c
+ 2+=end
+ echo $2
+0:append to positional parameter
+>bend
+
+ a=(first second)
+ a+=last
+ print -l $a
+0:add scalar to array
+>first
+>second
+>last
+
+ setopt ksharrays
+ a=(first second)
+ a+=last
+ print -l $a
+ unsetopt ksharrays
+0:add scalar to array with ksharrays set
+>firstlast
+
+ a=(1 2)
+ a[@]+=3
+ print -l $a
+0:add scalar to array with alternate syntax
+>1
+>2
+>3
+
+ integer i=10
+ i+=20
+ (( i == 30 ))
+0:add to integer
+
+ float f=3.4
+ f+=2.3
+ printf "%g\n" f
+0:add to float
+>5.7
+
+ typeset -A hash
+ hash=(one 1)
+ hash+=string
+ [[ $hash[@] == string ]]
+0:add scalar to association
+
+# tests of var+=(array)
+
+ unset a
+ a+=(1 2 3)
+ print -l $a
+0:add array to unset parameter
+>1
+>2
+>3
+
+ a=(a)
+ a+=(b)
+ print -l $a
+0:add array to existing array
+>a
+>b
+
+ s=foo
+ s+=(bar)
+ print -l $s
+0:add array to scalar
+>foo
+>bar
+
+ integer i=1
+ i+=(2 3)
+ print -l $i
+0:add array to integer
+>1
+>2
+>3
+
+ float f=2.5
+ f+=(3.5 4.5)
+ printf '%g\n' $f
+0:add array to float
+>2.5
+>3.5
+>4.5
+
+ typeset -A h
+ h+=(a 1 b 2)
+ print -l $h
+0:add to empty association
+>1
+>2
+
+ typeset -A h
+ h=(a 1)
+ h+=(b 2 c 3)
+ print -l $h
+0:add to association
+>1
+>2
+>3
+
+ typeset -A h
+ h=(a 1 b 2)
+ h+=()
+ print -l $h
+0:add empty array to association
+>1
+>2
+
+# tests of var[range]+=scalar
+
+ s=sting
+ s[2]+=art
+ echo $s
+0:insert scalar inside another
+>starting
+
+ s=inert
+ s[-4]+=s
+ echo $s
+0:insert scalar inside another with negative index
+>insert
+
+ s=append
+ s[2,6]+=age
+ echo $s
+0:append scalar to scalar using a range
+>appendage
+
+ s=123456789
+ s[3,-5]+=X
+ echo $s
+0:insert scalar inside another, specifying a slice
+>12345X6789
+
+ a=(a b c)
+ a[2]+=oo
+ echo $a
+0:append to array element
+>a boo c
+
+ a=(a b c d)
+ a[-2]+=ool
+ echo $a
+0:append to array element with negative index
+>a b cool d
+
+ a=(a b c d)
+ a[2,-1]+=oom
+ echo $a
+0:append to array element, specifying a slice
+>a b c doom
+
+ setopt ksharrays
+ a=(a b c d)
+ a[0]+=0
+ echo $a
+ unsetopt ksharrays
+0:append to array element with ksharrays set
+>a0
+
+ typeset -A h
+ h=(one foo)
+ h[one]+=bar
+ echo $h
+0:append to association element
+>foobar
+
+ typeset -A h
+ h[foo]+=bar
+ echo ${(kv)h}
+0:append to non-existent association element
+>foo bar
+
+ typeset -A h
+ h=(one a two b three c four d)
+ h[(I)*o*]+=append
+1:attempt to append to slice of association
+?(eval):3: h: attempt to set slice of associative array
+
+ integer i=123
+ i[2]+=6
+1:attempt to add to indexed integer variable
+?(eval):2: attempt to add to slice of a numeric variable
+
+ float f=1234.5
+ f[2,4]+=3
+1:attempt to add to slice of float variable
+?(eval):2: attempt to add to slice of a numeric variable
+
+ unset u
+ u[3]+=third
+ echo $u[1]:$u[3]
+0:append to unset variable with index
+>:third
+
+# tests of var[range]+=(array)
+
+ a=(1 2 3)
+ a[2]+=(a b)
+ echo $a
+0:insert array inside another
+>1 2 a b 3
+
+ a=(a b c)
+ a[-1]+=(d)
+ echo $a
+0:append to array using negative index
+>a b c d
+
+ a=(1 2 3 4)
+ a[-1,-3]+=(x)
+ echo $a
+0:insert array using negative range
+>1 2 x 3 4
+
+ s=string
+ s[2]+=(a b)
+1:attempt to insert array into string
+?(eval):2: s: attempt to assign array value to non-array
+
+ integer i=365
+ i[2]+=(1 2)
+1:attempt to insert array into string
+?(eval):2: i: attempt to assign array value to non-array
+
+ typeset -A h
+ h=(a 1)
+ h[a]+=(b 2)
+1:attempt to append array to hash element
+?(eval):3: h: attempt to set slice of associative array
+
+ unset u
+ u[-34,-2]+=(a z)
+ echo $u
+0:add array to indexed unset variable
+>a z
+
+ repeat 10 PATH=. echo hello
+0:saving and restoring of exported special parameters
+>hello
+>hello
+>hello
+>hello
+>hello
+>hello
+>hello
+>hello
+>hello
+>hello
+
+ repeat 10 FOO=BAR BAR=FOO echo $FOO $BAR
+0:save and restore multiple variables around builtin
+>
+>
+>
+>
+>
+>
+>
+>
+>
+>
+
+ call() { print $HELLO; }
+ export HELLO=world
+ call
+ HELLO=universe call
+ call
+ HELLO=${HELLO}liness call
+ call
+ unset HELLO
+0:save and restore when using original value in temporary
+>world
+>universe
+>world
+>worldliness
+>world
+
+ (integer i n x
+ float f
+ setopt globassign
+ i=tmpfile1
+ n=tmpf*
+ x=*2
+ f=2+2
+ typeset -p i n x f)
+0:GLOB_ASSIGN with numeric types
+>typeset -i i=0
+>typeset -a n=( tmpfile1 tmpfile2 )
+>typeset x=tmpfile2
+>typeset -E f=4.000000000e+00
+
+ setopt globassign
+ foo=tmpf*
+ print $foo
+ unsetopt globassign
+ foo=tmpf*
+ print $foo
+0:GLOB_ASSIGN option
+>tmpfile1 tmpfile2
+>tmpf*
+
+ (setopt globassign
+ typeset -A foo
+ touch gatest1 gatest2
+ foo=(gatest*)
+ print ${(t)foo}
+ rm -rf gatest*)
+0:GLOB_ASSIGN doesn't monkey with type if not scalar assignment.
+>association-local
+
+ A=(first second)
+ A="${A[*]}" /bin/sh -c 'echo $A'
+ print -l "${A[@]}"
+0:command execution with assignments shadowing array parameter
+>first second
+>first
+>second
+
+ setopt ksharrays
+ A=(first second)
+ A="${A[*]}" /bin/sh -c 'echo $A'
+ print -l "${A[@]}"
+ unsetopt ksharrays
+0:command execution with assignments shadowing array parameter with ksharrays
+>first second
+>first
+>second
+
+ typeset -aU unique_array=(first second)
+ unique_array[1]=second
+ print $unique_array
+0:assignment to unique array
+>second
+
+ typeset -a array=(first)
+ array[1,3]=(FIRST)
+ print $array
+0:slice beyond length of array
+>FIRST
+
+# tests of string assignments
+
+ a="abc"
+ a[1]=x
+ print $a
+0:overwrite first character in string
+>xbc
+
+ a="abc"
+ a[2]="x"
+ print $a
+0:overwrite middle character in string
+>axc
+
+ a="abc"
+ a[3]="x"
+ print $a
+0:overwrite last character in string
+>abx
+
+ a="abc"
+ a[-1]="x"
+ print $a
+0:overwrite -1 character in string
+>abx
+
+ a="abc"
+ a[-2]="x"
+ print $a
+0:overwrite -2 character (middle) in string
+>axc
+
+ a="ab"
+ a[-2]="x"
+ print $a
+0:overwrite -2 character (first) in string
+>xb
+
+ a="abc"
+ a[-3]="x"
+ print $a
+0:overwrite -3 character (first) in string
+>xbc
+
+ a="abc"
+ a[-4]="x"
+ print $a
+0:overwrite -4 character (before first) in string
+>xabc
+
+ a="abc"
+ a[-5]="x"
+ print $a
+0:overwrite -5 character (before-before first) in string
+>xabc
+
+ a="abc"
+ a[-4,0]="x"
+ print $a
+0:overwrite [-4,0] characters (before first) in string
+>xabc
+
+ a="abc"
+ a[-4,-4]="x"
+ print $a
+0:overwrite [-4,-4] character (before first) in string
+>xabc
+
+ a="abc"
+ a[-40,-30]="x"
+ print $a
+0:overwrite [-40,-30] characters (far before first) in string
+>xabc
+
+ a="abc"
+ a[-40,1]="x"
+ print $a
+0:overwrite [-40,1] characters in short string
+>xbc
+
+ a="abc"
+ a[-40,40]="x"
+ print $a
+0:overwrite [-40,40] characters in short string
+>x
+
+ a="abc"
+ a[2,40]="x"
+ print $a
+0:overwrite [2,40] characters in short string
+>ax
+
+ a="abc"
+ a[2,-1]="x"
+ print $a
+0:overwrite [2,-1] characters in short string
+>ax
+
+ a="abc"
+ a[-2,-1]="x"
+ print $a
+0:overwrite [-2,-1] characters in short string
+>ax
+
+ a="a"
+ a[-1]="xx"
+ print $a
+0:overwrite [-1] character with "xx"
+>xx
+
+ a="a"
+ a[-2]="xx"
+ print $a
+0:overwrite [-2] character (before first) with "xx"
+>xxa
+
+ a="a"
+ a[2]="xx"
+ print $a
+0:overwrite [2] character (after last) with "xx"
+>axx
+
+ a=""
+ a[1]="xx"
+ print $a
+0:overwrite [1] character (string: "") with "xx"
+>xx
+
+ a=""
+ a[-1]="xx"
+ print $a
+0:overwrite [-1] character (string: "") with "xx"
+>xx
+
+ a=""
+ a[2]="xx"
+ print $a
+0:overwrite [2] character (string: "") with "xx"
+>xx
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/A07control.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/A07control.ztst
new file mode 100644
index 0000000..b1a2487
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/A07control.ztst
@@ -0,0 +1,165 @@
+# Test control commands for loops and functions.
+
+%test
+
+ fn3() { return $1; print Error }
+ fn2() { fn3 $1 }
+ fn() {
+ print start $1
+ fn2 $1
+ return
+ print Error
+ }
+ for val in -1 0 1 255; do
+ fn $val; print $?
+ done
+0:Passing of return values back through functions
+>start -1
+>-1
+>start 0
+>0
+>start 1
+>1
+>start 255
+>255
+
+ $ZTST_testdir/../Src/zsh -fc 'fn() {
+ continue
+ }
+ fn'
+1:continue outside loop
+?fn:continue:1: not in while, until, select, or repeat loop
+
+ for outer in 0 1 2 3; do
+ print outer $outer
+ for inner in 0 1 2 3; do
+ print inner $inner
+ continue $(( (outer & 1) ? 2 : 1 ))
+ print error
+ done
+ print outer end
+ done
+0:continue with valid argument
+>outer 0
+>inner 0
+>inner 1
+>inner 2
+>inner 3
+>outer end
+>outer 1
+>inner 0
+>outer 2
+>inner 0
+>inner 1
+>inner 2
+>inner 3
+>outer end
+>outer 3
+>inner 0
+
+ for outer in 0 1; do
+ continue 0
+ print -- $outer got here, status $?
+ done
+1:continue error case 0
+?(eval):continue:2: argument is not positive: 0
+
+ for outer in 0 1; do
+ continue -1
+ print -- $outer got here, status $?
+ done
+1:continue error case -1
+?(eval):continue:2: argument is not positive: -1
+
+ fn() {
+ break
+ }
+ for outer in 0 1; do
+ print $outer
+ fn
+ done
+0:break from within function (this is a feature, I disovered)
+>0
+
+ for outer in 0 1 2 3; do
+ print outer $outer
+ for inner in 0 1 2 3; do
+ print inner $inner
+ break $(( (outer & 1) ? 2 : 1 ))
+ print error
+ done
+ print outer end
+ done
+0:break with valid argument
+>outer 0
+>inner 0
+>outer end
+>outer 1
+>inner 0
+
+ for outer in 0 1; do
+ break 0
+ print -- $outer got here, status $?
+ done
+1:break error case 0
+?(eval):break:2: argument is not positive: 0
+
+ for outer in 0 1; do
+ break -1
+ print -- $outer got here, status $?
+ done
+1:break error case -1
+?(eval):break:2: argument is not positive: -1
+
+ false
+ for x in; do
+ print nothing executed
+ done
+0:Status 0 from for with explicit empty list
+
+ set --
+ false
+ for x; do
+ print nothing executed
+ done
+0:Status 0 from for with implicit empty list
+
+ (exit 2)
+ for x in 1 2; do
+ print $?
+ done
+0:Status from previous command propagated into for loop
+>2
+>0
+
+ false
+ for x in $(echo 1 2; (exit 3)); do
+ print $?
+ done
+0:Status from expansion propagated into for loop
+>3
+>0
+
+ false
+ for x in $(exit 4); do
+ print not executed
+ done
+0:Status from expansion not propagated after unexecuted for loop
+
+ false
+ for x in NonExistentFilePrefix*(N); do
+ print not executed, either
+ done
+0:Status from before for loop not propagated if empty after expansion
+
+ for x in $(echo 1; false); do
+ done
+0:Status reset by empty list in for loop
+
+ false
+ for x in $(echo 1; false); do
+ echo $?
+ (exit 4)
+ done
+4:Last status from loop body is kept even with other funny business going on
+>1
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B01cd.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B01cd.ztst
new file mode 100644
index 0000000..94447e7
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B01cd.ztst
@@ -0,0 +1,144 @@
+# This file serves as a model for how to write tests, so is more heavily
+# commented than the others. All tests are run in the Test subdirectory
+# of the distribution, which must be writable. They should end with
+# the suffix `.ztst': this is not required by the test harness itself,
+# but it is needed by the Makefile to run all the tests.
+
+# Blank lines with no other special meaning (e.g. separating chunks of
+# code) and all those with a `#' in the first column are ignored.
+
+# All section names start with a % in the first column. The names
+# must be in the expected order, though not all sections are required.
+# The sections are %prep (preparatory setup: code executed should return
+# status 0, but no other tests are performed), %test (the main tests), and
+# %clean (to cleanup: the code is simply unconditionally executed).
+#
+# Literal shell code to be evaluated must be indented with any number
+# of spaces and/or tabs, to differentiate it from tags with a special
+# meaning to the test harness. Note that this is true even in sections
+# where there are no such tags. Also note that file descriptor 9
+# is reserved for input from the test script, and file descriptor 8
+# preserves the original stdout. Option settings are preserved between the
+# execution of different code chunks; initially, all standard zsh options
+# (the effect of `emulate -R zsh') are set.
+
+%prep
+# This optional section prepares the test, creating directories and files
+# and so on. Chunks of code are separated by blank lines (which is not
+# necessary before the end of the section); each chunk of code is evaluated
+# in one go and must return status 0, or the preparation is deemed to have
+# failed and the test ends with an appropriate error message. Standard
+# output from this section is redirected to /dev/null, but standard error
+# is not redirected.
+#
+# Tests should use subdirectories ending in `.tmp'. These will be
+# removed with all the contents even if the test is aborted.
+ mkdir cdtst.tmp cdtst.tmp/real cdtst.tmp/sub
+
+ ln -s ../real cdtst.tmp/sub/fake
+
+ setopt chaselinks
+ cd .
+ unsetopt chaselinks
+ mydir=$PWD
+
+%test
+# This is where the tests are run. It consists of blocks separated
+# by blank lines. Each block has the same format and there may be any
+# number of them. It consists of indented code, plus optional sets of lines
+# beginning '<', '>' and '?' which may appear in any order. These correspond
+# to stdin (fed to the code), stdout (compared with code output) and
+# stderr (compared with code error output) respectively. These subblocks
+# may occur in any order, but the natural one is: code, stdin, stdout,
+# stderr.
+#
+# The rules for '<', '>' and '?' lines are the same: only the first
+# character is stripped (with the excpetion for '*' noted below), with
+# subsequent whitespace being significant; lines are not subject to any
+# substitution unless the `q' flag (see below) is set.
+#
+# Each line of a '>' and '?' chunk may be preceded by a '*', so the line
+# starts '*>' or '*?'. This signifies that for any line with '*' in front
+# the actual output should be pattern matched against the corresponding
+# lines in the test output. Each line following '>' or '?' must be a
+# valid pattern, so characters special to patterns such as parentheses
+# must be quoted with a backslash. The EXTENDED_GLOB option is used for
+# all such patterns.
+#
+# Each chunk of indented code is to be evaluated in one go and is to
+# be followed by a line starting (in the first column) with
+# the expected status returned by the code when run, or - if it is
+# irrelevant. An optional set of single-letter flags follows the status
+# or -. The following are understood:
+# . d Don't diff stdout against the expected stdout.
+# D Don't diff stderr against the expected stderr.
+# q All redirection lines given in the test script (not the lines
+# actually produced by the test) are subject to ordinary quoted shell
+# expansion (i.e. not globbing).
+# This can be followed by a `:' and a message describing the
+# test, which will be printed if the test fails, along with a
+# description of the failure that occurred. The `:' and message are
+# optional, but highly recommended.
+# Hence a complete status line looks something like:
+# 0dDq:Checking whether the world will end with a bang or a whimper
+#
+# If either or both of the '>' and '?' sets of lines is absent, it is
+# assumed the corresponding output should be empty and it is an error if it
+# is not. If '<' is empty, stdin is an empty (but opened) file.
+#
+# It is also possible to add lines in the redirection section beginning
+# with `F:'. The remaining text on all such lines will be concatenated
+# (with newlines in between) and displayed in the event of an error.
+# This text is useful for explaining certain frequent errors, for example
+# ones which may arise from the environment rather than from the shell
+# itself. (The example below isn't particularly useful as errors with
+# `cd' are unusual.)
+#
+# A couple of features aren't used in this file, but are usefuil in cases
+# where features may not be available so should not be tested. They boh
+# take the form of variables. Note that to keep the test framework simple
+# there is no magic in setting the variables: the chunk of code being
+# executed needs to avoid executing any test code by appropriate structure
+# (typically "if"). In both cases, the value of the variable is output
+# as a warning that the test was skipped.
+# ZTST_unimplemented: Set this in the %prep phase if the entire test file
+# is to be skipped.
+# ZTST_skip: Set this in any test case if that single test case is to be
+# skipped. Testing resumes at the next test case in the same file.
+ cd cdtst.tmp/sub/fake &&
+ pwd &&
+ print $PWD
+0q:Preserving symbolic links in the current directory string
+>$mydir/cdtst.tmp/sub/fake
+>$mydir/cdtst.tmp/sub/fake
+F:This test shouldn't really fail. The fact that it has indicates
+F:something is broken. But you already knew that.
+
+ cd ../../.. &&
+ pwd &&
+ print $PWD
+0q:Changing directory up through symbolic links without following them
+>$mydir
+>$mydir
+
+ setopt chaselinks
+ cd cdtst.tmp/sub/fake &&
+ pwd &&
+ print $PWD
+0q:Resolving symbolic links with chaselinks set
+>$mydir/cdtst.tmp/real
+>$mydir/cdtst.tmp/real
+
+ ln -s nonexistent link_to_nonexistent
+ pwd1=$(pwd -P)
+ cd -s link_to_nonexistent
+ pwd2=$(pwd -P)
+ [[ $pwd1 = $pwd2 ]] || print "Ooops, changed to directory '$pwd2'"
+0:
+?(eval):cd:3: not a directory: link_to_nonexistent
+
+%clean
+# This optional section cleans up after the test, if necessary,
+# e.g. killing processes etc. This is in addition to the removal of *.tmp
+# subdirectories. This is essentially like %prep, except that status
+# return values are ignored.
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B02typeset.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B02typeset.ztst
new file mode 100644
index 0000000..b27bb4f
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B02typeset.ztst
@@ -0,0 +1,723 @@
+# There are certain usages of typeset and its synonyms that it is not
+# possible to test here, because they must appear at the top level and
+# everything that follows is processed by an "eval" within a function.
+
+# Equivalences:
+# declare typeset
+# export typeset -xg
+# float typeset -E
+# functions typeset -f
+# integer typeset -i
+# local typeset +g -m approximately
+# readonly typeset -r
+
+# Tested elsewhere:
+# Equivalence of autoload and typeset -fu A05execution
+# Associative array creation & assignment D04parameter, D06subscript
+# Effects of GLOBAL_EXPORT E01options
+# Function tracing (typeset -ft) E02xtrace
+
+# Not yet tested:
+# Assorted illegal flag combinations
+
+%prep
+ ## Do not remove the next line, it's used by V10private.ztst
+ # test_zsh_param_private
+
+ mkdir typeset.tmp && cd typeset.tmp
+
+ setopt noglob
+
+ scalar=scalar
+ array=(a r r a y)
+
+ scope00() {
+ typeset scalar
+ scalar=local
+ typeset -a array
+ array=(l o c a l)
+ print $scalar $array
+ }
+ scope01() {
+ local scalar
+ scalar=local
+ local -a array
+ array=(l o c a l)
+ print $scalar $array
+ }
+ scope02() {
+ declare scalar
+ scalar=local
+ declare -a array
+ array=(l o c a l)
+ print $scalar $array
+ }
+ scope10() {
+ export outer=outer
+ /bin/sh -fc 'echo $outer'
+ }
+ scope11() {
+ typeset -x outer=outer
+ /bin/sh -fc 'echo $outer'
+ }
+ scope12() {
+ local -x outer=inner
+ /bin/sh -fc 'echo $outer'
+ }
+ scope13() {
+ local -xT OUTER outer
+ outer=(i n n e r)
+ /bin/sh -fc 'echo $OUTER'
+ }
+
+ # Bug? `typeset -h' complains that ! # $ * - ? @ are not identifiers.
+ stress00() {
+ typeset -h +g -m [[:alpha:]_]*
+ unset -m [[:alpha:]_]*
+ typeset +m [[:alpha:]_]*
+ }
+
+%test
+
+ typeset +m scalar array
+0:Report types of parameters with typeset +m
+>scalar
+>array array
+
+ scope00
+ print $scalar $array
+0:Simple local declarations
+>local l o c a l
+>scalar a r r a y
+
+ scope01
+ print $scalar $array
+0:Equivalence of local and typeset in functions
+>local l o c a l
+>scalar a r r a y
+
+ scope02
+ print $scalar $array
+0:Basic equivalence of declare and typeset
+>local l o c a l
+>scalar a r r a y
+
+ declare +m scalar
+0:declare previously lacked -m/+m options
+>scalar
+
+ scope10
+ print $outer
+0:Global export
+>outer
+>outer
+
+ scope11
+ print $outer
+0:Equivalence of export and typeset -x
+>outer
+>outer
+
+ scope12
+ print $outer
+0:Local export
+>inner
+>outer
+
+ float f=3.14159
+ typeset +m f
+ float -E3 f
+ print $f
+ float -F f
+ print $f
+0:Floating point, adding a precision, and fixed point
+>float local f
+>3.14e+00
+>3.142
+
+ integer i=3.141
+ typeset +m i
+ integer -i2 i
+ print $i
+0:Integer and changing the base
+>integer local i
+>2#11
+
+ float -E3 f=3.141
+ typeset +m f
+ integer -i2 f
+ typeset +m f
+ print $f
+0:Conversion of floating point to integer
+>float local f
+>integer 2 local f
+>2#11
+
+ typeset -f
+0q:Equivalence of functions and typeset -f
+>$(functions)
+
+ readonly r=success
+ print $r
+ r=failure
+1:Readonly declaration
+>success
+?(eval):3: read-only variable: r
+
+ typeset r=success
+ readonly r
+ print $r
+ r=failure
+1:Convert to readonly
+>success
+?(eval):4: read-only variable: r
+
+ typeset -gU array
+ print $array
+0:Uniquified arrays and non-local scope
+>a r y
+
+ typeset -T SCALAR=l:o:c:a:l array
+ print $array
+ typeset -U SCALAR
+ print $SCALAR $array
+0:Tied parameters and uniquified colon-arrays
+>l o c a l
+>l:o:c:a l o c a
+
+ (setopt NO_multibyte cbases
+ LC_ALL=C 2>/dev/null
+ typeset -T SCALAR=$'l\x83o\x83c\x83a\x83l' array $'\x83'
+ print $array
+ typeset -U SCALAR
+ for (( i = 1; i <= ${#SCALAR}; i++ )); do
+ char=$SCALAR[i]
+ print $(( [#16] #char ))
+ done
+ print $array)
+0:Tied parameters and uniquified arrays with meta-character as separator
+>l o c a l
+>0x6C
+>0x83
+>0x6F
+>0x83
+>0x63
+>0x83
+>0x61
+>l o c a
+
+ typeset -T SCALAR=$'l\000o\000c\000a\000l' array $'\000'
+ typeset -U SCALAR
+ print $array
+ [[ $SCALAR == $'l\000o\000c\000a' ]]
+0:Tied parameters and uniquified arrays with NUL-character as separator
+>l o c a
+
+ typeset -T SCALAR array
+ typeset +T SCALAR
+1:Untying is prohibited
+?(eval):typeset:2: use unset to remove tied variables
+
+ OUTER=outer
+ scope13
+ print $OUTER
+0:Export of tied parameters
+>i:n:n:e:r
+>outer
+
+ typeset -TU MORESTUFF=here-we-go-go-again morestuff '-'
+ print -l $morestuff
+0:Tied arrays with separator specified
+>here
+>we
+>go
+>again
+
+ typeset -T THIS will not work
+1:Tied array syntax
+?(eval):typeset:1: too many arguments for -T
+
+ local array[2]=x
+1:Illegal local array element assignment
+?(eval):local:1: array[2]: can't create local array elements
+
+ local -a array
+ typeset array[1]=a array[2]=b array[3]=c
+ print $array
+0:Legal local array element assignment
+>a b c
+
+ local -A assoc
+ local b=1 ;: to stomp assoc[1] if assoc[b] is broken
+ typeset assoc[1]=a assoc[b]=2 assoc[3]=c
+ print $assoc[1] $assoc[b] $assoc[3]
+0:Legal local associative array element assignment
+>a 2 c
+
+ local scalar scalar[1]=a scalar[2]=b scalar[3]=c
+ print $scalar
+0:Local scalar subscript assignment
+>abc
+
+ typeset -L 10 fools
+ for fools in " once" "twice" " thrice" " oops too long here"; do
+ print "'$fools'"
+ done
+0:Left justification of scalars
+>'once '
+>'twice '
+>'thrice '
+>'oops too l'
+
+ typeset -L 10 -F 3 foolf
+ for foolf in 1.3 4.6 -2.987 -4.91031; do
+ print "'$foolf'"
+ done
+0:Left justification of floating point
+>'1.300 '
+>'4.600 '
+>'-2.987 '
+>'-4.910 '
+
+ typeset -L 10 -Z foolzs
+ for foolzs in 001.3 04.6 -2.987 -04.91231; do
+ print "'$foolzs'"
+ done
+0:Left justification of scalars with zero suppression
+>'1.3 '
+>'4.6 '
+>'-2.987 '
+>'-04.91231 '
+
+ typeset -R 10 foors
+ for foors in short longer even-longer; do
+ print "'$foors'"
+ done
+0:Right justification of scalars
+>' short'
+>' longer'
+>'ven-longer'
+
+ typeset -Z 10 foozs
+ for foozs in 42 -42 " 43" " -43"; do
+ print "'$foozs'"
+ done
+0:Right justification of scalars with zeroes
+>'0000000042'
+>' -42'
+>' 000000043'
+>' -43'
+
+ integer -Z 10 foozi
+ for foozi in 42 -42 " 43" " -43"; do
+ print "'$foozi'"
+ done
+0:Right justification of integers with zero, no initial base
+>'0000000042'
+>'-000000042'
+>'0000000043'
+>'-000000043'
+# In case you hadn't twigged, the spaces are absorbed in the initial
+# math evaluation, so don't get through.
+
+ unsetopt cbases
+ integer -Z 10 -i 16 foozi16
+ for foozi16 in 42 -42 " 43" " -43"; do
+ print "'$foozi16'"
+ done
+0:Right justification of integers with zero, base 16, C_BASES off
+>'16#000002A'
+>'-16#00002A'
+>'16#000002B'
+>'-16#00002B'
+
+ setopt cbases
+ integer -Z 10 -i 16 foozi16c
+ for foozi16c in 42 -42 " 43" " -43"; do
+ print "'$foozi16c'"
+ done
+0:Right justification of integers with zero, base 16, C_BASES on
+>'0x0000002A'
+>'-0x000002A'
+>'0x0000002B'
+>'-0x000002B'
+
+ setopt cbases
+ integer -Z 10 -i 16 foozi16c
+ for foozi16c in 0x1234 -0x1234; do
+ for (( i = 1; i <= 5; i++ )); do
+ print "'${foozi16c[i,11-i]}'"
+ done
+ print "'${foozi16c[-2]}'"
+ done
+0:Extracting substrings from padded integers
+>'0x00001234'
+>'x0000123'
+>'000012'
+>'0001'
+>'00'
+>'3'
+>'-0x0001234'
+>'0x000123'
+>'x00012'
+>'0001'
+>'00'
+>'3'
+
+ typeset -F 3 -Z 10 foozf
+ for foozf in 3.14159 -3.14159 4 -4; do
+ print "'$foozf'"
+ done
+0:Right justification of fixed point numbers with zero
+>'000003.142'
+>'-00003.142'
+>'000004.000'
+>'-00004.000'
+
+ stress00
+ print $scalar $array
+0q:Stress test: all parameters are local and unset, using -m
+>scalar a r y
+
+ local parentenv=preserved
+ fn() {
+ typeset -h +g -m \*
+ unset -m \*
+ integer i=9
+ float -H f=9
+ declare -t scalar
+ declare -H -a array
+ typeset
+ typeset +
+ }
+ fn
+ echo $parentenv
+0:Parameter hiding and tagging, printing types and values
+>array local array
+>float local f
+>integer local i=9
+>local tagged scalar=''
+>array local array
+>float local f
+>integer local i
+>local tagged scalar
+>preserved
+
+ export ENVFOO=bar
+ print ENVFOO in environment
+ env | grep '^ENVFOO'
+ print Changing ENVFOO
+ ENVFOO="not bar any more"
+ env | grep '^ENVFOO'
+ unset ENVFOO
+ print ENVFOO no longer in environment
+ env | grep '^ENVFOO'
+1:Adding and removing values to and from the environment
+>ENVFOO in environment
+>ENVFOO=bar
+>Changing ENVFOO
+>ENVFOO=not bar any more
+>ENVFOO no longer in environment
+
+ (export FOOENV=BAR
+ env | grep '^FOOENV'
+ print Exec
+ exec $ZTST_testdir/../Src/zsh -fc '
+ print Unset
+ unset FOOENV
+ env | grep "^FOOENV"')
+1:Can unset environment variables after exec
+>FOOENV=BAR
+>Exec
+>Unset
+
+ local case1=upper
+ typeset -u case1
+ print $case1
+ upper="VALUE OF \$UPPER"
+ print ${(P)case1}
+0:Upper case conversion, does not apply to values used internally
+>UPPER
+>VALUE OF $UPPER
+
+ local case2=LOWER
+ typeset -l case2
+ print $case2
+ LOWER="value of \$lower"
+ print ${(P)case2}
+0:Lower case conversion, does not apply to values used internally
+>lower
+>value of $lower
+
+ typeset -a array
+ array=(foo bar)
+ fn() { typeset -p array nonexistent; }
+ fn
+1:declare -p shouldn't create scoped values
+>typeset -g -a array=( foo bar )
+?fn:typeset: no such variable: nonexistent
+
+ unsetopt typesetsilent
+ silent1(){ typeset -g silence; }
+ silent2(){ local silence; silent1; }
+ silent2
+0:typeset -g should be silent even without TYPESET_SILENT
+
+ typeset -T TIED_SCALAR tied_array
+ TIED_SCALAR=foo:bar
+ print $tied_array
+ typeset -T TIED_SCALAR=goo:car tied_array
+ print $tied_array
+ typeset -T TIED_SCALAR tied_array=(poo par)
+ print $TIED_SCALAR
+0:retying arrays to same array works
+>foo bar
+>goo car
+>poo:par
+
+ (
+ setopt POSIXBUILTINS
+ readonly pbro
+ print ${+pbro} >&2
+ (typeset -g pbro=3)
+ (pbro=4)
+ readonly -p pbro >&2 # shows up as "readonly" although unset
+ typeset -gr pbro # idempotent (no error)...
+ print ${+pbro} >&2 # ...so still readonly...
+ typeset -g +r pbro # ...can't turn it off
+ )
+1:readonly with POSIX_BUILTINS
+?0
+?(eval):5: read-only variable: pbro
+?(eval):6: read-only variable: pbro
+?typeset -g -r pbro
+?0
+?(eval):10: read-only variable: pbro
+
+ readonly foo=bar novalue
+ readonly -p
+0:readonly -p output (no readonly specials)
+>typeset -r foo=bar
+>typeset -r novalue=''
+
+ local -a a1 a2
+ local -r r1=yes r2=no
+ a1=(one two) a2=(three four)
+ readonly a1
+ typeset -pm 'a[12]'
+ typeset -pm 'r[12]'
+0:readonly -p output
+>typeset -ar a1=( one two )
+>typeset -a a2=( three four )
+>typeset -r r1=yes
+>typeset -r r2=no
+
+ one=hidden two=hidden three=hidden four=hidden five=hidden
+ fn() {
+ local bleugh="four=vier"
+ typeset -R10 one=eins two=(zwei dio) three $bleugh five=(cinq cinque)
+ three=drei
+ print -l $one $two $three $four $five
+ }
+ fn
+ print -l $one $two $three $four $five
+0:typeset reserved word interface: basic
+> eins
+>zwei
+>dio
+> drei
+> vier
+>cinq
+>cinque
+>hidden
+>hidden
+>hidden
+>hidden
+>hidden
+
+ (
+ setopt glob
+ mkdir -p arrayglob
+ touch arrayglob/{one,two,three,four,five,six,seven}
+ fn() {
+ typeset array=(arrayglob/[tf]*)
+ print -l ${array:t}
+ #
+ typeset {first,second,third}=the_same_value array=(
+ extends
+ over
+ multiple
+ lines
+ )
+ print -l $first $second $third "$array"
+ #
+ integer i=$(echo 1 + 2 + 3 + 4)
+ print $i
+ #
+ # only noted by accident this was broken..
+ # we need to turn off special recognition
+ # of assignments within assignments...
+ typeset careful=( i=1 j=2 k=3 )
+ print -l $careful
+ }
+ fn
+ )
+0:typeset reserved word, more complicated cases
+>five
+>four
+>three
+>two
+>the_same_value
+>the_same_value
+>the_same_value
+>extends over multiple lines
+>10
+>i=1
+>j=2
+>k=3
+
+ (
+ # reserved word is recognised at parsing.
+ # yes, this is documented.
+ # anyway, that means we need to
+ # re-eval the function...
+ fn='
+ fn() {
+ typeset foo=`echo one word=two`
+ print $foo
+ print $word
+ }
+ '
+ print reserved
+ eval $fn; fn
+ print builtin
+ disable -r typeset
+ eval $fn; fn
+ enable -r typeset
+ disable typeset
+ print reserved
+ eval $fn; fn
+ )
+0:reserved word and builtin interfaces
+>reserved
+>one word=two
+>
+>builtin
+>one
+>two
+>reserved
+>one word=two
+>
+
+ fn() {
+ emulate -L zsh
+ setopt typeset_silent
+ local k
+ typeset -A hash=(k1 v1 k2 v2)
+ typeset foo=word array=(more than one word)
+ for k in ${(ko)hash}; do
+ print $k $hash[$k]
+ done
+ print -l $foo $array
+ typeset -A hash
+ typeset foo array
+ for k in ${(ko)hash}; do
+ print $k $hash[$k]
+ done
+ print -l $foo $array
+ typeset hash=(k3 v3 k4 v4) array=(odd number here)
+ for k in ${(ko)hash}; do
+ print $k $hash[$k]
+ done
+ print -l $array
+ }
+ fn
+0:typeset preserves existing variable types
+>k1 v1
+>k2 v2
+>word
+>more
+>than
+>one
+>word
+>k1 v1
+>k2 v2
+>word
+>more
+>than
+>one
+>word
+>k3 v3
+>k4 v4
+>odd
+>number
+>here
+
+ fn() { typeset foo bar thing=this stuff=(that other) more=woevva; }
+ which -x2 fn
+ fn2() { typeset assignfirst=(why not); }
+ which -x2 fn2
+0:text output from typeset
+>fn () {
+> typeset foo bar thing=this stuff=(that other) more=woevva
+>}
+>fn2 () {
+> typeset assignfirst=(why not)
+>}
+
+ fn() {
+ typeset array=()
+ print ${(t)array} ${#array}
+ typeset gnothergarray=() gnothergarray[1]=yes gnothergarray[2]=no
+ print -l ${(t)gnothergarray} $gnothergarray
+ }
+ fn
+0:can set empty array
+>array-local 0
+>array-local
+>yes
+>no
+
+ array=(nothing to see here)
+ fn() {
+ typeset array=(one two three four five)
+ typeset array[2,4]=(umm er)
+ print ${#array} $array
+ typeset array[2,3]=()
+ print ${#array} $array
+ }
+ fn
+ print ${#array} $array
+0:can update array slices in typeset
+>4 one umm er five
+>2 one five
+>4 nothing to see here
+
+ array=(no really nothing here)
+ fn() {
+ typeset array=() array[2]=two array[4]=four
+ typeset -p array
+ typeset array=() array[3]=three array[1]=one
+ typeset -p array
+ }
+ fn
+ print $array
+0:setting empty array in typeset
+>typeset -a array=( '' two '' four )
+>typeset -a array=( one '' three )
+>no really nothing here
+
+ readonly isreadonly=yes
+ typeset isreadonly=still
+1:typeset returns status 1 if setting readonly variable
+?(eval):2: read-only variable: isreadonly
+
+ if (( UID )); then
+ UID=$((UID+1)) date; echo "Status is printed, $?"
+ else
+ ZTST_skip="cannot test setuid error when tests run as superuser"
+ fi
+0:when cannot change UID, the command isn't run
+# 'date' did not run.
+>Status is printed, 1
+*?*: failed to change user ID: *
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B03print.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B03print.ztst
new file mode 100644
index 0000000..c65568a
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B03print.ztst
@@ -0,0 +1,336 @@
+# Tests for the echo, print, printf and pushln builtins
+
+# Tested elsewhere:
+# Use of print -p to output to coprocess A01grammar
+# Prompt expansion with print -P D01prompt
+# -l, -r, -R and -n indirectly tested in various places
+
+# Not yet tested:
+# echo and pushln
+# print's -b -c -s -z -N options
+
+
+%test
+
+ print -D "${HOME:-~}"
+0:replace directory name
+>~
+
+ print -u2 'error message'
+0:output to file-descriptor
+?error message
+
+ print -o foo bar Baz
+0:argument sorting
+>Baz bar foo
+
+ print -f
+1:print -f needs a format specified
+?(eval):print:1: argument expected: -f
+
+ print -Of '%s\n' foo bar baz
+0:reverse argument sorting
+>foo
+>baz
+>bar
+
+# some locales force case-insensitive sorting
+ (LC_ALL=C; print -o a B c)
+0:case-sensitive argument sorting
+>B a c
+
+ (LC_ALL=C; print -io a B c)
+0:case-insensitive argument sorting
+>a B c
+
+ print -m '[0-9]' one 2 three 4 five 6
+0:removal of non-matching arguments
+>2 4 6
+
+ printf '%s\n' string
+0:test s format specifier
+>string
+
+ printf '%b' '\t\\\n'
+0:test b format specifier
+> \
+
+ printf '%q\n' '=a=b \ c!'
+0: test q format specifier
+>\=a=b\ \\\ c!
+
+ printf '%c\n' char
+0:test c format specifier
+>c
+
+ printf '%.10e%n\n' 1 count >/dev/null
+ printf '%d\n' $count
+0:test n format specifier
+>16
+
+ printf '%5b%n\n' abc count >/dev/null; echo $count
+0:check count of width-specified %b
+>5
+
+ printf '%s!%5b!\n' abc
+0:ensure width is applied to empty param
+>abc! !
+
+ printf '%d %d\n' 123.45 678 90.1
+0:test d format specifier
+>123 678
+>90 0
+
+ printf '%g %g\n' 123.45 678 90.1
+0:test g format specifier
+>123.45 678
+>90.1 0
+
+ print -f 'arg: %b\n' -C2 '\x41' '\x42' '\x43'
+0:override -C when -f was given
+>arg: A
+>arg: B
+>arg: C
+
+# Is anyone not using ASCII
+ printf '%d\n' \'A
+0:initial quote to get numeric value of character with int
+>65
+
+ printf '%.1E\n' \'B
+0:initial quote to get numeric value of character with double
+>6.6E+01
+
+ printf '%x\n' $(printf '"\xf0')
+0:numeric value of high numbered character
+>f0
+
+ printf '\x25s\n' arg
+0:using \x25 to print a literal % in format
+>%s
+
+ printf '%3c\n' c
+0:width specified in format specifier
+> c
+
+ printf '%.4s\n' chopped
+0:precision specified in format specifier
+>chop
+
+ printf '%*.*f\n' 6 2 10.2
+0:width/precision specified in arguments
+> 10.20
+
+ printf '%z'
+1:use of invalid directive
+?(eval):printf:1: %z: invalid directive
+
+ printf '%d\n' 3a
+1:bad arithmetic expression
+?(eval):1: bad math expression: operator expected at `a'
+>0
+
+ printf '%12$s' 1 2 3
+1:out of range argument specifier
+?(eval):printf:1: 12: argument specifier out of range
+
+ printf '%2$s\n' 1 2 3
+1:out of range argument specifier on format reuse
+?(eval):printf:1: 2: argument specifier out of range
+>2
+
+ printf '%*0$d'
+1:out of range argument specifier on width
+?(eval):printf:1: 0: argument specifier out of range
+
+ print -m -f 'format - %s.\n' 'z' a b c
+0:format not printed if no arguments left after -m removal
+
+ print -f 'format - %s%b.\n'
+0:format printed despite lack of arguments
+>format - .
+
+ printf 'x%4sx\n'
+0:with no arguments empty string where string needed
+>x x
+
+ printf '%d\n'
+0:with no arguments, zero used where number needed
+>0
+
+ printf '%s\t%c:%#x%%\n' one a 1 two b 2 three c 3
+0:multiple arguments with format reused
+>one a:0x1%
+>two b:0x2%
+>three c:0x3%
+
+ printf '%d%n' 123 val val val > /dev/null
+ printf '%d\n' val
+0:%n count zeroed on format reuse
+>1
+
+# this may fill spec string with '%0'+- #*.*lld\0' - 14 characters
+ printf '%1$0'"'+- #-08.5dx\n" 123
+0:maximal length format specification
+>+00123 x
+
+ printf "x:%-20s:y\n" fubar
+0:left-justification of string
+>x:fubar :y
+
+ printf '%*smorning\n' -5 good
+0:negative width specified
+>good morning
+
+ printf '%.*g\n' -1 .1
+0:negative precision specified
+>0.1
+
+ printf '%2$s %1$d\n' 1 2
+0:specify argument to output explicitly
+>2 1
+
+ printf '%3$.*1$d\n' 4 0 3
+0:specify output and precision arguments explicitly
+>0003
+
+ printf '%2$d%1$d\n' 1 2 3 4
+0:reuse format where arguments are explicitly specified
+>21
+>43
+
+ printf '%1$*2$d' 1 2 3 4 5 6 7 8 9 10; echo .EoL.
+0:reuse of specified arguments
+> 1 3 5 7 9.EoL.
+
+ echo -n 'Now is the time'; echo .EoL.
+0:testing -n with echo
+>Now is the time.EoL.
+
+ printf '%1$0+.3d\n' 3
+0:flags mixed with specified argument
+>+003
+
+# Test the parsing of the \c escape.
+
+ echo '1 2!\c3 4' a b c d; echo .EoL.
+0:Truncating first echo arg using backslash-c
+>1 2!.EoL.
+
+ echo a b '1 2?\c5 6' c d; echo .EoL.
+0:Truncating third echo arg using backslash-c
+>a b 1 2?.EoL.
+
+ printf '1 2!\c3 4'; echo .EoL.
+0:Truncating printf literal using backslash-c
+>1 2!.EoL.
+
+ printf '%s %b!\c%s %s' 1 2 3 4 5 6 7 8 9; echo .EoL.
+0:Truncating printf format using backslash-c
+>1 2!.EoL.
+
+ printf '%s %b!\c%s %s' '1\c' '2\n\c' 3 4 5 6 7 8 9
+0:Truncating printf early %b arg using backslash-c
+>1\c 2
+
+ printf '%b %b\n' 1 2 3 4 '5\c' 6 7 8 9; echo .EoL.
+0:Truncating printf late %b arg using backslash-c
+>1 2
+>3 4
+>5.EoL.
+
+# The following usage, as stated in the manual, is not recommended and the
+# results are undefined. Tests are here anyway to ensure some form of
+# half-sane behaviour.
+
+ printf '%2$s %s %3$s\n' Morning Good World
+0:mixed style of argument selection
+>Good Morning World
+
+ printf '%*1$.*d\n' 1 2
+0:argument specified for width only
+>00
+
+ print -f '%*.*1$d\n' 1 2 3
+0:argument specified for precision only
+>2
+>000
+
+ printf -- '%s\n' str
+0:initial `--' ignored to satisfy POSIX
+>str
+
+ printf '%'
+1:nothing after % in format specifier
+?(eval):printf:1: %: invalid directive
+
+ printf $'%\0'
+1:explicit null after % in format specifier
+?(eval):printf:1: %: invalid directive
+
+ printf '%b\n' '\0123'
+0:printf handles \0... octal escapes in replacement text
+>S
+
+ print -lO $'a' $'a\0' $'a\0b' $'a\0b\0' $'a\0b\0a' $'a\0b\0b' $'a\0c' |
+ while read -r line; do
+ for (( i = 1; i <= ${#line}; i++ )); do
+ foo=$line[i]
+ printf "%02x" $(( #foo ))
+ done
+ print
+ done
+0:sorting with embedded nulls
+>610063
+>6100620062
+>6100620061
+>61006200
+>610062
+>6100
+>61
+
+ foo=$'one\ttwo\tthree\tfour\n'
+ foo+=$'\tone\ttwo\tthree\tfour\n'
+ foo+=$'\t\tone\t\ttwo\t\tthree\t\tfour'
+ print -x4 $foo
+ print -X4 $foo
+0:Tab expansion by print
+>one two three four
+> one two three four
+> one two three four
+>one two three four
+> one two three four
+> one two three four
+
+ unset foo
+ print -v foo once more
+ typeset -p foo
+ printf -v foo "%s\0%s-" into the breach
+ typeset -p foo
+0:print and printf into a variable
+>typeset -g foo='once more'
+>typeset -g foo=$'into\C-@the-breach\C-@-'
+
+ typeset -a foo
+ print -f '%2$d %4s' -v foo one 1 two 2 three 3
+ typeset -p foo
+0:printf into an array variable
+>typeset -a foo=( '1 one' '2 two' '3 three' )
+
+ typeset -a foo
+ print -f '%s' -v foo string
+ typeset -p foo
+0:printf to an array variable without format string reuse
+>typeset foo=string
+
+ printf -
+ printf - -
+ printf --
+ printf -- -
+ printf -- --
+ printf -x -v foo
+ # Final print for newline on stdout
+ print
+0:regression test of printf with assorted ambiguous options or formats
+>------x
+?(eval):printf:3: not enough arguments
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B04read.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B04read.ztst
new file mode 100644
index 0000000..25c3d41
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B04read.ztst
@@ -0,0 +1,112 @@
+# Tests for the read builtin
+
+# Tested elsewhere:
+# reading from a coprocess A01grammar, A04redirect
+
+# Not tested:
+# -c/-l/-n (options for compctl functions)
+# -q/-s (needs a tty)
+
+%test
+
+ read <<<'hello world'
+ print $REPLY
+0:basic read command
+>hello world
+
+ read -A <<<'hello world'
+ print $reply[2]
+0:array read
+>world
+
+ read -k3 -u0 <<foo
+
+ for char in y Y n N X $'\n'; do
+ read -q -u0 <<<$char
+ print $?
+ done
+0:read yes or no, default no
+>0
+>0
+>1
+>1
+>1
+>1
+
+ read -d: <<foo
+
+ print foo:bar|IFS=: read -A
+ print $reply
+0:use different, IFS separator to array
+>foo bar
+
+ print -z hello world; read -z
+ print $REPLY
+0:read from editor buffer stack
+>hello world
+
+ unset REPLY
+ read -E <<hello
+>hello
+
+ unset REPLY
+ read -e <<hello
+>
+
+ read -e -t <<hello
+
+ SECONDS=0
+ read -e -t 5 <<hello
+>0
+
+ print -n 'Testing the\0null hypothesis\0' |
+ while read -d $'\0' line; do print $line; done
+0:read with null delimiter
+>Testing the
+>null hypothesis
+
+# Note that trailing NULLs are not stripped even if they are in
+# $IFS; only whitespace characters contained in $IFS are stripped.
+ print -n $'Aaargh, I hate nulls.\0\0\0' | read line
+ print ${#line}
+0:read with trailing metafied characters
+>24
+
+ (typeset -r foo
+ read foo) <<one
+>two
+>three
+>one:two:three
+
+ array=()
+ read -Ae array <<<'four five six'
+ print ${(j.:.)array}
+0:Behaviour of -A and -e combination
+>four
+>five
+>six
+>
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B05eval.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B05eval.ztst
new file mode 100644
index 0000000..6427d6f
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B05eval.ztst
@@ -0,0 +1,34 @@
+# Tests for the eval builtin.
+# This is quite short; eval is widely tested throughout the test suite
+# and its basic behaviour is fairly straightforward.
+
+%prep
+
+ cmd='print $?'
+
+%test
+
+ false
+ eval $cmd
+0:eval retains value of $?
+>1
+
+ # no point getting worked up over what the error message is...
+ ./command_not_found 2>/dev/null
+ eval $cmd
+0:eval after command not found
+>127
+
+ # trick the test system
+ sp=
+ false
+ eval "
+ $sp
+ $sp
+ $sp
+ "
+0:eval with empty command resets the status
+
+ false
+ eval
+0:eval with empty command resets the status
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B06fc.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B06fc.ztst
new file mode 100644
index 0000000..922b001
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B06fc.ztst
@@ -0,0 +1,25 @@
+# Tests of fc command
+%prep
+
+ mkdir fc.tmp
+ cd fc.tmp
+ print 'fc -l foo' >fcl
+
+%test
+ $ZTST_testdir/../Src/zsh -f ./fcl
+1:Checking that fc -l foo doesn't core dump when history is empty
+?./fcl:fc:1: event not found: foo
+
+ PS1='%% ' $ZTST_testdir/../Src/zsh +Z -fsi <<< $'fc -p /dev/null 0 0\n:'
+0:Checking that fc -p doesn't core dump when history size is zero
+*?*%*
+
+ PS1='%% ' $ZTST_testdir/../Src/zsh +Z -fsi <<< 'fc -p /dev/null a 0'
+1:Checking that fc -p rejects non-integer history size
+*?*% fc: HISTSIZE must be an integer
+*?*%*
+
+ PS1='%% ' $ZTST_testdir/../Src/zsh +Z -fsi <<< 'fc -p /dev/null 0 a'
+1:Checking that fc -p rejects non-integer history save size
+*?*% fc: SAVEHIST must be an integer
+*?*%*
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B07emulate.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B07emulate.ztst
new file mode 100644
index 0000000..2de097e
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B07emulate.ztst
@@ -0,0 +1,253 @@
+# Test the "emulate" builtin and related functions.
+
+%prep
+
+ isset() {
+ print -n "${1}: "
+ if [[ -o $1 ]]; then print yes; else print no; fi
+ }
+ showopts() {
+ # Set for Bourne shell emulation
+ isset shwordsplit
+ # Set in native mode and unless "emulate -R" is in use
+ isset banghist
+ }
+ cshowopts() {
+ showopts
+ # Show a csh option, too
+ isset cshnullglob
+ }
+
+%test
+
+ (print Before
+ showopts
+ fn() {
+ emulate sh
+ }
+ fn
+ print After
+ showopts)
+0:Basic use of emulate
+>Before
+>shwordsplit: no
+>banghist: yes
+>After
+>shwordsplit: yes
+>banghist: yes
+
+ fn() {
+ emulate -L sh
+ print During
+ showopts
+ }
+ print Before
+ showopts
+ fn
+ print After
+ showopts
+0:Use of emulate -L
+>Before
+>shwordsplit: no
+>banghist: yes
+>During
+>shwordsplit: yes
+>banghist: yes
+>After
+>shwordsplit: no
+>banghist: yes
+
+ (print Before
+ showopts
+ emulate -R sh
+ print After
+ showopts)
+0:Use of emulate -R
+>Before
+>shwordsplit: no
+>banghist: yes
+>After
+>shwordsplit: yes
+>banghist: no
+
+ print Before
+ showopts
+ emulate sh -c 'print During; showopts'
+ print After
+ showopts
+0:Use of emulate -c
+>Before
+>shwordsplit: no
+>banghist: yes
+>During
+>shwordsplit: yes
+>banghist: yes
+>After
+>shwordsplit: no
+>banghist: yes
+
+ print Before
+ showopts
+ emulate -R sh -c 'print During; showopts'
+ print After
+ showopts
+0:Use of emulate -R -c
+>Before
+>shwordsplit: no
+>banghist: yes
+>During
+>shwordsplit: yes
+>banghist: no
+>After
+>shwordsplit: no
+>banghist: yes
+
+ print Before
+ showopts
+ emulate -R sh -c 'shshowopts() { showopts; }'
+ print After definition
+ showopts
+ print In sticky emulation
+ shshowopts
+ print After sticky emulation
+ showopts
+0:Basic sticky function emulation
+>Before
+>shwordsplit: no
+>banghist: yes
+>After definition
+>shwordsplit: no
+>banghist: yes
+>In sticky emulation
+>shwordsplit: yes
+>banghist: no
+>After sticky emulation
+>shwordsplit: no
+>banghist: yes
+
+ print Before
+ cshowopts
+ emulate -R sh -c 'shshowopts() { cshowopts; }'
+ emulate csh -c 'cshshowopts() {
+ cshowopts
+ print In nested sh emulation
+ shshowopts
+ }'
+ print After definition
+ cshowopts
+ print In sticky csh emulation
+ cshshowopts
+ print After sticky emulation
+ cshowopts
+0:Basic sticky function emulation
+>Before
+>shwordsplit: no
+>banghist: yes
+>cshnullglob: no
+>After definition
+>shwordsplit: no
+>banghist: yes
+>cshnullglob: no
+>In sticky csh emulation
+>shwordsplit: no
+>banghist: yes
+>cshnullglob: yes
+>In nested sh emulation
+>shwordsplit: yes
+>banghist: no
+>cshnullglob: no
+>After sticky emulation
+>shwordsplit: no
+>banghist: yes
+>cshnullglob: no
+
+ isalp() { if [[ -o alwayslastprompt ]]; then print on; else print off; fi; }
+ emulate sh -c 'shfunc_inner() { setopt alwayslastprompt; }'
+ emulate csh -c 'cshfunc_inner() { setopt alwayslastprompt; }'
+ emulate sh -c 'shfunc_outer() {
+ unsetopt alwayslastprompt;
+ shfunc_inner;
+ isalp
+ unsetopt alwayslastprompt
+ cshfunc_inner
+ isalp
+ }'
+ shfunc_outer
+0:Sticky emulation not triggered if sticky emulation unchanged
+>on
+>off
+
+ (
+ setopt ignorebraces
+ emulate zsh -o extendedglob -c '
+ [[ -o ignorebraces ]] || print "Yay, ignorebraces was reset"
+ [[ -o extendedglob ]] && print "Yay, extendedglob is set"
+ '
+ )
+0:emulate -c with options
+>Yay, ignorebraces was reset
+>Yay, extendedglob is set
+
+ (
+ setopt ignorebraces
+ emulate zsh -o extendedglob
+ [[ -o ignorebraces ]] || print "Yay, ignorebraces is no longer set"
+ [[ -o extendedglob ]] && print "Yay, extendedglob is set"
+ )
+0:emulate with options but no -c
+>Yay, ignorebraces is no longer set
+>Yay, extendedglob is set
+
+ emulate zsh -o fixallmybugs 'print This was executed, bad'
+1:emulate -c with incorrect options
+?(eval):emulate:1: no such option: fixallmybugs
+
+ emulate zsh -c '
+ func() { [[ -o extendedglob ]] || print extendedglob is off }
+ '
+ func
+ emulate zsh -o extendedglob -c '
+ func() { [[ -o extendedglob ]] && print extendedglob is on }
+ '
+ func
+0:options specified alongside emulation are also sticky
+>extendedglob is off
+>extendedglob is on
+
+ emulate zsh -o extendedglob -c '
+ func_inner() { setopt nobareglobqual }
+ '
+ emulate zsh -o extendedglob -c '
+ func_outer() {
+ func_inner
+ [[ -o bareglobqual ]] || print bareglobqual was turned off
+ [[ -o extendedglob ]] && print extendedglob is on, though
+ }
+ '
+ [[ -o extendedglob ]] || print extendedglob is initially off
+ func_outer
+0:options propagate between identical emulations
+>extendedglob is initially off
+>bareglobqual was turned off
+>extendedglob is on, though
+
+ emulate zsh -o extendedglob -c '
+ func_inner() { setopt nobareglobqual }
+ '
+ emulate zsh -o extendedglob -o cbases -c '
+ func_outer() {
+ func_inner
+ [[ -o bareglobqual ]] && print bareglobqual is still on
+ [[ -o extendedglob ]] && print extendedglob is on, too
+ }
+ '
+ [[ -o extendedglob ]] || print extendedglob is initially off
+ func_outer
+0:options do not propagate between different emulations
+>extendedglob is initially off
+>bareglobqual is still on
+>extendedglob is on, too
+
+ emulate sh -c '[[ a == a ]]'
+0:regression test for POSIX_ALIASES reserved words
+F:Some reserved tokens are handled in alias expansion
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B08shift.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B08shift.ztst
new file mode 100644
index 0000000..0aa9226
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B08shift.ztst
@@ -0,0 +1,33 @@
+# Test the shift builtin.
+
+%test
+
+ set -- one two three four five six seven eight nine ten
+ shift
+ print $*
+ shift 2
+ print $*
+ shift -p 3
+ print $*
+ shift -p
+ print $*
+0:shifting positional parameters
+>two three four five six seven eight nine ten
+>four five six seven eight nine ten
+>four five six seven
+>four five six
+
+ array=(yan tan tether mether pip azer sezar akker conter dick)
+ shift 2 array
+ print $array
+ shift array
+ print $array
+ shift -p 3 array
+ print $array
+ shift -p array
+ print $array
+0:shifting array
+>tether mether pip azer sezar akker conter dick
+>mether pip azer sezar akker conter dick
+>mether pip azer sezar
+>mether pip azer
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B09hash.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B09hash.ztst
new file mode 100644
index 0000000..7b5dfb4
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/B09hash.ztst
@@ -0,0 +1,79 @@
+# The hash builtin is most used for the command hash table, which is
+# populated automatically. This is therefore highly system specific,
+# so mostly we'll test with the directory hash table: the logic is
+# virtually identical but with the different table, and furthermore
+# the shell doesn't care whether the directory exists unless you refer
+# to it in a context that needs one.
+
+%prep
+ populate_hash() {
+ hash -d one=/first/directory
+ hash -d two=/directory/the/second
+ hash -d three=/noch/ein/verzeichnis
+ hash -d four=/bored/with/this/now
+ }
+
+%test
+
+ hash -d
+0:Directory hash initially empty
+
+ populate_hash
+ hash -d
+0:Populating directory hash and output with sort
+>four=/bored/with/this/now
+>one=/first/directory
+>three=/noch/ein/verzeichnis
+>two=/directory/the/second
+
+ hash -rd
+ hash -d
+0:Empty hash
+
+ populate_hash
+ hash -d
+0:Refill hash
+>four=/bored/with/this/now
+>one=/first/directory
+>three=/noch/ein/verzeichnis
+>two=/directory/the/second
+
+ hash -dL
+0:hash -L option
+>hash -d four=/bored/with/this/now
+>hash -d one=/first/directory
+>hash -d three=/noch/ein/verzeichnis
+>hash -d two=/directory/the/second
+
+ hash -dm 't*'
+0:hash -m option
+>three=/noch/ein/verzeichnis
+>two=/directory/the/second
+
+ hash -d five=/yet/more six=/here/we/go seven=/not/yet/eight
+ hash -d
+0:Multiple assignments
+>five=/yet/more
+>four=/bored/with/this/now
+>one=/first/directory
+>seven=/not/yet/eight
+>six=/here/we/go
+>three=/noch/ein/verzeichnis
+>two=/directory/the/second
+
+ hash -d one two three
+0:Multiple arguments with no assignment not in verbose mode
+
+ hash -vd one two three
+0:Multiple arguments with no assignment in verbose mode
+>one=/first/directory
+>two=/directory/the/second
+>three=/noch/ein/verzeichnis
+
+ hash -d t-t=/foo
+ i="~t-t"
+ print ~t-t/bar
+ print ${~i}/rab
+0:Dashes are untokenized in directory hash names
+>/foo/bar
+>/foo/rab
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/C01arith.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/C01arith.ztst
new file mode 100644
index 0000000..61da763
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/C01arith.ztst
@@ -0,0 +1,422 @@
+# Tests corresponding to the texinfo node `Arithmetic Evaluation'
+
+%test
+
+ integer light there
+ (( light = 42 )) &&
+ let 'there = light' &&
+ print $(( there ))
+0:basic integer arithmetic
+>42
+
+ float light there
+ integer rnd
+ (( light = 3.1415 )) &&
+ let 'there = light' &&
+ print -- $(( rnd = there * 10000 ))
+# save rounding problems by converting to integer
+0:basic floating point arithmetic
+>31415
+
+ integer rnd
+ (( rnd = ((29.1 % 13.0 * 10) + 0.5) ))
+ print $rnd
+0:Test floating point modulo function
+>31
+
+ print $(( 0x10 + 0X01 + 2#1010 ))
+0:base input
+>27
+
+ float light
+ (( light = 4 ))
+ print $light
+ typeset -F light
+ print $light
+0:conversion to float
+>4.000000000e+00
+>4.0000000000
+
+ integer i
+ (( i = 32.5 ))
+ print $i
+0:conversion to int
+>32
+
+ integer i
+ (( i = 4 - - 3 * 7 << 1 & 7 ^ 1 | 16 ** 2 ))
+ print $i
+0:precedence (arithmetic)
+>1591
+
+ fn() {
+ setopt localoptions c_precedences
+ integer i
+ (( i = 4 - - 3 * 7 << 1 & 7 ^ 1 | 16 ** 2 ))
+ print $i
+ }
+ fn
+0:precedence (arithmetic, with C_PRECEDENCES)
+>259
+
+ print $(( 1 < 2 || 2 < 2 && 3 > 4 ))
+0:precedence (logical)
+>1
+
+ print $(( 1 + 4 ? 3 + 2 ? 4 + 3 ? 5 + 6 ? 4 * 8 : 0 : 0 : 0 : 0 ))
+0:precedence (ternary)
+>32
+
+ print $(( 3 ? 2 ))
+1:parsing ternary (1)
+?(eval):1: bad math expression: ':' expected
+
+ print $(( 3 ? 2 : 1 : 4 ))
+1:parsing ternary (2)
+?(eval):1: bad math expression: ':' without '?'
+
+ print $(( 0, 4 ? 3 : 1, 5 ))
+0:comma operator
+>5
+
+ foo=000
+ print $(( ##A + ##\C-a + #foo + $#foo ))
+0:#, ## and $#
+>117
+
+ print $((##))
+1:## without following character
+?(eval):1: bad math expression: character missing after ##
+
+ print $((## ))
+0:## followed by a space
+>32
+
+ integer i
+ (( i = 3 + 5 * 1.75 ))
+ print $i
+0:promotion to float
+>11
+
+ typeset x &&
+ (( x = 3.5 )) &&
+ print $x &&
+ (( x = 4 )) &&
+ print $x
+0:use of scalars to store integers and floats
+>3.5
+>4
+
+ (( newarray[unsetvar] = 1 ))
+2:error using unset variable as index
+?(eval):1: newarray: assignment to invalid subscript range
+
+ integer setvar=1
+ (( newarray[setvar]++ ))
+ (( newarray[setvar]++ ))
+ print ${(t)newarray} ${#newarray} ${newarray[1]}
+0:setting array elements in math context
+>array 1 2
+
+ xarr=()
+ (( xarr = 3 ))
+ print ${(t)xarr} $xarr
+0:converting type from array
+>integer 3
+
+ print $(( 13 = 42 ))
+1:bad lvalue
+?(eval):1: bad math expression: lvalue required
+
+ x=/bar
+ (( x = 32 ))
+ print $x
+0:assigning to scalar which contains non-math string
+>32
+
+ print $(( ))
+0:empty math parse e.g. $(( )) acts like a zero
+>0
+
+ print $(( a = ))
+1:empty assignment
+?(eval):1: bad math expression: operand expected at end of string
+
+ print $(( 3, ))
+1:empty right hand of comma
+?(eval):1: bad math expression: operand expected at end of string
+
+ print $(( 3,,4 ))
+1:empty middle of comma
+?(eval):1: bad math expression: operand expected at `,4 '
+
+ print $(( (3 + 7, 4), 5 ))
+0:commas and parentheses, part 1
+>5
+
+ print $(( 5, (3 + 7, 4) ))
+0:commas and parentheses, part 1
+>4
+
+ print $(( 07.5 ))
+ (setopt octalzeroes; print $(( 09.5 )))
+0:leading zero doesn't affect floating point
+>7.5
+>9.5
+
+ (setopt octalzeroes; print $(( 09 )))
+1:octalzeroes rejects invalid constants
+?(eval):1: bad math expression: operator expected at `9 '
+
+ (setopt octalzeroes; print $(( 08#77 )))
+0:octalzeroes doesn't affect bases
+>63
+
+ print $(( 36#z ))
+0:bases up to 36 work
+>35
+
+ print $(( 37#z ))
+1:bases beyond 36 don't work
+?(eval):1: invalid base (must be 2 to 36 inclusive): 37
+
+ print $(( 3 + "fail" ))
+1:parse failure in arithmetic
+?(eval):1: bad math expression: operand expected at `"fail" '
+
+ alias 3=echo
+ print $(( 3 + "OK"); echo "Worked")
+0:not a parse failure because not arithmetic
+>+ OK Worked
+
+ fn() {
+ emulate -L zsh
+ print $(( [#16] 255 ))
+ print $(( [##16] 255 ))
+ setopt cbases
+ print $(( [#16] 255 ))
+ print $(( [##16] 255 ))
+ }
+ fn
+0:doubled # in base removes radix
+>16#FF
+>FF
+>0xFF
+>FF
+
+ array=(1)
+ x=0
+ (( array[++x]++ ))
+ print $x
+ print $#array
+ print $array
+0:no double increment for subscript
+>1
+>1
+>2
+
+ # This is a bit naughty... the value of array
+ # isn't well defined since there's no sequence point
+ # between the increments of x, however we just want
+ # to be sure that in this case, unlike the above,
+ # x does get incremented twice.
+ x=0
+ array=(1 2)
+ (( array[++x] = array[++x] + 1 ))
+ print $x
+0:double increment for repeated expression
+>2
+
+ # Floating point. Default precision should take care of rounding errors.
+ print $(( 1_0.000_000e0_1 ))
+ # Integer.
+ print $(( 0x_ff_ff_ ))
+ # _ are parts of variable names that don't start with a digit
+ __myvar__=42
+ print $(( __myvar__ + $__myvar__ ))
+ # _ is not part of variable name that does start with a digit
+ # (which are substituted before math eval)
+ set -- 6
+ print $(( $1_000_000 ))
+ # Underscores in expressions with no whitespace
+ print $(( 3_000_+4_000_/2 ))
+ # Underscores may appear in the base descriptor, for what it's worth...
+ print $(( 1_6_#f_f_ ))
+0:underscores in math constants
+>100.
+>65535
+>84
+>6000000
+>5000
+>255
+
+ # Force floating point.
+ for expr in "3/4" "0x100/0x200" "0x30/0x10"; do
+ print $(( $expr ))
+ setopt force_float
+ print $(( $expr ))
+ unsetopt force_float
+ done
+0:Forcing floating point constant evaluation, or not.
+>0
+>0.75
+>0
+>0.5
+>3
+>3.
+
+ print $(( 0x30 + 0.5 ))
+ print $(( 077 + 0.5 ))
+ (setopt octalzeroes; print $(( 077 + 0.5 )) )
+0:Mixed float and non-decimal integer constants
+>48.5
+>77.5
+>63.5
+
+ underscore_integer() {
+ setopt cbases localoptions
+ print $(( [#_] 1000000 ))
+ print $(( [#16_] 65536 ))
+ print $(( [#16_4] 65536 * 32768 ))
+ }
+ underscore_integer
+0:Grouping output with underscores: integers
+>1_000_000
+>0x10_000
+>0x8000_0000
+
+ print $(( [#_] (5. ** 10) / 16. ))
+0:Grouping output with underscores: floating point
+>610_351.562_5
+
+ env SHLVL=1+RANDOM $ZTST_testdir/../Src/zsh -f -c 'print $SHLVL'
+0:Imported integer functions are not evaluated
+>2
+
+ print $(( 0b0 + 0b1 + 0b11 + 0b110 ))
+0:Binary input
+>10
+
+ print $(( 0b2 ))
+1:Binary numbers don't tend to have 2's in
+?(eval):1: bad math expression: operator expected at `2 '
+# ` for emacs shell mode
+
+ integer varassi
+ print $(( varassi = 5.5 / 2.0 ))
+ print $varassi
+0:Integer variable assignment converts result to integer
+>2
+>2
+# It's hard to test for integer to float.
+
+ integer ff1=3 ff2=4
+ print $(( ff1/ff2 ))
+ setopt force_float
+ print $(( ff1/ff2 ))
+ unsetopt force_float
+0:Variables are forced to floating point where necessary
+# 0.75 is exactly representable, don't expect rounding error.
+>0
+>0.75
+
+ # The following tests for a bug that only happens when
+ # backing up over input read a line at a time, so we'll
+ # read the input from stdin.
+ $ZTST_testdir/../Src/zsh -f <<<'
+ print $((echo first command
+ ); echo second command)
+ print third command
+ '
+0:Backing up a line of input when finding out it's not arithmetic
+>first command second command
+>third command
+
+ $ZTST_testdir/../Src/zsh -f <<<'
+ print $((3 +
+ 4))
+ print next line
+ '
+0:Not needing to back up a line when reading multiline arithmetic
+>7
+>next line
+
+ $ZTST_testdir/../Src/zsh -f <<<'
+ print $((case foo in
+ bar)
+ echo not this no, no
+ ;;
+ foo)
+ echo yes, this one
+ ;;
+ esac)
+ print after case in subshell)
+ '
+0:Non-arithmetic subst with command subsitution parse from hell
+>yes, this one after case in subshell
+
+ print "a$((echo one subst)
+ (echo two subst))b"
+0:Another tricky case that is actually a command substitution
+>aone subst
+>two substb
+
+ print "x$((echo one frob); (echo two frob))y"
+0:Same on a single line
+>xone frob
+>two froby
+
+ # This case actually only works by accident: if it wasn't for the
+ # unbalanced parenthesis this would be a valid math substitution.
+ # Hence it's definitely not recommended code. However, it does give
+ # the algorithm an extra check.
+ print $((case foo in
+ foo)
+ print Worked OK
+ ;;
+ esac))
+0:Would-be math expansion with extra parenthesis making it a cmd subst
+>Worked OK
+
+ (setopt extendedglob
+ set -- 32.463
+ print ${$(( $1 * 100 ))%%.[0-9]#})
+0:Arithmetic substitution nested in parameter substitution
+>3246
+
+ print $((`:`))
+0:Null string in arithmetic evaluation after command substitution
+>0
+
+ print $(( 1 + $(( 2 + 3 )) ))
+ print $(($((3+4))))
+ print $((1*$((2*$((3))*4))*5))
+0:Nested math substitutions. Yes, I know, very useful.
+>6
+>7
+>120
+
+ foo="(1)"
+ print $((foo))
+ print $(($foo))
+ print $(((2)))
+ foo="3)"
+ (print $((foo))) 2>&1
+ (print $(($foo))) 2>&1
+1: Good and bad trailing parentheses
+>1
+>1
+>2
+>(eval):6: bad math expression: unexpected ')'
+>(eval):7: bad math expression: unexpected ')'
+
+ unset number
+ (( number = 3 ))
+ print ${(t)number}
+ unset number
+ (setopt posix_identifiers
+ (( number = 3 ))
+ print ${(t)number})
+0:type of variable when created in arithmetic context
+>integer
+>scalar
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/C02cond.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/C02cond.ztst
new file mode 100644
index 0000000..3852501
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/C02cond.ztst
@@ -0,0 +1,448 @@
+# Tests corresponding to the texinfo node `Conditional Expressions'
+
+%prep
+
+ umask 077
+
+ mkdir cond.tmp
+
+ cd cond.tmp
+
+ typeset -gi isnfs
+ [[ "$(find . -prune -fstype nfs 2>/dev/null)" == "." ]] && isnfs=1
+ if (( isnfs )) &&
+ (cd -q ${ZTST_tmp} >/dev/null 2>&1 &&
+ [[ "$(find . -prune -fstype nfs 2>/dev/null)" != "." ]]); then
+ filetmpprefix=${ZTST_tmp}/condtest-$$-
+ isnfs=0
+ else
+ filetmpprefix=
+ fi
+ newnewnew=${filetmpprefix}newnewnew
+ unmodified=${filetmpprefix}unmodified
+ zlnfs=${filetmpprefix}zlnfs
+
+ touch $unmodified
+
+ touch zerolength
+ chgrp $EGID zerolength
+
+ touch $zlnfs
+ chgrp $EGID $zlnfs
+
+ print 'Garbuglio' >nonzerolength
+
+ mkdir modish
+ chgrp $EGID modish
+
+ chmod 7710 modish # g+xs,u+s,+t
+ chmod g+s modish # two lines combined work around chmod bugs
+
+ touch unmodish
+ chmod 000 unmodish
+
+ print 'MZ' > cmd.exe
+ chmod +x cmd.exe
+%test
+
+ [[ -a zerolength && ! -a nonexistent ]]
+0:-a cond
+
+ # Find a block special file system. This is a little tricky.
+ block=$(find /dev(|ices)/ -type b -print)
+ if [[ -n $block ]]; then
+ [[ -b $block[(f)1] && ! -b zerolength ]]
+ else
+ print -u$ZTST_fd 'Warning: Not testing [[ -b blockdevice ]] (no devices found)'
+ [[ ! -b zerolength ]]
+ fi
+0D:-b cond
+
+ # Use hardcoded /dev/tty because globbing inside /dev fails on Cygwin
+ char=/dev/tty
+ [[ -c $char && ! -c $zerolength ]]
+0:-c cond
+
+ [[ -d . && ! -d zerolength ]]
+0:-d cond
+
+ [[ -e zerolength && ! -e nonexistent ]]
+0:-e cond
+
+ if [[ -n $block ]]; then
+ [[ -f zerolength && ! -f cond && ! -f $char && ! -f $block[(f)1] && ! -f . ]]
+ else
+ print -u$ZTST_fd 'Warning: Not testing [[ -f blockdevice ]] (no devices found)'
+ [[ -f zerolength && ! -f cond && ! -f $char && ! -f . ]]
+ fi
+0:-f cond
+
+ [[ -g modish && ! -g zerolength ]]
+0:-g cond
+
+ ln -s zerolength link
+ [[ -h link && ! -h zerolength ]]
+0:-h cond
+
+ [[ -k modish && ! -k zerolength ]]
+0:-k cond
+
+ foo=foo
+ bar=
+ [[ -n $foo && ! -n $bar && ! -n '' ]]
+0:-n cond
+
+ [[ -o rcs && ! -o norcs && -o noerrexit && ! -o errexit ]]
+0:-o cond
+
+ if ! grep '#define HAVE_FIFOS' $ZTST_testdir/../config.h; then
+ print -u$ZTST_fd 'Warning: Not testing [[ -p pipe ]] (FIFOs not supported)'
+ [[ ! -p zerolength ]]
+ else
+ if whence mkfifo && mkfifo pipe || mknod pipe p; then
+ [[ -p pipe && ! -p zerolength ]]
+ else
+ print -u$ZTST_fd 'Warning: Not testing [[ -p pipe ]] (cannot create FIFO)'
+ [[ ! -p zerolength ]]
+ fi
+ fi
+0dD:-p cond
+
+ if (( EUID == 0 )); then
+ print -u$ZTST_fd 'Warning: Not testing [[ ! -r file ]] (root reads anything)'
+ [[ -r zerolength && -r unmodish ]]
+ elif [[ $OSTYPE = cygwin ]]; then
+ print -u$ZTST_fd 'Warning: Not testing [[ ! -r file ]]
+ (all files created by user may be readable)'
+ [[ -r zerolength ]]
+ else
+ [[ -r zerolength && ! -r unmodish ]]
+ fi
+0:-r cond
+
+ [[ -s nonzerolength && ! -s zerolength ]]
+0:-s cond
+
+# no simple way of guaranteeing test for -t
+
+ [[ -u modish && ! -u zerolength ]]
+0:-u cond
+
+ [[ -x cmd.exe && ! -x zerolength ]]
+0:-x cond
+
+ [[ -z $bar && -z '' && ! -z $foo ]]
+0:-z cond
+
+ [[ -L link && ! -L zerolength ]]
+0:-L cond
+
+# hard to guarantee a file not owned by current uid
+ [[ -O zerolength ]]
+0:-O cond
+
+ [[ -G zerolength ]]
+0:-G cond
+
+# can't be bothered with -S
+
+ if [[ ${mtab::="$({mount || /sbin/mount || /usr/sbin/mount} 2>/dev/null)"} = *[(]?*[)] ]]; then
+ print -u $ZTST_fd 'This test takes two seconds...'
+ else
+ unmodified_ls="$(ls -lu $unmodified)"
+ print -u $ZTST_fd 'This test takes up to 60 seconds...'
+ fi
+ sleep 2
+ touch $newnewnew
+ if [[ $OSTYPE == "cygwin" ]]; then
+ ZTST_skip="[[ -N file ]] not supported on Cygwin"
+ elif (( isnfs )); then
+ ZTST_skip="[[ -N file ]] not supported with NFS"
+ elif { (( ! $+unmodified_ls )) &&
+ cat $unmodified &&
+ { df -k -- ${$(print -r -- "$mtab" |
+ awk '/noatime/ {print $1,$3}'):-""} | tr -s ' ' |
+ fgrep -- "$(df -k . | tail -1 | tr -s ' ')" } >&/dev/null } ||
+ { (( $+unmodified_ls )) && SECONDS=0 &&
+ ! until (( SECONDS >= 58 )); do
+ ZTST_hashmark; sleep 2; cat $unmodified
+ [[ $unmodified_ls != "$(ls -lu $unmodified)" ]] && break
+ done }; then
+ ZTST_skip="[[ -N file ]] not supported with noatime file system"
+ else
+ [[ -N $newnewnew && ! -N $unmodified ]]
+ fi
+0:-N cond
+F:This test can fail on NFS-mounted filesystems as the access and
+F:modification times are not updated separately. The test will fail
+F:on HFS+ (Apple Mac OS X default) filesystems because access times
+F:are not recorded. Also, Linux ext3 filesystems may be mounted
+F:with the noatime option which does not update access times.
+F:Failures in these cases do not indicate a problem in the shell.
+
+ [[ $newnewnew -nt $zlnfs && ! ($unmodified -nt $zlnfs) ]]
+0:-nt cond
+
+ [[ $zlnfs -ot $newnewnew && ! ($zlnfs -ot $unmodified) ]]
+0:-ot cond
+
+ [[ link -ef zerolength && ! (link -ef nonzerolength) ]]
+0:-ef cond
+
+ [[ foo = foo && foo != bar && foo == foo && foo != '' ]]
+0:=, == and != conds
+
+ [[ bar < foo && foo > bar ]]
+0:< and > conds
+
+ [[ $(( 3 + 4 )) -eq 0x07 && $(( 5 * 2 )) -ne 0x10 ]]
+0:-eq and -ne conds
+
+ [[ 3 -lt 04 && 05 -gt 2 ]]
+0:-lt and -gt conds
+
+ [[ 3 -le 3 && ! (4 -le 3) ]]
+0:-le cond
+
+ [[ 3 -ge 3 && ! (3 -ge 4) ]]
+0:-ge cond
+
+ [[ 1 -lt 2 || 2 -lt 2 && 3 -gt 4 ]]
+0:|| and && in conds
+
+ if ! grep '#define PATH_DEV_FD' $ZTST_testdir/../config.h; then
+ print -u$ZTST_fd "Warning: not testing [[ -e /dev/fd/0 ]] (/dev/fd not supported)"
+ true
+ else
+ [[ -e /dev/fd/0 ]]
+ fi
+0dD:/dev/fd support in conds handled by access
+
+ if ! grep '#define PATH_DEV_FD' $ZTST_testdir/../config.h; then
+ print -u$ZTST_fd "Warning: not testing [[ -O /dev/fd/0 ]] (/dev/fd not supported)"
+ true
+ else
+ [[ -O /dev/fd/0 ]]
+ fi
+0dD:/dev/fd support in conds handled by stat
+
+ [[ ( -z foo && -z foo ) || -z foo ]]
+1:complex conds with skipping
+
+ [ '' != bar -a '' = '' ]
+0:strings with `[' builtin
+
+ [ `echo 0` -lt `echo 1` ]
+0:substitution in `[' builtin
+
+ [ -n foo scrimble ]
+2:argument checking for [ builtin
+?(eval):[:1: too many arguments
+
+ test -n foo scramble
+2:argument checking for test builtin
+?(eval):test:1: too many arguments
+
+ [ -n foo scrimble scromble ]
+2:argument checking for [ builtin
+?(eval):[:1: too many arguments
+
+ test -n foo scramble scrumble
+2:argument checking for test builtin
+?(eval):test:1: too many arguments
+
+ [ -n foo -a -n bar scrimble ]
+2:argument checking for [ builtin
+?(eval):[:1: too many arguments
+
+ test -n foo -a -z "" scramble
+2:argument checking for test builtin
+?(eval):test:1: too many arguments
+
+ fn() {
+ # careful: first file must exist to trigger bug
+ [[ -e $unmodified ]] || print Where\'s my file\?
+ [[ $unmodified -nt NonExistentFile ]]
+ print status = $?
+ }
+ fn
+0:-nt shouldn't abort on non-existent files
+>status = 1
+
+ str='string' empty=''
+ [[ -v IFS && -v str && -v empty && ! -v str[3] && ! -v not_a_variable ]]
+0:-v cond
+
+ arr=( 1 2 3 4 ) empty=()
+ [[ -v arr && -v arr[1,4] && -v arr[1] && -v arr[4] && -v arr[-4] &&
+ -v arr[(i)3] && ! -v arr[(i)x] &&
+ ! -v arr[0] && ! -v arr[5] && ! -v arr[-5] && ! -v arr[2][1] &&
+ ! -v arr[3]extra && -v empty && ! -v empty[1] ]]
+0:-v cond with array
+
+ typeset -A assoc=( key val num 4 )
+ [[ -v assoc && -v assoc[key] && -v assoc[(i)*] && -v assoc[(I)*] &&
+ ! -v assoc[x] && ! -v assoc[key][1] ]]
+0:-v cond with association
+
+ () { [[ -v 0 && -v 1 && -v 2 && ! -v 3 ]] } arg ''
+0:-v cond with positional parameters
+
+# core dumps on failure
+ if zmodload zsh/regex 2>/dev/null; then
+ echo >regex_test.sh 'if [[ $# = 1 ]]; then
+ if [[ $1 =~ /?[^/]+:[0-9]+:$ ]]; then
+ :
+ fi
+ fi
+ exit 0'
+ $ZTST_testdir/../Src/zsh -f ./regex_test.sh
+ fi
+0:regex tests shouldn't crash
+
+ if zmodload zsh/regex 2>/dev/null; then
+ ( # subshell in case coredump test failed
+ string="this has stuff in it"
+ bad_regex=0
+ if [[ $string =~ "h([a-z]*) s([a-z]*) " ]]; then
+ if [[ "$MATCH $MBEGIN $MEND" != "has stuff 6 15" ]]; then
+ print -r "regex variables MATCH MBEGIN MEND:
+ '$MATCH $MBEGIN $MEND'
+ should be:
+ 'has stuff 6 15'"
+ bad_regex=1
+ else
+ results=("as 7 8" "tuff 11 14")
+ for i in 1 2; do
+ if [[ "$match[$i] $mbegin[$i] $mend[$i]" != $results[i] ]]; then
+ print -r "regex variables match[$i] mbegin[$i] mend[$i]:
+ '$match[$i] $mbegin[$i] $mend[$i]'
+ should be
+ '$results[$i]'"
+ bad_regex=1
+ break
+ fi
+ done
+ fi
+ (( bad_regex )) || print OK
+ else
+ print -r "regex failed to match '$string'"
+ fi
+ )
+ else
+ # if it didn't load, tough, but not a test error
+ ZTST_skip="regexp library not found."
+ fi
+0:MATCH, MBEGIN, MEND, match, mbegin, mend
+>OK
+
+ if zmodload zsh/regex 2>/dev/null; then
+ ( # subshell because regex module may dump core, see above
+ if [[ a =~ a && b == b ]]; then
+ print OK
+ else
+ print "regex =~ inverted following test"
+ fi
+ )
+ else
+ # not a test error
+ ZTST_skip="regexp library not found."
+ fi
+0:regex infix operator should not invert following conditions
+>OK
+
+ [[ -fail badly ]]
+2:Error message for unknown prefix condition
+?(eval):1: unknown condition: -fail
+
+ [[ really -fail badly ]]
+2:Error message for unknown infix condition
+?(eval):1: unknown condition: -fail
+
+ crashme() {
+ if [[ $1 =~ ^http:* ]]
+ then
+ url=${1#*=}
+ fi
+ }
+ which crashme
+0:Regression test for examining code with regular expression match
+>crashme () {
+> if [[ $1 =~ ^http:* ]]
+> then
+> url=${1#*=}
+> fi
+>}
+
+ weirdies=(
+ '! -a !'
+ '! -o !'
+ '! -a'
+ '! -o'
+ '! -a ! -a !'
+ '! = !'
+ '! !'
+ '= -a o'
+ '! = -a o')
+ for w in $weirdies; do
+ eval test $w
+ print $?
+ done
+0:test compatability weirdness: treat ! as a string sometimes
+>0
+>0
+>1
+>0
+>0
+>0
+>1
+>0
+>1
+
+ foo=''
+ [[ $foo ]] || print foo is empty
+ foo=full
+ [[ $foo ]] && print foo is full
+0:bash compatibility with single [[ ... ]] argument
+>foo is empty
+>foo is full
+
+ test -z \( || print Not zero 1
+ test -z \< || print Not zero 2
+ test -n \( && print Not zero 3
+ test -n \) && print Not zero 4
+ [ -n \> ] && print Not zero 5
+ [ -n \! ] && print Not zero 6
+0:test with two arguments and a token
+>Not zero 1
+>Not zero 2
+>Not zero 3
+>Not zero 4
+>Not zero 5
+>Not zero 6
+
+ [ '(' = ')' ] || print OK 1
+ [ '((' = '))' ] || print OK 2
+ [ '(' = '(' ] && print OK 3
+ [ '(' non-empty-string ')' ] && echo OK 4
+ [ '(' '' ')' ] || echo OK 5
+0:yet more old-fashioned test fix ups: prefer comparison to parentheses
+>OK 1
+>OK 2
+>OK 3
+>OK 4
+>OK 5
+
+ fn() { [[ 'a' == 'b' || 'b' = 'c' || 'c' != 'd' ]] }
+ which -x2 fn
+0: = and == appear as input
+>fn () {
+> [[ 'a' == 'b' || 'b' = 'c' || 'c' != 'd' ]]
+>}
+
+%clean
+ # This works around a bug in rm -f in some versions of Cygwin
+ chmod 644 unmodish
+ for tmpfile in $newnewnew $unmodified $zlnfs; do
+ [[ -f $tmpfile ]] && rm -f $tmpfile
+ done
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/C03traps.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/C03traps.ztst
new file mode 100644
index 0000000..7bc0b48
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/C03traps.ztst
@@ -0,0 +1,761 @@
+# Tests for both trap builtin and TRAP* functions.
+
+%prep
+
+ setopt localtraps
+ mkdir traps.tmp && cd traps.tmp
+
+%test
+
+ fn1() {
+ trap 'print EXIT1' EXIT
+ fn2() { trap 'print EXIT2' EXIT; }
+ fn2
+ }
+ fn1
+0:Nested `trap ... EXIT'
+>EXIT2
+>EXIT1
+
+ fn1() {
+ TRAPEXIT() { print EXIT1; }
+ fn2() { TRAPEXIT() { print EXIT2; }; }
+ fn2
+ }
+ fn1
+0: Nested TRAPEXIT
+>EXIT2
+>EXIT1
+
+ fn1() {
+ trap 'print EXIT1' EXIT
+ fn2() { trap - EXIT; }
+ fn2
+ }
+ fn1
+0:Nested `trap - EXIT' on `trap ... EXIT'
+>EXIT1
+
+ fn1() {
+ TRAPEXIT() { print EXIT1; }
+ fn2() { trap - EXIT; }
+ fn2
+ }
+ fn1
+0:Nested `trap - EXIT' on `TRAPEXIT'
+>EXIT1
+
+# We can't test an EXIT trap for the shell as a whole, because
+# we're inside a function scope which we don't leave when the
+# subshell exits. Not sure if that's the correct behaviour, but
+# it's sort of consistent.
+ ( fn1() { trap 'print Function 1 going' EXIT; exit; print Not reached; }
+ fn2() { trap 'print Function 2 going' EXIT; fn1; print Not reached; }
+ fn2
+ )
+0:EXIT traps on functions when exiting from function
+>Function 1 going
+>Function 2 going
+
+# $ZTST_exe is relative to the parent directory.
+# We ought to fix this in ztst.zsh...
+ (cd ..
+ $ZTST_exe -fc 'TRAPEXIT() { print Exited.; }')
+0:EXIT traps on a script
+>Exited.
+
+ trap -
+ trap
+ trap int INT
+ trap sigterm SIGTERM
+ trap quit 3
+ trap
+0: Outputting traps correctly
+>trap -- int INT
+>trap -- quit QUIT
+>trap -- sigterm TERM
+
+ fn1() {
+ trap -
+ trap
+ trap 'print INT1' INT
+ fn2() { trap 'print INT2' INT; trap; }
+ trap
+ fn2
+ trap
+ }
+ fn1
+0: Nested `trap ... INT', not triggered
+>trap -- 'print INT1' INT
+>trap -- 'print INT2' INT
+>trap -- 'print INT1' INT
+
+ fn1() {
+ trap -
+ trap
+ TRAPINT() { print INT1; }
+ fn2() { TRAPINT() { print INT2; }; trap; }
+ trap
+ fn2
+ trap
+ }
+ fn1
+0: Nested TRAPINT, not triggered
+>TRAPINT () {
+> print INT1
+>}
+>TRAPINT () {
+> print INT2
+>}
+>TRAPINT () {
+> print INT1
+>}
+
+ fn1() {
+ trap -
+ trap 'print INT1' INT
+ fn2() { trap - INT; trap; }
+ trap
+ fn2
+ trap
+ }
+ fn1
+0: Nested `trap - INT' on untriggered `trap ... INT'
+>trap -- 'print INT1' INT
+>trap -- 'print INT1' INT
+
+# Testing the triggering of traps here is very unpleasant.
+# The delays are attempts to avoid race conditions, though there is
+# no guarantee that they will work. Note the subtlety that the
+# `sleep' in the function which receives the trap does *not* get the
+# signal, only the parent shell, which is waiting for a SIGCHILD.
+# (At least, that's what I think is happening.) Thus we have to wait at
+# least the full two seconds to make sure we have got the output from the
+# execution of the trap.
+
+ print -u $ZTST_fd 'This test takes at least three seconds...'
+ fn1() {
+ trap 'print TERM1' TERM
+ fn2() { trap 'print TERM2; return 1' TERM; sleep 2; }
+ fn2 &
+ sleep 1
+ kill -TERM $!
+ sleep 2
+ }
+ fn1
+0: Nested `trap ... TERM', triggered on inner loop
+>TERM2
+
+ print -u $ZTST_fd 'This test, too, takes at least three seconds...'
+ fn1() {
+ trap 'print TERM1; return 1' TERM
+ fn2() { trap 'print TERM2; return 1' TERM; }
+ fn2
+ sleep 2
+ }
+ fn1 &
+ sleep 1
+ kill -TERM $!
+ sleep 2
+0: Nested `trap ... TERM', triggered on outer loop
+>TERM1
+
+ TRAPZERR() { print error activated; }
+ fn() { print start of fn; false; print end of fn; }
+ fn
+ fn() {
+ setopt localoptions localtraps
+ unfunction TRAPZERR
+ print start of fn
+ false
+ print end of fn
+ }
+ fn
+ unfunction TRAPZERR
+ print finish
+0: basic localtraps handling
+>start of fn
+>error activated
+>end of fn
+>start of fn
+>end of fn
+>finish
+
+ TRAPZERR() { print 'ERR-or!'; }
+ f() { print f; false; }
+ t() { print t; }
+ f
+ f && t
+ t && f && true
+ t && f
+ testunset() {
+ setopt localtraps
+ unset -f TRAPZERR
+ print testunset
+ false
+ true
+ }
+ testunset
+ f
+ print status $?
+ unfunction TRAPZERR
+0: more sophisticated error trapping
+>f
+>ERR-or!
+>f
+>t
+>f
+>t
+>f
+>ERR-or!
+>testunset
+>f
+>ERR-or!
+>status 1
+
+ f() {
+ setopt localtraps
+ TRAPWINCH() { print "Window changed. That wrecked the test."; }
+ }
+ f
+ f
+ functions TRAPWINCH
+1:Unsetting ordinary traps with localtraps.
+
+#
+# Returns from within traps are a perennial problem.
+# The following two apply to returns in and around standard
+# ksh-style traps. The intention is that a return value from
+# within the function is preserved (i.e. statuses set by the trap
+# are ignored) unless the trap explicitly executes `return', which makes
+# it return from the enclosing function.
+#
+ fn() { trap 'true' EXIT; return 1; }
+ fn
+1: ksh-style EXIT traps preserve return value
+
+ inner() { trap 'return 3' EXIT; return 2; }
+ outer() { inner; return 1; }
+ outer
+3: ksh-style EXIT traps can force return status of enclosing function
+
+# Autoloaded traps are horrid, but unfortunately people expect
+# them to work if we support them.
+ echo "print Running exit trap" >TRAPEXIT
+ ${${ZTST_exe##[^/]*}:-$ZTST_testdir/$ZTST_exe} -fc '
+ fpath=(. $fpath)
+ autoload TRAPEXIT
+ print "Exiting, attempt 1"
+ exit
+ print "What?"
+ '
+ ${${ZTST_exe##[^/]*}:-$ZTST_testdir/$ZTST_exe} -fc '
+ fpath=(. $fpath)
+ autoload TRAPEXIT;
+ fn() { print Some function }
+ fn
+ print "Exiting, attempt 2"
+ exit
+ '
+0: autoloaded TRAPEXIT (exit status > 128 indicates an old bug is back)
+>Exiting, attempt 1
+>Running exit trap
+>Some function
+>Exiting, attempt 2
+>Running exit trap
+
+ print -u $ZTST_fd Another test that takes three seconds
+ gotsig=0
+ signal_handler() {
+ echo "parent received signal"
+ gotsig=1
+ }
+ child() {
+ sleep 1
+ echo "child sending signal"
+ kill -15 $parentpid
+ sleep 2
+ echo "child exiting"
+ exit 33
+ }
+ parentpid=$$
+ child &
+ childpid=$!
+ trap signal_handler 15
+ echo "parent waiting"
+ wait $childpid
+ cstatus=$?
+ echo "wait #1 finished, gotsig=$gotsig, status=$cstatus"
+ gotsig=0
+ wait $childpid
+ cstatus=$?
+ echo "wait #2 finished, gotsig=$gotsig, status=$cstatus"
+0:waiting for trapped signal
+>parent waiting
+>child sending signal
+>parent received signal
+>wait #1 finished, gotsig=1, status=143
+>child exiting
+>wait #2 finished, gotsig=0, status=33
+
+ fn1() {
+ setopt errexit
+ trap 'echo error1' ZERR
+ false
+ print Shouldn\'t get here 1a
+ }
+ fn2() {
+ setopt errexit
+ trap 'echo error2' ZERR
+ return 1
+ print Shouldn\'t get here 2a
+ }
+ fn3() {
+ setopt errexit
+ TRAPZERR() { echo error3; }
+ false
+ print Shouldn\'t get here 3a
+ }
+ fn4() {
+ setopt errexit
+ TRAPZERR() { echo error4; }
+ return 1
+ print Shouldn\'t get here 4a
+ }
+ (fn1; print Shouldn\'t get here 1b)
+ (fn2; print Shouldn\'t get here 2b)
+ (fn3; print Shouldn\'t get here 3b)
+ (fn4; print Shouldn\'t get here 4b)
+1: Combination of ERR_EXIT and ZERR trap
+>error1
+>error2
+>error3
+>error4
+
+ fn1() { TRAPZERR() { print trap; return 42; }; false; print Broken; }
+ (fn1)
+ print Working $?
+0: Force return of containing function from TRAPZERR.
+>trap
+>Working 42
+
+ fn2() { trap 'print trap; return 42' ZERR; false; print Broken }
+ (fn2)
+ print Working $?
+0: Return with non-zero status triggered from within trap '...' ZERR.
+>trap
+>Working 42
+
+ fn3() { TRAPZERR() { print trap; return 0; }; false; print OK this time; }
+ (fn3)
+ print Working $?
+0: Normal return from TRAPZERR.
+>trap
+>OK this time
+>Working 0
+
+ fn4() { trap 'print trap; return 0' ZERR; false; print Broken; }
+ (fn4)
+ print Working $?
+0: Return with zero status triggered from within trap '...' ZERR.
+>trap
+>Working 0
+
+ { trap 'echo This subshell is exiting' EXIT; } | cat
+0: EXIT trap set in current shell at left of pipeline
+>This subshell is exiting
+
+ ( trap 'echo This subshell is also exiting' EXIT; ) | cat
+0: EXIT trap set in subshell at left of pipeline
+>This subshell is also exiting
+
+ ( trap 'echo Should only appear once at the end' EXIT
+ ( : trap reset here ) | cat
+ : trap not reset but not part of shell command list | cat
+ echo nothing after this should appear $( : trap reset here too)
+ )
+0: EXIT trap set in subshell reset in subsubshell
+>nothing after this should appear
+>Should only appear once at the end
+
+ echo $( trap 'echo command substitution exited' EXIT )
+0: EXIT trap set in command substitution
+>command substitution exited
+
+ (cd ..; $ZTST_exe -fc 'setopt posixtraps;
+ TRAPEXIT() { print Exited; }
+ fn1() { trap; }
+ setopt localtraps # should be ignored by EXIT
+ fn2() { TRAPEXIT() { print No, really exited; } }
+ fn1
+ fn2
+ fn1')
+0:POSIX_TRAPS option
+>TRAPEXIT () {
+> print Exited
+>}
+>TRAPEXIT () {
+> print No, really exited
+>}
+>No, really exited
+
+ (cd ..; $ZTST_exe -fc 'unsetopt posixtraps;
+ echo start program
+ emulate sh -c '\''testfn() {
+ echo start function
+ set -o | grep posixtraps
+ trap "echo EXIT TRAP TRIGGERED" EXIT
+ echo end function
+ }'\''
+ testfn
+ echo program continuing
+ echo end of program')
+0:POSIX_TRAPS effect on EXIT trap is sticky
+>start program
+>start function
+>noposixtraps off
+>end function
+>program continuing
+>end of program
+>EXIT TRAP TRIGGERED
+
+ (cd ..; $ZTST_exe -fc '
+ echo entering program
+ emulate sh -c '\''trap "echo POSIX exit trap triggered" EXIT'\''
+ fn() {
+ trap "echo native zsh function-local exit trap triggered" EXIT
+ echo entering native zsh function
+ }
+ fn
+ echo exiting program
+ ')
+0:POSIX EXIT trap can have nested native mode EXIT trap
+>entering program
+>entering native zsh function
+>native zsh function-local exit trap triggered
+>exiting program
+>POSIX exit trap triggered
+
+ (cd ..; $ZTST_exe -fc '
+ echo entering program
+ emulate sh -c '\''spt() { trap "echo POSIX exit trap triggered" EXIT; }'\''
+ fn() {
+ trap "echo native zsh function-local exit trap triggered" EXIT
+ echo entering native zsh function
+ }
+ spt
+ fn
+ echo exiting program
+ ')
+0:POSIX EXIT trap not replaced if defined within function
+>entering program
+>entering native zsh function
+>native zsh function-local exit trap triggered
+>exiting program
+>POSIX exit trap triggered
+
+ (set -e
+ printf "a\nb\n" | while read line
+ do
+ [[ $line = a* ]] || continue
+ ((ctr++))
+ [[ $line = foo ]]
+ done
+ echo "ctr = $ctr"
+ )
+1:ERREXIT in loop with simple commands
+
+ fn() {
+ emulate -L zsh
+ setopt errreturn
+ if false; then
+ false
+ print No.
+ else
+ print Oh, yes
+ fi
+ }
+ fn
+0:ERR_RETURN not triggered in if condition
+>Oh, yes
+
+ fn() {
+ emulate -L zsh
+ setopt errreturn
+ if true; then
+ false
+ print No.
+ else
+ print No, no.
+ fi
+ }
+ fn
+1:ERR_RETURN in "if"
+
+ fn() {
+ emulate -L zsh
+ setopt errreturn
+ if false; then
+ print No.
+ else
+ false
+ print No, no.
+ fi
+ }
+ fn
+1:ERR_RETURN in "else" branch (regression test)
+
+ $ZTST_testdir/../Src/zsh -f =(<<<"
+ if false; then
+ :
+ else
+ if [[ -n '' ]]; then
+ a=2
+ fi
+ print Yes
+ fi
+ ")
+0:ERR_RETURN when false "if" is the first statement in an "else" (regression)
+>Yes
+F:Must be tested with a top-level script rather than source or function
+
+ fn() {
+ emulate -L zsh
+ setopt errreturn
+ print before
+ false
+ print after
+ }
+ fn
+1:ERR_RETURN, basic case
+>before
+
+ fn() {
+ emulate -L zsh
+ setopt errreturn
+ print before
+ ! true
+ ! false
+ print after
+ }
+ fn
+0:ERR_RETURN with "!"
+>before
+>after
+
+ fn() {
+ emulate -L zsh
+ setopt errreturn
+ print before
+ ! true
+ ! false
+ false
+ print after
+ }
+ fn
+1:ERR_RETURN with "!" and a following false
+>before
+
+ fn() {
+ emulate -L zsh
+ setopt errreturn
+ print before
+ ! if true; then
+ false
+ fi
+ print after
+ }
+ fn
+0:ERR_RETURN with "!" suppressed inside complex structure
+>before
+>after
+
+ fn() {
+ emulate -L zsh
+ setopt errreturn
+ print before
+ if true; then
+ false
+ fi
+ print after
+ }
+ fn
+1:ERR_RETURN with no "!" suppression (control case)
+>before
+
+ (setopt err_return
+ fn() {
+ print before-in
+ false && false
+ }
+ print before-out
+ fn
+ print after-out
+ )
+1:ERR_RETURN with "&&" in function (regression test)
+>before-out
+>before-in
+
+ (setopt err_return
+ fn() {
+ print before-in
+ false && false
+ print after-in
+ }
+ print before-out
+ fn
+ print after-out
+ )
+0:ERR_RETURN not triggered on LHS of "&&" in function
+>before-out
+>before-in
+>after-in
+>after-out
+
+ (setopt err_return
+ fn() {
+ print before-in
+ true && false
+ print after-in
+ }
+ print before-out
+ fn
+ print after-out
+ )
+1:ERR_RETURN triggered on RHS of "&&" in function
+>before-out
+>before-in
+
+ (setopt err_exit
+ for x in y; do
+ false && true
+ done
+ print OK
+ )
+0:ERR_EXIT not triggered by status 1 at end of for
+>OK
+
+ (setopt err_exit
+ integer x=0
+ while (( ! x++ )); do
+ false && true
+ done
+ print OK
+ )
+0:ERR_EXIT not triggered by status 1 at end of while
+>OK
+
+ (setopt err_exit
+ repeat 1; do
+ false && true
+ done
+ print OK
+ )
+0:ERR_EXIT not triggered by status 1 at end of repeat
+>OK
+
+ (setopt err_exit
+ if true; then
+ false && true
+ fi
+ print OK
+ )
+0:ERR_EXIT not triggered by status 1 at end of if
+>OK
+
+ (setopt err_exit
+ {
+ false && true
+ }
+ print OK
+ )
+0:ERR_EXIT not triggered by status 1 at end of { }
+>OK
+
+ (setopt err_exit
+ for x in y; do
+ false
+ done
+ print OK
+ )
+1:ERR_EXIT triggered by status 1 within for
+
+ (setopt err_exit
+ integer x=0
+ while (( ! x++ )); do
+ false
+ done
+ print OK
+ )
+1:ERR_EXIT triggered by status 1 within while
+
+ (setopt err_exit
+ repeat 1; do
+ false
+ done
+ print OK
+ )
+1:ERR_EXIT triggered by status 1 within repeat
+
+ (setopt err_exit
+ if true; then
+ false
+ fi
+ print OK
+ )
+1:ERR_EXIT triggered by status 1 within if
+
+ (setopt err_exit
+ {
+ false
+ }
+ print OK
+ )
+1:ERR_EXIT triggered by status 1 within { }
+
+ (setopt err_exit
+ () {
+ false && true
+ print Still functioning
+ false && true
+ }
+ print OK
+ )
+1:ERR_EXIT triggered by status 1 at end of anon func
+>Still functioning
+
+ if zmodload zsh/system 2>/dev/null; then
+ (
+ trap 'echo TERM; exit 2' TERM
+ trap 'echo EXIT' EXIT
+ kill -s TERM "$sysparams[pid]"
+ echo 'FATAL: we should never get here!' 1>&2
+ exit 1
+ )
+ else
+ ZTST_skip="zsh/system library not found."
+ fi
+2:EXIT trap from TERM trap
+>TERM
+>EXIT
+
+ # Should not get "hello" in the single quotes.
+ (
+ trap "echo hello" EXIT;
+ { :; } | { read line; print "'$line'"; }
+ )
+0:EXIT trap not called in LHS of pipeline: Shell construct on LHS
+>''
+>hello
+
+ (
+ trap "echo hello" EXIT;
+ cat ''
+>hello
+
+%clean
+
+ rm -f TRAPEXIT
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/C04funcdef.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/C04funcdef.ztst
new file mode 100644
index 0000000..0cf2b58
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/C04funcdef.ztst
@@ -0,0 +1,502 @@
+%prep
+
+ mkdir funcdef.tmp
+ cd funcdef.tmp
+ setopt chaselinks
+ cd .
+ unsetopt chaselinks
+ mydir=$PWD
+
+%test
+
+ fn1() { return 1; }
+ fn2() {
+ fn1
+ print $?
+ return 2
+ }
+ fn2
+2:Basic status returns from functions
+>1
+
+ fnz() { }
+ false
+ fnz
+0:Empty function body resets status
+
+ fn3() { return 3; }
+ fnstat() { print $?; }
+ fn3
+ fnstat
+0:Status is not reset on non-empty function body
+>3
+
+ function f$$ () {
+ print regress expansion of function names
+ }
+ f$$
+0:Regression test: 'function f$$ () { ... }'
+>regress expansion of function names
+
+ function foo () print bar
+ foo
+0:Function definition without braces
+>bar
+
+ functions -M m1
+ m1() { (( $# )) }
+ print $(( m1() ))
+ print $(( m1(1) ))
+ print $(( m1(1,2) ))
+0:User-defined math functions, argument handling
+>0
+>1
+>2
+
+ functions -M m2
+ m2() {
+ integer sum
+ local val
+ for val in $*; do
+ (( sum += $val ))
+ done
+ }
+ print $(( m2(1) ))
+ print $(( m2(1,3+3,4**2) ))
+0:User-defined math functions, complex argument handling
+>1
+>23
+
+ functions -M m3 1 2
+ m3() { (( 1 )) }
+ print zero
+ (print $(( m3() )))
+ print one
+ print $(( m3(1) ))
+ print two
+ print $(( m3(1,2) ))
+ print three
+ (print $(( m3(1,2,3) )))
+1:User-defined math functions, argument checking
+>zero
+>one
+>1
+>two
+>1
+>three
+?(eval):4: wrong number of arguments: m3()
+?(eval):10: wrong number of arguments: m3(1,2,3)
+
+ functions -M m4 0 0 testmathfunc
+ functions -M m5 0 0 testmathfunc
+ testmathfunc() {
+ if [[ $0 = m4 ]]; then
+ (( 4 ))
+ else
+ (( 5 ))
+ fi
+ }
+ print $(( m4() ))
+ print $(( m5() ))
+0:User-defined math functions, multiple interfaces
+>4
+>5
+
+ command_not_found_handler() {
+ print "Great News! I've handled the command:"
+ print "$1"
+ print "with arguments:"
+ print -l ${argv[2,-1]}
+ }
+ ACommandWhichHadBetterNotExistOnTheSystem and some "really useful" args
+0:Command not found handler, success
+>Great News! I've handled the command:
+>ACommandWhichHadBetterNotExistOnTheSystem
+>with arguments:
+>and
+>some
+>really useful
+>args
+
+# ' deconfuse emacs
+
+ command_not_found_handler() {
+ print "Your command:" >&2
+ print "$1" >&2
+ print "has gone down the tubes. Sorry." >&2
+ return 42
+ }
+ ThisCommandDoesNotExistEither
+42:Command not found handler, failure
+?Your command:
+?ThisCommandDoesNotExistEither
+?has gone down the tubes. Sorry.
+
+ local variable=outside
+ print "I am $variable"
+ function {
+ local variable=inside
+ print "I am $variable"
+ }
+ print "I am $variable"
+ () {
+ local variable="inside again"
+ print "I am $variable"
+ }
+ print "I am $variable"
+0:Anonymous function scope
+>I am outside
+>I am inside
+>I am outside
+>I am inside again
+>I am outside
+
+ integer i
+ for (( i = 0; i < 10; i++ )); do function {
+ case $i in
+ ([13579])
+ print $i is odd
+ ;|
+ ([2468])
+ print $i is even
+ ;|
+ ([2357])
+ print $i is prime
+ ;;
+ esac
+ }; done
+0:Anonymous function with patterns in loop
+>1 is odd
+>2 is even
+>2 is prime
+>3 is odd
+>3 is prime
+>4 is even
+>5 is odd
+>5 is prime
+>6 is even
+>7 is odd
+>7 is prime
+>8 is even
+>9 is odd
+
+ echo stuff in file >file.in
+ function {
+ sed 's/stuff/rubbish/'
+ } file.out
+ cat file.out
+0:Anonymous function redirection
+>rubbish in file
+
+ variable="Do be do"
+ print $variable
+ function {
+ print $variable
+ local variable="Da de da"
+ print $variable
+ function {
+ print $variable
+ local variable="Dum da dum"
+ print $variable
+ }
+ print $variable
+ }
+ print $variable
+0:Nested anonymous functions
+>Do be do
+>Do be do
+>Da de da
+>Da de da
+>Dum da dum
+>Da de da
+>Do be do
+
+ () (cat $1 $2) <(print process expanded) =(print expanded to file)
+0:Process substitution with anonymous functions
+>process expanded
+>expanded to file
+
+ () { print This has arguments $*; } of all sorts; print After the function
+ function { print More stuff $*; } and why not; print Yet more
+0:Anonymous function with arguments
+>This has arguments of all sorts
+>After the function
+>More stuff and why not
+>Yet more
+
+ fn() {
+ (){ print Anonymous function 1 $*; } with args
+ function { print Anonymous function 2 $*; } with more args
+ print Following bit
+ }
+ functions fn
+0:Text representation of anonymous function with arguments
+>fn () {
+> () {
+> print Anonymous function 1 $*
+> } with args
+> () {
+> print Anonymous function 2 $*
+> } with more args
+> print Following bit
+>}
+
+ touch yes no
+ () { echo $1 } (y|z)*
+ (echo here)
+ () { echo $* } some (y|z)*
+ () { echo empty };(echo here)
+0:Anonymous function arguments and command arguments
+>yes
+>here
+>some yes
+>empty
+>here
+
+ if true; then f() { echo foo1; } else f() { echo bar1; } fi; f
+ if false; then f() { echo foo2; } else f() { echo bar2; } fi; f
+0:Compatibility with other shells when not anonymous functions
+>foo1
+>bar2
+
+ (
+ setopt ignorebraces
+ fpath=(.)
+ print "{ echo OK }\n[[ -o ignorebraces ]] || print 'ignorebraces is off'" \
+ >emufunctest
+ (autoload -z emufunctest; emufunctest) 2>&1
+ emulate zsh -c 'autoload -Uz emufunctest'
+ emufunctest
+ [[ -o ignorebraces ]] && print 'ignorebraces is still on here'
+ )
+0:sticky emulation applies to autoloads and autoloaded function execution
+>emufunctest:3: parse error near `\n'
+>OK
+>ignorebraces is off
+>ignorebraces is still on here
+#` (matching error message for editors parsing the file)
+
+# lsfoo should not be expanded as an anonymous function argument
+ alias lsfoo='This is not ls.'
+ () (echo anon func; echo "$@") lsfoo
+0:Anonmous function with arguments in a form nobody sane would ever use but unfortunately we have to support anyway
+>anon func
+>lsfoo
+
+ print foo | () cat
+0:Simple anonymous function should not simplify enclosing pipeline
+>foo
+
+ alias fooalias=barexpansion
+ funcwithalias() { echo $(fooalias); }
+ functions funcwithalias
+ barexpansion() { print This is the correct output.; }
+ funcwithalias
+0:Alias expanded in command substitution does not appear expanded in text
+>funcwithalias () {
+> echo $(fooalias)
+>}
+>This is the correct output.
+
+ unfunction command_not_found_handler # amusing but unhelpful
+ alias first='firstfn1 firstfn2' second='secondfn1 secondfn2'
+ function first second { print This is function $0; }
+ first
+ second
+ firstfn1
+ secondfn1
+127:No alias expansion after "function" keyword
+>This is function first
+>This is function second
+?(eval):6: command not found: firstfn1
+?(eval):7: command not found: secondfn1
+
+ (
+ fpath=(.)
+ print "print oops was successfully autoloaded" >oops
+ oops() { eval autoload -X }
+ oops
+ which -x2 oops
+ )
+0:autoload containing eval
+>oops was successfully autoloaded
+>oops () {
+> print oops was successfully autoloaded
+>}
+
+ (
+ fpath=(.)
+ printf '%s\n' 'oops(){}' 'ninjas-earring(){}' 'oops "$@"' >oops
+ autoload oops
+ oops
+ whence -v oops
+ )
+0q:whence -v of zsh-style autoload
+>oops is a shell function from $mydir/oops
+
+ (
+ fpath=(.)
+ mkdir extra
+ print 'print "I have been loaded by explicit path."' >extra/spec
+ autoload -Uz $PWD/extra/spec
+ spec
+ )
+0:autoload with explicit path
+>I have been loaded by explicit path.
+
+ (
+ fpath=(.)
+ print 'print "I have been loaded by default path."' >def
+ autoload -Uz $PWD/extra/def
+ def
+ )
+1:autoload with explicit path with function in normal path, no -d
+?(eval):5: def: function definition file not found
+
+ (
+ fpath=(.)
+ autoload -dUz $PWD/extra/def
+ def
+ )
+0:autoload with explicit path with function in normal path, with -d
+>I have been loaded by default path.
+
+ (
+ cd extra
+ fpath=(.)
+ autoload -r spec
+ cd ..
+ spec
+ )
+0:autoload -r
+>I have been loaded by explicit path.
+
+ (
+ cd extra
+ fpath=(.)
+ autoload -r def
+ cd ..
+ def
+ )
+0:autoload -r is permissive
+>I have been loaded by default path.
+
+ (
+ cd extra
+ fpath=(.)
+ autoload -R def
+ )
+1:autoload -R is not permissive
+?(eval):4: def: function definition file not found
+
+ (
+ spec() { autoload -XUz $PWD/extra; }
+ spec
+ )
+0:autoload -X with path
+>I have been loaded by explicit path.
+
+# The line number 1 here and in the next test seems suspect,
+# but this example proves it's not down to the new features
+# being tested here.
+ (
+ fpath=(.)
+ cod() { autoload -XUz; }
+ cod
+ )
+1:autoload -X with no path, failure
+?(eval):1: cod: function definition file not found
+
+ (
+ fpath=(.)
+ def() { autoload -XUz $PWD/extra; }
+ def
+ )
+1:autoload -X with wrong path and no -d
+?(eval):1: def: function definition file not found
+
+ (
+ fpath=(.)
+ def() { autoload -dXUz $PWD/extra; }
+ def
+ )
+0:autoload -dX with path
+>I have been loaded by default path.
+
+ (
+ fpath=(.)
+ print 'loadthisfunc() { autoload -X }' >loadthisfunc_sourceme
+ print 'print Function was loaded correctly.' >loadthisfunc
+ source $PWD/loadthisfunc_sourceme
+ loadthisfunc
+ )
+0: autoload -X interaction with absolute filename used for source location
+>Function was loaded correctly.
+
+ (
+ fpath=()
+ mkdir extra2
+ for f in fun2a fun2b; do
+ print "print $f" >extra2/$f
+ done
+ repeat 3; do
+ autoload $PWD/extra2/fun2{a,b} $PWD/extra/spec
+ fun2a
+ fun2b
+ spec
+ unfunction fun2a fun2b spec
+ autoload $PWD/extra2/fun2{a,b} $PWD/extra/spec
+ spec
+ fun2b
+ fun2a
+ unfunction fun2a fun2b spec
+ done
+ )
+0: Exercise the directory name cache for autoloads
+>fun2a
+>fun2b
+>I have been loaded by explicit path.
+>I have been loaded by explicit path.
+>fun2b
+>fun2a
+>fun2a
+>fun2b
+>I have been loaded by explicit path.
+>I have been loaded by explicit path.
+>fun2b
+>fun2a
+>fun2a
+>fun2b
+>I have been loaded by explicit path.
+>I have been loaded by explicit path.
+>fun2b
+>fun2a
+
+ not_trashed() { print This function was not trashed; }
+ autoload -Uz /foo/bar/not_trashed
+ not_trashed
+0:autoload with absolute path doesn't trash loaded function
+>This function was not trashed
+
+ # keep spec from getting loaded in parent shell for simplicity
+ (
+ if whence spec; then print spec already loaded >&2; exit 1; fi
+ autoload -Uz $PWD/spec
+ autoload -Uz $PWD/extra/spec
+ spec
+ )
+0:autoload with absolute path can be overridden if not yet loaded
+>I have been loaded by explicit path.
+
+ (
+ if whence spec; then print spec already loaded >&2; exit 1; fi
+ autoload -Uz $PWD/extra/spec
+ autoload spec
+ spec
+ )
+0:autoload with absolute path not cancelled by bare autoload
+>I have been loaded by explicit path.
+
+%clean
+
+ rm -f file.in file.out
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/C05debug.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/C05debug.ztst
new file mode 100644
index 0000000..9a8df1d
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/C05debug.ztst
@@ -0,0 +1,159 @@
+%prep
+
+ setopt localtraps
+
+%test
+
+ unsetopt DEBUG_BEFORE_CMD
+ debug-trap-bug1() {
+ setopt localtraps
+ print "print bug file here" >bug-file
+ print "print this is line one
+ print this is line two
+ print this is line three
+ print and this is line fifty-nine." >bug-file2
+ function debug_trap_handler {
+ print $functrace[1]
+ do_bug
+ }
+ function do_bug {
+ . ./bug-file
+ }
+ trap 'echo EXIT hit' EXIT
+ trap 'debug_trap_handler' DEBUG
+ . ./bug-file2
+ }
+ debug-trap-bug1
+0: Relationship between traps and sources
+>debug-trap-bug1:15
+>bug file here
+>this is line one
+>./bug-file2:1
+>bug file here
+>this is line two
+>./bug-file2:2
+>bug file here
+>this is line three
+>./bug-file2:3
+>bug file here
+>and this is line fifty-nine.
+>./bug-file2:4
+>bug file here
+>debug-trap-bug1:16
+>bug file here
+>EXIT hit
+
+ cat >zsh-trapreturn-bug2 <<-'HERE'
+ cmd='./fdasfsdafd'
+ [[ -x $cmd ]] && rm $cmd
+ set -o DEBUG_BEFORE_CMD
+ trap '[[ $? -ne 0 ]] && exit 0' DEBUG
+ $cmd # invalid command
+ # Failure
+ exit 10
+ HERE
+ $ZTST_testdir/../Src/zsh -f ./zsh-trapreturn-bug2 2>erroutput.dif
+ mystat=$?
+ (
+ setopt extendedglob
+ print ${"$(< erroutput.dif)"%%:[^:]#: ./fdasfsdafd}
+ )
+ (( mystat == 0 ))
+0: trapreturn handling bug is properly fixed
+>./zsh-trapreturn-bug2:5
+
+ fn() {
+ setopt localtraps localoptions debugbeforecmd
+ trap '(( LINENO == 4 )) && setopt errexit' DEBUG
+ print $LINENO three
+ print $LINENO four
+ print $LINENO five
+ [[ -o errexit ]] && print "Hey, ERREXIT is set!"
+ }
+ fn
+1:Skip line from DEBUG trap
+>3 three
+>5 five
+
+ # Assignments are a special case, since they use a simpler
+ # wordcode type, so we need to test skipping them separately.
+ fn() {
+ setopt localtraps localoptions debugbeforecmd
+ trap '(( LINENO == 4 )) && setopt errexit' DEBUG
+ x=three
+ x=four
+ print $LINENO $x
+ [[ -o errexit ]] && print "Hey, ERREXIT is set!"
+ }
+ fn
+1:Skip assignment from DEBUG trap
+>5 three
+
+ fn() {
+ setopt localtraps localoptions debugbeforecmd
+ trap 'print $LINENO' DEBUG
+ [[ a = a ]] && print a is ok
+ }
+ fn
+0:line numbers of complex sublists
+>3
+>a is ok
+
+ fn() {
+ setopt localtraps localoptions debugbeforecmd
+ trap 'print $LINENO' DEBUG
+ print before
+ x=' first
+ second
+ third'
+ print $x
+ }
+ fn
+0:line numbers of multiline assignments
+>3
+>before
+>4
+>7
+> first
+> second
+> third
+
+ fn() {
+ emulate -L zsh; setopt debugbeforecmd
+ trap 'print "$LINENO: '\''$ZSH_DEBUG_CMD'\''"' DEBUG
+ print foo &&
+ print bar ||
+ print rod
+ x=y
+ print $x
+ fn2() { echo wow }
+ fn2
+ }
+ fn
+0:ZSH_DEBUG_CMD in debug traps
+>3: 'print foo && print bar || print rod'
+>foo
+>bar
+>6: 'x=y '
+>7: 'print $x'
+>y
+>8: 'fn2 () {
+> echo wow
+>}'
+>9: 'fn2'
+>0: 'echo wow'
+>wow
+
+ foo() {
+ emulate -L zsh; setopt debugbeforecmd
+ trap '[[ $ZSH_DEBUG_CMD == *bar* ]] && return 2' DEBUG
+ echo foo
+ echo bar
+ }
+ foo
+2:Status of forced return from eval-style DEBUG trap
+>foo
+
+%clean
+
+ rm -f bug-file bug-file2 erroutput.dif zsh-trapreturn-bug2
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D01prompt.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D01prompt.ztst
new file mode 100644
index 0000000..607ffb6
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D01prompt.ztst
@@ -0,0 +1,203 @@
+%prep
+
+ mkdir prompt.tmp
+ cd prompt.tmp
+ mydir=$PWD
+ SHLVL=2
+ setopt extendedglob
+
+%test
+
+ hash -d mydir=$mydir
+ print -P ' %%%): %)
+ %%~: %~
+ %%d: %d
+ %%1/: %1/
+ %%h: %h
+ %%L: %L
+ %%M: %M
+ %%m: %m
+ %%n: %n
+ %%N: %N
+ %%i: %i
+ a%%{...%%}b: a%{%}b
+ '
+0q:Basic prompt escapes as shown.
+> %): )
+> %~: ~mydir
+> %d: $mydir
+> %1/: ${mydir:t}
+> %h: 0
+> %L: 2
+> %M: $HOST
+> %m: ${HOST%%.*}
+> %n: $USERNAME
+> %N: (eval)
+> %i: 2
+> a%{...%}b: ab
+>
+
+ true
+ print -P '%?'
+ false
+ print -P '%?'
+0:`%?' prompt escape
+>0
+>1
+
+ PS4="%_> "
+ setopt xtrace
+ if true; then true; else false; fi
+ unsetopt xtrace
+0:`%_' prompt escape
+?if> true
+?then> true
+?> unsetopt xtrace
+
+ diff =(print -P '%#') =(print -P '%(!.#.%%)')
+0:`%#' prompt escape and its equivalent
+
+ psvar=(caesar adsum jam forte)
+ print -P '%v' '%4v'
+0:`%v' prompt escape
+>caesar forte
+
+ true
+ print -P '%(?.true.false)'
+ false
+ print -P '%(?.true.false)'
+0:ternary prompt escapes
+>true
+>false
+
+ print -P 'start %10<......>truncated at 10%>> Not truncated%3> ...>Not shown'
+0:prompt truncation
+>start ...d at 10 Not truncated ...
+>start truncat... Not truncated ...
+
+# It's hard to check the time and date as they are moving targets.
+# We therefore just check that various forms of the date are consistent.
+# In fact, if you perform this at midnight it can still fail.
+# We could test for that, but we can't be bothered.
+# I hope LC_ALL is enough to make the format what's expected.
+
+ LC_ALL=C
+ date1=$(print -P %w)
+ date2=$(print -P %W)
+ date3=$(print -P %D)
+ if [[ $date1 != [A-Z][a-z][a-z][[:blank:]]##[0-9]## ]]; then
+ print "Date \`$date1' is not in the form \`Day DD' (e.g. \`Mon 1'"
+ fi
+ if [[ $date2 != [0-9][0-9]/[0-9][0-9]/[0-9][0-9] ]]; then
+ print "Date \`$date2' is not in the form \`DD/MM/YYYY'"
+ fi
+ if [[ $date3 != [0-9][0-9]-[0-9][0-9]-[0-9][0-9] ]]; then
+ print "Date \`$date3' is not in the form \`YY-MM-DD'"
+ fi
+ if (( $date1[5,-1] != $date2[4,5] )) || (( $date2[4,5] != $date3[7,8] ))
+ then
+ print "Days of month do not agree in $date1, $date2, $date3"
+ fi
+ if (( $date2[1,2] != $date3[4,5] )); then
+ print "Months do not agree in $date2, $date3"
+ fi
+ if (( $date2[7,8] != $date3[1,2] )); then
+ print "Years do not agree in $date2, $date3"
+ fi
+0:Dates produced by prompt escapes
+
+ mkdir foo
+ mkdir foo/bar
+ mkdir foo/bar/rod
+ (zsh_directory_name() {
+ emulate -L zsh
+ setopt extendedglob
+ local -a match mbegin mend
+ if [[ $1 = d ]]; then
+ if [[ $2 = (#b)(*bar)/rod ]]; then
+ reply=(barmy ${#match[1]})
+ else
+ return 1
+ fi
+ else
+ if [[ $2 = barmy ]]; then
+ reply=($mydir/foo/bar)
+ else
+ return 1
+ fi
+ fi
+ }
+ # success
+ print ~[barmy]/anything
+ cd foo/bar/rod
+ print -P %~
+ # failure
+ setopt nonomatch
+ print ~[scuzzy]/rubbish
+ cd ../..
+ print -P %~
+ # catastrophic failure
+ unsetopt nonomatch
+ print ~[scuzzy]/rubbish
+ )
+1q:Dynamic named directories
+>$mydir/foo/bar/anything
+>~[barmy]/rod
+>~[scuzzy]/rubbish
+>~mydir/foo
+?(eval):33: no directory expansion: ~[scuzzy]
+
+ (
+ zsh_directory_name() {
+ emulate -L zsh
+ setopt extendedglob
+ local -a match mbegin mend
+ if [[ $1 = n ]]; then
+ if [[ $2 = *:l ]]; then
+ reply=(${2%%:l}/very_long_directory_name)
+ return 0
+ else
+ return 1
+ fi
+ else
+ if [[ $2 = (#b)(*)/very_long_directory_name ]]; then
+ reply=(${match[1]}:l ${#2})
+ return 0
+ else
+ return 1
+ fi
+ fi
+ }
+ parent=$PWD
+ dir=$parent/very_long_directory_name
+ mkdir $dir
+ cd $dir
+ fn() {
+ PS4='+%N:%i> '
+ setopt localoptions xtrace
+ # The following is the key to the test.
+ # It invokes zsh_directory_name which does PS4 output stuff
+ # while we're doing prompt handling for the parameter
+ # substitution. This checks recursion works OK.
+ local d=${(%):-%~}
+ print ${d//$parent/\}
+ }
+ fn 2>stderr
+ # post process error to remove variable contents
+ while read line; do
+ # tricky: reply is set to include directory length which is variable
+ [[ $line = *reply* ]] && continue
+ print ${line//$parent/\}
+ done &2
+ )
+0:Recursive use of prompts
+>~[:l]
+?+zsh_directory_name:1> emulate -L zsh
+?+zsh_directory_name:2> setopt extendedglob
+?+zsh_directory_name:3> local -a match mbegin mend
+?+zsh_directory_name:4> [[ d = n ]]
+?+zsh_directory_name:12> [[ /very_long_directory_name = (#b)(*)/very_long_directory_name ]]
+?+zsh_directory_name:14> return 0
+?+fn:7> local d='~[:l]'
+?+fn:8> print '~[:l]'
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D02glob.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D02glob.ztst
new file mode 100644
index 0000000..1385d57
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D02glob.ztst
@@ -0,0 +1,688 @@
+# Tests for globbing
+
+%prep
+ mkdir glob.tmp
+ mkdir glob.tmp/dir{1,2,3,4}
+ mkdir glob.tmp/dir3/subdir
+ : >glob.tmp/{,{dir1,dir2}/}{a,b,c}
+
+ globtest () {
+ $ZTST_testdir/../Src/zsh -f $ZTST_srcdir/../Misc/$1
+ }
+
+ regress_absolute_path_and_core_dump() {
+ local absolute_dir=$(cd glob.tmp && pwd -P)
+ [[ -n $absolute_dir ]] || return 1
+ setopt localoptions extendedglob nullglob
+ print $absolute_dir/**/*~/*
+ setopt nonullglob nomatch
+ print glob.tmp/**/*~(.)#
+ }
+
+%test
+
+ globtest globtests
+0:zsh globbing
+>0: [[ foo~ = foo~ ]]
+>0: [[ foo~ = (foo~) ]]
+>0: [[ foo~ = (foo~|) ]]
+>0: [[ foo.c = *.c~boo* ]]
+>1: [[ foo.c = *.c~boo*~foo* ]]
+>0: [[ fofo = (fo#)# ]]
+>0: [[ ffo = (fo#)# ]]
+>0: [[ foooofo = (fo#)# ]]
+>0: [[ foooofof = (fo#)# ]]
+>0: [[ fooofoofofooo = (fo#)# ]]
+>1: [[ foooofof = (fo##)# ]]
+>1: [[ xfoooofof = (fo#)# ]]
+>1: [[ foooofofx = (fo#)# ]]
+>0: [[ ofxoofxo = ((ofo#x)#o)# ]]
+>1: [[ ofooofoofofooo = (fo#)# ]]
+>0: [[ foooxfooxfoxfooox = (fo#x)# ]]
+>1: [[ foooxfooxofoxfooox = (fo#x)# ]]
+>0: [[ foooxfooxfxfooox = (fo#x)# ]]
+>0: [[ ofxoofxo = ((ofo#x)#o)# ]]
+>0: [[ ofoooxoofxo = ((ofo#x)#o)# ]]
+>0: [[ ofoooxoofxoofoooxoofxo = ((ofo#x)#o)# ]]
+>0: [[ ofoooxoofxoofoooxoofxoo = ((ofo#x)#o)# ]]
+>1: [[ ofoooxoofxoofoooxoofxofo = ((ofo#x)#o)# ]]
+>0: [[ ofoooxoofxoofoooxoofxooofxofxo = ((ofo#x)#o)# ]]
+>0: [[ aac = ((a))#a(c) ]]
+>0: [[ ac = ((a))#a(c) ]]
+>1: [[ c = ((a))#a(c) ]]
+>0: [[ aaac = ((a))#a(c) ]]
+>1: [[ baaac = ((a))#a(c) ]]
+>0: [[ abcd = ?(a|b)c#d ]]
+>0: [[ abcd = (ab|ab#)c#d ]]
+>0: [[ acd = (ab|ab#)c#d ]]
+>0: [[ abbcd = (ab|ab#)c#d ]]
+>0: [[ effgz = (bc##d|ef#g?|(h|)i(j|k)) ]]
+>0: [[ efgz = (bc##d|ef#g?|(h|)i(j|k)) ]]
+>0: [[ egz = (bc##d|ef#g?|(h|)i(j|k)) ]]
+>0: [[ egzefffgzbcdij = (bc##d|ef#g?|(h|)i(j|k))# ]]
+>1: [[ egz = (bc##d|ef##g?|(h|)i(j|k)) ]]
+>0: [[ ofoofo = (ofo##)# ]]
+>0: [[ oxfoxoxfox = (oxf(ox)##)# ]]
+>1: [[ oxfoxfox = (oxf(ox)##)# ]]
+>0: [[ ofoofo = (ofo##|f)# ]]
+>0: [[ foofoofo = (foo|f|fo)(f|ofo##)# ]]
+>0: [[ oofooofo = (of|oofo##)# ]]
+>0: [[ fffooofoooooffoofffooofff = (f#o#)# ]]
+>1: [[ fffooofoooooffoofffooofffx = (f#o#)# ]]
+>0: [[ fofoofoofofoo = (fo|foo)# ]]
+>0: [[ foo = ((^x)) ]]
+>0: [[ foo = ((^x)*) ]]
+>1: [[ foo = ((^foo)) ]]
+>0: [[ foo = ((^foo)*) ]]
+>0: [[ foobar = ((^foo)) ]]
+>0: [[ foobar = ((^foo)*) ]]
+>1: [[ foot = z*~*x ]]
+>0: [[ zoot = z*~*x ]]
+>1: [[ foox = z*~*x ]]
+>1: [[ zoox = z*~*x ]]
+>0: [[ moo.cow = (*~*.*).(*~*.*) ]]
+>1: [[ mad.moo.cow = (*~*.*).(*~*.*) ]]
+>0: [[ moo.cow = (^*.*).(^*.*) ]]
+>1: [[ sane.moo.cow = (^*.*).(^*.*) ]]
+>1: [[ mucca.pazza = mu(^c#)?.pa(^z#)? ]]
+>1: [[ _foo~ = _(|*[^~]) ]]
+>0: [[ fff = ((^f)) ]]
+>0: [[ fff = ((^f)#) ]]
+>0: [[ fff = ((^f)##) ]]
+>0: [[ ooo = ((^f)) ]]
+>0: [[ ooo = ((^f)#) ]]
+>0: [[ ooo = ((^f)##) ]]
+>0: [[ foo = ((^f)) ]]
+>0: [[ foo = ((^f)#) ]]
+>0: [[ foo = ((^f)##) ]]
+>1: [[ f = ((^f)) ]]
+>1: [[ f = ((^f)#) ]]
+>1: [[ f = ((^f)##) ]]
+>0: [[ foot = (^z*|*x) ]]
+>1: [[ zoot = (^z*|*x) ]]
+>0: [[ foox = (^z*|*x) ]]
+>0: [[ zoox = (^z*|*x) ]]
+>0: [[ foo = (^foo)# ]]
+>1: [[ foob = (^foo)b* ]]
+>0: [[ foobb = (^foo)b* ]]
+>1: [[ foob = (*~foo)b* ]]
+>0: [[ foobb = (*~foo)b* ]]
+>1: [[ zsh = ^z* ]]
+>0: [[ a%1X = [[:alpha:][:punct:]]#[[:digit:]][^[:lower:]] ]]
+>1: [[ a%1 = [[:alpha:][:punct:]]#[[:digit:]][^[:lower:]] ]]
+>0: [[ [: = [[:]# ]]
+>0: [[ :] = []:]# ]]
+>0: [[ :] = [:]]# ]]
+>0: [[ [ = [[] ]]
+>0: [[ ] = []] ]]
+>0: [[ [] = [^]]] ]]
+>0: [[ fooxx = (#i)FOOXX ]]
+>1: [[ fooxx = (#l)FOOXX ]]
+>0: [[ FOOXX = (#l)fooxx ]]
+>1: [[ fooxx = (#i)FOO(#I)X(#i)X ]]
+>0: [[ fooXx = (#i)FOO(#I)X(#i)X ]]
+>0: [[ fooxx = ((#i)FOOX)x ]]
+>1: [[ fooxx = ((#i)FOOX)X ]]
+>1: [[ BAR = (bar|(#i)foo) ]]
+>0: [[ FOO = (bar|(#i)foo) ]]
+>0: [[ Modules = (#i)*m* ]]
+>0: [[ fooGRUD = (#i)(bar|(#I)foo|(#i)rod)grud ]]
+>1: [[ FOOGRUD = (#i)(bar|(#I)foo|(#i)rod)grud ]]
+>0: [[ readme = (#i)readme~README|readme ]]
+>0: [[ readme = (#i)readme~README|readme~README ]]
+>0: [[ 633 = <1-1000>33 ]]
+>0: [[ 633 = <-1000>33 ]]
+>0: [[ 633 = <1->33 ]]
+>0: [[ 633 = <->33 ]]
+>0: [[ 12345678901234567890123456789012345678901234567890123456789012345678901234567890foo = <42->foo ]]
+>0: [[ READ.ME = (#ia1)readme ]]
+>1: [[ READ..ME = (#ia1)readme ]]
+>0: [[ README = (#ia1)readm ]]
+>0: [[ READM = (#ia1)readme ]]
+>0: [[ README = (#ia1)eadme ]]
+>0: [[ EADME = (#ia1)readme ]]
+>0: [[ READEM = (#ia1)readme ]]
+>1: [[ ADME = (#ia1)readme ]]
+>1: [[ README = (#ia1)read ]]
+>0: [[ bob = (#a1)[b][b] ]]
+>1: [[ bob = (#a1)[b][b]a ]]
+>0: [[ bob = (#a1)[b]o[b]a ]]
+>1: [[ bob = (#a1)[c]o[b] ]]
+>0: [[ abcd = (#a2)XbcX ]]
+>0: [[ abcd = (#a2)ad ]]
+>0: [[ ad = (#a2)abcd ]]
+>0: [[ abcd = (#a2)bd ]]
+>0: [[ bd = (#a2)abcd ]]
+>0: [[ badc = (#a2)abcd ]]
+>0: [[ adbc = (#a2)abcd ]]
+>1: [[ dcba = (#a2)abcd ]]
+>0: [[ dcba = (#a3)abcd ]]
+>0: [[ aabaXaaabY = (#a1)(a#b)#Y ]]
+>0: [[ aabaXaaabY = (#a1)(a#b)(a#b)Y ]]
+>0: [[ aaXaaaaabY = (#a1)(a#b)(a#b)Y ]]
+>0: [[ aaaXaaabY = (#a1)(a##b)##Y ]]
+>0: [[ aaaXbaabY = (#a1)(a##b)##Y ]]
+>1: [[ read.me = (#ia1)README~READ.ME ]]
+>0: [[ read.me = (#ia1)README~READ_ME ]]
+>1: [[ read.me = (#ia1)README~(#a1)READ_ME ]]
+>0: [[ test = *((#s)|/)test((#e)|/)* ]]
+>0: [[ test/path = *((#s)|/)test((#e)|/)* ]]
+>0: [[ path/test = *((#s)|/)test((#e)|/)* ]]
+>0: [[ path/test/ohyes = *((#s)|/)test((#e)|/)* ]]
+>1: [[ atest = *((#s)|/)test((#e)|/)* ]]
+>1: [[ testy = *((#s)|/)test((#e)|/)* ]]
+>1: [[ testy/path = *((#s)|/)test((#e)|/)* ]]
+>1: [[ path/atest = *((#s)|/)test((#e)|/)* ]]
+>1: [[ atest/path = *((#s)|/)test((#e)|/)* ]]
+>1: [[ path/testy = *((#s)|/)test((#e)|/)* ]]
+>1: [[ path/testy/ohyes = *((#s)|/)test((#e)|/)* ]]
+>1: [[ path/atest/ohyes = *((#s)|/)test((#e)|/)* ]]
+>0: [[ XabcdabcY = X(ab|c|d)(#c5)Y ]]
+>0: [[ XabcdabcY = X(ab|c|d)(#c1,5)Y ]]
+>0: [[ XabcdabcY = X(ab|c|d)(#c5,8)Y ]]
+>0: [[ XabcdabcY = X(ab|c|d)(#c4,)Y ]]
+>1: [[ XabcdabcY = X(ab|c|d)(#c6,)Y ]]
+>1: [[ XabcdabcY = X(ab|c|d)(#c1,4)Y ]]
+>0: [[ ZX = Z(|)(#c1)X ]]
+>0: [[ froofroo = (fro(#c2))(#c2) ]]
+>1: [[ froofroofroo = (fro(#c2))(#c2) ]]
+>1: [[ froofro = (fro(#c2))(#c2) ]]
+>0: [[ ax = ?(#c1,2)x ]]
+>0: [[ ax = ?(#c1,)x ]]
+>0: [[ ax = ?(#c0,1)x ]]
+>1: [[ ax = ?(#c0,0)x ]]
+>1: [[ ax = ?(#c2,)x ]]
+>0: [[ aa = a(#c1,2)a ]]
+>0: [[ aa = a(#c1,)a ]]
+>0: [[ aa = a(#c0,1)a ]]
+>1: [[ aa = a(#c0,0)a ]]
+>1: [[ aa = a(#c2,)a ]]
+>0: [[ test.zsh = *.?(#c1)sh ]]
+>0: [[ test.bash = *.?(#c2)sh ]]
+>0: [[ test.bash = *.?(#c1,2)sh ]]
+>0: [[ test.bash = *.?(#c1,)sh ]]
+>0: [[ test.zsh = *.?(#c1,)sh ]]
+>0 tests failed.
+
+ globtest globtests.ksh
+0:ksh compatibility
+>0: [[ fofo = *(f*(o)) ]]
+>0: [[ ffo = *(f*(o)) ]]
+>0: [[ foooofo = *(f*(o)) ]]
+>0: [[ foooofof = *(f*(o)) ]]
+>0: [[ fooofoofofooo = *(f*(o)) ]]
+>1: [[ foooofof = *(f+(o)) ]]
+>1: [[ xfoooofof = *(f*(o)) ]]
+>1: [[ foooofofx = *(f*(o)) ]]
+>0: [[ ofxoofxo = *(*(of*(o)x)o) ]]
+>1: [[ ofooofoofofooo = *(f*(o)) ]]
+>0: [[ foooxfooxfoxfooox = *(f*(o)x) ]]
+>1: [[ foooxfooxofoxfooox = *(f*(o)x) ]]
+>0: [[ foooxfooxfxfooox = *(f*(o)x) ]]
+>0: [[ ofxoofxo = *(*(of*(o)x)o) ]]
+>0: [[ ofoooxoofxo = *(*(of*(o)x)o) ]]
+>0: [[ ofoooxoofxoofoooxoofxo = *(*(of*(o)x)o) ]]
+>0: [[ ofoooxoofxoofoooxoofxoo = *(*(of*(o)x)o) ]]
+>1: [[ ofoooxoofxoofoooxoofxofo = *(*(of*(o)x)o) ]]
+>0: [[ ofoooxoofxoofoooxoofxooofxofxo = *(*(of*(o)x)o) ]]
+>0: [[ aac = *(@(a))a@(c) ]]
+>0: [[ ac = *(@(a))a@(c) ]]
+>1: [[ c = *(@(a))a@(c) ]]
+>0: [[ aaac = *(@(a))a@(c) ]]
+>1: [[ baaac = *(@(a))a@(c) ]]
+>0: [[ abcd = ?@(a|b)*@(c)d ]]
+>0: [[ abcd = @(ab|a*@(b))*(c)d ]]
+>0: [[ acd = @(ab|a*(b))*(c)d ]]
+>0: [[ abbcd = @(ab|a*(b))*(c)d ]]
+>0: [[ effgz = @(b+(c)d|e*(f)g?|?(h)i@(j|k)) ]]
+>0: [[ efgz = @(b+(c)d|e*(f)g?|?(h)i@(j|k)) ]]
+>0: [[ egz = @(b+(c)d|e*(f)g?|?(h)i@(j|k)) ]]
+>0: [[ egzefffgzbcdij = *(b+(c)d|e*(f)g?|?(h)i@(j|k)) ]]
+>1: [[ egz = @(b+(c)d|e+(f)g?|?(h)i@(j|k)) ]]
+>0: [[ ofoofo = *(of+(o)) ]]
+>0: [[ oxfoxoxfox = *(oxf+(ox)) ]]
+>1: [[ oxfoxfox = *(oxf+(ox)) ]]
+>0: [[ ofoofo = *(of+(o)|f) ]]
+>0: [[ foofoofo = @(foo|f|fo)*(f|of+(o)) ]]
+>0: [[ oofooofo = *(of|oof+(o)) ]]
+>0: [[ fffooofoooooffoofffooofff = *(*(f)*(o)) ]]
+>1: [[ fffooofoooooffoofffooofffx = *(*(f)*(o)) ]]
+>0: [[ fofoofoofofoo = *(fo|foo) ]]
+>0: [[ foo = !(x) ]]
+>0: [[ foo = !(x)* ]]
+>1: [[ foo = !(foo) ]]
+>0: [[ foo = !(foo)* ]]
+>0: [[ foobar = !(foo) ]]
+>0: [[ foobar = !(foo)* ]]
+>0: [[ moo.cow = !(*.*).!(*.*) ]]
+>1: [[ mad.moo.cow = !(*.*).!(*.*) ]]
+>1: [[ mucca.pazza = mu!(*(c))?.pa!(*(z))? ]]
+>1: [[ _foo~ = _?(*[^~]) ]]
+>0: [[ fff = !(f) ]]
+>0: [[ fff = *(!(f)) ]]
+>0: [[ fff = +(!(f)) ]]
+>0: [[ ooo = !(f) ]]
+>0: [[ ooo = *(!(f)) ]]
+>0: [[ ooo = +(!(f)) ]]
+>0: [[ foo = !(f) ]]
+>0: [[ foo = *(!(f)) ]]
+>0: [[ foo = +(!(f)) ]]
+>1: [[ f = !(f) ]]
+>1: [[ f = *(!(f)) ]]
+>1: [[ f = +(!(f)) ]]
+>0: [[ foot = @(!(z*)|*x) ]]
+>1: [[ zoot = @(!(z*)|*x) ]]
+>0: [[ foox = @(!(z*)|*x) ]]
+>0: [[ zoox = @(!(z*)|*x) ]]
+>0: [[ foo = *(!(foo)) ]]
+>1: [[ foob = !(foo)b* ]]
+>0: [[ foobb = !(foo)b* ]]
+>0: [[ fooxx = (#i)FOOXX ]]
+>1: [[ fooxx = (#l)FOOXX ]]
+>0: [[ FOOXX = (#l)fooxx ]]
+>1: [[ fooxx = (#i)FOO@(#I)X@(#i)X ]]
+>0: [[ fooXx = (#i)FOO@(#I)X@(#i)X ]]
+>0: [[ fooxx = @((#i)FOOX)x ]]
+>1: [[ fooxx = @((#i)FOOX)X ]]
+>1: [[ BAR = @(bar|(#i)foo) ]]
+>0: [[ FOO = @(bar|(#i)foo) ]]
+>0: [[ Modules = (#i)*m* ]]
+>0 tests failed.
+
+ (unsetopt multibyte
+ [[ bj�rn = *[������]* ]])
+0:single byte match with top bit set
+
+ ( regress_absolute_path_and_core_dump )
+0:exclusions regression test
+>
+>glob.tmp/a glob.tmp/b glob.tmp/c glob.tmp/dir1 glob.tmp/dir1/a glob.tmp/dir1/b glob.tmp/dir1/c glob.tmp/dir2 glob.tmp/dir2/a glob.tmp/dir2/b glob.tmp/dir2/c glob.tmp/dir3 glob.tmp/dir3/subdir glob.tmp/dir4
+
+ print glob.tmp/*(/)
+0:Just directories
+>glob.tmp/dir1 glob.tmp/dir2 glob.tmp/dir3 glob.tmp/dir4
+
+ print glob.tmp/*(.)
+0:Just files
+>glob.tmp/a glob.tmp/b glob.tmp/c
+
+ print glob.tmp/*(.e^'reply=( glob.tmp/*/${REPLY:t} )'^:t)
+0:Globbing used recursively (inside e glob qualifier)
+>a a b b c c
+
+ print glob.tmp/*/*(e:'reply=( glob.tmp/**/*([1]) )'::t)
+0:Recursive globbing used recursively (inside e glob qualifier)
+>a a a a a a a
+
+ print glob.tmp/**/(:h)
+0:Head modifier
+>. glob.tmp glob.tmp glob.tmp glob.tmp glob.tmp/dir3
+
+ print glob.tmp(:r)
+0:Remove extension modifier
+>glob
+
+ print glob.tmp/*(:s/./_/)
+0:Substitute modifier
+>glob_tmp/a glob_tmp/b glob_tmp/c glob_tmp/dir1 glob_tmp/dir2 glob_tmp/dir3 glob_tmp/dir4
+
+ print glob.tmp/*(F)
+0:Just full dirs
+>glob.tmp/dir1 glob.tmp/dir2 glob.tmp/dir3
+
+ print glob.tmp/*(^F)
+0:Omit full dirs
+>glob.tmp/a glob.tmp/b glob.tmp/c glob.tmp/dir4
+
+ print glob.tmp/*(/^F)
+0:Just empty dirs
+>glob.tmp/dir4
+
+ setopt extendedglob
+ print glob.tmp/**/*~*/dir3(/*|(#e))(/)
+0:Exclusions with complicated path specifications
+>glob.tmp/dir1 glob.tmp/dir2 glob.tmp/dir4
+
+ print -l -- glob.tmp/*(P:-f:)
+0:Prepending words to each argument
+>-f
+>glob.tmp/a
+>-f
+>glob.tmp/b
+>-f
+>glob.tmp/c
+>-f
+>glob.tmp/dir1
+>-f
+>glob.tmp/dir2
+>-f
+>glob.tmp/dir3
+>-f
+>glob.tmp/dir4
+
+ print -l -- glob.tmp/*(P:one word:P:another word:)
+0:Prepending two words to each argument
+>one word
+>another word
+>glob.tmp/a
+>one word
+>another word
+>glob.tmp/b
+>one word
+>another word
+>glob.tmp/c
+>one word
+>another word
+>glob.tmp/dir1
+>one word
+>another word
+>glob.tmp/dir2
+>one word
+>another word
+>glob.tmp/dir3
+>one word
+>another word
+>glob.tmp/dir4
+
+ [[ "" = "" ]] && echo OK
+0:Empty strings
+>OK
+
+ foo="this string has a : colon in it"
+ print ${foo%% #:*}
+0:Must-match arguments in complex patterns
+>this string has a
+
+ mkdir glob.tmp/ra=1.0_et=3.5
+ touch glob.tmp/ra=1.0_et=3.5/foo
+ print glob.tmp/ra=1.0_et=3.5/???
+0:Bug with intermediate paths with plain strings but tokenized characters
+>glob.tmp/ra=1.0_et=3.5/foo
+
+ doesmatch() {
+ setopt localoptions extendedglob
+ print -n $1 $2\
+ if [[ $1 = $~2 ]]; then print yes; else print no; fi;
+ }
+ doesmatch MY_IDENTIFIER '[[:IDENT:]]##'
+ doesmatch YOUR:IDENTIFIER '[[:IDENT:]]##'
+ IFS=$'\n' doesmatch $'\n' '[[:IFS:]]'
+ IFS=' ' doesmatch $'\n' '[[:IFS:]]'
+ IFS=':' doesmatch : '[[:IFSSPACE:]]'
+ IFS=' ' doesmatch ' ' '[[:IFSSPACE:]]'
+ WORDCHARS="" doesmatch / '[[:WORD:]]'
+ WORDCHARS="/" doesmatch / '[[:WORD:]]'
+0:Named character sets handled internally
+>MY_IDENTIFIER [[:IDENT:]]## yes
+>YOUR:IDENTIFIER [[:IDENT:]]## no
+>
+> [[:IFS:]] yes
+>
+> [[:IFS:]] no
+>: [[:IFSSPACE:]] no
+> [[:IFSSPACE:]] yes
+>/ [[:WORD:]] no
+>/ [[:WORD:]] yes
+
+ [[ foo = (#c0)foo ]]
+2:Misplaced (#c...) flag
+?(eval):1: bad pattern: (#c0)foo
+
+ mkdir glob.tmp/dir5
+ touch glob.tmp/dir5/N123
+ print glob.tmp/dir5/N<->(N)
+ rm -rf glob.tmp/dir5
+0:Numeric glob is not usurped by process substitution.
+>glob.tmp/dir5/N123
+
+ tpd() {
+ [[ $1 = $~2 ]]
+ print -r "$1, $2: $?"
+ }
+ test_pattern_disables() {
+ emulate -L zsh
+ tpd 'forthcoming' 'f*g'
+ disable -p '*'
+ tpd 'forthcoming' 'f*g'
+ tpd 'f*g' 'f*g'
+ tpd '[frog]' '[frog]'
+ tpd '[frog]' '\[[f]rog\]'
+ disable -p '['
+ tpd '[frog]' '[frog]'
+ tpd '[frog]' '\[[f]rog\]'
+ setopt extendedglob
+ tpd 'foo' '^bar'
+ disable -p '^'
+ tpd 'foo' '^bar'
+ tpd '^bar' '^bar'
+ tpd 'rumble' '(rumble|bluster)'
+ tpd '(thunder)' '(thunder)'
+ disable -p '('
+ tpd 'rumble' '(rumble|bluster)'
+ tpd '(thunder)' '(thunder)'
+ setopt kshglob
+ tpd 'scramble' '@(panic|frenzy|scramble)'
+ tpd '@(scrimf)' '@(scrimf)'
+ disable -p '@('
+ tpd 'scramble' '@(panic|frenzy|scramble)'
+ tpd '@(scrimf)' '@(scrimf)'
+ disable -p
+ }
+ test_pattern_disables
+ print Nothing should be disabled.
+ disable -p
+0:disable -p
+>forthcoming, f*g: 0
+>forthcoming, f*g: 1
+>f*g, f*g: 0
+>[frog], [frog]: 1
+>[frog], \[[f]rog\]: 0
+>[frog], [frog]: 0
+>[frog], \[[f]rog\]: 1
+>foo, ^bar: 0
+>foo, ^bar: 1
+>^bar, ^bar: 0
+>rumble, (rumble|bluster): 0
+>(thunder), (thunder): 1
+>rumble, (rumble|bluster): 1
+>(thunder), (thunder): 0
+>scramble, @(panic|frenzy|scramble): 0
+>@(scrimf), @(scrimf): 1
+>scramble, @(panic|frenzy|scramble): 1
+>@(scrimf), @(scrimf): 0
+>'(' '*' '[' '^' '@('
+>Nothing should be disabled.
+
+ (
+ setopt nomatch
+ x=( '' )
+ print $^x(N)
+ )
+0:No error with empty null glob with (N).
+>
+
+ (setopt kshglob
+ test_array=(
+ '+fours' '+*'
+ '@titude' '@*'
+ '!bang' '!*'
+ # and check they work in the real kshglob cases too...
+ '+bus+bus' '+(+bus|-car)'
+ '@sinhats' '@(@sinhats|wrensinfens)'
+ '!kerror' '!(!somethingelse)'
+ # and these don't match, to be sure
+ '+more' '+(+less)'
+ '@all@all' '@(@all)'
+ '!goesitall' '!(!goesitall)'
+ )
+ for str pat in $test_array; do
+ eval "[[ $str = $pat ]]" && print "$str matches $pat"
+ done
+ true
+ )
+0:kshglob option does not break +, @, ! without following open parenthesis
+>+fours matches +*
+>@titude matches @*
+>!bang matches !*
+>+bus+bus matches +(+bus|-car)
+>@sinhats matches @(@sinhats|wrensinfens)
+>!kerror matches !(!somethingelse)
+
+ (
+ setopt extendedglob
+ cd glob.tmp
+ [[ -n a*(#qN) ]] && print File beginning with a
+ [[ -z z*(#qN) ]] && print No file beginning with z
+ setopt nonomatch
+ [[ -n z*(#q) ]] && print Normal string if nullglob not set
+ )
+0:Force glob expansion in conditions using (#q)
+>File beginning with a
+>No file beginning with z
+>Normal string if nullglob not set
+
+ (){ print $#@ } glob.tmp/dir*(Y1)
+ (){ print $#@ } glob.tmp/file*(NY1)
+ (){ [[ "$*" == */dir?\ */dir? ]] && print Returns matching filenames } glob.tmp/dir*(Y2)
+ (){ print "Limit is upper bound:" ${(o)@:t} } glob.tmp/dir*(Y5)
+ (){ print "Negated:" $@:t } glob.tmp/dir*(Y1^Y)
+ (){ print "Sorting:" $@:t } glob.tmp/dir*(Y4On)
+ (){ [[ $#@ -eq 1 ]] && print Globs before last path component } glob.tmp/dir?/subdir(NY1)
+ (){ [[ $1 == glob.tmp/a ]] } glob.tmp/**/a(Y1) && print Breadth first
+ (){ [[ $#@ -eq 0 ]] && print Respects qualifiers } glob.tmp/dir*(NY1.)
+ (print -- *(Y)) 2>/dev/null || print "Argument required"
+0:short-circuit modifier
+>1
+>0
+>Returns matching filenames
+>Limit is upper bound: dir1 dir2 dir3 dir4
+>Negated: dir1 dir2 dir3 dir4
+>Sorting: dir4 dir3 dir2 dir1
+>Globs before last path component
+>Breadth first
+>Respects qualifiers
+>Argument required
+
+ [[ "ce fichier n'existe pas" = (#b)ce\ (f[^ ]#)\ *s(#q./) ]]
+ print $match[1]
+0:(#q) is ignored completely in conditional pattern matching
+>fichier
+
+# The following should not cause excessive slowdown.
+ print glob.tmp/*.*
+ print glob.tmp/**************************.*************************
+0:Optimisation to squeeze multiple *'s used as ordinary glob wildcards.
+>glob.tmp/ra=1.0_et=3.5
+>glob.tmp/ra=1.0_et=3.5
+
+ [[ 1_2_ = (*_)(#c1) ]] && print 1 OK # because * matches 1_2
+ [[ 1_2_ = (*_)(#c2) ]] && print 2 OK
+ [[ 1_2_ = (*_)(#c3) ]] || print 3 OK
+0:Some more complicated backtracking with match counts.
+>1 OK
+>2 OK
+>3 OK
+
+ [[ foo = 'f'\o"o" ]]
+0:Stripping of quotes from patterns (1)
+
+ [[ foo = 'f'('o'|'a')('o'|'b') ]]
+0:Stripping of quotes from patterns (2)
+
+ [[ fob = 'f'('o'|'a')('o'|'b') ]]
+0:Stripping of quotes from patterns (3)
+
+ [[ fab = 'f'('o'|'a')('o'|'b') ]]
+0:Stripping of quotes from patterns (4)
+
+ [[ fib != 'f'('o'|'a')('o'|'b') ]]
+0:Stripping of quotes from patterns (4)
+
+ [[ - != [a-z] ]]
+0:- is a special character in ranges
+
+ [[ - = ['a-z'] ]]
+0:- is not a special character in ranges if quoted
+
+ [[ b-1 = [a-z]-[0-9] ]]
+0:- untokenized following a bracketed subexpression
+
+ [[ b-1 = []a-z]-[]0-9] ]]
+0:- "]" after "[" is normal range character and - still works
+
+ headremove="bcdef"
+ print ${headremove#[a-z]}
+0:active - works in pattern in parameter
+>cdef
+
+ headremove="bcdef"
+ print ${headremove#['a-z']}
+ headremove="-cdef"
+ print ${headremove#['a-z']}
+0:quoted - works in pattern in parameter
+>bcdef
+>cdef
+
+ [[ a != [^a] ]]
+0:^ active in character class if not quoted
+
+ [[ a = ['^a'] ]]
+0:^ not active in character class if quoted
+
+ [[ a != [!a] ]]
+0:! active in character class if not quoted
+
+ [[ a = ['!a'] ]]
+0:! not active in character class if quoted
+
+ # Actually, we don't need the quoting here,
+ # c.f. the next test. This just makes it look
+ # more standard.
+ cset="^a-z"
+ [[ "^" = ["$cset"] ]] || print Fail 1
+ [[ "a" = ["$cset"] ]] || print Fail 2
+ [[ "-" = ["$cset"] ]] || print Fail 3
+ [[ "z" = ["$cset"] ]] || print Fail 4
+ [[ "1" != ["$cset"] ]] || print Fail 5
+ [[ "b" != ["$cset"] ]] || print Fail 6
+0:character set specified as quoted variable
+
+ cset="^a-z"
+ [[ "^" = [$~cset] ]] || print Fail 1
+ [[ "a" != [$~cset] ]] || print Fail 2
+ [[ "-" = [$~cset] ]] || print Fail 3
+ [[ "z" != [$~cset] ]] || print Fail 4
+ [[ "1" = [$~cset] ]] || print Fail 5
+ [[ "b" != [$~cset] ]] || print Fail 6
+0:character set specified as active variable
+
+ () { print -l -- $@:a } / /..{,/} /1 /nonexistent/..{,/} /deeper/nonexistent/..{,/}
+0:modifier ':a' doesn't require existence
+>/
+>/
+>/
+>/1
+>/
+>/
+>/deeper
+>/deeper
+
+ () { set -- ${PWD}/$^@; print -l -- $@:A } glob.tmp/nonexistent/foo/bar/baz
+0:modifier ':A' doesn't require existence
+*>*/glob.tmp/nonexistent/foo/bar/baz
+
+ ln -s dir3/subdir glob.tmp/link
+ () {
+ print ${1:A} | grep glob.tmp
+ } glob.tmp/link/../../hello
+ rm glob.tmp/link
+0:modifier ':A' resolves '..' components before symlinks
+# There should be no output
+
+ ln -s dir3/subdir glob.tmp/link
+ () {
+ print ${1:P}
+ } glob.tmp/link/../../hello/world
+ rm glob.tmp/link
+0:modifier ':P' resolves symlinks before '..' components
+*>*glob.tmp/hello/world
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D03procsubst.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D03procsubst.ztst
new file mode 100644
index 0000000..ca8d56f
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D03procsubst.ztst
@@ -0,0 +1,151 @@
+# Tests for process substitution: <(...), >(...) and =(...).
+
+%prep
+ if grep '#define PATH_DEV_FD' $ZTST_testdir/../config.h > /dev/null 2>&1 ||
+ grep '#define HAVE_FIFOS' $ZTST_testdir/../config.h > /dev/null 2>&1; then
+ mkdir procsubst.tmp
+ cd procsubst.tmp
+ print 'First\tSecond\tThird\tFourth' >FILE1
+ print 'Erste\tZweite\tDritte\tVierte' >FILE2
+ else
+ ZTST_unimplemented="process substitution is not supported"
+ true
+ fi
+
+ function copycat { cat "$@" }
+
+%test
+ paste <(cut -f1 FILE1) <(cut -f3 FILE2)
+0:<(...) substitution
+>First Dritte
+
+# slightly desperate hack to force >(...) to be synchronous
+ { paste <(cut -f2 FILE1) <(cut -f4 FILE2) } > >(sed 's/e/E/g' >OUTFILE)
+ cat OUTFILE
+0:>(...) substitution
+>SEcond ViErtE
+
+ diff =(cat FILE1) =(cat FILE2)
+1:=(...) substituion
+>1c1
+>< First Second Third Fourth
+>---
+>> Erste Zweite Dritte Vierte
+
+ copycat <(print First) <(print Zweite)
+0:FDs remain open for external commands called from functions
+>First
+>Zweite
+
+ catfield2() {
+ local -a args
+ args=(${(s.,.)1})
+ print $args[1]
+ cat $args[2]
+ print $args[3]
+ }
+ catfield2 up,<(print $'\x64'own),sideways
+0:<(...) when embedded within an argument
+>up
+>down
+>sideways
+
+ outputfield2() {
+ local -a args
+ args=(${(s.,.)1})
+ print $args[1]
+ echo 'How sweet the moonlight sits upon the bank' >$args[2]
+ print $args[3]
+ }
+ outputfield2 muddy,>(sed -e s/s/th/g >outputfield2.txt),vesture
+ # yuk
+ while [[ ! -e outputfield2.txt || ! -s outputfield2.txt ]]; do :; done
+ cat outputfield2.txt
+0:>(...) when embedded within an argument
+>muddy
+>vesture
+>How thweet the moonlight thitth upon the bank
+
+ catfield1() {
+ local -a args
+ args=(${(s.,.)1})
+ cat $args[1]
+ print $args[2]
+ }
+ catfield1 =(echo s$'\x69't),jessica
+0:=(...) followed by something else without a break
+>sit
+>jessica
+
+ (
+ setopt nonomatch
+ # er... why is this treated as a glob?
+ print everything,=(here is left),alone
+ )
+0:=(...) preceded by other stuff has no special effect
+>everything,=(here is left),alone
+
+ print something=${:-=(echo 'C,D),(F,G)'}
+1: Graceful handling of bad substitution in enclosed context
+?(eval):1: unterminated `=(...)'
+# '`
+
+ () {
+ print -n "first: "
+ cat $1
+ print -n "second: "
+ cat $2
+ } =(echo This becomes argument one) =(echo and this argument two)
+ function {
+ print -n "third: "
+ cat $1
+ print -n "fourth: "
+ cat $2
+ } =(echo This becomes argument three) =(echo and this argument four)
+0:Process environment of anonymous functions
+>first: This becomes argument one
+>second: and this argument two
+>third: This becomes argument three
+>fourth: and this argument four
+
+ () {
+ # Make sure we don't close the file descriptor too early
+ eval 'print "Execute a complicated command first" | sed s/command/order/'
+ cat $1
+ } <(echo This line was brought to you by the letters F and D)
+0:Process substitution as anonymous function argument
+>Execute a complicated order first
+>This line was brought to you by the letters F and D
+
+ alias foo='cat <('
+ eval 'foo echo this is bound to work)'
+0:backtacking within command string parsing with alias still pending
+>this is bound to work
+
+ alias foo='cat <( print'
+ eval 'foo here is some output)'
+0:full alias expanded when substitution starts in alias
+>here is some output
+
+ if ! (mkfifo test_pipe >/dev/null 2>&1); then
+ ZTST_skip="mkfifo not available"
+ else
+ echo 1 | tee >(cat > test_pipe) | (){
+ local pipein
+ read pipein 1
+>1
+
+ if [[ ! -e test_pipe ]]; then
+ ZTST_skip="mkfifo not available"
+ else
+ echo 1 | tee >(cat > test_pipe) | paste - test_pipe
+ fi
+0:proc subst fd in forked subshell closed in parent (external command)
+>1 1
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D04parameter.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D04parameter.ztst
new file mode 100644
index 0000000..9128c3c
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D04parameter.ztst
@@ -0,0 +1,2058 @@
+# Test parameter expansion. Phew.
+# (By the way, did I say "phew"?)
+
+%prep
+
+ mkdir parameter.tmp
+
+ cd parameter.tmp
+
+ touch boringfile evenmoreboringfile
+
+%test
+
+ foo='the first parameter'
+ bar='the second parameter'
+ print -l $foo ${bar}
+0:Basic scalar parameter substitution
+>the first parameter
+>the second parameter
+
+ array1=(the first array)
+ array2=(the second array)
+ print -l $array1 ${array2}
+0:Basic array parameter substitution
+>the
+>first
+>array
+>the
+>second
+>array
+
+ setopt ksharrays
+ print -l $array1 ${array2}
+ unsetopt ksharrays
+0:Basic ksharray substitution
+>the
+>the
+
+ setopt shwordsplit
+ print -l $foo ${bar}
+ print -l ${==bar}
+ unsetopt shwordsplit
+0:Basic shwordsplit option handling
+>the
+>first
+>parameter
+>the
+>second
+>parameter
+>the second parameter
+
+ print $+foo ${+foo} $+notappearinginthistest ${+notappearinginthistest}
+0:$+...
+>1 1 0 0
+
+ x=()
+ print ${+x} ${+x[1]} ${+x[(r)foo]} ${+x[(r)bar]}
+ x=(foo)
+ print ${+x} ${+x[1]} ${+x[(r)foo]} ${+x[(r)bar]}
+0:$+... with arrays
+>1 0 0 0
+>1 1 1 0
+
+ set1=set1v
+ null1=
+ print ${set1:-set1d} ${set1-set2d} ${null1:-null1d} ${null1-null2d} x
+ print ${unset1:-unset1d} ${unset1-unset2d} x
+0:${...:-...} and ${...-...}
+>set1v set1v null1d x
+>unset1d unset2d x
+
+ set2=irrelevant
+ print ${set1:=set1d} ${set2::=set2d}
+ print $set2
+ wasnull1=
+ wasnull2=
+ print ${wasnull1=wasnull1d} ${wasnull2:=wasnull2d}
+ print $wasnull1 $wasnull2
+0:${...:=...}, ${...::=...}, ${...=...}
+>set1v set2d
+>set2d
+>wasnull2d
+>wasnull2d
+
+ unset array
+ print ${#${(A)=array=word}}
+0:${#${(A)=array=word}} counts array elements
+>1
+
+ (print ${set1:?okhere}; print ${unset1:?exiting1}; print not reached;)
+ (print ${null1?okhere}; print ${null1:?exiting2}; print not reached;)
+1:${...:?...}, ${...?...}
+>set1v
+>
+?(eval):1: unset1: exiting1
+?(eval):2: null1: exiting2
+
+ PROMPT="" $ZTST_testdir/../Src/zsh -fis <<<'
+ unsetopt PROMPT_SP
+ PS1="" PS2="" PS3="" PS4="" RPS1="" RPS2=""
+ exec 2>&1
+ foo() {
+ print ${1:?no arguments given}
+ print not reached
+ }
+ foo
+ print reached
+ ' 2>/dev/null
+0:interactive shell returns to top level on ${...?...} error
+*>*foo:1: 1: no arguments given
+>reached
+
+ print ${set1:+word1} ${set1+word2} ${null1:+word3} ${null1+word4}
+ print ${unset1:+word5} ${unset1+word6}
+0:${...:+...}, ${...+...}
+>word1 word2 word4
+>
+
+ str1='This is very boring indeed.'
+ print ${str1#*s}
+ print ${str1##*s}
+ print $str1##s
+0:${...#...}, ${...##...}
+> is very boring indeed.
+> very boring indeed.
+>This is very boring indeed.##s
+
+ str2='If you'\''re reading this you should go and fix some bugs instead.'
+ print ${str2%d*}
+ print ${str2%%d*}
+0:${...%...}, ${...%%...}
+>If you're reading this you should go and fix some bugs instea
+>If you're rea
+
+ str1='does match'
+ str2='does not match'
+ print ${str1:#does * match}
+ print ${str2:#does * match}
+0:${...:#...}
+>does match
+>
+
+ array1=(arthur boldly claws dogs every fight)
+ print ${array1:#[aeiou]*}
+ print ${(M)array1:#[aeiou]*}
+0:${...:#...}, ${(M)...:#...} with array
+>boldly claws dogs fight
+>arthur every
+
+ str1="$array1"
+ print ${str1/[aeiou]*g/a braw bricht moonlicht nicht the nic}
+ print ${(S)str1/[aeiou]*g/relishe}
+0:scalar ${.../.../...}, ${(S).../.../...}
+>a braw bricht moonlicht nicht the nicht
+>relishes every fight
+
+ print ${array1/[aeiou]*/Y}
+ print ${(S)array1/[aeiou]*/Y}
+0:array ${.../.../...}, ${(S).../.../...}
+>Y bY clY dY Y fY
+>Yrthur bYldly clYws dYgs Yvery fYght
+
+ str1='o this is so, so so very dull'
+ print ${str1//o*/Please no}
+ print ${(S)str1//o*/Please no}
+0:scalar ${...//.../...}, ${(S)...//.../...}
+>Please no
+>Please no this is sPlease no, sPlease no sPlease no very dull
+
+ print ${array1//[aeiou]*/Y}
+ print ${(S)array1//[aeiou]*/Y}
+0:array ${...//.../...}, ${(S)...//.../...}
+>Y bY clY dY Y fY
+>YrthYr bYldly clYws dYgs YvYry fYght
+
+ print ${array1:/[aeiou]*/expletive deleted}
+0:array ${...:/...}
+>expletive deleted boldly claws dogs expletive deleted fight
+
+ str1='a\string\with\backslashes'
+ str2='a/string/with/slashes'
+ print "${str1//\\/-}"
+ print ${str1//\\/-}
+ print "${str2//\//-}"
+ print ${str2//\//-}
+0:use of backslashes in //-substitutions
+>a-string-with-backslashes
+>a-string-with-backslashes
+>a-string-with-slashes
+>a-string-with-slashes
+
+ args=('one' '#foo' '(bar' "'three'" two)
+ mod=('#foo' '(bar' "'three'" sir_not_appearing_in_this_film)
+ print ${args:|mod}
+ print ${args:*mod}
+ print "${(@)args:|mod}"
+ print "${(@)args:*mod}"
+ args=(two words)
+ mod=('one word' 'two words')
+ print "${args:|mod}"
+ print "${args:*mod}"
+ scalar='two words'
+ print ${scalar:|mod}
+ print ${scalar:*mod}
+ print ${args:*nonexistent}
+ empty=
+ print ${args:*empty}
+0:"|" array exclusion and "*" array intersection
+>one two
+>#foo (bar 'three'
+>one two
+>#foo (bar 'three'
+>
+>two words
+>
+>two words
+>
+>
+
+ str1='twocubed'
+ array=(the number of protons in an oxygen nucleus)
+ print $#str1 ${#str1} "$#str1 ${#str1}" $#array ${#array} "$#array ${#array}"
+0:${#...}, $#...
+>8 8 8 8 8 8 8 8
+
+ set 1 2 3 4 5 6 7 8 9
+ print ${##}
+ set 1 2 3 4 5 6 7 8 9 10
+ print ${##}
+ print ${##""}
+ print ${##1}
+ print ${##2}
+ print ${###<->} # oh, for pete's sake...
+0:${##} is length of $#, and other tales of hash horror
+>1
+>2
+>10
+>0
+>10
+>
+
+ array=(once bitten twice shy)
+ print IF${array}THEN
+ print IF${^array}THEN
+0:basic ${^...}
+>IFonce bitten twice shyTHEN
+>IFonceTHEN IFbittenTHEN IFtwiceTHEN IFshyTHEN
+
+ # Quote ${array} here because {...,...} doesn't like unquoted spaces.
+ print IF{"${array}",THEN}ELSE
+ print IF{${^array},THEN}ELSE
+0:combined ${^...} and {...,...}
+>IFonce bitten twice shyELSE IFTHENELSE
+>IFonceELSE IFTHENELSE IFbittenELSE IFTHENELSE IFtwiceELSE IFTHENELSE IFshyELSE IFTHENELSE
+
+ str1='one word'
+ print -l $str1 ${=str1} "split ${=str1}wise"
+0:${=...}
+>one word
+>one
+>word
+>split one
+>wordwise
+
+ str1='*'
+ print $str1 ${~str1} $~str1
+ setopt globsubst
+ print $str1
+ unsetopt globsubst
+0:${~...} and globsubst
+>* boringfile evenmoreboringfile boringfile evenmoreboringfile
+>boringfile evenmoreboringfile
+
+# The following tests a bug where globsubst didn't preserve
+# backslashes when printing out the original string.
+ str1='\\*\\'
+ (
+ setopt globsubst nonomatch
+ [[ \\\\ = $str1 ]] && print -r '\\ matched by' $str1
+ [[ \\foo\\ = $str1 ]] && print -r '\\foo matched by' $str1
+ [[ a\\b\\ = $str1 ]] || print -r 'a\\b not matched by' $str1
+ )
+0:globsubst with backslashes
+>\\ matched by \\*\\
+>\\foo matched by \\*\\
+>a\\b not matched by \\*\\
+
+ (
+ setopt globsubst
+ foo="boring*"
+ print ${foo+$foo}
+ print ${foo+"$foo"}
+ print ${~foo+"$foo"}
+ )
+0:globsubst together with nested quoted expansion
+>boringfile
+>boring*
+>boringfile
+
+ print -l "${$(print one word)}" "${=$(print two words)}"
+0:splitting of $(...) inside ${...}
+>one word
+>two
+>words
+
+ (setopt shwordsplit # ensure this doesn't get set in main shell...
+ test_splitting ()
+ {
+ array="one two three"
+ for e in $array; do
+ echo "'$e'"
+ done
+ }
+ test_split_var=
+ echo _${test_split_var:=$(test_splitting)}_
+ echo "_${test_split_var}_")
+0:SH_WORD_SPLIT inside $(...) inside ${...}
+>_'one' 'two' 'three'_
+>_'one'
+>'two'
+>'three'_
+
+ print -l "${(f)$(print first line\\nsecond line\\nthird line)}"
+0:${(f)$(...)}
+>first line
+>second line
+>third line
+
+ array1=( uno )
+ print -l ${(A)newarray=splitting by numbers}
+ print -l ${(t)newarray}
+ print -l ${(A)=newarray::=splitting by spaces, actually}
+ print -l ${(t)newarray}
+ print -l ${(A)newarray::=$array1}
+ print -l ${(t)newarray}
+ print -l ${newarray::=$array1}
+ print -l ${(t)newarray}
+ print -l ${newarray::=$array2}
+ print -l ${(t)newarray}
+0:${(A)...=...}, ${(A)...::=...}, ${scalar=$array}
+>splitting by numbers
+>array
+>splitting
+>by
+>spaces,
+>actually
+>array
+>uno
+>array
+>uno
+>scalar
+>the second array
+>scalar
+
+ newarray=("split me" "split me" "I\'m yours")
+ print -l "${(@)newarray}"
+0:"${(@)...}"
+>split me
+>split me
+>I'm yours
+
+ foo='$(print Howzat usay)'
+ print -l ${(e)foo}
+0:${(e)...}
+>Howzat
+>usay
+
+ foo='`print Howzat usay`'
+ print -l ${(e)foo}
+0:Regress ${(e)...} with backticks (see zsh-workers/15871)
+>Howzat
+>usay
+
+ foo='\u65\123'
+ print -r ${(g:o:)foo}
+ foo='\u65\0123^X\C-x'
+ print -r ${(g::)foo}
+ foo='^X'
+ bar='\C-\130'
+ [[ ${(g:c:)foo} == ${(g:oe:)bar} ]]
+ echo $?
+0:${(g)...}
+>eS
+>eS^X\C-x
+>0
+
+ foo='I'\''m nearly out of my mind with tedium'
+ bar=foo
+ print ${(P)bar}
+0:${(P)...}
+>I'm nearly out of my mind with tedium
+#' deconfuse emacs
+
+ foo=(I could be watching that programme I recorded)
+ print ${(o)foo}
+ print ${(oi)foo}
+ print ${(O)foo}
+ print ${(Oi)foo}
+0:${(o)...}, ${(O)...}
+>I I be could programme recorded that watching
+>be could I I programme recorded that watching
+>watching that recorded programme could be I I
+>watching that recorded programme I I could be
+
+ foo=(yOU KNOW, THE ONE WITH wILLIAM dALRYMPLE)
+ bar=(doing that tour of India.)
+ print ${(L)foo}
+ print ${(U)bar}
+0:${(L)...}, ${(U)...}
+>you know, the one with william dalrymple
+>DOING THAT TOUR OF INDIA.
+
+ foo='instead here I am stuck by the computer'
+ print ${(C)foo}
+0:${(C)...}
+>Instead Here I Am Stuck By The Computer
+
+ foo=$'\x7f\x00'
+ print -r -- ${(V)foo}
+0:${(V)...}
+>^?^@
+
+ foo='playing '\''stupid'\'' "games" \w\i\t\h $quoting.'
+ print -r ${(q)foo}
+ print -r ${(qq)foo}
+ print -r ${(qqq)foo}
+ print -r ${(qqqq)foo}
+ print -r ${(q-)foo}
+0:${(q...)...}
+>playing\ \'stupid\'\ \"games\"\ \\w\\i\\t\\h\ \$quoting.
+>'playing '\''stupid'\'' "games" \w\i\t\h $quoting.'
+>"playing 'stupid' \"games\" \\w\\i\\t\\h \$quoting."
+>$'playing \'stupid\' "games" \\w\\i\\t\\h $quoting.'
+>'playing '\'stupid\'' "games" \w\i\t\h $quoting.'
+
+ print -r ${(qqqq):-""}
+0:workers/36551: literal empty string in ${(qqqq)...}
+>$''
+
+ x=( a '' '\b' 'c d' '$e' )
+ print -r ${(q)x}
+ print -r ${(q-)x}
+0:Another ${(q...)...} test
+>a '' \\b c\ d \$e
+>a '' '\b' 'c d' '$e'
+
+ print -r -- ${(q-):-foo}
+ print -r -- ${(q-):-foo bar}
+ print -r -- ${(q-):-"*(.)"}
+ print -r -- ${(q-):-"wow 'this is cool' or is it?"}
+ print -r -- ${(q-):-"no-it's-not"}
+0:${(q-)...} minimal single quoting
+>foo
+>'foo bar'
+>'*(.)'
+>'wow '\''this is cool'\'' or is it?'
+>no-it\'s-not
+
+ foo="'and now' \"even the pubs\" \\a\\r\\e shut."
+ print -r ${(Q)foo}
+0:${(Q)...}
+>and now even the pubs are shut.
+
+ foo="X$'\x41'$'\x42'Y"
+ print -r ${(Q)foo}
+0:${(Q)...} with handling of $'...'
+>XABY
+
+ # The following may look a bit random.
+ # For the split we are checking that anything that
+ # would normally be followed by a different word has
+ # an argument break after it and anything that wouldn't doesn't.
+ # For the (Q) we are simply checking that nothing disappears
+ # in the parsing.
+ foo=' {six} (seven) >eight< }nine{ |forty-two| $many$ )ten( more'
+ array=(${(z)foo})
+ print -l ${(Q)array}
+0:${(z)...} and ${(Q)...} for some hard to parse cases
+><
+>five
+>>
+>{six}
+>(
+>seven
+>)
+>>
+>eight
+><
+>}nine{
+>|
+>forty-two
+>|
+>$many$
+>)
+>ten( more
+
+ strings=(
+ 'foo=(1 2 3)'
+ '(( 3 + 1 == 8 / 2 ))'
+ 'for (( i = 1 ; i < 10 ; i++ ))'
+ '((0.25542 * 60) - 15)*60'
+ 'repeat 3 (x)'
+ 'repeat 3 (echo foo; echo bar)'
+ 'repeat $(( 2 + 4 )) (x)'
+ 'repeat $( : foo bar; echo 4) (x)'
+ 'repeat "1"'\''2'\''$(( 3 + 0 ))$((echo 4);)\ 5 (x)'
+ )
+ for string in $strings; do
+ array=(${(z)string})
+ for (( i = 1; i <= ${#array}; i++ )); do
+ print -r -- "${i}:${array[i]}:"
+ done
+ done
+0:Some syntactical expressions that are hard to split into words with (z).
+>1:foo=(:
+>2:1:
+>3:2:
+>4:3:
+>5:):
+>1:(( 3 + 1 == 8 / 2 )):
+>1:for:
+>2:((:
+# Leading whitespace is removed, because the word proper hasn't started;
+# trailing whitespace is left because the word is terminated by the
+# semicolon or double parentheses. Bit confusing but sort of consistent.
+>3:i = 1 ;:
+>4:i < 10 ;:
+>5:i++ :
+>6:)):
+# This one needs resolving between a math expression and
+# a command, which causes interesting effects internally.
+>1:(:
+>2:(:
+>3:0.25542:
+>4:*:
+>5:60:
+>6:):
+>7:-:
+>8:15:
+>9:):
+>10:*60:
+>1:repeat:
+>2:3:
+>3:(:
+>4:x:
+>5:):
+>1:repeat:
+>2:3:
+>3:(:
+>4:echo:
+>5:foo:
+>6:;:
+>7:echo:
+>8:bar:
+>9:):
+>1:repeat:
+>2:$(( 2 + 4 )):
+>3:(:
+>4:x:
+>5:):
+>1:repeat:
+>2:$( : foo bar; echo 4):
+>3:(:
+>4:x:
+>5:):
+>1:repeat:
+>2:"1"'2'$(( 3 + 0 ))$((echo 4);)\ 5:
+>3:(:
+>4:x:
+>5:):
+
+
+ line=$'A line with # someone\'s comment\nanother line # (1 more\nanother one'
+ print "*** Normal ***"
+ print -l ${(z)line}
+ print "*** Kept ***"
+ print -l ${(Z+c+)line}
+ print "*** Removed ***"
+ print -l ${(Z+C+)line}
+0:Comments with (z)
+>*** Normal ***
+>A
+>line
+>with
+>#
+>someone's comment
+>another line # (1 more
+>another one
+>*** Kept ***
+>A
+>line
+>with
+># someone's comment
+>;
+>another
+>line
+># (1 more
+>;
+>another
+>one
+>*** Removed ***
+>A
+>line
+>with
+>;
+>another
+>line
+>;
+>another
+>one
+
+ line='with comment # at the end'
+ print -l ${(Z+C+)line}
+0:Test we don't get an additional newline token
+>with
+>comment
+
+ line=$'echo one\necho two # with a comment\necho three'
+ print -l ${(Z+nc+)line}
+0:Treating zplit newlines as ordinary whitespace
+>echo
+>one
+>echo
+>two
+># with a comment
+>echo
+>three
+
+ print -rl - ${(z):-":;(( echo 42 "}
+0:${(z)} with incomplete math expressions
+>:
+>;
+>(( echo 42
+
+ # From parse error on it's not possible to split.
+ # Just check we get the complete string.
+ foo='echo $(|||) bar'
+ print -rl ${(z)foo}
+0:$($(z)} with parse error in command substitution.
+>echo
+>$(|||) bar
+
+ psvar=(dog)
+ setopt promptsubst
+ foo='It shouldn'\''t $(happen) to a %1v.'
+ bar='But `echo what can you do\?`'
+ print -r ${(%)foo}
+ print -r ${(%%)bar}
+0:${(%)...}
+>It shouldn't $(happen) to a dog.
+>But what can you do?
+
+ foo='unmatched "'
+ print ${(QX)foo}
+1:${(QX)...}
+?(eval):2: unmatched "
+# " deconfuse emacs
+
+ array=(characters in an array)
+ print ${(c)#array}
+0:${(c)#...}
+>22
+
+ print ${(w)#array}
+ str='colon::bolon::solon'
+ print ${(ws.:.)#str}
+ print ${(Ws.:.)#str}
+0:${(w)...}, ${(W)...}
+>4
+>3
+>5
+
+ typeset -A assoc
+ assoc=(key1 val1 key2 val2)
+ print ${(o)assoc}
+ print ${(ok)assoc}
+ print ${(ov)assoc}
+ print ${(okv)assoc}
+0:${(k)...}, ${(v)...}
+>val1 val2
+>key1 key2
+>val1 val2
+>key1 key2 val1 val2
+
+ word="obfuscatory"
+ print !${(l.16.)word}! +${(r.16.)word}+
+0:simple padding
+>! obfuscatory! +obfuscatory +
+
+ foo=(resulting words uproariously padded)
+ print ${(pl.10..\x22..X.)foo}
+0:${(pl...)...}
+>Xresulting """"Xwords roariously """Xpadded
+#" deconfuse emacs
+
+ print ${(l.5..X.r.5..Y.)foo}
+ print ${(l.6..X.r.4..Y.)foo}
+ print ${(l.7..X.r.3..Y.)foo}
+ print ${(l.6..X..A.r.6..Y..B.)foo}
+ print ${(l.6..X..AROOGA.r.6..Y..BARSOOM.)foo}
+0:simultaneous left and right padding
+>Xresulting XXXwordsYY proariousl XXpaddedYY
+>XXresultin XXXXwordsY uproarious XXXpaddedY
+>XXXresulti XXXXXwords Xuproariou XXXXpadded
+>XAresultingB XXXAwordsBYY uproariously XXApaddedBYY
+>GAresultingB OOGAwordsBAR uproariously OGApaddedBAR
+
+ foo=(why in goodness name am I doing this)
+ print ${(r.5..!..?.)foo}
+0:${(r...)...}
+>why?! in?!! goodn name? am?!! I?!!! doing this?
+
+ array=(I\'m simply putting a brave face on)
+ print ${(j:--:)array}
+0:${(j)...}
+>I'm--simply--putting--a--brave--face--on
+
+ print ${(F)array}
+0:${(F)...}
+>I'm
+>simply
+>putting
+>a
+>brave
+>face
+>on
+
+ string='zometimez zis getz zplit on a z'
+ print -l ${(s?z?)string}
+0:${(s...)...}
+>ometime
+>
+>is get
+>
+>plit on a
+
+ str=s
+ arr=(a)
+ typeset -A ass
+ ass=(a a)
+ integer i
+ float f
+ print ${(t)str} ${(t)arr} ${(t)ass} ${(t)i} ${(t)f}
+0:${(t)...}
+>scalar array association-local integer-local float-local
+
+ # it's not quite clear that these are actually right unless you know
+ # the algorithm: search along the string for the point at which the
+ # first (last) match occurs, for ## (%%), then take the shortest possible
+ # version of that for # (%). it's as good a definition as anything.
+ string='where is the white windmill, whispered walter wisely'
+ print ${(S)string#h*e}
+ print ${(S)string##h*e}
+ print ${(S)string%h*e}
+ print ${(S)string%%h*e}
+0:${(S)...#...} etc.
+>wre is the white windmill, whispered walter wisely
+>wly
+>where is the white windmill, wred walter wisely
+>where is the white windmill, wly
+
+ setopt extendedglob
+ print ${(SI:1:)string##w[^[:space:]]# }
+ print ${(SI:1+1:)string##w[^[:space:]]# }
+ print ${(SI:1+1+1:)string##w[^[:space:]]# }
+ print ${(SI:1+1+1+1:)string##w[^[:space:]]# }
+0:${(I:...:)...}
+>is the white windmill, whispered walter wisely
+>where is the windmill, whispered walter wisely
+>where is the white whispered walter wisely
+>where is the white windmill, walter wisely
+
+ print ${(MSI:1:)string##w[^[:space:]]# }
+0:${(M...)...}
+>where
+
+ print ${(R)string//w[a-z]# #}
+0:${(R)...}
+>is the ,
+
+ # This (1) doesn't work with // or /
+ # (2) perhaps ought to be 18, to be consistent with normal zsh
+ # substring indexing and with backreferences.
+ print ${(BES)string##white}
+0:${(BE...)...}
+>14 19
+
+ print ${(NS)string##white}
+0:${(N)...}
+>5
+
+ string='abcdefghijklmnopqrstuvwxyz'
+ print ${${string%[aeiou]*}/(#m)?(#e)/${(U)MATCH}}
+0:Rule 1: Nested substitutions
+>abcdefghijklmnopqrsT
+
+ array=(et Swann avec cette muflerie intermittente)
+ string="qui reparaissait chez lui"
+ print ${array[4,5]}
+ print ${array[4,5][1]}
+ print ${array[4,5][1][2,3]}
+ print ${string[4,5]}
+ print ${string[4,5][1]}
+0:Rule 2: Parameter subscripting
+>cette muflerie
+>cette
+>et
+> r
+>
+
+ foo=stringalongamax
+ print ${${(P)foo[1,6]}[1,3]}
+0:Rule 3: Parameter Name Replacement
+>qui
+
+ print "${array[5,6]}"
+ print "${(j.:.)array[1,2]}"
+0:Rule 4: Double-Quoted Joining
+>muflerie intermittente
+>et:Swann
+
+ print "${${array}[5,7]}"
+ print "${${(@)array}[1,2]}"
+0:Rule 5: Nested Subscripting
+>wan
+>et Swann
+
+ print "${${(@)array}[1,2]#?}"
+ print "${(@)${(@)array}[1,2]#?}"
+0:Rule 6: Modifiers
+>t Swann
+>t wann
+
+ array=(she sells z shells by the z shore)
+ (IFS='+'; print ${(s.s.)array})
+0:Rule 7: Forced Joining, and 8: Forced splitting
+>he+ ell +z+ hell +by+the+z+ hore
+
+ setopt shwordsplit
+ string='another poxy boring string'
+ print -l ${${string}/o/ }
+ unsetopt shwordsplit
+0:Rule 9: Shell Word Splitting
+>an
+>ther
+>p
+>xy
+>b
+>ring
+>string
+
+ setopt nonomatch
+ foo='b* e*'
+ print ${(e)~foo}
+ print ${(e)~=foo}
+ setopt nomatch
+0:Rule 10: Re-Evaluation
+>b* e*
+>boringfile evenmoreboringfile
+
+ # ${bar} -> $bar here would yield "bad substitution".
+ bar=confinement
+ print ${(el.20..X.)${bar}}
+0:Rule 11: Padding
+>XXXXXXXXXconfinement
+
+ foo=(bar baz)
+ bar=(ax1 bx1)
+ print "${(@)${foo}[1]}"
+ print "${${(@)foo}[1]}"
+ print -l ${(s/x/)bar}
+ print -l ${(j/x/s/x/)bar}
+ print -l ${(s/x/)bar%%1*}
+0:Examples in manual on parameter expansion
+>b
+>bar
+>a
+>1 b
+>1
+>a
+>1
+>b
+>1
+>a
+> b
+
+ set If "this test fails" "we have broken" the shell again
+ print -l ${1+"$@"}
+0:Regression test of ${1+"$@"} bug
+>If
+>this test fails
+>we have broken
+>the
+>shell
+>again
+
+ set If "this test fails" "we have broken" the shell again
+ print -l "${(A)foo::=$@}"
+ print -l ${(t)foo}
+ print -l $foo
+0:Regression test of "${(A)foo=$@}" bug
+>If this test fails we have broken the shell again
+>array
+>If
+>this test fails
+>we have broken
+>the
+>shell
+>again
+
+ local sure_that='sure that' varieties_of='varieties of' one=1 two=2
+ extra=(5 4 3)
+ unset foo
+ set Make $sure_that "this test keeps" on 'preserving all' "$varieties_of" quoted whitespace
+ print -l ${=1+"$@"}
+ print -l ${(A)=foo=Make $sure_that "this test keeps" on 'preserving all' "$varieties_of" quoted whitespace}
+ print ${(t)foo}
+ print -l ${=1+$one $two}
+ print -l ${1+$extra$two$one}
+0:Regression test of ${=1+"$@"} bug and some related expansions
+>Make
+>sure that
+>this test keeps
+>on
+>preserving all
+>varieties of
+>quoted
+>whitespace
+>Make
+>sure
+>that
+>this test keeps
+>on
+>preserving all
+>varieties of
+>quoted
+>whitespace
+>array
+>1
+>2
+>5
+>4
+>321
+
+ splitfn() {
+ emulate -L sh
+ local HOME="/differs from/bash" foo='1 2' bar='3 4'
+ print -l ${1:-~}
+ touch has\ space
+ print -l ${1:-*[ ]*}
+ print -l ${1:-*[\ ]*}
+ print -l ${1:-*}
+ print -l ${1:-"$foo" $bar}
+ print -l ${==1:-$foo $bar}
+ rm has\ space
+ }
+ splitfn
+0:More bourne-shell-compatible nested word-splitting with wildcards and ~
+>/differs from/bash
+>*[
+>]*
+>has space
+>boringfile
+>evenmoreboringfile
+>has space
+>1 2
+>3
+>4
+>1 2 3 4
+
+ splitfn() {
+ local IFS=.-
+ local foo=1-2.3-4
+ #
+ print "Called with argument '$1'"
+ print "No quotes"
+ print -l ${=1:-1-2.3-4} ${=1:-$foo}
+ print "With quotes on default argument only"
+ print -l ${=1:-"1-2.3-4"} ${=1:-"$foo"}
+ }
+ print 'Using "="'
+ splitfn
+ splitfn 5.6-7.8
+ #
+ splitfn() {
+ emulate -L zsh
+ setopt shwordsplit
+ local IFS=.-
+ local foo=1-2.3-4
+ #
+ print "Called with argument '$1'"
+ print "No quotes"
+ print -l ${1:-1-2.3-4} ${1:-$foo}
+ print "With quotes on default argument only"
+ print -l ${1:-"1-2.3-4"} ${1:-"$foo"}
+ }
+ print Using shwordsplit
+ splitfn
+ splitfn 5.6-7.8
+0:Test of nested word splitting with and without quotes
+>Using "="
+>Called with argument ''
+>No quotes
+>1
+>2
+>3
+>4
+>1
+>2
+>3
+>4
+>With quotes on default argument only
+>1-2.3-4
+>1-2.3-4
+>Called with argument '5.6-7.8'
+>No quotes
+>5
+>6
+>7
+>8
+>5
+>6
+>7
+>8
+>With quotes on default argument only
+>5
+>6
+>7
+>8
+>5
+>6
+>7
+>8
+>Using shwordsplit
+>Called with argument ''
+>No quotes
+>1
+>2
+>3
+>4
+>1
+>2
+>3
+>4
+>With quotes on default argument only
+>1-2.3-4
+>1-2.3-4
+>Called with argument '5.6-7.8'
+>No quotes
+>5
+>6
+>7
+>8
+>5
+>6
+>7
+>8
+>With quotes on default argument only
+>5
+>6
+>7
+>8
+>5
+>6
+>7
+>8
+
+# Tests a long-standing bug with joining on metafied characters in IFS
+ (array=(one two three)
+ IFS=$'\0'
+ foo="$array"
+ for (( i = 1; i <= ${#foo}; i++ )); do
+ char=${foo[i]}
+ print $(( #char ))
+ done)
+0:Joining with NULL character from IFS
+>111
+>110
+>101
+>0
+>116
+>119
+>111
+>0
+>116
+>104
+>114
+>101
+>101
+
+ unset SHLVL
+ (( SHLVL++ ))
+ print $SHLVL
+0:Unsetting and recreation of numerical special parameters
+>1
+
+ unset manpath
+ print $+MANPATH
+ manpath=(/here /there)
+ print $MANPATH
+ unset MANPATH
+ print $+manpath
+ MANPATH=/elsewhere:/somewhere
+ print $manpath
+0:Unsetting and recreation of tied special parameters
+>0
+>/here:/there
+>0
+>/elsewhere /somewhere
+
+ local STRING=a:b
+ typeset -T STRING string
+ print $STRING $string
+ unset STRING
+ set -A string x y z
+ print $STRING $string
+ STRING=a:b
+ typeset -T STRING string
+ print $STRING $string
+ unset STRING
+ set -A string x y z
+ print $STRING $string
+ STRING=a:b
+ typeset -T STRING string
+ print $STRING $string
+ unset string
+ STRING=x:y:z
+ print $STRING $string
+ STRING=a:b
+ typeset -T STRING string
+ print $STRING $string
+ unset string
+ STRING=x:y:z
+ print $STRING $string
+0:Unsetting and recreation of tied normal parameters
+>a:b a b
+>x y z
+>a:b a b
+>x y z
+>a:b a b
+>x:y:z
+>a:b a b
+>x:y:z
+
+ typeset -T tied1 tied2 +
+ typeset -T tied2 tied1 +
+1:Attempts to swap tied variables are safe but futile
+?(eval):typeset:2: already tied as non-scalar: tied2
+
+ string='look for a match in here'
+ if [[ ${string%%(#b)(match)*} = "look for a " ]]; then
+ print $match[1] $mbegin[1] $mend[1] $string[$mbegin[1],$mend[1]]
+ print $#match $#mbegin $#mend
+ else
+ print That didn\'t work.
+ fi
+0:Parameters associated with backreferences
+>match 12 16 match
+>1 1 1
+#' deconfuse emacs
+
+ string='and look for a MATCH in here'
+ if [[ ${(S)string%%(#m)M*H} = "and look for a in here" ]]; then
+ print $MATCH $MBEGIN $MEND $string[$MBEGIN,$MEND]
+ print $#MATCH
+ else
+ print Oh, dear. Back to the drawing board.
+ fi
+0:Parameters associated with (#m) flag
+>MATCH 16 20 MATCH
+>5
+
+ string='this is a string'
+ print ${string//(#m)s/$MATCH $MBEGIN $MEND}
+0:(#m) flag with pure string
+>this 4 4 is 7 7 a s 11 11tring
+
+ print ${${~:-*}//(#m)*/$MATCH=$MATCH}
+0:(#m) flag with tokenized input
+>*=*
+
+ print -l JAMES${(u)${=:-$(echo yes yes)}}JOYCE
+ print -l JAMES${(u)${=:-$(echo yes yes she said yes i will yes)}}JOYCE
+0:Bug with (u) flag reducing arrays to one element
+>JAMESyesJOYCE
+>JAMESyes
+>she
+>said
+>i
+>willJOYCE
+
+ print -l JAMES${(u)${=:-$(echo yes yes she said yes i will yes she said she will and yes she did yes)}}JOYCE
+0:New hash seive unique algorithm for arrays of more than 10 elements
+>JAMESyes
+>she
+>said
+>i
+>will
+>and
+>didJOYCE
+
+ foo=
+ print "${${foo}/?*/replacement}"
+0:Quoted zero-length strings are handled properly
+>
+
+ file=aleftkept
+ print ${file//(#b)(*)left/${match/a/andsome}}
+ print ${file//(#b)(*)left/${match//a/andsome}}
+0:Substitutions where $match is itself substituted in the replacement
+>andsomekept
+>andsomekept
+
+ file=/one/two/three/four
+ print ${file:fh}
+ print ${file:F.1.h}
+ print ${file:F+2+h}
+ print ${file:F(3)h}
+ print ${file:F<4>h}
+ print ${file:F{5}h}
+0:Modifiers with repetition
+>/
+>/one/two/three
+>/one/two
+>/one
+>/
+>/
+
+ baz=foo/bar
+ zab=oof+rab
+ print ${baz:s/\//+/}
+ print "${baz:s/\//+/}"
+ print ${zab:s/+/\//}
+ print "${zab:s/+/\//}"
+0:Quoting of separator in substitution modifier
+>foo+bar
+>foo+bar
+>oof/rab
+>oof/rab
+
+ bsbs='X\\\\Y'
+ print -r -- ${bsbs:s/\\/\\/}
+ print -r -- "${bsbs:s/\\/\\/}"
+ print -r -- ${bsbs:s/\\\\/\\\\/}
+ print -r -- "${bsbs:s/\\\\/\\\\/}"
+ print -r -- ${bsbs:gs/\\/\\/}
+ print -r -- "${bsbs:gs/\\/\\/}"
+ print -r -- ${bsbs:gs/\\\\/\\\\/}
+ print -r -- "${bsbs:gs/\\\\/\\\\/}"
+0:Handling of backslashed backslashes in substitution modifier
+>X\\\\Y
+>X\\\\Y
+>X\\\\Y
+>X\\\\Y
+>X\\\\Y
+>X\\\\Y
+>X\\\\Y
+>X\\\\Y
+
+ print -r ${${:-one/two}:s,/,X&Y,}
+ print -r ${${:-one/two}:s,/,X\&Y,}
+ print -r ${${:-one/two}:s,/,X\\&Y,}
+ print -r "${${:-one/two}:s,/,X&Y,}"
+ print -r "${${:-one/two}:s,/,X\&Y,}"
+ print -r "${${:-one/two}:s,/,X\\&Y,}"
+0:Quoting of ampersand in substitution modifier RHS
+>oneX/Ytwo
+>oneX&Ytwo
+>oneX\/Ytwo
+>oneX/Ytwo
+>oneX&Ytwo
+>oneX\/Ytwo
+
+ nully=($'a\0c' $'a\0b\0b' $'a\0b\0a' $'a\0b\0' $'a\0b' $'a\0' $'a')
+ for string in ${(o)nully}; do
+ for (( i = 1; i <= ${#string}; i++ )); do
+ foo=$string[i]
+ printf "%02x" $(( #foo ))
+ done
+ print
+ done
+0:Sorting arrays with embedded nulls
+>61
+>6100
+>610062
+>61006200
+>6100620061
+>6100620062
+>610063
+
+ array=(X)
+ patterns=("*X*" "spong" "a[b")
+ for pat in $patterns; do
+ print A${array[(r)$pat]}B C${array[(I)$pat]}D
+ done
+0:Bad patterns should never match array elements
+>AXB C1D
+>AB C0D
+>AB C0D
+
+ foo=(a6 a117 a17 b6 b117 b17)
+ print ${(n)foo}
+ print ${(On)foo}
+0:Numeric sorting
+>a6 a17 a117 b6 b17 b117
+>b117 b17 b6 a117 a17 a6
+
+ x=sprodj
+ x[-10]=scrumf
+ print $x
+0:Out of range negative scalar subscripts
+>scrumfsprodj
+
+ a=(some sunny day)
+ a[-10]=(we\'ll meet again)
+ print -l $a
+0:Out of range negative array subscripts
+>we'll
+>meet
+>again
+>some
+>sunny
+>day
+
+# ' emacs likes this close quote
+
+ a=(sping spang spong bumble)
+ print ${a[(i)spong]}
+ print ${a[(i)spung]}
+ print ${a[(ib.1.)spong]}
+ print ${a[(ib.4.)spong]}
+ print ${a[(ib.10.)spong]}
+0:In and out of range reverse matched indices without and with b: arrays
+>3
+>5
+>3
+>5
+>5
+
+ a="thrimblewuddlefrong"
+ print ${a[(i)w]}
+ print ${a[(i)x]}
+ print ${a[(ib.3.)w]}
+ print ${a[(ib.10.)w]}
+ print ${a[(ib.30.)w]}
+0:In and out of range reverse matched indices without and with b: strings
+>9
+>20
+>9
+>20
+>20
+
+ foo="line:with::missing::fields:in:it"
+ print -l ${(s.:.)foo}
+0:Removal of empty fields in unquoted splitting
+>line
+>with
+>missing
+>fields
+>in
+>it
+
+ foo="line:with::missing::fields:in:it"
+ print -l "${(s.:.)foo}"
+0:Hacky removal of empty fields in quoted splitting with no "@"
+>line
+>with
+>missing
+>fields
+>in
+>it
+
+ foo="line:with::missing::fields:in:it:"
+ print -l "${(@s.:.)foo}"
+0:Retention of empty fields in quoted splitting with "@"
+>line
+>with
+>
+>missing
+>
+>fields
+>in
+>it
+>
+
+ str=abcd
+ print -l ${(s..)str}
+ print -l "${(s..)str}"
+0:splitting of strings into characters
+>a
+>b
+>c
+>d
+>a
+>b
+>c
+>d
+
+ array=('%' '$' 'j' '*' '$foo')
+ print ${array[(i)*]} "${array[(i)*]}"
+ print ${array[(ie)*]} "${array[(ie)*]}"
+ key='$foo'
+ print ${array[(ie)$key]} "${array[(ie)$key]}"
+ key='*'
+ print ${array[(ie)$key]} "${array[(ie)$key]}"
+0:Matching array indices with and without quoting
+>1 1
+>4 4
+>5 5
+>4 4
+
+# Ordering of associative arrays is arbitrary, so we need to use
+# patterns that only match one element.
+ typeset -A assoc_r
+ assoc_r=(star '*' of '*this*' and '!that!' or '(the|other)')
+ print ${(kv)assoc_r[(re)*]}
+ print ${(kv)assoc_r[(re)*this*]}
+ print ${(kv)assoc_r[(re)!that!]}
+ print ${(kv)assoc_r[(re)(the|other)]}
+ print ${(kv)assoc_r[(r)*at*]}
+ print ${(kv)assoc_r[(r)*(ywis|bliss|kiss|miss|this)*]}
+ print ${(kv)assoc_r[(r)(this|that|\(the\|other\))]}
+0:Reverse subscripting associative arrays with literal matching
+>star *
+>of *this*
+>and !that!
+>or (the|other)
+>and !that!
+>of *this*
+>or (the|other)
+
+ print $ZSH_SUBSHELL
+ (print $ZSH_SUBSHELL)
+ ( (print $ZSH_SUBSHELL) )
+ ( (print $ZSH_SUBSHELL); print $ZSH_SUBSHELL )
+ print $(print $ZSH_SUBSHELL)
+ cat =(print $ZSH_SUBSHELL)
+0:ZSH_SUBSHELL
+>0
+>1
+>2
+>2
+>1
+>1
+>1
+
+ foo=("|" "?")
+ [[ "|" = ${(j.|.)foo} ]] && print yes || print no
+ [[ "|" = ${(j.|.)~foo} ]] && print yes || print no
+ [[ "|" = ${(~j.|.)foo} ]] && print yes || print no
+ [[ "|" = ${(~~j.|.)foo} ]] && print yes || print no
+ [[ "|" = ${(j.|.~)foo} ]] && print yes || print no
+ [[ "x" = ${(j.|.)foo} ]] && print yes || print no
+ [[ "x" = ${(j.|.)~foo} ]] && print yes || print no
+ [[ "x" = ${(~j.|.)foo} ]] && print yes || print no
+ [[ "x" = ${(~~j.|.)foo} ]] && print yes || print no
+ [[ "x" = ${(j.|.~)foo} ]] && print yes || print no
+0:GLOBSUBST only on parameter substitution arguments
+>no
+>yes
+>yes
+>no
+>no
+>no
+>yes
+>no
+>no
+>no
+
+ rcexbug() {
+ emulate -L zsh
+ setopt rcexpandparam
+ local -A hash
+ local -a full empty
+ full=(X x)
+ hash=(X x)
+ print ORDINARY ARRAYS
+ : The following behaves as documented in zshoptions
+ print FULL expand=$full
+ : Empty arrays remove the adjacent argument
+ print EMPTY expand=$empty
+ print ASSOCIATIVE ARRAY
+ print Subscript flags returning many values
+ print FOUND key=$hash[(I)X] val=$hash[(R)x]
+ : This should behave like $empty, and does
+ print LOST key=$hash[(I)y] val=$hash[(R)Y]
+ print Subscript flags returning single values
+ : Doc says "substitutes ... empty string"
+ : so must not behave like an empty array
+ print STRING key=$hash[(i)y] val=$hash[(r)Y]
+ }
+ rcexbug
+0:Lookup failures on elements of arrays with RC_EXPAND_PARAM
+>ORDINARY ARRAYS
+>FULL expand=X expand=x
+>EMPTY
+>ASSOCIATIVE ARRAY
+>Subscript flags returning many values
+>FOUND key=X val=x
+>LOST
+>Subscript flags returning single values
+>STRING key= val=
+
+ print $zsh_eval_context[1]
+ [[ $ZSH_EVAL_CONTEXT = ${(j.:.)zsh_eval_context} ]] || print Not equal!
+ (( icontext = ${#zsh_eval_context} + 1 ))
+ contextfn() { print $(print $zsh_eval_context[icontext,-1]); }
+ contextfn
+0:$ZSH_EVAL_CONTEXT and $zsh_eval_context
+>toplevel
+>shfunc cmdsubst
+
+ foo="123456789"
+ print ${foo:3}
+ print ${foo: 1 + 3}
+ print ${foo:$(( 2 + 3))}
+ print ${foo:$(echo 3 + 3)}
+ print ${foo:3:1}
+ print ${foo: 1 + 3:(4-2)/2}
+ print ${foo:$(( 2 + 3)):$(( 7 - 6 ))}
+ print ${foo:$(echo 3 + 3):`echo 4 - 3`}
+ print ${foo: -1}
+ print ${foo: -10}
+ print ${foo:5:-2}
+0:Bash-style offsets, scalar
+>456789
+>56789
+>6789
+>789
+>4
+>5
+>6
+>7
+>9
+>123456789
+>67
+
+ foo=(1 2 3 4 5 6 7 8 9)
+ print ${foo:3}
+ print ${foo: 1 + 3}
+ print ${foo:$(( 2 + 3))}
+ print ${foo:$(echo 3 + 3)}
+ print ${foo:3:1}
+ print ${foo: 1 + 3:(4-2)/2}
+ print ${foo:$(( 2 + 3)):$(( 7 - 6 ))}
+ print ${foo:$(echo 3 + 3):`echo 4 - 3`}
+ print ${foo: -1}
+ print ${foo: -10}
+ print ${foo:5:-2}
+0:Bash-style offsets, array
+>4 5 6 7 8 9
+>5 6 7 8 9
+>6 7 8 9
+>7 8 9
+>4
+>5
+>6
+>7
+>9
+>1 2 3 4 5 6 7 8 9
+>6 7
+
+ testfn() {
+ emulate -L sh
+ set -A foo 1 2 3
+ set -- 1 2 3
+ str=abc
+ echo ${foo[*]:0:1}
+ echo ${foo[*]:1:1}
+ echo ${foo[*]: -1:1}
+ :
+ echo ${*:0:1}
+ echo ${*:1:1}
+ echo ${*: -1:1}
+ :
+ echo ${str:0:1}
+ echo ${str:1:1}
+ echo ${str: -1:1}
+ }
+ testfn
+0:Bash-style offsets, Bourne-style indexing
+>1
+>2
+>3
+>testfn
+>1
+>3
+>a
+>b
+>c
+
+ printf "%n" '[0]'
+1:Regression test for identifier test
+?(eval):1: not an identifier: [0]
+
+ str=rts
+ print ${str:0:}
+1:Regression test for missing length after offset
+?(eval):2: unrecognized modifier
+
+ foo="123456789"
+ print ${foo:5:-6}
+1:Regression test for total length < 0 in string
+?(eval):2: substring expression: 3 < 5
+
+ foo=(1 2 3 4 5 6 7 8 9)
+ print ${foo:5:-6}
+1:Regression test for total length < 0 in array
+?(eval):2: substring expression: 3 < 5
+
+ foo=(${(0)"$(print -n)"})
+ print ${#foo}
+0:Nularg removed from split empty string
+>0
+
+ (set -- a b c
+ setopt shwordsplit
+ IFS=
+ print -rl "$*"
+ unset IFS
+ print -rl "$*")
+0:Regression test for shwordsplit with null or unset IFS and quoted array
+>abc
+>a b c
+
+ foo=
+ print ${foo:wq}
+ print ${:wq}
+0:Empty parameter should not cause modifiers to crash the shell
+>
+>
+
+# This used to cause uncontrolled behaviour, but at best
+# you got the wrong output so the check is worth it.
+ args() { print $#; }
+ args ${:*}
+ args ${:|}
+0:Intersection and disjunction with empty parameters
+>0
+>0
+
+ foo=(a b c)
+ bar=(1 2 3)
+ print ${foo:^bar}
+ print ${foo:^^bar}
+ foo=(a b c d)
+ bar=(1 2)
+ print ${foo:^bar}
+ print ${foo:^^bar}
+ foo=('a a' b)
+ bar=(1 '2 2')
+ print -l "${foo:^bar}"
+ print -l "${(@)foo:^bar}"
+0:Zipping arrays, correct output
+>a 1 b 2 c 3
+>a 1 b 2 c 3
+>a 1 b 2
+>a 1 b 2 c 1 d 2
+# maybe this should be changed to output "a a b 1"
+>a a b
+>1
+>a a
+>1
+>b
+>2 2
+
+ foo=(a b c)
+ bar=()
+ print ${foo:^bar}
+ print ${foo:^^bar}
+ print ${bar:^foo}
+ print ${bar:^^foo}
+ print ${bar:^bar}
+ print ${bar:^^bar}
+0:Zipping arrays, one or both inputs empty
+>
+>a b c
+>
+>a b c
+>
+>
+
+ foo=text
+ bar=()
+ print ${foo:^bar}
+ print ${bar:^^foo}
+ bar=other
+ print ${foo:^bar}
+ bar=(array elements)
+ print ${foo:^bar}
+ print ${foo:^^bar}
+ print ${bar:^foo}
+ print ${bar:^^foo}
+0:Zipping arrays, scalar input
+>
+>text
+>text other
+>text array
+>text array text elements
+>array text
+>array text elements text
+
+ foo=(a b c)
+ print ${foo:^^^bar}
+1:Zipping arrays, parsing
+?(eval):2: not an identifier: ^bar
+
+ (setopt nounset
+ print ${foo:^noexist})
+1:Zipping arrays, NO_UNSET part 1
+?(eval):2: noexist: parameter not set
+
+ (setopt nounset
+ print ${noexist:^foo})
+1:Zipping arrays, NO_UNSET part 2
+?(eval):2: noexist: parameter not set
+
+ expr="a@b,c@d:e@f,g@h:i@j,k@l"
+ for sep in : , @; do
+ print -l ${(ps.$sep.)expr}
+ done
+0:Use of variable to get separator when splitting parameter
+>a@b,c@d
+>e@f,g@h
+>i@j,k@l
+>a@b
+>c@d:e@f
+>g@h:i@j
+>k@l
+>a
+>b,c
+>d:e
+>f,g
+>h:i
+>j,k
+>l
+
+ SHLVL=1
+ $ZTST_testdir/../Src/zsh -fc 'echo $SHLVL'
+ $ZTST_testdir/../Src/zsh -fc '(echo $SHLVL)'
+0:SHLVL appears sensible when about to exit shell
+>2
+>2
+
+ # SHLVL is incremented twice and decremented once in between.
+ SHLVL=1
+ $ZTST_testdir/../Src/zsh -fc $ZTST_testdir/../Src/zsh' -fc "echo \$SHLVL"'
+ $ZTST_testdir/../Src/zsh -fc '('$ZTST_testdir/../Src/zsh' -fc "echo \$SHLVL")'
+ $ZTST_testdir/../Src/zsh -fc '( ('$ZTST_testdir/../Src/zsh' -fc "echo \$SHLVL"))'
+0:SHLVL decremented upon implicit exec optimisation
+>2
+>2
+>2
+
+ # SHLVL is incremented twice with no decrement in between.
+ SHLVL=1
+ $ZTST_testdir/../Src/zsh -fc '('$ZTST_testdir/../Src/zsh' -fc "echo \$SHLVL"); exit'
+ $ZTST_testdir/../Src/zsh -fc '(exec '$ZTST_testdir/../Src/zsh' -fc "echo \$SHLVL"); exit'
+ $ZTST_testdir/../Src/zsh -fc '( ('$ZTST_testdir/../Src/zsh' -fc "echo \$SHLVL"); exit)'
+0:SHLVL not decremented upon exec in subshells
+>3
+>3
+>3
+
+# The following tests the return behaviour of parsestr/parsestrnoerr
+ alias param-test-alias='print $'\''\x45xpanded in substitution'\'
+ param='$(param-test-alias)'
+ print ${(e)param}
+0:Alias expansion in command substitution in parameter evaluation
+>Expanded in substitution
+
+ a=1 b=2 c=3
+ : One;
+ function {
+ : Two
+ echo $_
+ print -l $argv
+ } $_ Three
+ print -l $_ Four;
+0:$_ with anonymous function
+>Two
+>One
+>Three
+>Three
+>Four
+
+ a=1 b=2 c=3
+ : One
+ function {
+ : Two
+ echo $_
+ print -l $argv
+ }
+ print -l "$_" Four
+0:$_ with anonymous function without arguments
+>Two
+>
+>
+>Four
+
+ funnychars='The qu*nk br!wan f@x j/mps o[]r \(e la~# ^"&;'
+ [[ $funnychars = ${~${(b)funnychars}} ]]
+0:${(b)...} quoting protects from GLOB_SUBST
+
+ set -- foo
+ echo $(( $#*3 ))
+ emulate sh -c 'nolenwithoutbrace() { echo $#-1; }'
+ nolenwithoutbrace
+0:Avoid confusion after overloaded characters in braceless substitution in sh
+>13
+>0-1
+
+ a="aaa bab cac"
+ b=d
+ echo $a:gs/a/${b}/
+ a=(aaa bab cac)
+ echo $a:gs/a/${b}/
+0:History modifier works the same for scalar and array substitution
+>ddd bdb cdc
+>ddd bdb cdc
+
+ a=1_2_3_4_5_6
+ print ${a#(*_)(#c2)}
+ print ${a#(*_)(#c5)}
+ print ${a#(*_)(#c7)}
+0:Complicated backtracking with match counts
+>3_4_5_6
+>6
+>1_2_3_4_5_6
+
+ (setopt shwordsplit
+ do_test() {
+ print $#: "$@"
+ }
+ foo=bar
+ foo2="bar bar"
+ do_test ${:- foo }
+ do_test ${:- foo bar }
+ do_test ${:- $foo }
+ do_test ${:- $foo2 }
+ do_test x${:- foo }y
+ do_test x${:- foo bar }y
+ do_test x${:- $foo }y
+ do_test x${:- $foo2 }y
+ do_test x${foo:+ $foo }y
+ )
+0:We Love SH_WORD_SPLIT Day celebrated with space at start of internal subst
+>1: foo
+>2: foo bar
+>1: bar
+>2: bar bar
+>3: x foo y
+>4: x foo bar y
+>3: x bar y
+>4: x bar bar y
+>3: x bar y
+
+ (unsetopt shwordsplit # default, for clarity
+ do_test() {
+ print $#: "$@"
+ }
+ foo=bar
+ foo2="bar bar"
+ do_test ${:- foo }
+ do_test ${:- foo bar }
+ do_test ${:- $foo }
+ do_test ${:- $foo2 }
+ do_test x${:- foo }y
+ do_test x${:- foo bar }y
+ do_test x${:- $foo }y
+ do_test x${:- $foo2 }y
+ do_test x${foo:+ $foo }y
+ )
+0:We Love NO_SH_WORD_SPLIT Even More Day celebrated as sanity check
+>1: foo
+>1: foo bar
+>1: bar
+>1: bar bar
+>1: x foo y
+>1: x foo bar y
+>1: x bar y
+>1: x bar bar y
+>1: x bar y
+
+ testfn() {
+ local scalar=obfuscation
+ local -a array=(alpha bravo charlie delta echo foxtrot)
+ local -A assoc=(one eins two zwei three drei four vier)
+ local name subscript
+ for name subscript in scalar 3 array 5 assoc three; do
+ print ${${(P)name}[$subscript]}
+ done
+ }
+ testfn
+0:${(P)...} with normal subscripting
+>f
+>echo
+>drei
+
+ testfn() {
+ local s1=foo s2=bar
+ local -a val=(s1)
+ print ${${(P)val}[1,3]}
+ val=(s1 s2)
+ print ${${(P)val}[1,3]}
+ }
+ testfn
+1:${(P)...} with array as name
+>foo
+?testfn:5: parameter name reference used with array
+
+ testfn() {
+ local -A assoc=(one buckle two show three knock four door)
+ local name='assoc[two]'
+ print ${${(P)name}[2,3]}
+ }
+ testfn
+0:${(P)...} with internal subscripting
+>ho
+
+ testfn() {
+ local one=two
+ local two=three
+ local three=four
+ local -a four=(all these worlds belong to foo)
+ print ${(P)${(P)${(P)one}}}
+ print ${${(P)${(P)${(P)one}}}[3]}
+ }
+ testfn
+0:nested parameter name references
+>all these worlds belong to foo
+>worlds
+
+ (
+ path=(/random /value)
+ testfn1() {
+ local path=
+ print $#path
+ }
+ testfn1
+ testfn2() {
+ local path=/somewhere
+ print $#path $path
+ }
+ testfn2
+ print $#path $path
+ )
+0:Local special variables with loose typing
+>0
+>1 /somewhere
+>2 /random /value
+
+ print -r -- ${(q+):-}
+ print -r -- ${(q+)IFS}
+ print -r -- ${(q+):-oneword}
+ print -r -- ${(q+):-two words}
+ print -r -- ${(q+):-three so-called \'words\'}
+ (setopt rcquotes; print -r -- ${(q+):-three so-called \'words\'})
+0:${(q+)...}
+>''
+>$' \t\n\C-@'
+>oneword
+>'two words'
+>'three so-called '\''words'\'
+>'three so-called ''words'''
+
+ array=(one two three)
+ array[1]=${nonexistent:-foo}
+ print $array
+0:"-" works after "[" in same expression (Dash problem)
+>foo two three
+
+ (
+ setopt shwordsplit
+ set -- whim:wham:whom
+ IFS=:
+ print -l $@
+ )
+0:Splitting of $@ on IFS: single element
+>whim
+>wham
+>whom
+
+ (
+ setopt shwordsplit
+ set -- one:two bucklemy:shoe
+ IFS=:
+ print -l $@
+ )
+0:Splitting of $@ on IFS: multiple elements
+# No forced joining in this case
+>one
+>two
+>bucklemy
+>shoe
+
+ (
+ set -- one:two bucklemy:shoe
+ print -l ${(s.:.)@}
+ )
+0:Splitting of $@ on (s): multiple elements
+# Forced joining in this case
+>one
+>two bucklemy
+>shoe
+
+ (
+ set -- one:two bucklemy:shoe
+ print -l ${(@s.:.)@}
+ )
+0:Splitting of $@ on (@s): multiple elements
+# Forced non-joining in this case
+>one
+>two
+>bucklemy
+>shoe
+
+ (
+ set -- one:two bucklemy:shoe
+ IFS=
+ setopt shwordsplit
+ print -l ${@} ${(s.:.)*} ${(s.:.j.-.)*}
+ )
+0:Joining of $@ does not happen when IFS is empty, but splitting $* does
+>one:two
+>bucklemy:shoe
+>one
+>twobucklemy
+>shoe
+>one
+>two-bucklemy
+>shoe
+
+ (
+ set -- "one two" "bucklemy shoe"
+ IFS=
+ setopt shwordsplit rcexpandparam
+ print -l "X${(@j.-.)*}"
+ )
+0:Use of @ does not prevent forced join with j
+>Xone two-bucklemy shoe
+
+ () { print -r -- "${(q)1}" "${(b)1}" "${(qq)1}" } '=foo'
+0:(q) and (b) quoting deal with the EQUALS option
+>\=foo =foo '=foo'
+
+ args() { print $#; }
+ a=(foo)
+ args "${a[3,-1]}"
+ args "${(@)a[3,-1]}"
+0:Out-of-range multiple array subscripts with quoting, with and without (@)
+>1
+>0
+
+ a='~-/'; echo $~a
+0:Regression: "-" became Dash in workers/37689, breaking ~- expansion
+*>*
+F:We do not care what $OLDPWD is, as long as it doesn't cause an error
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D05array.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D05array.ztst
new file mode 100644
index 0000000..1fa607d
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D05array.ztst
@@ -0,0 +1,112 @@
+# Tests for array indexing
+
+%prep
+
+ foo=(a b c d e f g)
+ arr=(foo bar baz)
+ mkdir array.tmp
+ touch array.tmp/{1..9}
+
+%test
+
+ echo .$foo[1].
+0:The first element
+>.a.
+
+ echo .$foo[1,4].
+0:Normal multi-item indexing
+>.a b c d.
+
+ echo .$foo[1,0].
+0:This should be empty
+>..
+
+ echo .$foo[4,1].
+0:Another empty slice
+>..
+
+ echo .$foo[1,-8].
+0:An empty slice with a negative end
+>..
+
+ echo .$foo[0].
+0:Treat 0 as empty
+>..
+
+ echo .$foo[0,0].
+0:Treat 0,0 as empty
+>..
+
+ echo .$foo[0,1].
+0:Another weird way to access the first element
+>.a.
+
+ echo .$foo[3].
+0:An inner element
+>.c.
+
+ echo .$foo[2,2].
+0:Another inner element
+>.b.
+
+ echo .$foo[2,-4].
+0:A slice with a negative end
+>.b c d.
+
+ echo .$foo[-4,5].
+0:A slice with a negative start
+>.d e.
+
+ echo .$foo[-6,-2].
+0:A slice with a negative start and end
+>.b c d e f.
+
+ echo .${${arr[2]}[1]}.
+ echo .${${arr[-2]}[1]}.
+ echo .${${arr[2,2]}[1]}.
+ echo .${${arr[-2,-2]}[1]}.
+ echo .${${arr[2,-2]}[1]}.
+ echo .${${arr[-2,2]}[1]}.
+0:Slices should return an array, elements a scalar
+>.b.
+>.b.
+>.bar.
+>.bar.
+>.bar.
+>.bar.
+
+ setopt ksh_arrays
+ echo .${foo[1,2]}.
+ unsetopt ksh_arrays
+0:Ksh array indexing
+>.b c.
+
+ setopt ksh_arrays
+ echo .${foo[0,1]}.
+ unsetopt ksh_arrays
+0:Ksh array indexing (ii)
+>.a b.
+
+ setopt ksh_arrays
+ echo .${foo[1,-1]}.
+ unsetopt ksh_arrays
+0:Ksh array indexing (iii)
+>.b c d e f g.
+
+ cd array.tmp
+ echo . ?([3,5]) .
+ cd ..
+0:Glob array indexing
+>. 3 4 5 .
+
+ cd array.tmp
+ echo . ?([2,-2]) .
+ cd ..
+0:Glob array indexing (ii)
+>. 2 3 4 5 6 7 8 .
+
+ cd array.tmp
+ echo . ?([-6,-4]) .
+ cd ..
+0:Glob array indexing (iii)
+>. 4 5 6 .
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D06subscript.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D06subscript.ztst
new file mode 100644
index 0000000..1449236
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D06subscript.ztst
@@ -0,0 +1,268 @@
+# Test parameter subscripting.
+
+%prep
+
+ s='Twinkle, twinkle, little *, [how] I [wonder] what? You are!'
+ a=('1' ']' '?' '\2' '\]' '\?' '\\3' '\\]' '\\?' '\\\4' '\\\]' '\\\?')
+ typeset -g -A A
+ A=($a)
+
+%test
+
+ x=','
+ print $s[(i)winkle] $s[(I)winkle]
+ print ${s[(i)You are]} $#s
+ print ${s[(r)$x,(R)$x]}
+0:Scalar pattern subscripts without wildcards
+>2 11
+>53 60
+>, twinkle, little *,
+
+ x='*'
+ print $s[(i)*] $s[(i)\*] $s[(i)$x*] $s[(i)${(q)x}*] $s[(I)$x\*]
+ print $s[(r)?,(R)\?] $s[(r)\?,(R)?]
+ print $s[(r)\*,(R)*]
+ print $s[(r)\],(R)\[]
+0:Scalar pattern subscripts with wildcards
+>1 26 1 26 26
+>Twinkle, twinkle, little *, [how] I [wonder] what? ? You are!
+>*, [how] I [wonder] what? You are!
+>] I [
+
+ print $s[(i)x] : $s[(I)x]
+ print $s[(r)x] : $s[(R)x]
+0:Scalar pattern subscripts that do not match
+>61 : 0
+>:
+
+ print -R $s[$s[(i)\[]] $s[(i)$s[(r)\*]] $s[(i)${(q)s[(r)\]]}]
+0:Scalar subscripting using a pattern subscript to get the index
+>[ 1 33
+
+ print -R $a[(r)?] $a[(R)?]
+ print $a[(n:2:i)?] $a[(n:2:I)?]
+ print $a[(i)\?] $a[(I)\?]
+ print $a[(i)*] $a[(i)\*]
+0:Array pattern subscripts
+>1 ?
+>2 2
+>3 3
+>1 13
+
+ # It'd be nice to do some of the following with (r), but we run into
+ # limitations of the ztst script parsing of backslashes in the output.
+ print -R $a[(i)\\\\?] $a[(i)\\\\\?]
+ print -R $a[(i)\\\\\\\\?] $a[(i)\\\\\\\\\?]
+ print -R ${a[(i)\\\\\\\\?]} ${a[(i)\\\\\\\\\?]}
+ print -R "$a[(i)\\\\\\\\?] $a[(i)\\\\\\\\\?]"
+ print -R $a[(i)\]] $a[(i)\\\\\]] $a[(i)\\\\\\\\\]] $a[(i)\\\\\\\\\\\\\]]
+ print -R $a[(i)${(q)a[5]}] $a[(i)${(q)a[8]}] $a[(i)${(q)a[11]}]
+ print -R $a[(i)${a[3]}] $a[(i)${a[6]}] $a[(i)${a[9]}] $a[(i)${a[12]}]
+0:Array pattern subscripts with multiple backslashes
+>4 6
+>7 9
+>7 9
+>7 9
+>2 5 8 11
+>5 8 11
+>1 3 4 6
+
+ print -R $A[1] $A[?] $A[\\\\3] $A[\\\]]
+ print -R $A[$a[11]]
+ print -R $A[${(q)a[5]}]
+0:Associative array lookup (direct subscripting)
+>] \2 \\] \?
+>\\\?
+>\\\?
+
+ # The (o) is necessary here for predictable output ordering
+ print -R $A[(I)\?] ${(o)A[(I)?]}
+ print -R $A[(i)\\\\\\\\3]
+ print -R $A[(I)\\\\\\\\\?] ${(o)A[(I)\\\\\\\\?]}
+0:Associative array lookup (pattern subscripting)
+>? 1 ?
+>\\3
+>\\? \\3 \\?
+
+ print -R $A[(R)\?] : ${(o)A[(R)?]}
+ print -R $A[(R)\\\\\?] ${(o)A[(R)\\\\?]} ${(o)A[(R)\\\\\?]}
+ print -R ${(o)A[(R)\\\\\\\\\]]}
+0:Associative array lookup (reverse subscripting)
+>: ]
+>\? \2 \? \?
+>\\]
+
+ eval 'A[*]=star'
+1:Illegal associative array assignment
+?(eval):1: A: attempt to set slice of associative array
+
+ x='*'
+ A[$x]=xstar
+ A[${(q)x}]=qxstar
+ print -R ${(k)A[(r)xstar]} $A[$x]
+ print -R ${(k)A[(r)qxstar]} $A[${(q)x}]
+ A[(e)*]=star
+ A[\*]=backstar
+ print -R ${(k)A[(r)star]} $A[(e)*]
+ print -R ${(k)A[(r)backstar]} $A[\*]
+0:Associative array assignment
+>* xstar
+>\* qxstar
+>* star
+>\* backstar
+
+ o='['
+ c=']'
+ A[\]]=cbrack
+ A[\[]=obrack
+ A[\\\[]=backobrack
+ A[\\\]]=backcbrack
+ print -R $A[$o] $A[$c] $A[\[] $A[\]] $A[\\\[] $A[\\\]]
+ print -R $A[(i)\[] $A[(i)\]] $A[(i)\\\\\[] $A[(i)\\\\\]]
+0:Associative array keys with open and close brackets
+>obrack cbrack obrack cbrack backobrack backcbrack
+>[ ] \[ \]
+
+ print -R $A[$o] $A[$s[(r)\[]]
+ print -R $A[(r)$c] $A[(r)$s[(r)\]]]
+ print -R $A[$A[(i)\\\\\]]]
+0:Associative array lookup using a pattern subscript to get the key
+>obrack obrack
+>] ]
+>backcbrack
+
+ print -R ${A[${A[(r)\\\\\\\\\]]}]::=zounds}
+ print -R ${A[${A[(r)\\\\\\\\\]]}]}
+ print -R $A[\\\\\]]
+0:Associative array substitution-assignment with reverse pattern subscript key
+>zounds
+>zounds
+>zounds
+
+ print -R ${(o)A[(K)\]]}
+ print -R ${(o)A[(K)\\\]]}
+0:Associative array keys interpreted as patterns
+>\2 backcbrack cbrack star
+>\\\4 \\\? star zounds
+
+# It doesn't matter which element we get, since we never guarantee
+# ordering of an associative array. So just test the number of matches.
+ array=(${(o)A[(k)\]]})
+ print ${#array}
+ array=(${(o)A[(k)\\\]]})
+ print ${#array}
+0:Associative array keys interpreted as patterns, single match
+>1
+>1
+
+ typeset -g "A[one\"two\"three\"quotes]"=QQQ
+ typeset -g 'A[one\"two\"three\"quotes]'=qqq
+ print -R "$A[one\"two\"three\"quotes]"
+ print -R $A[one\"two\"three\"quotes]
+ A[one"two"three"four"quotes]=QqQq
+ print -R $A[one"two"three"four"quotes]
+ print -R $A[$A[(i)one\"two\"three\"quotes]]
+ print -R "$A[$A[(i)one\"two\"three\"quotes]]"
+0:Associative array keys with double quotes
+>QQQ
+>qqq
+>QqQq
+>qqq
+>QQQ
+
+ print ${x::=$A[$A[(i)one\"two\"three\"quotes]]}
+ print $x
+ print ${x::="$A[$A[(i)one\"two\"three\"quotes]]"}
+ print $x
+0:More keys with double quotes, used in assignment-expansion
+>qqq
+>qqq
+>QQQ
+>QQQ
+
+ qqq=lower
+ QQQ=upper
+ print ${(P)A[one\"two\"three\"quotes]}
+ print "${(P)A[$A[(i)one\"two\"three\"quotes]]}"
+0:Keys with double quotes and the (P) expansion flag
+>lower
+>upper
+
+ typeset -ga empty
+ echo X${${empty##*}[-1]}X
+0:Negative index applied to substition result from empty array
+>XX
+
+ print $empty[(i)] $empty[(I)]
+0:(i) returns 1 for empty array, (I) returns 0.
+>1 0
+
+ array=(one two three four)
+ print X$array[0]X
+0:Element zero is empty if KSH_ZERO_SUBSCRIPT is off.
+>XX
+
+ array[0]=fumble
+1:Can't set element zero if KSH_ZERO_SUBSCRIPT is off.
+?(eval):1: array: assignment to invalid subscript range
+
+ print X$array[(R)notfound]X
+0:(R) returns empty if not found if KSH_ZERO_SUBSCRIPT is off.
+>XX
+
+ setopt KSH_ZERO_SUBSCRIPT
+ print X$array[0]X
+0:Element zero is element one if KSH_ZERO_SUBSCRIPT is on.
+>XoneX
+
+ array[0]=fimble
+ print $array
+0:Can set element zero if KSH_ZERO_SUBSCRIPT is on.
+>fimble two three four
+
+ print X$array[(R)notfound]X
+0:(R) yuckily returns the first element on failure withe KSH_ZERO_SUBSCRIPT
+>XfimbleX
+
+ unsetopt KSH_ZERO_SUBSCRIPT
+ array[(R)notfound,(r)notfound]=(help help here come the seventies retreads)
+ print $array
+0:[(R)notfound,(r)notfound] replaces the whole array
+>help help here come the seventies retreads
+
+ string="Why, if it isn't Officer Dibble"
+ print "[${string[0]}][${string[1]}][${string[0,3]}]"
+0:String subscripts with KSH_ZERO_SUBSCRIPT unset
+>[][W][Why]
+
+ setopt KSH_ZERO_SUBSCRIPT
+ print "[${string[0]}][${string[1]}][${string[0,3]}]"
+0:String subscripts with KSH_ZERO_SUBSCRIPT set
+>[W][W][Why]
+
+ unsetopt KSH_ZERO_SUBSCRIPT
+ string[0,3]="Goodness"
+ print $string
+0:Assignment to chunk of string ignores element 0
+>Goodness, if it isn't Officer Dibble
+
+ string[0]=!
+1:Can't set only element zero of string
+?(eval):1: string: assignment to invalid subscript range
+
+ typeset -A assoc=(leader topcat officer dibble sidekick choochoo)
+ alias myind='echo leader' myletter='echo 1' myletter2='echo 4'
+ print ${assoc[$(myind)]}
+ print $assoc[$(myind)]
+ print ${assoc[$(myind)][$(myletter)]}${assoc[$(myind)][$(myletter2)]}
+ assoc[$(myind)]='of the gang'
+ print ${assoc[$(myind)]}
+ print $assoc[$(myind)]
+ print $assoc[leader]
+0: Parsing subscript with non-trivial tokenisation
+>topcat
+>topcat
+>tc
+>of the gang
+>of the gang
+>of the gang
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D07multibyte.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D07multibyte.ztst
new file mode 100644
index 0000000..e203153
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D07multibyte.ztst
@@ -0,0 +1,587 @@
+%prep
+
+# Find a UTF-8 locale.
+ setopt multibyte
+# Don't let LC_* override our choice of locale.
+ unset -m LC_\*
+ mb_ok=
+ langs=(en_{US,GB}.{UTF-,utf}8 en.UTF-8
+ $(locale -a 2>/dev/null | egrep 'utf8|UTF-8'))
+ for LANG in $langs; do
+ if [[ é = ? ]]; then
+ mb_ok=1
+ break;
+ fi
+ done
+ if [[ -z $mb_ok ]]; then
+ ZTST_unimplemented="no UTF-8 locale or multibyte mode is not implemented"
+ else
+ print -u $ZTST_fd Testing multibyte with locale $LANG
+ mkdir multibyte.tmp && cd multibyte.tmp
+ fi
+
+%test
+
+ a=ténébreux
+ for i in {1..9}; do
+ print ${a[i]}
+ for j in {$i..9}; do
+ print $i $j ${a[i,j]} ${a[-j,-i]}
+ done
+ done
+0:Basic indexing with multibyte characters
+>t
+>1 1 t x
+>1 2 té ux
+>1 3 tén eux
+>1 4 téné reux
+>1 5 ténéb breux
+>1 6 ténébr ébreux
+>1 7 ténébre nébreux
+>1 8 ténébreu énébreux
+>1 9 ténébreux ténébreux
+>é
+>2 2 é u
+>2 3 én eu
+>2 4 éné reu
+>2 5 énéb breu
+>2 6 énébr ébreu
+>2 7 énébre nébreu
+>2 8 énébreu énébreu
+>2 9 énébreux ténébreu
+>n
+>3 3 n e
+>3 4 né re
+>3 5 néb bre
+>3 6 nébr ébre
+>3 7 nébre nébre
+>3 8 nébreu énébre
+>3 9 nébreux ténébre
+>é
+>4 4 é r
+>4 5 éb br
+>4 6 ébr ébr
+>4 7 ébre nébr
+>4 8 ébreu énébr
+>4 9 ébreux ténébr
+>b
+>5 5 b b
+>5 6 br éb
+>5 7 bre néb
+>5 8 breu énéb
+>5 9 breux ténéb
+>r
+>6 6 r é
+>6 7 re né
+>6 8 reu éné
+>6 9 reux téné
+>e
+>7 7 e n
+>7 8 eu én
+>7 9 eux tén
+>u
+>8 8 u é
+>8 9 ux té
+>x
+>9 9 x t
+
+ s=é
+ print A${s[-2]}A B${s[-1]}B C${s[0]}C D${s[1]}D E${s[2]}E
+0:Out of range subscripts with multibyte characters
+>AA BéB CC DéD EE
+
+ print ${a[(i)é]} ${a[(I)é]} ${a[${a[(i)é]},${a[(I)é]}]}
+0:Reverse indexing with multibyte characters
+>2 4 éné
+
+ print ${a[(r)én,(r)éb]}
+0:Subscript searching with multibyte characters
+>énéb
+
+ print ${a[(rb:1:)é,-1]}
+ print ${a[(rb:2:)é,-1]}
+ print ${a[(rb:3:)é,-1]}
+ print ${a[(rb:4:)é,-1]}
+ print ${a[(rb:5:)é,-1]}
+0:Subscript searching with initial offset
+>énébreux
+>énébreux
+>ébreux
+>ébreux
+>
+
+ print ${a[(rn:1:)é,-1]}
+ print ${a[(rn:2:)é,-1]}
+ print ${a[(rn:3:)é,-1]}
+0:Subscript searching with count
+>énébreux
+>ébreux
+>
+
+ print ${a[(R)én,(R)éb]}
+0:Backward subscript searching with multibyte characters
+>énéb
+
+# Starting offsets with (R) seem to be so strange as to be hardly
+# worth testing.
+
+ setopt extendedglob
+ [[ $a = (#b)t(én)(éb)reux ]] || print "Failed to match." >&2
+ for i in {1..${#match}}; do
+ print $match[i] $mbegin[i] $mend[i] ${a[$mbegin[i],$mend[i]]}
+ done
+0:Multibyte offsets in pattern tests
+>én 2 3 én
+>éb 4 5 éb
+
+ b=${(U)a}
+ print $b
+ print ${(L)b}
+ desdichado="Je suis le $a, le veuf, l'inconsolé"
+ print ${(C)desdichado}
+ lxiv="l'état c'est moi"
+ print ${(C)lxiv}
+0:Case modification of multibyte strings
+>TÉNÉBREUX
+>ténébreux
+>Je Suis Le Ténébreux, Le Veuf, L'Inconsolé
+>L'État C'Est Moi
+
+ array=(ølaf ødd øpened án encyclopædia)
+ barray=(${(U)array})
+ print $barray
+ print ${(L)barray}
+ print ${(C)array}
+ print ${(C)barray}
+0:Case modification of arrays with multibyte strings
+>ØLAF ØDD ØPENED ÁN ENCYCLOPÆDIA
+>ølaf ødd øpened án encyclopædia
+>Ølaf Ødd Øpened Án Encyclopædia
+>Ølaf Ødd Øpened Án Encyclopædia
+
+ print $(( ##¥ ))
+ pound=£
+ print $(( #pound ))
+ alpha=α
+ print $(( ##α )) $(( #alpha ))
+0:Conversion to Unicode in mathematical expressions
+>165
+>163
+>945 945
+
+ unsetopt posix_identifiers
+ expr='hähä=3 || exit 1; print $hähä'
+ eval $expr
+ setopt posix_identifiers
+ (eval $expr)
+1:POSIX_IDENTIFIERS option
+>3
+?(eval):1: command not found: hähä=3
+
+ foo="Ølaf«Ødd«øpénëd«ån«àpple"
+ print -l ${(s.«.)foo}
+ ioh="Ἐν ἀρχῇ ἦν ὁ λόγος, καὶ ὁ λόγος ἦν πρὸς τὸν θεόν, καὶ θεὸς ἦν ὁ λόγος."
+ print -l ${=ioh}
+ print ${(w)#ioh}
+0:Splitting with multibyte characters
+>Ølaf
+>Ødd
+>øpénëd
+>ån
+>àpple
+>Ἐν
+>ἀρχῇ
+>ἦν
+>ὁ
+>λόγος,
+>καὶ
+>ὁ
+>λόγος
+>ἦν
+>πρὸς
+>τὸν
+>θεόν,
+>καὶ
+>θεὸς
+>ἦν
+>ὁ
+>λόγος.
+>17
+
+ read -d £ one
+ read -d £ two
+ print $one
+ print $two
+0:read with multibyte delimiter
+first
+>second
+
+ (IFS=«
+ read -d » -A array
+ print -l $array)
+0:read -A with multibyte IFS
+dominus
+>illuminatio
+>mea
+
+ read -k2 -u0 twochars
+ print $twochars
+0:read multibyte characters
+<«»ignored
+>«»
+
+ read -q -u0 mb
+ print $?
+0:multibyte character makes read -q return false
+<«
+>1
+
+ # See if the system grokks first-century Greek...
+ ioh="Ἐν ἀρχῇ ἦν ὁ λόγος, καὶ ὁ λόγος ἦν πρὸς τὸν θεόν, καὶ θεὸς ἦν ὁ λόγος."
+ for (( i = 1; i <= ${#ioh}; i++ )); do
+ # FC3 doesn't recognise ῇ (U+1FC7: Greek small letter eta with
+ # perispomeni and ypogegrammeni, of course) as a lower case character.
+ if [[ $ioh[i] != [[:lower:]] && $i != 7 ]]; then
+ for tp in upper space punct invalid; do
+ if [[ $tp = invalid || $ioh[i] = [[:${tp}:]] ]]; then
+ print "$i: $tp"
+ break
+ fi
+ done
+ fi
+ done
+0:isw* functions on non-ASCII wide characters
+>1: upper
+>3: space
+>8: space
+>11: space
+>13: space
+>19: punct
+>20: space
+>24: space
+>26: space
+>32: space
+>35: space
+>40: space
+>44: space
+>49: punct
+>50: space
+>54: space
+>59: space
+>62: space
+>64: space
+>70: punct
+
+ ioh="Ἐν ἀρχῇ ἦν ὁ λόγος, καὶ ὁ λόγος ἦν πρὸς τὸν θεόν, καὶ θεὸς ἦν ὁ λόγος"
+ print ${ioh#[[:alpha:]]##}
+ print ${ioh##[[:alpha:]]##}
+ print ${ioh%[[:alpha:]]##}
+ print ${ioh%%[[:alpha:]]##}
+ print ${(S)ioh#λ*ς}
+ print ${(S)ioh##λ*ς}
+ print ${(S)ioh%θ*ς}
+ print ${(S)ioh%%θ*ς}
+0:Parameter #, ##, %, %% with multibyte characters
+>ν ἀρχῇ ἦν ὁ λόγος, καὶ ὁ λόγος ἦν πρὸς τὸν θεόν, καὶ θεὸς ἦν ὁ λόγος
+> ἀρχῇ ἦν ὁ λόγος, καὶ ὁ λόγος ἦν πρὸς τὸν θεόν, καὶ θεὸς ἦν ὁ λόγος
+>Ἐν ἀρχῇ ἦν ὁ λόγος, καὶ ὁ λόγος ἦν πρὸς τὸν θεόν, καὶ θεὸς ἦν ὁ λόγο
+>Ἐν ἀρχῇ ἦν ὁ λόγος, καὶ ὁ λόγος ἦν πρὸς τὸν θεόν, καὶ θεὸς ἦν ὁ
+>Ἐν ἀρχῇ ἦν ὁ , καὶ ὁ λόγος ἦν πρὸς τὸν θεόν, καὶ θεὸς ἦν ὁ λόγος
+>Ἐν ἀρχῇ ἦν ὁ
+>Ἐν ἀρχῇ ἦν ὁ λόγος, καὶ ὁ λόγος ἦν πρὸς τὸν θεόν, καὶ ἦν ὁ λόγος
+>Ἐν ἀρχῇ ἦν ὁ λόγος, καὶ ὁ λόγος ἦν πρὸς τὸν θεόν, καὶ
+
+ a="1ë34ë6"
+ print ${(BEN)a#*4}
+ print ${(BEN)a##*ë}
+ print ${(BEN)a%4*}
+ print ${(BEN)a%%ë*}
+ print ${(SBEN)a#ë3}
+ print ${(SBEN)a%4ë}
+0:Flags B, E, N and S in ${...#...} and ${...%...}
+>1 5 4
+>1 6 5
+>4 7 3
+>2 7 5
+>2 4 2
+>4 6 2
+
+ foo=(κατέβην χθὲς εἰς Πειραιᾶ)
+ print ${(l.3..¥.r.3..£.)foo}
+ print ${(l.4..¥.r.2..£.)foo}
+ print ${(l.5..¥.r.1..£.)foo}
+ print ${(l.4..¥..«.r.4..£..».)foo}
+ print ${(l.4..¥..Σωκράτης.r.4..£..Γλαύκωνος.)foo}
+0:simultaneous left and right padding
+>κατέβη ¥χθὲς£ ¥¥εἰς£ Πειραι
+>¥κατέβ ¥¥χθὲς ¥¥¥εἰς ¥Πειρα
+>¥¥κατέ ¥¥¥χθὲ ¥¥¥¥εἰ ¥¥Πειρ
+>«κατέβην ¥«χθὲς»£ ¥¥«εἰς»£ «Πειραιᾶ
+>ςκατέβην ηςχθὲςΓλ τηςεἰςΓλ ςΠειραιᾶ
+# er... yeah, that looks right...
+
+ foo=picobarn
+ print ${foo:s£bar£rod£:s¥rod¥stick¥}
+0:Delimiters in modifiers
+>picostickn
+
+# TODO: if we get paired multibyte bracket delimiters to work
+# (as Emacs does, the smug so-and-so), the following should change.
+ foo=bar
+ print ${(r£5££X£)foo}
+ print ${(l«10««Y««HI«)foo}
+0:Delimiters in parameter flags
+>barXX
+>YYYYYHIbar
+
+ printf "%4.3s\n" főobar
+0:Multibyte characters in printf widths
+> főo
+
+# We ask for case-insensitive sorting here (and supply upper case
+# characters) so that we exercise the logic in the shell that lowers the
+# case of the string for case-insensitive sorting.
+ print -oi HÛH HÔH HÎH HÊH HÂH
+ (LC_ALL=C; print -oi HAH HUH HEH HÉH HÈH)
+0:Multibyte characters in print sorting
+>HÂH HÊH HÎH HÔH HÛH
+>HAH HEH HUH HÈH HÉH
+
+# These are control characters in Unicode, so don't show up.
+# We just want to check they're not being treated as tokens.
+ for x in {128..150}; do
+ print ${(#)x}
+ done | while read line; do
+ print ${#line} $(( #line ))
+ done
+0:evaluated character number with multibyte characters
+>1 128
+>1 129
+>1 130
+>1 131
+>1 132
+>1 133
+>1 134
+>1 135
+>1 136
+>1 137
+>1 138
+>1 139
+>1 140
+>1 141
+>1 142
+>1 143
+>1 144
+>1 145
+>1 146
+>1 147
+>1 148
+>1 149
+>1 150
+
+ touch ngs1txt ngs2txt ngs10txt ngs20txt ngs100txt ngs200txt
+ setopt numericglobsort
+ print -l ngs*
+0:NUMERIC_GLOB_SORT option in UTF-8 locale
+>ngs1txt
+>ngs2txt
+>ngs10txt
+>ngs20txt
+>ngs100txt
+>ngs200txt
+
+# Not strictly multibyte, but gives us a well-defined locale for testing.
+ foo=$'X\xc0Y\x07Z\x7fT'
+ print -r ${(q)foo}
+0:Backslash-quoting of unprintable/invalid characters uses $'...'
+>X$'\300'Y$'\a'Z$'\177'T
+
+# This also isn't strictly multibyte and is here to reduce the
+# likelihood of a "cannot do character set conversion" error.
+ (print $'\u00e9') 2>&1 | read
+ if [[ $REPLY != é ]]; then
+ print "warning: your system can't do simple Unicode conversion." >&$ZTST_fd
+ print "Check you have a correctly installed iconv library." >&$ZTST_fd
+ # cheat
+ repeat 4 print OK
+ else
+ testfn() { (LC_ALL=C; print $'\u00e9') }
+ repeat 4 testfn 2>&1 | while read line; do
+ if [[ $line = *"character not in range"* ]]; then
+ print OK
+ elif [[ $line = "?" ]]; then
+ print OK
+ else
+ print Failed: no error message and no question mark
+ fi
+ done
+ fi
+ true
+0:error handling in Unicode quoting
+>OK
+>OK
+>OK
+>OK
+
+ tmp1='glob/\(\)Ą/*'
+ [[ glob/'()Ą'/foo == $~tmp1 ]] && print "Matched against $tmp1"
+ tmp1='glob/\(\)Ā/*'
+ [[ glob/'()Ā'/bar == $~tmp1 ]] && print "Matched against $tmp1"
+0:Backslashes and metafied characters in patterns
+>Matched against glob/()Ą/*
+>Matched against glob/()Ā/*
+
+ mkdir 梶浦由記 'Пётр Ильич Чайковский'
+ (cd 梶浦由記; print ${${(%):-%~}:t})
+ (cd 'Пётр Ильич Чайковский'; print ${${(%):-%~}:t})
+0:Metafied characters in prompt expansion
+>梶浦由記
+>Пётр Ильич Чайковский
+
+ (
+ setopt nonomatch
+ tmp1=Ą
+ tmpA=(Ą 'Пётр Ильич Чайковский' 梶浦由記)
+ print ${tmp1} ${(%)tmp1} ${(%%)tmp1}
+ print ${#tmp1} ${#${(%)tmp1}} ${#${(%%)tmp1}}
+ print ${tmpA}
+ print ${(%)tmpA}
+ print ${(%%)tmpA}
+ )
+0:More metafied characters in prompt expansion
+>Ą Ą Ą
+>1 1 1
+>Ą Пётр Ильич Чайковский 梶浦由記
+>Ą Пётр Ильич Чайковский 梶浦由記
+>Ą Пётр Ильич Чайковский 梶浦由記
+
+ setopt cbases
+ print $'\xc5' | read
+ print $(( [#16] #REPLY ))
+0:read passes through invalid multibyte characters
+>0xC5
+
+ word=abcま
+ word[-1]=
+ print $word
+ word=abcま
+ word[-2]=
+ print $word
+ word=abcま
+ word[4]=d
+ print $word
+ word=abcま
+ word[3]=not_c
+ print $word
+0:assignment with negative indices
+>abc
+>abま
+>abcd
+>abnot_cま
+
+ # The following doesn't necessarily need UTF-8, but this gives
+ # us the full effect --- if we parse this wrongly the \xe9
+ # in combination with the tokenized input afterwards looks like a
+ # valid UTF-8 character. But it isn't.
+ print $'$\xe9#``' >test_bad_param
+ (setopt nonomatch
+ . ./test_bad_param)
+127:Invalid parameter name with following tokenized input
+?./test_bad_param:1: command not found: $\M-i#
+
+ lines=$'one\tZSH\tthree\nfour\tfive\tsix'
+ print -X8 -r -- $lines
+0:Tab expansion with extra-wide characters
+>one ZSH three
+>four five six
+# This doesn't look aligned in my editor because actually the characters
+# aren't quite double width, but the arithmetic is correct.
+# It appears just to be an effect of the font.
+
+ () {
+ emulate -L zsh
+ setopt errreturn
+ local cdpath=(.)
+ mkdir ホ
+ cd ホ
+ cd ..
+ cd ./ホ
+ cd ..
+ }
+0:cd with special characters
+
+ test_array=(
+ '[[ \xcc = \xcc ]]'
+ '[[ \xcc != \xcd ]]'
+ '[[ \xcc != \ucc ]]'
+ '[[ \ucc = \ucc ]]'
+ '[[ \ucc = [\ucc] ]]'
+ '[[ \xcc != [\ucc] ]]'
+ # Not clear how useful the following is...
+ '[[ \xcc = [\xcc] ]]'
+ )
+ for test in $test_array; do
+ if ! eval ${(g::)test} ; then
+ print -rl "Test $test failed" >&2
+ fi
+ done
+0:Invalid characters in pattern matching
+
+ [[ $'\xe3' == [[:INCOMPLETE:]] ]] || print fail 1
+ [[ $'\xe3\x83' == [[:INCOMPLETE:]][[:INVALID:]] ]] || print fail 2
+ [[ $'\xe3\x83\x9b' != [[:INCOMPLETE:][:INVALID:]] ]] || print fail 3
+ [[ $'\xe3\x83\x9b' = ? ]] || print fail 4
+0:Testing incomplete and invalid multibyte character components
+
+ print -r -- ${(q+):-ホ}
+ foo='She said "ホ". I said "You can'\''t '\''ホ'\'' me!'
+ print -r -- ${(q+)foo}
+0:${(q+)...} with printable multibyte characters
+>ホ
+>'She said "ホ". I said "You can'\''t '\''ホ'\'' me!'
+
+# This will silently succeed if zsh/parameter isn't available
+ (zmodload zsh/parameter >/dev/null 2>&1
+ f() {
+ : $(:)
+ "↓"
+ }
+ : $functions)
+0:Multibyte handling of functions parameter
+
+# c1=U+0104 (Ą) and c2=U+0120 (Ġ) are chosen so that
+# u1 = utf8(c1) = c4 84 < u2 = utf8(c2) = c4 a0
+# metafy(u1) = c4 83 a4 > metafy(u2) = c4 83 80
+# in both UTF-8 and ASCII collations (the latter is used in macOS
+# and some versions of BSDs).
+ local -a names=( $'\u0104' $'\u0120' )
+ print -o $names
+ mkdir -p colltest
+ cd colltest
+ touch $names
+ print ?
+0:Sorting of metafied characters
+>Ą Ġ
+>Ą Ġ
+
+ printf '%q%q\n' 你你
+0:printf %q and quotestring and general metafy / token madness
+>你你
+
+# This test is kept last as it introduces an additional
+# dependency on the system regex library.
+ if zmodload zsh/regex 2>/dev/null; then
+ [[ $'\ua0' =~ '^.$' ]] && print OK
+ [[ $'\ua0' =~ $'^\ua0$' ]] && print OK
+ [[ $'\ua0'X =~ '^X$' ]] || print OK
+ else
+ ZTST_skip="regexp library not found."
+ fi
+0:Ensure no confusion on metafied input to regex module
+>OK
+>OK
+>OK
+F:A failure here may indicate the system regex library does not
+F:support character sets outside the portable 7-bit range.
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D08cmdsubst.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D08cmdsubst.ztst
new file mode 100644
index 0000000..3625373
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D08cmdsubst.ztst
@@ -0,0 +1,169 @@
+# Tests for command substitution.
+
+%prep
+ mkdir cmdsubst.tmp
+ touch cmdsubst.tmp/file{1,2}.txt
+
+%test
+ foo="two words"
+ print -l `echo $foo bar`
+0:Basic `...` substitution
+>two
+>words
+>bar
+
+ foo="two words"
+ print -l $(echo $foo bar)
+0:Basic $(...) substitution
+>two
+>words
+>bar
+
+ foo='intricate buffoonery'
+ print -l "`echo $foo and licentiousness`"
+0:Quoted `...` substitution
+>intricate buffoonery and licentiousness
+
+ foo="more words"
+ print -l "$(echo $foo here)"
+0:Quoted $(...) substitution
+>more words here
+
+# we used never to get this one right, but I think it is now...
+ print -r "`print -r \\\\\\\\`"
+0:Stripping of backslasshes in quoted `...`
+>\\
+
+ print -r "$(print -r \\\\\\\\)"
+0:Stripping of backslashes in quoted $(...)
+>\\\\
+
+ fnify() { print \"$*\"; }
+ print `fnify \`fnify understatement\``
+0:Nested `...`
+>""understatement""
+
+ print $(fnify $(fnify overboard))
+0:Nested $(...)
+>""overboard""
+
+ fructify() { print \'$*\'; }
+ print "`fructify \`fructify indolence\``"
+0:Nested quoted `...`
+>''indolence''
+
+ print "$(fructify $(fructify obtuseness))"
+0:Nested quoted $(...)
+>''obtuseness''
+
+ gesticulate() { print \!$*\!; }
+ print $((gesticulate wildly); gesticulate calmly)
+0:$(( ... ) ... ) is not arithmetic
+>!wildly! !calmly!
+
+ commencify() { print +$*+; }
+ print "$((commencify output); commencify input)"
+0:quoted $(( ... ) .. ) is not arithmetic
+>+output+
+>+input+
+
+ (
+ cd cmdsubst.tmp
+ print first: ${$(print \*)}
+ print second: ${~$(print \*)}
+ print third: ${$(print *)}
+ print fourth: "${~$(print \*)}"
+ print fifth: ${~"$(print \*)"}
+ )
+0:mixing $(...) with parameter substitution and globbing
+>first: *
+>second: file1.txt file2.txt
+>third: file1.txt file2.txt
+>fourth: *
+>fifth: file1.txt file2.txt
+
+ $(exit 0) $(exit 3) || print $?
+0:empty command uses exit value of last substitution
+>3
+
+ X=$(exit 2) $(exit 0) || print $?
+0:variable assignments processed after other substitutions
+>2
+
+ false
+ ``
+0:Empty command substitution resets status
+
+ false
+ echo `echo $?`
+0:Non-empty command substitution inherits status
+>1
+
+ echo $(( ##\" ))
+ echo $(echo \")
+ echo $((echo \"); echo OK)
+0:Handling of backslash double quote in parenthesised substitutions
+>34
+>"
+>" OK
+
+ echo $(case foo in
+ foo)
+ echo This test worked.
+ ;;
+ bar)
+ echo This test failed in a rather bizarre way.
+ ;;
+ *)
+ echo This test failed.
+ ;;
+ esac)
+0:Parsing of command substitution with unmatched parentheses: case, basic
+>This test worked.
+
+ echo "$(case bar in
+ foo)
+ echo This test spoobed.
+ ;;
+ bar)
+ echo This test plurbled.
+ ;;
+ *)
+ echo This test bzonked.
+ ;;
+ esac)"
+0:Parsing of command substitution with unmatched parentheses: case with quotes
+>This test plurbled.
+
+ echo before $(
+ echo start; echo unpretentious |
+ while read line; do
+ case $line in
+ u*)
+ print Word began with u
+ print and ended with a crunch
+ ;;
+ esac
+ done | sed -e 's/Word/Universe/'; echo end
+ ) after
+0:Parsing of command substitution with ummatched parentheses: with frills
+>before start Universe began with u and ended with a crunch end after
+
+ alias foo='echo $('
+ eval 'foo echo this just works, OK\?)'
+0:backtracking within command string parsing with alias still pending
+>this just works, OK?
+
+ (
+ set errexit
+ show_nargs() { print $#; }
+ print a $() b
+ print c "$()" d
+ )
+0:Empty $() is a valid empty substitution.
+>a b
+>c d
+
+ empty=$() && print "'$empty'"
+0:Empty $() is a valid assignment
+>''
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D09brace.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D09brace.ztst
new file mode 100644
index 0000000..3e667a8
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/D09brace.ztst
@@ -0,0 +1,114 @@
+# Tests for brace expansion
+
+%prep
+
+ foo=(a b c)
+ arr=(foo bar baz)
+
+%test
+
+ print X{1,2,{3..6},7,8}Y
+0:Basic brace expansion
+>X1Y X2Y X3Y X4Y X5Y X6Y X7Y X8Y
+
+ print ${foo}{one,two,three}$arr
+0:Brace expansion with arrays, no RC_EXPAND_PARAM
+>a b conefoo ctwofoo cthreefoo bar baz
+
+ print ${^foo}{one,two,three}$arr
+0:Brace expansion with arrays, with RC_EXPAND_PARAM (1)
+>aonefoo atwofoo athreefoo bonefoo btwofoo bthreefoo conefoo ctwofoo cthreefoo bar baz
+
+ print ${foo}{one,two,three}$^arr
+0:Brace expansion with arrays, with RC_EXPAND_PARAM (2)
+>a b conefoo ctwofoo cthreefoo conebar ctwobar cthreebar conebaz ctwobaz cthreebaz
+
+ print ${^foo}{one,two,three}$^arr
+0:Brace expansion with arrays, with RC_EXPAND_PARAM (3)
+>aonefoo atwofoo athreefoo aonebar atwobar athreebar aonebaz atwobaz athreebaz bonefoo btwofoo bthreefoo bonebar btwobar bthreebar bonebaz btwobaz bthreebaz conefoo ctwofoo cthreefoo conebar ctwobar cthreebar conebaz ctwobaz cthreebaz
+
+ print X{01..4}Y
+0:Numeric range expansion, padding (1)
+>X01Y X02Y X03Y X04Y
+
+ print X{1..04}Y
+0:Numeric range expansion, padding (2)
+>X01Y X02Y X03Y X04Y
+
+ print X{7..12}Y
+0:Numeric range expansion, padding (or not) (3)
+>X7Y X8Y X9Y X10Y X11Y X12Y
+
+ print X{07..12}Y
+0:Numeric range expansion, padding (4)
+>X07Y X08Y X09Y X10Y X11Y X12Y
+
+ print X{7..012}Y
+0:Numeric range expansion, padding (5)
+>X007Y X008Y X009Y X010Y X011Y X012Y
+
+ print X{4..1}Y
+0:Numeric range expansion, decreasing
+>X4Y X3Y X2Y X1Y
+
+ print X{1..4}{1..4}Y
+0:Numeric range expansion, combined braces
+>X11Y X12Y X13Y X14Y X21Y X22Y X23Y X24Y X31Y X32Y X33Y X34Y X41Y X42Y X43Y X44Y
+
+ print X{-4..4}Y
+0:Numeric range expansion, negative numbers (1)
+>X-4Y X-3Y X-2Y X-1Y X0Y X1Y X2Y X3Y X4Y
+
+ print X{4..-4}Y
+0:Numeric range expansion, negative numbers (2)
+>X4Y X3Y X2Y X1Y X0Y X-1Y X-2Y X-3Y X-4Y
+
+ print X{004..-4..2}Y
+0:Numeric range expansion, stepping and padding (1)
+>X004Y X002Y X000Y X-02Y X-04Y
+
+ print X{4..-4..02}Y
+0:Numeric range expansion, stepping and padding (1)
+>X04Y X02Y X00Y X-2Y X-4Y
+
+ print X{1..32..3}Y
+0:Numeric range expansion, step alignment (1)
+>X1Y X4Y X7Y X10Y X13Y X16Y X19Y X22Y X25Y X28Y X31Y
+
+ print X{1..32..-3}Y
+0:Numeric range expansion, step alignment (2)
+>X31Y X28Y X25Y X22Y X19Y X16Y X13Y X10Y X7Y X4Y X1Y
+
+ print X{32..1..3}Y
+0:Numeric range expansion, step alignment (3)
+>X32Y X29Y X26Y X23Y X20Y X17Y X14Y X11Y X8Y X5Y X2Y
+
+ print X{32..1..-3}Y
+0:Numeric range expansion, step alignment (4)
+>X2Y X5Y X8Y X11Y X14Y X17Y X20Y X23Y X26Y X29Y X32Y
+
+ setopt brace_ccl
+ print X{za-q521}Y
+ unsetopt brace_ccl
+0:BRACE_CCL on
+>X1Y X2Y X5Y XaY XbY XcY XdY XeY XfY XgY XhY XiY XjY XkY XlY XmY XnY XoY XpY XqY XzY
+
+ print X{za-q521}Y
+0:BRACE_CCL off
+>X{za-q521}Y
+
+ print -r hey{a..j}there
+0:{char..char} ranges, simple case
+>heyathere heybthere heycthere heydthere heyethere heyfthere heygthere heyhthere heyithere heyjthere
+
+ print -r gosh{1,{Z..a},2}cripes
+0:{char..char} ranges, ASCII ordering
+>gosh1cripes goshZcripes gosh[cripes gosh\cripes gosh]cripes gosh^cripes gosh_cripes gosh`cripes goshacripes gosh2cripes
+
+ print -r crumbs{y..p}ooh
+0:{char..char} ranges, reverse
+>crumbsyooh crumbsxooh crumbswooh crumbsvooh crumbsuooh crumbstooh crumbssooh crumbsrooh crumbsqooh crumbspooh
+
+ print -r left{[..]}right
+0:{char..char} ranges with tokenized characters
+>left[right left\right left]right
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/E01options.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/E01options.ztst
new file mode 100644
index 0000000..2bd4fdb
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/E01options.ztst
@@ -0,0 +1,1313 @@
+# Test various shell options.
+# Interactive options not tested here:
+# ALWAYS_LAST_PROMPT
+# ALWAYS_TO_END
+# APPEND_HISTORY (history not maintained)
+# AUTO_LIST
+# AUTO_MENU
+# AUTO_NAME_DIRS (named directory table not maintained)
+# AUTO_PARAM_KEYS
+# AUTO_PARAM_SLASH
+# AUTO_REMOVE_SLASH
+# AUTO_RESUME
+# BANG_HIST
+# BASH_AUTO_LIST
+# BEEP (!)
+# BG_NICE
+# CHECK_JOBS
+# COMPLETE_ALIASES
+# COMPLETE_IN_WORD
+# CORRECT
+# CORRECT_ALL
+# CSH_JUNKIE_HISTORY
+# DVORAK
+# EXTENDED_HISTORY
+# FLOW_CONTROL
+# GLOB_COMPLETE
+# HIST_ALLOW_CLOBBER
+# HIST_BEEP
+# HIST_EXPIRE_DUPS_FIRST
+# HIST_FIND_NO_DUPS
+# HIST_IGNORE_ALL_DUPS
+# HIST_IGNORE_DUPS (-h)
+# HIST_IGNORE_SPACE (-g)
+# HIST_NO_FUNCTIONS
+# HIST_NO_STORE
+# HIST_REDUCE_BLANKS
+# HIST_SAVE_NO_DUPS
+# HIST_VERIFY
+# HUP
+# IGNORE_EOF
+# INC_APPEND_HISTORY
+# INTERACTIVE
+# INTERACTIVE_COMMENTS
+# LIST_AMBIGUOUS
+# LIST_BEEP
+# LIST_PACKED
+# LIST_ROWS_FIRST
+# LIST_TYPES
+# LOGIN
+# LONG_LIST_JOBS
+# MAIL_WARNING
+# MENU_COMPLETE
+# MONITOR
+# NOTIFY
+# OVERSTRIKE
+# PRINT_EIGHT_BIT
+# PROMPT_CR
+# PUSHD_SILENT
+# REC_EXACT
+# RM_STAR_SILENT
+# RM_STAR_WAIT
+# SHARE_HISTORY
+# SINGLE_LINE_ZLE
+# SUN_KEYBOARD_HACK
+# ZLE
+# The following require SHINSTDIN and are not (yet) tested:
+# AUTO_CD
+# SHINSTDIN
+#
+# Other difficult things I haven't done:
+# GLOBAL_RCS (uses fixed files outside build area)
+# HASH_CMDS )
+# HASH_DIRS ) fairly seriously internal, hard to test at all
+# HASH_LIST_ALL )
+# PRINT_EXIT_STATUS haven't worked out what this does yet, although
+# Bart suggested a fix.
+# PRIVILEGED (similar to GLOBAL_RCS)
+# RCS ( " " " " )
+# SH_OPTION_LETTERS even I found this too dull to set up a test for
+# SINGLE_COMMAND kills shell
+# VERBOSE hard because done on input (c.f. SHINSTDIN).
+
+%prep
+ mkdir options.tmp && cd options.tmp
+
+ mkdir tmpcd homedir
+
+ touch tmpfile1 tmpfile2
+
+ mydir=$PWD
+ mydirt=`print -P %~`
+ mydirhome=`export HOME=$mydir/homedir; print -P %~`
+ catpath=$(which cat)
+ lspath==ls
+
+%test
+
+ alias echo='print foo'
+ unsetopt aliases
+ # use eval else aliases are all parsed at start
+ eval echo bar
+ setopt aliases
+ eval echo bar
+ unalias echo
+0:ALIASES option
+>bar
+>foo bar
+
+ setopt allexport
+ testpm1=exported
+ unsetopt allexport
+ testpm2=unexported
+ print ${(t)testpm1}
+ print ${(t)testpm2}
+0:ALL_EXPORT option
+>scalar-export
+>scalar
+
+ # Count the number of directories on the stack. Don't care what they are.
+ dircount() { dirs -v | tail -1 | awk '{ print $1 + 1}'; }
+ unsetopt autopushd
+ cd tmpcd
+ dircount
+ cd ..
+ setopt autopushd
+ cd tmpcd
+ dircount
+ unsetopt autopushd
+ popd >/dev/null
+0:AUTO_PUSHD option
+>1
+>2
+
+ unsetopt badpattern
+ print [a
+ setopt badpattern
+ print [b
+1:BAD_PATTERN option
+>[a
+?(eval):4: bad pattern: [b
+
+ unsetopt bareglobqual nomatch
+ print *(.)
+ setopt bareglobqual nomatch
+ print *(.)
+0:BARE_GLOB_QUAL option
+>*(.)
+>tmpfile1 tmpfile2
+
+ setopt braceccl
+ print {abcd}
+ unsetopt braceccl
+ print {abcd}
+0:BRACE_CCL option
+>a b c d
+>{abcd}
+
+# Don't use NUL as a field separator in the following.
+ setopt braceccl
+ print {$'\0'-$'\5'} | IFS=' ' read -A chars
+ for c in $chars; do print $(( #c )); done
+ unsetopt braceccl
+0:BRACE_CCL option starting from NUL
+>0
+>1
+>2
+>3
+>4
+>5
+
+ setopt bsdecho
+ echo "histon\nimpington"
+ echo -e "girton\ncottenham"
+ unsetopt bsdecho
+ echo "newnham\ncomberton"
+0:BSD_ECHO option
+>histon\nimpington
+>girton
+>cottenham
+>newnham
+>comberton
+
+ unsetopt c_bases
+ print $(( [#16]15 ))
+ print $(( [#8]9 ))
+ setopt c_bases
+ print $(( [#16]31 ))
+ print $(( [#8]17 ))
+ setopt octal_zeroes
+ print $(( [#8]19 ))
+ unsetopt c_bases octal_zeroes
+0:C_BASES option
+>16#F
+>8#11
+>0x1F
+>8#21
+>023
+
+ setopt cdablevars
+ # only absolute paths are eligible for ~-expansion
+ cdablevar1=tmpcd
+ (cd cdablevar1)
+ cdablevar2=$PWD/tmpcd
+ cd cdablevar2
+ cd ..
+ print back in ${PWD:t}
+ unsetopt cdablevars
+ cd cdablevar2
+1q:CDABLE_VARS option
+>back in options.tmp
+?(eval):cd:4: no such file or directory: cdablevar1
+?(eval):cd:10: no such file or directory: cdablevar2
+
+# CHASE_DOTS should go with CHASE_LINKS in B01cd.ztst
+# which saves me having to write it here.
+
+ setopt noclobber
+ rm -f foo1 bar1 rod1
+ echo waterbeach >foo1
+ (echo landbeach >foo1)
+ cat foo1
+ (echo lode >>bar1)
+ [[ -f bar1 ]] && print That shouldn\'t be there.
+ echo denny >rod1
+ echo wicken >>rod1
+ cat rod1
+ unsetopt noclobber
+ rm -f foo2 bar2 rod2
+ echo ely >foo2
+ echo march >foo2
+ cat foo2
+ echo wimpole >>bar2
+ cat bar2
+ echo royston >rod2
+ echo foxton >>rod2
+ cat rod2
+ rm -f foo* bar* rod*
+0:CLOBBER option
+>waterbeach
+>denny
+>wicken
+>march
+>wimpole
+>royston
+>foxton
+?(eval):4: file exists: foo1
+?(eval):6: no such file or directory: bar1
+
+ setopt cshjunkieloops
+ eval 'for f in swaffham bulbeck; print $f; end'
+ print next one should fail >&2
+ unsetopt cshjunkieloops
+ eval 'for f in chesterton arbury; print $f; end'
+1:CSH_JUNKIE_LOOPS option (for loop)
+>swaffham
+>bulbeck
+?next one should fail
+?(eval):1: parse error near `end'
+
+# ` emacs deconfusion
+
+ setopt cshjunkiequotes
+ print this should cause an error >&2
+ eval "print 'line one
+ line two'"
+ print this should not >&2
+ eval "print 'line three\\
+ line four'"
+ unsetopt cshjunkiequotes
+0:CSH_JUNKIE_QUOTES option
+>line three
+> line four
+?this should cause an error
+?(eval):1: unmatched '
+?this should not
+
+# ' emacs deconfusion
+
+ nullcmd() { print '$NULLCMD run'; }
+ readnullcmd() { print 'Running $READNULLCMD'; cat; }
+ NULLCMD=nullcmd
+ READNULLCMD=readnullcmd
+ setopt cshnullcmd
+ rm -f foo
+ print "This should fail" >&2
+ (>foo)
+ print "This should succeed" >&2
+ print "These are the contents of foo" >foo
+ cat foo
+ print "This should also fail" >&2
+ (foo
+ These are the contents of foo
+>Running $READNULLCMD
+>$NULLCMD run
+?This should fail
+?(eval):8: redirection with no command
+?This should succeed
+?This should also fail
+?(eval):13: redirection with no command
+
+# nomatch should be overridden by cshnullglob
+ setopt nomatch cshnullglob
+ print tmp* nothing* blah
+ print -n 'hoping for no match: ' >&2
+ (print nothing* blah)
+ print >&2
+ unsetopt cshnullglob nomatch
+ print tmp* nothing* blah
+ print nothing* blah
+0:CSH_NULL_GLOB option
+>tmpcd tmpfile1 tmpfile2 blah
+>tmpcd tmpfile1 tmpfile2 nothing* blah
+>nothing* blah
+?hoping for no match: (eval):4: no match
+?
+
+# The trick is to avoid =cat being expanded in the output while $catpath is.
+ setopt NO_equals
+ print -n trick; print =cat
+ setopt equals
+ print -n trick; print =cat
+0q:EQUALS option
+>trick=cat
+>trick$catpath
+
+# explanation of expected TRAPZERR output: from false and from
+# testfn() with ERR_EXIT on (hmm, should we really get a second one from
+# the function exiting?), then from the false only with ERR_EXIT off.
+ TRAPZERR() { print ZERR trapped; }
+ testfn() { setopt localoptions $2; print $1 before; false; print $1 after; }
+ (testfn on errexit)
+ testfn off
+ unfunction TRAPZERR testfn
+0:ERR_EXIT option
+>on before
+>ZERR trapped
+>ZERR trapped
+>off before
+>ZERR trapped
+>off after
+
+ (print before; setopt noexec; print after)
+0:NO_EXEC option
+>before
+
+ (setopt noexec
+ typeset -A hash
+ hash['this is a string'])
+0:NO_EXEC option should not attempt to parse subscripts
+
+ (setopt noexec nomatch
+ echo *NonExistentFile*)
+0:NO_EXEC option should not do globbing
+
+ (setopt noexec
+ echo ${unset_var?Not an error})
+0:NO_EXEC should not test for unset variables
+
+ (setopt noexec
+ : ${${string%[aeiou]*}/(#m)?(#e)/${(U)MATCH}} Rule 1
+ : ${array[4,5][1][2,3]} Rule 2
+ : ${${(P)foo[1,6]}[1,3]} Rule 3
+ : "${${(@)array}[1,2]}" Rule 5
+ : "${(@)${(@)array}[1,2]#?}" Rule 6
+ : ${(el.20..X.)${bar}} Rule 11 success case)
+0:NO_EXEC handles parameter substitution examples
+
+ (setopt noexec
+ : ${(el.20..X.)$bar} Rule 11 failure case)
+1:NO_EXEC does recognize bad substitution syntax
+*?* bad substitution
+
+ setopt NO_eval_lineno
+ eval 'print $LINENO'
+ setopt eval_lineno
+ eval 'print $LINENO'
+0:EVAL_LINENO option
+>2
+>1
+
+ # The EXTENDED_GLOB test doesn't test globbing fully --- it just tests
+ # that certain patterns are treated literally with the option off
+ # and as patterns with the option on.
+ testfn() { print -n "$1 $2 $3 "; if [[ $1 = ${~2} ]];
+ then print yes; else print no; fi; }
+ tests=('a#' '?~b' '^aa')
+ strings=('a' 'aa' 'b' 'a#' '?~b' '^aa')
+ for opt in noextendedglob extendedglob; do
+ setopt $opt
+ for test in $tests; do
+ for string in $strings; do
+ testfn $string $test $opt
+ done
+ done
+ done
+0:EXTENDED_GLOB option
+>a a# noextendedglob no
+>aa a# noextendedglob no
+>b a# noextendedglob no
+>a# a# noextendedglob yes
+>?~b a# noextendedglob no
+>^aa a# noextendedglob no
+>a ?~b noextendedglob no
+>aa ?~b noextendedglob no
+>b ?~b noextendedglob no
+>a# ?~b noextendedglob no
+>?~b ?~b noextendedglob yes
+>^aa ?~b noextendedglob no
+>a ^aa noextendedglob no
+>aa ^aa noextendedglob no
+>b ^aa noextendedglob no
+>a# ^aa noextendedglob no
+>?~b ^aa noextendedglob no
+>^aa ^aa noextendedglob yes
+>a a# extendedglob yes
+>aa a# extendedglob yes
+>b a# extendedglob no
+>a# a# extendedglob no
+>?~b a# extendedglob no
+>^aa a# extendedglob no
+>a ?~b extendedglob yes
+>aa ?~b extendedglob no
+>b ?~b extendedglob no
+>a# ?~b extendedglob no
+>?~b ?~b extendedglob no
+>^aa ?~b extendedglob no
+>a ^aa extendedglob yes
+>aa ^aa extendedglob no
+>b ^aa extendedglob yes
+>a# ^aa extendedglob yes
+>?~b ^aa extendedglob yes
+>^aa ^aa extendedglob yes
+
+ foo() { print My name is $0; }
+ unsetopt functionargzero
+ foo
+ setopt functionargzero
+ foo
+ unfunction foo
+0:FUNCTION_ARGZERO option
+>My name is (anon)
+>My name is foo
+
+ setopt _NO_glob_
+ print tmp*
+ set -o glob
+ print tmp*
+0:GLOB option
+>tmp*
+>tmpcd tmpfile1 tmpfile2
+
+ showit() { local v;
+ for v in first second third; do
+ eval print \$$v \$\{\(t\)$v\}
+ done;
+ }
+ setit() { typeset -x first=inside1;
+ typeset +g -x second=inside2;
+ typeset -g -x third=inside3;
+ showit;
+ }
+ first=outside1 second=outside2 third=outside3
+ unsetopt globalexport
+ setit
+ showit
+ setopt globalexport
+ setit
+ showit
+ unfunction setit showit
+0:GLOBAL_EXPORT option
+>inside1 scalar-local-export
+>inside2 scalar-local-export
+>inside3 scalar-export
+>outside1 scalar
+>outside2 scalar
+>inside3 scalar-export
+>inside1 scalar-export
+>inside2 scalar-local-export
+>inside3 scalar-export
+>inside1 scalar-export
+>outside2 scalar
+>inside3 scalar-export
+
+# GLOB_ASSIGN is tested in A06assign.ztst.
+
+ mkdir onlysomefiles
+ touch onlysomefiles/.thisfile onlysomefiles/thatfile
+ setopt globdots
+ print onlysomefiles/*
+ unsetopt globdots
+ print onlysomefiles/*
+ rm -rf onlysomefiles
+0:GLOB_DOTS option
+>onlysomefiles/.thisfile onlysomefiles/thatfile
+>onlysomefiles/thatfile
+
+ # we've tested this enough times already...
+ # could add some stuff for other sorts of expansion
+ foo='tmp*'
+ setopt globsubst
+ print ${foo}
+ unsetopt globsubst
+ print ${foo}
+0:GLOB_SUBST option
+>tmpcd tmpfile1 tmpfile2
+>tmp*
+
+ setopt histsubstpattern
+ print *(:s/t??/TING/)
+ foo=(tmp*)
+ print ${foo:s/??p/THUMP/}
+ foo=(one.c two.c three.c)
+ print ${foo:s/#%(#b)t(*).c/T${match[1]}.X/}
+ print *(#q:s/#(#b)tmp(*e)/'scrunchy${match[1]}'/)
+ unsetopt histsubstpattern
+0:HIST_SUBST_PATTERN option
+>TINGcd TINGfile1 TINGfile2 homedir
+>THUMPcd THUMPfile1 THUMPfile2
+>one.c Two.X Three.X
+>homedir scrunchyfile1 scrunchyfile2 tmpcd
+
+ setopt ignorebraces
+ echo X{a,b}Y
+ unsetopt ignorebraces
+ echo X{a,b}Y
+0:IGNORE_BRACES option
+>X{a,b}Y
+>XaY XbY
+
+ setopt ksh_arrays
+ array=(one two three)
+ print $array $array[2]
+ print ${array[0]} ${array[1]} ${array[2]} ${array[3]}
+ unsetopt ksh_arrays
+ print $array $array[2]
+ print ${array[0]} ${array[1]} ${array[2]} ${array[3]}
+ unset array
+0:KSH_ARRAYS option
+>one one[2]
+>one two three
+>one two three two
+>one two three
+
+ fpath=(.)
+ echo >foo 'echo foo loaded; foo() { echo foo run; }'
+ echo >bar 'bar() { echo bar run; }'
+ setopt kshautoload
+ autoload foo bar
+ foo
+ bar
+ unfunction foo bar
+ unsetopt kshautoload
+ autoload foo bar
+ foo
+ bar
+0:KSH_AUTOLOAD option
+>foo loaded
+>foo run
+>bar run
+>foo loaded
+>bar run
+
+# ksh_glob is tested by the glob tests.
+
+ setopt kshoptionprint globassign
+ print set
+ setopt | grep kshoptionprint
+ setopt | grep globassign
+ unsetopt kshoptionprint
+ print unset
+ setopt | grep kshoptionprint
+ setopt | grep globassign
+ unsetopt globassign
+0:KSH_OPTION_PRINT option
+>set
+>kshoptionprint on
+>globassign on
+>unset
+>globassign
+
+ # This test is now somewhat artificial as
+ # KSH_TYPESET only applies to the builtin
+ # interface. Tests to the more standard
+ # reserved word interface appear elsewhere.
+ (
+ # reserved words are handled during parsing,
+ # hence eval...
+ disable -r typeset
+ eval '
+ setopt kshtypeset
+ ktvars=(ktv1 ktv2)
+ typeset ktfoo=`echo arg1 arg2` $ktvars
+ print $+ktv1 $+ktv2 $+ktv3
+ print $ktfoo
+ unsetopt kshtypeset
+ typeset noktfoo=`echo noktarg1 noktarg2`
+ print $noktfoo
+ print $+noktarg1 $+noktarg2
+ unset ktfoo ktv1 ktv2 noktfoo noktarg2
+ '
+ )
+0:KSH_TYPESET option
+>1 1 0
+>arg1 arg2
+>noktarg1
+>0 1
+
+ showopt() { setopt | egrep 'localoptions|ksharrays'; }
+ f1() { setopt localoptions ksharrays; showopt }
+ f2() { setopt ksharrays; showopt }
+ setopt kshoptionprint
+ showopt
+ f1
+ showopt
+ f2
+ showopt
+ unsetopt ksh_arrays
+0:LOCAL_OPTIONS option
+>ksharrays off
+>localoptions off
+>ksharrays on
+>localoptions on
+>ksharrays off
+>localoptions off
+>ksharrays on
+>localoptions off
+>ksharrays on
+>localoptions off
+
+# LOCAL_TRAPS was tested in C03traps (phew).
+
+ fn() {
+ local HOME=/any/old/name
+ print -l var=~ 'anything goes/here'=~ split=`echo maybe not`;
+ }
+ setopt magicequalsubst
+ fn
+ setopt kshtypeset
+ fn
+ unsetopt magicequalsubst kshtypeset
+ fn
+0:MAGIC_EQUAL_SUBST option
+>var=/any/old/name
+>anything goes/here=/any/old/name
+>split=maybe
+>not
+>var=/any/old/name
+>anything goes/here=/any/old/name
+>split=maybe not
+>var=~
+>anything goes/here=~
+>split=maybe
+>not
+
+ setopt MARK_DIRS
+ print tmp*
+ unsetopt MARK_DIRS
+ print tmp*
+0:MARK_DIRS option
+>tmpcd/ tmpfile1 tmpfile2
+>tmpcd tmpfile1 tmpfile2
+
+# maybe should be in A04redirect
+ print "This is in1" >in1
+ print "This is in2" >in2
+ unsetopt multios
+ print Test message >foo1 >foo2
+ print foo1: $(foo1 >foo2
+ sleep 1 # damn, race in multios
+ print foo1: $(foo1:
+>foo2: Test message
+>This is in2
+>foo1: Test message
+>foo2: Test message
+>This is in1
+>This is in2
+
+# This is trickier than it looks. There's a hack at the end of
+# execcmd() to catch the multio processes attached to the
+# subshell, which otherwise sort of get lost in the general turmoil.
+# Without that, the multios aren't synchronous with the subshell
+# or the main shell starting the "cat", so the output files appear
+# empty.
+ setopt multios
+ ( echo hello ) >multio_out1 >multio_out2 && cat multio_out*
+0:Multios attached to a subshell
+>hello
+>hello
+
+# This tests for another race in multios.
+ print -u $ZTST_fd 'This test hangs the shell when it fails...'
+ setopt multios
+ echo These are the contents of the file >multio_race.out
+ multio_race_fn() { cat; }
+ multio_race_fn <$(echo multio_race.out multio_race.out)
+0:Fix for race with input multios
+>These are the contents of the file
+>These are the contents of the file
+
+# tried this with other things, but not on its own, so much.
+ unsetopt nomatch
+ print with nonomatch: flooble*
+ setopt nomatch
+ print with nomatch flooble*
+1:NOMATCH option
+>with nonomatch: flooble*
+?(eval):4: no matches found: flooble*
+
+# NULL_GLOB should override NONOMATCH...
+ setopt nullglob nomatch
+ print frooble* tmp*
+ unsetopt nullglob nomatch
+ print frooble* tmp*
+0:NULL_GLOB option
+>tmpcd tmpfile1 tmpfile2
+>frooble* tmpcd tmpfile1 tmpfile2
+
+ touch ngs1.txt ngs2.txt ngs10.txt ngs20.txt ngs100.txt ngs200.txt
+ setopt numericglobsort
+ print -l ngs*
+ unsetopt numericglobsort
+ print -l ngs*
+0:NUMERIC_GLOB_SORT option
+>ngs1.txt
+>ngs2.txt
+>ngs10.txt
+>ngs20.txt
+>ngs100.txt
+>ngs200.txt
+>ngs1.txt
+>ngs10.txt
+>ngs100.txt
+>ngs2.txt
+>ngs20.txt
+>ngs200.txt
+
+ typeset -i 10 oznum
+ setopt octalzeroes
+ (( oznum = 012 + 013 ))
+ print $oznum
+ unsetopt octalzeroes
+ (( oznum = 012 + 013 ))
+ print $oznum
+ unset oznum
+0:OCTAL_ZEROES options
+>21
+>25
+
+ typeset -a oldpath
+ oldpath=($path)
+ mkdir pdt_topdir pathtestdir pdt_topdir/pathtestdir
+ print "#!/bin/sh\necho File in upper dir" >pathtestdir/findme
+ print "#!/bin/sh\necho File in lower dir" >pdt_topdir/pathtestdir/findme
+ chmod u+x pathtestdir/findme pdt_topdir/pathtestdir/findme
+ pathtestdir/findme
+ rm -f pathtestdir/findme
+ setopt pathdirs
+ path=($PWD $PWD/pdt_topdir)
+ pathtestdir/findme
+ print unsetting option...
+ unsetopt pathdirs
+ pathtestdir/findme
+ path=($oldpath)
+ unset oldpath
+ rm -rf pdt_topdir pathtestdir
+0:PATH_DIRS option
+>File in upper dir
+>File in lower dir
+>unsetting option...
+?(eval):14: no such file or directory: pathtestdir/findme
+
+ (setopt pathdirs; path+=( /usr/bin ); type ./env)
+1:whence honours PATH_DIRS option
+>./env not found
+
+ setopt posixbuiltins
+ PATH= command -v print
+ PATH= command -V print
+ PATH= command print foo
+ unsetopt posixbuiltins
+ print unsetting...
+ PATH= command -V print
+ PATH= command print foo
+127:POSIX_BUILTINS option
+>print
+>print is a shell builtin
+>foo
+>unsetting...
+>print is a shell builtin
+?(eval):8: command not found: print
+
+ # With non-special command: original value restored
+ # With special builtin: new value kept
+ # With special builtin preceeded by "command": original value restored.
+ (setopt posixbuiltins
+ FOO=val0
+ FOO=val1 true; echo $FOO
+ FOO=val2 times 1>/dev/null 2>&1; echo $FOO
+ FOO=val3 command times 1>/dev/null 2>&1; echo $FOO)
+0:POSIX_BUILTINS and restoring variables
+>val0
+>val2
+>val2
+
+# PRINTEXITVALUE only works if shell input is coming from standard input.
+# Goodness only knows why.
+ $ZTST_testdir/../Src/zsh -f <<<'
+ setopt printexitvalue
+ func() {
+ false
+ }
+ func
+ '
+1:PRINT_EXIT_VALUE option
+?zsh: exit 1
+
+ $ZTST_testdir/../Src/zsh -f <<<'
+ setopt printexitvalue
+ () { false; }
+ '
+1:PRINT_EXIT_VALUE option for anonymous function
+?zsh: exit 1
+
+ setopt promptbang
+ print -P !
+ setopt nopromptbang
+ print -P !
+0:PROMPT_BANG option
+>0
+>!
+
+ unsetopt promptpercent
+ print -P '%/'
+ setopt promptpercent
+ print -P '%/'
+0q:PROMPT_PERCENT option
+>%/
+>$mydir
+
+ setopt promptsubst
+ print -P '`echo waaah`'
+ unsetopt promptsubst
+ print -P '`echo waaah`'
+0:PROMPT_SUBST option
+>waaah
+>`echo waaah`
+
+ dirs
+ pushd $mydir/tmpcd
+ dirs
+ pushd $mydir/tmpcd
+ dirs
+ setopt pushdignoredups
+ pushd $mydir/tmpcd
+ dirs
+ unsetopt pushdignoredups
+ popd >/dev/null
+ popd >/dev/null
+0q:PUSHD_IGNOREDUPS option
+>$mydirt
+>$mydirt/tmpcd $mydirt
+>$mydirt/tmpcd $mydirt/tmpcd $mydirt
+>$mydirt/tmpcd $mydirt/tmpcd $mydirt
+
+ mkdir newcd
+ cd $mydir
+ pushd $mydir/tmpcd
+ pushd $mydir/newcd
+ dirs
+ pushd -0
+ dirs
+ setopt pushdminus pushdsilent
+ pushd -0
+ dirs
+ unsetopt pushdminus
+ popd >/dev/null
+ popd >/dev/null
+ cd $mydir
+0q:PUSHD_MINUS option
+>$mydirt/newcd $mydirt/tmpcd $mydirt
+>$mydirt $mydirt/newcd $mydirt/tmpcd
+>$mydirt $mydirt/newcd $mydirt/tmpcd
+
+# Do you have any idea how dull this is?
+
+ (export HOME=$mydir/homedir
+ pushd $mydir/tmpcd
+ pushd
+ dirs
+ setopt pushdtohome
+ pushd
+ dirs
+ unsetopt pushdtohome
+ popd
+ pushd
+ popd
+ dirs)
+0q:PUSHD_TO_HOME option
+>$mydirhome $mydirhome/tmpcd
+>~ $mydirhome $mydirhome/tmpcd
+>$mydirhome
+
+ array=(one two three four)
+ setopt rcexpandparam
+ print aa${array}bb
+ unsetopt rcexpandparam
+ print aa${array}bb
+0:RC_EXPAND_PARAM option
+>aaonebb aatwobb aathreebb aafourbb
+>aaone two three fourbb
+
+ setopt rcquotes
+ # careful, this is done when parsing a complete block
+ eval "print 'one''quoted''expression'"
+ unsetopt rcquotes
+ eval "print 'another''quoted''expression'"
+0:RC_QUOTES option
+>one'quoted'expression
+>anotherquotedexpression
+
+# too lazy to test jobs -Z and ARGV0.
+ (setopt restricted; cd /)
+ (setopt restricted; PATH=/bin:/usr/bin)
+ (setopt restricted; /bin/ls)
+ (setopt restricted; hash ls=/bin/ls)
+ (setopt restricted; print ha >outputfile)
+ (setopt restricted; exec ls)
+ (setopt restricted; unsetopt restricted)
+ :
+0:RESTRICTED option
+?(eval):cd:1: restricted
+?(eval):2: PATH: restricted
+?(eval):3: /bin/ls: restricted
+?(eval):hash:4: restricted: /bin/ls
+?(eval):5: writing redirection not allowed in restricted mode
+?(eval):exec:6: ls: restricted
+?(eval):unsetopt:7: can't change option: restricted
+
+# ' emacs deconfusion
+
+ fn() {
+ print =ls ={ls,}
+ local foo='=ls'
+ print ${~foo}
+ }
+ setopt shfileexpansion
+ fn
+ unsetopt shfileexpansion
+ fn
+0q:SH_FILE_EXPANSION option
+>$lspath =ls =
+>=ls
+>$lspath $lspath =
+>$lspath
+
+ testpat() {
+ if [[ $1 = ${~2} ]]; then print $1 $2 yes; else print $1 $2 no; fi
+ }
+ print option on
+ setopt shglob
+ repeat 2; do
+ for str in 'a(b|c)' ab; do
+ testpat $str 'a(b|c)'
+ done
+ for str in 'a<1-10>' a9; do
+ testpat $str 'a<1-10>'
+ done
+ [[ ! -o shglob ]] && break
+ print option off
+ unsetopt shglob
+ done
+0:SH_GLOB option
+>option on
+>a(b|c) a(b|c) yes
+>ab a(b|c) no
+>a<1-10> a<1-10> yes
+>a9 a<1-10> no
+>option off
+>a(b|c) a(b|c) no
+>ab a(b|c) yes
+>a<1-10> a<1-10> no
+>a9 a<1-10> yes
+
+ print this is bar >bar
+ fn() {
+ local NULLCMD=cat READNULLCMD=cat
+ { echo hello | >foo } 2>/dev/null
+ cat foo
+ option set
+>option unset
+>hello
+>this is bar
+
+ fn() {
+ eval 'for f in foo bar; print $f'
+ eval 'for f (word1 word2) print $f'
+ eval 'repeat 3 print nonsense'
+ }
+ unsetopt shortloops
+ print option unset
+ fn
+ setopt shortloops
+ print option set
+ fn
+0:SHORT_LOOPS option
+>option unset
+>option set
+>foo
+>bar
+>word1
+>word2
+>nonsense
+>nonsense
+>nonsense
+?(eval):1: parse error near `print'
+?(eval):1: parse error near `print'
+?(eval):1: parse error near `print'
+
+ fn() { print -l $*; }
+ setopt shwordsplit
+ print option set
+ repeat 2; do
+ foo='two words'
+ fn $foo
+ fn "${=foo}"
+ [[ ! -o shwordsplit ]] && break
+ unsetopt shwordsplit
+ print option unset
+ done
+0:SH_WORD_SPLIT option
+>option set
+>two
+>words
+>two
+>words
+>option unset
+>two words
+>two
+>words
+
+ fn() { unset foo; print value is $foo; }
+ setopt nounset
+ print option unset unset by setting nounset
+ eval fn
+ print option unset reset
+ setopt unset
+ fn
+0:UNSET option
+>option unset unset by setting nounset
+>option unset reset
+>value is
+?fn: foo: parameter not set
+
+ fn1() { unset foo; print value 1 is ${foo#bar}; }
+ fn2() { unset foo; print value 2 is ${foo%bar}; }
+ fn3() { unset foo; print value 3 is ${foo/bar}; }
+ setopt nounset
+ print option unset unset by setting nounset
+ eval fn1
+ eval fn2
+ eval fn3
+ print option unset reset
+ setopt unset
+ fn1
+ fn2
+ fn3
+0:UNSET option with operators
+>option unset unset by setting nounset
+>option unset reset
+>value 1 is
+>value 2 is
+>value 3 is
+?fn1: foo: parameter not set
+?fn2: foo: parameter not set
+?fn3: foo: parameter not set
+
+ fn() {
+ emulate -L zsh
+ setopt warncreateglobal
+ foo1=bar1
+ unset foo1
+ foo1=bar2
+ local foo2=bar3
+ unset foo2
+ foo2=bar4
+ typeset -g foo3
+ foo3=bar5
+ fn2() {
+ foo3=bar6
+ }
+ foo4=bar7 =true
+ (( foo5=8 ))
+ integer foo6=9
+ (( foo6=10 ))
+ }
+ # don't pollute the test environment with the variables...
+ (fn)
+0:WARN_CREATE_GLOBAL option
+?fn:3: scalar parameter foo1 created globally in function fn
+?fn:5: scalar parameter foo1 created globally in function fn
+?fn:15: numeric parameter foo5 created globally in function fn
+
+ fn() {
+ emulate -L zsh
+ setopt warncreateglobal
+ TZ=UTC date >&/dev/null
+ local um=$(TZ=UTC date 2>/dev/null)
+ }
+ fn
+0:WARN_CREATE_GLOBAL negative cases
+
+ (
+ foo1=global1 foo2=global2 foo3=global3 foo4=global4
+ integer foo5=5
+ # skip foo6, defined in fn_wnv
+ foo7=(one two)
+ fn_wnv() {
+ # warns
+ foo1=bar1
+ # doesn't warn
+ local foo2=bar3
+ unset foo2
+ # still doesn't warn
+ foo2=bar4
+ # doesn't warn
+ typeset -g foo3=bar5
+ # warns
+ foo3=bar6
+ fn2() {
+ # warns if global option, not attribute
+ foo3=bar6
+ }
+ fn2
+ # doesn't warn
+ foo4=bar7 =true
+ # warns
+ (( foo5=8 ))
+ integer foo6=9
+ # doesn't warn
+ (( foo6=10 ))
+ foo7[3]=three
+ foo7[4]=(four)
+ }
+ print option off >&2
+ fn_wnv
+ print option on >&2
+ setopt warnnestedvar
+ fn_wnv
+ unsetopt warnnestedvar
+ print function attribute on >&2
+ functions -W fn_wnv
+ fn_wnv
+ print all off again >&2
+ functions +W fn_wnv
+ fn_wnv
+ )
+0:WARN_NESTED_VAR option
+?option off
+?option on
+?fn_wnv:2: scalar parameter foo1 set in enclosing scope in function fn_wnv
+?fn_wnv:11: scalar parameter foo3 set in enclosing scope in function fn_wnv
+?fn2:2: scalar parameter foo3 set in enclosing scope in function fn2
+?fn_wnv:20: numeric parameter foo5 set in enclosing scope in function fn_wnv
+?function attribute on
+?fn_wnv:2: scalar parameter foo1 set in enclosing scope in function fn_wnv
+?fn_wnv:11: scalar parameter foo3 set in enclosing scope in function fn_wnv
+?fn_wnv:20: numeric parameter foo5 set in enclosing scope in function fn_wnv
+?all off again
+
+
+ (
+ setopt warnnestedvar
+ () {
+ typeset -A a
+ : ${a[hello world]::=foo}
+ print ${(t)a}
+ key="hello world"
+ print $a[$key]
+ }
+ )
+0:No false positive on parameter used with subscripted assignment
+>association-local
+>foo
+
+ (
+ setopt warnnestedvar
+ () {
+ local var=(one two)
+ () { var=three; }
+ print $var
+ }
+ )
+0:Warn when changing type of nested variable: array to scalar.
+?(anon): scalar parameter var set in enclosing scope in function (anon)
+>three
+
+ (
+ setopt warnnestedvar
+ () {
+ local var=three
+ () { var=(one two); }
+ print $var
+ }
+ )
+0:Warn when changing type of nested variable: scalar to array.
+?(anon): array parameter var set in enclosing scope in function (anon)
+>one two
+
+# This really just tests if XTRACE is egregiously broken.
+# To test it properly would need a full set of its own.
+ fn() { print message; }
+ PS4='+%N:%i> '
+ setopt xtrace
+ fn
+ unsetopt xtrace
+ fn
+0:XTRACE option
+>message
+>message
+?+(eval):4> fn
+?+fn:0> print message
+?+(eval):5> unsetopt xtrace
+
+ setopt ignoreclosebraces
+ eval "icb_test() { echo this is OK; }"
+ icb_test
+ icb_args() { print $#; }
+ eval "icb_args { this, is, ok, too }"
+0:IGNORE_CLOSE_BRACES option
+>this is OK
+>6
+
+ (setopt pipefail
+ true | true | true
+ print $?
+ true | false | true
+ print $?
+ exit 2 | false | true
+ print $?
+ false | exit 2 | true
+ print $?)
+0:PIPE_FAIL option
+>0
+>1
+>1
+>2
+
+ for (( i = 0; i < 10; i++ )); do
+ () {
+ print $i
+ break
+ }
+ done
+0:NO_LOCAL_LOOPS
+>0
+
+ () {
+ emulate -L zsh
+ setopt localloops
+ for (( i = 0; i < 10; i++ )); do
+ () {
+ setopt nolocalloops # ignored in parent
+ print $i
+ break
+ }
+ done
+ }
+0:LOCAL_LOOPS
+>0
+>1
+>2
+>3
+>4
+>5
+>6
+>7
+>8
+>9
+?(anon):4: `break' active at end of function scope
+?(anon):4: `break' active at end of function scope
+?(anon):4: `break' active at end of function scope
+?(anon):4: `break' active at end of function scope
+?(anon):4: `break' active at end of function scope
+?(anon):4: `break' active at end of function scope
+?(anon):4: `break' active at end of function scope
+?(anon):4: `break' active at end of function scope
+?(anon):4: `break' active at end of function scope
+?(anon):4: `break' active at end of function scope
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/E02xtrace.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/E02xtrace.ztst
new file mode 100644
index 0000000..da6191c
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/E02xtrace.ztst
@@ -0,0 +1,148 @@
+# Test that xtrace output is correctly generated
+
+%prep
+ mkdir xtrace.tmp && cd xtrace.tmp
+
+ function xtf {
+ local regression_test_dummy_variable
+ print "$*"
+ }
+ function xtfx {
+ local regression_test_dummy_variable
+ print "Tracing: (){ builtin 2>file }" 2>>xtrace.err
+ { print "Tracing: (){ { builtin } 2>file }" } 2>>xtrace.err
+ }
+ echo 'print "$*"' > xt.in
+
+%test
+
+ PS4='+%N:%i> '
+ set -x
+ print 'Tracing: builtin'
+ print 'Tracing: builtin 2>file' 2>xtrace.err
+ cat <<<'Tracing: external'
+ cat <<<'Tracing: external 2>file' 2>>xtrace.err
+ ( print 'Tracing: ( builtin )' )
+ ( print 'Tracing: ( builtin ) 2>file' ) 2>>xtrace.err
+ ( cat <<<'Tracing: ( external )' )
+ ( cat <<<'Tracing: ( external ) 2>file' ) 2>>xtrace.err
+ { print 'Tracing: { builtin }' }
+ { print 'Tracing: { builtin } 2>file' } 2>>xtrace.err
+ { cat <<<'Tracing: { external }' }
+ { cat <<<'Tracing: { external } 2>file' } 2>>xtrace.err
+ repeat 1 do print 'Tracing: do builtin done'; done
+ repeat 1 do print 'Tracing: do builtin done 2>file'; done 2>>xtrace.err
+ repeat 1 do cat <<<'Tracing: do external done'; done
+ repeat 1 do cat <<<'Tracing: do external done 2>file'; done 2>>xtrace.err
+ xtf 'Tracing: function'
+ xtf 'Tracing: function 2>file' 2>>xtrace.err
+ xtfx
+ . ./xt.in 'Tracing: source'
+ . ./xt.in 'Tracing: source 2>file' 2>>xtrace.err
+ set +x
+ cat xtrace.err
+0:xtrace with and without redirection
+>Tracing: builtin
+>Tracing: builtin 2>file
+>Tracing: external
+>Tracing: external 2>file
+>Tracing: ( builtin )
+>Tracing: ( builtin ) 2>file
+>Tracing: ( external )
+>Tracing: ( external ) 2>file
+>Tracing: { builtin }
+>Tracing: { builtin } 2>file
+>Tracing: { external }
+>Tracing: { external } 2>file
+>Tracing: do builtin done
+>Tracing: do builtin done 2>file
+>Tracing: do external done
+>Tracing: do external done 2>file
+>Tracing: function
+>Tracing: function 2>file
+>Tracing: (){ builtin 2>file }
+>Tracing: (){ { builtin } 2>file }
+>Tracing: source
+>Tracing: source 2>file
+>+(eval):8> print 'Tracing: ( builtin ) 2>file'
+>+(eval):10> cat
+>+(eval):12> print 'Tracing: { builtin } 2>file'
+>+(eval):14> cat
+>+(eval):16> print 'Tracing: do builtin done 2>file'
+>+(eval):18> cat
+>+xtf:1> local regression_test_dummy_variable
+>+xtf:2> print 'Tracing: function 2>file'
+>+xtfx:3> print 'Tracing: (){ { builtin } 2>file }'
+?+(eval):3> print 'Tracing: builtin'
+?+(eval):4> print 'Tracing: builtin 2>file'
+?+(eval):5> cat
+?+(eval):6> cat
+?+(eval):7> print 'Tracing: ( builtin )'
+?+(eval):9> cat
+?+(eval):11> print 'Tracing: { builtin }'
+?+(eval):13> cat
+?+(eval):15> print 'Tracing: do builtin done'
+?+(eval):17> cat
+?+(eval):19> xtf 'Tracing: function'
+?+xtf:1> local regression_test_dummy_variable
+?+xtf:2> print 'Tracing: function'
+?+(eval):20> xtf 'Tracing: function 2>file'
+?+(eval):21> xtfx
+?+xtfx:1> local regression_test_dummy_variable
+?+xtfx:2> print 'Tracing: (){ builtin 2>file }'
+?+(eval):22> . ./xt.in 'Tracing: source'
+?+./xt.in:1> print 'Tracing: source'
+?+(eval):23> . ./xt.in 'Tracing: source 2>file'
+?+./xt.in:1> print 'Tracing: source 2>file'
+?+(eval):24> set +x
+
+ typeset -ft xtf
+ xtf 'Tracing: function'
+0:tracing function
+>Tracing: function
+?+xtf:1> local regression_test_dummy_variable
+?+xtf:2> print 'Tracing: function'
+
+ echo 'PS4="+%x:%I> "
+ fn() {
+ print This is fn.
+ }
+ :
+ fn
+ ' >fnfile
+ $ZTST_testdir/../Src/zsh -fx ./fnfile 2>errfile
+ grep '\./fnfile' errfile 1>&2
+0:Trace output with sourcefile and line number.
+>This is fn.
+?+./fnfile:1> PS4='+%x:%I> '
+?+./fnfile:5> :
+?+./fnfile:6> fn
+?+./fnfile:3> print This is fn.
+
+ set -x
+ [[ 'f o' == 'f x'* || 'b r' != 'z o' && 'squashy sound' < 'squishy sound' ]]
+ [[ 'f o' = 'f x'* || 'b r' != 'z o' && 'squashy sound' < 'squishy sound' ]]
+ [[ -e nonexistentfile || ( -z '' && -t 3 ) ]]
+ set +x
+0:Trace for conditions
+?+(eval):2> [[ 'f o' == f\ x* || 'b r' != z\ o && 'squashy sound' < 'squishy sound' ]]
+?+(eval):3> [[ 'f o' = f\ x* || 'b r' != z\ o && 'squashy sound' < 'squishy sound' ]]
+?+(eval):4> [[ -e nonexistentfile || -z '' && -t 3 ]]
+?+(eval):5> set +x
+
+ # Part 1: Recurses into nested anonymous functions
+ fn() {
+ () { () { true } }
+ }
+ functions -T fn
+ fn
+ # Part 2: Doesn't recurse into named functions
+ gn() { true }
+ fn() { gn }
+ functions -T fn
+ fn
+0:tracing recurses into anonymous functions
+?+fn:1> '(anon)'
+?+(anon):0> '(anon)'
+?+(anon):0> true
+?+fn:0> gn
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/Makefile.in b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/Makefile.in
new file mode 100644
index 0000000..083df49
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/Makefile.in
@@ -0,0 +1,75 @@
+#
+# Makefile for Test subdirectory
+#
+# Copyright (c) 1999 Peter Stephensons
+# All rights reserved.
+#
+# Permission is hereby granted, without written agreement and without
+# license or royalty fees, to use, copy, modify, and distribute this
+# software and to distribute modified versions of this software for any
+# purpose, provided that the above copyright notice and the following
+# two paragraphs appear in all copies of this software.
+#
+# In no event shall Peter Stephenson or the Zsh Development Group be liable
+# to any party for direct, indirect, special, incidental, or consequential
+# damages arising out of the use of this software and its documentation,
+# even if Peter Stephenson and the Zsh Development Group have been advised of
+# the possibility of such damage.
+#
+# Peter Stephenson and the Zsh Development Group specifically disclaim any
+# warranties, including, but not limited to, the implied warranties of
+# merchantability and fitness for a particular purpose. The software
+# provided hereunder is on an "as is" basis, and Peter Stephenson and the
+# Zsh Development Group have no obligation to provide maintenance,
+# support, updates, enhancements, or modifications.
+#
+
+subdir = Test
+dir_top = ..
+SUBDIRS =
+
+@VERSION_MK@
+
+# source/build directories
+VPATH = @srcdir@
+sdir = @srcdir@
+sdir_top = @top_srcdir@
+INSTALL = @INSTALL@
+
+@DEFS_MK@
+
+# ========== DEPENDENCIES FOR TESTING ==========
+
+check test:
+ if test -n "$(DLLD)"; then \
+ cd $(dir_top) && DESTDIR= \
+ $(MAKE) MODDIR=`pwd`/$(subdir)/Modules install.modules > /dev/null; \
+ fi
+ if ZTST_testlist="`for f in $(sdir)/$(TESTNUM)*.ztst; \
+ do echo $$f; done`" \
+ ZTST_srcdir="$(sdir)" \
+ ZTST_exe=$(dir_top)/Src/zsh@EXEEXT@ \
+ $(dir_top)/Src/zsh@EXEEXT@ +Z -f $(sdir)/runtests.zsh; then \
+ stat=0; \
+ else \
+ stat=1; \
+ fi; \
+ sleep 1; \
+ rm -rf Modules .zcompdump; \
+ exit $$stat
+
+# ========== DEPENDENCIES FOR CLEANUP ==========
+
+@CLEAN_MK@
+
+mostlyclean-here:
+ rm -rf Modules .zcompdump *.tmp
+
+distclean-here:
+ rm -f Makefile
+
+realclean-here:
+
+# ========== DEPENDENCIES FOR MAINTENANCE ==========
+
+@CONFIG_MK@
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/README b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/README
new file mode 100644
index 0000000..d012277
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/README
@@ -0,0 +1,30 @@
+There are now different sections, expressed by the first letter in the
+scripts names:
+
+ A: basic command parsing and execution
+ B: builtins
+ C: shell commands with special syntax
+ D: substititution
+ E: options
+ V: modules
+ W: builtin interactive commands and constructs
+ X: line editing
+ Y: completion
+ Z: separate systems and user contributions
+
+You will need to run these by using `make test' in the Test subdirectory of
+the build area for your system (which may or may not be the same as the
+Test subdirectory of the source tree), or the directory above. You can get
+more information about the tests being performed with
+ ZTST_verbose=1 make check
+(`test' is equivalent to `check') or change 1 to 2 for even more detail.
+
+Individual or groups of tests can be performed with
+ make TESTNUM=C02 check
+or
+ make TESTNUM=C check
+to perform just the test beginning C02, or all tests beginning C,
+respectively.
+
+Instructions on how to write tests are given in B01cd.ztst, which acts as a
+model.
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V02zregexparse.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V02zregexparse.ztst
new file mode 100644
index 0000000..b4cec42
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V02zregexparse.ztst
@@ -0,0 +1,382 @@
+# Tests corresponding to the texinfo node `Conditional Expressions'
+
+%prep
+
+ if ! zmodload zsh/zutil 2>/dev/null; then
+ ZTST_unimplemented="can't load the zsh/zutil module for testing"
+ fi
+
+%test
+
+ zregexparse p1 p2 ''
+0:empty
+
+ zregexparse p1 p2 a /a/
+0:element
+
+ zregexparse p1 p2 aaaaaa /a/ \#
+0:closure
+
+ zregexparse p1 p2 ab /a/ /b/
+0:concatenation
+
+ zregexparse p1 p2 a /a/ \| /b/
+0:alternation 1
+
+ zregexparse p1 p2 b /a/ \| /b/
+0:alternation 2
+
+ zregexparse p1 p2 a \( /a/ \)
+0:grouping
+
+ zregexparse p1 p2 abbaaab \( /a/ \| /b/ \) \#
+0:alternation, grouping and closure
+
+ zregexparse p1 p2 abcdef /ab/ %cd% /cdef/
+0:lookahead 1
+
+ zregexparse p1 p2 abcdef /ab/ %ZZ% /cdef/
+1:lookahead 2
+
+ zregexparse p1 p2 abcd /ab/ %cd% '-print guard' ':print caction' /cd/
+0:pattern, lookahead, guard and completion action
+>guard
+
+ zregexparse p1 p2 abcd /ab/ %cd% '-print guard; false' ':print caction' /cd/
+1:guard failure
+>guard
+>caction
+
+ zregexparse p1 p2 abcdef /ab/ '{print AB}' /cd/ '{print CD}' /ef/ '{print EF}'
+0:action
+>AB
+>CD
+>EF
+
+ zregexparse p1 p2 aaa
+ print $? $p1 $p2
+0:aaa
+>2 0 0
+
+ zregexparse p1 p2 aaa /a/
+ print $? $p1 $p2
+0:aaa /a/
+>2 1 1
+
+ zregexparse p1 p2 aaa /a/ /a/
+ print $? $p1 $p2
+0:aaa 2*/a/
+>2 2 2
+
+ zregexparse p1 p2 aaa /a/ /a/ /a/
+ print $? $p1 $p2
+0:aaa 3*/a/
+>0 3 3
+
+ zregexparse p1 p2 aaa /a/ /a/ /a/ /a/
+ print $? $p1 $p2
+0:aaa 4*/a/
+>1 3 3
+
+ zregexparse p1 p2 aaa /a/ /a/ /a/ /a/ /a/
+ print $? $p1 $p2
+0:aaa 5*/a/
+>1 3 3
+
+ zregexparse p1 p2 aaa /aaa/
+ print $? $p1 $p2
+0:aaa /aaa/
+>0 3 3
+
+ zregexparse p1 p2 aaa /aaa/ /a/
+ print $? $p1 $p2
+0:aaa /aaa/ /a/
+>1 3 3
+
+ zregexparse p1 p2 aaa /a/ \#
+ print $? $p1 $p2
+0:aaa /aaa/ #
+>0 3 3
+
+ zregexparse p1 p2 aaa /a/ \# \#
+ print $? $p1 $p2
+0:aaa /aaa/ # #
+>0 3 3
+
+ zregexparse p1 p2 aaa \( /a/ \)
+ print $? $p1 $p2
+0:aaa ( /a/ )
+>2 1 1
+
+ zregexparse p1 p2 aaa \( /a/ \) \#
+ print $? $p1 $p2
+0:aaa ( /a/ ) #
+>0 3 3
+
+ zregexparse p1 p2 aaa /a/ /b/
+ print $? $p1 $p2
+0:aaa /a/ /b/
+>1 1 1
+
+ zregexparse p1 p2 a /a/ '{print A}'
+ print $? $p1 $p2
+0:a /a/ '{A}'
+>A
+>0 1 1
+
+ zregexparse p1 p2 a /b/ '{print A}'
+ print $? $p1 $p2
+0:a /b/ '{A}'
+>1 0 0
+
+ zregexparse p1 p2 a /b/ ':print A' '{print B}'
+ print $? $p1 $p2
+0:a /b/ ':A' '{B}'
+>A
+>1 0 0
+
+ zregexparse p1 p2 ab /a/ '{print A}'
+ print $? $p1 $p2
+0:ab /a/ '{A}'
+>2 1 1
+
+ zregexparse p1 p2 ab /a/ '{print A}' /b/ '{print B}'
+ print $? $p1 $p2
+0:ab /a/ '{A}' /b/ '{B}'
+>A
+>B
+>0 2 2
+
+ zregexparse p1 p2 ab /a/ ':print A' '{print B}' /b/ ':print C' '{print D}'
+ print $? $p1 $p2
+0:ab /a/ ':A' '{B}' /b/ ':C' '{D}'
+>B
+>D
+>0 2 2
+
+ zregexparse p1 p2 abc /a/ '{print A}' /b/ '{print B}' /c/ '{print C}'
+ print $? $p1 $p2
+0:abc /a/ '{A}' /b/ '{B}' /c/ '{C}'
+>A
+>B
+>C
+>0 3 3
+
+ zregexparse p1 p2 abz /a/ '{print A}' /b/ '{print B}' /c/ '{print C}'
+ print $? $p1 $p2
+0:abz /a/ '{A}' /b/ '{B}' /c/ '{C}'
+>A
+>1 2 2
+
+ zregexparse p1 p2 azz /a/ '{print A}' /b/ '{print B}' /c/ '{print C}'
+ print $? $p1 $p2
+0:azz /a/ '{A}' /b/ '{B}' /c/ '{C}'
+>1 1 1
+
+ zregexparse p1 p2 aba '{print A}' /a/ '{print B}' /b/ '{print C}' /c/ '{print D}'
+ print $? $p1 $p2
+0:aba '{A}' /a/ '{B}' /b/ '{C}' /c/ '{D}'
+>A
+>B
+>1 2 2
+
+ zregexparse p1 p2 a /a/ '{print "$match[1]"}'
+ print $? $p1 $p2
+0:a /a/ '{M1}'
+>a
+>0 1 1
+
+ zregexparse p1 p2 aaa /a/ '{print A}' //
+ print $? $p1 $p2
+0:aaa /a/ '{A}' //
+>A
+>2 1 1
+
+ zregexparse p1 p2 aaa /a/ '{print "$match[1]"}' // '{print A}'
+ print $? $p1 $p2
+0:aaa /a/ '{M1}' // '{A}'
+>a
+>2 1 1
+
+ zregexparse p1 p2 abcdef /a/ '{print $match[1]}' /b/ '{print $match[1]}' /c/ '{print $match[1]}' // '{print A}'
+ print $? $p1 $p2
+0:abcdef /a/ '{M1}' /b/ '{M1}' /c/ '{M1}' // '{A}'
+>a
+>b
+>c
+>2 3 3
+
+ zregexparse p1 p2 abcdef /a/ '{print A}' /b/ '{print B}' /c/ '{print C}' // '{print D}'
+ print $? $p1 $p2
+0:abcdef /a/ '{A}' /b/ '{B}' /c/ '{C}' // '{D}'
+>A
+>B
+>C
+>2 3 3
+
+ zregexparse p1 p2 a /a/ '{print A}' /b/ '{print B}'
+ print $? $p1 $p2
+0:a /a/ {A} /b/ {B}
+>1 1 1
+
+ zregexparse p1 p2 abcdef \
+ /a/ '-print Ga:$p1:$p2:$match[1]' '{print Aa:$p1:$p2:$match[1]}' \
+ /b/ '-print Gb:$p1:$p2:$match[1]' '{print Ab:$p1:$p2:$match[1]}' \
+ /c/ '-print Gc:$p1:$p2:$match[1]' '{print Ac:$p1:$p2:$match[1]}' \
+ //
+ print $? $p1 $p2
+0:abcdef /a/ -Ga {Aa} /b/ -Gb {Aa} /c/ -Gc {Ac} //
+>Ga:0:0:a
+>Gb:1:1:b
+>Aa:1:1:a
+>Gc:2:2:c
+>Ab:2:2:b
+>Ac:3:3:c
+>2 3 3
+
+ zregexparse p1 p2 abcdef \
+ /a/ '-print Ga:$p1:$p2:$match[1]' '{print Aa:$p1:$p2:$match[1]}' \
+ /b/ '-print Gb:$p1:$p2:$match[1]' '{print Ab:$p1:$p2:$match[1]}' \
+ /c/ '-print Gc:$p1:$p2:$match[1]' '{print Ac:$p1:$p2:$match[1]}' \
+ '/[]/' ':print F:$p1:$p2'
+ print $? $p1 $p2
+0:abcdef /a/ -Ga {Aa} /b/ -Gb {Ab} /c/ -Gc {Ac} /[]/ :F
+>Ga:0:0:a
+>Gb:1:1:b
+>Aa:1:1:a
+>Gc:2:2:c
+>Ab:2:2:b
+>F:3:3
+>1 3 3
+
+ zregexparse p1 p2 abcdef \
+ /a/ '-print Ga:$p1:$p2:$match[1]' '{print Aa:$p1:$p2:$match[1]}' \
+ /b/ '-print Gb:$p1:$p2:$match[1]' '{print Ab:$p1:$p2:$match[1]}' \
+ /c/ '-print Gc:$p1:$p2:$match[1]' '{print Ac:$p1:$p2:$match[1]}' \
+ \( '/[]/' ':print F1:$p1:$p2' \| /z/ ':print F2' \)
+ print $? $p1 $p2
+0:abcdef /a/ -Ga {Aa} /b/ -Gb {Ab} /c/ -Gc {Ac} ( /[]/ :F1 | /z/ :F2 )
+>Ga:0:0:a
+>Gb:1:1:b
+>Aa:1:1:a
+>Gc:2:2:c
+>Ab:2:2:b
+>F1:3:3
+>F2
+>1 3 3
+
+ zregexparse p1 p2 a '/[]/' ':print A'
+ print $? $p1 $p2
+0:a /[]/ :A
+>A
+>1 0 0
+
+ zregexparse p1 p2 $'\0' $'/\0/' '{print A}'
+ print $? $p1 $p2
+0:"\0" /\0/ {A}
+>A
+>0 1 1
+
+ zregexparse p1 p2 $'\0' $'/\0/' '{print A}' '/ /' '{print B}'
+ print $? $p1 $p2
+0:"\0" /\0/ {A} / / {B}
+>1 1 1
+
+ zregexparse p1 p2 abcdef \( '/?/' '{print $match[1]}' \) \#
+ print $? $p1 $p2
+0:abcdef ( /?/ {M1} ) #
+>a
+>b
+>c
+>d
+>e
+>f
+>0 6 6
+
+ zregexparse p1 p2 abcdef \( '/c?|?/' '{print $match[1]}' \) \#
+ print $? $p1 $p2
+0:abcdef ( /c?|?/ {M1} ) #
+>a
+>b
+>cd
+>e
+>f
+>0 6 6
+
+ zregexparse p1 p2 abcacdef \( /a/ '{print $match[1]}' \| /b/ '{print $match[1]}' \| /c/ '{print $match[1]}' \) \#
+ print $? $p1 $p2
+0:abcacdef ( /a/ {M1} | /b/ {M1} | /c/ {M1} ) #
+>a
+>b
+>c
+>a
+>1 5 5
+
+ zregexparse p1 p2 abcdef \( /a/ ':print A' \| /b/ ':print B' \| /c/ ':print C' \) \#
+ print $? $p1 $p2
+0:abcdef ( /a/ :A | /b/ :B | /c/ :C ) #
+>A
+>B
+>C
+>1 3 3
+
+ zregexparse p1 p2 abcdef \( /a/ ':print A' '{print $match[1]}' \| /b/ ':print B' '{print $match[1]}' \| /c/ ':print C' '{print $match[1]}' \) \#
+ print $? $p1 $p2
+0:abcdef ( /a/ :A {M1} | /b/ :B {M1} | /c/ :C {M1} ) #
+>a
+>b
+>A
+>B
+>C
+>1 3 3
+
+ zregexparse p1 p2 $'com\0xx' /$'[^\0]#\0'/ \( /$'[^\0]#\0'/ :'print A' /$'[^\0]#\0'/ :'print B' \) \#
+ print $? $p1 $p2
+0:"com\0xx" /W/ ( /W/ :A /W/ :B ) #
+>A
+>1 4 4
+
+ zregexparse p1 p2 $'com\0xx\0yy' /$'[^\0]#\0'/ \( /$'[^\0]#\0'/ :'print A' /$'[^\0]#\0'/ :'print B' \) \#
+ print $? $p1 $p2
+0:"com\0xx\0yy" /W/ ( /W/ :A /W/ :B ) #
+>B
+>1 7 7
+
+ zregexparse p1 p2 $'com\0xx\0yy\0zz' /$'[^\0]#\0'/ \( /$'[^\0]#\0'/ :'print A' /$'[^\0]#\0'/ :'print B' \) \#
+ print $? $p1 $p2
+0:"com\0xx\0yy\0zz" /W/ ( /W/ :A /W/ :B ) #
+>A
+>1 10 10
+
+ zregexparse p1 p2 abcdez /abc/ ':print A:$p1:$p2' /def/ ':print B:$p1:$p2'
+ print $? $p1 $p2
+0:abcdez /abc/ :A /def/ :B
+>B:3:3
+>1 3 3
+
+ zregexparse p1 p2 abcdez /abc/+ ':print A:$p1:$p2' /def/ ':print B:$p1:$p2'
+ print $? $p1 $p2
+0:abcdez /abc/+ :A /def/ :B
+>A:0:3
+>B:0:3
+>1 0 3
+
+ zregexparse p1 p2 abcdez /abc/+ ':print A:$p1:$p2' // /def/ ':print B:$p1:$p2'
+ print $? $p1 $p2
+0:abcdez /abc/+ :A // /def/ :B
+>A:0:3
+>B:0:3
+>1 0 3
+
+ zregexparse p1 p2 abcdez /abc/+ ':print A:$p1:$p2' //- /def/ ':print B:$p1:$p2'
+ print $? $p1 $p2
+0:abcdez /abc/+ :A //- /def/ :B
+>B:3:3
+>1 3 3
+
+ zregexparse p1 p2 $'ZZZZ\0abcdef' $'/ZZZZ\0/' /abc/+ ':print A:$p1:$p2' /dee/ ':print B:$p1:$p2'
+ print $? $p1 $p2
+0:"ZZZZ\0abcdef" /ZZZZ\0/ /abc/+ :A /dee/ :B
+>A:5:8
+>B:5:8
+>1 5 8
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V03mathfunc.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V03mathfunc.ztst
new file mode 100644
index 0000000..1edb7a2
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V03mathfunc.ztst
@@ -0,0 +1,141 @@
+# Tests for the module zsh/mathfunc
+
+%prep
+ if ! zmodload zsh/mathfunc 2>/dev/null; then
+ ZTST_unimplemented="The module zsh/mathfunc is not available."
+ fi
+
+%test
+ # -g makes pi available in later tests
+ float -gF 5 pi
+ (( pi = 4 * atan(1.0) ))
+ print $pi
+0:Basic operation with atan
+>3.14159
+
+ float -F 5 result
+ (( result = atan(3,2) ))
+ print $result
+0:atan with two arguments
+>0.98279
+
+ print $(( atan(1,2,3) ))
+1:atan can't take three arguments
+?(eval):1: wrong number of arguments: atan(1,2,3)
+
+ float r1=$(( rand48() ))
+ float r2=$(( rand48() ))
+ float r3=$(( rand48() ))
+ # Yes, this is a floating point equality test like they tell
+ # you not to do. As the pseudrandom sequence is deterministic,
+ # this is the right thing to do in this case.
+ if (( r1 == r2 )); then
+ print "Seed not updated correctly the first time"
+ else
+ print "First two random numbers differ, OK"
+ fi
+ if (( r2 == r3 )); then
+ print "Seed not updated correctly the second time"
+ else
+ print "Second two random numbers differ, OK"
+ fi
+0:rand48 with default initialisation
+F:This test fails if your math library doesn't have erand48().
+>First two random numbers differ, OK
+>Second two random numbers differ, OK
+
+ seed=f45677a6cbe4
+ float r1=$(( rand48(seed) ))
+ float r2=$(( rand48(seed) ))
+ seed2=$seed
+ float r3=$(( rand48(seed) ))
+ float r4=$(( rand48(seed2) ))
+ # Yes, this is a floating point equality test like they tell
+ # you not to do. As the pseudrandom sequence is deterministic,
+ # this is the right thing to do in this case.
+ if (( r1 == r2 )); then
+ print "Seed not updated correctly the first time"
+ else
+ print "First two random numbers differ, OK"
+ fi
+ if (( r2 == r3 )); then
+ print "Seed not updated correctly the second time"
+ else
+ print "Second two random numbers differ, OK"
+ fi
+ if (( r3 == r4 )); then
+ print "Identical seeds generate identical numbers, OK"
+ else
+ print "Indeterminate result from identical seeds"
+ fi
+0:rand48 with pre-generated seed
+F:This test fails if your math library doesn't have erand48().
+>First two random numbers differ, OK
+>Second two random numbers differ, OK
+>Identical seeds generate identical numbers, OK
+
+ float -F 5 pitest
+ (( pitest = 4.0 * atan(1) ))
+ # This is a string test of the output to 5 digits.
+ if [[ $pi = $pitest ]]; then
+ print "OK, atan on an integer seemed to work"
+ else
+ print "BAD: got $pitest instead of $pi"
+ fi
+0:Conversion of arguments from integer
+>OK, atan on an integer seemed to work
+
+ float -F 5 result
+ typeset str
+ for str in 0 0.0 1 1.5 -1 -1.5; do
+ (( result = abs($str) ))
+ print $result
+ done
+0:Use of abs on various numbers
+>0.00000
+>0.00000
+>1.00000
+>1.50000
+>1.00000
+>1.50000
+
+ print $(( sqrt(-1) ))
+1:Non-negative argument checking for square roots.
+?(eval):1: math: argument to sqrt out of range
+
+# Simple test that the pseudorandom number generators are producing
+# something that could conceivably be pseudorandom numbers in a
+# linear range. Not a detailed quantitative verification.
+ integer N=10000 isource ok=1
+ float -F f sum sumsq max max2 av sd
+ typeset -a randoms
+ randoms=('f = RANDOM' 'f = rand48()')
+ for isource in 1 2; do
+ (( sum = sumsq = max = 0 ))
+ repeat $N; do
+ let $randoms[$isource]
+ (( f > max )) && (( max = f ))
+ (( sum += f, sumsq += f * f ))
+ done
+ (( av = sum / N ))
+ (( sd = sqrt((sumsq - N * av * av) / (N-1)) ))
+ (( max2 = 0.5 * max ))
+ if (( av > max2 * 1.1 )) || (( av < max2 * 0.9 )); then
+ print "WARNING: average of random numbers is suspicious.
+ Was testing: $randoms[$isource]"
+ (( ok = 0 ))
+ fi
+ if (( sd < max / 4 )); then
+ print "WARNING: distribution of random numbers is suspicious.
+ Was testing: $randoms[$isource]"
+ (( ok = 0 ))
+ fi
+ done
+ (( ok ))
+0:Test random number generator distributions are not grossly broken
+
+ float -F 5 g l
+ (( g = gamma(2), l = lgamma(2) ))
+ print $g, $l
+0:Test Gamma function gamma and lgamma
+>1.00000, 0.00000
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V04features.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V04features.ztst
new file mode 100644
index 0000000..6939053
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V04features.ztst
@@ -0,0 +1,172 @@
+%prep
+
+# Do some tests on handling of features.
+# This also does some slightly more sophisticated loading and
+# unloading tests than we did in V01zmodload.ztst.
+#
+# We use zsh/datetime because it has a list of features that is short
+# but contains two types.
+
+ # Subshell for prep test so we can load individual features later
+ if ! (zmodload zsh/datetime 2>/dev/null); then
+ ZTST_unimplemented="can't load the zsh/datetime module for testing"
+ fi
+
+%test
+ zmodload -F zsh/datetime
+ zmodload -lF zsh/datetime
+0:Loading modules with no features
+>-b:strftime
+>-p:EPOCHSECONDS
+>-p:EPOCHREALTIME
+>-p:epochtime
+
+ zmodload -F zsh/datetime b:strftime
+ zmodload -lF zsh/datetime
+0:Enabling features
+>+b:strftime
+>-p:EPOCHSECONDS
+>-p:EPOCHREALTIME
+>-p:epochtime
+
+ zmodload -F zsh/datetime +p:EPOCHSECONDS -b:strftime
+ zmodload -lF zsh/datetime
+0:Disabling features
+>-b:strftime
+>+p:EPOCHSECONDS
+>-p:EPOCHREALTIME
+>-p:epochtime
+
+ zmodload -Fe zsh/datetime p:EPOCHSECONDS b:strftime
+0:Testing existing features
+
+ zmodload -Fe zsh/datetime +p:EPOCHSECONDS
+0:Testing features are in given state (on feature is on)
+
+ zmodload -Fe zsh/datetime -p:EPOCHSECONDS
+1:Testing features are in given state (on feature is not off
+
+ zmodload -Fe zsh/datetime +p:strftime
+1:Testing features are in given state (off feature is not on)
+
+ zmodload -Fe zsh/datetime -b:strftime
+0:Testing features are in given state (off feature is off
+
+ zmodload -Fe zsh/datetime p:EPOCHSECONDS b:strftime b:mktimebetter
+1:Testing non-existent features
+
+ zmodload -FlP dtf zsh/datetime
+ for feature in b:strftime p:EPOCHSECONDS; do
+ if [[ ${${dtf[(R)?$feature]}[1]} = + ]]; then
+ print $feature is enabled
+ else
+ print $feature is disabled
+ fi
+ done
+0:Testing features via array parameter
+>b:strftime is disabled
+>p:EPOCHSECONDS is enabled
+
+ fn() {
+ local EPOCHSECONDS=scruts
+ print $EPOCHSECONDS
+ print ${(t)EPOCHSECONDS}
+ }
+ fn
+ if [[ $EPOCHSECONDS = <-> ]]; then
+ print EPOCHSECONDS is a number
+ else
+ print EPOCHSECONDS is some random piece of junk
+ fi
+ print ${(t)EPOCHSECONDS}
+0:Module special parameter is hidden by a local parameter
+>scruts
+>scalar-local
+>EPOCHSECONDS is a number
+>integer-readonly-hide-hideval-special
+
+ typeset +h EPOCHSECONDS
+ fn() {
+ local EPOCHSECONDS=scruts
+ print Didn\'t get here >&2
+ }
+ fn
+1:Unhidden readonly special can't be assigned to when made local
+?fn:1: read-only variable: EPOCHSECONDS
+
+ zmodload -u zsh/datetime
+0:Module unloaded
+
+ zmodload -e zsh/datetime
+1:Module doesn't exist when unloaded
+
+ zmodload -Fe zsh/datetime p:EPOCHSECONDS
+1:Module doesn't have features when unloaded
+
+ fn() {
+ local EPOCHSECONDS=scrimf
+ zmodload zsh/datetime
+ }
+ fn
+2:Failed to add parameter if local parameter present
+?fn:2: Can't add module parameter `EPOCHSECONDS': local parameter exists
+?fn:zsh/datetime:2: error when adding parameter `EPOCHSECONDS'
+
+ zmodload -lF zsh/datetime
+0:Feature state with loading after error enabling
+>+b:strftime
+>-p:EPOCHSECONDS
+>+p:EPOCHREALTIME
+>+p:epochtime
+
+ zmodload -F zsh/datetime p:EPOCHSECONDS
+ zmodload -Fe zsh/datetime +p:EPOCHSECONDS
+0:Successfully added feature parameter that previously failed
+
+ fn() {
+ local EPOCHSECONDS=scrooble
+ zmodload -u zsh/datetime
+ print $EPOCHSECONDS
+ }
+ fn
+ print ${+EPOCHSECONDS}
+0:Successfully unloaded a module despite a parameter being hidden
+>scrooble
+>0
+
+ EPOCHSECONDS=(any old parameter)
+ print -l $EPOCHSECONDS
+0:Using parameter as normal after unloading is OK
+>any
+>old
+>parameter
+
+ print strftime is ${builtins[strftime]:-undefined}
+ zmodload -F zsh/datetime b:strftime
+ print strftime is ${builtins[strftime]:-undefined}
+ zmodload -F zsh/datetime -b:strftime
+ print strftime is ${builtins[strftime]:-undefined}
+0:Enabling and disabling of builtins as features
+>strftime is undefined
+>strftime is defined
+>strftime is undefined
+
+ zmodload -u zsh/datetime
+ zmodload zsh/datetime
+2:Loading won't override global parameter
+?(eval):2: Can't add module parameter `EPOCHSECONDS': parameter already exists
+?(eval):zsh/datetime:2: error when adding parameter `EPOCHSECONDS'
+
+ unset EPOCHSECONDS
+ zmodload -F zsh/datetime p:EPOCHSECONDS
+ zmodload -Fe zsh/datetime +p:EPOCHSECONDS
+0:unsetting a global parameter allows feature parameter to be enabled
+
+ zmodload -F zsh/datetime -b:strftime -p:EPOCHSECONDS
+ zmodload zsh/datetime
+ zmodload -lF zsh/datetime
+0:zmodload with no -F enables all features
+>+b:strftime
+>+p:EPOCHSECONDS
+>+p:EPOCHREALTIME
+>+p:epochtime
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V05styles.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V05styles.ztst
new file mode 100644
index 0000000..ca95b63
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V05styles.ztst
@@ -0,0 +1,143 @@
+%prep
+
+# Test the use of styles, if the zsh/zutil module is available.
+
+ if ! zmodload zsh/zutil 2>/dev/null; then
+ ZTST_unimplemented="can't load the zsh/zutil module for testing"
+ fi
+
+%test
+ zstyle :random:stuff any-old-style with any old value
+ zstyle :randomly:chosen some-other-style I can go on and on
+ zstyle -d
+ zstyle
+0:zstyle -d restores a pristine state
+
+# patterns should be ordered by weight, so add in reverse order to check
+ zstyle ':ztst:context*' scalar-style other-scalar-value
+ zstyle ':ztst:context:*' scalar-style second-scalar-value
+ zstyle ':ztst:context:sub1' scalar-style scalar-value
+ zstyle ':ztst:context:sub1' array-style array value elements 'with spaces'
+ zstyle ':ztst:context*' boolean-style false
+ zstyle ':ztst:context:sub1' boolean-style true
+0:defining styles
+
+# styles are now sorted, but patterns are in order of definition
+ zstyle
+0:listing styles in default format
+>array-style
+> :ztst:context:sub1 array value elements 'with spaces'
+>boolean-style
+> :ztst:context:sub1 true
+> :ztst:context* false
+>scalar-style
+> :ztst:context:sub1 scalar-value
+> :ztst:context:* second-scalar-value
+> :ztst:context* other-scalar-value
+
+ zstyle -L
+0:listing styles in zstyle format
+>zstyle :ztst:context:sub1 array-style array value elements 'with spaces'
+>zstyle :ztst:context:sub1 boolean-style true
+>zstyle ':ztst:context*' boolean-style false
+>zstyle :ztst:context:sub1 scalar-style scalar-value
+>zstyle ':ztst:context:*' scalar-style second-scalar-value
+>zstyle ':ztst:context*' scalar-style other-scalar-value
+
+ zstyle -b :ztst:context:sub1 boolean-style bool; print $bool
+ zstyle -t :ztst:context:sub1 boolean-style
+0:boolean test -b/-t + true
+>yes
+
+ zstyle -b :ztst:context:sub2 boolean-style bool; print $bool
+ zstyle -t :ztst:context:sub2 boolean-style
+1:boolean test -b/-t + false
+>no
+
+ zstyle -b :ztst:context:sub1 boolean-unset-style bool; print $bool
+ zstyle -t :ztst:context:sub1 boolean-unset-style
+2:boolean test -b/-t + unset
+>no
+
+ zstyle -T :ztst:context:sub1 boolean-style
+0:boolean test -T + true
+
+ zstyle -T :ztst:context:sub2 boolean-style
+1:boolean test -T + false
+
+ zstyle -T :ztst:context:sub1 boolean-unset-style
+0:boolean test -T + unset
+
+ zstyle -s :ztst:context:sub1 scalar-style scalar && print $scalar
+ zstyle -s :ztst:context:sub2 scalar-style scalar && print $scalar
+ zstyle -s :ztst:contextual-psychedelia scalar-style scalar && print $scalar
+ zstyle -s :ztst:contemplative scalar-style scalar || print no match
+0:pattern matching rules
+>scalar-value
+>second-scalar-value
+>other-scalar-value
+>no match
+
+ zstyle -s :ztst:context:sub1 array-style scalar + && print $scalar
+0:scalar with separator
+>array+value+elements+with spaces
+
+ zstyle -e :ztst:\* eval-style 'reply=($something)'
+ something=(one two three)
+ zstyle -a :ztst:eval eval-style array && print -l $array
+0:zstyle -e evaluations
+>one
+>two
+>three
+
+# pattern ordering on output is not specified, so although in the
+# current implementation it's deterministic we shouldn't
+# assume it's always the same. Thus we sort the array.
+# (It might be a nice touch to order patterns by weight, which is
+# the way they are stored for each separate style.)
+ zstyle -g array && print -l ${(o)array}
+0:retrieving patterns
+>:ztst:*
+>:ztst:context*
+>:ztst:context:*
+>:ztst:context:sub1
+
+ zstyle -m :ztst:context:sub1 array-style 'w* *s'
+0:positive pattern match
+
+ zstyle -m :ztst:context:sub1 array-style 'v'
+1:negative pattern match
+
+ zstyle -g array ':ztst:context*' && print -l $array
+0:retrieving styles by pattern
+>boolean-style
+>scalar-style
+
+ zstyle -g array ':ztst:context:sub1' array-style && print -l $array
+0:retrieving values by pattern and name
+>array
+>value
+>elements
+>with spaces
+
+ zstyle -d :ztst:context:sub1
+ zstyle
+0:deleting styles by pattern only
+>boolean-style
+> :ztst:context* false
+>eval-style
+>(eval) :ztst:* 'reply=($something)'
+>scalar-style
+> :ztst:context:* second-scalar-value
+> :ztst:context* other-scalar-value
+
+ zstyle -d :ztst:context\* scalar-style
+ zstyle
+0:deleting styles by pattern and style name
+>boolean-style
+> :ztst:context* false
+>eval-style
+>(eval) :ztst:* 'reply=($something)'
+>scalar-style
+> :ztst:context:* second-scalar-value
+
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V07pcre.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V07pcre.ztst
new file mode 100644
index 0000000..ad17707
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V07pcre.ztst
@@ -0,0 +1,139 @@
+%prep
+
+ if ! zmodload -F zsh/pcre C:pcre-match 2>/dev/null
+ then
+ ZTST_unimplemented="the zsh/pcre module is not available"
+ return 0
+ fi
+# Load the rest of the builtins
+ zmodload zsh/pcre
+ setopt rematch_pcre
+# Find a UTF-8 locale.
+ setopt multibyte
+# Don't let LC_* override our choice of locale.
+ unset -m LC_\*
+ mb_ok=
+ langs=(en_{US,GB}.{UTF-,utf}8 en.UTF-8
+ $(locale -a 2>/dev/null | egrep 'utf8|UTF-8'))
+ for LANG in $langs; do
+ if [[ é = ? ]]; then
+ mb_ok=1
+ break;
+ fi
+ done
+ if [[ -z $mb_ok ]]; then
+ ZTST_unimplemented="no UTF-8 locale or multibyte mode is not implemented"
+ else
+ print -u $ZTST_fd Testing PCRE multibyte with locale $LANG
+ mkdir multibyte.tmp && cd multibyte.tmp
+ fi
+
+%test
+
+ [[ 'foo→bar' =~ .([^[:ascii:]]). ]]
+ print $MATCH
+ print $match[1]
+0:Basic non-ASCII regexp matching
+>o→b
+>→
+
+ unset match mend
+ s=$'\u00a0'
+ [[ $s =~ '^.$' ]] && print OK
+ [[ A${s}B =~ .(.). && $match[1] == $s ]] && print OK
+ [[ A${s}${s}B =~ A([^[:ascii:]]*)B && $mend[1] == 3 ]] && print OK
+ unset s
+0:Raw IMETA characters in input string
+>OK
+>OK
+>OK
+
+ [[ foo =~ f.+ ]] ; print $?
+ [[ foo =~ x.+ ]] ; print $?
+ [[ ! foo =~ f.+ ]] ; print $?
+ [[ ! foo =~ x.+ ]] ; print $?
+ [[ foo =~ f.+ && bar =~ b.+ ]] ; print $?
+ [[ foo =~ x.+ && bar =~ b.+ ]] ; print $?
+ [[ foo =~ f.+ && bar =~ x.+ ]] ; print $?
+ [[ ! foo =~ f.+ && bar =~ b.+ ]] ; print $?
+ [[ foo =~ f.+ && ! bar =~ b.+ ]] ; print $?
+ [[ ! ( foo =~ f.+ && bar =~ b.+ ) ]] ; print $?
+ [[ ! foo =~ x.+ && bar =~ b.+ ]] ; print $?
+ [[ foo =~ x.+ && ! bar =~ b.+ ]] ; print $?
+ [[ ! ( foo =~ x.+ && bar =~ b.+ ) ]] ; print $?
+0:Regex result inversion detection
+>0
+>1
+>1
+>0
+>0
+>1
+>1
+>1
+>1
+>1
+>0
+>1
+>0
+
+# Note that PCRE_ANCHORED only means anchored at the start
+# Also note that we don't unset MATCH/match on failed match (and it's an
+# open issue as to whether or not we should)
+ pcre_compile '.(→.)'
+ pcre_match foo→bar
+ print $? $MATCH $match ; unset MATCH match
+ pcre_match foo.bar
+ print $? $MATCH $match ; unset MATCH match
+ pcre_match foo†bar
+ print $? $MATCH $match ; unset MATCH match
+ pcre_match foo→†ar
+ print $? $MATCH $match ; unset MATCH match
+ pcre_study
+ pcre_match foo→bar
+ print $? $MATCH $match ; unset MATCH match
+ pcre_compile -a '.(→.)'
+ pcre_match foo→bar
+ print $? $MATCH $match ; unset MATCH match
+ pcre_match o→bar
+ print $? $MATCH $match ; unset MATCH match
+ pcre_match o→b
+ print $? $MATCH $match ; unset MATCH match
+ pcre_compile 'x.(→.)'
+ pcre_match xo→t
+ print $? $MATCH $match ; unset MATCH match
+ pcre_match Xo→t
+ print $? $MATCH $match ; unset MATCH match
+ pcre_compile -i 'x.(→.)'
+ pcre_match xo→t
+ print $? $MATCH $match ; unset MATCH match
+ pcre_match Xo→t
+ print $? $MATCH $match ; unset MATCH match
+0:pcre_compile interface testing: basic, anchored & case-insensitive
+>0 o→b →b
+>1
+>1
+>0 o→† →†
+>0 o→b →b
+>1
+>0 o→b →b
+>0 o→b →b
+>0 xo→t →t
+>1
+>0 xo→t →t
+>0 Xo→t →t
+
+ string="The following zip codes: 78884 90210 99513"
+ pcre_compile -m "\d{5}"
+ pcre_match -b -- $string && print "$MATCH; ZPCRE_OP: $ZPCRE_OP"
+ pcre_match -b -n $ZPCRE_OP[(w)2] -- $string || print failed
+ print "$MATCH; ZPCRE_OP: $ZPCRE_OP"
+0:pcre_match -b and pcre_match -n
+>78884; ZPCRE_OP: 25 30
+>90210; ZPCRE_OP: 31 36
+
+# Subshell because crash on failure
+ ( setopt re_match_pcre
+ [[ test.txt =~ '^(.*_)?(test)' ]]
+ echo $match[2] )
+0:regression for segmentation fault, workers/38307
+>test
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V08zpty.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V08zpty.ztst
new file mode 100644
index 0000000..b0cbfa0
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V08zpty.ztst
@@ -0,0 +1,29 @@
+# zpty is required by tests of interactive modes of the shell itself.
+# This tests some extra things.
+
+%prep
+
+ if ! zmodload zsh/zpty 2>/dev/null
+ then
+ ZTST_unimplemented="the zsh/zpty module is not available"
+ elif [[ $OSTYPE = cygwin ]]; then
+ ZTST_unimplemented="the zsh/zpty module does not work on Cygwin"
+ fi
+
+%test
+
+ zpty cat cat
+ zpty -w cat a line of text
+ var=
+ zpty -r cat var && print -r -- ${var%%$'\r\n'}
+ zpty -d cat
+0:zpty with a process that does not set up the terminal: internal write
+>a line of text
+
+ zpty cat cat
+ print a line of text | zpty -w cat
+ var=
+ zpty -r cat var && print -r -- ${var%%$'\r\n'}
+ zpty -d cat
+0:zpty with a process that does not set up the terminal: write via stdin
+>a line of text
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V09datetime.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V09datetime.ztst
new file mode 100644
index 0000000..7905155
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V09datetime.ztst
@@ -0,0 +1,74 @@
+%prep
+
+ if zmodload zsh/datetime 2>/dev/null; then
+ setopt multibyte
+ unset LC_ALL
+ LC_TIME=C
+ TZ=UTC+0
+ # It's not clear this skip_extensions is correct, but the
+ # format in question is causing problems on Solaris.
+ # We'll revist this after the release.
+ [[ "$(strftime %^_10B 0)" = " JANUARY" ]] || skip_extensions=1
+ [[ "$(LC_TIME=ja_JP.UTF-8 strftime %OS 1)" = 一 ]] || skip_japanese=1
+ else
+ ZTST_unimplemented="can't load the zsh/datetime module for testing"
+ fi
+
+%test
+
+ strftime %y 0
+ strftime %Y 1000000000
+ strftime %x 1200000000
+ strftime %X 1200000001
+0:basic format specifiers
+>70
+>2001
+>01/10/08
+>21:20:01
+
+ strftime %-m_%f_%K_%L 1181100000
+ strftime %6. 0
+0:zsh extensions
+>6_6_3_3
+>000000
+
+ if [[ $skip_extensions = 1 ]]; then
+ ZTST_skip="strftime extensions not supported"
+ elif [[ $skip_japanese = 1 ]]; then
+ ZTST_skip="Japanese UTF-8 locale not supported"
+ else
+ (
+ LC_TIME=ja_JP.UTF-8
+ strftime %Ey 1000000000
+ strftime %Oy 1000000000
+ strftime %Ex 1000000000
+ strftime %OS 1000000000
+ strftime %03Ey 650000000
+ )
+ fi
+0:alternate format extensions
+>13
+>一
+>平成13年09月09日
+>四十
+>002
+
+ if [[ $skip_extensions = 1 ]]; then
+ ZTST_skip="strftime extensions not supported"
+ else
+ (
+ strftime '%#A' 0
+ strftime '%^_10B' 0
+ strftime %03Ey 650000000
+ strftime %-Oe 0
+ )
+ fi
+0:various extensions
+>THURSDAY
+> JANUARY
+>090
+>1
+
+ print -r -- ${(V)"$(strftime $'%Y\0%m\0%d' 100000000)"}
+0:Embedded nulls
+>1973^@03^@03
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V10private.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V10private.ztst
new file mode 100644
index 0000000..78ecd48
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/V10private.ztst
@@ -0,0 +1,304 @@
+# Tests for the zsh/param/private module
+
+%prep
+
+ if ! zmodload zsh/param/private 2>/dev/null; then
+ ZTST_unimplemented="can't load the zsh/param/private module for testing"
+ else
+ # Do not use .tmp here, ztst.zsh will remove it too soon (see %cleanup)
+ mkdir private.TMP
+ sed -e 's,# test_zsh_param_private,zmodload zsh/param/private,' < $ZTST_srcdir/B02typeset.ztst > private.TMP/B02
+ fi
+
+%test
+
+ (zmodload -u zsh/param/private && zmodload zsh/param/private)
+0:unload and reload the module without crashing
+
+ typeset scalar_test=toplevel
+ () {
+ print $scalar_test
+ private scalar_test
+ print $+scalar_test
+ unset scalar_test
+ print $+scalar_test
+ }
+ print $scalar_test
+0:basic scope hiding
+>toplevel
+>1
+>0
+>toplevel
+
+ typeset scalar_test=toplevel
+ print $scalar_test
+ () {
+ private scalar_test=function
+ print $scalar_test
+ }
+ print $scalar_test
+0:enter and exit a scope
+>toplevel
+>function
+>toplevel
+
+ print $+unset_test
+ () {
+ private unset_test
+ print $+unset_test
+ unset_test=setme
+ print $unset_test
+ }
+ print $+unset_test
+0:variable defined only in scope
+>0
+>1
+>setme
+>0
+
+ # Depends on zsh-5.0.9 typeset keyword
+ typeset -a array_test=(top level)
+ () {
+ local -Pa array_test=(in function)
+ () {
+ private array_test
+ print $+array_test
+ }
+ print $array_test
+ }
+ print $array_test
+0:nested scope with different type, correctly restored
+>1
+>in function
+>top level
+
+ typeset -a array_test=(top level)
+ () {
+ private array_test
+ array_test=(in function)
+ }
+1:type of private may not be changed by assignment
+?(anon):2: array_test: attempt to assign array value to non-array
+
+ typeset -A hash_test=(top level)
+ () {
+ setopt localoptions noglob
+ private hash_test[top]
+ }
+1:associative array fields may not be private
+?(anon):private:2: hash_test[top]: can't create local array elements
+
+ () {
+ private path
+ }
+1:tied params may not be private, part 1
+?(anon):private:1: can't change scope of existing param: path
+
+ () {
+ private PATH
+ }
+1:tied params may not be private, part 2
+?(anon):private:1: can't change scope of existing param: PATH
+
+ () {
+ private -h path
+ print X$path
+ }
+0:privates may hide tied paramters
+>X
+
+ # Deliberate type mismatch here
+ typeset -a hash_test=(top level)
+ typeset -p hash_test
+ inner () {
+ private -p hash_test
+ print ${(t)hash_test} ${(kv)hash_test}
+ }
+ outer () {
+ local -PA hash_test=(in function)
+ typeset -p hash_test
+ inner
+ }
+ outer
+ print ${(kv)hash_test}
+0:private hides value from surrounding scope in nested scope
+>typeset -a hash_test=( top level )
+>typeset -A hash_test=( in function )
+>typeset -g -a hash_test=( top level )
+>array-local top level
+>top level
+F:note "typeset" rather than "private" in output from outer
+
+ () {
+ private -a array_test
+ local array_test=scalar
+ }
+1:private cannot be re-declared as local
+?(anon):local:2: array_test: inconsistent type for assignment
+
+ () {
+ local hash_test=scalar
+ private -A hash_test
+ }
+1:local cannot be re-declared as private
+?(anon):private:2: can't change scope of existing param: hash_test
+
+ inner () {
+ print $+scalar_test
+ $ZTST_testdir/../Src/zsh -fc 'print X $scalar_test'
+ }
+ () {
+ private -x scalar_test=whaat
+ $ZTST_testdir/../Src/zsh -fc 'print X $scalar_test'
+ inner
+ print Y $scalar_test
+ }
+0:exported private behaves like a local, part 1
+>X whaat
+>0
+>X whaat
+>Y whaat
+
+ inner () {
+ typeset -p array_test
+ $ZTST_testdir/../Src/zsh -fc 'print X $array_test'
+ }
+ () {
+ local -Pax array_test=(whaat)
+ print Y $array_test
+ $ZTST_testdir/../Src/zsh -fc 'print X $array_test'
+ inner
+ }
+0:exported private behaves like a local, part 2 (arrays do not export)
+?inner:typeset:1: no such variable: array_test
+>Y whaat
+>X
+>X
+
+ inner () {
+ print $+scalar_test
+ $ZTST_testdir/../Src/zsh -fc 'print X $scalar_test'
+ }
+ () {
+ private scalar_test=whaat
+ export scalar_test
+ $ZTST_testdir/../Src/zsh -fc 'print X $scalar_test'
+ inner
+ () {
+ print $+scalar_test
+ $ZTST_testdir/../Src/zsh -fc 'print X $scalar_test'
+ }
+ print Y $scalar_test
+ }
+0:exported private behaves like a local, part 3 (export does not change scope)
+>X whaat
+>0
+>X whaat
+>0
+>X whaat
+>Y whaat
+
+ typeset -A hash_test=(top level)
+ () {
+ local -PA hash_test=(in function)
+ () {
+ print X ${(kv)hash_test}
+ }
+ print Y ${(kv)hash_test}
+ }
+ print ${(kv)hash_test}
+0:privates are not visible in anonymous functions, part 1
+>X top level
+>Y in function
+>top level
+
+ typeset -A hash_test=(top level)
+ () {
+ local -PA hash_test=(in function)
+ () {
+ print X ${(kv)hash_test}
+ hash_test[in]=deeper
+ }
+ print Y ${(kv)hash_test}
+ }
+ print ${(okv)hash_test}
+0:privates are not visible in anonymous functions, part 2
+>X top level
+>Y in function
+>deeper in level top
+
+ typeset -A hash_test=(top level)
+ () {
+ local -Pa array_test=(in function)
+ local -PA hash_test=($array_test)
+ () {
+ print X ${(kv)hash_test}
+ hash_test=(even deeper)
+ {
+ array_test+=(${(kv)hash_test})
+ } always {
+ print ${array_test-array_test not set} ${(t)array_test}
+ }
+ }
+ print Y ${(kv)hash_test} Z $array_test
+ }
+ print ${(kv)hash_test} ${(t)array_test}
+1:privates are not visible in anonymous functions, part 3
+>X top level
+>array_test not set
+?(anon):4: array_test: attempt to assign private in nested scope
+F:future revision will create a global with this assignment
+
+ typeset -a array_test
+ typeset -A hash_test=(top level)
+ () {
+ local -Pa array_test=(in function)
+ local -PA hash_test=($array_test)
+ () {
+ print X ${(kv)hash_test}
+ hash_test=(even deeper)
+ array_test+=(${(kv)hash_test})
+ }
+ print Y ${(kv)hash_test} Z $array_test
+ }
+ print ${(kv)hash_test} $array_test
+0:privates are not visible in anonymous functions, part 4
+>X top level
+>Y in function Z in function
+>even deeper even deeper
+
+ typeset -A hash_test=(top level)
+ () {
+ local -PA hash_test=(in function)
+ () {
+ print X ${(kv)hash_test}
+ unset hash_test
+ }
+ print Y ${(kv)hash_test}
+ }
+ print ${(t)hash_test} ${(kv)hash_test}
+0:privates are not visible in anonymous functions, part 5
+>X top level
+>Y in function
+>
+
+ # Subshell because otherwise this silently dumps core when broken
+ ( () { private SECONDS } )
+1:special parameters cannot be made private
+?(anon):private: can't change scope of existing param: SECONDS
+
+ () { private -h SECONDS }
+0:private parameter may hide a special parameter
+
+ if (( UID )); then
+ ZTST_verbose=0 $ZTST_exe +Z -f $ZTST_srcdir/ztst.zsh private.TMP/B02
+ else
+ ZTST_skip="cannot re-run typeset tests when tests run as superuser"
+ fi
+0:typeset still works with zsh/param/private module loaded
+*>*
+*>*
+
+%clean
+
+ rm -r private.TMP
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/W01history.ztst b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/W01history.ztst
new file mode 100644
index 0000000..6ef9b11
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/W01history.ztst
@@ -0,0 +1,60 @@
+# Tests for BANG_HIST replacements
+
+%prep
+
+ if [[ -t 0 ]]; then print -u $ZTST_fd History tests write to /dev/tty; fi
+
+%test
+
+ $ZTST_testdir/../Src/zsh -fis <<<'
+ print one two three four five six seven eight nine ten
+ print !:$ !:10 !:9 !:1 !:0
+ print one two three four five six seven eight nine ten
+ print !:0-$ !:1-2
+ ' 2>/dev/null
+0:History word references
+>one two three four five six seven eight nine ten
+>ten ten nine one print
+>one two three four five six seven eight nine ten
+>print one two three four five six seven eight nine ten one two
+
+ $ZTST_testdir/../Src/zsh -fis <<<'
+ print line one of an arbitrary series
+ print issue two for some mystery sequence
+ print !-1:5-$
+ print !1:2
+ print !2:2
+ print !-3:1-$
+ ' 2>/dev/null
+0:History line numbering
+>line one of an arbitrary series
+>issue two for some mystery sequence
+>mystery sequence
+>one
+>two
+>mystery sequence
+
+ $ZTST_testdir/../Src/zsh -fis <<<'
+ print All metaphor, Malachi, stilts and all
+ print !1:2:s/,/\\\\?/ !1:2:s/m/shm/:s/,/\!/
+ print !1:2:&
+ print -l !1:2-3:gs/a/o/
+ ' 2>/dev/null
+0:History substitution
+>All metaphor, Malachi, stilts and all
+>metaphor? shmetaphor!
+>metaphor!
+>metophor,
+>Molochi,
+
+ $ZTST_testdir/../Src/zsh -fis <<<'
+ echo foo bar
+ echo $(!!) again
+ echo more $( !! )' 2>/dev/null
+0:Regression test for history references in command substitution
+>foo bar
+>foo bar again
+>more foo bar again
+*?*
+F:Check that a history bug introduced by workers/34160 is working again.
+# Discarded line of error output consumes prompts printed by "zsh -i".
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/comptest b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/comptest
new file mode 100644
index 0000000..166d0b4
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/comptest
@@ -0,0 +1,177 @@
+comptestinit () {
+ setopt extendedglob
+ [[ -d $ZTST_testdir/Modules/zsh ]] && module_path=( $ZTST_testdir/Modules )
+ fpath=( $ZTST_srcdir/../Functions/*~*/CVS(/)
+ $ZTST_srcdir/../Completion
+ $ZTST_srcdir/../Completion/*/*~*/CVS(/) )
+
+ zmodload zsh/zpty || return $?
+
+ comptest_zsh=${ZSH:-zsh}
+ comptest_keymap=e
+
+ while getopts vz: opt; do
+ case $opt in
+ z) comptest_zsh="$OPTARG";;
+ v) comptest_keymap="v";;
+ esac
+ done
+ (( OPTIND > 1 )) && shift $(( OPTIND - 1 ))
+
+ export PS1=""
+ zpty zsh "$comptest_zsh -f +Z"
+
+ zpty -r zsh log1 "**" || {
+ print "first prompt hasn't appeared."
+ return 1
+ }
+
+ comptesteval \
+"export LC_ALL=${ZSH_TEST_LANG:-C}" \
+"emulate -R zsh" \
+"export ZDOTDIR=$ZTST_testdir" \
+"module_path=( $module_path )" \
+"fpath=( $fpath )" \
+"bindkey -$comptest_keymap" \
+'LISTMAX=10000000
+stty 38400 columns 80 rows 24 tabs -icanon -iexten
+TERM=vt100
+KEYTIMEOUT=1
+setopt zle
+autoload -U compinit
+compinit -u
+zstyle ":completion:*:default" list-colors "no=" "fi=" "di=" "ln=" "pi=" "so=" "bd=" "cd=" "ex=" "mi=" "tc=" "sp=" "lc=" "ec=\n" "rc="
+zstyle ":completion:*" group-name ""
+zstyle ":completion:*:messages" format "%d
+"
+zstyle ":completion:*:descriptions" format "%d
+"
+zstyle ":completion:*:options" verbose yes
+zstyle ":completion:*:values" verbose yes
+setopt noalwayslastprompt listrowsfirst completeinword
+zmodload zsh/complist
+expand-or-complete-with-report () {
+ print -lr ""
+ zle expand-or-complete
+ print -lr - "$LBUFFER" "$RBUFFER"
+ zle clear-screen
+ zle -R
+}
+list-choices-with-report () {
+ print -lr ""
+ zle list-choices
+ zle clear-screen
+ zle -R
+}
+comp-finish () {
+ print ""
+ zle kill-whole-line
+ zle clear-screen
+ zle -R
+}
+zle-finish () {
+ local buffer="$BUFFER" cursor="$CURSOR" mark="$MARK"
+ (( region_active)) || unset mark
+ BUFFER=""
+ zle -I
+ zle clear-screen
+ zle redisplay
+ print -lr "" "BUFFER: $buffer" "CURSOR: $cursor"
+ (( $+mark )) && print -lr "MARK: $mark"
+ zle accept-line
+}
+zle -N expand-or-complete-with-report
+zle -N list-choices-with-report
+zle -N comp-finish
+zle -N zle-finish
+bindkey "^I" expand-or-complete-with-report
+bindkey "^D" list-choices-with-report
+bindkey "^Z" comp-finish
+bindkey "^X" zle-finish
+bindkey -a "^X" zle-finish
+'
+}
+
+zpty_flush() {
+ local junk
+ if zpty -r -t zsh junk \*; then
+ (( ZTST_verbose > 2 )) && print -n -u $ZTST_fd "$*: ${(V)junk}"
+ while zpty -r -t zsh junk \* ; do
+ (( ZTST_verbose > 2 )) && print -n -u $ZTST_fd "${(V)junk}"
+ done
+ (( ZTST_verbose > 2 )) && print -u $ZTST_fd ''
+ fi
+}
+
+zpty_run() {
+ zpty -w zsh "$*"
+ zpty -r -m zsh log "**" || {
+ print "prompt hasn't appeared."
+ return 1
+ }
+}
+
+comptesteval () {
+ local tmp=/tmp/comptest.$$
+
+ print -lr - "$@" > $tmp
+ # zpty_flush Before comptesteval
+ zpty -w zsh ". $tmp"
+ zpty -r -m zsh log_eval "**" || {
+ print "prompt hasn't appeared."
+ return 1
+ }
+ zpty_flush After comptesteval
+ rm $tmp
+}
+
+comptest () {
+ input="$*"
+ zpty -n -w zsh "$input"$'\C-Z'
+ zpty -r -m zsh log "***" || {
+ print "failed to invoke finish widget."
+ return 1
+ }
+
+ logs=(${(s::)log})
+ shift logs
+
+ for log in "$logs[@]"; do
+ if [[ "$log" = (#b)*$''(*)$'\r\n'(*)$''* ]]; then
+ print -lr "line: {$match[1]}{$match[2]}"
+ fi
+ while (( ${(N)log#*(#b)(<(??)>(*)|(*)|(*)|(*)|(*))} )); do
+ log="${log[$mend[1]+1,-1]}"
+ if (( 0 <= $mbegin[2] )); then
+ if [[ $match[2] != TC && $match[3] != \ # ]]; then
+ print -lr "$match[2]:{${match[3]%${(%):-%E}}}"
+ fi
+ elif (( 0 <= $mbegin[4] )); then
+ print -lr "DESCRIPTION:{$match[4]}"
+ elif (( 0 <= $mbegin[5] )); then
+ print -lr "MESSAGE:{$match[5]}"
+ elif (( 0 <= $mbegin[6] )); then
+ print -lr "COMPADD:{${${match[6]}//[$'\r\n']/}}"
+ elif (( 0 <= $mbegin[7] )); then
+ print -lr "INSERT_POSITIONS:{${${match[7]}//[$'\r\n']/}}"
+ fi
+ done
+ done
+}
+
+zletest () {
+ local first=0
+ for input; do
+ # zpty_flush Before zletest
+ # sleep for $KEYTIMEOUT
+ (( first++ )) && { sleep 2 & } | read -t 0.011 -u 0 -k 1
+ zpty -n -w zsh "$input"
+ done
+ zpty -n -w zsh $'\C-X'
+ zpty -r -m zsh log "***" || {
+ print "failed to invoke finish widget."
+ return 1
+ }
+ # zpty_flush After zletest
+ print -lr "${(@)${(@ps:\r\n:)log##*}[2,-2]}"
+}
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/runtests.zsh b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/runtests.zsh
new file mode 100644
index 0000000..562234d
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/runtests.zsh
@@ -0,0 +1,27 @@
+#!/bin/zsh -f
+
+emulate zsh
+
+# Run all specified tests, keeping count of which succeeded.
+# The reason for this extra layer above the test script is to
+# protect from catastrophic failure of an individual test.
+# We could probably do that with subshells instead.
+
+integer success failure skipped retval
+for file in "${(f)ZTST_testlist}"; do
+ $ZTST_exe +Z -f $ZTST_srcdir/ztst.zsh $file
+ retval=$?
+ if (( $retval == 2 )); then
+ (( skipped++ ))
+ elif (( $retval )); then
+ (( failure++ ))
+ else
+ (( success++ ))
+ fi
+done
+print "**************************************
+$success successful test script${${success:#1}:+s}, \
+$failure failure${${failure:#1}:+s}, \
+$skipped skipped
+**************************************"
+return $(( failure ? 1 : 0 ))
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/ztst.zsh b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/ztst.zsh
new file mode 100755
index 0000000..f172ae1
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/Test/ztst.zsh
@@ -0,0 +1,547 @@
+#!/bin/zsh -f
+# The line above is just for convenience. Normally tests will be run using
+# a specified version of zsh. With dynamic loading, any required libraries
+# must already have been installed in that case.
+#
+# Takes one argument: the name of the test file. Currently only one such
+# file will be processed each time ztst.zsh is run. This is slower, but
+# much safer in terms of preserving the correct status.
+# To avoid namespace pollution, all functions and parameters used
+# only by the script begin with ZTST_.
+#
+# Options (without arguments) may precede the test file argument; these
+# are interpreted as shell options to set. -x is probably the most useful.
+
+# Produce verbose messages if non-zero.
+# If 1, produce reports of tests executed; if 2, also report on progress.
+# Defined in such a way that any value from the environment is used.
+: ${ZTST_verbose:=0}
+
+# We require all options to be reset, not just emulation options.
+# Unfortunately, due to the crud which may be in /etc/zshenv this might
+# still not be good enough. Maybe we should trick it somehow.
+emulate -R zsh
+
+# Ensure the locale does not screw up sorting. Don't supply a locale
+# unless there's one set, to minimise problems.
+[[ -n $LC_ALL ]] && LC_ALL=C
+[[ -n $LC_COLLATE ]] && LC_COLLATE=C
+[[ -n $LC_NUMERIC ]] && LC_NUMERIC=C
+[[ -n $LC_MESSAGES ]] && LC_MESSAGES=C
+[[ -n $LANG ]] && LANG=C
+
+# Don't propagate variables that are set by default in the shell.
+typeset +x WORDCHARS
+
+# Set the module load path to correspond to this build of zsh.
+# This Modules directory should have been created by "make check".
+[[ -d Modules/zsh ]] && module_path=( $PWD/Modules )
+# Allow this to be passed down.
+export MODULE_PATH
+
+# We need to be able to save and restore the options used in the test.
+# We use the $options variable of the parameter module for this.
+zmodload zsh/parameter
+
+# Note that both the following are regular arrays, since we only use them
+# in whole array assignments to/from $options.
+# Options set in test code (i.e. by default all standard options)
+ZTST_testopts=(${(kv)options})
+
+setopt extendedglob nonomatch
+while [[ $1 = [-+]* ]]; do
+ set $1
+ shift
+done
+# Options set in main script
+ZTST_mainopts=(${(kv)options})
+
+# We run in the current directory, so remember it.
+ZTST_testdir=$PWD
+ZTST_testname=$1
+
+integer ZTST_testfailed
+
+# This is POSIX nonsense. Because of the vague feeling someone, somewhere
+# may one day need to examine the arguments of "tail" using a standard
+# option parser, every Unix user in the world is expected to switch
+# to using "tail -n NUM" instead of "tail -NUM". Older versions of
+# tail don't support this.
+tail() {
+ emulate -L zsh
+
+ if [[ -z $TAIL_SUPPORTS_MINUS_N ]]; then
+ local test
+ test=$(echo "foo\nbar" | command tail -n 1 2>/dev/null)
+ if [[ $test = bar ]]; then
+ TAIL_SUPPORTS_MINUS_N=1
+ else
+ TAIL_SUPPORTS_MINUS_N=0
+ fi
+ fi
+
+ integer argi=${argv[(i)-<->]}
+
+ if [[ $argi -le $# && $TAIL_SUPPORTS_MINUS_N = 1 ]]; then
+ argv[$argi]=(-n ${argv[$argi][2,-1]})
+ fi
+
+ command tail "$argv[@]"
+}
+
+# The source directory is not necessarily the current directory,
+# but if $0 doesn't contain a `/' assume it is.
+if [[ $0 = */* ]]; then
+ ZTST_srcdir=${0%/*}
+else
+ ZTST_srcdir=$PWD
+fi
+[[ $ZTST_srcdir = /* ]] || ZTST_srcdir="$ZTST_testdir/$ZTST_srcdir"
+
+# Set the function autoload paths to correspond to this build of zsh.
+fpath=( $ZTST_srcdir/../Functions/*~*/CVS(/)
+ $ZTST_srcdir/../Completion
+ $ZTST_srcdir/../Completion/*/*~*/CVS(/) )
+
+: ${TMPPREFIX:=/tmp/zsh}
+ZTST_tmp=${TMPPREFIX}.ztst.$$
+if ! rm -f $ZTST_tmp || ! mkdir -p $ZTST_tmp || ! chmod go-w $ZTST_tmp; then
+ print "Can't create $ZTST_tmp for exclusive use." >&2
+ exit 1
+fi
+# Temporary files for redirection inside tests.
+ZTST_in=${ZTST_tmp}/ztst.in
+# hold the expected output
+ZTST_out=${ZTST_tmp}/ztst.out
+ZTST_err=${ZTST_tmp}/ztst.err
+# hold the actual output from the test
+ZTST_tout=${ZTST_tmp}/ztst.tout
+ZTST_terr=${ZTST_tmp}/ztst.terr
+
+ZTST_cleanup() {
+ cd $ZTST_testdir
+ rm -rf $ZTST_testdir/dummy.tmp $ZTST_testdir/*.tmp(N) ${ZTST_tmp}
+}
+
+# This cleanup always gets performed, even if we abort. Later,
+# we should try and arrange that any test-specific cleanup
+# always gets called as well.
+##trap 'print cleaning up...
+##ZTST_cleanup' INT QUIT TERM
+# Make sure it's clean now.
+rm -rf dummy.tmp *.tmp
+
+# Report failure. Note that all output regarding the tests goes to stdout.
+# That saves an unpleasant mixture of stdout and stderr to sort out.
+ZTST_testfailed() {
+ print -r "Test $ZTST_testname failed: $1"
+ if [[ -n $ZTST_message ]]; then
+ print -r "Was testing: $ZTST_message"
+ fi
+ print -r "$ZTST_testname: test failed."
+ if [[ -n $ZTST_failmsg ]]; then
+ print -r "The following may (or may not) help identifying the cause:
+$ZTST_failmsg"
+ fi
+ ZTST_testfailed=1
+ return 1
+}
+
+# Print messages if $ZTST_verbose is non-empty
+ZTST_verbose() {
+ local lev=$1
+ shift
+ if [[ -n $ZTST_verbose && $ZTST_verbose -ge $lev ]]; then
+ print -r -u $ZTST_fd -- $*
+ fi
+}
+ZTST_hashmark() {
+ if [[ ZTST_verbose -le 0 && -t $ZTST_fd ]]; then
+ print -n -u$ZTST_fd -- ${(pl:SECONDS::\#::\#\r:)}
+ fi
+ (( SECONDS > COLUMNS+1 && (SECONDS -= COLUMNS) ))
+}
+
+if [[ ! -r $ZTST_testname ]]; then
+ ZTST_testfailed "can't read test file."
+ exit 1
+fi
+
+exec {ZTST_fd}>&1
+exec {ZTST_input}<$ZTST_testname
+
+# The current line read from the test file.
+ZTST_curline=''
+# The current section being run
+ZTST_cursect=''
+
+# Get a new input line. Don't mangle spaces; set IFS locally to empty.
+# We shall skip comments at this level.
+ZTST_getline() {
+ local IFS=
+ while true; do
+ read -u $ZTST_input -r ZTST_curline || return 1
+ [[ $ZTST_curline == \#* ]] || return 0
+ done
+}
+
+# Get the name of the section. It may already have been read into
+# $curline, or we may have to skip some initial comments to find it.
+# If argument present, it's OK to skip the reset of the current section,
+# so no error if we find garbage.
+ZTST_getsect() {
+ local match mbegin mend
+
+ while [[ $ZTST_curline != '%'(#b)([[:alnum:]]##)* ]]; do
+ ZTST_getline || return 1
+ [[ $ZTST_curline = [[:blank:]]# ]] && continue
+ if [[ $# -eq 0 && $ZTST_curline != '%'[[:alnum:]]##* ]]; then
+ ZTST_testfailed "bad line found before or after section:
+$ZTST_curline"
+ exit 1
+ fi
+ done
+ # have the next line ready waiting
+ ZTST_getline
+ ZTST_cursect=${match[1]}
+ ZTST_verbose 2 "ZTST_getsect: read section name: $ZTST_cursect"
+ return 0
+}
+
+# Read in an indented code chunk for execution
+ZTST_getchunk() {
+ # Code chunks are always separated by blank lines or the
+ # end of a section, so if we already have a piece of code,
+ # we keep it. Currently that shouldn't actually happen.
+ ZTST_code=''
+ # First find the chunk.
+ while [[ $ZTST_curline = [[:blank:]]# ]]; do
+ ZTST_getline || break
+ done
+ while [[ $ZTST_curline = [[:blank:]]##[^[:blank:]]* ]]; do
+ ZTST_code="${ZTST_code:+${ZTST_code}
+}${ZTST_curline}"
+ ZTST_getline || break
+ done
+ ZTST_verbose 2 "ZTST_getchunk: read code chunk:
+$ZTST_code"
+ [[ -n $ZTST_code ]]
+}
+
+# Read in a piece for redirection.
+ZTST_getredir() {
+ local char=${ZTST_curline[1]} fn
+ ZTST_redir=${ZTST_curline[2,-1]}
+ while ZTST_getline; do
+ [[ $ZTST_curline[1] = $char ]] || break
+ ZTST_redir="${ZTST_redir}
+${ZTST_curline[2,-1]}"
+ done
+ ZTST_verbose 2 "ZTST_getredir: read redir for '$char':
+$ZTST_redir"
+
+ case $char in
+ ('<') fn=$ZTST_in
+ ;;
+ ('>') fn=$ZTST_out
+ ;;
+ ('?') fn=$ZTST_err
+ ;;
+ (*) ZTST_testfailed "bad redir operator: $char"
+ return 1
+ ;;
+ esac
+ if [[ $ZTST_flags = *q* && $char = '<' ]]; then
+ # delay substituting output until variables are set
+ print -r -- "${(e)ZTST_redir}" >>$fn
+ else
+ print -r -- "$ZTST_redir" >>$fn
+ fi
+
+ return 0
+}
+
+# Execute an indented chunk. Redirections will already have
+# been set up, but we need to handle the options.
+ZTST_execchunk() {
+ setopt localloops # don't let continue & break propagate out
+ options=($ZTST_testopts)
+ () {
+ unsetopt localloops
+ eval "$ZTST_code"
+ }
+ ZTST_status=$?
+ # careful... ksh_arrays may be in effect.
+ ZTST_testopts=(${(kv)options[*]})
+ options=(${ZTST_mainopts[*]})
+ ZTST_verbose 2 "ZTST_execchunk: status $ZTST_status"
+ return $ZTST_status
+}
+
+# Functions for preparation and cleaning.
+# When cleaning up (non-zero string argument), we ignore status.
+ZTST_prepclean() {
+ # Execute indented code chunks.
+ while ZTST_getchunk; do
+ ZTST_execchunk >/dev/null || [[ -n $1 ]] || {
+ [[ -n "$ZTST_unimplemented" ]] ||
+ ZTST_testfailed "non-zero status from preparation code:
+$ZTST_code" && return 0
+ }
+ done
+}
+
+# diff wrapper
+ZTST_diff() {
+ emulate -L zsh
+ setopt extendedglob
+
+ local diff_out
+ integer diff_pat diff_ret
+
+ case $1 in
+ (p)
+ diff_pat=1
+ ;;
+
+ (d)
+ ;;
+
+ (*)
+ print "Bad ZTST_diff code: d for diff, p for pattern match"
+ ;;
+ esac
+ shift
+
+ if (( diff_pat )); then
+ local -a diff_lines1 diff_lines2
+ integer failed i
+
+ diff_lines1=("${(f)$(<$argv[-2])}")
+ diff_lines2=("${(f)$(<$argv[-1])}")
+ if (( ${#diff_lines1} != ${#diff_lines2} )); then
+ failed=1
+ else
+ for (( i = 1; i <= ${#diff_lines1}; i++ )); do
+ if [[ ${diff_lines2[i]} != ${~diff_lines1[i]} ]]; then
+ failed=1
+ break
+ fi
+ done
+ fi
+ if (( failed )); then
+ print -rl "Pattern match failed:" \<${^diff_lines1} \>${^diff_lines2}
+ diff_ret=1
+ fi
+ else
+ diff_out=$(diff "$@")
+ diff_ret="$?"
+ if [[ "$diff_ret" != "0" ]]; then
+ print -r -- "$diff_out"
+ fi
+ fi
+
+ return "$diff_ret"
+}
+
+ZTST_test() {
+ local last match mbegin mend found substlines
+ local diff_out diff_err
+ local ZTST_skip
+
+ while true; do
+ rm -f $ZTST_in $ZTST_out $ZTST_err
+ touch $ZTST_in $ZTST_out $ZTST_err
+ ZTST_message=''
+ ZTST_failmsg=''
+ found=0
+ diff_out=d
+ diff_err=d
+
+ ZTST_verbose 2 "ZTST_test: looking for new test"
+
+ while true; do
+ ZTST_verbose 2 "ZTST_test: examining line:
+$ZTST_curline"
+ case $ZTST_curline in
+ (%*) if [[ $found = 0 ]]; then
+ break 2
+ else
+ last=1
+ break
+ fi
+ ;;
+ ([[:space:]]#)
+ if [[ $found = 0 ]]; then
+ ZTST_getline || break 2
+ continue
+ else
+ break
+ fi
+ ;;
+ ([[:space:]]##[^[:space:]]*) ZTST_getchunk
+ if [[ $ZTST_curline == (#b)([-0-9]##)([[:alpha:]]#)(:*)# ]]; then
+ ZTST_xstatus=$match[1]
+ ZTST_flags=$match[2]
+ ZTST_message=${match[3]:+${match[3][2,-1]}}
+ else
+ ZTST_testfailed "expecting test status at:
+$ZTST_curline"
+ return 1
+ fi
+ ZTST_getline
+ found=1
+ ;;
+ ('<'*) ZTST_getredir || return 1
+ found=1
+ ;;
+ ('*>'*)
+ ZTST_curline=${ZTST_curline[2,-1]}
+ diff_out=p
+ ;&
+ ('>'*)
+ ZTST_getredir || return 1
+ found=1
+ ;;
+ ('*?'*)
+ ZTST_curline=${ZTST_curline[2,-1]}
+ diff_err=p
+ ;&
+ ('?'*)
+ ZTST_getredir || return 1
+ found=1
+ ;;
+ ('F:'*) ZTST_failmsg="${ZTST_failmsg:+${ZTST_failmsg}
+} ${ZTST_curline[3,-1]}"
+ ZTST_getline
+ found=1
+ ;;
+ (*) ZTST_testfailed "bad line in test block:
+$ZTST_curline"
+ return 1
+ ;;
+ esac
+ done
+
+ # If we found some code to execute...
+ if [[ -n $ZTST_code ]]; then
+ ZTST_hashmark
+ ZTST_verbose 1 "Running test: $ZTST_message"
+ ZTST_verbose 2 "ZTST_test: expecting status: $ZTST_xstatus"
+ ZTST_verbose 2 "Input: $ZTST_in, output: $ZTST_out, error: $ZTST_terr"
+
+ ZTST_execchunk <$ZTST_in >$ZTST_tout 2>$ZTST_terr
+
+ if [[ -n $ZTST_skip ]]; then
+ ZTST_verbose 0 "Test case skipped: $ZTST_skip"
+ ZTST_skip=
+ if [[ -n $last ]]; then
+ break
+ else
+ continue
+ fi
+ fi
+
+ # First check we got the right status, if specified.
+ if [[ $ZTST_xstatus != - && $ZTST_xstatus != $ZTST_status ]]; then
+ ZTST_testfailed "bad status $ZTST_status, expected $ZTST_xstatus from:
+$ZTST_code${$(<$ZTST_terr):+
+Error output:
+$(<$ZTST_terr)}"
+ return 1
+ fi
+
+ ZTST_verbose 2 "ZTST_test: test produced standard output:
+$(<$ZTST_tout)
+ZTST_test: and standard error:
+$(<$ZTST_terr)"
+
+ # Now check output and error.
+ if [[ $ZTST_flags = *q* && -s $ZTST_out ]]; then
+ substlines="$(<$ZTST_out)"
+ rm -rf $ZTST_out
+ print -r -- "${(e)substlines}" >$ZTST_out
+ fi
+ if [[ $ZTST_flags != *d* ]] && ! ZTST_diff $diff_out -u $ZTST_out $ZTST_tout; then
+ ZTST_testfailed "output differs from expected as shown above for:
+$ZTST_code${$(<$ZTST_terr):+
+Error output:
+$(<$ZTST_terr)}"
+ return 1
+ fi
+ if [[ $ZTST_flags = *q* && -s $ZTST_err ]]; then
+ substlines="$(<$ZTST_err)"
+ rm -rf $ZTST_err
+ print -r -- "${(e)substlines}" >$ZTST_err
+ fi
+ if [[ $ZTST_flags != *D* ]] && ! ZTST_diff $diff_err -u $ZTST_err $ZTST_terr; then
+ ZTST_testfailed "error output differs from expected as shown above for:
+$ZTST_code"
+ return 1
+ fi
+ fi
+ ZTST_verbose 1 "Test successful."
+ [[ -n $last ]] && break
+ done
+
+ ZTST_verbose 2 "ZTST_test: all tests successful"
+
+ # reset message to keep ZTST_testfailed output correct
+ ZTST_message=''
+}
+
+
+# Remember which sections we've done.
+typeset -A ZTST_sects
+ZTST_sects=(prep 0 test 0 clean 0)
+
+print "$ZTST_testname: starting."
+
+# Now go through all the different sections until the end.
+# prep section may set ZTST_unimplemented, in this case the actual
+# tests will be skipped
+ZTST_skipok=
+ZTST_unimplemented=
+while [[ -z "$ZTST_unimplemented" ]] && ZTST_getsect $ZTST_skipok; do
+ case $ZTST_cursect in
+ (prep) if (( ${ZTST_sects[prep]} + ${ZTST_sects[test]} + \
+ ${ZTST_sects[clean]} )); then
+ ZTST_testfailed "\`prep' section must come first"
+ exit 1
+ fi
+ ZTST_prepclean
+ ZTST_sects[prep]=1
+ ;;
+ (test)
+ if (( ${ZTST_sects[test]} + ${ZTST_sects[clean]} )); then
+ ZTST_testfailed "bad placement of \`test' section"
+ exit 1
+ fi
+ # careful here: we can't execute ZTST_test before || or &&
+ # because that affects the behaviour of traps in the tests.
+ ZTST_test
+ (( $? )) && ZTST_skipok=1
+ ZTST_sects[test]=1
+ ;;
+ (clean)
+ if (( ${ZTST_sects[test]} == 0 || ${ZTST_sects[clean]} )); then
+ ZTST_testfailed "bad use of \`clean' section"
+ else
+ ZTST_prepclean 1
+ ZTST_sects[clean]=1
+ fi
+ ZTST_skipok=
+ ;;
+ *) ZTST_testfailed "bad section name: $ZTST_cursect"
+ ;;
+ esac
+done
+
+if [[ -n "$ZTST_unimplemented" ]]; then
+ print "$ZTST_testname: skipped ($ZTST_unimplemented)"
+ ZTST_testfailed=2
+elif (( ! $ZTST_testfailed )); then
+ print "$ZTST_testname: all tests successful."
+fi
+ZTST_cleanup
+exit $(( ZTST_testfailed ))
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/aclocal.m4 b/dots/.config/zsh/config/plugins/fzf-tab/modules/aclocal.m4
new file mode 100644
index 0000000..e91be3c
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/aclocal.m4
@@ -0,0 +1,77 @@
+# Local additions to Autoconf macros.
+# Copyright (C) 1992, 1994 Free Software Foundation, Inc.
+# Francois Pinard , 1992.
+
+# @defmac fp_PROG_CC_STDC
+# @maindex PROG_CC_STDC
+# @ovindex CC
+# If the C compiler in not in ANSI C mode by default, try to add an option
+# to output variable @code{CC} to make it so. This macro tries various
+# options that select ANSI C on some system or another. It considers the
+# compiler to be in ANSI C mode if it defines @code{__STDC__} to 1 and
+# handles function prototypes correctly.
+#
+# If you use this macro, you should check after calling it whether the C
+# compiler has been set to accept ANSI C; if not, the shell variable
+# @code{fp_cv_prog_cc_stdc} is set to @samp{no}. If you wrote your source
+# code in ANSI C, you can make an un-ANSIfied copy of it by using the
+# program @code{ansi2knr}, which comes with Ghostscript.
+# @end defmac
+
+define(fp_PROG_CC_STDC,
+[AC_CACHE_CHECK(for ${CC-cc} option to accept ANSI C,
+fp_cv_prog_cc_stdc,
+[fp_cv_prog_cc_stdc=no
+ac_save_CFLAGS="$CFLAGS"
+# Don't try gcc -ansi; that turns off useful extensions and
+# breaks some systems' header files.
+# AIX -qlanglvl=ansi
+# Ultrix and OSF/1 -std1
+# HP-UX -Ae or -Aa -D_HPUX_SOURCE
+# SVR4 -Xc
+# For HP-UX, we try -Ae first; this turns on ANSI but also extensions,
+# as well as defining _HPUX_SOURCE, and we can then use long long.
+# We keep the old version for backward compatibility.
+for ac_arg in "" -qlanglvl=ansi -std1 -Ae "-Aa -D_HPUX_SOURCE" -Xc
+do
+ CFLAGS="$ac_save_CFLAGS $ac_arg"
+ AC_TRY_COMPILE(
+[#ifndef __STDC__
+choke me
+#endif
+], [int test (int i, double x);
+struct s1 {int (*f) (int a);};
+struct s2 {int (*f) (double a);};],
+[fp_cv_prog_cc_stdc="$ac_arg"; break])
+done
+CFLAGS="$ac_save_CFLAGS"
+])
+case "x$fp_cv_prog_cc_stdc" in
+ x|xno) ;;
+ *) CC="$CC $fp_cv_prog_cc_stdc" ;;
+esac
+])
+
+AC_DEFUN(AC_PROG_LN,
+[AC_MSG_CHECKING(whether ln works)
+AC_CACHE_VAL(ac_cv_prog_LN,
+[rm -f conftestdata conftestlink
+echo > conftestdata
+if ln conftestdata conftestlink 2>/dev/null
+then
+ rm -f conftestdata conftestlink
+ ac_cv_prog_LN="ln"
+else
+ rm -f conftestdata
+ ac_cv_prog_LN="cp"
+fi])dnl
+LN="$ac_cv_prog_LN"
+if test "$ac_cv_prog_LN" = "ln"; then
+ AC_MSG_RESULT(yes)
+else
+ AC_MSG_RESULT(no)
+fi
+AC_SUBST(LN)dnl
+])
+
+builtin(include, aczsh.m4)
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/aczsh.m4 b/dots/.config/zsh/config/plugins/fzf-tab/modules/aczsh.m4
new file mode 100644
index 0000000..0219ae2
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/aczsh.m4
@@ -0,0 +1,690 @@
+dnl
+dnl Autconf tests for zsh.
+dnl
+dnl Copyright (c) 1995-1997 Richard Coleman
+dnl All rights reserved.
+dnl
+dnl Permission is hereby granted, without written agreement and without
+dnl license or royalty fees, to use, copy, modify, and distribute this
+dnl software and to distribute modified versions of this software for any
+dnl purpose, provided that the above copyright notice and the following
+dnl two paragraphs appear in all copies of this software.
+dnl
+dnl In no event shall Richard Coleman or the Zsh Development Group be liable
+dnl to any party for direct, indirect, special, incidental, or consequential
+dnl damages arising out of the use of this software and its documentation,
+dnl even if Richard Coleman and the Zsh Development Group have been advised of
+dnl the possibility of such damage.
+dnl
+dnl Richard Coleman and the Zsh Development Group specifically disclaim any
+dnl warranties, including, but not limited to, the implied warranties of
+dnl merchantability and fitness for a particular purpose. The software
+dnl provided hereunder is on an "as is" basis, and Richard Coleman and the
+dnl Zsh Development Group have no obligation to provide maintenance,
+dnl support, updates, enhancements, or modifications.
+dnl
+
+dnl
+dnl zsh_64_BIT_TYPE
+dnl Check whether the first argument works as a 64-bit type.
+dnl If there is a non-zero third argument, we just assume it works
+dnl when we're cross compiling. This is to allow a type to be
+dnl specified directly as --enable-lfs="long long".
+dnl Sets the variable given in the second argument to the first argument
+dnl if the test worked, `no' otherwise. Be careful testing this, as it
+dnl may produce two words `long long' on an unquoted substitution.
+dnl Also check that the compiler does not mind it being cast to int.
+dnl This macro does not produce messages as it may be run several times
+dnl before finding the right type.
+dnl
+
+AC_DEFUN(zsh_64_BIT_TYPE,
+[AC_TRY_RUN([
+#ifdef HAVE_SYS_TYPES_H
+#include
+#endif
+
+main()
+{
+ $1 foo = 0;
+ int bar = (int) foo;
+ return sizeof($1) != 8;
+}
+], $2="$1", $2=no,
+ [if test x$3 != x ; then
+ $2="$1"
+ else
+ $2=no
+ fi])
+])
+
+
+dnl
+dnl zsh_SHARED_FUNCTION
+dnl
+dnl This is just a frontend to zsh_SHARED_SYMBOL
+dnl
+dnl Usage: zsh_SHARED_FUNCTION(name[,rettype[,paramtype]])
+dnl
+
+AC_DEFUN(zsh_SHARED_FUNCTION,
+[zsh_SHARED_SYMBOL($1, ifelse([$2], ,[int ],[$2]) $1 [(]ifelse([$3], ,[ ],[$3])[)], $1)])
+
+dnl
+dnl zsh_SHARED_VARIABLE
+dnl
+dnl This is just a frontend to zsh_SHARED_SYMBOL
+dnl
+dnl Usage: zsh_SHARED_VARIABLE(name[,type])
+dnl
+
+AC_DEFUN(zsh_SHARED_VARIABLE,
+[zsh_SHARED_SYMBOL($1, ifelse([$2], ,[int ],[$2]) $1, [&$1])])
+
+dnl
+dnl zsh_SHARED_SYMBOL
+dnl Check whether symbol is available in static or shared library
+dnl
+dnl On some systems, static modifiable library symbols (such as environ)
+dnl may appear only in statically linked libraries. If this is the case,
+dnl then two shared libraries that reference the same symbol, each linked
+dnl with the static library, could be given distinct copies of the symbol.
+dnl
+dnl Usage: zsh_SHARED_SYMBOL(name,declaration,address)
+dnl Sets zsh_cv_shared_$1 cache variable to yes/no
+dnl
+
+AC_DEFUN(zsh_SHARED_SYMBOL,
+[AC_CACHE_CHECK([if $1 is available in shared libraries],
+zsh_cv_shared_$1,
+[if test "$zsh_cv_func_dlsym_needs_underscore" = yes; then
+ us=_
+else
+ us=
+fi
+echo '
+void *zsh_getaddr1()
+{
+#ifdef __CYGWIN__
+ __attribute__((__dllimport__))
+#endif
+ extern $2;
+ return $3;
+};
+' > conftest1.c
+sed 's/zsh_getaddr1/zsh_getaddr2/' < conftest1.c > conftest2.c
+if AC_TRY_COMMAND($CC -c $CFLAGS $CPPFLAGS $DLCFLAGS conftest1.c 1>&AC_FD_CC) &&
+AC_TRY_COMMAND($DLLD -o conftest1.$DL_EXT $LDFLAGS $DLLDFLAGS conftest1.o $LIBS 1>&AC_FD_CC) &&
+AC_TRY_COMMAND($CC -c $CFLAGS $CPPFLAGS $DLCFLAGS conftest2.c 1>&AC_FD_CC) &&
+AC_TRY_COMMAND($DLLD -o conftest2.$DL_EXT $LDFLAGS $DLLDFLAGS conftest2.o $LIBS 1>&AC_FD_CC); then
+ AC_TRY_RUN([
+#ifdef HPUX10DYNAMIC
+#include
+#define RTLD_LAZY BIND_DEFERRED
+#define RTLD_GLOBAL DYNAMIC_PATH
+
+char *zsh_gl_sym_addr ;
+
+#define dlopen(file,mode) (void *)shl_load((file), (mode), (long) 0)
+#define dlclose(handle) shl_unload((shl_t)(handle))
+#define dlsym(handle,name) (zsh_gl_sym_addr=0,shl_findsym((shl_t *)&(handle),name,TYPE_UNDEFINED,&zsh_gl_sym_addr), (void *)zsh_gl_sym_addr)
+#define dlerror() 0
+#else
+#ifdef HAVE_DLFCN_H
+#include
+#else
+#include
+#include
+#include
+#endif
+#endif
+#ifndef RTLD_LAZY
+#define RTLD_LAZY 1
+#endif
+#ifndef RTLD_GLOBAL
+#define RTLD_GLOBAL 0
+#endif
+
+main()
+{
+ void *handle1, *handle2;
+ void *(*zsh_getaddr1)(), *(*zsh_getaddr2)();
+ void *sym1, *sym2;
+ handle1 = dlopen("./conftest1.$DL_EXT", RTLD_LAZY | RTLD_GLOBAL);
+ if(!handle1) exit(1);
+ handle2 = dlopen("./conftest2.$DL_EXT", RTLD_LAZY | RTLD_GLOBAL);
+ if(!handle2) exit(1);
+ zsh_getaddr1 = (void *(*)()) dlsym(handle1, "${us}zsh_getaddr1");
+ zsh_getaddr2 = (void *(*)()) dlsym(handle2, "${us}zsh_getaddr2");
+ sym1 = zsh_getaddr1();
+ sym2 = zsh_getaddr2();
+ if(!sym1 || !sym2) exit(1);
+ if(sym1 != sym2) exit(1);
+ dlclose(handle1);
+ handle1 = dlopen("./conftest1.$DL_EXT", RTLD_LAZY | RTLD_GLOBAL);
+ if(!handle1) exit(1);
+ zsh_getaddr1 = (void *(*)()) dlsym(handle1, "${us}zsh_getaddr1");
+ sym1 = zsh_getaddr1();
+ if(!sym1) exit(1);
+ if(sym1 != sym2) exit(1);
+ exit(0);
+}
+], [zsh_cv_shared_$1=yes],
+[zsh_cv_shared_$1=no],
+[zsh_cv_shared_$1=no]
+)
+else
+ zsh_cv_shared_$1=no
+fi
+])
+])
+
+dnl
+dnl zsh_SYS_DYNAMIC_CLASH
+dnl Check whether symbol name clashes in shared libraries are acceptable.
+dnl
+
+AC_DEFUN(zsh_SYS_DYNAMIC_CLASH,
+[AC_CACHE_CHECK([if name clashes in shared objects are OK],
+zsh_cv_sys_dynamic_clash_ok,
+[if test "$zsh_cv_func_dlsym_needs_underscore" = yes; then
+ us=_
+else
+ us=
+fi
+echo 'int fred () { return 42; }' > conftest1.c
+echo 'int fred () { return 69; }' > conftest2.c
+if AC_TRY_COMMAND($CC -c $CFLAGS $CPPFLAGS $DLCFLAGS conftest1.c 1>&AC_FD_CC) &&
+AC_TRY_COMMAND($DLLD -o conftest1.$DL_EXT $LDFLAGS $DLLDFLAGS conftest1.o $LIBS 1>&AC_FD_CC) &&
+AC_TRY_COMMAND($CC -c $CFLAGS $CPPFLAGS $DLCFLAGS conftest2.c 1>&AC_FD_CC) &&
+AC_TRY_COMMAND($DLLD -o conftest2.$DL_EXT $LDFLAGS $DLLDFLAGS conftest2.o $LIBS 1>&AC_FD_CC); then
+ AC_TRY_RUN([
+#ifdef HPUX10DYNAMIC
+#include
+#define RTLD_LAZY BIND_DEFERRED
+#define RTLD_GLOBAL DYNAMIC_PATH
+
+char *zsh_gl_sym_addr ;
+
+#define dlopen(file,mode) (void *)shl_load((file), (mode), (long) 0)
+#define dlclose(handle) shl_unload((shl_t)(handle))
+#define dlsym(handle,name) (zsh_gl_sym_addr=0,shl_findsym((shl_t *)&(handle),name,TYPE_UNDEFINED,&zsh_gl_sym_addr), (void *)zsh_gl_sym_addr)
+#define dlerror() 0
+#else
+#ifdef HAVE_DLFCN_H
+#include
+#else
+#include
+#include
+#include
+#endif
+#endif
+#ifndef RTLD_LAZY
+#define RTLD_LAZY 1
+#endif
+#ifndef RTLD_GLOBAL
+#define RTLD_GLOBAL 0
+#endif
+
+
+main()
+{
+ void *handle1, *handle2;
+ int (*fred1)(), (*fred2)();
+ handle1 = dlopen("./conftest1.$DL_EXT", RTLD_LAZY | RTLD_GLOBAL);
+ if(!handle1) exit(1);
+ handle2 = dlopen("./conftest2.$DL_EXT", RTLD_LAZY | RTLD_GLOBAL);
+ if(!handle2) exit(1);
+ fred1 = (int (*)()) dlsym(handle1, "${us}fred");
+ fred2 = (int (*)()) dlsym(handle2, "${us}fred");
+ if(!fred1 || !fred2) exit(1);
+ exit((*fred1)() != 42 || (*fred2)() != 69);
+}
+], [zsh_cv_sys_dynamic_clash_ok=yes],
+[zsh_cv_sys_dynamic_clash_ok=no],
+[zsh_cv_sys_dynamic_clash_ok=no]
+)
+else
+ zsh_cv_sys_dynamic_clash_ok=no
+fi
+])
+if test "$zsh_cv_sys_dynamic_clash_ok" = yes; then
+ AC_DEFINE(DYNAMIC_NAME_CLASH_OK)
+fi
+])
+
+dnl
+dnl zsh_SYS_DYNAMIC_GLOBAL
+dnl Check whether symbols in one dynamically loaded library are
+dnl available to another dynamically loaded library.
+dnl
+
+AC_DEFUN(zsh_SYS_DYNAMIC_GLOBAL,
+[AC_CACHE_CHECK([for working RTLD_GLOBAL],
+zsh_cv_sys_dynamic_rtld_global,
+[if test "$zsh_cv_func_dlsym_needs_underscore" = yes; then
+ us=_
+else
+ us=
+fi
+echo 'int fred () { return 42; }' > conftest1.c
+echo 'extern int fred(); int barney () { return fred() + 27; }' > conftest2.c
+if AC_TRY_COMMAND($CC -c $CFLAGS $CPPFLAGS $DLCFLAGS conftest1.c 1>&AC_FD_CC) &&
+AC_TRY_COMMAND($DLLD -o conftest1.$DL_EXT $LDFLAGS $DLLDFLAGS conftest1.o $LIBS 1>&AC_FD_CC) &&
+AC_TRY_COMMAND($CC -c $CFLAGS $CPPFLAGS $DLCFLAGS conftest2.c 1>&AC_FD_CC) &&
+AC_TRY_COMMAND($DLLD -o conftest2.$DL_EXT $LDFLAGS $DLLDFLAGS conftest2.o $LIBS 1>&AC_FD_CC); then
+ AC_TRY_RUN([
+#ifdef HPUX10DYNAMIC
+#include
+#define RTLD_LAZY BIND_DEFERRED
+#define RTLD_GLOBAL DYNAMIC_PATH
+
+char *zsh_gl_sym_addr ;
+
+#define dlopen(file,mode) (void *)shl_load((file), (mode), (long) 0)
+#define dlclose(handle) shl_unload((shl_t)(handle))
+#define dlsym(handle,name) (zsh_gl_sym_addr=0,shl_findsym((shl_t *)&(handle),name,TYPE_UNDEFINED,&zsh_gl_sym_addr), (void *)zsh_gl_sym_addr)
+#define dlerror() 0
+#else
+#ifdef HAVE_DLFCN_H
+#include
+#else
+#include
+#include
+#include
+#endif
+#endif
+#ifndef RTLD_LAZY
+#define RTLD_LAZY 1
+#endif
+#ifndef RTLD_GLOBAL
+#define RTLD_GLOBAL 0
+#endif
+
+main()
+{
+ void *handle;
+ int (*barneysym)();
+ handle = dlopen("./conftest1.$DL_EXT", RTLD_LAZY | RTLD_GLOBAL);
+ if(!handle) exit(1);
+ handle = dlopen("./conftest2.$DL_EXT", RTLD_LAZY | RTLD_GLOBAL);
+ if(!handle) exit(1);
+ barneysym = (int (*)()) dlsym(handle, "${us}barney");
+ if(!barneysym) exit(1);
+ exit((*barneysym)() != 69);
+}
+], [zsh_cv_sys_dynamic_rtld_global=yes],
+[zsh_cv_sys_dynamic_rtld_global=no],
+[zsh_cv_sys_dynamic_rtld_global=no]
+)
+else
+ zsh_cv_sys_dynamic_rtld_global=no
+fi
+])
+])
+
+dnl
+dnl zsh_SYS_DYNAMIC_EXECSYMS
+dnl Check whether symbols in the executable are available to dynamically
+dnl loaded libraries.
+dnl
+
+AC_DEFUN(zsh_SYS_DYNAMIC_EXECSYMS,
+[AC_CACHE_CHECK([whether symbols in the executable are available],
+zsh_cv_sys_dynamic_execsyms,
+[if test "$zsh_cv_func_dlsym_needs_underscore" = yes; then
+ us=_
+else
+ us=
+fi
+echo 'extern int fred(); int barney () { return fred() + 27; }' > conftest1.c
+if AC_TRY_COMMAND($CC -c $CFLAGS $CPPFLAGS $DLCFLAGS conftest1.c 1>&AC_FD_CC) &&
+AC_TRY_COMMAND($DLLD -o conftest1.$DL_EXT $LDFLAGS $DLLDFLAGS conftest1.o $LIBS 1>&AC_FD_CC); then
+ save_ldflags=$LDFLAGS
+ LDFLAGS="$LDFLAGS $EXTRA_LDFLAGS"
+ AC_TRY_RUN([
+#ifdef HPUX10DYNAMIC
+#include
+#define RTLD_LAZY BIND_DEFERRED
+#define RTLD_GLOBAL DYNAMIC_PATH
+
+char *zsh_gl_sym_addr ;
+
+#define dlopen(file,mode) (void *)shl_load((file), (mode), (long) 0)
+#define dlclose(handle) shl_unload((shl_t)(handle))
+#define dlsym(handle,name) (zsh_gl_sym_addr=0,shl_findsym((shl_t *)&(handle),name,TYPE_UNDEFINED,&zsh_gl_sym_addr), (void *)zsh_gl_sym_addr)
+#define dlerror() 0
+#else
+#ifdef HAVE_DLFCN_H
+#include
+#else
+#include
+#include
+#include
+#endif
+#endif
+#ifndef RTLD_LAZY
+#define RTLD_LAZY 1
+#endif
+#ifndef RTLD_GLOBAL
+#define RTLD_GLOBAL 0
+#endif
+
+main()
+{
+ void *handle;
+ int (*barneysym)();
+ handle = dlopen("./conftest1.$DL_EXT", RTLD_LAZY | RTLD_GLOBAL);
+ if(!handle) exit(1);
+ barneysym = (int (*)()) dlsym(handle, "${us}barney");
+ if(!barneysym) exit(1);
+ exit((*barneysym)() != 69);
+}
+
+int fred () { return 42; }
+], [zsh_cv_sys_dynamic_execsyms=yes],
+[zsh_cv_sys_dynamic_execsyms=no],
+[zsh_cv_sys_dynamic_execsyms=no]
+)
+ LDFLAGS=$save_ldflags
+else
+ zsh_cv_sys_dynamic_execsyms=no
+fi
+])
+])
+
+dnl
+dnl zsh_SYS_DYNAMIC_STRIP_EXE
+dnl Check whether it is safe to strip executables.
+dnl
+
+AC_DEFUN(zsh_SYS_DYNAMIC_STRIP_EXE,
+[AC_REQUIRE([zsh_SYS_DYNAMIC_EXECSYMS])
+AC_CACHE_CHECK([whether executables can be stripped],
+zsh_cv_sys_dynamic_strip_exe,
+[if test "$zsh_cv_sys_dynamic_execsyms" != yes; then
+ zsh_cv_sys_dynamic_strip_exe=yes
+elif
+ if test "$zsh_cv_func_dlsym_needs_underscore" = yes; then
+ us=_
+ else
+ us=
+ fi
+ echo 'extern int fred(); int barney() { return fred() + 27; }' > conftest1.c
+ AC_TRY_COMMAND($CC -c $CFLAGS $CPPFLAGS $DLCFLAGS conftest1.c 1>&AC_FD_CC) &&
+ AC_TRY_COMMAND($DLLD -o conftest1.$DL_EXT $LDFLAGS $DLLDFLAGS conftest1.o $LIBS 1>&AC_FD_CC); then
+ save_ldflags=$LDFLAGS
+ LDFLAGS="$LDFLAGS $EXTRA_LDFLAGS -s"
+ AC_TRY_RUN([
+#ifdef HPUX10DYNAMIC
+#include
+#define RTLD_LAZY BIND_DEFERRED
+#define RTLD_GLOBAL DYNAMIC_PATH
+
+char *zsh_gl_sym_addr ;
+
+#define dlopen(file,mode) (void *)shl_load((file), (mode), (long) 0)
+#define dlclose(handle) shl_unload((shl_t)(handle))
+#define dlsym(handle,name) (zsh_gl_sym_addr=0,shl_findsym((shl_t *)&(handle),name,TYPE_UNDEFINED,&zsh_gl_sym_addr), (void *)zsh_gl_sym_addr)
+#define dlerror() 0
+#else
+#ifdef HAVE_DLFCN_H
+#include
+#else
+#include
+#include
+#include
+#endif
+#endif
+#ifndef RTLD_LAZY
+#define RTLD_LAZY 1
+#endif
+#ifndef RTLD_GLOBAL
+#define RTLD_GLOBAL 0
+#endif
+
+main()
+{
+ void *handle;
+ int (*barneysym)();
+ handle = dlopen("./conftest1.$DL_EXT", RTLD_LAZY | RTLD_GLOBAL);
+ if(!handle) exit(1);
+ barneysym = (int (*)()) dlsym(handle, "${us}barney");
+ if(!barneysym) exit(1);
+ exit((*barneysym)() != 69);
+}
+
+int fred () { return 42; }
+], [zsh_cv_sys_dynamic_strip_exe=yes],
+[zsh_cv_sys_dynamic_strip_exe=no],
+[zsh_cv_sys_dynamic_strip_exe=no]
+)
+ LDFLAGS=$save_ldflags
+else
+ zsh_cv_sys_dynamic_strip_exe=no
+fi
+])
+])
+
+dnl
+dnl zsh_SYS_DYNAMIC_STRIP_EXE
+dnl Check whether it is safe to strip dynamically loaded libraries.
+dnl
+
+AC_DEFUN(zsh_SYS_DYNAMIC_STRIP_LIB,
+[AC_CACHE_CHECK([whether libraries can be stripped],
+zsh_cv_sys_dynamic_strip_lib,
+[if test "$zsh_cv_func_dlsym_needs_underscore" = yes; then
+ us=_
+else
+ us=
+fi
+echo 'int fred () { return 42; }' > conftest1.c
+if AC_TRY_COMMAND($CC -c $CFLAGS $CPPFLAGS $DLCFLAGS conftest1.c 1>&AC_FD_CC) &&
+AC_TRY_COMMAND($DLLD -o conftest1.$DL_EXT $LDFLAGS $DLLDFLAGS -s conftest1.o $LIBS 1>&AC_FD_CC); then
+ AC_TRY_RUN([
+#ifdef HPUX10DYNAMIC
+#include
+#define RTLD_LAZY BIND_DEFERRED
+#define RTLD_GLOBAL DYNAMIC_PATH
+
+char *zsh_gl_sym_addr ;
+
+#define dlopen(file,mode) (void *)shl_load((file), (mode), (long) 0)
+#define dlclose(handle) shl_unload((shl_t)(handle))
+#define dlsym(handle,name) (zsh_gl_sym_addr=0,shl_findsym((shl_t *)&(handle),name,TYPE_UNDEFINED,&zsh_gl_sym_addr), (void *)zsh_gl_sym_addr)
+#define dlerror() 0
+#else
+#ifdef HAVE_DLFCN_H
+#include
+#else
+#include
+#include
+#include
+#endif
+#endif
+#ifndef RTLD_LAZY
+#define RTLD_LAZY 1
+#endif
+#ifndef RTLD_GLOBAL
+#define RTLD_GLOBAL 0
+#endif
+
+main()
+{
+ void *handle;
+ int (*fredsym)();
+ handle = dlopen("./conftest1.$DL_EXT", RTLD_LAZY | RTLD_GLOBAL);
+ if(!handle) exit(1);
+ fredsym = (int (*)()) dlsym(handle, "${us}fred");
+ if(!fredsym) exit(1);
+ exit((*fredsym)() != 42);
+}
+], [zsh_cv_sys_dynamic_strip_lib=yes],
+[zsh_cv_sys_dynamic_strip_lib=no],
+[zsh_cv_sys_dynamic_strip_lib=no]
+)
+else
+ zsh_cv_sys_dynamic_strip_lib=no
+fi
+])
+])
+
+dnl
+dnl zsh_PATH_UTMP(filename)
+dnl Search for a specified utmp-type file.
+dnl
+
+AC_DEFUN(zsh_PATH_UTMP,
+[AC_CACHE_CHECK([for $1 file], [zsh_cv_path_$1],
+[for dir in /etc /usr/etc /var/adm /usr/adm /var/run /var/log ./conftest; do
+ zsh_cv_path_$1=${dir}/$1
+ test -f $zsh_cv_path_$1 && break
+ zsh_cv_path_$1=no
+done
+])
+AH_TEMPLATE([PATH_]translit($1, [a-z], [A-Z])[_FILE],
+[Define to be location of ]$1[ file.])
+if test $zsh_cv_path_$1 != no; then
+ AC_DEFINE_UNQUOTED([PATH_]translit($1, [a-z], [A-Z])[_FILE],
+ "$zsh_cv_path_$1")
+fi
+])
+
+dnl
+dnl zsh_TYPE_EXISTS(#includes, type name)
+dnl Check whether a specified type exists.
+dnl
+
+AC_DEFUN(zsh_TYPE_EXISTS,
+[AC_CACHE_CHECK([for $2], [zsh_cv_type_exists_[]translit($2, [ ], [_])],
+[AC_TRY_COMPILE([$1], [$2 testvar;],
+[zsh_cv_type_exists_[]translit($2, [ ], [_])=yes],
+[zsh_cv_type_exists_[]translit($2, [ ], [_])=no])
+])
+AH_TEMPLATE([HAVE_]translit($2, [ a-z], [_A-Z]),
+[Define to 1 if ]$2[ is defined by a system header])
+if test $zsh_cv_type_exists_[]translit($2, [ ], [_]) = yes; then
+ AC_DEFINE([HAVE_]translit($2, [ a-z], [_A-Z]))
+fi
+])
+
+dnl
+dnl zsh_STRUCT_MEMBER(#includes, type name, member name)
+dnl Check whether a specified aggregate type exists and contains
+dnl a specified member.
+dnl
+
+AC_DEFUN(zsh_STRUCT_MEMBER,
+[AC_CACHE_CHECK([for $3 in $2], [zsh_cv_struct_member_[]translit($2, [ ], [_])_$3],
+[AC_TRY_COMPILE([$1], [$2 testvar; testvar.$3;],
+[zsh_cv_struct_member_[]translit($2, [ ], [_])_$3=yes],
+[zsh_cv_struct_member_[]translit($2, [ ], [_])_$3=no])
+])
+AH_TEMPLATE([HAVE_]translit($2_$3, [ a-z], [_A-Z]),
+[Define if your system's ]$2[ has a member named ]$3[.])
+if test $zsh_cv_struct_member_[]translit($2, [ ], [_])_$3 = yes; then
+ AC_DEFINE([HAVE_]translit($2_$3, [ a-z], [_A-Z]))
+fi
+])
+
+dnl
+dnl zsh_ARG_PROGRAM
+dnl Handle AC_ARG_PROGRAM substitutions into other zsh configure macros.
+dnl After processing this macro, the configure script may refer to
+dnl and $tzsh_name, and @tzsh@ is defined for make substitutions.
+dnl
+
+AC_DEFUN(zsh_ARG_PROGRAM,
+[AC_ARG_PROGRAM
+# Un-double any \ or $ (doubled by AC_ARG_PROGRAM).
+cat <<\EOF_SED > conftestsed
+s,\\\\,\\,g; s,\$\$,$,g
+EOF_SED
+zsh_transform_name=`echo "${program_transform_name}" | sed -f conftestsed`
+rm -f conftestsed
+tzsh_name=`echo zsh | sed -e "${zsh_transform_name}"`
+# Double any \ or $ in the transformed name that results.
+cat <<\EOF_SED >> conftestsed
+s,\\,\\\\,g; s,\$,$$,g
+EOF_SED
+tzsh=`echo ${tzsh_name} | sed -f conftestsed`
+rm -f conftestsed
+AC_SUBST(tzsh)dnl
+])
+
+AC_DEFUN(zsh_COMPILE_FLAGS,
+ [AC_ARG_ENABLE(cppflags,
+ AC_HELP_STRING([--enable-cppflags=...], [specify C preprocessor flags]),
+ if test "$enableval" = "yes"
+ then CPPFLAGS="$1"
+ else CPPFLAGS="$enable_cppflags"
+ fi)
+ AC_ARG_ENABLE(cflags,
+ AC_HELP_STRING([--enable-cflags=...], [specify C compiler flags]),
+ if test "$enableval" = "yes"
+ then CFLAGS="$2"
+ else CFLAGS="$enable_cflags"
+ fi)
+ AC_ARG_ENABLE(ldflags,
+ AC_HELP_STRING([--enable-ldflags=...], [specify linker flags]),
+ if test "$enableval" = "yes"
+ then LDFLAGS="$3"
+ else LDFLAGS="$enable_ldflags"
+ fi)
+ AC_ARG_ENABLE(libs,
+ AC_HELP_STRING([--enable-libs=...], [specify link libraries]),
+ if test "$enableval" = "yes"
+ then LIBS="$4"
+ else LIBS="$enable_libs"
+ fi)])
+
+dnl
+dnl zsh_CHECK_SOCKLEN_T
+dnl
+dnl check type of third argument of some network functions; currently
+dnl tested are size_t *, unsigned long *, int *.
+dnl call the result ZSOCKLEN_T since some systems have SOCKLEN_T already
+dnl
+AC_DEFUN([zsh_CHECK_SOCKLEN_T],[
+ AC_CACHE_CHECK(
+ [base type of the third argument to accept],
+ [zsh_cv_type_socklen_t],
+ [zsh_cv_type_socklen_t=
+ for zsh_type in socklen_t int "unsigned long" size_t ; do
+ AC_TRY_COMPILE(
+ [#include
+ #include ],
+ [extern int accept (int, struct sockaddr *, $zsh_type *);],
+ [zsh_cv_type_socklen_t="$zsh_type"; break],
+ []
+ )
+ done
+ if test -z "$zsh_cv_type_socklen_t"; then
+ zsh_cv_type_socklen_t=int
+ fi]
+ )
+ AC_DEFINE_UNQUOTED([ZSOCKLEN_T], [$zsh_cv_type_socklen_t],
+ [Define to the base type of the third argument of accept])]
+)
+
+dnl Check for limit $1 e.g. RLIMIT_RSS.
+AC_DEFUN(zsh_LIMIT_PRESENT,
+[AH_TEMPLATE([HAVE_]$1,
+[Define to 1 if ]$1[ is present (whether or not as a macro).])
+AC_CACHE_CHECK([for limit $1],
+zsh_cv_have_$1,
+[AC_TRY_COMPILE([
+#include
+#ifdef HAVE_SYS_TIME_H
+#include
+#endif
+#include ],
+[$1],
+ zsh_cv_have_$1=yes,
+ zsh_cv_have_$1=no)])
+
+if test $zsh_cv_have_$1 = yes; then
+ AC_DEFINE(HAVE_$1)
+fi])
+
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/config.guess b/dots/.config/zsh/config/plugins/fzf-tab/modules/config.guess
new file mode 100755
index 0000000..dc84c68
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/config.guess
@@ -0,0 +1,1501 @@
+#! /bin/sh
+# Attempt to guess a canonical system name.
+# Copyright (C) 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999,
+# 2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009
+# Free Software Foundation, Inc.
+
+timestamp='2009-11-20'
+
+# This file is free software; you can redistribute it and/or modify it
+# under the terms of the GNU General Public License as published by
+# the Free Software Foundation; either version 2 of the License, or
+# (at your option) any later version.
+#
+# This program is distributed in the hope that it will be useful, but
+# WITHOUT ANY WARRANTY; without even the implied warranty of
+# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
+# General Public License for more details.
+#
+# You should have received a copy of the GNU General Public License
+# along with this program; if not, write to the Free Software
+# Foundation, Inc., 51 Franklin Street - Fifth Floor, Boston, MA
+# 02110-1301, USA.
+#
+# As a special exception to the GNU General Public License, if you
+# distribute this file as part of a program that contains a
+# configuration script generated by Autoconf, you may include it under
+# the same distribution terms that you use for the rest of that program.
+
+
+# Originally written by Per Bothner. Please send patches (context
+# diff format) to and include a ChangeLog
+# entry.
+#
+# This script attempts to guess a canonical system name similar to
+# config.sub. If it succeeds, it prints the system name on stdout, and
+# exits with 0. Otherwise, it exits with 1.
+#
+# You can get the latest version of this script from:
+# http://git.savannah.gnu.org/gitweb/?p=config.git;a=blob_plain;f=config.guess;hb=HEAD
+
+me=`echo "$0" | sed -e 's,.*/,,'`
+
+usage="\
+Usage: $0 [OPTION]
+
+Output the configuration name of the system \`$me' is run on.
+
+Operation modes:
+ -h, --help print this help, then exit
+ -t, --time-stamp print date of last modification, then exit
+ -v, --version print version number, then exit
+
+Report bugs and patches to ."
+
+version="\
+GNU config.guess ($timestamp)
+
+Originally written by Per Bothner.
+Copyright (C) 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999, 2000, 2001,
+2002, 2003, 2004, 2005, 2006, 2007, 2008 Free Software Foundation, Inc.
+
+This is free software; see the source for copying conditions. There is NO
+warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE."
+
+help="
+Try \`$me --help' for more information."
+
+# Parse command line
+while test $# -gt 0 ; do
+ case $1 in
+ --time-stamp | --time* | -t )
+ echo "$timestamp" ; exit ;;
+ --version | -v )
+ echo "$version" ; exit ;;
+ --help | --h* | -h )
+ echo "$usage"; exit ;;
+ -- ) # Stop option processing
+ shift; break ;;
+ - ) # Use stdin as input.
+ break ;;
+ -* )
+ echo "$me: invalid option $1$help" >&2
+ exit 1 ;;
+ * )
+ break ;;
+ esac
+done
+
+if test $# != 0; then
+ echo "$me: too many arguments$help" >&2
+ exit 1
+fi
+
+trap 'exit 1' 1 2 15
+
+# CC_FOR_BUILD -- compiler used by this script. Note that the use of a
+# compiler to aid in system detection is discouraged as it requires
+# temporary files to be created and, as you can see below, it is a
+# headache to deal with in a portable fashion.
+
+# Historically, `CC_FOR_BUILD' used to be named `HOST_CC'. We still
+# use `HOST_CC' if defined, but it is deprecated.
+
+# Portable tmp directory creation inspired by the Autoconf team.
+
+set_cc_for_build='
+trap "exitcode=\$?; (rm -f \$tmpfiles 2>/dev/null; rmdir \$tmp 2>/dev/null) && exit \$exitcode" 0 ;
+trap "rm -f \$tmpfiles 2>/dev/null; rmdir \$tmp 2>/dev/null; exit 1" 1 2 13 15 ;
+: ${TMPDIR=/tmp} ;
+ { tmp=`(umask 077 && mktemp -d "$TMPDIR/cgXXXXXX") 2>/dev/null` && test -n "$tmp" && test -d "$tmp" ; } ||
+ { test -n "$RANDOM" && tmp=$TMPDIR/cg$$-$RANDOM && (umask 077 && mkdir $tmp) ; } ||
+ { tmp=$TMPDIR/cg-$$ && (umask 077 && mkdir $tmp) && echo "Warning: creating insecure temp directory" >&2 ; } ||
+ { echo "$me: cannot create a temporary directory in $TMPDIR" >&2 ; exit 1 ; } ;
+dummy=$tmp/dummy ;
+tmpfiles="$dummy.c $dummy.o $dummy.rel $dummy" ;
+case $CC_FOR_BUILD,$HOST_CC,$CC in
+ ,,) echo "int x;" > $dummy.c ;
+ for c in cc gcc c89 c99 ; do
+ if ($c -c -o $dummy.o $dummy.c) >/dev/null 2>&1 ; then
+ CC_FOR_BUILD="$c"; break ;
+ fi ;
+ done ;
+ if test x"$CC_FOR_BUILD" = x ; then
+ CC_FOR_BUILD=no_compiler_found ;
+ fi
+ ;;
+ ,,*) CC_FOR_BUILD=$CC ;;
+ ,*,*) CC_FOR_BUILD=$HOST_CC ;;
+esac ; set_cc_for_build= ;'
+
+# This is needed to find uname on a Pyramid OSx when run in the BSD universe.
+# (ghazi@noc.rutgers.edu 1994-08-24)
+if (test -f /.attbin/uname) >/dev/null 2>&1 ; then
+ PATH=$PATH:/.attbin ; export PATH
+fi
+
+UNAME_MACHINE=`(uname -m) 2>/dev/null` || UNAME_MACHINE=unknown
+UNAME_RELEASE=`(uname -r) 2>/dev/null` || UNAME_RELEASE=unknown
+UNAME_SYSTEM=`(uname -s) 2>/dev/null` || UNAME_SYSTEM=unknown
+UNAME_VERSION=`(uname -v) 2>/dev/null` || UNAME_VERSION=unknown
+
+# Note: order is significant - the case branches are not exclusive.
+
+case "${UNAME_MACHINE}:${UNAME_SYSTEM}:${UNAME_RELEASE}:${UNAME_VERSION}" in
+ *:NetBSD:*:*)
+ # NetBSD (nbsd) targets should (where applicable) match one or
+ # more of the tupples: *-*-netbsdelf*, *-*-netbsdaout*,
+ # *-*-netbsdecoff* and *-*-netbsd*. For targets that recently
+ # switched to ELF, *-*-netbsd* would select the old
+ # object file format. This provides both forward
+ # compatibility and a consistent mechanism for selecting the
+ # object file format.
+ #
+ # Note: NetBSD doesn't particularly care about the vendor
+ # portion of the name. We always set it to "unknown".
+ sysctl="sysctl -n hw.machine_arch"
+ UNAME_MACHINE_ARCH=`(/sbin/$sysctl 2>/dev/null || \
+ /usr/sbin/$sysctl 2>/dev/null || echo unknown)`
+ case "${UNAME_MACHINE_ARCH}" in
+ armeb) machine=armeb-unknown ;;
+ arm*) machine=arm-unknown ;;
+ sh3el) machine=shl-unknown ;;
+ sh3eb) machine=sh-unknown ;;
+ sh5el) machine=sh5le-unknown ;;
+ *) machine=${UNAME_MACHINE_ARCH}-unknown ;;
+ esac
+ # The Operating System including object format, if it has switched
+ # to ELF recently, or will in the future.
+ case "${UNAME_MACHINE_ARCH}" in
+ arm*|i386|m68k|ns32k|sh3*|sparc|vax)
+ eval $set_cc_for_build
+ if echo __ELF__ | $CC_FOR_BUILD -E - 2>/dev/null \
+ | grep -q __ELF__
+ then
+ # Once all utilities can be ECOFF (netbsdecoff) or a.out (netbsdaout).
+ # Return netbsd for either. FIX?
+ os=netbsd
+ else
+ os=netbsdelf
+ fi
+ ;;
+ *)
+ os=netbsd
+ ;;
+ esac
+ # The OS release
+ # Debian GNU/NetBSD machines have a different userland, and
+ # thus, need a distinct triplet. However, they do not need
+ # kernel version information, so it can be replaced with a
+ # suitable tag, in the style of linux-gnu.
+ case "${UNAME_VERSION}" in
+ Debian*)
+ release='-gnu'
+ ;;
+ *)
+ release=`echo ${UNAME_RELEASE}|sed -e 's/[-_].*/\./'`
+ ;;
+ esac
+ # Since CPU_TYPE-MANUFACTURER-KERNEL-OPERATING_SYSTEM:
+ # contains redundant information, the shorter form:
+ # CPU_TYPE-MANUFACTURER-OPERATING_SYSTEM is used.
+ echo "${machine}-${os}${release}"
+ exit ;;
+ *:OpenBSD:*:*)
+ UNAME_MACHINE_ARCH=`arch | sed 's/OpenBSD.//'`
+ echo ${UNAME_MACHINE_ARCH}-unknown-openbsd${UNAME_RELEASE}
+ exit ;;
+ *:ekkoBSD:*:*)
+ echo ${UNAME_MACHINE}-unknown-ekkobsd${UNAME_RELEASE}
+ exit ;;
+ *:SolidBSD:*:*)
+ echo ${UNAME_MACHINE}-unknown-solidbsd${UNAME_RELEASE}
+ exit ;;
+ macppc:MirBSD:*:*)
+ echo powerpc-unknown-mirbsd${UNAME_RELEASE}
+ exit ;;
+ *:MirBSD:*:*)
+ echo ${UNAME_MACHINE}-unknown-mirbsd${UNAME_RELEASE}
+ exit ;;
+ alpha:OSF1:*:*)
+ case $UNAME_RELEASE in
+ *4.0)
+ UNAME_RELEASE=`/usr/sbin/sizer -v | awk '{print $3}'`
+ ;;
+ *5.*)
+ UNAME_RELEASE=`/usr/sbin/sizer -v | awk '{print $4}'`
+ ;;
+ esac
+ # According to Compaq, /usr/sbin/psrinfo has been available on
+ # OSF/1 and Tru64 systems produced since 1995. I hope that
+ # covers most systems running today. This code pipes the CPU
+ # types through head -n 1, so we only detect the type of CPU 0.
+ ALPHA_CPU_TYPE=`/usr/sbin/psrinfo -v | sed -n -e 's/^ The alpha \(.*\) processor.*$/\1/p' | head -n 1`
+ case "$ALPHA_CPU_TYPE" in
+ "EV4 (21064)")
+ UNAME_MACHINE="alpha" ;;
+ "EV4.5 (21064)")
+ UNAME_MACHINE="alpha" ;;
+ "LCA4 (21066/21068)")
+ UNAME_MACHINE="alpha" ;;
+ "EV5 (21164)")
+ UNAME_MACHINE="alphaev5" ;;
+ "EV5.6 (21164A)")
+ UNAME_MACHINE="alphaev56" ;;
+ "EV5.6 (21164PC)")
+ UNAME_MACHINE="alphapca56" ;;
+ "EV5.7 (21164PC)")
+ UNAME_MACHINE="alphapca57" ;;
+ "EV6 (21264)")
+ UNAME_MACHINE="alphaev6" ;;
+ "EV6.7 (21264A)")
+ UNAME_MACHINE="alphaev67" ;;
+ "EV6.8CB (21264C)")
+ UNAME_MACHINE="alphaev68" ;;
+ "EV6.8AL (21264B)")
+ UNAME_MACHINE="alphaev68" ;;
+ "EV6.8CX (21264D)")
+ UNAME_MACHINE="alphaev68" ;;
+ "EV6.9A (21264/EV69A)")
+ UNAME_MACHINE="alphaev69" ;;
+ "EV7 (21364)")
+ UNAME_MACHINE="alphaev7" ;;
+ "EV7.9 (21364A)")
+ UNAME_MACHINE="alphaev79" ;;
+ esac
+ # A Pn.n version is a patched version.
+ # A Vn.n version is a released version.
+ # A Tn.n version is a released field test version.
+ # A Xn.n version is an unreleased experimental baselevel.
+ # 1.2 uses "1.2" for uname -r.
+ echo ${UNAME_MACHINE}-dec-osf`echo ${UNAME_RELEASE} | sed -e 's/^[PVTX]//' | tr 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' 'abcdefghijklmnopqrstuvwxyz'`
+ exit ;;
+ Alpha\ *:Windows_NT*:*)
+ # How do we know it's Interix rather than the generic POSIX subsystem?
+ # Should we change UNAME_MACHINE based on the output of uname instead
+ # of the specific Alpha model?
+ echo alpha-pc-interix
+ exit ;;
+ 21064:Windows_NT:50:3)
+ echo alpha-dec-winnt3.5
+ exit ;;
+ Amiga*:UNIX_System_V:4.0:*)
+ echo m68k-unknown-sysv4
+ exit ;;
+ *:[Aa]miga[Oo][Ss]:*:*)
+ echo ${UNAME_MACHINE}-unknown-amigaos
+ exit ;;
+ *:[Mm]orph[Oo][Ss]:*:*)
+ echo ${UNAME_MACHINE}-unknown-morphos
+ exit ;;
+ *:OS/390:*:*)
+ echo i370-ibm-openedition
+ exit ;;
+ *:z/VM:*:*)
+ echo s390-ibm-zvmoe
+ exit ;;
+ *:OS400:*:*)
+ echo powerpc-ibm-os400
+ exit ;;
+ arm:RISC*:1.[012]*:*|arm:riscix:1.[012]*:*)
+ echo arm-acorn-riscix${UNAME_RELEASE}
+ exit ;;
+ arm:riscos:*:*|arm:RISCOS:*:*)
+ echo arm-unknown-riscos
+ exit ;;
+ SR2?01:HI-UX/MPP:*:* | SR8000:HI-UX/MPP:*:*)
+ echo hppa1.1-hitachi-hiuxmpp
+ exit ;;
+ Pyramid*:OSx*:*:* | MIS*:OSx*:*:* | MIS*:SMP_DC-OSx*:*:*)
+ # akee@wpdis03.wpafb.af.mil (Earle F. Ake) contributed MIS and NILE.
+ if test "`(/bin/universe) 2>/dev/null`" = att ; then
+ echo pyramid-pyramid-sysv3
+ else
+ echo pyramid-pyramid-bsd
+ fi
+ exit ;;
+ NILE*:*:*:dcosx)
+ echo pyramid-pyramid-svr4
+ exit ;;
+ DRS?6000:unix:4.0:6*)
+ echo sparc-icl-nx6
+ exit ;;
+ DRS?6000:UNIX_SV:4.2*:7* | DRS?6000:isis:4.2*:7*)
+ case `/usr/bin/uname -p` in
+ sparc) echo sparc-icl-nx7; exit ;;
+ esac ;;
+ s390x:SunOS:*:*)
+ echo ${UNAME_MACHINE}-ibm-solaris2`echo ${UNAME_RELEASE}|sed -e 's/[^.]*//'`
+ exit ;;
+ sun4H:SunOS:5.*:*)
+ echo sparc-hal-solaris2`echo ${UNAME_RELEASE}|sed -e 's/[^.]*//'`
+ exit ;;
+ sun4*:SunOS:5.*:* | tadpole*:SunOS:5.*:*)
+ echo sparc-sun-solaris2`echo ${UNAME_RELEASE}|sed -e 's/[^.]*//'`
+ exit ;;
+ i86pc:AuroraUX:5.*:* | i86xen:AuroraUX:5.*:*)
+ echo i386-pc-auroraux${UNAME_RELEASE}
+ exit ;;
+ i86pc:SunOS:5.*:* | i86xen:SunOS:5.*:*)
+ eval $set_cc_for_build
+ SUN_ARCH="i386"
+ # If there is a compiler, see if it is configured for 64-bit objects.
+ # Note that the Sun cc does not turn __LP64__ into 1 like gcc does.
+ # This test works for both compilers.
+ if [ "$CC_FOR_BUILD" != 'no_compiler_found' ]; then
+ if (echo '#ifdef __amd64'; echo IS_64BIT_ARCH; echo '#endif') | \
+ (CCOPTS= $CC_FOR_BUILD -E - 2>/dev/null) | \
+ grep IS_64BIT_ARCH >/dev/null
+ then
+ SUN_ARCH="x86_64"
+ fi
+ fi
+ echo ${SUN_ARCH}-pc-solaris2`echo ${UNAME_RELEASE}|sed -e 's/[^.]*//'`
+ exit ;;
+ sun4*:SunOS:6*:*)
+ # According to config.sub, this is the proper way to canonicalize
+ # SunOS6. Hard to guess exactly what SunOS6 will be like, but
+ # it's likely to be more like Solaris than SunOS4.
+ echo sparc-sun-solaris3`echo ${UNAME_RELEASE}|sed -e 's/[^.]*//'`
+ exit ;;
+ sun4*:SunOS:*:*)
+ case "`/usr/bin/arch -k`" in
+ Series*|S4*)
+ UNAME_RELEASE=`uname -v`
+ ;;
+ esac
+ # Japanese Language versions have a version number like `4.1.3-JL'.
+ echo sparc-sun-sunos`echo ${UNAME_RELEASE}|sed -e 's/-/_/'`
+ exit ;;
+ sun3*:SunOS:*:*)
+ echo m68k-sun-sunos${UNAME_RELEASE}
+ exit ;;
+ sun*:*:4.2BSD:*)
+ UNAME_RELEASE=`(sed 1q /etc/motd | awk '{print substr($5,1,3)}') 2>/dev/null`
+ test "x${UNAME_RELEASE}" = "x" && UNAME_RELEASE=3
+ case "`/bin/arch`" in
+ sun3)
+ echo m68k-sun-sunos${UNAME_RELEASE}
+ ;;
+ sun4)
+ echo sparc-sun-sunos${UNAME_RELEASE}
+ ;;
+ esac
+ exit ;;
+ aushp:SunOS:*:*)
+ echo sparc-auspex-sunos${UNAME_RELEASE}
+ exit ;;
+ # The situation for MiNT is a little confusing. The machine name
+ # can be virtually everything (everything which is not
+ # "atarist" or "atariste" at least should have a processor
+ # > m68000). The system name ranges from "MiNT" over "FreeMiNT"
+ # to the lowercase version "mint" (or "freemint"). Finally
+ # the system name "TOS" denotes a system which is actually not
+ # MiNT. But MiNT is downward compatible to TOS, so this should
+ # be no problem.
+ atarist[e]:*MiNT:*:* | atarist[e]:*mint:*:* | atarist[e]:*TOS:*:*)
+ echo m68k-atari-mint${UNAME_RELEASE}
+ exit ;;
+ atari*:*MiNT:*:* | atari*:*mint:*:* | atarist[e]:*TOS:*:*)
+ echo m68k-atari-mint${UNAME_RELEASE}
+ exit ;;
+ *falcon*:*MiNT:*:* | *falcon*:*mint:*:* | *falcon*:*TOS:*:*)
+ echo m68k-atari-mint${UNAME_RELEASE}
+ exit ;;
+ milan*:*MiNT:*:* | milan*:*mint:*:* | *milan*:*TOS:*:*)
+ echo m68k-milan-mint${UNAME_RELEASE}
+ exit ;;
+ hades*:*MiNT:*:* | hades*:*mint:*:* | *hades*:*TOS:*:*)
+ echo m68k-hades-mint${UNAME_RELEASE}
+ exit ;;
+ *:*MiNT:*:* | *:*mint:*:* | *:*TOS:*:*)
+ echo m68k-unknown-mint${UNAME_RELEASE}
+ exit ;;
+ m68k:machten:*:*)
+ echo m68k-apple-machten${UNAME_RELEASE}
+ exit ;;
+ powerpc:machten:*:*)
+ echo powerpc-apple-machten${UNAME_RELEASE}
+ exit ;;
+ RISC*:Mach:*:*)
+ echo mips-dec-mach_bsd4.3
+ exit ;;
+ RISC*:ULTRIX:*:*)
+ echo mips-dec-ultrix${UNAME_RELEASE}
+ exit ;;
+ VAX*:ULTRIX*:*:*)
+ echo vax-dec-ultrix${UNAME_RELEASE}
+ exit ;;
+ 2020:CLIX:*:* | 2430:CLIX:*:*)
+ echo clipper-intergraph-clix${UNAME_RELEASE}
+ exit ;;
+ mips:*:*:UMIPS | mips:*:*:RISCos)
+ eval $set_cc_for_build
+ sed 's/^ //' << EOF >$dummy.c
+#ifdef __cplusplus
+#include /* for printf() prototype */
+ int main (int argc, char *argv[]) {
+#else
+ int main (argc, argv) int argc; char *argv[]; {
+#endif
+ #if defined (host_mips) && defined (MIPSEB)
+ #if defined (SYSTYPE_SYSV)
+ printf ("mips-mips-riscos%ssysv\n", argv[1]); exit (0);
+ #endif
+ #if defined (SYSTYPE_SVR4)
+ printf ("mips-mips-riscos%ssvr4\n", argv[1]); exit (0);
+ #endif
+ #if defined (SYSTYPE_BSD43) || defined(SYSTYPE_BSD)
+ printf ("mips-mips-riscos%sbsd\n", argv[1]); exit (0);
+ #endif
+ #endif
+ exit (-1);
+ }
+EOF
+ $CC_FOR_BUILD -o $dummy $dummy.c &&
+ dummyarg=`echo "${UNAME_RELEASE}" | sed -n 's/\([0-9]*\).*/\1/p'` &&
+ SYSTEM_NAME=`$dummy $dummyarg` &&
+ { echo "$SYSTEM_NAME"; exit; }
+ echo mips-mips-riscos${UNAME_RELEASE}
+ exit ;;
+ Motorola:PowerMAX_OS:*:*)
+ echo powerpc-motorola-powermax
+ exit ;;
+ Motorola:*:4.3:PL8-*)
+ echo powerpc-harris-powermax
+ exit ;;
+ Night_Hawk:*:*:PowerMAX_OS | Synergy:PowerMAX_OS:*:*)
+ echo powerpc-harris-powermax
+ exit ;;
+ Night_Hawk:Power_UNIX:*:*)
+ echo powerpc-harris-powerunix
+ exit ;;
+ m88k:CX/UX:7*:*)
+ echo m88k-harris-cxux7
+ exit ;;
+ m88k:*:4*:R4*)
+ echo m88k-motorola-sysv4
+ exit ;;
+ m88k:*:3*:R3*)
+ echo m88k-motorola-sysv3
+ exit ;;
+ AViiON:dgux:*:*)
+ # DG/UX returns AViiON for all architectures
+ UNAME_PROCESSOR=`/usr/bin/uname -p`
+ if [ $UNAME_PROCESSOR = mc88100 ] || [ $UNAME_PROCESSOR = mc88110 ]
+ then
+ if [ ${TARGET_BINARY_INTERFACE}x = m88kdguxelfx ] || \
+ [ ${TARGET_BINARY_INTERFACE}x = x ]
+ then
+ echo m88k-dg-dgux${UNAME_RELEASE}
+ else
+ echo m88k-dg-dguxbcs${UNAME_RELEASE}
+ fi
+ else
+ echo i586-dg-dgux${UNAME_RELEASE}
+ fi
+ exit ;;
+ M88*:DolphinOS:*:*) # DolphinOS (SVR3)
+ echo m88k-dolphin-sysv3
+ exit ;;
+ M88*:*:R3*:*)
+ # Delta 88k system running SVR3
+ echo m88k-motorola-sysv3
+ exit ;;
+ XD88*:*:*:*) # Tektronix XD88 system running UTekV (SVR3)
+ echo m88k-tektronix-sysv3
+ exit ;;
+ Tek43[0-9][0-9]:UTek:*:*) # Tektronix 4300 system running UTek (BSD)
+ echo m68k-tektronix-bsd
+ exit ;;
+ *:IRIX*:*:*)
+ echo mips-sgi-irix`echo ${UNAME_RELEASE}|sed -e 's/-/_/g'`
+ exit ;;
+ ????????:AIX?:[12].1:2) # AIX 2.2.1 or AIX 2.1.1 is RT/PC AIX.
+ echo romp-ibm-aix # uname -m gives an 8 hex-code CPU id
+ exit ;; # Note that: echo "'`uname -s`'" gives 'AIX '
+ i*86:AIX:*:*)
+ echo i386-ibm-aix
+ exit ;;
+ ia64:AIX:*:*)
+ if [ -x /usr/bin/oslevel ] ; then
+ IBM_REV=`/usr/bin/oslevel`
+ else
+ IBM_REV=${UNAME_VERSION}.${UNAME_RELEASE}
+ fi
+ echo ${UNAME_MACHINE}-ibm-aix${IBM_REV}
+ exit ;;
+ *:AIX:2:3)
+ if grep bos325 /usr/include/stdio.h >/dev/null 2>&1; then
+ eval $set_cc_for_build
+ sed 's/^ //' << EOF >$dummy.c
+ #include
+
+ main()
+ {
+ if (!__power_pc())
+ exit(1);
+ puts("powerpc-ibm-aix3.2.5");
+ exit(0);
+ }
+EOF
+ if $CC_FOR_BUILD -o $dummy $dummy.c && SYSTEM_NAME=`$dummy`
+ then
+ echo "$SYSTEM_NAME"
+ else
+ echo rs6000-ibm-aix3.2.5
+ fi
+ elif grep bos324 /usr/include/stdio.h >/dev/null 2>&1; then
+ echo rs6000-ibm-aix3.2.4
+ else
+ echo rs6000-ibm-aix3.2
+ fi
+ exit ;;
+ *:AIX:*:[456])
+ IBM_CPU_ID=`/usr/sbin/lsdev -C -c processor -S available | sed 1q | awk '{ print $1 }'`
+ if /usr/sbin/lsattr -El ${IBM_CPU_ID} | grep ' POWER' >/dev/null 2>&1; then
+ IBM_ARCH=rs6000
+ else
+ IBM_ARCH=powerpc
+ fi
+ if [ -x /usr/bin/oslevel ] ; then
+ IBM_REV=`/usr/bin/oslevel`
+ else
+ IBM_REV=${UNAME_VERSION}.${UNAME_RELEASE}
+ fi
+ echo ${IBM_ARCH}-ibm-aix${IBM_REV}
+ exit ;;
+ *:AIX:*:*)
+ echo rs6000-ibm-aix
+ exit ;;
+ ibmrt:4.4BSD:*|romp-ibm:BSD:*)
+ echo romp-ibm-bsd4.4
+ exit ;;
+ ibmrt:*BSD:*|romp-ibm:BSD:*) # covers RT/PC BSD and
+ echo romp-ibm-bsd${UNAME_RELEASE} # 4.3 with uname added to
+ exit ;; # report: romp-ibm BSD 4.3
+ *:BOSX:*:*)
+ echo rs6000-bull-bosx
+ exit ;;
+ DPX/2?00:B.O.S.:*:*)
+ echo m68k-bull-sysv3
+ exit ;;
+ 9000/[34]??:4.3bsd:1.*:*)
+ echo m68k-hp-bsd
+ exit ;;
+ hp300:4.4BSD:*:* | 9000/[34]??:4.3bsd:2.*:*)
+ echo m68k-hp-bsd4.4
+ exit ;;
+ 9000/[34678]??:HP-UX:*:*)
+ HPUX_REV=`echo ${UNAME_RELEASE}|sed -e 's/[^.]*.[0B]*//'`
+ case "${UNAME_MACHINE}" in
+ 9000/31? ) HP_ARCH=m68000 ;;
+ 9000/[34]?? ) HP_ARCH=m68k ;;
+ 9000/[678][0-9][0-9])
+ if [ -x /usr/bin/getconf ]; then
+ sc_cpu_version=`/usr/bin/getconf SC_CPU_VERSION 2>/dev/null`
+ sc_kernel_bits=`/usr/bin/getconf SC_KERNEL_BITS 2>/dev/null`
+ case "${sc_cpu_version}" in
+ 523) HP_ARCH="hppa1.0" ;; # CPU_PA_RISC1_0
+ 528) HP_ARCH="hppa1.1" ;; # CPU_PA_RISC1_1
+ 532) # CPU_PA_RISC2_0
+ case "${sc_kernel_bits}" in
+ 32) HP_ARCH="hppa2.0n" ;;
+ 64) HP_ARCH="hppa2.0w" ;;
+ '') HP_ARCH="hppa2.0" ;; # HP-UX 10.20
+ esac ;;
+ esac
+ fi
+ if [ "${HP_ARCH}" = "" ]; then
+ eval $set_cc_for_build
+ sed 's/^ //' << EOF >$dummy.c
+
+ #define _HPUX_SOURCE
+ #include
+ #include
+
+ int main ()
+ {
+ #if defined(_SC_KERNEL_BITS)
+ long bits = sysconf(_SC_KERNEL_BITS);
+ #endif
+ long cpu = sysconf (_SC_CPU_VERSION);
+
+ switch (cpu)
+ {
+ case CPU_PA_RISC1_0: puts ("hppa1.0"); break;
+ case CPU_PA_RISC1_1: puts ("hppa1.1"); break;
+ case CPU_PA_RISC2_0:
+ #if defined(_SC_KERNEL_BITS)
+ switch (bits)
+ {
+ case 64: puts ("hppa2.0w"); break;
+ case 32: puts ("hppa2.0n"); break;
+ default: puts ("hppa2.0"); break;
+ } break;
+ #else /* !defined(_SC_KERNEL_BITS) */
+ puts ("hppa2.0"); break;
+ #endif
+ default: puts ("hppa1.0"); break;
+ }
+ exit (0);
+ }
+EOF
+ (CCOPTS= $CC_FOR_BUILD -o $dummy $dummy.c 2>/dev/null) && HP_ARCH=`$dummy`
+ test -z "$HP_ARCH" && HP_ARCH=hppa
+ fi ;;
+ esac
+ if [ ${HP_ARCH} = "hppa2.0w" ]
+ then
+ eval $set_cc_for_build
+
+ # hppa2.0w-hp-hpux* has a 64-bit kernel and a compiler generating
+ # 32-bit code. hppa64-hp-hpux* has the same kernel and a compiler
+ # generating 64-bit code. GNU and HP use different nomenclature:
+ #
+ # $ CC_FOR_BUILD=cc ./config.guess
+ # => hppa2.0w-hp-hpux11.23
+ # $ CC_FOR_BUILD="cc +DA2.0w" ./config.guess
+ # => hppa64-hp-hpux11.23
+
+ if echo __LP64__ | (CCOPTS= $CC_FOR_BUILD -E - 2>/dev/null) |
+ grep -q __LP64__
+ then
+ HP_ARCH="hppa2.0w"
+ else
+ HP_ARCH="hppa64"
+ fi
+ fi
+ echo ${HP_ARCH}-hp-hpux${HPUX_REV}
+ exit ;;
+ ia64:HP-UX:*:*)
+ HPUX_REV=`echo ${UNAME_RELEASE}|sed -e 's/[^.]*.[0B]*//'`
+ echo ia64-hp-hpux${HPUX_REV}
+ exit ;;
+ 3050*:HI-UX:*:*)
+ eval $set_cc_for_build
+ sed 's/^ //' << EOF >$dummy.c
+ #include
+ int
+ main ()
+ {
+ long cpu = sysconf (_SC_CPU_VERSION);
+ /* The order matters, because CPU_IS_HP_MC68K erroneously returns
+ true for CPU_PA_RISC1_0. CPU_IS_PA_RISC returns correct
+ results, however. */
+ if (CPU_IS_PA_RISC (cpu))
+ {
+ switch (cpu)
+ {
+ case CPU_PA_RISC1_0: puts ("hppa1.0-hitachi-hiuxwe2"); break;
+ case CPU_PA_RISC1_1: puts ("hppa1.1-hitachi-hiuxwe2"); break;
+ case CPU_PA_RISC2_0: puts ("hppa2.0-hitachi-hiuxwe2"); break;
+ default: puts ("hppa-hitachi-hiuxwe2"); break;
+ }
+ }
+ else if (CPU_IS_HP_MC68K (cpu))
+ puts ("m68k-hitachi-hiuxwe2");
+ else puts ("unknown-hitachi-hiuxwe2");
+ exit (0);
+ }
+EOF
+ $CC_FOR_BUILD -o $dummy $dummy.c && SYSTEM_NAME=`$dummy` &&
+ { echo "$SYSTEM_NAME"; exit; }
+ echo unknown-hitachi-hiuxwe2
+ exit ;;
+ 9000/7??:4.3bsd:*:* | 9000/8?[79]:4.3bsd:*:* )
+ echo hppa1.1-hp-bsd
+ exit ;;
+ 9000/8??:4.3bsd:*:*)
+ echo hppa1.0-hp-bsd
+ exit ;;
+ *9??*:MPE/iX:*:* | *3000*:MPE/iX:*:*)
+ echo hppa1.0-hp-mpeix
+ exit ;;
+ hp7??:OSF1:*:* | hp8?[79]:OSF1:*:* )
+ echo hppa1.1-hp-osf
+ exit ;;
+ hp8??:OSF1:*:*)
+ echo hppa1.0-hp-osf
+ exit ;;
+ i*86:OSF1:*:*)
+ if [ -x /usr/sbin/sysversion ] ; then
+ echo ${UNAME_MACHINE}-unknown-osf1mk
+ else
+ echo ${UNAME_MACHINE}-unknown-osf1
+ fi
+ exit ;;
+ parisc*:Lites*:*:*)
+ echo hppa1.1-hp-lites
+ exit ;;
+ C1*:ConvexOS:*:* | convex:ConvexOS:C1*:*)
+ echo c1-convex-bsd
+ exit ;;
+ C2*:ConvexOS:*:* | convex:ConvexOS:C2*:*)
+ if getsysinfo -f scalar_acc
+ then echo c32-convex-bsd
+ else echo c2-convex-bsd
+ fi
+ exit ;;
+ C34*:ConvexOS:*:* | convex:ConvexOS:C34*:*)
+ echo c34-convex-bsd
+ exit ;;
+ C38*:ConvexOS:*:* | convex:ConvexOS:C38*:*)
+ echo c38-convex-bsd
+ exit ;;
+ C4*:ConvexOS:*:* | convex:ConvexOS:C4*:*)
+ echo c4-convex-bsd
+ exit ;;
+ CRAY*Y-MP:*:*:*)
+ echo ymp-cray-unicos${UNAME_RELEASE} | sed -e 's/\.[^.]*$/.X/'
+ exit ;;
+ CRAY*[A-Z]90:*:*:*)
+ echo ${UNAME_MACHINE}-cray-unicos${UNAME_RELEASE} \
+ | sed -e 's/CRAY.*\([A-Z]90\)/\1/' \
+ -e y/ABCDEFGHIJKLMNOPQRSTUVWXYZ/abcdefghijklmnopqrstuvwxyz/ \
+ -e 's/\.[^.]*$/.X/'
+ exit ;;
+ CRAY*TS:*:*:*)
+ echo t90-cray-unicos${UNAME_RELEASE} | sed -e 's/\.[^.]*$/.X/'
+ exit ;;
+ CRAY*T3E:*:*:*)
+ echo alphaev5-cray-unicosmk${UNAME_RELEASE} | sed -e 's/\.[^.]*$/.X/'
+ exit ;;
+ CRAY*SV1:*:*:*)
+ echo sv1-cray-unicos${UNAME_RELEASE} | sed -e 's/\.[^.]*$/.X/'
+ exit ;;
+ *:UNICOS/mp:*:*)
+ echo craynv-cray-unicosmp${UNAME_RELEASE} | sed -e 's/\.[^.]*$/.X/'
+ exit ;;
+ F30[01]:UNIX_System_V:*:* | F700:UNIX_System_V:*:*)
+ FUJITSU_PROC=`uname -m | tr 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' 'abcdefghijklmnopqrstuvwxyz'`
+ FUJITSU_SYS=`uname -p | tr 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' 'abcdefghijklmnopqrstuvwxyz' | sed -e 's/\///'`
+ FUJITSU_REL=`echo ${UNAME_RELEASE} | sed -e 's/ /_/'`
+ echo "${FUJITSU_PROC}-fujitsu-${FUJITSU_SYS}${FUJITSU_REL}"
+ exit ;;
+ 5000:UNIX_System_V:4.*:*)
+ FUJITSU_SYS=`uname -p | tr 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' 'abcdefghijklmnopqrstuvwxyz' | sed -e 's/\///'`
+ FUJITSU_REL=`echo ${UNAME_RELEASE} | tr 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' 'abcdefghijklmnopqrstuvwxyz' | sed -e 's/ /_/'`
+ echo "sparc-fujitsu-${FUJITSU_SYS}${FUJITSU_REL}"
+ exit ;;
+ i*86:BSD/386:*:* | i*86:BSD/OS:*:* | *:Ascend\ Embedded/OS:*:*)
+ echo ${UNAME_MACHINE}-pc-bsdi${UNAME_RELEASE}
+ exit ;;
+ sparc*:BSD/OS:*:*)
+ echo sparc-unknown-bsdi${UNAME_RELEASE}
+ exit ;;
+ *:BSD/OS:*:*)
+ echo ${UNAME_MACHINE}-unknown-bsdi${UNAME_RELEASE}
+ exit ;;
+ *:FreeBSD:*:*)
+ case ${UNAME_MACHINE} in
+ pc98)
+ echo i386-unknown-freebsd`echo ${UNAME_RELEASE}|sed -e 's/[-(].*//'` ;;
+ amd64)
+ echo x86_64-unknown-freebsd`echo ${UNAME_RELEASE}|sed -e 's/[-(].*//'` ;;
+ *)
+ echo ${UNAME_MACHINE}-unknown-freebsd`echo ${UNAME_RELEASE}|sed -e 's/[-(].*//'` ;;
+ esac
+ exit ;;
+ i*:CYGWIN*:*)
+ echo ${UNAME_MACHINE}-pc-cygwin
+ exit ;;
+ *:MINGW*:*)
+ echo ${UNAME_MACHINE}-pc-mingw32
+ exit ;;
+ i*:windows32*:*)
+ # uname -m includes "-pc" on this system.
+ echo ${UNAME_MACHINE}-mingw32
+ exit ;;
+ i*:PW*:*)
+ echo ${UNAME_MACHINE}-pc-pw32
+ exit ;;
+ *:Interix*:*)
+ case ${UNAME_MACHINE} in
+ x86)
+ echo i586-pc-interix${UNAME_RELEASE}
+ exit ;;
+ authenticamd | genuineintel | EM64T)
+ echo x86_64-unknown-interix${UNAME_RELEASE}
+ exit ;;
+ IA64)
+ echo ia64-unknown-interix${UNAME_RELEASE}
+ exit ;;
+ esac ;;
+ [345]86:Windows_95:* | [345]86:Windows_98:* | [345]86:Windows_NT:*)
+ echo i${UNAME_MACHINE}-pc-mks
+ exit ;;
+ 8664:Windows_NT:*)
+ echo x86_64-pc-mks
+ exit ;;
+ i*:Windows_NT*:* | Pentium*:Windows_NT*:*)
+ # How do we know it's Interix rather than the generic POSIX subsystem?
+ # It also conflicts with pre-2.0 versions of AT&T UWIN. Should we
+ # UNAME_MACHINE based on the output of uname instead of i386?
+ echo i586-pc-interix
+ exit ;;
+ i*:UWIN*:*)
+ echo ${UNAME_MACHINE}-pc-uwin
+ exit ;;
+ amd64:CYGWIN*:*:* | x86_64:CYGWIN*:*:*)
+ echo x86_64-unknown-cygwin
+ exit ;;
+ p*:CYGWIN*:*)
+ echo powerpcle-unknown-cygwin
+ exit ;;
+ prep*:SunOS:5.*:*)
+ echo powerpcle-unknown-solaris2`echo ${UNAME_RELEASE}|sed -e 's/[^.]*//'`
+ exit ;;
+ *:GNU:*:*)
+ # the GNU system
+ echo `echo ${UNAME_MACHINE}|sed -e 's,[-/].*$,,'`-unknown-gnu`echo ${UNAME_RELEASE}|sed -e 's,/.*$,,'`
+ exit ;;
+ *:GNU/*:*:*)
+ # other systems with GNU libc and userland
+ echo ${UNAME_MACHINE}-unknown-`echo ${UNAME_SYSTEM} | sed 's,^[^/]*/,,' | tr '[A-Z]' '[a-z]'``echo ${UNAME_RELEASE}|sed -e 's/[-(].*//'`-gnu
+ exit ;;
+ i*86:Minix:*:*)
+ echo ${UNAME_MACHINE}-pc-minix
+ exit ;;
+ alpha:Linux:*:*)
+ case `sed -n '/^cpu model/s/^.*: \(.*\)/\1/p' < /proc/cpuinfo` in
+ EV5) UNAME_MACHINE=alphaev5 ;;
+ EV56) UNAME_MACHINE=alphaev56 ;;
+ PCA56) UNAME_MACHINE=alphapca56 ;;
+ PCA57) UNAME_MACHINE=alphapca56 ;;
+ EV6) UNAME_MACHINE=alphaev6 ;;
+ EV67) UNAME_MACHINE=alphaev67 ;;
+ EV68*) UNAME_MACHINE=alphaev68 ;;
+ esac
+ objdump --private-headers /bin/sh | grep -q ld.so.1
+ if test "$?" = 0 ; then LIBC="libc1" ; else LIBC="" ; fi
+ echo ${UNAME_MACHINE}-unknown-linux-gnu${LIBC}
+ exit ;;
+ arm*:Linux:*:*)
+ eval $set_cc_for_build
+ if echo __ARM_EABI__ | $CC_FOR_BUILD -E - 2>/dev/null \
+ | grep -q __ARM_EABI__
+ then
+ echo ${UNAME_MACHINE}-unknown-linux-gnu
+ else
+ echo ${UNAME_MACHINE}-unknown-linux-gnueabi
+ fi
+ exit ;;
+ avr32*:Linux:*:*)
+ echo ${UNAME_MACHINE}-unknown-linux-gnu
+ exit ;;
+ cris:Linux:*:*)
+ echo cris-axis-linux-gnu
+ exit ;;
+ crisv32:Linux:*:*)
+ echo crisv32-axis-linux-gnu
+ exit ;;
+ frv:Linux:*:*)
+ echo frv-unknown-linux-gnu
+ exit ;;
+ i*86:Linux:*:*)
+ LIBC=gnu
+ eval $set_cc_for_build
+ sed 's/^ //' << EOF >$dummy.c
+ #ifdef __dietlibc__
+ LIBC=dietlibc
+ #endif
+EOF
+ eval `$CC_FOR_BUILD -E $dummy.c 2>/dev/null | grep '^LIBC'`
+ echo "${UNAME_MACHINE}-pc-linux-${LIBC}"
+ exit ;;
+ ia64:Linux:*:*)
+ echo ${UNAME_MACHINE}-unknown-linux-gnu
+ exit ;;
+ m32r*:Linux:*:*)
+ echo ${UNAME_MACHINE}-unknown-linux-gnu
+ exit ;;
+ m68*:Linux:*:*)
+ echo ${UNAME_MACHINE}-unknown-linux-gnu
+ exit ;;
+ mips:Linux:*:* | mips64:Linux:*:*)
+ eval $set_cc_for_build
+ sed 's/^ //' << EOF >$dummy.c
+ #undef CPU
+ #undef ${UNAME_MACHINE}
+ #undef ${UNAME_MACHINE}el
+ #if defined(__MIPSEL__) || defined(__MIPSEL) || defined(_MIPSEL) || defined(MIPSEL)
+ CPU=${UNAME_MACHINE}el
+ #else
+ #if defined(__MIPSEB__) || defined(__MIPSEB) || defined(_MIPSEB) || defined(MIPSEB)
+ CPU=${UNAME_MACHINE}
+ #else
+ CPU=
+ #endif
+ #endif
+EOF
+ eval `$CC_FOR_BUILD -E $dummy.c 2>/dev/null | grep '^CPU'`
+ test x"${CPU}" != x && { echo "${CPU}-unknown-linux-gnu"; exit; }
+ ;;
+ or32:Linux:*:*)
+ echo or32-unknown-linux-gnu
+ exit ;;
+ padre:Linux:*:*)
+ echo sparc-unknown-linux-gnu
+ exit ;;
+ parisc64:Linux:*:* | hppa64:Linux:*:*)
+ echo hppa64-unknown-linux-gnu
+ exit ;;
+ parisc:Linux:*:* | hppa:Linux:*:*)
+ # Look for CPU level
+ case `grep '^cpu[^a-z]*:' /proc/cpuinfo 2>/dev/null | cut -d' ' -f2` in
+ PA7*) echo hppa1.1-unknown-linux-gnu ;;
+ PA8*) echo hppa2.0-unknown-linux-gnu ;;
+ *) echo hppa-unknown-linux-gnu ;;
+ esac
+ exit ;;
+ ppc64:Linux:*:*)
+ echo powerpc64-unknown-linux-gnu
+ exit ;;
+ ppc:Linux:*:*)
+ echo powerpc-unknown-linux-gnu
+ exit ;;
+ s390:Linux:*:* | s390x:Linux:*:*)
+ echo ${UNAME_MACHINE}-ibm-linux
+ exit ;;
+ sh64*:Linux:*:*)
+ echo ${UNAME_MACHINE}-unknown-linux-gnu
+ exit ;;
+ sh*:Linux:*:*)
+ echo ${UNAME_MACHINE}-unknown-linux-gnu
+ exit ;;
+ sparc:Linux:*:* | sparc64:Linux:*:*)
+ echo ${UNAME_MACHINE}-unknown-linux-gnu
+ exit ;;
+ vax:Linux:*:*)
+ echo ${UNAME_MACHINE}-dec-linux-gnu
+ exit ;;
+ x86_64:Linux:*:*)
+ echo x86_64-unknown-linux-gnu
+ exit ;;
+ xtensa*:Linux:*:*)
+ echo ${UNAME_MACHINE}-unknown-linux-gnu
+ exit ;;
+ i*86:DYNIX/ptx:4*:*)
+ # ptx 4.0 does uname -s correctly, with DYNIX/ptx in there.
+ # earlier versions are messed up and put the nodename in both
+ # sysname and nodename.
+ echo i386-sequent-sysv4
+ exit ;;
+ i*86:UNIX_SV:4.2MP:2.*)
+ # Unixware is an offshoot of SVR4, but it has its own version
+ # number series starting with 2...
+ # I am not positive that other SVR4 systems won't match this,
+ # I just have to hope. -- rms.
+ # Use sysv4.2uw... so that sysv4* matches it.
+ echo ${UNAME_MACHINE}-pc-sysv4.2uw${UNAME_VERSION}
+ exit ;;
+ i*86:OS/2:*:*)
+ # If we were able to find `uname', then EMX Unix compatibility
+ # is probably installed.
+ echo ${UNAME_MACHINE}-pc-os2-emx
+ exit ;;
+ i*86:XTS-300:*:STOP)
+ echo ${UNAME_MACHINE}-unknown-stop
+ exit ;;
+ i*86:atheos:*:*)
+ echo ${UNAME_MACHINE}-unknown-atheos
+ exit ;;
+ i*86:syllable:*:*)
+ echo ${UNAME_MACHINE}-pc-syllable
+ exit ;;
+ i*86:LynxOS:2.*:* | i*86:LynxOS:3.[01]*:* | i*86:LynxOS:4.[02]*:*)
+ echo i386-unknown-lynxos${UNAME_RELEASE}
+ exit ;;
+ i*86:*DOS:*:*)
+ echo ${UNAME_MACHINE}-pc-msdosdjgpp
+ exit ;;
+ i*86:*:4.*:* | i*86:SYSTEM_V:4.*:*)
+ UNAME_REL=`echo ${UNAME_RELEASE} | sed 's/\/MP$//'`
+ if grep Novell /usr/include/link.h >/dev/null 2>/dev/null; then
+ echo ${UNAME_MACHINE}-univel-sysv${UNAME_REL}
+ else
+ echo ${UNAME_MACHINE}-pc-sysv${UNAME_REL}
+ fi
+ exit ;;
+ i*86:*:5:[678]*)
+ # UnixWare 7.x, OpenUNIX and OpenServer 6.
+ case `/bin/uname -X | grep "^Machine"` in
+ *486*) UNAME_MACHINE=i486 ;;
+ *Pentium) UNAME_MACHINE=i586 ;;
+ *Pent*|*Celeron) UNAME_MACHINE=i686 ;;
+ esac
+ echo ${UNAME_MACHINE}-unknown-sysv${UNAME_RELEASE}${UNAME_SYSTEM}${UNAME_VERSION}
+ exit ;;
+ i*86:*:3.2:*)
+ if test -f /usr/options/cb.name; then
+ UNAME_REL=`sed -n 's/.*Version //p' /dev/null >/dev/null ; then
+ UNAME_REL=`(/bin/uname -X|grep Release|sed -e 's/.*= //')`
+ (/bin/uname -X|grep i80486 >/dev/null) && UNAME_MACHINE=i486
+ (/bin/uname -X|grep '^Machine.*Pentium' >/dev/null) \
+ && UNAME_MACHINE=i586
+ (/bin/uname -X|grep '^Machine.*Pent *II' >/dev/null) \
+ && UNAME_MACHINE=i686
+ (/bin/uname -X|grep '^Machine.*Pentium Pro' >/dev/null) \
+ && UNAME_MACHINE=i686
+ echo ${UNAME_MACHINE}-pc-sco$UNAME_REL
+ else
+ echo ${UNAME_MACHINE}-pc-sysv32
+ fi
+ exit ;;
+ pc:*:*:*)
+ # Left here for compatibility:
+ # uname -m prints for DJGPP always 'pc', but it prints nothing about
+ # the processor, so we play safe by assuming i586.
+ # Note: whatever this is, it MUST be the same as what config.sub
+ # prints for the "djgpp" host, or else GDB configury will decide that
+ # this is a cross-build.
+ echo i586-pc-msdosdjgpp
+ exit ;;
+ Intel:Mach:3*:*)
+ echo i386-pc-mach3
+ exit ;;
+ paragon:*:*:*)
+ echo i860-intel-osf1
+ exit ;;
+ i860:*:4.*:*) # i860-SVR4
+ if grep Stardent /usr/include/sys/uadmin.h >/dev/null 2>&1 ; then
+ echo i860-stardent-sysv${UNAME_RELEASE} # Stardent Vistra i860-SVR4
+ else # Add other i860-SVR4 vendors below as they are discovered.
+ echo i860-unknown-sysv${UNAME_RELEASE} # Unknown i860-SVR4
+ fi
+ exit ;;
+ mini*:CTIX:SYS*5:*)
+ # "miniframe"
+ echo m68010-convergent-sysv
+ exit ;;
+ mc68k:UNIX:SYSTEM5:3.51m)
+ echo m68k-convergent-sysv
+ exit ;;
+ M680?0:D-NIX:5.3:*)
+ echo m68k-diab-dnix
+ exit ;;
+ M68*:*:R3V[5678]*:*)
+ test -r /sysV68 && { echo 'm68k-motorola-sysv'; exit; } ;;
+ 3[345]??:*:4.0:3.0 | 3[34]??A:*:4.0:3.0 | 3[34]??,*:*:4.0:3.0 | 3[34]??/*:*:4.0:3.0 | 4400:*:4.0:3.0 | 4850:*:4.0:3.0 | SKA40:*:4.0:3.0 | SDS2:*:4.0:3.0 | SHG2:*:4.0:3.0 | S7501*:*:4.0:3.0)
+ OS_REL=''
+ test -r /etc/.relid \
+ && OS_REL=.`sed -n 's/[^ ]* [^ ]* \([0-9][0-9]\).*/\1/p' < /etc/.relid`
+ /bin/uname -p 2>/dev/null | grep 86 >/dev/null \
+ && { echo i486-ncr-sysv4.3${OS_REL}; exit; }
+ /bin/uname -p 2>/dev/null | /bin/grep entium >/dev/null \
+ && { echo i586-ncr-sysv4.3${OS_REL}; exit; } ;;
+ 3[34]??:*:4.0:* | 3[34]??,*:*:4.0:*)
+ /bin/uname -p 2>/dev/null | grep 86 >/dev/null \
+ && { echo i486-ncr-sysv4; exit; } ;;
+ NCR*:*:4.2:* | MPRAS*:*:4.2:*)
+ OS_REL='.3'
+ test -r /etc/.relid \
+ && OS_REL=.`sed -n 's/[^ ]* [^ ]* \([0-9][0-9]\).*/\1/p' < /etc/.relid`
+ /bin/uname -p 2>/dev/null | grep 86 >/dev/null \
+ && { echo i486-ncr-sysv4.3${OS_REL}; exit; }
+ /bin/uname -p 2>/dev/null | /bin/grep entium >/dev/null \
+ && { echo i586-ncr-sysv4.3${OS_REL}; exit; }
+ /bin/uname -p 2>/dev/null | /bin/grep pteron >/dev/null \
+ && { echo i586-ncr-sysv4.3${OS_REL}; exit; } ;;
+ m68*:LynxOS:2.*:* | m68*:LynxOS:3.0*:*)
+ echo m68k-unknown-lynxos${UNAME_RELEASE}
+ exit ;;
+ mc68030:UNIX_System_V:4.*:*)
+ echo m68k-atari-sysv4
+ exit ;;
+ TSUNAMI:LynxOS:2.*:*)
+ echo sparc-unknown-lynxos${UNAME_RELEASE}
+ exit ;;
+ rs6000:LynxOS:2.*:*)
+ echo rs6000-unknown-lynxos${UNAME_RELEASE}
+ exit ;;
+ PowerPC:LynxOS:2.*:* | PowerPC:LynxOS:3.[01]*:* | PowerPC:LynxOS:4.[02]*:*)
+ echo powerpc-unknown-lynxos${UNAME_RELEASE}
+ exit ;;
+ SM[BE]S:UNIX_SV:*:*)
+ echo mips-dde-sysv${UNAME_RELEASE}
+ exit ;;
+ RM*:ReliantUNIX-*:*:*)
+ echo mips-sni-sysv4
+ exit ;;
+ RM*:SINIX-*:*:*)
+ echo mips-sni-sysv4
+ exit ;;
+ *:SINIX-*:*:*)
+ if uname -p 2>/dev/null >/dev/null ; then
+ UNAME_MACHINE=`(uname -p) 2>/dev/null`
+ echo ${UNAME_MACHINE}-sni-sysv4
+ else
+ echo ns32k-sni-sysv
+ fi
+ exit ;;
+ PENTIUM:*:4.0*:*) # Unisys `ClearPath HMP IX 4000' SVR4/MP effort
+ # says
+ echo i586-unisys-sysv4
+ exit ;;
+ *:UNIX_System_V:4*:FTX*)
+ # From Gerald Hewes .
+ # How about differentiating between stratus architectures? -djm
+ echo hppa1.1-stratus-sysv4
+ exit ;;
+ *:*:*:FTX*)
+ # From seanf@swdc.stratus.com.
+ echo i860-stratus-sysv4
+ exit ;;
+ i*86:VOS:*:*)
+ # From Paul.Green@stratus.com.
+ echo ${UNAME_MACHINE}-stratus-vos
+ exit ;;
+ *:VOS:*:*)
+ # From Paul.Green@stratus.com.
+ echo hppa1.1-stratus-vos
+ exit ;;
+ mc68*:A/UX:*:*)
+ echo m68k-apple-aux${UNAME_RELEASE}
+ exit ;;
+ news*:NEWS-OS:6*:*)
+ echo mips-sony-newsos6
+ exit ;;
+ R[34]000:*System_V*:*:* | R4000:UNIX_SYSV:*:* | R*000:UNIX_SV:*:*)
+ if [ -d /usr/nec ]; then
+ echo mips-nec-sysv${UNAME_RELEASE}
+ else
+ echo mips-unknown-sysv${UNAME_RELEASE}
+ fi
+ exit ;;
+ BeBox:BeOS:*:*) # BeOS running on hardware made by Be, PPC only.
+ echo powerpc-be-beos
+ exit ;;
+ BeMac:BeOS:*:*) # BeOS running on Mac or Mac clone, PPC only.
+ echo powerpc-apple-beos
+ exit ;;
+ BePC:BeOS:*:*) # BeOS running on Intel PC compatible.
+ echo i586-pc-beos
+ exit ;;
+ BePC:Haiku:*:*) # Haiku running on Intel PC compatible.
+ echo i586-pc-haiku
+ exit ;;
+ SX-4:SUPER-UX:*:*)
+ echo sx4-nec-superux${UNAME_RELEASE}
+ exit ;;
+ SX-5:SUPER-UX:*:*)
+ echo sx5-nec-superux${UNAME_RELEASE}
+ exit ;;
+ SX-6:SUPER-UX:*:*)
+ echo sx6-nec-superux${UNAME_RELEASE}
+ exit ;;
+ SX-7:SUPER-UX:*:*)
+ echo sx7-nec-superux${UNAME_RELEASE}
+ exit ;;
+ SX-8:SUPER-UX:*:*)
+ echo sx8-nec-superux${UNAME_RELEASE}
+ exit ;;
+ SX-8R:SUPER-UX:*:*)
+ echo sx8r-nec-superux${UNAME_RELEASE}
+ exit ;;
+ Power*:Rhapsody:*:*)
+ echo powerpc-apple-rhapsody${UNAME_RELEASE}
+ exit ;;
+ *:Rhapsody:*:*)
+ echo ${UNAME_MACHINE}-apple-rhapsody${UNAME_RELEASE}
+ exit ;;
+ *:Darwin:*:*)
+ UNAME_PROCESSOR=`uname -p` || UNAME_PROCESSOR=unknown
+ case $UNAME_PROCESSOR in
+ i386)
+ eval $set_cc_for_build
+ if [ "$CC_FOR_BUILD" != 'no_compiler_found' ]; then
+ if (echo '#ifdef __LP64__'; echo IS_64BIT_ARCH; echo '#endif') | \
+ (CCOPTS= $CC_FOR_BUILD -E - 2>/dev/null) | \
+ grep IS_64BIT_ARCH >/dev/null
+ then
+ UNAME_PROCESSOR="x86_64"
+ fi
+ fi ;;
+ unknown) UNAME_PROCESSOR=powerpc ;;
+ esac
+ echo ${UNAME_PROCESSOR}-apple-darwin${UNAME_RELEASE}
+ exit ;;
+ *:procnto*:*:* | *:QNX:[0123456789]*:*)
+ UNAME_PROCESSOR=`uname -p`
+ if test "$UNAME_PROCESSOR" = "x86"; then
+ UNAME_PROCESSOR=i386
+ UNAME_MACHINE=pc
+ fi
+ echo ${UNAME_PROCESSOR}-${UNAME_MACHINE}-nto-qnx${UNAME_RELEASE}
+ exit ;;
+ *:QNX:*:4*)
+ echo i386-pc-qnx
+ exit ;;
+ NSE-?:NONSTOP_KERNEL:*:*)
+ echo nse-tandem-nsk${UNAME_RELEASE}
+ exit ;;
+ NSR-?:NONSTOP_KERNEL:*:*)
+ echo nsr-tandem-nsk${UNAME_RELEASE}
+ exit ;;
+ *:NonStop-UX:*:*)
+ echo mips-compaq-nonstopux
+ exit ;;
+ BS2000:POSIX*:*:*)
+ echo bs2000-siemens-sysv
+ exit ;;
+ DS/*:UNIX_System_V:*:*)
+ echo ${UNAME_MACHINE}-${UNAME_SYSTEM}-${UNAME_RELEASE}
+ exit ;;
+ *:Plan9:*:*)
+ # "uname -m" is not consistent, so use $cputype instead. 386
+ # is converted to i386 for consistency with other x86
+ # operating systems.
+ if test "$cputype" = "386"; then
+ UNAME_MACHINE=i386
+ else
+ UNAME_MACHINE="$cputype"
+ fi
+ echo ${UNAME_MACHINE}-unknown-plan9
+ exit ;;
+ *:TOPS-10:*:*)
+ echo pdp10-unknown-tops10
+ exit ;;
+ *:TENEX:*:*)
+ echo pdp10-unknown-tenex
+ exit ;;
+ KS10:TOPS-20:*:* | KL10:TOPS-20:*:* | TYPE4:TOPS-20:*:*)
+ echo pdp10-dec-tops20
+ exit ;;
+ XKL-1:TOPS-20:*:* | TYPE5:TOPS-20:*:*)
+ echo pdp10-xkl-tops20
+ exit ;;
+ *:TOPS-20:*:*)
+ echo pdp10-unknown-tops20
+ exit ;;
+ *:ITS:*:*)
+ echo pdp10-unknown-its
+ exit ;;
+ SEI:*:*:SEIUX)
+ echo mips-sei-seiux${UNAME_RELEASE}
+ exit ;;
+ *:DragonFly:*:*)
+ echo ${UNAME_MACHINE}-unknown-dragonfly`echo ${UNAME_RELEASE}|sed -e 's/[-(].*//'`
+ exit ;;
+ *:*VMS:*:*)
+ UNAME_MACHINE=`(uname -p) 2>/dev/null`
+ case "${UNAME_MACHINE}" in
+ A*) echo alpha-dec-vms ; exit ;;
+ I*) echo ia64-dec-vms ; exit ;;
+ V*) echo vax-dec-vms ; exit ;;
+ esac ;;
+ *:XENIX:*:SysV)
+ echo i386-pc-xenix
+ exit ;;
+ i*86:skyos:*:*)
+ echo ${UNAME_MACHINE}-pc-skyos`echo ${UNAME_RELEASE}` | sed -e 's/ .*$//'
+ exit ;;
+ i*86:rdos:*:*)
+ echo ${UNAME_MACHINE}-pc-rdos
+ exit ;;
+ i*86:AROS:*:*)
+ echo ${UNAME_MACHINE}-pc-aros
+ exit ;;
+esac
+
+#echo '(No uname command or uname output not recognized.)' 1>&2
+#echo "${UNAME_MACHINE}:${UNAME_SYSTEM}:${UNAME_RELEASE}:${UNAME_VERSION}" 1>&2
+
+eval $set_cc_for_build
+cat >$dummy.c <
+# include
+#endif
+main ()
+{
+#if defined (sony)
+#if defined (MIPSEB)
+ /* BFD wants "bsd" instead of "newsos". Perhaps BFD should be changed,
+ I don't know.... */
+ printf ("mips-sony-bsd\n"); exit (0);
+#else
+#include
+ printf ("m68k-sony-newsos%s\n",
+#ifdef NEWSOS4
+ "4"
+#else
+ ""
+#endif
+ ); exit (0);
+#endif
+#endif
+
+#if defined (__arm) && defined (__acorn) && defined (__unix)
+ printf ("arm-acorn-riscix\n"); exit (0);
+#endif
+
+#if defined (hp300) && !defined (hpux)
+ printf ("m68k-hp-bsd\n"); exit (0);
+#endif
+
+#if defined (NeXT)
+#if !defined (__ARCHITECTURE__)
+#define __ARCHITECTURE__ "m68k"
+#endif
+ int version;
+ version=`(hostinfo | sed -n 's/.*NeXT Mach \([0-9]*\).*/\1/p') 2>/dev/null`;
+ if (version < 4)
+ printf ("%s-next-nextstep%d\n", __ARCHITECTURE__, version);
+ else
+ printf ("%s-next-openstep%d\n", __ARCHITECTURE__, version);
+ exit (0);
+#endif
+
+#if defined (MULTIMAX) || defined (n16)
+#if defined (UMAXV)
+ printf ("ns32k-encore-sysv\n"); exit (0);
+#else
+#if defined (CMU)
+ printf ("ns32k-encore-mach\n"); exit (0);
+#else
+ printf ("ns32k-encore-bsd\n"); exit (0);
+#endif
+#endif
+#endif
+
+#if defined (__386BSD__)
+ printf ("i386-pc-bsd\n"); exit (0);
+#endif
+
+#if defined (sequent)
+#if defined (i386)
+ printf ("i386-sequent-dynix\n"); exit (0);
+#endif
+#if defined (ns32000)
+ printf ("ns32k-sequent-dynix\n"); exit (0);
+#endif
+#endif
+
+#if defined (_SEQUENT_)
+ struct utsname un;
+
+ uname(&un);
+
+ if (strncmp(un.version, "V2", 2) == 0) {
+ printf ("i386-sequent-ptx2\n"); exit (0);
+ }
+ if (strncmp(un.version, "V1", 2) == 0) { /* XXX is V1 correct? */
+ printf ("i386-sequent-ptx1\n"); exit (0);
+ }
+ printf ("i386-sequent-ptx\n"); exit (0);
+
+#endif
+
+#if defined (vax)
+# if !defined (ultrix)
+# include
+# if defined (BSD)
+# if BSD == 43
+ printf ("vax-dec-bsd4.3\n"); exit (0);
+# else
+# if BSD == 199006
+ printf ("vax-dec-bsd4.3reno\n"); exit (0);
+# else
+ printf ("vax-dec-bsd\n"); exit (0);
+# endif
+# endif
+# else
+ printf ("vax-dec-bsd\n"); exit (0);
+# endif
+# else
+ printf ("vax-dec-ultrix\n"); exit (0);
+# endif
+#endif
+
+#if defined (alliant) && defined (i860)
+ printf ("i860-alliant-bsd\n"); exit (0);
+#endif
+
+ exit (1);
+}
+EOF
+
+$CC_FOR_BUILD -o $dummy $dummy.c 2>/dev/null && SYSTEM_NAME=`$dummy` &&
+ { echo "$SYSTEM_NAME"; exit; }
+
+# Apollos put the system type in the environment.
+
+test -d /usr/apollo && { echo ${ISP}-apollo-${SYSTYPE}; exit; }
+
+# Convex versions that predate uname can use getsysinfo(1)
+
+if [ -x /usr/convex/getsysinfo ]
+then
+ case `getsysinfo -f cpu_type` in
+ c1*)
+ echo c1-convex-bsd
+ exit ;;
+ c2*)
+ if getsysinfo -f scalar_acc
+ then echo c32-convex-bsd
+ else echo c2-convex-bsd
+ fi
+ exit ;;
+ c34*)
+ echo c34-convex-bsd
+ exit ;;
+ c38*)
+ echo c38-convex-bsd
+ exit ;;
+ c4*)
+ echo c4-convex-bsd
+ exit ;;
+ esac
+fi
+
+cat >&2 < in order to provide the needed
+information to handle your system.
+
+config.guess timestamp = $timestamp
+
+uname -m = `(uname -m) 2>/dev/null || echo unknown`
+uname -r = `(uname -r) 2>/dev/null || echo unknown`
+uname -s = `(uname -s) 2>/dev/null || echo unknown`
+uname -v = `(uname -v) 2>/dev/null || echo unknown`
+
+/usr/bin/uname -p = `(/usr/bin/uname -p) 2>/dev/null`
+/bin/uname -X = `(/bin/uname -X) 2>/dev/null`
+
+hostinfo = `(hostinfo) 2>/dev/null`
+/bin/universe = `(/bin/universe) 2>/dev/null`
+/usr/bin/arch -k = `(/usr/bin/arch -k) 2>/dev/null`
+/bin/arch = `(/bin/arch) 2>/dev/null`
+/usr/bin/oslevel = `(/usr/bin/oslevel) 2>/dev/null`
+/usr/convex/getsysinfo = `(/usr/convex/getsysinfo) 2>/dev/null`
+
+UNAME_MACHINE = ${UNAME_MACHINE}
+UNAME_RELEASE = ${UNAME_RELEASE}
+UNAME_SYSTEM = ${UNAME_SYSTEM}
+UNAME_VERSION = ${UNAME_VERSION}
+EOF
+
+exit 1
+
+# Local variables:
+# eval: (add-hook 'write-file-hooks 'time-stamp)
+# time-stamp-start: "timestamp='"
+# time-stamp-format: "%:y-%02m-%02d"
+# time-stamp-end: "'"
+# End:
diff --git a/dots/.config/zsh/config/plugins/fzf-tab/modules/config.h.in b/dots/.config/zsh/config/plugins/fzf-tab/modules/config.h.in
new file mode 100644
index 0000000..89a65b7
--- /dev/null
+++ b/dots/.config/zsh/config/plugins/fzf-tab/modules/config.h.in
@@ -0,0 +1,1242 @@
+/* config.h.in. Generated from configure.ac by autoheader. */
+
+/***** begin user configuration section *****/
+
+/* Define this to be the location of your password file */
+#define PASSWD_FILE "/etc/passwd"
+
+/* Define this to be the name of your NIS/YP password *
+ * map (if applicable) */
+#define PASSWD_MAP "passwd.byname"
+
+/* Define to 1 if you want user names to be cached */
+#define CACHE_USERNAMES 1
+
+/* Define to 1 if system supports job control */
+#define JOB_CONTROL 1
+
+/* Define this if you use "suspended" instead of "stopped" */
+#define USE_SUSPENDED 1
+
+/* The default history buffer size in lines */
+#define DEFAULT_HISTSIZE 30
+
+/* The default editor for the fc builtin */
+#define DEFAULT_FCEDIT "vi"
+
+/* The default prefix for temporary files */
+#define DEFAULT_TMPPREFIX "/tmp/zsh"
+
+/***** end of user configuration section *****/
+/***** shouldn't have to change anything below here *****/
+
+
+
+/* Define to 1 if you want to use dynamically loaded modules on AIX. */
+#undef AIXDYNAMIC
+
+/* Define to 1 if the isprint() function is broken under UTF-8 locale. */
+#undef BROKEN_ISPRINT
+
+/* Define to 1 if kill(pid, 0) doesn't return ESRCH, ie BeOS R4.51. */
+#undef BROKEN_KILL_ESRCH
+
+/* Define to 1 if sigsuspend() is broken */
+#undef BROKEN_POSIX_SIGSUSPEND
+
+/* Define to 1 if compiler incorrectly cast signed to unsigned. */
+#undef BROKEN_SIGNED_TO_UNSIGNED_CASTING
+
+/* Define to 1 if tcsetpgrp() doesn't work, ie BeOS R4.51. */
+#undef BROKEN_TCSETPGRP
+
+/* Define to 1 if you use BSD style signal handling (and can block signals).
+ */
+#undef BSD_SIGNALS
+
+/* Undefine if you don't want local features. By default this is defined. */
+#undef CONFIG_LOCALE
+
+/* Define to one of `_getb67', `GETB67', `getb67' for Cray-2 and Cray-YMP
+ systems. This function is required for `alloca.c' support on those systems.
+ */
+#undef CRAY_STACKSEG_END
+
+/* Define to a custom value for the ZSH_PATCHLEVEL parameter */
+#undef CUSTOM_PATCHLEVEL
+
+/* Define to 1 if using `alloca.c'. */
+#undef C_ALLOCA
+
+/* Define to 1 if you want to debug zsh. */
+#undef DEBUG
+
+/* The default path; used when running commands with command -p */
+#undef DEFAULT_PATH
+
+/* Define default pager used by readnullcmd */
+#undef DEFAULT_READNULLCMD
+
+/* Define to 1 if you want to avoid calling functions that will require
+ dynamic NSS modules. */
+#undef DISABLE_DYNAMIC_NSS
+
+/* Define to 1 if an underscore has to be prepended to dlsym() argument. */
+#undef DLSYM_NEEDS_UNDERSCORE
+
+/* The extension used for dynamically loaded modules. */
+#undef DL_EXT
+
+/* Define to 1 if you want to use dynamically loaded modules. */
+#undef DYNAMIC
+
+/* Define to 1 if multiple modules defining the same symbol are OK. */
+#undef DYNAMIC_NAME_CLASH_OK
+
+/* Define to 1 if you want use unicode9 character widths. */
+#undef ENABLE_UNICODE9
+
+/* Define to 1 if getcwd() calls malloc to allocate memory. */
+#undef GETCWD_CALLS_MALLOC
+
+/* Define to 1 if the `getpgrp' function requires zero arguments. */
+#undef GETPGRP_VOID
+
+/* Define to 1 if getpwnam() is faked, ie BeOS R4.51. */
+#undef GETPWNAM_FAKED
+
+/* The global file to source whenever zsh is run as a login shell; if
+ undefined, don't source anything */
+#undef GLOBAL_ZLOGIN
+
+/* The global file to source whenever zsh was run as a login shell. This is
+ sourced right before exiting. If undefined, don't source anything. */
+#undef GLOBAL_ZLOGOUT
+
+/* The global file to source whenever zsh is run as a login shell, before
+ zshrc is read; if undefined, don't source anything. */
+#undef GLOBAL_ZPROFILE
+
+/* The global file to source absolutely first whenever zsh is run; if
+ undefined, don't source anything. */
+#undef GLOBAL_ZSHENV
+
+/* The global file to source whenever zsh is run; if undefined, don't source
+ anything */
+#undef GLOBAL_ZSHRC
+
+/* Define if TIOCGWINSZ is defined in sys/ioctl.h but not in termios.h. */
+#undef GWINSZ_IN_SYS_IOCTL
+
+/* Define to 1 if you have `alloca', as a function or macro. */
+#undef HAVE_ALLOCA
+
+/* Define to 1 if you have and it should be used (not on Ultrix).
+ */
+#undef HAVE_ALLOCA_H
+
+/* Define to 1 if you have the header file. */
+#undef HAVE_BIND_NETDB_H
+
+/* Define if you have the termcap boolcodes symbol. */
+#undef HAVE_BOOLCODES
+
+/* Define if you have the terminfo boolnames symbol. */
+#undef HAVE_BOOLNAMES
+
+/* Define to 1 if you have the `brk' function. */
+#undef HAVE_BRK
+
+/* Define to 1 if there is a prototype defined for brk() on your system. */
+#undef HAVE_BRK_PROTO
+
+/* Define to 1 if you have the `canonicalize_file_name' function. */
+#undef HAVE_CANONICALIZE_FILE_NAME
+
+/* Define to 1 if you have the `cap_get_proc' function. */
+#undef HAVE_CAP_GET_PROC
+
+/* Define to 1 if you have the `clock_gettime' function. */
+#undef HAVE_CLOCK_GETTIME
+
+/* Define to 1 if you have the header file. */
+#undef HAVE_CURSES_H
+
+/* Define to 1 if you have the `cygwin_conv_path' function. */
+#undef HAVE_CYGWIN_CONV_PATH
+
+/* Define to 1 if you have the `difftime' function. */
+#undef HAVE_DIFFTIME
+
+/* Define to 1 if you have the header file, and it defines `DIR'.
+ */
+#undef HAVE_DIRENT_H
+
+/* Define to 1 if you have the `dlclose' function. */
+#undef HAVE_DLCLOSE
+
+/* Define to 1 if you have the `dlerror' function. */
+#undef HAVE_DLERROR
+
+/* Define to 1 if you have the header file. */
+#undef HAVE_DLFCN_H
+
+/* Define to 1 if you have the `dlopen' function. */
+#undef HAVE_DLOPEN
+
+/* Define to 1 if you have the `dlsym' function. */
+#undef HAVE_DLSYM
+
+/* Define to 1 if you have the header file. */
+#undef HAVE_DL_H
+
+/* Define to 1 if you have the `endutxent' function. */
+#undef HAVE_ENDUTXENT
+
+/* Define to 1 if you have the `erand48' function. */
+#undef HAVE_ERAND48
+
+/* Define to 1 if you have the header file. */
+#undef HAVE_ERRNO_H
+
+/* Define to 1 if you have the `faccessx' function. */
+#undef HAVE_FACCESSX
+
+/* Define to 1 if you have the `fchdir' function. */
+#undef HAVE_FCHDIR
+
+/* Define to 1 if you have the `fchmod' function. */
+#undef HAVE_FCHMOD
+
+/* Define to 1 if you have the `fchown' function. */
+#undef HAVE_FCHOWN
+
+/* Define to 1 if you have the header file. */
+#undef HAVE_FCNTL_H
+
+/* Define to 1 if system has working FIFOs. */
+#undef HAVE_FIFOS
+
+/* Define to 1 if you have the `fseeko' function. */
+#undef HAVE_FSEEKO
+
+/* Define to 1 if you have the `fstat' function. */
+#undef HAVE_FSTAT
+
+/* Define to 1 if you have the `ftello' function. */
+#undef HAVE_FTELLO
+
+/* Define to 1 if you have the `ftruncate' function. */
+#undef HAVE_FTRUNCATE
+
+/* Define to 1 if you have the header file. */
+#undef HAVE_GDBM_H
+
+/* Define to 1 if you have the `gdbm_open' function. */
+#undef HAVE_GDBM_OPEN
+
+/* Define to 1 if you have the `getcchar' function. */
+#undef HAVE_GETCCHAR
+
+/* Define to 1 if you have the `getcwd' function. */
+#undef HAVE_GETCWD
+
+/* Define to 1 if you have the `getenv' function. */
+#undef HAVE_GETENV
+
+/* Define to 1 if you have the `getgrgid' function. */
+#undef HAVE_GETGRGID
+
+/* Define to 1 if you have the `getgrnam' function. */
+#undef HAVE_GETGRNAM
+
+/* Define to 1 if you have the `gethostbyname2' function. */
+#undef HAVE_GETHOSTBYNAME2
+
+/* Define to 1 if you have the `gethostname' function. */
+#undef HAVE_GETHOSTNAME
+
+/* Define to 1 if you have the `getipnodebyname' function. */
+#undef HAVE_GETIPNODEBYNAME
+
+/* Define to 1 if you have the `getline' function. */
+#undef HAVE_GETLINE
+
+/* Define to 1 if you have the `getlogin' function. */
+#undef HAVE_GETLOGIN
+
+/* Define to 1 if you have the `getpagesize' function. */
+#undef HAVE_GETPAGESIZE
+
+/* Define to 1 if you have the `getpwent' function. */
+#undef HAVE_GETPWENT
+
+/* Define to 1 if you have the `getpwnam' function. */
+#undef HAVE_GETPWNAM
+
+/* Define to 1 if you have the `getpwuid' function. */
+#undef HAVE_GETPWUID
+
+/* Define to 1 if you have the `getrlimit' function. */
+#undef HAVE_GETRLIMIT
+
+/* Define to 1 if you have the `getrusage' function. */
+#undef HAVE_GETRUSAGE
+
+/* Define to 1 if you have the `gettimeofday' function. */
+#undef HAVE_GETTIMEOFDAY
+
+/* Define to 1 if you have the `getutent' function. */
+#undef HAVE_GETUTENT
+
+/* Define to 1 if you have the `getutxent' function. */
+#undef HAVE_GETUTXENT
+
+/* Define to 1 if you have the `getxattr' function. */
+#undef HAVE_GETXATTR
+
+/* Define to 1 if you have the `grantpt' function. */
+#undef HAVE_GRANTPT
+
+/* Define to 1 if you have the header file. */
+#undef HAVE_GRP_H
+
+/* Define to 1 if you have the `htons' function. */
+#undef HAVE_HTONS
+
+/* Define to 1 if you have the `iconv' function. */
+#undef HAVE_ICONV
+
+/* Define to 1 if you have the header file. */
+#undef HAVE_ICONV_H
+
+/* Define to 1 if you have the `inet_aton' function. */
+#undef HAVE_INET_ATON
+
+/* Define to 1 if you have the `inet_ntop' function. */
+#undef HAVE_INET_NTOP
+
+/* Define to 1 if you have the `inet_pton' function. */
+#undef HAVE_INET_PTON
+
+/* Define to 1 if you have the `initgroups' function. */
+#undef HAVE_INITGROUPS
+
+/* Define to 1 if you have the `initscr' function. */
+#undef HAVE_INITSCR
+
+/* Define to 1 if you have the header file. */
+#undef HAVE_INTTYPES_H
+
+/* Define to 1 if there is a prototype defined for ioctl() on your system. */
+#undef HAVE_IOCTL_PROTO
+
+/* Define to 1 if you have the `isblank' function. */
+#undef HAVE_ISBLANK
+
+/* Define to 1 if you have the `isinf' function. */
+#undef HAVE_ISINF
+
+/* Define to 1 if you have the `isnan' function. */
+#undef HAVE_ISNAN
+
+/* Define to 1 if you have the `iswblank' function. */
+#undef HAVE_ISWBLANK
+
+/* Define to 1 if you have the `killpg' function. */
+#undef HAVE_KILLPG
+
+/* Define to 1 if you have the header file. */
+#undef HAVE_LANGINFO_H
+
+/* Define to 1 if you have the `lchown' function. */
+#undef HAVE_LCHOWN
+
+/* Define to 1 if you have the `cap' library (-lcap). */
+#undef HAVE_LIBCAP
+
+/* Define to 1 if you have the header file. */
+#undef HAVE_LIBC_H
+
+/* Define to 1 if you have the `dl' library (-ldl). */
+#undef HAVE_LIBDL
+
+/* Define to 1 if you have the `gdbm' library (-lgdbm). */
+#undef HAVE_LIBGDBM
+
+/* Define to 1 if you have the `m' library (-lm). */
+#undef HAVE_LIBM
+
+/* Define to 1 if you have the `rt' library (-lrt). */
+#undef HAVE_LIBRT
+
+/* Define to 1 if you have the `socket' library (-lsocket). */
+#undef HAVE_LIBSOCKET
+
+/* Define to 1 if you have the header file. */
+#undef HAVE_LIMITS_H
+
+/* Define to 1 if system has working link(). */
+#undef HAVE_LINK
+
+/* Define to 1 if you have the `load' function. */
+#undef HAVE_LOAD
+
+/* Define to 1 if you have the `loadbind' function. */
+#undef HAVE_LOADBIND
+
+/* Define to 1 if you have the `loadquery' function. */
+#undef HAVE_LOADQUERY
+
+/* Define to 1 if you have the header file. */
+#undef HAVE_LOCALE_H
+
+/* Define to 1 if you have the `log2' function. */
+#undef HAVE_LOG2
+
+/* Define to 1 if you have the `lstat' function. */
+#undef HAVE_LSTAT
+
+/* Define to 1 if you have the `memcpy' function. */
+#undef HAVE_MEMCPY
+
+/* Define to 1 if you have the `memmove' function. */
+#undef HAVE_MEMMOVE
+
+/* Define to 1 if you have the header file. */
+#undef HAVE_MEMORY_H
+
+/* Define to 1 if you have the `mkfifo' function. */
+#undef HAVE_MKFIFO
+
+/* Define to 1 if there is a prototype defined for mknod() on your system. */
+#undef HAVE_MKNOD_PROTO
+
+/* Define to 1 if you have the `mkstemp' function. */
+#undef HAVE_MKSTEMP
+
+/* Define to 1 if you have the `mktime' function. */
+#undef HAVE_MKTIME
+
+/* Define to 1 if you have a working `mmap' system call. */
+#undef HAVE_MMAP
+
+/* Define to 1 if you have the `msync' function. */
+#undef HAVE_MSYNC
+
+/* Define to 1 if you have the `munmap' function. */
+#undef HAVE_MUNMAP
+
+/* Define to 1 if you have the `nanosleep' function. */
+#undef HAVE_NANOSLEEP
+
+/* Define to 1 if you have the